 Vinod Patidar
Vinod Patidar Gurpreet Kaur
Gurpreet Kaur- 1Sir Padampat Singhania University, Udaipur, Rajasthan, India
- 2Amity Institute of Information Technology, Amity University, Noida, UP, India
Recently, many image encryption algorithms based on hybrid DNA and chaos have been developed. Most of these algorithms utilize chaotic systems exhibiting dissipative dynamics and periodic windows/patterns in the bifurcation diagrams along with co-existing attractors in the neighborhoods of parameter space. Therefore, such algorithms generate several weak keys, thereby making them prone to various chaos- specific attacks. In this paper, we propose a novel conservative chaotic standard map-driven dynamic DNA coding (encoding, addition, subtraction and decoding) for image encryption. It is the first hybrid DNA and conservative chaos-based image encryption algorithm having effectively infinite key space. The proposed image encryption algorithm is a dynamic DNA coding algorithm i.e., for the encryption of each pixel different rules for encoding, addition/subtraction, decoding etc. are randomly selected based on the pseudorandom sequences generated with the help of the conservative chaotic standard map. We propose a novel way to generate pseudo-random sequences through the conservative chaotic standard map and also test them rigorously through the most stringent test suite of pseudo-randomness, the NIST test suite, before using them in the proposed image encryption algorithm. Our image encryption algorithm incorporates unique feed-forward and feedback mechanisms to generate and modify the dynamic one-time pixels that are further used for the encryption of each pixel of the plain image, therefore, bringing in the desired sensitivity on plaintext as well as ciphertext. All the controlling pseudorandom sequences used in the algorithm are generated for a different value of the parameter (part of the secret key) with inter-dependency through the iterates of the chaotic map (in the generation process) and therefore possess extreme key sensitivity too. The performance and security analysis has been executed extensively through histogram analysis, correlation analysis, information entropy analysis, DNA sequence-based analysis, perceptual quality analysis, key sensitivity analysis, plaintext sensitivity analysis, classical attack analysis, etc. The results are promising and prove the robustness of the algorithm against various common cryptanalytic attacks.
1. Introduction
Due to advancements in network and communication technologies, the exchange of digital multimedia content has become one of the frequent tasks. It has consequently posed a requirement to protect such digital multimedia information from eavesdropping. Amongst various digital multimedia contents, images (and hence videos too) require special attention due to some of the inherent properties of digital images like the bulk of information, high spatial correlation and redundancies. Consequently, over the years, the encryption of images has been one of the active areas of research in image processing and allied fields and therefore a variety of technologies like optical image encryption, chaos-based image encryption, DNA based encryption, and a suitable combination of these technologies have emerged as alternative means to encrypt the images.
Shanon [1] in his masterpiece “Communication theory of secrecy systems,” suggested that good mixing transformations governed by simple repeating and non-commuting nonlinear operations involving the secret key in a complex way are the key ingredients for developing an ideal encryption system. Such transformations may be comfortably realized through the confusion (substitution) and diffusion (permutation) mechanisms. Here the confusion means a complex and involved relationship between the cipher image pixels and key whereas diffusion refers to spreading the plain image pixels information over the entire cipher image.
The optical image encryption systems utilize optical setups (lenses, spatial lens modulators, etc.) [2–4], double random phase encoding (DRPE) with optically or electronically generated random phase masks [4–8], and mathematical modeling with integral transforms [4, 9, 10]. Such systems have the advantage of sending complex data in parallel and are also capable of carrying out usually time-consuming operations in a faster way, therefore are found suitable in image encryption. Besides having above mentioned clear advantages, the optical processes governed by the integral transforms possess the linearity and symmetry properties which make the optical encryption system vulnerable to various cryptanalytic attacks [4, 11–13]. On the other hand, DNA computing, since its advent in 1994 [14], has attracted the attention of researchers due to some of its peculiar features like huge information-carrying capacity, parallelism, ultra-low energy consumption etc. DNA computing mainly requires the biochemical reaction environment, expensive laboratory equipment, and restricted laboratory conditions like precise control of concentration, temperature and pH of biochemical reactants etc., which make it difficult to realize in a wet lab. Rather than implementing it at a molecular level, researchers have preferred DNA coding to carry the information in digital form and manipulate it using the corresponding feasible DNA operations. It has induced a new way of concealing the information through DNA microdots [15] and subsequently following this development, Gehani et al. [16], Xiao et al. [17], and Kang [18] too presented the new perspectives of information hiding using the DNA concepts. Optical transforms and DNA encoding/operations do not offer non-linearity therefore solely are not suitable to develop secure encryption systems as per Shanon's criterion. Contemporary to the above-mentioned developments of optical and DNA-based image encryption, dynamical chaos has also been extensively used to develop secure image encryption systems owing to the fact that chaotic systems are essentially non-linear systems (having sensitivity on initial conditions/parameters, ergodicity, mixing property etc.) and have been found most suitable to introduce the substitution and permutation of image pixels as recommended in Shannon's confusion-diffusion framework [19–24]. Chaos-based image encryption systems, have also been preferred due to their fast-processing time which is one of the essential requirements in real-time transmission. However, there are some limitations associated with chaos-based encryption systems like smaller key space, floating-point representation, dynamic degradation, periodic windows and patterns in the bifurcation diagram, coexisting attractors in the neighborhoods of parameter space etc. [25, 26]. Interestingly, a very recent study proves that chaotic systems resist dynamic degradation through an anti-dynamic degradation theorem [27].
Since each of the technologies, mentioned above has its inherent advantages as well as disadvantages, therefore, researchers find it worthwhile to hybridize various techniques in order to either incorporate each of their pros or eliminate any of their cons. In such hybrid methods, the chaotic dynamical systems have been mainly utilized to introduce the non-linear effects in the substitution and permutation of pixels in a variety of ways. On the other hand, the optical transforms, DNA operations have been utilized to do encoding/decoding of image pixels that too sometimes under the control of chaotic systems [4]. As the present manuscript deals with hybrid chaos and DNA based image encryption, therefore we are elaborating more on this category in our further discussion.
In hybrid DNA and chaos-based image encryption systems, the images are firstly encoded into the DNA sequences followed by scrambling of these sequences using chaotic systems (one dimensional, combination of multiple chaotic maps, hyperchaotic maps, combination of hyperchaotic maps). The DNA bases of scrambled sequences are then changed by the application of DNA operations (addition, subtraction, XOR, XNOR, DNA complements, or combinations of some of these operations etc.) under the control of chaotic systems and then the resultant sequences are decoded into the digital format to produce the encrypted image. Broadly the DNA and chaos-based image encryption can be classified into the following categories [28]: (i) fixed DNA coding, (ii) dynamic DNA coding, (iii) DNA base complement operations, (iv) DNA sequence algebraic operations, and (v) combinations of multiple DNA operations. In the fixed DNA coding schemes, a particular rule is used for encoding followed by some DNA operations and decoding using the same rule [29–33], however in the dynamic DNA coding schemes, different rules are used for the encoding and decoding (either row-wise, column-wise, block-wise, pixel-wise or sometimes at the base-wise too) under the control of chaotic system [34–37]. In DNA base compliment operations schemes, one of the three types of complement methods (single base direct complement method, static regular base complement method, dynamic regular base complement method) are used [30, 37–39]. However, in DNA sequence algebraic operations-based schemes, addition, subtraction, XOR, XNOR operations on DNA sequences are used [40–43] under the control of chaotic systems to change the pixel values. In the last category, combined DNA coding and multiple/different DNA operations are used to scramble and change the pixel values [38, 41] and therefore are the most complex scenario. We are reviewing some of the very important and recent research works which have paved the way and led to the advancements in this field of hybrid DNA and chaos-based image encryption algorithms.
Zhang et al. [30] proposed an image encryption scheme based on DNA addition operation in which a DNA encoded image is divided into blocks and DNA addition is used to add these blocks followed by a complement operation with the help of the chaotic logistic map. A 4D hyperchaotic map is used to generate pseudo-random number sequences and a circular permutation along with classical diffusion is used for the encryption [44]. Liu et al. [32] also used DNA addition and complement to develop the image encryption of RGB images. Wei et al. [31] used Chen's hyperchaotic system to scramble the pixels of RGB layers and then divide them into some equal blocks followed by the addition of these blocks under the influence of Chen's hyperchaotic system. A confusion-diffusion based image encryption based on a piecewise linear chaotic map and Chebyshev map and DNA complementary rules has been proposed by Liu et al. [45]. Enayatifar et al. [46] proposed a hybrid genetic algorithm which is used for determining the best DNA mask out of several such masks generated through the chaotic system and then further used for image encryption. Wu et al. [47] proposed a new robust color image encryption scheme based on dynamic DNA sequence operations and multiple improved/compound 1D chaotic systems which utilizes a division shuffling process and the key streams are dependent on the secret key and plaintext. Kalpana and Murali [34] introduced the concept of using more than one DNA rule and more than one operation (subtraction/addition) in the algorithm which is randomly chosen for each pixel with the help of multiple chaotic systems such as Chen's hyperchaotic map, sine map, cubic map, logistic map and Arnold's chaotic maps have been used. A chaotic logistic map and spatiotemporal system (coupled map lattices) are used in combination with the DNA rules to achieve the image encryption system through a permutation-substitution architecture [35]. Chai et al. [48] proposed an image encryption algorithm using the 2D logistic map to execute the row and column circular permutations where SHA256 is used to generate the initial conditions for chaotic maps. A new DNA coding of images along with two rounds of DNA-based confusion and diffusion, where a piecewise linear chaotic map is used to generate the key stream, is proposed by Zhang [49]. A combined Block-based permutation, pixel-based substitution, DNA encoding, bit-level substitution (i.e., DNA complementing), DNA decoding, and bit-level diffusion are used for image encryption where the logistic-Chebyshev map, sine-Chebyshev map produces the key-streams at various stages given above [50]. Chai et al. [51] proposed a novel diffusion mechanism based on random numbers related to plaintext (DMRNRP) is used along with DNA operations under the control of a four wings hyperchaotic system. A one-time pad color image encryption based on a 3D skew tent map utilizing the secret keys and Hamming distance is proposed in which DNA XOR, addition and subtraction are used [52]. Wang et al. [37] proposed a one-time pad image encryption algorithm based on the coupled map lattices (CML system) and DNA diffusion sequences. The initial values and control parameters of the CML system and logistics map serve as keys for a one-time pad and are calculated by utilizing the SHA256 hash algorithm. DNA encoding along with other operations is used at the base level under the influence of chaos. A new scheme was proposed by combining the optimal coding mechanism with the optimal DNA coding operation [28]. Another one-time pad DNA-chaos image encryption algorithm, based on multiple keys and utilizing the chaotic logistic and sine maps, is proposed by Zhou [53] in which plaintext sensitivity is integrated by having dependence of four of the keys on the original image. A robust medical image encryption based on a combined DNA-chaos approach for secure telemedicine utilizing the logistic map, piecewise linear chaotic map (PWLCM), DNA encoding and various DNA algebraic operations like XOR, addition, subtraction etc. for the diffusion [54]. Wang et al. [55] proposed an image encryption strategy based on random number embedding in the plaintext and DNA-level self-adaptive permutation and diffusion based on a 4D memristive hyperchaotic system. A new four-dimensional hyperchaotic system is proposed by Hui et al. [56] and used further to encrypt the original image through pixel scrambling and pixel diffusion based on DNA encoding. A chaotic logistic map-based image encryption algorithm utilizing the arithmetic sequence model scrambling method and DNA operations is proposed by Yan et al. [57]. An efficient DNA-inspired image encryption algorithm based on the fusion of hyper-chaotic diffusion and wavelet-based confusion is proposed by El-Khamy and Mohamed [58]. In Table 1, we have summarized the recent algorithm that are most relevant to present work along with their characteristic components and performance metrics. Particularly, Table 1 summarizes the details of the chaotic system(s) used in various recent hybrid DNA chaos-based image encryption algorithms and their performance characteristic like: key space, correlation coefficients of cipher images produced by these algorithms and plain text sensitivity metrics (NPCR and UACI; all the results quoted here are for the image “Lena”) to clearly contrasting the proposed image encryption with these recent algorithms and emphasizing that it is the first hybrid DNA and conservative chaos-based image encryption algorithm having infinite key space and ideal correlation and plaintext sensitivity properties.
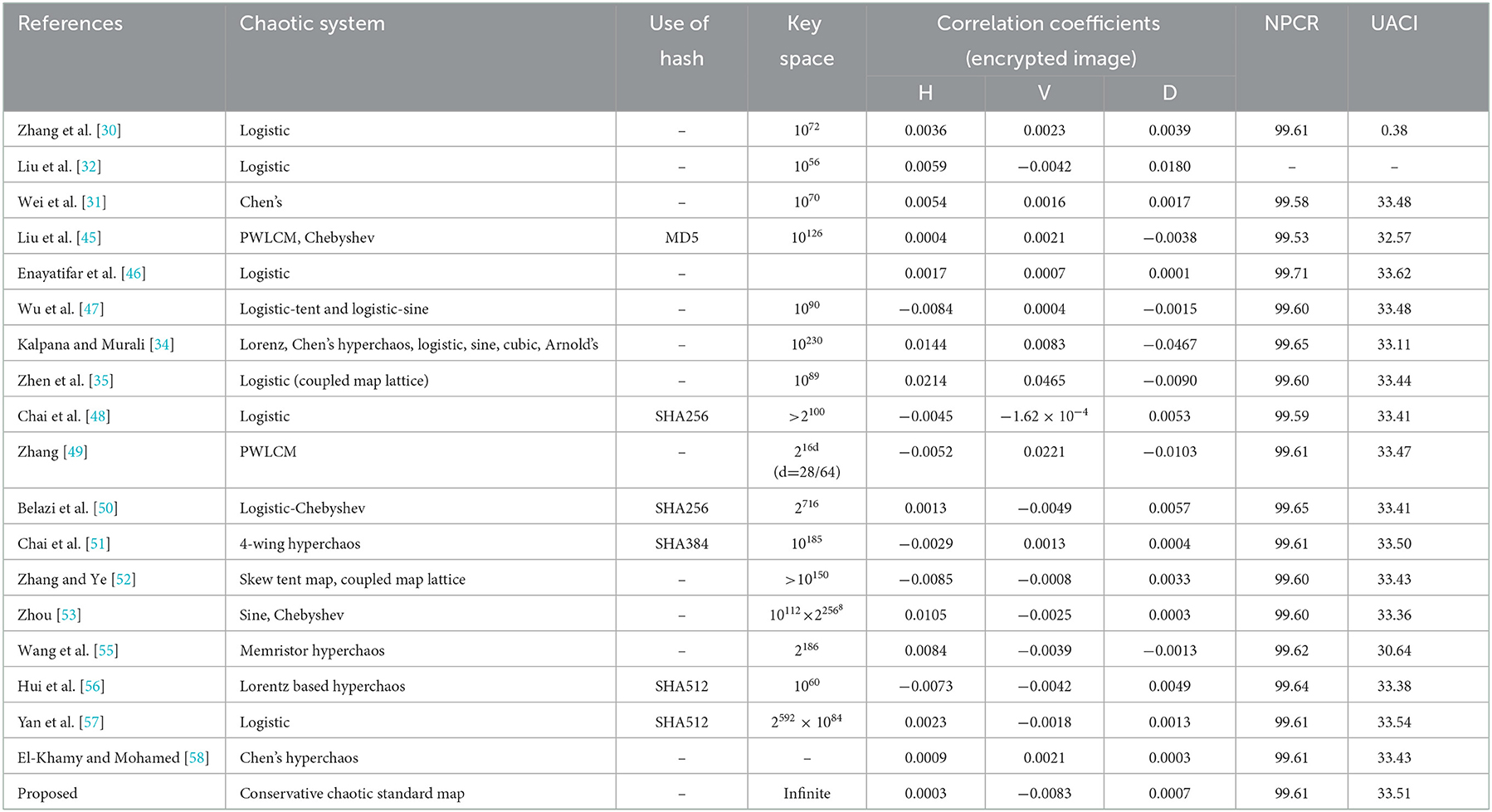
Table 1. Comparison of recent hybrid DNA chaos-based image encryption algorithms.
It is evident from the review of hybrid DNA chaos-based image encryption algorithms and the summary described in Table 1 that almost all of them are based on the chaotic logistic maps, sine map, cubic map, Arnold map, piecewise linear chaotic maps, their compound higher dimensional versions, Lorenz system, Rossler systems, 4D hyperchaotic systems like Chen's system and some of the newly developed hyperchaotic systems. In all such hybrid algorithms, chaotic systems are either used to control the substitution and permutation (DNA coding, encoding and algebraic operations) through the pseudo-random sequences generated by chaotic systems and/or to generate the one-time pads for further DNA based coding and operations to be used in the encryption. The chaotic systems used in all these algorithms are dissipative chaotic systems and exhibit several periodic windows and patterns in bifurcation diagrams and co-existing attractors in the neighborhoods of parameter space and therefore possess several weak keys. Moreover, the processes of generating pseudorandom sequences, which are mainly controlling these algorithms and responsible for the non-linearity in the algorithms, have not been rigorously tested for their pseudo-randomness. Consequently, such algorithms may be prone to chaos-based analysis/attacks.
To counter such possibilities, we propose a novel combination of conservative chaotic standard map-driven dynamic DNA encoding/decoding and operations (addition/subtractions) for image encryption. The conservative chaos map used in the proposed image encryption algorithm is a 2D map which exhibits robust chaos for all parameter values above a threshold (critical) value, and there exists no co-existing attractor too therefore, the chaotic orbit visits the entire phase space ergodically. Such ergodic orbits are highly recommended and proven best for the generation of pseudo-random sequence generations [59, 60]. We also propose a novel way to generate pseudo-random sequences (to be used in the proposed image encryption algorithm) through the conservative chaotic standard map and also test them rigorously through the most stringent test suite of pseudo randomness, the NIST test suite [61], by following all the recommendations of the test suite before using them in the proposed algorithm. Our image encryption algorithm incorporates a unique feed-forward and feedback mechanisms to generate and modify the dynamic one-time pixels that are further used for the encryption of each pixel of the plain image, thereby bringing in the desired extreme sensitivity on plaintext as well ciphertext. All the pseudo-random sequences used in the proposed image encryption algorithm are generated for an independent value of the parameter (part of the secret key) of the chaotic map and also have inter-dependency through the iterates of the chaotic map (in the generation process) therefore, the entire proposed algorithm possesses the extreme key sensitivity too. The proposed algorithm is the first hybrid DNA and conservative chaos-based image encryption algorithm having effectively infinite key space and possessing all the desired properties of an ideal image encryption system. The complete details of the proposed image encryption algorithm have been described, in detail, in the next section.
2. The proposed image encryption algorithm
In this section, we describe the DNA coding/encoding and corresponding addition and subtraction operations being used in the proposed image encryption algorithm, the novel way of generating pseudorandom sequences based on a conservative chaotic standard map and their testing with the NIST pseudo-randomness test suite, and the finer algorithmic step-by-step details of the proposed image encryption algorithm and the entire flow of the encryption process.
2.1. The DNA encoding/decoding and corresponding operations
The DNA sequences are comprised of four nucleic acid bases: Adenine (A), Thymine (T), Cytosine (C), and Guanine (G), here A and T are complements of each other and G and C are complements of each other. In DNA computing, these four nucleic bases are represented by 00, 01, 10, and 11. A total of 24 different combinations are possible for such representations out of which only eight are allowed according to the complementarity rules of binary numbers (00 and 11 are complements, 01 and 10 are complements) and consistent with the DNA complement rule too. In Table 2, all eight allowed representations or DNA encoding/decoding rules for binary numbers 00, 01, 10, and 11 have been depicted. In 8-bit image representation, each pixel value lies between 0 and 255 i.e., its binary representation is an 8-bit code therefore a pixel is represented by a combination of four nucleic bases. Therefore, a pixel can be encoded in eight different ways by following the DNA encoding rules given in Table 2 [37].
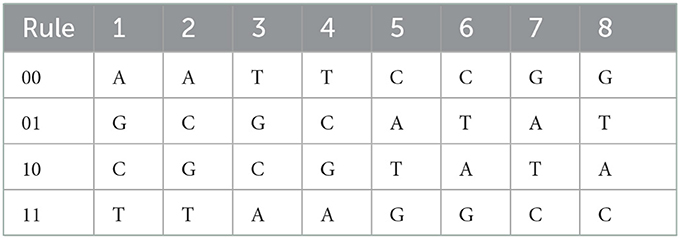
Table 2. DNA encoding/decoding rules.
For each DNA encoding rule, the operations like addition, subtraction, XOR, XNOR, etc. can be defined by following the corresponding binary operation rules. Therefore, there are different rules for these operations corresponding to each DNA encoding rule. In the present algorithm, we are using addition and subtraction operations along with DNA coding/encoding. For brevity, only addition and subtraction tables (Tables 3, 4) corresponding to one of the DNA encoding/decoding rules (for rule no. 4) are provided here. Similarly, the addition/ subtraction tables for the remaining rules can also be developed.
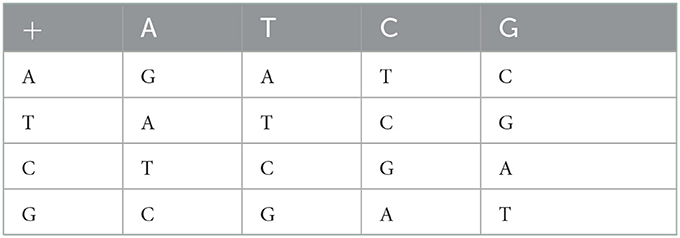
Table 3. DNA addition rules (corresponding to DNA encoding/decoding rule no. 4).
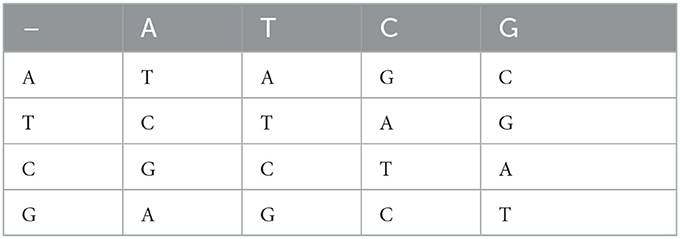
Table 4. DNA subtraction rules (corresponding to DNA encoding/decoding rule no. 4).
In the proposed image encryption, we use any one of all eight DNA encoding/decoding rules, any one of all eight addition rules and any one of all eight subtraction rules randomly for each pixel under the control of pseudorandom sequences generated through the conservative chaotic standard map.
2.2. The generation of pseudorandom sequences based on conservative chaos and their testing
In the proposed image encryption algorithm, the conservative chaotic standard map is used in a novel way for the generation of pseudo-random number sequences which drives the entire process of DNA encryption. The following form of the 2D conservative chaotic standard map is used for this purpose.
Here X and Y are the state variables and K is the parameter. The chaotic region in the phase space increases with the increase in parameter K and chaos becomes completely global for K > 18 and the chaotic orbit visits the entire phase space ergodically. For more details on the bifurcations and dynamics of the chaotic standard map, Patidar and Sud [59] may be referred.
The iterates of the abovementioned map are used for the generation of pseudo-random number sequences. For this purpose, we divide the entire phase space (0 < X < 2π, 0 < Y < 2π) of the conservative chaotic map into eight equal parts as depicted in Figure 1 and assign numbers 1–8 to these parts. After each iteration, we observe the pair of values of X and Y, depending on which region of the phase space this belongs to, we record the corresponding region number in the sequence. In this way, we generate a sequence comprising numbers 1–8 of the desired length using the iterates of the above-mentioned map.
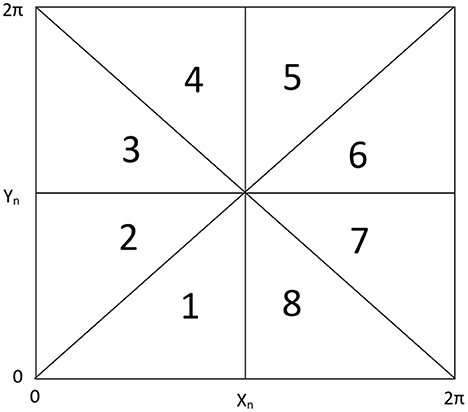
Figure 1. Divisions of the phase space of the conservative chaotic standard map.
We have also tested the randomness of pseudorandom sequences generated in the above-mentioned manner using the NIST test suite [61]. For the testing purpose, we have generated 1,000 sequences of 106 bits each starting with random choices of initial conditions and parameter values of the conservative chaotic standard map and run the entire test suite comprising 15 different parametric and non-parametric tests (in total there are 188 tests which include all variants of different tests in the suite). For each sequence, using each test statistic, a p-value is generated. If the p-value is >0.01 (determined by the chosen significance level) then the test is labeled as passed. A certain number of sequences, out of the total tested, are expected to fail the test depending on the level of significance chosen. The NIST test suite also predicts how many sequences out of the total sequences have passed the test, it is defined as the proportion (no. of sequences passing the test/total no. of sequences) of the sequences passing the test. For a significance level of 0.01, the allowed range of proportions is (0.9833245, 0.9966745). In Figure 2A we have depicted the proportions for all 188 different tests for the testing set of 1,000 sequences. It is observed that the proportion for all the tests falls within the allowed range of proportions. To check the uniformity of the distribution of all p-values (1,000 in number) for a particular test, we obtain a p−valueT using χ2 test (i.e., p-value of the p-values). If the p−valueT is >0.0001, it is declared that the sequences have uniformly distributed p-values for that test and the test is termed as passed. We have depicted the p−valueT for the distribution of p-values for all 188 statistical tests in Figure 2B which indicates that uniformity is observed for all the tests included in the NIST test suite. For more details on various test statistics and testing procedures, readers are referred to [61]. With these testing results, we may conclude that the pseudorandom sequences generated in the above manner are cryptographically secure and hence these sequences may be used in any encryption algorithm.
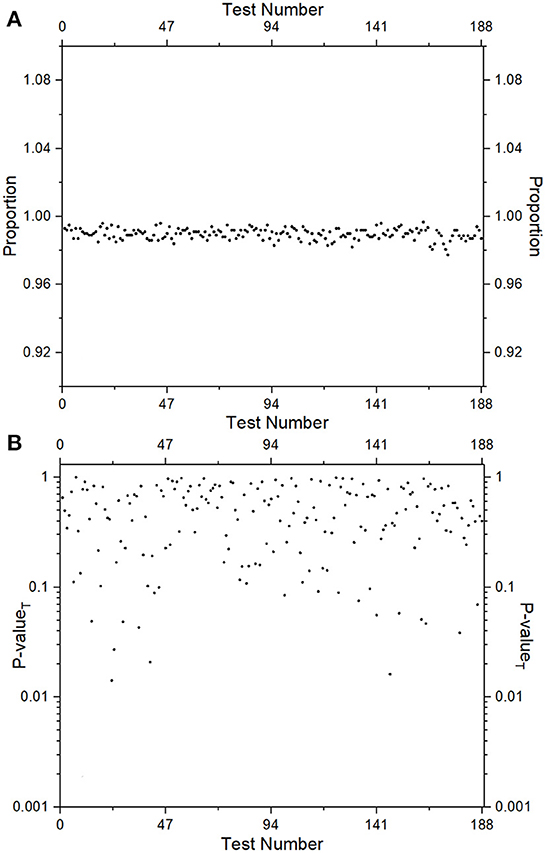
Figure 2. Testing of pseudorandom sequences using NIST test suite: (A) Proportions and (B) p−valueT.
2.3. The encryption process
The DNA operations are capable of shuffling as well as altering the pixel values therefore if implemented in a specific and strategic manner these operations may produce the desired permutation-substitution effect as recommended by Shanon [1]. For this purpose, in the proposed image encryption algorithm, we use a conservative chaos-driven dynamic DNA coding procedure. We use DNA encoding, addition/subtraction and decoding of pixels in the encryption (the procedure of DNA addition is replaced with DNA subtraction in the decryption process). We use all eight possible DNA encoding rules and corresponding addition, subtraction and decoding rules in the proposed image encryption algorithm which are dynamically chosen for each pixel at various stages of encryption. All these processes are executed pixel-wise and the DNA encoding, addition, and decoding rules for each pixel are selected randomly with the help of pseudorandom number sequences generated through the conservative chaotic standard map. While executing the two-step DNA addition, we bring in the ciphertext dependence through the feedback mechanism wherein the last cipher pixel is also used in the second step of DNA addition (see Step 12 below). Before executing the DNA operations as explained above, we also use the conservative chaotic standard map to generate a dynamic one-time pixel (DOTP) value for the encryption of each pixel of the plain image. The DOTP is generated in such a way that it also possesses the sensitive dependence on all the plain image pixels ahead of the pixel being encrypted (feed-forward mechanism) as well as on all the cipher image pixels generated before the encryption of that pixel (feedback mechanism) (see Steps 7 and 8 below). Before introducing this plain image and cipher image sensitivity, we also use DNA encoding of the DOTP using the randomly selected DNA encoding rule controlled by a pseudo-random sequence generated through the conservative chaotic standard map. Below we give the process flow and finer details of the entire image encryption algorithm.
The proposed image encryption algorithm has been explained for a gray image of size H×W as the plain image. However, it can be easily extended to RGB images by converting/reshaping the 3D RGB pixels matrix to a 2D matrix and considering it as the input to this algorithm. The other way is to encrypt all three layers separately. The secret key in the proposed image encryption algorithm is a set of one integer and seven floating-point numbers. The two floating-point numbers (X0, Y0)∈(0, 2π) serve as the initial conditions for the chaotic conservative standard map, the remaining five floating-point numbers (K, K1, K2, K3, K4)>18.0 serve as the parameter value for the conservative chaotic standard map at various stages of the algorithm and an integer 0 < N < 1000 serves as the number of iterations to skip before using the map for the encryption purpose. The entire process of proposed image encryption can be divided into two parts:
2.3.1. Part-I
This part of the encryption process requires the secret key and the information on the size of the plain image. If in certain applications e.g., online streaming of videos in TV broadcasting through viewing cards where the size of images and secret keys are fixed, this part of the encryption process may be pre-computed and stored to speed up the encryption. This part of the encryption process can be identified with the red dotted block in the block diagram of the encryption process in Figure 3.
1. The conservative chaotic standard map is iterated N number of times with the initial conditions (X0, Y0) and parameter K specified in the secret key. The iterates are thrown out and only the values (XN, YN) are stored for further use.
2. The conservative chaotic standard map is iterated H × W number of times with the initial conditions (XN, YN) and parameter K, all the iterates X and Y are used in the following way to generate the DOTP1 and DOTP2.
3. The conservative chaotic standard map is iterated H × W number of times with the initial conditions (XN+HW, YN+HW) and parameter K1. All the iterates X and Y are used to generate a pseudo-random number sequence RSQ1i (i = 1 to H×W) having integers 1–8 using the procedure explained in subsection 2.2.
4. Repeat Step 3 with the initial condition (XN+2HW, YN+2HW) and parameter K2 to generate a pseudo-random number sequence RSQ2i (i = 1 to H×W) having integers 1–8.
5. Repeat Step 3 with the initial condition (XN+3HW, YN+3HW) and parameter K3 to generate a pseudo-random number sequence RSQ3i (i = 1 to H×W) having integers 1–8.
6. Repeat Step 3 with the initial condition (XN+4HW, YN+4HW) and parameter K4 to generate a pseudo-random number sequence RSQ4i (i = 1 to H×W) having integers 1–8.
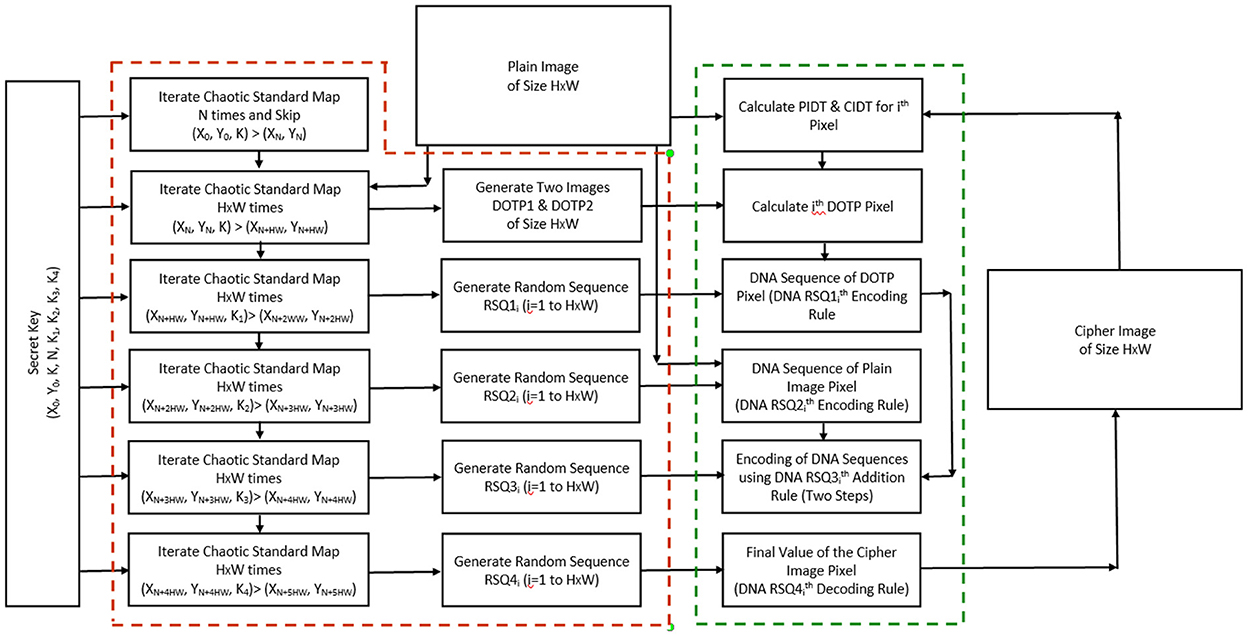
Figure 3. Block diagram of the proposed image encryption process.
2.3.2. Part-II
This part of encryption is executed pixel-wise and therefore repeated H×W times. Here we are explaining the process for the ith pixel of the plain image. This part of the encryption process may be identified with the green dotted block in the block diagram of the encryption process in Figure 3.
7. Compute the two terms plain image dependent term (PIDT) and cipher image dependent term (CIDT) in the following way.
Here PIk and CIk are kth plain image and cipher image pixels. For the first pixel of the plain image, the value CIDT will be zero.
8. Compute and modify the DOTP for the encryption of ith pixel
here ⊕ is the XOR operation. This step of encryption brings in extreme sensitivity to the plain image and cipher image too and makes it very robust against known plaintext and chosen-ciphertext attacks.
This step onward the role of conservative chaos-driven DNA encoding, decoding and addition starts.
9. Encode the DOTP(i) in DNA sequence using the DNA Encoding Rule. Here first we convert the DOTP(i) value in the 8-bit binary form.
10. Encode the ith pixel of the plain image (first converted to 8-bit binary form) i.e., PIi in DNA sequence using the DNA Encoding Rule.
11. Add the DNA sequences of DOTP(i) and PIi using the DNA Addition Rule.
12. Now we generate the DNA sequence of the ith pixel of cipher image in the following way: The resultant DNA sequence from Step 11 is added to the DNA sequence of the (i−1)th pixel of cipher image using the DNA Addition Rule. For the encryption process of the first plain image pixel, the DNA sequence of the cipher image pixel to be added here is fixed to “ATCG” as the 0th cipher image pixel does not exist.
13. The DNA sequence of the ith pixel of cipher image (generated in Step 12) is converted to the 8-bit binary form using the DNA Decoding Rule.
The decimal equivalent of this 8-bit is finally considered as the intensity of the ith pixel of the cipher image CIi.
The entire Part-II of the proposed encryption (except Steps 7 and 8) is based on the dynamic lookup table operations (DNA encoding, DNA addition, DNA subtraction, DNA decoding tables) controlled by the pseudo-random sequences generated in Part-I, therefore, almost negligible arithmetic operations are involved in Part-II of the encryption and hence can be executed very fast.
In the next section, we analyze the performance and security of the proposed image encryption algorithm through various statistical and perceptual quality analyses.
3. Performance and security analysis
For the performance and security analysis of the proposed image encryption algorithm, we have used five different images Lena, Baboon, Peppers, All Black (all pixel values are “0”), and All White (all pixel values are “255”) each of size 200 × 200. For the encryption of these images, we have considered five different randomly chosen secret key combinations which are depicted in Figure 4 along with their corresponding cipher images produced using the proposed image encryption algorithm.

Figure 4. Plain images, corresponding secret keys and cipher images.
3.1. Histogram analysis
For an ideal cipher image, the histogram must be uniform i.e., the number of pixels corresponding to all intensity levels should be equal irrespective of the content of the plain image as well as of the secret key. The histograms for all five pairs of plain and cipher images are shown in Figure 5. From the visual inspection of cipher images and their histograms, we may easily infer that the histograms are uniform.
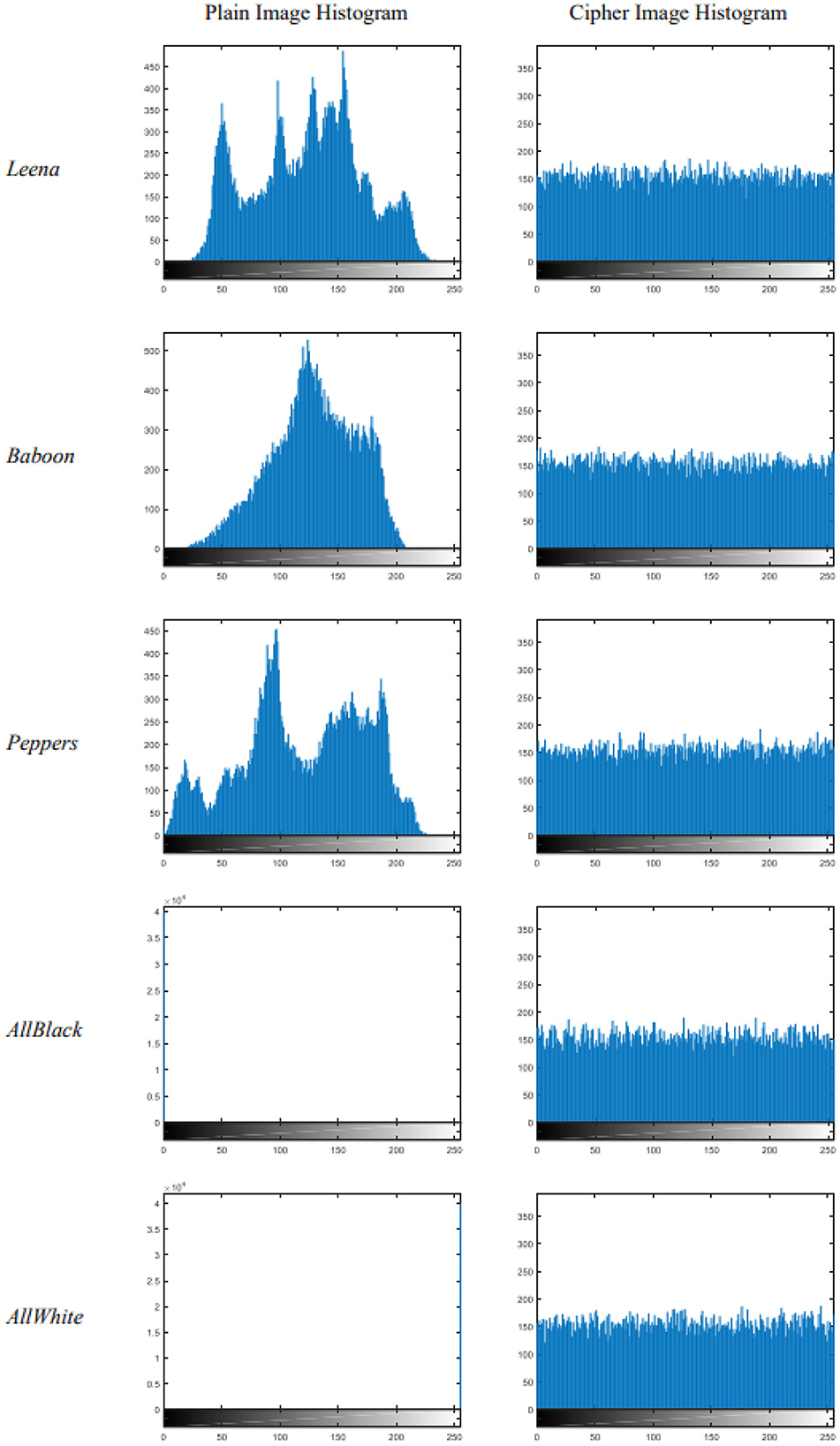
Figure 5. Histograms of plain images and corresponding cipher images.
However, for quantitative confirmation, we have also computed the statistical measures like chi-square distribution, histogram variance, deviation from ideality, maximum deviation and irregular deviation for the histograms which mainly confirms the uniformity of the cipher image histograms and also predicts the amount of deviation between the histograms of plain and cipher images. The details of these measures and the results of our analysis are described in the following subsections.
3.1.1. Chi-square and histogram variance
To understand the pixel distribution quantitively, we compute the χ2 from the histograms of the plain and cipher images using the following statistical formula.
here and fi is the total number of pixels at the ith intensity level.
For perfect uniform distribution, the value of χ2 is zero and a standard value of the χ2 for typically acceptable random cipher image (significance level 0.05) is around 293. We have displayed the results of χ2 for all five pairs of plain and cipher images in Table 5. We observe that the χ2 values for plain images are very high and it is lower than the acceptable standard value for the cipher images produced using the proposed image encryption algorithm.

Table 5. χ2 and histogram variance for the plain and cipher images.
We have also calculated the histogram variances (HistVar) for the plain and cipher images using the following statistics:
here fi and fj are the total number of pixels at the ith and jth intensity levels, respectively, and N is the total number of intensity levels i.e., 256. The results of our computation for all the five pairs of plain and cipher images are shown in Table 5, the results clearly show that the histogram variances are very high for the plain images and very low for the cipher images (almost 1% of the histogram variance of plain images).
3.1.2. Deviation from ideality, maximum deviation, and irregular deviation
Another way to measure the uniformity of the histograms of cipher images is using a metric Deviation from Ideality (DI). It measures the deviation of the histogram of the cipher image from the ideal uniform histogram. The DI metric is calculated in the following way:
here and fi(C) is the histogram of ith level (total number of pixels at the ith intensity level) in the encrypted image.
The histogram of the cipher image is nearly uniform if the value of the DI metric is nearly zero or very low. For a completely uniform/ideal histogram, the value of DI is zero. In Table 6, we have shown the values of DI metric for all five cipher images corresponding to the five plain images used in the analysis. We observe that the DI values are nearly zero or negligible hence the histograms of cipher images are almost uniform.
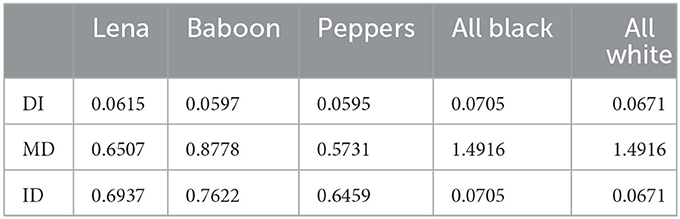
Table 6. Deviation of cipher images from ideality, maximum and irregular deviations between plain and cipher images.
Similarly, another metric referred as Maximum Deviation (MD) measures the deviation of the histogram of the cipher image from the histogram of the plain image. The computation of MD can be done using the following statistics:
here di is the absolute difference between the histograms corresponding to the ith level of plain and encrypted images. The higher the value of MD, the larger the deviation between the histograms of the plain and cipher images. We have shown the values of metric MD also in Table 6 for all five pairs of plain and cipher images used in the present analysis. The results clearly show that the histograms of plain and cipher images are significantly different.
Sometimes, the Maximum Deviation does not provide the correct information about the deviation between the histograms therefore may mislead the interpretation. To overcome this, another metric Irregular Deviation (ID) is also used which measures the deviation of the difference of the histograms between plain and cipher images with the mean of the difference of the histograms and high value of ID signifies a better encryption algorithm. The metric ID is calculated using the following formula/statistics:
here di is the absolute difference between the histograms corresponding to the ith level of plain and encrypted images and Md is the mean of the difference of histograms. The higher values signify the larger deviation. The results for the metric ID for all five pairs of plain and cipher images are given in Table 6. The results indicate that the plain and cipher images are significantly different in terms of statistical deviations.
All the above results of the histogram analysis confirm the desired level of uniformity of pixel distribution in the cipher images and remove the possibility of implementing statistical attacks based on histogram analysis.
3.2. DNA sequence-based analysis
3.2.1. Hamming distance
Hamming distance is used to compare two character/symbol strings of equal length and is defined as the number of positions where two corresponding symbols/characters are different in two strings. For two image DNA sequences I1 and I2 the Hamming distance (HD) is defined as:
I1i and I2i are the ith symbol/base in the DNA sequence of the images I1 and I2, respectively, H and W are the height and width of images I1 and I2.
The higher the value of Hamming distance, the more dissimilar the strings are. In our analysis, we are comparing the DNA sequences of plain images and cipher images. Considering the images of 200 × 200 size used in the test run, there are total 40,000 pixels in each image and hence 160,000 bases in their corresponding DNA sequences. The results of our computation for the Hamming distance for all five pairs of plain and cipher images are recorded in Table 7. It is observed that in all the cases the Hamming distance is nearly 120,000 irrespective of the content of the plain image as well as the secret key used for the encryption. It signifies that 75% of the bases in the DNA sequences of plain and cipher images are different.

Table 7. Hamming distance (HD) between plain and cipher images.
3.2.2. Base ratio
The base ratio (BR) of a particular base in a DNA sequence is the percentage of the occurrence of that base in the sequence. For an image of height H and width W, the base ratio can be calculated in the following way
where S is one of the symbol/base (out of A, T, C, and G) in the DNA sequence of an Image. As every pixel in the image is represented by four DNA bases therefore the total symbols in the DNA sequence of an image shall be four times the number of image pixels. We have shown the results of the base ratio for all four bases (A, T, C, and G) for all five pairs of plain and cipher images in Table 8. We observe that in all cases the occurrence of DNA bases is uniform (nearly 25%) in both the plain and cipher images. It is interesting to note here that in the proposed image encryption algorithm chaos-based randomized encoding of the plain image is used as the first step of encryption and the base ratio results show that this first step of encoding itself brings in so much uniformity in the encryption process. This is testimony to the fact that the proposed image encryption method is robust against any sort of statistical attack on the DNA bases.

Table 8. Base ratio (BR) for various plain and corresponding cipher images.
3.3. Fixed-point ratio
A particular pixel in an image is identified as the fixed-point if it does not change its gray value after the entire encryption process. The fixed-point ratio is the percentage number of such fixed points which exist in an image after the encryption. For a pair of plain and cipher images, the fixed-point ratio (FPR) is calculated in the following way:
where Pi and Ci are the ith pixel values in the images P and C, respectively, H and W are the height and width of images P and C.
For all five pairs of plain and cipher images, we have summarized the values of the FPR metric in Table 9, these results clearly show that the percentage of pixels which do not change after encryption through the proposed method is below 0.5% and thus it signifies the existence of effective substitution and diffusion in the proposed image encryption algorithm.

Table 9. Fixed point ratio (FPR) for various pairs of plain and cipher images.
3.4. Correlation analysis
In an image having definite visual content, the adjacent pixels are highly correlated and a weak encryption process does not completely remove such correlations. In addition to this, cryptanalysts sometimes use pairs of plain and corresponding cipher images to identify some meaningful relationship between the plain and cipher images by analyzing the correlation between the pairs of plain and cipher images. An ideal cipher should produce cipher images possessing almost zero correlation with the plain images.
To analyze the above mention types of correlations, we have computed the correlation coefficients for all horizontally and vertically adjacent pixel pairs in all plain and their corresponding cipher images using the following expressions:
here xi and yi form ith pair of horizontally/vertically adjacent pixels and N is the total number of pairs of horizontally/vertically adjacent pixels.
In general, for plain images having definite visual content, the correlation coefficients are very high and ideally, for cipher images, these correlation coefficients should be negligible or zero. The results of such horizontal and vertical correlation coefficients have been given in Table 10. The results indicate that there is no correlation between plain and cipher image pixels thereby eliminating the possibility of implementing any statistical attack based on the correlation.
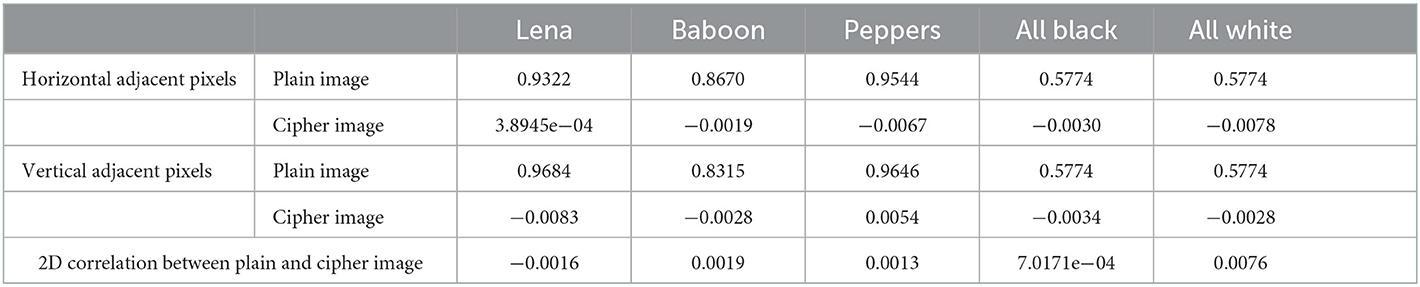
Table 10. Correlation between horizontally and vertically adjacent pixels in plain & cipher images and 2D correlation between pairs of plain and cipher images.
We have also computed the 2D correlation coefficient between the plain and corresponding cipher image using the following statistics:
with and , here P and C are the plain and encrypted images, respectively.
The result of such 2D correlation coefficients for all five pairs of plain and cipher images are given in Table 10, which clearly shows that the pairs of plain and cipher images do not possess any correlation, therefore, removing the possibility of implementing statistical attacks based on correlation.
3.5. Information entropy analysis
Information entropy (also referred to as Shanon entropy or global information entropy) is a measure of uncertainty associated with a random image or it may be considered as the measure of disorder. It quantifies the amount of information contained in the image (in bits) per pixel. It can also be interpreted as the minimum number of bits per pixel necessary to communicate it correctly. It is also a statistical measure of randomness in the image. The information entropy for a greyscale image may be computed in the following way:
where P(Ii) is the probability of occurrence of the pixel value Ii in the image I. For a flat image, the information entropy is zero and for an image whose pixel distribution is perfectly uniform [i.e., P(Ii) = 1/256] the information entropy is 8-bits per pixel. The results of global information entropy for the plain and cipher images are given in Table 11. It is observed that the global information entropy for the encrypted images is very close to the maximum possible value i.e., 8-bits.
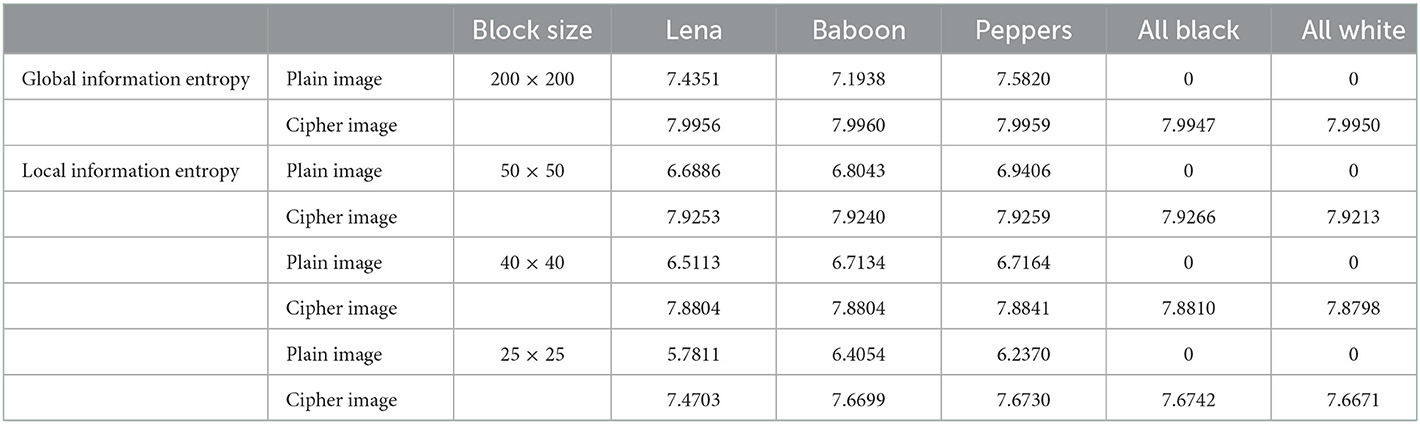
Table 11. Global and local information entropy.
The Shanon entropy or global information entropy measure may possess some weaknesses such as inaccuracy, inconsistency, and low efficiency in certain cases and to overcome such weakness, a new variant named local information entropy is suggested which is the mean entropy of several or all non-overlapping image blocks that are randomly selected from image. For an image I divided into k number of non-overlapping blocks Ii (i = 1 to k), the local information entropy may be computed in the following manner:
here H(Ii) is the Shanon entropy of the ith block Ii and k is the total number of non-overlapping blocks of the image I. The result of local information entropy for the plain and cipher images corresponding to three different block sizes (25 × 25, 40 × 40, 50 × 50) are given in Table 11. We observe that the local information entropy of cipher images is also close to the global information entropy and well-above the standard values of local information entropy of random images.
3.6. Perceptual quality analysis
One of the major objectives of the image encryption algorithm is to secure the content by making the unintelligible and obfuscating the visual data to appear random. It can be observed from the Figure 4, that after the encryption the images look completely random with no visual patterns/content. In addition to the visual inspection of the encrypted images, quantitative perceptual quality analysis is also done for the image encryption processes to observe how much quality degradation is introduced (of course recoverable at the decryption) by the encryption algorithm so that the information becomes completely unintelligible and appear garbage. For an encryption algorithm, it is expected that encrypted images have low perceptual quality with reference to the plain image and it is measured with metrics such as mean absolute error (MAE), Mean square error (MSE), peak-signal-to-noise ratio (PSNR), spectral distortion (SD), structural similarity index measure (SSIM), and feature similarity index measure (FSIM).
The MAE, MSE, and PSNR are used to quantify the image fidelity or spatial dissimilarities between two images. Although these metrics do not include the characteristics of image signal and the human vision system (HVS), they are widely used as the first full-reference measures. In encryption, it is expected to have large values of MAE and MSE and low values of PSNR (< <28) which convey the higher amount of average dissimilarity in the pixel values between the plain and cipher images. These metrics may be computed in the following way:
here Pij and Cij are the ijth pixel values of the plain and encrypted images, respectively, and Max(f) is the highest intensity level i.e., 255.
To measure the spectral dissimilarity between the plain and encrypted images, the spectral distortion (SD) measure is used. It is computed using the following expression: , here Fp and Fc are the discrete Fourier transform of the plain and encrypted images, respectively.
Another metric structural similarity index measure (SSIM) takes into consideration the human vision system (HVS) and compares the images with respect to luminance, contrasts and structural features [62]. For perfectly identical images SSIM is “1” and very low for dissimilar images with respect to the above features. It can be computed using the following statistics: where μa is the average of all pixels of image a, μb is the average of all pixels of image b, is the variance of the pixel values of image a, is the variance of the pixel values of image b and σab is the covariance of pixels of images a and b.
Another comparatively new perceptual image quality measure: the feature similarity index measure (FSIM) takes into consideration the phase congruency (PC) and gradient magnitude (GM) as two complementary feature measures to characterize the image local quality. FSIM metric is computed for two images in the following way [63].
, here f indicates one of the features (PC or GM). FSIM is computed individually for the PC and GM and then multiplied to obtain the final FSIM. For perfectly similar images FSIM is “1” and low for the dissimilar images with respect to PC and GM.
We have computed all six above explained measures for all the five pairs of plain and cipher images, to observe the perceptual quality of the encrypted images produced using the proposed image encryption algorithm and the results have been summarized in Table 12. It can be easily observed from the results that as desired for an encrypted image the MAE, MSE are very high, PSNR is very low, SD is very high and SSIM and FSIM are small which confirms the very low perceptual quality of encrypted images.
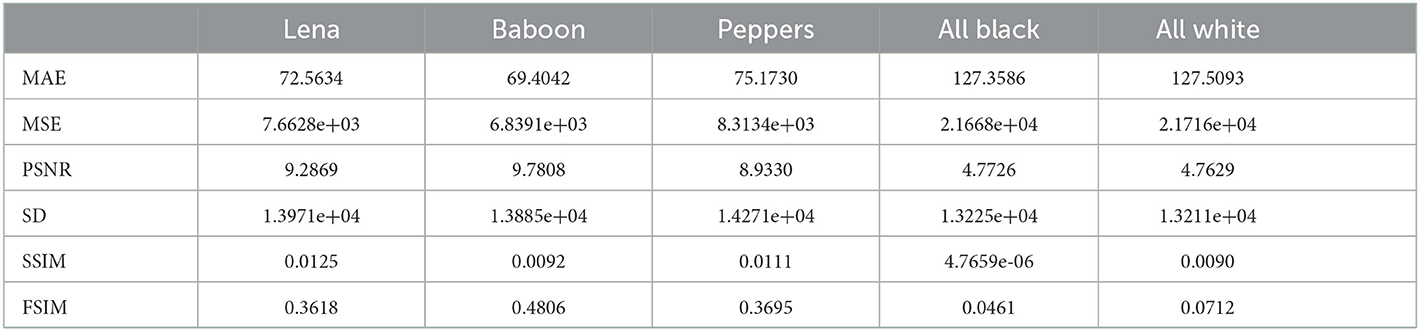
Table 12. Perceptual quality metrics.
3.7. Plaintext sensitivity analysis (differential analysis)
To resist the differential analysis in which the attacker may analyze the relationship between the plaintext and ciphertext by making minor changes in the plaintext and observing the effects in the ciphertext to discover the secret key. To check the robustness of the encryption algorithm against such differential analysis, we quantify the plaintext sensitivity of the encryption algorithm using two metrics Net Pixel Change Rate (NPCR) which measures the percentage number of pixels in the encrypted image which change their values after making an infinitesimal change in the plaintext and encrypted with the same secret key and Unified Average Change in Intensity (UACI) which measures the net average change in the intensity of each pixel in the encrypted image after making an infinitesimal change in the plaintext and encrypted with the same secret key. The computation is done by comparing the two cipher images which are produced using the same secret key and their corresponding plaintexts are differing in only one-pixel value at any random location. Several random combinations of the secret key and locations of the pixel in plain image are considered one by one and average values of NPCR and UACI are computed. Following mathematical formulae are used for the computation of the NPCR and UACI.
Cij and are two different cipher images produced with the same secret key and for slightly different plain images (only one pixel different). The standard values of NPCR and UACI for two random images are 99.6094 and 33.4635, respectively. The results of our computation for the NPCR and UACI for various plain images used in our analysis are summarized in Table 13. It can be observed that the NPCR and UACI for the proposed image encryption algorithm converge to the values for standard random images hence the two cipher images corresponding to two plain images having an infinitesimal difference are almost random therefore the proposed image encryption algorithm has required plaintext sensitivity to resist the differential attacks.
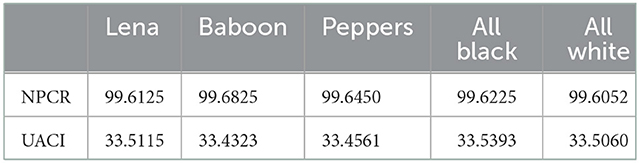
Table 13. NPCR and UACI in the proposed image encryption algorithm.
3.8. Key sensitivity analysis
In general, an ideal encryption algorithm should possess a complex and sensitive relationship between the secret key, plaintext and ciphertext. One of the ways to measure this sensitive behavior is to observe the key sensitivity of the encryption algorithm. The key sensitivity may be measured in two ways: one at the encryption level and another at the decryption level.
To observe the key sensitivity at the encryption level, we encrypt the same plain image with two slightly different secret keys (differing by an infinitesimal change) and compare the two cipher images by computing KS1: the percentage of the total number of corresponding pixels which are different in both cipher images and KS2: the average change in the intensity of corresponding pixels in both the cipher images. It is done by using the following formulae:
Here and are two different cipher images corresponding to the same plain image produced with a minute change in one of the parts of the secret key.
In the proposed image encryption algorithm, there are eight parts of the secret key, seven of them are floating-point numbers and one is an integer. For computing the key sensitivity metrics, we make a change of 10−14 in only one of the parts of the secret key (if it is a floating-point number) or a change of 1 (if it is an integer) and then compute KS1 and KS2 for the corresponding cipher images produced for the same plain image. The results of our computation for all five plain images are summarized in Table 14. The top row in the table indicates the part of the secret key which has been changed in the above-mentioned manner to compute KS1 and KS2. The results converge to the values for standard random images hence the two cipher images compared are perfectly random and therefore proposed image encryption algorithm possesses the extreme key sensitivity at the encryption level.
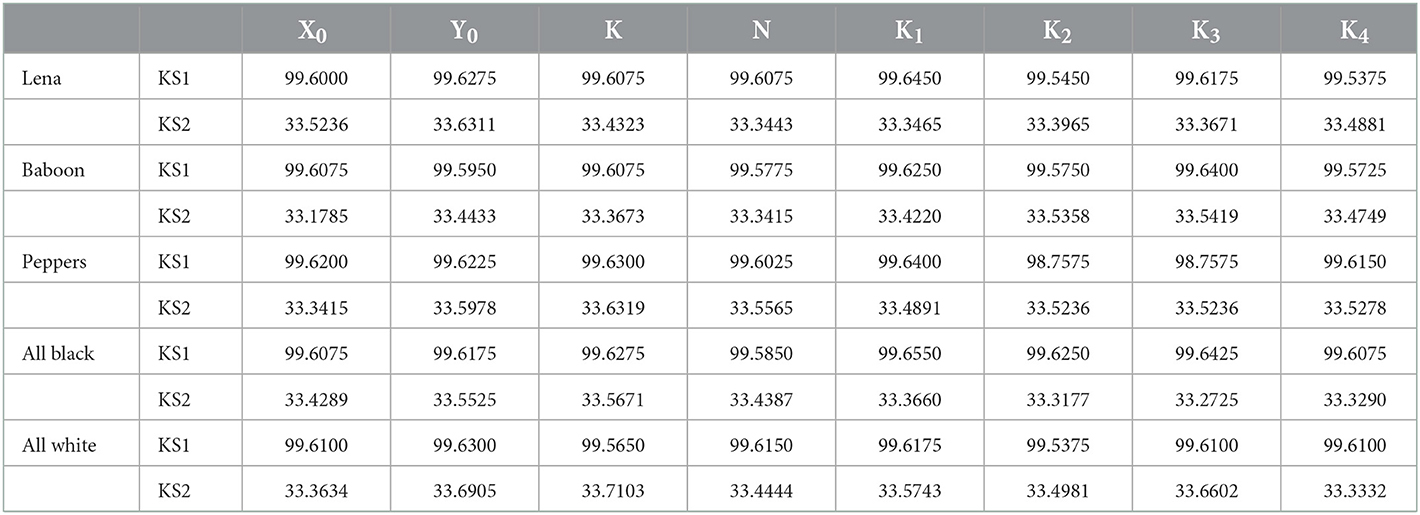
Table 14. Key sensitivity analysis results at the encryption level.
To observe the key sensitivity at the decryption level, we encrypt the plain image with a secret key and decrypt it with a slightly different secret key and then compare the correctness of the decrypted image with respect to the plain image by computing the perceptual metrics MAE, MSE, and PSNR (already explained above). The strategy of a minor change in the secret key is the same as adopted above for the computation of KS1 and KS2. The results of our computation are summarized in Table 15. It is observed that the decryption with a slightly different key obtains a completely dissimilar image as compared to the plain image.
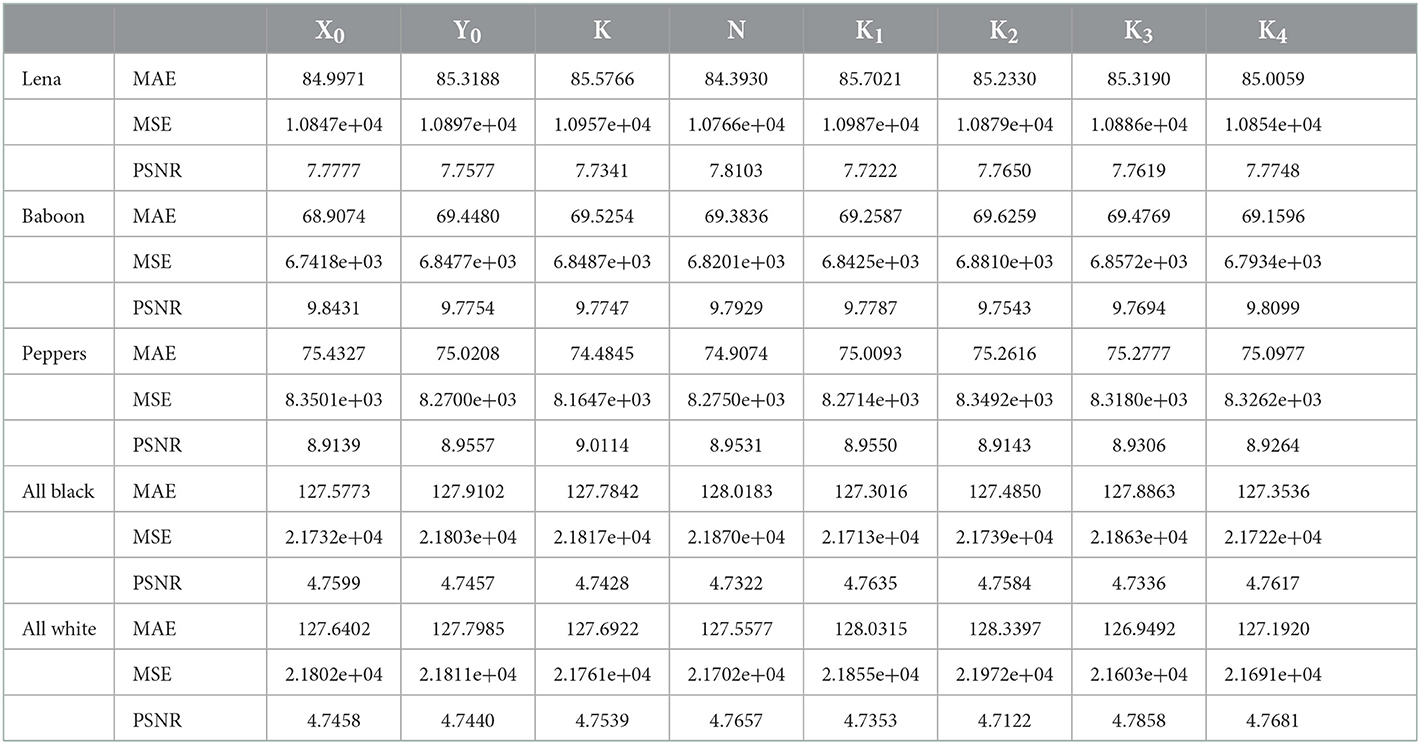
Table 15. Key sensitivity analysis results at the decryption level.
3.9. Key space analysis
The secret key in the proposed image encryption algorithm is a set of one integer and seven floating-point numbers. The two floating-point numbers (X0, Y0)∈(0, 2π) serve as the initial conditions for the chaotic conservative standard map, the remaining five floating-point numbers (K, K1, K2, K3, K4)>18.0 serve as the parameter value for the conservative chaotic standard map at various stages of the algorithm and an integer 0 < N < 1000 serves as the number of iterations to skip before using the map for the encryption purpose. The key sensitivity analysis reveals that the parameter and initial conditions of the conservative chaotic standard map differing by 10−14 can be treated as a distinct key. Since the initial conditions (X0, Y0)∈(0, 2π) therefore there are (2π × 10−14)2 combinations of different keys for the Initial conditions. The parameter of standard chaotic map can have any value larger than 18.0 with a precision of 10−14 consequently, have infinite number of distinct combinations and there are 103 different combinations for the value N. In this way, we may conclude that the proposed image encryption algorithm has infinite key space and consequently brute force attack is infeasible.
3.10. Classical attack analysis
The most common and frequently used cryptanalytic attacks are known-plaintext attacks and chosen-plaintext attacks. In a known-plaintext attack the cryptanalyst knows the plaintext and its corresponding ciphertext and by establishing a meaningful relationship between the two along with the knowledge of the encryption algorithm tries to discover the secret key. In chosen plaintext attack, the cryptanalyst chooses multiple plaintexts of his/her choice (based on the intuition and knowledge of the structure of the encryption algorithm), generates the corresponding ciphertext for the same secret key (which is unknown) and then extracts some correlation, statistical information etc. to discover the secret key. The differential attack (see Section 3.7) is also a kind of chosen-plaintext attack only. Sometimes adaptive chosen plaintext attacks are also implemented where one pair of plaintext (chosen in the first step) and corresponding ciphertext is analyzed and based on the results, the cryptanalyst chooses/creates a specific plaintext for the next step and further carries out the analysis and continues till the secret key is discovered.
Since the proposed image encryption algorithm exhibits extreme key, plaintext and ciphertext sensitivity (refer to Sections 3.7 and 3.8) therefore it is very difficult to extract any meaningful information through the pairs of plaintexts and cyphertexts. In the proposed image encryption algorithm, the dynamic one-time pixel (DOTP) is generated with the help of a part of the key and modified at the encryption of each pixel through the information from the plaintext and ciphertext generated so far. This DOTP is further used to encrypt the pixel and then the ciphertext generated so far will be used along with the plaintext information for the next DOTP modification and so on (i.e., feed -forward and feedback mechanisms). Moreover, the rules chosen for the encryption of each pixel are also dynamic and key-dependent. In the entire encryption process the secret key, plaintext and ciphertext are closely and sensitively interconnected such that an infinitesimal change in any of the components leads to a diverse effect in the resultant therefore implementation of any of the above-mentioned attacks appears completely infeasible.
3.11. Encryption time analysis
We have also done the encryption time analysis for the proposed image encryption algorithm using various images of widely different visual content, different sizes on an Intel(R) Core(TM) i7-8565U CPU @ 1.80 GHz with 16 GB RAM running on Windows 10 64-bit OS. The analysis has been done for three different sizes of images 200 × 200, 256 × 256, and 512 × 512, with 100 different images of each size, encrypted with the proposed algorithm using 100 randomly chosen different keys. In all for each size, a total of 10,000 experimentations have been done and an average encryption time is calculated. The results have been summarized in Table 16.
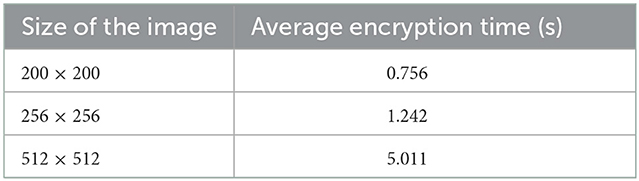
Table 16. Encryption time.
3.12. Comparison with other recent similar algorithms
In this section, we give a comparison of various performance metrics for the recent hybrid DNA chaos-based image encryption algorithms along with the proposed image encryption algorithm to highlight its features and robustness. For the comparison, we have chosen various hybrid DNA chaos-based image encryption algorithms published in the year 2021. The comparison, shown in Table 17, has been done for the correlation coefficients of cipher images produced with these algorithms, plaintext sensitivity metrics (NPCR and UACI), uniformity of histograms of cipher images produced using these algorithms (Histogram variance, and Chi-square distribution), global information entropy and encryption time. All the results quoted here are produced for the image “Lena” and taken from the respective references.
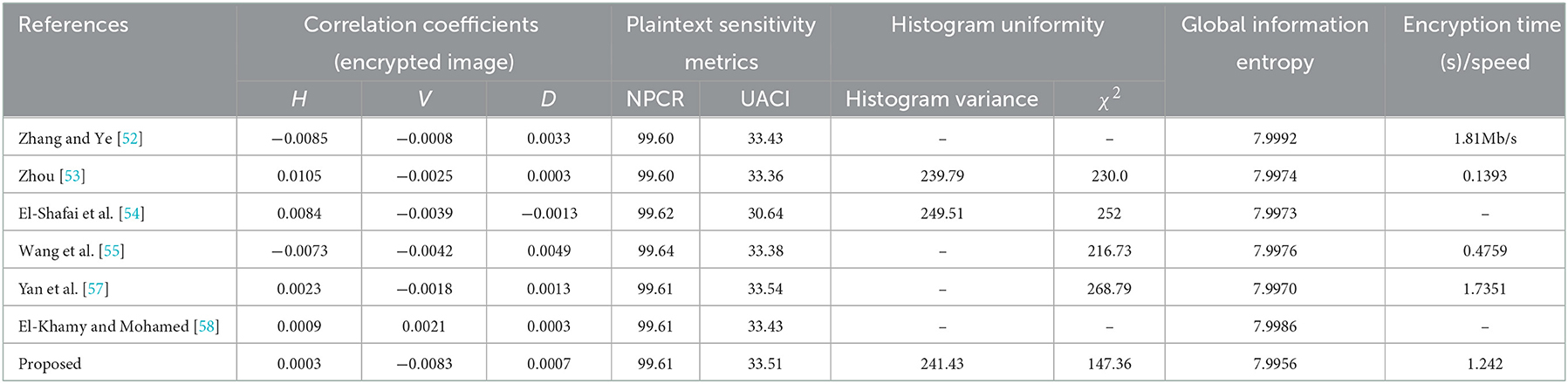
Table 17. Comparative between various recent hybrid DNA chaos-based image encryption algorithms.
4. Conclusion
The DNA encoding/decoding and operations (addition, subtraction, XOR, XNOR, complementing, etc.) if implemented jointly in a specific and strategic manner, under the control of chaotic systems, are capable of shuffling as well as altering the pixel values, therefore, may be effectively utilized for the image encryption. So far, many such algorithms have been developed and most of them are based on dissipative chaotic systems which possess the periodic windows and patterns in bifurcation diagrams, co-existing attractors in the neighborhoods of parameter space and are also characterized by the strange attractor which makes them prone to chaos-specific attacks and sometimes statistical attacks too. In this paper, we have proposed a novel conservative chaotic standard map-driven dynamic DNA coding (encoding, addition, subtraction, and decoding) for the image encryption, which is the first (to the best of our knowledge) hybrid DNA and chaos-based image encryption based on conservative chaos. The algorithm also uses a novel method of generating pseudorandom sequences from the 2D conservative chaotic standard map which is validated for the pseudo randomness through NIST test suite before using it in the proposed algorithm. A unique combination of feed-forward and feedback mechanisms has been incorporated along with a sequential inter-dependence (through the iterates of the chaotic map) while producing multiple pseudorandom sequences in the proposed image encryption algorithm to produce the desired plaintext, ciphertext and key sensitivities. The algorithm has been analyzed for its performance and security extensively through the most frequent, popular, contemporary and up-to-date quantitative metrics used in the field. The results of our analysis are encouraging and prove the superiority, and robustness of the proposed algorithm against the most common cryptanalytic and statistical attacks.
Data availability statement
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
Author contributions
VP: concept, development of the algorithm and code, and review of the existing work. GK and VP: analysis of the algorithm, interpretation of results, comparison, and writing of the manuscript. All authors contributed to the article and approved the submitted version.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
1. Shannon CE. Communication theory of secrecy systems. Bell Syst Tech J. (1949) 28:656–715. doi: 10.1002/j.1538-7305.1949.tb00928.x
2. Wang Q, Xiong D, Alfalou A, Brosseau C. Optical image encryption method based on incoherent imaging and polarized light encoding. Opt Commun. (2018) 415:56–63. doi: 10.1016/j.optcom.2018.01.018
3. Gopinathan U, Naughton TJ, Sheridan JT. Polarization encoding and multiplexing of two-dimensional signals: application to image encryption. Appl Opt. (2006) 45:5693–700. doi: 10.1364/AO.45.005693
4. Kaur G, Agarwal R, Patidar V. Image encryption using fractional integral transforms: vulnerabilities, threats and future scope. Front Appl Math Statist. (2022) 8:1039758. doi: 10.3389/fams.2022.1039758
5. Singh H, Yadav AK, Vashisth S, Singh K. Double phase-image encryption using gyrator transforms, and structured phase mask in the frequency plane. Opt Lasers Eng. (2015) 67:145–56. doi: 10.1016/j.optlaseng.2014.10.011
6. Hennelly B, Sheridan JT. Optical image encryption by random shifting in fractional Fourier domains. Opt Lett. (2003) 28:269–71. doi: 10.1364/OL.28.000269
7. Unnikrishnan G, Joseph J, Singh K. Optical encryption by double-random phase encoding in the fractional Fourier domain. Opt Lett. (2000) 25:887–9. doi: 10.1364/OL.25.000887
8. Zhou K, Fan J, Fan H, Li M. Secure image encryption scheme using double random-phase encoding and compressed sensing. Opt Laser Technol. (2020) 121:105769. doi: 10.1016/j.optlastec.2019.105769
9. Kaur G, Agarwal R, Patidar V. Color image encryption scheme based on fractional Hartley transform and chaotic substitution–permutation. Vis Comp. (2022) 38:1027–50. doi: 10.1007/s00371-021-02066-w
10. Kaur G, Agarwal R, Patidar V. Color image encryption system using combination of robust chaos and chaotic order fractional Hartley transformation. J King Saud Univ Comp Inf Sci. (2022) 34:5883–97. doi: 10.1016/j.jksuci.2021.03.007
11. Hai H, Pan S, Liao M, Lu D, He W, Peng X. Cryptanalysis of random-phase-encoding-based optical cryptosystem via deep learning. Opt Exp. (2019) 27:21204–13. doi: 10.1364/OE.27.021204
12. Jiao S, Gao Y, Lei T, Yuan X. Known-plaintext attack to optical encryption systems with space and polarization encoding. Opt Exp. (2020) 28:8085–97. doi: 10.1364/OE.387505
13. Song W, Liao X, Weng D, Zheng Y, Liu Y, Wang Y. Cryptanalysis of phase information based on a double random-phase encryption method. Opt Commun. (2021) 497:127172. doi: 10.1016/j.optcom.2021.127172
14. Adleman LM. Molecular computation of solutions of combinatorial problems. Science. (1994) 266:1021–4. doi: 10.1126/science.7973651
15. Clelland CT, Risca V, Bancroft C. Hiding messages in DNA microdots. Nature. (1999) 399:533–4. doi: 10.1038/21092
16. Gehani A, LaBean TH, Reif JH. DNA-based cryptography, DIMACS series in discrete mathematics. Theor Comput Sci. (2000) 54:233–49. doi: 10.1090/dimacs/054/19
17. Xiao GZ, Lu MX, Qin L, Lai XJ. New field of cryptography: DNA cryptography. Chin Sci Bull. (2006) 51:1413–20. doi: 10.1007/s11434-006-2012-5
18. Kang N. A pseudo DNA cryptography. arXiv [Preprint]. Available online at: https://arxiv.org/abs/0903.2693
19. Patidar V, Pareek NK, Purohit G, Sud KK. A robust and secure chaotic standard map based pseudorandom permutation-substitution scheme for image encryption. Opt Commun. (2011) 284:4331–9. doi: 10.1016/j.optcom.2011.05.028
20. Patidar V, Pareek NK, Purohit G, Sud KK. Modified substitution-diffusion image cipher using chaotic standard and logistic maps. Commun Nonlinear Sci Numer Simul. (2010) 15:2755–65. doi: 10.1016/j.cnsns.2009.11.010
21. Patidar V, Pareek NK, Purohit G. A novel quasigroup substitution scheme for chaos based image encryption. J Appl Nonlinear Dyn. (2018) 7:393–412. doi: 10.5890/JAND.2018.12.007
22. Liu H, Wang X. Color image encryption based on one-time keys and robust chaotic maps. Comp Math Appl. (2010) 59:3320–7. doi: 10.1016/j.camwa.2010.03.017
23. Liu H, Wang X. Color image encryption using spatial bit-level permutation and high-dimension chaotic system. Opt Commun. (2011) 284:3895–903. doi: 10.1016/j.optcom.2011.04.001
24. Wang X, Zhang M. An image encryption algorithm based on new chaos and diffusion values of a truth table. Inf Sci. (2021) 579:128–49. doi: 10.1016/j.ins.2021.07.096
25. Teh JS, Alawida M, Sii YC. Implementation and practical problems of chaos-bases cryptography revisited. J Inf Sec Appl. (2020) 50:102421. doi: 10.1016/j.jisa.2019.102421
26. Alvarez G, Li S. Cryptanalyzing a nonlinear chaotic algorithm (NCA) for image encryption. Commun Nonlinear Sci Numer Simul. (2009) 14:3743–9. doi: 10.1016/j.cnsns.2009.02.033
27. Wang X, Liu P. Chaos coupled mapping lattice and its application in privacy image encryption. IEEE Transact Circ Syst I Reg Papers. (2022) 69:1291–301. doi: 10.1109/TCSI.2021.3133318
28. Xue X, Zhou D, Zhou C. New insights into the existing image encryption algorithms based on DNA coding. PLoS ONE. (2020) 15:e0241184. doi: 10.1371/journal.pone.0241184
29. Xue XL, Zhang Q, Wei XP, Guo L, Wang Q. An image fusion encryption algorithm based on DNA sequence and multi-chaotic maps. J Comp Theor Nanosci. (2010) 7:397–403. doi: 10.1166/jctn.2010.1372
30. Zhang Q, Guo L, Wei XP. Image encryption using DNA addition combining with chaotic maps. Math Comput Model. (2010) 52:2028–35. doi: 10.1016/j.mcm.2010.06.005
31. Wei XP, Guoa L, Zhanga Q, Zhang J, Lian S. A novel color image encryption algorithm based on DNA sequence operation and hyper-chaotic system. J Syst Softw. (2012) 85:290–9. doi: 10.1016/j.jss.2011.08.017
32. Liu LL, Zhang Q, Wei X. A RGB image encryption algorithm based on DNA encoding and chaos map. Comp Elect Eng. (2012) 38:1240–8. doi: 10.1016/j.compeleceng.2012.02.007
33. Zhang Q, Wei XP. A novel couple images encryption algorithm based on DNA subsequence operation and chaotic system. Optik. (2013) 124:6276–81. doi: 10.1016/j.ijleo.2013.05.009
34. Kalpana J, Murali P. An improved color image encryption based on multiple DNA sequence operations with DNA synthetic image and chaos. Optik. (2015) 126:5703–9. doi: 10.1016/j.ijleo.2015.09.091
35. Zhen P, Zhao G, Min L, Jin X. Chaos-based image encryption scheme combining DNA coding and entropy. Multimed Tools Appl. (2016) 75:6303–19. doi: 10.1007/s11042-015-2573-x
36. Dagadu JC, Li J, Aboagye EO, Deynu FK. Medical image encryption scheme based on multiple chaos and DNA coding. Int J Netw Sec. (2019) 21:83–90.
37. Wang XY, Wang Y, Zhu XQ, Luo C, A. novel chaotic algorithm for image encryption utilizing one-time pad based on pixel level and DNA level. Opt Lasers Eng. (2020) 125:105851. doi: 10.1016/j.optlaseng.2019.105851
38. Zhang J, Hou DZ, Ren HG, Islam N. Image encryption algorithm based on dynamic DNA coding and Chen's hyperchaotic system. Math Probl Eng. (2016) 126:1–11. doi: 10.1155/2016/6408741
39. Zhang S, Gao TG. An image encryption scheme based on DNA coding and permutation of hyperimage. Multimed Tools Appl. (2016) 75:17157–70. doi: 10.1007/s11042-015-2982-x
40. Mondal B, Mandal TA. light weight secure image encryption scheme based on chaos & DNA computing. J King Saud Univ Comp Inf Sci. (2017) 29:499–504. doi: 10.1016/j.jksuci.2016.02.003
41. Babaei MA. A novel text and image encryption method based on chaos theory and DNA computing. Nat Comput. (2013) 12:101–7. doi: 10.1007/s11047-012-9334-9
42. Rehman A, Liao XF, Ashraf R, Ullah S, Wang HW. A color image encryption technique using exclusiveOR with DNA complementary rules based on chaos theory and SHA-2. Optik. (2018) 159:348–67. doi: 10.1016/j.ijleo.2018.01.064
43. Chen JX, Zhu ZL, Zhang LB, Zhang YS, Yang BQ. Exploiting self-adaptive permutation–diffusion and DNA random encoding for secure and efficient image encryption. Signal Process. (2018) 141:340–53. doi: 10.1016/j.sigpro.2017.07.034
44. Huang X, Ye G. An image encryption algorithm based on hyper-chaos and DNA sequence. Multimed Tools Appl. (2014) 72:57–70. doi: 10.1007/s11042-012-1331-6
45. Liu H, Wang X, Kadir A. Image encryption using DNA complementary rule and chaotic maps. Appl Soft Comput. (2012) 12:1457–66. doi: 10.1016/j.asoc.2012.01.016
46. Enayatifar R, Abdullah AH, Isnin IF. Chaos-based image encryption using a hybrid genetic algorithm and a DNA sequence. Opt Lasers Eng. (2014) 56:83–93. doi: 10.1016/j.optlaseng.2013.12.003
47. Wu X, Kan H, Kurths J. A new color image encryption scheme based on DNA sequences and multiple improved 1D chaotic maps. Appl Soft Comput. (2015) 37:24–39. doi: 10.1016/j.asoc.2015.08.008
48. Chai X, Chen Y, Broyde L, A. novel chaos-based image encryption algorithm using DNA sequence operations. Opt Lasers Eng. (2017) 88:197–213. doi: 10.1016/j.optlaseng.2016.08.009
49. Zhang Y. The image encryption algorithm based on chaos and DNA computing. Multimeda Tools Appl. (2018) 77:21589–615. doi: 10.1007/s11042-017-5585-x
50. Belazi A, Talha M, Kharbech S, Xiang W. Novel medical image encryption scheme based on chaos and DNA encoding. IEEE Access. (2019) 7:36667–81. doi: 10.1109/ACCESS.2019.2906292
51. Chai X, Fu, Gan Z, Lu Y, Chen Y. A color image cryptosystem based on dynamic DNA encryption and chaos. Signal Process. (2019) 155:44–62. doi: 10.1016/j.sigpro.2018.09.029
52. Zhang X, Ye R. A novel RGB image encryption algorithm based on DNA sequences and chaos. Multimed Tools Appl. (2021) 80:8809–33. doi: 10.1007/s11042-020-09465-6
53. Zhou S. A real-time one-time pad DNA-chaos image encryption algorithm based on multiple keys. Opt Laser Technol. (2021) 143:107359. doi: 10.1016/j.optlastec.2021.107359
54. El-Shafai W, Khallaf F, El-Sayed M, El-Rabaie M, Abd El-Samie FE. Robust medical image encryption based on DNA-chaos cryptosystem for secure telemedicine and healthcare applications. J Ambient Intell Human Comp. (2021) 12:9007–35. doi: 10.1007/s12652-020-02597-5
55. Wang J, Zhi X, Chai X, Lu Y. Chaos-based image encryption strategy based on random number embedding and DNA-level self-adaptive permutation and diffusion. Multimed Tools Appl. (2021) 80:16087–122. doi: 10.1007/s11042-020-10413-7
56. Hui Y, Liu H, Fang P, A DNA. image encryption based on a new hyperchaotic system. Multimed Tools Appl. (2021). doi: 10.1007/s11042-021-10526-7
57. Yan X, Wang X, Xian Y. Chaotic image encryption algorithm based on arithmetic sequence scrambling model and DNA encoding operation. Multimed Tools Appl. (2021) 80:10949–83. doi: 10.1007/s11042-020-10218-8
58. El-Khamy SE, Mohamed AG. An efficient DNA-inspired image encryption algorithm based on hyperchaotic maps and wavelet fusion. Multim Tools Appl. (2021) 80:23319–35. doi: 10.1007/s11042-021-10527-6
59. Patidar V, Sud KK, A. novel pseudo random bit generator based on chaotic standard map and its testing. Electron J Theoret Phys. (2009) 6:327–44.
60. Dong E, Yuan M, Du S, Chen Z, A. new class of Hamiltonian conservative chaotic systems with multistability and design of pseudo-random number generator. Appl Math Model. (2019) 73:40–71. doi: 10.1016/j.apm.2019.03.037
61. Rukhin A, Soto J, Nechvatal J, Smid M, Barker E. A statistical test suite for random and pseudorandom number generators for cryptographic applications. In: Special Publication, National Institute of Standards and Technology. Technology Administration U.S. Department of Commerce (2010).
62. Wang Z, Bovik AC, Sheikh HR, Simoncelli EP. Image quality assessment: from error visibility to structural similarity. IEEE Trans Image Process. (2004) 13:600–12. doi: 10.1109/TIP.2003.819861
Keywords: images encryption, conservative chaos, chaotic standard map, DNA coding, chaos-based image encryption, DNA encryption
Citation: Patidar V and Kaur G (2023) A novel conservative chaos driven dynamic DNA coding for image encryption. Front. Appl. Math. Stat. 8:1100839. doi: 10.3389/fams.2022.1100839
Received: 17 November 2022; Accepted: 12 December 2022;
Published: 09 January 2023.
Edited by:
Akif Akgul, Hittite University, TurkeyCopyright © 2023 Patidar and Kaur. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Vinod Patidar,  cGF0aWRhci52aW5vZEBnbWFpbC5jb20=; dmlub2QucGF0aWRhckBzcHN1LmFjLmlu
cGF0aWRhci52aW5vZEBnbWFpbC5jb20=; dmlub2QucGF0aWRhckBzcHN1LmFjLmlu
†ORCID: Vinod Patidar orcid.org/0000-0002-1270-3454
Gurpreet Kaur orcid.org/0000-0002-2611-5143