 Yang Chen
Yang Chen Yijia Ma
Yijia Ma Wei Wu
Wei Wu- Department of Statistics, Florida State University, Tallahassee, FL, United States
Temporal point process, an important area in stochastic process, has been extensively studied in both theory and applications. The classical theory on point process focuses on time-based framework, where a conditional intensity function at each given time can fully describe the process. However, such a framework cannot directly capture important overall features/patterns in the process, for example, characterizing a center-outward rank or identifying outliers in a given sample. In this article, we propose a new, data-driven model for regular point process. Our study provides a probabilistic model using two factors: (1) the number of events in the process, and (2) the conditional distribution of these events given the number. The second factor is the key challenge. Based on the equivalent inter-event representation, we propose two frameworks on the inter-event times (IETs) to capture large variability in a given process—One is to model the IETs directly by a Dirichlet mixture, and the other is to model the isometric logratio transformed IETs by a classical Gaussian mixture. Both mixture models can be properly estimated using a Dirichlet process (for the number of components) and Expectation-Maximization algorithm (for parameters in the models). In particular, we thoroughly examine the new models on the commonly used Poisson processes. We finally demonstrate the effectiveness of the new framework using two simulations and one real experimental dataset.
1. Introduction
Temporal point process is a collection of mathematical points randomly located on the real line, where the domain can be a finite interval or the whole line [1]. It is very common to observe temporal point pattern data in practice, for example, a sequence of time points of incoming calls in a phone, the occurrence of earthquakes, or the usage of a mobile app [2]. Studying the underlying mechanisms of these random times is an important subject in the field of stochastic process. Classical models on temporal point process are time-based, where we treat the sequence of times as having an “evolutionary character.” That is, what happens now may depend on what happened in the past, but not on what is going to happen in the future [3]. A time-based function, referred to as conditional intensity function, is used to describe the process. For regular point processes [4], it was shown that the conditional intensity function can determine the probability structure of the process uniquely [1]. However, because of the computational complexity, it is often a significant challenge to estimate the conditional intensity function. Various simplified or parametric forms have been introduced to model practical observations. For example, renewal processes are used to approximate complex point processes [5]; Hawkes processes are often used in the finance area [6]; and neuronal spike trains have been commonly modeled using parametric point processes [7, 8].
We point out that these time-based methods only focus on modeling the probability distribution at every time point. They do not characterize patterns or structures of the process as a whole. For example, they do not provide a notion of “center” (or “template”) of a set of point process realizations, provide a center-outward rank on each realization, or identify outliers in the data. The center-outward rank has been thoroughly studied with the notion of statistical depth for multivariate and functional observations. Conditioned on the number of events, a point process can be treated as a multivariate sequence [9]. Commonly used depth methods such as halfspace depth [10], simplicial depth [11], Mahalanobis depth [9, 12], and likelihood depth [13], can be directly applied. All these depth methods own desirable mathematical properties, which are well summarized by Zuo and Serfling, [14]. Alternatively, a smoothing procedure can be adopted to convert point process to a smooth function. In this case, commonly used depth on functional data such as projection-based functional depths [15], band depth [16], half region depth [17], multivariate functional halfspace depth [18], and Pareto depth [19] can be adopted to examine center-outward rank in the given data. A formal definition of statistical depth was provided for functional data [20], where they pointed out six properties that a valid functional depth should satisfy. Note that all depth methods only provide a rank, but do not describe a model or distribution for given observations. In contrast, we aim to propose rank-based models on the temporal point processes in this article.
In practice, point processes are often studied in a finite time domain [0, T]. In this case, the event times can be equivalently represented using inter-event times (IETs). As the IETs are non-negative with sum being the constant T, one may adopt a Dirichlet distribution to describe them directly. This uni-modal distribution can naturally define a center-outward rank of the data, and the depth function on a point process is called a Dirichlet depth [21]. This is shown in Figure 1A as one illustration, where we generate 2000 two-event realizations from a binomial point process (see details in Section 3). The IETs of two events from a binomial process are displayed in a three-dimensional space.
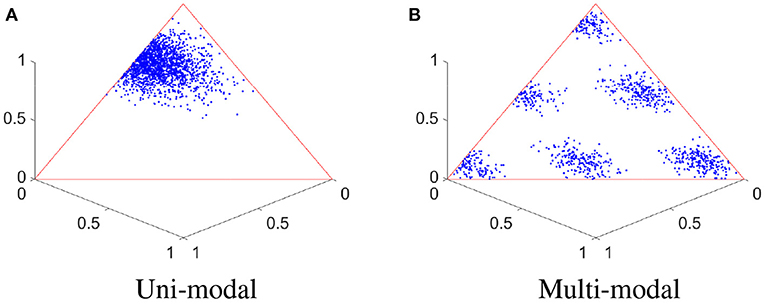
Figure 1. Uni-modal and multi-modal IETs. (A) IETs of a two-event binomial process, with a uni-modal distribution. (B) IETs of another two-event binomial process, with a multi-modal distribution.
However, practical data may have more complicated structures than a uni-modal distribution; that is, a single Dirichlet distribution may not be able to fully characterize the details of the conditional distribution of IETs. Using another binomial point process, its 2000 two-event IET vectors are shown in Figure 1B, where a clear multi-modal distribution is observed. In this article, we further propose to extend the notion of rank-based Dirichlet model to a more general framework—a Dirichlet mixture model, where we model the IETs of a point process (conditioned on the number of events) using a mixture of Dirichlet distributions.
For uni-modal Dirichlet distribution, the parameters in the model can be easily estimated using a classical maximum likelihood approach. However, the estimation is more challenging for a mixture model. In principle, we need to do two estimations: one is on the number of mixture components, and the other is on the parameter values given the component number. We propose to use a Dirichlet process and Expectation-Maximization (EM) algorithm to handle these two estimations, respectively. Dirichlet Process Mixture (DPM) model is a nonparametric mixture model which allows infinitely many components. The method can conduct clustering on observations without model selection. The Dirichlet Process was first presented as a class of prior distributions for nonparametric problems [22], and then extended with the formal definition for Dirichlet Process Mixture [23]. In particular, Markov chain Monte Carlo (MCMC) methods are often used for the purposes of inference and sampling in the DPM model.
For the Dirichlet model, conjugate prior is often not available [24, 25]. In this case, approximations based on Monte Carlo methods can be computationally expensive. In order to take advantage of the conjugate priors and simplify the calculation, instead of modeling IETs directly using a Dirichlet mixture, we also propose an indirect model by adopting the isometric logratio transformation in compositional data analysis [26, 27]. By this bijective transformation, the IETs are transformed to an unconstrained Euclidean space. Then, a classical multivariate Gaussian Mixture model (GMM) can be adopted to model the transformed data. For GMM, the closed-form estimations in the Dirichlet process posterior and EM algorithm are thoroughly studied in Murphy [28] and Bilmes [29] and no approximation is needed.
The rest of this manuscript is organized as follows: In Section 2, we will provide details of the Dirichlet model, Dirichlet mixture model on the IETs and Gaussian mixture model on the transformed IETs. The estimation procedures, including Dirichlet process and EM algorithm will also be given. In Section 3, two simulation experiments will be used to illustrate the center-outward ranking of the proposed models. We will also apply the new methods to conduct a classification task in a real experimental data set. Finally, we will summarize our work in Section 4.
2. Methods
2.1. Likelihood in a Temporal Point Process
Mathematical modeling on the temporal point process has been a central problem in stochastic process. We will at first review the classical theory on point process and then provide a new framework for the likelihood representation.
2.1.1. Review of the Classical Theory
Classical methods have focused on regular point processes, where the event times can be ordered increasingly without overlapping. Only finite number of events are allowed in any finite time interval, and the commonly used conditional intensity function can be well defined. In practical use, point process observations are often in a finite domain and we limit our study in an interval [0, T], where T > 0 denotes the time length.
Assume a temporal point process is given as with and i = 1, 2, ⋯ . Denote the conditional density function of the event time sn+1 given the history of previous events . Using the chain rule of the conditional distribution, the joint density can be represented as follows:
For any u > sn, the conditional intensity function is defined in the following form:
where is the conditional cumulative distribution function. The conditional intensity function λ*(u) models the mean number of events in a region conditional on the past, and it can determine the probability structure of a regular point process uniquely [1]. Using λ*(u), the likelihood of a point process realization (s1, ⋯ , sn) on (0, T) is given by
where is the integrated conditional intensity function.
This time-based description characterizes the probability structure at any time. However, it does not describe the center-outward rank, or relative “importance,” of each realization. For example, for a homogeneous Poisson process (HPP) with constant intensity λ*(s) = λ, the likelihood is:
Given the time interval [0, T] and intensity rate λ, the likelihood only depends on n. That is, realizations with the same number of events will have equal likelihood, regardless of their event times. Such likelihood cannot properly define a center-outward rank to indicate the centrality (or outlyingness) of each realization. In the article, we aim to propose a data-driven model on point processes which leads to a proper center-outward rank.
2.1.2. Rank-Based Likelihood Representation
To characterize the overall pattern of a temporal point process s = (s1, ⋯ , sn), we need to measure the likelihood of two types of randomnesses: (1) the number of events in the process and (2) the distribution of these events. That is, the likelihood of the process s can also be calculated via the following equation.
where |s| denotes the cardinality of the sequence s.
Note that |s| is a random variable. For a regular point process on [0, T], p(|s| < ∞) = 1. As |s| is only a one-dimensional counting variable, there are a lot of possible ways to model it such as a parametric Poisson model or a nonparametric model. The key challenge is at the conditional distribution p(s||s|). In the special case of a Poisson process with (history-independent) intensity function λ(t), it is known that and
A point process, however, in general is history-dependent, and there will be no such explicit formula for the conditional distribution. Parametric models such as Gaussian distribution [9] and Dirichlet distribution [21] can be considered. Our main goal of this article is to provide a rank-based parsimonious model on this conditional distribution which can properly characterize practical observations. This will be clearly given in the following subsections.
2.2. Rank-Based Conditional Model
2.2.1. Dirichlet Model
In this section, we will provide models for the conditional distribution p(s = (s1, ⋯ , sd)| |s| = d) in Equation (1). Given the number of events, a parsimonious Dirichlet distribution is proposed to describe the conditional distribution of inter-event times. Note that this model may not describe the true likelihood of the realization, but provides a reasonable data-driven description of the importance or center-outward rank of the given realization. Therefore, the probability representation is actually a “pseudo-likelihood,” and is denoted as .
It is commonly known that a point process can be equivalently represented by their inter-event times (IETs). That is, for a point process with d events 0 < s1 < s2 < ⋯ < sd < T, its IETs are given as u1 = s1, u2 = s2−s1, ⋯ , ud = sd−sd−1, ud+1 = T−sd. The IET sequence u = (u1, u2, ⋯ , ud+1) forms a d-dimensional simplex (scaled standard simplex) as:
which has the same support as a Dirichlet distribution. Therefore, it is natural to adopt a Dirichlet distribution to model the conditional distribution of the IETs as follows.
2.2.1.1. Dirichlet Model
For a point process s = (s1, ⋯ , sd) in time interval (0, T), let s0 = 0 and sd+1 = T. Then its IET vector lies on a d-dimensional simplex. We model the conditional distribution of this process using a d+1 dimensional Dirichlet distribution with parameters on its IET vector. That is:
where Γ(·) is a Gamma function, and αi > 1 for i = 1, ⋯ , d+1 to guarantee the unique mode in the Dirichlet model.
Based on the IET representation, the Dirichlet model in Equation (2) can naturally take into account the orderedness and boundedness of all events in a point process. In addition, the center of the process can be characterized by the mode of the Dirichlet distribution. In a Dirichlet model, the likelihood reaches the maximum when , i = 1, ⋯ , d+1. Also, it is easy to verify that the likelihood value decreases from the center monotonically. That is, a center-outward rank can be naturally given by the likelihood value.
2.2.2. Model Identification
Given point process observations, we will need to estimate the parameter α of the Dirichlet model in Equation (2). We propose to conduct the conventional Maximum Likelihood Estimate (MLE) procedure. Assume we have observed N independent realizations with d events, that is S = (S1, S2, ⋯ , SN), where Sn = (sn, 1, sn, 2, ⋯ , sn, d). Then the log-likelihood function L(α) is given as follows:
We propose to use the Newton-Raphson (N-R) method to find the maximum of L(α) [30]. In order to use the method, we need to derive the gradient ∇L and Hessian matrix H with respect to the parameter α. The gradient is obtained by calculating the first-order derivatives:
where is known as the digamma function. To get the Hessian matrix , we need to calculate the second-order derivatives:
Note that for a large value of d, the computation of H−1 can be very costly. To make the procedure more efficient, we can rewrite the hessian matrix as H = Q+c11T, where Q = diag(q1, ⋯ , qd+1) with , , and 1 ∈ ℝd+1 is a column vector with every entry being 1. It is easy to see that . Therefore, the parameter α can be updated using the following iteration:
The MLE estimate above is for a given number of events d. For a point process, we need to estimate the Dirichlet parameters in each dimension. In practice, we will set an upper bound D and only make estimations for the cases with up to D events.
2.3. Dirichlet Mixture Models
We have proposed to use a Dirichlet model to represent the likelihood of the IETs of a given point process realization. However, the underlying distribution of the IETs of a point process may be more complicated than a unimodal Dirichlet distribution. In this section, we will propose to adopt a mixture model to address this issue.
2.3.1. Mixture of Dirichlet Distribution
We will at first use an example to illustrate the insufficiency of Dirichlet model for complicated IET patterns. In Figure 2A, the scatter plot is the point cloud from a binomial point process with 2 events (see simulation detail in Section 3). A single Dirichlet model (shown with multiple contour lines) cannot properly describe the multi-modal pattern. In Figure 2B, we adopt a mixture of Dirichlet distributions, which apparently provides a more appropriate characterization on the observed IETs.
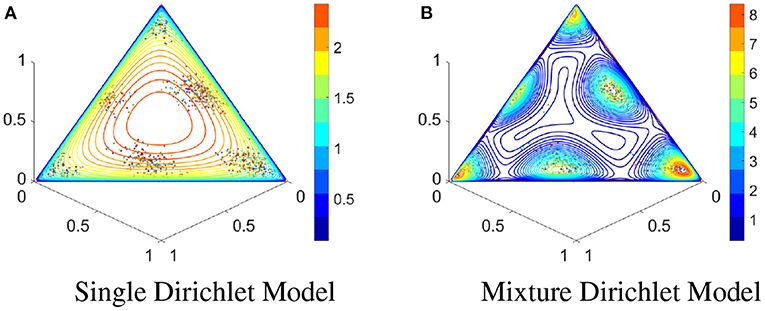
Figure 2. IETs of a binomial point process and contours of Dirichlet models. (A) IETs of simulated binomial point process with 2 events and contours of a fitted single Dirichlet model. (B) Same as (A) except using a Dirichlet mixture model with 6 components.
The Dirichlet mixture model on the conditional distribution of IETs is formally given as follows:
2.3.1.1. Dirichlet Mixture Model
For a point process s given |s| = d in time interval (0, T), let s0 = 0, sd+1 = T, and the IETs u = (u1, u2, ⋯ , ud+1) = (s1−s0, s2−s1, ⋯ , sd+1−sd). The conditional distribution of IETs is modeled using a Dirichlet mixture model:
where K denotes the number of the mixture components, wk is the weight parameter of kth component, α·, k = (α1, k, ⋯ , αd+1, k) are the parameters of the kth Dirichlet distribution, k = 1, ⋯ , K.
In practice, we need to estimate parameters in a Dirichlet mixture model for given IETs. To do so, we need to estimate (1) the number of components K and (2) parameters {αi, k} and {wk} in each component. Estimation of K is a classical model selection problem. We propose to adopt a nonparametric Dirichlet process to find an optimal component number. Once this number is known, we will use an Expectation-Maximization (EM) algorithm to estimate parameters {αi, k} and {wk}. These two procedures are clearly given in the following subsections.
2.3.2. Model Selection via Dirichlet Process
Dirichlet Process [22] defines a prior distribution for the mixture. In this subsection, we propose to use a Monte-Carlo method to estimate the optimal number of components in the mixture.
2.3.2.1. Prior
Assume the mixture of Dirichlet distributions in Section 2.3.1 has a prior of Dirichlet Process with exponential base distribution G0 = exp(λ) and a scalar precision parameter γ > 0 for the components concentration. N observations X = {X1, ⋯ , XN} are given in the Dirichlet mixture model, where each observation comes from one of the mixture components. Using the Dirichlet process, we can write the prior information of the mixture model as:
where λ is a hyperparameter of the base distribution G0, Xi = (xi1, ⋯ , xid) is the ith observation, θi = (α1, (i), ⋯ , αd, (i)) is the parameters of the component that the ith observation Xi belongs to. Note that if θi = θj, then the ith and jth components are from the same component.
To sample from the posterior distribution easily, we need to introduce the equivalent view of the Dirichlet Process, known as “Chinese Restaurant Process” [31]. Given the Dirichlet process prior we described in Equations (3), the indicator variable follows the Chinese Restaurant Process. That is
where zi is the indicator variable corresponding to the ith observation, , and is the number of observations in (X1, ⋯ , Xi−1, Xi+1, ⋯ , XN) belonging to jth component.
2.3.2.2. Posterior of Indicator
Assume we fix the currently existing component parameters Θ = (θ1, …, θk). Given γ and observations X, the posterior probability of indicators can be written as:
For the existing components:
For the new component:
Integrating over Θ, we get
where H−i(θj) is the posterior distribution of θ based on the prior G0 and all observations , zl = j, and .
2.3.2.3. Non-conjugate Estimation
The integrals in Equations (8) and (9) can be integrated analytically in a conjugate context. Dirichlet and Exponential distributions, however, are not conjugate, and we need to find another method to estimate the posterior distribution of indicators Z = (z1, ⋯ , zn) [24]. In this article, we propose to substitute Θ into Equations (6) and (7) to estimate the posterior distribution of Z.
Then for Equation (6)
When θj is available, it is straight forward to obtain the result in Equation (10). For Equation (7)
In Equation (11), the integral term is on one sample Xi. Therefore, a Monte-Carlo method can be adopted. We will generate M samples of θ from G0, denoted as , and then estimate the integral term as.
2.3.2.4. Maximum a Posteriori (MAP) for Estimating Θ
Next, we will use the MAP to estimate the new θj after each iteration. The likelihood with the prior knowledge is
Hence, the log-likelihood is
where {X1, X2, …, Xnj} is a set of observed multinomial data in component j, and . Similar to Section 2.2.2, we can use the Newton-Raphson's method to find the maximum of l(θ). The details are omitted here.
So far we have sampled Dirichlet Mixture Distributions from the posterior DP iteratively. For each sample, we have a number of components. Therefore, we obtain an empirical distribution of number of components and an “optimal” number of components for the given data can be taken as the mean, median, or mode of the distribution thereafter. In practice, such distribution often has a narrow range of optimal values. The MCMC algorithm is given in Algorithm 1 as follows, where NumOfComponents denotes the number of components for the given data.

Algorithm 1. Dirichlet Process to Estimate the Number of Components.
2.3.3. Model Identification via EM Algorithm
Once an optimal number of events is estimated using the Dirichlet process, we can estimate parameters in the Dirichlet mixture model. This estimation can be effectively done with an EM algorithm.
Let S = {s1, s2, ⋯ , sN} denote N observed realizations with d events. Their equivalent representations using IETs are denoted by U = {u1, ⋯ , uN} in simplex . We will model these IETs using a Dirichlet mixture model with K components. The likelihood of all observations is given as
where denote all parameters with wk being the weight coefficient and α·, k = (α0, k, ⋯ , αd, k) in the density of Dirichlet distribution fk, k = 1, ⋯ , K. We use Z = {Z1, Z2, ⋯ , ZN} to denote the missing labels of all observations, where Zi = (zi, 1, ⋯ , zi, K) with
2.3.3.1. E-Step
Our goal is to maximize f(U|θ). Based on conditional representation f(U, Z|θ) = f(U|θ)f(Z|U, θ), we get
Taking expectation on both side with respect to the density function f(Z|U, θ(m)) for estimate θ(m) after m-th iteration, we have
where Q(θ|θ(m), U) = E[logf(U, Z|θ)|θ(m), U] and H(θ|θ(m), U) = E[logf(Z|U, θ)|θ(m), U].
According to (14), the Q function can be written as.
2.3.3.2. M-Step
We will update {αd, k} to maximize Q function by solving
with the Newton-Raphson method. Update {wk} by solving
where
and λ is the Lagrange multiplier.
In summary, the EM-algorithm is given in Algorithm 2 as follows.

Algorithm 2. Parameter Estimation using the EM Algorithm.
2.3.4. Multiple Mixture Models
When the number of events, d, is given in the point process, we have proposed a combination of Dirichlet process and EM algorithm to estimate the parameters in the model. However, point process data often have observations with various numbers of events, and we need to estimate a model for each case. In practice, we can set an upper bound D, and only estimate models with number of events up to D. To make the estimation procedure feasible, we will only use Dirichlet process to estimate the number of mixture components for d = D, and then use the same component number for d = 1, ⋯ , D − 1. To identify these mixture models, the EM algorithm will be used for each value of d = 1, ⋯ , D. We use wk:d to denote the weight parameter and α·, k:d to denote the Dirichlet parameters for kth component in d dimensional cases. The algorithm is shown below.
2.4. Alternative Mixture Model
In Subsection 2.3, we have proposed a Dirichlet Mixture Model to describe the conditional distribution of IETs of a point process. Dirichlet distribution has the same support as IETs so that it is suitable for the IET modeling. However, the Dirichlet process and EM algorithm for the mixture Dirichlet distributions have no closed-form updates. We choose to rely on Monte Carlo or gradient methods to approximate the solutions, which are computationally expensive. In this subsection, we introduce an alternative approach based on compositional data analysis. Firstly, we apply the bijective isometric logratio transformation (ilr) [26] to map the IETs from D-dimensional simplex to ℝD−1. Then a Gaussian Mixture model can be utilized to characterize the distribution of transformed IETs in the Euclidean space and we can take advantages of the conjugate prior with closed-form solutions.
2.4.1. Isometric Logratio Transformation and Gaussian Mixture Model
Compositional data is fundamentally different from unconstrained multivariate data that it has a constant sum constraint [27]. The bijective logratio transformation methods such as centered logratio transformation (clr) and isometric logratio transformation (ilr) [32] have been successfully used to deal with such type of data. They transform the original data to an unconstrained space, making it possible to use various conventional multivariate models on the transformed data. The isometric logratio transformation is a preferred version of such transformation with the apparent advantages such as distance and angle preserving and full rank covariance. Given , we can denote the centered logratio transformation as:
where is the component-wise geometric mean. Together with an appropriate clr-matrix of the orthonormal basis, Ψ ∈ ℝD × (D−1), the isometric logratio transformation can be expressed as:
Gram-Schmidt techniques [26] can be utilized to obtain an appropriate orthonormal basis of the simplex easily. The entries of Ψ can be expressed as:
Assuming we have N observations and their corresponding IETs U = {u1, ⋯ , uN} in simplex , the ilr transformation can help remove the constant-sum constraint of U by mapping it to an unconstrained Euclidean space ℝd−1, i.e., . Because of its isometric property, the clustering components will be preserved (See one example in Figure 3). This makes the commonly used Gaussian Mixture model appropriate for ilr(U).
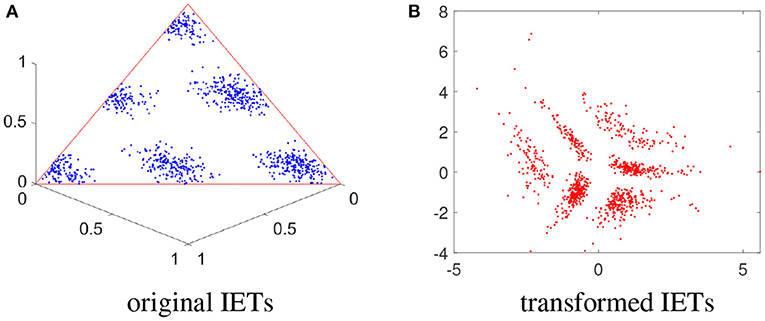
Figure 3. 2-event IETs on simplex and transformed IETs on Euclidean space. (A) Scatter plot for the original IETs on the 3-D simplex. (B) Transformed IETs after ilr transformation in the 2-D Euclidean space.
After removing the constant sum restriction, the transformed IET vector ilr(U) is in an unconstrained Euclidean space so that the classical multivariate Gaussian Mixture model (GMM) can be used directly. For a given process, we firstly conduct the ilr transformation, and then fit a GMM on the transformed data. This modeling procedure is given as follows:
2.4.1.1. Gaussian Mixture Model
For a point process s given |s| = d in time interval [0, T), let s0 = 0, sd+1 = T, and the IET vector u = (u1, u2, ⋯ , ud+1) = (s1−s0, s2−s1, ⋯ , sd+1−sd). Using the ilr transformation, we have u* = ilr(u) ∈ ℝd−1, the conditional distribution of point process is modeled using a Gaussian mixture model on u*:
where K denotes the number of the mixture components, wk is the weight parameter of kth component, and and are the mean and covariance of the kth Gaussian distribution, respectively, k = 1, ⋯ , K.
For a given number of events d, we still use the Dirichlet Process to conduct the model selection and EM-algorithm to estimate the mixture model parameters. For observations with various number of events, we follow the same procedure in Algorithm 3 to identify Gaussian mixture models for each dimension. The details are given in the following subsections.

Algorithm 3. Estimate Parameters for Multiple Dirichlet Mixture Models.
2.4.2. Dirichlet Process on Gaussian Mixture Model
Dirichlet process Gaussian mixture model (DPGMM) [33] is a classical Dirichlet process mixture model. We can naturally choose the conjugate priors for the mean and precision matrix (inverse of covariance matrix) to get a closed-form posterior. For a Gaussian distribution N(μi, Ri) with mean μi and precision Ri, we assume the joint distribution of (μi, Ri) has a Normal-Wishart distribution, denoted as
where m and κRi are the mean and precision of the Normal prior; ν and U are the parameters of the Wishart prior. The DP can be written as:
where κ0, m0, ν0, U0 are four hyperparameters of the base distribution G0, Xi = (xi1, ⋯ , xid) is the ith observation, θi = (μ·, (i), R(i)) is the mean and precision of the component that the ith observation Xi belongs to.
With this conjugate prior base distribution, the integral parts in Equations (8) and (9) can be calculated analytically. Meanwhile, the posterior distribution of component parameters Θ will also be a Normal-Wishart distribution and the parameters κ, m, ν, U|X can be expressed in closed-forms [28]. Instead of calculating the MAP estimation of Θ, we can sample from the posterior directly. The algorithm is summarized as follows:
In Algorithm 4, we can take advantage of the closed-form solutions to avoid estimating the integral in Equations (10) and (11) without using Monte Carlo method or Newton-Raphson numerical approximation. It can lead to more accurate and efficient sampling procedure for the posterior distribution.

Algorithm 4. Dirichlet Process Gaussian Mixture Model (DPGMM).
2.4.3. EM Algorithm on Gaussian Mixture Model
Gaussian Mixture Model (GMM) is one of the most classical examples for model estimation by the EM algorithm. The closed-form update is well studied in many articles [29]. We will only list the update equations and omit the details.
2.4.3.1. E-Step
For observation , the posterior probability for component k is given by:
2.4.3.2. M-Step
The updated parameters , , and are given by:
We point out that although the closed-form solutions for GMM can make Dirichlet Process and EM algorithm more efficient to calculate, the second-order covariance matrices need to be estimated. This may not be robust when sample size is small. In this study, we will use both DMM on the original IETs and GMM on the transformed IETs, and compare their performance on simulations and real data in the next section.
3. Experimental Studies
In this section, we will at first show a simulation study on a homogeneous Poisson process (HPP) to illustrate the center-outward ranking of our models. We will then examine the likelihood contours and classification performances to show the advantage of the mixture models on simulated inhomogeneous Poisson processes (IPPs). Finally, both Dirichlet Mixture model and Gaussian Mixture model will be evaluated on a real experimental dataset.
3.1. Example 1: Homogeneous Poisson Process (HPP)
We set the upper bound of number of events to be D = 10. For every dimension d ∈ {1, 2, ⋯ , 10}, 1,000 realizations are generated from an HPP. Once we get enough data for all dimensions, Gaussian models and Dirichlet models can be fitted, respectively. In this HPP example, we fit single Dirichlet model and Gaussian model by maximum likelihood estimation (MLE) method.
Figure 4A shows the single Dirichlet model fitted by 1,000 2-event realizations from the HPP. It is clear that the points near the center of the simplex have a higher likelihood. Figure 4B illustrate the corresponding center-outward ranking performance for the top 5 and bottom 5 processes using the single Dirichlet model. It is clear that realizations with evenly distributed events tend to have higher ranks. Similarly, the single Gaussian model likelihood contour and ranking pattern are shown in Figures 4C,D, respectively. Here we fit the single Gaussian models on the transformed IETs in Euclidean space at first, and then transform the IETs and contours back to the simplex space.
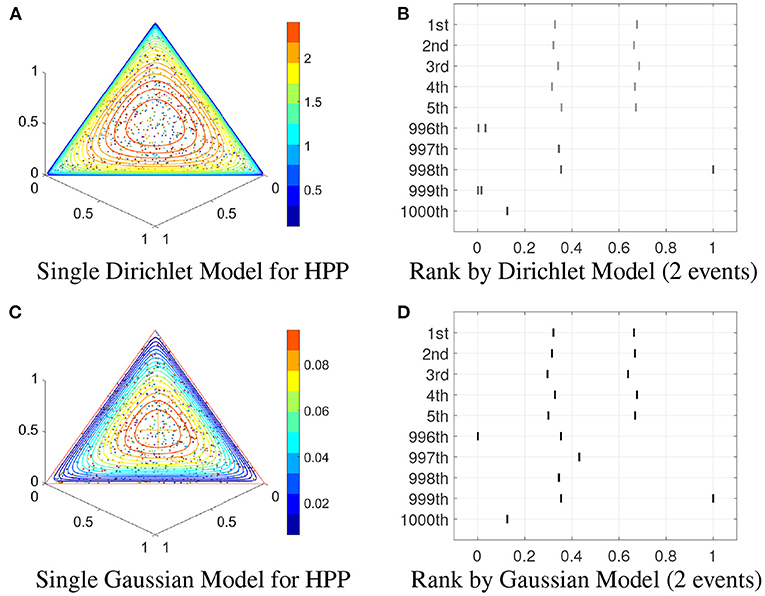
Figure 4. Single models on HPP. (A) Contour of single Dirichlet model for 2-event realizations. (B) Center-outward rank given by the single Dirichlet model for 2-event realizations. (C,D) Same as (A,B) except for the Gaussian model.
To further evaluate the ranking performance, 1,000 realizations with 5 events are tested on the well-trained Dirichlet and Gaussian model and sorted by the likelihood. Figure 5 shows the center-outward ranking of these realizations. We can see the ranking results based on Dirichlet model and Gaussian model are very similar in the five top-ranked and the five bottom-ranked realizations. This indicates both methods produce similar ranks for “central” realizations, as well as similar ranks for extreme outliers.
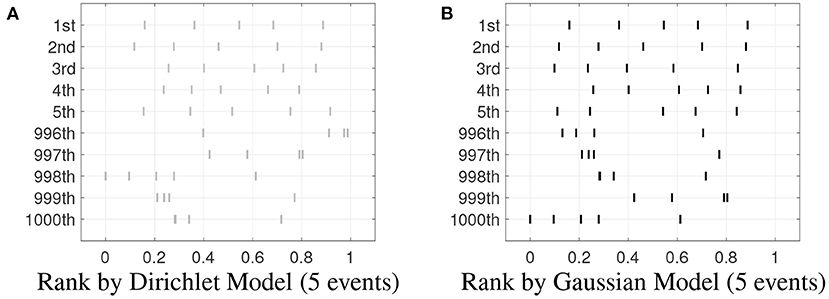
Figure 5. Center-outward Rank given by the models. (A) Center-outward rank given by the single Dirichlet model for 5-event realizations. (B) Same as (A) except for the Gaussian model.
3.2. Example 2: Inhomogeneous Poisson Processes (IPPs)
We generate N = 1, 000 realizations from each of four IPPs on [0, 1] with intensity functions given below:
where the first two intensity functions are uni-modal and the last two are multi-modal. Figure 6 shows all intensity functions.
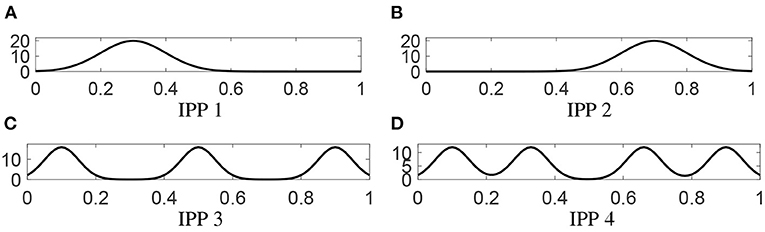
Figure 6. Intensities of four inhomogeneous Poisson processes. (A) The intensity of the first IPP. (B–D) Same as (A) except for the other three processes, respectively.
3.2.1. Uni-Modal Cases
For processes IPP1 and IPP2, we still use single models to describe the IETs' distribution and use MLE method to identify the models. Their IETs of 2-events realizations are shown in Figure 7. It is clear to see that in each process, the IETs are clustering together to one class on the 3-D simplex . Therefore, it is natural to use a Dirichlet distribution to model the likelihood of IETs. Instead of modeling the intensity of each process, our models describe the distribution of the IETs.
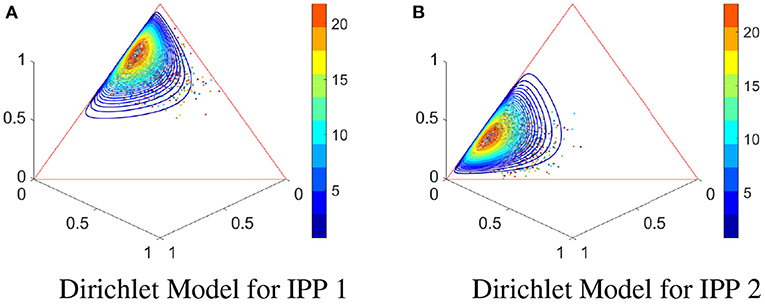
Figure 7. Uni-modal IETs of 2-event realizations for IPP1 and IPP2 and single Dirichlet models. (A) 1,000 2-event realizations of IPP1 and the fitted single Dirichlet model with contours. (B) Same as (A) except for IPP2.
Figure 8 illustrates the ilr-transformation-based approach to model the IETs. Figures 8A,C show the ilr-transformed IETs with the fitted Gaussian contours in these two processes, respectively. Panels (b) and (d) show the corresponding original IETs and the contours transformed back to 3-D simplex from the 2-D Gaussian contours. The shapes of the contours look different from the single Dirichlet models in Figure 7, whereas both methods can properly represent single cluster patterns in the given IETs.
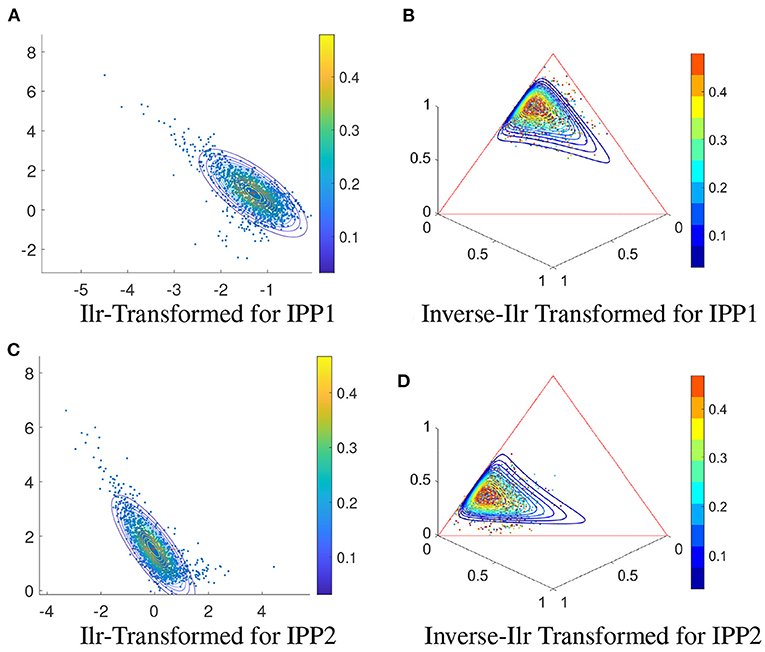
Figure 8. Uni-modal IETs of 2-event realizations for IPP1 and IPP2 and single Gaussian models: (A) Ilr-transformed realizations of IPP1 given in Figure 7A and the fitted Gaussian contours. (B) Original realizations of IPP1 and ilr-inverse-transformed contours from the Gaussian contours in (A). (C,D) Same as (A,B) except for IPP2.
3.2.2. Multi-Modal Cases
For processes IPP3 and IPP4, we model the IETs using mixture models. To fit the models, firstly we do the Dirichlet Process model selection based on Algorithms 1 and 4 to get the optimal number of components. Then, the mixture models are identified by the EM method according to Algorithm 3.
Figures 6C,D are two IPPs with multi-modal intensity functions. In these cases, we use Algorithm 3 to fit Gaussian mixture and Dirichlet mixture models on each dimension. Dirichlet mixture contours with 2-event cases are shown in Figure 9. Similarly to Figures 8B,D, these 2-event realizations with the ilr-inverse-transformed contours are shown in Figure 10.
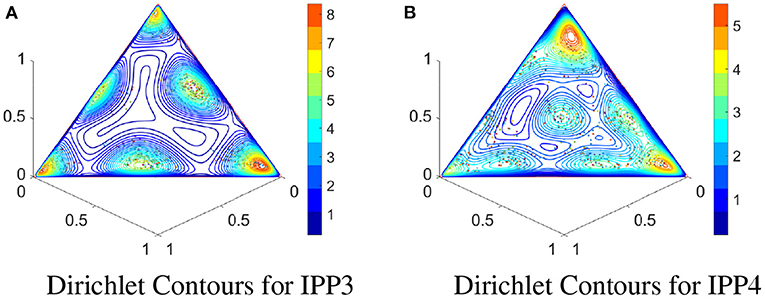
Figure 9. Dirichlet mixture models on IPPs. (A) 1,000 2-event realizations of IPP3 and the density contours by using the Dirichlet mixture model. (B) Same as (A) except for IPP4.
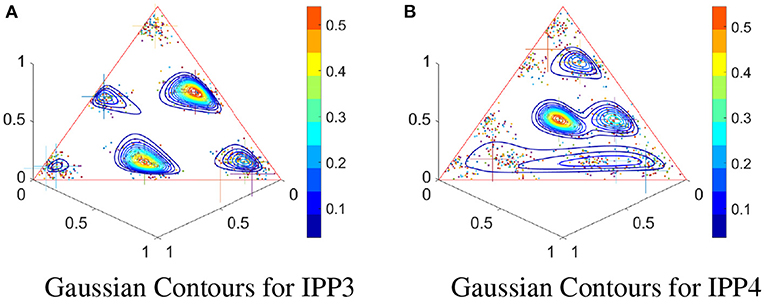
Figure 10. Gaussian mixture models on IPPs: (A) 1,000 2-event realizations from the original 1,000 realizations of IPP3, and the density contours by using the Gaussian mixture model. (B) The same as (A) except for IPP4.
It is easy to see from Figures 9, 10 that these IETs have a clear multi-modal distribution on the simplex, and therefore the single uni-modal distribution cannot describe the distribution appropriately. We adopt the Dirichlet and Gaussian mixture models to characterize the multi-modality. Figure 9 shows that the contours of the Dirichlet mixture model can properly fit the multi-modal pattern. As a comparison, Figure 10 shows the contours of the Gaussian mixture model, which also has the ability to describe the multi-modal pattern, but it is more sensitive to the number of points in each cluster. We can see the contours' shapes fit the data well, whereas the value of likelihoods is very sensitive to the density and location of the points. The clusters at the corner of the triangle tend to have lower likelihood than those at the center. This may be due to the ilr transformation which bijectively maps the cluster points near boundaries of the simplex to sparse points in the unbounded Euclidean space and a Gaussian model on these sparse points can be sensitive to outliers.
In order to demonstrate the advantage of the mixture models, we conduct a classification comparison by using all four models (single Dirichlet, single Gaussian, Dirichlet mixture, and Gaussian mixture). Another 20,000 realizations from IPP3 and IPP4 were generated respectively as the test set. For each realization, we feed it to the four models we proposed. In each case, the label with higher likelihood will be the predicted label of this realization. The classification result of these models is shown in Figure 11. We can see the two mixture models have much higher accuracies for any given number of events (varying from 1 to 10) than the two single models. This result illustrates that the mixture models do have a better representation for data with multi-modal structures.
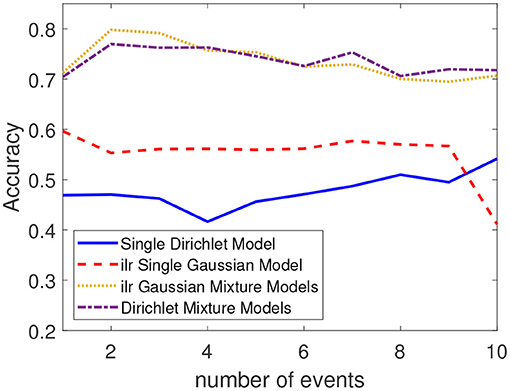
Figure 11. Classification accuracy for each method with respect to the number of events.
3.3. Real Data
In additional to the simulation examples shown above, we will apply these new models on a real experimental recording. This recording was previously used and clearly described in Wu and Srivastava [34]. Briefly, a juvenile male macaque monkey was trained to perform a closed Squared-Path (SP) task by moving a cursor to targets via contralateral arm movements in the horizontal plane. In each trial the subject reached a sequence of five targets consists of the four corners of the square counterclockwise with the first and last one overlapped. If we label the upper left corner as A, lower left as B, lower right as C, and upper right as D, then there will be four different paths, namely, Path 1: ABCDA, Path 2: BCDAB, Path 3: CDABC, and Path 4: DABCD. During the movement, silicon microelectrode arrays were implanted in the arm area of primary motor cortex in the monkey. Signals were filtered, amplified and recorded digitally and single units were manually extracted. There are 60 trials for each path with time length 5–6 s. To fit the models, all these 240 trials were normalized to 5 s. Figure 12 shows 10 trials of spike trains from each path.
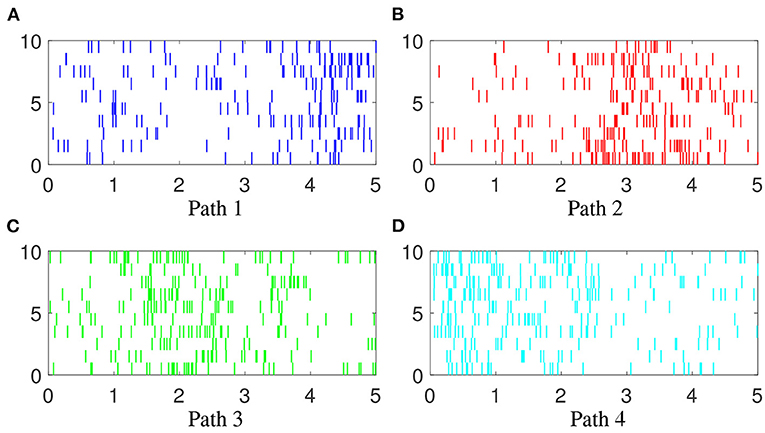
Figure 12. Examples of spike trains. 10 examples of spike trains generated from each path. The four colors (blue, red, green and cyan) indicate spiking activity during hand movement in Paths 1, 2, 3, and 4, (A–D), respectively. Each vertical line represents one event. Each row represents one trial.
For the 60 trials in each path, we randomly select 45 trials as the training data and use the other 15 trials as the test data. The number of events of the 240 trials varies between 12 to 61. It is not robust to train a mixture model for each number of events with such small samples. Therefore, for each trial in the training data, we resample 10 events randomly and use this 10-event realization as one training sample. 10 resampled realizations are randomly generated from each training trial so that we have 45 × 10 = 450 training samples for each path, which are sufficient for the training purpose in this study.
In the training stage, for each path, 450 samples with 10 events described above are used to fit a Dirichlet mixture model and a Gaussian mixture model, respectively. The classification on the test stage is also done for these two models. In the Dirichlet case, we sample 500 10-event realizations for each trial and then fit them to all four Dirichlet mixture models. For each realization, we have 4 likelihoods representing Paths 1, 2, 3, and 4, respectively, and the one with the largest likelihood will be the label of this realization. As a result, 500 labels can be calculated for each trial and the mode will be used as the final label of this trial. The same procedure also applies to the Gaussian case.
Figure 13 are the confusion matrices of Dirichlet and Gaussian mixture models to summarize the classification result. We can see that both methods can identify the trials from Paths 1, 3 and 4 almost perfectly, but perform a little bit worse on identifying trials from Path 2. The overall accuracy of Dirichlet mixture model is 88.33% and of Gaussian mixture model is 86.67%. This result is comparable with the state-of-the-art nearest neighbor method [35].
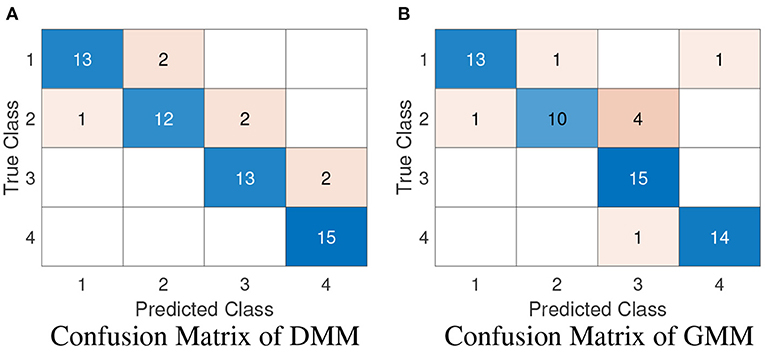
Figure 13. Confusion matrices in 60 testing trials (15 trials for each path). (A) The confusion matrix of the Dirichlet mixture model. (B) The confusion matrix of the Gaussian mixture model.
4. Summary
Instead of estimating the conditional intensity function, we have proposed an alternative approach to model the point process using two factors: (1) the number of events in the process, and (2) the conditional distribution of these events given the number. Our study focuses on the conditional distribution and two approaches are given in this study. One approach adopts Dirichlet distribution to describe the conditional distribution by modeling the equivalent inter-event time representation. To fit more complicated multi-modal distribution of IETs, we extend the notion of rank-based Dirichlet model to rank-based Dirichlet mixture model. The other approach is based on Gaussian model or Gaussian mixture models on the transformed IETs using isometric logratio transformation. This is to avoid the computational inefficiency in the Dirichlet method. In the model fitting stage, we have proposed to use Dirichlet processes to identify the number of components in the mixture models and well-known Expectation-Maximization algorithms for parameter estimations.
This novel, data-driven, rank-based modeling framework can naturally provide a center-outward rank to the realizations, and it is easy to be fitted given enough data. For practical application, realizations from Poisson processes and real experimental recording of spike trains are used to investigate the center-outward ranking and classification performances. In multi-modal cases, it shows that the mixture models offer a more appropriate description and better classification performances than single models. Further applications such as outlier detection will be studied in the future. In addition, we will explore other modeling approaches than the Gaussian mixtures on the transformed IETs.
Data Availability Statement
The original contributions presented in the study are included in the article, further inquiries can be directed to the corresponding author.
Author Contributions
All authors listed have made a substantial, direct, and intellectual contribution to the work and approved it for publication.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
1. Daley DJ, Vere-Jones D. An Introduction to the Theory of Point Processes: Volume I: Elementary Theory and Methods. Probability and Its Applications. New York, NY: Springer (2003).
2. Brown L, Gans N, Mandelbaum A, Sakov A, Shen H, Zeltyn S, et al. Statistical analysis of a telephone call center: a queueing-science perspective. J Am Stat Assoc. (2005) 100:36–50. doi: 10.1198/016214504000001808
3. Rasmussen JG. Lecture notes: temporal point processes and the conditional intensity function. arXiv preprint arXiv:180600221. (2018).
4. Rubin I. Regular point processes and their detection. IEEE Trans Inf Theory. (1972) 18:547–57. doi: 10.1109/TIT.1972.1054897
5. Whitt W. Approximating a point process by a renewal process, I: two basic methods. Oper Res. (1982) 30:125–47. doi: 10.1287/opre.30.1.125
6. Hawkes AG. Hawkes processes and their applications to finance: a review. Quant Finance. (2018) 18:193–8. doi: 10.1080/14697688.2017.1403131
7. Brown EN, Frank LM, Tang D, Quirk MC, Wilson MA. A statistical paradigm for neural spike train decoding applied to position prediction from ensemble firing patterns of rat hippocampal place cells. J Neurosci. (1998) 18:7411–25. doi: 10.1523/JNEUROSCI.18-18-07411.1998
8. Kass RE, Ventura V. A spike-train probability model. Neural Comput. (2001) 13:1713–20. doi: 10.1162/08997660152469314
9. Liu S, Wu W. Generalized Mahalanobis depth in point process and its application in neural coding. Ann Appl Stat. (2017) 11:992–1010. doi: 10.1214/17-AOAS1030
10. Tukey JW. Mathematics and the picturing of data. In: Proceedings of the International Congress of Mathematicians, Vol. 2. Vancouver, BC (1975). p. 523–31.
11. Liu RY. On a notion of data depth based on random simplices. Ann Stat. (1990) 18:405–14. doi: 10.1214/aos/1176347507
12. Liu RY, Singh K. A quality index based on data depth and multivariate rank tests. J Am Stat Assoc. (1993) 88:252–60. doi: 10.1080/01621459.1993.10594317
13. Fraiman R, Liu RY, Meloche J. Multivariate density estimation by probing depth. Lecture Notes Onogr Ser. (1997) 31:415–30. doi: 10.1214/lnms/1215454155
14. Zuo Y, Serfling R. General notions of statistical depth function. Ann Stat. (2000) 28:461–82. doi: 10.1214/aos/1016218226
15. Cuevas A, Febrero M, Fraiman R. Robust estimation and classification for functional data via projection-based depth notions. Comput Stat. (2007) 22:481–96. doi: 10.1007/s00180-007-0053-0
16. López-Pintado S, Romo J. On the concept of depth for functional data. J Am Stat Assoc. (2009) 104:718–34. doi: 10.1198/jasa.2009.0108
17. López-Pintado S, Romo J. A half-region depth for functional data. Comput Stat Data Anal. (2011) 55:1679–95. doi: 10.1016/j.csda.2010.10.024
18. Claeskens G, Hubert M, Slaets L, Vakili K. Multivariate functional halfspace depth. J Am Stat Assoc. (2014) 109:411–23. doi: 10.1080/01621459.2013.856795
19. Helander S, Van Bever G, Rantala S, Ilmonen P. Pareto depth for functional data. Statistics. (2020) 54:182–204. doi: 10.1080/02331888.2019.1700418
20. Nieto-Reyes A, Battey H. A topologically valid definition of depth for functional data. Stat Sci. (2016) 31:61–79. doi: 10.1214/15-STS532
21. Qi K, Chen Y, Wu W. Dirichlet depths for point process. Electron J Stat. (2021) 15:3574–610. doi: 10.1214/21-EJS1867
22. Ferguson TS. A Bayesian analysis of some nonparametric problems. Ann Statist. (1973) 1:209–30. doi: 10.1214/aos/1176342360
23. Antoniak CE. Mixtures of Dirichlet processes with applications to Bayesian nonparametric problems. Ann Statist. (1974) 2:1152–74. doi: 10.1214/aos/1176342871
24. Neal RM. Markov chain sampling methods for Dirichlet process mixture models. J Comput Graph Stat. (2000) 9:249–65. doi: 10.1080/10618600.2000.10474879
25. Nguyen VA, Boyd-Graber J, Altschul SF. Dirichlet mixtures, the Dirichlet process, and the structure of protein space. J Comput Biol. (2013) 20:1–18. doi: 10.1089/cmb.2012.0244
26. Egozcue JJ, Pawlowsky-Glahn V, Mateu-Figueras G, Barcelo-Vidal C. Isometric logratio transformations for compositional data analysis. Math Geol. (2003) 35:279–300. doi: 10.1023/A:1023818214614
27. Pawlowsky-Glahn V, Egozcue JJ, Tolosana Delgado R. Lecture Notes on Compositional Data Analysis. Girona: Universitat de Girona (2007).
29. Bilmes JA. A gentle tutorial of the EM algorithm and its application to parameter estimation for Gaussian mixture and hidden Markov models. Int Comput Sci Institute. (1998) 4:126.
30. Huang J. Maximum likelihood estimation of Dirichlet distribution parameters. CMU Technique Report (2005).
31. Aldous DJ. Exchangeability and related topics. In: École d'Été de Probabilités de Saint-Flour XIII—1983. Springer (1985). p. 1–198. Available online at: https://link.springer.com/chapter/10.1007/BFb0099421
32. Aitchison J. The Statistical Analysis of Compositional Data. Monographs on Statistics and Applied Probability. Dordrecht: Springer Netherlands (1986).
33. Görür D, Rasmussen CE. Dirichlet process gaussian mixture models: choice of the base distribution. J Comput Sci Technol. (2010) 25:653–64. doi: 10.1007/s11390-010-9355-8
34. Wu W, Srivastava A. An information-geometric framework for statistical inferences in the neural spike train space. J Comput Neurosci. (2011) 31:725–48. doi: 10.1007/s10827-011-0336-x
Keywords: temporal point process, center-outward rank, Dirichlet mixture, Gaussian mixture, Dirichlet process, isometric logratio transformation
Citation: Chen Y, Ma Y and Wu W (2022) Rank-Based Mixture Models for Temporal Point Processes. Front. Appl. Math. Stat. 8:852314. doi: 10.3389/fams.2022.852314
Received: 11 January 2022; Accepted: 10 March 2022;
Published: 04 April 2022.
Edited by:
Hien Duy Nguyen, The University of Queensland, AustraliaCopyright © 2022 Chen, Ma and Wu. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Wei Wu, d3d1QHN0YXQuZnN1LmVkdQ==