 Jérémy Magnanensi1,2
Jérémy Magnanensi1,2 Frédéric Bertrand
Frédéric Bertrand- 1IRMA, CNRS UMR 7501, Labex IRMIA, Université de Strasbourg and CNRS, Strasbourg, France
- 2Laboratoire de Biostatistique et Informatique Médicale, Faculté de Médecine, EA3430, Université de Strasbourg and CNRS, Strasbourg, France
- 3LIST3N, Université de Technologie de Troyes, Troyes, France
Methods based on partial least squares (PLS) regression, which has recently gained much attention in the analysis of high-dimensional genomic datasets, have been developed since the early 2000s for performing variable selection. Most of these techniques rely on tuning parameters that are often determined by cross-validation (CV) based methods, which raises essential stability issues. To overcome this, we have developed a new dynamic bootstrap-based method for significant predictor selection, suitable for both PLS regression and its incorporation into generalized linear models (GPLS). It relies on establishing bootstrap confidence intervals, which allows testing of the significance of predictors at preset type I risk α, and avoids CV. We have also developed adapted versions of sparse PLS (SPLS) and sparse GPLS regression (SGPLS), using a recently introduced non-parametric bootstrap-based technique to determine the numbers of components. We compare their variable selection reliability and stability concerning tuning parameters determination and their predictive ability, using simulated data for PLS and real microarray gene expression data for PLS-logistic classification. We observe that our new dynamic bootstrap-based method has the property of best separating random noise in y from the relevant information with respect to other methods, leading to better accuracy and predictive abilities, especially for non-negligible noise levels.
1. Introduction
Partial least squares (PLS) regression, introduced by [1], is a well-known dimension-reduction method, notably in chemometrics and spectrometric modeling [2]. In this paper, we focus on the PLS univariate response framework, better known as PLS1. Let n be the number of observations and p the number of covariates. Then,
where
with the constraint
The final regression model is thus:
with
This particular regression technique, based on reductions in the original dimension, avoids matrix inversion and diagonalization, using only deflation. It allows us to deal with high-dimensional datasets efficiently, and notably solves the collinearity problem [6].
With great technological advances in recent decades, PLS regression has been gaining attention, and has been successfully applied to many domains, notably genomics. Indeed, the development of both microarray and allelotyping techniques result in high-dimensional datasets from which information has to be efficiently extracted. To this end, PLS regression has become a benchmark as an efficient statistical method for prediction, regression and dimension reduction [3]. Practically speaking, the observed response related to such studies does commonly not follow a continuous distribution. Frequent goals with gene expression datasets involve classification problems, such as cancer stage prediction, disease relapse, and tumor classification. For such reasons, PLS regression has had to be adapted to take into account discrete responses. This has been an intensive research subject in recent years, leading globally to two types of adapted PLS regression for classification. The first, studied and developed notably by Nguyen and Rocke [7], Nguyen and Rocke [8] and Boulesteix [9], is a two-step method. The first step consists of building standard PLS components by treating the response as continuous. In the second step, classification methods are run, e.g., logistic discrimination (LD) or quadratic discriminant analysis (QDA). The second type of adapted PLS regression consists of building PLS components using either an adapted version of or the original iteratively reweighted least squares (IRLS) algorithm, followed by generalized linear regression on these components. This type of method was first introduced by Marx [10]. Different modifications and improvements, using notably ridge regression [11] or Firth’s procedure [12] to avoid non-convergence and infinite parameter-value estimations, have been developed, notably by Nguyen and Rocke [13], Ding and Gentleman [14], Fort and Lambert-Lacroix [15] and Bastien et al. [16]. In this work, we focus on the second type of adapted PLS regression, referred to from now on as GPLS.
As previously mentioned, a feature of datasets of interest is their high-dimensional setting, i.e.,
with
This method cannot be considered parsimonious, but rather as a pre-processing stage for exclusion of uninformative covariates. Reliably selecting relevant predictors in PLS regression is of interest for several reasons. Practically speaking, it would allow users to identify the original covariates which are significantly linked to the response, as is done in OLS regression with Student-type tests. Statistically speaking, it would avoid the establishment of over-complex models and ensure consistency of PLS estimators. Several methods for variable selection have already been developed [19]. Lazraq et al. [20] group these techniques into two main categories. The first, model-wise selection, consists of first establishing the PLS model before performing a variable selection. The second, dimension-wise selection, consists of selecting variables on one PLS component at a time.
A dimension-wise method, introduced by Chun and Keleş [17] and called Sparse PLS (SPLS), has become the benchmark for selecting relevant predictors using PLS methodology. The technique is for continuous responses and consists of simultaneous dimension reduction and variable selection, computing sparse linear combinations of covariates as PLS components. This is achieved by introducing an
where λ determines the amount of sparsity. More details are available in Chun and Keleş [17]. Two tuning parameters are thus involved:
Chung and Keles [21] have developed an extension of this technique by integrating it into the generalized linear model (GLM) framework, leading it to be able to solve classification problems. They also integrate Firth’s procedure, in order to deal with non-convergence issues. Both tuning parameters are selected using CV MSE. We refer to this method as SGPLS CV in the following.
A well-known model-wise selection method is the one introduced by Lazraq et al. [20]. It consists of bootstrapping pairs
Two important related issue should be mentioned. Firstly, the presence of variables unrelated to the phenomenon under study strongly increases the level of inherent noise in the response and in the predictors. This phenomenon occurs frequently in various contexts and has been studied by several authors both in the context of PLS regression and its extensions [22, 23] and in the more general context of machine learning where the use of techniques related to least squares have proven to be relevant and effective [24–28].
Secondly, while performing this technique, approximations of distributions are achieved conditionally on the fixed dimension of the extracted subspace. In other words, it approximates the uncertainty of these coefficients, conditionally on the fact that estimations are performed in a K-dimensional subspace for each bootstrap sample. The determination of an optimal number of components is crucial for achieving reliable estimations of the regression coefficients [29]. Thus, since this determination is specific to the dataset in question, it must be performed for each bootstrap sample, in order to obtain reliable bootstrap-based CI. We have established some theoretical results which confirm this (Supplementary Section 1.3).
Determining tuning parameters by using q-fold cross-validation (q-CV) based criteria may induce important issues concerning the stability of extracted results (Hastie et al. [30], p.249; Boulesteix [31]; Magnanensi et al. [32]). Thus, using such criteria for successive choosing of the number of components should be avoided. As mentioned, amongst others, by Efron and Tibshirani [33], p.255 and Kohavi [34], bootstrap-based criteria are known to be more stable than CV-based ones. In this context, Magnanensi et al. [32] developed a robust bootstrap-based criterion for the determination of the number of PLS components, characterized by a high level of stability and suitable for both the PLS and GPLS regression frameworks. Thus, this criterion opens up the possibility of reliable successive choosing for each bootstrap sample.
In this article, we introduce a new dynamic bootstrap-based technique for covariate selection suitable for both the PLS and GPLS frameworks. It consists of bootstrapping pairs
We also succeed in adapting the bootstrap-based criterion introduced by Magnanensi et al. [32] to the determination of a unique optimal number of components related to each preset value of η in both the SPLS and SGPLS frameworks. Thus, these adapted versions, by reducing the use of CV, improve the reliability of the hyper-parameter tuning. We will refer to these adapted techniques as SPLS BootYT and SGPLS BootYT, respectively.
There is some constructive attributes of our proposed approach as follows:
1. theoretical results are developed and presented to give indications on the number of components related to a bootstrap sample and showed the necessity for a dynamic algorithm for Sparse PLS;
2. adapt our stable stopping criterion in the construction of PLS components to the Sparse PLS;
3. for each value of the parsimony parameter, a determination of the optimal number of components is performed using our new algorithm;
4. the number of models to be compared is considerably reduced;
5. possible thanks to the adaptation of our stable stopping criterion for PLS components and by its properties, especially its stability.
The article is organized as follows. In Section 2, we introduce our new dynamic bootstrap-based technique, followed by the description of our adaptation of the BootYT stopping criterion to the SPLS and SGPLS frameworks. In Section 3, we present simulations related to the PLS framework, and summarize the results, depending notably on different noise levels in y. In Section 4, we treat a real microarray gene expression dataset with a binary response, here the original localization of colon tumors, by benchmarking our new dynamic bootstrap-based approach for GPLS regression. Lastly, we discuss results and conclusions in Section 5 as well as possible future work.
2 Bootstrap-Based Approaches for Predictor Selection
2.1 A New Dynamic Bootstrap-Based Technique
As mentioned in Section 1, the selected number of extracted components is crucial for reliable estimation of
In order to take into account these theoretical results, we have developed a new dynamic bootstrap-based approach for variable selection relevant for both the PLS and GPLS frameworks. The approach consists of estimating the optimal number of components for each bootstrap sample created during the algorithm. To obtain consistent results, a robust and resample-stable stopping criterion in component construction has to be used. Let us use
1. Let
2.
• Extract the number of PLS components that is needed for
• Compute the estimations
3.
4.
5. Obtain the reduced model
Note that here, we set
2.2 An Adapted Bootstrap-Based Sparse PLS Implementation
As mentioned by Boulesteix [31], using q-CV based methods for tuning parameters potentially induces problems, notably concerning variability of results due to dependency on the way folds are randomly chosen. However, as detailed in Section New developments in Sparse PLS regression, the selection of both tuning parameters involved in the SPLS regression developed by Chun and Keleş [17] is performed using q-CV MSE. Therefore, to improve the reliability of this selection, we adapt the bootstrap-based stopping criterion to this method, which gives the following algorithm:
1. Let
2. Let
3. If
4. While
5. Return the set of the extracted numbers of components
6. Return the pair
Retesting all components obtained after each increase in
While the original implementation compares
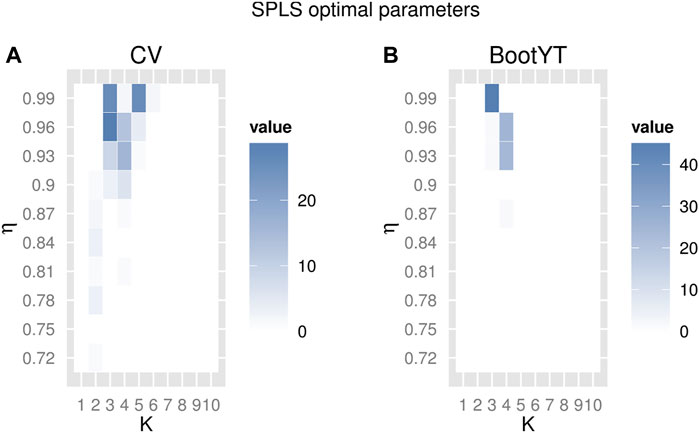
FIGURE 1. Repartition of 100 selections of
3 Simulations Studies
3.1 Simulations for Accuracy Comparisons
These simulations are based on a simulation scheme proposed by Chun and Keleş [17, p.14] and modified in order to study high-dimensional settings. We consider the case where there are less observations than predictors, i.e.,
Using this simulation scheme, accuracy of the SPLS technique using 10 fold-CV for selecting tuning parameters (SPLS CV), and our new dynamic bootstrap method combined with the bootstrap-based stopping criterion (BootYTdyn), is compared. In order to do so, for each parameter setting, 50 selections of the sparse support related to both methods were established. Lastly, mean accuracy values over the 50 trials were calculated. Results are summarized in Table 1.
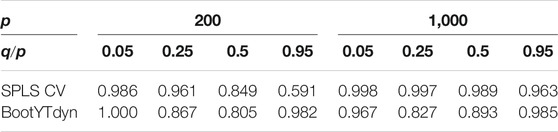
TABLE 1. Mean accuracy values (SNR).
Based on these results, SPLS CV gives better accuracy than BootYTdyn for ratio values
Nevertheless, in this simulation set-up, covariates are collected into four groups. While within-group correlations between covariates are close to one, between-group ones are close to zero. This unrealistic situation makes irrelevant the determination of an optimal support, and seems more appropriate to selecting the number of components. As an illustration, 50 additional samples in the
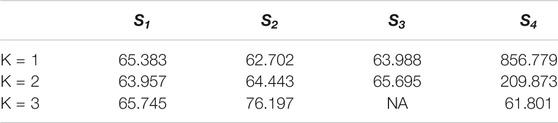
TABLE 2. PMSE values for different supports.
In the light of these observations, the aim of this simulation scheme is instead the extraction if an optimal number of components rather than an optimal support. We thus decided to use a real dataset as covariate matrix for a more general and relevant comparison.
3.2 Simulations for Global Comparison
3.3.1 Dataset Simulations
In this study, we used a real microarray gene expression dataset, which was created using fresh-frozen primary tumors samples, from a multi-center cohort, with stage I to IV colon cancer. 566 samples fulfilled RNA quality requirement, and constituted our database. These samples were split into a 443 sample discovery set and a 123 sample test set, well balanced for the main anatomo-clinical characteristics. This database has already been studied by Marisa et al. [35] and more details on it are available in their article.
In order to reduce computational time, a preliminary selection of 100 predictors was performed. Based on the original localization of the tumors as response vector, and the full 566 samples, the 100 most differentially expressed probe sets were extracted. As mentioned in Section New developments in Sparse PLS regression, this pre-processing is based on a Bayesian technique and gives us our benchmark predictors matrix.
Then, based on correlation values, four positively-correlated predictors were selected to form the set of significant covariates (Supplementary Section 1.1). To this end, let
with
We performed simulations for six distinct levels of random noise standard deviation in order to investigate the performance of the different methods. Both these standard deviations and their related SNR are shown in Table 3.

TABLE 3. Noise standard deviation (SNR).
3.3.2 Benchmarked Methods
Using these simulated datasets, eight methods were analyzed and compared.
1.
2. BIC. The bootstrap-based method, introduced by Lazraq et al. [20], combined with the corrected BIC using estimated degrees of freedom (DoF) [36] for pre-selecting the number of components.
3. BootYT. The bootstrap-based method, introduced by Lazraq et al. [20], combined with the bootstrap-based criterion [32] for previously selecting the number of components.
4. BICdyn. Our new dynamic bootstrap-based method combined with the corrected BIC criterion for successive selections of number of components.
5. BootYTdyn. Our new dynamic bootstrap-based method combined with the bootstrap-based criterion for successive selections of number of components.
6. SPLS CV. The original SPLS method using 10-fold CV for tuning parameter determination [17].
7. SPLS BootYT. The new adapted SPLS version using the bootstrap-based criterion for component selection.
8. Lasso. Lasso regression, included as a benchmark [37].
3.3.3 Simulation Scheme and Notation
In order to perform reliable comparisons between the eight methods, each type of trial was performed one hundred times. Numbers of components, sparse supports and sparse tuning parameters are the main examples of these. Results linked to the highest occurrence rates are then chosen for method comparison. All bootstrap-based techniques were performed with
The global comparison has two main parts. First, in order to compare accuracy and stability related to each technique, we focus both on different supports, and models extracted by the different variable selection methods. Indeed, in the PLS framework, a specific model results from both a set of predictors and a specific number of components. Due to the sparsity parameter in SPLS approaches, the same support can be extracted, but with a different number of components leading to different models. Lasso regression can also extract the same support for several different sparsity parameters, leading to different estimations of model coefficients. Therefore, for clarity, the following notation, related to each specific variable selection technique, is introduced.
•
•
•
•
•
•
•
Second, in order to compare the predictive ability of models, 10-fold CV MSE, related to each selected sparse model through PLS regression, were computed one hundred times. The test set was also used in order to confirm results obtained by CV.
Note that, concerning the dynamic BIC-based method for
3.3.4 Stability and Accuracy Results
Both the mean accuracy values over trials in each case, and stability results based on extracted supports, are given in Table 4. The numbers of components used for the original bootstrap-based approach [20] are summarized in Supplementary Section 1.2.
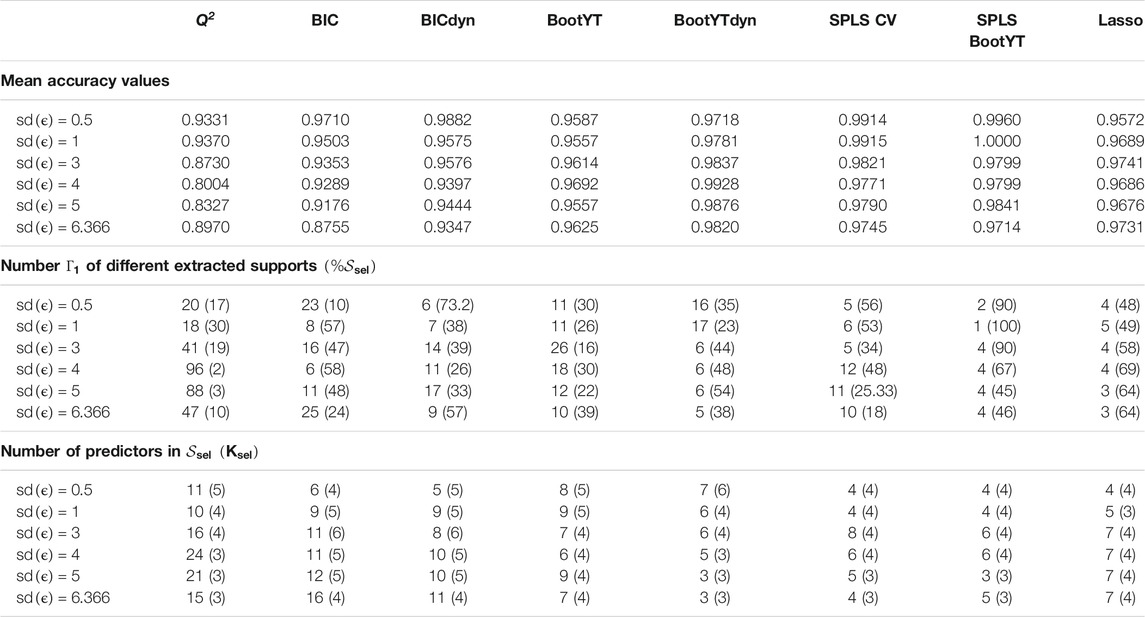
TABLE 4. Mean accuracy values over trials in each case and stability results based on extracted supports and number of predictors.
Concerning the number of different models, results related to lasso regression are the same as those concerning the number of different supports. Only the result for
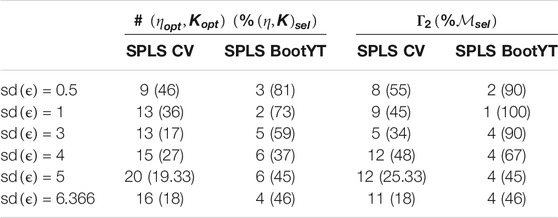
TABLE 5. Results for SPLS model stability.
Concerning the three bootstrap-based techniques and in the light of accuracy results (Table 4), BootYT outperforms both the others, except in the case where
Based on results introduced in Tables 4,5, the
The last descriptive statistic concerns the number of significant predictors retained (Table 4). The
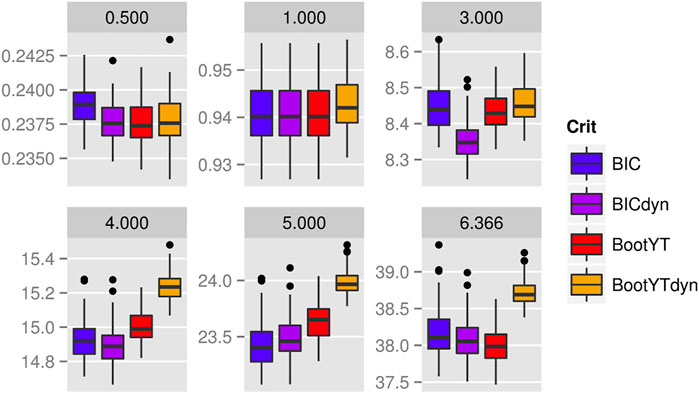
FIGURE 2. Boxplots of 10-CV MSE based on y with noise.
These results tend to confirm our suspicion of over-fitting since, except for results related to BootYTdyn, the others have MSE that do not match with the theoretical random noise variances, suggesting that a part of the noise is being modeled. As for the two SPLS methods, there is no pertinent difference to mention, both of them concluding on similar numbers of selected predictors. Lastly, like in BIC-based approaches, the lasso extracts an increasing number of significant predictors.
As a first conclusion, we can thus reasonably conclude that, based on these first simulation results, BootYTdyn and SPLS BootYT should be used in practice.
3.3.5 Complexity and Predictive Ability Results
To confirm and strengthen the conclusions of Section 3.3.2, we will now focus on the predictive abilities of the models selected by the various approaches. We calculate one hundred times the 10-fold CV MSE based on the original simulated response values (without noise) of the various selected models. These results thus reflect the accuracy in predicting the original information by leaving out random noise. We also compute the Predictive MSE (PMSE) based on the test set, by using its simulated response
Graphical results for these statistics, related to
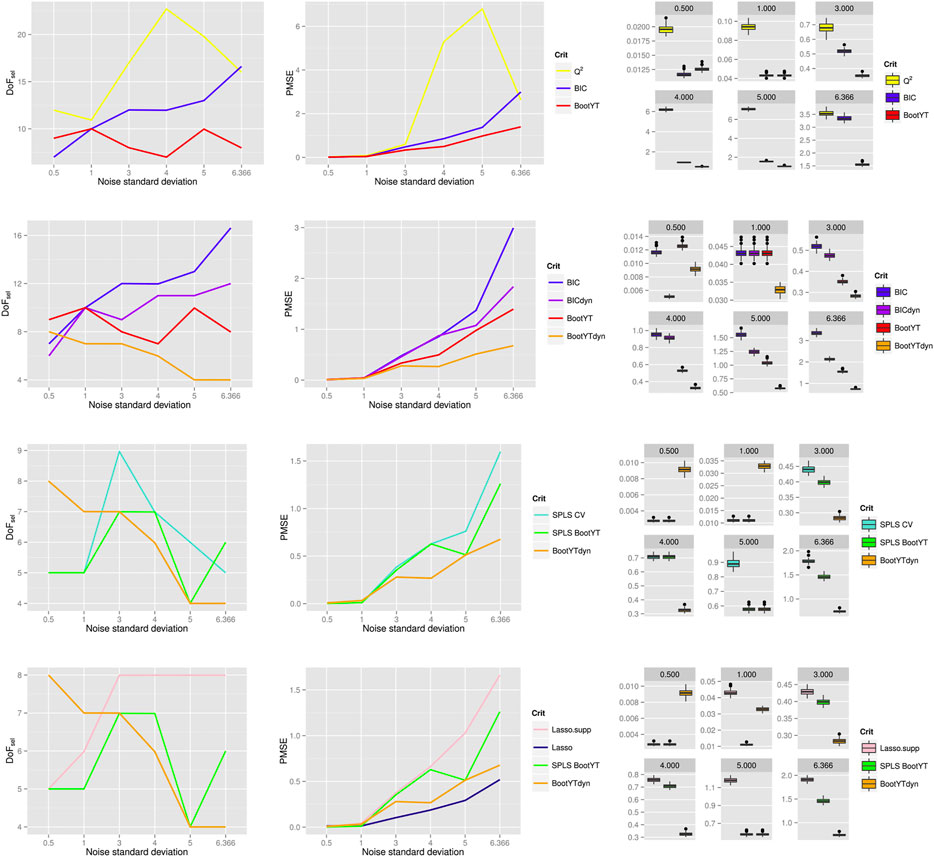
FIGURE 3. From left to right: DoF of the extracted sparse models, PMSE based on
The evolution of estimated DoF both highlights and confirms BIC and
The results shown in the second row of Figure 3 highlight that BootYTdyn is the only method that models with decreasing DoF, ensuring a complexity reduction suitable to the avoidance of prediction issues. Indeed, BootYTdyn selects models with the lowest PMSE and 10-CV MSE.
In light of these results, only BootYTyn is retained for further comparison. Comparing the two SPLS implementations with respect to their predictive abilities lead us to recommend SPLS BootYT, since models selected by this bootstrap-adapted SPLS technique feature comparable if not lower PMSE and 10-CV MSE (third row of Figure 3). Let us clarify that, in order to ensure relevant comparisons, we used ordinary PLS regressions with both the support and the number of components selected by the SPLS methods, and not SPLS methods with selected tuning parameters, for computing the 10-CV MSE.
For datasets characterized by a low level of random noise variability in
Lastly, we compare the two retained methods BootYTdyn and SPLS BootYT, and the lasso is run. As for SPLS methods, in order to perform relevant comparisons, the supports extracted by the lasso are used as sets of covariates for a PLS regression. The number of PLS components is then established by performing one hundred times their selection using the bootstrap-based stopping criterion; the number of components related to the highest occurrence rate was selected. In this way, results shown in the fourth row of Figure 3 concerning 10-CV MSE give the predictive ability of the extracted supports for PLS regression. In order to provide a clear picture of the impact of this choice, the PMSE obtained through the lasso is also displayed on the fourth row of Figure 3. These approaches are referred to as Lasso and Lasso.supp.
Except for negligible values of random noise variability in y, the support extracted by the lasso regression and applied as explanatory variables for PLS regression are linked to both the highest 10-CV MSE and highest PMSE. This is a direct consequence of the lasso’s accuracy issues mentioned in Section 3.3.4, notably the increasing number of extracted covariate while the random noise variability rises. However, performing predictions using the model obtained by the original lasso regression lead to the lowest PMSE values. This is due to the
To conclude, we summarize our conclusions in the following Table 6, and recommend certain approaches, depending on whether the initial aim was to select significant predictors or to obtain a sparse model with attractive predictive ability.

TABLE 6. Recommended approaches.
4 Real Dataset Application
In this section, we deal with the predictors matrix introduced in Section 3.3.1 and the original binary response vector. Five approaches for variable selection, adapted for the GPLS framework, are considered for comparison.
1. BootYT. The bootstrap-based method, introduced by Lazraq et al. [20], combined with the bootstrap-based criterion [32] for pre-selecting the number of components.
2. BootYTdyn. The new dynamic bootstrap-based method combined with the bootstrap-based criterion for successive determinations of the number of components.
3. SGPLS CV. The original SGPLS method using 10-fold CV for tuning parameter selection [21].
4. SGPLS BootYT. The new adapted SGPLS version using the bootstrap-based criterion for component selection.
5. RSGPLS. An approach developed by Durif et al. [38]. It consists of adapting the SGPLS method by introducing a ridge penalty to ensure convergence of parameter estimations, and stability in hyper-parameter tuning. They also propose an adjustment of the
6. Lasso. The adapted lasso regression for logistic framework, available in the R package glmnet, as a benchmark.
Concerning bootstrap-based approaches, the incorporation of PLS methodology into GLM, developed by Bastien et al. [16], was used. Due to non-convergence issues for parameter estimations, some samples were excluded using a threshold for parameter estimations. Indeed, a model built using a bootstrap sample with at least one parameter estimate that is higher in absolute value than
Each method was performed one hundred times in order to obtain relevant results. However, due to the high observed stability of results extracted with the BootYTdyn approach, and in order to save computational time, this was only performed twenty times instead of a hundred.
Stability results for tuning parameter selection, except for the bootstrap-based methods, are shown in Figure 4 and Table 7.
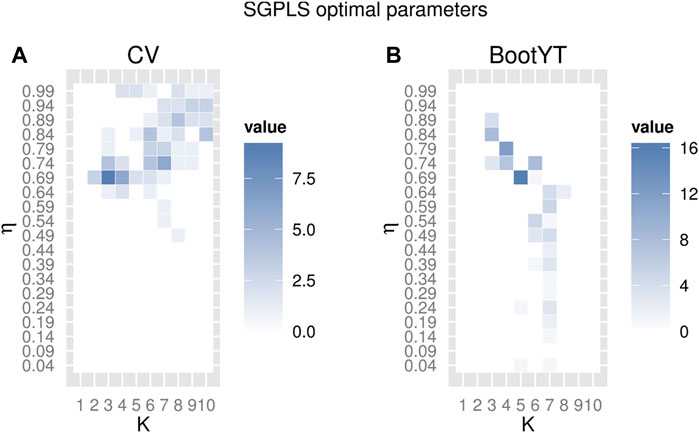
FIGURE 4. Repartition of selected sets of tuning parameters over the 100 trials, for SGPLS CV (A) and SGPLS BootYT (B).

TABLE 7. Number of different selected sets of tuning parameters over the 100 trials (rate of occurrence of the retained set of tuning parameters).
Based on results summarized in Table 7, the lasso methodology, using CV-based MSE or deviance values for the selection of its hyper-parameter, is the most stable. This can be explained by the fact that only one hyper-parameter is involved, while the other techniques are based on two or three tuning parameters. Using the number of misclassified values for CV has to be avoided for stable selection of the sparsity parameter. Our SGPLS adaptation with the BootYT criterion improves reliability in selecting the set of tuning parameters, as previously observed in the PLS framework (Sections 2.2, 3.3.4). Note that, concerning RSGPLS, three different sets of optimal parameters were extracted with maximal occurrence rate of five, all of them selecting the same set of predictors. Thus, the set of parameters which leads to the smallest number of misclassified values on the training dataset was retained. As already mentioned in Section 3.3.3, extracting the same support does not necessarily lead to the same model when sparsity or ridge parameters are involved. Therefore, the numbers of sparse supports and models retained are summarized in Table 8.

TABLE 8. Number
In light of these results, BootYTdyn and both the MSE- and deviance-based lasso techniques are the most stable in extracting supports and models. This could be due in part to the fact than all of them depend on only one tuning parameter. Even if this hyper-parameter for the BootYTdyn approach, i.e., the number of components, has to be chosen R times, the high stability of the bootstrap-based stopping criterion introduced by Magnanensi et al. [32] endows this approach with good stability in selecting the sparse support. As for the PLS framework, our new bootstrap-based SGPLS implementation improves the stability here. The lack of stability of the lasso based on misclassified values is directly induced by the discrete form of this statistic. This issue was also observed and mentioned in Magnanensi et al. [32].
The various selected supports are displayed in Figure 5. Note that both the MSE- and deviance-based lasso regressions select the same support and the same model, noted Lasso.MSE.Dev in the following.

FIGURE 5. Summary of selected supports.
In the following, two additional independent public datasets, stated by Marisa et al. [35] as being comparable with our original dataset, were included for comparison of predictive abilities. These datasets are named GSE18088 (n = 53) [39] and GSE14333 (n = 247) [40]. Both the MSE and number of misclassified (MC) value of the selected models were computed on both the training and test parts of the original dataset, as well as on the two additional datasets. These results are summarized in Table 9. Since independent datasets were available, we decided to follow the suggestion of Van Wieringen et al. [41, p.1596]: “the true evaluation of a predictor’s performance is to be done on independent data”.
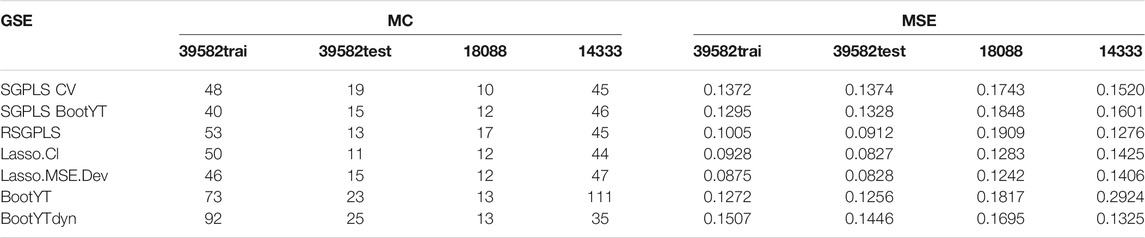
TABLE 9. Summary of model fitting and predictive abilities.
In this real data study, BootYTdyn retains only one predictor, which is also retained by all other methods. Thus, as expected, this most sparse support induced the highest values of both the MSE and number of misclassified observations, based on the training subset of the original dataset. It also provided the highest values based on the test subset of the original dataset, which is to be expected since, as explained in Section 3.3.1, these two parts are well-balanced in terms of anatomo-clinical characteristics. Thus, this causes a bias in evaluation of model’s predictive abilities, by making comparable MSE and misclassified values based on both the training and testing subsets. Results in Table 9 confirm this property, and also highlight the usefulness of additional independent datasets for reliably comparing predictive abilities. While a well-designed model for predictive purposes will provide similar PMSE values on comparable independent additional datasets compared to MSE obtained on the training dataset, an over-fitted one would be related to higher PMSE values, due to its dependance on training data. Thus, the differences, noted
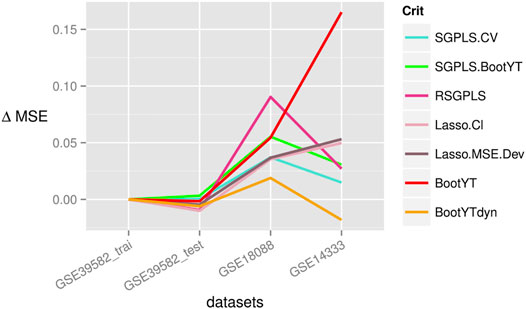
FIGURE 6. Differences between the MSE computed on the training subset of the original dataset and the PMSE obtained on test sets.
Our new dynamic bootstrap-based approach is the only one that exhibits this MSE stability property. In contrast, all other approaches provided higher PMSE values on the two other datasets than on the original. This led BootYTdyn to have only 48 (16%) misclassified values on these two additional datasets, representing the best result among all studied approaches. Thus, we can reasonably assume that our new method has helped to remove non-informative predictors, in the sense of not being relevant for improving predictive ability.
Lastly, the unique extracted probe set, named 230784_at, is already known to be related to the original location in the distal colon. The sign of the regression coefficient obtained with BootYTdyn is coherent with this state-of-the-art result, and thus strengthens our conclusion.
5 Discussion
In this article, we developed a new dynamic bootstrap-based technique for variable selection, suitable for both the PLS and GPLS frameworks, and proposed a bootstrap-based version of the SPLS and SGPLS methods for selecting the number of components. While the first of these lets us completely avoid CV, the second lets us select the set of tuning parameters in a more reliable way.
In state-of-the-art approaches, the use of CV-based techniques for selection of hyper-parameters is common, and can lead to important stability issues, observed notably by Boulesteix [31] and Magnanensi et al. [32], and confirmed in our studies. Our new dynamic bootstrap-based technique represents a useful method for avoiding CV-related issues, since the unique hyper-parameter is successively selected using a bootstrap-based criterion. This new technique improves on the original bootstrap-based methodology introduced by Lazraq et al. [20], in that it permits us to approximate the distribution of covariates’ regression coefficients by removing the condition of working in a subspace of fixed dimension K. Theoretical results have been established that strengthen the usefulness of building subspaces spanned by a dynamic number of components for performing PLS regressions on bootstrap samples.
In the PLS framework, conclusions based on our simulations are twofold. First, for datasets with negligible random noise in
Results obtained from our classification study using real datasets match with previous conclusions. Indeed, BootYTdyn is the only one which leads to the expected PMSE values on two additional independent datasets, which allows us to suppose that over-fitting issues were avoided, and that these PMSE are induced by noise or information which cannot be modeled using only gene expression. Furthermore, the extracted probe set is already known to be linked to the relevant location in the distal colon, which strengthens our confidence in this new dynamic approach.
Lastly, our new bootstrap-based SPLS implementation improves the stability of this method. Indeed, in all cases studied, both the SPLS CV and SGPLS CV select a higher number of unique sets of hyper-parameters than our bootstrap-based versions do, leading to higher numbers of unique supports and models too.
In the future, our work may be extended in the following three directions. Firstly, Sun et al. [42] also worked on this subject, and proposed a methodology for selecting tuning parameters of penalized regressions in order to stabilize variable selection. Even if their method is not applicable to the selection of the number of components in PLS regression, it would be interesting to adapt it to both SPLS CV and our new SPLS BootYT implementation, in order to look for potential stability gains.
Secondly combining partial least squares based regular or sparse techniques with the existing techniques that were developed in [24–28] may speed up, specialize toward a specific target or improve the accuracy of those existing algorithms by taking into account some latent structure of the data.
Thirdly, simulations may be performed to strengthen the results obtained on real data sets for the logistic framework (Section 4). In addition, testing the performance of these new approaches for responses following other distributions -such as Poisson, Gamma-should also be done. However, based on all the results obtained in this paper, our new dynamic method seems to be the most efficient compared to the state of the art approaches for datasets with non-negligible noise variability, a common situation in daily practice.
Data Availability Statement
The datasets analyzed for this study can be found in the Datasets_benchmark Github repository, https://github.com/fbertran/Datasets_benchmark. The packages used for the simulations in this article are available on the CRAN, https://cran.r-project.org and especially the plsRglm package that implements partial least squares generalized regression, https://CRAN.R-project.org/package=plsRglm and the bootPLS package that implements number of components selection using bootstrap for PLS regression and generalized regression models, https://github.com/fbertran/bootPLS.
Author Contributions
JM, FB, MM-B and NM designed the study. JM did the simulations. JM, FB and MM-B wrote the manuscript.
Funding
This work was supported by grants from the Agence Nationale de la Recherche (ANR) (ANR-11-LABX-0055_IRMIA); the CNRS (UMR 7501) LabEx IRMIA to FB, NM and MM-B; Mastére Spécialisé® Expert Big Data Engineer of the University of Technology of Troyes to FB and MM.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fams.2021.693126/full#supplementary-material
References
1. Wold, S, Martens, H, and Wold, H. The Multivariate Calibration Problem in Chemistry Solved by the PLS Method. In: Matrix Pencils. Heidelberg, Deutschland: Springer-Verlag (1983) p. 286–93. doi:10.1007/bfb0062108
2. Wold, S, Sjöström, M, and Eriksson, L. PLS-regression: a Basic Tool of Chemometrics. Chemometrics Intell Lab Syst (2001) 58:109–30. doi:10.1016/s0169-7439(01)00155-1
3. Boulesteix, AL, and Strimmer, K. Partial Least Squares: a Versatile Tool for the Analysis of High-Dimensional Genomic Data. Brief Bioinform (2007) 8:32–44. doi:10.1093/bib/bbl016
4. Höskuldsson, A. PLS Regression Methods. J Chemometrics (1988) 2:211–28. doi:10.1002/cem.1180020306
6. Wold, S, Ruhe, A, Wold, H, and Dunn, III, WJ. The Collinearity Problem in Linear Regression. The Partial Least Squares (PLS) Approach to Generalized Inverses. SIAM J Sci Stat Comput (1984) 5:735–43. doi:10.1137/0905052
7. Nguyen, DV, and Rocke, DM. Multi-class Cancer Classification via Partial Least Squares with Gene Expression Profiles. Bioinformatics (2002) 18:1216–26. doi:10.1093/bioinformatics/18.9.1216
8. Nguyen, DV, and Rocke, DM. Tumor Classification by Partial Least Squares Using Microarray Gene Expression Data. Bioinformatics (2002) 18:39–50. doi:10.1093/bioinformatics/18.1.39
9. Boulesteix, A-L. PLS Dimension Reduction for Classification with Microarray Data. Stat Appl Genet Mol Biol (2004) 3:1–30. doi:10.2202/1544-6115.1075
10. Marx, BD. Iteratively Reweighted Partial Least Squares Estimation for Generalized Linear Regression. Technometrics (1996) 38:374–81. doi:10.1080/00401706.1996.10484549
11. Cessie, SL, and Houwelingen, JCV. Ridge Estimators in Logistic Regression. Appl Stat (1992) 41:191–201. doi:10.2307/2347628
12. Firth, D. Bias Reduction of Maximum Likelihood Estimates. Biometrika (1993) 80:27–38. doi:10.1093/biomet/80.1.27
13. Nguyen, DV, and Rocke, DM. On Partial Least Squares Dimension Reduction for Microarray-Based Classification: a Simulation Study. Comput Stat Data Anal (2004) 46:407–25. doi:10.1016/j.csda.2003.08.001
14. Ding, B, and Gentleman, R. Classification Using Generalized Partial Least Squares. J Comput Graphical Stat (2005) 14:280–98. doi:10.1198/106186005x47697
15. Fort, G, and Lambert-Lacroix, S. Classification Using Partial Least Squares with Penalized Logistic Regression. Bioinformatics (2005) 21:1104–11. doi:10.1093/bioinformatics/bti114
16. Bastien, P, Vinzi, VE, and Tenenhaus, M. PLS Generalised Linear Regression. Comput Stat Data Anal (2005) 48:17–46. doi:10.1016/j.csda.2004.02.005
17. Chun, H, and KeleÅŸ, S. Sparse Partial Least Squares Regression for Simultaneous Dimension Reduction and Variable Selection. J R Stat Soc Ser B (Statistical Methodology) (2010) 72:3–25. doi:10.1111/j.1467-9868.2009.00723.x
18. Smyth, GK. Linear Models and Empirical Bayes Methods for Assessing Differential Expression in Microarray Experiments. Stat Appl Genet Mol Biol (2004) 3:Article3. doi:10.2202/1544-6115.1027
19. Mehmood, T, Liland, KH, Snipen, L, and Sæbø, S. A Review of Variable Selection Methods in Partial Least Squares Regression. Chemometrics Intell Lab Syst (2012) 118:62–9. doi:10.1016/j.chemolab.2012.07.010
20. Lazraq, A, Cléroux, R, and Gauchi, J-P. Selecting Both Latent and Explanatory Variables in the PLS1 Regression Model. Chemometrics Intell Lab Syst (2003) 66:117–26. doi:10.1016/s0169-7439(03)00027-3
21. Chung, D, and Keles, S. Sparse Partial Least Squares Classification for High Dimensional Data. Stat Appl Genet Mol Biol (2010) 9. Article 17. doi:10.2202/1544-6115.1492
22. Bastien, P, Bertrand, F, Meyer, N, and Maumy-Bertrand, M. Deviance Residuals-Based Sparse PLS and Sparse Kernel PLS Regression for Censored Data. Bioinformatics (2015) 31:397–404. doi:10.1093/bioinformatics/btu660
23. Meyer, N, Maumy-Bertrand, M, and Bertrand, F. Comparaison de variantes de régressions logistiques PLS et de régression PLS sur variables qualitatives: application aux données d’allélotypage. J de la Société Française de Statistique (2010) 151:1–18.
24. Gupta, D, and Richhariya, B. Entropy Based Fuzzy Least Squares Twin Support Vector Machine for Class Imbalance Learning. Appl Intell (2018) 48:4212–31. doi:10.1007/s9489-018-1204-4
25. Gupta, U, Gupta, D, and Prasad, M. Kernel Target Alignment Based Fuzzy Least Square Twin Bounded Support Vector Machine. In: Proceedings of the 2018 IEEE Symposium Series on Computational Intelligence; 18-21 Nov. 2018; Bangalore, IndiaSSCI (2018) p. 228–35. doi:10.1109/SSCI.2018.8628903
26. Borah, P, and Gupta, D. A Two-Norm Squared Fuzzy-Based Least Squares Twin Parametric-Margin Support Vector Machine. In: M Tanveer, and RB Pachori, editors. Machine Intelligence and Signal Analysis Advances in Intelligent Systems and Computing, 748. Singapore: Springer Singapore (2019) p. 119–34. doi:10.1007/978-981-13-0923-610.1007/978-981-13-0923-6_11
27. Borah, P, Gupta, D, and Prasad, M. Improved 2-norm Based Fuzzy Least Squares Twin Support Vector Machine. In: 2018 IEEE Symposium Series on Computational Intelligence (SSCI); 18-21 Nov. 2018; Bangalore, IndiaIEEE (2018) p. 412–9. doi:10.1109/SSCI.2018.8628818
28. Gupta, U, and Gupta, D. Least Squares Large Margin Distribution Machine for Regression. Appl Intell (2021). doi:10.1007/s10489-020-02166-5
29. Wiklund, S, Nilsson, D, Eriksson, L, Sjöström, M, Wold, S, and Faber, K. A Randomization Test for PLS Component Selection. J Chemometrics (2007) 21:427–39. doi:10.1002/cem.1086
30. Hastie, T, Tibshirani, R, and Friedman, JJH. The Elements of Statistical Learning. 2nd ed., Vol. 1. New York, USANew York: Springer (2009).
31. Boulesteix, AL. Accuracy Estimation for PLS and Related Methods via Resampling-Based Procedures. Paris: PLS’14 Book of Abstracts (2014). p. 13–4.
32. Magnanensi, J, Bertrand, F, Maumy-Bertrand, M, and Meyer, N. A New Universal Resample-Stable Bootstrap-Based Stopping Criterion for PLS Component Construction. Stat Comput (2017) 27:1–18. doi:10.1007/s11222-016-9651-4
33. Efron, B, and Tibshirani, RJ. An Introduction to the Bootstrap, Vol. 57. Boca Raton, USA: Chapman & Hall/CRC (1993).
34. Kohavi, R. A Study of Cross-Validation and Bootstrap for Accuracy Estimation and Model Selection. In: Proceedings of the 14th international joint conference on Artificial intelligence-Volume 2, Montreal, Quebec, Canada, August 20–25, 1995. USA: Morgan Kaufmann Publishers Inc.) (1995). p. 1137–43.
35. Marisa, L, de Reyniès, A, Duval, A, Selves, J, Gaub, MP, Vescovo, L, et al. Gene Expression Classification of colon Cancer into Molecular Subtypes: Characterization, Validation, and Prognostic Value. Plos Med (2013) 10:e1001453. doi:10.1371/journal.pmed.1001453
36. Krämer, N, and Sugiyama, M. The Degrees of freedom of Partial Least Squares Regression. J Am Stat Assoc (2011) 106:697–705. doi:10.1198/jasa.2011.tm10107
37. Efron, B, Hastie, T, Johnstone, I, Tibshirani, R, et al. Least Angle Regression. Ann Stat (2004) 32:407–99. doi:10.1214/009053604000000067
38. Durif, G, Modolo, L, Michaelsson, J, Mold, JE, Lambert-Lacroix, S, and Picard, F. High Dimensional Classification with Combined Adaptive Sparse Pls and Logistic Regression. Bioinformatics (2017) 34:485–93. doi:10.1093/bioinformatics/btx571
39. Gröne, J, Lenze, D, Jurinovic, V, Hummel, M, Seidel, H, Leder, G, et al. Molecular Profiles and Clinical Outcome of Stage UICC II colon Cancer Patients. Int J Colorectal Dis (2011) 26:847–58. doi:10.1007/s00384-011-1176-x
40. Jorissen, RN, Gibbs, P, Christie, M, Prakash, S, Lipton, L, Desai, J, et al. Metastasis-associated Gene Expression Changes Predict Poor Outcomes in Patients with Dukes Stage B and C Colorectal Cancer. Clin Cancer Res (2009) 15:7642–51. doi:10.1158/1078-0432.ccr-09-1431
41. Van Wieringen, WN, Kun, D, Hampel, R, and Boulesteix, A-L. Survival Prediction Using Gene Expression Data: a Review and Comparison. Comput Stat Data Anal (2009) 53:1590–603. doi:10.1016/j.csda.2008.05.021
Keywords: variable selection, partial least squares, sparse partial least squares, generalized partial least squares, bootstrap, stability
Citation: Magnanensi J, Maumy-Bertrand M, Meyer N and Bertrand F (2021) New Developments in Sparse PLS Regression. Front. Appl. Math. Stat. 7:693126. doi: 10.3389/fams.2021.693126
Received: 09 April 2021; Accepted: 21 June 2021;
Published: 16 July 2021.
Edited by:
Hong Zhu, Jiangsu University, ChinaReviewed by:
Yunlong Feng, University at Albany, United StatesDeepak Gupta, National Institute of Technology, Arunachal Pradesh, India
Copyright © 2021 Magnanensi, Maumy-Bertrand, Meyer and Bertrand. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Frédéric Bertrand, ZnJlZGVyaWMuYmVydHJhbmRAdXR0LmZy