 Srinjoy Das
Srinjoy Das Hrushikesh N. Mhaskar
Hrushikesh N. Mhaskar Alexander Cloninger
Alexander Cloninger- 1School of Mathematical and Data Sciences, West Virginia University, Morgantown, WV, United States
- 2Institute of Mathematical Sciences, Claremont Graduate University, Claremont, CA, United States
- 3Department of Mathematics and Hagiğolou Data Science Institute, University of California, San Diego, San Diego, CA, United States
This paper introduces kdiff, a novel kernel-based measure for estimating distances between instances of time series, random fields and other forms of structured data. This measure is based on the idea of matching distributions that only overlap over a portion of their region of support. Our proposed measure is inspired by MPdist which has been previously proposed for such datasets and is constructed using Euclidean metrics, whereas kdiff is constructed using non-linear kernel distances. Also, kdiff accounts for both self and cross similarities across the instances and is defined using a lower quantile of the distance distribution. Comparing the cross similarity to self similarity allows for measures of similarity that are more robust to noise and partial occlusions of the relevant signals. Our proposed measure kdiff is a more general form of the well known kernel-based Maximum Mean Discrepancy distance estimated over the embeddings. Some theoretical results are provided for separability conditions using kdiff as a distance measure for clustering and classification problems where the embedding distributions can be modeled as two component mixtures. Applications are demonstrated for clustering of synthetic and real-life time series and image data, and the performance of kdiff is compared to competing distance measures for clustering.
1 Introduction and Motivation
Clustering and classification tasks in applications such as time series and image processing are critically dependent on the distance measure used to identify similarities in the available data. Distance measures are named as such because they may not satisfy all assumptions of a metric (e.g., they may induce equivalence classes of time series that are distance zero from one another, they may not satisfy the triangle inequality). In such contexts, several distance measures have been proposed in the literature:
• Point-to-point matching e.g. Euclidean distance or Dynamic Time Warping distance [1, 2]
• Matching features of the series e.g. autocorrelation coefficients [3], Pearson correlation coefficients [4], periodograms [5], extreme value behavior [6]
• Number of matching subsequences in the series [7]
• Similarity of embedding distributions of the series [8]
In this paper we consider distance measures for applications involving clustering, classification and related data mining tasks in time series, random fields and other forms of possibly non i. i.d data. In particular, we focus on problems where membership in a specific class is characterized by instances matching only over a portion of their region of support. In addition, the regions where such feature matching occurs may not be overlapping in time, or on the underlying grid of the random field. Distance measures must take these data characteristics into consideration when determining similarity in such applications. Previously MPdist has been proposed as a distance measure for such time series datasets [7] which match only over part of their region of support and is constructed using Euclidean metrics. Inspired by MPdist, we propose a new kernel-based distance measure kdiff for estimating distances between instances of such univariate and multivariate time series, random field and other types of structured data.
For constructing kdiff, we first create sliding window based embeddings over the given time series or random fields. We then estimate a distance distribution by using a kernel-based distance measure between such embeddings over given pairs of data instances. Finally the distance measure used in clustering, classification and related tasks is defined by a pre-specified lower quantile of this distance distribution. This kernel-based distance measure based on such embeddings can also be constructed using the Reproducing Kernel Hilbert Space (RKHS) based Maximum Mean Discrepancy (MMD) previously discussed in [9]. Our kernel based measure kdiff can be considered as a more general distance compared to RKHS MMD for applications where class instances match only over a part of the region of support. More details about the connections between kdiff and RKHS MMD are provided later in the paper. We also note that the kernel construction in kdiff allows for data-dependent kernel construction similar to MMD [10–12], though we focus on isotropic localized kernels in this work and compare to standard MMD.
The rest of the paper is organized as follows. Section 2 outlines the main idea and motivation behind the construction of our distance measure kdiff. Section 2 also outlines some theoretical results for separability of data using kdiff as a distance measure for clustering, classification and related tasks by modeling the embedding distributions derived from the original data as two component mixtures. Section 3 outlines some practical considerations and data-driven strategies to determine optimal parameters for the algorithm to estimate kdiff. Section 4 presents simulation results using kdiff on both synthetic and real-life datasets and compares them with existing methods. Finally Section 5 outlines some conclusions and directions for future work.
2 Main Idea
2.1 Overview
Consider two real-valued datasets
A distance measure that has been proposed previously to determine similarity between two such time series embedded point clouds constructed over
In [7], the distance measure MPdist was estimated for univariate time series by choosing the kth smallest element in the set D2. In general, MPdist can be constructed using a lower quantile of the distance distribution D2.
Our proposed distance measure kdiff generalizes MPdist using a kernel-based construction, and by considering both cross-similarity and self-similarity. Similar to MPdist, we first construct sliding window based embeddings over the original data instances
• We use a kernel based similarity measure over the obtained sliding window based embeddings X and Y for kdiff instead of the Euclidean metric used in MPdist.
• For kdiff the final distance is estimated based on both self and cross-similarities between the embeddings X, Y respectively. The inclusion of self-similarity in the construction of kdiff as compared to only cross-similarity for MPdist leads to better clustering performance for data with reduced signal-to-noise ratio of the matching region versus the background. This is demonstrated empirically for both synthetic and real-life data in Section 4.
2.2 The Construction of kdiff
To define our kdff statistic, we will begin with a discussion of general distributions defined on
In general, we can define the distributions on
and similarly the magnitude of the witness function
In the context of defining a distance between μ1, μ2, we take τ = μ1 − μ2, which results in a witness function
To quantify where T (μ1 − μ2) is small, we define the cumulative distribution function (CDF) of a Borel measurable function
and its “inverse” CDF by
Both Λ(f) and f# are non-decreasing functions, and f#(u) defines the u-th quartile of f.
Finally, we are prepared to define our kdiff distance between probability measures μ1, μ2. Having defined T (μ1 − μ2) (z), we now define kdiff to be the α quantile of T (μ1 − μ2),
The intuition of (6) is that, if μ1 = μ2, the resulting kdiff statistic will be zero. But beyond this, if T (μ1 − μ2) (z) = 0 for a set
2.3 Separability Theorems for kdiff
For the purposes of analyzing the kdiff statistic, we will focus on the setting of resolving mixture models of probabilities on
We first present some preparatory material before reaching our desired statements. For any subset
The support of a finite positive measure μ, denoted by
The following lemma summarizes some important but easy properties of quantities Λ(f) and f# defined in Eqs. 4, 5 respectively.
Lemma 1. (a) For t, u ∈ [0, ∞),
(b) If ϵ > 0,
Our goal is to investigate sufficient conditions on two measures in
Theorem 2. Let
a) If η > 0 and μ1,F = μ2,F then for any α ≤ ϕB(η), we have kdiff (μ1, μ2; α) ≤ (1 − δ)η.
b) If η > 0 such that
Proof. To prove part (a), we observe that since μ1,F = μ2,F, T(μ1 − μ2) (z) = (1 − δ) ⋅ T(μ1,B − μ2,B) (z) for all
Therefore, ϕB(η) ≤ Λ(T (μ1 − μ2)) ((1 − δ)η). In view of (8), this proves part (a).
To prove part (b), we will write
Our hypothesis that ϕF(θ) < 1 means that μ1,F ≠ μ2,F and
Moreover, for
Note that because
This means that Λ(T (μ1 − μ2)) (2 (1 − δ)η) ≤ 1 − ψ(θ, η). Since α ≥ 1 − ψ(θ, η), this estimate together with (8) leads to the conclusion in part (b).
We wish to comment on the practicality of the constants
We consider the results of Theorem 2 in the well-separated setting with
a)
b) Because of the well-separated assumption,
Thus we can choose η, θ as large as possible to satisfy the assumptions, and even then for very small quantiles α > ξ we kdiff (μ1, μ2; α) > 2 (1 − δ)η.
These above descriptions clarify the theorem in the simplest setting. When the foreground distributions are small but concentrated, and far from the separate backgrounds, then the hypothesis of
In practice, of course, we need to estimate kidff (μ1, μ2; α) from samples taken from μ1 and μ2. In turn, this necessitates an estimation of the witness function of probability measure from samples from this probability. We need to do this separately for μ1 and μ2, but it is convenient to formulate the result for a generic probability measure μ. To estimate the error in the resulting approximation, we need to stipulate some further conditions enumerated below. We will denote by
Essential compact support For any t > 0, there exists R(t) > 0 such that
Covering property For t > 0, let
Lipschitz condition We have
Then Höffding’s inequality leads to the following theorem.
Theorem 3. Let ϵ > 0, M ≥ 2 be an integer, and μ be any probability measure on
The proof of Theorem 3 mirrors the results for the witness function in [14].
2.4 Conclusions From Separability Theorems
To illustrate the benefit of the above theory, we recall the MMD distance measure between two probability measures μ1 and μ2 defined by
When
Since K is a positive definite kernel, it is thus impossible for MMD2 (μ1, μ2) = 0 unless μ1,B = μ2,B. One of the motivations for our construction is to devise a test statistic that can be arbitrarily small even if μ1,B ≠ μ2,B.
The results derived above provide certain insights regarding when it is possible to perform tasks such as clustering and classification of data using distance measures such as kdiff and MMD based on the characteristics of their foreground and background distributions. The results in Theorem 2 show that, provided the backgrounds are sufficiently separated, the kdiff statistic will be significantly smaller when μ1,F = μ2,F than when μ1,F and μ2,F are separated.
This enables kdiff to perform accurate discrimination i.e. data belonging to the same class will be clustered correctly in this case. On the other hand, it is clear that even if μ1,F = μ2,F, MMD2 (μ1, μ2) will still be highly dependent on the backgrounds. In this paper we consider the case where data instances belonging to the same class have the same foreground but different background distributions. In such situations using synthetic and real life examples we demonstrate the comparative performance and effectiveness of kdiff for clustering tasks versus other distance measures including MMD.
As a final note, we wish to mention the relationship between MMD and kdiff. It can be shown that MMD2 is the mean of the witness function with respect to
3 Estimation of Algorithm Parameters
The following parameters are required for estimation of the distance measure kdiff:
• Length of sliding window SL used to generate subsequences over given data (embedding dimension)
• Kernel bandwidth (σ) of the Gaussian kernel
• Lower quantile α of the kernel-based distance distribution T(z)
Determining SL:
In this paper we demonstrate the application of kdiff for clustering time series and random fields. The sliding window length SL is used to create subsequences (i.e. sliding window based embeddings) over such time series or random fields over which kdiff is estimated. The number of subsequences formed depend on SL, the number of points in the time series or random field and the dimensionality of the data under consideration. Some examples are given as below:
• In case of a univariate time series of length n if each subsequence is of length L = SL then there are m = n − SL + 1 embeddings
• For a two dimensional n x n random field if each subsequence has dimension L = SL ∗ SL then there are m = (n − SL + 1)2 embeddings
• For a p-variate time series if each subsequence is of length L = p ∗ SL then there are m = n − L + 1 embeddings
The distance measure kdiff is estimated over these m points in the L dimensional embedding space. It is necessary to determine an optimal value of SL to obtain accurate values of kdiff. Very small values of SL may result in erroneous identification of the region where the time series or random field under consideration match. For example embeddings obtained in this manner may result in two dissimilar time series containing noise related fluctuations over a small region identified as “matching”. On the other hand very high values of SL can lead to erroneous estimation of the distance distribution owing to less number of subsequences or sub-regions which results in incorrect estimates for kdiff. As an optimal tradeoff between these competing considerations we determine the value of SL based on the best clustering performance over a training set selected from the original data.
Determining σ: Since kdiff is a kernel-based similarity measure determination of the kernel bandwidth σ is critical to the accuracy of estimation. In this case very small bandwidths for sliding window based embeddings X and Y derived from two corresponding time series or random fields can lead to incorrect estimates since only points in the immediate neighborhood of embeddings X and Y are considered in the estimation of the kdiff statistic. On the other hand very large bandwidths are also problematic since in this case any point Z becomes nearly equidistant from X and Y (here all points are considered in the embedding space), thereby causing the distance measure to lose sensitivity. To achieve a suitable tradeoff between these extremes we select σ over a range of values of order equal to the k nearest neighbor distance over all points in the embedding space of Z = X ∪ Y for a suitably chosen value of k. The optimal value of σ is selected from this range based on the best clustering performance over a training set selected from the original data.
Determining α: The distance measure kdiff is based on a lower quantile α of the estimated distance distribution over the embedding spaces of two time series or random fields. This quantile can be specified as a fraction of the total number of points in the distance distribution using either of the following methods below:
• Based on exploratory data analysis, visual inspection or other methods if the extent of the matching portions of the time series, random fields or other data under investigation can be determined then α can be set as a fraction of the length or area of this matching region versus the overall span of the data.
• For high dimensional time series or random fields α can be determined from a range of values based on the best clustering performance over a training set selected from the original data.
4 Numerical Work: Simulations and Real Data
The effectiveness of the our novel distance measure kdiff for comparing two sets of data which match only partially over their region of support is estimated using kmedoids clustering [16]. The kmedoids algorithm is a similar partitional clustering algorithm as kmeans which works by minimizing the distance between the points belonging to a cluster and the center of the cluster. However kmeans can work only with Euclidean distances or a distance measure which can be directly expressed in terms of Euclidean for example the cosine distance. In contrast the kmedoids algorithm can work with non Euclidean distance measures such as kdiff and is also advantageous because the obtained cluster centers belong to one of the input data points thereby leading to greater interpretability of the results. For these reasons in this paper we consider kmedoids clustering with k = 2 classes and measure the accuracy of clustering for distance measures kdiff, MMD [9], MPdist [7] and dtw [1, 2] over synthetic and real time series and random field datasets as described in the following sections. Suitably chosen combinations of the parameters can be specified as described in Section 3 and the derived optimal values can then be used for measuring clustering performance with the test data using kdiff. Similar to kdiff, distances measures using Maximum Mean Discrepancy (MMD) and MPdist are computed by first creating subsequences over the original time series or random fields. In both these cases the length of the sliding window SL is determined based on the best clustering performance over a training set selected from the original data. Additionally for MMD which is also a kernel-based measure we determine the optimal kernel bandwidth (σ) based on training.
In this work we consider two synthetic and one real-life datasets for measuring clustering performance with four distance measures kdiff, MMD, MPdist and dtwd (Dynamic Time Warping distance). For the synthetic datasets we generate the foregrounds and backgrounds as described in Section 2.3 using autoregressive models of order p, denoted as AR(p). These are models for a time series Wt generated by
where ϕ1, … , ϕp are the p coefficients of the AR(p) model and ϵt can be i. i.d. Gaussian errors. We perform 50 Monte Carlo runs over each dataset and in each run we randomly divide the data into training and test sets. For each set of training data we determine the optimal values of the algorithm parameters based on the best clustering performance. Following this we use these parameter values on the test data in each of the 50 runs. The final performance metric for a given distance measure is given by the total number of clustering errors for the test data over all 50 runs. The dtwclust package [17] of R 3.6.2 has been used for implementation of the kmedoids clustering algorithm and to evaluate the results of clustering.
As a techincal note, as MPdist and MMD are generally computed as squared distances, we similarly work with
4.1 Simulation: Matching Sub-regions in Univariate Time Series
Data Yi for i = 1, 2, … , 1,000 are simulated using the model (15). To generate this the series Wi are constructed via an AR (5) model driven by i. i.d errors
Following this we form a background dataset
Next we generate a dataset XF consisting of 2 foregrounds XFA and XFB which enable forming the 2 classes to be considered for k-medoids clustering as follows. For foreground XFA data Yi for i = 1, 2, … , 50 are simulated using the model (15). The series Wi is constructed via an AR (1) model driven by i. i.d errors
Finally the dataset used for clustering Zij where i = 1, 2, … , 1,000 and j = 1, 2, … , 21 is formed by mixing backgrounds XB and foregrounds XF as follows:
The dataset Zij formed in this manner consists of two types of subregions (foregrounds) which define the two classes used for k-medoids clustering. We perform 50 random splits of the dataset Zij where each split consists of a training set of size 10 and a test set of size 11. The results for clustering are shown for the 4 distance measures in Table 1.

TABLE 1. Clustering Performance for Univariate Time Series dataset with τ = 1
From the results it can be seen that both kdiff and MPdist produce the best clustering performance with 0 errors for this dataset. This is attributed to the fact that the subregions of interest are well defined for both classes and using suitable values of parameters determined from training it is possible to accurately cluster all the time series data into two separate groups. On the other hand the performance of MMD is inferior to both kdiff and MPdist because the backgrounds are well separated with different mean values for time series within and across the two classes. This results in time series even belonging to the same class to be placed in separate clusters when MMD is used as a distance measure. Similarly dtwd suffers from poor performance as this distance measure tends to place time series with smaller separation between the mean background values in the same cluster. However these may have distinct values for the foregrounds i.e., they can in general belong to different classes and as a result this causes errors during clustering.
Noise robustness We explore the performance of the distance measures by considering noisy foregrounds. For foreground XFA data Yi for i = 1, 2, … , 50 are simulated using the model (15). The series Wi is constructed via an AR (1) model driven by i. i.d errors
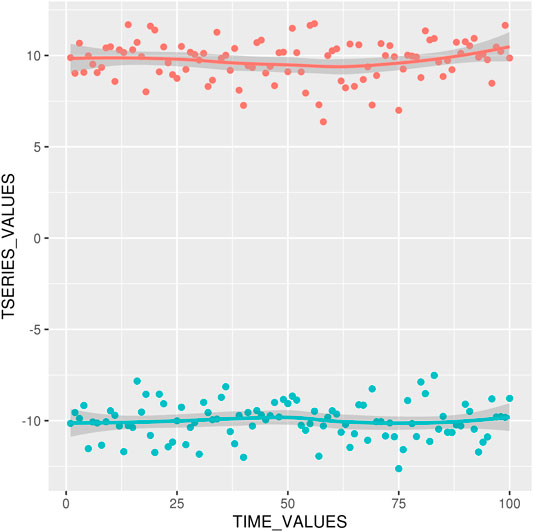
FIGURE 1. Foreground Time Series Realization with mean = 10, − 10 for τ = 1
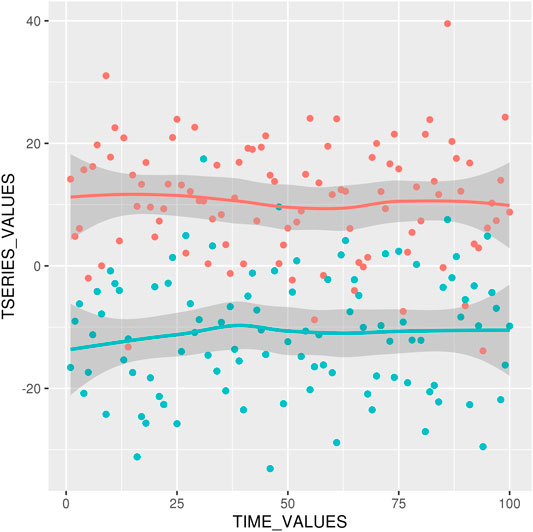
FIGURE 2. Foreground Time Series Realizations with mean = 10, − 10 for τ = 10.
The results for clustering using these noisy foregrounds are shown in Table 2. The data shows empirically that as the noise level of the foreground increases kdiff is more resilient and performs better than MPdist. This is because after constructing sliding window based embeddings over the original data, MPdist is computed using Euclidean metric based cross-similarities between the embeddings whereas kdiff is estimated using kernel based self and cross similarities over the embeddings.
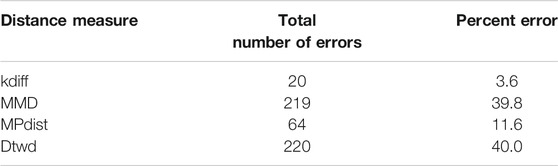
TABLE 2. Clustering Performance for Univariate Time Series dataset with τ = 10
4.2 Simulation: Matching Sub-regions in 3-Dimensional Time Series in Spherical Coordinates
We generate a 3d multivariate background dataset sB as follows. Data
Following the generation of Wi values for the data Y = (Ya, Yb) we form a background dataset
Our next step involves transforming these 21 instances of the 2d backgrounds into a 3d spherical surface of radius 1 as described in the following steps. We first map each series Ya and Yb linearly into the region [0, π/2]. The corresponding mapped series are denoted as
Next we generate a 3d foreground dataset sF consisting of 2 foregrounds sFA and sFB which will enable forming the 2 classes to be considered for k-medoids clustering as follows. Data
Finally the dataset used for clustering Zij where i = 1, 2, … , 1,000 and j = 1, 2, … , 21 is formed by mixing backgrounds sB and foregrounds sF as follows:
The dataset Zij formed in this manner consists of two types of subregions (foregrounds) which define the two classes used for k-medoids clustering. An illustration of the data on such a spherical surface with 5 backgrounds and 2 foregrounds is shown in Figure 3.
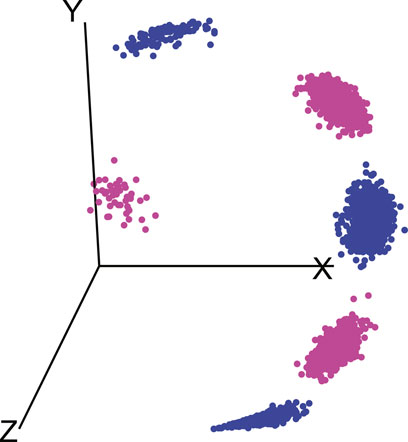
FIGURE 3. Illustration of data consisting of 5 backgrounds and 2 foregrounds on a spherical surface, similar colors indicate association of foregrounds with respective backgrounds.
We perform 50 random splits of the dataset Zij where each split consists of a training set of size 10 and a test set of size 11. The results for clustering are shown for the 4 distance measures in Table 3.
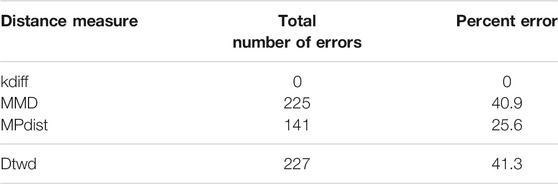
TABLE 3. Clustering Performance for 3d Multivariate Time Series dataset.
From the results it can be seen that kdiff produces the best clustering performance with 0 errors for this dataset. This is attributed to the fact that the subregions of interest are well defined for both classes and using suitable values of parameters determined from training it is possible to accurately cluster all the time series data into two separate groups. On the other hand the performance of MMD is inferior to kdiff because the backgrounds are well separated with different mean values for time series within and across the two classes. This results in time series even belonging to the same class to be placed in separate clusters when MMD is used as a distance measure. Similarly dtwd suffers from poor performance as this distance measure tends to put time series with smaller separation between the mean background values in the same cluster. However these may have distinct values for the foregrounds i.e. they can in general belong to different classes and as a result this causes errors during clustering. For this dataset the performance of MPdist is inferior to kdiff even though the former can find matching sub-regions with zero errors in the case of univariate time series. This difference is attributed to the nature of the spherical region over which the sub-region matching is done where the 1-nearest neighbor strategy employed by MPdist using Euclidean metrics to construct the distance distribution. In case of spherical surfaces it is necessary to use appropriate geodesic distances for nearest neighbor search as discussed in ([18]). This issue is resolved in kdiff which can find the matching subregion over a non Euclidean region which in this case is a spherical surface thereby giving the most accurate clustering results for this dataset.
4.3 Real Life Example: MNIST-M Dataset
The MNIST-M dataset used in [19, 20] was selected as a real-life example to demonstrate the differences in clustering performance using the four distance measures kdiff, MMD, MPdist and dtwd. The MNIST-M dataset consists of MNIST digits [21] which are difference blended over patches selected from the BSDS500 database of color photos [22]. In our experiments where we consider k-medoid clustering over k = 2 classes we select 10 instances each of the MNIST digits 0 and 1 to be blended with a selection of background images to form our dataset MNIST-M-1. Since BSDS500 is a dataset of color images the components of this dataset are random fields whose dimensions are 28 × 28 × 3. We form our final dataset for clustering consisting of random fields with dimensions 28 × 28 by averaging over all three channels. Examples of individual zero and one digits on different backgrounds for all three channels of MNIST-M-1 are shown in Figures 4–7.

FIGURE 4. Example 1 of MNIST-M-1 digit zero.
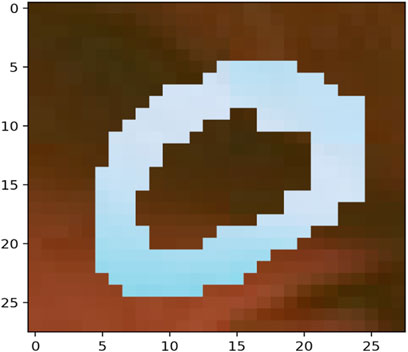
FIGURE 5. Example 2 of MNIST-M-1 digit zero.

FIGURE 6. Example 1 of MNIST-M-1 digit one.
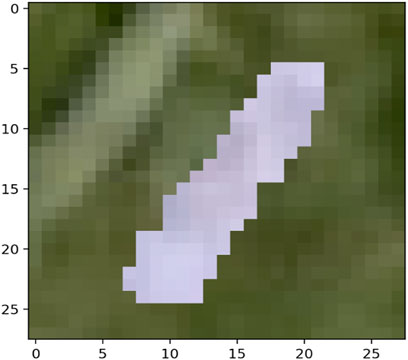
FIGURE 7. Example 2 of MNIST-M-1 digit one.
We perform 50 random splits of the dataset where each split consists of a training set of size 10 and a test set of size 10. The results for clustering are shown for the distance measures in Table 4.
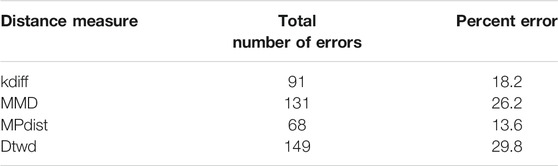
TABLE 4. Clustering performance for MNIST-M-1.
From the results it can be seen that for MNIST-M-1 MPdist somewhat outperforms our proposed distance measure kdiff however the latter is superior to both MMD and dtwd. Since in general the background statistics of the MNIST-M images are different, two images belonging to the same class can be placed in separate clusters when MMD is used as a distance measure and this causes MMD to underperform versus kdiff. Similarly dtwd suffers from poor performance as this distance measure tends to put images with smaller separation between the mean background values in the same cluster. However these may have distinct values for the foregrounds i.e. they can in general belong to different classes and as a result this causes errors during clustering.
Noise robustness Following the discussion in Section 4.1 we explore the performance of the distance measures by considering a selection of noisy backgrounds from the BSDS500 database over which the same 10 instances of the MNIST digits 0 and 1 are blended to form a second version of our dataset called MNIST-M-2. Similar to the earlier case we form our final dataset for clustering consisting of random fields with dimensions 28 × 28 by averaging over all three channels of the color image. Examples of individual zero and one digits on different backgrounds for a single channel are shown in Figures 8–11. Note that these correspond to the same MNIST digits shown in Figures 4–7 however are blended with different backgrounds which have been chosen such that the distinguishability of the two classes is reduced.
FIGURE 8. Example 1 of MNIST-M-2 digit zero.

FIGURE 9. Example 2 of MNIST-M-2 digit zero.
FIGURE 10. Example 1 of MNIST-M-2 digit one.
FIGURE 11. Example 2 of MNIST-M-2 digit one.
We use the Kolmogorov-Smirnov (KS) test statistic to characterize the differences between the backgrounds (BSDS500 images) and the foregrounds (MNIST digits 0 and 1) as below:
• The mean KS statistic between the distribution of the pixels where a digit 0 is present and the distribution of the pixel values which make up the background (KS-bg-fg-0)
• The mean KS statistic between the distribution of the pixels where a digit 1 is present and the distribution of the pixel values which make up the background (KS-bg-fg-1)
• The mean KS statistic between pairs of distributions which make up the corresponding backgrounds (KS-bg)
The KS values shown in Table 5 confirm our visual intuition that the distinguishability of the foreground (MNIST 0 and 1 digits) and the background is less for MNIST-M-2 as compared to MNIST-M-1. Additionally it can be seen that for the noisier dataset MNIST-M-2 the separation between the background distribution of pixels is less than that of MNIST-M-1.

TABLE 5. KS statistic for MNIST-M foregrounds and backgrounds.
We perform 50 random splits of the dataset Z where each split consists of a training set of size 10 and a test set of size 10. The results for clustering are shown for the distance measures in Table 6.
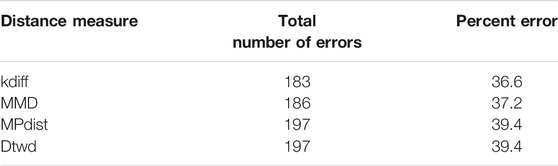
TABLE 6. Clustering performance for MNIST-M
From the results it can be seen that for this noisy dataset the clustering accuracy results for all four distance measures are lower as expected, however kdiff slightly outperforms MPdist. As discussed in Section 4.1 this can be attributed to the fact that in such cases with a lower signal to noise ratio between the foreground and the background kdiff which is estimated using kernel based self and cross similarities over the embeddings can outperform MPdist which is computed using only Euclidean metric based cross-similarities over the embeddings. The expected noise characterizaion is confirmed by our KS statistic values of KS-bg-fg-0 and KS-bg-fg-1 in Table 6. Moreover the lower values of the KS statistic value KS-bg for MNIST-M-2 compared to MNIST-M-1 manifest in similar clustering performances of MMD and kdiff for MNIST-M-2 in contrast with the trends for MNIST-M-1.
Additional comments: For kdiff we used L = SL ∗ SL windows for capturing the image sub-regions leading to (n − SL + 1)2 embeddings which were subsequently “flattened” to form subsequences of size L = SL2 over which kdiff was estimated using a one dimensional Gaussian kernel. This process can be augmented by estimating kdiff with two dimensional anisotropic Gaussian kernels to improve performance. However this augmented method of kdiff estimation using a higher dimensional kernel with more parameters will significantly increase the computation time and implementation complexity. Note that in the case of MPdist flattening the subregion is not as much of an issue since it does not use kernel based estimations which need accurate bandwidths.
5 Conclusions and Future Work
In this work we have proposed a kernel-based measure kdiff for estimating distances between time series, random fields and similar univariate or multivariate and possibly non-iid data. Such a distance measure can be used for clustering and classification in applications where data belonging to a given class match only partially over their region of support. In such cases kdiff is shown to outperform both Maximum Mean Discrepancy and Dynamic Time Warping based distance measures for both synthetic and real-life datasets. We also compare the performance of kdiff which is constructed using kernel-based embeddings over the given data versus MPdist which uses Euclidean distance based embeddings. In this case we empirically demonstrate that for data with high signal-to-noise ratio between the matching region and the background both kdiff and MPdist perform equally well for synthetic datasets and MPdist somewhat outperforms kdiff for real life MNIST-M data. For data where the foreground is less distinguishable versus the background kdiff outperforms MPdist for both synthetic and real-life datasets. Additionally for multivariate time series on a spherical manifold we show that kdiff outperforms MPdist because of its kernel-based construction which leads to superior performance in non Euclidean spaces. Our future work will focus on application of kdiff for applications on spherical manifolds such as text embedding [23] and hyperspectral imagery [18, 24] as well as clustering and classification applications for time series and random fields with noisy motifs and foregrounds.
Data Availability Statement
Publicly available datasets were analyzed in this study. This data can be found here: Ganin et al., 2016 [19].
Author Contributions
SD and AC contributed to conception and design. All authors contributed to the theory. SD performed the computation and analysis, and wrote the first draft of the manuscript. All authors contributed to the manuscript revision.
Funding
This work was supported in part by the NSF awards CNS1730158, ACI-1540112, ACI-1541349, OAC-1826967, the University of California Office of the President, and the California Institute for Telecommunications and Information Technology’s Qualcomm Institute (Calit2-QI). SD was partially supported by an Intel Sponsored Research grant. AC was supported by NSF awards 1819222, 2012266, Russel Sage Founation 2196, and an Intel Sponsored Research grant. HM is supported in part by NSF grant DMS 2012355 and ARO Grant W911NF2110218.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Acknowledgments
Thanks to CENIC for the 100Gpbs networks. The authors thank Siqiao Ruan for helpful discussions.
References
1. Ratanamahatana, CA, and Keogh, E. Everything You Know about Dynamic Time Warping Is Wrong. In: Third Workshop on Mining Temporal and Sequential Data, Vol. 32, Seattle. Citeseer (2004).
2. Keogh, E, and Ratanamahatana, CA. Exact Indexing of Dynamic Time Warping. Knowl Inf Syst (2005) 7(3):358–86. doi:10.1007/s10115-004-0154-9
3. D’Urso, P, and Maharaj, EA. Autocorrelation-based Fuzzy Clustering of Time Series. Fuzzy Sets Syst (2009) 160(24):3565–89.
4. Golay, X, Kollias, S, Stoll, G, Meier, D, Valavanis, A, and Boesiger, P. A New Correlation-Based Fuzzy Logic Clustering Algorithm for Fmri. Magn Reson Med (1998) 40(2):249–60. doi:10.1002/mrm.1910400211
5. Alonso, AM, Casado, D, López-Pintado, S, and Romo, J. Robust Functional Supervised Classification for Time Series. J Classif (2014) 31(3):325–50. doi:10.1007/s00357-014-9163-x
6. D’Urso, P, Maharaj, EA, and Alonso, AM. Fuzzy Clustering of Time Series Using Extremes. Fuzzy Sets Syst (2017) 318:56–79.
7. Gharghabi, S, Imani, S, Bagnall, A, Darvishzadeh, A, and Keogh, E. Matrix Profile Xii: Mpdist: A Novel Time Series Distance Measure to Allow Data Mining in More Challenging Scenarios. In: 2018 IEEE International Conference on Data Mining (ICDM). IEEE (2018). p. 965–70. doi:10.1109/icdm.2018.00119
8. Brandmaier, AM. Permutation Distribution Clustering and Structural Equation Model Trees. CRAN (2011).
9. Gretton, A, Borgwardt, KM, Rasch, MJ, Schölkopf, B, and Smola, A. A Kernel Two-Sample Test. J Machine Learn Res (2012) 13:723–73.
10. Gretton, A, Sejdinovic, D, Strathmann, H, Balakrishnan, S, Pontil, M, Fukumizu, K, et al. Optimal Kernel Choice for Large-Scale Two-Sample Tests. In: Advances in Neural Information Processing Systems. Citeseer (2012). p. 1205–13.
11. Szabo, Z, Chwialkowski, K, Gretton, A, and Jitkrittum, W. Interpretable Distribution Features with Maximum Testing Power. In: Proceedings of the 30th International Conference on Neural Information Processing Systems. IEEE (2016).
12. Cheng, X, Cloninger, A, and Coifman, RR. Two-sample Statistics Based on Anisotropic Kernels. Inf Inference: A J IMA (2020) 9(3):677–719. doi:10.1093/imaiai/iaz018
13. Bandt, C, and Pompe, B. Permutation Entropy: a Natural Complexity Measure for Time Series. Phys Rev Lett (2002) 88(17):174102. doi:10.1103/physrevlett.88.174102
14. Mhaskar, HN, Cheng, X, and Cloninger, A. A Witness Function Based Construction of Discriminative Models Using Hermite Polynomials. Front Appl Math Stat (2020) 6:31. doi:10.3389/fams.2020.00031
15. Cloninger, A. Bounding the Error from Reference Set Kernel Maximum Mean Discrepancy. arXiv preprint arXiv:1812.04594 (2018).
16. Kaufmann, L, and Rousseeuw, P. Clustering by Means of Medoids. In: Proc. Statistical Data Analysis Based on the L1 Norm Conference. Neuchatel (19871987). p. 405–16.
17. Sardá-Espinosa, A. Comparing Time-Series Clustering Algorithms in R Using the Dtwclust Package. R Package Vignette (2017) 12:41.
18. Lunga, D, and Ersoy, O. Spherical Nearest Neighbor Classification: Application to Hyperspectral Data. In: International Workshop on Machine Learning and Data Mining in Pattern Recognition. Springer (2011). p. 170–84. doi:10.1007/978-3-642-23199-5_13
19. Ganin, Y, Ustinova, E, Ajakan, H, Germain, P, Larochelle, H, Laviolette, F, et al. Domain-adversarial training of neural networks, J Machine Learn Res 17(1), pp. 2096 (2030, 2016).
20. Haeusser, P, Frerix, T, Mordvintsev, A, and Cremers, D. Associative Domain Adaptation. In: Proceedings of the IEEE International Conference on Computer Vision. IEEE (2017). p. 2765–73. doi:10.1109/iccv.2017.301
21. LeCun, Y, Bottou, L, Bengio, Y, and Haffner, P. Gradient-based Learning Applied to Document Recognition. Proc IEEE (1998) 86(11):2278–324. doi:10.1109/5.726791
22. Arbeláez, P, Maire, M, Fowlkes, C, and Malik, J. Contour Detection and Hierarchical Image Segmentation. IEEE Trans Pattern Anal Mach Intell (2010) 33(5):898–916. doi:10.1109/TPAMI.2010.161
23. Meng, Y, Huang, J, Wang, G, Zhang, C, Zhuang, H, Kaplan, L, et al. Spherical Text Embedding. In: Advances in Neural Information Processing Systems. Springer (2019). p. 8208–17.
Keywords: Kernels, time series, statistical distances, random fields, Motif detection
Citation: Das S, Mhaskar HN and Cloninger A (2021) Kernel Distance Measures for Time Series, Random Fields and Other Structured Data. Front. Appl. Math. Stat. 7:787455. doi: 10.3389/fams.2021.787455
Received: 30 September 2021; Accepted: 16 November 2021;
Published: 22 December 2021.
Edited by:
Yiming Ying, University at Albany, United StatesReviewed by:
Xin Guo, Hong Kong Polytechnic University, Hong Kong SAR, ChinaYunwen Lei, Southern University of Science and Technology, China
Copyright © 2021 Das, Mhaskar and Cloninger. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Srinjoy Das, c3JpbmpveS5kYXNAbWFpbC53dnUuZWR1