 Glen Evenbly
Glen Evenbly
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
METHODS article
Front. Appl. Math. Stat. , 01 June 2022
Sec. Mathematics of Computation and Data Science
Volume 8 - 2022 | https://doi.org/10.3389/fams.2022.806549
This article is part of the Research Topic High-Performance Tensor Computations in Scientific Computing and Data Science View all 11 articles
We present an overview of the key ideas and skills necessary to begin implementing tensor network methods numerically, which is intended to facilitate the practical application of tensor network methods for researchers that are already versed with their theoretical foundations. These skills include an introduction to the contraction of tensor networks, to optimal tensor decompositions, and to the manipulation of gauge degrees of freedom in tensor networks. The topics presented are of key importance to many common tensor network algorithms such as DMRG, TEBD, TRG, PEPS, and MERA.
Tensor networks have been developed as a useful formalism for the theoretical understanding of quantum many-body wavefunctions [1–10], especially in regards to entanglement [11–13], and are also applied as powerful numeric tools and simulation algorithms. Although developed primarily for the description of quantum many-body systems, they have since found use in a plethora of other applications such as quantum chemistry [14–18], holography [19–24], machine learning [25–29] and the simulation of quantum circuits [30–35].
There currently exist many useful references designed to introduce newcomers to the underlying theory of tensor networks [1–10]. Similarly, for established tensor network methods, there often exist instructional or review articles that address the particular method in great detail [36–40]. Nowadays, many research groups have also made available tensor network code libraries [41–48]. These libraries typically allow other researchers to make use of highly optimized tensor network routines for practical purposes (such as for the numerical simulation of quantum many-body systems).
Comparatively few are resources intended to help researchers that already possess a firm theoretical grounding to begin writing their own numerical implementations of tensor network codes. Yet such numerical skills are essential in many areas of tensor network research: new algorithmic proposals typically require experimentation, testing and bench-marking using numerics. Furthermore, even researchers solely interested in the application of tensor network methods to a problem of interest may be required to program their own version of a method, as a pre-built package may not contain the necessary features as to be suitable for the unique problem under consideration. The purpose of our present work is to help fill this aforementioned gap: to aid students and researchers, who are assumed to possess some prior theoretical understanding of tensor networks, to learn the practical skills required to program their own tensor networks codes and libraries. Indeed, our intent is to arm the interested reader with the key knowledge that would allow them to implement their own versions of algorithms such as the density matrix renormalization group (DMRG) [49–51], time-evolving block decimation (TEBD) [52, 53], projected entangled pair states (PEPS) [54–56], multi-scale entanglement renormalization ansatz (MERA) [57], tensor renormalization group (TRG) [58, 59], or tensor network renormalization (TNR) [60]. Furthermore, this manuscript is designed to compliment online tensor network tutorials [61], which have a focus on code implementation, with more detailed explanations on tensor network theory.
As stated above, the goal of this manuscript is to help readers that already possess some understanding of tensor network theory to apply this knowledge toward numeric calculations. Thus we assume that the reader has some basic knowledge of tensor networks, specifically that they understand what a tensor network is and have some familiarity with the standard diagrammatic notation used to represent them. An overview of these concepts is presented in Figure 1, otherwise more comprehensive introductions to tensor network theory can be found in [1–10].
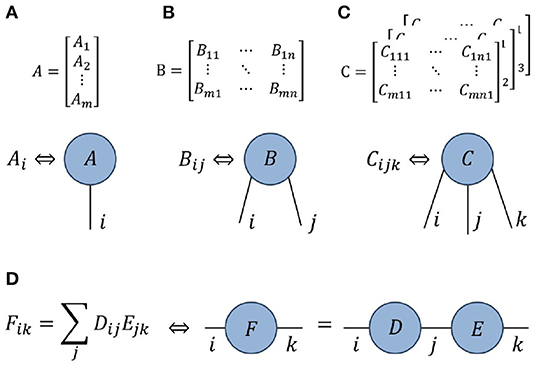
Figure 1. (A–C) Diagrammatic representations of a vector Ai (or order-1 tensor), a matrix Bij (or order-2 tensor) and an order-3 tensor Cijk. (D) A contraction, or summation over an index, between two tensors is represented by a line joining two tensors.
Note that we shall not assume prior knowledge of quantum many-body physics, which is the most common application of tensor network algorithms. The skills and ideas that we introduce in this manuscript are intended to be general for the tensor network formalism, rather than for their use in a specific application, thus can also carry over to other area in which tensor networks have proven useful such as quantum chemistry [14–18], holography [19–24], machine learning [25–29], and the simulation of quantum circuits [30–35].
Currently there exists a wide variety of tensor network code libraries, which include [41–48]. Many of these libraries differ greatly in not only their functioning but also their intended applications, and may have their own specific strengths and weaknesses (which we will not attempt to survey in the present manuscript). Almost all of these libraries contain tools to assist in the tasks described in this manuscript, such as contracting, decomposing and re-gauging tensor networks. Additionally many of these libraries also contain full featured versions of complete tensor network algorithms, such as DMRG or TEBD. For a serious numerical calculation involving tensor networks, one where high performance is required, most researchers would be well-advised to utilize an existing library.
However, even if ultimate intent is to use existing library, it is still desirable that one should understand the fundamental tensor network manipulations used in numerical calculations. Indeed, this understanding is necessary to properly discern the limitations of various tensor network tools, to ensure that they are applied in an appropriate way, and to customize the existing tools if necessary. Moreover, exploratory research into new tensor network ansatz, algorithms and applications often requires non-standard operations and tensor manipulations which may not be present in any existing library, thus may require the development of extensive new tensor code. In this setting it can be advantageous to minimize or to forgo the usage of an existing library (unless one was already intimately familiar with its inner workings), given the inherent challenge of extending a library beyond its intended function and the possibility of unintended behavior that this entails.
In the remaining manuscript we aim to describe key tensor network operations (namely contracting, decomposing and re-gauging tensor networks) with sufficient detail that would allow the interested reader to implement tasks numerically without the need to rely on an existing code library.
Before attempting to implement tensor methods numerically one must, of course, decide on which programming language to use. High-level languages with a focus on scientific computation, such as MATLAB, Julia, and Python (with Numpy) are well-suited for implementing tensor network methods as they have native support for multi-dimensional arrays (i.e., tensors), providing simple and convenient syntax for common operations on these arrays (indexing, slicing, scalar operations) as well as providing a plethora of useful functions for manipulating these tensor objects. Alternatively, some tensor network practitioners may prefer to use lower-level languages such as Fortran or C++ when implementing tensor network algorithms usually for the reason of maximizing performance. However, in many tensor network codes the bulk of the computation time is spent performing large matrix-matrix multiplications, for which even interpreted languages (like MATLAB) still have competitive performance with compiled languages as they call the same underlying BLAS routines. Nonetheless, there are some particular scenarios, such as in dealing with tensor networks in the presence of global symmetries [62–68], where a complied language may offer a significant performance advantage. In this circumstance Julia, which is a compiled language, or Python, in conjunction with various frameworks which allow it to achieve some degree of compilation, may be appealing options.
Before proceeding, let us establish the terminology that we will use when discussing tensor networks. We define the order of a tensor as the number of indices it has, i.e., such that a vector is order-1 and a matrix is order-2. The term rank (or decomposition rank) of a tensor will refer to the number of non-zero singular values with respect to a some bi-partition of the tensor indices. Note that many researchers also use the term rank to describe the number of tensor indices; here we use the alternative term order specifically to avoid the confusion that arises from the double usage of rank. The number of values a tensor index can take will be referred to as the dimension of an index (or bond dimension), which is most often denoted by χ but can also be denoted by m, d, or D. In most cases, the use of d or D to denote a bond dimension is less preferred, as this can be confused which the spatial dimension of the problem under consideration (e.g., when considering a model on a 1D or 2D lattice geometry).
The foundation of all tensor networks routines is the contraction of a network containing multiple tensors into a single tensor. An example of the type problem that we consider is depicted in Figure 2A, where we wish to contract the network of tensors {A, B, C} to form an order-3 tensor F, which has components defined
Note that a convention for tensor index ordering is required for the figure to be unambiguously translated to an equation; here we assumed that indices progress clock-wise on each tensor starting from 6 o'clock. Perhaps the most obvious way to evaluate Equation (1) numerically would be through a direct summation over the indices (l, m, n), which could be implemented using a set of nested “FOR” loops. While this approach of summing over all internal indices of a network will produce the correct answer, there are numerous reasons why this is not the preferred approach for evaluating tensor networks. The foremost reason is that it is not the most computationally efficient approach (excluding, perhaps, certain contractions involving sparse tensors, which we will not consider here). Let us analyse the contraction cost for the example given in Equation (1), assuming all tensor indices are χ-dimensional. A single element of tensor F, which has χ3 elements in total, is given through a sum over indices (l, m, n), which requires O(χ3) operations. Thus the total cost of evaluating tensor F through a direct summation over all internal indices is O(χ6).
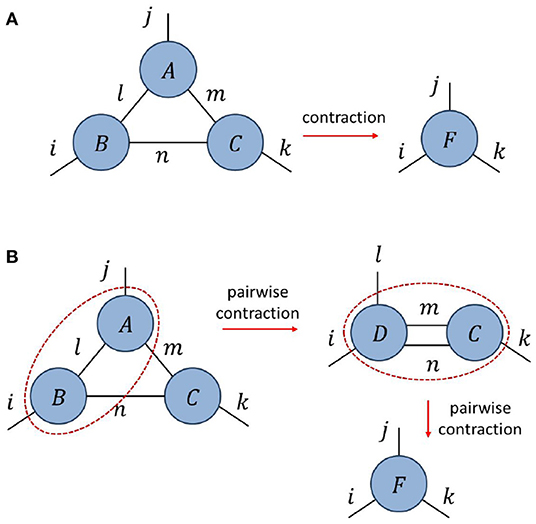
Figure 2. (A) The internal indices (l, m, n) of the network {A, B, C} are contracted to give tensor F. (B) The network is contracted via a sequence of two pairwise tensor contractions, the first of which results in the intermediate tensor D.
Now, let us instead consider the evaluation of tensor F broken up into two steps, where we first compute an intermediate tensor D as depicted in Figure 2B,
before performing a second contraction to give the final tensor F,
Through similar logic as before, one finds that the cost of evaluating intermediate tensor D scales as O(χ5), whilst the subsequent evaluation of F in Equation (3) is also O(χ5). Thus breaking the network contraction down into a sequence of smaller contractions each only involving a pair of tensors (which we refer to as a pairwise tensor contraction) is as computationally cheap or cheaper for any non-trivial bond dimension (χ> 1). This is true in general: for any network of 3 or more (dense) tensors it is always at least as efficient (and usually vastly more efficient) to break network contraction into sequence of pairwise contractions, as opposed to directly summing over all the internal indices of the network.
Two natural questions arise at this point. (i) What is optimal way to implement a single pairwise tensor contraction? (ii) Does the chosen sequence of pairwise contractions affect the total computational cost and, if so, how does one decide what sequence to use? We begin by addressing the first question.
Let us consider the problem of evaluating a pairwise tensor contraction, denoted (A × B), between tensors A and B that are connected by one or more common indices. A straight-forward method to evaluate such contractions, as in the examples of Equations (2) and (3), is by using nested “FOR” loops to sum over the shared indices. The computational cost of this evaluation, in terms of the number of scalar multiplications required, can be expressed concisely as
with |dim(A)| as the total dimension of A (i.e., the product of its index dimensions) and |dim(A∩B)| as the total dimension of the shared indices.
Alternatively, one can recast a pairwise contraction as a matrix multiplication as follows: first reorder the free indices and contracted indices on each of A and B such that they appear sequentially (which can be achieved in MATLAB using the “permute” function) and then group the free-indices and the contracted indices each into a single index (which can be achieved in MATLAB using the “reshape” function). After these steps the contraction is evaluated using a single matrix-matrix multiplication, although the final product may also need to be reshaped back into a tensor. Recasting as a matrix multiplication does not reduce the formal computational cost from Equation (4). However, modern computers, leveraging highly optimized BLAS routines, typically perform matrix multiplications significantly more efficiently than the equivalent “FOR” loop summations. Thus, especially in the limit of tensors with large total dimension, recasting as a matrix multiplication is most often the preferred approach to evaluate pairwise tensor contractions, even though this requires some additional computational overhead from the necessity of rearranging tensor elements in memory when using “permute”. Note that the “tensordot” function in the Numpy module for Python conveniently evaluates a pairwise tensor contraction using this matrix multiplication approach.
It is straight-forward to establish that, when breaking a network contraction into a sequence of binary contractions, the choice of sequence can affect the total computational cost. As an example, we consider the product of two matrices A, B with vector C,
where all indices are assumed to be dimension χ, see also Figure 3. If we evaluate this expression by first performing the matrix-matrix multiplication, i.e., as F = (A × B) × C, then the leading order computational cost scales as O(χ3) by Equation (4). Alternatively, if we evaluate the expression by first performing the matrix-vector multiplication, i.e., as F = A × (B × C), then the leading order computational cost scales as O(χ2). Thus it is evident that the sequence of binary contractions needs to be properly considered in order to minimize the overall computational cost.
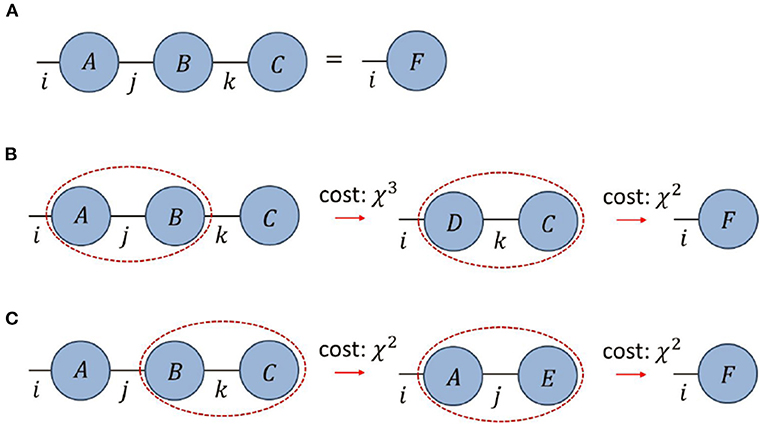
Figure 3. (A) A product of three tensors {A, B, C} is contracted to a tensor F, where all indices are assumed to be of dimension χ. (B,C) The total computational cost of contracting the network depends on the sequence of pairwise contractions; the cost from following the sequence in (B) scales as (χ3+χ2) as compared to the cost from (C) which scales as (2χ2).
So how does one find the optimal contraction sequence for some tensor network of interest? For the networks that arise in common algorithms (such as DMRG, MERA, PEPS, TRG and TNR) it is relatively easy, with some practice, to find the optimal sequence through manual inspection or trial-and-error. This follows as most networks one needs to evaluate contain fewer than 10 tensors and the tensor index dimensions take a only single or a few distinct values within a network, which limits the number of viable contraction sequences that need be considered. More generally, determination of optimal contraction sequences is known to be an NP-hard problem [69], such that it is very unlikely that an algorithm which scales polynomially with the number of tensors in the network will ever be found to exist. However, numerical methods based on exhaustive searches and/or heuristics can typically find optimal sequences for networks with fewer than 20 tensors in a reasonable amount of time [69–72], and larger networks are seldom encountered in practice.
Note that many tensor network optimization algorithms based on an iterative sweep, where the same network diagrams are contracted each iteration (although perhaps containing different tensors and with different bond dimensions). The usual approach in this setting is to determine the optimal sequences once, before beginning the iterative sweeps, using the initial bond dimensions and then cache the sequences for re-use in later iterations. The contraction sequences are then only recomputed the if the bond dimensions stray too far from the initial values.
Although certainly feasible, manually writing the code for each tensor network contraction as a sequence of pairwise contractions is not recommended. Not only is substantial programming effort required, but this also results in code which is error-prone and difficult to check. There is also a more fundamental problem: contracting a network by manually writing a sequence of binary contractions requires specifying a particular contraction sequence at the time of coding. However, in many cases the index dimensions within networks are variable, and the optimal sequence can change depending on the relative sizes of dimensions. For instance, one may have a network which contains indices of dimensions χ1 and χ2, where the optimal contraction sequence changes dependant of whether χ1 is larger or smaller than χ2. In order to have a program which works efficiently in both regimes, one would have to write code separately for both contraction sequences.
Given the considerations above, the use of an automated contraction routine, such as the “ncon” (Network-CONtractor) function [61, 73] or something similar from an existing tensor network library [41–48], is highly recommended. Automated contraction routines can evaluate any network contraction in a single call by appropriately generating and evaluating a sequence of binary contractions, hence greatly reducing both the programming effort required and the risk of programming errors occurring. Most contraction routines, such as “ncon”, also remove the need to fix a contraction sequence at the time of writing the code, as the sequence can be specified as an input variable to the routine and thus can be changed without the need to rewrite any code. This can also allow the contraction sequence to be adjusted dynamically at run-time to ensure that the sequence is optimal given the specific index dimensions in use.
In evaluating a network of multiple tensors, it is always more efficient to break the contraction into a sequence of pairwise tensor contractions, each of which should (usually) be recast into a matrix-matrix multiplication in order to achieve optimal computational performance. The total cost of evaluating a network can depend on the particular sequence of pairwise contractions chosen. While there is no known method for determining an optimal contraction sequence that is efficiently scalable in the size of the network, manual inference or brute-force numeric searches are usually viable for the relatively small networks encountered in common tensor network algorithms. When coding a tensor network program it is useful to utilize an automated network contraction routine which can evaluate a tensor network in a single call by properly chaining together a sequence of pairwise contractions. This not only reduces the programming effort required, but also grants a program more flexibility in allowing a contraction sequence to be easily changed.
Another key operation common in tensor network algorithms, complimentary to the tensor contractions considered previously, are factorizations. In this section, we will discuss some of the various means by which a higher-order tensor can be split into a product of fewer-order tensors. In particular, the means that we consider involve applying standard matrix decompositions [74, 75], to tensor unfoldings, such that this section may serve as a review of the linear algebra necessary before consideration of more sophisticated network decompositions. Specifically we recount the spectral decomposition, QR decomposition and singular value decomposition and outline their usefulness in the context of tensor networks, particular in achieving optimal low-rank tensor approximations. Before discussing decompositions, we define some special types of tensor.
A d-by-d matrix U is said to be unitary if it has orthonormal rows and columns, which implies that it annihilates to the identity when multiplied with its conjugate,
where I is the d-by-d identity matrix. We define a tensor (whose order is greater than 2) as unitary with respect to a particular bi-partition of indices if the tensor can be reshaped into a unitary matrix according to this partition. Similarly an d1-by-d2 matrix W, with d1 > d2 is said to be an isometry if
with I the d2-by-d2 identity matrix. Likewise we say that a tensor (order greater than 2) is isometric with respect to a particular bi-partition of indices if the tensor can be reshaped into a isometric matrix. Notice that, rather than equalling identity, the reverse order product does now evaluate to a projector P,
where projectors are defined as Hermitian matrices that square to themselves,
A commonly used matrix decomposition is the spectral decomposition (or eigen-decomposition). In the context of tensor network codes it is most often used for Hermitian, positive semi-definite matrices, such as for the density matrices used to describe quantum states. If H is a d × d Hermitian matrix, or tensor that can be reshaped into such, then the spectral decomposition yields
where U is d × d unitary matrix and D is diagonal matrix of eigenvalues, see also Figure 4A. The numerical cost of performing the decomposition scales as O(d3). In the context of tensor network algorithms the spectral decomposition is often applied to approximate a Hermitian tensor with one of smaller rank, as will be discussed in Section 4.4.
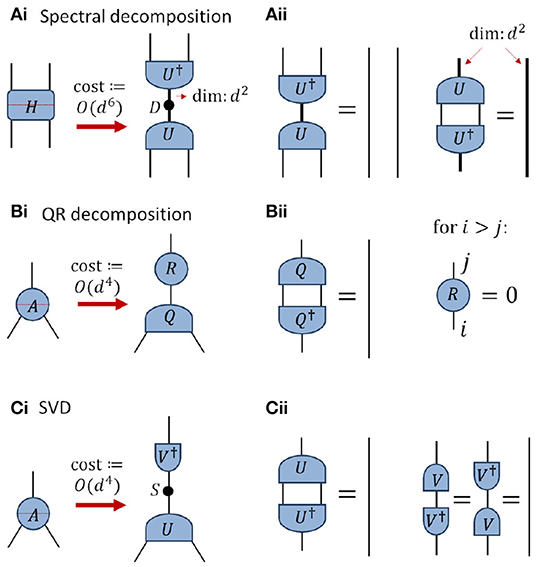
Figure 4. Depiction of some common matrix decompositions. All indices are assumed to be of dimension d unless otherwise indicated. (Ai) The spectral decomposition is applied to the order-4 Hermitian tensor H across the partition indicated by the dashed line, yielding a diagonal matrix of eigenvalues D and a unitary U. (Aii) The unitary tensor U annihilates to identity with its conjugate, as per Equation (6). (Bi) The QR decomposition is applied to the order-3 tensor A across the partition indicated, yielding an isometry Q and an upper triangular matrix R. (Bii) The isometry Q annihilates to identity with its conjugate as per Equation (7), while the R matrix is upper triangular. (Ci) The singular value decomposition (SVD) is applied to the order-3 tensor A across the partition indicated, yielding an isometry U, a diagonal matrix of singular values S, and a unitary V. (Cii) Depiction of the constraints satisfied by the isometry U and unitary V.
Another useful decomposition is the QR decomposition. If A be an arbitrary d1×d2 matrix with d1>d2, or tensor that can be reshaped into such, then the QR decomposition gives
see also Figure 4B. Here Q is d1 × d2 isometry, such that Q†Q = I, where I is the d2 × d2 identity matrix, and R is d2 × d2 upper triangular matrix. Note that we are considering the so-called economical decomposition (which is most often used in tensor network algorithms); otherwise the full decomposition gives Q as a d1 × d1 unitary and R is dimension d1 × d2. The numerical cost of the economical QR decomposition scales as the larger dimension times the square of the smaller dimension , as opposed to cost for the full decomposition. The QR decomposition is one of the most computationally efficient ways to obtain an orthonormal basis for the column space of a matrix, thus a common application is in orthogonalizing tensors within a network (i.e., transforming them into isometries), which will be discussed further in Section 5.3.1.
The final decomposition that we consider is the singular value decomposition (SVD), which is also widely used in many areas of mathematics, statistics, physics and engineering. The SVD allows an arbitrary d1 × d2 matrix A, where we assume for simplicity that d1 ≥ d2, to be decomposed as
where U is d1 × d2 isometry (or unitary if d1 = d2), S is diagonal d2 × d2 matrix of positive elements (called singular values), and V is d2 × d2 unitary matrix, see also Figure 4C. Similar to the economical QR decomposition, we have also considered the economical form of the SVD; the full SVD would otherwise produce U as a d1 × d1 unitary and S as a rectangular d1 × d2 matrix padded with zeros. The numerical cost of the economical SVD scales as , identical to that of the economical QR decomposition. The rank of a tensor (across a specified bi-partition) is defined as the number of non-zero singular values that appear in the SVD. A common application of the SVD is in finding an approximation to a tensor by another of smaller rank, which will be discussed further in Section 4.4.
Notice that for any matrix A the spectral decompositions of AA† and A†A are related to the SVD of A; more precisely, the eigenvectors of AA† and A†A are equivalent to the singular vectors in U and V respectively of the SVD in Equation (12). Furthermore the (non-zero) eigenvalues in AA† or A†A are the squares of the singular values in S. It can also be seen that, for a Hermitian positive semi-definite matrix H, the spectral decomposition is equivalent to an SVD.
The primary use for matrix decompositions, such as the SVD, in the context of tensor networks is in accurately approximating a higher-order tensor as a product lower-order tensors. However, before discussing tensor approximations, it is necessary to define the tensor norm in use. A tensor norm that is particularly convenient is the Frobenius norm (or Hilbert-Schmidt norm). Given a tensor Aijk… the Frobenius norm for A, denoted as ||A||, is defined as the square-root of the sum of the magnitude of each element squared,
This can be equivalently expressed as the tensor trace of A multiplied by its conjugate,
where the tensor trace, Ttr(A†, A), represents the contraction of tensor A with its conjugate over all matching indices, see Figure 5. It also follows that Frobenius norm is related to the singular values sk of A across any chosen bi-partition,
Notice that Equation (14) implies that the difference ε = ||A−B|| between two tensors A and B of equal dimension can equivalently be expressed as
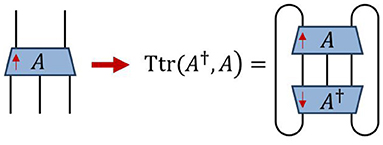
Figure 5. For any tensor A the tensor trace Ttr of A with its conjugate A† (drawn with opposite vertical orientation) is obtained by contracting over all matching indices. The Frobenius norm can be defined as the root of this tensor trace, see Equation (14).
Given some matrix A, or higher-order tensor that viewed as a matrix across a chosen bi-partition of its indices, we now focus on the problem of finding the tensor B that best approximates A according to the Frobenius norm (i.e., that which minimizes the difference in Equation 16), assuming B has a fixed rank r. Let us assume, without loss of generality, that tensor A is equivalent to a d1 × d2 matrix (with d1 ≥ d2) under a specified bi-partition of its indices, and that A has singular value decomposition,
where the singular values are assumed to be in descending order, sk ≥ sk+1. Then the optimal rank r tensor B that approximates A is known from the Eckart–Young–Mirsky theorem [76], which states that B is given by truncating to retain only the r largest singular values and their corresponding singular vectors,
see also Figure 6. It follows that the error of approximation ε = ||A−B||, as measured in the Frobenius norm, is related to the discarded singular values as
If the spectrum of singular values is sharply decaying then the error is well-approximated by the largest of the discarded singular values, ε≈s(r+1).
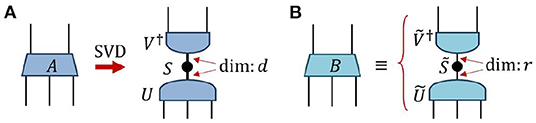
Figure 6. (A) The singular value decomposition is taken on tensor A across a bi-partition between its top two and bottom three indices, and is assumed to produce d non-zero singular values. (B) Tensor B is now defined by truncating the matrix of singular values to retain only r < d of the largest singular values, while similarly truncating the matrices of singular vectors, U → Ũ and V → Ṽ, to retain only the corresponding singular vectors. By the Eckart–Young–Mirsky theorem [76] it is known that B is the optimal rank-r approximation to A (across the chosen bi-partition of tensor indices).
Notice that, in the case that the tensor A under consideration is Hermitian and positive definite across the chosen bi-partition, that the spectral decomposition could instead be used in Equation (17). The low-rank approximation obtained by truncating the smallest eigenvalues would still be guaranteed optimal, as the spectral decomposition is equivalent to the SVD in this case.
In this section we have described how special types of matrices, such as unitary matrices and projections, can be generalized to the case of tensors (which can always be viewed as a matrix across a chosen bi-partition of their indices). Similarly we have shown how several concepts from matrices, such as the trace and the norm, are also generalized to tensors. Finally, we have described how the optimal low-rank approximation to a tensor can be obtained via the SVD.
All tensor networks possess gauge degrees of freedom; exploiting the gauge freedom allows one to change the tensors within a network whilst leaving the final product of the network unchanged. In this section, we describe methods for manipulating the gauge degrees of freedom and discuss the utility of fixing the gauge in a specific manner.
In this manuscript we shall restrict our considerations of gauge manipulations to focus only on tensors networks that do not possess closed loops (i.e., networks that correspond to acyclic graphs), which are commonly referred to as tree tensor networks (TTN) [77, 78]. Figure 7A presents an example of a tree tensor network. If we select a single tensor to act as the center (or root node) then we can understand the tree tensor network as being composed of a set of distinct branches extending from this chosen tensor. For instance, Figure 7B depicts the three branches (excluding the single trivial branch) extending from the 4th-order tensor A. It is important to note that connections between the different branches are not possible in networks without closed loops; this restriction is required for the re-gauging methods considered in this manuscript. However these methods can (mostly) be generalized to the case of networks containing closed loops by using a more sophisticated formalism as shown in [79].
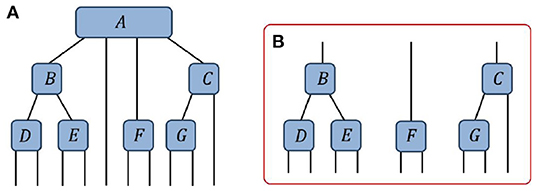
Figure 7. (A) An example of a tree tensor network (TTN), here composed of 7 tensors. (B) The three (non-trivial) branches of the tree with respect to choosing A as the root tensor.
Consider a tensor network of multiple tensors that, under contraction of all internal indices, evaluates to some product tensor H. We now pose the following question: is there a different choice of tensors with the same network geometry that also evaluates to H? Clearly the answer to this question is yes! As shown below in Figure 8A, on any of the internal indices of the network one can introduce a resolution of the identity (i.e., a pair of matrices X and X−1) which, by construction, does not change the final product that the network evaluates to. However, absorbing one of these matrices into each adjoining tensor changes the individual tensors, see Figure 8B, while leaving the product of the network unchanged. It follows that there are infinitely many choices of tensors such that the network product evaluates to some fixed output tensor, since the gauge change matrix X can be any invertible matrix. This ability to introduce an arbitrary resolution of the identity on an internal index, while leaving the product of the network unchanged, is referred to as the gauge freedom of the network.
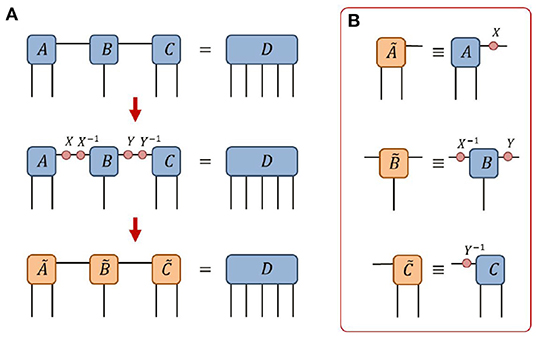
Figure 8. (A) Given a network of three tensors {A, B, C}, one can introduce gauge change matrices X and Y (together with their inverses) on the internal indices of the network while leaving the final product D of the network unchanged. (B) Definitions of the new tensors after the change of gauge.
While in some respects the gauge freedom could be considered bothersome, as it implies tensor decompositions are never unique, it can also be exploited to simplify many types of operations on tensor networks. Indeed, most tensor network algorithms require fixing the gauge in a prescribed manner in order to function correctly. In the following sections we discuss ways to fix the gauge degree of freedom as to create an orthogonality center and the benefits of doing so.
A given tensor A within a network is said to be an orthogonality center if every branch connected to tensor A annihilates to the identity when contracted with its conjugate as shown in Figure 9. Equivalently, each branch must (collectively) form an isometry across the bi-partition between its open indices and the index connected to tensor A. By properly manipulating the gauge degrees of freedom, it is possible to turn any tensor with a tree tensor network into an orthogonality center [80]. We now discuss two different methods for achieving this: a “pulling through” approach, which was a key ingredient in the original formulation of DMRG [49–51], and a “direct orthogonalization” approach, which was an important part of the TEBD algorithm [52, 53].
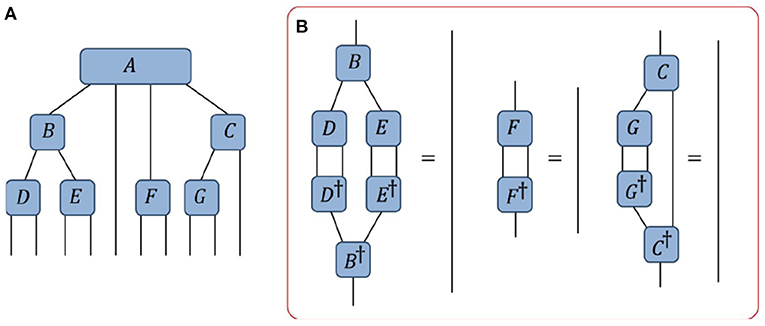
Figure 9. (A) An example of a tree tensor network. (B) A depiction of the constraints required for the tensor A to be an orthogonality center: each of the branches must annihilate to the identity when contracted with its conjugate.
Here we describe a method for setting a tensor A within a network as an orthogonality center through iterative use of the QR decomposition. The idea behind his method is very simple: if each individual tensor within a branch is transformed into a (properly oriented) isometry, then the entire branch collectively becomes an isometry and thus the tensor at center of the branches becomes an orthogonality center. Let us begin by orienting each index of the network by drawing an arrow pointing toward the desired center A. Then, starting at the tip of each branch, we should perform a QR decomposition on each tensor based on a bi-partition between its incoming and outgoing indices. The R part of the decomposition should then be absorbed into the next tensor in the branch (i.e., closer to the root tensor A), and the process repeated as depicted in Figures 10A–C. At the final step an R part of the QR decomposition from each branch is absorbed into the central tensor A and the process is complete, see also Figure 10D.
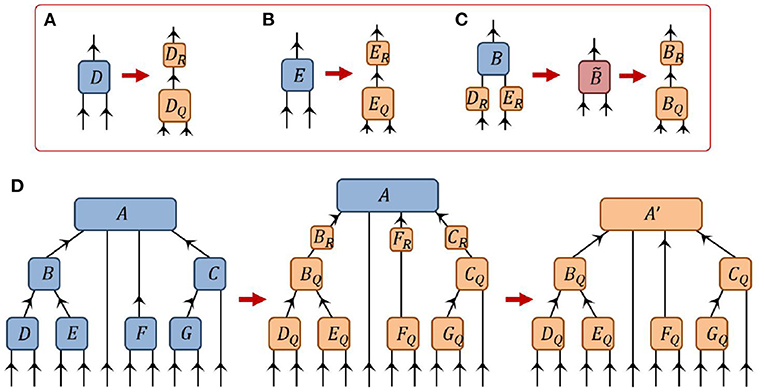
Figure 10. A depiction of how the tensor A can be made into an orthogonality center of the network from Figure 7 via the “pulling-though” approach. (A,B) Tensors D and E, which reside at the tips of a branch, are decomposed via the QR decomposition. (C) The R components of the previous QR decompositions are absorbed into the B tensor higher on the branch, which is then itself decomposed via the QR decomposition. (D) Following this procedure, all tensors in the network are orthogonalized (with respect to their incoming vs. outgoing indices) such that A′ becomes an orthogonality center of the network.
Note that the SVD could be used as an alternative to the QR decomposition: instead of absorbing the R part of the QR decomposition into the next tensor in the branch one could absorb the product of the S and V part of the SVD from Equation (12). However, in practice, the QR decomposition is most often preferable as it computationally cheaper than the SVD.
Here we describe a method for setting a tensor A within a network as an orthogonality center based on use of a single decomposition for each branch, as depicted in Figure 11. (i) We begin by computing the positive-definite matrix ρ for each branch (with respect to the center tensor A) by contracting the branch with its Hermitian conjugates. (ii) The principle square root X of each of the matrices ρ is then computed, i.e., such that ρ = XX†, which can be computed using the spectral decomposition if necessary. (iii) Finally, a change of gauge is made on each of the indices of tensor A using the appropriate X matrix and its corresponding inverse X−1, with the X part absorbed in tensor A and the X−1 absorbed in the leading tensor of the branch such that the branch matrix transforms as . It follows that the tensor A is now an orthogonality center as each branch matrix of the transformed network evaluates as the identity,
Note that, for simplicity, we have assumed that the branch matrices ρ do not have zero eigenvalues, such that their inverses exist. Otherwise, if zero eigenvalues are present, the current method is not valid unless the index dimensions are first reduced by truncating any zero eigenvalues.
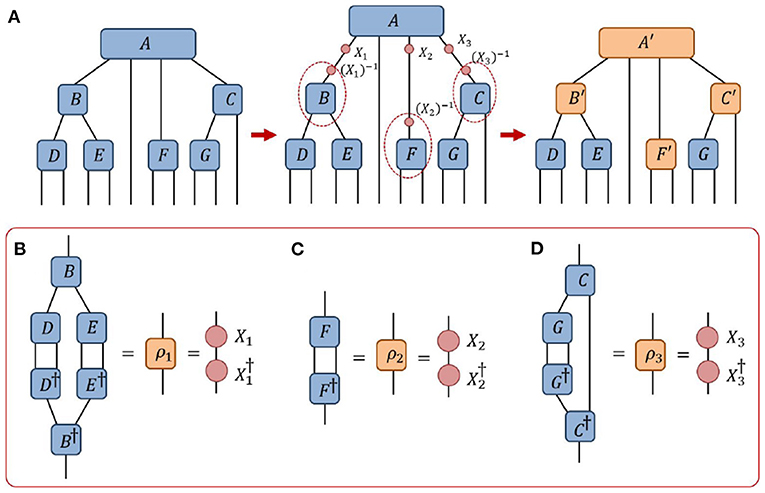
Figure 11. A depiction of how the tensor A from the network of Figure 7 can be made into an orthogonality center via the “direct orthogonalization” approach. (A) A change of gauge is made on every (non-trivial) branch connected to A, such that A becomes an orthogonality center. (B–D) The gauge change matrices {X1, X2, X3} are obtained by contracting each branch with its Hermitian conjugate and then taking the principle root.
Each of the two methods discussed to create an orthogonality center have their own advantages and disadvantages, such that the preferred method may depend on the specific application under consideration. In practice, the “direct orthogonalization” is typically computationally cheaper and easier to execute, since this method only requires changing the gauge on the indices connected to the center tensor. In contrast the “pulling through” method involves changing the gauge on all indices of the network. Additionally, the “direct orthogonalization” approach can easily be employed in networks of infinite extent, such as infinite MPS [52, 53], if the matrix ρ associated to a branch of infinite extent can be computed using by solving for a dominant eigenvector. While “pulling through” can also potentially be employed for networks of infinite extent, i.e., through successive decompositions until sufficient convergence is achieved, this is likely to be more computationally expensive. However the “pulling through” approach can be advantageous if the branch matrices ρ are ill-conditioned as the errors due to floating-point arithmetic are lesser. This follows since the “direct orthogonalization” requires one to square the tensors in each branch. The “pulling-through” approach also results in transforming every tensor in the network (with the exception of the center tensor) into an isometry, which may be desirable in certain applications.
In Section 4, it was described how the SVD could be applied to find the optimal low-rank approximation to a tensor in terms of minimizing the Frobenius norm between the original tensor and the approximation. In the present section we extend this concept further and detail how, by first creating an orthogonality center, a tensor within a network can be optimally decomposed as to minimize the global error coming from consideration of the entire network.
Let us consider a tree tensor network of tensors {A, B, C, D, E, F, G} that evaluates to a tensor H, as depicted in Figure 12A. We now replace a single tensor A from this network by a new tensor A′ such that the network now evaluates to a tensor H′ as depicted in Figure 12B. Our goal is to address the following question: how can we find the optimal low-rank approximation A′ to tensor A such that the error from the full network, ||H−H′||, is minimized? Notice that if we follow the method from Section 4 and simple truncate the smallest singular values of A, see Figure 12C, then this will only ensure that the local error, ||A−A′||, is minimized. The key to resolving this issue is through creation of an orthogonality center, which can reduce the global norm of a network to the norm of a single tensor. Specifically if tensor A is an orthogonality center of a network that evaluates to a final tensor H then it follow from the definition of an orthogonality center that ||H|| = ||A||, as depicted in Figure 13A. Thus it also can be seen that under replacement of the center tensor A with a new tensor A′, such that the network now evaluates to a new tensor H′, that the difference between the tensors ||A−A′|| is precisely equal to the global difference between the networks ||H−H′||. This follows as the overlap of H and H′ equals the overlap of A and A′, as depicted in Figure 13B. In other words, by appropriately manipulating the gauge degrees of freedom in a network, the global difference resulting from changing a single tensor in a network can become equivalent to the local difference between the single tensors. The solution to the problem of finding the optimal low-rank approximation A′ to a tensor A within a network thus becomes clear; we should first adjust the gauge such that A becomes an orthogonality center, after which we can follow the method from Section 4 and create the optimal global approximation (i.e., that which minimizes the global error) by truncating the smallest singular values of A. The importance of this result in the context tensor network algorithms cannot be overstated; this understanding for how to optimally truncate a single tensor within a tensor network, see also [81], is a key aspect of the DMRG algorithm [49–51], the TEBD algorithm [52, 53] and many other tensor network algorithms.
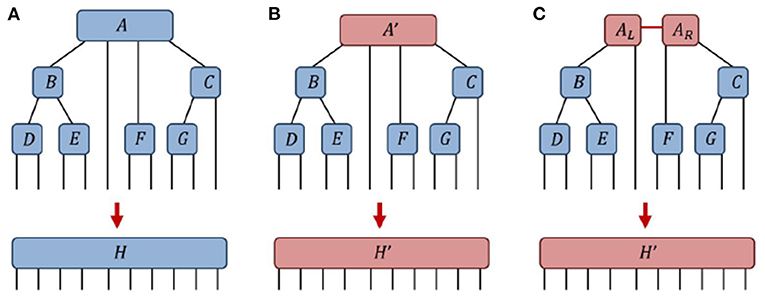
Figure 12. (A) A network of 7 tensors {A, B, C, D, E, F, G} contracts to give a tensor H. (B) After replacing a single tensor A→A′ the network contracts to a different tensor H′. (C) The tensor A′ is decomposed into a pair of tensors AL and AR, leaving the final tensor H′ unchanged.
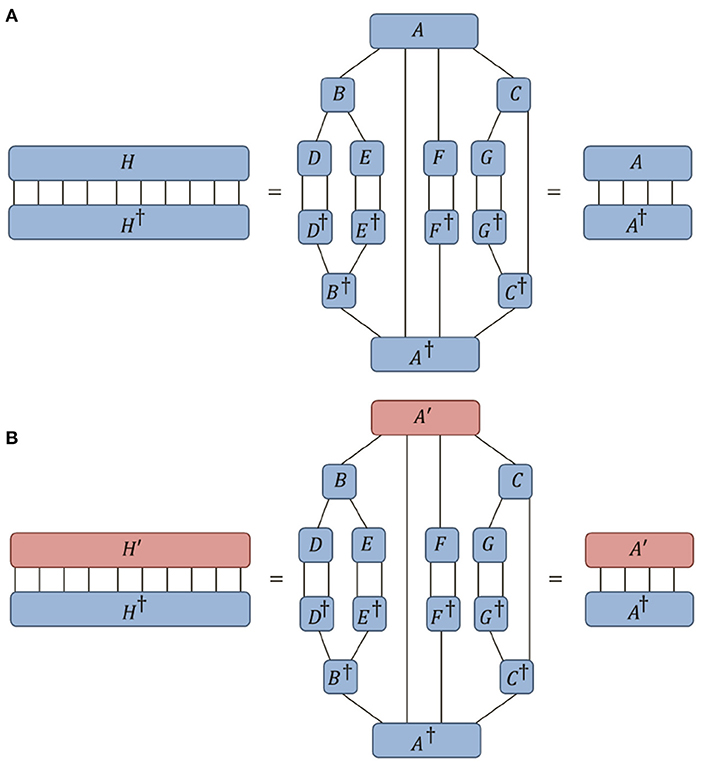
Figure 13. (A) In the network from Figure 12A, if the tensor A is an orthogonality center then it follows that the norm of the network ||H|| is equal to the norm of the center tensor ||A||. (B) Similarly it follows that, in changing only the center tensor A→A′, the global overlap between the networks H and H′ is equal to the local overlap between the center tensors A and A′.
In the preceding section, we discussed manipulations of the gauge degrees of freedom in a tensor network and described two methods that can be used to create an orthogonality center. The proper use of an orthogonality center was then demonstrated to allow one to decompose a tensor within a network in such a way as to minimize the global error. Note that while the results in this section were described only for tree tensor networks (i.e., networks based on acyclic graphs), they can be generalized to arbitrary networks by using more sophisticated methodology [79].
Network contractions and decompositions are the twin pillars of all tensor network algorithms. In this manuscript we have recounted the key theoretical considerations required for performing these operations efficiently and also discussed aspects of their implementation in numeric codes. We expect that a proper understanding of these results could facilitate an individuals effort to implement many common tensor network algorithms, such as DMRG, TEBD, TRG, PEPS and MERA, and also further aid researchers in the design and development of new tensor network algorithms.
However, there are still a wide variety of additional general ideas and methods, not covered in this manuscript, that are necessary for the implementation of more advanced tensor network algorithms. These include (i) strategies for performing variational optimization, (ii) methods for dealing with decompositions in networks containing closed loops, (iii) the use of approximations in tensor network contractions. We shall address several of these topics in a follow-up work.
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author/s.
GE was solely responsible for the preparation of this manuscript.
This work was funded by Institutional Startup Funds.
The author declares that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
1. Cirac JI, Verstraete F. Renormalization and tensor product states in spin chains and lattices. J Phys A Math Theor. (2009) 42:504004. doi: 10.1088/1751-8113/42/50/504004
2. Evenbly G, Vidal G. Tensor network states and geometry. J Stat Phys. (2011) 145:891–918. doi: 10.1007/s10955-011-0237-4
3. Orus R. A practical introduction to tensor networks: matrix product states and projected entangled pair states. Ann Phys. (2014) 349:117. doi: 10.1016/j.aop.2014.06.013
4. Bridgeman JC, Chubb CT. Hand-waving and interpretive dance: an introductory course on tensor networks. J Phys A Math Theor. (2017) 50:223001. doi: 10.1088/1751-8121/aa6dc3
5. Montangero S. Introduction to tensor network methods. In: Numerical Simulations of Low-Dimensional Many-body Quantum Systems. Berlin: Springer (2018). doi: 10.1007/978-3-030-01409-4
6. Orus R. Tensor networks for complex quantum systems. Nat Rev Phys. (2019) 1:538–50. doi: 10.1038/s42254-019-0086-7
7. Silvi P, Tschirsich F, Gerster M, Junemann J, Jaschke D, Rizzi M, et al. The tensor networks anthology: simulation techniques for many-body quantum lattice systems. SciPost Phys. (2019) 8. doi: 10.21468/SciPostPhysLectNotes.8
8. Ran S-J, Tirrito E, Peng C, Chen X, Tagliacozzo L, Su G, et al. Tensor Network Contractions Methods and Applications to Quantum Many-Body Systems. Springer (2020). doi: 10.1007/978-3-030-34489-4
9. Cirac JI, Perez-Garcia D, Schuch N, Verstraete F. Matrix product states and projected entangled pair states: concepts, symmetries, theorems. Rev Mod Phys. (2021) 93:045003. doi: 10.1103/RevModPhys.93.045003
10. Kolda TG, Bader BW. Tensor decompositions and applications. SIAM Rev. (2009) 51:455–500. doi: 10.1137/07070111X
11. Vidal G, Latorre JI, Rico E, Kitaev A. Entanglement in quantum critical phenomena. Phys Rev Lett. (2003) 90:227902. doi: 10.1103/PhysRevLett.90.227902
12. Hastings MB. An area law for one-dimensional quantum systems. J Stat Mech. (2007) 2007:P08024. doi: 10.1088/1742-5468/2007/08/P08024
13. Eisert J, Cramer M, Plenio M. Area laws for the entanglement entropy - a review. Rev Mod Phys. (2010) 82:277–306. doi: 10.1103/RevModPhys.82.277
14. Chan GKL, Sharma S. The density matrix renormalization group in quantum chemistry. Annu Rev Phys Chem. (2011) 62:465. doi: 10.1146/annurev-physchem-032210-103338
15. Keller S, Dolfi M, Troyer M, Reiher M. An efficient matrix product operator representation of the quantum chemical Hamiltonian. J Chem Phys. (2015) 143:244118. doi: 10.1063/1.4939000
16. Szalay S, Pfeffer M, Murg V, Barcza G, Verstraete F, Schneider R, et al. Tensor product methods entanglement optimization for ab initio. quantum chemistry. Int J Quant Chem. (2015) 115:1342. doi: 10.1002/qua.24898
17. Chan G K-L, Keselman A, Nakatani N, Li Z, White SR. Matrix product operators, matrix product states, and ab initio. density matrix renormalization group algorithms. J Chem Phys. (2016) 145:014102. doi: 10.1063/1.4955108
18. Zhai H, Chan GK-L. Low communication high performance ab initio. density matrix renormalization group algorithms. J Chem Phys. (2021) 154:224116. doi: 10.1063/5.0050902
19. Swingle B. Entanglement renormalization and holography. Phys Rev D. (2012) 86:065007. doi: 10.1103/PhysRevD.86.065007
20. Miyaji M, Numasawa T, Shiba N, Takayanagi T, Watanabe K. Continuous multiscale entanglement renormalization ansatz as holographic surface-state correspondence. Phys Rev Lett. (2015) 115:171602. doi: 10.1103/PhysRevLett.115.171602
21. Pastawski F, Yoshida B, Harlow D, Preskill J. Holographic quantum error-correcting codes: toy models for the bulk/boundary correspondence. J High Energy Phys. (2015) 6:149. doi: 10.1007/JHEP06(2015)149
22. Hayden P, Nezami S, Qi X-L, Thomas N, Walter M, Yang Z. Holographic duality from random tensor networks. J High Energy Phys. (2016) 11:009. doi: 10.1007/JHEP11(2016)009
23. Czech B, Lamprou L, McCandlish S, Sully J. Tensor networks from kinematic space. J High Energy Phys. (2016) 07:100. doi: 10.1007/JHEP07(2016)100
24. Evenbly G. Hyperinvariant tensor networks and holography. Phys Rev Lett. (2017) 119:141602. doi: 10.1103/PhysRevLett.119.141602
25. Stoudenmire EM, Schwab DJ. Supervised learning with tensor networks. Adv Neural Inf Process Syst. (2016) 29:4799–807.
26. Martyn J, Vidal G, Roberts C, Leichenauer S. Entanglement and tensor networks for supervised image classification. arXiv preprint arXiv:2007.06082. (2020). doi: 10.48550/arXiv.2007.06082
27. Cheng S, Wang L, Zhang P. Supervised learning with projected entangled pair states. Phys Rev B. (2021) 103:125117. doi: 10.1103/PhysRevB.103.125117
28. Liu J, Li S, Zhang J, Zhang P. Tensor networks for unsupervised machine learning. arXiv preprint arXiv:2106.12974. (2021). doi: 10.48550/arXiv.2106.12974
29. Liu Y, Li W-J, Zhang X, Lewenstein M, Su G, Ran SJ. Entanglement-based feature extraction by tensor network machine learning. Front Appl Math Stat. (2021) 7:716044. doi: 10.3389/fams.2021.716044
30. Fried ES, Sawaya NPD, Cao Y, Kivlichan ID, Romero J, Aspuru-Guzik A. qTorch: the quantum tensor contraction handler. PLoS ONE. (2018) 13:e0208510. doi: 10.1371/journal.pone.0208510
31. Villalonga B, Boixo S, Nelson B, Henze C, Rieffel E, Biswas R, et al. A flexible high-performance simulator for verifying and benchmarking quantum circuits implemented on real hardware. NPJ Quantum Inf . (2019) 5:86. doi: 10.1038/s41534-019-0196-1
32. Schutski R, Lykov D, Oseledets I. Adaptive algorithm for quantum circuit simulation. Phys Rev A. (2020) 101:042335. doi: 10.1103/PhysRevA.101.042335
33. Pan F, Zhang P. Simulation of quantum circuits using the big-batch tensor network method. Phys Rev Lett. (2022) 128:030501. doi: 10.1103/PhysRevLett.128.030501
34. Levental M. Tensor networks for simulating quantum circuits on FPGAs. arXiv preprint arXiv preprint arXiv:2108.06831. (2021). doi: 10.48550/arXiv.2108.06831
35. Vincent T, O'Riordan LJ, Andrenkov M, Brown J, Killoran N, Qi H, et al. Jet: fast quantum circuit simulations with parallel task-based tensor-network contraction. Quantum. (2022) 6:709. doi: 10.22331/q-2022-05-09-709
36. Evenbly G, Vidal G. Algorithms for entanglement renormalization. Phys Rev B. (2009) 79:144108. doi: 10.1103/PhysRevB.79.144108
37. Zhao H-H, Xie Z-Y, Chen Q-N, Wei Z-C, Cai JW, Xiang T. Renormalization of tensor-network states. Phys Rev B. (2010) 81:174411. doi: 10.1103/PhysRevB.81.174411
38. Schollwoeck U. The density-matrix renormalization group in the age of matrix product states. Ann Phys. (2011) 326:96. doi: 10.1016/j.aop.2010.09.012
39. Phien HN, Bengua JA, Tuan HD, Corboz P, Orus R. The iPEPS algorithm, improved: fast full update and gauge fixing. Phys Rev B. (2015) 92, 035142. doi: 10.1103/PhysRevB.92.035142
40. Evenbly G. Algorithms for tensor network renormalization. Phys Rev B. (2017) 95:045117. doi: 10.1103/PhysRevB.95.045117
41. Fishman M, White SR, Stoudenmire EM. The ITensor software library for tensor network calculations. arXiv:2007.14822. (2020). doi: 10.48550/arXiv.2007.14822
42. Kao Y-J, Hsieh Y-D, Chen P. Uni10: an open-source library for tensor network algorithms. J Phys Conf Ser. (2015) 640:012040. doi: 10.1088/1742-6596/640/1/012040
43. Haegeman J. TensorOperations. (2022). Available online at: https://github.com/Jutho/TensorOperations.jl (accessed April 14, 2022).
44. Hauschild J, Pollmann F. Efficient numerical simulations with Tensor Networks: Tensor Network Python (TeNPy). SciPost Phys. (2018). doi: 10.21468/SciPostPhysLectNotes.5
45. Al-Assam S, Clark SR, Jaksch D. The tensor network theory library. J Stat Mech. (2017) 2017:093102. doi: 10.1088/1742-5468/aa7df3
46. Olivares-Amaya R, Hu W, Nakatani N, Sharma S, Yang J, Chan G K-L. The ab-initio. density matrix renormalization group in practice. J Chem Phys. (2015) 142:034102. doi: 10.1063/1.4905329
47. Roberts C, Milsted A, Ganahl M, Zalcman A, Fontaine B, Zou Y, et al. TensorNetwork: a library for physics and machine learning. arXiv preprint arXiv:1905.01330. (2019). doi: 10.48550/arXiv.1905.01330
48. Oseledets V. TT Toolbox. (2014). Available online at: https://github.com/oseledets/TT-Toolbox (accessed July 7, 2021).
49. White SR. Density matrix formulation for quantum renormalization groups. Phys Rev Lett. (1992) 69:2863. doi: 10.1103/PhysRevLett.69.2863
50. White SR. Density-matrix algorithms for quantum renormalization groups. Phys Rev B. (1993) 48:10345. doi: 10.1103/PhysRevB.48.10345
51. Schollwoeck U. The density-matrix renormalization group. Rev Mod Phys. (2005) 77:259. doi: 10.1103/RevModPhys.77.259
52. Vidal G. Efficient classical simulation of slightly entangled quantum computations. Phys Rev Lett. (2003) 91:147902. doi: 10.1103/PhysRevLett.91.147902
53. Vidal G. Efficient simulation of one-dimensional quantum many-body systems. Phys Rev Lett. (2004) 93:040502. doi: 10.1103/PhysRevLett.93.040502
54. Verstraete F, Cirac JI. Renormalization algorithms for quantum-many-body systems in two and higher dimensions. arXiv preprint arXiv:cond-mat/0407066. doi: 10.48550/arXiv.cond-mat/0407066
55. Verstraete F, Cirac JI, Murg V. Matrix product states, projected entangled pair states, and variational renormalization group methods for quantum spin systems. Adv Phys. (2008) 57:143. doi: 10.1080/14789940801912366
56. Jordan J, Orus R, Vidal G, Verstraete F, Cirac JI. Classical simulation of infinite-size quantum lattice systems in two spatial dimensions. Phys Rev Lett. (2008) 101:250602. doi: 10.1103/PhysRevLett.101.250602
57. Vidal G. A class of quantum many-body states that can be efficiently simulated. Phys Rev Lett. (2008) 101:110501. doi: 10.1103/PhysRevLett.101.110501
58. Levin M, Nave CP. Tensor renormalization group approach to two-dimensional classical lattice models. Phys Rev Lett. (2007) 99:120601. doi: 10.1103/PhysRevLett.99.120601
59. Xie Z-Y, Chen J, Qin MP, Zhu JW, Yang LP, Xiang T. Coarse-graining renormalization by higher-order singular value decomposition. Phys Rev B. (2012) 86:045139. doi: 10.1103/PhysRevB.86.045139
60. Evenbly G, Vidal G. Tensor network renormalization. Phys Rev Lett. (2015) 115:180405. doi: 10.1103/PhysRevLett.115.180405
61. Evenbly G. Tensors.net Website. (2019). Available online at: https://www.tensors.net (accessed May 10, 2022).
62. Singh S, Pfeifer RNC, Vidal G. Tensor network decompositions in the presence of a global symmetry. Phys Rev A. (2010) 82:050301. doi: 10.1103/PhysRevA.82.050301
63. Singh S, Pfeifer RNC, Vidal G. Tensor network states and algorithms in the presence of a global U(1) symmetry. Phys Rev B. (2011) 83:115125. doi: 10.1103/PhysRevB.83.115125
64. Weichselbaum A. Non-abelian symmetries in tensor networks: a quantum symmetry space approach. Ann Phys. (2012) 327:2972–3047. doi: 10.1016/j.aop.2012.07.009
65. Sharma S. A general non-Abelian density matrix renormalization group algorithm with application to the C2 dimer. J Chem Phys. (2015) 142:024107. doi: 10.1063/1.4905237
66. Keller S, Reiher M. Spin-adapted matrix product states and operators. J Chem Phys. (2016) 144:134101. doi: 10.1063/1.4944921
67. Nataf P, Mila F. Density matrix renormalization group simulations of SU(N) Heisenberg chains using standard Young tableaus: fundamental representation and comparison with a finite-size Bethe ansatz. Phys Rev B. (2018) 97:134420. doi: 10.1103/PhysRevB.97.134420
68. Schmoll P, Singh S, Rizzi M, Oras R. A programming guide for tensor networks with global SU(2) symmetry. Ann Phys. (2020) 419:168232. doi: 10.1016/j.aop.2020.168232
69. Pfeifer RNC, Haegeman J, Verstraete F. Faster identification of optimal contraction sequences for tensor networks. Phys Rev E. (2014) 90:033315. doi: 10.1103/PhysRevE.90.033315
70. Pfeifer RNC, Evenbly G. Improving the efficiency of variational tensor network algorithms. Phys Rev B. (2014) 89, 245118. doi: 10.1103/PhysRevB.89.245118
71. Dudek JM, Duenas-Osorio L, Vardi MY. Efficient contraction of large tensor networks for weighted model counting through graph decompositions. arXiv preprint arXiv:1908.04381v2. (2019). doi: 10.48550/arXiv.1908.04381
72. Gray J, Kourtis S. Hyper-optimized tensor network contraction. Quantum. (2021) 5:410. doi: 10.22331/q-2021-03-15-410
73. Pfeifer RNC, Evenbly G, Singh S, Vidal G. NCON: a tensor network contractor for MATLAB. arXiv preprint arXiv:1402.0939. (2014). doi: 10.48550/arXiv.1402.0939
74. Horn RA, Johnson CR. Matrix Analysis. Cambridge: Cambridge University Press (1985). doi: 10.1017/CBO9780511810817
75. Horn RA, Johnson CR. Topics in Matrix Analysis. Cambridge: Cambridge University Press (1991). doi: 10.1017/CBO9780511840371
76. Eckart C, Young G. The approximation of one matrix by another of lower rank. Psychometrika. (1936) 1:211–8. doi: 10.1007/BF02288367
77. Shi Y, Duan L, Vidal G. Classical simulation of quantum many-body systems with a tree tensor network. Phys Rev A. (2006) 74:022320. doi: 10.1103/PhysRevA.74.022320
78. Tagliacozzo L, Evenbly G, Vidal G. Simulation of two-dimensional quantum systems using a tree tensor network that exploits the entropic area law. Phys Rev B. (2009) 80:235127. doi: 10.1103/PhysRevB.80.235127
79. Evenbly G, Gauge fixing canonical forms and optimal truncations in tensor networks with closed loops. Phys Rev B. (2018) 98:085155. doi: 10.1103/PhysRevB.98.085155
80. Holtz S, Rohwedder T, Schneider R. The alternating linear scheme for tensor optimization in the tensor train format. SIAM J Sci Comput. (2012) 34:A683–713. doi: 10.1137/100818893
Keywords: tensor network algorithm, MPS, tensor contraction, DMRG, quantum many body theory
Citation: Evenbly G (2022) A Practical Guide to the Numerical Implementation of Tensor Networks I: Contractions, Decompositions, and Gauge Freedom. Front. Appl. Math. Stat. 8:806549. doi: 10.3389/fams.2022.806549
Received: 31 October 2021; Accepted: 02 May 2022;
Published: 01 June 2022.
Edited by:
Edoardo Angelo Di Napoli, Julich Research Center, Helmholtz Association of German Research Centres (HZ), GermanyReviewed by:
Jutho Haegeman, Ghent University, BelgiumCopyright © 2022 Evenbly. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Glen Evenbly, Z2xlbi5ldmVuYmx5QGdtYWlsLmNvbQ==
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.