 Arianna Agosto
Arianna Agosto Paolo Giudici
Paolo Giudici Tom Leach
Tom Leach
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
METHODS article
Front. Artif. Intell., 16 May 2019
Sec. AI in Finance
Volume 2 - 2019 | https://doi.org/10.3389/frai.2019.00006
This article is part of the Research TopicAI and Financial TechnologyView all 10 articles
Calabrese et al. (2017) have shown how binary spatial regression models can be exploited to measure contagion effects in credit risk arising from bank failures. To illustrate their methodology, the authors have employed the Bank for International Settlements' data on flows between country banking systems. Here we apply a binary spatial regression model to measure contagion effects arising from corporate failures. To derive interconnectedness measures, we use the World Input-Output Trade (WIOT) statistics between economic sectors. Our application is based on a sample of 1,185 Italian companies. We provide evidence of high levels of contagion risk, which increases the individual credit risk of each company.
In recent years, the emergence of financial technologies (fintechs) is redefining the roles of financial intermediaries and introducing many opportunities for consumers and investors. In particular, peer-to-peer (P2P) online lending platforms allow private individuals to directly make small and unsecured loans to private borrowers.
P2P lending business models vary in scope and structure: a comprehensive review is provided by Claessens et al. (2018). Here we specifically refer to the platforms that lend to small and medium enterprises (SME).
While both classic banks and P2P platforms rely on credit scoring models for the purpose of estimating the credit risk of their loans, the incentive for model accuracy may differ significantly.
In a bank, credit risk assessment is conducted by the financial institution itself which, being the actual entity that assumes the risk, is interested to have the most accurate possible model. In a P2P lending platform, credit risk is determined by the platform but the risk is fully borne by the lender. In other words, P2P platforms allow for direct matching between borrowers and lenders.
A factor that penalizes the accuracy of P2P credit scoring models is that they often do not have access to borrowers' data usually employed by banks, such as account transaction data, financial data and credit bureau data. For these reasons, the accuracy of credit risk estimates provided by P2P lenders may be poor. However, P2P platforms involve their users and, in particular, the borrowers, in a continuous networking activity. Data from such activity can be leveraged not only for commercial purposes, as it is customarily done, but also to improve credit risk accuracy.
We believe that networking information can offset the lack of financial and credit behavioral data and improve credit risk measurement accuracy of P2P lenders, but also of banks. There are indeed cases in which also traditional financial intermediaries face lack of information about the borrower. Consider, for example, credit granting to new customers, for whom internal behavioral data—known to be the most predictive in rating models—are not available.
When financial networks are backed by statistical models, inferential statements can be obtained. Important contributions in this framework are Billio et al. (2012); Diebold and Yilmaz (2014); Hautsch et al. (2015); Ahelegbey et al. (2016); Giudici and Spelta (2016), and Giudici and Parisi (2018), who propose measures of connectedness based on similarities, Granger-causality tests, variance decompositions and partial correlations between market price variables.
We improve these contributions, extending them to the P2P context and linking network models, that are often merely descriptive, with econometric models, thus providing a predictive framework.
More specifically, we suggest to use spatial econometrics to study the interconnectedness in the corporate sector. Spatial econometrics incorporates dependence among observations that are in any kind of proximity, not only geographical.
In particular, the model we apply is a logit Spatial Autoregressive model based on an exogenously defined network. The main advantage of this approach over the traditional network analysis is that it can be used as both an early warning model, to forecast the failure of a given company, and as a stress testing technique taking systemic effects into account.
The paper is organized as follows. Section 2 explains the econometric methodology. Section 3 presents the results obtained by applying the proposed methodology to data collected from a European P2P lending information provider. Section 4 concludes.
The model we use in this paper has a binary spatial autoregressive structure, whereby the dependent variable is binary and a spatial autoregressive structure is assumed in the underlying latent variable. Taking the latent underlying quantity to be represented by a continuous variable , we consider the observation mechanism as
with i = 1, 2, …, n.
We implement the spatial structure with an autoregressive model specification, such that
where Y* is a continuous random vector, X represents an n × k matrix of explanatory variables with related coefficient vector β, ϵ is the error term and W is the spatial lag weight matrix with ρ the associated coefficient, which in our application to defaults will be interpreted as a contagion parameter.
The model implies heteroskedastic errors e as follows:
where
and
The defined model has been used by Calabrese et al. (2017) to study default interdependence in the European banking sector. Relative to the estimation, Calabrese and Elkink (2014) have provided a review of the main methodologies for model (3) in the literature. Among the various approaches, we focus on the Generalized Method of Moments (GMM) proposed by Pinkse and Slade (1998). They derive the Generalized Method of Moments (GMM) moment equations from the likelihood function of a spatial error probit model, for which Klier and McMillen (2008) provide the extension to logit models. The GMM approach does not rely on a potentially inaccurate assumption of normally distributed errors and is therefore more robust than maximum likelihood methods.
In general, a GMM estimator is defined by:
where mn(θ) are the moment conditions and Ωn is a weighting matrix to be determined.
In our case, we have:
To construct the moments, following Pinkse and Slade (1998) we use the generalized residuals
where:
It follows from specification (3) that the elements of the spatially lagged dependent vector WY* are correlated with those of the error vector, hence the need for instrumental variables. Following Kelijian and Prucha (1998), who suggest to choose the instruments as a subset of the linearly independent columns of:
we define the instrument matrix1
Thus, generating the moment conditions via the identity:
can be estimated by the following
The estimation algorithm used in our application is explained in detail in section 2.3.
The spatial regression model we propose is based on an exogenously defined network, where the nodes correspond to individual companies and the ties express the volume of trade between any pair of companies, i.e., the trade flow from company i to company j, for each i and each j. This information is generally not available, so we must approximate it using data on aggregate input-output trade between sectors.
The World Input Output Trade (WIOT) statistics provide information on the aggregate trade volumes of 52 economic sectors in each country with all sectors in all countries.
For a given country, define A as the sector of company i, B as the sector of company j, and let fAB be the trade flow from sector A to sector B, while fBA is the trade flow from sector B to sector A.
Replacing the individual flows with the aggregate ones, the entries of the approximate trade matrix F are then obtained as:
To use these data for proxying the individual companies' flows, we need to calculate the proportion of each company in terms of size over its sector using a suitable measure, such as turnover or the value of trade receivables (for inflows) and payables (for outflows).
Consider, for example, the case of determining the trade flows from company i, belonging to sector A, to company j, belonging to sector B, knowing the individual trade payables and receivables.
We first calculate the ratio between company i trade payables and the sum of sector A trade payables:
Then we calculate the ratio between company j trade receivables and the sum of sector B trade receivables:
The product xiyj is a proxy of the proportion of flows from company i to company j on the total flows from sector A to sector B.
Repeating this calculation for all companies, we get the matrix:
Finally, by calculating the entrywise product of R and the trade matrix F, we get the following matrix:
Note that the ij element can be interpreted as the proxy of the trade flow from company i to company j. Conversely, the ji element can be interpreted as the proxy of the trade flow from company j to company i. The estimated flows define the magnitude of intercompany connections. To use W as a spatial weighting matrix in our application, we need to set the entries on the diagonal to 0 and normalize the rows so as to sum to 1.
To estimate the SAR model parameters, we use a two-step estimation procedure:
(i) minimize Equation (8), letting Ω = I2k−1, to obtain parameter estimates and calculate the optimal weighting matrix by computing the covariance of the moments:
where the residual vector u is calculated as in (7).
(ii) recompute the parameter estimates by substituting the identity matrix with the optimal weight matrix:
Note that this procedure requires inversion and multiplication of large matrices, so the computation time can be very long when working with large datasets. Possible solutions should be based on suitable simplifications to the connectivity matrix W to make it more sparse, such as fixing a threshold for the relevance of trade flows. However, with our sample size (n = 1, 185) the computational time for the two-step algorithm is more than acceptable. We remark that the employed data is available as Supplementary Material.
In this section we empirically verify whether the predictive performance of P2P credit scoring models can be improved using correlation network models. In particular, we are interested in assessing significance and magnitude of the contagion parameter ρ. The more the contagion parameter is close to 1, the more the networking information can support credit risk evaluation. To achieve this goal, we have collected data from a European Credit Assessment Institution (ECAI), that supplies credit scorings to P2P platforms specialized in business lending. We use data relative to 1,185 borrowing Italian SMEs, in 2015–2016. The proportion of observed defaults in our sample is nearly 11%, which is large, in line with the observed impact of the recent financial crisis in Southern European countries. The available data include the status of the companies, classified as [1 = Defaulted] and [0 = Active], in 2016 as well as some main financial information, for year 2015. From the available data, we select three financial ratios reflecting the three most important aspects related to default probability: operational performance, business sustainability and financial sustainability. Specifically, we consider:
• the return on equity ratio (RATIO012)
• the activity ratio, expressed as the ratio between sales and total assets (RATIO018);
• the solvency ratio, expressed as the ratio between the net income and the total debt (RATIO027)
The spatial weight matrix W has been built from the WIOT database, as described in section 2.2 and using turnover as a company size measure. Figure 1 shows the network based on the estimated connections.
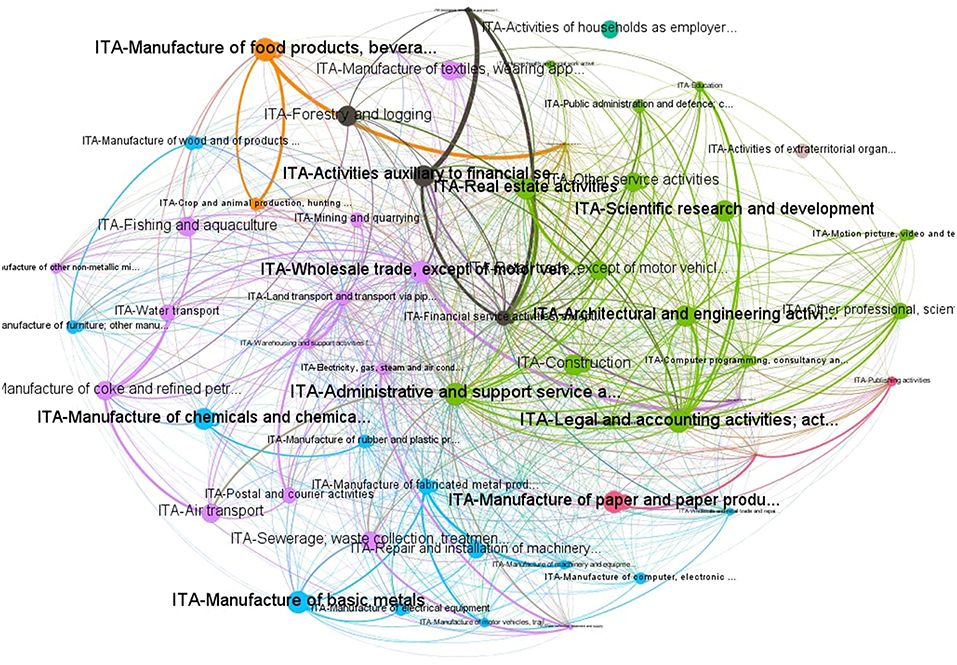
Figure 1. Network of P2P Italian SMEs.
Table 1 shows the parameter estimates obtained using a simple logit model, without the spatial component.
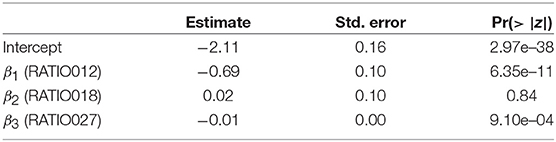
Table 1. Results of estimation of non-spatial logit model.
Then we estimate the SAR model (3) through the algorithm presented in section 2.3. The obtained results are reported in Table 2.
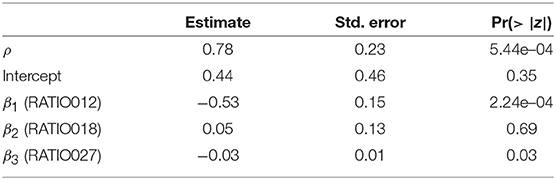
Table 2. Results of estimation of SAR model.
We first note from Table 2 that the contagion parameter is significant and its value is high (0.78). The effect of financial ratios is stable, supporting the SAR specification including both a spatial and an exogenous component. Thus, considering a measure of connectivity between companies significantly explains the credit risk arising from P2P lending, improving the traditional analysis based on individual financial indicators.
Including the spatial component also improves model accuracy, as shown in Figure 2 plotting the ROC curves of the simple logit and the spatial logit model. The AUC (Area Under the ROC Curve) values are 0.798 and 0.806, respectively. It is worth noting that the difference in the AUC values is modest and could turn out to be non-significant in an out-of-sample exercise. However, the proposed specification defines a contagion model which can support the analysis of interconnectedness between the agents' default risk, even when this does not improve the predictive performance in a crucial way. Future research may concern dealing with unbalanced samples (as in Calabrese and Giudici, 2015) and/or with multiple data sources (as in Figini and Giudici, 2011).
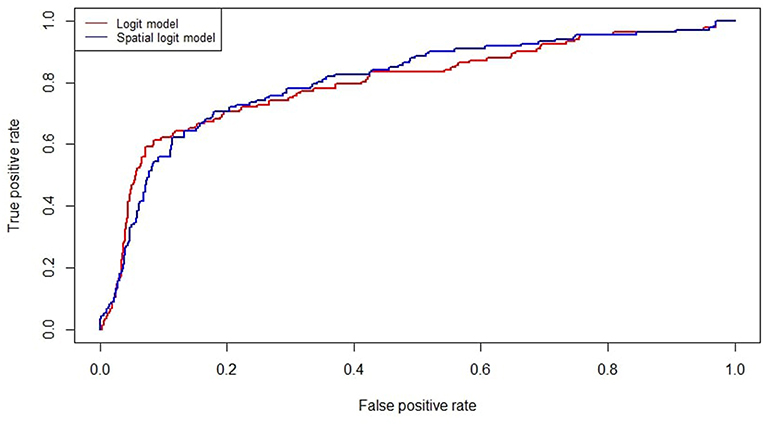
Figure 2. ROC curves of baseline and spatial logit models.
This paper provides a method, based on binary spatial regression models, to improve default prediction by estimating the interdependence between companies due to trade ties.
We have applied the methodology to a sample of Italian companies, finding evidence of a high level of spatial autocorrelation, interpretable as a credit contagion parameter.
The proposed model provides both a description of contagion (through the spatial component) and a predictive capability, differently from most existing contagion models, which provide either of the two. The model can be easily implemented, as a modification of a classical logistic regression that includes interconnectedness. We believe that the findings which can be derived from spatial autoregressive models may be useful, especially for P2P lenders who can use it to improve credit risk assessment.
From a methodological viewpoint, further research may involve employing a different generalized linear model, such as the generalized extreme value regression models discussed in Calabrese and Elkink (2016). Moreover, the dependence structure could be extended to the dynamic case (Arakelian and Dellaportas, 2012).
The datasets for this manuscript are not publicly available because the data were provided by a private company. Requests to access the datasets should be directed to paolo.giudici@unipv.it.
All authors listed have made a substantial, direct and intellectual contribution to the work, and approved it for publication.
This research has received funding from the European Union's Horizon 2020 research and innovation program FIN-TECH: A Financial supervision and Technology compliance training programme under the grant agreement No. 825215 (Topic: ICT-35-2018, Type of action: CSA).
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/frai.2019.00006/full#supplementary-material
1. ^As explained in Kelijian and Prucha (2010), H proxies the expected value of WY* using its projection on X.
Ahelegbey, D. F., Billio, M., and Casarin, R. (2016). Bayesian graphical models for structural vector autoregressive processes. J. Appl. Econometr. 31, 357–386. doi: 10.1002/jae.2443
Arakelian, V., and Dellaportas, P. (2012). Contagion determination via copula and volatility threshold models. Quant. Finan. 12, 295–310. doi: 10.1080/14697680903410023
Billio, M., Getmansky, M., Lo, A. W., and Pelizzon, L. (2012). Econometric measures of connectedness and systemic risk in the finance and insurance sectors. J. Finan. Econ. 104, 535–559. doi: 10.1016/j.jfineco.2011.12.010
Calabrese, R., and Elkink, J. (2014). Estimators of binary spatial autoregressive models: a Monte Carlo study. J. Reg. Sci. 54, 664–687. doi: 10.1111/jors.12116
Calabrese, R., and Elkink, J. (2016). Estimating binary spatial autoregressive models for rare events. Adv. Econometr. 37, 147–168. doi: 10.1108/S0731-905320160000037012
Calabrese, R., Elkink, J., and Giudici, P. (2017). Measuring bank contagion in Europe using binary spatial regression models. J. Operat. Res. Soc. 68, 1503–1511. doi: 10.1057/s41274-017-0189-4
Calabrese, R., and Giudici, P. (2015). Estimating bank default with generalised extreme value regression models. J. Operat. Res. Soc. 66, 1783–1792.
Claessens, S., Frost, J., Turner, G. and Zhu F. (2018). Fintech credit markets around the world: size, drivers and policy issues. BIS Q. Rev. 29–49.
Diebold, F. X., and Yilmaz, K. (2014) On the network topology of variance decompositions: measuring the connectedness of financial firms. J. Econometr. 182, 119–134. doi: 10.1016/j.jeconom.2014.04.012
Figini, S., and Giudici, P. (2011). Statistical merging of rating models. J. Operat. Res. Soc. 62, 1067–1074.
Giudici, P., and Parisi, L. (2018). CoRisk: credit risk contagion with correlation network models. Risks 6:95. doi: 10.3390/risks6030095
Giudici, P., and Spelta, A. (2016). Graphical network models for international financial flows. J. Bus. Econ. Stat. 34, 126–138. doi: 10.1080/07350015.2015.1017643
Hautsch, N., Schaumburg, J., and Schienle, M. (2015). Financial network systemic risk contributions. Rev. Finan. 19, 685–738. doi: 10.1093/rof/rfu010
Kelijian, H. H., and Prucha, I. R. (1998). A generalized spatial two-stage least squares procedure for estimating a spatial autoregressive model with autoregressive disturbances. J. Real Estate Finan. Econ. 17, 99–121. doi: 10.1023/A:1007707430416
Kelijian, H. H., and Prucha, I. R. (2010). Specification and estimation of spatial autoregressive models with autoregressive and heteroskedastic disturbances. J. Econometr. 157, 53–67. doi: 10.1016/j.jeconom.2009.10.025
Klier, T., and McMillen, D. (2008). Clustering of auto supplier plants in the United States: generalized method of moments spatial logit for large samples. J. Bus. Econ. Stat. 26, 460–471. doi: 10.1198/073500107000000188
Keywords: credit risk, systemic risk, contagion, spatial autoregressive models, binary data
Citation: Agosto A, Giudici P and Leach T (2019) Spatial Regression Models to Improve P2P Credit Risk Management. Front. Artif. Intell. 2:6. doi: 10.3389/frai.2019.00006
Received: 04 March 2019; Accepted: 30 April 2019;
Published: 16 May 2019.
Edited by:
Jiancheng Jiang, University of North Carolina at Charlotte, United StatesReviewed by:
Jianan Peng, Acadia University, CanadaCopyright © 2019 Agosto, Giudici and Leach. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Arianna Agosto, YXJpYW5uYS5hZ29zdG9AdW5pcHYuaXQ=
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.