 Daniel Felix Ahelegbey
Daniel Felix Ahelegbey Paolo Giudici
Paolo Giudici Branka Hadji-Misheva3
Branka Hadji-Misheva3- 1Department of Mathematics and Statistics, Boston University, Boston, MA, United States
- 2Department of Economics and Management, University of Pavia, Pavia, Italy
- 3Zurich University of Applied Sciences (ZHAW) University of Applied Sciences, Zurich, Switzerland
This paper investigates how to improve statistical-based credit scoring of SMEs involved in P2P lending. The methodology discussed in the paper is a factor network-based segmentation for credit score modeling. The approach first constructs a network of SMEs where links emerge from comovement of latent factors, which allows us to segment the heterogeneous population into clusters. We then build a credit score model for each cluster via lasso-type regularization logistic regression. We compare our approach with the conventional logistic model by analyzing the credit score of over 1,5000 SMEs engaged in P2P lending services across Europe. The result reveals that credit risk modeling using our network-based segmentation achieves higher predictive performance than the conventional model.
1. Introduction
Issuance of loans by traditional financial institutions, such as banks, to other firms and individuals, is often associated with major risks. The failure of loan recipients to honor their obligation at the time of maturity leaves the banks vulnerable and affects their operations. The risk associated with such transactions is referred to as credit risk. It is well known that some percentage of these non-performing loans are eventually imputed to economic losses. To minimize such risk exposures, various methods have been extensively discussed in the credit risk literature to enable credit-issuing institutions to undertake a thorough assessment to classify loan applicants into risky and non-risky customers. Some of these methods range from logistic and linear probability models to decision trees, neural networks and support vector machines. A conventional individual-level reduced-form approach is the credit scoring model which attributes a score of credit-worthiness to each loan applicant based on the available history of their financial characteristics. See Altman (1968) for some pioneer works on corporate bankruptcy prediction models using accounting-based measures as variables. For a comprehensive review on credit scoring models, see Alam et al. (2010).
Recent advancements gradually transforming the traditional economic and financial system is the emergence of digital-based systems. Such systems present a paradigm shift from traditional infrastructural systems to technological (digital) systems. Financial technological (“FinTech”) companies are gradually gaining ground in major developed economies across the world. The emergence of Peer-to-Peer (P2P) platforms is a typical example of a FinTech system. The P2P platform aims at facilitating credit services by connecting individual lenders with individual borrowers without the interference of traditional banks as intermediaries. Such platform serves as a digital financial market and an alternative to the traditional physical financial market. P2P platforms significantly improve the customer experience and the speed of the service and reduce costs to both individual borrowers and lenders as well as small business owners. Despite the various advantages, P2P systems inherit some of the challenges of traditional credit risk management. In addition, they are characterized by the asymmetry of information and by a strong interconnectedness among their users (see e.g., Giudici et al., 2019) that makes distinguishing healthy and risky credit applicants difficult, thus affecting credit issuers. There is, therefore, a need to explore methods that can help improve credit scoring of individual or companies that engage in P2P credit services.
This paper investigates how factor-network-based segmentation can be employed to improve the statistical-based credit score for small and medium enterprises (SMEs) involved in P2P lending. The approach is to first constructs a network of SMEs where links emerge from comovement of the latent factors that drive the observed financial characteristics. The network structure then allows us to segment the heterogeneous population into two sub-groups of connected and non-connected clusters. We then build a credit score model for each sub-population via lasso-type regularization logistic regression.
The contribution to the literature of this paper is manifold. Firstly, we extend the ideas contained in the factor network-based classification of Ahelegbey et al. (2019) to a more realistic setting, characterized by a large number of observations which, when links between them are the main object of analysis, becomes extremely challenging.
Secondly, we extend the network-based scoring model proposed in Giudici et al. (2019) to a setting characterized by a large number of explanatory variables. The variables are selected via lasso-type regularization (Tibshirani, 1996; Hastie et al., 2009) and, then, summarized by factor scores. Thus, we contribute to network-based models for credit risk quantification. Network models have been shown to be effective in gauging the vulnerabilities among financial institutions for risk transmission (see Battiston et al., 2012; Billio et al., 2012; Diebold and Yilmaz, 2014; Ahelegbey et al., 2016a), and a scheme to complement micro-prudential supervision with macro-prudential surveillance to ensure financial stability (see IMF, 2011; Moghadam and Viñals, 2010; Viñals et al., 2012). Recent application of networks have been shown to improve loan default predictions and capturing information that reflects underlying common features (see Letizia and Lillo, 2018; Ahelegbey et al., 2019).
Thirdly, our empirical application contributes to modeling credit risk in SMEs particularly engaged in P2P lending. For related works on P2P lending via logistic regression (see Andreeva et al., 2007; Barrios et al., 2014; Emekter et al., 2015; Serrano-Cinca and Gutiérrez-Nieto, 2016). We model the credit score of over 15,000 SMEs engaged in P2P credit services across Southern Europe. We compare the performance of our network-based segmentation credit score model (NS-CSM) with the conventional single credit score model (CSM). We show via our empirical results that our network-based segmentation presents a more efficient scheme that achieves higher performance than the conventional approach.
The paper is organized as follows. Section 2 presents the factor network segmentation methodology and the lasso-type regularization for credit scoring. Section 3 discusses the empirical application of our segmentation approach against the conventional single model.
2. Methodology
We present the formulation and inference of a latent factor network to improve credit scoring and model estimation. Our objective is to analyze the characteristics of the borrowers to build a model that predicts the likelihood of their default.
2.1. Logistic Model
Let Y be a vector of independent observations of the loan status of n firms, such that Yi = 1 if firm-i has defaulted on its loan obligation, and zero otherwise. Furthermore, let X = {Xij}, i = 1, …, n, j = 1, …, p, be a matrix of n observations with p financial characteristic variables or predictors. The conventional parameterization of the conditional distribution of Y given X is the logistic model with log-odds ratio given by
where πi = P(Yi = 1|Xi), β0 is a constant term, is a p × 1 vector of coefficients and Xi is the i-th row of X.
2.2. Decomposition of Data Matrix by Factors
The dataset X can be considered as points of n-institutions in a p-dimensional space. It can also be interpreted at observed outcomes driven by some underlying firm characteristics. More specifically, X can be expressed as a factor model given by
where F is n×k matrix of latent factors, W is p×k matrix of factor loadings, ε is n × p matrix of errors uncorrelated with F. The error term ε is typically assumed to be multivariate normal but F in general case need not be multivariate normal (see Tabachnick et al., 2007). Lastly, k < p is the number of factors required to summarize the pattern of correlations in the observed data matrix X. In the context of our application, we set k to be the number of factors that account for approximately 95% of the variation in X.
2.3. Factor Network-Based Segmentation
We present the construction of network structure for the segmentation of the population. Following the literature on graphical models (see Carvalho and West, 2007; Eichler, 2007; Ahelegbey et al., 2016a,b), we represent the network structure as an undirected binary matrix, G ∈ {0, 1}n×n, where Gij represents the presence or absence of a link between nodes i and j. We construct G via similarity of the latent firm characteristics, such that Gij = 1 if the latent coordinates of firm-i are strongly related to firm-j, and zero otherwise.
Given the latent factors matrix, F, we construct a network where the marginal probability of a link between nodes-i and j by
where γij ∈ (0, 1), Φ is the standard normal cumulative density function, θ ∈ ℝ is a network density parameter, and is the i-th row and the j-th column of FF′. Under the assumption that G is undirected, it follows that γij = P(Gij = 1|F) = P(Gji = 1|F) = γji. We validate the link between nodes-i and j in G by
where 1(γij > γ) is the indicator function, i.e., unity if γij > γ and zero otherwise, and γ ∈ (0, 1) is a threshold parameter. By definition, the parameters θ and γ control the density of G. Following Ahelegbey et al. (2019), we set . To broaden the robustness of the results, we compare γ = {0.05, 0.1} to capture a sparse but closely connected community.
2.4. Estimating High-Dimensional Logistic Models
When estimating high-dimensional logistic models with a relatively large number of predictors, there is the tendency to have redundant explanatory variables. Thus, to construct a predictable model, there is the need to select the subset of predictors that explains a large variation in the probability of defaults. Several variable selection methods have been discussed and applied for various regression models. In this paper, we consider variants of the lasso regularization for logistic regressions (Hastie et al., 2009).
2.4.1. Lasso
The lasso estimator (Tibshirani, 1996) solves a penalized log-likelihood function given by
where n is the number of observations, p the number of predictors, and λ is the penalty term, such that large values of λ shrinks a large number of the coefficients toward zero.
2.4.2. Adaptive Lasso
The adaptive lasso estimator (Zou, 2006) is an extension of the lasso that solves
where wj is a weight penalty such that , with as the ordinary least squares (or ridge regression) estimate and v > 0.
2.4.3. Elastic-Net
The elastic-net estimator (Zou and Hastie, 2005) solves the following
where α ∈ (0, 1) is an additional penalty such that when α = 1 we a lasso estimator (L1 penalty), and when α = 0 a ridge estimator (L2 penalty). For the elastic-net estimator, we set α = 0.5 giving equal weight to the L1 and L2 regularization.
2.4.4. Adaptive Elastic-Net
The adaptive elastic-net estimator (Zou and Zhang, 2009) combines the additional penalties of the adaptive lasso and the elastic-net to solve the following
In the empirical work, we focus on estimating the credit score using the four lasso-type regularization methods. We select the regularization parameter using 10-fold cross-validation on a grid of λ values for the penalized logistic regression problem. Two λ's are widely considered in the literature, i.e., λ.min and λ.1se. The former is the value of the λ that minimizes the mean square cross-validated errors, while the latter is the λ value that corresponds to one standard error from the minimum mean square cross-validated errors. Our preliminary analysis shows that λ.1se produces a larger penalty that is too restrictive in the sense that we lose almost all the regressors. Although our goal is to encourage a sparse credit scoring model for the purpose of interpretability, we do not want to impose too much sparsity that renders the majority of the features insignificant. Thus, we rather choose λ.min over λ.1se. For the additional penalty terms, we set α = 0.5, v = 2, and as the ridge regression estimate.
3. Application
3.1. Data: Description and Summary Statistics
To illustrate the effectiveness of the application of factor network methodology in credit scoring analysis, we obtained data from the European External Credit Assessment Institution (ECAI) on 15045 small-medium enterprises engaged in Peer-to-Peer lending on digital platforms across Southern Europe.
The observation on each institution is composed of 24 financial characteristic ratios constructed from official financial information recorded in 2015. Table 1 presents a description of the financial ratios with summary of mean statistics of the institutions grouped according to their default status. In all, the data consists of 1,632 (10.85%) defaulted institutions and 13,413 (89.15%) non-defaulted companies.
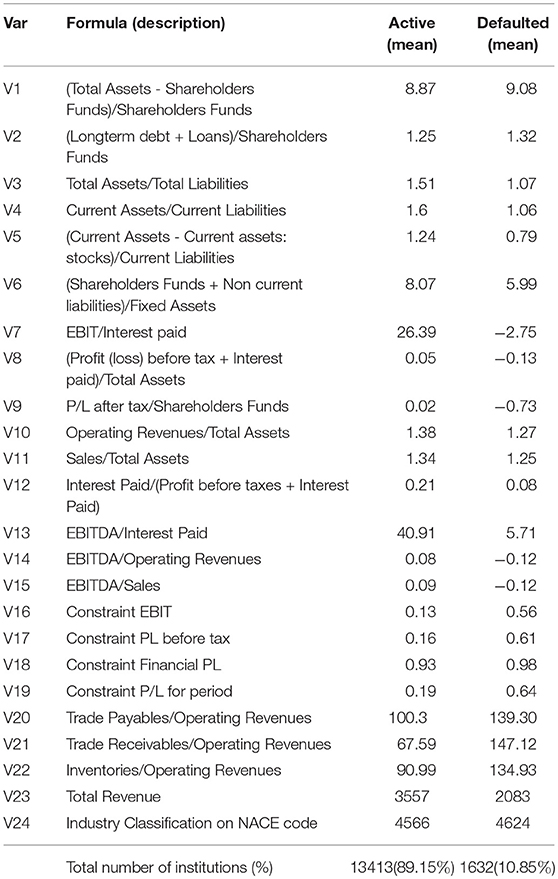
Table 1. Description of the financial ratios with summary of mean statistics according to default status.
3.2. Decomposition of the Observed Data Matrix by Factors
To estimate the underlying factors that drive the observed data matrix, we decompose the matrix of observed financial characteristics via a singular value decomposition given by,
where U and V are orthonormal, and D = Λ1/2 is a diagonal matrix of non-negative and decreasing singular values, with Λ as the diagonal matrix of the non-zero eigenvalues of X′X and XX′. U is n × p, D is p × p and V is p × p. Following the error approximation criteria, we obtain the factor matrix by, F = Un,kDk,k and W = Vk,p, where Un,k is n × k matrix composed of the first k columns of U, k < p, Dk,k is k × k matrix comprising the first k columns and rows of D, and Vk,p is k × p matrix of factor loadings. The matrix F can therefore be interpreted as a projection of X onto the eigenspace spanned by Un,k. We determine k by observing the number of eigenvalues associated with the largest variance matrix. Table 2 shows the eigenvalues of the singular value decomposition to determine the factors to retain. The eigenvalues reported are the normalized squared diagonal terms of D. From the table, we set k = 17 since the first 17 eigenvalues explain about 95% of the total variation in X.
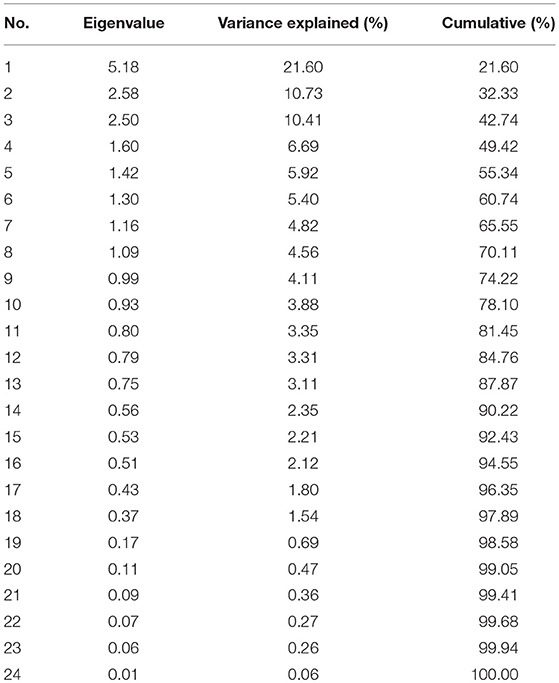
Table 2. The eigenvalues of the singular value decomposition to determine the factors to retain.
3.3. Factor Network Analysis
We use the estimated factor matrix, F, to construct the network for the segmentation of the companies. For purposes of graphical representations and to keep the companies name anonymous, we report the estimated network by representing the group of institutions with color-codes. The defaulted companies are represented in a red color code, and non-defaulted companies in the green color code (see Figure 1). Table 3 reports the summary statistics of the estimated network in terms of the default-status composition of the SMEs. For robustness purposes, we compare the results obtained with a threshold value γ = 0.05 against γ = 0.10.
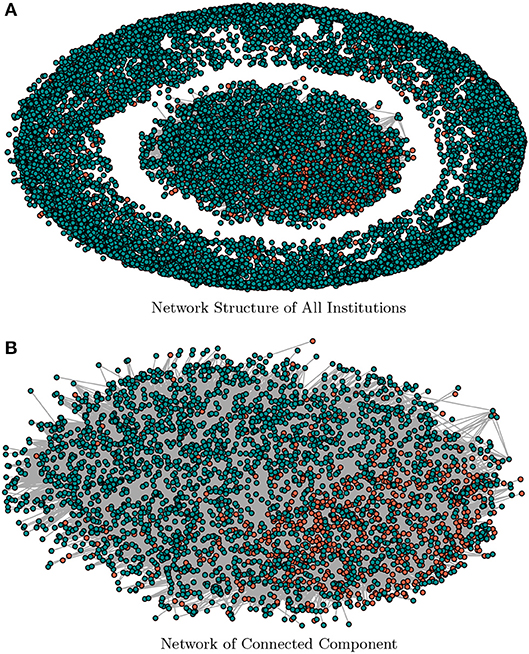
Figure 1. A graphical representation of the estimated factor network. (A) shows the structural representation of the factor network for threshold γ = 0.05, and (B) depicts the connected sub-population only. The nodes in red-color are defaulted class of companies and green-color coded nodes are non-defaulted class of companies. (A) Network Structure of All Institutions. (B) Network of Connected Component.
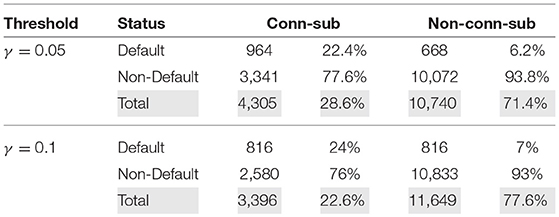
Table 3. Summary statistic of connected and non-connected sub-population obtained from the factor network-based segmentation for threshold values of γ = {0.05, 0.1}.
The result for the threshold γ = 0.05 of Table 3 shows that the connected sub-population is composed of 4,305 companies which constitute 28.6% of the full sample. The non-connected sub-population is composed of 10,740 (71.4%). The percentage of the defaulted class of companies are 22.4 and 6.2% among the connected- and non-connected sub-population, respectively. We notice that higher threshold values (say γ = 0.1) decrease (increase) the total number of connected (non-connected) sub-population and vice versa. Such higher threshold values also lead to a lower (higher) number of defaulted class of connected (non-connected) SMEs but (and) constituting a higher percentage of the defaulted population. Figure 1 presents the graphical representation of the estimated factor network with the sub-population of defaulted and non-defaulted companies color coded as red and green, respectively. Figure 1A shows the structural representation of both connected and non-connected sub-population while Figure 1B depicts the structure of connected sub-population only.
3.4. Credit Score Modeling
We compare the lasso, adaptive lasso, elastic-net, and adaptive elastic-net variable selection methods to model the credit score of the listed companies in our dataset. To estimate the models, we standardized each series to a zero mean and unit variance. Table 4 reports the variable selection and estimated coefficients of the four methods. The column CSM represents the benchmark credit scoring model, NS-CSM(C) - the network segmented connected sub-population credit scoring model, and NS-CSM(NC) for the network segmented non-connected sub-population credit scoring model. The top left panel represents the lasso method, the adaptive lasso is on the top right panel, elastic-net at the bottom left and adaptive elastic-net at the bottom right.
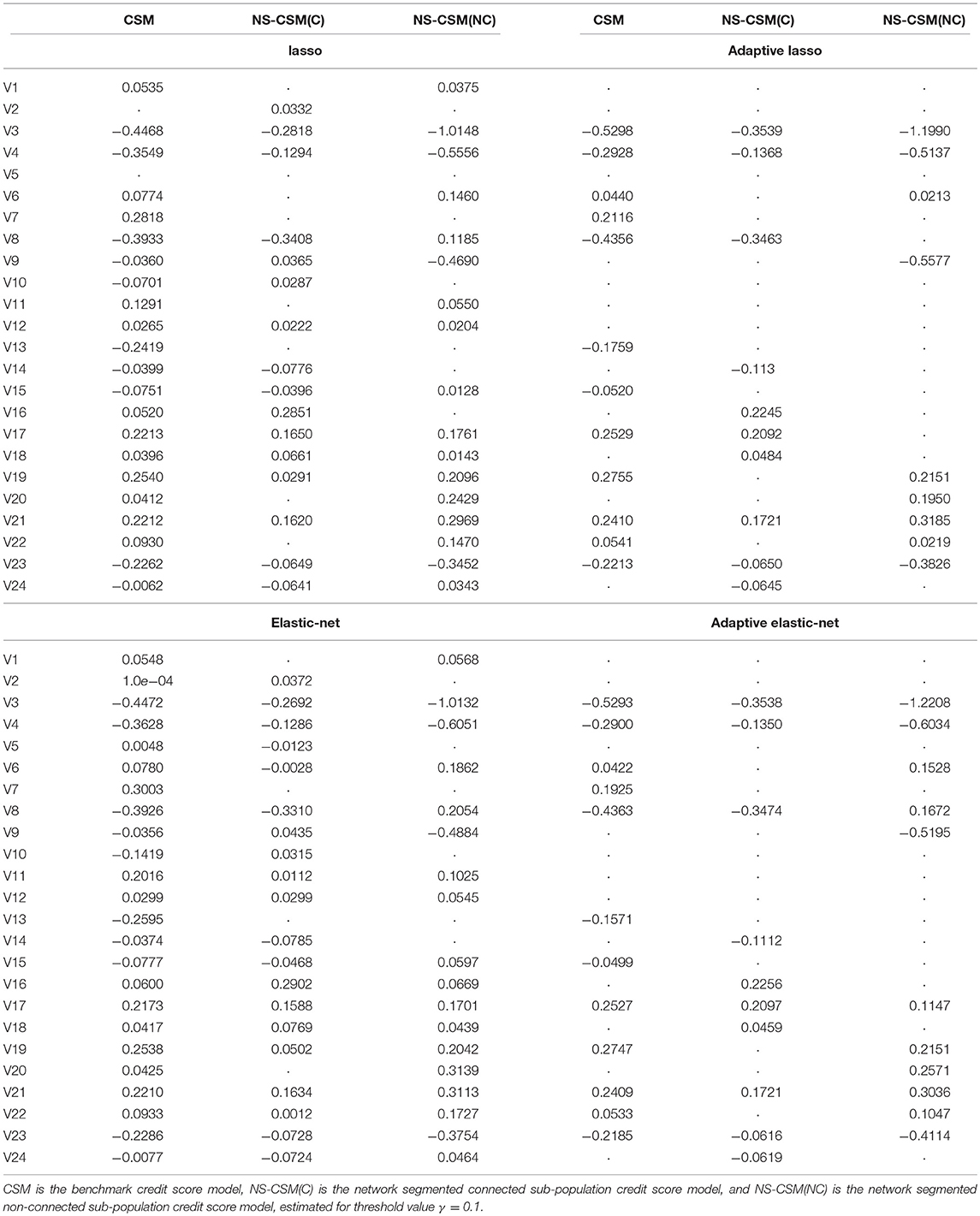
Table 4. Estimated coefficients from lasso (top left), adaptive lasso (top right), elastic-net (bottom left) and adaptive elastic-net (bottom right).
Table 5 reports the number of variables selected by each of the four competing methods for the credit score model estimation. From the table, the elastic-net is the least parsimonious, followed by the lasso, and lastly, the adaptive elastic-net and adaptive lasso are the most parsimonious. From Tables 4, 5, we observed a significant difference in the number of selected explanatory variables for the benchmark model and the network segmented models. More precisely, the former model the credit score of a given company by using more variables while the latter on the other hand uses a significantly lower number of variables. The similar results across the four variable selection methods, given their similarities, is not terribly surprising. But they do indicate that the general approach appears to be robust in this setting, which was the main purpose of the testing. The network-based segmentation framework is therefore more parsimonious than the benchmark full population credit score model, and this helps in interpretability.

Table 5. Number of selected variables of the four methods.
3.5. Comparing Default Predicting Accuracy
We analyzed the performance of the models by splitting the sample into 70% training and 30% testing sample. We now compare the default prediction accuracy of the models in terms of the standard area under the curve (AUC) derived from the receiver operator characteristic (ROC) curve. The AUC depicts the true positive rate (TPR) against the false positive rate (FPR) depending on some threshold. TPR is the number of correct positive predictions divided by the total number of positives. FPR is the ratio of false positives predictions overall negatives. See Figure 2 for the plot of the ROC curve for the competing methods.
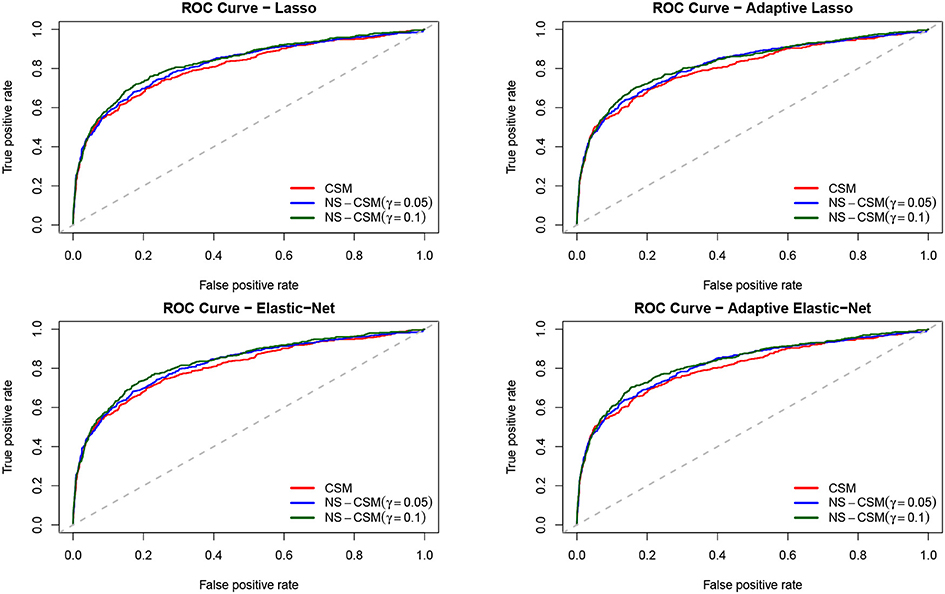
Figure 2. ROC curves of the four methods. CSM is the benchmark model, NS-CSM(C) is the network segmented connected sub-population model, and NS-CSM(NC) is the network segmented non-connected sub-population model, estimated for threshold values of γ = {0.05, 0.1}.
The comparison of the ROC curves from the competing methods shows that the CSM (in red) lies below the rest. Clearly, the curves of NS-CSM (γ = 0.1) depicted in green seems to dominate the others. The summary of the area under the ROC curve reported in Table 6 shows that NS-CSM (γ = 0.1) is ranked first, followed by NS-CSM (γ = 0.05), and the lowest AUC is obtained by the CSM. Overall, in terms of default predictive accuracy, the result of the AUC shows the NS-CSM outperforms the CSM, on average by two percentage points. This is an advantage that can be further increased considering as the cut-off the observed default percentages, which are different in the two samples.
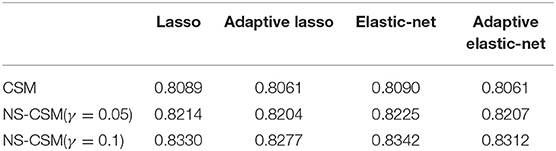
Table 6. Comparing area under the ROC curve (AUC) of the four methods.
We investigate whether the AUC of the network segmented model is significantly different from the benchmark model for the four methods. We applied the DeLong test (DeLong et al., 1988) to investigate the pairwise comparison of the AUC of the benchmark model (i.e., CSM) and that of the NS-CSM for γ = {0.05, 0.1}. We perform these tests under the null-hypotheses that H0: AUC (CSM) ≥ AUC (NS-CSM) and the alternative hypotheses, H1: AUC (CSM) < AUC (NS-CSM). Table 7 reports the one-sided statistical test of the AUC of the benchmark model relative to the network segmented models. The result of the De Long test shows that while the ROC of CSM is not statistically different from that of NS-CSM(γ = 0.05), the difference between the ROC of NS-CSM(γ = 0.1) and the benchmark (CSM) is statistically significant at 90% confidence level for all four methods.

Table 7. AUC of the benchmark model relative to the network segmented models under the four methods.
In conclusion, our proposed factor network approach to credit score modeling presents an efficient framework to analyze the interconnections among the borrowers of a peer to peer platform and provides a way to segment a heterogeneous population into clusters with more homogeneous characteristics. The results show that the lasso logistic model for credit scoring leads to better identification of the significant set of relevant financial characteristic variables, thereby producing a more interpretable model, especially when combined with the segmentation of the population via the factor network-based approach. These empirical results are promising, but certainly not definitive. More research is required to determine whether the observed ‘lift’ truly is significant rather than just an artifact of random chance or spurious correlation, especially given the fact that these p-values are not calibrated in any way (e.g., Sellke et al., 2001) and Calabrese and Giudici (2015). Further research may include a Bayesian approach, as in Figini and Giudici (2011) and Giudici (2001). We therefore find evidence of a modest improvement in the default predictive performance of our model compared to the conventional approach.
4. Conclusion
This paper improves credit risk management of SMEs engaged in P2P credit services by proposing a factor network-based approach to segment a heterogeneous population into a cluster of homogeneous sub-populations and estimating a credit score model on the clusters using a lasso-type regularization logistic model.
We demonstrate the effectiveness of our approach through empirical applications analyzing the probability of default of over 15,000 SMEs involved in P2P lending across Europe. We compare the results from our model with the one obtained with standard single credit score methods. We find evidence that our factor network approach helps to obtain sub-population clusters such that the resulting models associated with these clusters are more parsimonious than the conventional full population approach, leading to better interpretability and to a modest improved default predictive performance.
Data Availability
All datasets generated for this study are included in the manuscript and/or the supplementary files.
Author Contributions
In this manuscript, all the authors investigated how to improve the credit scoring of SMEs involved in P2P lending via a factor network-based segmentation method. The contribution of this work is manifold. DA extended a recently proposed concept of factor network-based classification to a more realistic setting. PG contributed to network-based models for credit risk quantification using a lasso logistic regression. BH-M presented an application of our approach to model the credit score of over 15,000 SMEs engaged in P2P credit services across Southern Europe.
Funding
Funding from the European Union's Horizon 2020 research and innovation programme under grant agreement No. 825215 (Topic: ICT-35-2018 Type of action: CSA).
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
Ahelegbey, D., Giudici, P., and Hadji-Misheva, B. (2019). Latent factor models for credit scoring in P2P systems. Physica A 522, 112–121. doi: 10.1016/j.physa.2019.01.130
Ahelegbey, D. F., Billio, M., and Casarin, R. (2016a). Bayesian graphical models for structural vector autoregressive processes. J. Appl. Econom. 31, 357–386. doi: 10.1002/jae.2443
Ahelegbey, D. F., Billio, M., and Casarin, R. (2016b). Sparse graphical vector autoregression: a bayesian approach. Ann. Econ. Stat. 123/124, 333–361. doi: 10.15609/annaeconstat2009.123-124.0333
Alam, M., Hao, C., and Carling, K. (2010). Review of the literature on credit risk modeling: development of the past 10 years. Banks Bank Syst. 5, 43–60.
Altman, E. I. (1968). Financial ratios, discriminant analysis and the prediction of corporate bankrupcy. J. Finance 23, 589–609. doi: 10.1111/j.1540-6261.1968.tb00843.x
Andreeva, G., Ansell, J., and Crook, J. (2007). Modelling profitability using survival combination scores. Eur. J. Oper. Res. 183, 1537–1549. doi: 10.1016/j.ejor.2006.10.064
Barrios, L. J. S., Andreeva, G., and Ansell, J. (2014). Monetary and relative scorecards to assess profits in consumer revolving credit. J. Oper. Res. Soc. 65, 443–453. doi: 10.1057/jors.2013.66
Battiston, S., Gatti, D. D., Gallegati, M., Greenwald, B., and Stiglitz, J. E. (2012). Liaisons dangereuses: increasing connectivity, risk sharing, and systemic risk. J. Econ. Dyn. Control 36, 1121–1141. doi: 10.1016/j.jedc.2012.04.001
Billio, M., Getmansky, M., Lo, A. W., and Pelizzon, L. (2012). Econometric measures of connectedness and systemic risk in the finance and insurance sectors. J. Financ. Econ. 104, 535–559. doi: 10.1016/j.jfineco.2011.12.010
Calabrese, R., and Giudici, P. (2015). Estimating bank default with generalized extreme value regression models. J. Oper. Res. Soc. 66, 1783–1792. doi: 10.1057/jors.2014.106
Carvalho, C. M., and West, M. (2007). Dynamic matrix-variate graphical models. Bayesian Anal. 2, 69–98. doi: 10.1214/07-BA204
DeLong, E. R., DeLong, D. M., and Clarke-Pearson, D. L. (1988). Comparing the areas under two or more correlated receiver operating characteristic curves: a nonparametric approach. Biometrics 44, 837–845. doi: 10.2307/2531595
Diebold, F., and Yilmaz, K. (2014). On the network topology of variance decompositions: measuring the connectedness of financial firms. J. Econom. 182, 119–134. doi: 10.1016/j.jeconom.2014.04.012
Eichler, M. (2007). Granger causality and path diagrams for multivariate time series. J. Econom. 137, 334–353. doi: 10.1016/j.jeconom.2005.06.032
Emekter, R., Tu, Y., Jirasakuldech, B., and Lu, M. (2015). Evaluating credit risk and loan performance in online peer-to-peer (P2P) lending. Appl. Econ. 47, 54–70. doi: 10.1080/00036846.2014.962222
Figini, S., and Giudici, P. (2011). Statistical merging of rating models. J. Oper. Res. Soc. 62, 1067–1074. doi: 10.1057/jors.2010.41
Giudici, P. (2001). Bayesian data mining, with applications to benchmarking and credit scoring. Appl. Stochastic Models Bus. Ind. 17, 69–81. doi: 10.1002/asmb.425
Giudici, P., Hadji-Misheva, B., and Spelta, A. (2019). Network-based scoring models to improve credit risk management in peer to peer lending platforms. Front. Artif. Intell., 2.doi: 10.3389/frai.2019.00003
Hastie, T., Tibshirani, R., and Friedman, M. F. (2009). The Elements of Statistical Learning: Data Mining, Inference and Prediction. Barlin: Springer.
IMF (2011). Global Financial Stability Report: Grappling with Crisis Legacies. Technical report, World Economic and Financial Services.
Letizia, E., and Lillo, F. (2018). Corporate Payments Networks and Credit Risk Rating. arXiv:1711.07677. Available online at: https://arxiv.org/abs/1711.07677
Moghadam, R., and Viñals, J. (2010). Understanding Financial Interconnectedness. Mimeo, Washington, DC: International Monetary Fund.
Sellke, T., Bayarri, M., and Berger, J. O. (2001). Calibration of ρ values for testing precise null hypotheses. Am. Stat. 55, 62–71. doi: 10.1198/000313001300339950
Serrano-Cinca, C., and Gutiérrez-Nieto, B. (2016). The use of profit scoring as an alternative to credit scoring systems in peer-to-peer lending. Decis. Support Syst. 89, 113–122. doi: 10.1016/j.dss.2016.06.014
Tabachnick, B. G., Fidell, L. S., and Ullman, J. B. (2007). Using Multivariate Statistics, Vol. 5. Boston, MA: Pearson Publisher.
Tibshirani, R. (1996). Regression shrinkage and selection via the LASSO. J. R. Stat. Soc. B 58, 267–288. doi: 10.1111/j.2517-6161.1996.tb02080.x
Viñals, J., Tiwari, S., and Blanchard, O. (2012). The IMF'S Financial Surveillance Strategy. Washington, DC: International Monetary Fund.
Zou, H. (2006). The adaptive lasso and its oracle properties. J. Am. stat. Assoc. 101, 1418–1429. doi: 10.1198/016214506000000735
Zou, H., and Hastie, T. (2005). Regularization and Variable Selection via the Elastic Net. J. R. Stat. Soc. B 67, 301–320. doi: 10.1111/j.1467-9868.2005.00503.x
Keywords: credit risk, factor models, FinTech, peer-to-peer lending, credit scoring, lasso, segmentation
Citation: Ahelegbey DF, Giudici P and Hadji-Misheva B (2019) Factorial Network Models to Improve P2P Credit Risk Management. Front. Artif. Intell. 2:8. doi: 10.3389/frai.2019.00008
Received: 26 February 2019; Accepted: 13 May 2019;
Published: 04 June 2019.
Edited by:
Dror Y. Kenett, Johns Hopkins University, United StatesReviewed by:
J. D. Opdyke, Allstate Insurance Company, United StatesAparna Gupta, Rensselaer Polytechnic Institute, United States
Copyright © 2019 Ahelegbey, Giudici and Hadji-Misheva. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Daniel Felix Ahelegbey, ZGZrYWhleUBidS5lZHU=