 Johannes Kleiner
Johannes Kleiner Sean Tull
Sean Tull
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Appl. Math. Stat., 04 June 2021
Sec. Dynamical Systems
Volume 6 - 2020 | https://doi.org/10.3389/fams.2020.602973
This article is part of the Research TopicMathematical and Empirical Foundations of Models of ConsciousnessView all 7 articles
Integrated Information Theory is one of the leading models of consciousness. It aims to describe both the quality and quantity of the conscious experience of a physical system, such as the brain, in a particular state. In this contribution, we propound the mathematical structure of the theory, separating the essentials from auxiliary formal tools. We provide a definition of a generalized IIT which has IIT 3.0 of Tononi et al., as well as the Quantum IIT introduced by Zanardi et al. as special cases. This provides an axiomatic definition of the theory which may serve as the starting point for future formal investigations and as an introduction suitable for researchers with a formal background.
Integrated Information Theory (IIT), developed by Giulio Tononi and collaborators [5, 45–47], has emerged as one of the leading scientific theories of consciousness. At the heart of the latest version of the theory [19, 25, 26, 31, 40] is an algorithm which, based on the level of integration of the internal functional relationships of a physical system in a given state, aims to determine both the quality and quantity (‘
While promising in itself [12, 43], the mathematical formulation of the theory is not satisfying to date. The presentation in terms of examples and accompanying explanation veils the essential mathematical structure of the theory and impedes philosophical and scientific analysis. In addition, the current definition of the theory can only be applied to comparably simple classical physical systems [1], which is problematic if the theory is taken to be a fundamental theory of consciousness, and should eventually be reconciled with our present theories of physics.
To resolve these problems, we examine the essentials of the IIT algorithm and formally define a generalized notion of Integrated Information Theory. This notion captures the inherent mathematical structure of IIT and offers a rigorous mathematical definition of the theory which has ‘classical’ IIT 3.0 of Tononi et al. [25, 26, 31] as well as the more recently introduced Quantum Integrated Information Theory of Zanardi, Tomka and Venuti [50] as special cases. In addition, this generalization allows us to extend classical IIT, freeing it from a number of simplifying assumptions identified in [3]. Our results are summarised in Figure 1.

FIGURE 1. An Integrated Information Theory specifies for every system in a particular state its conscious experience, described formally as an element of an experience space. In our formalization, this is a map
In the associated article [44] we show more generally how the main notions of IIT, including causation and integration, can be treated, and an IIT defined, starting from any suitable theory of physical systems and processes described in terms of category theory. Restricting to classical or quantum process then yields each of the above as special cases. This treatment makes IIT applicable to a large class of physical systems and helps overcome the current restrictions.
Our definition of IIT may serve as the starting point for further mathematical analysis of IIT, in particular if related to category theory [30, 49]. It also provides a simplification and mathematical clarification of the IIT algorithm which extends the technical analysis of the theory [1, 41, 42] and may contribute to its ongoing critical discussion [2, 4, 8, 23, 27, 28, 33]. The concise presentation of IIT in this article should also help to make IIT more easily accessible for mathematicians, physicists and other researchers with a strongly formal background.
This work is concerned with the most recent version of IIT as proposed in [25, 26, 31, 40] and similar papers quoted below. Thus our constructions recover the specific theory of consciousness referred to as IIT 3.0 or IIT 3.x, which we will call classical IIT in what follows. Earlier proposals by Tononi et al. that also aim to explicate the general idea of an essential connection between consciousness and integrated information constitute alternative theories of consciousness which we do not study here. A yet different approach would be to take the term ‘Integrated Information Theory’ to refer to the general idea of associating conscious experience with some pre-theoretic notion of integrated information, and to explore the different ways that this notion could be defined in formal terms [4, 27, 28, 37].
This work develops a thorough mathematical perspective of one of the promising contemporary theories of consciousness. As such it is part of a number of recent contributions which seek to explore the role and prospects of mathematical theories of consciousness [11, 15, 18, 30, 49], to help overcome problems of existing models [17, 18, 34] and to eventually develop new proposals [6, 13, 16, 20, 22, 29, 39].
We begin by introducing the necessary ingredients of a generalised Integrated Information Theory in Sections 2–4, namely physical systems, experience spaces and cause-effect repertoires. Our approach is axiomatic in that we state only the precise formal structure which is necessary to apply the IIT algorithm. We neither motivate nor criticize these structures as necessary or suitable to model consciousness. Our goal is simply to recover IIT 3.0. In Section 5, we introduce a simple formal tool which allows us to present the definition of the algorithm of an IIT in a concise form in Sections 6 and 7. Finally, in Section 8, we summarise the full definition of such a theory. The result is the definition of a generalized IIT. We call any application of this definition ‘an IIT’.
Following this we give several examples including IIT 3.0 in Section 9 and Quantum IIT in Section 10. In Section 11 we discuss how our formulation allows one to extend classical IIT in several fundamental ways, before discussing further modifications to our approach and other future work in Section 12. Finally, the appendix includes a detailed explanation of how our generalization of IIT coincides with its usual presentation in the case of classical IIT.
The first step in defining an Integrated Information Theory (IIT) is to specify a class
Definition 1. A system class
1. A set
2. for every
3. a set
4. for each
Moreover, we require that
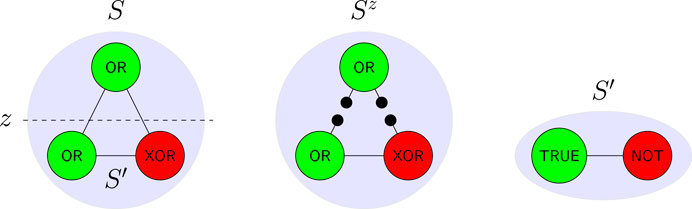
FIGURE 2. As an example of Definition 1 similar to IIT 3.0, consider simple systems given by sets of nodes (or ‘elements’), with a state assigning each node the state ‘on’ (depicted green) or ‘off’ (red). Each system comes with a time evolution shown by labelling each node with how its state in the next time-step depends on the states of the others. Decompositions of a system S correspond to binary partition of the nodes, such as z above. The cut system
An IIT aims to specify for each system in a particular state its conscious experience. As such, it will require a mathematical model of such experiences. Examining classical IIT, we find the following basic features of the final experiential states it describes which are needed for its algorithm.
Firstly, each experience e should crucially come with an intensity, given by a number
Definition 2. An experience space is a set E with:
1. An intensity function
2. A distance function
3. A scalar multiplication
for all
We remark that this same axiomatisation will apply both to the full space of experiences of a system, as well as to the spaces describing components of the experiences (‘concepts’ and ‘proto-experiences’ defined in later sections). We note that the distance function does not necessarily have to satisfy the axioms of a metric. While this and further natural axioms such as
Example 3. Any metric space
This is the definition used in classical IIT (cf. Section 9 and Appendix A). An important operation on experience spaces is taking their product.
Definition 4. For experience spaces E and F, we define the product to be the space
intensity
In order to define the experience space and individual experiences of a system S, an IIT utilizes basic building blocks called ‘repertoires’, which we will now define. Next to the specification of a system class, this is the essential data necessary for the IIT algorithm to be applied.
Each repertoire describes a way of ‘decomposing’ experiences, in the following sense. Let D denote any set with a distinguished element 1, for example the set
Definition 5. Let e be an element of an experience space E. A decomposition of e over D is a mapping
Definition 6. A cause-effect repertoire at S is given by a choice of experience space
and for each of them a decomposition over
Definition 7. A cause-effect structure is a specification of a cause-effect repertoire for every
The names ‘cause’ and ‘effect’ highlight that the definitions of
We have now introduced all of the data required to define an IIT; namely, a system class along with a cause-effect structure. From this, we will give an algorithm aiming to specify the conscious experience of a system. Before proceeding to do so, we introduce a conceptual short-cut which allows the algorithm to be stated in a concise form. This captures the core ingredient of an IIT, namely the computation of how integrated an entity is.
Definition 8. Let E be an experience space and e an element with a decomposition over some set D. The integration level of e relative to this decomposition is
Here, d denotes the distance function of E, and the minimum is taken over all elements of D besides 1. The integration scaling of e is then the element of E defined by
where
Finally, the integration scaling of a pair
where
Definition 9. The core of the collection
Let
For every choice of
The concept of M is then defined as the core integration scaling of this pair of collections,
It is an element of
The second level of the algorithm specifies the experience of system S in state s. To this end, all concepts of a system are collected to form its Q-shape, defined as
This Is an Element of the Space
where
Because of Eq. 4, and since the number of subsystems remains the same when cutting,
which is a decomposition of
This is the system level-object of relevance and is what specifies the experience of a system according to IIT.
Definition 10. The experience of system S in the state
The definition implies that
We can now summarize all that we have said about IITs.
Definition 11. An Integrated Information Theory is determined as follows. The data of the theory is a system class
into the class
which determines the experience of the system when in a state s, defined in Eq. 14.The quantity of the system’s experience is given by
and the quality of the system’s experience is given by the normalized experience
In this section we show how IIT 3.0 [25, 26, 31, 48] fits in into the framework developed here. A detailed explanation of how our earlier algorithm fits with the usual presentation of IIT is given in Appendix A. In [44] we give an alternative categorical presentation of the theory.
We first describe the system class underlying classical IIT. Physical systems S are considered to be built up of several components
We define a metric d on
Additionally, each system comes with a probabilistic (discrete) time evolution operator or transition probability matrix, sending each
Furthermore, the evolution T is required to satisfy a property called conditional independence, which we define shortly.
The class
In what follows, we will need to consider two operations on the map T. Let M be any subset of the elements of a system and
where
such that for each
In particular for any map T as above we call
where the right-hand side is again a probability distribution over
Let a system S in a state
where
The decomposition set
For any decomposition
where
For each system S, the first Wasserstein metric (or ‘Earth Mover’s Distance’) makes
where
It remains to define the cause-effect repertoires. Fixing a state s of S, the first step will be to define maps
where
taking the product over all elements
where λ is the unique normalisation scalar making
For General Mechanisms M, we Then Define
where the product is over all elements
with intensity 1 when viewed as elements of
The distributions
Remark 12. It is in fact possible for the right-hand side of Eq. 28 to be equal to 0 for all
where we have abused notation by equating each subset
In this section, we consider Quantum IIT defined in [50]. This is also a special case of the definition in terms of process theories we give in [44].
Similar to classical IIT, in Quantum IIT systems are conceived as consisting of elements
where
Subsystems are again defined to consist of subsets M of the elements of the system, with corresponding Hilbert space
where
Decompositions are also defined via partitions
where
For any
turns
We finally come to the definition of the cause-effect repertoire. Unlike classical IIT, the definition in [50] does not consider virtual elements. Let a system S in state
where
each with intensity 1, where
again with intensity 1, where
The physical systems to which IIT 3.0 may be applied are limited in a number of ways: they must have a discrete time-evolution, satisfy Markovian dynamics and exhibit a discrete set of states [3]. Since many physical systems do not satisfy these requirements, if IIT is to be taken as a fundamental theory about reality, it must be extended to overcome these limitations.
In this section, we show how IIT can be redefined to cope with continuous time, non-Markovian dynamics and non-compact state spaces, by a redefinition of the maps Eqs. 26 and 28 and, in the case of non-compact state spaces, a slightly different choice of Eq. 24, while leaving all of the remaining structure as it is. While we do not think that our particular definitions are satisfying as a general definition of IIT, these results show that the disentanglement of the essential mathematical structure of IIT from auxiliary tools (the particular definition of cause-effect repertoires used to date) can help to overcome fundamental mathematical or conceptual problems.
In Section 11.3, we also explain which solution to the problem of non-canonical metrics is suggested by our formalism.
In order to avoid the requirement of a discrete time and Markovian dynamics, instead of working with the time evolution operator Eq. 18, we define the cause- and effect repertoires in reference to a given trajectory of a physical state
Let
In what follows, we utilize the fact that in physics, state spaces are defined such that the dynamical laws of a system allow to determine the trajectory of each state. Thus for every
The idea behind the following is to define, for every
Let now
where κ is the unique normalization constant which ensures that
The probability distribution
So far, our construction can be applied for any time
to replace Eq. 27 and
to replace Eq. 29. The remainder of the definitions of classical IIT can then be applied as before.
The problem with applying the definitions of classical IIT to systems with continuous state spaces (e.g., neuron membrane potentials [3]) is that in certain cases, uniform probability distributions do not exist. E.g., if the state space of a system S consists of the positive real numbers
It is important to note that this problem is less universal than one might think. E.g., if the state space of the system is a closed and bounded subset of
This problem can be resolved for all well-understood physical systems by replacing the uniform probability distribution
In what follows, we explain how the construction of the last section needs to be modified in order to be applied to this case. In all relevant classical physical theories,
As before, the dynamical laws of the physical systems determine for every state
Using the fact that
which is a finite quantity. The
All that remains for this to give a cause-effect repertoire as in the last section, is to make sure that any measure (normalized or not) is an element of
and finally allows one to construct cause-effect repertoires as in the last section.
Another criticism of IIT’s mathematical structure mentioned [3] is that the metrics used in IIT’s algorithm are, to a certain extend, chosen arbitrarily. Different choices indeed imply different results of the algorithm, both concerning the quantity and quality of conscious experience, which can be considered problematic.
The resolution of this problem is, however, not so much a technical as a conceptual or philosophical task, for what is needed to resolve this issue is a justification of why a particular metric should be used. Various justifications are conceivable, e.g. identification of desired behavior of the algorithm when applied to simple systems. When considering our mathematical reconstruction of the theory, the following natural justification offers itself.
Implicit in our definition of the theory as a map from systems to experience spaces is the idea that the mathematical structure of experiences spaces (Definition 2) reflects the phenomenological structure of experience. This is so, most crucially, for the distance function d, which describes how similar two elements of experience spaces are. Since every element of an experience space corresponds to a conscious experience, it is naturally to demand that the similarly of the two mathematical objects should reflect the similarity of the experiences they describe. Put differently, the distance function d of an experience space should in fact mirror (or “model”) the similarity of conscious experiences as experienced by an experiencing subject.
This suggests that the metrics d used in the IIT algorithm should, ultimately, be defined in terms of the phenomenological structure of similarity of conscious experiences. For the case of color qualia, this is in fact feasible [18, Example 3.18], [21, 38]. In general, the mathematical structure of experience spaces should be intimately tied to the phenomenology of experience, in our eyes.
In this article, we have propounded the mathematical structure of Integrated Information Theory. First, we have studied which exact structures the IIT algorithm uses in the mathematical description of physical systems, on the one hand, and in the mathematical description of conscious experience, on the other. Our findings are the basis of definitions of a physical system class
Next, we needed to disentangle the essential mathematics of the theory from auxiliary formal tools used in the contemporary definition. To this end, we have introduced the precise notion of decomposition of elements of an experience space required by the IIT algorithm. The pivotal cause-effect repertoires are examples of decompositions so defined, which allowed us to view any particular choice, e.g. the one of ‘classical’ IIT developed by Tononi et al., or the one of ‘quantum’ IIT recently introduced by Zanardi et al. as data provided to a general IIT algorithm.
The formalization of cause-effect repertoires in terms of decompositions then led us to define the essential ingredients of IIT’s algorithm concisely in terms of integration levels, integration scalings and cores. These definitions describe and unify recurrent mathematical operations in the contemporary presentation, and finally allowed to define IIT completely in terms of a few lines of definition.
Throughout the paper, we have taken great care to make sure our definitions reproduce exactly the contemporary version of IIT 3.0. The result of our work is a mathematically rigorous and general definition of Integrated Information Theory. This definition can be applied to any meaningful notion of systems and cause-effect repertoires, and we have shown that this allows one to overcome most of the mathematical problems of the contemporary definition identified to date in the literature.
We believe that our mathematical reconstruction of the theory can be the basis for refined mathematical and philosophical analysis of IIT. We also hope that this mathematisation may make the theory more amenable to study by mathematicians, physicists, computer scientists and other researchers with a strongly formal background.
Our generalization of IIT is axiomatic in the sense that we have only included those formal structures in the definition which are necessary for the IIT algorithm to be applied. This ensured that our reconstruction is as general as possible, while still true to IIT 3.0. As a result, several notions used in classical IIT, e.g., system decomposition, subsystems or causation, are merely defined abstractly at first, without any reference to the usual interpretation of these concepts in physics.
In the related article [44], we show that these concepts can be meaningfully defined in any suitable process theory of physics, formulated in the language of symmetric monoidal categories. This approach can describe both classical and Quantum IIT and yields a complete formulation of contemporary IIT in a categorical framework.
IIT is constantly under development, with new and refined definitions being added every few years. We hope that our mathematical analysis of the theory might help to contribute to this development. For example, the working hypothesis that IIT is a fundamental theory, implies that technical problems of the theory need to be resolved. We have shown that our formalization allows one to address the technical problems mentioned in the literature. However, there are others which we have not addressed in this paper.
Most crucially, the IIT algorithm uses a series of maximalization and minimalization operations, unified in the notion of core subsystems in our formalization. In general, there is no guarantee that these operations lead to unique results, neither in classical nor Quantum IIT. Using different cores has major impact on the output of the algorithm, including the
Furthermore, the contemporary definition of IIT as well as our formalization rely on there being a finite number of subsystems of each system, which might not be the case in reality. Our formalisation may be extendable to the infinite case by assuming that every system has a fixed but potentially infinite indexing set
Finally, concerning more operational questions, it would be desirable to develop the connection to empirical measures such as the Perturbational Complexity Index (PCI) [7, 9] in more detail, as well as to define a controlled approximation of the theory whose calculation is less expensive. Both of these tasks may be achievable by substituting parts of our formalization with simpler mathematical structure.
On the conceptual side of things, it would be desirable to have a more proper understanding of how the mathematical structure of experiences spaces corresponds to the phenomenology of experience, both for the general definition used in our formalization—which comprises the minimal mathematical structure which is required for the IIT algorithm to be applied—and the specific definitions used in classical and Quantum IIT. In particular, it would be desirable to understand how it relates to the important notion of qualia, which is often asserted to have characteristic features such as ineffability, intrinsicality, non-contextuality, transparency or homogeneity [24]. For a first analysis toward this goal, cf [18]. A first proposal to add additional structure to IIT that accounts for relations between elements of consciousness in the case of spatial experiences was recently given in [14].
The original contributions presented in the study are included in the article/Supplementary Material, further inquiries can be directed to the corresponding author.
JK and ST conceived the project together and wrote the article together.
Author ST was employed by company Cambridge Quantum Computing Limited.
The remaining author declares that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
We would like to thank the organizers and participants of the Workshop on Information Theory and Consciousness at the Center for Mathematical Sciences of the University of Cambridge, of the Modeling Consciousness Workshop in Dorfgastein and of the Models of Consciousness Conference at the Mathematical Institute of the University of Oxford for discussions on this topic. Much of this work was carried out while Sean Tull was under the support of an EPSRC Doctoral Prize at the University of Oxford, from November 2018 to July 2019, and while Johannes Kleiner was under the support of postdoctoral funding at the Institute for Theoretical Physics of the Leibniz University of Hanover. We would like to thank both institutions.
1If the maximum does not exist, we define the core to be the empty system I.
2The problem of ‘unique existence’ has been studied extensively in category theory using universal properties and the notion of a limit. Rather than requiring that each
1. Barrett, AB. An Integration of Integrated Information Theory with Fundamental Physics. Front Psychol (2014) 5:63. doi:10.3389/fpsyg.2014.00063
2. Tim, B. On the Axiomatic Foundations of the Integrated Information Theory of Consciousness. Neurosci Conscious (2018). 2018(1) niy007. doi:10.1093/nc/niy007
3. Barrett, AB, and Mediano, PAM. The Phi Measure of Integrated Information Is Not Well-Defined for General Physical Systems. J Conscious Stud (2019). 21:133. doi:10.1021/acs.jpcb.6b05183.s001
4. Adam, B, and Seth, A. Practical Measures of Integrated Information for Time-Series Data. Plos Comput Biol (2011). 7(1):e1001052. doi:10.1371/journal.pcbi.1001052
5. Balduzzi, D, and Tononi, G. Integrated Information in Discrete Dynamical Systems: Motivation and Theoretical Framework. Plos Comput Biol (2008). 4(6):e1000091. doi:10.1371/journal.pcbi.1000091
6. Chang, AYC, Biehl, M, Yen, Y, and Kanai, R. Information Closure Theory of Consciousness. Front Psychol (2020). 11:121. doi:10.3389/fpsyg.2020.01504
7. Casarotto, S, Comanducci, A, Rosanova, M, Sarasso, S, Fecchio, M, Napolitani, M, et al. Stratification of Unresponsive Patients by an Independently Validated Index of Brain Complexity. Ann Neurol (2016). 80(5):718–29. doi:10.1002/ana.24779
8. Boly, MA. The Problem with Phi: a Critique of Integrated Information Theory. Plos Comput Biol (2015). 11(9):e1004286. doi:10.1371/journal.pcbi.1004286
9. Casali, AG, Gosseries, O, Rosanova, M, Boly, M, Sarasso, S, Casali, KR, et al. A Theoretically Based Index of Consciousness Independent of Sensory Processing and Behavior. Sci Translat Med (2015). 5:198ra105. doi:10.1126/scitranslmed.3006294
11. Hardy., L. Proposal to Use Humans to Switch Settings in a Bell Experiment (2017). arXiv preprint arXiv:1705.04620.
12. Haun, AM, Oizumi, M, Kovach, CK, Kawasaki, H, Oya, H, Howard, MA, et al. Contents of consciousness investigated as integrated information in direct human brain recordings. (2016). bioRxiv.
13. Hoffman, DD, and Prakash, C. Objects of Consciousness. Front Psychol (2014). 5:577. doi:10.3389/fpsyg.2014.00577
14. Haun, A, and Tononi, G. Why Does Space Feel the Way it Does? towards a Principled Account of Spatial Experience. Entropy (2019). 21(12):1160. doi:10.3390/e21121160
17. Kleiner, J, and Hoel, E. Falsification and Consciousness. Neurosci Consciousness (2021). 2021(1):niab001. doi:10.1093/nc/niab001
18. Kleiner, J. Mathematical Models of Consciousness. Entropy (2020). 22(6):609. doi:10.3390/e22060609
19. Koch, C, Massimini, M, Boly, M, and Tononi, G. Neural Correlates of Consciousness: Progress and Problems. Nat Rev Neurosci (2016). 17(5):307, 21. doi:10.1038/nrn.2016.22
20. Kremnizer, K, and Ranchin, A. Integrated Information-Induced Quantum Collapse. Found Phys (2015). 45(8):889–99. doi:10.1007/s10701-015-9905-6
22. Mason, JWD. Quasi‐conscious Multivariate Systems. Complexity (2016). 21(S1):125–47. doi:10.1002/cplx.21720
23. Kelvin, J. Interpretation-neutral Integrated Information Theory. J Conscious Stud (2019). 26(1-2):76–106. doi:10.1007/978-1-4419-9707-4_13
24. Metzinger, T. Grundkurs Philosophie des Geistes, Band 1. Berlin: Phänomenales Bewusstsein (2006).
25. Marshall, W, Gomez-Ramirez, J, and Tononi, G. Integrated Information and State Differentiation. Front Psychol (2016). 7:926. doi:10.3389/fpsyg.2016.00926
26. William, G, Mayner, P, Marshall, W, Albantakis, L, Findlay, G, Marchman, R, et al. PyPhi: A Toolbox for Integrated Information Theory. Plos Comput Biol (2018). 14(7):e1006343–21. doi:10.1371/journal.pcbi.1006343
27. Pedro, AM, Rosas, F, Carhart-Harris, RL, Seth, A, and Adam, B. Beyond Integrated Information: A Taxonomy of Information Dynamics Phenomena. (2019). arXiv preprint arXiv:1909.02297.
28. Pedro, AM, Seth, A, and Adam, B. Measuring Integrated Information: Comparison of Candidate Measures in Theory and Simulation. Entropy (2019). 21(1):17. doi:10.3390/e21010017
29. Mueller, MP. Could the Physical World Be Emergent Instead of Fundamental, and Why Should We Ask?(short Version). (2017). arXiv preprint arXiv:1712.01816.
30. Northoff, G, Tsuchiya, N, and Saigo, H. Mathematics and the Brain. A Category Theoretic Approach to Go beyond the Neural Correlates of Consciousness. (2019). bioRxiv.
31. Oizumi, M, Albantakis, L, and Tononi, G. From the Phenomenology to the Mechanisms of Consciousness: Integrated Information Theory 3.0. PLoS Comput Biol (2014). 10(5):e1003588. doi:10.1371/journal.pcbi.1003588
33. Anthony, P. Consciousness as Integrated Information a Provisional Philosophical Critique. J Conscious Stud (2013). 20(1–2):180–206. doi:10.2307/25470707
34. Pedro, R. Proceedings of the Workshop on Combining Viewpoints in Quantum Theory, 19–22. Edinburgh, UK: ICMS (2018).
36. Salamon, D. Measure and Integration. London: European Mathematical Society (2016). doi:10.4171/159
37. Seth, A, Adam, B, and Barnett, L. Causal Density and Integrated Information as Measures of Conscious Level. Philos Trans A Math Phys Eng Sci (1952). 369:3748–67. doi:10.1098/rsta.2011.0079
38. Sharma, G, Wu, W, and Edul, N. Dalal. The CIEDE2000 Color-Difference Formula: Implementation Notes, Supplementary Test Data, and Mathematical Observations. London: COLOR Research and Application (2004).
39. Miguel Signorelli, C, Wang, Q, and Khan, I. A Compositional Model of Consciousness Based on Consciousness-Only. (2020). arXiv preprint arXiv:2007.16138.
40. Tononi, G, Boly, M, Massimini, M, and Koch, C. Integrated Information Theory: from Consciousness to its Physical Substrate. Nat Rev Neurosci (2016). 17(7):450, 61. doi:10.1038/nrn.2016.44
41. Tegmark, M. Consciousness as a State of Matter. Chaos, Solitons Fractals (2015). 76:238–70. doi:10.1016/j.chaos.2015.03.014
42. Tegmark, M. Improved Measures of Integrated Information. PLoS Comput Biol (2016). 12(11). doi:10.1371/journal.pcbi.1005123
43. Tsuchiya, N, Haun, A, Cohen, D, and Oizumi, M. Empirical Tests of the Integrated Information Theory of consciousnessThe Return of Consciousness: A New Science on Old Questions. London: Axel and Margaret Ax. son Johnson Foundation (2016). p. 349–74.
44. Tull, S, and Kleiner, J. Integrated Information in Process Theories. J Cognit Sci (2021). 22:135–55.
45. Tononi, G. An Information Integration Theory of Consciousness. BMC Neurosci (2004). 5(1):42. doi:10.1186/1471-2202-5-42
46. Tononi, G. Consciousness, Information Integration, and the Brain. Prog Brain Res (2005). 150:109–26. doi:10.1016/s0079-6123(05)50009-8
47. Tononi, G. Consciousness as Integrated Information: a Provisional Manifesto. Biol Bull (2008). 215(3):216–42. doi:10.2307/25470707
48. Tononi, G. Integrated Information Theory. Scholarpedia (2015). 10(1):4164. doi:10.4249/scholarpedia.4164
49. Tsuchiya, N, Taguchi, S, and Saigo, H. Using Category Theory to Assess the Relationship between Consciousness and Integrated Information Theory. Neurosci Res (2016). 107(1–7):133. doi:10.1016/j.neures.2015.12.007
50. Zanardi, P, Tomka, M, and Venuti, LC. Quantum Integrated Information Theory. (2018). arXiv preprint arXiv:1806.01421, 2018 Comparison with Standard Presentation of IIT 3.0.
In Section 9, we have defined the system class and cause-effect repertoires which underlie classical IIT. The goal of this appendix is to explain in detail why applying our definition of the IIT algorithm yields IIT 3.0 defined by Tononi et al. In doing so, we will mainly refer to the terminology used in [25, 26, 31, 48]. We remark that a particularly detailed presentation of the algorithm of the theory, and of how the cause and effect repertoire are calculated, is given in the Supplementary Material S1 of [26].
The systems of classical IIT are given in Section 9.1. They are often represented as graphs whose nodes are the elements
in [25]. For each probability distribution
In contemporary presentations of the theory ([25], p. 14] or [48]), the effect repertoire is defined as
and
Here,
In our notation, the right hand side of Eq. 35 is exactly given by the right-hand side of Eq. 25, i.e.
Similarly, the cause repertoire is defined as ([25], p. 14] or [48])
and
where
Here, the whole right hand side of Eq. 37 gives the probability of finding the purview in state z at time t − 1 if the system is prepared in state mi,t at time t. In our terminology this same distribution is given by Eq. 27, where λ is the denominator in Eq. 37. Taking the product of these distributions and re-normalising is then precisely Eq. 28.
As a result, the cause and effect repertoire in the sense of [31] correspond precisely in our notation to
The behavior of the cause- and effect-repertoires when decomposing a system is described, in our formalism, by decompositions (Definition 5). Hence a decomposition
in [25], when expanded to the full state space, and equally so for the effect repertoire.
Next, we explicitly unpack our form of the IIT algorithm to see how it compares in the case of classical IIT with [31]. In our formalism, the integrated information φ of a mechanism M of system S when in state s is
defined in Eq. 10. This definition conjoins several steps in the definition of classical IIT. To explain why it corresponds exactly to classical IIT, we disentangle this definition step by step.
First, consider
in [48], where
The integration scaling in Eq. 10 simply changes the intensity of an element of
Consider now the collections (9) of decomposition maps. Applying Definition 9, the core of
Finally, to fully account for Eq. 10, we note that the integration scaling of a pair of decomposition maps rescales both elements to the minimum of the two integration levels. Hence the integration scaling of the pair
in [48], where
In summary, the following operations are combined in Eq. 10. The core of
i.e., the pair of maximally irreducible repertoires scaled by
We finally remark that it is also possible in classical IIT that a cause repertoire value
We finally explain how the system level definitions correspond to the usual definition of classical IIT.
The Q-shape
When comparing
Using Definition 3 and the fact that each concept’s intensity is
where
We remark that in Supplementary Material S1 of [26], an additional step is mentioned which is not described in any of the other papers we consider. Namely, if the integrated information of a mechanism is non-zero before cutting but zero after cutting, what is compared is not the distance of the corresponding concepts as in Eq. 40, but in fact the distance of the original concept with a special null concept, defined to be the unconstrained repertoire of the cut system. We have not included this step in our definitions, but it could be included by adding a choice of distinguished point to Example 3 and redefining the metric correspondingly.
In Eq. 14 the above comparison is being conducted for every subsystem of a system S. The subsystems of S are what is called candidate systems in [31], and which describe that ‘part’ of the system that is going to be conscious according to the theory (cf. below). Crucially, candidate systems are subsystems of S, whose time evolution is defined in Eq. 22. This definition ensures that the state of the elements of S which are not part of the candidate system are fixed in their current state, i.e., constitute background conditions as required in the contemporary version of classcial IIT [26].
Eq. 14 then compares the Q-shape of every candidate system to the Q-shape of all of its cuts, using the distance function described above, where the cuts are defined in Eq. 23. The cut system with the smallest distance gives the system-level minimum information partition and the integrated (conceptual) information of that candidate system, denoted as
The core integration scaling finally picks out that candidate system with the largest integrated information value. This candidate system is the major complex M of S, the part of S which is conscious according to the theory as part of the exclusion postulate of IIT. Its Q-shape is the maximally irreducible conceptual structure (MICS), also called quale sensu lato. The overall integrated conceptual information is, finally, simply the intensity of
Expanding our definitions, and denoting the major complex by M with state
This encodes the Q-shape
Keywords: Integrated Information Theory, experience spaces, mathematical consciousness science, IIT 3.0, IIT 3.x, generalized IIT
Citation: Kleiner J and Tull S (2021) The Mathematical Structure of Integrated Information Theory. Front. Appl. Math. Stat. 6:602973. doi: 10.3389/fams.2020.602973
Received: 07 September 2020; Accepted: 23 December 2020;
Published: 04 June 2021.
Edited by:
Heng Liu, Guangxi University for Nationalities, ChinaReviewed by:
Guangming Xue, Guangxi University of Finance and Economics, ChinaCopyright © 2021 Kleiner and Tull. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Johannes Kleiner, am9oYW5uZXMua2xlaW5lckBsbXUuZGU=; Sean Tull, c2Vhbi50dWxsQGNhbWJyaWRnZXF1YW50dW0uY29t
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.