 Giacomo Zamprogno
Giacomo Zamprogno Emmanuelle Dietz
Emmanuelle Dietz Linda Heimisch3*
Linda Heimisch3* Nele Russwinkel
Nele Russwinkel
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Artif. Intell. , 18 December 2023
Sec. Machine Learning and Artificial Intelligence
Volume 6 - 2023 | https://doi.org/10.3389/frai.2023.1223251
This article is part of the Research Topic The Translation and Implementation of Robotics and Embodied AI in Healthcare View all 5 articles
Human-awareness is an ever more important requirement for AI systems that are designed to assist humans with daily physical interactions and problem solving. This is especially true for patients that need support to stay as independent as possible. To be human-aware, an AI should be able to anticipate the intentions of the individual humans it interacts with, in order to understand the difficulties and limitations they are facing and to adapt accordingly. While data-driven AI approaches have recently gained a lot of attention, more research is needed on assistive AI systems that can develop models of their partners' goals to offer proactive support without needing a lot of training trials for new problems. We propose an integrated AI system that can anticipate actions of individual humans to contribute to the foundations of trustworthy human-robot interaction. We test this in Tangram, which is an exemplary sequential problem solving task that requires dynamic decision making. In this task the sequences of steps to the goal might be variable and not known by the system. These are aspects that are also recognized as real world challenges for robotic systems. A hybrid approach based on the cognitive architecture ACT-R is presented that is not purely data-driven but includes cognitive principles, meaning heuristics that guide human decisions. Core of this Cognitive Tangram Solver (CTS) framework is an ACT-R cognitive model that simulates human problem solving behavior in action, recognizes possible dead ends and identifies ways forward. Based on this model, the CTS anticipates and adapts its predictions about the next action to take in any given situation. We executed an empirical study and collected data from 40 participants. The predictions made by CTS were evaluated with the participants' behavior, including comparative statistics as well as prediction accuracy. The model's anticipations compared to the human test data provide support for justifying further steps built upon our conceptual approach.
The ability to adapt to a developing situation is a highly desired feature in every-day interaction. Humans are incredibly good at adapting to their environment and in interaction with other humans or (artificial) systems. This skill enables humans to enhance their performance and the performance of others in the environment.
In recent years, various disciplines that aim at implementing AI systems and robotic systems within an interactive environment have realized the need for human-aware AI or human-centered AI design (Kambhampati, 2020). Kambhampati (2020) defined Human-Aware AI Systems as goal-directed autonomous systems that are capable of effectively interacting, collaborating, and teaming with humans. Challenges in designing such human-aware AI systems include modeling the mental states of humans-in-the-loop, recognizing their desires and intentions, providing proactive support, exhibiting explicable behavior, giving cogent explanations on demand, and engendering trust.
While recent advances have focused on the emotional aspect of interaction, successful human-robot interaction requires the machine to understand, and model the intentions and strategies of the individual humans they interact with in order to adapt to the human partner (Rossi et al., 2017). It has been shown that interactions with robotic systems that do not show adequate feedback will cause frustration for their human cooperation partners (Weidemann and Russwinkel, 2021).
This is especially important for patients suffering from Parkinson's disease or other neural impairments that face challenges living on their own or being dependent on others even for simple tasks. 20% of the world's population lives with some level of cognitive impairment (World Health Organization and others, 2011). According to Kosch et al. (2018) an individual with such impairments may have difficulties in learning, remembering information, or making decisions. A cognitive impairment can impact someone's ability to complete traditional activities of daily living. Different facilities exist to provide specialized training to people with cognitive impairments as they learn independent living skills. The ultimative goal is to teach the patients to live independently. Contextualized assistance has been shown to be effective in helping people with cognitive impairments perform individual work. So far only displays or augmented reality tools have been used but with cognitive anticipative models future systems could provide better support. An assistance system that is adaptive to the individual and the task progress, that would understand the task state and offer adaptive support could ensure independence of such patients to a crucial degree. It has been shown that self efficiency for such tasks is crucial to preserve still intact skills and self esteem. But assistance systems that adapt to situation, task and context would enable a new generation of human-aware AI systems. We believe that the ability to anticipate the intentions and cognitive processes of a person is a key skill that underlies their adaptability. Especially the ability to anticipate high level (taks level) and low level intentions (actions) (Gomez Cubero and Rehm, 2021) is crucial to proactively offer support or anticipate dangerous situations in time.
According to Klein et al. (2007) anticipatory thinking is a critical macrocognitive function of individuals and teams. It is the ability to prepare in time for problems and opportunities. We distinguish it from prediction because anticipatory thinking is functional–people are preparing themselves for future events, not simply predicting what might happen. Therefore anticipation implies the skill to understand the task structure the partner is in and difficulties the partner is facing. For assisting the partner in a task where the final solution might not be known but - as a teacher - the assistant can still be aware of general pitfalls and short term solutions for the next step.
First steps toward such a goal would be an approach that
• is able to offer support even if the final goal is not known (or trained) in detail,
• understands state of the task and difficulties related to it,
• understands common mistakes and the problem that the individual partner might face,
• anticipates the partner,
• is flexible to the individual trace of actions, and
• offers appropriate support and only when needed, without taking over from the patient or partner.
Taking these requirements as a starting point, we will present an integrated AI system that has a computational theory of mind, which it uses to anticipate actions of individuals for a particular task and adapt according to previous anticipations. In real world tasks we are often faced with developing situations - each action or decision changes the state of the problem which is referred to as dynamic decision making.
According to Brehmer (1992) dynamic decision making occurs under conditions which require a series of decisions, where the decisions are not independent, where the state of the world changes, both autonomously and as a consequence of the decision maker's actions, and where the decisions have to be made in real time.
As a first step we developed an approach that involves dynamic decision making, and is simple to understand and investigate, but is sufficiently complex having a broad solution space where each step changes the problem state. The sequential problem solving task Tangram fits this requirement. This task will be explained in more detail in Section 3. Whenever a piece is chosen and placed the remaining pieces and remaining free spaces change - so we have a new situation. A solution with machine learning would need a lot of training trials for each problem and does not seem appropriate. On the other hand, when observing other humans solving the task, it seems straightforward for a human to understand the other's perspective and recognize their intent for the next move.
Regarding the requirement above of anticipating the partner a method is needed for this task that can trace the individual action decisions of a participant and apply general rules to understand the situation and possible approaching problems in order to support but not necessarily taking over the task.
Especially for patient-robot collaboration human-aware capabilities like non-verbal communication, shared-control and proactive support are crucial for successful patient assistance and therefore require new solutions how to take into account the individual in the task. In addition cognitive principles should be taken into account which are hypotheses for human strategies, one such cognitive principle can be affordance. According to Gibson (2014), the use of an object is intrinsically determined by its physical shape. Such clues indicate possibilities for action in a task. They are perceived in a direct, immediate way and might also lead to wrong solutions as we will show. In order to anticipate a person in a task it is necessary to include such cognitive principles to understand intentions and errors.
Different than purely data-driven approaches, we will present a hybrid approach, which exploits the strengths of various technologies. The paper's contribution is three-fold:
(a) The results and analysis of an empirical study to a problem solving geometrical task (the Tangram) that, while conceptually simple, requires skills that can probably be generalized to more complex tasks.
(b) A novel hypothesis for human strategies, so-called cognitive principles, for the case of the sequential problem solving task is suggested, taking as a baseline the concept of affordance and providing different variations thereof.
(c) A computational framework integrating the techniques of object recognition and modeling with cognitive architectures to enable an agent to reproduce the strategies and provides basic insights toward predicting and/or anticipating human behavior in the solution process. This system shows how the strengths of machine learning and the inherently explainable cognitive modeling approach can be combined. Finally, four different evaluation methods are presented to evaluate the framework, which, while extending on the main plan of studying the underlying principles, we hope will provide a basic benchmark for future studies.
The concept of macrocognition is a way of describing cognitive work as it naturally occurs (Klein and Wright, 2016). It is a term to indicate a level of description of the cognitive functions that are performed in natural decision-making settings. According to Klein and Wright (2016) important macrocognitive phenomena are problem detection, situation assessment, attention management and uncertainty management. The term comprises the mental activities that must be successfully accomplished to perform a task or achieve a goal. And this is needed for a human-aware AI approach that understands the partners task state on such a macrocognitive level. It is relevant to have tools that can achieve “understanding” at this macrocognitive level for supporting a human in a difficult task. This is sense making at an abstract task or situation understanding. Understanding that a person got herself in a dead-end or tries to find an impossible solution can provide valuable support. Not for every situation there will be a solution available but a macrocognitive understanding of a problem is high relevant.
During the last decades, theories on human reasoning that aimed to understand, model, and eventually predict their decisions [e.g. Johnson-Laird (1983), Rips (1994), Polk and Newell (1995), Chater and Oaksford (1999), Oaksford and Chater (2020), and Knauff and Gazzo Castañeda (2021)] can be seen as a theoretical foundation on human-awareness. These approaches differ fundamentally from the normative requirements of classical logical reasoning. The current two most dominant paradigms are either based on the mental model theory (Knauff and Gazzo Castañeda, 2021) or bayesian (Oaksford and Chater, 2020). Another view is to formalize commonly agreed-to patterns as cognitive principles and parametrize them to account for the variety among the human population [e.g., Dietz Saldanha and Schambach (2020)] and applied to cognitive argumentation [e.g., Dietz Saldanha and Kakas (2019)]. Dietz et al. (2022) integrated this approach for quantitative symbolic reasoning including the notion of Bayesian plausibility. Cognitive modeling in real world environments toward human-aware systems in the context of cockpit and pilots' mental state was done in (Klaproth et al., 2020; Blum et al., 2022). These approaches integrated the pilots' neurophysiological responses from a passive brain-computer interface within a cognitive model to trace pilots perception and processing of auditory alerts and messages during operations. Their work demonstrates how cognitive models can be complemented with the neurophysiological data for adaptation and action (sequence) anticipation. Another human-aware approach was implemented by Scharfe-Scherf et al. (2022) in the domain of highly automated driving. The question of how much time a driver needs to safely transition from autonomous driving to manual driving is still debated. Scharfe-Scherf et al. (2022) developed a cognitive model that simulates the construction of situation awareness depending on gazes to the relevant objects next to the car. This way the prediction of transition times depending on the complexity of the situation were possible. Dietz and Klaproth (2021) proposed the cognitive modeling library txt2actr which provides an interface between the environment specification and the cognitive architecture ACT-R (Anderson, 2007). It automates the construction of knowledge about the task environment and facilitates updating new information in dynamic environments, such as constantly changing values in milliseconds (Scharfe-Scherf et al., 2022).
The capability to understand someone else's purposes, intentions and goals seems to be a task that is simple for humans but difficult for AI systems (Lieto, 2021). One reason for this capability is often explained by the theory of mind (TOM) (Premack and Woodruff, 1978) stating that usually humans (from the age of 4 years on) can imagine themselves into someone's else mental state, that is they can take another person's perspective without the actual experience. One assumption is that if we know how to build the human mind computationally, we should be able to rebuild and simulate human behavior. This simulation could help AI systems to understand others' purposes, intentions and goals and adapt accordingly. According to Newell, a theory of the human mind should address all aspects of cognition. For this purpose he suggests to develop cognitive architectures (Newell, 1990), which unify different information processing structures. ACT-R (Anderson, 2007) and SOAR (Laird, 2012) are such architectures, allowing the simulation of cognitive processes. These architectures have made a significant contribution on building a baseline for formal methodologies by implementing and evaluating models based on existing theories. However, these architectures allow a high degree of freedom. Therefore the “standard model of the mind” (or “common model of cognition”) has been proposed by Laird et al. (2017) to “facilitate shared cumulative progress” and align theories on the architectural level. When considering again the challenges of human-aware AI systems, then Cognitive architectures could help overcome challenges of human-aware AI in understanding the human's awareness of a given environment. Ideally, “knowing” the human's perspective, the AI system should be capable to adapt accordingly.
Problem solving tasks have been repeatedly suggested and implemented in education in order to enhance learners mathematical and spatial skills (Lee et al., 2009; Judd and Klingberg, 2021). This can apply to a wide range of possible targets, from children (Bohning and Althouse, 1997) to elderly people (García et al., 2010; Frutos-Pascual et al., 2012). A cognitive model for the solution mechanism of puzzles could help support and improve already present techniques: first, it would offer a reference to compare with the results of the learner, possibly helping to target weaker points or understanding reasoning patterns and causes of mistakes. Secondly, as more and more automated systems start taking the roles of supporting agents, a system provided with some type of TOM could offer better understanding and support to the users.
This section has given a brief overview of the topics that are related to the approach we will propose in this paper: a Computational Human-Aware System for Sequential Problem Solving guided by Cognitive Principles. Social robotics and human-machine teaming require human aware AI, thus a system that has the capability to anticipate and adapt to their human users. Taking this challenge as a starting point we consider a specific sequential problem solving task (Section 3) and present a computational system that anticipates and adapts its predictions based on the simulation within a cognitive architecture (Section 5). The baseline of this system is provided by theories from macro-cognition and human-aware task analysis which are grounded in so-called cognitive principles (Section 4).
The Tangram is an ancient Chinese puzzle in which seven pieces, also called tans, are obtained from an original square and need to be reorganized into different figures.
The seven tans consist of 5 square triangles (2 small, 1 medium and 2 large), 1 square and 1 parallelogram, their relative dimensions and sizes is shown in Figure 1 left.1

Figure 1. The seven tans (left) and their usual starting position (right).
Usually players are presented with a homogeneous silhouette, likely in the shape of some stylized figure, and are asked to reproduce the pattern by positioning all the tans, without overlaps. Figure 1 right shows their usual starting position as presented to the players. Throughout the paper, we will use the symbols □, □,  ,
,  , and ⧌ to refer to the square, parallelogram, big triangle, middle triangle and small triangle, respectively. The advantage of Tangram as use case for modeling cognitive solving behavior comes from two factors. First, it is relatively easy to define and describe, with a short set of rules and limited ambiguity. Second, it is an example of a sequential problem solving task, in the sense that different sequences of steps can lead to very different solution procedures, and thus it cannot be simply defined by a deterministic evolution of states.
, and ⧌ to refer to the square, parallelogram, big triangle, middle triangle and small triangle, respectively. The advantage of Tangram as use case for modeling cognitive solving behavior comes from two factors. First, it is relatively easy to define and describe, with a short set of rules and limited ambiguity. Second, it is an example of a sequential problem solving task, in the sense that different sequences of steps can lead to very different solution procedures, and thus it cannot be simply defined by a deterministic evolution of states.
These factors contribute in making the Tangram a solid starting point for guiding research in sequential problem solving. If a plausible TOM is suggested for the puzzle, it might provide support to the fact that a similar approach can be further applied to practical tasks that, while more complex and elaborate, share common features with the Tangram, examples of which could be educational and rehabilitation activities.
In addition, the inclusion of the Tangram puzzle in HCI for education and medicine is a topic that despite a recent rise in interest (García et al., 2010; Frutos-Pascual et al., 2012; Kirschner et al., 2016) still offers plenty of space for research effort. As the usage of Tangram as an educational tool has been known for some years, developing HCI solutions based on the puzzle seem a natural and promising advance that could provide new tools for instructors and assistants alike. Until now, computer-based assistants for Tangram like the ones mentioned above have been based on search algorithm or machine-learning solutions and a natural extension would thus be agents that model and understand their partners' solution processes, in order to better interface with users and provide more explainable support.
In collaboration with the Technical University of Berlin (TUB) and Airbus Central R&T, Hamburg, an empirical study was developed and performed in order to obtain the training and test sets.
Altogether, 40 participants were acquired in two study phases, where one was dedicated to gather data for the later training and one for the later test set. Participants were recruited among students and PhD students at TU Berlin. In the first study phase, 31 participants were acquired (13 female), with a mean age of 21.53 years (SD = 3.21), ranging from 21 to 34 years. In the second study phase, 9 participants were acquired (6 female), with a mean age of 26.11 years (SD = 4.91), ranging from 20 to 35 years.
All participants signed an informed consent and were compensated with miniature aircraft models provided by the company and course credit, where applicable.
Each participant was presented with a virtual implementation of the Tangram puzzle running on a desktop computer, consisting of one of the four puzzles on the left of Figure 2. A screenshot is shown on the right of Figure 2. After an initial explanation of the controls, all of which were performed with the mouse, each participant was required to tackle the problem of the puzzles, which were always shown in the same order. There was no time limit, and at any moment a NEXT button was available, so that the player could give up on the specific Tangram and move to the next one. While backtracking was possible while working on a single task, once the button was pressed the solution was submitted and no option to go back was available.
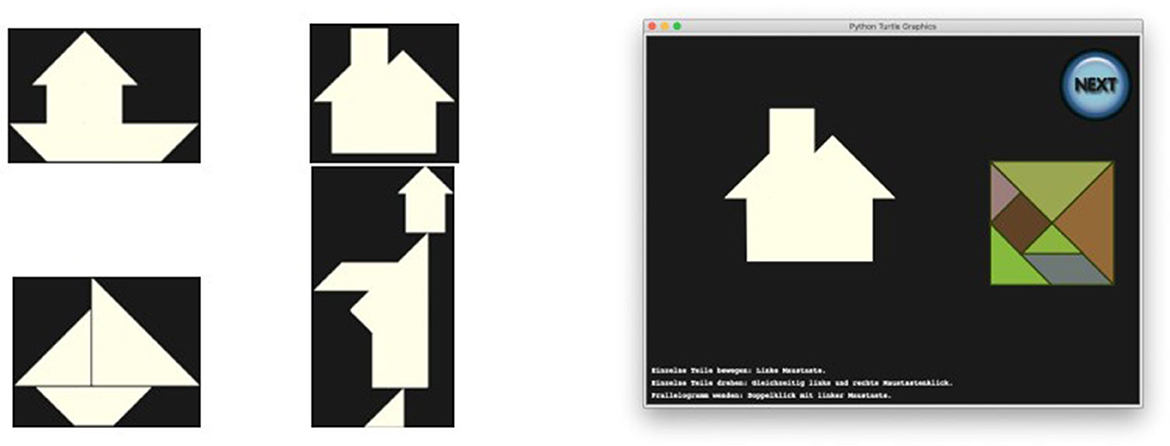
Figure 2. Tangrams to be solved in the empirical study were house boat, house with chimney, sailing boat and monk (left). Screenshot when house with chimney was presented (right).
The screen recording and application logs, including data recording times, piece action types (rotation, movement) and piece positioning were stored for the analysis. For simplicity, in the sequel, we will only discuss the HOUSE and MONK.
Humans seem to make assumptions and apply a variety of heuristics that guide their decisions, which are heavily context dependent. We call the generalization of these observed heuristics cognitive principles. The relevant cognitive principles that address the observations made while watching the videos from the training data of the Tangram task introduced in Section 3 will be introduced in this section.
In Human-Computer Interaction, immediately perceived possible actions are often referred to as affordances (Norman, 2002), and originate from Gibson (1979). The solving process for Tangrams across participants seems to be strongly guided by such immediately perceived possible actions. In particular it seems that participants first consider features in the silhouette that are particularly similar to the available piece. We call this the BEST FIT principle.
Let us illustrate this observation by considering the training data from the HOUSE and the MONK Tangram: The heatmap in Figure 3 left shows that the pattern {□, , □} appears in the majority of activities in the first steps. This pattern, intended as the unordered set of chosen pieces, would compose the upper section of the house in the puzzle's solution (see Figure 4, left): the sequence with which the pieces were chosen varies, but an initial analysis shows that 47% of participants presented this pattern by step 4, rising to 77% for pattern {, □}. Figure 3 right shows a heatmap produced by the training data for the MONK Tangram, where pattern {□, ⧌} is present in 60% of participants by step 4. This pattern would compose the head of the monk in the puzzle's solution (see Figure 4, right).
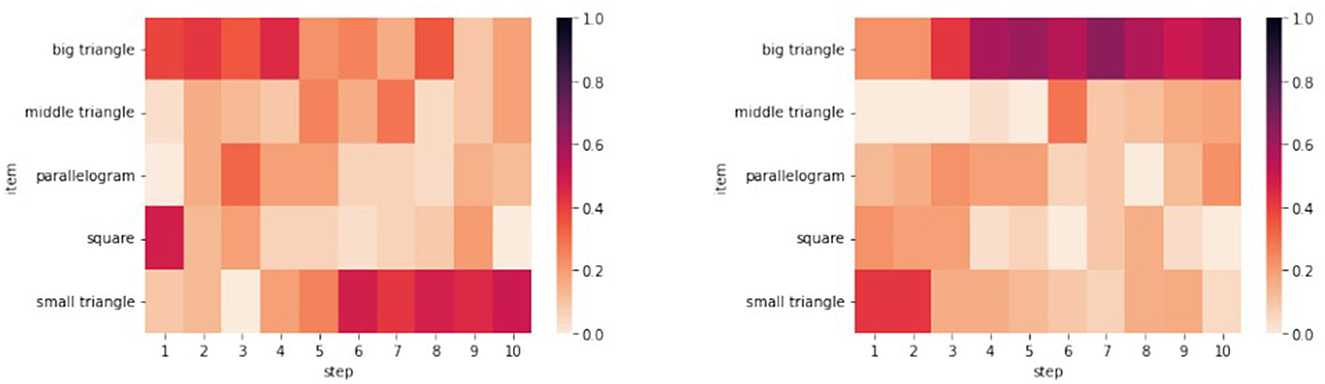
Figure 3. Frequency of chosen pieces by step for HOUSE (left) and MONK (right).

Figure 4. Common pattern for HOUSE (left) and MONK (right) Tangram.
A common feature of the patterns {□, , □} and {□, ⧌}, is that the shape of the area that the chosen pieces are covering clearly resembles (or coincides with) some parts of the shape of the object itself. Screen recordings showed that these combinations of actions were shared among the participants, especially during the early phases of the solution (see Section 4.4 for the PHASES OF SOLVING principle). While the specific sequence of steps might vary, when considering the unordered set of steps, the same patterns of action combinations can be found in the majority of the participants.
Best fits which require the composition of more than one tan are not always recognized in the initial phase. Consider the placement in Figure 5 left, where the two big triangles need to be composed into a huge triangle in order to perfectly fit the “belly” of the MONK. Quite consistently participants tend to first place a big triangle rotated so to match the rotation of the larger silhouette, aligned along one of the available edges as in Figure 5 right. They do not seem to notice the possibility of a perfect fit by the arrangement of the two triangles into the bigger one.

Figure 5. Correct placements (left) and wrong placement (right).
This can be observed in the starting phase of the MONK Tangram: Table 1 shows the frequencies of action taken by participants in the first 4 moves and it can be noticed how 47.5% of participants' actions involve big triangles rotated 270 degrees and put at location 17 in Figure 6,2 representing the incorrect positioning, against a combined 20% from the correct placements. In the sequel, we will call observations of this kind the UNRECOGNIZED COMPOSITION principle.
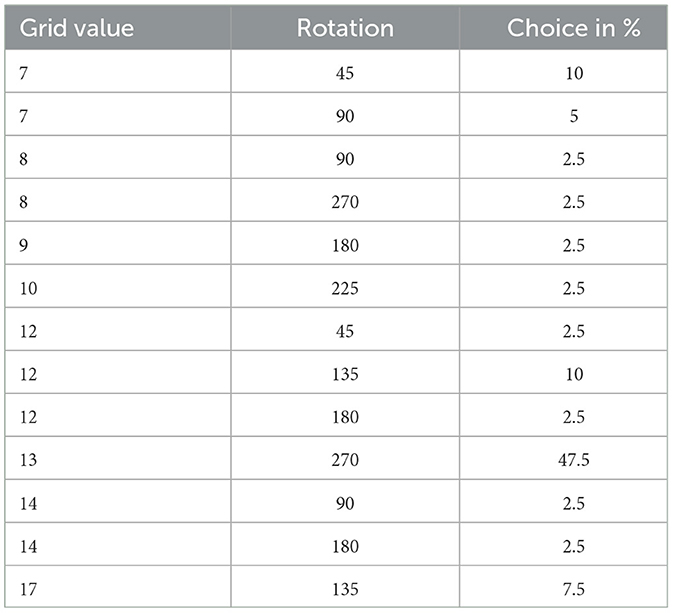
Table 1. Action frequencies of big triangle at initial phase.
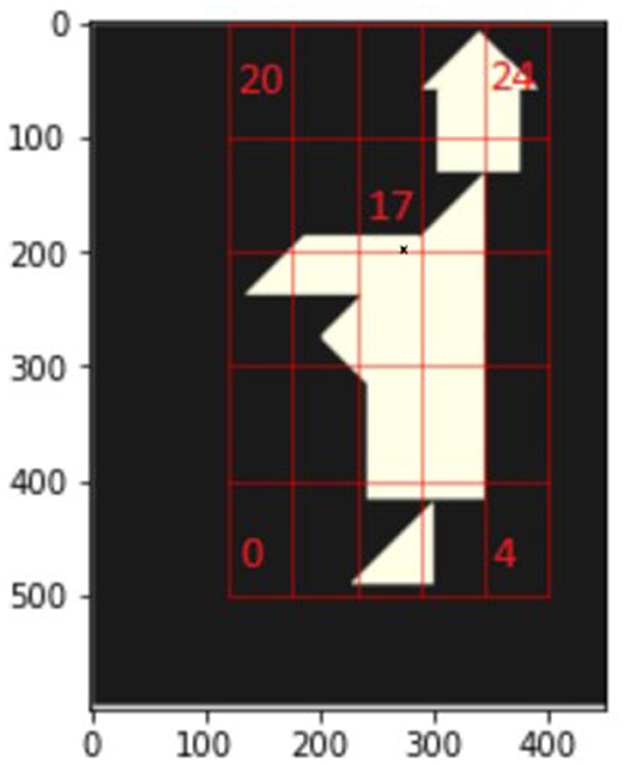
Figure 6. Grid layout of MONK.
The concept of backtracking involves any action or strategy aimed at removing or replacing tans that have already been moved into the silhouette. In a preliminary assessment of the data, we can observe two types of backtracking. The unfeasible region backtracking occurs when a region in the silhouette is considered unfeasible, i.e. it clearly cannot host any of the available pieces. Noticing the presence of such region clearly hints at the unfeasibility of the current partial solution and thus triggers backtracking. See Figure 7 for two examples. This type of backtracking should involve one (or all) the pieces creating the region, i.e. the pieces bordering with it. It is important to specify that this strategy triggers when the unfeasible region is noticed, not produced. It can thus be the case that further action are taken after its creation, but when the participant backtrack, they would first remove the problematic piece, possibly allowing following actions. This observation is called the UNFEASIBLE REGION BACKTRACK principle.

Figure 7. The uncovered areas in the HOUSE (left) and MONK (right) are unfeasible regions.
The second type of backtracking occurs even if no problematic regions are currently present. Participants might still decide to backtrack anyway. Possibly, the participants might have noticed that any further placement will trigger an unfeasible region, or that a previously placed tan did not result in a simple and clear path to the solution. In this case, there is not a clear candidate piece to be backtracked, but usually it can be expected that the piece that is not a BEST FIT might be a possible choice for backtracking. This observation is called the PIECE BACKTRACK principle.
The aforementioned principles appear to be present at different points in the solution process. Particularly, a common trend for a player is to start by exploiting the BEST FIT principle (see Section 4.1) until a mistake is made and an unfeasible region is found. In the analyzed Tangrams this often happens due to mistakes that can be traced back to the UNRECOGNIZED COMPOSITION (See Section 4.2 on initial placement errors). Backtracking follows, possibly combined with repetitions of combination mistakes, until a particular action is taken, which might trigger an aha moment [AHA MOMENT principle, see also Schulte (2005)]. The core strategy of the second phase was described as “random search” [RANDOM SEARCH principle, see also Wilson (2002)]: lacking clearer affordances, Aha moments can be often clearly noticed by video observations, as the search phase is followed by a very quick solution obtained by BEST FIT. Trials following these steps can thus be generally split in three phases: the starting phase, where BEST FIT is dominant, exploration phase, showing a combination of UNRECOGNIZED COMPOSITION, RANDOM SEARCH possibly including PIECE BACKTRACK and UNFEASIBLE REGION BACKTRACK (see Section 4.3), and eventually, the final phase, mostly including AHA MOMENT, characterized once more by BEST FIT.
In cases where the solution is accomplished by the minimal number of necessary steps, the starting phase and the final phase are present, but the exploration phase is missing.
We believe that the best way to understand how humans address sequential problem solving, or in particular, how they solve Tangrams, is by building a computational system which simulates their behavior. Therefore, we have developed the Cognitive Tangram Solver (CTS) framwork, whose aim is to behave as a human Tangram player. Given this objective, it was evident to implement the decision making process in a cognitive architecture. Cognitive architectures, especially in the form of hybrid architectures (combining symbolic and subsymbolic methods), can represent an interesting middle-ground approach to modeling the cognitive principles introduced in Section 4. The goal is to reproduce computationally the mechanisms of human cognition, using such mechanism as foundation and justification for the intelligent behavior of the system (Lieto et al., 2018). The theoretically founded nature of cognitive architectures imposes constraints and limits to the modeling process, but it provides also inherent explicability and plausibility properties once the system is functional. We chose the cognitive architecture ACT-R, as it provides a wide range of functionalities, is well established within the scientific community and has a very well documented manual (Bothell, 2022) including an extensive tutorial.
While solving a Tangram puzzle relies heavily on the visual perception (such as affordances, see Section 4.1) there is no such straightforward way to extract elaborate geometric shapes in an acceptable time through the visual module in ACT-R. Therefore, an additional visual-system module outside of ACT-R was developed to cover this functionality.
Figure 8 gives an overview of the different modules and their functions in the Cognitive Tangram Solver framework. The coordinator module (Section 5.1) handles the interaction of multiple sub-components (Section 5.2-5.4). These sub-components are distinct and provide various functionalities: the Tangram application module (Section 5.2) creates and updates the empirical study window, the visual-system module (Section 5.3) extracts “plausible” ACTION-OPTIONS in the current state and the cognitive model module (Section 5.4) performs the main reasoning task based on which it selects the next action.
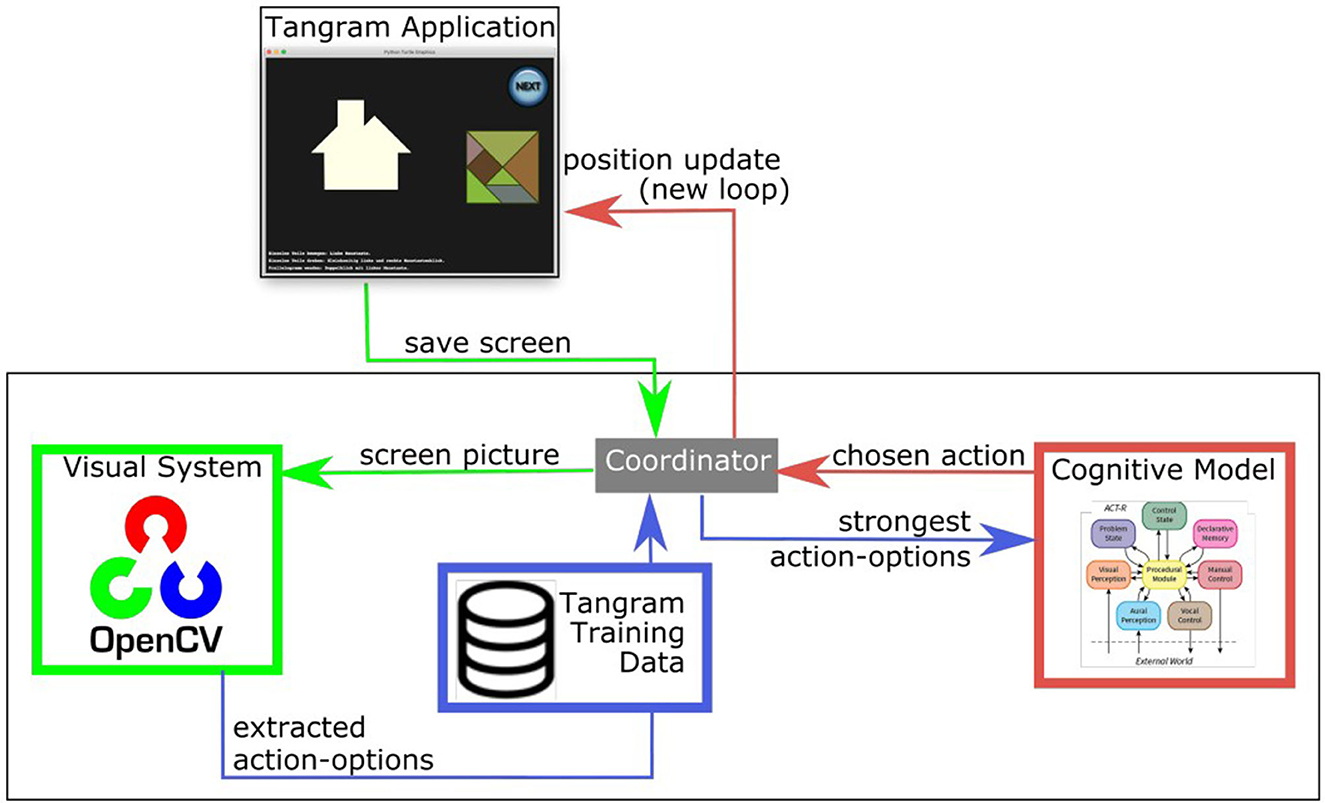
Figure 8. Overview of the Cognitive Tangram Solver framework.
The implementation of the Cognitive Tangram Solving and two videos that show the application in action can be found here: https://github.com/Thezamp/tangram-solver.
The coordinator is an application written in python, which is central as it provides the interfacing features between the other modules. It initializes the various sub-components, keeps an internal representation of the puzzle state and updates it according to the ACTION-OPTION chosen by the cognitive model.
An ACTION-OPTION is the interfacing element between the visual system, the training data and the cognitive model and based on the following assumptions: (1) cognitive principles have a strong influence on the decision making in Tangram (see Section 4) and (2) they are not all perceived and processed by humans in the same way and influence their decisions differently.
During Tangram solving, multiple cognitive principles might possibly influence different available actions. In order to abstract away from the single influence of one cognitive principle to one action, we introduce the concept of a unitary action choice, the ACTION-OPTION:
Action-Option. An area of the silhouette defines an action-option when the edges limiting such area can be (partly) overlapped with the edges of a given piece. Such action-option is then characterized by 1. its location, 2. the matching piece type and 3. a strength value representing the influence of the respective cognitive principle(s).
Besides the first two features that are mostly involved in the identification of the ACTION-OPTION, the third feature, the strength value allows comparing among different ACTION-OPTIONS.
The application of ACTION-OPTIONS to the Tangram solving strategy is as follows: At each step, the ACTION-OPTION with the highest strength defines the location and the tan TAN that best fits to this location, as most probably chosen by the player. This action is then expressed by the tuple (ACTION-OPTION, TAN). If no ACTION-OPTION with fitting TAN can be chosen, backtracking is necessary. In this case, from all previous actions, (ACTION-OPTION, TAN), the TAN that has the lowest frequency in training data will be chosen.
In order to provide interfacing functions, the coordinator maintains an internal “virtual” representation of the current state by storing the list of the chosen (ACTION-OPTION, TAN) still active (in the sense of actions taken and not backtracked) on the silhouette (i.e. the Tangram puzzle), together with the list of currently available ACTION-OPTIONS.
When the cognitive model responds with an ACTION-OPTION, the coordinator converts it into an actual action by creating the tuple (ACTION-OPTION, TAN) and updating the state as a consequence. This is required by the presence of tans of multiple types: while in principle an ACTION-OPTION already includes the involved piece type, it is necessary to keep track of which individual piece is still free, in order to avoid unintentional backtracking or re-using of a placed tan.
While the cognitive model module will provide the reasoning and eventually choose the ACTION-OPTION at each step, the processing and implementation into an actual action, (ACTION-OPTION, TAN), is then delegated to the coordinator. Methods are thus present to implement both updating and backtracking functionalities.
The empirical study window was derived by an existing Tangram demo application and included interactive features which allowed the users to manipulate and move the tans. While such features were not required in the developed model, as no simulation of motor functions was planned, most of the data gathered during the empricial study was framed in the context of the application. As a result, the same window environment was maintained for better correspondence, and the model runs on an adaptation of the code for the original empirical study, providing just two main functionalities: it updates the window to represent the current state, and it captures the window screen so that it can be forwarded to the visual system for processing.
An automated way to extract the ACTION-OPTION from the current puzzle's situation (or current context) from the empirical study window was required as hand-crafting the ACTION-OPTIONS for each available state was unfeasible due to the exponentially growing number of alternatives.
As a consequence, an external implementation based on classical computer vision techniques is proposed, its functionalities are limited by the following requirements in order to provide meaningful results: the algorithm should work on the silhouette edges, the algorithm should extract ACTION-OPTIONS that are plausibly exploited by humans, and the algorithm must associate an evaluation of the ACTION-OPTION's strength upon extraction.
The visual system was thus implemented in order to represent a structure cognitively inspired by the hierarchical structure of the human visual system. Given the strictly geometrical nature of the puzzle, and the fact that neurons in the primary visual cortex fire when matching certain oriented lines in the visual field (Hubel, 1982; Loffler, 2008), the algorithm simulates an hypothetical higher level construct able to identify certain line patterns representing the shapes.3 This was done via a pattern matching function applied on the edges of the current state and the template, using the sum of squared differences as similarity function.
Considering the binary nature of the images, a sum of absolute differences or a custom function might have been possible alternatives. However due to the amount of templates to match (for each shape and for each of its available rotations, which are discrete steps of 45°) the faster opencv (Bradski, 2000) implementation was preferred. Even though it is limited in the similarity functions options, it still provides acceptable results.
For each template, up to five candidate placements4 are extracted (parameter empirically chosen). These are then filtered for plausibility in two successive steps. First, it is checked whether the placement would intersect with other pieces currently placed, which can happen as the similarity function on edges might still tolerate limited intersection of corners. The second screening chooses only the placements that have some representation in the training data at the current phase of the solution.
The process is illustrated in Figure 9: the empirical study window returns the state of the puzzle and the image is binarized and its edges are extracted. For each possible rotation of each tan (here the small triangle at rotation 0 is shown, Figure 10 additionally shows the results for the other rotation angles), some potential matches are extracted. Finally the candidates are filtered for plausibility. The filtering also tackles an additional aspect: once an ACTION-OPTION is found its strength must be defined, which in turn will determine the baseline activation5 of the ACTION-OPTION in the model.
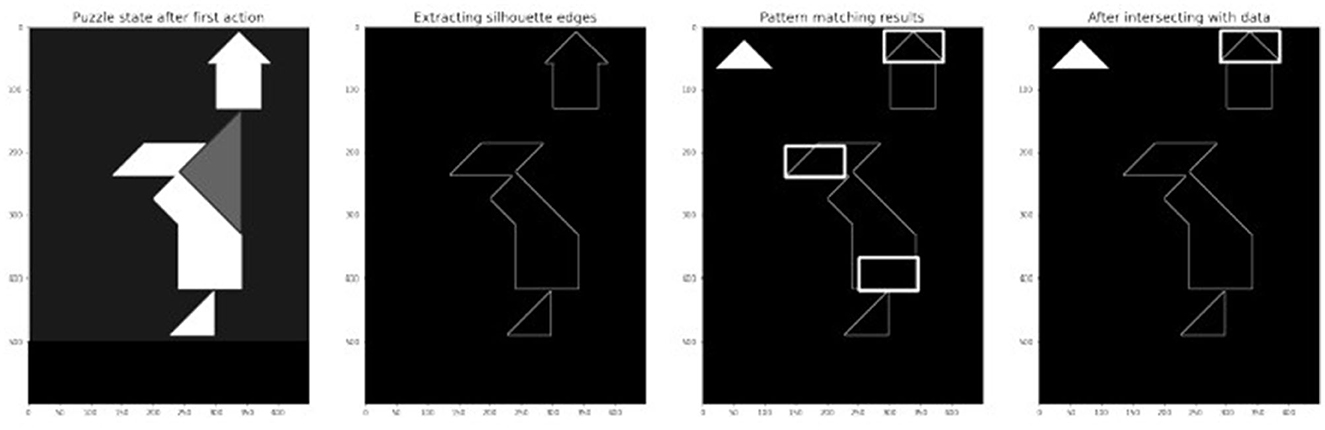
Figure 9. Steps of ACTION-OPTIONS extraction for small triangle at rotation 0.
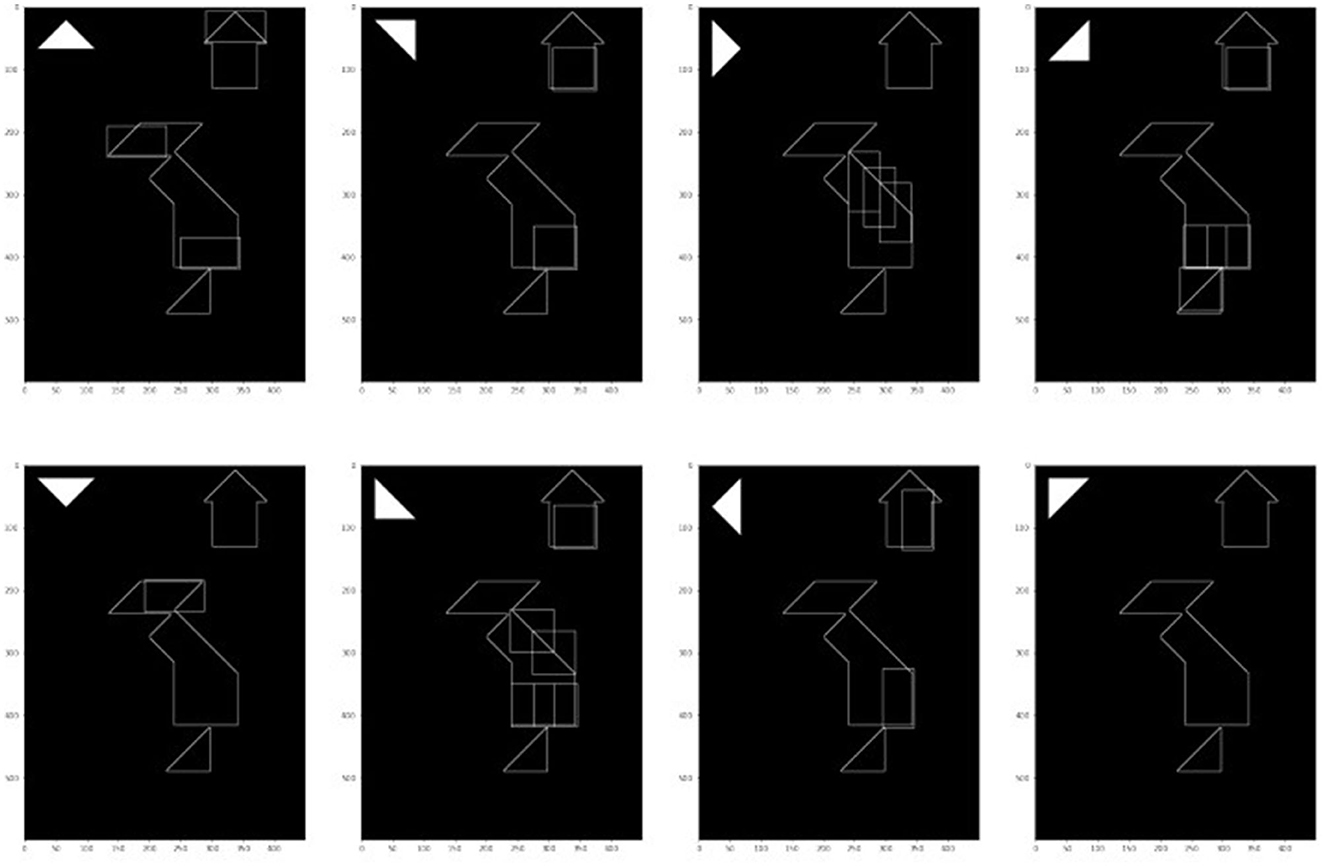
Figure 10. Results of the pattern matching for small triangles rotations, before intersecting with data.
The following equation takes into account the strength of the extracted ACTION-OPTION, based on similarity scores and the available data:
where

The values kd and kcv have been chosen empirically while performing the training. Motivated by the common assumption that the human's visual working memory is limited (Miller, 1956), only the six strongest ACTION-OPTIONS define the imaginal6 buffer to provide context and spreading activation.7 The number of ACTION-OPTIONS considered was chosen in order to be close to the 7 ± 2 from Miller's findings, but could probably be tuned as a parameter in further improvements of the framework.
It is thus possible to notice how the current implementation of the visual system has a particular focus on the aforementioned principle of Affordance (Section 4.1) coded as explicit pattern matching for the pieces. Nonetheless, frequency data from participants are also included in order to provide a proxy for the other principles.
Finally, the visual system attempts to recognize unfeasible regions (see Section 4.3, UNFEASIBLE REGION BACKTRACK principle). In principle, such regions are parts of the silhouette in which no tan can be placed respecting the rules. At the current state, they cannot be matched directly as they come in various different shapes and sizes, but a property of the task can be exploited to identify some of them: the silhouette area must eventually be fully covered and all available pieces used. Considering this, if at any point in time no available placement is found for a piece, it means that its area is split between two or more separate regions that cannot accommodate it. In such cases, the presence of a problematic region is found and the coordinator will tag the next action as uncertain.
The ACT-R model is tasked with choosing the next action to take at any given position, and it is mostly based on the baseline activation and spreading activation mechanisms. It mainly involves the goal module, the imaginal module, the declarative module and the procedural module.
After the processing from the visual system the current available action-options are extracted (Figure 11, left), added to the declarative memory (Figure 11, bottom left) and the six strongest are loaded into the imaginal buffer (Figure 11, bottom middle). In this context, the imaginal buffer represents the “most noticeable” action-options, and helps their retrieval by the spreading activation mechanism through the respective production rule (as an example consider the production rule in Figure 11, bottom right). The main task of the module is to retrieve an action-option from the declarative memory and forward the decision to the coordinator.
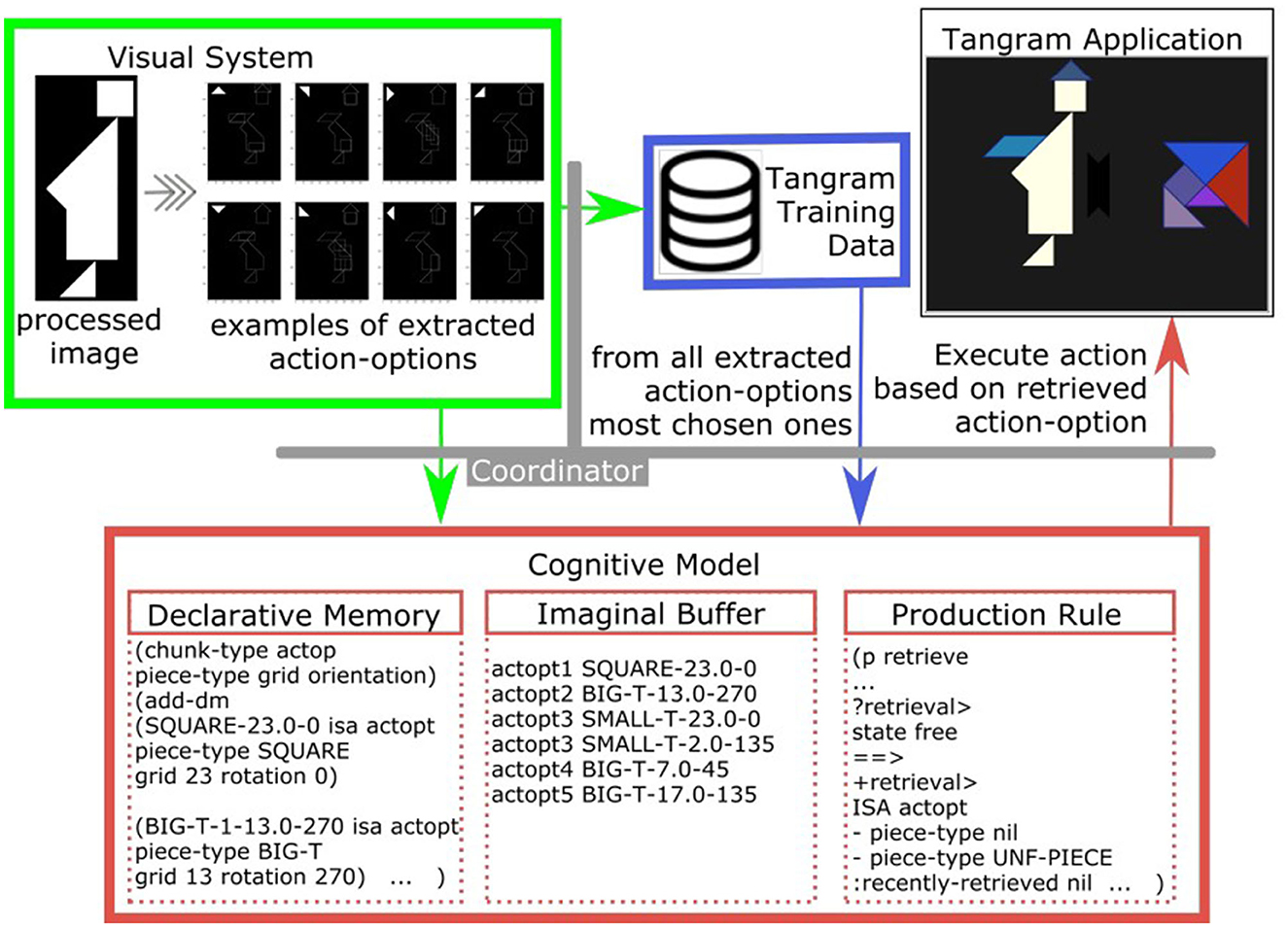
Figure 11. Example of action-options extraction in the visual system and their role in the model.
Using the spreading activation mechanism, the action-options currently in context will have the highest chance of being retrieved. Retrieved action options can trigger either one of two different production rules. If it involves a piece, then the action-option will be validated and forwarded for the status update. The alternatives are that either a unfeasible-region chunk is retrieved, or that a retrieval error happens as there is no available action-option, or due to noise and low strength no action-option was strong enough to be retrieved.
These two events correspond to the two types of observed backtracking explained in Section 4.3 and respectively trigger UNFEASIBLE REGION BACKTRACK and PIECE BACKTRACK action lines.
The interaction between the two types of backtracking should be noted: in some cases, a given incorrect placement of a piece does not create any recognizable unfeasible-region, but will cause all the following actions to be problematic. This will not be noticed by any of the two individual productions, but it will eventually be possible to backtrack by their combination. Due to the constraint on :recently-retrieved nil,8 after various iterations of the region_backtracking with no solution, no new action-options will be available. At this point the piece_backtracking will be triggered, which will remove the weakest action, which has been stored separately when the action was taken. At later phases of the solution, the problematic ACTION-OPTIONS will be less frequent, as more participants will actually have solved the puzzle, and its strength in the model will thus be lowered.
It must be noted that simplifications are also implemented in order to deal with UNFEASIBLE REGION BACKTRACK: as the model is currently not able to directly identify an unfeasible region, it instead relies on tagging chosen actions that become problematic. Thus the implementation of the strategy will differ from the suggested one by removing the first noticed action causing the problem and then proceeding in a queue-based manner until it is solved: a particular (production) rule will fire in the cognitive-model that will set the focus on solving the noticed issue until is not present anymore.
A slight simplification is also present with PIECE BACKTRACK: it will generally work as described, backtracking the action related to the weakest chosen action-option, but its strength will be determined uniquely by the frequency data and not any geometrical representation.
Due to the relative novelty of the topic, there are no clear metrics or benchmarks on how to evaluate the Cognitive Tangram Solver performance on given human performance data. Generally it seems a challenging task to find good evaluation methods for cognitive models as they consider different aspects that are relevant (e.g. standard deviation, response times). In the case of the Cognitive Tangram Solver, the focus is to imitate the solving process applied by humans in this puzzle setting, including their backtracking strategies, in order to anticipate their next steps. However, the absolute order of steps is often not relevant. Taking as an example the {, □, □} pattern in the solution of the HOUSE Tangram, it is possible to identify six possible sequences that can lead to the same pattern, any of which would be a desired behavior if shown by the model. A second challenge is that in the current implementation the model cannot distinguish between imagining and doing an action: a participant might realize while hovering over an area that the intended action will cause a problem region, and thus change the current placement (still considering as a single step). The Cognitive Tangram Solver does not implement “immediate thinking” and needs to actually conclude an action before possibly backtracking it. This is likely to cause longer solution procedures in case of mistakes.
In this section, we aim at providing the best possible picture of the behavior of the Cognitive Tangram Solver in relation to the human data. We first propose three variations of the CTS in Section 6.1. After that, Section 6.2 introduces four evaluation methods, including classical statistics and self-developed methods that focus on the solving process by humans, and provides the results with respect to the CTS variations.
The CTS framework includes a large number of parameters and design choices that can be optimized and discussed. Due to the exploratory nature of this work, and considering the additional need to identify acceptable metrics for evaluation, we decided to limit the analysis to few controllable and significant parameters. As a result, the CTS variations mostly differ on the relative weight of the parameters defining the strength of the ACTION-OPTIONS:
Vision-CTS The strength of an ACTION-OPTION is mainly defined by the template matching error function, applied by the template matching algorithm described in Section 5: the lower the error, the stronger the ACTION-OPTION. This implies a high influence from the BEST FIT principle.
Frequency-CTS The strength of a ACTION-OPTION is mainly guided by the participants data. ACTION-OPTIONS are extracted via template matching as described in Section 5, but the training set is the main contributor to the successive validation. This approach implies a high influence from the other principles.
Balanced-CTS The strength of a ACTION-OPTION is derived both by the data and the template matching. The frequency of choice suffers a penalty depending on the size of the template matching error. This approach is a combination of vision-CTS and frequency-CTS.
The evaluation was done for the HOUSE and the MONK tangram. The first three evaluation methods give us insights on how closely the Cognitive Tangram Solver reproduces data similar to the ones in the empirical study. For each of these versions, CTS ran 30 times and the runs where aggregated. The activation noise specified in ACT-R caused the variations. We will briefly describe each method in more detail and then show their results.
The mean and standard deviation of the number of steps to reach the solution is calculated and compared to the participants' data to evaluate compatibility. This is expected to be most affected by the difference between “imagining” and “doing” an action. Additionally, the ratio of “perfect solutions” is compared: to bypass the issue with imperfect backtracking, it is evaluated how often the participants and the model manage to solve the puzzle in the minimal number of steps (7, one per tan).
Table 2 shows the overall statistics. In this and the following tables, the evaluation value with respect to the test set is in brackets next to the evaluation value with respect to the training set. Comparing the mean and standard deviation of the participants' data and the three models, all three models seem to lie within the range of the training and the test set values. The last column shows the perfect strategy ratio, which is the fraction of participants that solved the puzzle with the minimum amount of steps (seven). It seems that there is quite a discrepancy between the training and the test set for both Tangrams. Additionally, the percentages seem to suggest that none of the puzzles was significantly more difficult than the other: for the HOUSE Tangram, 43% of the participants applied a perfect strategy, but in the test set it was only 22%. In the case of the MONK Tangram, the discrepancy between the training and the test set is not as high. 27% of the participants in the training set applied a perfect strategy, whereas in the test set, the percentage is slightly lower with 22%. When considering both sets, on average 38% and 25% of the participants applied the perfect strategy for HOUSE and MONK, respectively. Interestingly, the balanced-CTS's performance is similar to the participants' performance for HOUSE tangram, which is not the case for the MONK tangram. For both tangrams, the vision-CTS performs the best regarding the perfect-strategy ratio but also diverges most from the participants' performance. A difference between the groups is noticeable despite them still being comparable. This suggests a consistent variability between different participants, and might reduce the informative value of these statistical results. Nonetheless, by considering the mean and standard deviation, it is still possible to infer some degrees of accordance with the performances of the models which still show a degree of alignment to the data sets, especially in the case of HOUSE Tangram. The ratio of perfect solutions appears instead to be widely ranging even among the participants, and might thus not offer useful insights in the evaluation.
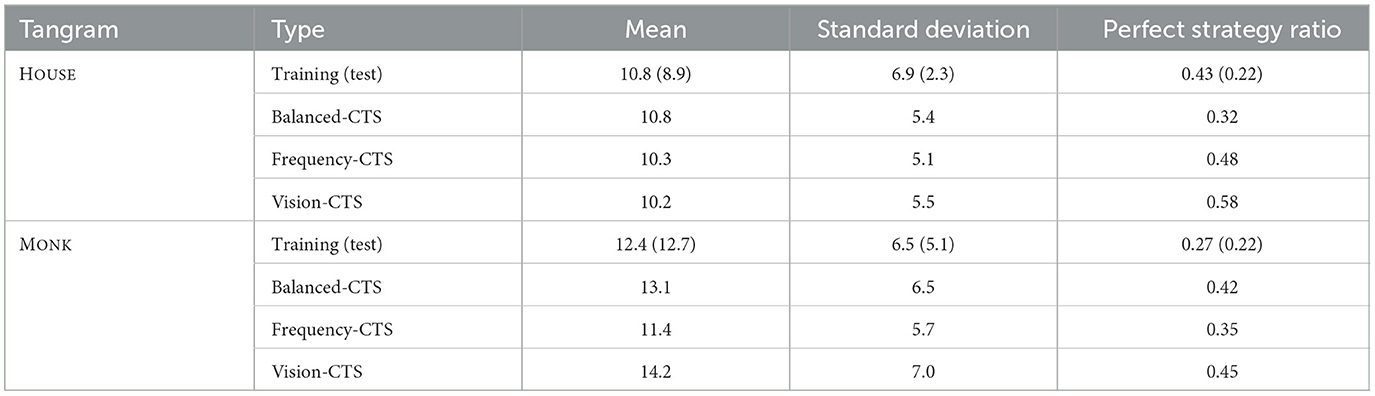
Table 2. Overall statistics for total steps counts (test set values in brackets).
During the analysis of data, heatmaps were produced which showed the relative frequency with which each tan type is chosen at each step. Even from a purely visual inspection, the heatmaps allow to consider similarities in the solution patterns. The data from model runs is thus similarly processed, and the results are compared. Following Schunn and Wallach (2005) we do not consider the or ANOVA, but use the root mean square error (RMSE) as the evaluation metric. The RMSE between the histograms at each step is calculated and averaged as follows:
where s is the step, p is the piece-type identifier, hs(p, model) is the frequency histogram value of piece-type p in the model, at step s and hs(p, data) is the frequency histogram value of piece-type p in the data, at step s.
The third column in Table 3 shows the heatmap RMSE and choice error. The heatmaps shown in Figure 12 give additional insights to their RMSE value. The horizontal axis denotes the step and the vertical axis denotes the tan that was chosen at this step. The darker the color of the bock, the higher the percentage of participants who have chosen the respective tan at that step. At first glance, the heatmaps of the data for both the HOUSE and MONK Tangram, are very similar to the heatmaps produced by the models. For the HOUSE tangram (heatmaps on the top left of Figure 12) a tendency to use the big triangles in the initial 1–4 steps and to use the small triangles in the last 5–10 steps can be observed in all heatmaps. The heatmap of the training data (left) shows lighter colors for these steps which indicates a more heterogenous group of the individuals. For the MONK tangram (four heatmaps in the bottom of Figure 12) a less strong tendency can be observed as the used tans among the different steps is more distributed.
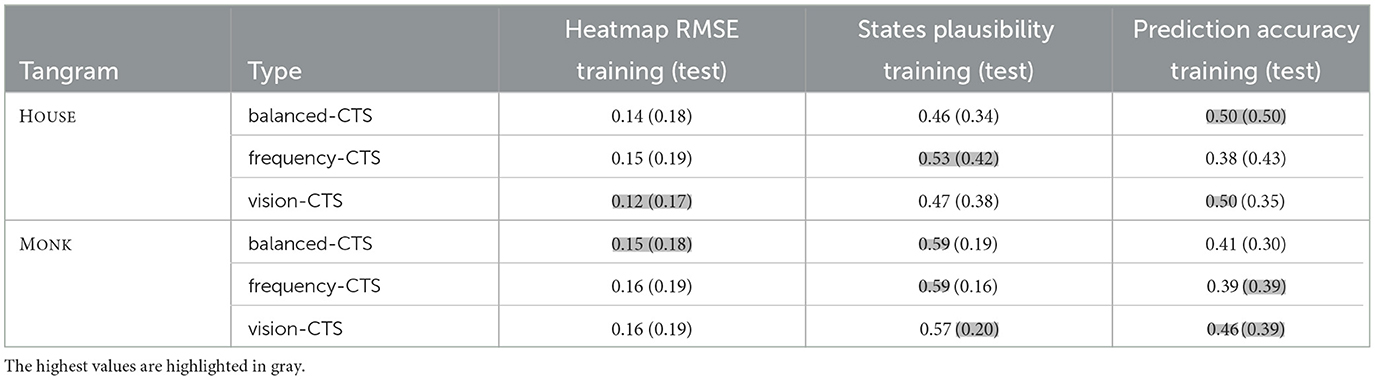
Table 3. Heatmap RMSE, plausibility and prediction accuracy of the three CTS variations (test set values in brackets).
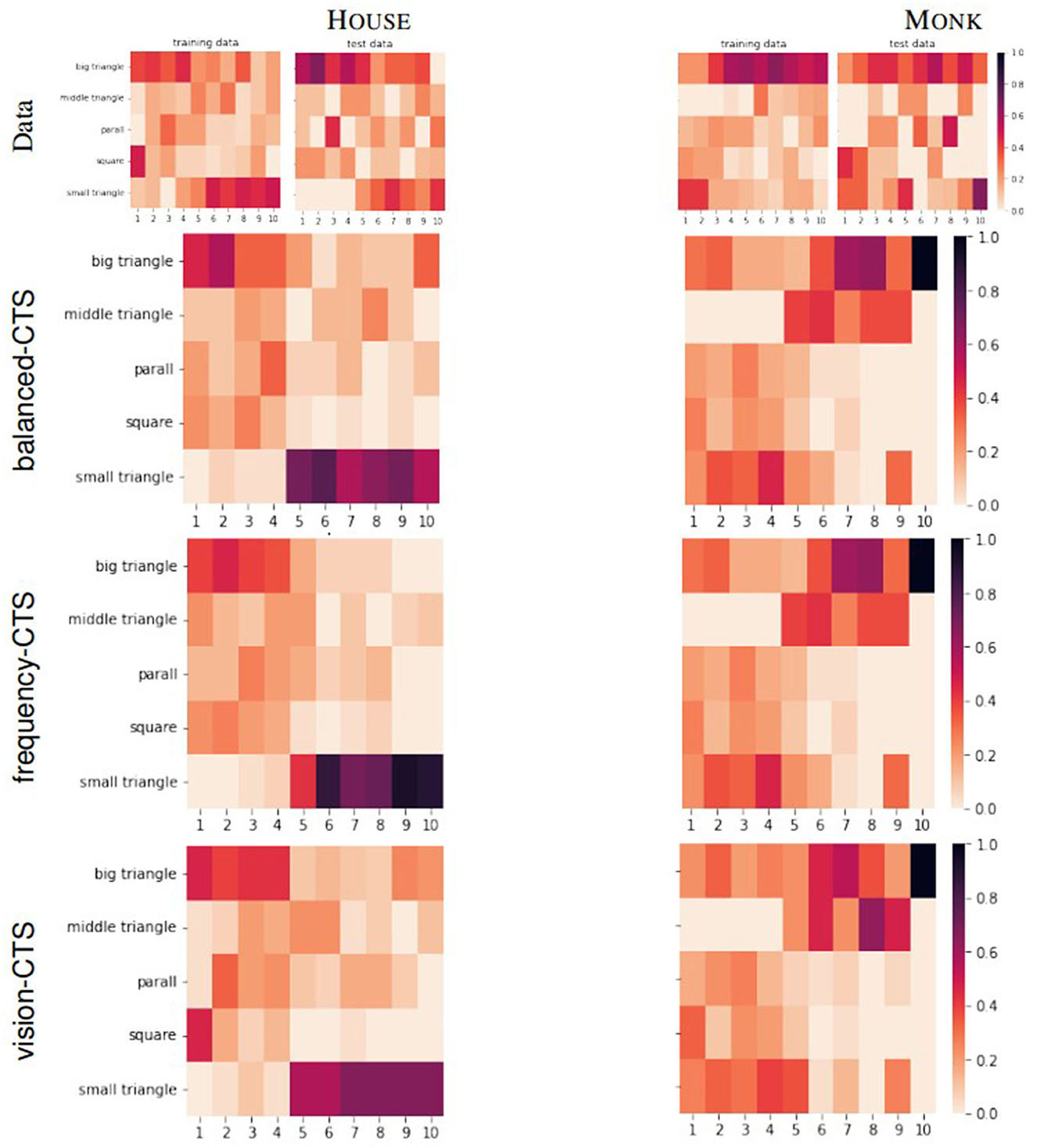
Figure 12. Heatmaps of the participants' data for HOUSE (left) and MONK (right) compared to the heatmaps produced by the three models.
The evaluation methods presented so far are widely used and helpful to compare the performance of different approaches. However, they do not give us any insight on whether CTS uses similar solving strategies as the humans, let alone how well CTS anticipates the humans' next steps. For this purpose, we developed two additional evaluation methods, the step-by-step states plausibility and the predictive accuracy. An elaborate discussion on their role will be given in Section 7.
First, we consider the plausibility of how the puzzle state evolves with the model's actions. In this regard a state consists in the list of (grid_loc, rotation) values for each tan that is currently placed inside the solution grid. The steps from 3 to mean+1*sd (varying on the puzzle) are considered, trying to capture the majority of the available data. Each state in the model runs is compared with the user states at step ± offset, where offset is a flexibility parameter increasing with the number of steps, in order to exclude mismatches due to longer backtracking. The overall accuracy of the model is then computed by considering the states presenting matches with the data over the overall number of model states.
The fourth column in Table 3 shows the step-by-step states plausibility. The plausibility values reflect whether the states obtained by the model at a given step also appear among the users' states around the same step, trying to provide a performance scoring that captures the plausibility of the model's strategy. It is possible to notice how generally all the models perform worse for the HOUSE Tangram, and significantly worse for the MONK Tangram. Predictably, the frequency model has generally high training-set performances, but it is interesting to notice how the vision model has instead relatively higher performance in the test set, suggesting once more how an affordance based on shape similarity might be guiding the strategy.
This last proposed evaluation metric also considers contextual information, and compares the model's actions in the context of the game sequence. It defines an accuracy evaluation when the framework is used as a predictor, predicting the next step when any participant is solving the Tangrams. By minimal changes in the CTS, it is possible to have it predict the plausible next action at any given step during a participant's solution process. Trying to predict the exact following move would likely be too restrictive: consider as an example the roof pattern in the HOUSE tangram as shown in Figure 4 left. Once the big triangle is placed, at the current state it would be hard to distinguish the reasoning for which the square would be placed before the parallelogram, or vice versa. As a consequence, a prediction is accepted as valid if the suggested action happens in the following 2 steps.
The last column in Table 3 shows the prediction accuracy. The predictive accuracy evaluates the anticipatory performance of the model by running the trials of the participants and having the model predict the following move (accepting up to two steps forward as a match, due to the lower importance of strict sequences). Once more, different models perform differently in the two Tangrams, with the vision model having overall better training set accuracy, and with the frequency model improving in test set accuracy.
It is generally possible to notice a certain degree of overfitting, which can be expected when including the training data, which is still mostly limited to 5-10 percentage units. While the models' performances have a significant variation between the Tangrams, in this aspect the frequency-CTS seems more accurate.
Summarizing the observed results, no system shows consistently better results with respect to the others, neither within nor between the different puzzles. It is still possible to notice how the vision-CTS has the best performance in most cases, which could point toward a certain importance of the affordance principle.
It must be noted how the three models only focused on a limited number of variable parameters (specifically, the relations between data and similarity score for the strength in ACTION-OPTIONS), but a more comprehensive study could probably benefit from extending the scope to other evaluations too.
In any case, as the framework was meant to be considered a proof-of-concept for the application of the described cognitive principles, we suggest for these results to be seen as a basic benchmark, to be used and expanded upon for future attempts and studies.
The intended contributions of the presented approach, which were presented in the introduction, can be summarized as: (a) an empirical study to an adequate problem solving geometrical task, (b) A novel hypothesis for human strategies for this task, and (c) A computational framework to reproduce the strategies and predict human behavior in the solution process. The first aspect is addressed by the design, the analysis and the results of the Tangram empirical study in Section 3. The second aspect to define hypotheses for human strategies, so-called cognitive principles, is addressed in Section 4. Finally, the third aspect is provided by the Cognitive Tangram Solver itself, which is a hybrid framework that integrates object recognition and cognitive modeling. This last aspect also includes an evaluating part, i.e. in how far the CTS is able to reproduce the strategies and predict human behavior in the solving process. This is addressed by the last two proposed evaluation methods in Section 6, the step-by-step stages plausibility and the prediction accuracy. Overall, even though CTS does not fully understand common mistakes, it can weakly anticipate the human's next steps: when CTS backtracks, we can assume that humans also has difficulties in finding a solution immediately.
Finally, as discussed in the introduction, the overall objective we are aiming at is the development of systems that can interpret the state of a task, in particular when there is no definite solution path. Even though the final goal is not known, the system needs to have a sense of anticipating difficulties and pitfalls, in order to predict individuals' traces of action and optimally support them whenever needed. As this objective contains a variety of highly demanding challenges, we have only addressed some of these challenges in a very controlled environment. The work presented offers a proof-of-concept showing the potentiality of the approach and justifies further studies in the field.
The presented approach can be improved in the future considering several aspects. It necessarily renounces some of the principles for practical implementation, a more fine-grained analysis that involves the strength definition should be considered.
In the specific case of this empirical study the available data were strictly dependent on the implementation of the empirical study window: the coordinates for the placements of the tans were expressed with respect to the empirical study window, and the tans themselves were defined as shapes within the framework. Even though most cognitive architectures provide a model of visual mechanisms, it seems that reproducing the setting purely within a architecture would likely have caused loss of precision in the shapes and coordinates definition, besides an additional overhead due to the lack of established methods for complex image manipulation. The development of visual recognition systems within cognitive architectures would be beneficial for the implementation of these types of tasks.
The datasets presented in this study can be found in online repositories. The names of the repository/repositories and accession number(s) can be found below: https://github.com/Thezamp/tangram-solver.
The requirement of ethical approval was waived by Ethics Committee of the Institute for Psychology and Ergonomics (IPA) at Technische Universität Berlin for the studies involving humans because Ethics Committee of the Institute for Psychology and Ergonomics (IPA) at Technische Universität Berlin. The studies were conducted in accordance with the local legislation and institutional requirements. The participants provided their written informed consent to participate in this study. Written informed consent was obtained from the individual(s) for the publication of any potentially identifiable images or data included in this article.
GZ implemented the original model of the CTS and performed the extraction and analysis of the model results, defining together with ED the metrics to be used. ED provided support and supervision during the model development and results analysis, worked as main reviewer for the manuscript, and contributed to most of its structure. LH organized the human experiment and gathered the data, analyzed the demographics of participants, contributed in the review of the results, and additionally she curated the bibliographic aspects and consistency. NR wrote most of the introductory sections, was heavily involved in the literary review for the related works, and also worked as supervisor in the cognitive aspects of the model. All authors collaborated in the related work section based on their expertise topics. All authors contributed to the article and approved the submitted version.
We acknowledge support by the German Research Foundation and the Open Access Publication Fund of TU Berlin. GZ thanks the University of Bologna and his internal supervisor prof. Giuseppe Di Pellegrino at the University of Bologna. The authors thank Arnd Schirmann from Airbus for the support of the empirical study.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
1. ^In the following, screenshots showing tans or Tangram puzzles are taken from an adapted version of http://python4kids.net/downloads/py4k_cda4/turtledemo-python31/tdemo_games/tangram.py.
2. ^Here, the correct placement of the triangle is defined by a discrete value in the 5 x 5 grid determined according to where the center point of its hypotenuse is located. For the big triangle this placement is shown in the MONK Tangram by the small black cross just above the horizontal line in location 17 in Figure 6. It must be noted that small pixel differences can influence grid values, thus introducing a noise component in the system.
3. ^However, the intention was not to reproduce participants' visual behavior such as processing times but to provide a model with the ability to recognize shapes.
4. ^Please notice that in the currently available version of the framework, such candidates are named “landmarks” and not “action-options”. This is due to a previous version of the framework which had a focus on the “technical” implementation, and will likely be changed in future revisions of the code.
5. ^In the ACT-R architecture, this represents the likelihood that a given piece of information is extracted from the declarative memory when a retrieval process is triggered (i.e. when asking to retrieve a “geometrical shape”, retrieving a square might be more likely than retrieving an hexagon).
6. ^ACT-R representation of information chunks related to the current task and context.
7. ^ACT-R mechanism that allows contextual information to influence retrieval: chunks in the imaginal buffer related to context and task increase the activation of information chunks in the declarative memory beyond the baseline activation (Bothell, 2022, p.290ff).
8. ^Parameter that will avoid the retrieval of the same action-option (and in general, informtion chunk) multiple times in a row.
Anderson, J. R. (2007). How Can the Human Mind Occur in the Physical Universe? Oxford: Oxford University Press.
Blum, S., Klaproth, O., and Russwinkel, N. (2022). Cognitive Modeling of Anticipation: Unsupervised Learning and Symbolic Modeling of Pilots' Mental Representations. Topics in Cognitive Science. Hoboken: John Wiley & Sons, Ltd.
Bohning, G., and Althouse, J. K. (1997). Using tangrams to teach geometry to young children. Early Child. Educ. J. 24:239–242. doi: 10.1007/BF02354839
Bothell, D. (2022). ACT−R7.26+ Reference Manual. Available online at: http://act-r.psy.cmu.edu/actr7.x/reference-manual.pdf (accessed May 15, 2023).
Brehmer, B. (1992). Dynamic decision making: human control of complex systems. Acta Psychol. 81, 211–241. doi: 10.1016/0001-6918(92)90019-A
Chater, N., and Oaksford, M. (1999). The probability heuristics model of syllogistic reasoning. Cogn. Psychol. 38, 191–258. doi: 10.1006/cogp.1998.0696
Dietz Saldanha, E., and Kakas, A. (2019). Cognitive argumentation for human syllogistic reasoning. KI - Künstliche Intelligenz 33, 229–242. doi: 10.1007/s13218-019-00608-y
Dietz Saldanha, E., and Schambach, R. (2020). “A computational approach for predicting individuals' response patterns in human syllogistic reasoning,” in Armstrong. Proceedings of the Annual Meeting of the Cognitive Science Society, eds. S. Denison, M. Mack, Y. Xu, and B. C. Sydney: Cognitive Science Society, 1247–1253.
Dietz, E., Fichte, J., and Hamiti, F. (2022). “A quantitative symbolic approach to individual human reasoning,” in Proceedings of the Annual Meeting of the Cognitive Science Society, eds. J. Culbertson, A. Perfors, H. R. and Ramenzoni, V. Sydney: Cognitive Science Society, 2838–2846.
Dietz, E., and Klaproth, O. W. (2021). “Towards benchmarking cognitive models: a python library for modular environment specification and partial model generation in act-r,” in Proceedings of the 19th International Conference on Cognitive Modeling (ICCM 2021). Vienna: AUT, 50–56.
Frutos-Pascual, M., Garca-Zapirain, B., and Mandez-Zorrilla, A. (2012). Improvement in cognitive therapies aimed at the elderly using a mixed-reality tool based on tangram game. Commun. Comput. Inf. Sci. 351, 68–75. doi: 10.1007/978-3-642-35600-1_10
García Zapirain, B., Méndez Zorrilla, A., and Larrañaga, S. (2010). Psycho-stimulation for Elderly People Using Puzzle Game. Hong Kong: IEEE.
Gibson, J. J. (2014). The Ecological Approach to Visual Perception: Classic Edition. London: Psychology Press.
Gomez Cubero, C., and Rehm, M. (2021). “Intention recognition in human robot interaction based on eye tracking,” in Human-Computer Interaction-INTERACT 2021: 18th IFIP TC 13 International Conference, Bari, Italy. Cham: Springer, 428–437.
Hubel, D. H. (1982). Exploration of the primary visual cortex, 1955-78. Nature 299, 515–524. doi: 10.1038/299515a0
Johnson-Laird, P. N. (1983). Mental Models: Towards a Cognitive Science of Language, Inference, and Consciousness. Cambridge, MA: Harvard University Press.
Judd, N., and Klingberg, T. (2021). Training spatial cognition enhances mathematical learning in a randomized study of 17,000 children. Nat. Human Behav. 5, 1548–1554. doi: 10.1038/s41562-021-01118-4
Kambhampati, S. (2020). Challenges of human-aware ai systems. AI Magazine 41, 3–17. doi: 10.1609/aimag.v41i3.5257
Kirschner, D., Velik, R., Yahyanejad, S., Brandster, M., and Hofbaur, M. (2016). Yumi, come and play with me! a collaborative robot for piecing together a tangram puzzle. Lect. Notes Computer Sci. 9812, 243–251. doi: 10.1007/978-3-319-43955-6_29
Klaproth, O. W., Halbrge, M., Krol, L. R., Vernaleken, C., Zander, T. O., and Russwinkel, N. (2020). A neuroadaptive cognitive model for dealing with uncertainty in tracing pilots' cognitive state. Top. Cognit. Sci. 12, 1012–1029. doi: 10.1111/tops.12515
Klein, G., Phillips, J. K., Rall, E. L., and Peluso, D. A. (2007). “A data-frame theory of sensemaking,” in Proc. of the Sixth International Conference on Naturalistic Decision Making, R. eds. R. Hoffman. Mahwah: Lawrence Erlbaum Associates Publishers, 113–155.
Klein, G., and Wright, C. (2016). Macrocognition: From theory to toolbox. Front. Psychol. 7, 54. doi: 10.3389/fpsyg.2016.00054
Knauff, M., and Gazzo Casta neda, L. E. (2021). When nomenclature matters: is the “new paradigm” really a new paradigm for the psychology of reasoning? Thinking & Reason. 0, 1–30. doi: 10.31234/osf.io/xz62y
Kosch, T., Woźniak, P. W., Brady, E., and Schmidt, A. (2018). “Smart kitchens for people with cognitive impairments: A qualitative study of design requirements,” in Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems (New York, NY: Association for Computing Machinery), 1–12. doi: 10.1145/3173574.3173845
Laird, J. E., Lebiere, C., and Rosenbloom, P. S. (2017). A standard model of the mind: toward a common computational framework across artificial intelligence, cognitive science, neuroscience, and robotics. AI Magazine 38, 13. doi: 10.1609/aimag.v38i4.2744
Lee, J., Lee, J. O., and Collins, D. (2009). Enhancing children's spatial sense using tangrams. Childh. Educ. 86, 92–94. doi: 10.1080/00094056.2010.10523120
Lieto, A. (2021). Cognitive Design for Artificial Minds. London, UK: Routledge, Taylor & Francis Ltd.
Lieto, A., Bhatt, M., Oltramari, A., and Vernon, D. (2018). The role of cognitive architectures in general artificial intelligence. Cognit. Syst. Res. 48, 1–3. doi: 10.1016/j.cogsys.2017.08.003
Loffler, G. (2008). Perception of contours and shapes: low and intermediate stage mechanisms. Vision Res. 48, 2106–2127. doi: 10.1016/j.visres.2008.03.006
Miller, G. A. (1956). The magical number seven, plus or minus two: Some limits on our capacity for processing information. Psychol. Rev. 63, 81–97. doi: 10.1037/h0043158
Oaksford, M., and Chater, N. (2020). New paradigms in the psychology of reasoning. Annu. Rev. Psychol. 71, 305–330. doi: 10.1146/annurev-psych-010419-051132
Polk, T. A., and Newell, A. (1995). Deduction as verbal reasoning. Psychol. Rev. 102, 533–566. doi: 10.1037/0033-295X.102.3.533
Premack, D., and Woodruff, G. (1978). Does the chimpanzee have a theory of mind? Behav. Brain Sci. 1, 515–526. doi: 10.1017/S0140525X00076512
Rips, L. J. (1994). The Psychology of Proof: Deductive Reasoning in Human Thinking. Cambridge, MA: The MIT Press.
Rossi, S., Ferland, F., and Tapus, A. (2017). User profiling and behavioral adaptation for hri: A survey. Pattern Recognit. Lett. 99, 3–12. doi: 10.1016/j.patrec.2017.06.002
Scharfe-Scherf, M. S. L., Wiese, S., and Russwinkel, N. (2022). A cognitive model to anticipate variations of situation awareness and attention for the takeover in highly automated driving. Information 13, 418. doi: 10.3390/info13090418
Schulte, K. M. (2005). Lernen durch Einsicht. Erweiterung des gestaltpsychologischen Lernbegriffs. 1. Aufl. Forschung Pdagogik. Wiesbaden: VS Verl. fr Sozialwissenschaften.
Schunn, C. D., and Wallach, D. (2005). “Evaluating goodness-of-fit in comparison of models to data,” in Psychologie der Kognition Reden und Vorträge anlässlich der Emeritierung Tack, eds. H. von Werner H. Saarbrücken, Germany: University of Saarland Press, 115–154.
Weidemann, A., and Russwinkel, N. (2021). The role of frustration in human-robot interaction-what is needed for a successful collaboration? Front. Psychol. 707, 640186. doi: 10.3389/fpsyg.2021.640186
Wilson, M. (2002). Six views of embodied cognition. Psychonomic Bullet. Rev. 9, 625–636. doi: 10.3758/BF03196322
Keywords: cognitive modeling, hybrid (symbolic sub-symbolic) approach, sequential problem solving, anticipation, human-robot collaboration (HRC)
Citation: Zamprogno G, Dietz E, Heimisch L and Russwinkel N (2023) A hybrid computational approach to anticipate individuals in sequential problem solving. Front. Artif. Intell. 6:1223251. doi: 10.3389/frai.2023.1223251
Received: 29 May 2023; Accepted: 28 November 2023;
Published: 18 December 2023.
Edited by:
Thomas Hartung, Johns Hopkins University, United StatesReviewed by:
Manuel Gentile, Institute for Educational Technology - National Research Council of Italy, ItalyCopyright © 2023 Zamprogno, Dietz, Heimisch and Russwinkel. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Linda Heimisch, aGVpbWlzY2hAdHUtYmVybGluLmRl; Giacomo Zamprogno, Zy56YW1wcm9nbm9AdnUubmw=
†Present address: Giacomo Zamprogno, Department of Computer Science, Vrije Universiteit Amsterdam, Amsterdam, Netherlands
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.