 Jan Tönshoff
Jan Tönshoff Martin Ritzert
Martin Ritzert Hinrikus Wolf
Hinrikus Wolf Martin Grohe
Martin Grohe- Chair of Computer Science 7 (Logic and Theory of Discrete Systems), Department of Computer Science, RWTH Aachen University, Aachen, Germany
Many combinatorial optimization problems can be phrased in the language of constraint satisfaction problems. We introduce a graph neural network architecture for solving such optimization problems. The architecture is generic; it works for all binary constraint satisfaction problems. Training is unsupervised, and it is sufficient to train on relatively small instances; the resulting networks perform well on much larger instances (at least 10-times larger). We experimentally evaluate our approach for a variety of problems, including Maximum Cut and Maximum Independent Set. Despite being generic, we show that our approach matches or surpasses most greedy and semi-definite programming based algorithms and sometimes even outperforms state-of-the-art heuristics for the specific problems.
1 Introduction
Constraint satisfaction is a general framework for casting combinatorial search and optimization problems; many well-known NP-complete problems, for example, k-colorability, Boolean satisfiability and maximum cut can be modeled as constraint satisfaction problems (CSPs). Our focus is on the optimization version of constraint satisfaction, usually referred to as maximum constraint satisfaction (Max-CSP), where the objective is to satisfy as many constraints of a given instance as possible. There is a long tradition of designing exact and heuristic algorithms for all kinds of CSPs. Our work should be seen in the context of a recently renewed interest in heuristics for NP-hard combinatorial problems based on neural networks, mostly GNNs (for example, Khalil et al., 2017; Selsam et al., 2019; Lemos et al., 2019; Prates et al., 2019).
We present a generic graph neural network (GNN) based architecture called RUN-CSP (Recurrent Unsupervised Neural Network for Constraint Satisfaction Problems) with the following key features:
Unsupervised: Training is unsupervised and just requires a set of instances of the problem.
Scalable: Networks trained on small instances achieve good results on much larger inputs.
Generic: The architecture is generic and can learn to find approximate solutions for any binary Max-CSP.
We remark that in principle, every CSP can be transformed into an equivalent binary CSP (see Section 2 for a discussion).
To solve Max-CSPs, we train a GNN, which we view as a message passing protocol. The protocol is executed on a graph with nodes for all variables and edges for all constraints of the instance. After running the protocol for a fixed number of rounds, we extract probabilities for the possible values of each variable from its current state. All parameters determining the messages, the update of the internal states, and the readout function are learned. Since these parameters are shared over all variables, we can apply the model to instances of arbitrary size1. Our loss function rewards solutions with many satisfied constraints. Thus, our networks learn to satisfy the maximum number of constraints which naturally puts the focus on the optimization version Max-CSP of the constraint satisfaction problem.
This focus on the optimization problem allows us to train unsupervised, which is a major point of distinction between our work and recent neural approaches to Boolean satisfiability (Selsam et al., 2019) and the coloring problem (Lemos et al., 2019). Both approaches require supervised training and output a prediction for satisfiability or coloring number. Furthermore, our approach not only returns a prediction whether the input instance is satisfiable, but it returns an (approximately optimal) variable assignment. The variable assignment is directly produced by a neural network, which distinguishes our end-to-end approach from methods that combine neural networks with conventional heuristics, such as Khalil et al., (2017) and Li et al., (2018).
We experimentally evaluate our approach on the following NP-hard problems: the maximum 2-satisfiability problem (Max-2-SAT), which asks for an assignment maximizing the number of satisfied clauses for a given Boolean formula in 2-conjunctive normal form; the maximum cut problem (Max-Cut), which asks for a partition of a graph in two parts such that the number of edges between the parts is maximal (see Figure 1); the 3-colorability problem (3-COL), which asks for a 3-coloring of the vertices of a given graph such that the two endvertices of each edge have distinct colors. We also consider the maximum independent set problem (Max-IS), which asks for an independent set of maximum cardinality in a given graph. Strictly speaking, Max-IS is not a maximum constraint satisfaction problem, because its objective is not to maximize the number of satisfied constraints, but to satisfy all constraints while maximizing the number of variables with a certain value. We include this problem to demonstrate that our approach can easily be adapted to such related problems.

FIGURE 1. A 2-coloring for a grid graph found by RUN-CSP in 40 iterations. Conflicting edges are shown in red.
Our experiments show that our approach works well for all four problems and matches competitive baselines. Since our approach is generic for all Max-CSPs, those baselines include other general approaches such as greedy algorithms and semi-definite programming (SDP). The latter is particularly relevant, because it is known (under certain complexity theoretic assumptions) that SDP achieves optimal approximation ratios for all Max-CSPs (Raghavendra, 2008). For Max-2-SAT, our approach even manages to surpass a state-of-the-art heuristic. In general, our method is not competitive with the highly specialized state-of-the-art heuristics. However, we demonstrate that our approach clearly improves on the state-of-the-art for neural methods on small and medium-sized binary CSP instances, while still being completely generic. We remark that our approach does not give any guarantees, as opposed to some traditional solvers which guarantee that no better solution exists.
Almost all models are trained on quite small training sets consisting of small random instances. We evaluate those models on unstructured random instances as well as more structured benchmark instances. Instance sizes vary from small instances with 100 variables and 200 constraints to medium sized instances with more than 1,000 variables and over 10,000 constraints. We observe that RUN-CSP is able to generalize well from small instances to instances both smaller and much larger. The largest (benchmark) instance we evaluate on has approximately 120,000 constraints, but that instance required the use of large training graphs. Computations with RUN-CSP are very fast in comparison to many heuristics and profit from modern hardware like GPUs. For medium-sized instances with 10,000 constraints inference takes less than 5 s.
1.1 Related Work
Traditional methods for solving CSPs include combinatorial constraint propagation algorithms, logic programming techniques and domain specific approaches, for an overview see Apt (2003), Dechter (2003). Our experimental baselines include a wide range of classical algorithms, mostly designed for specific problems. For Max-2-SAT, we compare the performance to that of WalkSAT (Selman et al., 1993; Kautz, 2019), which is a popular stochastic local search heuristic for Max-SAT. Furthermore, we use the state-of-the-art Max-SAT solver Loandra (Berg et al., 2019), which combines linear search and core-guided algorithms. On the Max-Cut problem, we compare our method to multiple implementations of a heuristic approach by Goemans and Williamson (1995). This method is based on semi-definite programming (SDP) and is particularly popular since it has a proven approximation ratio of
Beyond these traditional approaches there have been several attempts to apply neural networks to NP-hard problems and more specifically CSPs. An early group of papers dates back to the 1980s and uses Hopfield Networks (Hopfield and Tank, 1985) to approximate TSP and other discrete problems using neural networks. Hopfield and Tank use a single-layer neural network with sigmoid activation and apply gradient descent to come up with an approximative solution. The loss function adopts soft assignments and uses the length of the TSP tour and a term penalizing incorrect tours as loss, hence being unsupervised. This approach has been extended to k-colorability (Dahl, 1987; Takefuji and Lee, 1991; Gassen and Carothers, 1993; Harmanani et al., 2010) and other CSPs (Adorf and Johnston, 1990). The loss functions used in some of these approaches are similar to ours.
Newer approaches involve modern machine learning techniques and are usually based on GNNs. NeuroSAT (Selsam et al., 2019), a learned message passing network for predicting satisfiability, reignited the interest in solving NP-complete problems with neural networks. Prates et al., (2019) use GNNs to learn TSP and trained on instances of the form
2 Constraint Satisfaction Problems
Formally, a CSP-instance is a triple
For example, an instance of 3-COL has a variable
In this paper, we only consider binary CSPs, that is, CSPs whose constraint language only contains unary and binary relations. From a theoretical perspective, this is no real restriction, because it is well known that every CSP can be transformed into an “equivalent” binary CSP (see Dechter, 2003). Let us review the construction. Suppose we have a constraint language
However, the construction is not approximation preserving. For example, it is not the case that an assignment satisfying 90% of the constraints of
3 Method
3.1 Architecture
We use a randomized recurrent GNN architecture to evaluate a given problem instance using message passing. For any binary constraint language
Every message passing step uses the same weights and thus we are free to choose the number
Variables x and y that co-occur in a constraint
The output of
The internal states
For every variable x and iteration
Input: Instance
Output:
for
//random initialization
for
for
//generate messages
for
//combine messages and update
Algorithm 1: Network Architecture.
Algorithm 1 specifies the architecture in pseudocode. Figure 2 illustrates the message passing graph for a Max-2-SAT instance and the internal update procedure of RUN-CSP. Note that the network’s output depends on the random initialization of the short-term states
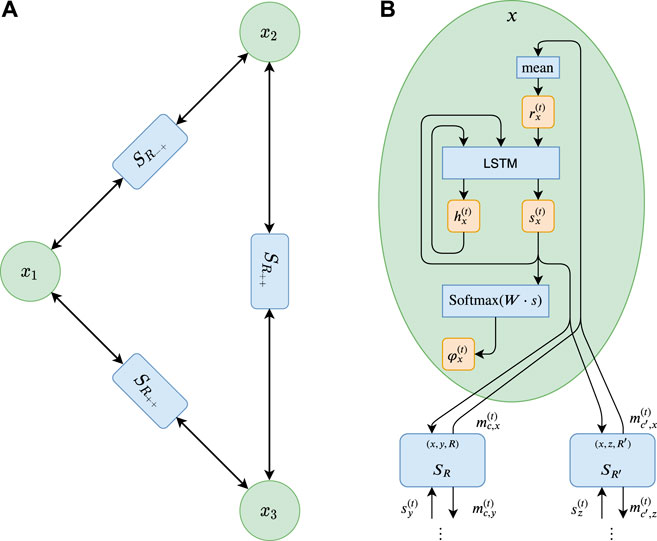
FIGURE 2. (A) The graph corresponding to the Max-2-SAT-instance f = (¬X1
We did evaluate more complex variants of this architecture with multi-layered messaging functions and multiple stacked recurrent cells. No increase in performance was observed with these modifications, while the running time increased. Replacing the LSTM cells with GRU cells slightly decreased the performance. Therefore, we use the simple LSTM-based architecture presented here.
3.2 Loss Function
In the following we derive our loss function used for unsupervised training. Let
where
We combine the loss function
This loss function allows us to train unsupervised since it does not depend on any ground truth assignments. Furthermore, it avoids reinforcement learning, which is computationally expensive. In general, computing optimal solutions for supervised training can easily turn out to be prohibitive; our approach completely avoids such computations.
We remark that it is also possible to extend the framework to weighted Max-CSPs where a real weight is associated with each constraint. To achieve this, we can replace the averages in the loss function and message collection steps by weighted averages. Negative constraint weights can be incorporated by swapping the relation with its complement. We demonstrate this in Section 4.2 where we evaluate RUN-CSP on the weighted Max-Cut problem.
4 Experiments
To validate our method empirically, we performed experiments for Max-2-SAT, Max-Cut, 3-COL and Max-IS. For all experiments, we used internal states of size
We ran our experiments on machines with two Intel Xeon 8160 CPUs and one NVIDIA Tesla V100 GPU but got very similar runtime on consumer hardware. Evaluating 64 runs on an instance with 1,000 variables and 1,000 constraints takes about 1.5 s, 10,000 constraints about 5 s, and 20,000 constraints about 8 s. Training a model takes less than 30 min. Thus, the computational cost of RUN-CSP is relatively low.
4.1 Maximum 2-Satisfiability
We view Max-2-SAT as a binary CSP with domain
4.1.1 Random Instances
For the evaluation of RUN-CSP in Max-2-SAT we start with random instances and compare it to a number of problem-specific heuristics. All baselines can solve Max-SAT for arbitrary arities, not only Max-2-SAT, while RUN-CSP can solve a variety of binary Max-CSPs. The state-of-the-art Max-SAT Solver Loandra (Berg et al., 2019) won the unweighted track for incomplete solvers in the Max-SAT Evaluation 2019 (Bacchus et al., 2019). We ran Loandra in its default configuration with a timeout of 20 min on each formula. To put this into context, on the largest evaluation instance used here (9,600 constraints) RUN-CSP takes less than 7 min on a single CPU core and about 5 s using the GPU. WalkSAT (Selman et al., 1993; Kautz, 2019) is a stochastic local search algorithm for approximating Max-Sat. We allowed WalkSAT to perform 10 million flips on each formula using its “noise” strategy with parameters
For evaluation we generated random formulas with 100, 400, 800, and 1,600 variables. The ratio between clauses and variables was varied in steps of 0.1 from 1 to 6. Figure 3 shows the average percentage of satisfied clauses in the solutions found by each method over 100 formulas for each size and density. The methods yield virtually identical results for formulas with less than 2 clauses per variable. For denser instances, RUN-CSP yields slightly worse results than both baselines when only 100 variables are present. However, RUN-CSP matches the results of Loandra for formulas with 400 variables and outperforms it for instances with 800 and 1,600 variables. The performance of WalkSAT degrades on these formulas and is significantly worse than RUN-CSP.
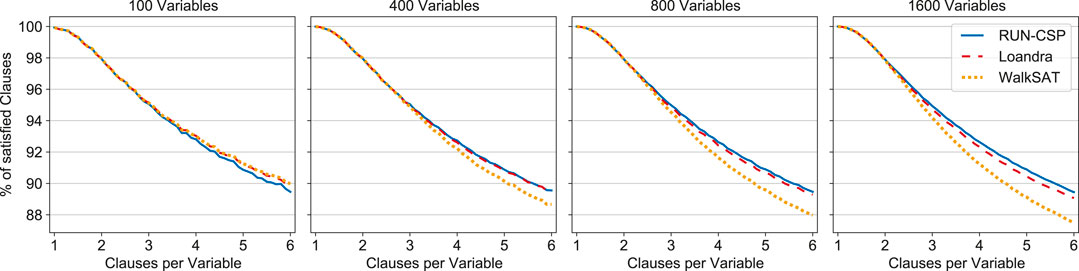
FIGURE 3. Percentage of satisfied clauses of random 2-CNF formulas for RUN-CSP, Loandra and WalkSAT. Each data point is the average of 100 formulas; the ratio of clauses per variable increases in steps of 0.1.
4.1.2 Benchmark Instances
For more structured formulas, we use Max-2-SAT benchmark instances from the unweighted track of the Max-SAT Evaluation 2016 (Argelich, 2016) based on the Ising spin glass problem (De Simone et al., 1995; Heras et al., 2008). We used the same general setup as in the previous experiment but increased the timeout for Loandra to 60 min. In particular we use the same RUN-CSP model trained entirely on random formulas. Table 1 contains the achieved numbers of unsatisfied constraints across the benchmark instances. All methods produced optimal results on the first and the third instance. RUN-CSP slightly deviates from the optimum on the second instance. For the fourth instance RUN-CSP found an optimal solution while both WalkSAT and Loandra did not. On the largest benchmark formula, RUN-CSP again produced the best result.
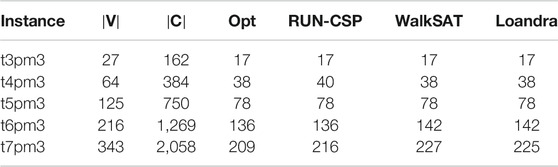
TABLE 1. Max-2-SAT: Number of unsatisfied constraints for Max-2-SAT benchmark instances derived from the Ising spin glass problem.
Thus, RUN-CSP is competitive for random as well as spin-glass-based structured Max-2-SAT instances. Especially on larger instances it also outperforms conventional methods. Furthermore, training on random instances generalized well to the structured spin-glass instances.
4.2 Max Cut
Max-Cut is a classical Max-CSP with domain
4.2.1 Regular Graphs
In this section we evaluate RUN-CSP’s performance on this problem. Yao et al., (2019) proposed two unsupervised GNN architectures for Max-Cut. One was trained through policy gradient descent on a non-differentiable loss function while the other used a differentiable relaxation of this loss. They evaluated their architectures on random regular graphs, where the asymptotic Max-Cut optimum is known. We use their results as well as their baseline results for Extremal Optimization (EO) (Boettcher and Percus, 2001) and a classical approach based on semi-definite programming (SDP) (Goemans and Williamson, 1995) as baselines for RUN-CSP. To evaluate the sizes of graph cuts, Yao et al., (2019) introduced a relative performance measure called P-value given by
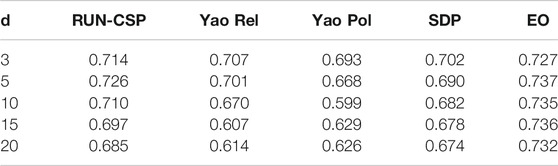
TABLE 2. Max-Cut: P-values of graph cuts produced by RUN-CSP, Yao, SDP, and EO for regular graphs with 500 nodes and varying degrees. We report the mean across 1,000 random graphs for each degree.
4.2.2 Benchmark Instances
We performed additional experiments on standard Max-Cut benchmark instances. The Gset dataset (Ye, 2003) is a set of 71 weighted and unweighted graphs that are commonly used for testing Max-Cut algorithms. The dataset contains three different types of random graphs. Those graphs are Erdős–Rényi graphs with uniform edge probability, graphs where the connectivity gradually decays from node 1 to n, and 4-regular toroidal graphs. Here, we use two unweighted graphs for each type from this dataset. We reused the RUN-CSP model from the previous experiment but increased the number of iterations for evaluation to
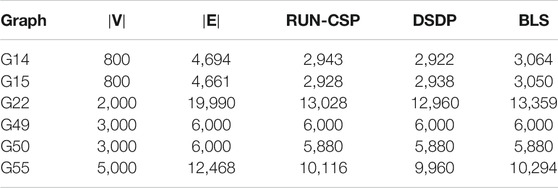
TABLE 3. Max-Cut: Achieved cut sizes on Gset instances for RUN-CSP, DSDP, and BLS.
4.2.3 Weighted Maximum Cut Problem
Additionally, we evaluate RUN-CSP on the weighted Max-Cut problem, where every edge
where the partition
We evaluate this model on 10 benchmark instances obtained from the Optsicom Project2, namely the 10 smallest graphs of set 2. These instances are based on the lsing spin glass problem and are commonly used to evaluate heuristics empirically. All 10 graphs have
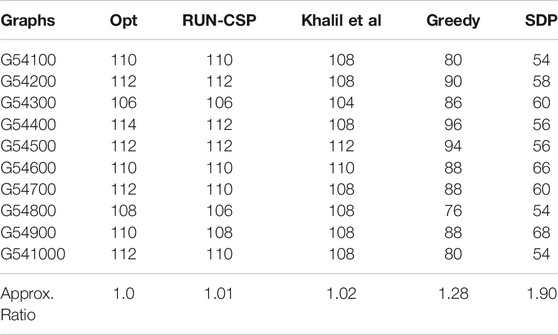
TABLE 4. Max-Cut: Achieved cut sizes on Optsicom Benchmarks. The optimal values were estimated by Khalil et al., (2017) by running CPLEX for 1 h on each instance.
4.3 Coloring
Within coloring we focus on the case of three colors, i.e., we consider CSPs over the domain
4.3.1 Hard Instances
We evaluate RUN-CSP on so-called “hard” random instances, similar to those defined by Lemos et al., (2019). These instances are a special subclass of Erdős–Rényi graphs where an additional edge can make the graph no longer 3-colorable. We describe our exact generation procedure in the Supplementary Material. We trained five RUN-CSP models on 4,000 hard 3-colorable instances with 100 nodes each. In Table 5 we present results for RUN-CSP, a greedy heuristic with DSatur strategy (Brélaz, 1979), and the state-of-the-art heuristic HybridEA (Galinier and Hao, 1999; Lewis et al., 2012; Lewis, 2015). HybridEA was allowed to make 500 million constraint checks on each graph. We observe that larger instances are harder for all tested methods and between the three algorithms there is a clear hierarchy. The state-of-the-art heuristic HybridEA clearly performs best and finds solutions even for some of the largest graphs. RUN-CSP finds optimal colorings for a large fraction of graphs with up to 100 nodes and even a few correct colorings for graphs of size 200. The weakest algorithm is DSatur which even fails on most of the small 50 node graphs and gets rapidly worse for larger instances.
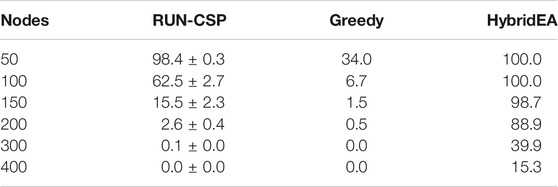
TABLE 5. 3-COL: Percentages of hard 3-colorable instances for which optimal 3-colorings were found by RUN-CSP, Greedy, and HybridEA. We evaluate on 1,000 instances for each size. We provide mean and standard deviation across five different RUN-CSP models.
Choosing larger or more training graphs for RUN-CSP did not significantly improve its performance on larger hard graphs. We assume that a combination of increasing the state size, complexity of the message generation functions, and number and size of training instances is able to achieve better results, but on the cost of efficiency.
In Table 5 we do not report results for GNN-GCP by Lemos et al., (2019) as the structure of the output is fundamentally different. While the three algorithms in Table 5 output a coloring, GNN-GCP outputs a guess on the chromatic number without providing a proof that this is achievable. We trained instances of GNN-GCP on 32,000 pairs of hard graphs of size 40 to 60 (small) and 50 to 100 (medium). For testing, we restricted the model to only choose between the chromatic numbers 3 and 4, when allowing a wider range of possible values, the accuracy of GNN-GCP drops considerably. The network was able to achieve test accuracies of 75% (respectively 65% when trained and evaluated on medium instances). The model generalizes fairly well, with the small model achieving 64% on the medium test set and the large model achieving 74% on the small test set, almost matching the performance of the network trained on graphs of the respective size. On a set of test instances of hard graphs with 150 nodes, GNN-GCP achieved an accuracy of 52% (54% for the model trained on medium instances). Thus, the model performs significantly worse than RUN-CSP which achieves 81% (GNN-GCP 59%) accuracy on a test set of graphs of size 100, and 68% on graphs of size 150 where GNN-GCP achieves up to 54%. The numbers for RUN-CSP are larger than those reported in Table 5 since in the table only 3-colorable instances were considered. Here, the accuracy is computed over 3-colorable instances as well as their non-3-colorable counter parts. By design, RUN-CSP achieves perfect classification on negative instances.
Overall, we see that despite being designed for maximization tasks, RUN-CSP outperforms greedy heuristics and neural baselines on the decision variant of 3-COL for hard random instances.
4.3.2 Structure Specific Performance
On the example of the coloring problem, we evaluate generalization to other graph classes. We expect a network trained on instances of a particular structure to adapt toward this class and outperform models trained on different graph classes. We briefly evaluate this hypothesis for four different classes of graphs.
Erdős–Rényi Graphs: Graphs are generated by uniformly sampling m distinct edges between n nodes.
Geometric Graphs: A graph is generated by first assigning random positions within a
Powerlaw-Cluster Graphs: This graph model was introduced by Holme and Kim (2002). Each graph is generated by iteratively adding n nodes and connected to m existing nodes. After each edge is added, a triangle is closed with probability p, i.e., an additional edge is added between the new node and a random neighbor of the other endpoint of the edge.
Regular Graphs: We consider random 5-regular graphs as an example for graphs with a very specific structure.
We trained five RUN-CSP models on 4,000 random instances of each type where each graph had between 50 and 100 nodes. We refer to these groups of models as
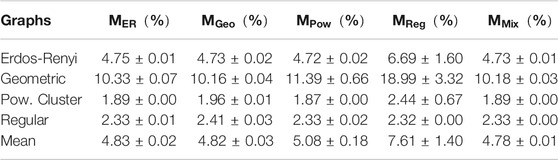
TABLE 6. Max-3-Col: Percentages of unsatisfied constraints for each graph class under the different RUN-CSP models. Values are averaged over 1,000 graphs and the standard deviation is computed with respect to the five RUN-CSP models.
Overall, this demonstrates that training on locally diverse graphs (e.g., geometric graphs or a mixture of graph classes) leads to good generalization toward other graph classes. While all tested networks achieved competitive results on the structure that they were trained on, they were not always the best for that particular structure. Therefore, our original hypothesis appears to be overly simplistic and restricting the training data to the structure of the evaluation instances is not necessarily optimal.
4.4 Independent Set
Finally, we experimented with the maximum independent set problem Max-IS. The independence condition can be modeled through a constraint language
Here,
4.4.1 Random Instances
We start by evaluating the performance on random graphs. We trained a network on 4,000 random Erdős–Rényi graphs with 100 nodes and
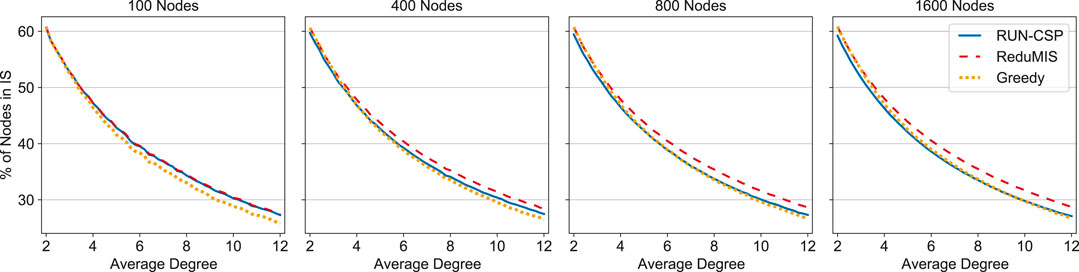
FIGURE 4. Independent set sizes on random graphs produced by RUN-CSP, ReduMIS and a greedy heuristic. The sizes are given as the percentage of nodes contained in the independent set. Every data point is the average for 100 graphs; the degree increases in steps of 0.2.
4.4.2 Benchmark Instances
For more structured instances, we use a set of benchmark graphs from a collection of hard instances for combinatorial problems (Xu, 2005). The instances are divided into five sets with five graphs each. These graphs were generated through the RB Model (Xu and Li, 2003; Xu et al., 2005), a model for generating hard CSP instances. A graph of the class frbc-k consists of c interconnected k-cliques and the MAX-IS has a forced size of c. The previous model trained on Erdős–Rényi graphs did not perform well on these instances and produced sets with many induced edges. Thus, we trained a new network on 2,000 instances we generated ourselves through the RB model. The exact generation procedure of this dataset is provided in the Supplementary Material. We set
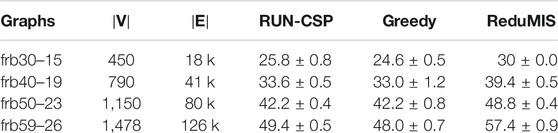
TABLE 7. Max-IS: Achieved IS sizes for the benchmark graphs. We report the mean and std. deviation for the five graphs in each group.
5 Conclusions
We have presented a universal approach for approximating Max-CSPs with recurrent neural networks. Its key feature is the ability to train without supervision on any available data. Our experiments on the optimization problems Max-2-SAT, Max-Cut, 3-COL and Max-IS show that RUN-CSP produces high quality approximations for all four problems. Our network can compete with traditional approaches like greedy heuristics or semi-definite programming on random data as well as benchmark instances. For Max-2-SAT, RUN-CSP was able to outperform a state-of-the-art MAX-SAT Solver. Our approach also achieved better results than neural baselines, where those were available. RUN-CSP networks trained on small random instances generalize well to other instances with larger size and different structure. Our approach is very efficient and inference takes only a few seconds, even for larger instances with over 10,000 constraints. The runtime scales linearly in the number of constraints and our approach can fully utilize modern hardware, like GPUs.
Overall, RUN-CSP seems like a promising approach for approximating Max-CSPs with neural networks. The strong results are somewhat surprising, considering that our networks consist of just one LSTM cell and a few linear functions. We believe that our observations point toward a great potential of machine learning in combinatorial optimization.
Future Work
We plan to extend RUN-CSP to CSPs of arbitrary arity and to weighted CSPs. It will be interesting to see, for example, how it performs on 3-SAT and its maximization variant. Another possible future extension could combine RUN-CSP with traditional local search methods, similar to the approach by Li et al., (2018) for Max-IS. The soft assignments can be used to guide a tree search and the randomness can be exploited to generate a large pool of initial solutions for traditional refinement methods.
Data Availability Statement
The code for RUN-CSP including the generated datasets and their generators can be found on github https://github.com/toenshoff/RUN-CSP. The additional datasets can be downloaded at their sources as specified in the following: Spinglass 2-CNF (Heras et al., 2008), http://maxsat.ia.udl.cat/benchmarks/ (Unweighted Crafted Benchmarks); Gset (Ye, 2003), https://www.cise.ufl.edu/research/sparse/matrices/Gset/; Max-IS Graphs (Xu, 2005), http://sites.nlsde.buaa.edu.cn/kexu/benchmarks/graph-benchmarks.htm; Optsicom (Corberán et al., 2006), http://grafo.etsii.urjc.es/optsicom/maxcut/.
Author Contributions
Starting from an initial idea by JT, all authors contributed to the presented design and the writing of this manuscript. Most of the implementation was done by JT, with help and feedback from MR and HW. The work was supervised by MG.
Funding
This work was supported by the German Research Foundation (DFG) under grants GR 1,492/16–1 Quantitative Reasoning About Database Queries and GRK 2236 (UnRAVeL).
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
This work is part of Jan Tönshoff’s Master’s Thesis and already appeared as a preprint on arXiv (Toenshoff et al., 2019).
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/frai.2020.580607/full#supplementary-material.
Acronyms
RUN-CSP Recurrent Unsupervised Neural Network for Constraint Satisfaction Problems.
3-COL 3-Coloring Problem.
CSP Constrain Satisfaction Problem.
GNN Graph Neural Network.
MVC Maximum Vertex Cover Problem.
Max-Cut Maximum Cut Problem.
Max-2-SAT Maximum Satisfiability Problem for Boolean formulas with two literals per clause.
Max-3-Col Maximum 3-Coloring Problem.
Max-IS Maximum Independent Set.
TSP Traveling Sales Person Problem.
Footnotes
1Our Tensorflow implementation of RUN-CSP is available at https://github.com/toenshoff/RUN-CSP.
2http://grafo.etsii.urjc.es/optsicom/maxcut/.
References
Abboud, R., Ceylan, I. I., and Lukasiewicz, T. (2019). Learning to reason: leveraging neural networks for approximate DNF counting. Preprint repository name [Preprint]. Available at:arXiv preprint arXiv:1904.02688 (Accessed June 4, 2019).
Adorf, H.-M., and Johnston, M. D. (1990). “A discrete stochastic neural network algorithm for constraint satisfaction problems,” in IJCNN international joint conference on neural networks, San Diego, CA, USA, June 17–21, 1990 (IEEE), 917–924.
Akiba, T., and Iwata, Y. (2016). Branch-and-reduce exponential/FPT algorithms in practice: a case study of vertex cover. Theor. Comput. Sci. 609, 211–225. doi:10.1016/j.tcs.2015.09.023
Amizadeh, S., Matusevych, S., and Weimer, M. (2019). “Learning to solve circuit-SAT: an unsupervised differentiable approach,” in International conference on learning representations, New Orleans, Louisiana, USA, May 6–9, 2019 (Amherst).
Apt, K. (2003). Principles of constraint programming. Amsterdam, NL: Cambridge University Press, 1–17.
F. Bacchus, M. Järvisalo, and R. Martins (Editors) (2019). MaxSAT evaluation 2019: solver and benchmark descriptions. Helsinki: University of Helsinki, 49.
Benlic, U., and Hao, J.-K. (2013). Breakout local search for the max-cutproblem. Eng. Appl. Artif. Intell. 26, 1162–1173. doi:10.1016/j.engappai.2012.09.001
Berg, J., Demirović, E., and Stuckey, P. J. (2019). “Core-boosted linear search for incomplete maxSAT,” in International conference on integration of constraint programming, artificial intelligence, and operations research, Thessaloniki, Greece, June 4–7, 2019 (Cham, Switzerland: Springer), 39–56.
Boettcher, S., and Percus, A. G. (2001). Extremal optimization for graph partitioning. Phys. Rev. 64, 026114. doi:10.1103/physreve.64.026114
Brélaz, D. (1979). New methods to color the vertices of a graph. Commun. ACM 22, 251–256. doi:10.1145/359094.359101
Chen, Z., Li, L., and Bruna, J. (2019). “Supervised community detection with line graph neural networks,” in International Conference on Learning Representations, New Orleans, Louisiana, USA, May 6–9, 2019 (Amherst).
Choi, C., and Ye, Y. (2000). Solving sparse semidefinite programs using the dual scaling algorithm with an iterative solver. Iowa City, IA: Department of Management Sciences, University of Iowa.
Dahl, E. (1987). “Neural network algorithms for an np-complete problem: map and graph coloring,” in Proceedings First International Conference Neural Networks III, (San Diego, NY: IEEE), 113–120.
De Simone, C., Diehl, M., Jünger, M., Mutzel, P., Reinelt, G., and Rinaldi, G. (1995). Exact ground states of Ising spin glasses: new experimental results with a branch-and-cut algorithm. J. Stat. Phys. 80, 487–496. doi:10.1007/bf02178370
Dembo, A., Montanari, A., and Sen, S. (2017). Extremal cuts of sparse random graphs. Ann. Probab. 45, 1190–1217. doi:10.1214/15-aop1084
Galinier, P., and Hao, J.-K. (1999). Hybrid evolutionary algorithms for graph coloring. J. Combin. Optim. 3, 379–397. doi:10.1023/a:1009823419804
Gassen, D. W., and Carothers, J. D. (1993). “Graph color minimization using neural networks,” in Proceedings of 1993 international conference on neural networks, October 25–29, 1993 (Nagoya, Japan: IEEE), 1541–1544.
Goemans, M. X., and Williamson, D. P. (1995). Improved approximation algorithms for maximum cut and satisfiability problems using semidefinite programming. J. ACM 42, 1115–1145. doi:10.1145/227683.227684
Harmanani, H., Hannouche, J., and Khoury, N. (2010). A neural networks algorithm for the mi nimum coloring problem using FPGAs†. Int. J. Model. Simulat. 30, 506–513. doi:10.1080/02286203.2010.11442597
Heras, F., Larrosa, J., De Givry, S., and Schiex, T. (2008). 2006 and 2007 max-SAT evaluations: contributed instances. Schweiz. Arch. Tierheilkd. 4, 239–250. doi:10.3233/sat190046
Holme, P., and Kim, B. J. (2002). Growing scale-free networks with tunable clustering. Phys. Rev. 65, 026107. doi:10.1103/physreve.65.026107
Hopfield, J. J., and Tank, D. W. (1985). “Neural” computation of decisions in optimization problems. Biol. Cybern. 52, 141–5210. doi:10.1007/BF00339943
Khalil, E., Dai, H., Zhang, Y., Dilkina, B., and Song, L. (2017). “Learning combinatorial optimization algorithms over graphs,” in Advances in neural information processing systems 30: annual conference on neural information processing systems 2017, Long Beach, CA, USA, December 4–9, 2017. 6348–6358. Red Hook (NY): Curran Associates.
Lamm, S., Sanders, P., Schulz, C., Strash, D., and Werneck, R. F. (2017). Finding near-optimal independent sets at scale. J. Heuristics 23, 207–229. doi:10.1007/s10732-017-9337-x
Lemos, H., Prates, M., Avelar, P., and Lamb, L. (2019). Graph coloring meets deep learning: effective graph neural network models for combinatorial problems. Preprint repository name [Preprint]. Available at:arXiv preprint arXiv:1903.04598 (Accessed March 11, 2019).
Lewis, R., Thompson, J., Mumford, C., and Gillard, J. (2012). A wide-ranging computational comparison of high-performance graph coloring algorithms. Comput. Oper. Res. 39, 1933–1950. doi:10.1016/j.cor.2011.08.010
Li, Z., Chen, Q., and Koltun, V. (2018). “Combinatorial optimization with graph convolutional networks and guided tree search,” in Advances in Neural Information Processing Systems, 539–548.
Prates, M., Avelar, P. H. C., Lemos, H., Lamb, L. C., and Vardi, M. Y. (2019). “Learning to solve NP-complete problems: a graph neural network for decision TSP, Aaai,” in Proceedings of the AAAI conference on artificial intelligence, New York, USA, February 7–12, 2020 (Palo Alto, California USA: AAAI Press), 4731–4738.
Raghavendra, P. (2008). “Optimal algorithms and inapproximability results for every CSP?” in Proceedings of the 40th ACM symposium on theory of computing, New York, USA, May, 2018 (New York, NY: Association for Computing Machinery), 245–254.
Selman, B., Kautz, H. A., and Cohen, B. (1993). Local search strategies for satisfiability testing. Cliques Coloring Satisfiab. 26, 521–532. doi:10.1090/dimacs/026/25
Selsam, D., Lamm, M., Bünz, B., Liang, P., de Moura, L., and Dill, D. L. (2019). “Learning a SAT solver from single-bit supervision,” in international conference on learning representations, New Orleans, LA, Apr 30, 2019(Amherst).
Takefuji, Y., and Lee, K. C. (1991). Artificial neural networks for four-coloring map problems and k-colorability problems. IEEE Trans. Circ. Syst. 38, 326–333. doi:10.1109/31.101328
Toenshoff, J., Ritzert, M., Wolf, H., and Grohe, M. (2019). Graph neural networks for maximum constraint satisfaction[Preprint]. arXiv:1909.08387.
Xu, K. (2005). [Dataset] BHOSLIB: benchmarks with hidden optimum solutions for graph problems (maximum clique, maximum independent set, minimum vertex cover and vertex coloring). Available at: http://www.nlsde.buaa.edu.cn/∼kexu/benchmarks/graph-benchmarks.htm (Accessed April 20, 2014).
Xu, K., Boussemart, F., Hemery, F., and Lecoutre, C. (2005). “A simple model to generate hard satisfiable instances,” in IJCAI-05, Proceedings of the nineteenth international joint Conference on artificial intelligence, Edinburgh, Scotland, UK, July 30–August 5, 2005. 337–342. Denver: Professional Book Center
Xu, K., and Li, W. (2003). Many hard examples in exact phase transitions with application to generating hard satisfiable instances. Preprint repository name [Preprint]. Available at:arXiv preprint cs/0302001 (Accessed November 11, 2003).
Yao, W., Bandeira, A. S., and Villar, S. (2019). Experimental performance of graph neural networks on random instances of max-cut. Preprint repository name [Preprint]. Available at:arXiv preprint arXiv:1908.05767 (Accessed August 15, 2019).
Keywords: graph neural networks, combinatorial optimization, unsupervised learning, constraint satisfaction problem, graph problems, constraint maximization
Citation: Tönshoff J, Ritzert M, Wolf H and Grohe M (2021) Graph Neural Networks for Maximum Constraint Satisfaction. Front. Artif. Intell. 3:580607. doi: 10.3389/frai.2020.580607
Received: 06 July 2020; Accepted: 29 October 2020;
Published: 25 February 2021.
Edited by:
Sriraam Natarajan, The University of Texas at Dallas, United StatesReviewed by:
Mayukh Das, Samsung (India), IndiaUgur Kursuncu, University of South Carolina, United States
Copyright © 2021 Tönshoff, Ritzert, Wolf and Grohe. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Jan Tönshoff, dG9lbnNob2ZmQGluZm9ybWF0aWsucnd0aC1hYWNoZW4uZGU=