 Niklas Bussmann
Niklas Bussmann Paolo Giudici
Paolo Giudici Dimitri Marinelli
Dimitri Marinelli Jochen Papenbrock
Jochen Papenbrock
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Artif. Intell., 24 April 2020
Sec. AI in Finance
Volume 3 - 2020 | https://doi.org/10.3389/frai.2020.00026
This article is part of the Research TopicFinancial intermediation versus disintermediation: Opportunities and challenges in the FinTech eraView all 9 articles
The paper proposes an explainable AI model that can be used in fintech risk management and, in particular, in measuring the risks that arise when credit is borrowed employing peer to peer lending platforms. The model employs Shapley values, so that AI predictions are interpreted according to the underlying explanatory variables. The empirical analysis of 15,000 small and medium companies asking for peer to peer lending credit reveals that both risky and not risky borrowers can be grouped according to a set of similar financial characteristics, which can be employed to explain and understand their credit score and, therefore, to predict their future behavior.
Black box Artificial Intelligence (AI) is not suitable in regulated financial services. To overcome this problem, Explainable AI models, which provide details or reasons to make the functioning of AI clear or easy to understand, are necessary.
To develop such models, we first need to understand what “Explainable” means. During this year, some important benchmark definitions have been provided, at the institutional level. We report some of them, in the context of the European Union.
For example, the Bank of England (Joseph, 2019) states that “Explainability means that an interested stakeholder can comprehend the main drivers of a model-driven decision.” The Financial Stability Board (FSB, 2017) suggests that “lack of interpretability and auditability of AI and ML methods could become a macro-level risk.” Finally, the UK Financial Conduct Authority (Croxson et al., 2019) establishes that “In some cases, the law itself may dictate a degree of explainability.”
The European GDPR (EU, 2016) regulation states that “the existence of automated decision-making, should carry meaningful information about the logic involved, as well as the significance and the envisaged consequences of such processing for the data subject.” Under the GDPR regulation, the data subject is therefore, under certain circumstances, entitled to receive meaningful information about the logic of automated decision-making.
Finally, the European Commission High-Level Expert Group on AI presented the Ethics Guidelines for Trustworthy Artificial Intelligence in April 2019. Such guidelines put forward a set of seven key requirements that AI systems should meet in order to be deemed trustworthy. Among them three related to XAI, and are the following.
• Human agency and oversight: decisions must be informed, and there must be a human-in-the-loop oversight.
• Transparency: AI systems and their decisions should be explained in a manner adapted to the concerned stakeholder. Humans need to be aware that they are interacting with an AI system.
• Accountability: AI systems should develop mechanisms for responsibility and accountability, auditability, assessment of algorithms, data and design processes.
Following the need to explain AI models, stated by legislators and regulators of different countries, many established and startup companies have started to embrace Explainable AI (XAI) models.
From a mathematical viewpoint, it is well-known that, while “simpler” statistical learning models, such as linear and logistic regression models, provide a high interpretability but, possibly, a limited predictive accuracy, “more complex” machine learning models, such as neural networks and tree models provide a high predictive accuracy at the expense of a limited interpretability.
To solve this trade-off, we propose to boost machine learning models, that are highly accurate, with a novel methodology, that can explain their predictive output. Our proposed methodology acts in the post-processing phase of the analysis, rather than in the preprocessing part. It is agnostic (technologically neutral) as it is applied to the predictive output, regardless of which model generated it: a linear regression, a classification tree or a neural network model.
More precisely, our proposed methodology is based on Shapley values (see Lundberg and Lee, 2017 and references therein). We consider a relevant application of AI in financial technology: peer to peer lending.
We employ Shapley values to predict the credit risk of a large sample of small and medium enterprises which apply for credit to a peer to peer lending platform. The obtained empirical evidence shows that, while improving the predictive accuracy with respect to a standard logistic regression model, we maintain and, possibly, improve, the interpretability (explainability) of the results.
In other words, our results confirm the validity of this approach in discriminating between defaulted and sound institutions, and it shows the power of explainable AI in both prediction accuracy and in the interpretation of the results.
The rest of the paper is organized as follows: section 2 introduces the proposed methodology. Section 3 shows the results of the analysis in the credit risk context. Section 4 concludes.
Credit risk models are useful tools for modeling and predicting individual firm default. Such models are usually grounded on regression techniques or machine learning approaches often employed for financial analysis and decision-making tasks.
Consider N firms having observation regarding T different variables (usually balance-sheet measures or financial ratios). For each institution n define a variable γn to indicate whether such institution has defaulted on its loans or not, i.e., γn = 1 if company defaults, γn = 0 otherwise. Credit risk models develop relationships between the explanatory variables embedded in T and the dependent variable γ.
The logistic regression model is one of the most widely used method for credit scoring. The model aims at classifying the dependent variable into two groups, characterized by different status (defaulted vs. active) by the following model:
where pn is the probability of default for institution n, xi = (xi, 1, …, xi, T) is the T-dimensional vector of borrower specific explanatory variables, the parameter α is the model intercept while βt is the t-th regression coefficient. It follows that the probability of default can be found as:
Credit risk can be measured with very different Machine Learning (ML) models, able to extract non-linear relations among the financial information in the balance sheets. In a standard data science life cycle, models are chosen to optimize the predictive accuracy. In highly regulated sectors, like finance or medicine, models should be chosen balancing accuracy with explainability (Murdoch et al., 2019). We improve the choice selecting models based on their predictive accuracy, and employing a posteriori an explanations algorithm. This does not limit the choice of the best performing models.
To exemplify our approach we consider, without loss of generality, the XGBoost model, one of the most popular and fast algorithm (Chen and Guestrin, 2016), that implements gradient tree boosting learning models.
For evaluating the performance of each learning model, we employ, as a reference measure, the indicator γ ∈ {0, 1}, a binary variable which takes value one whenever the institutions has defaulted and value zero otherwise. For detecting default events represented in γ, we need a continuous measurement p ∈ [0, 1] to be turned into a binary prediction B assuming value one if p exceeds a specified threshold τ ∈ [0, 1] and value zero otherwise. The correspondence between the prediction B and the ideal leading indicator γ can then be summarized in a so-called confusion matrix. From the confusion matrix we can easy illustrate the performance capabilities of a binary classifier system. To this aim, we compute the receiver operating characteristic (ROC) curve and the corresponding area under the curve (AUC). The ROC curve plots the false positive rate (FPR) against the true positive rate (TPR), as follows:
The overall accuracy of each model can be computed as:
and it characterizes the proportion of true results (both true positives and true negatives) among the total number of cases.
We now explain how to exploit the information contained in the explanatory variables to localize and cluster the position of each individual (company) in the sample. This information, coupled with the predicted default probabilities, allows a very insightful explanation of the determinant of each individual's creditworthiness. In our specific context, information on the explanatory variables is derived from the financial statements of borrowing companies, collected in a vector xn representing the financial composition of the balance sheet of institution n.
We propose calculate the Shapley value associated with each company. In this way we provide an agnostic tool that can interpret in a technologically neutral way the output from a highly accurate machine learning model. As suggested in Joseph (2019), the Shapley values of a model can be used as a tool to transfer predictive inferences into a linear space, opening a wide possibility of using the toolbox of econometrics, hypothesis testing, and network analysis.
We develop our Shapley approach using the SHAP (Lundberg and Lee, 2017) computational framework, which allows to express each single prediction as a sum of the contributions of the different explanatory variables.
More formally, the Shapley explanation model for each prediction is obtained by an additive feature attribution method, which decomposes them as:
where M is the number of available explanatory variables, ϕ ∈ ℝM, ϕk ∈ ℝ. The local functions ϕk(xi) are called Shapley values.
Indeed, Lundberg and Lee (2017) prove that the only additive feature attribution method that satisfies the properties of local accuracy, missingness, and consistency is obtained attributing to each feature xk, k = 1, …, M, a SHapley Additive exPlanation (SHAP) defined by
where is the set of all the possible models excluding variable xk (with m = 1, …, M), |x′| denotes the number of variables included in model x′, M is the number of the available variables, and are the predictions associated with all the possible model configurations including variable xk and excluding variable xk, respectively.
The quantity defines the contribution of variable xk to each individual prediction.
We test our proposed model to data supplied by European External Credit Assessment Institution (ECAI) that specializes in credit scoring for P2P platforms focused on SME commercial lending. The data is described by Giudici et al. (2019a) to which we refer for further details. In summary, the analysis relies on a dataset composed of official financial information (balance-sheet variables) on 15,045 SMEs, mostly based in Southern Europe, for the year 2015. The information about the status (0 = active, 1 = defaulted) of each company 1 year later (2016) is also provided. Using this data, Giudici (2018); Ahelegbey et al. (2019), and Giudici et al. (2019a,b) have constructed logistic regression scoring models that aim at estimating the probability of default of each company, using the available financial data from the balance sheets and, in addition, network centrality measures that are obtained from similarity networks.
Here we aim to improve the predictive performance of the model and, for this purpose, we run an XGBoost tree algorithm (see e.g., Chen and Guestrin, 2016). To explain the results from the model, typically highly predictive, we employ Shapley values.
The proportion of defaulted companies within this dataset is 10.9%.
We first split the data in a training set (80%) and a test set (20%).
We then estimate the XGBoost model on the training set, apply the obtained model to the test set and compare it with the optimal logistic regression model. The ROC curves of the two models are contained in Figure 1 below.
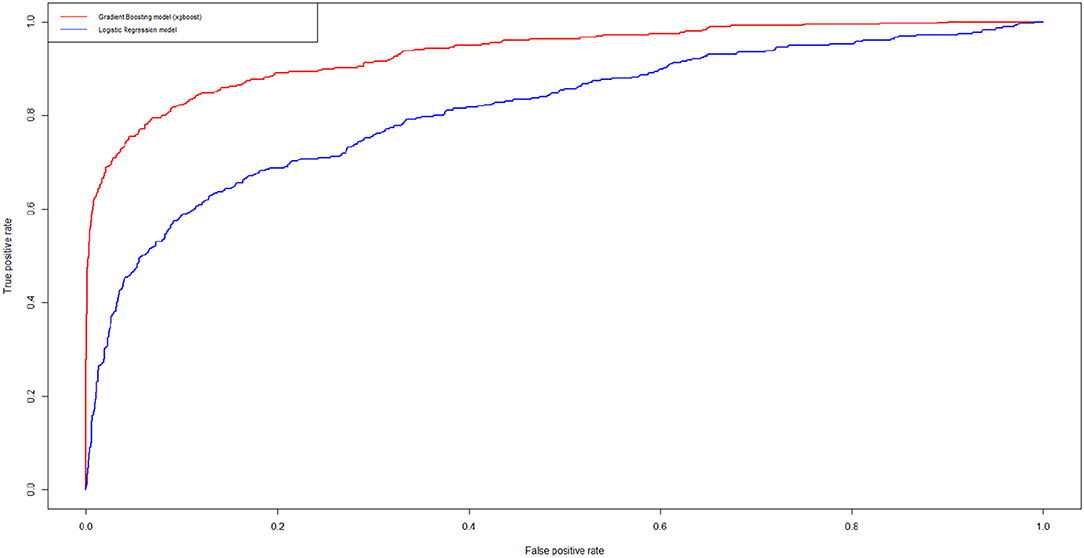
Figure 1. Receiver Operating Characteristic (ROC) curves for the logistic credit risk model and for the XGBoost model. In blue, we show the results related to the logistic models while in red we show the results related to the XGBoost model.
From Figure 1 note that the XGBoost clearly improves predictive accuracy. Indeed the calculation of the AUROC of the two curves indicate an increase from 0.81 (best logistic regression model) to 0.93 (best XGBoost model).
We then calculate the Shapley values for the companies in the test set.
To exemplify our results, Figure 2 we provide the interpretation of the estimated credit scoring of four companies: two that default and two that do not default.
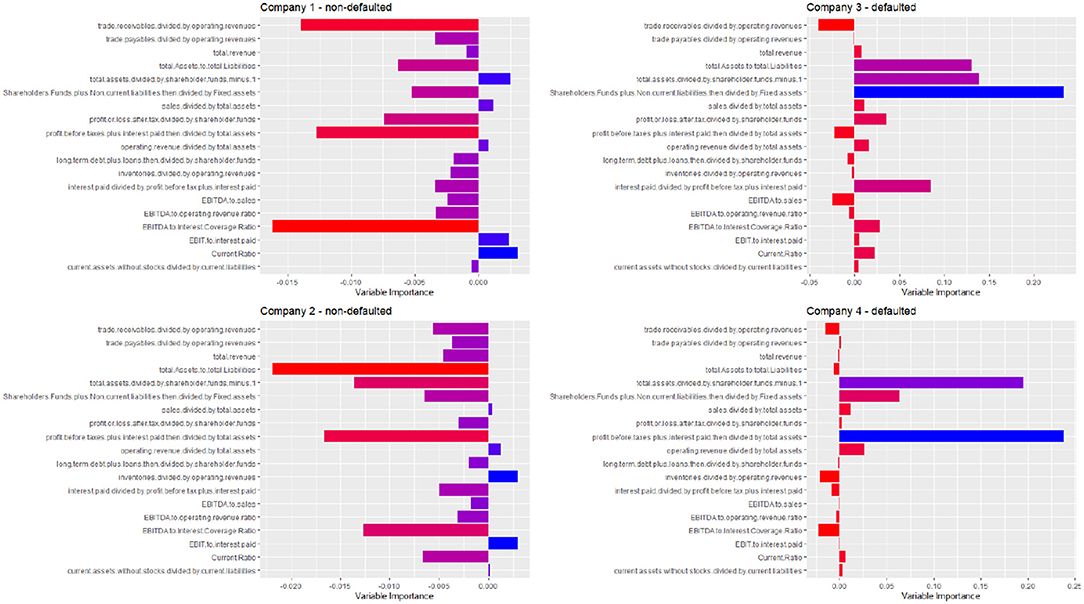
Figure 2. Contribution of each explanatory variable to the Shapley's decomposition of four predicted default probabilities, for two defaulted and two non-defaulted companies. A red color indicates a low variable importance, and a blue color a high variable importance.
Figure 2 clearly shows the advantage of our explainable model. It can indicate which variables contribute more to the prediction. Not only in general, as is typically done by feature selection models, but differently and specifically for each company in the test set. Note how the explanations are rather different (“personalized”) for each of the four considered companies.
The need to leverage the high predictive accuracy brought by sophisticated machine learning models, making them interpretable, has motivated us to introduce an agnostic, post-processing methodology, based on Shapley values. This allows to explain any single prediction in terms of the potential contribution of each explanatory variable.
Future research should include a better understanding of the predictions through clustering of the Shapley values. This can be achieved, for example, using correlation network models. A second direction would be to extend the approach developing model selection procedures based on Shapley values, which would require appropriate statistical testing. A last extension would be to develop a Shapley like measure that applies also to ordinal response variables.
Our research has important policy implications for policy makers and regulators who are in their attempt to protect the consumers of artificial intelligence services. While artificial intelligence effectively improve the convenience and accessibility of financial services, they also trigger new risks, and among them is the lack of model interpretability. Our empirical findings suggest that explainable AI models can effectively advance our understanding and interpretation of credit risks in peer to peer lending.
Future research may involve further experimentation and the application to other case studies.
The datasets generated for this study are available on request to the corresponding author.
All authors listed have made a substantial, direct and intellectual contribution to the work, and approved it for publication.
This research has received funding from the European Union's Horizon 2020 research and innovation program FIN-TECH: A Financial supervision and Technology compliance training programme under the grant agreement No 825215 (Topic: ICT-35-2018, Type of action: CSA), and from the European Union's Horizon 2020 research and innovation programme under the Marie Skłodowska-Curie grant agreement No 750961.
NB, DM, and JP are employed by the company FIRAMIS. The remaining author declares that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
In addition, the authors thank ModeFinance, a European ECAI, for the data; the partners of the FIN-TECH European project, for useful comments and discussions.
Ahelegbey, D., Giudici, P., and Hadji-Misheva, B. (2019). Latent factor models for credit scoring in P2P systems. Phys. A Stat. Mech. Appl. 522, 112–121. doi: 10.1016/j.physa.2019.01.130
Chen, T., and Guestrin, C. (2016). “Xgboost: a scalable tree boosting system,” in Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (New York, NY: ACM), 785–794.
Croxson, K., Bracke, P., and Jung, C. (2019). Explaining Why the Computer Says ‘no'. London, UK: FCA-Insight.
FSB (2017). Artificial Intelligence and Machine Learning in Financial Services–Market Developments and Financial Stability Implication. Technical report, Financial Stability Board.
Giudici, P. (2018). “Financial data science,” in Statistics and Probability Letters, Vol. 136 (Elsevier). 160–164.
Giudici, P., Hadji Misheva, B., and Spelta, A. (2019a). Correlation network models to improve P2P credit risk management. Artif. Intell. Finance.
Giudici, P., Hadji-Misheva, B., and Spelta, A. (2019b). Network based credit risk models. Qual. Eng. 32, 199–211. doi: 10.1080/08982112.2019.1655159
Joseph, A. (2019). Shapley Regressions: A Framework for Statistical Inference on Machine Learning Models. Resreport 784, Bank of England.
Lundberg, S., and Lee, S.-I. (2017). “A unified approach to interpreting model predictions,” in Advances in Neural Information Processing Systems 30, eds I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, et al. (New York, NY: Curran Associates, Inc.), 4765–4774.
Murdoch, W. J., Singh, C., Kumbier, K., Abbasi-Asl, R., and Yu, B. (2019). Definitions, methods, and applications in interpretable machine learning. Proc. Natl. Acad. Sci. U.S.A. 116, 22071–22080. doi: 10.1073/pnas.1900654116
Keywords: credit risk management, explainable AI, financial technologies, peer to peer lending, logistic regression, predictive models
Citation: Bussmann N, Giudici P, Marinelli D and Papenbrock J (2020) Explainable AI in Fintech Risk Management. Front. Artif. Intell. 3:26. doi: 10.3389/frai.2020.00026
Received: 18 December 2019; Accepted: 30 March 2020;
Published: 24 April 2020.
Edited by:
Shatha Qamhieh Hashem, An-Najah National University, PalestineReviewed by:
Paolo Barucca, University College London, United KingdomCopyright © 2020 Bussmann, Giudici, Marinelli and Papenbrock. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Paolo Giudici, Z2l1ZGljaUB1bmlwdi5pdA==
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.