
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Appl. Math. Stat. , 17 March 2022
Sec. Mathematics of Computation and Data Science
Volume 8 - 2022 | https://doi.org/10.3389/fams.2022.832883
This article is part of the Research Topic High-Performance Tensor Computations in Scientific Computing and Data Science View all 11 articles
 Stijn Hendrikx1,2*
Stijn Hendrikx1,2* Lieven De Lathauwer1,2
Lieven De Lathauwer1,2Several problems in compressed sensing and randomized tensor decomposition can be formulated as a structured linear system with a constrained tensor as the solution. In particular, we consider block row Kronecker-structured linear systems with a low multilinear rank multilinear singular value decomposition, a low-rank canonical polyadic decomposition or a low tensor train rank tensor train constrained solution. In this paper, we provide algorithms that serve as tools for finding such solutions for a large, higher-order data tensor, given Kronecker-structured linear combinations of its entries. Consistent with the literature on compressed sensing, the number of linear combinations of entries needed to find a constrained solution is far smaller than the corresponding total number of entries in the original tensor. We derive conditions under which a multilinear singular value decomposition, canonical polyadic decomposition or tensor train solution can be retrieved from this type of structured linear systems and also derive the corresponding generic conditions. Finally, we validate our algorithms by comparing them to related randomized tensor decomposition algorithms and by reconstructing a hyperspectral image from compressed measurements.
In a wide array of applications within signal processing, machine learning, and data analysis, sampling all entries of a dataset is infeasible. Datasets can be infeasibly large either because their dimensions are huge, like a matrix with millions of rows and columns, or because they are higher-order. In several cases, a relatively limited set of indirectly sampled datapoints, i.e., linear combinations A x = b of the datapoints x, suffices for recovering an accurate approximation of the full dataset, making the problem tractable again. For example in compressed sensing [1, 2] and randomized tensor decomposition algorithms [3], random measurement matrices are used to compress the data x. Directly sampling a subset of the datapoints can also be written in the format A x = b, in which the measurement matrix a now consists of a subset of the rows of the identity matrix. Hence, problems such as incomplete tensor decomposition [4], non-uniform sampling [5] and cross-approximation [6] can also be formulated in this manner.
Retrieving the original data from such a linear system is generally only possible if it is overdetermined. This would mean that the number of indirectly sampled datapoints equals at least the total number of dataset entries, which is the opposite of what is needed in the compressed sensing (CS) setting. This requirement becomes especially restrictive for higher-order datasets. “Higher-order” means that the dataset consists of more than two dimensions or modes, in which case the number of entries increases exponentially with the number of modes. This phenomenon is commonly known as the curse of dimensionality (CoD).
Real data often allows compact representations thanks to some intrinsic structure, such as the data being generated by an underlying lower-dimensional process [1, 7]. In this case, x can be well approximated by a sparsifying basis Φ and a sparse coefficient vector θ, namely x ≈ Φθ. The literature on compressed sensing (CS) shows that for a measurement matrix and sparsifying basis pair with low coherence, the linear system can be solved in the underdetermined case [1, 2]. This means that x can be recovered using far fewer compressed measurements Ax than the total number of entries in x, breaking the CoD in the case of a higher-order dataset. An appropriate sparsifying basis is known a priori for some types of data, for example a wavelet basis for images, or can be obtained through dictionary learning [8]. If the sparsifying basis is known, then the measurement matrix can be chosen such that the coherence between the sparsifying basis and the measurement matrix is low. If no sparsifying basis for x is known a priori, one often chooses a random measurement matrix, as they are largely incoherent with any fixed basis [1].
In this paper, we exploit intrinsic structure that is common in real data by compactly approximating x using tensor decompositions, which in turn allows us to solve A x = b in the underdetermined case. This means that we will solve
Concretely, we will consider constrained to a multilinear singular value decomposition (MLSVD), a canonical polyadic decomposition (CPD) or a tensor train (TT) of low rank1. Note that at this point we have addressed the dimensionality issue only partially: on one hand, x is compactly modeled by a tensor decomposition; however, on the other hand, the number of columns of A remains equal to the total number of entries in x and thus still suffers from the CoD. Therefore, we will employ a block row Kronecker-structured (BRKS) measurement matrix A. Efficient algebraic algorithms for solving this linear system will be obtained by combining this Kronecker structure with the low-rank constraints on x such that A and x do not need to be fully constructed. A standard approach for computing the CPD of a tensor is to first orthogonally compress this tensor, for example using the MLSVD, and then compute the CPD of the compressed tensor [9]. In this paper, we generalize this approach to the CS-setting.
Unstructured measurement matrices compress all modes of simultaneously. On the contrary, Kronecker-structured measurement matrices produce compressed versions of by compressing each mode individually, making them useful for higher-order datasets. Therefore, these Kronecker-structured measurement matrices are used in the CS-setting [10–12]. In Sidiropoulos and Kyrillidis [10] the CPD of a tensor is computed by first decomposing multiple compressed versions of and then retrieving the factor matrices of the full tensor under the assumption that their columns are sparse. There is some similarity between the Kronecker compressive sampling (KCS) approach [11] and ours, because it uses a Kronecker-structured measurement matrix and assumes that x is sparse in a Kronecker-structured basis. However, in KCS this basis is assumed to be known a priori, while in our approach it is estimated as well. In Kressner and Tobler [13], a low-rank approximation to the solution of a parametrized set of linear systems, which can be rewritten as a large linear system in which the coefficient matrix consists of a sum of Kronecker products, is computed. This approach is suited toward applications such as solving partial differential equations rather than CS, as the requirement that the smaller individual systems should be overdetermined makes it infeasible for the latter purpose. Additionally, this approach utilizes the hierarchical Tucker decomposition to constrain the solution, as opposed to the MLSVD, CPD and TT constraints in this paper.
Algorithms similar to the ones in this paper appear in the literature on randomized tensor decomposition (RTD) [3, 14–16]. The main difference is that the full tensor is available in such a randomized algorithm, while our algorithms can also be applied when only compressed measurements are available. In a randomized algorithm, the tensor is compressed in multiple modes to speed up further computations. In Zhou et al. [16] the factor matrices of an MLSVD are computed by randomly compressing the tensor. However, this compression is carried out simultaneously in multiple modes in a manner that is not Kronecker-structured. Also, the full tensor is needed to retrieve the core , as opposed to only compressed measurements like in our approach. A similar randomized approach for computing the MLSVD is introduced in Che et al. [15], with the difference that the compression is carried out independently in different modes. An overview of RTD algorithms for computing an MLSVD is given in Ahmadi-Asl et al. [3, Section 5]. In Sidiropoulos et al. [12], a CPD is computed by decomposing multiple randomly compressed versions of the tensor in parallel and then combining the results. The algorithm in Yang et al. [17] improves upon this by replacing the dense random matrices with sketching matrices in the compression step to reduce the computational complexity. In Battaglino et al. [14], sketching matrices are used to speed up the least squares subproblems in the alternating least squares approach for computing the CPD. Multiplication with a sketching matrix is a Johnson-Lindenstrauss Transform (JLT), which transforms points in a high dimensional subspace to a lower dimensional subspace while preserving the distance between points up to a certain bound. In Jin et al. [18], it is proven that applying a JLT along each mode of a tensor is also a JLT. On the other hand, in cross approximation, CUR decompositions and pseudo-skeleton decompositions, a tensor is decomposed using a subset of directly sampled vectors along each mode [6, 19–21]. These subsets are determined on the basis of heuristics, for which algebraic results on the obtained quality of the approximation are available [22].
In the next part of this section, we introduce notations and definitions for further use in this paper. In Section 2, we propose an algorithm for computing an MLSVD from a BRKS linear system and derive conditions under which a solution can be found. In Section 3, we generalize the standard approach for computing a CPD, in which the tensor is first compressed using its MLSVD, to computing a CPD from a BRKS linear system. We also derive conditions under which the CPD can be retrieved. In Section 4, we compute a TT from a BRKS linear system and derive conditions under which the TT can be retrieved. Finally, in Section 5, we validate our algorithms by computing tensor decompositions in a randomized approach using synthetic data and by applying them to a hyperspectral imaging application.
A scalar, vector, matrix and tensor are, respectively, denoted by x, x, X and . The dimensions of a tensor of order N are denoted by In for n = 1, …, N. The rank of a matrix X is denoted by r (X). The identity matrix is denoted by . A set and its complementary set are, respectively, denoted by and . A matricization of a tensor is obtained by reshaping the tensor into a matrix and is denoted by , with . The sets and , respectively, indicate which modes of the tensor are in the rows and columns of the matricization. See Kolda [23] for a more detailed, elementwise definition of a matricization. We use a shorthand notation for the matricization that contains a single mode in its rows, also known as the mode-n unfolding, namely
The mode-n, outer, Kronecker and Khatri–Rao product are denoted by and ⊙. The mixed product property of the Kronecker product is (A ⊗ B)(C ⊗ D) = (AC) ⊗ (BD), with A ∈ ℝI × J, B ∈ ℝL × M, C ∈ ℝJ × K and D ∈ ℝM × N. Similarly, the mixed product property of the Khatri–Rao product is (A ⊗ B)(C ⊙ D) = (AC) ⊙ (BD). The rank of the Kronecker product of matrices equals the product of the ranks of those matrices, i.e., r (A ⊗ B) = r (A) r (B). A shorthand notation for a sequence of products is:
The multilinear singular value decomposition (MLSVD) decomposes a tensor as
with column-wise orthonormal factor matrices for n = 1, …, N and an all-orthogonal core tensor [24]. The tuple (R1, …, RN) is the multilinear rank of , in which Rn = r (X[n]) for n = 1, …, N. In vectorized form, this decomposition equals
The canonical polyadic decomposition (CPD) decomposes a tensor as a minimal sum of rank-1 tensors
with factor matrices for n = 1, …, N. The number of rank-1 tensors R equals the rank of . In vectorized form, the CPD equals
with 1R a vector of length R containing all ones. The tensor train (TT) factorizes each entry of as a sequence of matrix products
with for n = 1, …, N and R0 = RN = 1 [25]. An index that has not been fixed is indicated by :, meaning that is the ith mode-2 slice of a third-order tensor. The cores of the TT are obtained by stacking for n = 2, …, N − 1 and for n = 1, N into third-order tensors and matrices , respectively. The tuple (R0, …, RN) is the TT-rank of . We use
as a shorthand notation for the TT.
Using a BRKS linear system avoids the need for constructing and storing the full measurement matrix A and results in efficient algorithms for retrieving a low-rank constrained x. With this structure, Equation (1) becomes
with generating matrices and compressed measurements for m = 1, …, M and n = 1, …, N. This type of linear system appears, for instance, in RTD and hyperspectral imaging, as illustrated in Section 5. Each block row of this linear system corresponds to a linear subsystem that produces a compressed version of . This can be seen by tensorizing the mth block row as
in which is b(m) reshaped into a tensor of dimensions Pm1 × ⋯ × PmN. Each mode of has been compressed by mode-n multiplication with A(m,n) for n = 1, …, N.
If is approximately of low multilinear rank (R1, …, RN), reflecting some inherent structure, then the vectorized MLSVD in Equation (2) can be substituted into Equation (3):
Note that the factor matrices would be in the reverse order when vectorizing conventionally, meaning . However, by vectorizing like in Equation (5), the index n of the generating matrices A(m,n) for m = 1, …, M and n = 1, …, N corresponds nicely to the mode it operates on.
In order to solve the linear system in Equation (5) in the underdetermined case, it will not be directly solved for . Instead, the factor matrices U(n) for n = 1, …, N will be retrieved individually using the linear subsystems
in Equation (5). If the BRKS linear system consists of N linear subsystems, then all factor matrices can be computed. Therefore, we assume from this point on that M = N. The case where M < N is of use when not all factor matrices need to be retrieved. Next, the core tensor will be retrieved using the computed factor matrices. The linear system in Equation (6) is similar to the problem that is solved in KCS, namely and , respectively, correspond to the Kronecker-structured measurement matrix, the Kronecker-structured sparsifying basis and the sparse coefficients. In CS, choosing a good basis that sparsifies the data [8] and determining the sparse coefficients of the data in this basis [1, 2] are separate problems. In this paper, both problems are solved simultaneously using one BRKS linear system. Furthermore, unlike in the CS-setting, the coefficients are not necessarily sparse. In the remainder of this section, we discuss the methods for retrieving the factor matrices and the core tensor.
The mth linear subsystem in Equation (6) can be simplified to
using the mixed product property of the Kronecker product. This corresponds to a vectorized MLSVD with factor matrices A(m,n)U(n) for n = 1, …, N and core . Rearranging Equation (7) as the mode-m matrix unfolding of this MLSVD
shows that solving the linear system
for the unknown matrix F(m) yields linear combinations of the columns of U(m). Therefore, the dominant column space of F(m) is the same as the subspace spanned by the columns of U(m) if S(m) is of full column rank. This means that we can find the column space of the mth factor matrix by computing an orthonormal basis that spans the dominant column space of F(m). In applications that allow the generating matrices to be chosen, setting for m = 1, …, N avoids the need for solving this linear system altogether. In this case, in Equation (4) equals multiplied in every mode except the mth with a generating matrix. This situation is similar to RTD methods for computing an MLSVD, where the tensor is compressed in all modes except the mth in order to retrieve U(m) [15, 16]. Generically, the dimensions Pmn, for m, n = 1, …, N and n ≠ m, of the generating matrices can be chosen much smaller than the rank Rn of the mode-n unfolding of , as we will further explain in Section 2.4. As a first indication, note that for the factorization in the right-hand side of Equation (9), we expect ∏n ≠ m Pmn = Rm to be sufficient, allowing Pmn ≪ Rm for m, n = 1, …, N and n ≠ m.
In some applications, not only the factor matrices U(n) for n = 1, …, N but also the core are needed. At first sight, it looks like a data efficient way to compute the core is reusing the linear combinations with which the column space of the factor matrices has been computed. The core tensor that corresponds to the retrieved column spaces of the factor matrices is then obtained by solving the linear system in Equation (5) for , with the column space of U(n) already available for n = 1, …, N, which is
The core can be retrieved if the coefficient matrix of this system is of full column rank. However, the requirement that this coefficient matrix must be of full column rank imposes much more severe constraints on the dimensions Pmn than the constraints for computing the factor matrices in Section 2.4. Under these harder constraints, the right hand sides b(n) would have to contain far more compressed measurements than actually needed to retrieve the nth factor matrix U(n) for n = 1, …, N. The reason is that in the coefficient matrix in Equation (10) there are many linear dependencies between the rows, because the same factor matrices U(n) appear in each block row. Therefore, it is not practical to compute the core by solving the system in Equation (10) for .
Instead, the core can be computed by solving a separate linear system, independent from the N block rows of the BRKS system used for computing the factor matrices, for , namely
with extra generating matrices for n = 1, …, N and compressed measurements . This approach allows us to choose the dimensions Qn for n = 1, …, N such that the core can be retrieved, without the need to increase the dimensions Pmn for m, n = 1, …, N. Additionally, this additional system can be solved efficiently by subsequently solving smaller linear systems
for . Here, , in which D[1] is the mode-1 matrix unfolding of the tensorization of d, and for n = 2, …, N. After solving all N systems, is the mode-N matrix unfolding of . These linear systems, with coefficient matrices of size Qn × Rn for n = 1, …, N, are much smaller than the linear system in Equation (10), consisting of all compressed measurements used to estimate the factor matrices, with a coefficient matrix of size . This coefficient matrix is so large because of the Kronecker products. In Section 2.4, we show that generically the core can be retrieved if the dimensions Qn are greater than or equal to Rn for n = 1, …, N. Therefore, solving the subsequent systems in Equation (12) is a computationally much cheaper approach for computing than solving the system in Equation (10) is. This additional linear system can be added to the BRKS linear system in Equation (3) by renaming C(n) for n = 1, …, N and d to A(N+1,n) and b(N+1), respectively. The complete BRKS linear system now consists of N + 1 block rows with generating matrices and compressed measurements for m = 1, …, N + 1 and for n = 1, …, N.
If we estimate the core tensor using a separate linear system, we do not use all available compressed measurements, since we disregard the first N block rows of the BRKS linear system. This can be resolved by solving the full BRKS linear system for with a numerical algorithm such as conjugate gradients, using the matrix-vector product
which can be computed efficiently by exploiting the block rowwise Kronecker structure. Alternatively, all block rows of the system can also be used if the full BRKS system is solved for a sparse core , which we will illustrate in an experiment in Section 5.
By combining the steps in Sections 2.1 and 2.2, we obtain Algorithm 1 for computing the MLSVD of from a BRKS linear system. In the outlined version of the algorithm, the additional linear system in Equation (11) is used to estimate the core tensor. The computation of each factor matrix depends only on one compressed tensor for m = 1, …, N, allowing the different factor matrices to be computed in parallel. In the RTD-setting, the full tensor is available and is then randomly compressed in order to efficiently compute a tensor decomposition. On the other hand, compressed measurements can be obtained directly in the data acquisition stage in the CS-setting. To accommodate for both settings, Algorithm 1 accepts either the generating matrices and the compressed measurements or the generating matrices and the full tensor as inputs.

Algorithm 1. MLSVD from a BRKS linear system (lsmlsvd_brks).
In this section, we derive the conditions in Theorem 1, under which the retrieval of the MLSVD of from a BRKS system is guaranteed. Since the factor matrices and the core are intrinsic to the data , the conditions in this section are to be seen as constraints on the generating matrices.
Theorem 1. Consider a tensor of multilinear rank (R1, …, RN), admitting an MLSVD with factor matrices for n = 1, …, N and core tensor . Given linear combinations b of obtained from a BRKS linear system with generating matrices for m = 1, …, N + 1 and n = 1, …, N, the factor matrices U(n) for n = 1, …, N can be retrieved if and only if
The core can be retrieved if and only if
Proof: Condition 1): The linear system in Equation (9) can be uniquely solved for F(m) if and only if A(m,m) is of full column rank Im for m = 1, …, N.
Condition 2): An orthonormal basis of dimension Rm for the column space of F(m) can be retrieved if and only if
holds. Since , which follows from the definition of the MLSVD, this condition reduces to
Condition 3): The linear system in Equation (11) can be uniquely solved for if and only if the coefficient matrix is of full column rank:
The conditions in Theorem 1 are satisfied in the generic case, in which the generating matrices are sampled from a continuous probability distribution and thus are of full rank with probability 1, if and only if the conditions in Theorem 2 hold. The conditions in the latter theorem allow us to determine the dimensions Pmn for m = 1, …, N + 1 and n = 1, …, N of the generating matrices such that generically the MLSVD of can be retrieved.
Theorem 2. With generic generating matrices A(m,n) for m = 1, …, N + 1 and n = 1, …, N, the conditions in Theorem 1 hold if and only if
Proof: The proof of these conditions follows from the conditions in Theorem 1 and the properties of generic matrices.
Condition 1): Since a generic matrix is of full rank, for m = 1, …, N.
Condition 2): The matrix product A(m,n)U(n) is of full rank min(Pmn, Rn) with probability 1 for a generic matrix A(m,n) and U(n) of full column rank (the latter following from the definition of an MLSVD) with Pmn, Rn ≤ In for m = 1, …, N + 1 and n = 1, …, N [10, Lemma 1].
Condition 3): Similar to the proof of condition 2), generically for n = 1, …, N according to Sidiropoulos and Kyrillidis [10, Lemma 1]. Condition 3) in Theorem 1 then reduces to , which holds if and only if condition 3) in this theorem is satisfied.
In practice, the dimensions Pmn can easily be chosen such that the second generic condition is satisfied with Pmn < Rn for m, n = 1, …, N and n ≠ m. The second condition then reduces to for m = 1, …, N. Assuming that Pmn for m = 1, …, N and n ≠ m are approximately equally large, we obtain the condition , meaning that the generating matrices for m, n = 1, …, N and n ≠ m can be chosen as fat matrices. Therefore, the mth block row of Equation (3) compresses all modes of except the mth, as illustrated in Figure 1, similar to an RTD algorithm for the MLSVD. Additionally, this implies that holds at least Rm columns, which is indeed the minimum required number for estimating the Rm-dimensional mode-m subspace of . Algorithm 1 uses an oversampling factor q ≥ 1 such that this matrix holds more than the minimum required number of columns, namely ∏n ≠ m Pmn = qRm columns for m = 1, …, N. These additional compressed measurements allow a better estimation of the factor matrices if the data is noisy.
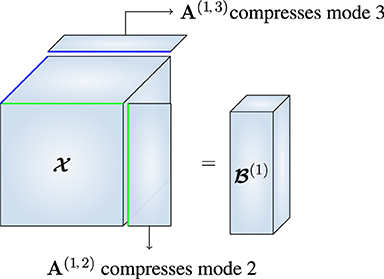
Figure 1. Similar to the RTD algorithm in Che et al. [15], we recover the first MLSVD factor matrix from , which is a version of that is compressed in every mode except the first.
In applications, noise can be present on the compressed measurements and/or on the entries of the tensor. In the former case, the linear system becomes , in which the noise vector n is partitioned into subvectors n(m) for m = 1, …, N, consistent with the partitioning of b in Equation (3). The linear system in Equation (8), with a noise term n, becomes
in which is the tensor representation of n(m) and its mode-m matrix unfolding. The rank of the matrix, obtained by solving this subsystem for F(m), generically equals due to the presence of the noise and thus exceeds Rm if q > 1 for m = 1, …, N. If the signal-to-noise ratio is sufficiently high, then the dominant column space of F(m) is nevertheless expected to be a good approximation for the column space of U(m). A basis for this dominant column space can be computed with the singular value decomposition (SVD) and the approximation is optimal in least squares sense if n(m) is white Gaussian noise.
In the case of noisy tensor entries, the linear system becomes , with . In contrast with the former case, the coefficient matrix now also operates on the noise. Equation (8) then becomes
Because of the noise, the rank of F(m) + N(m) generically exceeds Rm for m = 1, …, N. The least squares optimal approximation of the column space of U(m) can again be retrieved using the SVD if is white Gaussian noise. As derived in Sidiropoulos et al. [12], this holds true if is white Gaussian noise and for m, n = 1, …, N. The latter condition is approximately satisfied for large tensor dimensions if the generating matrices are sampled from a zero-mean uncorrelated distribution.
Since the core of the MLSVD of an Nth order tensor is also an Nth order tensor, the MLSVD suffers from the CoD. On the contrary, the number of parameters of the CPD scales linearly with the order of the tensor. Additionally, the CPD is unique under mild conditions. For applications that are more suited to these properties, such as blind signal separation, we introduce an algorithm for computing a CPD from a BRKS linear system in this section. An efficient, three-step approach for computing the CPD of a tensor is: 1) compressing the tensor, 2) decomposing the compressed tensor and 3) expanding the factor matrices to the original dimensions. In Bro and Andersson [9], the tensor is orthogonally compressed using the factor matrices of its MLSVD, i.e., the orthogonally compressed tensor corresponds to the core tensor of the MLSVD. In this section, we generalize this popular approach to computing a CPD from the BRKS linear system in Equation (3). Following this approach, we can find the CPD of a large tensor of order N by computing the CPDs of N small tensors.
If is approximately of rank R, it admits a CPD
with for n = 1, …, N. Since the dimension of the subspace spanned by the mode-n vectors of is at most of dimension R for n = 1, …, N, as is of rank R, also admits an MLSVD
with for n = 1, …, N and . Note that the rank Rn of the mode-n vectors of can be smaller than R for any n = 1, …, N, namely when W(n) is not of full column rank. In this case, an orthogonal compression matrix U(n) of dimensions In × Rn can still be used. Equation (13) and (14) together imply that the core tensor admits the following CPD:
Alternatively, the CPD of can be written as
by substituting Equation (15) into Equation (14). This CPD can be substituted for in the BRKS system in Equation (3). Using the mixed product property of the Khatri–Rao product, the mth block row of the BRKS system becomes
Tensorizing this equation yields a polyadic decomposition (PD) expression for each block row of the BRKS system:
(Note that, since the number of rank-1 terms in this PD is not necessarily minimal, it is a priori not necessarily canonical. However, we will assume further on that the m-th factor matrix in the PD of is unique for m = 1, …, N. As that implies that a decomposition in fewer terms is impossible, the PDs are CPDs by our assumption). After solving Equation (9) for F(m) and estimating U(m) for m = 1, …, N as described in Section 2.1, the tensorization of F(m) is orthogonally compressed
The CPD of the compressed tensor shares the factor matrix V(m) with the CPD of the core tensor . The factor matrices V(n) for n = 1, …, N of the CPD of the core can thus be found by computing the CPD of each compressed tensor if the mth factor matrix of the CPD of is unique for m = 1, …, N. If the CPD of the full tensor is also unique, its factor matrices can be retrieved by expanding the factor matrices W(n) = U(n)V(n) for n = 1, …, N. Since a CPD can only be unique up to the factor scaling and permutation indeterminacies and each factor matrix V(n) for n = 1, …, N is retrieved from a different compressed tensor, the indeterminacies must be addressed. To this end, the fact that the N tensors all have the same CPD, up to the (known) compression matrices A(m,n) for m, n = 1, …, N, can be exploited.
The steps in Section 3.1 mimic the popular approach in Bro and Andersson [9] for computing the CPD of a fully given tensor, which is: 1) compute the MLSVD of , 2) compute the CPD of the core and 3) expand the factor matrices W(n) = U(n)V(n) for n = 1, …, N. The corresponding steps in the approach in this paper are: 1) compute the MLSVD factor matrices U(n) for n = 1, …, N and orthogonally compress the tensors for m = 1, …, N, 2) compute the CPD of the compressed tensors and 3) expand the factor matrices W(n) = U(n)V(n) for n = 1, …, N. Instead of computing the CPD of a core tensor of dimensions R × ⋯ × R, this approach computes the CPD of the N tensors in Equation (16) which are of dimensions Pm1 × ⋯ × Pm,m−1 × R × Pm,m+1 × ⋯ × Pm,N for m = 1, …, N. As will be shown in Section 3.3, these tensors can be far smaller than the core tensor. Algorithm 2 outlines all steps needed to compute a CPD with orthogonal compression from a BRKS linear system. All steps of this algorithm can be computed in parallel. Like Algorithm 1, Algorithm 2 accomodates both the RTD- and CS-setting.

Algorithm 2. Orthogonally compressed CPD from a BRKS linear system (lscpd_brks).
Instead of computing the CPDs of the tensors for m = 1, …, N separately, they can also be computed simultaneously as a set of coupled CPDs. These CPDs are coupled since their factor matrices all depend linearly, with coefficients A(m,n)U(n), on the same factors V(n) for m, n = 1, …, N with n ≠ m. This set of coupled CPDs can be computed in Tensorlab [26] through structured data fusion [27].
In this section, we derive conditions for the identifiability of the CPD of from a BRKS system. The CPD can be identified if the conditions in Theorem 3 hold. In Domanov and De Lathauwer [28], conditions are provided to guarantee that one factor matrix of the CPD is unique.
Theorem 3. Consider a tensor of rank R, admitting a CPD with factor matrices for n = 1, …, N. Given linear combinations b of , obtained from a BRKS linear system with generating matrices for m, n = 1, …, N, the factor matrices W(n) for n = 1, …, N can be retrieved if
Proof: Conditions 1) and 2): For the compression matrices U(n) for n = 1, …, N, the factor matrices of the MLSVD of must be retrievable. These conditions are the same as the first two conditions in Theorem 1.
Condition 3): The CPD of the compressed tensor for m = 1, …, N in Equation (16) shares the mth factor matrix with the core of the MLSVD of if the mth factor matrix is unique for m = 1, …, N.
Condition 4): While condition 3) ensures that the factor matrices W(n) for n = 1, …, N are unique, condition 4) is needed to ensure that there is only one set of rank-1 tensors, consisting of the columns of W(n) for n = 1, …, N, that forms a CPD of , i.e., to exclude different ways of pairing.
In the generic case, in which the generating matrices and the factor matrices of the CPD are sampled from a continuous probability distribution, the CPD of can be identified if the conditions in Theorem 4 hold. Here we used a generic condition to prove the uniqueness of the full CPD of for m = 1, …, N, which a fortiori guarantees the uniqueness of its mth factor matrix. The conditions in Theorem 4 can be used to determine the dimensions of the generating matrices that are generically required for the identifiability of the CPD of .
Theorem 4. With generic generating matrices A(m,n) for m,n = 1, …, N, the conditions in Theorem 3 hold if
Proof: Conditions 1) and 2): These conditions are the same as the first two conditions in Theorem 2.
Condition 3) and 4): The mth factor matrix of is unique for m = 1, …, N if the CPD of these tensors is unique. The Nth order tensor can be reshaped to a third-order tensor , with J1 = Im, , and , of which the first mode corresponds to the uncompressed mth mode of . The second and third mode, respectively, correspond to a subset of the remaining N − 1 modes and its complementary subset . The rank R CPD of is unique if there exists a subset such that the rank R CPD of the reshaped third-order tensor is unique. Generically, a third-order tensor of rank R is unique if J1 ≥ R, min(J2, J3) ≥ 3 and (J2 − 1)(J3 − 1) ≥ R [29]. Condition 3) guarantees that the former condition is satisfied and condition 4) guarantees that the latter two conditions are satisfied for for m = 1, …, N. Additionally, condition 3) guarantees generic uniqueness of the CPD of since for each reshaped, third-order version of , all dimensions exceed R [30, Theorem 3].
As explained in Section 2.4, the second condition in Theorem 4 implies that if the values Pmn are approximately equally large for m, n = 1, …, N and n ≠ m. Similarly, the fourth condition in Theorem 4 implies that
(Note that this bound is derived for tensors of uneven order N. The bound for tensors of even order is similar, but does not have a simple expression). The latter constraint poses only slightly more restrictive bounds than the former, meaning that the dimensions Pmn for m, n = 1, …, N and n ≠ m can still be chosen such that they are much smaller than R. In real applications, tensor dimensions often exceed the tensor rank, satisfying the third condition in Theorem 4.
Remark: Note that the rank of a tensor can exceed some of its dimensions, in which case Theorem 4 cannot be satisfied. This can be resolved by using a different uniqueness condition to guarantee the uniqueness of the CPDs of for m = 1, …, N, such as the generic version of Kruskal's condition [31]. However, using this condition also results in stricter bounds on Pmn for m, n = 1, …, N and n ≠ m.
Since the TT also does not suffer from the CoD, we derive an algorithm for computing a TT from a BRKS linear system in this section. The TT-SVD algorithm in Oseledets [25] computes the cores using sequential SVDs. Unlike in TT-SVD, for a BRKS linear system the SVDs can be computed in parallel by processing the compressed tensors for m = 1, …, N of separately.
If is approximately of TT-rank (R0, …, RN), it admits a TT with cores for n = 1, …, N. Substituting this TT for into the BRKS linear system in Equation (3) leads to
It follows that the tensorized mth block row of this BRKS system corresponds to the TT of transformed through mode-n multiplication with the generating matrices A(m,n):
with for n = 1, …, N. Rearranging this transformed TT into its mode-m unfolding leads to
This unfolding corresponds to a linear system
that can be solved for . The tensor is a transformed TT of that shares the mth core with the TT of the full tensor . Following the definition of a TT, this core can be retrieved from the column space of the following matrix unfolding
(W.r.t. the matricization, note that while consists of m cores, it is a tensor of order m + 1 since Rm is not necessarily equal to one). First, we retrieve by computing an orthonormal basis of dimension R1 for the dominant column space of the matrix unfolding in Equation (18) for m = 1. For m = 2, …, N, the column space of this unfolding also involves the preceding cores . If the cores are computed in order, then these preceding cores are known and can be compensated for by subsequently solving smaller linear systems
for , with and for n = 2, …, m − 1. After solving these systems, is retrieved by computing an orthonormal basis of dimension Rm for the dominant column space of for m = 1, …, N.
Alternatively, we can immediately compute an orthonormal basis of dimension Rm for the dominant column space of the matrix unfolding in Equation (18) for m = 1, …, N, without compensating for preceding cores first. Computing these bases is more expensive, since they are obtained from a larger matrix than in the case where the preceding cores have already been compensated for. On the other hand, the orthonormal bases can be computed in parallel, as there is no dependency on any preceding core. If after the orthonormal bases have been found, also the cores of the TT are desired, compensation of preceding cores can be done in a similar manner as described above, namely by subsequently solving linear systems. These linear systems have the same coefficient matrix as the linear systems in Equation (19).
Algorithm 3 outlines all steps needed to compute a TT from a BRKS linear system for the approach in which the orthonormal bases are computed first and the preceding cores are compensated for second. Note that only N − 1 SVDs need to be computed, just like in the standard TT-SVD algorithm, in which the final SVD reveals both cores N − 1 and N. Like Algorithm 1 and 2, Algorithm 3 also accommodates both the RTD- and CS-setting.

Algorithm 3. TT from a BRKS linear system (lstt_brks).
Remark: When computing the mth core in Algorithm 3, the m − 1 preceding compressed cores in are compensated for from left to right, i.e., for m = 1, …, n − 1. If is unfolded in reverse, i.e.,
then the column space of the unfolding contains, besides , the N − m next compressed cores . This way, it is possible to compute the mth core by compensating for these next compressed cores from right to left, i.e., . The efficiency of Algorithm 3 can be improved by computing the first half of the cores using the unfolding in Equation (18) and compensating for the preceding cores from left to right, and the second half of the cores using the unfolding in Equation (20) and compensating for the next cores from right to left. This halves the number of cores that need to be compensated for compared to Algorithm 3, in which cores are only compensated for from left to right to simplify the pseudocode.
In this section, we derive the conditions in Theorem 5, under which retrieval of the TT of from a BRKS system is guaranteed. The compensation for preceding cores occurs in both approaches for computing the TT in Section 4.1. Therefore, the linear systems that are solved to compensate for them must have a unique solution. Since these linear systems have the same coefficient matrices in both approaches, the condition under which they have a unique solution is the same, regardless of the chosen approach.
Theorem 5. Consider a tensor of TT-rank (R0, …, RN), admitting a TT with cores for n = 1, …, N. Given linear combinations b of , obtained from a BRKS linear system with generating matrices for m, n = 1, …, N, the cores for n = 1, …, N can be retrieved if and only if
Proof: Condition 1): The linear system in Equation (17) can be uniquely solved for if and only if A(m,m) is of full column rank Im for m = 1, …, N.
Condition 2): An orthonormal basis of dimension Rm for the column space of the matricization in Equation (18) can be retrieved if and only if the rank of this matricization equals Rm.
Condition 3): The linear systems that are solved to compensate for compressed cores have a unique solution if and only if
holds.
In the generic case, in which the generating matrices are sampled from a continuous probability distribution, the TT of can be retrieved if the conditions in Theorem 6 hold. These conditions can be used to determine the dimensions of the generating matrices such that the TT of can generically be retrieved.
Theorem 6. With generic generating matrices A(m,n) for m, n = 1, …, N, the conditions in Theorem 1 hold if and only if
Proof: Condition 1): This condition is the same as condition 1) in Theorem 2.
Condition 2): The matricization in Equation (18) equals
Generically, the rank of equals Rm if and only if the rank of both D and E equals Rm. Condition 2) relates to D and condition 3) to E. Since is of full rank, which follows from the definition of a TT, and for n ≠ m is generically of full rank, each matrix product in Equation (21) is also of full rank [10, Lemma 1]. Therefore, the rank of D generically equals
Both arguments of the leftmost min(·) must at least equal Rm such that r (D) ≥ Rm holds. Following the definition of a TT, this always holds true for the first argument . The second argument is min(·)Im, so both arguments of this second min(·) must at least equal . Generically , leading to the conditions and Rm−1Im ≥ Rm. The latter condition is satisfied by the definition of a TT. Repeating the same steps for each subsequent min(·) leads to the conditions
Condition 3): In a similar fashion, it can be proven that r (E) ≥ Rm holds if and only if
Condition 4): Since a generic matrix is of full rank, for m, n = 1, …, N.
In this section, we validate our algorithms using synthetic and real data. The algorithms are implemented in MATLAB and are available at https://www.tensorlabplus.net. In the practical implementation of the algorithms, column spaces are estimated using the SVD and linear systems are solved using the MATLAB backslash operator. All experiments are performed on a laptop with an AMD Ryzen 7 PRO 3700U processor and 32GB RAM. The algorithms are run sequentially even though each algorithm can (partly) be executed in parallel.
Since it is possible to choose the generating matrices in the experiments in this section, we set Amm = IIm for m = 1, …, N. This means that the first step in each algorithm, namely solving a linear system with Amm as the coefficient matrix, can be skipped. First, we use synthetic data to compare the accuracy and computation time of these algorithms to related algorithms. All synthetic problems are constructed by sampling the entries of the factor matrices and/or core(s) of a tensor decomposition from the standard normal distribution. Additive Gaussian noise is added to these randomly generated tensors and the noise level is quantified using the signal-to-noise ratio (SNR):
In the first experiment, a random third-order tensor of low multilinear rank (R, R, R), with I = 200 and R = 10, is generated with varying levels of noise. The factor matrices of the MLSVD of are then retrieved from a BRKS linear system using Algorithm 1. The entries of the generating matrices are sampled from the standard normal distribution. This means that we are using Algorithm 1 in the RTD-setting in this experiment. The dimensions of the generating matrices are determined using the oversampling factor q = 5 and the multilinear rank of . For this value of q, the sampling ratio equals 0.005. This ratio is defined as the number of compressed measurements in b divided by the number of entries in . We compare the accuracy of our algorithm with related RTD algorithms and a cross-approximation algorithm for low multilinear rank approximation. These algorithms are:
• rand_tucker Algorithm 2 in [16]: The factor matrices U(n) for n = 1, …, N are retrieved as follows: 1) the mode-n matrix unfolding of is compressed through multiplication with a random Gaussian matrix and 2) an orthonormal basis for this compressed matrix unfolding is computed using the QR decomposition. After computing each factor matrix, is orthogonally compressed using this factor matrix like in the sequentially truncated higher-order SVD algorithm [32]. The oversampling factor is set to p = 5, which means that this algorithm actually estimates an MLSVD of multilinear rank (R + p, R + p, R + p).
• rand_tucker_kron algorithm 4.2 in [15]: Similar to rand_tucker, but the algorithm uses a Kronecker-structured matrix for compression and the SVD for computing an orthonormal basis. The oversampling factor for this algorithm is chosen such that it is the same as our oversampling factor q in Section 2.4.
• mlsvd_rsi [33]: Computes an MLSVD using sequential truncation [32] and uses randomized compression and subspace iteration for estimating the SVD [34]. In the randomized compression step, the mode-n unfolding X[n] is compressed through matrix multiplication with a random matrix of dimensions ∏i ≠ nIi × Rn + p, with an oversampling factor p = 5. Next, the nth factor matrix is estimated by computing an SVD of this randomly compressed matrix and further refined using two subspace iteration steps with the full mode-n unfolding X[n].
• lmlra_aca [21]: Cross approximation approach for low multilinear rank approximation.
The last two algorithms are available in Tensorlab [26]. As the full tensor is usually available in the RTD-setting, the core is computed as
Figure 2 compares the accuracy, quantified as a relative error
with and for n = 1, …, N the estimated core and factor matrices, of these algorithms. The error shown in Figure 2 is the average relative error over 10 trials. Algorithm lsmlsvd_brks is more accurate than rand_tucker and lmlra_aca. Algorithm mlsvd_rsi is far more accurate than all other algorithms because it uses subspace iteration with the full mode-n matrix unfolding of for computing the nth factor matrix. For this reason it also has the longest computation time of all algorithms. Algorithm rand_tucker_kron is more accurate than lsmlsvd_brks due to the sequential truncation step in rand_tucker_kron after each factor matrix is computed. If this step is omitted, which corresponds to Che et al. algorithm 4.1 in [15], it achieves the same accuracy as lsmlsvd_brks. This sequential truncation step is not possible in lsmlsvd_brks since this algorithm only uses the compressed measurements b instead of the full tensor . Note that increasing the oversampling factors of the algorithms results in higher accuracy in exchange for a longer computation time and requiring more compressed datapoints.

Figure 2. Algorithm mlsvd_rsi is by far the most accurate because it used the full-sized matrix unfolding in the subspace iteration step. Algorithm lsmlsvd_brks is more accurate than lmlra_aca and rand_tucker and less accurate than rand_tucker_kron. If the sequential truncation step in rand_tucker_kron is omitted, it achieves the same accuracy as lsmlsvd_brks.
In this experiment, we generate a CPD with random factor matrices of a third-order tensor , with I = 100, of rank R = 10. Varying levels of noise are added to this tensor. Algorithm 2 is used in the RTD-setting to estimate the factor matrices of the CPD of . To compute the CPDs of the compressed tensors, we use the cpd function in Tensorlab [26]. This function initializes the factor matrices with a generalized eigenvalue decomposition if possible and further improves them using (second-order) optimization algorithms. The accuracy of the factor matrices estimated by this algorithm are compared to results obtained with related RTD algorithms:
• cpd_rbs [35]: In each iteration, a random subtensor of is sampled and the corresponding rows of the factor matrices are updated. These updates are computed using a Gauss–Newton algorithm. In this experiment, the algorithm starts with random initial factor matrices.
• cp_arls [14]: Alternating least squares with random sketching for solving the least squares subproblems.
The accuracy of the estimated factor matrices is quantified as a relative error
in which the scaling and permutation ambiguities between the true U(n) and estimated factor matrix have been resolved for n = 1, …, N. Figure 3 shows the average relative error on the left and the average computation time for tensors with increasing dimensions on the right. Both averages are computed over 10 trials. For lscpd_brks, sampling the randomly compressed tensors, i.e., evaluating Equation (3), is included in the computation time. The oversampling factor q of lscpd_brks is set to 5, 10 or 50. For a larger value of q, U(n) better captures the mode-n subspace of and less information is lost during the orthogonal compression step. Figure 3 illustrates that the algorithm is much more accurate for q = 50, while the increase in computation time compared to q = 5 is negligible. If q is set such that the size of the compressed tensors in Equation (4) is of the same order as the full tensor , then the computation time will of course increase significantly. For q = 50, the number of compressed datapoints in b equals just 15% of the total number of datapoints in . This sampling ratio can be even lower for tensors with order greater than three. Algorithm cp_arls is slightly more accurate than lscpd_brks with q = 50 while being much slower in terms of computation time. Algorithm cpd_rbs is even more accurate and is situated in between lscpd_brks and cp_arls for smaller values of I. The computation time of lscpd_brksis dominated by sampling the randomly compressed tensors, since computing the CPD of these small tensors is very fast. Therefore, the computation time of cpd_rbs scales better for higher values of I since sampling random subtensors of is less time consuming than the random compression of in lsmlsvd_brks, which requires multiple large matrix products. In contrast to lscpd_brks, which uses a fixed amount of compressed datapoints determined by the size of the problem and the oversampling factor, cpd_rbs and cp_arls continue randomly sampling from every iteration until a stopping criterion is met.
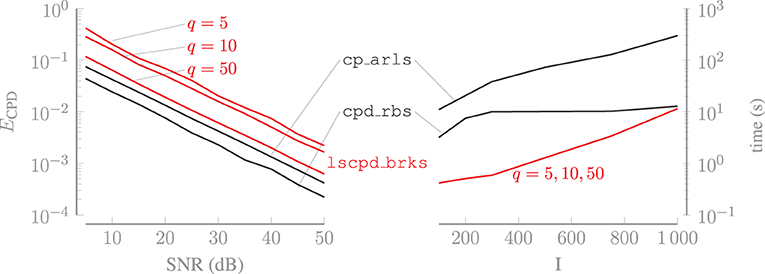
Figure 3. Increasing the oversampling factor q of lscpd_brks, for which the value is shown in the figure, greatly improves its accuracy while having a negligible effect on the computation time. Algorithm lscpd_brks is faster than cp_arls and cp_rbs, for a range of tensor dimensions that are relevant for applications, with a limited loss of accuracy.
In this experiment, we generate a TT with random core tensors of a third-order tensor , with I = 500, of TT-rank (1, 10, 10, 1). We add varying levels of noise to this tensor and estimate the cores using Algorithm 3 in the RTD-setting. For this experiment, we use the version of this algorithm that first computes orthonormal bases and then compensates for preceding cores. Additionally, preceding cores are compensated for from left to right for the first half of the cores and from right to left for the second half, as explained in Section 4.2. The dimensions of the generating matrices are chosen such that the sampling ratio equals 0.005.
The results of lstt_brks are compared with the results of a related RTD algorithm and a TT cross-approximation approach:
• rand_tt Algorithm 5.1 in [36]: This algorithm is a randomized version of the standard TT-SVD algorithm. The TT-SVD algorithm consists of three steps that are performed for the first N − 1 cores: 1) tensor is matricized, 2) a core is estimated by computing a basis for the column space of this matricization using the SVD and 3) tensor is compressed using this basis. In rand_tt, the matricization in the first step is compressed by multiplying it with a random matrix from the right in order to speed up the computation of the SVD in the next step.
• cross_tt [37]: This algorithm reduces the size of the matricizations of using a maximal volume cross-approximation approach. The matricizations used in this algorithm allow the TT-ranks to be determined adaptively.
The accuracy of the results of these algorithms are quantified as a relative error
in which for n = 1, …, N are the estimated cores. Figure 4 shows the relative error, averaged over 50 trials, and the computation time, averaged over 10 trials, for all algorithms. Tensors of increasing size are used to estimate the computation time. The relative errors achieved by the algorithms with these tensors are in proportion with the errors shown in Figure 4. The relative error is approximately the same for both rand_tt and lstt_brks. The former is faster thanks to the compression step that is performed after computing each core, which causes the tensor to get progressively smaller as the algorithm progresses. However, this algorithm requires the full tensor to be available, whereas the latter works with a limited amount of Kronecker-structured linear combinations of the entries of . Therefore, lstt_brks enables us to achieve accuracy comparable to rand_tt in CS applications. If a method for obtaining any entry of is available, then cross_tt can be used to recover a more accurate approximation of the tensor, in exchange for a longer computation time. However, this algorithm is not applicable in the CS-setting either.
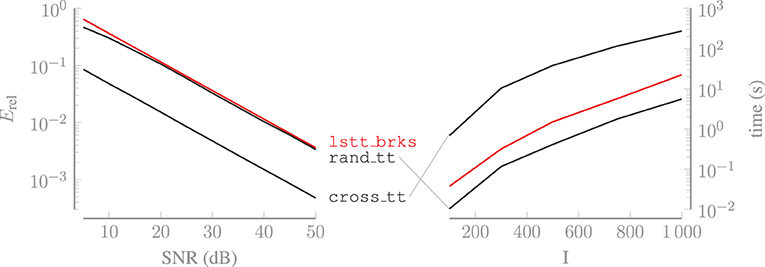
Figure 4. Algorithm lstt_brks enables us to achieve accuracy similar to that of rand_tt in CS applications. If a method for obtaining any entry of is available, then cross_tt can be used to recover a more accurate approximation of the tensor, in exchange for a longer computation time.
In the RTD-setting, the tensor is fully acquired first and then randomly compressed. In the CS-setting, the data can in some applications be compressed during the data acquisition step. For example in hyperspectral imaging, compressed measurements can be obtained using the single-pixel camera [38] or the coded aperture snapshot spectral imager (CASSI) [39]. A hyperspectral image is a third-order tensor , consisting of images of I1 by I2 pixels taken at I3 different wavelengths. The single-pixel camera randomly compresses the spatial dimensions of a hyperspectral image. In CASSI, a mask is applied to each I1 by I2 image for different wavelengths and these masked images are then aggregated into a single one, i.e., a snapshot. In general, compressed measurements are often obtained in (hyperspectral) imaging by compressing along each dimension separately, meaning that the measurement matrix is Kronecker-structured [11, 40]. With a small number of compressed measurements, a large hyperspectral image can often be accurately reconstructed. Whereas, the random compression step dominated the computation time of our algorithms in the previous experiments, it is missing altogether in this experiment since it is inherent to the application. Therefore, our algorithms enable fast reconstruction of hyperspectral images.
We use lsmlsvd_brks to reconstruct a hyperspectral image using compressed measurements sampled at different sampling ratios. Similar to KCS, this approach expresses in a Kronecker-structured basis, namely the Kronecker product of U(n) for n = 1, 2, 3, in which the core tensor contains the coefficients. In KCS, the bases are chosen a priori such that these coefficients are sparse, which is not necessarily true for the core of an MLSVD. Also, in lsmlsvd_brks, the bases do not have to be chosen a priori as this algorithm also estimates them using compressed measurements. Additionally, in KCS the measurement matrix is Kronecker-structured, whereas it consists of multiple Kronecker-structured block rows in our approach.
Instead of using just the final, (N + 1)th block row of the BRKS system to estimate the core, it makes more sense to use all available compressed measurements to improve the quality of the estimation, since the number of measurements is limited. Therefore, we solve the full BRKS system, with all N + 1 block rows, for a sparse by optimizing:
This is a basis pursuit denoising problem, which can be solved using the SPGL1 solver [41, 42]. The reason for imposing sparsity is as follows. If we were to estimate a dense core tensor using lsmlsvd_brks in this experiment, the number of compressed measurements b(N+1) certainly cannot be less than the number of entries in the core if we want to be able to retrieve it. However, it turns out that the mode-n vectors of the hyperspectral imaging data cannot be well approximated as linear combinations of a small number of multilinear singular vectors, indicating that the multilinear rank is not small. Estimating a dense core tensor would then require a large number of measurements. On the other hand, it also turns out that in this data only a relatively small number of the entries in a relatively large core is important. We exploit this by computing a sparse approximation of the core, which results in reconstructions of better quality than with the dense core approach, while requiring far less compressed measurements.
The reconstruction results of our algorithm are compared with two other approaches for reconstructing a hyperspectral image from compressed measurements:
• GAP_TV [43]: A generalized alternating projection algorithm that solves the total variation minimization problem. Minimizing total variation leads to accurate image reconstruction because images are generally locally self-similar.
• KCS [11]: We used a two-dimensional Daubechies wavelet basis to sparsify the spatial dimensions and the Fourier basis for the spectral dimension. The sparse coefficients are computed using the SPGL1 solver.
The quality of the reconstructed images is quantified using the peak signal-to-noise ratio (PSNR)
in which is the reconstructed hyperspectral image. In this experiment, we used the corrected Indian Pines dataset, in which some very noisy wavelengths have been left out [44]. This results in a hyperspectral image of dimensions 145 × 145 × 200. For lsmlsvd_brks, we compute an MLSVD of multilinear rank (70, 70, 30) with a sparse core. This multilinear rank was obtained by trying a wide range of multilinear ranks and assessing the quality of their corresponding reconstructions.
Table 1 shows the quality of the reconstructed images for a range of sampling ratios. Whereas, GAP_TV is specifically designed for imaging applications, lsmlsvd_brks can be applied to a wide range of problems. Regardless, lsmlsvd_brks performs approximately equally well in terms of reconstruction quality. The reconstruction quality achieved by lsmlsvd_brks is higher than for KCS, indicating that the bases estimated by the former suit the data better than the a priori determined bases used in the latter.
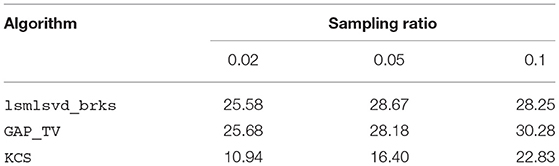
Table 1. This table shows the reconstruction quality, quantified in PSNR (dB), of a hyperspectral image for a range of sampling ratios, obtained with different algorithms. Algorithm lsmlsvd_brks performs approximately equally well as GAP_TV, which is an algorithm specifically suited for image reconstruction. The lower reconstruction quality for KCS indicates that the bases estimated by lsmlsvd_brks suit the data better than the a priori determined bases used in KCS.
In this work, we have considered a general framework of BRKS linear systems with a compact solution, which suits a wide variety of problems. We developed efficient algorithms for computing an MLSVD, CPD or TT constrained solution from a BRKS system, allowing the user to choose the decomposition that best matches their specific application. The efficiency of these algorithms is enabled on one hand by the BRKS linear system, since such a system produces multiple compressed versions of the tensor and thus splits the problem into a number of smaller ones, and on the other hand by the low (multilinear-/TT-)rank constrained solution. With these algorithms, real data can be accurately reconstructed using far fewer compressed measurements than the total number of entries in the dataset. We have derived conditions under which an MLSVD, CPD or TT can be retrieved from a BRKS system. The corresponding generic versions of these conditions allow us to choose the dimensions of the generating matrices such that a solution can generically be found. Through numerical experiments, we have shown that these algorithms can be used for computing tensor decompositions in a randomized approach. In the case of the CPD, our algorithm needs less computation time than the alternative algorithms. Additionally, we have illustrated the good performance of the algorithms for reconstructing compressed hyperspectral images, despite not being specifically developed for this application. In further work, we will look into parallel implementations for the algorithms in this paper.
Publicly available datasets were analyzed in this study. This data can be found at: https://rslab.ut.ac.ir/data.
SH derived the algorithms and theory and implemented the algorithms in Matlab. LDL conceived the main idea and supervised the research. Both authors contributed to the article and approved the submitted version.
This research received funding from the Flemish Government (AI Research Program). LDL and SH are affiliated to Leuven.AI - KU Leuven institute for AI, B-3000, Leuven, Belgium. This work was supported by the Fonds de la Recherche Scientifique–FNRS and the Fonds Wetenschappelijk Onderzoek- Vlaanderen under EOS Project no G0F6718N (SeLMA). KU Leuven Internal Funds: C16/15/059, IDN/19/014.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
The authors would like to thank N. Vervliet and M. Ayvaz for proofreading the manuscript and E. Evert for his help with the mathematical proofs.
1. ^In this context, rank pertains to the definition of rank that corresponds to the respective tensor decomposition.
1. Candès EJ, Wakin MB. An introduction to compressive sampling. IEEE Signal Process Mag. (2008). 25:21–30. doi: 10.1109/MSP.2007.914731
2. Donoho DL. Compressed sensing. IEEE Trans Inf Theory. (2006) 52:1289–306. doi: 10.1109/TIT.2006.871582
3. Ahmadi-Asl S, Abukhovich S, Asante-Mensah MG, Cichocki A, Phan AH, Tanaka T, et al. Randomized algorithms for computation of tucker decomposition and higher order SVD (HOSVD). IEEE Access. (2021) 9:28684–706. doi: 10.1109/ACCESS.2021.3058103
4. Acar E, Dunlavy DM, Kolda TG, Morup M. Scalable tensor factorizations for incomplete data. Chemometr Intell Lab. (2011) 3106:41–56. doi: 10.1016/j.chemolab.2010.08.004
5. Aldroubi A, Gröchenig K. Nonuniform sampling and reconstruction in shift-invariant spaces. SIAM Rev. (2001) 43:585–620. doi: 10.1137/S0036144501386986
6. Oseledets I, Tyrtyshnikov E. TT-cross approximation for multidimensional arrays. Linear Algebra Appl. (2010) 432:70–88. doi: 10.1016/j.laa.2009.07.024
7. Udell M, Townsend A. Why are big data matrices approximately low rank? SIAM J Math Data Sci. (2019) 1:144–60. doi: 10.1137/18M1183480
8. Rubinstein R, Bruckstein AM, Elad M. Dictionaries for sparse representation modeling. Proc IEEE. (2010) 98:1045–57. doi: 10.1109/JPROC.2010.2040551
9. Bro R, Andersson C. Improving the speed of multiway algorithms: part II: compression. Chemometr Intell Lab Syst. (1998) 42:105–13. doi: 10.1016/S0169-7439(98)00011-2
10. Sidiropoulos ND, Kyrillidis A. Multi-way compressed sensing for sparse low-rank tensors. IEEE Signal Process. Lett. (2012) 19:757–60. doi: 10.1109/LSP.2012.2210872
11. Duarte MF, Baraniuk RG. Kronecker compressive sensing. IEEE Trans Image Process. (2012) 21:494–504. doi: 10.1109/TIP.2011.2165289
12. Sidiropoulos N, Papalexakis EE, Faloutsos C. Parallel randomly compressed cubes: a scalable distributed architecture for big tensor decomposition. IEEE Signal Process Mag. (2014) 31:57–70. doi: 10.1109/MSP.2014.2329196
13. Kressner D, Tobler C. Low-rank tensor krylov subspace methods for parametrized linear systems. SIAM J Matrix Anal Appl. (2011). 32:1288–316. doi: 10.1137/100799010
14. Battaglino C, Ballard G, Kolda TG. A practical randomized CP tensor decomposition. SIAM J Matrix Anal Appl. (2018) 39:876–901. doi: 10.1137/17M1112303
15. Che M, Wei Y, Yan H. Randomized algorithms for the low multilinear rank approximations of tensors. J Computat Appl Math. (2021) 390:113380. doi: 10.1016/j.cam.2020.113380
16. Zhou G, Cichocki A, Xie S. Decomposition of big tensors with low multilinear rank. (2014) CoRR. abs/1412.1885.
17. Yang B, Zamzam A, Sidiropoulos ND. ParaSketch: parallel tensor factorization via sketching. In: Proceedings of the 2018 SIAM International Conference on Data Mining (SDM). (2018). p. 396–404.
18. Jin R, Kolda TG, Ward R. Faster johnson–lindenstrauss transforms via kronecker products. Inf Inference. (2020) 10:1533–62. doi: 10.1093/imaiai/iaaa028
19. Mahoney MW, Maggioni M, Drineas P. Tensor-CUR decompositions for tensor-based data. SIAM J Matrix Anal Appl. (2008). 30:957–87. doi: 10.1137/060665336
20. Oseledets I, Savostianov DV, Tyrtyshnikov E. Tucker dimensionality reduction of three-dimensional arrays in linear time. SIAM J Matrix Anal Appl. (2008) 30:939–56. doi: 10.1137/060655894
21. Caiafa CF, Cichocki A. Generalizing the column-row matrix decomposition to multi-way arrays. Linear Algebra Appl. (2010) 433:557–73. doi: 10.1016/j.laa.2010.03.020
22. Goreinov SA, Tyrtyshnikov EE, Zamarashkin NL. A theory of pseudoskeleton approximations. Linear Algebra Appl. (1997) 261:1–21. doi: 10.1016/S0024-3795(96)00301-1
23. Kolda TG. Multilinear Operators for Higher-Order Decompositions. Albuquerque, NM; Livermore, CA: Sandia National Laboratories (2006).
24. De Lathauwer L, De Moor B, Vandewalle J. A multilinear singular value decomposition. SIAM J Matrix Anal Appl. (2000) 21:1253–78. doi: 10.1137/S0895479896305696
25. Oseledets I. Tensor-train decomposition. SIAM J Sci Comput. (2011) 33:2295–317. doi: 10.1137/090752286
26. Vervliet N, Debals O, Sorber L, Van Barel M, De Lathauwer L. Tensorlab 3.0. (2016). Available online at: https://www.tensorlab.net.
27. Sorber L, Van Barel M, De Lathauwer L. Structured data fusion. IEEE J Select Top Signal Process. (2015) 9:586–600. doi: 10.1109/JSTSP.2015.2400415
28. Domanov I, De Lathauwer L. On the uniqueness of the canonical polyadic decomposition of third-order tensors- Part I: Basic results and uniqueness of one factor matrix. SIAM J Matrix Anal Appl. (2013) 34:855–75. doi: 10.1137/120877234
29. Chiantini L, Ottaviani G. On generic identifiability of 3-tensors of small rank. SIAM J Matrix Anal Appl. (2012) 33:1018–37. doi: 10.1137/110829180
30. Sidiropoulos N, De Lathauwer L, Fu X, Huang K, Papalexakis EE, Faloutsos C. Tensor decomposition for signal processing and machine learning. IEEE Trans Signal Process. (2017) 65:3551–82. doi: 10.1109/TSP.2017.2690524
31. Kruskal JB. Three-way arrays: rank and uniqueness of trilinear decompositions, with application to arithmetic complexity and statistics. Linear Algebra Appl. (1977) 18:95–138. doi: 10.1016/0024-3795(77)90069-6
32. Vannieuwenhoven N, Vandebril R, Meerbergen K. A new truncation strategy for the higher-order singular value decomposition. SIAM J Sci Comput. (2012) 34:A1027–52. doi: 10.1137/110836067
33. Vervliet N, Debals O, De Lathauwer L. Tensorlab 3.0 – Numerical optimization strategies for large-scale constrained and coupled matrix/tensor factorization. In: Proceedings of the 50th Asilomar Conference on Signals, Systems and Computers. Pacific Grove, CA (2016). p. 1733–8.
34. Halko N, Martinsson PG, Tropp JA. Finding structure with randomness: probabilistic algorithms for constructing approximate matrix decompositions. SIAM Rev. (2011) 53:217–88. doi: 10.1137/090771806
35. Vervliet N, De Lathauwer L. A randomized block sampling approach to canonical polyadic decomposition of large-scale tensors. IEEE J Select Top Signal Process. (2016) 10:284–95. doi: 10.1109/JSTSP.2015.2503260
36. Che M, Wei Y. Randomized algorithms for the approximations of Tucker and the tensor train decompositions. Adv Comput Math. (2019) 45:395–428. doi: 10.1007/s10444-018-9622-8
37. Savostyanov D, Oseledets I. Fast adaptive interpolation of multi-dimensional arrays in tensor train format. In: The 2011 International Workshop on Multidimensional (nD) Systems. (2011). p. 1–8.
38. Duarte MF, Davenport MA, Takhar D, Laska JN, Sun T, Kelly KF, et al. Single-pixel imaging via compressive sampling. IEEE Signal Process Mag. (2008) 25:83–91. doi: 10.1109/MSP.2007.914730
39. Wagadarikar AA, Pitsianis NP, Sun X, Brady DJ. Video rate spectral imaging using a coded aperture snapshot spectral imager. Optics Express. (2009) 17:6368–6388. doi: 10.1364/OE.17.006368
40. Rivenson Y, Stern A. Compressed imaging with a separable sensing operator. IEEE Signal Process Lett. (2009) 16:449–52. doi: 10.1109/LSP.2009.2017817
41. den berg EV, Friedlander MP. Probing the Pareto frontier for basis pursuit solutions. SIAM J Sci Comput. (2008) 31:890–912. doi: 10.1137/080714488
42. den berg EV, Friedlander MP. SPGL1: A Solver for Large-Scale Sparse Reconstruction. (2019). Available online at: https://friedlander.io/spgl1.
Keywords: tensor, decomposition, compressed sensing (CS), randomized, Kronecker, linear system
Citation: Hendrikx S and De Lathauwer L (2022) Block Row Kronecker-Structured Linear Systems With a Low-Rank Tensor Solution. Front. Appl. Math. Stat. 8:832883. doi: 10.3389/fams.2022.832883
Received: 10 December 2021; Accepted: 14 February 2022;
Published: 17 March 2022.
Edited by:
Jiajia Li, College of William & Mary, United StatesReviewed by:
Mark Iwen, Michigan State University, United StatesCopyright © 2022 Hendrikx and De Lathauwer. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Stijn Hendrikx, c3Rpam4uaGVuZHJpa3hAa3VsZXV2ZW4uYmU=
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.