 Santiago Hernández-Orozco1,2
Santiago Hernández-Orozco1,2 Hector Zenil2,3,4,5*
Hector Zenil2,3,4,5* Jürgen Riedel2,4
Jürgen Riedel2,4 Adam Uccello4
Adam Uccello4 Narsis A. Kiani3,4
Narsis A. Kiani3,4 Jesper Tegnér5*
Jesper Tegnér5*- 1Facultad de Ciencias, Universidad Nacional Autónoma de México, Mexico City, Mexico
- 2Oxford Immune Algorithmics, Oxford, United Kingdom
- 3Algorithmic Dynamics Lab, Unit of Computational Medicine, Karolinska Institutet, Solna, Sweden
- 4Algorithmic Nature Group, LABORES, Paris, France
- 5King Abdullah University of Science and Technology (KAUST), Computer, Electrical and Mathematical Sciences and Engineering, Thuwal, Saudi Arabia
We show how complexity theory can be introduced in machine learning to help bring together apparently disparate areas of current research. We show that this model-driven approach may require less training data and can potentially be more generalizable as it shows greater resilience to random attacks. In an algorithmic space the order of its element is given by its algorithmic probability, which arises naturally from computable processes. We investigate the shape of a discrete algorithmic space when performing regression or classification using a loss function parametrized by algorithmic complexity, demonstrating that the property of differentiation is not required to achieve results similar to those obtained using differentiable programming approaches such as deep learning. In doing so we use examples which enable the two approaches to be compared (small, given the computational power required for estimations of algorithmic complexity). We find and report that 1) machine learning can successfully be performed on a non-smooth surface using algorithmic complexity; 2) that solutions can be found using an algorithmic-probability classifier, establishing a bridge between a fundamentally discrete theory of computability and a fundamentally continuous mathematical theory of optimization methods; 3) a formulation of an algorithmically directed search technique in non-smooth manifolds can be defined and conducted; 4) exploitation techniques and numerical methods for algorithmic search to navigate these discrete non-differentiable spaces can be performed; in application of the (a) identification of generative rules from data observations; (b) solutions to image classification problems more resilient against pixel attacks compared to neural networks; (c) identification of equation parameters from a small data-set in the presence of noise in continuous ODE system problem, (d) classification of Boolean NK networks by (1) network topology, (2) underlying Boolean function, and (3) number of incoming edges.
1 Introduction
Given a labeled data-set, a loss function is a mathematical construct that assigns a numerical value to the discrepancy between a predicted model-based outcome and its real outcome. A cost function aggregates all losses incurred into a single numerical value that, in simple terms, evaluates how close the model is to the real data. The goal of minimizing an appropriately formulated cost function is ubiquitous and central to any machine learning algorithm. The main heuristic behind most training algorithms is that fitting a sufficiently representative training set will result in a model that will capture the structure behind the elements of the target set, where a model is fitted to a set when the absolute minimum of the cost function is reached.
The algorithmic loss function that we introduce is designed to quantify the discrepancy between an inferred program (effectively a computable model of the data) and the data.
Algorithmic complexity (Solomonoff, 1964; Kolmogorov, 1965; Chaitin, 1969), along with its associated complexity function K, is the accepted mathematical definition of randomness. Here, we adopt algorithmic randomness—with its connection to algorithmic probability—to formulate a universal search method for exploring non-entropy-based loss/cost functions in application to AI, and to supervised learning in particular. We exploit novel numerical approximation methods based on algorithmic randomness to navigate undifferentiable problem representations capable of implementing and comparing local estimations of algorithmic complexity, as a generalization of particular entropy-based cases, such as those rooted in cross entropy or KL divergence, among others. The property of universality is inherited from the universal distribution (Levin, 1974; Solomonoff, 1986; Hutter, 2001).
Given a Turing-complete language L, the algorithmic complexity
where L is any Turing-complete binary language L. A binary language is any that is expressed using a binary alphabet1. In simpler terms,
The previous definition can be understood as the amount of information needed to define x given y.
In (Zenil, 2011; Delahaye & Zenil, 2012) and (Soler-Toscano et al., 2014; Zenil et al., 2018), a family of numerical methods was introduced for computing lower bounds of non-conditional algorithmic complexity using algorithmic probability under assumptions of optimality and for a universal reference enumeration.
The algorithmic probability (Solomonoff, 1964; Levin, 1974) of an object x is the probability
Solomonoff (Solomonoff, 1960) and Levin (Levin, 1974) show that the concept of Algorithmic Probability (also known as Solomonoff induction) used in a Bayesian context with the Universal Distribution as a prior is an optimal inference method (Hutter et al., 2007) under a computability assumption and that any other inference method is either a special case less powerful than
The Coding theorem (Delahaye and Zenil, 2012; Soler-Toscano et al., 2014) and Block Decomposition methods (Zenil et al., 2018) provide a procedure to navigate the space of computable models matching a piece of data, allowing the identification of sets of programs sufficient to reproduce the data regardless of its length, and thus relaxing the minimal length requirement. In conjunction with classical information theory, these techniques constitute a hybrid, divide-and-conquer approach to universal pattern matching, combining the best of both worlds in a hybrid measure (BDM). The divide-and-conquer approach entails the use of an unbiased library of computable models, each capturing small segments of the data. These explore and build an unbiased library of computable models that can explain small segments of a larger piece of data, the conjoined sequence of which can reproduce the whole and constitute a computable model–as a generalization of statistical approaches typically used in current approaches to machine learning.
Interestingly, the use of algorithmic probability and information theory to define AI algorithms has theoretically been proposed before (Solomonoff, 1986; Hutter, 2001; Solomonoff, 2003). Yet, it has received limited attention in practice compared to other less powerful but more accessible techniques, due to the theoretical barrier that has prevented researchers from exploring the subject further. However, in one of his latest interviews, if not the last one, Marvin Minsky suggested that the most important direction for AI was actually the study and introduction of Algorithmic Probability (Minsky, 2014).
2 An Algorithmic Probability Loss Function
The main task of a loss function is to measure the discrepancy between a value predicted by the model and the actual value as specified by the training data set. In most currently used machine learning paradigms this discrepancy is measured in terms of the differences between numerical values, and in case of cross-entropy loss, between predicted probabilities. Algorithmic information theory offers us another option for measuring this discrepancy–in terms of the algorithmic distance or information deficit between the predicted output of the model and the real value, which can be expressed by the following definition:
Definition 1. For computable y and
There is a strong theoretical argument to justify the Def. 1. Let us recall that given a set
Let us assume a prefix-free universal Turing machine and denote by
Thus, by minimizing the algorithmic loss function over the samples, along with the algorithmic complexity of M itself, we are approaching the ideal model
An algorithmic cost function must be defined as a function that aggregates the algorithmic loss incurred over a supervised data sample. At this moment, we do not have any reason, theoretical or otherwise, to propose any particular loss aggregation strategy. As we will show in subsequent sections, considerations such as continuity, smoothness and differentiability of the cost function are not applicable to the algorithmic cost function. We conjecture that any aggregation technique that correctly and uniformly weights the loss incurred through all the samples will be equivalent, the only relevant considerations being training efficiency and the statistical properties of the data. However, in order to remain congruent with the most widely used cost functions, we will, for the purpose of illustration, use the sum of the squared algorithmic differences
3 Categorical Algorithmic Probability Classification
One of the main fields of application for automated learning is the classification of objects. These classification tasks are often divided into supervised and unsupervised problems. In its most basic form, a supervised classification task can be defined, given a set of objects
Now, it is important to note that it is not constructive to apply the algorithmic loss function (Def. 1) to the abstract representations of classes that are commonly used in machine learning classifiers. For instance, the output of a softmax function is a vector of probabilities that represent how likely it is for an object to belong to each of the classes (Bishop & et al., 1995), which is then assigned to a one-hot vector that represents the class. However, the integer that such a one-hot vector signifies is an abstract representation of the class that was arbitrarily assigned, and therefore has little to no algorithmic information pertaining to the class.
Accordingly, in order to apply the algorithmic loss function to classification tasks, we need to seek a model that outputs an information rich object that can be used to identify the class regardless of the context within which the problem was defined. In other words, the model must output the class itself or a similar enough object that identifies it.
We can find the needed output in the definition of the classification problem: let us define a class
For instance, if we have a computable classifier M such that
Now, on the other hand, the general definition of the algorithmic loss function (def. 1) states that
where
What the Eq. 1 is saying is that the model must produce as an output an object that is algorithmically close to all the elements of the class. In unsupervised classification tasks this object is known as a centroid of a cluster (Lloyd, 1982; Uppada, 2014). This means that the algorithmic loss function is inducing us to universally define algorithmic probability classification as a clustering by an algorithmic distance model2. A general schema in our algorithmic classification proposal is based on the concept of a nearest centroid classifier.
Definition 2. Given a training set
where
In short, we assign to each object the closest class according to its algorithmic distance to one of the centroids in the set of objects
Now, note that given that
4 Approximating the Algorithmic Similarity Function
While theoretically sound, the proposed algorithmic loss (Def. 1) and classification (Def. 2) cost functions rely on the uncomputable mathematical object K (Kolmogorov, 1965; Chaitin, 1982). However, recent research and the existence of increasing computing power (Delahaye & Zenil, 2012; Zenil et al., 2018) have made available a number of techniques for the computable approximation of the non-conditional version of K. In this Section we present three methods for approximating the conditional algorithmic information function
4.1 Conditional CTM and Domain Specific CTM
The Coding Theorem Method (Delahaye & Zenil, 2012) is a numerical approximation to the algorithmic complexity of single objects. A generalization of CTM for approximating the conditional algorithmic complexity is the following:
Definition 4. Lets recall that a relation R between two sets X and Y is a subset of the Cartesian product,
where
The previous Def. is based on the Coding theorem (Levin, 1974), which establishes a relationship between the information complexity of an object and its algorithmic probability. For Turing complete spaces we have that as M increases in size,
In the case where x is the empty string and M is the relation induced by the space of small Turing machines with 2 symbols and 5 states, with M computed exhaustively,
When M refers to a non-(necessarily) Turing complete space, or a computable input/output object different from ordered Turing machines, or if P has not been computed exhaustively over this space, then we have a domain specific version of CTM, and its application depends on this space. This version of CTM is also an approximation to K, given that, if M is a computable relation, then we can define a Turing machine with input x that outputs y. However, we cannot guarantee that this approximation is consistent or (relatively) unbiased. Therefore we cannot say that it is domain independent.
4.2 Coarse Conditional BDM
The Block Decomposition Method (BDM (Zenil et al., 2018)) decomposes an object () into smaller parts for which there exist, thanks to CTM (Zenil et al., 2018), good approximations to their algorithmic complexity, and we then aggregate these quantities by following the rules of algorithmic information theory. We can apply the same concept to computing a coarse approximation to the conditional algorithmic information complexity between two objects. Formally:
Definition 5. We define the coarse conditional BDM of X with respect to the tensor Y with respect to
where
The sub-objects
The motivation behind this definition is to enable us to consider partitions for the tensors X and Y into sets of subtensors
The term
4.3 Strong Conditional BDM
The previous definition featured the adjective coarse because we can define a stronger version of conditional BDM approximating K with greater accuracy that uses conditional CTM. As explained in Section 10.2, one of the main weaknesses of coarse conditional BDM was the inability to detect the algorithmic relationship between base blocks. This is in contrast with conditional CTM.
Definition 6. The strong conditional BDM of X with respect to Y corresponding to the partition strategy
where P is a functional relation
While we assert that the pairing strategy minimizing the given sum will yield the best approximation to K in all cases, prior knowledge of the algorithmic structure of the objects can be used to facilitate the computation by reducing the number of possible pairings to be explored, especially when using the domain specific version of conditional BDM. For instance, if two objects are known to be produced from local dynamics, then restricting the algorithmic comparisons by considering pairs based on their respective position on the tensors will, with high probability, yield the best approximation to their algorithmic distance.
4.3.1 The Relationship Between CTM, Coarse and Strong Conditional BDM
Of the three method introduced in this section, Conditional CTM yields the best approximation to conditional algorithmic complexity and should be used whenever possible. Coarse conditional BDM and strong conditional BDM are designed as a way to extend the applicability of conditional CTM to objects for which a good CTM approximation is unknown. These extensions work by separating the larger object into smaller blocks for which we have an approximation of
It is easy to see that under the same partition strategy, strong conditional BDM will always present a better approximation to K than its coarse counterpart. If the partition of two tensors
The properties of strong and coarse conditional BDM and their relation with entropy are shown in the appendix (Section 10). In particular, we show that conditional BDM is well behaved by defining joint and mutual BDM (Section 10.1), and we show that its behavior is analogous to the corresponding Shannon’s entropy functions. We also discuss the relation that both measures have with entropy (Section 10.2), showing that, in the worst case, we converge toward conditional entropy.
5 Algorithmic Optimization Methodology
In the previous sections we proposed algorithmic loss and cost functions (Def. 1) for supervised learning tasks, along with means to compute approximations to these theoretical mathematical objects. Here we ask how to perform model parameter optimization based on such measures. Many of the most widely used optimization techniques rely on the cost function being (sufficiently) differentiable, smooth and convex (Armijo, 1966), for instance gradient descent and associated methods (Bottou, 2010; Kingma and Adam, 2014). In the next section we will show that such methods are not adequate for the algorithmic cost function.
5.1 The Non-smooth Nature of the Algorithmic Space
Let us start with a simple bilinear regression problem. Let
be a linear function used to produce a set of 20 random data points
According to the Def. 1, the loss function associated with this optimization problem is
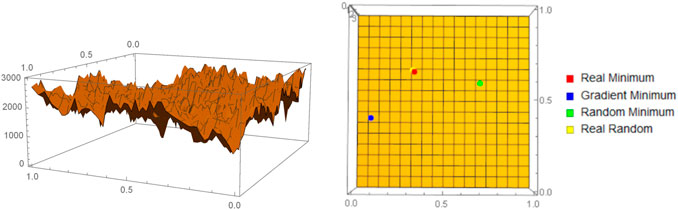
FIGURE 1. On the left we have a visualization of the algorithmic cost function, as approximated by coarse BDM, corresponding to a simple bilinear regression problem. From the plot we can see the complex nature of the optimization problem. On the right we have confirmation of these intuitions in the fact that the best performing optimization algorithm is a random pooling of 5,000 points.
5.2 Algorithmic Parameter Optimization
The established link between algorithmic information and algorithmic probability theory (Levin, 1974) provides a path for defining optimal (under the only assumption of computable algorithms) optimization methods. The central question in the area of parameter optimization is the following: Given a data set
Algorithmic probability theory establishes and quantifies the fact that the most probable computable program is also the least complex one (Solomonoff, 1964; Levin, 1974), thereby formalizing a principal of parsimony such as Ockham’s razor. Formally, we define the algorithmic parameter optimization problem as the problem of finding a model M such that (a) minimizes
By searching for the solution using the algorithmic order we can meet both requirements in an efficient amount of time. We start with the least complex solution, therefore the most probable one, and then we move toward the most complex candidates, stopping once we find a good enough value for
Definition 7. Let M be a model,
minCost =
while condition do
i++
if
end
end
Return
where the halting condition is defined in terms of the number of iterations or a specific value for
The algorithmic cost function is not expected to reach zero. In a perfect fit scenario, the loss of a sample is the relative algorithmic complexity of y with respect to the model itself, which can be unbounded. Depending on the learning task, we can search for heuristics to define an approximation to the optimum value for
By Def. 7, it follows that the parameter space is countable and computable. This is justified, given that any program is bound by the same requirements. For instance, in order to fit the output of the function f (Eq. 2) by means of the model M, we must optimize over two continuous parameters
Now, consider a fixed model structure M. Given that the algorithmic parameter optimization always finds the lowest algorithmically complex parameters that fit the data
5.2.1 On the Expected Optimization Time
Computing the algorithmic order needed for definition 7 is not a trivial task and requires the use of approximations to K such as CTM, which require extensive computational resources. However, just as with BDM and CTM, this computation just needs to be done once and can be reused in constant time for retrieving the object at i’th position of the algorithmic order by means of a table or array. For instance, in (Delahaye & Zenil, 2012) it was presented an approximation to the algorithmic complexity of strings of up to 16 bits, which can be used for all parameters of up to 16 bits of precision. A greedy approach was used in 6.2 to apply algorithmic parameter optimization beyond the precision available in the existing CTM databases.
Given the way that algorithmic parameter optimization works, the optimization time, as measured by the number of iterations, will converge faster if the optimal parameters have low algorithmic complexity. Therefore they are more plausible in the algorithmic sense. In other words, if we assume that, for the model we are defining, the parameters have an underlying algorithmic cause, then they will be found faster by algorithmic search, sometimes much faster. How much faster depends on the problem and its algorithmic complexity. In the context of artificial evolution and genetic algorithms, it has been previously shown that, by using an algorithmic probability distribution, the exponential random search can be sped up to quadratic (Chaitin, 2009; Chaitin, 2013; Hernández-Orozco et al., 2018).
Following the example of inferring the function in Section 5.1, the mean and median BDM value for the parameter space of pairs of 8-bit binary strings are 47.6737 and 47.7527, respectively; while the optimum parameters
The assumption that the optimum parameters have an underlying simplicity bias is strong, but has been investigated (Dingle et al., 2018; Zenil, 2020) and is compatible with principles of parsimony. This bias favors objects of interest that are of low algorithmic complexity, though they may appear random, For example, the decimal expansions of the constant π or e to an accuracy of 32 bits have a BDM value of 666.155 and 674.258, respectively, while the expected BDM for a random binary string of the same size is significantly larger:
At the same time, we are aware that, for the example given, mathematical analysis-based optimization techniques have a perfect and efficient solution in terms of the gradient of the MSE cost function. While algorithmic search is faster than random search for a certain class of problems, it may be slower for another large class of problems. However, algorithmic parameter optimization (Def. 7) is a domain and problem-independent general method. While this new field of algorithmic machine learning that we are introducing is at an early stage of development. in the next sections we set forth some further developments that may help boost the performance of our algorithmic search for specific cases, such as greedy search over the subtensors, and there is no reason to believe that more boosting techniques will not be developed and introduced in the future.
6 Methods
6.1 Traversing Non-smooth Algorithmic Surfaces for Solving Ordinary Differential Equations
Thus far we have provided the mathematical foundation for machine learning based on the power of algorithmic probability at the price of operating on a non-smooth loss surface in the space of algorithmic complexity. While the directed search technique we have formulated succeeds with discrete problems, here we ask whether our tools generalize to problems in a continuous domain. To gain insight, we evaluate whether we can estimate parameters for ordinary differential equations. Parameter identification is well-known to be a challenging problem in general, and in particular for continuous models when the data-set is small and in the presence of noise. Following (Dua & Dua, 2011), as a sample system we have
6.2 Finding Computable Generative Mechanisms
An elementary cellular automaton (ECA) is a discrete and linear binary dynamical system where the state of a node is defined by the states of the node itself and its two adjacent neighbors (Wolfram, 2002). Despite their simplicity, the dynamics of these systems can achieve Turing completeness. The task was to classify a set of
Aside from the Turing-complete rule with number 110, the others were randomly selected among all 256 possible ECA. The training set was composed of 275 black and white images, 25 for each automaton or “class”. An independent validation set of the same size was also generated, along with a test-set with 1,375 evenly distributed samples. An example of the data in these data sets is shown in Figure 2.
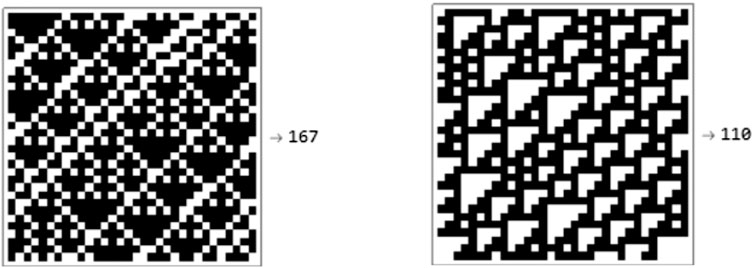
FIGURE 2. Two
First we will illustrate the difficulty of the problem by training neural networks with simple topologies over the data. In total we trained three naive5 neural networks that consisted of a flattened layer, followed by either 1, 2, 3 or 4 fully connected linear layers, ending with a softmax layer for classification. The networks were trained using ADAM optimization for 500 rounds. Of these 4 models, the network with 3 linear layers performed best, with an accuracy of 40.3%.
However, as shown in (Fernandes, 2018), it is possible to design a deep network that achieves a higher accuracy for this particular classification task. This topology consists of 16 convolutional layers with a kernel of
6.2.1 Algorithmic-Probability Classifier Based on Coarse Conditional BDM
The algorithmic probability model chosen consists of eleven
is minimized, where
• First, we start with the eleven
• Then, we perform algorithmic optimization, but only changing the bits contained in the upper left
• After minimizing with respect to only the upper left quadrant, we minimize over the upper right
• We repeat the procedure for the lower left and lower right quadrants.
These four steps are illustrated in Figure 3 for the class corresponding to the automaton 11.
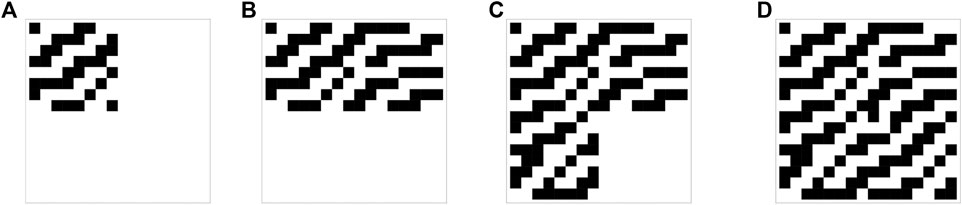
FIGURE 3. The evolution of the center for the four steps of the greedy algorithmic information optimization method used to train the model in the first experiment. This classifier center corresponds to class 11.
6.3 Finding the Initial Conditions for Cellular Automata
The next problem was to classify black and white images representing the evolution of elementary cellular automata. In this case, we are classifying according to the initialization string that produced the corresponding evolution for a randomly chosen automaton. The classes for the experiment consisted of 10 randomly chosen binary strings, each 12 bits in length. These strings correspond to the binary representation of the following integers:
The training, validation and test sets each consisted of two hundred
We trained and tested a group of neural network topologies on the data in order to establish the difficulty of the classification task. These networks were an (adapted version of) Fernandes’ topology and 4 naive neural networks that consisted of a flattened (fully-connected) layer, followed by 1, 2, and 5 groups of layers, each consisting of a fully connected linear layer with rectilinear activation (ReLU) function followed by a dropout layer, ending with a linear layer and a softmax unit for classification. The adaptation of the Fernandes topology was only for the purpose of changing the kernel of the pooling layer to
The best performing network was the shallower one, which consists of a flattened layer, followed by a fully connected ReLU, a dropout layer, a linear layer with 10 inputs and a sotfmax unit. This neural network achieved an accuracy of 60.1%. At 18.5%, the performance of Fernandes’ topology was very low, being barely above random choice. This last result is to be expected, given that the topology is domain specific, and should not be expected to extend well to different problems, even though at first glance the problem may seem to be related.
6.3.1 Algorithmic-Probability Classifier Based on Strong Conditional BDM
The algorithmic probability model M chosen for these tasks consisted of eleven 12-bit binary vectors. The model was trained using algorithmic information greedy block optimization by first optimizing the loss function over the 6 leftmost bits and then over the remaining six.
However, for this particular problem, the coarse version of conditional BDM proved inadequate for approximating the universal algorithmic distance
• First, we computed all the outputs of all possible 12-bit binary strings for each of the first 128 ECA for a total of 528,384 pairs of 12 bit binary vectors and
• Then, by considering only the inner 6 bits of the vectors (discarding the 3 bits on the left and the 3 bits on the right) and, similarly, the inner
• where
• If a particular pair
In the end we obtained a database of the algorithmic distance between all 6 bit vectors and their respective
The previous procedure might at first seem to be too computationally costly. However, just as with Turing Machine based CTM (Soler-Toscano et al., 2014; Zenil et al., 2018), this computation only needs to be done once, with the data obtained being reusable in various applications.
The trained model M consisted of 10 binary vectors that, as expected, corresponded to the binary expansion of each of the classes. The accuracy of the classifier was 95.5% on the test set.
6.4 Classifying NK Networks
An NK network is a dynamical system that consists of a binary Boolean network where the parameter n specifies the number of nodes or vertices and k defines the number of incoming connections that each vertex has (Kauffman, 1969; Aldana et al., 2003; Dubrova et al., 2005). Each node has an associated k-ary Boolean function which uses the states of the nodes corresponding to the incoming connections to determine the new state of the nodes over a discrete time scale. The number of incoming connections k defines the stability (or lack thereof) of the network.
Given the extensive computational resources it would require to compute a CTM database, such as the one used in section 6.4, for Boolean networks of 24 nodes we opted to do a classification based only on the algorithmic complexity of the samples as approximated by BDM. This approach is justified, considering that according to the definition 2, an algorithmic information model for the classifier can consist of three sets. Each of these sets is composed of all possible algorithmic relations, including the adjacency matrix and related binary operations, corresponding to the number of incoming connections per node (the parameter k). Therefore, given the combinatorial order of growth of these sets, we can expect the quantity of information required to specify the members of each class to increase as a function of k.
Specifically, the number of possible Boolean operations of degree k is
Following this idea we defined a classifier where the model M consisted of the mean BDM value for each of the classes in the training set
For classifying according to the Boolean rules assigned to each node, we used 10 randomly generated (ordered) lists of 4 binary Boolean rules. These rules were randomly chosen (with repetitions) from
To classify according to network topology we used 10 randomly generated topologies consisting of 10 binary matrices of size
6.5 Classifying Kauffman Networks
Kauffman networks are a special case of Boolean NK networks where the number of incoming connections for each node is two, that is,
6.5.1 Algorithmic-Probability Classifier Based on Conditional CTM
For this problem we used a different type of algorithmic cluster center. For the Boolean rules classifier, the model M consisted of ten lists of Boolean operators. More precisely, the model consisted of binary strings that codified a list composed of each of the four Boolean functions used (
The use of different kinds of models for this task showcases another layer of abstraction that can be used within the wider framework of algorithmic probability classification: context. Rather than using binary tensors, we can use a structured object that has meaning for the underlying problem. Yet, as we will show next, the underlying mechanics will remain virtually unchanged.
Let’s go back to the definition 2, which states that to train both models we have to minimize the cost function
So far we have approximated K by means of conditional BDM. However, given that at the time of writing this article a sufficiently complete conditional CTM database has yet to be computed, we have estimated the CTM function by using instances of the computable objects, as previously shown in Section 6.3.1. Moreover, owing to the non-local nature of NK networks and the abstraction layer that the models themselves are working at, rather than using BDM, we have opted to use a context dependent version of CTM directly. In the last task we will show that BDM can be used to classify a similar, yet more general problem.
Following similar steps to the ones used in Section 6.3.1, by computing all the 331,776 possible NK networks with
or as 19 if the pair is not present on either of the lists. Then we approximated K by using the defined
6.6 Hybrid Machine Learning
So far we have presented supervised learning techniques that, in a way, diverge. In this section we will introduce one of the ways in which the two paradigms can coexist and complement each other, combining statistical machine learning with an algorithmic-probability approach.
6.6.1 Algorithmic Information Regularization
The choice of an appropriate level of model complexity that avoids both under- and over-fitting is a key hyperparameter in machine learning. Indeed, on the one hand, if the model is too complex, it will fit the data used to construct the model very well but generalize poorly to unseen data. On the other hand, if the complexity is too low, the model will not capture all the information in the data. This is often referred to as the bias-variance trade-off, because a complex model will exhibit large variance, while an overly simple one will be strongly biased. Most traditional methods feature this choice in the form of a free hyperparameter via, eg, what is known as regularization.
A family of mathematical techniques or processes that has been developed to control over-fitting of a model goes under the rubric “regularization”, which can be summarized as the introduction of information from the model to the training process in order to prevent over-fitting of the data. A widely used method is the Tikhonov regularization (Tikhonov, 1963; Press et al., 2007), also known as ridge regression or weight decay, which consists in adding a penalty term to the cost function of a model, which increases in direct proportion to the norms of the variables of the model. This method of regularization can be formalized in the following way: Let J be the cost function associated with the model M trained over the data set
The core premise of the previous function is that we are disincentivizing fitting toward certain parameters of the model by assigning them a higher cost in proportion to λ, which is a hyperparameter that is learned empirically from the data. In current machine learning processes, the most commonly used weighting functions are the sum of the
We can employ the basic form of Eq. 3 and define a regularization term based on the algorithmic complexity of the model and, in that way, disincentivize training toward algorithmically complex models, thus increasing their algorithmic plausibility. Formally:
Definition 8. Let J be the cost function associated with the model M trained over the data set
The justification of the previous definition follows from algorithmic probability and the coding theorem: Assuming an underlying computable structure, the most probable model that fits the data is the least complex one. Given the universality of algorithmic probability, we argue that the stated definition is general enough to improve the plausibility of the model of any machine learning algorithm with an associated cost function. Furthermore, the stated definition is compatible with other regularization schemes.
Just as with the algorithmic loss function (Def. 2), the resulting function is not smooth, and therefore cannot be optimized by means of gradient-based methods. One option for minimizing this class of functions is by means of algorithmic parameter optimization (Def 7). It is important to recall that computing approximations to the algorithmic probability and complexity of objects is a recent development, and we hope to promote the development of more powerful techniques.
6.7 Algorithmic-Probability Weighting
Another, perhaps more direct way to introduce algorithmic probability into the current field of machine learning, is the following. Given that in the field of machine learning all model inference methods must be computable, the following inequality holds for any fixed training methodology:
where
Accordingly, the heuristic for our definition of algorithmic probability weighting is that, to each training sample, we assign an importance factor (weight) according to its algorithmic complexity value, in order to increase or diminish the loss incurred by the sample. Formally:
Definition 9. Let J be a cost function of the form
We define the weighted approximation to the algorithmic complexity regularization of J or algorithmic probability weighting as
where
We have opted for flexibility regarding the specification of the function f. However taking into account the noncontinuous nature of K, we have recommended a discrete definition for f. The following characterization has worked well with our trials and we hold that it is general enough to be used in a wide number of application domains:
where
As its names implies, the previous Def. 9 can be considered analogous to sample weighting, which is normally used as a means to confer predominance or diminished importance on certain samples in the data set according to specific statistical criteria, such as survey weights and inverse variance weight (Hartung & Sinha, 2008). However, a key difference of our definition is that traditional weighting strategies rely on statistical methods to infer values from the population, while with algorithmic probability weighting we use the universal distribution for this purpose. This makes algorithmic probability weighting a natural extension or universal generalization of the concept of sample weighting, and given its universality, it is domain independent.
Now, given that the output of f and its parameters are constant from the point of view of the parameters of the model M, it is easy to see that if the original cost function J is continuous, differentiable, convex and smooth, so is the weighted version
7 Results
7.1 Estimating ODE Parameters
A key step to enabling progress between a fundamentally discrete theory such as computability and algorithmic probability, and a fundamentally continuous theory such as that of differential equations and dynamical systems, is to find ways to combine both worlds. As shown in Section 5.1, optimizing the parameters with respect to the algorithmic cost function is a challenge (Figure 4). Following algorithmic optimization, we note that parameters (5 and 1) have low algorithmic complexity due to their functional relation. This is confirmed by BDM, which assigns the unknown solution to the ODE a value of 153.719 when the expected complexity is approximately 162.658, which means that the number of more complex parameter candidates than
we need only 2 samples to identify the solution, supporting the expectation that algorithmic parameter optimization ensures a solution with high probability, despite a low number of samples as long as the solution has low complexity in a relatively low number of iterations. This is proof-of-principle that our search technique can not only be used to identify parameters for an ODE problem, but also affords the advantage of faster convergence (fewer iterations), requiring less data to solve the parameter identification problem. In Figure 5, equivalent to the pixel attacks for discrete objects, we show that the parameter identification is robust to even more than 25% of additive noise. Operating in a low complexity regime—as above—is compatible with a principal of parsimony such as Ockham’s razor, which is empirically found to be able to explain data simplicity bias (Zenil & Delahaye, 2010; Dingle et al., 2018; Zenil et al., 2018), suggesting that the best explanation is the simplest, but also that what is modeled is not algorithmically random (Zenil, 2020).
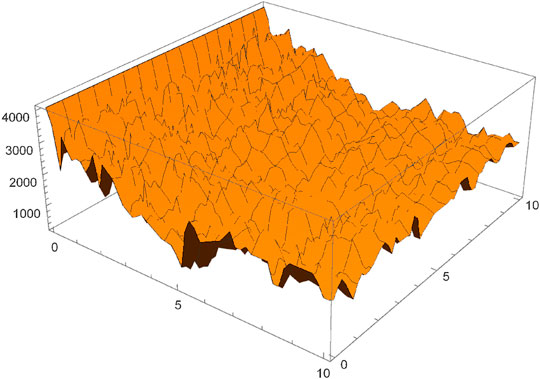
FIGURE 4. A visualization of the algorithmic cost function, as approximated by coarse BDM, corresponding to the parameter approximation of an ordinary differential Eq. 2. From the surface obtained we can see the complexity of finding the optimal parameters for this problem. Gradient based methods are not optimal for optimizing algorithmic information based functions.
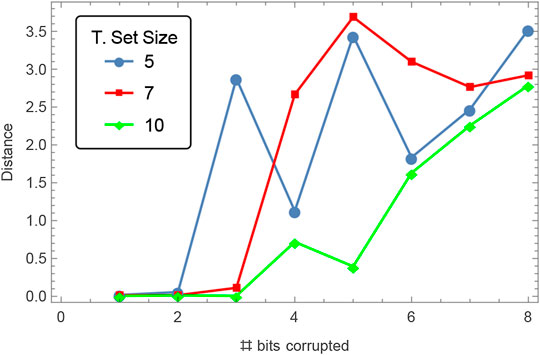
FIGURE 5. The average Euclidean distance between the solution inferred by algorithmic optimization and the hidden parameters of the ODE in Section 6.1 when a number of bits of the binary representation of the labeled data has been randomly corrupted (flipped), from 1 to 8 bits. The binary representation of the states
7.2 Finding Generative Rules of Elementary Cellular Automata
Following optimization, a classification function was defined to assign a new object to the class corresponding to the center
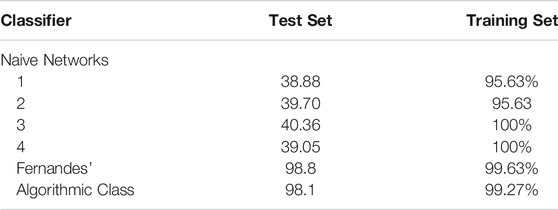
TABLE 1. The accuracy of the Tested Classifiers.

TABLE 2. Expected number of vulnerability per sample.
From the data we can see that the algorithmic classifier outperformed the four naive (or simple) neural networks, but it was outperformed slightly by the Fernandes classifier, built expressly for the purpose. But as we will show over the following sections, this last classifier is less robust and is domain specific.
Last but not least, we have tested the robustness of the classifiers by measuring how good they are at resisting one-pixel attacks ((Su et al., 2019)). A one-pixel attack occurs when a classifier can be fooled into misclassifying an object by changing just a small portion of its information (one pixel). Intuitively, such small changes should not affect the classification of the object in most cases, yet it has recently been shown that deep neural network classifiers present just such vulnerabilities.
Algorithmic information theory tells us that algorithmic probability classifier models should have a relatively high degree of resilience in the face of such attacks: if an object belongs to a class according to a classifier it means that it is algorithmically close to a center defining that class. A one-pixel attack constitutes a relatively small information change in an object. Therefore there is a relatively high probability that a one-pixel attack would not alter the information content of an image enough to increase the distance to the center in a significant way. In order to test this hypothesis, we systematically and exhaustively searched for vulnerabilities in the following way: a) One by one, we flipped (from 0 to 1 or vice versa) each of the
From the results we can see that for the DNN, 13.56% of the pixels are vulnerable to one-pixel attacks, and that only 1% of the pixels manifest that vulnerability for the algorithmic classifier. These results confirm our hypothesis that the algorithmic classifier is significantly more robust in the face of small perturbations compared to the deep network classifier designed without a specific purpose in mind. It is important to clarify that we are not stating that it is not possible to increase the robustness of a neural network, but rather pointing out that algorithmic classification has a high degree of robustness naturally.
7.3 Finding Initial Conditions
The accuracy obtained using the different classifiers is represented in Supplementary Appendix Table A1. Based on these results we can see that the algorithmic classifier performed significantly better than the neural networks tested. Furthermore, the first two naive topologies have enough variance present to have a good fit vis-a-vis the training set, in an obvious case of over-fitting. The domain specific Fernandes topology maintained a considerably high error rate—exceeding 80%—over 3,135 ADAM training rounds. It is important to note that in this case collisions, that is, two samples that belong to two different classes, can exist. Therefore it is impossible to obtain 100% perfect accuracy. An exhaustive search classifier that searches through the space for the corresponding initialization string reached an accuracy of 97.75% over the test set.
In order to test the generalization of the CTM database computed for this experiment, we tested our algorithmic classifying scheme on a different instance of the same basic premise: binary images of size
7.3.1 Network Topology Algorithmic-Information Classifier
The results are summarized in Supplementary Appendix Table S2. Here we can see that only the coarse BDM algorithmic information classifier—with 70% accuracy—managed to reach an accuracy that is significantly better than random choice, validating our method.
Furthermore, by analyzing the confusion matrix plot (Figure 6) we can see that the algorithmic classifier performs (relatively) well at classifying the frozen and chaotic networks, while the deep learning classifier seems to be random in its predictions. The fact that the critical stage was harder to classify is evidence of its rich dynamics, accounting for more varied algorithmic behaviors.
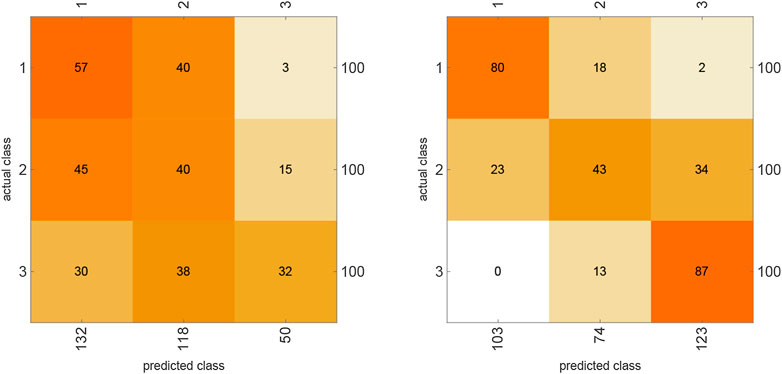
FIGURE 6. The confusion matrix for the neural network (left) and the algorithmic information classifier (right) while classifying binary vectors representing the degree of connection (parameter k) of 300 randomly generated Boolean NK networks. From the plots we can see that the algorithmic classifier can predict with relatively high accuracy the elements belonging to class
A second task was to classify a set of binary vectors of size 40 that represent the evolution of an NK network of four nodes (
7.4 Classifying Kauffman Networks
The task was to determine whenever a random Boolean network belonged to the frozen, critical or chaotic phase by determining when
For the task at hand we trained the following classifiers: a neural network, gradient boosted trees and a convolutional neural network. The first neural network had a naive classifier that consisted of a ReLU layer, followed by a Dropout layer, a linear layer and a final softmax unit for classification. For the convolutional model we used prior knowledge of the problem and used a specialized topology that consisted of 10 convolutional layers with a kernel of size 24, each kernel representing a stage of the evolution, with a ReLU, a pooling layer of kernel size 24, a flattened layer, a fully connected linear layer and a final softmax layer. The tree-based classifier manages an accuracy of 35% on the test set, while the naive and convolutional neural networks managed an accuracy of 43% and 31% percent respectively. Two of the three classifiers are nearly indistinguishable from random classification, while the naive neural network is barely above it.
For comparison purposes, we trained a neural network and a logistic regression classifier on the data. The neural network consisted of a naive topology consisting of a ReLU layer, followed by a dropout layer, a linear layer and a softmax unit. The results are shown in Supplementary Appendix Table A3.
From the results obtained we can see that the neural network, with 92.50% accuracy, performed slightly better than the algorithmic classifier (91.35%) on the test set. The logistic regression accuracy is a bit further behind, at 82.35%.
However, the difference in the performance of the topology test set is much greater, with both the logistic regression and the neural network reaching very high error rates. In contrast, our algorithmic classifier reaches an accuracy of 72.4%.
7.5 A First Experiment and Proof of Concept of Algorithmic-Probability Weighting
As a first experiment in algorithmic weighing, we designed an experiment using the MNIST dataset of hand written digits (Deng, 2012). This dataset, which consists of a training set of 60,000 labeled images representing hand written digits from 0 to 9 and a test set with 10,000 examples, was chosen given its historical importance for the field and also because it offered a direct way to deploy the existing tools for measuring algorithmic complexity via binarization without compromising the integrity of the data.
The binarization was performed by using a simple mask: if the value of a (gray scale) pixel was above 0.5 then the value of the pixel was set to one, using zero in the other case. This transformation did not affect the performance of any of the deep learning models tested, including the LeNet-5 topology (LeCun et al., 1998), in a significant way.
Next we salted or corrupted 40% of the training samples by randomly shuffling 30% of their pixels. An example of these corrupted samples can be seen in Figure 7. With this second transformation we are reducing the useful information within a random selected subset of samples by a random amount, thus simulating a case where the expected amount of incidental information is high, as in the case of data loss or corruption.
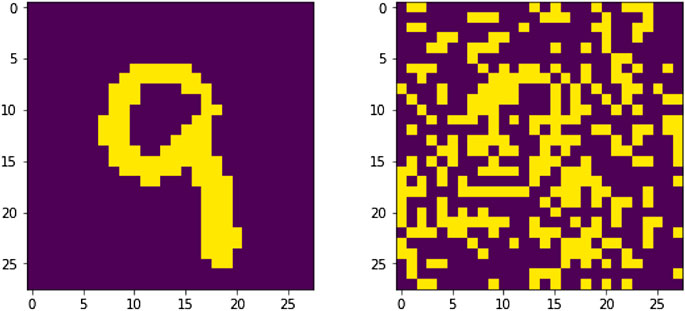
FIGURE 7. At left we have an image representing a binarized version of a randomly chosen sample. At right we have the salted version of the same sample, with 30% of its pixels randomly shuffled.
Finally, we trained 10 neural networks with increasing depth, setting aside 20% of the training data as a verification set, thereby obtaining neural networks of increasing depth and, more importantly, variance. The topology of these networks consisted of a flattened layer, followed by an increasing number of fully connected linear layers with rectified linear (ReLU) activation functions, and a final softmax layer for classification. In order to highlight the effect of our regularization proposal, we abstained from using other regularization techniques and large batch sizes. For instance, optimizing using variable learning rates such as RMSProp along with small stochastic batches is an alternative way of steering the samples away from the salted samples.
For purposes of comparison, the neural networks were trained with and without weighting, using the option sample_weight for the train_on_batch on Keras.The training parameters for the networks, which were trained using Keras on Python 3, were the following:
Stochastic gradient descent with batch size of 5,000 samples.
40 epochs, (therefore 80 training stages), with the exception of the last model with 10 ReLU layers, which was trained for 150 training stages.
Categorical crossentropy as loss function.
ADAM optimizer.
The hyperparameters for the algorithmic weighting function used were:
which means that if the BDM value for the ith sample was in the 75th quantile of the algorithmic complexity within its class, then it was assigned a weight of 0.01; the assigned weight was 0.5 if it was in the 50th quantile, and 2 if it was among the lower half in terms of algorithmic complexity within its class. The value for these hyperparameters was found by random search. That is, we tried various candidates for the function on the validation set and we are reporting the one that worked best. Although not resorted to for this particular experiment, more efficient hyperparameter optimization methods such as grid search can be used.
Following the theoretical properties of algorithmic regularization, by introducing algorithmic probability weighting we expected to steer the fitting of the target parameters away from random noise and toward the regularities found in the training set. Furthermore, the convergence toward the minimum of the loss function is expected to be significantly faster, in another instance of algorithmic probability speed-up (Hernández-Orozco et al., 2018). We expected the positive effects of the algorithmic probability weighting to increase with the variance of the model to which it was applied. This expectation confirms the hypothesis of the next numerical experiment.
The differences in the accuracy of the models observed through the experiments as a function of variance (number of ReLU layers) are summarized in Figure 8. The upper plots show the difference between the mean accuracy and the maximum accuracy obtained through the optimization of the network parameters for networks of varying depth. A positive value indicates that the networks trained with the algorithmic weights showed a higher accuracy than the unweighted ones. The difference in the steepness of the loss function between the models is shown in the left plot of Figure 9, which is also presented as a function of the number of ReLU layers. A positive value indicates that a linear approximation to the loss function had a steeper gradient for the weighted models when compared to the unweighted ones. In Figure 10, we can see the evolution of this difference with respect to the percentages of corrupted samples and the corrupted pixels within these samples.
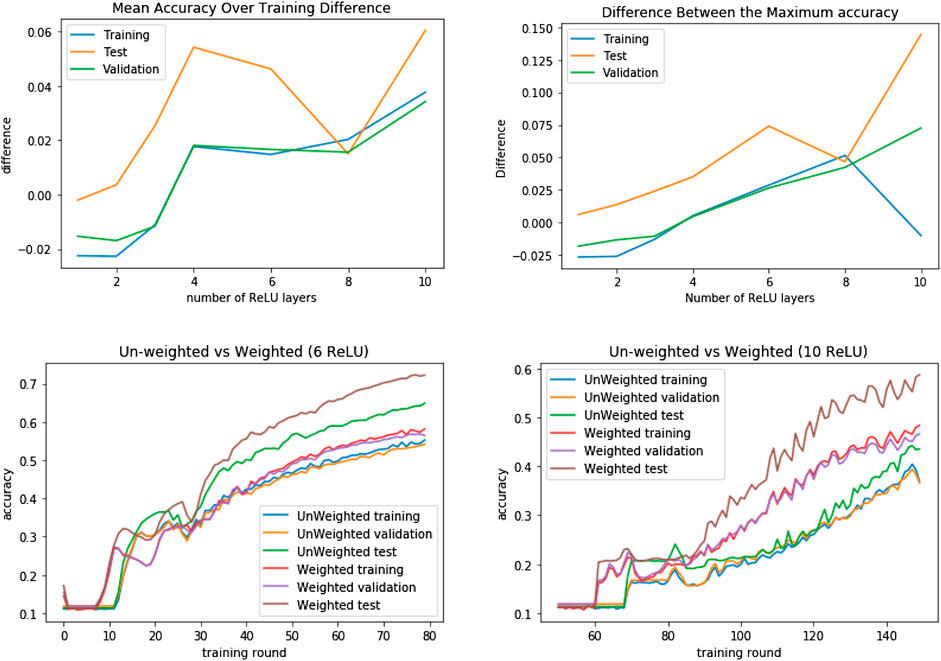
FIGURE 8. The first two (upper) plots show the difference between the mean and maximum accuracy obtained through the training of each of the models. The last two (lower) plots show the evolution of accuracy through training for the data sets. The data sets used are (training, test and validation), with data from the MNIST dataset. The (training and validation) data sets were salted with %40 of the data randomly corrupted while the test set was not. From the first two plots we can see that the accuracy of the models trained with algorithmic sample weights is consistently higher than the models trained without them, and this effect increases with the variance of the models. The drops observed after 4 ReLU layers are because, until depth 10, the number of training rounds was constant, with more training rounds therefore needed to achieve a minimum in the cost function. When directly comparing the training history of the models of depth 6 and 10 we can see that the stated effect is consistent. Furthermore, at 10 rectilinear units, we can see significant overfitting, while for the unweighted model, using the algorithmic weights still leaves room for improvement.
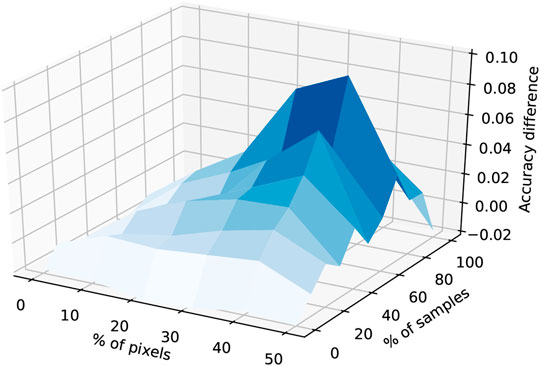
FIGURE 9. On the left are shown the differences between the slopes of the linear approximation to the evolution of the loss function for the first six weighted and unweighted models. The linear approximation was computed using linear regression over the first 20 training rounds. On the right we have the loss function of the models with 10 ReLU units. From both plots we can see that training toward the minimum of the loss function is consistently faster on the models with the algorithmic complexity sample weights, and that this difference increases with the variance of the model.
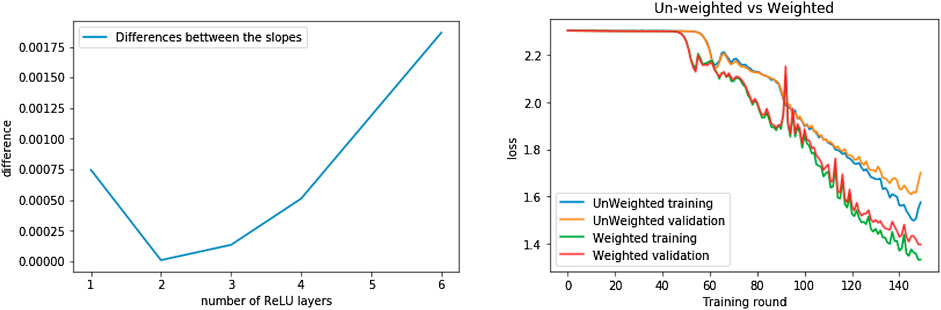
FIGURE 10. The difference in accuracy with respect to the percentage of corrupted pixels and samples in the data set for the weighing function 5 for a neural network of depth 4 (four rectilinear units). A positive value indicates that the network trained on the weighted samples reached greater accuracy. The maximum difference was reached for 70% of the samples with 40% of pixels corrupted. From the plot we can see that the networks trained over the weighed samples steadily gained in accuracy until the maximum point was reached. The values shown are the average differences over five networks trained over the same data.
As the data show (Figure 8), the networks trained with the algorithmic weights are more accurate at classifying all three sets: the salted training set, the (unsalted) test set and the (salted) validation set. This is shown when the difference of the mean accuracy (over all the training epochs) and the maximum accuracy attained by each of the networks is positive. Also, as predicted, this difference increases with the variance of the networks: at higher variance, the difference between the accuracy of the data sets increases. Moreover, as shown in Figure 9, the weighted models reach the minimum of the loss function in a lower number of iterations, exemplified when the linear approximation to the evolution of the cost is steeper for the weighted models. This difference also increases the variance of the model.
8 Conclusion
Here we have presented a mathematical foundation within which to solve supervised machine learning tasks using algorithmic information and algorithmic probability theories in discrete spaces. We think this is the first time that a symbolic inference engine is integrated to more traditional machine learning approaches constituting not only a path toward putting both symbolic computation and statistical machine learning together but allowing a state-to-state and cause-and-effect correspondence between model and data and therefore a powerful interpretable white-box approach to machine learning. This framework is applicable to any supervised learning task, does not require differentiability, and is naturally biased against complex models, hence inherently designed against over-fitting, robust in the face of adversarial attacks and more tolerant to noise in continuous identification problems.
We have shown specific examples of its application to different problems. These problems included the estimation of the parameters of an ODE system, the classification of the evolution of elementary cellular automata according to their underlying generative rules; the classification of binary matrices with respect to 10 initial conditions that evolved according to a random elementary cellular automaton; and the classification of the evolution of a Boolean NK network with respect to 10 associated binary rules or ten different network topologies, and the classification of the evolution of a randomly chosen network according to its connectivity (the parameter k). These tasks were chosen to highlight different approaches that can be taken to applying our model. We also assert that for these tasks it is generally hard for non-specialized classifiers to get accurate results with the amount of data given.
While simple, the ODE parameter estimation example illustrates the range of applications even in the context of a simple set of equations where the unknown parameters are those explored above in the context of a neural network (Dua & Dua, 2011),
From the results obtained from the first classification task (6.2), we can conclude that our vanilla algorithmic classification scheme performed significantly better than the non-specialized vanilla neural network tested. For the second task (Section 6.3), our algorithmic classifier achieved an accuracy of 95.5%, which was considerably higher than the 60.11% achieved by the best performing neural network tested.
For finding the underlying topology and the Boolean functions associated with each node, the naive neural network achieved a performance of 92.50%, compared to 91.35% for our algorithmic classifier. However, when classifying with respect to the topology, our algorithmic classifier showed a significant difference in performance, with over 39.75% greater accuracy. There was also a significant difference in performance on the fourth task, with the algorithmic classifier reaching an accuracy of 70%, compared to the 43% of the best neural network tested.
We also discussed some of the limitations and challenges of our approach, but also how to combine and complement other more traditional statistical approaches in machine learning. Chief among them is the current lack of a comprehensive Turing machine based conditional CTM database required for the strong version of conditional BDM. We expect to address this limitation in the future.
It is important to emphasize that we are not stating that there is no neural network that is able to obtain similar, or even better, results than our algorithms. Neither do we affirm that algorithmic probability classification in its current form is better on any metric than the existing extensive methods developed for deep learning classification. However, we have introduced a completely different view, with a new set of strengths and weaknesses, that with further development could represent a better grounded alternative suited to a subset of tasks beyond statistical classification, where finding generative mechanisms or first principles are the main goals, with all its attendant difficulties and challenges.
Data Availability Statement
Publicly available datasets were analyzed in this study. This data can be found here: https://www.nist.gov/srd/nist-special-database-19.
Author Contributions
SH-O designed and executed experiments, HZ conceived and designed experiments. HZ, JR, NK, and JT contributed to experiments and supervision. SH-O, HZ, JR, AU, and NK contributed to interpreting results and conceiving experiments. SH-O and HZ wrote the paper. All authors revised the paper.
Funding
SH-O was supported by grant SECTEI/137/2019 awarded by Subsecretaría de Ciencia, Tecnología e Innovación de la Ciudad de México (SECTEI).
Conflict of Interest
Authors HZ, SH-O, and JR are employed by the company Oxford Immune Algorithmics Ltd.
The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/frai.2020.567356/full#supplementary-material.
Footnotes
1All modern computing languages process this property, given that they are stored and interpreted by binary systems.
2An unlabeled classificatory algorithmic information schema has been proposed by (Cilibrasi & Vitányi, 2005).
3The notion of degree of sophistication for computable objects was defined by Koppel (Koppel, 1991; Koppel & Atlan, 1991; Antunes & Fortnow, 2009).
4A number w is incompressible or random if
5We say that a NN topology is naive when its design does not use specific knowledge of the target data.
References
Aldana, M., Coppersmith, S., and Kadanoff, L. (2003). Boolean dynamics with random couplings perspectives and problems in nonlinear science: a celebratory volume in honor of lawrence sirovich. (Berlin, Germany: Springer-Verlag). doi:10.1007/978-0-387-21789-5
Antunes, L., and Fortnow, L. (2009). Sophistication revisited. Theor. Comput. Syst. 45 (1), 150–161. doi:10.1007/s00224-007-9095-5
Armijo, L. (1966). Minimization of functions having lipschitz continuous first partial derivatives. Pac. J. Math. 16 (1), 1–3.
Atlan, H., Fogelman-Soulie, F., Salomon, J., and Weisbuch, G. (1981). Random boolean networks. Cybern. Syst. 12 (1–2), 103–121. doi:10.1080/01969728108927667
Bishop, C. M., et al. (1995). Neural networks for pattern recognition. Oxford, UK: Oxford University Press.
Bottou, L. (2010). Large-scale machine learning with stochastic gradient descent. in Proceedings of COMPSTAT’2010. Editor Y. Lechevallier (Berlin, Germany: Springer, 177–186.
Chaitin, G. J. (1969). On the length of programs for computing finite binary sequences: statistical considerations. J. ACM. 16 (1), 145–159. doi:10.1142/9789814434058_0020
Chaitin, G. J. (1982). Algorithmic information theory. in Encyclopedia of Statistical Sciences., Vol. 1. (Hoboken, NJ: Wiley), 38–41.
Cilibrasi, R., and Vitányi, P. M. (2005). Clustering by compression. IEEE Trans. Inf. Theor. 51 (4), 1523–1545. doi:10.1109/TIT.2005.844059
Delahaye, J.-P., and Zenil, H. (2012). Numerical evaluation of algorithmic complexity for short strings: a glance into the innermost structure of randomness. Appl. Math. Comput. 219 (1), 63–77. doi:10.1016/j.amc.2011.10.006
Deng, L. (2012). The mnist database of handwritten digit images for machine learning research [best of the web]. IEEE Signal Process. Mag. 29 (6), 141–142. doi:10.1109/MSP.2012.2211477
Dingle, K., Camargo, C., and Louis, A. (2018). Input-output maps are strongly biased towards simple outputs. Nat. Commun. 9 (761), 761. doi:10.1038/s41467-018-03101-6
Dua, V., and Dua, P. (2011). A simultaneous approach for parameter estimation of a system of ordinary differential equations, using artificial neural network approximation. Ind. Eng. Chem. Res. 51 (4), 1809–1814. doi:10.1021/ie200617d
Dubrova, E., Teslenko, M., and Martinelli, A. (2005). “Kauffman networks: analysis and applications,” in Proceedings of the 2005 IEEE/ACM International conference on Computer-aided design, San Jose, CA, November 6–10, 2005. (Washington, DC: IEEE Computer Society), 479–484.
Hartung, J., and Sinha, G. K. B. K. (2008). Statistical meta-analysis with applications. Hoboken, NJ: John Wiley & Sons.
Hernández-Orozco, S., Kiani, N. A., and Zenil, H. (2018). Algorithmically probable mutations reproduce aspects of evolution, such as convergence rate, genetic memory and modularity. Royal Society Open Science. 5 (8), 180399. doi:10.1098/rsos.180399
Hoerl, A. E., and Kennard, R. W. (1970). Ridge regression: biased estimation for nonorthogonal problems. Technometrics. 12 (1), 55–67. doi:10.1080/00401706.1970.10488634
Hutter, M., Legg, S., and Vitanyi, P. M. (2007). Algorithmic probability. Scholarpedia. 2 (8), 2572. doi:10.4249/scholarpedia.2572
Hutter, M. (2001). “Towards a universal theory of artificial intelligence based on algorithmic probability and sequential decisions,” in Proceedings of the European conference on machine learning, Freiburg, Germany, September 2001. (Berlin, Germany: Springer), 226–238.
Kauffman, S. A. (1969). Metabolic stability and epigenesis in randomly constructed genetic nets. J. Theor. Biol. 22 (3), 437–67. doi:10.1016/0022-5193(69)90015-0
Kingma, D. P., and Adam, J. Ba. (2014). A method for stochastic optimization. Available at: https://arxiv.org/abs/1412.6980.
Kolmogorov, A. N. (1965). Three approaches to the quantitative definition of information. Probl. Inf. Transm. 1 (1), 1–7. doi:10.1080/00207166808803030
Koppel, M., and Atlan, H. (1991). An almost machine-independent theory of program-length complexity, sophistication, and induction. Inf. Sci. 56 (1–3), 23–33. doi:10.1016/0020-0255(91)90021-L
Koppel, M. (1991). Learning to predict non-deterministically generated strings. Mach. Learn. 7 (1), 85–99. doi:10.1023/A:1022671126433
LeCun, Y., Bottou, L., Bengio, Y., Haffner, P., et al. (1998). Gradient-based learning applied to document recognition. Proc. IEEE. 86 (11), 2278–2324. doi:10.1109/5.726791
Levin, L. A. (1974). Laws of information conservation (nongrowth) and aspects of the foundation of probability theory. Probl. Peredachi Inf. 10 (3), 30–35.
Lloyd, S. (1982). Least squares quantization in pcm. IEEE Trans. Inf. Theor. 28 (2), 129–137. doi:10.1109/TIT.1982.1056489
Minsky, M. (2014). Panel discussion on the limits of understanding. (New York, NY: World Science Festival).
Press, W. H., Flannery, B. P., Teukolsky, S. A., and Vetterling, W. T. (2007). Linear Regularization Methods. 3rd Edn. (Cambridge, UK: Cambridge University Press). 1006–1016.
Soler-Toscano, F., Zenil, H., Delahaye, J. P., and Gauvrit, N. (2014). Calculating Kolmogorov complexity from the output frequency distributions of small turing machines. PLoS One. 9 (5), e96223–18. doi:10.1371/journal.pone.0096223
Soler-Toscano, F., Zenil, H., Delahaye, J. P., and Gauvrit, N. (2014). Calculating Kolmogorov complexity from the output frequency distributions of small turing machines. PLoS One. 9 (5), e96223. doi:10.1371/journal.pone.0096223
Solomonoff, R. (1960). A preliminary report on a general theory of inductive inference. Technical report. Cambridge, UK: Zator Co.
Solomonoff, R. J. (1964). A formal theory of inductive inference: parts 1 and 2. Inf. Control. 7 (1), 1–22. doi:10.1016/S0019-9958(64)90223-2
Solomonoff, R. (1986). “The application of algorithmic probability to problems in artificial intelligence,” in Machine Intelligence and Pattern Recognition., (Amsterdam, Netherlands: Elsevier), Vol. 4. 473–491.
Solomonoff, R. J. (2003). The Kolmogorov lecture the universal distribution and machine learning. Comput. J. 46 (6), 598–601. doi:10.1093/comjnl/46.6.598
Su, J., Vargas, D. V., and Sakurai, K. (2019). One pixel attack for fooling deep neural networks. IEEE Transactions on Evolutionary Computation. 23 (5), 828–841. doi:10.1109/TEVC.2019.2890858
Tikhonov, A. N. (1963). Solution of incorrectly formulated problems and the regularization method. Soviet Math. Dokl. 4, 1035–1038.
Uppada, S. K. (2014). Centroid based clustering algorithms—a clarion study. Int. J. Comput. Sci. Inf. Technol. 5 (6), 7309–7313. doi:10.5772/intechopen.75433
Zenil, H., and Delahaye, J.-P. On the algorithmic nature of the world. in Information and Computation. Editors G. dodig-crnkovic, and M. burgin (Singapore: World Scientific Publishing Company), (2010).
Zenil, H., Soler-Toscano, F., Delahaye, J.-P., and Gauvrit, N. (2015). Two-dimensional Kolmogorov complexity and an empirical validation of the coding theorem method by compressibility. PeerJ Computer Science. 1, e23. doi:10.7717/peerj-cs.23
Zenil, H., Badillo, L., Hernádez-Orozco, S., and Hernádez-Quiroz, F. (2018). Coding-theorem like behaviour and emergence of the universal distribution from resource-bounded algorithmic probability. Int. J. Parallel, Emergent Distributed Syst. 34 (2), 161–180. doi:10.1080/17445760.2018.1448932
Zenil, H., Hernández-Orozco, S., Kiani, N., Soler-Toscano, F., Rueda-Toicen, A., and Tegnér, J. (2018). A decomposition method for global evaluation of shannon entropy and local estimations of algorithmic complexity. Entropy. 20 (8), 605. doi:10.3390/e20080605
Zenil, H., Kiani, N., Zea, A., and Tegnér, J. (2019). Causal deconvolution by algorithmic generative models. Nature Machine Intelligence. 1, 58–66. doi:10.1038/S42256-018-0005-0
Zenil, H. (2011). Une approche expérimentale à la théorie algorithmique de la complexité. PhD thesis. Villeneuve-d’Ascq (France): Université de Lille 1.
Keywords: algorithmic causality, generative mechanisms, program synthesis, non-differentiable machine learning, explainable AI
Citation: Hernández-Orozco S, Zenil H, Riedel J, Uccello A, Kiani NA and Tegnér J (2021) Algorithmic Probability-Guided Machine Learning on Non-Differentiable Spaces. Front. Artif. Intell. 3:567356. doi: 10.3389/frai.2020.567356
Received: 29 May 2020; Accepted: 19 November 2020;
Published: 25 January 2021.
Edited by:
Huajin Tang, Zhejiang University, ChinaCopyright © 2021 Hernández-Orozco, Zenil, Riedel, Uccello, Kiani and Tegnér. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Hector Zenil, aGVjdG9yLnplbmlsQGNzLm94LmFjLnVr; Jesper Tegnér, amVzcGVyLnRlZ25lckBraS5zZQ==