 Daniel Potts
Daniel Potts Michael Schmischke
Michael Schmischke- Faculty of Mathematics, Chemnitz University of Technology, Chemnitz, Germany
The distribution of data points is a key component in machine learning. In most cases, one uses min-max-normalization to obtain nodes in [0, 1] or Z-score normalization for standard normal distributed data. In this paper, we apply transformation ideas in order to design a complete orthonormal system in the L2 space of functions with the standard normal distribution as integration weight. Subsequently, we are able to apply the explainable ANOVA approximation for this basis and use Z-score transformed data in the method. We demonstrate the applicability of this procedure on the well-known forest fires dataset from the UCI machine learning repository. The attribute ranking obtained from the ANOVA approximation provides us with crucial information about which variables in the dataset are the most important for the detection of fires.
1. Introduction
In machine learning, the scale of our features is a key component in building models. When we work with data from applications, we have to accept it as it is. In most cases, we cannot control where the nodes are lying. Let us, e.g., take recommendations in online shopping. We are only able to analyze the customers that actually exist and what they bought in the shop. However, the features may lie on immensely different scales. If we measure, e.g., the time a customer spent in the shop in seconds, as well as their age in years, the result will be a scale that contains values with thousands of seconds and a scale ranging from up to 90 years. Bringing those features on similar scales trough normalization may significantly improve performance of our model.
Two common methods for data normalization are min-max-normalization and Z-score normalization, see, e.g.,[1]. The former method will yield data in the interval [0, 1] and is especially useful if there is an intrinsic upper and lower bound for the values, e.g., when considering age. If we come back to our previous example, the time a customer spends in the shop would be less suitable since the values may have a wide range and we will probably have very few people with a significantly small or large time. In this case, the Z-score normalization makes much more sense. It tells us how many standard deviations our value lies away from the mean of the data resulting in a distribution with zero mean and variance one.
The explainable ANOVA approximation method introduced in [2–4] is based on the well-known multi-variate analysis of variance (ANOVA) decomposition, see, e.g,.,[5–10], and relies on the existence of a complete orthonormal system in the space which is suitable for fast matrix-vector multiplication algorithms in grouped transformations, c.f.[11]. Until now, this method was always applied with min-max-normalization since it relied on the space of square-integrable functions over the cube with the half-period cosine basis. It is our goal to modify the approach in order to create the possibility to work with standard normal distributed data, i.e., data that has been obtained trough Z-score normalization.
We aim to achieve this by using the transformation ideas from [12] and [13] in order to construct a complete orthonormal system in the space
with the probability density of the standard normal distribution
The cumulative distribution function of the standard normal distribution is given by
(see Figure 1) for visualization, with the error function defined as
Combining this transformation with the half-period cosine basis allows for fast multiplications in the grouped transformations and makes the ANOVA approximation method applicable for Z-score normalized data.
Figure 1. Cumulative distribution function Φ of the standard normal distribution from Equation (3).
As an example, we apply this approach to a dataset about the detection of forest fires, see [14, 15]. Constructing a model with the capability of efficiently predicting the size of the fire in this dataset may provide a way of predicting the occurrences of fires. This creates the possibility of efficiently implementing appropriate counter-measures. In our time of climate change with massive forest fires every year, e.g., in Australia or the USA, this is an extremely current topic. With the interpretation capabilities of the ANOVA method, c.f.[4], we are additionally able to explain the importance of our features and give reasonable explanation for the predictions.
2. Transformed Half-Period Cosine
In this section, it is our goal to construct a complete orthonormal system in the space from Equation (1) with the product density ω(x) from Equation (2). This is the probability density function of the standard normal distribution, i.e., the normal distribution with zero mean and variance one. We have , as well as which implies .
We aim to construct the basis using transformation ideas from [12, 13] and the half-period cosine basis on . The orthonormal basis functions on are given by
with ‖k‖0 := |supp k| for supp k := {s ∈ {1, 2, …, d}:ks ≠ 0} and |supp k| the cardinality of supp k. We start from a given function f : ℝd → ℝ, , and aim to transform it onto the cube [0, 1]d. As transformation from the interval [0, 1] to ℝ, we apply the inverse cumulative distribution function Φ−1 in each variable to obtain
with the inverse transformation being
The transformation is related to inverse transform sampling, see, e.g.,[16]. As a result, we have the commutative diagram in Figure 2. This allows us to transform the half-period cosine to a complete orthonormal system on with the help of the following lemma.
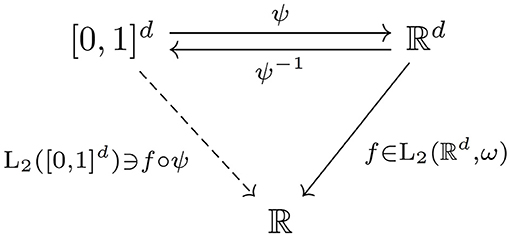
Figure 2. Commutative diagram of the function and the transformations.
Lemma 2.1. Let , with probability density ω from Equation (2), and transformation ψ, ψ−1 as in Equations (5) and (6), respectively. Then
and subsequently and .
Proof. Let and . Then we insert the definition and perform a change of variables as follows
As functional determinant we obtain and subsequently
This proves the first equality. For the second equality, we use an analogous procedure.
Lemma 2.1 is not surprising since we have based the transformation on the cumulative distribution function Φ from Equation (3). In the following, we obtain the new orthonormal system.
Theorem 2.2. The functions with
form a complete orthonormal system in .
Proof. We have that Φ from Equation (3) is a bijection and Lemma 2.1 shows that f↦f ∘ ψ −1 is an isometric isomorphism between and . Now, an isometric isomorphism between two spaces maps an orthonormal basis in one space to an orthonormal basis in the other. We obtain that is an orthonormal basis in .
In summary, we have constructed a complete orthonormal system on the weighted space using transformation ideas from [13] and the well-known half-period cosine basis on . The basis functions are visualized in Figure 3.
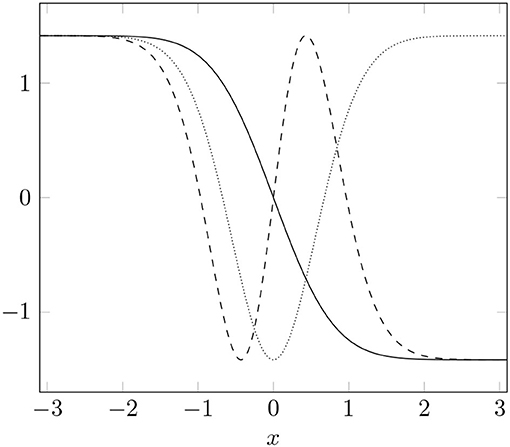
Figure 3. Transformed basis functions for k = 1 (solid), k = 2 (dotted), and k = 3 (dashed), in one dimension.
3. Interpretable ANOVA Approximation
In this section, we briefly summarize the interpretable ANOVA (analysis of variance) approximation method and the idea of grouped transformations, see [2, 11]. The approach was considered for periodic functions, but has been expanded to non-periodic functions in [3, 4]. In this paper, we focus on functions f : ℝd → ℝ from with probability density ω from Equation (2). Since ω is the density of the standard normal distribution, this function space is of a high relevance. It allows us, e.g., to work with data from applications that has been Z-transformed, i.e., data with zero mean and variance one, see, e.g.,[1]. Since the transformed half-period cosine , see Theorem 2.2, is a complete orthonormal system in the space , we have
and through Parseval's identity .
The classical ANOVA decomposition, c.f. [5–7, 9], provides us with a unique decomposition in the frequency domain as shown in [2]. We denote the set of coordinate indices with [d] = {1, 2, …, d}. The ANOVA terms are defined as
The function can then be uniquely decomposed as
into ANOVA terms where is the power set of [d]. Here, the exponentially growing number of terms shows an expression of the curse of dimensionality in the decomposition.
It is our goal to obtain information on how important the ANOVA terms fu are with respect to the function f. In order to measure this, we define the variance of a function f as
Note that, we have the special case , u ⊆ [d]. The relative importance with respect to f is then measured via global sensitivity indices (GSI) or Sobol indices, see [7, 17, 18], defined as
From the GSI we get a motivation for the concept of effective dimensions, specifically the superposition dimension as one notion of effective dimension. For a given α ∈ [0, 1] it is defined as
The superposition dimension d(sp) tells us that we can explain the α-part of the variance of f by terms fu with u ≤ d(sp).
Using subsets of ANOVA terms , it is our goal to find a way to circumvent the curse of dimensionality for efficient approximation. In order to achieve this, we aim to truncate the ANOVA decomposition by taking only the ANOVA terms in U into account. The truncated ANOVA decomposition is then defined as
A specific idea for the truncation comes from the superposition dimension d(sp) in Equation (10). The idea is to take only variable interactions into account that contain ds or less variables, i.e., the subset of ANOVA terms is
Here, we call ds a superposition threshold. Since ds does not necessarily have to coincide to the superposition dimension d(sp), we call it superposition threshold. A well-known fact from learning theory is that the number of terms in U(d, ds) grows only polynomially in d for fixed ds < d, i.e.,
which has reduced the curse of dimensionality.
In the following, we argue why the truncation by a superposition threshold ds works well in relevant cases. For the approximation of functions that belong to a space that characterizes the smoothness s>0 by the decay of the basis coefficients ck(f), we can show upper bounds on the superposition dimension d(sp) for α ∈ [0, 1], see, e.g.,[2]. In fact, there are types of smoothness that are proven to yield a low upper bound for the superposition dimension specifically dominating-mixed smoothness with POD (product and order-dependent) weights, c.f. [2, 19–22].
In terms of real data from applications, the situation is much different. Here, we cannot make the assumption that in complete generality we have a low superposition dimension. However, there are many application scenarios where numerical experiments successfully showed that this is indeed the case, see, e.g., [5]. Since we generally do not have a-priori information, we work with low superposition thresholds ds for truncation and validate on our test data.
3.1. Approximation Procedure
In this section, we briefly discuss how the approximation is numerically obtained and how we can interpreted the results. In this section, we assume a given subset of ANOVA terms . This set may be equal to or a subset of U(d, ds). We have given scattered data in the form of a set of standard normal distributed nodes and values y ∈ ℝM, M ∈ ℕ. Moreover, we assume that there is an function f of form Equation (8) with f(xi) ≈ yi which we want to approximate.
First, we truncate f to the set U such that f ≈ TUf. However, there are still infinitely many coefficients and, therefore, we perform a truncation to partial sums on finite support index sets
with order-dependent parameters N|u| ∈ ℕ, |u| = 1, 2, …, ds, for every ANOVA term fu, u ∈ U. Using the projections with uc: = [d]\u, we obtain
Now, taking the union yields
However, the coefficients ck(f) are unknown and it is our goal to determine approximations to them. We aim to achieve this by solving the regularized least-squares problem
c.f. [2, 3, 11], with the basis matrix . For the approximate coefficients, we have and we define the resulting approximation as
We solve problem Equation (13) using the iterative LSQR solver [23]. In order to apply LSQR, we rewrite Equation (13) by observing the equality
with 0 the zero vector in and I ∈ ℝ|I(U)|, |I(U)| the identity matrix. Note that, we always have a unique solution in this case since the matrix
has full column rank. However, the solution depends on the regularization parameter λ.
We apply the matrix-free variant of LSQR, i.e., we never explicitly construct the matrix . The grouped transformations introduced in [11] provide oracle functions for the multiplications of and its transposed with vectors. For our specific basis functions the grouped transformations are based on the non-equispaced fast cosine transform or NFCT, see [24, 25]. The transformation uses parallelization to separate our multiplication into smaller, up to ds-dimensional NFCTs which results in an efficient algorithm. For more details we refer to [11].
One key fact is that the nodes have to be distributed according to the probability density ω of the space such that the Moore–Penrose inverse is well-conditioned. In our case, ω is the density of the standard normal distribution, i.e., the nodes have to be distributed accordingly. For a detailed discussion on the properties of those matrices we refer to [26, 27] where our basis is a special case.
We use the global sensitivity indices , u∈U, from the approximation to compute approximations for the global sensitivity indices ϱ(u, f) of the function f. Here, we do not consider the index to be a good approximation if the values are close together, but rather if there order is identical, i.e., we have
for any pair u1, u2 ∈ U. We assume that this is the case for our choices of index sets . In particular, the quality of the approximation corresponds to the accuracy of this assumption.
In order to rank the influence of the variables x1, x2, …, xd we use the ranking score
for i = 1, 2, …, d which was introduced in [4]. Note that this score has order-dependent weight and is normalized such that . Computing every score r(i), i ∈ [d] provides an attribute ranking with respect to U showing the percentage that every variable adds to the variance of the approximation. We then conclude that if we have a good approximation , the corresponding attribute ranking will be close to the attribute ranking of the function f.
3.2. Active Set
In this section, we describe how to obtain a set of ANOVA terms U for approximation. We are still working with the scattered data and y ∈ ℝM, M ∈ ℕ. The values y may also contain noise. Our first step is to limit the variable interactions by a superposition threshold ds ∈ [d] which may have been estimated by known smoothness properties (or different a-priori information) or set to a sensible value if nothing is known. It is also possible to determine an optimal value through cross-validation. We choose the order-dependent parameters N|u|, |u| = 1, 2, …, ds, c.f. Equation (12), to obtain and with the procedure described in Section 3.1, the approximation .
From the approximation we can then calculate the global sensitivity indices , u ∈ U(d, ds), and an attribute ranking r(i), i ∈ [d], see Equation (15). Then we are able to apply the strategies proposed in [4] to truncate terms from the set U(d, ds).
One obvious method is the truncation of an entire variable xi, i ∈ [d], if the attribute ranking r(i) shows that its influence is insignificant. Specifically, that would translate to an active set . This leads to a reduction in dimensionality of the problem and greatly simplifies our model.
A different method is active set thresholding where we chooses a threshold vector and reduce the ANOVA terms to the set
Here, ε|u| denotes the |u|th entry of the vector ε. The parameter vector ε allows control over how much of the variance may be sacrificed in order to simplify the model function.
In summary, it is necessary to interpret the information from the approximation and decide on strategies for truncating the set of ANOVA terms. One may also use different strategies to obtain an active set or any combination of the multiple approaches, see, e.g.,[3, 4]. Of course, it is also possible to repeat the procedure multiple times, i.e., through cross-validation.
4. Forest Fire Prevention
We now apply the previously described method to the dataset [14] from the UC Irvine machine learning repository. The dataset contains information about forest fires in the Montesinho national park in the Trás-os-Montes northeast region of Portugal. The data was collect from 2002 to 2003. Specifically, we have d = 12 attributes about the fires and the target variable is the area of the forest that was destroyed by it. If we obtain an efficient model, it can be possible to predict the risk for a future forest fire using parameters that can be easily measured. This information can then be used to prepare appropriate countermeasures. The dataset has been thoroughly considered in [15] and we compare to the results they obtained. The authors considered several different methods: the naive average predictor (Naive), multiple regression (MR), decision tree (DT), random forest (RF), neural network (NN), and support vector machine (SVM).
We group the 12 attributes into 4 categories as in [15], i.e., spatial, temporal, FWI system, and meteorological data, (see Table 1). The spatial attributes describe the spatial location of the fire in a 9 by 9 grid of our considered region. The temporal attributes are the month of the year and the day of the week when the fire occurred. The forest fire weather index (FWI), c.f.[28], is the Canadian system for rating fire danger and the dataset collects several components of it, see also Table 2. Moreover, four meteorological attributes which are used by the FWI index were selected. The target variable describes the area that was burned by the fire.
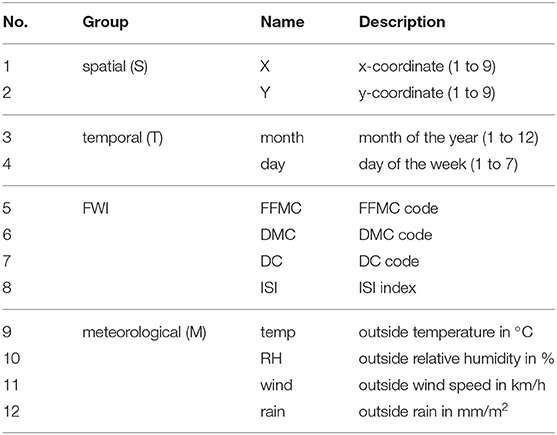
Table 1. Attributes of the forest fires dataset and their corresponding groups.
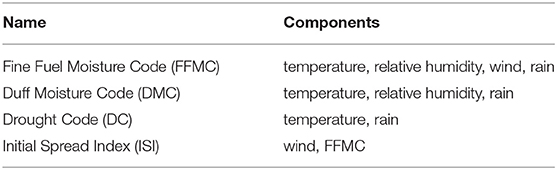
Table 2. Codes of the FWI with their base components from the weather data according to [28].
In terms of pre-processing, we apply a Z-score transformation to the variables and the logarithmic transformation log(1+·) to the burned area. The Z-score transformation achieves that our data has zero mean and unit variance. The logarithmic transformation on the target is opportune since it shows a positive skew with a large number of fires that have a small size. We denote the data with , M = 517, and y ∈ ℝM. In the following, we do not use all of the variables, but build models based only on some groups as denoted in Table 1, e.g., STM says that we use spatial, temporal, and meteorological attributes without the FWI.
Table 3 shows the overall results of our experiment (ANOVA) combined with the benchmark data from [15]. Each value, our ANOVA results, as well as the others, were obtained by averaging over executing a 10-fold cross-validation 30 times. This results in a total of 300 experiments. We used a superposition threshold of ds = 2, c.f. Equation (11), and, therefore, needed to detect optimal choices for the parameters N1 and N2 from Equation (12), (see Table 4). Every experiment utilized 90% of the data as training set and 10% of the data as test set . The best performing model was selected based on the mean absolute deviation
with the predictions of our model for the data points in the test set . As a second error measure, we use the root mean square error.
We are able to outperform the previously applied method for every subset of attributes in both MAD and RMSE error. Notably, the difference in the RMSE that penalizes larger deviations in the burned area stronger than the MAD is much more significant.
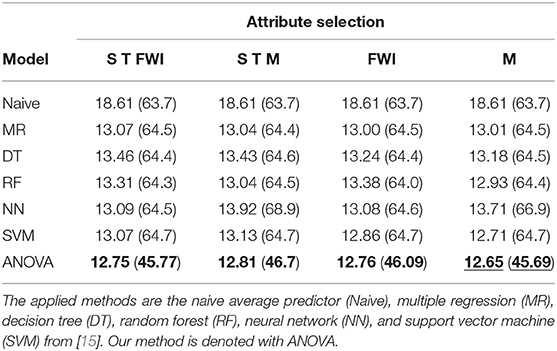
Table 3. MAD and RMSE (in brackets) for the best performing model in the corresponding attribute subset (underline—overall best result, bold—best result for this selection).
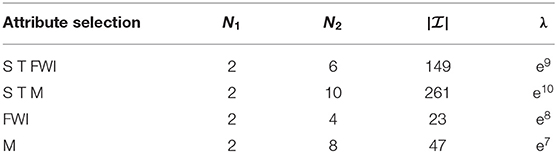
Table 4. Optimal parameter choices for the experiments from Table 3.
While we replicated the setting of [15] for benchmark purposes, it remains our goal to identify the most important attributes for the detection of forest fires. Therefore, we now use all 12 attributes of the dataset in obtaining our approximation and subsequently interpret the results. Figure 4 shows the attribute ranking r(i), i = 1, 2, …, 12, and Figure 5 the global sensitivity indices , u ∈ U(12, 2), after computing for an approximation with N1 = N2 = 2 and λ = 1.0.
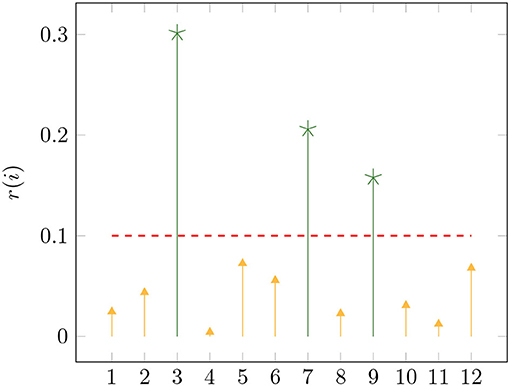
Figure 4. Attribute ranking r(i), i = 1, 2, …, 12, of the approximation with all twelve attributes using N1 = N2 = 2 and λ = 1.0.
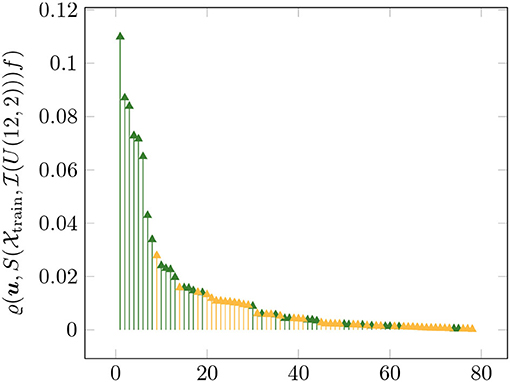
Figure 5. Global sensitivity indices , , of the approximation with all twelve attributes using N1 = N2 = 2 and λ = 1.0 (sorted). The green indices belong to sets u such that ∃s ∈ {3, 7, 9} with s ∈ u.
The attributes 3, 7, and 9 are clearly the most important. They represent the month of the year (3), the DC code of the FWI (7), and the outside temperature (9). Using only these three attributes and superposition threshold ds = 2, we computed an approximation with N1 = 2, N2 = 10, and λ = e8. The resulting model yielded an MAD of 12.64 and an RMSE of 45.57 with 30 times of 10-fold cross validation as before. In summary, we know that the most important information of our problem is contained in only three attributes and we also obtained a better performing model using only those three attributes.
Data Availability Statement
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author/s.
Author Contributions
Both authors listed have made a substantial, direct, and intellectual contribution to the work and approved it for publication.
Funding
DP acknowledges funding by Deutsche Forschungsgemeinschaft (German Research Foundation)—Project–ID 416228727—SFB 1410. MS was supported by the German Federal Ministry of Education and Research grant 01|S20053A. The publication of this article was funded by Chemnitz University of Technology.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Acknowledgments
The authors thank their colleagues in the research group SAlE for valuable discussions on the contents of this paper. Moreover, we thank the reviewers for their valuable comments and suggestions.
References
1. Hastie T, Tibshirani R, Friedman J. The Elements of Statistical Learning - Data Mining, Inference, and Prediction. New York, NY: Springer (2013).
2. Potts D, Schmischke M. Approximation of high-dimensional periodic functions with Fourier-based methods. SIAM J Numer Anal. (2021) 59:2393–429. doi: 10.1137/20M1354921
3. Potts D, Schmischke M. Learning multivariate functions with low-dimensional structures using polynomial bases. J Comput Appl Math. (2022) 403:113821. doi: 10.1016/j.cam.2021.113821
4. Potts D, Schmischke M. Interpretable approximation of high-dimensional data. SIAM J Math Data Sci. (2021) 3:1301–23. doi: 10.1137/21M1407707
5. Caflisch R, Morokoff W, Owen A. Valuation of mortgage-backed securities using Brownian bridges to reduce effective dimension. J Comput Finance. (1997) 1:27–46.
6. Rabitz H, F Alis O. General foundations of high dimensional model representations. J Math Chem. (1999) 25:197–233.
7. Liu R, Owen AB. Estimating mean dimensionality of analysis of variance decompositions. J Amer Statist Assoc. (2006) 101:712–21. doi: 10.1198/016214505000001410
8. Kuo FY, Sloan IH, Wasilkowski GW, Woźniakowski H. On decompositions of multivariate functions. Math Comput. (2009) 79:953–66. doi: 10.1090/S0025-5718-09-02319-9
9. Holtz M. “Sparse grid quadrature in high dimensions with applications in finance and insurance,” In: Lecture Notes in Computational Science and Engineering. Vol. 77. Berlin; Heidelberg: Springer (2011).
10. Owen AB. Monte Carlo theory, methods and examples. (2013). Available online at: https://artowen.su.domains/mc/
11. Bartel F, Potts D, Schmischke M. Grouped transformations in high-dimensional explainable ANOVA approximation. SIAM J Sci Comput. (2022). Available online at: https://arxiv.org/abs/2010.10199
12. Nichols JA, Kuo FY. Fast CBC construction of randomly shifted lattice rules achieving convergence for unbounded integrands over ℝs in weighted spaces with POD weights. J Complex. (2014) 30:444–68. doi: 10.1016/j.jco.2014.02.004
13. Nasdala R, Potts D. Transformed rank-1 lattices for high-dimensional approximation. Electron Trans Numer Anal. (2020) 53:239–82. doi: 10.1553/etna_vol53s239
14. Forest Fires (2008). UCI Machine Learning Repository. Available online at: https://archive-beta.ics.uci.edu/ml/datasets/forest+fires
15. Cortez P, Morais A. A data mining approach to predict forest fires using meteorological data. In: New Trends in Artificial Intelligence, 13th EPIA 2007 - Portuguese Conference on Artificial Intelligence. Guimarães: APPIA (2007). p. 512–23.
17. Sobol IM. On sensitivity estimation for nonlinear mathematical models. Matem Mod. (1990) 2: 112–8.
18. Sobol IM. Global sensitivity indices for nonlinear mathematical models and their Monte Carlo estimates. Math Comput Simulat. (2001) 55:271–280. doi: 10.1016/S0378-4754(00)00270-6
19. Kuo FY, Schwab C, Sloan IH. Quasi-Monte Carlo finite element methods for a class of elliptic partial differential equations with random coefficients. SIAM J Numer Anal. (2012) 50:3351–74. doi: 10.1137/110845537
20. Graham IG, Kuo FY, Nichols JA, Scheichl R, Schwab C, Sloan IH. Quasi-Monte Carlo finite element methods for elliptic PDEs with lognormal random coefficients. Numer Math. (2014) 131:329–68. doi: 10.1007/s00211-014-0689-y
21. Kuo FY, Nuyens D. Application of Quasi-Monte Carlo methods to elliptic PDEs with random diffusion coefficients: a survey of analysis and implementation. Found Comput Math. (2016) 16:1631–96. doi: 10.1007/s10208-016-9329-5
22. Graham IG, Kuo FY, Nuyens D, Scheichl R, Sloan IH. Circulant embedding with QMC: analysis for elliptic PDE with lognormal coefficients. Numer Math. (2018) 140:479–511. doi: 10.1007/s00211-018-0968-0
23. Paige CC, Saunders MA. LSQR: an algorithm for sparse linear equations and sparse least squares. ACM Trans Math Softw. (1982) 8:43–71.
24. Keiner J, Kunis S, Potts D. Using NFFT3 - a software library for various nonequispaced fast Fourier transforms. ACM Trans Math Softw. (2009) 36:1–30. doi: 10.1145/1555386.1555388
25. Plonka G, Potts D, Steidl G, Tasche M. Numerical Fourier Analysis. In: Applied and Numerical Harmonic Analysis. Cham: Birkhäuser (2018).
26. Kämmerer L, Ullrich T, Volkmer T. Worst case recovery guarantees for least squares approximation using random samples. Constr Approx. (2021) 54:295–352. doi: 10.1007/s00365-021-09555-0
27. Moeller M, Ullrich T. L2-norm sampling discretization and recovery of functions from RKHS with finite trace. Sampl Theory Sign Process Data Anal. (2021) 19:13. doi: 10.1007/s43670-021-00013-3
Keywords: ANOVA, high-dimensional, approximation, interpretability, normal distribution
Citation: Potts D and Schmischke M (2022) Interpretable Transformed ANOVA Approximation on the Example of the Prevention of Forest Fires. Front. Appl. Math. Stat. 8:795250. doi: 10.3389/fams.2022.795250
Received: 14 October 2021; Accepted: 04 January 2022;
Published: 26 January 2022.
Edited by:
Juergen Prestin, University of Lübeck, GermanyReviewed by:
Nadiia Derevianko, University of Göttingen, GermanyMichael Gnewuch, Osnabrück University, Germany
Copyright © 2022 Potts and Schmischke. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Daniel Potts, cG90dHNAbWF0aGVtYXRpay50dS1jaGVtbml0ei5kZQ==