 Graziella Orrù
Graziella Orrù Andrea Piarulli
Andrea Piarulli Ciro Conversano
Ciro Conversano Angelo Gemignani
Angelo Gemignani
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Artif. Intell., 24 May 2023
Sec. AI for Human Learning and Behavior Change
Volume 6 - 2023 | https://doi.org/10.3389/frai.2023.1199350
Backgrounds: The field of Artificial Intelligence (AI) has seen a major shift in recent years due to the development of new Machine Learning (ML) models such as Generative Pre-trained Transformer (GPT). GPT has achieved previously unheard-of levels of accuracy in most computerized language processing tasks and their chat-based variations.
Aim: The aim of this study was to investigate the problem-solving abilities of ChatGPT using two sets of verbal insight problems, with a known performance level established by a sample of human participants.
Materials and methods: A total of 30 problems labeled as “practice problems” and “transfer problems” were administered to ChatGPT. ChatGPT's answers received a score of “0” for each incorrectly answered problem and a score of “1” for each correct response. The highest possible score for both the practice and transfer problems was 15 out of 15. The solution rate for each problem (based on a sample of 20 subjects) was used to assess and compare the performance of ChatGPT with that of human subjects.
Results: The study highlighted that ChatGPT can be trained in out-of-the-box thinking and demonstrated potential in solving verbal insight problems. The global performance of ChatGPT equalled the most probable outcome for the human sample in both practice problems and transfer problems as well as upon their combination. Additionally, ChatGPT answer combinations were among the 5% of most probable outcomes for the human sample both when considering practice problems and pooled problem sets. These findings demonstrate that ChatGPT performance on both set of problems was in line with the mean rate of success of human subjects, indicating that it performed reasonably well.
Conclusions: The use of transformer architecture and self-attention in ChatGPT may have helped to prioritize inputs while predicting, contributing to its potential in verbal insight problem-solving. ChatGPT has shown potential in solving insight problems, thus highlighting the importance of incorporating AI into psychological research. However, it is acknowledged that there are still open challenges. Indeed, further research is required to fully understand AI's capabilities and limitations in verbal problem-solving.
The use of machine learning (ML) in psychology is becoming increasingly widespread. Large amounts of data generated in psychological studies can be effectively analyzed and interpreted using ML algorithms. Such methods can assist researchers in identifying patterns and relationships in data that are not immediately obvious. ML algorithms can, for example, be used to analyse brain imaging data and identify features associated with various neurological or psychiatric disorders (Orrù et al., 2012, 2021; Ferrucci et al., 2022), or in overlapping futures of chronic conditions (i.e., fibromyalgia: Orrù et al., 2020a) which are particularly frequent (Dell'Osso et al., 2015). ML can be effectively applied in a range of fields such as forensic sciences (malingering: i.e., Sartori et al., 2017; Pace et al., 2019; personality faking-good: i.e., Mazza et al., 2019) and psychological research (Orrù et al., 2020b), amongst others.
New ML models such as large language models (LLM) are purportedly the promoters of a recent “paradigm shift” in artificial intelligence-based (AI-based) language analysis. Indeed, LLMs are sophisticated AI systems that are trained on vast amounts of textual data. These models have the ability to generate human-like language and perform a wide range of language tasks such as translation, question-answering and sentiment analysis, amongst others. These models, like the Bidirectional Encoder Representations from Transformers (BERT) and the Generative Pre-trained Transformer (GPT) and their chat-based variations (i.e., ChatGPT), have produced previously unheard-of levels of accuracy (Devlin et al., 2018) in most computerized language processing tasks and have recently gained widespread attention. GPT is a language model created by OpenAI. The latest and most advanced language model developed is known as GPT and has been trained on a massive amount of text data from the internet. It can generate human-like text and perform various language tasks such as translation, summarization, question answering and coding. GPT-3 enables a personalized conversation with an AI bot capable of providing detailed responses to questions (prompts) at significant speed. Specifically, GPT-3 is a deep learning autoregressive language model (a simple feed-forward model), that produces human-like text from a set of words given in a specific context. In general terms, the ability of the LLM to mathematically represent words in context is presumably largely responsible for its success.
The Transformer-based model is a specific neural network architecture introduced by Vaswani et al. (2017) in “Attention is all you need” (2017) and has become the foundation of many state-of-the-art models in Natural Language Processing (NPL), including GPT-3. The main innovation of transformer architecture is the use of attention mechanisms, which allow the model to selectively focus on different parts of the input during its processing, and thus to understand more effectively the relationships between words and phrases in the input. Specifically, attention allows the association of distant portions of text within a sentence; for example, it enables the understanding that in the sentence “the boy chasing the horse is fat,” “fat” refers to the boy and not the horse. LLMs are massive neural networks, consisting of billions of parameters, that are trained on vast quantities of text and rely on an attention mechanism. One of the most efficient training systems is the one used in GPT-3, which involves predicting the next word in a sentence; for example, by displaying the sentence “the dog barks and the cat…,” it predicts the word “meows.”
Fine-tuning is a method used for training a pre-trained transformer-based model on a new dataset, with the aim of adapting it to a specific task. This is achieved by training the model on a smaller dataset that is specific to a certain task, while maintaining the weights from the pre-trained model fixed. This procedure enables the model to employ the knowledge that it has learned from the larger dataset to quickly learn how to perform a new task.
The purpose of the present work was to evaluate the ability of ChatGPT in solving verbal insight problems from two sets of problems, both of which were originally solved by a group of 20 human participants in a study conducted by Ansburg and Dominowski (2000). The aim of this evaluation was twofold: firstly, to determine whether ChatGPT could solve these types of verbal insight problems, which are typically associated with human intelligence and have been previously considered challenging for computers to solve; secondly, to compare ChatGPT's problem-solving abilities to those of humans, as established in the mentioned study.
Overall, the present study sought to assess the potential of ChatGPT as an intelligent tool for problem-solving and to explore the extent to which machine intelligence can match or surpass human intelligence in this domain.
In the sections that follow, the study begins by providing (i) a framework to better understand problem-solving; (ii) a summary of the state-of-the-art classification techniques used in speech contexts and of the transformer architecture, emphasizing the components involved in encoding and decoding; (iii) the major findings are then presented; (vi) finally, the difficulties involved, and potential futures directions are discussed.
To comprehend insight problem-solving, key terms must first be defined. Problem-solving is defined as a set of cognitive processes aimed at transforming a given circumstance into a desirable scenario when there is no clear solution (Mayer and Wittrock, 2006). In other words, it represents the process of finding a solution to a problem or a set of problems that involves the use of different strategies or techniques to overcome obstacles and reach a specific goal, “when no solution method is obvious to the problem solver” (Mayer, 1992). There are different approaches to problem-solving, including analytical, creative, and intuitive methods: analytical methods involve breaking down the problem into smaller parts and systematically analyzing each part to find a solution (i.e., Polya, 2004); creative methods involve generating new and unique ideas to solve the problem; intuitive methods involve the use of past experiences and knowledge to inform the problem-solving process. Problem-solving has been thoroughly investigated by cognitive science in general with a number of theories and models being put forward. One of the most influential theories is the “General Problem Solver” (GPS) hypothesis of Newell and Simon (1972) which states that problem-solving is a logical and systematic process that adheres to a set of norms and processes. Another important theory is the “Dual-Process Hypothesis” (DPT), proposed by Kahneman (2011), which suggests that problem-solving can be achieved through both quick, intuitive processes (System 1) and slow, deliberate processes (System 2). A further problem-solving method is known as “Insight” can be defined as the unexpected development of a new concept or a fresh perspective on the issue and it is frequently characterized by an “Aha!” moment. Insight problem-solving has been extensively studied by cognitive psychologists and was first described by Wallas (1926) as a four-stage process consisting of preparation, incubation, illumination, and verification.
In end-to-end sequence classification, ML, and specifically deep learning, are becoming increasingly popular. This type of classification requires only a single model to learn all those stages in between initial inputs and the final outputs. There are two basic methods for analyzing sequential data in text or speech; these methods are referred to as Transformers and Recurrent Neural Networks (RNNs).
A transformer-based model, as mentioned above, is a type of neural network architecture introduced by Vaswani et al. (2017). The key innovation of the transformer is the self-attention mechanism, also known as intra-attention, which connects “different positions in a single sequence to compute a representation of the sequence” according to the authors. Self-attention allows the model to evaluate the importance of different parts of the input when making a prediction. Reading comprehension, meaningful summarization, and learning task-independent sentence representations have all been effectively implemented with self-attention using transformer architecture, which has been widely employed in a wide range of NPL processing applications (i.e., BERT and GPT-2), serving as the foundation for a number of pioneering models (i.e., Parikh et al., 2016; Petrov et al., 2016). In contrast, RNNs, the predecessors to transformers, process inputs sequentially word after word (i.e., text or speech) and struggle with long-range dependencies (Li et al., 2018). In an RNN, the hidden state of the network at each timestep is a function of the hidden state at the previous timestep and the current input. This means that the prediction at each timestep depends on predictions at all previous timesteps, making it difficult to parallelize computation (Le et al., 2015). RNNs generate a vector from a sequence in order to capture the meaning of an entire sentence, a strategy that performs poorly when dealing with long and complex sentences. In this context, the transformer architecture was specifically designed to overcome this RNN limitation by introducing a self-attention mechanism.
Most competitive neural sequence transduction models, such as those used in NLP tasks, have an encoder-decoder structure. The encoder-decoder structure was first introduced in the paper “Sequence to Sequence Learning with Neural Networks” by Sutskever et al. (2014). They suggested employing RNNs for both the encoder and the decoder. This architecture was later improved by the incorporation of the attention mechanism, which allows the decoder to evaluate the importance of different parts of the input when generating the output, as proposed in “Neural Machine Translation by Jointly Learning to Align and Translate” by Bahdanau et al. (2014). This structure consists of two main components: an encoder, which processes the input sequence and produces a fixed-length representation, and a decoder, which generates the output sequence based on the fixed-length representation, for example in a machine translation application from Italian to English (Figure 1).
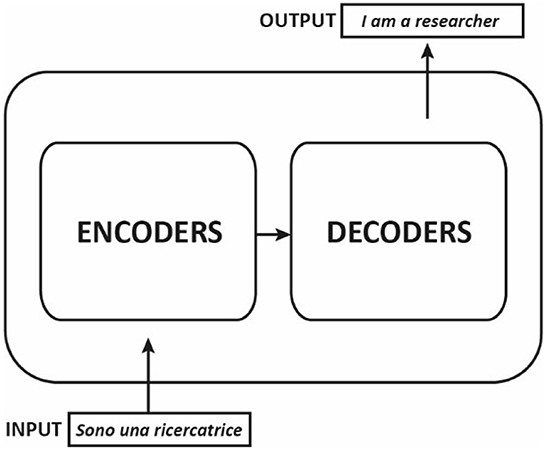
Figure 1. Encoding and decoding components in a machine translation application.
Each encoder has the same structure and is made up of two sub-layers: Self-Attention and Feed Forward Network. Encoder inputs first pass through a self-attention layer, which assists the encoder in looking at other words in the input sentence while encoding a specific word. Self-attention layer outputs are fed into a feed-forward neural network. The same feed-forward network is applied to each position independently. Both layers are also present in the decoder yet between them is an attention layer, the encoder-decoder attention, that assists the decoder in focusing on relevant parts of the input sentence such as constituents, dependencies, semantic roles and coreferences, among others (Figure 2).
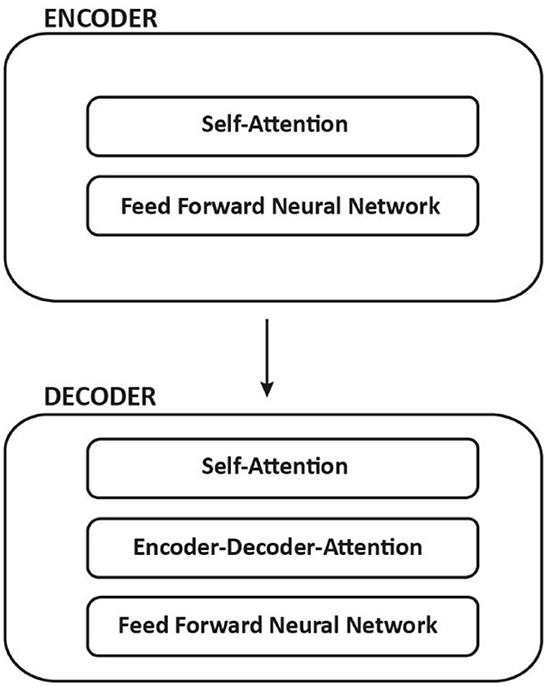
Figure 2. Encoder and decoder structure and sublayers.
Thirty verbal insight problems were administered to ChatGPT, as listed in the study by Ansburg and Dominowski (2000): the first set of 15 problems was referred to as “practice problems,” while the second set of 15 problems was referred to as “transfer problems” (see Ansburg and Dominowski, 2000; Appendix A, p. 54–59). The two sets of problems were only used to verify the ability of ChatGPT to solve verbal problem-solving tasks, not to replicate their experimental procedure.
Before beginning the administration of verbal insight problems to ChatGPT, a contest was created (known as a prompt in LLM jargon) for ChatGPT with the following short instruction: “Try to solve this practice problem. The first one is the following” and the first practice problem was provided: “A farmer in California owns a beautiful pear tree. He supplies the fruit to a nearby grocery store. The store owner has called the farmer to see how much fruit is available for him to purchase. The farmer knows that the main trunk has 24 branches. Each branch has exactly 6 twigs. Since each twig bears one piece of fruit, how many plums will the farmer be able to deliver?”. In this case ChatGPT failed to solve the problem and the feedback “The answer provided is not correct” was provided. It was then fed with “control instructions” (CI) (see Ansburg and Dominowski, 2000, Appendix B, p. 59) before solving the first problem again. After the second failure, the ChatGPT was provided with “strategic instructions” (SI) (see Ansburg and Dominowski, 2000, Appendix C, p. 60). The CI and SI were listed by Ansburg and Dominowski (2000; p. 59–60). The remaining verbal tasks were then subsequently presented, and relevant feedback was provided to ChatGPT based on the correct/incorrect answer given, such as “The answer is correct. The correct answer is + solution” or “The answer is not correct. The correct answer is + solution.”
The ChatGPT (Jan. 9, 2023) was employed. As stated above, a total of 30 problems, labeled “practice problems” and “transfer problems” (see the study of Ansburg and Dominowski for more information) were administered to ChatGPT. According to the solutions for the practice problems and transfer problems described by Ansburg and Dominowski (2000), the score “0” was assigned for each problem which ChatGPT answered incorrectly and “1” was attributed for each correct answer. For the two sets of 15 problems, the maximum score attributable was 15. For an exhaustive overview of the administered problems and of human sample and ChatGPT's performance refer to Tables 1, 2. The performance of ChatGPT was compared to that of the human sample by using the solution rate to each problem (Tables 1, 2) wich was derived from Ansburg and Dominowski (2000)'s study based on a sample of 20 subjects. Our intention was to utilize only the stimuli from Ansburg and Dominowski, rather than replicate the study itself.
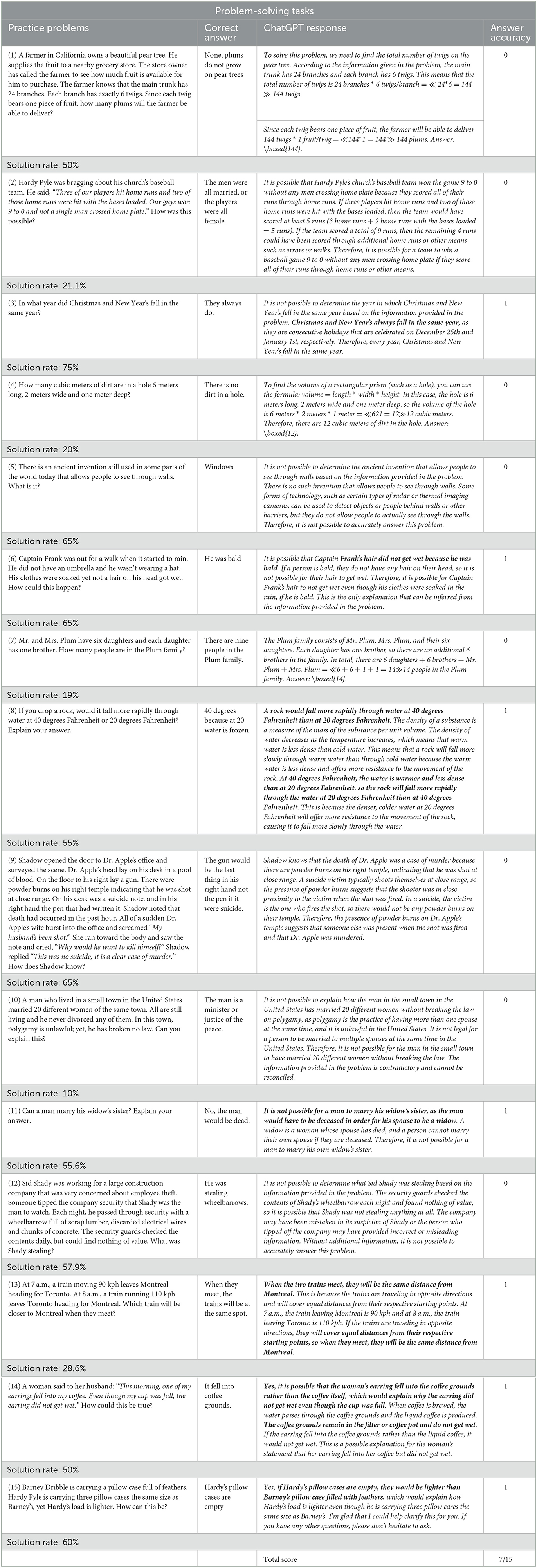
Table 1. Problem-solving tasks: the 15 practice problems and solutions (correct answers), ChatGPT answers, the score attributed (answer accuracy) and solution rate of the human sample.
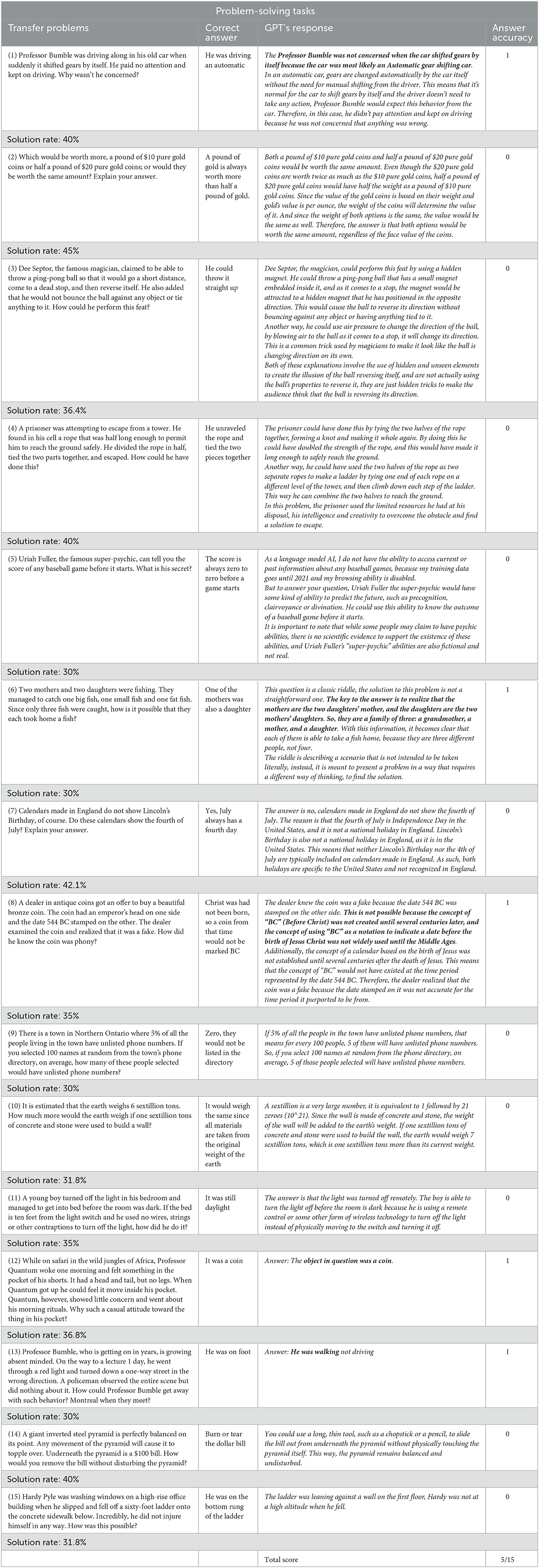
Table 2. Problem-solving tasks: the 15 transfer problems and solutions (correct answers), ChatGPT answers, the score attributed (answer accuracy) and solution rate of the human sample.
Putative between-set differences were estimated both for ChatGPT and for the human sample (n = 20). In the former case significance was assessed using Fischer Exact Test, while in the latter by performing a Wilcoxon rank sum test on the solution rates. Unless otherwise stated, descriptive statistics are presented as median and interquartile ranges (25 percentile-75 percentile).
For both problem sets, the probability distribution related to each possible total score (i.e., number of correct answers) on the human sample (see Supplementary material 1) was estimated. Note that the most likely outcome is the score showing the higher occurrence probability.
The kth score probability was obtained as follows:
- The set of all possible answer combinations was first identified, producing the desired score. As an example, let us consider a score of three (three correct answers out of fifteen): such a score can be obtained by various combinations of answers, their number equalling the binomial coefficient . Given a set of n items (problems/answers, n = 15), for each kth score (kth ranging from 0 to 15), all answer combinations composed by k correct answers were identified (the total number of combinations is equal to: ).
- As a second step, the probability associated with the ki combination was computed, ( as:
- Finally, the total probability of obtaining a total score of kth was obtained as the sum of the related probabilities over the entire set of combinations (): .
For each set of problems, the most likely outcome in the human sample was compared (i.e., the total score showing the highest occurrence probability) to the total score obtained by ChatGPT. It should be noted that this test accounts for the similarities between humans and ChatGPT global performance on a set of problems irrespective of paired differences/similarities related to the performance on the single problems within the set.
Among possible answer combinations leading to a total score equal to that obtained by ChatGPT, those corresponding to ChatGPT answer combinations were identified and subsequently compared to the occurrence probability of all other answer patterns leading to the same total score. This procedure was applied both problems.
The same analyses were then conducted by pooling together the two problem sets. This choice was motivated by the utility of having a general view of ChatGPT performance as compared to that of the human population, independently of the problem type and the related solution strategy. The appropriateness of the pooling in based on the fact that the number of problems is balanced across the two sets (15 problems each).
The performance of ChatGPT on practice and transfer problems are shown in Tables 1, 2, respectively. Each table displays the problems assigned to ChatGPT as well as the proper solutions (correct answers), ChatGPT answers, the score obtained (answer accuracy) and the solution rate of the human sample.
The performance of ChatGPT was subsequently compared with those of a sample of individuals (n = 20) in the two sets of problems.
ChatGPT answered correctly to seven problems out of fifteen in the case of the practice problems, and to five out of fifteen in the case of transfer problems: the ChatGPT performance between-set difference was not significant (Fischer Exact Test, p < 0.72, see Supplementary material 2). Human sample solution rates were respectively 0.55 (0.23–0.64) on the Practice set, and 0.35 (0.30–0.40) on the transfer set. While the solution rate was higher for the former set as compared to the latter, the between-set difference was not significant (Wilcoxon rank sum test, z = 1.29, p < 0.20, see Supplementary material 3).
Notably, for both sets of problems, ChatGPT performance (i.e., the number of correct answers) was equal to the total score of the human sample showing the highest occurrence probability, as clearly apparen from Figures 3A, B.
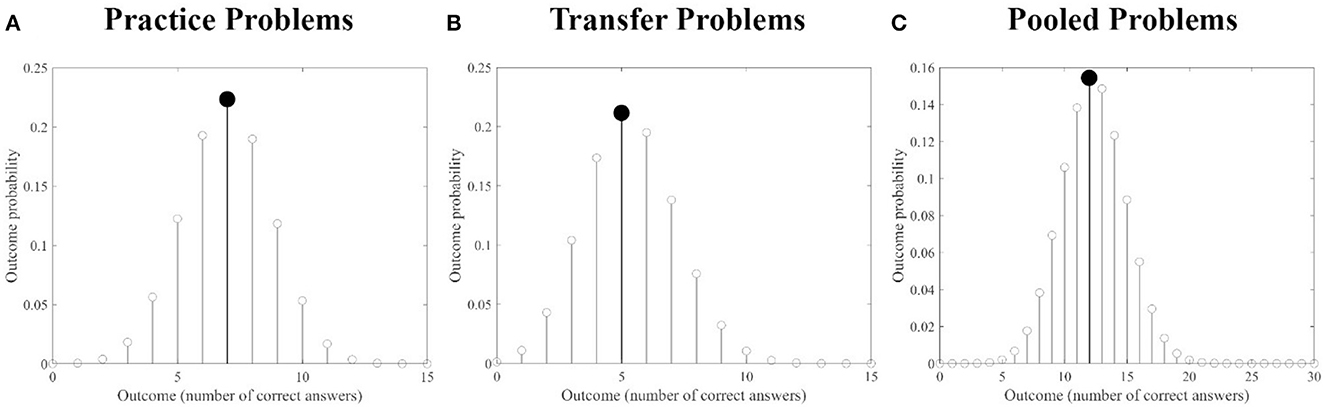
Figure 3. Human sample outcome probabilities: outcome probabilities for each possible total score (i.e., number of correct answers, range 0–15) are presented for the Practice set (A), the Transfer set (B) and the pooled set [(C), Practice + Transfer Problems]. In each plot, the outcome with the highest probability is highlighted in black. Notably, the total score with the highest probability is equal to the performance of ChatGPT for both for each set of problems and for the pooled set.
For each problem set, all answer combinations leading to the total ChatGPT score was identified (see Figures 4A, B) and their occurrence probability on the human sample estimated (see Figures 3A, B). For each set, the ensemble of combinations included that of ChatGPT:
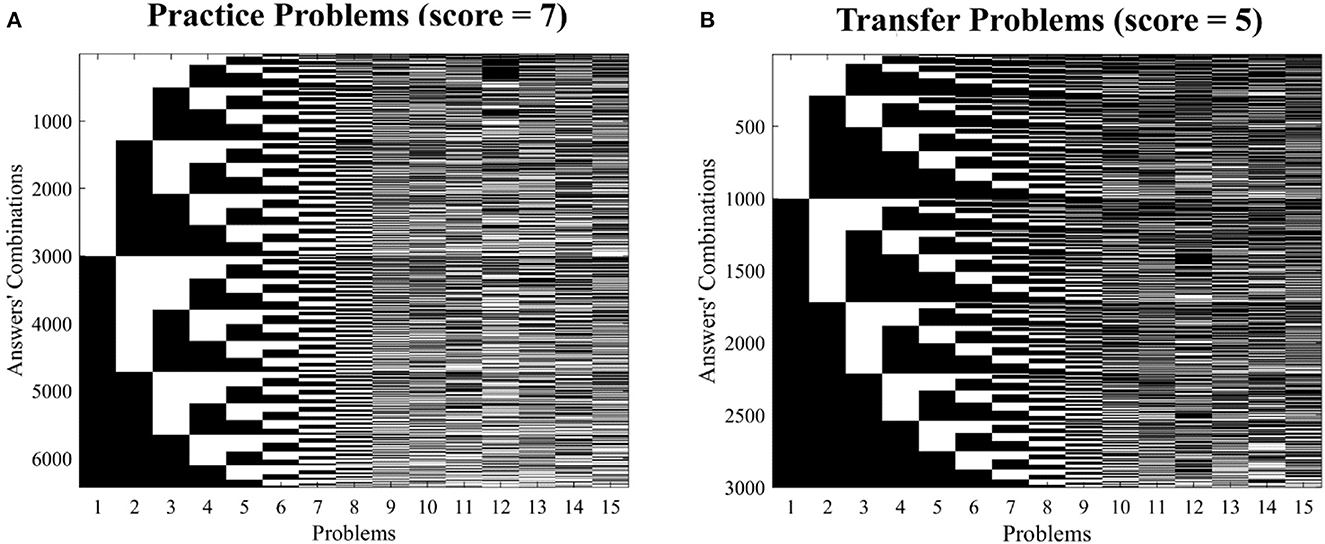
Figure 4. Answer patterns equalling the ChatGPT total score: for each set of problems, all possible answer combinations leading to a score equal to that obtained by ChatGPT are presented [Practice set, (A) and Transfer set, (B)]. In each matrix, rows correspond to all possible combinations and columns to the answers. Each matrix element identifies a possible answer within a combination (black = correct, white = wrong). The matrix related to the pooled set is not presented as the number of possible combinations exceeded 86,000,000 and as such the image would have been unintelligible.
First set of problems (practice problems): [0, 0, 1, 0, 0, 1, 0, 1, 0, 0, 1, 0, 1, 1, 1].
Second set of problems (transfer problems): [1, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 1, 1, 0, 0].
When considering the Practice Problems, the ChatGPT combination occurrence probability (p ≅ 1.52e-04), was observed as being above the threshold identifying the 5% percentile of those combinations showing the highest occurrence probability in the human sample (p ≅ 1.50e-04, see Figure 5A, and Supplementary material), thus indicating an association between the human sample problem by problem performance and that of ChatGPT. However, the ChatGPT combination occurrence probability on the Transfer set (p ≅ 5.01e-05) neared the 27th percentile of the occurrence probability distribution, thus resulting in a high unlikely solution for the human population (i.e., no association between the problems correctly solved by ChatGPT and those with a higher solution rate for the human sample, see Figure 5B).
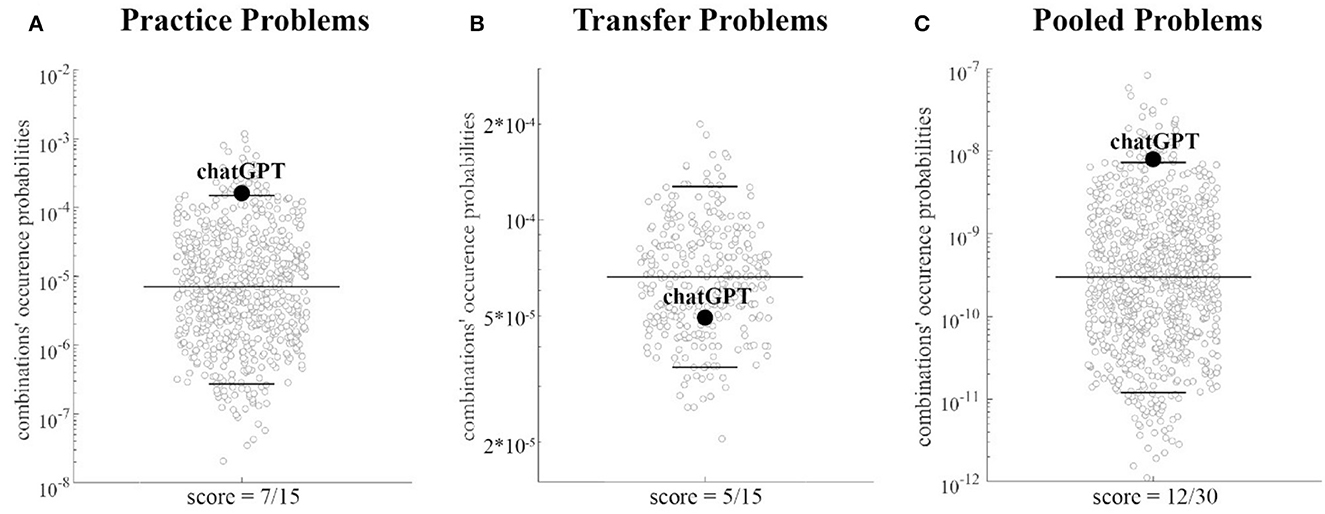
Figure 5. Distributions of answer combination probabilities equalling ChatGPT score: for each set of problems the distribution of probabilities associated with all possible answer combinations leading to a total score equal to that obtained by ChatGPT is presented using a scatterplot. The 5th, 50th, and 95th percentiles of the distribution are highlighted by black horizontal lines, whereas the probability associated with answer combinations equalling that of ChatGPT is identified by a black dot. Note that for ease of visualization, in each plot a down sampled number of combinations and probabilities are presented using a logarithmic scale (y-axis). (A–C) refer, respectively to Practice Problems, Transfer Problems, and Pooled Problems sets.
As a further step the two sets of problems were pooled together. This choice was supported by the following three main points:
1. The number of problems was balanced across the two sets (15 problems each).
2. ChatGPT performance on the Practice set was not significantly different from that obtained on the Transfer set (Fischer Exact Test, p < 0.72, see Supplementary material 1).
3. The median solution rate of the human population on the Practice set was not significantly different from that obtained on the transfer set (Wilcoxon rank sum test, z = 1.53, p < 0.13, Supplementary material 2).
When considering the pooled datasets, ChatGPT performance (i.e., number of correct answers = 12), was again equal to the total score of the human population showing the highest occurrence probability (Figure 3A). The ChatGPT combination (p ≅7.61e-09) was above the threshold identifying the 5% percentile of those patterns showing the highest occurrence probability in the human sample (p ≅ 7.35e-09, see Figure 5C), thus indicating an association between the human sample problem by problem performance and that of ChatGPT, including when considering the entire dataset.
In the current study, ChatGPT was provided with two sets of verbal insight problems, namely one set of practice and one of transfer problems (each set consisting of 15 problems, for a total of 30 problems). The score was assigned based on the accuracy of the answers provided by ChatGPT. The study's findings revealed that the global performance of ChatGPT was equal, as apparent from Figure 3, to the one showing the highest occurrence probability in the human sample: this finding is consistent for the practice, transfer and pooled problems sets. These results indicate that ChatGPT performance on both tasks (and on the pooled tasks), were completely in line with those of the average human subject, indicating that it performed similarly to humans. Moreover, both when considering the practice and the pooled problem sets, the ChatGPT answers' combination occurrence probability was above the threshold identifying the 5% percentile of those combinations (producing the same total score), showing the highest occurrence probability in the human sample. This was not the case for the transfer problems set.
In general terms, LLMs are unquestionably highly competent at making connections and the research presented demonstrates how such connections may be used to complete tasks which were once thought to be impossible. Indeed, LLMs, such as ChatGPT-3, are neural networks that have undergone training to forecast the most probable verbal output (i.e., word/sentence) based on a certain order of words. They make predictions by identifying the word with the strongest association (or probability). It is worth noting that associationism, first introduced as one of the earliest theories in psychology (James, 1890, 2007) waned in popularity when the rise of other theoretical frameworks such as behaviorism and cognitive psychology demonstrated that associationism could not fully explained the intricacy of human language production.
An issue that has sparked widespread debate in the cognitive science community is whether LLMs truly have problem-solving abilities, or such abilities are the result of a deep understanding of the problem. In this context, our findings suggest the possibility that LLMs could employ associationism, thus drastically reducing the number of tasks that complex associational models are unable to perform. Some LLMs, like ChatGPT-3, are able to complete tasks in line with the average human ability and certainly are advanced associators. From this perspective, this calls into question theories which may have led cognitive psychology to rule out associationism., of note this concept was also highlighted by a pre-print paper by Loconte et al. (2023).
It is therefore evident that the number of tasks that an associator is unable to solve is gradually reducing and future research will have to identify limits that cannot be pushed any further as LLMs become ever more competent.
While this study sheds light on the “behavior” of ChatGPT when dealing with verbal problems, it presents some limitations: (i) the size of the sample representative of humans (n = 20) to which ChatGPT was compared, was relatively small, and as such, additional testing is required to validate the results herein presented; (ii) the study examined the performance of ChatGPT using only a single version of the model. From this perspective, it would be beneficial to replicate the current study with more recent and/or advanced versions of the model in order to verify whether there has been any improvement; (iii) finally, the study only examined ChatGPT performance on verbal insight problems; it would be of utter interest to investigate how the model performs on other types of problems or tasks.
In conclusion, while this study provides some evidence that ChatGPT performance on verbal insight problems, is similar to those of an average human subject, it is important to recognize its limitations and to continue exploring both the potential and limitations of the model in future studies. Additional research may be carried out in order to expand on the methods and findings presented in this study, allowing for a more comprehensive understanding of the capabilities and limitations of ChatGPT and other LLMs.
The data analyzed in this study is subject to the following licenses/restrictions: The dataset used and analyzed during the current study is available from the corresponding author upon reasonable request. Requests to access these datasets should be directed to Z3JhemllbGxhLm9ycnVAdW5pcGkuaXQ=.
GO: conceived the experiment, designed the experimental task, and drafted the manuscript. GO and AP: contributed to data acquisition, data analysis, and writing the final version of the manuscript. All authors: data interpretation. All authors revised the manuscript critically and gave final approval of the version to be published.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/frai.2023.1199350/full#supplementary-material
Ansburg, P. I., and Dominowski, R. I. (2000). Promoting insightful problem solving. J. Creat. Behav. 34, 30–60. doi: 10.1002/j.2162-6057.2000.tb01201.x
Bahdanau, D., Cho, K., and Bengio, Y. (2014). Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473.
Dell'Osso, L., Bazzichi, L., Baroni, S., Falaschi, V., Conversano, C., Carmassi, C., et al. (2015). The inflammatory hypothesis of mood spectrum broadened to fibromyalgia and chronic fatigue syndrome. Clin. Exp. Rheumatol. 33(1 Suppl. 88), S109–S116.
Devlin, J., Chang, M. W., Lee, K., and Toutanova, K. (2018). Bert: pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
Ferrucci, R., Mameli, F., Ruggiero, F., Reitano, M., Miccoli, M., Gemignani, A., et al. (2022). Alternate fluency in Parkinson's disease: a machine learning analysis. PLoS ONE 17, e0265803. doi: 10.1371/journal.pone.0265803
James, W. (1890). The Principles of Psychology Volume II By William James. Bristol: Thoemmes Press. doi: 10.1037/10538-000
Le, Q. V., Jaitly, N., and Hinton, G. E. (2015). A simple way to initialize recurrent networks of rectified linear units. arXiv preprint arXiv:1504.00941.
Li, S., Li, W., Cook, C., Zhu, C., and Gao, Y. (2018). “Independently recurrent neural network (indrnn): building a longer and deeper rnn,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (Salt Lake City, UT: IEEE), 5457–5466. doi: 10.1109/CVPR.2018.00572
Loconte, R., Orrù, G., Tribastone, M., Pietrini, P., and Sartori, G. (2023). Challenging ChatGPT ' Intelligence' with Human Tools: A Neuropsychological Investigation on Prefrontal Functioning of a Large Language Model. Available online at: https://ssrn.com/abstract=4377371 (accessed March 20, 2023).
Mayer, R. E. (1992). Thinking, Problem Solving, Cognition. WH Freeman/Times Books/Henry Holt and Co.
Mayer, R. E., and Wittrock, M. C. (2006). “Problem solving,” in Handbook of Educational Psychology, eds P. A. Alexander and P. H. Winne (Mahwah, NJ: Erlbaum), 287–303.
Mazza, C., Monaro, M., Orrù, G., Burla, F., Colasanti, M., Ferracuti, S., et al. (2019). Introducing machine learning to detect personality faking-good in a male sample: a new model based on Minnesota multiphasic personality inventory-2 restructured form scales and reaction times. Front. Psychiatry 10, 389. doi: 10.3389/fpsyt.2019.00389
Newell, A., and Simon, H. A. (1972). Human Problem Solving (Vol. 104, No. 9). Englewood Cliffs, NJ: Prentice-Hall.
Orrù, G., Conversano, C., Ciacchini, R., and Gemignani, A. (2021). A brief overview on the contribution of machine learning in systems neuroscience. Curr. Psychiatry Res. Rev. Formerly Curr. Psychiatry Rev. 17, 66–71. doi: 10.2174/2666082217666210913101627
Orrù, G., Gemignani, A., Ciacchini, R., Bazzichi, L., and Conversano, C. (2020a). Machine learning increases diagnosticity in psychometric evaluation of alexithymia in fibromyalgia. Front. Med. 6, 319. doi: 10.3389/fmed.2019.00319
Orrù, G., Monaro, M., Conversano, C., Gemignani, A., and Sartori, G. (2020b). Machine learning in psychometrics and psychological research. Front. Psychol. 10, 2970. doi: 10.3389/fpsyg.2019.02970
Orrù, G., Pettersson-Yeo, W., Marquand, A. F., Sartori, G., and Mechelli, A. (2012). Using support vector machine to identify imaging biomarkers of neurological and psychiatric disease: a critical review. Neurosci. Biobehav. Rev. 36, 1140–1152. doi: 10.1016/j.neubiorev.2012.01.004
Pace, G., Orrù, G., Monaro, M., Gnoato, F., Vitaliani, R., Boone, K. B., et al. (2019). Malingering detection of cognitive impairment with the B test is boosted using machine learning. Front. Psychol. 10, 1650. doi: 10.3389/fpsyg.2019.01650
Parikh, A., Täckström, O., Das, D., and Uszkoreit, J. (2016). “A decomposable attention model,” in Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing (Austin, TX: Association of Computational Linguistics), 2249–2255.
Petrov, S., Barrett, L., Thibaux, R., and Klein, D. (2016). “Learning accurate, compact, and interpretable tree annotation,” in Proceedings of the 21st International Conference on Computational Linguistics and 44th Annual Meeting of the ACL (ACL), 433–440.
Polya, G. (2004). How to Solve It: A New Aspect of Mathematical Method (No. 246). Princeton university press.
Sartori, G., Zangrossi, A., Orrù, G., and Monaro, M. (2017). “Detection of malingering in psychic damage ascertainment,” in P5 Medicine and Justice: Innovation, Unitariness and Evidence (Springer), 330–341. doi: 10.1007/978-3-319-67092-8_21
Sutskever, I., Vinyals, O., and Le, Q. V. (2014). Sequence to sequence learning with neural networks. Adv. Neural Inform. Process. Syst. 27, 1–9.
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., et al. (2017). Attention is all you need. Adv. Neural Inform. Process. Syst. 30, 1–11.
Keywords: ChatGPT, machine learning, NLP, problem-solving, AI, Artificial Intelligence
Citation: Orrù G, Piarulli A, Conversano C and Gemignani A (2023) Human-like problem-solving abilities in large language models using ChatGPT. Front. Artif. Intell. 6:1199350. doi: 10.3389/frai.2023.1199350
Received: 06 April 2023; Accepted: 09 May 2023;
Published: 24 May 2023.
Edited by:
Christos Troussas, University of West Attica, GreeceReviewed by:
Francisco Antonio Castillo, Polytechnic University of Querétaro, MexicoCopyright © 2023 Orrù, Piarulli, Conversano and Gemignani. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Graziella Orrù, Z3JhemllbGxhLm9ycnVAdW5pcGkuaXQ=
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.