 Alexander Jung
Alexander Jung
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Appl. Math. Stat. , 10 July 2018
Sec. Mathematics of Computation and Data Science
Volume 4 - 2018 | https://doi.org/10.3389/fams.2018.00022
This article is part of the Research Topic Compressed Sensing over Complex Networks for Learning from Big Data over Networks View all 4 articles
This paper investigates the computational complexity of sparse label propagation which has been proposed recently for processing network-structured data. Sparse label propagation amounts to a convex optimization problem and might be considered as an extension of basis pursuit from sparse vectors to clustered graph signals representing the label information contained in network-structured datasets. Using a standard first-order oracle model, we characterize the number of iterations for sparse label propagation to achieve a prescribed accuracy. In particular, we derive an upper bound on the number of iterations required to achieve a certain accuracy and show that this upper bound is sharp for datasets having a chain structure (e.g., time series).
A powerful approach to processing massive datasets is via using graph models. In particular, we consider datasets which can be characterized by an “empirical graph” (cf. [1, Ch. 11]) whose nodes represent individual data points and whose edges connect data points which are similar in an application-specific sense. The empirical graph for a particular dataset might be obtained by (domain) expert knowledge, an intrinsic network structure (e.g., for social network data) or in a data-driven fashion by imposing smoothness constrains on observed realizations of graph signals (which serve as training data) [2–8]. Besides the graph structure, datasets carry additional information in the form of labels (e.g., class membership) associated with individual data points. We will represent such label information as graph signals defined over the empirical graph [9].
Using graph signals for representing datasets is appealing for several reasons. Indeed, having a graph model for datasets facilitates scalable distributed data processing in the form of message passing over the empirical graph [10]. Moreover, graph models allow to cope with heterogeneous datasets containing mixtures of different data types, since they only require an abstract notion of similarity between individual data points. In particular, the structure encoded in the graph model of a dataset enables to capitalize, by exploiting the similarity between data points, on massive amounts of unlabeled data via semi-supervised learning [1]. This is important, since labeling of data points is often expensive and therefore label information is typically available only for a small fraction of the overall dataset. The labels of individual data points induce a graph signal which is defined over the associated empirical graph. We typically only have access to the signal values (labels) of few data points and the goal is learn or recover the remaining graph signal values (labels) for all other data points.
The processing of graph signals relies on particular models for graph signals. A prominent line of uses applies spectral graph theory to extend the notion of band-limited signals from the time domain (which corresponds to the special case of a chain graph) to arbitrary graphs [1, 9, 11–14]. These band-limited graph signals are smooth in the sense of having a small variation over well-connected subsets of nodes, where the variation is measured by the Laplacian quadratic form. However, our approach targets datasets whose labels induce piece-wise constant graph signals, i.e., the signal values (labels) of data points belonging to well connected subset of data points (clusters) [15], are nearly identical. This signal model is useful, e.g., in change-point detection, image segmentation or anomaly detection where signal values might change abruptly [16–20].
The closest to our work is Hallac et al.[16], Sharpnack et al. [17], and Wang et al.[18] for general graph models, as well as a line of work on total variation-based image processing [21–23]. In contrast to Chambolle [21], Chambolle and Pock [22], and Pock and Chambolle. [23], which consider only regular grid graphs, our approach applies to arbitrary graph topology. The methods presented in Fan and Guan [16], Sharpnack et al. [17], and Wang et al. [20] apply also to arbitrary graph topologies but require (noisy) labels available for all data points, while we consider labels available only on a small subset of nodes.
In section 2, we formulate the problem of recovering clustered graph signals as a convex optimization problem. We solve this optimization problem by applying a preconditioned variant of the primal-dual method of Pock and Chambolle [23]. As detailed in section 3, the resulting algorithm can be implemented as a highly scalable message passing protocol, which we coin sparse label propagation (SLP). In section 4, we present our main result which is an upper bound on the number of SLP iterations ensuring a particular accuracy. We also discuss the tightness of the upper bound for datasets whose empirical graph is a chain graph (e.g, time series).
Given a vector , we define the norms and , respectively. The spectral norm of a matrix D is denoted . For a positive semidefinite (psd) matrix Q ∈ ℝn×n, with spectral decomposition , we define its square root as . For a positive definite matrix Q, we define the norm . The signum sign{x} of a vector x = (x1, …, xd) is defined as the vector with the scalar signum function
Throughout this paper we consider convex functions g(x) whose epigraphs epi g: = {(x, t):x ∈ ℝn, g(x) ≤ t} ⊆ ℝn×ℝ are non-empty closed convex sets [24]. Given such a convex function g(x), we denote its subdifferential at by
and its convex conjugate function by Boyd and Vandenberghe [25]
We can re-obtain a convex function g(y) from its convex conjugate via [25]
We consider network-structured datasets which are represented by an undirected weighted graph , referred to as the “empirical graph” (see Figure 1). The nodes of the empirical graph represent individual data points, such as user profiles in a social network or documents of a repository. An undirected edge of the empirical graph encodes a notion of (physical or statistical) proximity of neighboring data points, such as profiles of befriended social network users or documents which have been co-authored by the same person. This network structure is identified with conditional independence relations within probabilistic graphical models (PGM) [4–8].
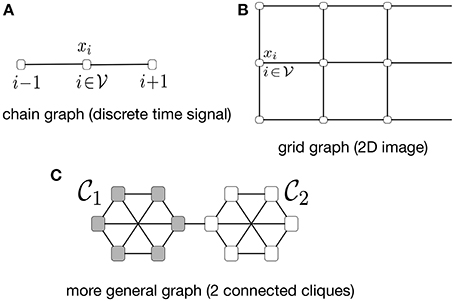
Figure 1. Some examples of network-structured datasets with associated empirical graph being (A) a chain graph (discrete time signals), (B) grid graph (2D-images) and (C) a clustered graph (social networks).
As opposed to PGM, we consider a fully deterministic graph-based model which does not invoke an underlying probability distribution for the observed data. In particular, given an edge , the nonzero value Wi,j > 0 represents the amount of similarity between the data points . The edge set can be read off from the non-zero pattern of the weight matrix W ∈ ℝN×N since
According to (4), we could in principle handle network-structured datasets using traditional multivariate (vector/matrix based) methods. However, putting the emphasis on the empirical graph leads naturally to scalable algorithms which are implemented as message passing methods (see Algorithm 2 below).
The neighborhood and weighted degree (strength) di of node are
In what follows we assume the empirical graph to be connected, i.e., di > 0 for all nodes and having no self-loops such that Wi,i = 0 for all . The maximum (weighted) node degree is
It will be convenient to orient the undirected empirical graph , which yields the directed version . The orientation amounts to declaring for each edge e = {i, j} one node as the head (origin node) and the other node as the tail (destination node) denoted e+ and e−, respectively. Given a set of edges in the undirected graph , we denote the corresponding set of directed edges in as . The incidence matrix of is [16]
If we number the nodes and orient the edges in the chain graph in Figure 1A from left to right, its weighted incidence matrix would be
The directed neighborhoods of a node are defined as and , respectively. We highlight that the particular choice of orientation for the empirical graph has no effect on our results andmethods and will be only used for notational convenience.
In many applications we can associate each data point with a label xi, e.g., in a social network application the label xi might encode the group membership of the member in a social network . We interpret the labels xi as values of a graph signal x defined over the empirical graph . Formally, a graph signal defined over the graph maps each node to the graph signal value x[i] ∈ ℝ. Since acquiring labels is often costly and error-prone, we typically have access to a few noisy labels for the data points within a (small) subset of nodes in the empirical graph. Thus, we are interested in recovering the entire graph signal x from knowledge of its values on a small subset of labeled nodes . The signal recovery will be based on a clustering assumption [1]. Clustering Assumption (informal). Consider a graph signal whose signal values are the (mostly unknown) labels of the data points . The signal values x[i], x[j] at nodes within a well-connected subset (cluster) of nodes in the empirical graph are similar, i.e., x[i] ≈ x[j].
This assumption of clustered graph signals x can be made precise by requiring a small total variation (TV)
The incidence matrix D (cf. (7)) allows to represent the TV of a graph signal conveniently as
We note that related but different measures for the total variation of a graph signal have been proposed previously (see, e.g., [26, 27]). The definition (8) is appealing for several reasons. First, it conforms with the class of piece-wise constant or clustered graph signals which has proven useful in several applications including meteorology and binary classification [29, 28]. Second, as we demonstrate in what follows, the definition (8) allows to derive semi-supervised learning methods which can be implemented by efficient massing passing over the underlying empirical graph and thus ensure scalability of the resulting algorithm to large-scale (big) data.
A sensible strategy for recovering a graph signal with small TV is via minimizing the TV while requiring consistency with the observed noisy labels , i.e.,
The objective function of the optimization problem (10) is the seminorm ||x||TV, which is a convex function. 1 Since moreover the constraints in (10) are linear, the optimization problem (10) is a convex optimization problem [25]. Rather trivially, the problem (10) is equivalent to
Here, we used the constraint set which collects all graph signals which match the observed labels for the nodes of the sampling set .
The usefulness of the learning problem (10) depends on two aspects: (i) the deviation of the solutions of (10) from the true underlying graph signal and (ii) the difficulty (complexity) of computing the solutions of (10). The first aspect has been addressed in [30] which presents precise conditions on the sampling set and topology of the empirical graph such that any solution of (10) is close to the true underlying graph signal if it is (approximately) piece-wise constant over well-connected subsets of nodes (clusters). The focus of this paper is the second aspect, i.e., the difficulty or complexity of computing approximate solutions of (10).
In what follows we will apply an efficient primal-dual method to solving the convex optimization problem (10). This primal-dual method is appealing since it provides a theoretical convergence guarantee and also allows for an efficient implementation as message passing over the underlying empirical graph (cf. Algorithm 2 below). We coin the resulting semi-supervised learning algorithm sparse label propagation (SLP) since it bears some conceptual similarity to the ordinary label propagation (LP) algorithm for semi-supervised learning over graph models. In particular, LP algorithms can be interpreted as message passing methods for solving a particular recovery (or, learning) problem [1, Chap 11.3.4.]:
The recovery problem (12) amounts to minimizing the weighted sum of squares, while SLP (10) minimize a weighted sum of absolute values, of the signal differences (x[i] − x[j])2 arising over the edges in the empirical graph . It turns out that using the absolute values of signal differences instead of their squares allows SLP methods to accurately learn graph signals x which vary abruptly over few edges, e.g., clustered graph signals considered in [29, 28]. In contrast, LP methods tends to smooth out such abrupt signal variations.
The SLP problem (10) is also closely related to the recently proposed network Lasso [18, 31]
Indeed, according to Lagrangian duality [32, 25], by choosing λ in (13) suitably, the solutions of (13) coincide with those of (10). The tuning parameter λ trades small empirical label fitting error against small total variation of the learned graph signal . Choosing a large value of λ enforces small total variation of the learned graph signal, while using a small value for λ puts more emphasis on the empirical error. In contrast to network Lasso (13), which requires to choose the parameter λ (e.g., using (cross-)validation [33, 34]), the SLP method (10) does not require any parameter tuning.
The recovery problem (10) is a convex optimization problem with a non-differentiable objective function, which precludes the use of standard gradient methods such as (accelerated) gradient descent. However, both the objective function and the constraint set of the optimization problem (10) have rather a simple structure individually. This suggests the use of efficient proximal methods [35] for solving (10). In particular, we apply a preconditioned variant of the primal-dual method introduced by [36] to solve (10).
In order to apply the primal-dual method of [36], we reformulate (10) as an unconstrained problem (see (11))
The function h(x) in (14) is the indicator function (cf. [24]) of the convex set and can be described also via its epigraph
It will be useful to define another optimisation problem which might be considered as a dual problem to (14), i.e.,
Note that the objective function of the dual SLP problem (15) involves the convex conjugates h*(x) and g*(y) (cf. (2)) of the convex functions h(x) and g(y) which define the primal SLP problem (14).
By elementary convex analysis [24], the solutions of (14) are characterized by the zero-subgradient condition
A particular class of iterative methods for solving (14), referred to as proximal methods, is obtained via fixed-point iterations of some operator whose fixed-points are precisely the solutions of (16), i.e.,
In general, the operator is not unique, i.e., there are different choices for such that (17) is valid. These different choices for the operator in (17) result in different proximal methods [35].
One approach to constructing the operator in (17) is based on convex duality [24, Thm. 31.3], according to which a graph signal solves (14) if and only if there exists a (dual) vector such that
The dual vector represents a signal defined over the edges in the empirical graph , with the entry ŷSLP[e] being the signal value associated with the particular edge .
Let us now rewrite the two coupled conditions in (18) as
with the invertible diagonal matrices (cf. (4) and (5))
The specific choice (20) for the matrices Γ and Λ can be shown to satisfy [23, Lemma 2]
which will turn out to be crucial for ensuring the convergence of the iterative algorithm we will propose for solving (14).
It will be convenient to define the resolvent operator for the functions g*(y) and h(x) (cf. (14) and (2)), [23, section 1.1.]
We can now rewrite the optimality condition (3) (for , to be primal and dual optimal) more compactly as
The characterization (23) of the solution for the SLP problem (10) leads naturally to the following fixed-point iterations for finding (cf.[23])
The fixed-point iterations (24) are similar to those considered in [36, section 6.2.] for grid graphs arising in image processing. In contrast, the iterations (24) are formulated for an arbitrary graph (network) structure which is represented by the incidence matrix . By evaluating the application of the resolvent operators (cf. (22)), we obtain simple closed-form expressions (cf. [36, section 6.2.]) for the updates in (24) yielding, in turn, Algorithm 1.

Algorithm 1. Sparse Label Propagation
Note that the Algorithm 1 does not directly output the iterate but its running average . Computing the running average (see step 8 in Algorithm 1) requires only little effort but allows for a simpler convergence analysis (see the proof of Theorem 1 in the Appendix).
One of the appealing properties of Algorithm 1 is that it allows for a highly scalable implementation via message passing over the underlying empirical graph . This message passing implementation, summarized in Algorithm 1, is obtained by implementing the application of the graph incidence matrix D and its transpose DT (cf. steps 2 and 5 of Algorithm 1) by local updates of the labels , i.e., updates which involve only the neighborhoods , of all edges in the empirical graph .
Note that executing Algorithm 2 does not require to collect global knowledge about the entire empircal graph (such as the maximum node degree dmax (6)) at some central processing unit. Indeed, if we associate each node in the data graph with a computational unit, the execution of Algorithm 2 requires each node only to store the values and . Moreover, the number of arithmetic operations required at each node during each time step is proportional to the number of the neighbors . These characteristics allow Algorithm 2 to scale to massive datasets (big data) if they can be represented using sparse networks having a small maximum degree dmax (6)). The datasets generated in many important applications have been found to be accurately represented by such sparse networks [37].
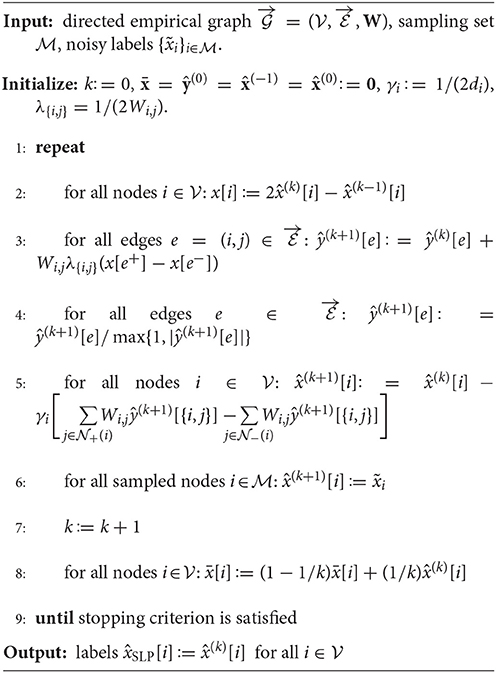
Algorithm 2. Sparse Label Propagation as Message Passing
There are various options for the stopping criterion in Algorithm 1, e.g., using a fixed number of iterations or testing for sufficient decrease of the objective function (cf.[38]). When using a fixed number of iterations, the following characterization of the convergence rate of Algorithm 1, we need to have a precise characterization of how many iterations are required to guarantee a prescribed accuracy of the resulting estimate. Such a characterization is provided by the following result.
Theorem 1. Consider the sequences and obtained from the update rule (24) and starting from some arbitrary initalizations and . The averages
obtained after K iterations (for k = 0, …, K − 1) of (24), satisfy
with . Moreover, the sequence , for K = 1, …, is bounded.
Proof. see Appendix.□
According to (26), the sub-optimality in terms of objective value function incurred by the output of Algorithm 1 after K iterations is bounded as
where the constant c does not depend on K but might depend on the empirical graph via its weighted incidence matrix D (cf. (7)) as well as on the initial labels . The bound (27) suggests that in order to ensure reducing the sub-optimality by a factor of two, we need to run Algorithm 1 for twice as many iterations.
Let us now show that the bound (27) on the convergence speed is essentially tight. What is more, the bound cannot be improved substantially by any learning method, such as SLP (14) or network Lasso (13), which is implemented as message passing over the underlying empirical graph . To this end we consider a dataset whose empirical graph is a weighted chain graph (see Figure 2) with nodes which are connected by N − 1 edges . The weights of the edges are Wi,i+1 = 1/i. The labels of the data points induce a graph signal x defined over with x[i] = 1 for all nodes i = {1, …, N − 1} and x[N] = 0. We observe the graph signal noise free on the sampling set , resulting in the observations and . According to [30, Theorem 3], the solution of the SLP problem (14) is unique and coincides with the true underlying graph signal x. Thus, the optimal objective function value is . On the other hand, the output of Algorithm 1 after K iterations satisfies and for all nodes i ∈ {K + 1, …, N}. Thus,
implying, in turn,
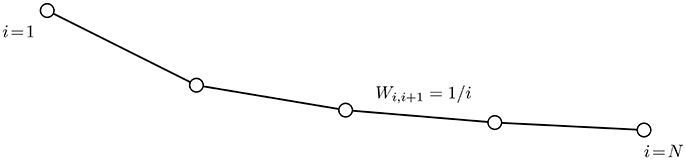
Figure 2. The empirical graph is a chain graph with edge weights Wi,i+1 = 1/i. We aim at recovering the graph a graph signal from the observations and using Algorithm 2.
For the regime of K/N ≪ 1 which is reasonable for big data applications where the number of iterations K computed in Algorithm 1 is small compared to the size N of the dataset, the dependency of the lower bound (29) on the number of iterations is essentially ∝1/K and therefore matches the upper bound (27). This example indicates that, for certain structure of edge weights, chain graphs are among the most challenging topologies regarding the convergence speed of SLP.
We have studied the intrinsic complexity of sparse label propagation by deriving an upper bound on the number of iterations required to achieve a given accuracy. This upper bound is essentially tight as it cannot be improved substantially for the particular class of graph signals defined over a chain graph (such as time series).
The author confirms being the sole contributor of this work and approved it for publication.
The author declares that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fams.2018.00022/full#supplementary-material
1. ^The seminorm ||x||TV is convex since it is homogeneous (||αx||TV = |α|||x||TV for α ∈ ℝ) and satisfies the triangle inequality (||x+y||TV ≤ ||x||TV+||y||TV). These two properties imply convexity [25, section 3.1.5].
1. Chapelle O, Schölkopf B, Zien A. editors. Semi-Supervised Learning. Cambridge, Massachusetts: The MIT Press (2006).
2. Zhu Z, Jin S, Song X, Luo X. Learning graph structure with stationary graph signals via first-order approximation. In: 2017 22nd International Conference on Digital Signal Processing (DSP), (London) (2017). 1–5.
3. Kalofolias V. How to learn a graph from smooth signals. In: A. Gretton and C. C. Robert, editors, Proceedings of the 19th International Conference on Artificial Intelligence and Statistics, volume 51 of Proceedings of Machine Learning Research, (Cadiz) (2016). 920–9.
4. Jung A. Learning the conditional independence structure of stationary time series: a multitask learning approach. IEEE Trans. Signal Process. (2015) 63:21. doi: 10.1109/TSP.2015.2460219
5. Jung A, Hannak G, Görtz N. Graphical LASSO Based Model Selection for Time Series. IEEE Sig. Proc. Lett. (2015) 22:1781–5.
6. Jung A, Heckel R, Bölcskei H, Hlawatsch F. Compressive nonparametric graphical model selection for time series. In: IEEE International Conference on Acoustics, Speech and Signal Processing (Florence) (2014).
7. Quang NT, Jung A. Learning conditional independence structure for high-dimensional uncorrelated vector processes. In: IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (New Orleans, LA) (2017). 5920–5924.
8. Quang NT, Jung A. On the sample complexity of graphical model selection from non-stationary samples. In: IEEE International Conference on Acoustics, Speech and Signal Processing (Calgary, AB) (2018).
9. Zhu X, Ghahramani Z. Learning From Labeled and Unlabeled Data With Label Propagation. Technical report, School of Computer Science Carnegie Mellon University (2002).
10. Sandryhaila A, Moura JMF. Big data analysis with signal processing on graphs: Representation and processing of massive data sets with irregular structure. IEEE Signal Process. Magaz. (2014) 31:80–90.
11. Chen S, Sandryhaila A, Moura JMF, Kovačević J. Signal denoising on graphs via graph filtering. In: IEEE Global Conference on Signal and Information Processing (Atlanta, GA), (2014). 872–876.
12. Chen S, Sandryhaila A, Kovačević J. Sampling theory for graph signals. In: IEEE International Conference on Acoustics, Speech and Signal Processing (Brisbane, QLD) (2015). 3392–6.
13. Chen S, Varma R, Sandryhaila A, Kovačević J. Discrete signal processing on graphs: Sampling theory. IEEE Trans. Signal Process. (2015) 63:6510–23.
14. Gadde A, Anis A, Ortega A. Active semi-supervised learning using sampling theory for graph signals. In: Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (New York, NY) (2014). 492–501.
16. Sharpnack J, Rinaldo A, Singh A. Sparsistency of the edge lasso over graphs. AIStats (JMLR WCP) (La Palma) (2012).
17. Wang Y-X, Sharpnack J, Smola AJ, Tibshirani RJ. Trend filtering on graphs. J. Mach. Lear. Res. (2016). 17:15–14.
18. Hallac D, Leskovec J, Boyd S. Network lasso: clustering and optimization in large graphs. In: Proceedings SIGKDD (Sydney) (2015). 387–96.
19. Chen S, Varma R, Singh A, Kovačević J. Representations of piecewise smooth signals on graphs. In: Proc. IEEE ICASSP 2016, pages, March 2016.
20. Fan Z, Guan L. Approximate l0-penalized estimation of piecewise-constant signals on graphs. (2017) arxiv.
21. Chambolle A. An algorithm for total variation minimization and applications. J. Math. Imaging Vis. (2004) 20:89–97. doi: 10.1023/B:JMIV.0000011325.36760.1e
22. Chambolle V, Pock T. An introduction to continuous optimization for imaging. Acta Numer. (2016) 25:161–319. doi: 10.1017/S096249291600009X
23. Pock T. Chambolle A. Diagonal preconditioning for first order primal-dual algorithms in convex optimization. In: IEEE International Conference on Computer Vision (ICCV), (Barcelona) (2011).
26. Chen S, Sandryhaila A, Moura JMF, Kovačević J. Signal recovery on graphs: Variation minimization. IEEE Trans Signal Process. (2015) 63:4609–24. doi: 10.1109/TSP.2015.2441042
27. Sandryhaila A, Moura JMF. Discrete signal processing on graphs. IEEE Trans. Signal Process. (2013) 61:1644–56.
28. Chen S, Varma R, Sandryhaila A, Kovačević J. Representations of piecewise smooth signals on graphs. In: 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (Shanghai) (2016). 6370–74.
30. Jung A, Hulsebos M. The network nullspace property for compressed sensing of big data over networks. (2018) Front. Appl. Math. Stat. 4:9. doi: 10.3389/fams.2018.00009
34. Hastie T, Tibshirani R, Friedman J. The Elements of Statistical Learning. Springer; New York, NY: Springer Series in Statistics (2001).
36. Chambolle A, Pock T. A first-order primal-dual algorithm for convex problems with applications to imaging. J Math Imaging Vi. (2011) 40:120–145. doi: 10.1007/s10851-010-0251-1
Keywords: graph signal processing, semi-supervised learning, convex optimization, compressed sensing, complexity, complex networks, big data
Citation: Jung A (2018) On the Complexity of Sparse Label Propagation. Front. Appl. Math. Stat. 4:22. doi: 10.3389/fams.2018.00022
Received: 26 April 2018; Accepted: 08 June 2018;
Published: 10 July 2018.
Edited by:
Ding-Xuan Zhou, City University of Hong Kong, Hong KongReviewed by:
Shao-Bo Lin, Wenzhou University, ChinaCopyright © 2018 Jung. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Alexander Jung, YWxleGFuZGVyLmp1bmdAYWFsdG8uZmk=
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.