
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
METHODS article
Front. Artif. Intell., 31 March 2022
Sec. Medicine and Public Health
Volume 4 - 2021 | https://doi.org/10.3389/frai.2021.550603
This article is part of the Research TopicCoronavirus Disease (COVID-19): Pathophysiology, Epidemiology, Clinical Management and Public Health ResponseView all 400 articles
 Frank Wood1,2
Frank Wood1,2 Andrew Warrington3
Andrew Warrington3 Saeid Naderiparizi1
Saeid Naderiparizi1 Christian Weilbach1Vaden Masrani1
Christian Weilbach1Vaden Masrani1 William Harvey1Adam Ścibior1
William Harvey1Adam Ścibior1 Boyan Beronov1John Grefenstette4Duncan Campbell4
Boyan Beronov1John Grefenstette4Duncan Campbell4 S. Ali Nasseri1*
S. Ali Nasseri1*In this work we demonstrate how to automate parts of the infectious disease-control policy-making process via performing inference in existing epidemiological models. The kind of inference tasks undertaken include computing the posterior distribution over controllable, via direct policy-making choices, simulation model parameters that give rise to acceptable disease progression outcomes. Among other things, we illustrate the use of a probabilistic programming language that automates inference in existing simulators. Neither the full capabilities of this tool for automating inference nor its utility for planning is widely disseminated at the current time. Timely gains in understanding about how such simulation-based models and inference automation tools applied in support of policy-making could lead to less economically damaging policy prescriptions, particularly during the current COVID-19 pandemic.
Our goal in this paper is to demonstrate how the “planning as inference” methodology at the intersection of Bayesian statistics and optimal control can directly aid policy-makers in assessing policy options and achieving policy goals, when implemented using epidemiological simulators and suitable automated software tools for probabilistic inference. Such software tools can be used to quickly identify the range of values towards which controllable variables should be driven by means of policy interventions, social pressure, or public messaging, so as to limit the spread and impact of an infectious disease such as COVID-19.
In this work, we introduce and apply a simple form of planning as inference in epidemiological models to automatically identify policy decisions that achieve a desired, high-level outcome. As but one example, if our policy aim is to contain infectious population totals below some threshold at all times in the foreseeable future, we can condition on this putative future holding and examine the allowable values of controllable behavioural variables at the agent or population level, which in the framework of planning as inference is formalized in terms of a posterior distribution. As we already know, to control the spread of COVID-19 and its impact on society, policies must be enacted that reduce disease transmission probability or lower the frequency and size of social interactions. This is because we might like to, for instance, not have the number of infected persons requiring hospitalization exceed the number of available hospital beds.
Throughout this work, we take a Bayesian approach, or at the very least, a probabilistic consideration of the task. Especially in the early stages of a new outbreak, the infectious dynamics are not known precisely. Furthermore, the spread of the disease cannot be treated deterministically, as a result of either fundamental variability in the social dynamics that drive infections, or of uncertainty over the current infection levels, or of uncertainty over appropriate models for analyzing the dynamics. Therefore, developing methods capable of handling such uncertainty correctly will allow for courses of action to be evaluated and compared more effectively, and could lead to “better” policies: a policy that surpasses the desired objective with 55% probability, but fails with 45% probability, may be considered “worse” than a policy that simply meets the objective with 90% probability. Bayesian analysis also offers a form of probabilistic inference in which the contribution of individual variables to the overall uncertainty can be identified and quantified. Beyond simply obtaining “the most effective policy measure,” this may be of interest to analysts trying to further understand why certain measures are more effective than others.
We first show how the problem of policy planning can be formulated as a Bayesian inference task in epidemiological models. This framing is general and extensible. We then demonstrate how particular existing software tools can be employed to perform this inference task in preexisting stochastic epidemiological models, without modifying the model itself or placing restrictions on the models that can be analyzed. This approach is particularly appealing, as it decouples the specification of epidemiological models by domain experts from the computational task of performing inference. This shift allows for more expressive and interpretable models to be expediently analyzed, and the sophistication of inference algorithms to be adjusted flexibly.
As a result, the techniques and tools we review in this paper are applicable to simulators ranging from simple compartmental models to highly expressive agent-based population dynamics models. In the former, the controls available to policy-makers are blunt–e.g., “reduce social interactions by some fractional amount”–but how best to achieve this is left as an exercise for policy-makers. In the latter, variables like “probability of individuals adhering to self-isolation” and “how long should schools be closed if at all” can be considered and evaluated in combination and comparison to others as potential fine-grained controls that could achieve the same policy objective more efficiently.
When governments impose any such controls, both citizens and financial markets want to know how draconian these measures must be and for how long they have to be in effect. Policy analysis based on models that reflect variability in resources such as healthcare facilities in different jurisdictions could hopefully make the answers to these questions more precise and the controls imposed more optimal in the utility maximizing sense. The same holds for the difference between models that can or cannot reflect variations in population mixing between rural and urban geographic areas. A person living in a farming county in central Illinois might reasonably wonder if it is as necessary to shelter in place there as it is in Chicago.
Current approaches to model-based policy-making are likely to be blunt. Simple models, e.g., compartmental models with few compartments, are rapid to fit to new diseases and easy to compute, but are incapable of evaluating policy options that are more fine-grained than the binning used, such as regionalized measures. The net effect of being able to only consider blunt controls arguably has contributed to a collective dragging of feet, even in the face of the current COVID-19 pandemic. This delayed reaction, combined with brute application of control, has led to devastating socioeconomic impact, with many sectors such as education, investment markets and small-medium enterprises being directly impacted.
We can and should be able to do better. We believe, and hope to demonstrate, that models and software automation focused on planning as inference for policy analysis and recommendation is one path forward that can help us better react to this and future pandemics, and improve our public health preparedness.
We upfront note that the specific models that we use in this paper are far from perfect. First, the pre-existing models we use to demonstrate our points in this paper are only crudely calibrated to present-day population dynamics and specific COVID-19 characteristics. We have made some efforts on the latter point, in particular sourcing a COVID-19 adapted compartmental model (Ogilvy Kermack and McKendrick, 1927; Blackwood and Childs, 2018b; Hill et al., 2020) and parameters from (Bhalchandra and SnehalShekatkar, 2020; Ferguson et al., 2020; Magdon-Ismail, 2020; Massonnaud et al., 2020; Peng et al., 2020; Riou and Althaus, 2020; Rovetta et al., 2020; Russo et al., 2020; Traini et al., 2020; Wen et al., 2020), but we stress this limitation. In addition, in simple cases, the type of problems for which we discuss solutions in this paper may be solved with more straightforward implementations involving parameter sweeps and “manual” checking for desired policy effects, albeit at potentially higher human cost. In this sense, our goal is not to claim fundamental novelty, uniqueness or superiority of any particular inference technique, but rather to raise awareness for the practical feasibility of the Bayesian formulation of planning as inference, which offers a higher level of flexibility and automation than appears to be understood widely in the policy-making arena.
Note also that current automated inference techniques for stochastic simulation-based models (Toni et al., 2009; Kypraios et al., 2017; McKinley et al., 2018; Chatzilena et al., 2019; Minter and Retkute, 2019) are computationally demanding and are by their very nature approximate. The academic topic at the core of this paper and the subject of a significant fraction of our academic work (Paige et al., 2014; Wood et al., 2014; Tolpin et al., 2015; van de Meent et al., 2015; Paige and Wood, 2016; Rainforth et al., 2016; Rainforth et al., 2018; Naderiparizi et al., 2019; Zhou et al., 2019; Warrington et al., 2020) deals with this challenge. Furthermore, the basic structure of simulators currently available may lack important policy-influenceable interaction parameters that one might like to examine. If viewed solely in light of the provided examples, our contribution could reasonably be seen both as highlighting the utility of inference for planning in this application setting, and as automating the manual selection of promising policy parameters. The tools we showcase are capable of significantly more; however, for expediency and clarity, we have focused on control as inference, an application that has seen relatively little specific coverage in the literature, and the simplest possible inference methods which do not require familiarity with the technical literature on approximate Bayesian inference. We leave other straightforward applications of automated inference tools in this application area, like parameter inference from observed outbreak data (Toni et al., 2009; Kypraios et al., 2017; McKinley et al., 2018; Chatzilena et al., 2019; Minter and Retkute, 2019), to others.
That being said, our hope is to inform field epidemiologists and policy-makers about an existing technology that could, right now, be used to support public policy planning towards more precise, potentially tailored interventions that ensure safety while also potentially leading to fewer economic ramifications. Fully probabilistic methods are apparently only relatively recently being embraced by the epidemiology community (Lessler et al., 2016; Funk and King, 2020), while the communities for approximate Bayesian inference and simulation-based inference have remained mostly focused on the tasks of parameter estimation and forecasting (Toni et al., 2009; Kypraios et al., 2017; McKinley et al., 2018), rather than control as inference. Beyond this demonstration, we hope to encourage timely and significant developments on the modeling side, and, if requested, to actually aid in the fight against COVID-19 by helping arm policy-makers with a new kind of tool and training them how to use it rapidly. Finally, we hope to engage the machine learning community in the fight against COVID-19 by helping translate between the specific epidemiological control problem and the more general control problem formulations on which we work regularly.
We start with the assumption that the effectiveness of policy-making can be significantly improved by consulting the outputs of model-based tools which provide quantitative metrics for the ability of particular policy actions to achieve specific formalized goals. In particular, we imagine the following scenario. There exists some current population, and the health status of its constituents is only partially known. There exists a disease whose transmission properties may be only partially known, but whose properties cannot themselves be readily controlled. There exists a population dynamic that can be controlled in some limited ways at the aggregate level. There exists a “policy goal” or target which we will refer to as the allowable, allowed, or goal set of system trajectories. An example of this could be “the total number of infectious persons should not ever exceed some percentage of the population” or “the first date at which the total number of infectious persons exceeds some threshold is at least some number of days away.” We finally assume an implied set of allowable policy prescriptions, defined in the sense that population dynamics behaving according to such policies will be exactly the ones to attain the goal with high probability. In general, this set of allowable policies is intractable to compute exactly, motivating the use of automated tools implementing well established approximate Bayesian inference methods. We explicitly do not claim “completeness” of the stochastic dynamic models in any realistic sense, disregarding complications such as potential agent behaviour in strategic response to regionalized policies, and do not attempt to quantify all costs and benefits of the considered policies, for example economic or cultural impacts. Rather, formulating the problem described above in terms of Bayesian inference results in a posterior distribution over policies which have been conditioned on satisfying the formalized policy desiderata within the formalized dynamical model. Effectively, this is to be understood as “scrutinizing,” “weighting,” “prioritizing,” or “focusing” potential policy actions for further consideration, rather than as an “optimal” prescription. When selecting a policy based on the posterior distribution, policy-makers are expected to account for additional, more complex socio-economic phenomena, costs and benefits using their own judgment.
The only things that may safely be taken away from this paper are the following:
• Existing compartmental models and agent-based simulators can be used as an aid for policy assessment via a Bayesian planning as inference formulation.
• Existing automated inference tools can be used to perform the required inferential computation.
• Opportunities exist for various fields to come together to improve both understanding of and availability of these techniques and tools.
• Further research and development into modeling and inference is recommended to be immediately undertaken to explore the possibility of more efficient, less economically devastating control of the COVID-19 pandemic.
What should not be taken away from this paper are any other conclusions, including in particular the following:
• Any conclusion or statements that there might exist less aggressive measures that could still be effective in controlling COVID-19.
• Any substantial novelty, uniqueness or performance claims about the particular numerical methods and software implementations for Bayesian inference which were used for the purpose of demonstrating the findings above. In particular, on the one hand, similar results could have been obtained using other software implementation strategies in principle, and on the other hand, more advanced inference methods could have been applied using the same software tools at the expense of rendering the conceptual exposition less accessible to audiences outside of the Bayesian inference community.
As scientists attempting to contribute “across the aisle,” we use more qualifying statements than usual throughout this work in an attempt to reduce the risk of misunderstandings and sensationalism.
In this section we formalize the policy-making task in terms of computing conditional probabilities in a probabilistic model of the disease spread. While the technical description can get involved at times, we emphasize that in practice the probabilistic model is already defined by an existing epidemiological simulator and the probabilistic programming tools we describe in this paper provide the ability to compute the required conditional probabilities automatically, including automatically introducing required approximations, so the users only need to focus on identifying which variables to condition on, and feeding real-world data to the system. Readers familiar with framing planning as inference may wish to skip directly to Section 4.
Being able to perform probabilistic inference is crucial for taking full advantage of available simulators in order to design good policies. This is because in the real world, many of the variables crucially impacting the dynamics of simulations are not directly observable, such as the number of infectious but asymptomatic carriers or the actual number of contacts people make in different regions each day. These variables are called latent, as opposed to observable variables such as the number of deaths or the number of passengers boarding a plane each day, which can often be directly measured with high accuracy. It is often absolutely crucial to perform inference over some latent variables to achieve reliable forecasts. For example, the future course of an epidemic like COVID-19 is driven by the number of people currently infected, rather than the number of people currently hospitalized, while in many countries in the world currently only the latter is known.
While performing inference over latent variables is very broadly applicable, the scenario described above being but one example, in this paper we primarily address the problem of choosing good policies to reduce the impact of an epidemic which can also be formulated as an inference problem. This choice of problem was driven by the hypothesis that the search for effective controls may not in fact be particularly well-served by automation at the current time. In the epidemiological context, the questions we are trying to answer are ones like “when and for how long do we need to close schools to ensure that we have enough ventilators for everyone who needs them?” While obviously this is overly simplistic and many different policy decisions need to be enacted in tandem to achieve good outcomes, we use this example to illustrate tools and techniques that can be applied to problems of realistic complexity.
Our approach is not novel, it has been studied extensively under the name “control via planning as inference” and is now well understood (Todorov, 2008; Toussaint, 2009; Kappen et al., 2012; Levine, 2018). What is more, the actual computations that result from following the recipes for planning as inference can be, in some cases readily, manually replicated. Again, our aim here is to inform or remind a critically important set of policy-makers and modellers that these methodologies are extremely relevant to the current crisis. Moreover, at least partial automation of model-informed policy-guidance is achievable using existing tools, and, may even lead to sufficient computational savings to make their use in current policy-making practical. Again, our broader hope here is to encourage rapid collaborations leading to more targeted and less-economically-devastating policy recommendations.
In this work we will look at both compartmental and agent-based models. An overview of these specific types of models appears later. For the purposes of understanding our approach to planning as inference, it is helpful to describe the planning as inference problem in a formalism that can express both types of models. The approach of conducting control via planning as inference follows a general recipe:
1) Define the latent and control parameters of the model and place a prior distribution over them.
2) Either or both define a likelihood for the observed disease dynamics data and design constraints that define acceptable disease progression outcomes.
3) Do inference to generate a posterior distribution on control values that conditions both on the observed data and the defined constraints.
4) Make a policy recommendation by picking from the posterior distribution consisting of effective control values according to some utility maximizing objective.
We focus on steps 1–3 of this recipe, and in particular do not explore simultaneous conditioning. We ignore the observed disease dynamics data and focus entirely on inference with future constraints. We explain the rationale behind these choices near the end of the paper.
Very generally, an epidemiological model consists of a set of global parameters and time dependent variables. Global parameters are (θ, η), where θ denotes parameters that can be controlled by policy directives (e.g. close schools for some period of time or decrease the general level of social interactions by some amount), and η denotes parameters which cannot be affected by such measures (e.g. the incubation period or fatality rate of the disease).
The time dependent variables are (Xt, Yt, Zt) and jointly they constitute the full state of the simulator. Xt are the latent variables we are doing inference over (e.g. the total number of infected people or the spatio-temporal locations of outbreaks), Yt are the observed variables whose values we obtain by measurements in the real world (e.g. the total number of deaths or diagnosed cases), and Zt are all the other latent variables whose values we are not interested in knowing (e.g. the number of contacts between people or hygiene actions of individuals). For simplicity, we assume that all variables are either observed at all times or never, but this can be relaxed.
The time t can be either discrete or continuous. In the discrete case, we assume the following factorization
Note that we do not assume access to any particular factorization between observed and latent variables. We assume that a priori the controllable parameters θ are independent of non-controllable parameters η to avoid situations where milder control measures are associated with better outcomes because they tend to be deployed when the circumstances are less severe, which would lead to erroneous conclusions when conditioning on good outcomes in Section 3.3.
The classical inference task (Toni et al., 2009; Kypraios et al., 2017; McKinley et al., 2018; Chatzilena et al., 2019; Minter and Retkute, 2019) is to compute the following conditional probability
In the example given earlier Xt would be the number of infected people at time t and Yt would be the number of hospitalized people at time t. If the non-controllable parameters η are known they can be plugged into the simulator, otherwise we can also perform inference over them, like in the equation above. This procedure automatically takes into account prior information, in the form of a model, and available data, in the form of observations. It produces estimates with appropriate amount of uncertainty depending on how much confidence can be obtained from the information available.
The difficulty lies in computing this conditional probability, since the simulator does not provide a mechanism to sample from it directly and for all but the simplest models the integral cannot be computed analytically. The main purpose of probabilistic programming tools is to provide a mechanism to perform the necessary computation automatically, freeing the user from having to come up with and implement a suitable algorithm. In this case, approximate Bayasian computation (ABC) would be a suitable tool. We describe it below, emphasizing again that its implementations are already provided by existing tools (Toni et al., 2009; Kypraios et al., 2017; McKinley et al., 2018; Chatzilena et al., 2019; Minter and Retkute, 2019).
The main problem in this model is that we do not have access to the likelihood p(Yt ∣ Xt, θ, η) so we cannot apply the standard importance sampling methods. To use ABC, we extend the model with auxiliary variables
which we can solve by importance sampling from the prior. Algorithmically, this means independently sampling a large number N of trajectories from the simulator
computing their importance weights
and approximating the posterior distribution
where δ is the Dirac delta putting all the probability mass on the point in its subscript. In more intuitive terms, we are approximating the posterior distribution with a collection of weighted samples where weights indicate their relative probabilities.
In traditional inference tasks we condition on data observed in the real world. In order to do control as inference, we instead condition on what we want to observe in the real world, which tells us which actions are likely to lead to such observations. This is accomplished by introducing auxiliary variables that indicate how desirable a future state is or is not. In order to keep things simple, here we restrict ourselves to the binary case where Yt ∈ {0, 1}, where 1 means that the situation at time t is acceptable and 0 means it is not. This indicates which outcomes are acceptable, allowing us to compute a distribution over those policies, while leaving the choice of which specific policy is likely to produce an acceptable outcome to policy-maker(s). For example, Yt can be 1 when the number of patients needing hospitalization at a given time t is smaller than the number of hospital beds available and 0 otherwise.
To find a policy θ that is likely to lead to acceptable outcomes, we need to compute the posterior distribution
Once again, probabilistic programming tools provide the functionality to compute this posterior automatically. In this case, rejection sampling would be a simple and appropriate inference algorithm. The rejection sampling algorithm repeatedly samples values of θ from the prior p(θ), runs the full simulator using θ, and keeps the sampled θ only if all Yt are 1. The collection of accepted samples approximates the desired posterior. We use rejection sampling in our agent-based modeling experiments, but emphasize that other, more complex and potentially more computationally efficient, approaches to computing this posterior exist.
This tells us which policies are most likely to lead to a desired outcome but not how likely a given policy is to lead to that outcome. To do that, we can evaluate the conditional probability p(∀t>0 : Yt = 1 ∣ θ), which is known as the model evidence, for a particular θ. A more sophisticated approach would be to condition on the policy leading to a desired outcome with a given probability p0, that is
For example, we could set p0 = 0.95 to find a policy that ensures availability of hospital beds for everyone who needs one with at least 95% probability. The conditional probability in Eq. 8 is more difficult to compute than the one in Eq. 7. It can be approximated by methods such as nested Monte Carlo (NMC) (Rainforth et al., 2018), which are natively available in advanced probabilistic programming systems such as Anglican (Tolpin et al., 2016) and WebPPL (Goodman and Stuhlmüller, 2014a) but in specific cases can also be implemented on top of other systems, such as PyProb (Le et al., 2017), with relatively little effort, although using NMC usually has enormous computational cost.
To perform rejection sampling with nested Monte Carlo, we first draw a sample θi ∼ p(θ), then draw N samples of
However we compute the posterior distribution, it contains multiple values of θ that represent different policies that, if implemented, can achieve the desired result. In this setup it is up to the policy-maker(s) to choose a policy θ* that has support under the posterior, i.e., yields the desired outcomes, taking into account some notion of utility.
Crucially, despite their relative simplicity, the rejection sampling algorithms we have discussed evaluate randomly sampled values of θ. This is a fundamental difference from the commonly used grid search over a deterministic array of parameter values. In practical terms, this is important because “well distributed” random samples are sufficient for experts to gauge the quantities of interest, and avoid grid searches that would be prohibitively expensive for θ with more than a few dimensions.
During an outbreak governments continuously monitor and assess the situation, adjusting their policies based on newly available data. A convenient theoretical and general framework to formalize this is that of model predictive control (Camacho and Alba, 2013). In this case, Yt consists of variables
Then at time t = 1 they will have gained additional information
Generally, at time t we compute the posterior distribution conditioned on the current state and on achieving desirable outcomes in the future
Policy-maker(s) then can use this distribution to choose the policy
Eq. 11 can be computed using methods described in Section 3.2, while Eq. 10 can be computed using methods described in Section 3.3. As such, the policy enacted evolves over time, as a result of re-solving for the optimal control based on new information.
We note that what we introduce here as MPC may appear to be slightly different from what is commonly referred to as model predictive control (García et al., 1989). Firstly, instead of solving a finite-dimensional optimization problem over controls at each step, we perform a Bayesian update step and sample from the resulting posterior distribution over controls. Secondly, in more traditional applications of MPC a receding horizon (Jacob et al., 2011) is considered, where a finite and fixed-length window is considered. The controls required to satisfy the constraint over that horizon are then solved for and applied–without consideration of timesteps beyond this fixed window. At the next time step, the controls are then re-solved for. In this work, we rather consider a constant policy for the remaining T − t time steps, as opposed to allowing a variable policy (discussed below) over a fixed window. We note that time-varying controls are fully permissible under the framework we present, as we demonstrate in Section 3.5. Furthermore, we could easily consider a fixed horizon, just by changing the definition of
Before we proceed, it is critical to note that the posterior
It is also possible to explicitly model changing policy decisions over time, which enables more detailed planning, such as when to enact certain preventive measures such as closing schools. Notationally, this means instead of a single θ there is a separate θt for each time t. We can then find a good sequence of policy decisions by performing inference just like in Section 3.3 by conditioning on achieving the desired outcome
The inference problem is now more challenging, since the number of possible control sequences grows exponentially with the time horizon. Still, the posterior can be efficiently approximated with methods such as Sequential Monte Carlo.
It is straightforward to combine this extension with model predictive control from Section 3.4. The only required modification is that in Eq. 10 we need to compute the posterior over all future policies,
At each time t the policy-maker(s) only choose the current policy
In models with per-timestep control variables θt, it is very important that in the model (but not in the real world) the enacted policies must not depend on anything else. If the model includes feedback loops for changing policies based on the evolution of the outbreak, it introduces positive correlations between lax policies and low infection rates (or other measures of severity of the epidemic), which in turn means that conditioning on low infection rates is more likely to produce lax policies. This is a known phenomenon of reversing causality when correlated observational data is used to learn how to perform interventions (Pearl, 2000).
We note another potential pitfall that may be exacerbated by time-varying control: if the model used does not accurately reflect reality, any form of model-based control is likely to lead to poor results. To some extent, this can be accounted for with appropriate distributions reflecting uncertainty in parameter values. However, given the difficulty of modeling human behavior, and especially of modeling people’s reactions to novel policies, there is likely to be some mismatch between modeled and real behavior. To give an example of a possible flaw in an agent-based model: if a proposed fine-grained policy closed one park while keeping open a second, nearby, park, the model may not account for the likely increase in visitors to the second park. The larger and more fine-grained (in terms of time or location) the space of considered policies is, the more such deficiencies may exist. We therefore recommend that practitioners restrict the space of considered policies to those which are likely to be reasonably well modeled.
We have intentionally not really explained how one might actually computationally characterize any of the conditional distributions defined in the preceding section. For the compartmental models that follow, we provide code that directly implements the necessary computations. Alternatively we could have used the automated inference facilities provided by any number of packages or probabilistic programming systems. Performing inference as described in existing, complex simulators is much more complex and not nearly as easy to implement from scratch. However, it can now be automated using the tools of probabilistic programming.
Probabilistic programming (van de Meent et al., 2018) is a growing subfield of machine learning that aims to build an analogous set of tools for automating inference as automatic differentiation did for continuous optimization. Like the gradient operator of languages that support automatic differentiation, probabilistic programming languages introduce observe operators that denote conditioning in the probabilistic or Bayesian sense. In those few languages that natively support nested Monte Carlo (Goodman and Stuhlmüller, 2014b; Tolpin et al., 2016), language constructs for defining conditional probability objects are introduced as well. Probabilistic programming languages (PPLs) have semantics (Staton et al., 2016) that can be understood in terms of Bayesian inference (Bishop, 2006; Gelman et al., 2013; Ghahramani, 2015). The major challenge in designing useful PPL systems is the development of general-purpose inference algorithms that work for a variety of user-specified programs. The work in the paper uses only the very simplest, and often least efficient, general purpose inference algorithms, importance sampling and rejection sampling. Others are covered in detail in (van de Meent et al., 2018).
Of all the various probabilistic programming systems, only one is readily compatible with inference in existing stochastic simulators: PyProb (Le et al., 2019). Quoting from its website1 “PyProb is a PyTorch-based library for probabilistic programming and inference compilation. The main focus of PyProb is on coupling existing simulation codebases with probabilistic inference with minimal intervention.” A textbook, technical description of how PyProb works appears in (van de Meent et al., 2018, Chapt. 6).
Recent examples of its use include inference in the standard model of particle physics conditioning on observed detector outputs (Baydin et al., 2018; Baydin et al., 2019), inference about internal composite material cure processes through a composite material cure simulator conditioned on observed surface temperatures (Munk et al., 2020), and inference about malaria spread in a malaria simulator (Gram-Hansen et al., 2019).
It is important to note upfront that our ultimate objective is to understand the dependence of the policy outcome on the controllable parameters (for instance, as defined by Eqs 7, 8). There are a litany of methods to quantify this dependency. Each method imposes different constraints on the model family that can be analyzed, and the nature of the solution obtained. For instance, the fully Bayesian approach we take aims to quantify the entire distribution, whereas traditional optimal control methods may only seek a pointwise maximizer of this probability. Therefore, before we introduce the models we analyze and examples we use to explore the proposed formulation, we give a brief survey of alternative approaches one could use to solve this problem, and give the benefits and drawbacks of our proposed formulation compared to these approaches.
The traditional toolkits used to analyze problems of this nature are optimal control (Vinter and Vinter, 2010; Lewis et al., 2012; Sharomi and Malik, 2017; Bertsekas, 2019) and robust control (Zhou and Doyle, 1998; Hansen and Sargent, 2001; Green and Limebeer, 2012). Most generally, optimal control solves for the control inputs (here denoted θ) such that some outcome is achieved (here denoted
Many traditional control approaches can exploit a mathematical model of the system to solve for controls that consider multiple timesteps, referred to as model predictive control (MPC) (Morari and Lee, 1999; Rawlings, 2000; Camacho and Alba, 2013). Alternatively, control methods can be model-free, where there is no notion of the temporal dynamics of the system being controlled, such as the canonical PID control. Model-based methods often solve for more effective control measures with lower overall computational costs, by exploiting the information encoded in the model. However, model predictive control methods are only applicable when an (accurate) model is available.
One could re-frame the objective as trying to maximize the reward of some applied controls. Here, reward may be a 0–1 indicator corresponding to whether or not the hospital capacity was exceeded at any point in time. The reward may also be more sophisticated, such as by reflecting the total number of people requiring hospital treatment, weighted by how critical each patient was. Reward may also internalize some notion of the cost of a particular control. Shutting workplaces may prevent the spread of infection, but has economic and social implications that (at least partially) counteract the benefit of reducing the infection rate. This can be implemented as earning progressively more negative reward for stronger policies.
This type of analysis is formalized through reinforcement learning (RL) (Sutton, 1992; Kaelbling et al., 1996; Sutton and Barto, 2018; Bertsekas, 2019; Warrington et al., 2021). In RL, a policy, here θ, is solved for that maximizes the expected reward. RL is an incredibly powerful toolkit that can learn highly expressive policies that vary as a function of time, state, different objectives etc. RL methods can also be described as model-based (Moerland et al., 2021) and model-free (Bertsekas, 2019) analogously to traditional control methods. While we do not delve into RL in detail here, it is important to highlight as an alternative approach, and we refer the reader to Levine (2018) for a more detailed introduction of RL, to Bertsekas (2019) for a discussion of the relationship between RL and control methods, and to Levine (2018) for a discussion of the relationship between RL and planning-as-inference.
However, a critical drawback of both control and RL is the strong dependence on the loss functions or specific models considered, both in terms of convergence and the optimal solution recovered (Adam and DeJong, 2003). This dependence may therefore mean that the solution recovered is not representative of the “true” optimal solution. Furthermore, RL approaches can be incredibly expensive to train, especially in high-dimensional time series models, with a large array of controls and sparse rewards. More traditional control-based methods can be limited in the models that they can analyze, both in terms of the transition distribution and the range of controls that can be considered. Finally, both RL and control-based approaches offer limited insight into why certain controls were proposed. This can limit the ability of researchers and modellers to expediently investigate the emergent properties of complex, simulation-based models. Furthermore, this lack of transparency may be disadvantageous for policy-makers, who may be required to justify why certain policy decisions were made, and the confidence with which that policy decision was believed to be optimal.
All of these methods, at least in terms of their core intentions, are very similar. Different methods impose different restrictions on the models that can be analyzed, and the nature of the solution obtained. In this work, we take the approach of framing control and planning as fully Bayesian inference with a binary objective. We choose this formulation as it places very few restrictions on the model class that can be analyzed, allows uncertainty to be succinctly handled throughout the inference, a broad range of objectives to be defined under the same framework, and correctly calibrated posterior distributions over all random variables in the model to be recovered. Furthermore, this formulation allows us to access the ever-growing array of powerful inference algorithms to perform the inference. While naive approaches such as grid-search or random sampling may be performant in low-dimensional applications, they do not scale to high dimensions through the curse of dimensionality (Köppen, 2000; Owen, 2013). Therefore, we focus on methods that can scale to high-dimensional applications (Owen, 2013). Finally, Bayesian inference methods are, arguably, the most complete formulation. Once the full posterior or joint distribution have been recovered, many different methodologies, constraints, objectives etc. can be formulated and evaluated post facto. This flexibility allows for fine-grained analysis to be conducted on the inferred distributions to provide analysts with a powerful and general tool to further analyze and understand the model. Less myopically, this analysis and the understanding garnered may be more beneficial to our broader understanding of outbreaks and the feasibility and efficacy of particular responses.
Finally, we note that while throughout the experiments presented in Section 5.2 we use the PyProb framework, PyProb is not the only framework available. Any inference methodology could be used to compute the probability in Eq. 7. However, PyProb is a natural choice as it allows for greater flexibility in interfacing between black-box simulator code, and powerful and efficiently implemented inference algorithms, without modifying either simulator or inference code. This reduces the implementation overhead to the analyst, and reduces the scope for implementation bugs and oversights to be introduced.
Epidemiological dynamics models can be used to describe the spread of a disease such as COVID-19 in society. Different types span vastly different levels of fidelity. There are classical compartmental models (SIR, SEIR, etc.) (Blackwood and Childs, 2018a) that describe the bulk progression of diseases of different fundamental types. These models break the population down to a series of compartments (e.g. susceptible (S), infectious (I), exposed (E), and recovered (R)), and treat them as continuous quantities that vary smoothly and deterministically over time following dynamics defined by a particular system of ordinary differential equations. These models are amenable to theoretical analyses and are computationally efficient to forward simulate owing to their low dimensionality. As policy-making tools, they are rather blunt unless the number of compartments is made large enough to reflect different demographic information (age, socio-economic info, etc.), spatial strata, or combinations thereof.
At the other end of the spectrum are agent-based models (Hunter et al., 2017; Badham et al., 2018; Hunter et al., 2018; Tracy et al., 2018) (like the University of Pittsburgh Public Health Dynamics Laboratory’s FRED (Grefenstette et al., 2013) or the Institute for Disease Modeling’s EMOD (Anna et al., 2018)) that model populations and epidemiological dynamics via discrete agent interactions in “realistic” space and time. Imagine a simulation environment like the game Sim-CityTM, where the towns, populations, infrastructure (roads, airports, trains, etc.), and interactions (go to work, school, church, etc.) are modeled at a relatively high level of fidelity. These models exist only in the form of stochastic simulators, i.e., software programs that can be initialized with disease and population characteristics, then run forward to show in a more fine-grained way the spread of the disease over time and space.
Both types of models are useful for policy-making. Compartmental models are usually more blunt unless the number of compartments is very high and it is indexed by spatial location, demographics and age categories. Increasing the number of compartments adds more unknown parameters which must be estimated or marginalized. Agent-based models are complex by nature, but they may be more statistically efficient to estimate, as they are parameterized more efficiently, often directly in terms of actual individual and group behaviour choices. In many cases, predictions made by such models are more high fidelity, certainly more than compartmental models with few compartments, and this has implications for their use as predictive tools for policy analysis. For instance, policies based on simulating a single county in North Dakota with excellent hospital coverage and a highly dispersed, self-sufficient population could lead to different intervention recommendations compared to a compartmental model of the whole of the United States with only a few compartments.
We begin by introducing a low-dimensional compartmental model to explore our methods in a well-known model family, before transitioning to a more complex agent-based simulator. The model we use is an example of a classical SEIR model (Ogilvy Kermack and McKendrick, 1927; C Blackwood and Childs, 2018; Hill et al., 2020). In such models, the population is subdivided into a set of compartments, representing the susceptible (uninfected), exposed (infected but not yet infectious), infectious (able to infect/expose others) and recovered (unable to be infected). Within each compartment, all individuals are treated identically, and the full state of the simulator is simply the size of the population of each compartment. Our survey of the literature found a lack of consensus about the compartmental model and parameters which most faithfully simulate the COVID-19 scenario. Models used range from standard SEIR (Liu et al., 2020a; Massonnaud et al., 2020; Rovetta et al., 2020; Traini et al., 2020), SIR (Jia et al., 2020; Pujari and Shekatkar, 2020; Teles, 2020; Traini et al., 2020; Weber et al., 2020), SIRD (Anastassopoulou et al., 2020; Liu et al., 2020b; Caccavo, 2020), QSEIR (Liu et al., 2020c), and SEAIHRD (Arenas et al., 2020). The choice depends on many factors, such as how early or late in the stages of an epidemic one is, what type of measures are being simulated, and the availability of real word data. We opted for the model described in this section, which seems to acceptably represent the manifestation of the disease in populations. Existing work has investigated parameter estimation in stochastic SEIR models (Lekone and Finkenstädt, 2006; Roberts et al., 2015). Although we will discuss how we set the model parameters, we emphasize that our contribution is instead in demonstrating how a calibrated model could be used for planning.
We use an SEI3R model (Hill et al., 2020), a variation on the standard SEIR model which allows additional modeling freedom. It uses six compartments: susceptible (S), exposed (E), infectious with mild (I1), severe (I2) or critical infection (I3), and recovered (R). We do not include baseline birth and death rates in the model, although there is a death rate for people in the critically infected compartment. The state of the simulator at time t ∈ [0, T] is Xt = {St, Et, I1,t, I2,t, I3,t, Rt} with St, Et, I1,t, I2,t, I3,t, and Rt indicating the population sizes (or proportions) at time t. The unknown model parameters are η = {α, β1, β2, β3, p1, p2, γ1, γ2, γ3, κ}, each with their own associated prior. To the model we add a free control parameter, denoted

FIGURE 1. Flow chart of the SEI3R model we employ. A member of the susceptible population S moves to exposed E after being exposed to an infectious person, where “exposure” is defined as the previous susceptible person contracting the illness. After some incubation period, a random duration parameterized by α, they develop a mild infection (I1). They may then either recover, moving to R, or progress to a severe infection (I2). From I2, they again may recover, or else progress further to a critical infection (I3). From I3, the critically infected person will either recover or die.
For the purposes of simulations with this model, we initialize the state with 0.01% of the population having been exposed to the infection, and the remaining 99.99% of the population being susceptible. The population classified as infectious and recovered are zero, i.e.,
Before explaining how we set the SEI3R model parameters, or pose inference problems in the model, we first verify that we are able to simulate feasible state evolutions. As we will describe later, we use parameters that are as reflective of current COVID-19 epidemiological data as possible at the time of writing. Figures 2A,B show deterministic simulations from the model with differing control values u. Shown in green is the susceptible population, in blue is the exposed population, in red is the infectious population, and in purple is the recovered population. The total live population is shown as a black dotted line. All populations are normalized by the initial total population, N0. The dashed black line represents a threshold under which we wish to keep the number of infected people at all times. The following paragraph provides the rationale for this goal.
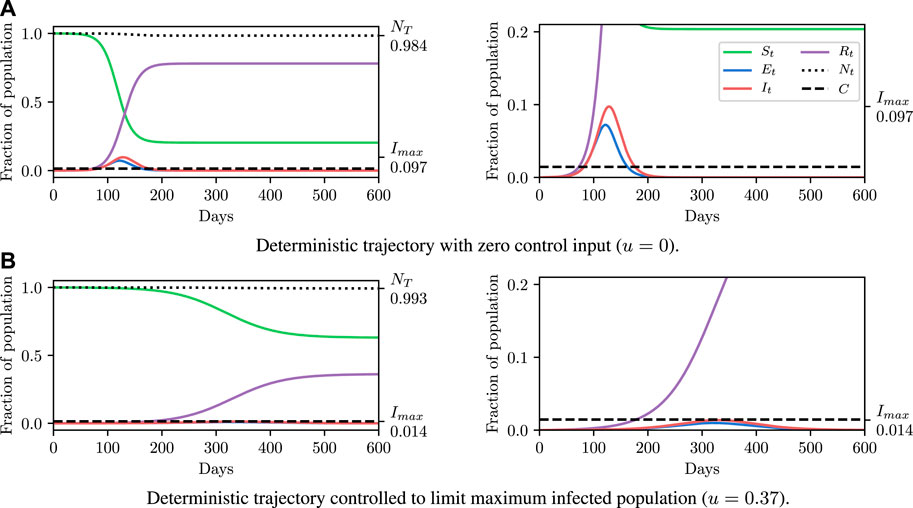
FIGURE 2. Populations per compartment during deterministic SEI3R simulations, both without intervention (A) and with intervention (B). Plots in the left column show the full state trajectory, and in the right column are cropped to more clearly show the exposed and infected populations. Without intervention, the infected population requiring hospitalization (20% of cases) exceeds the threshold for infected population (0.0145, black dashed line), overwhelming hospital capacities. With intervention (u = 0.37) the infected population always remains below this limit. Note that we re-use the colour scheme from this figure through the rest of the paper.
As described in Section 3.4, parameters should be selected to ensure that a desired goal is achieved. In all scenarios using the SEI3R model, we aim to maintain the maximal infectious population proportion requiring healthcare below the available number of hospital beds per capita, denoted C. This objective can be formulated as an auxiliary observation,
where I1,0:T, I2,0:T and I3,0:T are sampled from the model, conditioned on a θ value. This threshold value we use was selected to be 0.0145, as there are 0.0029 hospital beds per capita in the United States (World Bank, 2020), and roughly 20% of COVID-19 cases require hospitalization. This constraint was chosen to represent the notion that the healthcare system must have sufficient capacity to care for all those infected who require care, as opposed to just critical patients. However, this constraint is only intended as a demonstrative example of the nature of constraints and inference questions one can query using models such as these, and under the formalism used here, implementing and comparing inferences under different constraints is very straightforward. More complex constraints may account for the number of critical patients differently to those with mild and severe infections, model existing occupancy or seasonal variations in capacity, or, target other metrics such as the number of deceased or the duration of the epidemic.
The constraint is not met in Figure 2A, but is in Figure 2B, where a greater control input u has been used to slow the spread of the infection. This is an example of the widely discussed “flattening of the curve.” As part of this, the infection lasts longer but the death toll is considerably lower.
As noted before, we assume that only a single “controllable” parameter affects our model, u. This is the reduction in the “baseline reproductive ratio,” R0, due to policy interventions. Increasing u has the same effect as reducing the infectiousness parameters β1, β2 and β3 by the same proportion. u can be interpreted as the effectiveness of policy choices to prevent new infections. Various policies could serve to increase u, since it is a function of both, for example, reductions in the “number of contacts while infectious” (which could be achieved by social distancing and isolation policy prescriptions), and the “probability of transmission per contact” (which could be achieved by, e.g., eye, hand, or mouth protective gear policy prescriptions). It is likely that both of these kinds of reductions are necessary to maximally reduce u at the lowest cost.
For completeness, the baseline reproductive ratio, R0, is an estimate of the number of people a single infectious person will in turn infect and can be calculated from other model parameters (Hill et al., 2020). R0 is often reported by studies as a measure of the infectiousness of a disease, however, since R0 can be calculated from other parameters we do not explicitly parameterize the model using R0, but we will use R0 as a convenient notational shorthand. We compactly denote the action of u as controlling the baseline reproductive rate to be a “controlled reproductive rate,” denoted
We now explain how we set the model parameters to deterministic estimates of values which roughly match COVID-19. The following section will consider how to include uncertainty in the parameter values. Specifically, the parameters are the incubation period α−1; rates of disease progression p1 and p2; rates of recovery from each level of infection, γ1, γ2, and γ3; infectiousness for each level of infection, β1, β2, and β3; and a death rate for critical infections, κ. u ∈ [0, 1] is a control parameter, representing the strength of action taken to prevent new infections (Boldog et al., 2020). To estimate distributions over the uncontrollable model parameters, we consider their relationships with various measurable quantities
Given the values of the left-hand sides of each of Eqs 21–28, (as estimated by various studies) we can calculate model parameters α, p1, p2, γ1, γ2, γ3 and κ by inverting this system of Equations. These parameters, along with estimates for β1, β2, and β3, and a control input u, fully specify the model. Hill et al. (2020) use such a procedure to deterministically fit parameter values. Given the parameter values, the simulation is entirely deterministic. Therefore, setting parameters in this way enables us to make deterministic simulations of “typical” trajectories, as shown in Figure 2. Specifying parameters in this way and running simulations in this system provides a low overhead and easily interpretable environment, and hence is an invaluable tool to the modeller.
Deterministic simulations are easy to interpret on a high level, but they require strong assumptions as they fix the values of unknown parameters to point estimates. We therefore describe how we can perform inference and conditioning in a stochastic model requiring less strict assumptions, and show that we are able to provide meaningful confidence bounds on our inferences that can be used to inform policy decisions more intelligently than without this stochasticity. As described in Section 3, stochasticity can be introduced to a model through a distribution over the latent global parameters η. Examples of stochastic simulations are shown in Figure 3A. Clearly there is more capacity in this model for representing the underlying volatility and unpredictability of the precise nature of real-world phenomena, especially compared to the deterministic model.
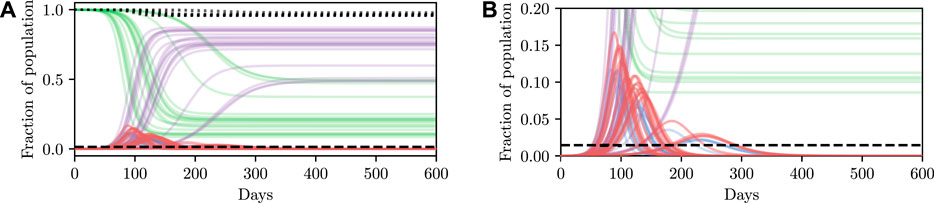
FIGURE 3. Stochastic simulations from the SEI3R model. (A) shows the full trajectory while (B) is cropped to the pertinent region. Compared to the deterministic simulations in Figure 2A, stochastic simulations have the capacity to be much more infectious. Therefore, fully stochastic simulations are required to accurately quantify the true risk in light of the uncertainty in the model. As a result of this, Bayesian methods, or at least methods that correctly handle uncertainty, are required for robust analysis. We reuse the colour scheme defined in Figure 2A for trajectories.
However, this capacity comes with the reality that increased effort must be invested to ensure that the unknown latent states are correctly accounted for. For more specific details on dealing with this stochasticity please refer back to Section 3, but, in short, one must simulate for multiple stochastic values of the unknown parameters, for each value of the controllable parameters, and agglomerate the many individual simulations appropriately for the inference objective. When asking questions such as “will this parameter value violate the constraint?” there are feasibly some trajectories that are slightly above and some slightly below the trajectory generated by the deterministic simulation due to the inherent stochasticity (aleatoric uncertainty) in the real world. This uncertainty is integrated over in the stochastic model, and hence we can ask questions such as “what is the probability that this parameter will violate the constraint?” Using confidence values is this way provides some measure of how certain one can be about the conclusion drawn from the inference–if the confidence value is very high then there is a measure of “tolerance” in the result, compared to a result with a much lower confidence.
We define a joint distribution over model parameters as follows. We consider the 95% confidence intervals of β1, β2, and β3 and the values in the left-hand sides of Eqs 21–24, and assume that their true values are uniformly distributed across these confidence intervals. Then at each time t in a simulation, we sample these values and then invert the system of Eqs 21–28 to obtain a sample of the model parameters. More sophisticated distributions could easily be introduced once this information becomes available. We now detail the nominal values used for typical trajectories (and the confidence intervals used for sampling). The nominal values are mostly the same as those used by (Hill et al., 2020). We use: an incubation period of 5.1 days (4.5–5.8) (Lauer et al., 2020); a mild infection duration of 6 days (5.5–6.5) (Wölfel et al., 2020); a severe infection duration of 4.5 days (3.5–5.5) (Sanche et al., 2020); a critical infection duration of 6.7 days (4.2–10.4); fractions of mild, severe, and critical cases of 81, 14, and 5% (Wu and McGoogan, 2020); and a fatality ratio of 2% (Wu and McGoogan, 2020). We also use β1 = 0.33/day (0.23–0.43), and β2 = 0/day (0–0.05), and β3 = 0/day (0–0.025). Where possible, the confidence intervals are obtained from the studies which estimated the quantities. Where these are not given, we use a small range centred on the nominal value to account for possible imprecision.
While compartmental models, such as the SEIR model described in Section 4.1, provide a mathematically well understood global approximation to disease dynamics, due to their coarse-grained statistical nature they cannot capture many important aspects and local details of the physical and social dynamics underlying the spread of a disease. These aspects include geographic information, spatio-temporal human interaction patterns in social hubs such as schools or workplaces, and the impact of individual beliefs on transmission events. To address these limitations, agent-based simulators (ABS) have been introduced. Such simulators have practically no restrictions in terms of expressiveness, i.e., they can make use of all features of modern Turing-complete programming languages, at the significant computational cost of simulating all details involved.
FRED2 (Grefenstette et al., 2013) is an instance of the class of epidemiological agent-based simulators that are currently available for use in policy-making. FRED is an agent-based modeling language and execution platform for simulating changes in a population over time. FRED represents individual persons, along with social contacts and interactions with the environment. This enables the model to include individual responses and behaviors that vary according to the individual’s characteristics, including demographics (age, sex, race, etc.), as well as the individual’s interactions with members of various social interaction groups, such as their neighborhood, school or workplace. The FRED user can define and track any dynamic condition for the individuals within the population, including diseases (such as COVID-19), attitudes (such as vaccine acceptance), and behaviors (such as social distancing).
FRED captures demographic and geographic heterogeneities of the population by modeling every individual in a region, including realistic households, workplaces and social networks. Using census-based models available for every state and county in the US and selected international locations, FRED simulates interactions within the population in discrete time steps of 1 h. Transmission kernels model the spatial interaction between infectious places and susceptible agents. These characteristics enable FRED to provide much more fine-grained policy advice at either the regional or national level, based on socio-economic and political information which cannot be incorporated into compartmental models.
We chose to use FRED in this work because it has been used to evaluate potential responses to previous infectious disease epidemics, including vaccination policies (Lee et al., 2011), school closure (Potter et al., 2012), and the effects of population structure (Kumar et al., 2015) and personal health behaviors (Kumar et al., 2013; Liu et al., 2015).
After 10 years of develoment as an academic project, FRED has been licensed by the University of Pittsburgh to Epistemix 3, to develop commercial applications of the FRED modeling technology. In turn, Epistemix has developed a detailed COVID-19 model in FRED, which is used in the experiments described here.
The FRED COVID-19 model includes three interconnected components: 1) The natural history of COVID-19; 2) The social dynamics/behavior of individuals; and 3) The Vaccination Program. The COVID-19 model was designed using the latest scientific data, survey information from local health authorities, and in consultation with expert epidemiologists. This model has been used to project COVID-19 cases in universities, K-12 school districts, large cities, and offices.
The FRED COVID-19 natural history model represents the period of time and trajectory of an individual from infection or onset to recovery or death. In the current version of the model, when an individual, or an agent, is exposed to SARS-CoV-2, the virus that causes COVID-19, the individual enters a 2-day latent period before they become infectious. In the infectious state, individuals can either be asymptomatic, symptomatic, or hospitalized. The probability of entering any of these infectious states is based on the individual’s age, infection history, and vaccination history. Individuals have a duration of illness (i.e., number of days they can transmit the virus) which is dependent on infectious state, a severity of disease (i.e., magnitude of transmissibility), and a disease outcome (recovery or death).
When an agent is exposed to SARS-CoV-2 and becomes symptomatic, the individual chooses whether or not to isolate themselves from normal activities. Approximately 20% of individuals continue regular daily activities while symptomatic. Agents who are exposed and develop an asymptomatic infection do not isolate themselves and go about their regular activities. This introduces both symptomatic and asymptomatic forms of transmission into the model.
Prevalence of mask wearing and adherence to social distancing are unique to each location and change over time. The level of compliance to these behaviors is set based on the number of active infections that were generated from reported cases in the previous 2 weeks. Social distancing is assumed to reduce the number of contacts between agents in each place the agent attends.
Following the general recipe for framing planning as inference in Section 3.1, the following section defines what a prior on controls θ is in terms of FRED internals, how FRED parameters relate to η, and how to condition FRED on desirable future outcomes
The FRED simulator has a parameter file which stipulates the values of θ and η. In other words, both the controllable and non-controllable parameters live in a parameter file. FRED, when run given a particular parameter file, produces a sample from the distribution p(X0:T, Z0:T|θ, η). Changing the random seed and re-running FRED will result in a new sample from this distribution.
The difference between X0:T and Z0:T in FRED is largely in the eye of the beholder. One way of thinking about it is that X0:T are all the values that are computed in a run and saved in an output file and Z0:T is everything else.
In order to turn FRED into a probabilistic programming model useful for planning via inference several small but consequential changes must be made to it. These changes can be directly examined by browsing one of the public source code repositories accompanying this paper.4 First, the random number generator and all random variable samples must be identified so that they can be intercepted and controlled by PyProb. Second, any variables that are determined to be controllable (i.e., part of θ) need to be identified and named. Third, in the main stochastic simulation loop, the state variables required to compute
In the interest of time and because we were familiar with the internals of PyProb and knew that we would not be using inference algorithms that were incompatible with this choice, the demonstration code does not show a full integration in which all random variables are controlled by the probabilistic programming system. Instead, it only controls the sampling of θ and the observation of
Our integration of PyProb into FRED required only minor modifications to FRED’s code base, performed in collaboration with the FRED developers at Epistemix. More details about the integration of FRED and PyProb include:
1) The simulator is connected to PyProb through a cross-platform execution protocol (PPX5). This allows PyProb to control the stochasticity in the simulator, and requires FRED to wait, at the beginning of its execution, for a handshake with PyProb through a messaging layer.
2) PyProb overwrites the policy parameter values θ with random draws from the user-defined prior. While PyProb internally keeps track of all random samples it generates, we also decided to write out the updated FRED parameters to a parameter file in order to make associating θ(i) and
3) For each daily iteration step in FRED’s simulation, we call PyProb’s observe function with a likelihood corresponding to the constraint we would like to hold in that day.
With these connections established, we are able to select an inference engine implemented by PyProb to compute the posterior. We use a particularly simple algorithm, namely rejection sampling, in order to focus our exposition on the conceptual framework of planning as inference. PyProb implements multiple other, more complex, algorithms, which may be able to better approximate the posterior with a given computational budget. However for the inference task we consider, in which we attempt to infer only a small fraction of the random variables in the simulator, we find that rejection sampling is sufficiently performant.
We also remind the reader that, like in Section 3.5, more complex controls can be considered, in principle allowing for complex time-dependent policies to be inferred. We do not examine this here, but note that this extension is straightforward to implement in the probabilistic programming framework, and that PyProb is particularly well adapted to coping with the additional complexity. Compared to sampling parameter values for FRED at the beginning of the simulation, such time-varying policies could be implemented through changing the FRED model source code directly. This approach will be explored in future research.
We now demonstrate how inference in epidemiological dynamics models can be used to inform policy-making decisions. We organize this section according to a reasonable succession of steps of increasing complexity that one might take when modeling a disease outbreak. We again stress that we are not making COVID-19 specific analyses here, but instead highlight how framing the task as in Section 3 allows existing machine learning machinery to be leveraged to enhance analysis and evaluation of outcomes; and avoid some potential pitfalls.
We begin by showing how a simple, deterministic compartmental SEIR-based model can be used to inform policy-making decisions, and show how analysis derived from such a deterministic model can fail to achieve stated policy goals in practice. Next, we demonstrate how using a stochastic model can achieve more reliable outcomes by accounting for the uncertainty present in real world systems. While these stochastic models address the limitations of the deterministic model, low-fidelity SEIR models are, in general, not of high enough fidelity to provide localized, region-specific policy recommendations. To address this we conclude by performing inference in an existing agent-based simulator of infectious disease spread and demonstrate automatic determination of necessary controls.
The most straightforward approach to modeling infectious diseases is to use low-dimensional, compartmental models such as the widely used susceptible-infectious-recovered (SIR) models, or the SEI3R variant introduced in Section 4.1. These models are fast to simulate and easy to interpret, and hence form a powerful, low-overhead analysis tool.
The system of equations defining the SEI3R model form a deterministic system when global parameter values, such as the mortality rates or incubation periods, are provided. However, the precise values of these parameter values are unknown, and instead only confidence intervals for these parameters are known, i.e., the incubation period is between 4.5 and 5.8 (Lauer et al., 2020). This variation may be due to underlying aleatoric uncertainty prevalent in biological systems, or epistemic uncertainty due to the low-fidelity nature of SIR-like models. We do not discuss them here, but work exists automatically fitting point-wise estimates of model parameter values directly from observed data (Wearing et al., 2005; Mamo and Koya, 2015).
Regardless of whether one obtains a point estimate of the parameter values by averaging confidence intervals, or by performing parameter optimization, the first step is to use these values to perform fully deterministic simulations, yielding simulations such as those shown in Figure 2A. Simulations such as these are invaluable for understanding the bulk dynamics of systems, investigating the influence of variations in global parameter values or investigating how controls affect the system. However, the ultimate utility in these models is to use them to inform policy decisions to reduce the impact of outbreaks. As eluded to above, this is the primary thrust of this work, combining epidemiological simulators with automated machine learning methodologies to model policy outcomes, by considering this problem as conditioning simulations on outcomes.
To demonstrate such an objective, we consider maintaining the infected population below a critical threshold C at all times. In a deterministic system there are no stochastic quantities and hence whether the threshold is exceeded is a deterministic function of the controlled parameters, i.e., the value of
Results for this are shown in Figure 4. It can then be read off that under the deterministic model
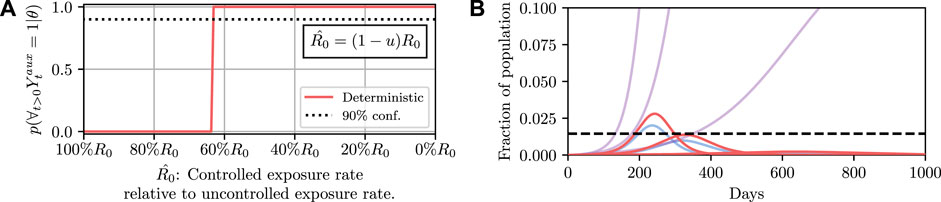
FIGURE 4. Here we demonstrate planning using the deterministic SEI3R model. (A) shows, in red, the probability that the constraint is met using the deterministic simulator. The probability jumps from zero to one at a value of approximately u = 0.37. (B) then shows trajectories using three salient parameter values, specifically,
While the above example demonstrates how parameters can be selected by conditioning on desired outcomes, we implicitly made a critical modeling assumption. While varying the free parameter u, we fixed the other model parameter values (α−1, γ1, etc.) to single values. We therefore found a policy intervention in an unrealistic scenario, namely one in which we (implicitly) claim to have certainty in all model parameters except u.
To demonstrate the pitfalls of analyzing deterministic systems and applying the results to an inherently stochastic system such as an epidemic, we use the permissible value of u solved for in the deterministic system, u = 0.375, and randomly sample values of the remaining simulation parameters. This “stochastic” simulator is a more realistic scenario than the deterministic variant, as each randomly sampled η represents a unique, plausible epidemic being rolled out from the current world state.
The results are shown in Figure 5A. Each line represents a possible epidemic. We can see that using the previously found value of u results in a large number of epidemics where the infectious population exceeds the constraint, represented by the red trajectories overshooting the dotted line. Simply put, the control parameter we found previously fails in an unacceptable number of simulations.
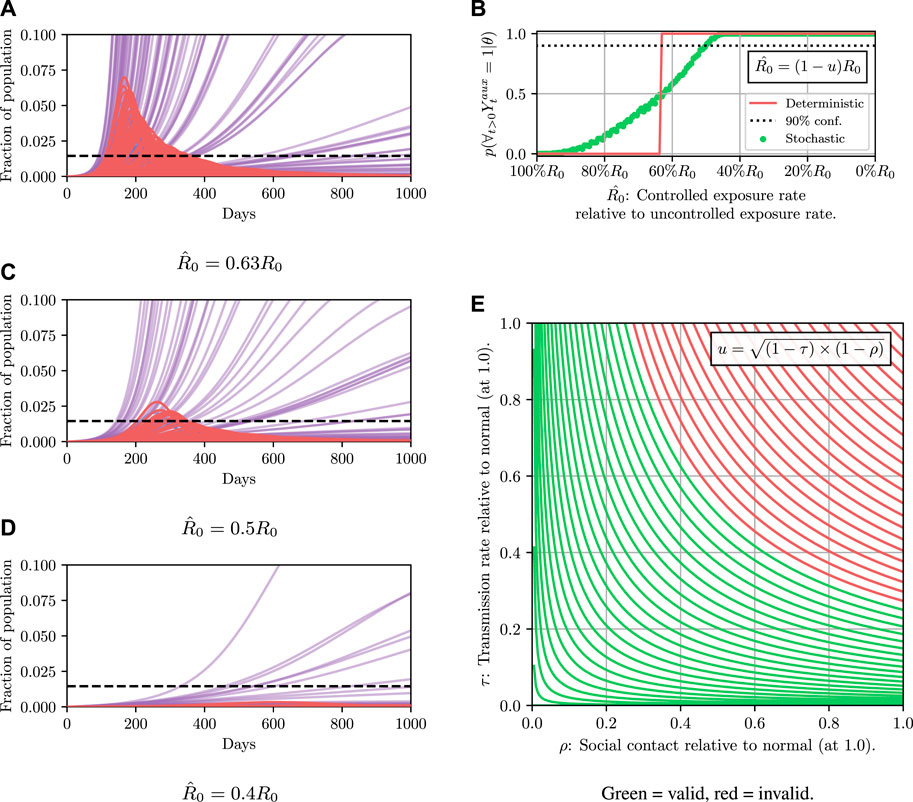
FIGURE 5. Comparison of stochastic and deterministic SEI3R models for policy selection. We reuse the colour scheme defined in Figure 2A for trajectories. (A) shows a stochastic simulation using
This detail highlights the shortcomings of the deterministic model: in the deterministic model a parameter value was either accepted or rejected with certainty. There was no notion of the variability in outcomes, and hence we have no mechanism to concretely evaluate the risk of a particular configuration.
Instead, we can use a stochastic model which at least does account for some aleatoric uncertainty about the world. We repeat the analysis picking the required value of u, but this time using the stochastic model detailed in Section 4.1. In practice, this means the (previously deterministic) model parameters detailed in Eqs 21–28 are randomly sampled for each simulation according to the procedure outlined following the equations.
To estimate the value of
The results are shown in Figure 5B. The likelihood of the result under the stochastic model is not a binary value like in the deterministic case, and instead occupies a continuum of values representing the confidence of the results. We see that the intersection between the red and green curves occurs at approximately 0.5, explaining the observation that approximately half of the simulations in Figure 5A exceed the threshold. We can now ask questions such as: “what is the parameter value that results in the constraint not being violated, with 90% confidence?” We can read off rapidly that we must instead reduce the value of
We have shown how one can select the required parameter values to achieve a desired objective. To conclude this example, we apply the methodology to iterative planning. The principal idea underlying this is that policies are not static and can be varied over time conditioned on the current observed state. Under the formalism used here, re-evaluating the optimal control to be applied, conditioned on the new information, is as simple as re-applying the planning algorithm at each time step. Note that here we consider constant control. However, more complex, time-varying control policies can easily be considered under this framework. For instance, instead of recovering a fixed control parameter, the parameter values of a polynomial function defining time-varying control input could be recovered, or, a scalar value determining the instantaneous control input at each time-step. This is a benefit of the fully Bayesian and probabilistic programming-based approach we have taken: the model class that can be analyzed is not fixed and can be determined (and easily changed and iterated on) by the modeller, and the inference back-end cleanly and efficiently handles the inference.
We show a demonstration of this in Figure 6. In this example, we begin at time t = 200 with non-zero infection rates. We solve for a policy that satisfies the constraint with 90% certainty, and show this confidence interval over trajectories as a shaded region. We then simulate the true evolution of the system for a single step sampling from the conditional distribution over state under the selected control parameter. We then repeat this process at regular intervals, iteratively adapting the control to the new world state. We see that the confidence criterion is always satisfied and that the infection is able to be maintained at a reasonable level. We do not discuss this example in more detail, and only include it as an example of the utility of framing the problem as we have, insomuch as iterative re-planning based on new information is a trivial extension under the formulation used.
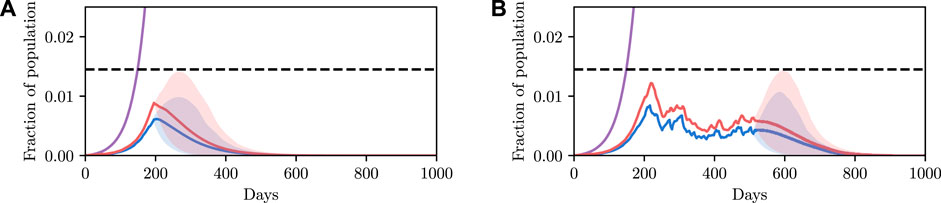
FIGURE 6. Here we briefly demonstrate the capacity of the SEI3R model in a model predictive control setting. (A) shows the state when we begin controlling the system at t = 200 with some level of infection already present. We solve for the minimum required control such that the constraint is satisfied. We plot the 90% confidence interval over trajectories conditioned on this control value. We then step through the system, randomly sampling continuations, and adapting the controls used such that the constraint is always met (B). We uncover that stronger controls must be applied early on to reduce the infected population, but that the amount of control required can then reduce over time as herd immunity becomes a stronger effect. We reuse the color scheme defined in Figure 2A for plotting trajectories.
We have illustrated how simulations can be used to answer questions about the suitability of parameter values we can influence, while marginalizing over those parameters we do not have control over. However, u is not something that is directly within our control. Instead, the value of u is set through changing policy level factors. As an exploratory example we suggest that the value of u is the square root of the product of two policy-influenceable factors: the fractional reduction in social contact, ρ, below its normal level (indicated as a value of 1.0), and the transmission rate relative to the normal level, τ, where we again denote normal levels as 1.0. This relationship is shown in Figure 5E.
We indicate u level sets that violate the constraint in red, and valid sets in green. We suggest taking the least invasive, valid policy, being represented by the highest green curve. Once the analysis above has been performed to obtain a value of u, that satisfies the required infection threshold, it defines the set of achievable policies. Any combination of τ and η along this curve renders the policy valid. Here, additional factors may come into consideration that make particular settings of τ and η more or less advantageous. For instance, wearing more PPE may be cheaper to implement and less economically and socially disruptive than social distancing, and so higher values of τ may be selected relative to η. This reduces to a simple one-dimensional optimization of the cost surface along the level-set.
While we have simply hypothesized this as a potential relationship, it demonstrates how policy level factors influence simulations and outcomes. While the SEIR model family is an invaluable tool for analyzing and understanding the bulk dynamics of outbreaks, it is too coarse-grained for actual, meaningful, localized policy decisions to be made, especially when those policy decisions are directly influencing populations. Further, these notions of “policy” are somewhat abstract here because of the high-level nature of the SEI3R model used. We now go on to resolve these issues by using the more sophisticated agent-based simulator FRED, where simulations are able to represent localized variations, and where real policy measures are more easily defined.
In this section, we turn to agent-based simulators. We showcase how control as inference might possibly be used to inform regional policy decisions through two scenarios presented in Sections 5.2.1, 5.2.2. In the first scenario, we consider an influenza outbreak and in the second a COVID-19 outbreak is simulated. In both scenarios the policy makers wish to “flatten the curve” by limiting some statistic of the infected population under a certain threshold.
In this section, we consider a scenario where an influenza (not COVID-19) outbreak has occurred in Allegheny County (similarly to (Grefenstette et al., 2013)), and policy makers wish to limit the number of infections to less than 10% of the county’s population. To achieve this hypothetical goal, policy-makers might consider the following controls among others (corresponding to the θ parameter defined in Table 1):
• A “social distancing” policy which mandates all citizens stay home for a fixed period of time. Here, policy makers must influence:1) θ1, a shelter-in-place duration, or the length of time a social distancing policy must be in place.2) θ2, a shelter-in-place compliance rate, or the percentage of the population to which this policy applies.
• θ3, a symptomatic isolation rate, the fraction of symptomatic individuals that self-isolate during an epidemic.
• θ4, a school closure attack rate threshold, a threshold on the total percentage of people infected that automatically triggers a 3-week school closure when exceeded.
• θ5, a hand washing compliance, the percentage of the population that washes their hands regularly.

TABLE 1. Prior over FRED control parameter θ = (θ1, …, θ5) for influenza simulations.
For simplicity of results interpretation we have put uniform priors, appropriately continuous or discrete, on intervals of interest for these controllable parameters.
Also relative to Eq. 7 we choose Yt to be a binary variable indicating if the proportion of the county’s infected population is below 10% on day t. By inferring p(θ | ∀t>0 : Yt = 1), we characterize which control values will lead to this desired outcome.
Using the model described in Section 4.2 with parameters as defined in this section, we used PyProb to perform automated inference over the policy parameters described in Table 1. To reiterate, we infer the posterior distribution over control parameters θ which satisfy the goal of limiting the instantaneous number of infections to less than 10% of the county’s population at all times up to a maximum of 150 days. In conducting our experiments we generated one million samples, 40% of which satisfied the policy goal.
We simulate Allegheny County, Pennsylvania, using 2010 U.S. Synthetic Population data. We use an older, publicly available version of FRED6 and its default parameters, which simulates a model of influenza “in which infectivity starts 1 day before symptoms and lasts for 7 days. Both symptoms and infectivity ramp up and ramp down.”7 All simulations begin with 10 random agents seeded with the virus at day zero. Person-to-person contact rates for various environments (household, office, etc.) were calibrated to specifically model Allegheny County. Parameter files for the four policies under consideration are available online8.
Figure 7 shows the SEIR statistics for both the uncontrolled (left) and controlled (right) simulations. We see that the confidence interval in red stays beneath our infection rate constraint indicated by the dashed black line, while in the uncontrolled scenario the confidence band well exceeds the constraint. We also observed the overall number of exposed and infectious populations is much lower using samples of control variables from the inferred posterior, which indicates that control variable values drawn from this posterior are indeed effective in limiting the spread of the virus.
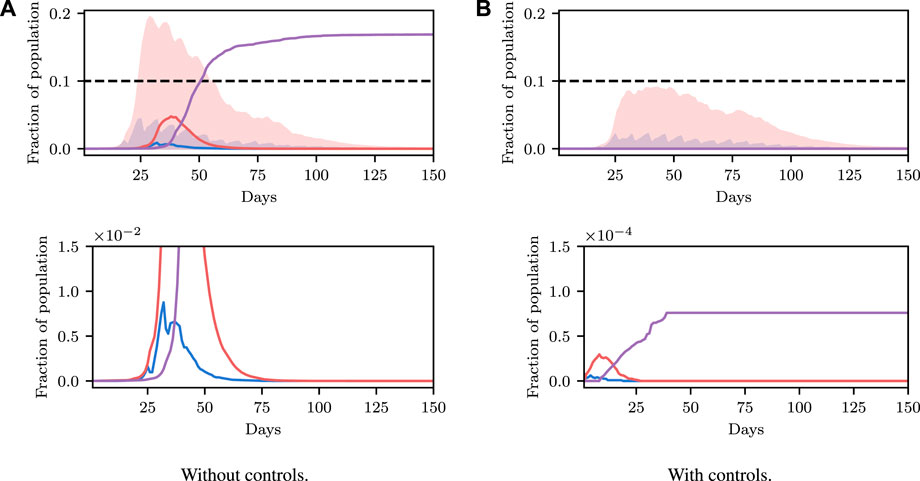
FIGURE 7. Aggregated SEIR statistics extracted from 100,000 FRED simulations of an influenza (not COVID-19) outbreak in Allegheny County. The objective in this scenario is to keep the number of infectious people (I in SEIR terminology, shown here in red) below 10%, indicated by the black dotted line. We plot the median and confidence intervals between the 3rd and 97th percentiles, shown by the shaded areas. To avoid clutter and focus on relevant dynamics, the susceptible statistic (S in SEIR terminology, shown previously in green) and confidence intervals for the Recovered (R in SEIR terminology, shown here in purple) statistic are omitted. Blue shows the fraction of the population that has been exposed (E in SEIR terminology). The bottom row shows a zoomed-in version of the top row, where all confidence intervals have been removed, for ease of visual inspection. (A) shows the evolution of the outbreak when no controls are applied. (B) shows the evolution of the outbreak when controls, solved for using our method, are applied. When no controls are applied we see the number of infectious people often exceeds the allowable threshold, whereas, when optimal controls are applied, the confidence interval for infectious people (red) stays below our constraint.
While Figure 7 indicates that the inferred controls can achieve the desired aims, it doesn’t indicate which policy to choose. To answer this, we plot the two-dimensional marginal distributions over controlled policy parameters in Figure 8. Policy-makers could use a figure like this, coupled with a utility function, to generate policy recommendations. Interpreting Figure 8, first we see the importance of influencing hand washing compliance and quick school closures. This plot indicates that hand washing compliance must be driven above 50% and the school closure attack rate threshold beneath 7% in order to achieve our stated goal. We also note the correlation between hand washing compliance and isolation rate. If we can achieve only 70% hand washing compliance then the isolation rate must be driven high, however, if hand washing compliance is very good then a lower isolation rate is tolerable. The importance of hygiene and long-term school closures has also been noted in the epidemiology literature (Lee et al., 2010; Saunders-Hastings et al., 2017; Germann et al., 2019).
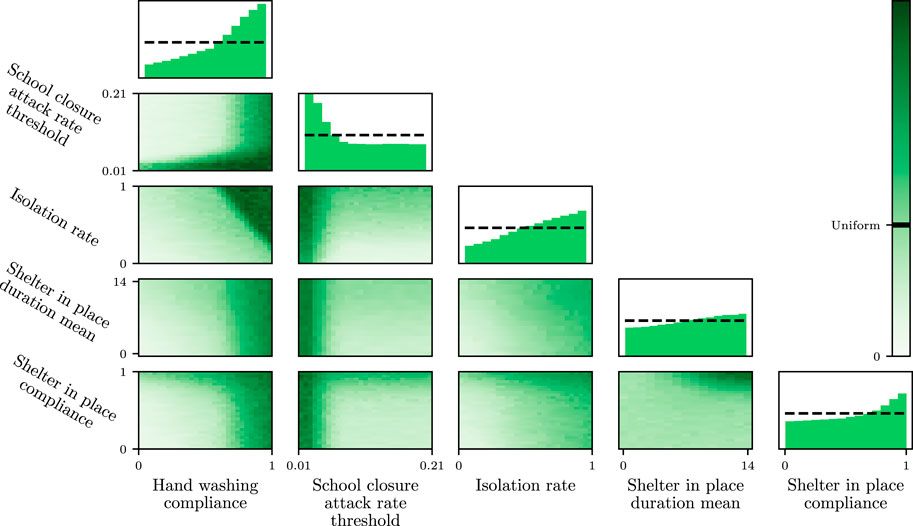
FIGURE 8. Empirically determined marginals of the full posterior distribution over controllable policy parameters that lead to desired outcomes (see Eq. 7) for a simulated influenza epidemic in Allegheny county. Along the diagonal: one-dimensional marginals of each control parameter with a uniform prior indicated by the dashed line. We can clearly see the efficacy of high rates of hand washing and a quick school closure policy, as indicated by the non-uniformity of the marginal distributions. The remaining array of plots show two-dimensional marginal distributions of any two parameters where the dark green color indicates higher probability density. For reference, the color corresponding to a uniform prior on the two-dimensional plots is indicated on the color bar on the right. This illustrates policy-level outcomes such as there being a strong interaction when jointly enforcing high isolation rate and hand washing compliance. In contrast, the effectiveness of school closure attack rate threshold is largely independent of the isolation rate (and indeed most other parameters). Such richly structured information is paramount for making effective and justifiable policy decisions, and is only provided through fully Bayesian analysis, as opposed to simpler reinforcement learning or optimal control methodologies which may only provide a point estimate of the optimal control to be applied, with no quantification of uncertainty or the joint interaction of parameters.
A final interpretation of the results of Figure 8 can be provided in terms of the outcome of a hypothetical influenza policy-making scenario. A recommendation one might extract from this visualization of the posterior inference results is a conjunction of the following controls:
1) Ensure that all schools close as soon as 2% of the population contracts the virus.
2) Attempt to drive the hand washing compliance to 80%.
3) Attempt to drive the symptomatic isolation rate to 50%.
4) No amount of sheltering in place is required.
Such a recommendation corresponds to what one could imagine would be, in comparison to more draconian options, a relatively mild, economically speaking, policy response that still attains the objective. Of course, in the presence of a real influenza outbreak, vaccination would be among the most critical controls to consider. We have intentionally excluded it here in order to be in some small way more reflective of the COVID-19 pandemic which is emerging at the time of conducting this experiment.
The results of applying this policy are shown in Figure 9, where we show a single simulation of the spread of influenza in Allegheny county over time in both the uncontrolled (left) and controlled (right) cases. Each red dot shows the household of an infectious person. This policy recommendation can be seen to work as it reduces the maximum number of infected households from 215,799 on day 29 in the uncontrolled case to 65,997 on day 83 in the uncontrolled case. The maximum in the controlled case actually occurs during a second “outbreak” after schools re-open (noticeable around day 90 in Figure 9C). While the controlled policy results in two “spikes,” our inference procedure accounts for this and correctly controls the maximum number of infectious persons to remain below 10% of the total at all times.
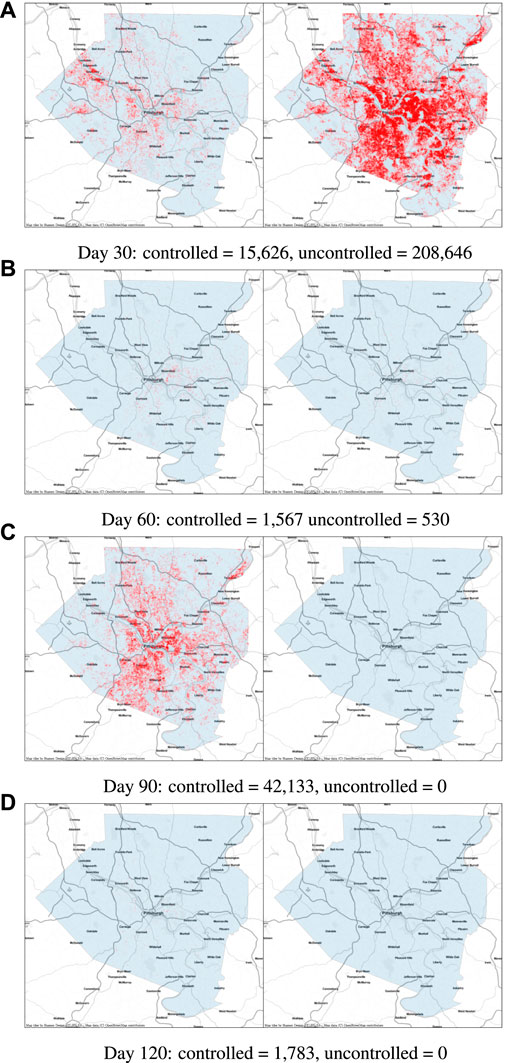
FIGURE 9. Progression of a simulated influenza epidemic in Allegheny county under controlled (left) and uncontrolled (right) scenarios. Each red dot represents the household of an infectious person. The count of the number of infected households in each scenario appears in the captions below each row. The peak number of cases in the uncontrolled scenario is 215, 799 on day 29, while the peak number of cases in the controlled scenario is 65, 997 on day 83. We see that the controls we solve for successfully “flatten the curve,” indicated by a much lower density of red dots. There is also a second spike predicted, visible in (C), where as controls are removed there is an increase in cases throughout the susceptible portion of the population. However, this second spike is still below the required threshold.
In this section, we consider COVID-19 outbreaks of/in the Seattle metropolitan area. The controls we consider in these experiments are the following (corresponding to the θ parameter defined in Table 2):
• θ1, a social distancing, or the fraction of population practising social distancing.
• θ2, a workplace closure, or the fraction of businesses deemed essential and exempt from workplace closure mandates.
• θ3, a school closure attack rate threshold, a threshold on fraction of population hospitalized per day. Schools get closed if the daily hospitalization rate exceeds this threshold.

TABLE 2. Prior over FRED control parameter θ = {θ1, θ2, θ3} for COVID-19 simulations.
Similar to Section 5.2.1, we have put uniform priors on these controllable parameters, as described in Table 2.
We put thresholds on the number of daily hospitalizations and daily deaths in different experiments. Hence, Yt in Eq. 7 is a binary variable indicating if any of the thresholds are exceeded.
Our simulations presented here are on a synthetic population of the Seattle metropolitan area incorporated in the FRED simulator (a population size of 3,416,570). The synthetic population closely matches the 2010 census data for the United States with high spatial resolution, differing from the American Community Survey by less than 1% for large counties. A detailed description of the methodology and further comparisons are provided in (Wheaton et al., 2009). The parameters of the disease are calibrated to COVID-19, as explained in Section 4.2. We have conducted simulations in three different time periods and the initial conditions of each simulation (number of active infections, total hospitalizations, total deaths and vaccinated people) is set according to the numbers reported by U.S. health officials for the chosen dates (see Table 3).

TABLE 3. Initial conditions and policy goals used in the COVID-19 simulations in the Seattle metropolitan area.
Figure 10 shows the number of daily cases, hospitalizations, and deaths (note that this is not the same as SEIR) for all time periods considered in this experiment. Similar to SEIR plots, it shows results for both the uncontrolled (left) and controlled (right) simulations.
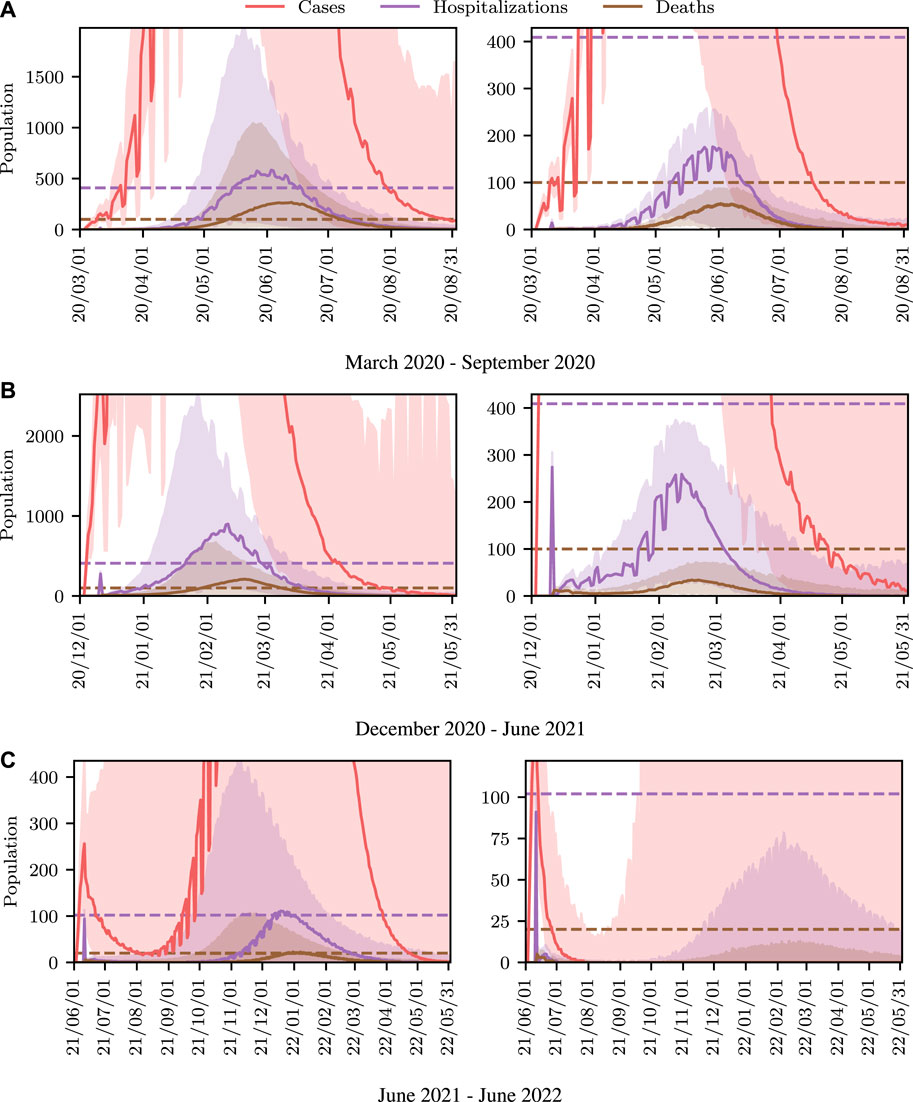
FIGURE 10. Aggregated statistics from 1,000 FRED simulations of a COVID-19 outbreak in the Seattle metropolitan area. We plot the median and confidence intervals between the 3rd and 97th percentiles of the daily cases, hospitalizations, and deaths. Each row shows a different period of time with different starting conditions and policy goals. The goal in these simulations is to keep the number of daily hospitalizations and deaths below the thresholds specified by dashed lines in matching colors. The left column shows the evolution of the outbreak when no control is applied. The right column shows the evolution of the outbreak when controls provided by our method are applied. As expected, without control the number of hospitalizations and deaths quickly exceeds the thresholds whereas in the controlled simulations it is ensured that all the desired conditions are met throughout the simulation period.
Figure 11 shows samples from two-dimensional marginals of the distribution over controlled policy parameters. According to these results, social distancing is the most important control among the three and policy makers should make sure more than 70% of the population practice it. Although enforcing a more strict school or workplace closure helps as well and allows a slightly wider range for social distancing compliance, they are far less effective than social distancing. Adding more relative control parameters (for example, public mask wearing, recommended vaccine booster shots, restricting large events, imposing travel restrictions, etc.) are planned extensions of future research.
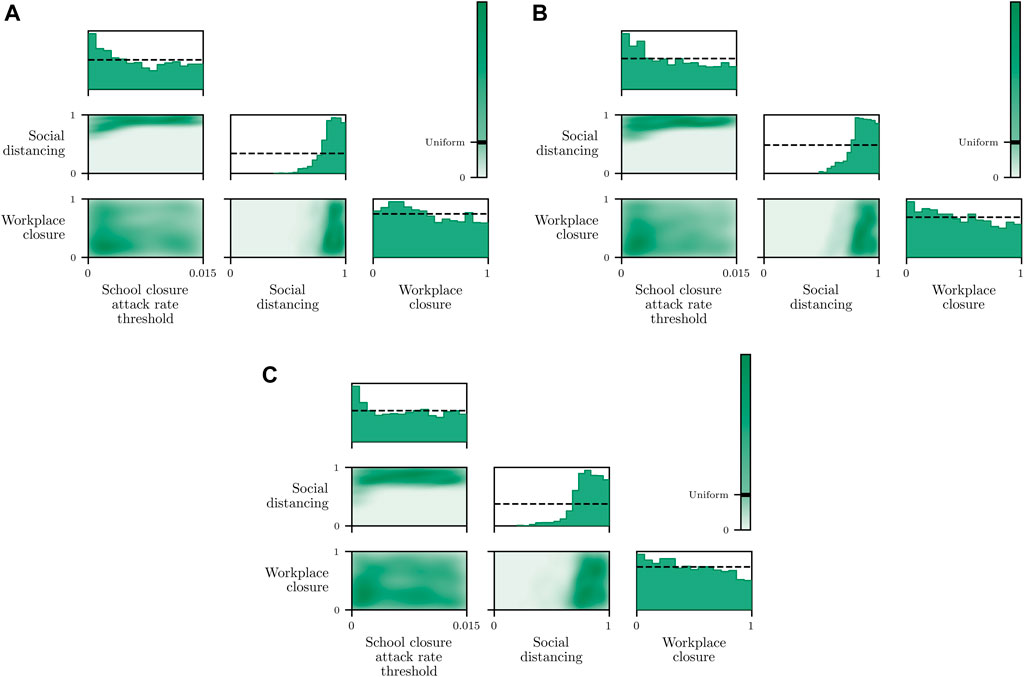
FIGURE 11. Empirically determined marginals of the full posterior distribution over controllable policy parameters that give rise to appropriately controlled outcomes (see Eq. 7) for simulations of COVID-19 of/in the Seattle metropolitan area. Similar to Figure 8, the diagonal of each figure shows one-dimensional marginals for each policy parameter, with the uniform prior indicated by the dashed line. The remaining array of plots shows kernel density estimation (KDE) plots fitted to samples from the two-dimensional marginals of the joint posterior distribution. For reference, the color corresponding to a uniform prior on the two-dimensional plots is indicated on the color bar on the right. Each of the Subfigures (A-C) shows the results of simulations for a different time period as indicated. The initial parameters and policy goals for each plot are reported in Table 3. We see that among the three policy parameters, social distancing is the most effective in all time periods. Furthermore, putting a more restrictive policy on closing schools or workplaces leads to a wider range of acceptable social distancing policies. Finally, note that in the June 2021 - June 2022 period, when the vaccination rates are high, a looser set of policy enforcements is acceptable even though the desired outcomes for this experiment are much tighter (see Table 3).
We have conducted COVID-19 simulations for three different scenarios:
• The 6 months following March 1, 2020 when the outbreak is in its early stages with a few cases.
• The 6 months following December 1, 2020 when there is a large number of cases, hospitalizations and deaths.
• The 12 months following June 1, 2021 when the number of hospitalizations is the largest among our simulations and there are more than 3000 active infections and near 3000 deaths. However, in this case 47% of the population are vaccinated at the beginning of the simulation.
The goal in the first two scenarios is to avoid the number of daily hospitalizations and daily deaths exceeding 409 and 100 people, respectively, while these numbers are 102 and 20 for the third scenario. For the third scenario our results in Figure 11 show the goals are achieved even with a slightly looser set of controls over the population despite the large number of active infections and hospitalizations and tighter goals. This is indeed the effect of higher vaccination rates in the initial conditions for the third scenario.
Finally, as a part of this project we have created a website9 where users can perform planning as inference in COVID-19 simulations for different locations in the U.S. and Canada. It allows users to choose initial conditions of the simulations, policy goals and the set of control parameters (or interventions) to explore. The website automatically runs simulations on the population of the specified location and produces an interactive version of Figures 10, 11. It also provides the location of infections on the selected location’s map, similar to Figure 9. We are working on expanding the features and set of controllable parameters on the website as well.
In this paper, we have introduced and reviewed control as inference in epidemiological dynamics models and illustrated how this technique can be used to substantially increase the level of automation and precision of some aspects of policy-making using models at two extremes of expressivity and fidelity–compartmental and agent-based. We are releasing accompanying source code for our SEIR-type COVID-19 model along with bespoke inference code that researchers in the machine learning, control, policy-making, and approximate Bayesian inference communities can use immediately in their own research. We are also releasing code that demonstrates how a complex, existing, agent-based epidemiological dynamics model can be quickly interfaced to an existing probabilistic programming system so as to automate, even in such a complex model, the inference tasks resulting from the problem formulation of control as inference. Again, we stress that we do not report methodological innovation per se, as there are other ways of recombining existing inference packages and existing models to approach the control as inference problem. In this sense, our principal goal is to demonstrate the feasibility of, and raise interdisciplinary awareness for, such approaches, rather than to champion any specific implementation.
The first part of the software release accompanying this paper is a pure Python implementation of the SEI3R model adapted to COVID-19 from Section 4.1. It is contained inside an online software version control repository and consists of the model, “custom” inference code that implements control as inference via approximate nested Monte Carlo (NMC), and code that shows how to perform stochastic model predictive control using the model, i.e., the code used to produce Figure 6.
The second part of the software release accompanying this paper encompasses an influenza model implemented using an older, open source version of the agent-based simulation platform FRED (Grefenstette et al., 2013), as well as the modifications necessary for the latter to be interfaced with the probabilistic programming system PyProb for simulator-based approximate Bayesian inference. This code is contained in three separate repositories: a fork of the FRED repository with PyProb integration10, a fork of the PyProb code with slight additions required for FRED integration11, and a collection of scripts for orchestrating and plotting artifacts from simulation and inference12. This last repository also contains a Singularity container (Kurtzer et al., 2017) image bundling all of the necessary software dependencies, including the repositories above. This should significantly reduce the setup time for interested parties, as Singularity images are supported at a large number of existing high performance computing facilities. While the current FRED source code is proprietary, we are happy to discuss the process of PyProb+FRED integration with any interested parties.
We believe that model-inference combinations such as FRED+PyProb could provide formidable policy analysis tools with potentially significant societal benefits, particularly because they would allow high-fidelity assessment of region-specific targeted policies. We expect that the set of effective policy interventions might differ across the regional characteristics of counties, states or countries, as well as their transient epidemiological situations. Testing this hypothesis depends upon expanding the number of counties, provinces, and countries with simulation profiles in FRED, or in any other agent-based epidemiological model that can be interfaced with a universal and language-agnostic probabilistic programming system such as PyProb.
Our experience in conducting this research has led us to identify a number of opportunities for improvement in the fields of simulation-based inference and control.
Building a simple SEIR-type model with very few compartments is a project of the scope of graduate homework. Building and maintaining a simulator like FRED or the US National Large Scale Agent Model (Parker and Epstein, 2011) is a massive undertaking, which would be prohibitive to replicate or significantly extend in a crisis situation. As far as we could find with limited search effort when conducting this work in March 2020, there was neither a central repository of up-to-date open-source agent-based epidemiological models, nor an organizing body we could interface to immediately.
There appear to be practically very consequential conceptual gaps between the fields of control, epidemiology, statistics, policy-making, and probabilistic programming. To quote Lessler et al. (Lessler et al., 2016), “the historic separation between the infectious disease dynamics and ‘traditional’ epidemiologic methods is beginning to erode.” We, like them, see our work as a new opportunity for “cross pollination between fields.” As discussed earlier, the most closely related work that we found in the literature is all focused on automatic model parameter estimation from observational data (Toni et al., 2009; Kypraios et al., 2017; McKinley et al., 2018; Chatzilena et al., 2019; Minter and Retkute, 2019). These methods and the models to which they have been applied could be repurposed for planning, as we have demonstrated, simply by changing the random variables they condition on to include safety or utility metrics. Our emphasis therefore lies on the feasibility of planning as inference using existing software tools for approximate Bayesian inference.
Looking closer at the implementation choices, we found at least two existing papers that explore using probabilistic programming coupled to epidemiological simulators; (Funk and King, 2020) which used Libbi (Murray, 2015) and (Gram-Hansen et al., 2019) which used PyProb. The latter is an example of work that “hijacks” a malaria simulator in the same way we “hijacked” the FRED simulator in this paper. Neither explicitly addresses control. Chatzilena et al., (2019) use the probabilistic programming system STAN Carpenter et al. (2017) to address parameter estimation in SEIR-type models, but it too does not explore control, nor could it be repurposed to control an agent-based model with non-differentiable joint densities or, more generally, any external simulator not directly defined in the STAN language.
Like (Toni et al., 2009; Kypraios et al., 2017; McKinley et al., 2018; Chatzilena et al., 2019; Minter and Retkute, 2019) we too could have demonstrated automated parameter estimation in both of the models that we consider, for instance to automatically adjust uncertainty in disease-specific parameters by conditioning on observable quantities such as death counts that are measured online during a breakout. However, as the epidemiological community already relies upon long-standing methods established for estimating confidence intervals for model parameters during evolving pandemics, we exclusively restricted ourselves to demonstrating how to achieve control via inference, assuming that the disease parameter priors have been obtained from established parameter estimation techniques. Combining the two kinds of observations in a single inference task is technically straightforward but does require care in interpretation.
At the time of writing all authors, apart from JG and DC at Epistemix Inc., Pittsburgh, were principally affiliated with the “Programming Languages for Artificial Intelligence” (PLAI) research group at UBC, Vancouver, which is primarily involved in developing next-generation probabilistic AI tools and techniques. We felt, however, that the acute circumstances demanded we lend whatever we could to the global fight against COVID-19. Beyond the specific contributions outlined above, our secondary aim in writing this paper was to encourage other researchers to contribute their expertise to the fight against COVID-19 as well. We believe the world will be in a better place more quickly if they do.
The FRED simulator and model configurations used for the COVID-19 experiments are proprietary products of Epistemix Inc. All the other source codes, parameters and datasets presented in this study can be found at the open source repository https://github.com/plai-group/covid.
FW - conception, formulation, SEIR, FRED, writing; AW - conception, formulation, SEIR, writing; SN - conception, formulation, FRED, writing; CW - conception, formulation, FRED, writing; VM - conception, formulation, FRED, writing; WH - conception, formulation, SEIR, writing; AS - conception, formulation, writing; BB - conception, formulation, writing; DC - FRED; JG - FRED, writing; SAN - conception, writing.
Frontiers Media SA remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Authors JG and DC were employed by the company Epistemix Inc.
The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
We acknowledge the support of the Natural Sciences and Engineering Research Council of Canada (NSERC), the Canada CIFAR AI Chairs Program, and the Intel Parallel Computing Centers program. This material is based upon work supported by the United States Air Force Research Laboratory (AFRL) under the Defense Advanced Research Projects Agency (DARPA) Data Driven Discovery Models (D3M) program (Contract No. FA8750-19-2-0222). Additional support was provided by UBC’s Composites Research Network (CRN), Data Science Institute (DSI), Support for Teams to Advance Interdisciplinary Research (STAIR) Grants, the Innovation for Defence Excellence and Security (IDEaS) program, under its COVID-19 Challenges (CPCA-0397), and a CIFAR AI and COVID-19 Catalyst Grant. This research was enabled in part by technical support and computational resources provided by WestGrid (https://www.westgrid.ca/) and Compute Canada (www.computecanada.ca). This article was submitted as a preprint to arXiv: Wood et al. 2020, available at https://arxiv.org/abs/2003.13221.
1https://github.com/pyprob/pyprob
2https://fred.publichealth.pitt.edu/
4https://github.com/plai-group/FRED
5https://github.com/pyprob/ppx
6https://github.com/PublicHealthDynamicsLab/FRED
7https://github.com/PublicHealthDynamicsLab/FRED/blob/FRED-v2.12.0/input_files/defaults
8https://github.com/plai-group/FRED/tree/FRED-v2.12.0/params
9https://covid19ideas.cs.ubc.ca/
10https://github.com/plai-group/FRED
11https://github.com/plai-group/pyprob
12https://github.com/plai-group/covid
Adam, L., and DeJong, G. (2003). “The Influence of Reward on the Speed of Reinforcement Learning: An Analysis of Shaping,” in Proceedings of the 20th International Conference on Machine Learning (ICML-03), Washington, DC, August 21–24, 2003, 440–447.
Anastassopoulou, C., Russo, L., Tsakris, A., and Siettos, C. (2020). Data-based Analysis, Modeling and Forecasting of the Novel Coronavirus (2019-nCoV) Outbreak. medRxiv [Preprint]. doi:10.1101/2020.02.11.20022186
Anna, B., Gerardin, J., Bridenbecker, D., Lorton, C. W., Bloedow, J., Baker, R. S., et al. (2018). Implementation and Applications of EMOD, An Individual-Based Multi-Disease Modeling Platform. Pathog. Dis. 76 (5), fty059. doi:10.1093/femspd/fty059
Arenas, A., Cota, W., Gómez-Gardeñes, J., Gómez, S., Granell, C., Matamalas, J. T., et al. (2020). A Mathematical Model for the Spatiotemporal Epidemic Spreading of COVID19. medRxiv [Preprint]. doi:10.1101/2020.03.21.20040022
Badham, J., Chattoe-Brown, E., Gilbert, N., Chalabi, Z., Kee, F., and Hunter, R. F. (2018). Developing Agent-Based Models of Complex Health Behaviour. Health & Place 54, 170–177. doi:10.1016/j.healthplace.2018.08.022
Baydin, A. G., Heinrich, L., Bhimji, W., Gram-Hansen, B., Louppe, G., Shao, L., et al. (2018). “Efficient Probabilistic Inference in the Quest for Physics Beyond the Standard Model,” in Thirty-second Conference on Neural Information Processing Systems (NeurIPS), Vancouver, British Columbia, December 8–14, 2018.
Baydin, A. G., Shao, L., Bhimji, W., Heinrich, L., Meadows, L., Liu, J., et al. (2019). “Etalumis: Bringing Probabilistic Programming to Scientific Simulators at Scale,” in Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, Denver, USA, November 17–22, 2018, 1–24.
Bertsekas, D. P. (2019). Reinforcement Learning and Optimal Control. Belmont, MA: Athena Scientific.
Bhalchandra, S. P., and SnehalShekatkar, M. (2020). Multi-city Modeling of Epidemics Using Spatial Networks: Application to 2019-nCov (COVID-19) Coronavirus in India. medRxiv [Preprint]. doi:10.1101/2020.03.13.20035386
Blackwood, J. C., and Childs, L. M. (2018a). An Introduction to Compartmental Modeling for the Budding Infectious Disease Modeler. Lett. Biomathematics 5 (1), 195–221. doi:10.1080/23737867.2018.1509026
Blackwood, J. C., and Childs, L. M. (2018b). An Introduction to Compartmental Modeling for the Budding Infectious Disease Modeler. Lett. Biomathematics 5 (1), 195–221. doi:10.30707/lib5.1blackwood
Boldog, P., Tekeli, T., Vizi, Z., Dénes, A., Bartha, F. A., and Röst, G. (2020). Risk Assessment of Novel Coronavirus Covid-19 Outbreaks Outside China. Jcm 9 (2), 571. doi:10.3390/jcm9020571
Caccavo, D. (2020). Chinese and Italian COVID-19 Outbreaks Can Be Correctly Described by a Modified SIRD Model. medRxiv [Preprint]. doi:10.1101/2020.03.19.20039388
Camacho, E. F., and Alba, C. B. (2013). Model Predictive Control. Springer science & business media.
Carpenter, B., Gelman, A., Hoffman, M. D., Lee, D., Goodrich, B., Betancourt, M., et al. (2017). Stan: A Probabilistic Programming Language. J. Stat. Softw. 76 (1), 1–32. doi:10.18637/jss.v076.i01
Chatzilena, A., van Leeuwen, E., Ratmann, O., Baguelin, M., and Demiris, N. (2019). Contemporary Statistical Inference for Infectious Disease Models Using Stan. Epidemics 29, 100367. doi:10.1016/j.epidem.2019.100367
Ferguson, N. M., Laydon, D., Nedjati-Gilani, G., Imai, N., Ainslie, K., Baguelin, M., et al. (2020). Impact of Non-pharmaceutical Interventions (NPIs) to Reduce COVID-19 Mortality and Healthcare Demand. Available at: https://www.imperial.ac.uk/media/imperial-college/medicine/sph/ide/gida-fellowships/Imperial-College-COVID19-NPI-modelling-16-03-2020.pdf.
Funk, S., and King, A. A. (2020). Choices and Trade-Offs in Inference with Infectious Disease Models. Epidemics 30, 100383. doi:10.1016/j.epidem.2019.100383
García, C. E., Prett, D. M., and Morari, M. (1989). Model Predictive Control: Theory and Practice-A Survey. Automatica 25 (3), 335–348. doi:10.1016/0005-1098(89)90002-2
Gelman, A., Stern, H. S., Carlin, J. B., Dunson, D. B., Aki, V., and Rubin, D. B. (2013). Bayesian Data Analysis. Chapman and Hall/CRC.
Germann, T. C., Gao, H., Gambhir, M., Plummer, A., Biggerstaff, M., Reed, C., et al. (2019). School Dismissal as a Pandemic Influenza Response: When, Where and for How Long. Epidemics 28, 100348. doi:10.1016/j.epidem.2019.100348
Ghahramani, Z. (2015). Probabilistic Machine Learning and Artificial Intelligence. Nature 521 (7553), 452–459. doi:10.1038/nature14541
Goodman, N. D., and Stuhlmüller, A. (2014). The Design and Implementation of Probabilistic Programming Languages. Available at: http://dippl.org (Accessed March 25, 2020).
Goodman, N. D., and Stuhlmüller, A. (2014). The Design and Implementation of Probabilistic Programming Languages. Available at: http://dippl.org (Accessed March 26, 2020).
Gram-Hansen, B., Schröder de Witt, C., Rainforth, T., Torr, P. H. S., Teh, Y. W., and Baydin, A. G. (2019). "Hijacking Malaria Simulators with Probabilistic Programming," in AI for Social Good Workshop, International Conference on Machine Learning, Long Beach, June 9–15, 2019.
Green, M., and Limebeer, D. J. N. (2012). Linear Robust Control. North Chelmsford, Massachusetts: Courier Corporation.
Grefenstette, J. J., Brown, S. T., Rosenfeld, R., DePasse, J., Stone, N. T., Cooley, P. C., et al. (2013). FRED (A Framework for Reconstructing Epidemic Dynamics): An Open-Source Software System for Modeling Infectious Diseases and Control Strategies Using Census-Based Populations. BMC public health 13 (1), 940. doi:10.1186/1471-2458-13-940
Hansen, L. P., and Sargent, T. J. (2001). Robust Control and Model Uncertainty. Am. Econ. Rev. 91 (2), 60–66. doi:10.1257/aer.91.2.60
Hill, A., Levy, M., Xie, S., Sheen, J., Shinnick, J., Gheorghe, A., et al. (2020). Modeling COVID-19 Spread vs Healthcare Capacity. Available at: https://alhill.shinyapps.io/COVID19seir/ (Accessed March 25, 2020).
Hunter, E., Mac Namee, B., and Kelleher, J. (2018). An Open-Data-Driven Agent-Based Model to Simulate Infectious Disease Outbreaks. PLOS ONE 13 (12), e0208775. doi:10.1371/journal.pone.0208775
Hunter, E., Mac Namee, B., and Kelleher, J. D. (2017). A Taxonomy for Agent-Based Models in Human Infectious Disease Epidemiology. Jasss 20 (3), 2. doi:10.18564/jasss.3414
Jacob, M., Wang, Y., and Boyd, S. (2011). Receding Horizon Control. IEEE Control. Syst. Mag. 31 (3), 52–65. doi:10.1109/CACSD.2010.5612665
Jia, W., Han, K., Song, Y., Cao, W., Wang, S., Yang, S., et al. (2020). Extended SIR Prediction of the Epidemics Trend of COVID-19 in Italy and Compared with Hunan, China. medRxiv [Preprint]. doi:10.1101/2020.03.18.20038570
Kaelbling, L. P., Littman, M. L., and Moore, A. W. (1996). Reinforcement Learning: A Survey. jair 4, 237–285. doi:10.1613/jair.301
Kappen, H. J., Gómez, V., and Opper, M. (2012). Optimal Control as a Graphical Model Inference Problem. Mach Learn. 87 (2), 159–182. doi:10.1007/s10994-012-5278-7
Köppen, M. (2000). “The Curse of Dimensionality,” in 5th Online World Conference on Soft Computing in Industrial Applications (WSC5), September 4–18, 2000, 1, 4–8.
Kumar, S., Piper, K., Galloway, D. D., Hadler, J. L., and Grefenstette, J. J. (2015). Is Population Structure Sufficient to Generate Area-Level Inequalities in Influenza Rates? an Examination Using Agent-Based Models. BMC public health 15 (1), 947. doi:10.1186/s12889-015-2284-2
Kumar, S., Grefenstette, J. J., Galloway, D., Albert, S. M., and Burke, D. S. (2013). Policies to Reduce Influenza in the Workplace: Impact Assessments Using an Agent-Based Model. Am. J. Public Health 103 (8), 1406–1411. doi:10.2105/ajph.2013.301269
Kurtzer, G. M., Sochat, V., and Bauer, M. W. (2017). Singularity: Scientific containers for mobility of compute. PLoS One 12, e0177459.
Kypraios, T., Neal, P., and Prangle, D. (2017). A Tutorial Introduction to Bayesian Inference for Stochastic Epidemic Models Using Approximate Bayesian Computation. Math. biosciences 287, 42–53. doi:10.1016/j.mbs.2016.07.001
Lauer, S. A., Grantz, K. H., Bi, Q., Jones, F. K., Zheng, Q., Meredith, H. R., et al. (2020). The Incubation Period of Coronavirus Disease 2019 (COVID-19) from Publicly Reported Confirmed Cases: Estimation and Application. Ann. Intern. Med. 172, 577–582. doi:10.7326/m20-0504
Le, T. A., Kosiorek, A. R., Siddharth, N., Teh, Y. W., and Wood, F. (2019). “Revisiting Reweighted Wake-Sleep for Models with Stochastic Control Flow,” in Proceedings of the conference on Uncertainty in Artificial Intelligence (UAI). Available at: https://arxiv.org/abs/1805.10469.
Le, T. A., Baydin, A. G., and Wood, F. (2017). “Inference Compilation and Universal Probabilistic Programming,” in Proceedings of the 20th International Conference on Artificial Intelligence and Statistics (AISTATS), volume 54 of Proceedings of Machine Learning Research (Fort Lauderdale, FL: PMLR), 1338–1348.
Lee, B. Y., Brown, S. T., Bailey, R. R., Zimmerman, R. K., Potter, M. A., McGlone, S. M., et al. (2011). The Benefits to All of Ensuring Equal and Timely Access to Influenza Vaccines in Poor Communities. Health Aff. 30 (6), 1141–1150. doi:10.1377/hlthaff.2010.0778
Lee, B. Y., Brown, S. T., Cooley, P., Potter, M. A., Wheaton, W. D., Voorhees, R. E., et al. (2010). Simulating School Closure Strategies to Mitigate an Influenza Epidemic. J. Public Health Manag. Pract. JPHMP 16 (3), 252–261. doi:10.1097/phh.0b013e3181ce594e
Lekone, P. E., and Finkenstädt, B. F. (2006). Statistical Inference in a Stochastic Epidemic SEIR Model with Control Intervention: Ebola as a Case Study. Biometrics 62 (4), 1170–1177. doi:10.1111/j.1541-0420.2006.00609.x
Lessler, J., Azman, A. S., Grabowski, M. K., Salje, H., and Rodriguez-Barraquer, I. (2016). Trends in the Mechanistic and Dynamic Modeling of Infectious Diseases. Curr. Epidemiol. Rep. 3 (3), 212–222. doi:10.1007/s40471-016-0078-4
Levine, S. (2018). Reinforcement Learning and Control as Probabilistic Inference: Tutorial and Review. arXiv [Preprint]. Available at: https://arxiv.org/abs/1805.00909 (Accessed May 2, 2018).
Liu, F., Enanoria, W. T., Zipprich, J., Blumberg, S., Harriman, K., Ackley, S. F., et al. (2015). The Role of Vaccination Coverage, Individual Behaviors, and the Public Health Response in the Control of Measles Epidemics: An Agent-Based Simulation for california. BMC public health 15 (1), 447. doi:10.1186/s12889-015-1766-6
Liu, Q., Liu, Z., Zhu, J., Zhu, Y., Li, D., Gao, Z., et al. (2020). Assessing the Global Tendency of COVID-19 Outbreak. medRxiv [Preprint]. doi:10.1101/2020.03.18.20038224
Liu, X., Hewings, G., Wang, S., Qin, M., Xiang, X., Zheng, S., et al. (2020). Modeling the Situation of COVID-19 and Effects of Different Containment Strategies in China with Dynamic Differential Equations and Parameters Estimation. medRxiv [Preprint]. doi:10.1101/2020.03.09.20033498
Liu, Z., Magal, P., Seydi, O., and Webb, G. (2020). Predicting the Cumulative Number of Cases for the COVID-19 Epidemic in China from Early Data. arXiv [Preprint]. Available at: https://arxiv.org/abs/2002.12298 (Accessed February 27, 2020).
Magdon-Ismail, M. (2020). Machine Learning the Phenomenology of COVID-19 from Early Infection Dynamics. medRxiv [Preprint].
Mamo, D. K., and Koya, P. R. (2015). Mathematical Modeling and Simulation Study of SEIR Disease and Data Fitting of Ebola Epidemic Spreading in West Africa. J. Multidisciplinary Eng. Sci. Technol. 2 (1), 106–114.
Massonnaud, C., Roux, J., and Crépey, P. (2020). COVID-19: Forecasting Short Term Hospital Needs in France. medRxiv [Preprint]. doi:10.1101/2020.03.16.20036939
McKinley, T. J., Vernon, I., Andrianakis, I., McCreesh, N., Oakley, J. E., Nsubuga, R. N., et al. (2018). Approximate Bayesian Computation and Simulation-Based Inference for Complex Stochastic Epidemic Models. Stat. Sci. 33 (1), 4–18. doi:10.1214/17-STS618
Minter, A., and Retkute, R. (2019). Approximate Bayesian Computation for Infectious Disease Modeling. Epidemics 29, 100368. doi:10.1016/j.epidem.2019.100368
Moerland, T. M., Broekens, J., and Jonker, C. M. (2021). Model-based Reinforcement Learning: A survey. arXiv [Preprint]. Available at: https://arxiv.org/abs/2006.16712 (Accessed Jun 30, 2020).
Morari, M., and Lee, J. H. (1999). Model Predictive Control: Past, Present and Future. Comput. Chem. Eng. 23 (4-5), 667–682. doi:10.1016/s0098-1354(98)00301-9
Munk, A., Adam, Ś., Baydin, A. G., Stewart, A., Fernlund, A., Poursartip, A., et al. (2020). “Deep Probabilistic Surrogate Networks for Universal Simulator Approximation,” in The second International Conference on Probabilistic Programming (PROBPROG), October 20–22, 2021.
Murray, L. M. (2015). Bayesian State-Space Modeling on High-Performance Hardware Using LibBi. J. Stat. Soft. 67, 1–36. doi:10.18637/jss.v067.i10
Naderiparizi, S., Ścibior, A., Munk, A., Ghadiri, M., Baydin, A. G., Gram-Hansen, B., et al. (2019). Amortized Rejection Sampling in Universal Probabilistic Programming. Available at: https://arxiv.org/abs/1910.09056.
Ogilvy Kermack, W., and McKendrick, A. G. (1927). A Contribution to the Mathematical Theory of Epidemics. Proc. R. Soc. Lond. Ser. A, Containing Pap. a Math. Phys. character 115 (772), 700–721.
Paige, B., Wood, F., Doucet, A., and Teh, Y. W. (2014). “Asynchronous Anytime Sequential Monte Carlo,” in Advances in Neural Information Processing Systems, 3410–3418.
Paige, B., and Wood, F. (2016). “Inference Networks for Sequential Monte Carlo in Graphical Models,” in Proceedings of the 33rd International Conference on Machine Learning (Cambridge, MA: PMLR).
Parker, J., and Epstein, J. M. (2011). A Distributed Platform for Global-Scale Agent-Based Models of Disease Transmission. ACM Trans. Model. Comput. Simul. 22 (1), 1–25. doi:10.1145/2043635.2043637
Pearl, J. (2000). Causality: Models, Reasoning, and Inference. New York, NY: Cambridge University Press.
Peng, L., Yang, W., Zhang, D., Zhuge, C., and Hong, L. (2020). Epidemic Analysis of COVID-19 in China by Dynamical Modeling. medRxiv [Preprint]. doi:10.1101/2020.02.16.20023465
Potter, M. A., Brown, S. T., Cooley, P. C., Sweeney, P. M., Hershey, T. B., Gleason, S. M., et al. (2012). School Closure as an Influenza Mitigation Strategy: How Variations in Legal Authority and Plan Criteria Can Alter the Impact. BMC public health 12 (1), 977–1011. doi:10.1186/1471-2458-12-977
Pujari, B. S., and Shekatkar, S. (2020). Multi-city Modeling of Epidemics Using Spatial Networks: Application to 2019-nCov (COVID-19) Coronavirus in India. medRxiv [Preprint]. doi:10.1101/2020.03.13.20035386
Rainforth, T., Cornish, R., Yang, H., Warrington, A., and Wood, F. (2018). “On Nesting Monte Carlo Estimators,” in International Conference on Machine Learning (Stockholmsmässan: PMLR), 4267–4276.
Rainforth, T., Naesseth, C. A., Lindsten, F., Paige, B., van de Meent, J. W., Doucet, A., et al. (2016). “Interacting Particle Markov Chain Monte Carlo,” in Proceedings of the 33rd International Conference on Machine Learning (Cambridge, MA: PMLR).
Rawlings, J. B. (2000). Tutorial Overview of Model Predictive Control. IEEE Control Syst. Mag. 20 (3), 38–52.
Riou, J., and Althaus, C. L. (2020). Pattern of Early Human-To-Human Transmission of Wuhan 2019 Novel Coronavirus (2019-nCoV), December 2019 to January 2020. Euro Surveill. 25 (4), 2020. doi:10.2807/1560-7917.ES.2020.25.4.2000058
Roberts, M., Andreasen, V., Lloyd, A., and Pellis, L. (2015). Nine Challenges for Deterministic Epidemic Models. Epidemics 10, 49–53. doi:10.1016/j.epidem.2014.09.006
Rovetta, A., Bhagavathula, A. S., and Castaldo, L. (2020). Modeling the Epidemiological Trend and Behavior of COVID-19 in Italy. medRxiv [Preprint]. doi:10.1101/2020.03.19.20038968
Russo, L., Anastassopoulou, C., Tsakris, A., Bifulco, G. N., Campana, E. F., Toraldo, G., et al. (2020). Tracing Day-Zero and Forecasting the COVID-19 Outbreak in Lombardy, Italy: A Compartmental Modeling and Numerical Optimization Approach. PLoS One 15, e0240649. doi:10.1371/journal.pone.0240649
Sanche, S., Lin, Y. T., Xu, C., Romero-Severson, E., Hengartner, N. W., and Ruian, Ke. (2020). The Novel Coronavirus, 2019-nCoV, Is Highly Contagious and More Infectious than Initially Estimated. arXiv [Preprint]. Available at: https://arxiv.org/abs/2002.03268 (Accessed Feb 9, 2020).
Saunders-Hastings, P., CrispoCrispo, J. A. G., Sikora, L., and Krewski, D. (2017). Effectiveness of Personal Protective Measures in Reducing Pandemic Influenza Transmission: A Systematic Review and Meta-Analysis. Epidemics 20, 1–20. doi:10.1016/j.epidem.2017.04.003
Sharomi, O., and Malik, T. (2017). Optimal Control in Epidemiology. Ann. Operations Res. 251 (1-2), 55–71. doi:10.1007/s10479-015-1834-4
Staton, S., Wood, F., Yang, H., Heunen, C., and Kammar, O. (2016). “Semantics for Probabilistic Programming: Higher-Order Functions, Continuous Distributions, and Soft Constraints,” in 2016 31st Annual ACM/IEEE Symposium on Logic in Computer Science (LICS) (New York: ACM), 1–10.
Sutton, R. (1992). “Reinforcement Learning,” in The Springer International Series in Engineering and Computer Science (Springer US).
Teles, P. (2020). Predicting the Evolution of COVID-19 in Portugal Using an Adapted SIR Model Previously Used in South Korea for the MERS Outbreak. medRxiv [Preprint]. doi:10.1101/2020.03.18.20038612
Todorov, E. (2008). “General Duality Between Optimal Control and Estimation,” in 2008 47th IEEE Conference on Decision and Control, Cancun, Mexico, December 9–11, 2008 (IEEE), 4286–4292. doi:10.1109/cdc.2008.4739438
Tolpin, D., van de Meent, J-W., Frank, P., and Wood, B. (2015). Output-Sensitive Adaptive Metropolis-Hastings for Probabilistic Programs. ECML PKDD, 311–326. doi:10.1007/978-3-319-23525-7_19
Tolpin, D., van de Meent, J. W., Yang, H., and Wood, F. (2016). “Design and Implementation of Probabilistic Programming Language Anglican,” in Proceedings of the 28th Symposium on the Implementation and Application of Functional programming Languages, Leuven, August 31–September 2, 2016, 1–12. doi:10.1145/3064899.3064910
Toni, T., Welch, D., Strelkowa, N., Ipsen, A., and Stumpf, M. P. H. (2009). Approximate Bayesian Computation Scheme for Parameter Inference and Model Selection in Dynamical Systems. J. R. Soc. Interf. 6 (31), 187–202. doi:10.1098/rsif.2008.0172
Toussaint, M. (2009). “Robot Trajectory Optimization Using Approximate Inference,” in Proceedings of the 26th annual international conference on machine learning, 1049–1056. doi:10.1145/1553374.1553508
Tracy, M., Cerdá, M., and Keyes, K. M. (2018). Agent-based Modeling in Public Health: Current Applications and Future Directions. Annu. Rev. Public Health 39 (1), 77–94. doi:10.1146/annurev-publhealth-040617-014317
Traini, M. C., Caponi, C., and De Socio, G. V. (2020). Modeling the Epidemic 2019-nCoV Event in Italy: A Preliminary Note. medRxiv [Preprint]. doi:10.1101/2020.03.14.20034884
van de Meent, J-W., Yang, H., Mansinghka, V., and Wood, F. (2015). “Particle Gibbs with Ancestor Sampling for Probabilistic Programs,” in Artificial Intelligence and Statistics (Cambridge, MA: PMLR).
van de Meent, J. W., Brooks, P., Yang, H., and Wood, F. (2018). An Introduction to Probabilistic Programming. Available at: https://arxiv.org/abs/1809.10756.
Warrington, A., Lavington, J. W., Adam, S., Schmidt, M., and Wood, F. (2021). “Robust Asymmetric Learning in POMDPs,” in International Conference on Machine Learning, July 18–24, 2021 (Cambridge, MA: PMLR), 11013–11023.
Warrington, A., Naderiparizi, S., and Wood, F. (2020). “Coping with Simulators that Don’t Always Return,” in The 23rd International Conference on Artificial Intelligence and Statistics (AISTATS 2020), August 26–28, 2020.
Wearing, H. J., Rohani, P., and Keeling, M. J. (2005). Appropriate Models for the Management of Infectious Diseases. Plos Med. 2 (7), e174. doi:10.1371/journal.pmed.0020174
Weber, A., Ianelli, F., and Goncalves, S. (2020). Trend Analysis of the COVID-19 Pandemic in China and the Rest of the World. arXiv [Preprint]. Available at: https://arxiv.org/abs/2003.09032 (Accessed March 19, 2020).
Wen, Y., Wei, L., Li, Y., Tang, X., Feng, S., Leung, K., et al. (2020). Epidemiological and Clinical Characteristics of COVID-19 in Shenzhen, the Largest Migrant City of China. medRxiv [Preprint]. doi:10.1101/2020.03.22.20035246
Wheaton, W., Cajka, J., Chasteen, B., Wagener, D., Cooley, P., Ganapathi, L., et al. (2009). Synthesized Population Databases: A Us Geospatial Database for Agent-Based Models. Methods Report (RTI Press. 2009 (10), 905. doi:10.3768/rtipress.2009.mr.0010.0905
Wingate, D., Stuhlmüller, A., and Goodman, N. (2011). “Lightweight Implementations of Probabilistic Programming Languages via Transformational Compilation,” in Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, April 1–13, 2011, 770–778.
Wölfel, R., Corman, V. M., Guggemos, W., Seilmaier, M., Zange, S., Müller, M. A., et al. (2020). Clinical Presentation and Virological Assessment of Hospitalized Cases of Coronavirus Disease 2019 in a Travel-Associated Transmission Cluster. medRxiv [Preprint]. doi:10.1101/2020.03.05.20030502
Wood, F., van de Meent, J. W., and Mansinghka, V. (2014). “A New Approach to Probabilistic Programming Inference,” in Artificial Intelligence and Statistics, 1024–1032.
Wood, F., Warrington, A., Naderiparizi, S., Weilbach, C., Masrani, V., Harvey, W., et al. (2020). Planning As Inference In Epidemiological Models. arXiv preprint arXiv:2003.13221.
World Bank (2020). Hospital Beds Per Capita in the united states. Available at: https://data.worldbank.org/indicator/SH.MED.BEDS.ZS?locations=US (Accessed March 25, 2020).
Wu, Z., and McGoogan, J. M. (2020). Characteristics of and Important Lessons from the Coronavirus Disease 2019 (COVID-19) Outbreak in China: Summary of a Report of 72 314 Cases from the Chinese Center for Disease Control and Prevention. JAMA 323 (13), 1239–1242. doi:10.1001/jama.2020.2648
Zhou, K., and Doyle, J. C. (1998). Essentials of Robust Control, 104. Upper Saddle River, NJ: Prentice-Hall.
Zhou, Y., Gram-Hansen, B. J., Kohn, T., Rainforth, T., Yang, H., and Frank, W. L. F-P. P. L. (2019). “A Low-Level First Order Probabilistic Programming Language for Non-differentiable Models,” in Proceedings of the Twentieth International Conference on Artificial Intelligence and Statistics (AISTATS), Naha, Okinawa, April 16–18, 2019.
Keywords: public health preparedness, epidemiological dynamics, Bayesian inference, probabilistic programming, COVID-19
Citation: Wood F, Warrington A, Naderiparizi S, Weilbach C, Masrani V, Harvey W, Ścibior A, Beronov B, Grefenstette J, Campbell D and Nasseri SA (2022) Planning as Inference in Epidemiological Dynamics Models. Front. Artif. Intell. 4:550603. doi: 10.3389/frai.2021.550603
Received: 09 April 2020; Accepted: 25 October 2021;
Published: 31 March 2022.
Edited by:
Weida Tong, National Center for Toxicological Research (FDA), United StatesReviewed by:
Theophane Weber, DeepMind Technologies Limited, United KingdomCopyright © 2022 Wood, Warrington, Naderiparizi, Weilbach, Masrani, Harvey, Ścibior, Beronov, Grefenstette, Campbell and Nasseri. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: S. Ali Nasseri, YWxpLm5hc3NlcmlAdWJjLmNh
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.