
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Artif. Intell., 04 February 2022
Sec. AI in Finance
Volume 5 - 2022 | https://doi.org/10.3389/frai.2022.837596
 Alessio Staffini1,2*
Alessio Staffini1,2*Stock market prices are known to be very volatile and noisy, and their accurate forecasting is a challenging problem. Traditionally, both linear and non-linear methods (such as ARIMA and LSTM) have been proposed and successfully applied to stock market prediction, but there is room to develop models that further reduce the forecast error. In this paper, we introduce a Deep Convolutional Generative Adversarial Network (DCGAN) architecture to deal with the problem of forecasting the closing price of stocks. To test the empirical performance of our proposed model we use the FTSE MIB (Financial Times Stock Exchange Milano Indice di Borsa), the benchmark stock market index for the Italian national stock exchange. By conducting both single-step and multi-step forecasting, we observe that our proposed model performs better than standard widely used tools, suggesting that Deep Learning (and in particular GANs) is a promising field for financial time series forecasting.
The systematic practice of developing instruments for the forecasting of economic phenomena is relatively recent. Indeed, it started to become possible only in the twentieth century, as a consequence of the development of quantitative tools for analyzing the evolution of business cycles (Persons, 1916).
Modern society is characterized by the need of accurate forecasting. For example, governments want to predict the trend of many indexes, such as unemployment, inflation, industrial production, as well as the expected revenue from taxation in order to formulate effective policies. Marketing managers want to predict product demand, sales volumes, and shifts in consumer preferences in order to take appropriate decisions about current and future policies and, more generally, to formulate adequate strategic planning.
At its core, forecasting is very much linked to pattern recognition: to make a guess of what could happen in the future is based on recognizing repetitive patterns in past realizations. Of course, to make predictions based on the past is founded on the belief that the future does not reserve any significative innovation compared to what we already can observe. This is not always the case: examples are the unexpected crashes of the stock market prices around March 2020 (due to the surge of the COVID-19 pandemic) and during the financial crisis of 2007–2008. It should therefore come as no surprise that mathematical forecasting methods sometimes give poor results, even if applied correctly (Richardson, 1979).
In particular, to predict the performance of a financial stock just by observing at its previous closing prices is not a simple task. Over the years, more and more accurate programs have emerged to help in determining when to sell or buy a security, and both investment banks and listed companies now heavily rely on algorithmic trading to establish how to act on the financial markets (Gomber and Zimmermann, 2018). If we exclude the news that can influence the performance of a stock, the shift in prices is in large part affected by the conclusions that these algorithms draw from price fluctuations. In a sense, the fact that the interactions in the financial markets are increasingly guided by algorithms makes it easier to forecast the trend of the closing price of a stock (Verheggen, 2017), because algorithms act following certain patterns, and the “human factor” that could introduce heterogeneity and potential irrationality (Heiner, 1983) assumes an increasingly marginal role in decisions.
The paper is structured as follows. In Section Literature Review, we provide an overview of the literature on stock price forecasting, motivating the introduction of our model. In Section Background, we discuss the theory behind Generative Adversarial Networks. We explain our proposed model in Section The Model. In Section Empirical Analysis, we describe the empirical analysis we conducted, and we present the obtained results in Section Results. Section Conclusion concludes.
The idea of rigorously analyzing stock market time series data dates back at least to 1965, when Eugene Fama analyzed if there was a correlation between stock prices over time, that is, the existence of a correlation between past and future realizations (Fama, 1965). He concluded that there was no correlation, and that each realization was random, establishing that it was not possible to simply predict stock market prices by observing their past realizations.
Over the years, Fama's conclusions have been repeatedly questioned. There are now numerous papers that try to forecast stock market prices (to name a few of them: Pai and Lin, 2005; Chang and Fan, 2008; Tsai and Wang, 2009; Sen, 2017; Khashei and Hajirahimi, 2018), using various techniques.
The most “baseline” and widely used models are undoubtedly ARIMA models. There exists a large literature of methods for forecasting stock market prices based on or originated from ARIMA (for example: Devi et al., 2013; Adebiyi et al., 2014; Banerjee, 2014; Alwadi et al., 2018).
The growth of technology allowed digital trading platforms to be born, and to perform what is called “technical analysis”, to better interpret the behavior of a stock price given its past prices.
Only recently, with the development and widespread deployment of artificial intelligence techniques, innovative models that seek to improve the performance of the existing tools have been born, especially in the context of forecasting.
The use of Artificial Neural Networks (ANNs) in developing forecasting models for financial markets gave promising results in “hybrid” models, where ANNs were combined with econometric models, such as ARIMA (Areekul et al., 2010) or GARCH (Gurusen et al., 2011). The introduction of more sophisticated neural networks designed for handling sequences of data, namely the Long Short-Term Memory (LSTM) networks, gave birth to several works that exploited their peculiarities (Roondiwala et al., 2017; Baek and Kim, 2018; Tan et al., 2019; Moghar and Hamiche, 2020). Other papers exploited Convolutional Neural Networks (CNNs) for stock price prediction (Tsantekidis et al., 2017; Hoseinzade and Haratizadeh, 2019) or Recurrent Neural Networks (RNNs) (Rather et al., 2015; Selvin et al., 2017). Researchers also used reinforcement learning techniques to build models to improve stock market trading strategies (Nevmyvaka et al., 2006).
Remaining in the field of Deep Learning, researchers have recently tried to adapt Generative Adversarial Networks (GANs) (Goodfellow et al., 2014) with the goal of analyzing and forecasting time series data. A detailed description of how GANs work is provided in Section Background but, in short, they are composed by a discriminative and a generative network that interact with each other: the former trying to distinguish whether a certain instance is real or fake, and the latter trying to confuse the discriminative network by generating increasingly realistic data. In 2018, Zhou et al. (2018) developed a GAN that used an LSTM as a generator and a CNN as a discriminator to forecast the high-frequency stock market. In the same year, Luo et al. (2018) proposed a similar model for predicting crude oil prices. The next year, Koochali et al. (2019) introduced a conditional GAN to compute probabilistic forecasts on web traffic data; again, in 2019, Zhang et al. proposed a GAN with a Multi-Layer Perceptron (MLP) acting as a discriminator for forecasting the closing price of some stocks of S&P 500 Index and PAICC, among others. All these works compared the obtained performances with those of other machine learning and time series models, such as LSTM and ARIMA, obtaining promising results. In 2020, Zhou et al. (2020a) compared their GAN with other models (such as ARIMA, Temporal Convolutional Network, and LSTM) by testing them on public benchmark datasets, concluding that the generative network achieved comparable forecasting accuracy with the other methods. In the same year, Zhou et al. (2020b) published another work on a web traffic dataset, further confirming that GAN results were neither better nor worse than the other considered models. On the other hand, Lin et al. (2021) obtained superior results using GANs but evaluated the considered models over the time series of a single stock (Apple Inc.).
In recent years, GANs have shown promising results in solving many complex problems (e.g., realistic image and video generation, image-to-image and text-to-image translation) but to show that they can provide better results also for financial time series forecasting (compared to more traditional approaches) remains a challenge yet to be solved.
The contribution of the present paper is 2-fold. First, we propose a novel and stable deep convolutional GAN architecture, both in the generative and discriminative network, for stock price forecasting. Second, we compare and evaluate the performance of the proposed model on 10 heterogeneous time series from the Italian stock market. To the best of our knowledge, this is the first GAN architecture applied to stock price forecasting that uses convolutional layers both in the generator and in the discriminator. We also propose a modification to the loss function of the generator, adding further terms that improves the forecasting process. Furthermore, as highlighted in Section Results, our proposed model is much more stable (in the sense that the standard deviation of the results is lower) compared to previously proposed GAN architectures for time series forecasting.
Generative Adversarial Networks are a class of generative models that has shown remarkable results in many tasks, in particular image generation and image-to-image translation. In its original formulation, a GAN is composed by two neural networks (the generator G and the discriminator D) that compete against each other in a zero-sum non-cooperative game. The generator produces “fake” samples by mapping a vector of random noise z ∈ Z, z ~ p(z), where Z denotes the latent space, and p(z) is the random noise distribution (typically a uniform or a Gaussian distribution). The goal of the generator is to fool the discriminator into believing that the generated sample is real (i.e., it wants to capture the characteristics of the real data distribution), while the discriminator acts as a classifier that must distinguish between fake and real data samples, outputting a scalar D(a) ∈ [0, 1], which can be understood as the probability that the discriminator assigns to the sample a to belong to the real distribution. More formally, G and D are trained by playing the following minimax game with value function V(G, D):
where p(r) denotes the real data distribution of the samples x. If we denote with the output of the generator, we can rewrite Equation (1) as:
where p(g) is the generator's distribution over data x. We can appreciate the adversarial nature of the game by noticing that, in the second term of Eq. 2, the discriminator cares about correctly classifying fake samples, while on the other hand the generator wants it to classify them as true. During training, each network forces the other to improve. If we denote with θD and θG the parameters of the discriminator and the generator respectively, the update at iteration n+1 is described by the following two rules:
that are calculated by sampling m real and fake samples, where ηD>0 and ηG>0 are the learning rates of the discriminator and the generator, respectively.
Figure 1 shows the architecture of the described GAN.
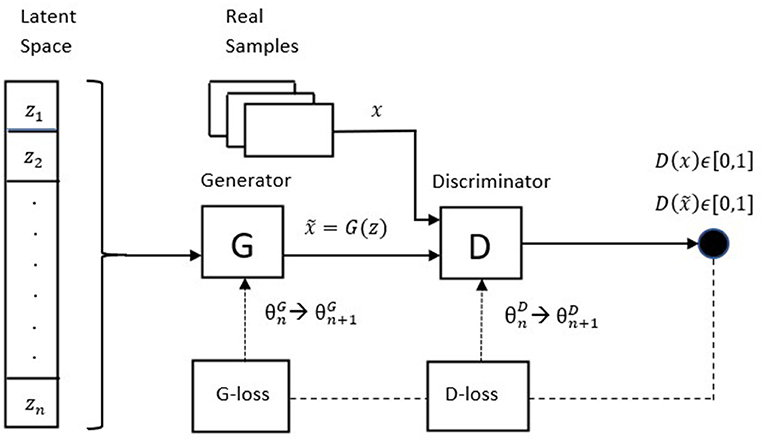
Figure 1. Stylized architecture of the original GAN.
The training process is supposed to continue until Nash equilibrium, that is, when and p(g) = p(r). In practice, reach equilibrium in non-convex games is difficult1. Without reaching equilibrium GANs can nevertheless produce good results, despite existing however a number of other unresolved problems with the original GAN implementation: in particular, vanishing gradients (when the discriminator does not provide a useful feedback) and mode collapse (when the generator finds how to trick the discriminator by producing samples with low variety).
In their paper, Goodfellow et al. (2014) showed that if the discriminator is trained to optimality before each update in the generator, then by minimizing V(G, D) the generator is minimizing the Jensen-Shannon (JS) divergence between p(r) and p(g). However, it can be shown that the JS divergence induces a strong topology, and it might be discontinuous, often leading in applications to the vanishing gradient problem since it is difficult to maintain the discriminator at the same level of the generator for the whole training process.
To overcome this problem, Arjovsky et al. (2017) introduced a variant of the original GAN based on the Wasserstein distance (WGAN), which is shown to induce a weaker topology and it is a more sensible cost function when we care about convergence in distribution. The Wasserstein-1 distance (also known as Earth-Mover distance) between p(r) and p(g) is defined as:
where Π(p(r), p(g)) denotes the set of all possible joint distributions of p(r) and p(g), and informally denotes how much “mass” has to be transported from point x to point in order to transform the fake distribution p(g) into the real distribution p(r). W(p(r), p(g)) is continuous everywhere and differentiable almost everywhere, leading to higher stability in training and a non-saturating discriminator. However, it is computationally intractable to consider all the possible joint distributions γ ϵ Π(p(r), p(g)) to compute the infimum. By applying the Kantorovich-Rubinstein duality, we can rewrite Equation (3) as:
where the supremum is taken over , the set of 1-Lipschitz continuous functions2. Since now the loss function measures the Wasserstein distance between p(r) and p(g), the discriminator in Equation (4) takes up the role of learning an appropriate function to compute such distance, rather than directly discriminating between fake and real samples. The minimax game is now defined by:
where the notation is consistent with above. However, in order for the discriminator's gradient to be informative, we have to enforce 1-Lipschitz continuity on the discriminator. In their paper, Arjovsky et al. (2017) did so by clipping the weights of the discriminator, constraining them within a compact space, but the authors themselves mentioned that such approach is not optimal and might lead to training instability.
A further improvement on the WGAN architecture moved in the direction of finding a more suitable way to enforce Lipschitz constraints. Gulrajani et al. (2017) proposed using gradient penalty (WGAN-GP) to deal with the problem, exploiting the fact that a function f is 1-Lipschitz if and only if ||∇f|| ≤ 1 everywhere. They added a further penalty term to the value function defined in Equation (5), which acts as a regularization by penalizing ||∇D||≠ 1:
where λ is a hyperparameter (Gulrajani et al., 2017 observed λ = 10 to work empirically well on a wide number of tasks) that controls the tradeoff between the new regularization term and the other terms. Since enforcing the unit gradient norm everywhere is intractable, the authors considered sampling interpolated points between the real samples x and the fake samples :
with α ~ U[0, 1], . Empirically, the added regularization term works well, and WGAN-GP is less prone to mode collapse and vanishing gradient problems than other architectures. More explicitly, from V(G, D) in Equation (6) we can separate the loss functions for the discriminator and the generator in WGAN-GP:
where LD and LG denote the loss functions of the discriminator and the generator, respectively.
We propose using a Deep Convolutional Generative Adversarial Network (DCGAN) for the task of accurately forecasting the stock price evolution. The idea behind why we use an adversarial network is because we want to mimic the learning process of a financial trader: using a set of available predictors, the unexperienced trader (the generator in the first epochs) makes certain predictions about the stock price, which are then progressively corrected by looking at the real realizations (the work of the discriminator), until he/she becomes experienced (the generator in the last epochs).
Since GANs are mainly used for generative modeling, the generator traditionally receives in input a random vector z from the latent space, and thanks to the learning process it tunes its own parameters to map that vector into a realistic object (very often, an image). However, when dealing with time series forecasting, it makes more sense to provide as input to the generator the matrix of predictors , where we include i variables observed over t time steps, and use X to forecast the value in t+1 of the variable of interest y (which might or might not be a variable included in X). We can think of the problem as wanting the generator to learn the data distribution of yt+ 1.
On the other hand, as for the data input for the discriminator, we constructed the fake samples by adding the generator's output to the real data sequence, ỹ = {y1, y2, …, yt, ỹt+1}, and the real samples by adding the true realization, y = {y1, y2, …, yt, yt+1}. Following Zhang et al. (2019), the idea of providing sequences to the discriminator instead of just ỹt+1 and yt+1 is because we want it to also extract and learn useful information on the correlation over time steps.
There are also other two important aspects that need to be mentioned. First, following Chintala (2016), we normalized the data to lie within [−1, 1]. This also has the benefits of bringing all the predictors to the same range. Second, following the WGAN paper, we trained the discriminator five times more than the generator, during each training iteration. The idea behind this is that in WGAN the discriminator will not saturate, so the more we train it the closer to optimality we get, obtaining therefore more reliable gradient information for the training process.
Due to their useful properties, we used both the Wasserstein distance and gradient penalty as suggested in the WGAN-GP paper but, since we are dealing with time series, we modified the loss function of the generator (Equation 7b) by including further information to “guide” the generator into producing good samples:
where the two losses in Equations (8a) and (8b) are computed over a batch of m samples. The second term in the generator loss computes the MSE (penalizing large errors between the real and fake samples), while the third term further guides the generator into producing fake samples that have the same sign (i.e., that are close to) the real samples (recall that we normalized the data to range between −1 and 1). ψ1 and ψ2 are two hyperparameters that weight the importance of these added loss components, and we found ψ1 = ψ2 = 0.5 to work well across the considered time series, but some tuning might be necessary for different applications. Notice that, at least theoretically, these added components are not strictly necessary: if D(.) is trained to be close to optimality in each epoch, we could in principle use only its gradient to update in a reliable way the generator. However, empirically we found that these added loss components significatively speeded up the training process, requiring less epochs to convergence (after 300 epochs, the measured loss was half the one observed in the standard formulation). We trained our architecture for 1,200 epochs.
For the generator network, we selected a CNN-BiLSTM architecture. First, we stacked a one-dimensional convolutional layer (32 filters, with a filter size of 2) to process the input values. Long Short-Term Memory networks (LSTMs) (Hochreiter and Schmidhuber, 1997) have been proven to be very effective in dealing with sequence data, so the results obtained from the convolutional layer are passed to a Bidirectional-LSTM (BiLSTM) layer with 64 units, the bidirectionality being useful in order to provide more context for the forecasting process. Finally, we stacked 2 fully connected layers of 64 and 32 neurons, respectively. The output layer is composed by a single neuron when we are forecasting only the next time step, and 5 neurons when we are forecasting the next 5 days.
For the discriminator network, we selected a CNN architecture, which is appropriate when we have to compare and discern two types of sequences (real and fake). To avoid possible imbalances while training, it is useful to have a symmetric architecture between the generator and the discriminator. Therefore, we stacked 2 one-dimensional convolutional layers (32 and 64 filters each, with a filter size of 2), followed by 2 fully connected layers of 64 and 32 neurons, respectively. Since the discriminator has to output a single scalar that represents how real the input sequence is, the output layer was made by a single neuron without any activation function.
Regarding the activation functions, we applied Leaky Rectified Linear Unit (Leaky ReLU) to all the hidden layers in the generator (except the BiLSTM layer that uses just standard ReLU) and in the discriminator. Its equation is given by:
where we set α = 0.1. To allow for a positive slope in the negative region is helpful when we might suffer from sparse gradients, as in GANs training.
To avoid overfitting and obtain greater regularization, we applied Dropout (Srivastava et al., 2014) in each hidden layer of the generator and the discriminator, with the exception of convolutional layers, where it is less effective. Since the number of neurons is not too high, we found a moderate dropout rate p = 0.2 to work well in practice (in the BiLSTM layer we applied p = 0.3).
We initialized the weights of the two networks by using a zero-centered Gaussian distribution with standard deviation 0.02, as in Radford et al. (2015). As for the optimization algorithm, we selected Adam (Kingma and Ba, 2014), but we tuned its hyperparameters to obtain more stability in training: in particular, we found that in addition to a higher number of discriminator iterations per generator iteration, it was also helpful to set a higher learning rate for the discriminator. Therefore, we set the learning rate of the discriminator ηD to 0.0004, and the learning rate of the generator ηG to 0.0001. Following Radford et al. (2015), we lowered the momentum term β1 to 0.5, but we also lowered β2 to 0.9.
Figure 2 shows the architecture of our GAN.
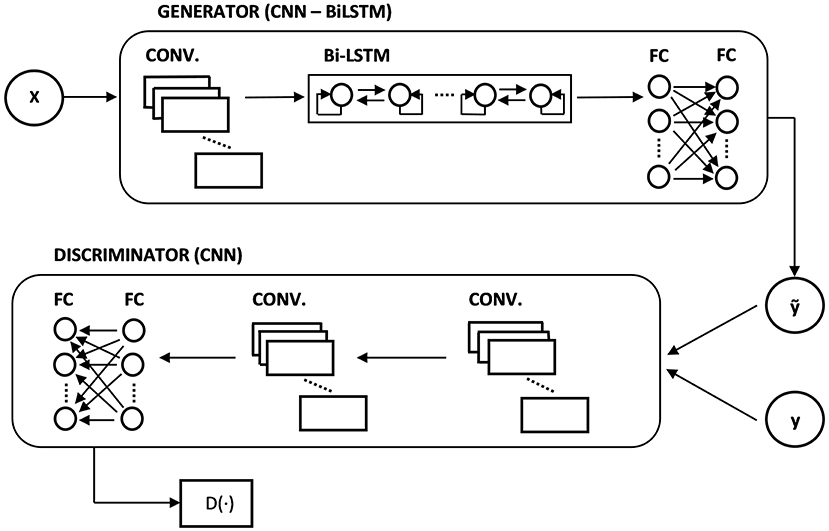
Figure 2. Stylized architecture of our DCGAN.
We conducted our empirical analysis starting from the time series data of closing, opening, maximum and minimum prices, as well as the daily trading volume of the stocks from the FTSE MIB (Financial Times Stock Exchange Milano Indice di Borsa) Index. The data are available online (https://it.finance.yahoo.com/). To train deep learning models successfully a “high enough” number of observations is required, and so we chose to include the stocks which values started from January 2005. We selected 26 stocks with these characteristics (starting from the original 40 in FTSE MIB). From this initial selection, we selected 10 stocks out of 26 (see Table 1) on which perform our analysis. The selection criteria for these 10 stocks were the heterogeneity (i.e., to include companies from different sectors) and the time series behaviors (i.e., we included stocks that did not display a clear tendency to increase or decrease, over the considered period of time).
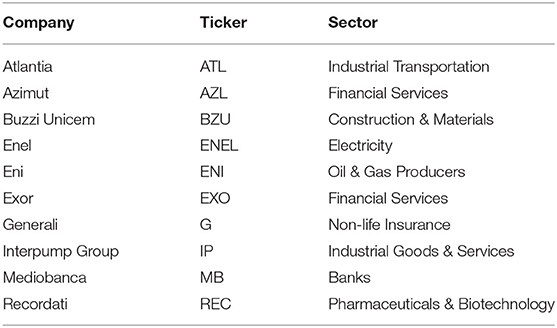
Table 1. The 10 selected stocks.
The time series for each stock is composed of 4,149 observations, from January 2005, 3rd to April 2021, 30th. Regarding data preprocessing, the missing values were very few for each stock, ranging from a maximum of 18 to a minimum of 0, with an average of 11.27 (0.27% of total length). We replaced those missing values with the previous observation in the time series.
Starting from these data, we constructed other variables that are often used for the technical analysis of stocks, as well as to forecast their future prices. Technical analysis has often been criticized for its reliance on past data and for ignoring the market fundamentals; however, technical indicators are still widely used for stock price forecasting and have been proven to be effective in many works (e.g., Oriani and Coelho, 2016; Aras, 2020; Agrawal et al., 2021). To keep a simple framework (technical indicators can be readily used by non-experts) and to compare our results with those of other works, we decided to use these indicators only, well-knowing that traders do not rely on technical analysis only when making investment choices.
The total list of the variables we used is reported in Table 2.

Table 2. List of the variables we considered for the empirical analysis.
For each stock, we checked the correlation matrix of the selected variables, and we observed how many variables have a correlation close to 0 with the closing price. Figure 3 shows the correlation matrix for EXO.
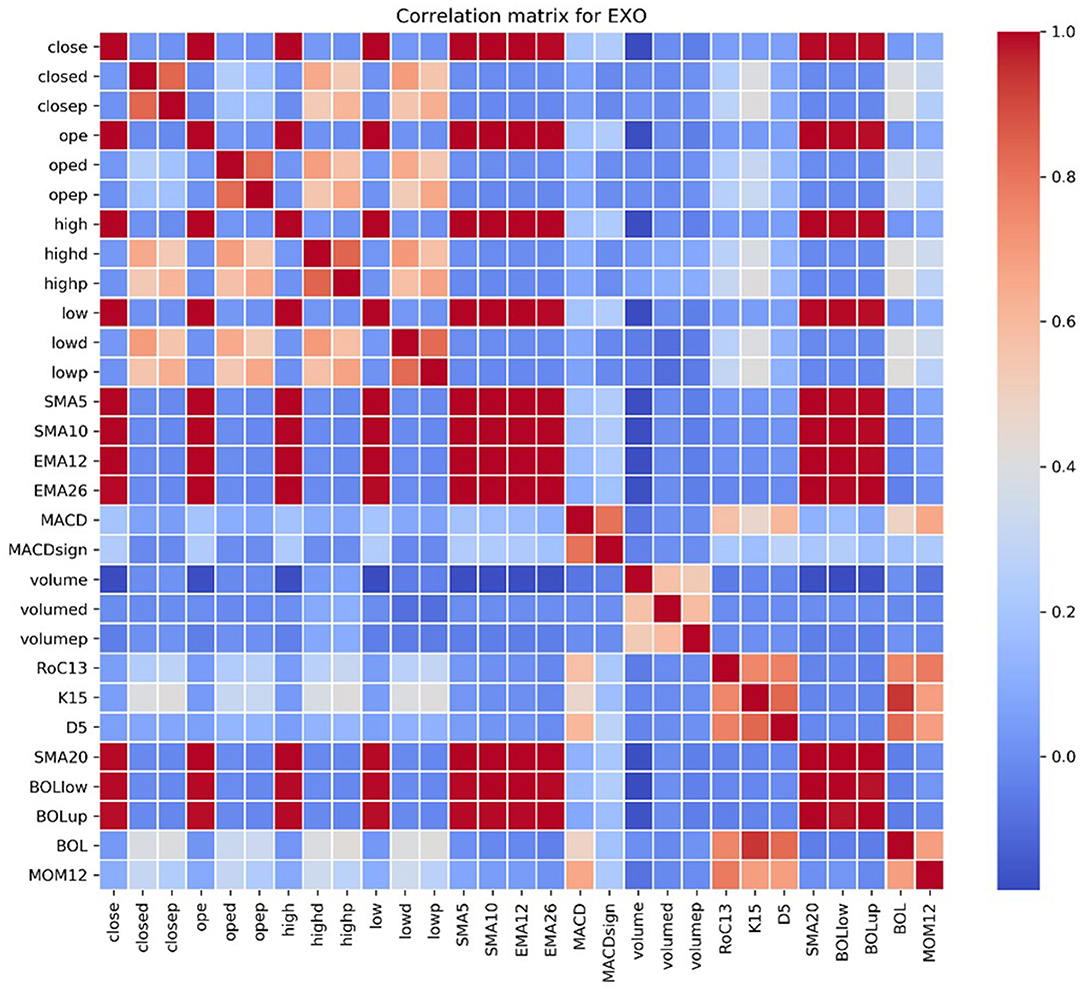
Figure 3. Correlation matrix for EXO of the considered technical indicators.
Furthermore, even if we selected stocks that did not exhibit clear trends, by performing the Augmented Dickey-Fuller (ADF) test (Dickey and Fuller, 1979) we could not rule out the existence of unit roots for the closing price, the opening price, the highest and the lowest price variables at significance level 0.01. Hence, when we ran the ARIMAX models (see Section Results), we took the first differences for these variables (the ADF test performed on the first differences rejected the presence of unit roots at significance level 0.01).
Our goal is to forecast the values of the closing price of the stocks, and among the technical indicators we constructed we therefore selected a subset of them that are meaningful and strongly correlated with the dependent variable, across the 10 selected stocks: ope, high, low, SMA5, SMA10, SMA20, EMA12, EMA26, MACD, MACDsign, volume, BOLlow, and BOLup.
Figure 4 shows the correlation matrices of the subset of regressors we considered for the analysis (at time t, t−1, t−2, and t−5) with the closing price (at time t), for the case of EXO. We can observe that the correlation matrices do not vary when we consider lagged values, indicating that the variables selection is robust.
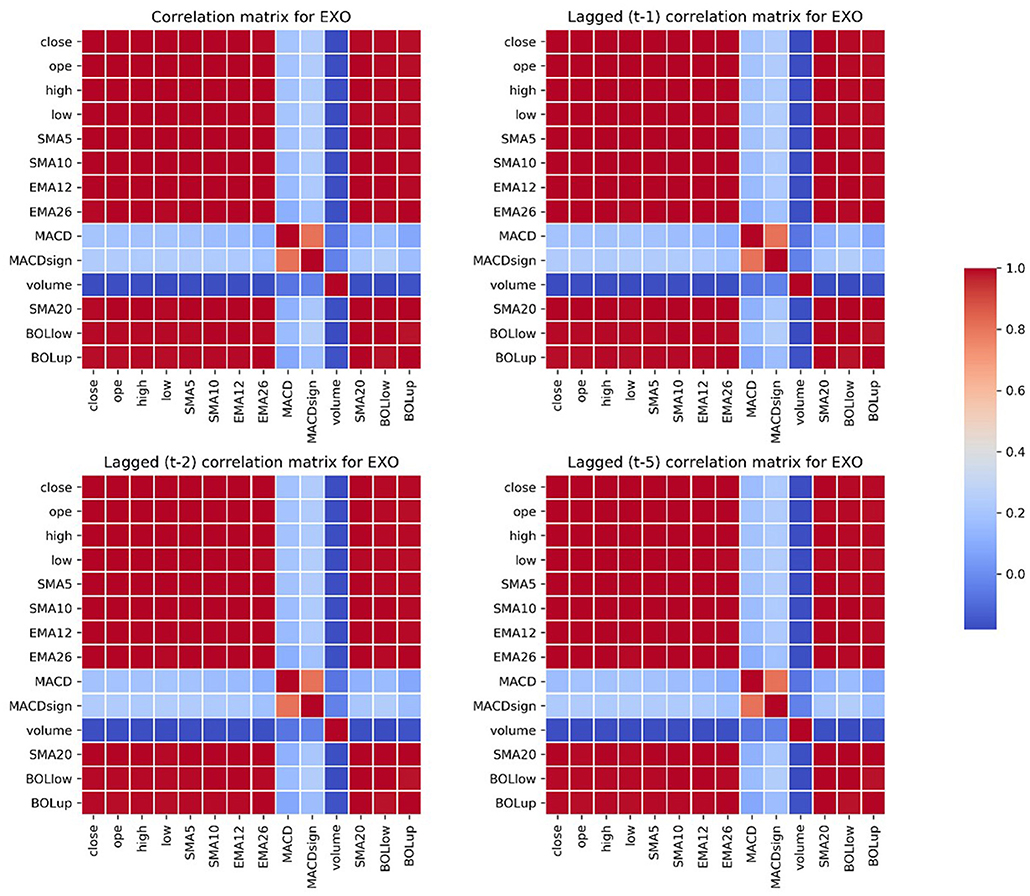
Figure 4. Contemporaneous and lagged correlation matrices for EXO of the selected variables.
To evaluate the performance of our GAN architecture we compared its results with those of four widely used models for stock price forecasting: ARIMAX-SVR, Random Forest Regressor, LSTM, and a benchmark GAN.
ARIMAX (Autoregressive Integrated Moving Average with Extra Input) is an extension of ARIMA, including not only the lagged values of the dependent variables but other variables as well as predictors. Considering that we want to model yt by including not only its p lagged observations and the q lagged observations of the residual error terms, but also the p lagged observations of n further predictors, the equation of an ARIMAX(p, d, q, n) is given by:
where is the vector of coefficients of the lagged values of the dependent variable, X = (x(1), x(2), …, x(n))T is the vector of extra predictors, is the vector of coefficients of the extra predictor s, with n, p > 0. Δd denotes the d-th difference of yt, and β0 is the intercept of the model (i.e., the mean of the series); denotes the error term and is the vector of lagged error terms coefficients, q>0. In the context of our analysis, the n further predictors are those strongly correlated with the closing price of the stocks (see Figure 4), so that n = 13. As explained in Section Empirical Analysis, we could not rule out that some considered predictors where I(1) processes; hence, we set d = 1, and a further ADF test on the differentiated data of these variables confirmed the absence of unit roots. For finding the most suitable order of p and q, we analyzed the autocorrelation function (ACF) and the partial autocorrelation function (PACF). We further compared the model specification suggested by ACF and PACF with the one suggested by the Akaike Information Criterion (AIC) (Akaike, 1973). The specifications suggested by ACF/PACF and AIC often matched; when they did not, we preferred the ones that empirically performed better.
One of the main features of financial time series is volatility clustering (conditional heteroskedasticity). To this end, following Pai and Lin (2005), we improved the forecasts obtained with the ARIMAX model by augmenting it with a Support Vector Regression (SVR) backend, in order to capture the non-linear patterns in the data. More specifically, denoting with εt the residual of the ARIMAX model at time t, we modeled it as follows:
with f being a non-linear function defined by the SVR model, which takes as input past realizations of the ARIMAX residuals, and ut being a random error. We used the radial basis function as kernel for the SVR algorithm. The number of inputs, as well as the kernel coefficient, the regularization parameter and the epsilon-tube parameter were optimized for each stock on the training data using a grid search approach.
The Random Forest (RF) Regressor is a non-linear machine learning algorithm which uses ensemble learning, constructing a group of decision trees and aggregating their predictions to tackle regression problems. Although typically not used for time series forecasting, it has proved to be successful in this area as well, and it is recently gaining popularity (Kane et al., 2014; Dudek, 2015; Masini et al., 2021). The number of inputs, as well as the number of decision trees in the forest and the number of features to consider when looking for the best split were optimized for each stock on the training data using a grid search approach. Since in RFs there is randomness coming both from bootstrapping and the sampling of the features to consider when looking for the best split at each node, in our experiments we considered the results over 10 different seeds.
LSTMs are a class of deep learning models, thought especially to deal with sequence data and to deal with the vanishing problem of RNNs. In particular, each LSTM cell contains three gates: a forget gate (which establishes what information should be discarded), an input gate (to establish which values from the input should be used to update the memory state), and an output gate (which decides what to output based on the input and the memory cell). The gates can be understood as weighted functions, and their parameters are updated using Backpropagation Through Time (BPTT) (Mozer, 1989). The LSTM cell equations at a given time step t are as follows:
where Ft, It, Ot denote the forget gate, the input gate and the output gate, respectively; is a cell input activation vector; Ct is the cell status; ht is the output vector of the LSTM cell; xt is the input vector to the LSTM cell; W·, U·, and b· are the weight matrices and bias vector parameters to be tuned during training, respectively; σ is the sigmoid activation function; and ∘ denotes the element-wise product.
To better deal with non-linearity in data, we can stack LSTM layers upon each other. In the context of our analysis, we built a three-layer stacked LSTM architecture: the first layer having 64 cells, the second 32, and the third 16. We applied a dropout rate of 0.3 after each LSTM layer, and we used the tanh activation function mainly due to its fast convergency properties (LeCun et al., 1998). We used Adam with a learning rate of 0.001 as the optimization algorithm, and we trained our network for 1200 epochs, applying early stopping to further avoid overfitting (Goodfellow et al., 2016). We initialized the weights of each LSTM layer with the Glorot uniform initializer (Glorot and Bengio, 2010), which in practice works well for deep networks (Calin, 2020).
We also considered a benchmark GAN, which architecture is similar to the one proposed by Zhang et al. (2019): we adopted LSTM as generator, and a 3-layer MLP as discriminator. As suggested by Zhang et al. (2019), we used Leaky ReLU as activation function for the hidden layers, dropout as regularization method, and Binary Cross Entropy (BCE) loss function. As in our proposed GAN, we chose Adam as optimization algorithm.
To compare the results of the considered models, we need to select a loss function. We selected three metrics: the Root Mean Squared Error (RMSE), the Mean Absolute Error (MAE), and the Mean Absolute Percentage Error (MAPE) to assess the performance of our models and measure the difference between real and predicted values. Considering n observations, their equations are given by:
where yi is the true value, and ŷi is the predicted value obtained with the selected model. In general, RMSE penalizes large errors more than the other considered metrics, being more sensitive to outliers; on the other hand, MAE is often considered an easy and interpretable metric to describe the average error committed by a model. Finally, MAPE expresses the committed error as a percentage, favoring the comparison with different data.
We split our data (4,149 observations per each stock, from January 3rd, 2005, to April 30th, 2021) into a training set and a test set at a ratio of 80–20 (i.e., the first 80% of the time series of each stock was used for training the models and the last 20% was used to evaluate their performance on out-of-sample data). The training set consisted therefore of 3,320 observations (from January 3rd, 2005, to January 18th, 2018), and the test set consisted of 829 observations (from January 19th, 2018, to April 30th, 2021). Multi-step forecasting was implemented using a rolling forecast approach, where the true realizations of the closing price were made available to the models after each forecast iteration.
ARIMAX models have been implemented using the statistical package gretl3, while their SVR backends, the RF Regressors, the LSTM models, the benchmark GAN, and our proposed GAN are built with Python4. We collected the results for single-step forecasts in Table 3 and those for multi-step forecasts in Table 4.
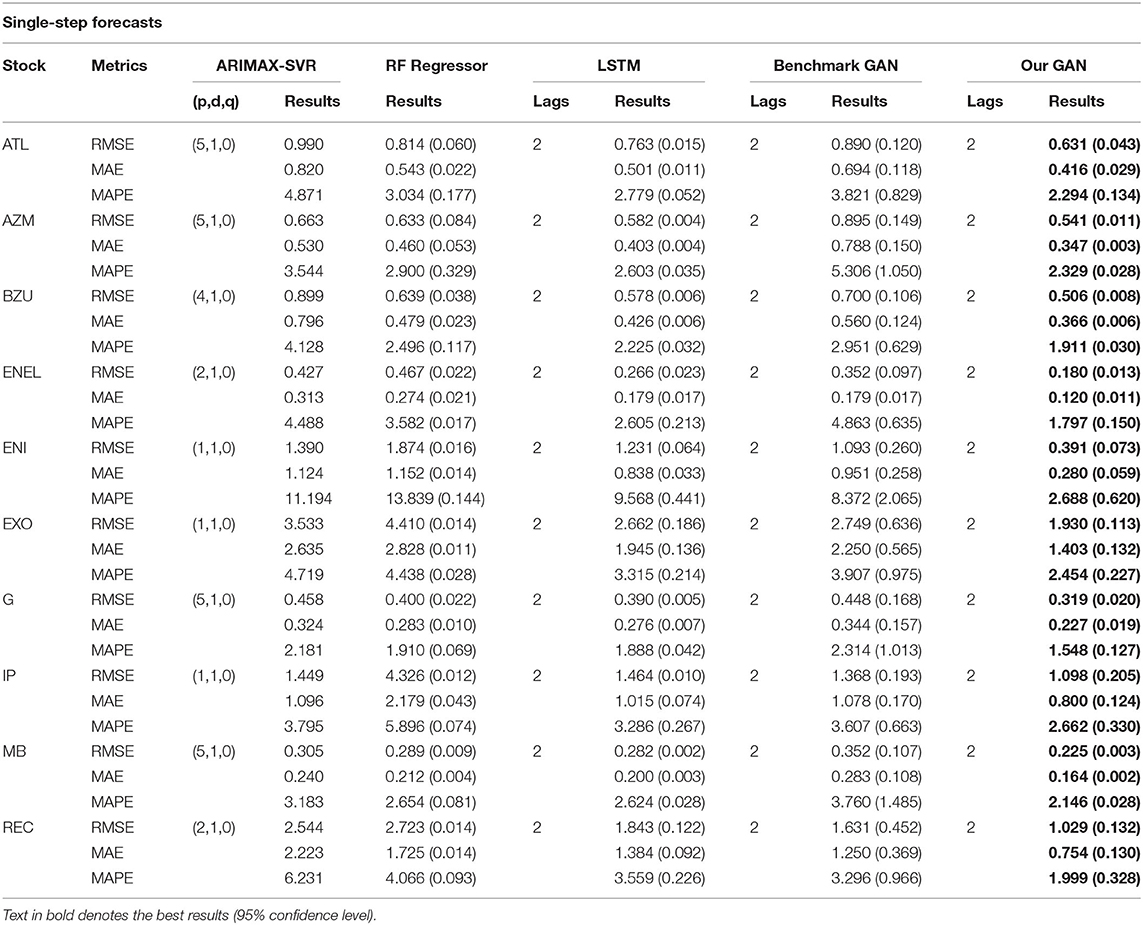
Table 3. Single-step forecast errors for ARIMAX, RF Regressor, LSTM, the benchmark GAN, and our GAN architecture.
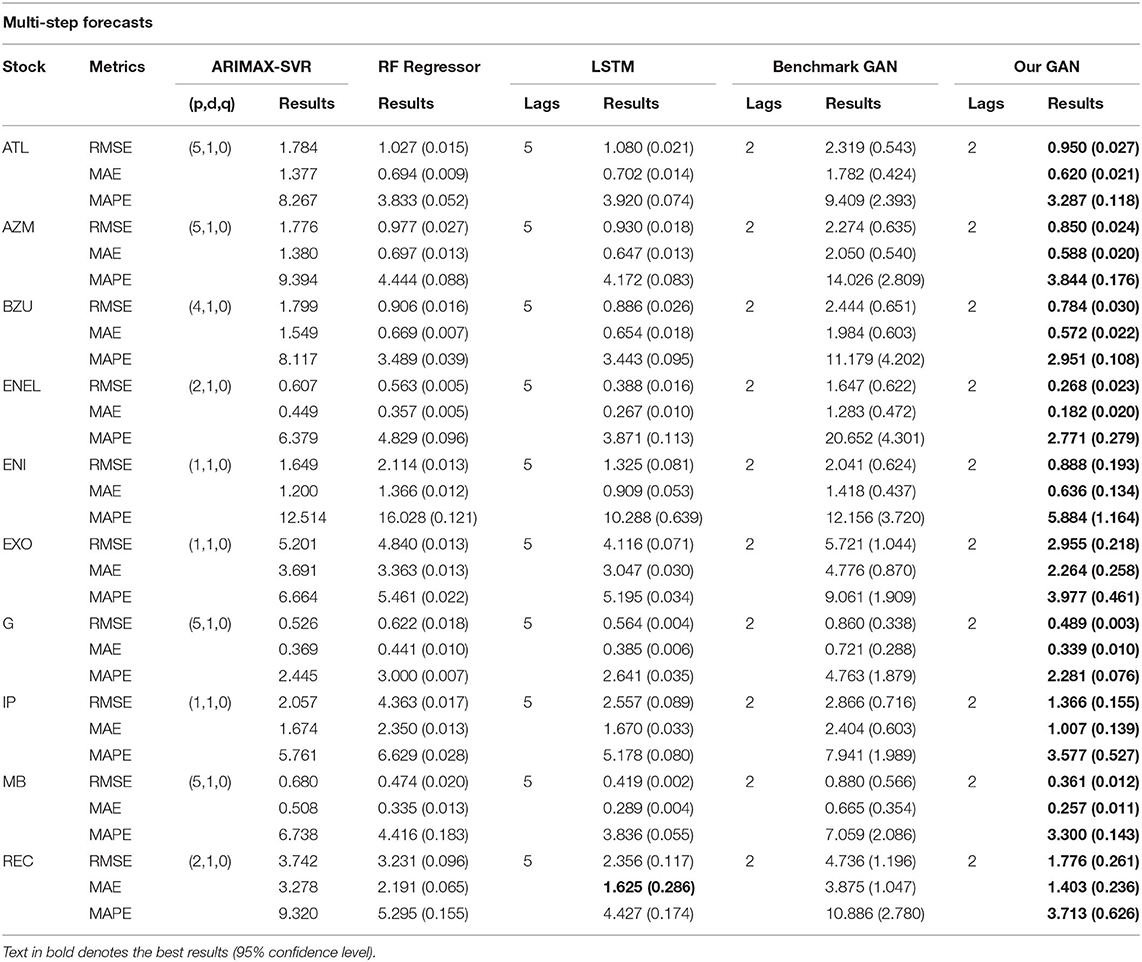
Table 4. Multi-step (5 days) forecast errors for ARIMAX, RF Regressor, LSTM, the benchmark GAN, and our GAN architecture.
In Tables 3, 4 we denoted, for each stock and metric, the best performance (lowest value) in bold. From Table 3, we can observe how the DCGAN architecture performed significatively better than the other considered models for all the 10 considered stocks. The same good performances are obtained when we tried to forecast the next week (i.e., the next 5 days) at once: indeed, as we can observe from Table 4, our GAN architecture again significatively performed better than its competitors for all the stocks and for all the metrics, except for the MAE of a single stock, where there was not a statistically significant difference. It is also interesting to note how our DCGAN performs with respect to the benchmark GAN. First, while the benchmark GAN results can be considered good when performing single-step forecasting, they get much worse in the multi-step scenario. On the other hand, our architecture is much more consistent. Second, both in the single-step and in the multi-step scenarios, the standard deviation of our GAN is much lower than that of the benchmark GAN, highlighting how the proposed architecture is stable and does not suffer much from unstable training, which is a well-known open problem in GANs training (Chen, 2021).
There is indeed an inherent stochastic component in the training process of deep learning models, mainly coming from the weight initialization scheme and the optimization process. We reported in tables the average mean of 10 independent runs of each model, and in brackets the standard deviation. For each stock, to confirm statistically significant differences in the metrics results, we ran independent t-tests with p <0.05.
We further compared the accuracy of the obtained forecasts using the Diebold-Mariano (DM) test (Diebold and Mariano, 1995). Considering two forecasts, the null hypothesis of the DM test is that they have the same accuracy (i.e., there are no differences in the forecasts), while the alternative hypothesis is that the two considered forecasts have different degrees of accuracy. We reported in Table 5 the results of the DM test for the considered models. We can observe that, at 95% confidence level, the null hypothesis of our GAN forecasts having the same accuracy with other models is rejected for all the scenarios, except for two cases in the multi-step comparison with RF Regressor and LSTM (highlighted in bold).
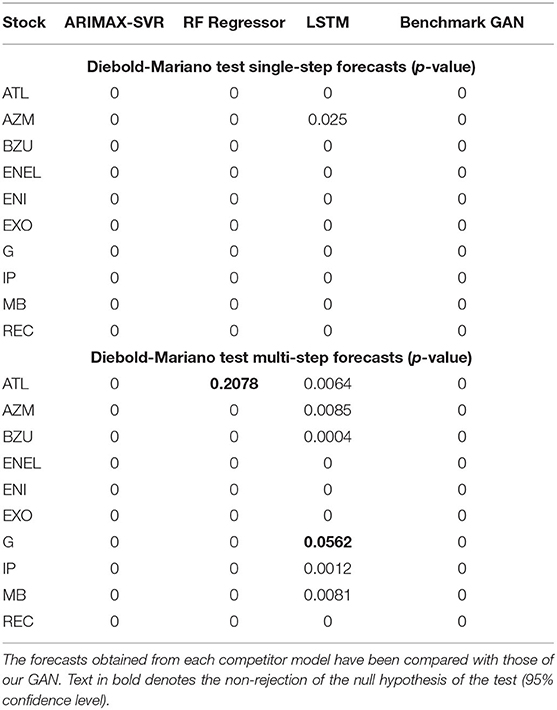
Table 5. Diebold-Mariano test for the single-step and multi-step forecasts.
We, respectively, reported in Figures 5, 6 the single-step and multi-step forecasts of three considered models for a stock (ENEL).
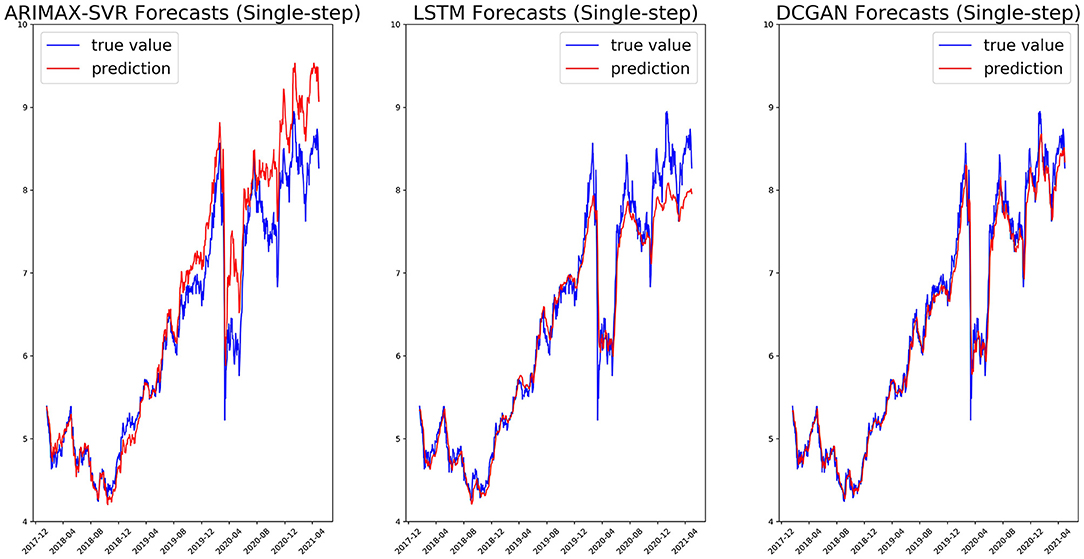
Figure 5. Single-step forecasts on the ENEL test set for ARIMAX-SVR (left), LSTM (center), and our GAN architecture (right).
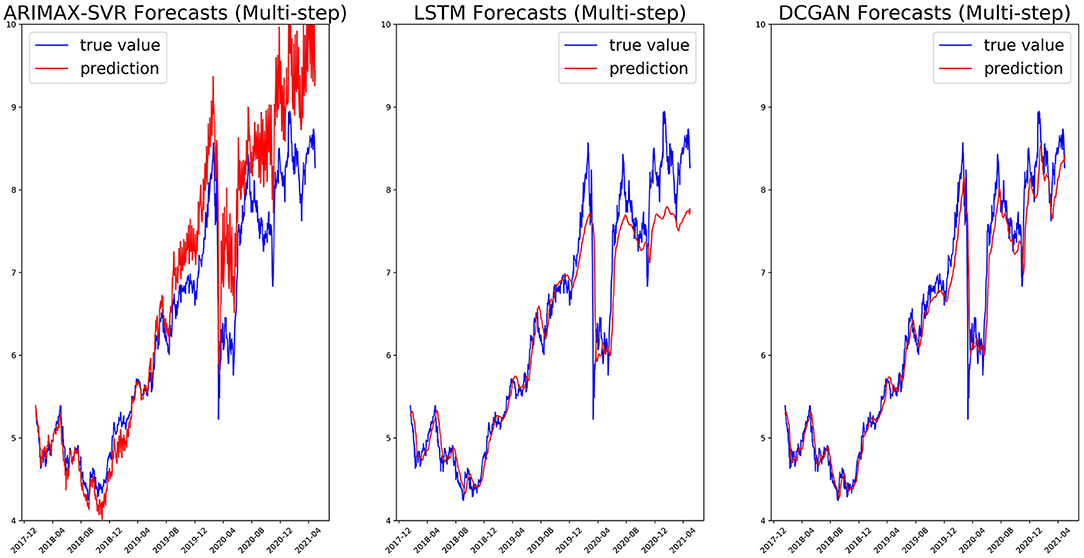
Figure 6. Multi-step (5 days) forecasts on the ENEL test set for ARIMAX-SVR (left), LSTM (center), and our GAN architecture (right).
The train-test split (80–20) has been chosen by comparing the model performances with those obtained with two others commonly used split percentages and considering the training set and test set representativeness. The results for one stock (EXO) are reported in Table 6, where the best performance for each metric (lowest value) is highlighted in bold. We can observe how the 80–20 split results in better performances across all the considered models and metrics.

Table 6. Train-test split results for one stock (EXO).
For what concerns the execution times of the considered models, they vary greatly according to the model complexity: ARIMAX-SVR is the faster, while our proposed GAN is the slowest. A more detailed description, with the average execution times and the standard deviations for each model, is reported in Table 7.
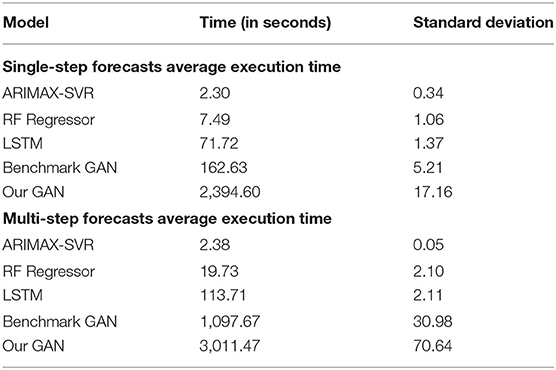
Table 7. Average execution times of the considered models (10 runs on a single stock). We ran our experiments on a Microsoft Windows 10 (Version 21H1), with 11th Gen Intel(R) Core (TM) i7-1165G7 processor (2.80 GHz, 16.0 GB of RAM).
In this paper, we proposed a DCGAN architecture with a CNN-BiLSTM generator and a CNN discriminator, with the goal of making accurate forecasts on the closing price of stocks. We compared its performance with those of four benchmark models (ARIMAX-SVR, Random Forest Regressor, LSTM, and a benchmark GAN) over 10 different stock time series. Both in the single-step and in the multi-step scenario, the results of our proposed architecture were always better (or on par, for a single metric in a single case) than the results of the benchmark models, suggesting that financial time series forecasting may benefit from employing GANs.
Despite having obtained promising results and a stable architecture, training GANs remains a difficult task due to the need of tuning many hyperparameters while keeping a balance between the generator and the discriminator network. Future research should move in the direction of finding a more systematic way to perform parameter tuning, as well as exploring other architecture configurations.
It should also be mentioned that we considered a fixed test set and evaluated all the models on it. An interesting extension of our work would be to compare the performances in other settings: for example, exclude crisis periods (such as the COVID-19 crisis), consider different forecasting horizons, and different time granularities.
The original contributions presented in the study are included in the article/supplementary materials, further inquiries can be directed to the corresponding author/s.
AS: conceptualization, methodology, software, validation, analysis, investigation, writing, and visualization.
Author AS was employed by ALBERT Inc.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
1. ^Technically, even only finding these points is NP-hard.
2. ^Given any , a function f:Rn→R is called 1-Lipschitz continuous if it satisfies |f(x1)−f(x2)| ≤ ||x1−x2||.
3. ^Version: 2020b.
4. ^Version: 3.7.3, run on an Anaconda platform.
Adebiyi, A. A., Adewumi, A. O., and Ayo, C. K. (2014). “Stock price prediction using the ARIMA model,” in 2014 UK Sim-AMSS 16th International Conference on Computer Modeling and Simulation (Cambridge).
Agrawal, M., Shukla, P. K., Nair, R., Nayyar, A., and Masud, M. (2021). Stock prediction based on technical indicators using deep learning model. Comp. Mater. Continua 70, 287–304. doi: 10.32604/cmc.2022.014637
Akaike, H.. (1973). “Information theory as an extension of the maximum likelihood principle,” in Second International Symposium on Information Theory, eds B. N. Petrov, and F. Csaki (Budapest: Akademiai Kiado), 267–281.
Alwadi, S., Almasarweh, M. S., and Alsaraireh, A. (2018). Predicting closed price time series data using ARIMA model. Modern Appl. Sci. 12, 181–185. doi: 10.5539/mas.v12n11p181
Aras, S.. (2020). “Using technical indicators to predict stock price index movements by machine learning techniques,” in Theory and Research in Social, Human and Administrative Sciences II, ed E. Sarikaya (Ankara: Gece Publishing).
Areekul, P., Senjyu, T., Toyama, H., and Yona, A. (2010). A hybrid ARIMA and neural network model for short-term price forecasting in deregulated market. IEEE Transact. Power Syst. 25, 524–530. doi: 10.1109/TPWRS.2009.2036488
Arjovsky, M., Chintala, S., and Bottou, L. (2017). “Wasserstein GAN”, in Proceedings of the 34th International Conference on Machine Learning (Sydney).
Baek, Y., and Kim, H. Y. (2018). ModAugNet: a new forecasting framework for stock market index value with an overfitting prevention LSTM module and a prediction LSTM module. Exp. Syst. Appl. 113, 457–480. doi: 10.1016/j.eswa.2018.07.019
Banerjee, D.. (2014). “Forecasting of Indian stock market using time-series ARIMA model,” in 2014 2nd International Conference on Business and Information Management (ICBIM) (Durgapur).
Calin, O.. (2020). Deep Learning Architectures: A Mathematical Approach. Springer Series in the Data Sciences. London: Springer Nature.
Chang, P. C., and Fan, C. Y. (2008). A hybrid system integrating a wavelet and TSK fuzzy rules for stock price forecasting. IEEE Transact. Syst. Man Cybern. Part C 38, 802–815. doi: 10.1109/TSMCC.2008.2001694
Chen, H.. (2021). Challenges and corresponding solutions of generative adversarial networks (GANs): a survey study. J. Phys. Conf. Ser. 1827, 012066. doi: 10.1088/1742-6596/1827/1/012066
Chintala, S.. (2016). How to Train a GAN? Tips and tricks to make GANs work. GitHub Repository. Available online at: https://github.com/soumith/ganhacks (accessed December 10, 2021).
Devi, B. U., Sundar, D., and Alli, P. (2013). An effective time series analysis for stock trend prediction using ARIMA model for nifty midcap-50. Int. J. Data Mining Knowl. Manag. Process 3, 65–78. doi: 10.5121/ijdkp.2013.3106
Dickey, D. A., and Fuller, W. A. (1979). Distribution of the estimators for autoregressive time series with a unit root. J. Am. Stat. Assoc. 74, 427–431. doi: 10.1080/01621459.1979.10482531
Diebold, F., and Mariano, R. (1995). Comparing predictive accuracy. J. Bus. Econ. Stat. 13, 253–263. doi: 10.1080/07350015.1995.10524599
Dudek, G.. (2015). “Short-term load forecasting using random forests,” in Intelligent Systems 2014 - Proceedings of the 7th IEEE International Conference Intelligent Systems IS'2014. Volume 2: Tools, Architectures, Systems, Applications (Warsaw), 821–828.
Fama, E.. (1965). Random walks in stock market prices. Financial Anal. J. 21, 55–59. doi: 10.2469/faj.v21.n5.55
Glorot, X., and Bengio, Y. (2010). Understanding the difficulty of training deep feedforward neural networks. J. Mach. Learn. Res. 9, 249–256.
Gomber, P., and Zimmermann, K. (2018). Algorithmic Trading in Practice. The Oxford Handbook of Computational Economics and Finance. Oxford: Oxford University Press.
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., et al. (2014). “Generative adversarial networks”, in Advances in Neural Information Processing Systems 27 (NIPS 2014) (Montreal), 3.
Gulrajani, I., Ahmed, F., Arjovsky, M., Dumoulin, V., and Courville, A. (2017). “Improved training of wasserstein GANs,” in Proceedings of the 31st International Conference on Neural Information Processing Systems (Long Beach, CA).
Gurusen, E., Kayakutlu, G., and Daim, T. (2011). Using artificial neural network models in stock market index prediction. Exp. Syst. Appl. 38,10389–10397. doi: 10.1016/j.eswa.2011.02.068
Hochreiter, S., and Schmidhuber, J. (1997). Long short-term memory. Neural Comp. 9, 1735–1780. doi: 10.1162/neco.1997.9.8.1735
Hoseinzade, E., and Haratizadeh, S. (2019). CNNpred: CNN-based stock market prediction using a diverse set of variables. Exp. Syst. Appl. 129, 273–285. doi: 10.1016/j.eswa.2019.03.029
Kane, M. J., Price, N., Scotch, M., and Rabinowitz, P. (2014). Comparison of ARIMA and Random Forest time series models for prediction of avian influenza H5N1 outbreaks. BMC Bioinformat. 15, 276. doi: 10.1186/1471-2105-15-276
Khashei, M., and Hajirahimi, Z. (2018). A comparative study of series arima/mlp hybrid models for stock price forecasting. Commun. Stat. Simulat. Comput. 48, 1–16. doi: 10.1080/03610918.2018.1458138
Kingma, D., and Ba, J. (2014). “Adam: a method for stochastic optimization,” in International Conference on Learning Representations (ICLR) (Banff).
Koochali, A., Schichtel, P., Dengel, A., and Ahmed, S. (2019). Probabilistic Forecasting of Sensory Data with Generative Adversarial Networks - ForGAN. Manhattan, NY: IEEE Access.
LeCun, Y., Bottou, L., Orr, G. B., and Muller, K. R. (1998). Efficient BackProp. Neural Networks: Tricks of the Trade. Berlin; Heidelberg: Springer.
Lin, H. C., Chen, C., Huang, G. F., and Jafari, A. (2021). Stock price prediction using generative adversarial networks. J. Comp. Sci. 17,188–196. doi: 10.3844/jcssp.2021.188.196
Luo, Z., Chen, J., Cai, X. J., Tanaka, K., Takiguchi, T., Kinkyo, T., et al. (2018). “Oil price forecasting using supervised GANs with continuous wavelet transform features,” in 24th International Conference on Pattern Recognition (ICPR) (Beijing).
Masini, R. P., Medeiros, M. C., and Mendes, E. F. (2021). Machine learning advances for time series forecasting. arXiv [Preprint]. arXiv:2012.12802.
Moghar, A., and Hamiche, M. (2020). Stock market prediction using LSTM recurrent neural network. Proc. Comp. Sci. 170, 1168–1173. doi: 10.1016/j.procs.2020.03.049
Mozer, M. C.. (1989). A focused backpropagation algorithm for temporal pattern recognition. Comp. Syst. 3, 349–381.
Nevmyvaka, Y., Feng, Y., and Kearns, M. (2006). “Reinforcement learning for optimized trade execution,” in Machine Learning, Proceedings of the Twenty-Third International Conference (ICML 2006) (Pittsburgh, PA), 673–680.
Oriani, F. B., and Coelho, G. P. (2016). “Evaluating the impact of technical indicators on stock forecasting,” in 2016 IEEE Symposium Series on Computational Intelligence (SSCI) (Athens).
Pai, P. F., and Lin, C. S. (2005). A hybrid ARIMA and support vector machines model in stock price forecasting. Omega 33, 497–505. doi: 10.1016/j.omega.2004.07.024
Persons, W. M.. (1916). Construction of a business barometer based upon annual data. Am. Econ. Rev. 6, 739–769.
Radford, A., Metz, L., and Chintala, S. (2015). Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv [Preprint]. arXiv:1511.06434.
Rather, A. M., Agarwal, A., and Sastry, V. N. (2015). Recurrent neural network and a hybrid model for prediction of stock returns. Exp. Syst. Appl. 42, 3234–3241. doi: 10.1016/j.eswa.2014.12.003
Richardson, B. C.. (1979). Limitations on the Use of Mathematical Models in Transportation Policy Analysis. Ann Arbor: UMI Research Press.
Roondiwala, M., Patel, H., and Shraddha, V. (2017). Predicting stock prices using LSTM. Int. J. Sci. Res. 6, 1754–1756. doi: 10.21275/23197064
Selvin, S., Vinayakumar, R., Gopalakrishnan, E. A., Menon, V. K., and Soman, K. P. (2017). “Stock price prediction using LSTM, RNN and CNN-sliding window model,” in 2017 International Conference on Advances in Computing, Communications and Informatics (ICACCI) (Udupi).
Sen, J.. (2017). A robust analysis and forecasting framework for the Indian mid cap sector using time series decomposition. J. Insur. Finan. Manag. 3, 1–32.
Srivastava, N., Hinton, G., Krizhevsky, A., and Sutskever, I. (2014). Dropout: a simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 15, 1929–1958.
Tan, K. K., Le, N. Q. K., Yeh, H. Y., and Chua, M. C. H. (2019). Ensemble of deep recurrent neural networks for identifying enhancers via dinucleotide physicochemical properties. Cell 8:767. doi: 10.3390/cells8070767
Tsai, C. F., and Wang, S. P. (2009). “Stock price forecasting by hybrid machine learning techniques,” in Proceedings of the International Multi Conference of Engineers and Computer Scientists, Vol. 1 (Hong Kong).
Tsantekidis, A., Passalis, N., Tefas, A., Kanniainen, J., Gabbouj, M., and Iosifidis, A. (2017). “Forecasting stock prices from the limit order book using convolutional neural networks,” in 19th IEEE Conference on Business Informatics, Vol. 1 (Thessaloniki), 7–12.
Verheggen, R.. (2017). The Rise of Algorithmic Trading and Its Effects on Return Dispersion and Market Predictability (master thesis). Tilburg University, Tilburg, Netherlands.
Zhang, K., Zhong, G., Dong, J., Wang, S., and Wang, Y. (2019). Stock market prediction based on generative adversarial network. Proc. Comp. Sci. 147,400–406. doi: 10.1016/j.procs.2019.01.256
Zhou, K., Wang, W., Hu, T., and Deng, K. (2020a). Time series forecasting and classification models based on recurrent with attention mechanism and generative adversarial networks. Sensors 20:7211. doi: 10.3390/s20247211
Zhou, K., Wang, W., Huang, L., and Liu, B. (2020b). Comparative study on the time series forecasting of web traffic based on statistical model and generative adversarial model. Knowl. Based Syst. 213:106467. doi: 10.1016/j.knosys.2020.106467
Keywords: Generative Adversarial Networks, time series forecasting, stock price forecasting, deep learning, neural networks, forecasting, financial time series
Citation: Staffini A (2022) Stock Price Forecasting by a Deep Convolutional Generative Adversarial Network. Front. Artif. Intell. 5:837596. doi: 10.3389/frai.2022.837596
Received: 16 December 2021; Accepted: 11 January 2022;
Published: 04 February 2022.
Edited by:
Gautier Marti, Abu Dhabi Investment Authority, United Arab EmiratesReviewed by:
Kristina Sutiene, Kaunas University of Technology, LithuaniaCopyright © 2022 Staffini. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Alessio Staffini, YWxlc3Npby5zdGFmZmluaUBib2Njb25pYWx1bW5pLml0
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.