 Alexander Jung
Alexander Jung Nguyen Tran
Nguyen Tran Alexandru Mara
Alexandru Mara
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Appl. Math. Stat. , 19 January 2018
Sec. Mathematics of Computation and Data Science
Volume 3 - 2017 | https://doi.org/10.3389/fams.2017.00028
This article is part of the Research Topic Compressed Sensing over Complex Networks for Learning from Big Data over Networks View all 4 articles
The “least absolute shrinkage and selection operator” (Lasso) method has been adapted recently for network-structured datasets. In particular, this network Lasso method allows to learn graph signals from a small number of noisy signal samples by using the total variation of a graph signal for regularization. While efficient and scalable implementations of the network Lasso are available, only little is known about the conditions on the underlying network structure which ensure network Lasso to be accurate. By leveraging concepts of compressed sensing, we address this gap and derive precise conditions on the underlying network topology and sampling set which guarantee the network Lasso for a particular loss function to deliver an accurate estimate of the entire underlying graph signal. We also quantify the error incurred by network Lasso in terms of two constants which reflect the connectivity of the sampled nodes.
In many applications ranging from image processing, social networks to bioinformatics, the observed datasets carry an intrinsic network structure. Such datasets can be represented conveniently by signals defined over a “data graph” which models the network structure inherent to the dataset [1, 2]. The nodes of this data graph represent individual data points which are labeled by some quantity of interest, e.g., the class membership in a classification problem. We represent this label information as a graph signal whose value for a particular node is given by its label [1, 3–8]. This graph signal representation of datasets allows to apply efficient methods from graph signal processing (GSP) which are obtained, in turn, by extending established methods (e.g., fast filtering and transforms) from discrete time signal processing (over chain graphs) to arbitrary graphs [9–11].
The resulting graph signals are typically clustered, i.e., these signals are nearly constant over well connected subset of nodes (clusters) in the data graph. Exploiting this clustering property enables the accurate recovery of graph signals from few noisy samples. In particular, using the total variation to measure how well a graph signal conforms with the underlying cluster structure, the authors of Hallac et al. [12] obtain the network Lasso (nLasso) by adapting the well-known Lasso estimator which is widely used for learning sparse models [13, 14]. The nLasso can be interpreted as an instance of the regularized empirical risk minimization principle, using total variation of a graph signal for the regularization. Some applications where the use of nLasso based methods has proven beneficial include housing price prediction and personalized medicine [12, 15].
A scalable implementation of the nLasso has been obtained via the alternating direction method of multipliers (ADMM) [16]. However, the authors of Boyd et al. [16] do not discuss conditions on the underlying network structure which ensure success of the network Lasso. We close this gap in the understanding of the performance of network Lasso, by deriving sufficient conditions on the data graph (cluster) structure and sampling set such that nLasso is accurate. To this end, we introduce a simple model for clustered graph signals which are constant over well connected groups or clusters of nodes. We then define the notion of resolving sampling sets, which relates the cluster structure of the data graph to the sampling set. Our main contribution is an upper bound on the estimation error obtained from nLasso when applied to resolving sampling sets. This upper bound depends on two numerical parameters which quantify the connectivity between sampled nodes and cluster boundaries.
Much of the existing work on recovery conditions and methods for graph signal recovery (e.g., [17–22]), relies on spectral properties of the data graph Laplacian matrix. In contrast, our approach is based directly on the connectivity properties of the underlying network structure. The closest to our work is Sharpnack et al. [23] and Wang et al. [24], which provide sufficient conditions such that a special case of the nLasso (referred to as the “edge Lasso”) accurately recovers piece-wise constant (or clustered) graph signals from noisy observations. However, these works require access to fully labeled datasets, while we consider datasets which are only partially labeled (as it is typical for machine learning applications where label information is costly).
The problem setting considered is formalized in section 2. In particular, we show how to formulate the problem of learning a clustered graph signal from a small amount of signal samples as a convex optimization problem, which is underlying the nLasso method. Our main result, i.e., an upper bound on the estimation error of nLasso is stated in section 3. Numerical experiments which illustrate our theoretical findings are discussed in section 4.
We will conform to standard notation of linear algebra as used, e.g., in Golub and Van Loan [25]. For a binary variable b, we denote its negation as .
We consider datasets which are represented by a network model, i.e., a data graph with node set , edge set and weight matrix . The nodes of the data graph represent individual data points. For example, the node might represent a (super-)pixel in image processing, a neuron of a neural network [26] or a social network user profile [27].
Many applications naturally suggest a notion of similarity between individual data points, e.g., the profiles of befriended social network users or grayscale values of neighboring image pixels. These domain-specific notions of similarity are represented by the edges of the data graph , i.e., the nodes representing similar data points are connected by an undirected edge . We denote the neighborhood of the node by . It will be convenient to associate with each undirected edge {i, j} a pair of directed edges, i.e., (i, j) and (j, i). With slight abuse of notation we will treat the elements of the edge set either as undirected edges {i, j} or as pairs of two directed edges (i, j) and (j, i).
In some applications it is possible to quantify the extent to which data points are similar, e.g., via the physical distance between neighboring sensors in a wireless sensor network application [28]. Given two similar data points , which are connected by an edge , we will quantify the strength of their connection by the edge weight Wi, j > 0 which we collect in the symmetric weight matrix . The absence of an edge between nodes is encoded by a zero weight Wi, j = 0. Thus the edge structure of the data graph is fully specified by the support (locations of the non-zero entries) of the weight matrix W.
Beside the network structure, encoded in the data graph , datasets typically also contain additional labeling information. We represent this additional label information by a graph signal defined over . A graph signal x[·] is a mapping , which associates every node with the signal value x[i]∈ℝ (which might representing a label characterizing the data point). We denote the set of all graph signals defined over a graph by .
Many machine learning methods for network structured data rely on a “cluster hypothesis” [4]. In particular, we assume the graph signals x[·] representing the label information of a dataset conforms with the cluster structure of the underlying data graph. Thus, any two nodes out of a well-connected region (“cluster”) of the data graph tend to have similar signal values, i.e., x[i] ≈ x[j]. Two important application domains where this cluster hypothesis has been applied successfully are digital signal processing where time samples at adjacent time instants are strongly correlated for sufficiently high sampling rate (cf. Figure 1A) as well as processing of natural images whose close-by pixels tend to be colored likely (cf. Figure 1B). The cluster hypothesis is verified also often in social networks where the clusters are cliques of individuals having similar properties (cf. Figure 1C and Newman [29, Chap. 3]).
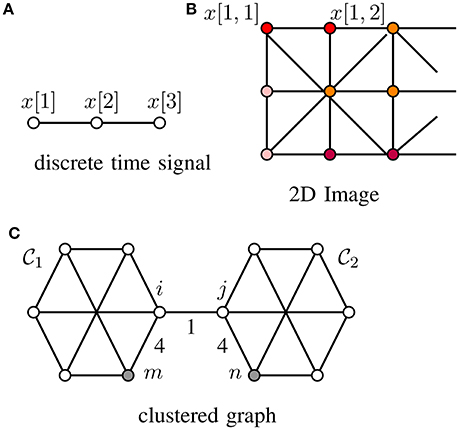
Figure 1. Graph signals defined over (A) a chain graph (representing, e.g., discrete time signals), (B) grid graph (representing, e.g., 2D-images) and (C) a general graph (representing, e.g., social network data), whose edges are captioned by edge weights Wi, j.
In what follows, we quantify the extend to which a graph signal conforms with the clustering structure of the data graph using its total variation (TV)
For a subset of edges , we use the shorthand
For a supervised machine learning application, the signal values x[i] might represent class membership in a classification problem or the target (output) value in a regression problem. For the house price example considered in Hallac et al. [12], the vector-valued graph signal x[i] corresponds to a regression weight vector for a local pricing model (used for the house market in a limited geographical area represented by the node i).
Consider a partition of the data graph into disjoint subsets of nodes (“clusters”) such that . We associate a subset of nodes with a particular “indicator” graph signal
A simple model of clustered graph signals is then obtained by piece-wise constant or clustered graph signals of the form
In Figure 2, we depict a clustered graph signal for a chain graph with 10 nodes which are partitioned into two clusters: and .
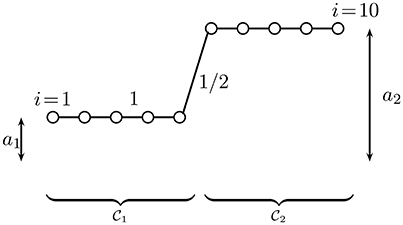
Figure 2. A clustered graph signal (cf. Equation 4) defined over a chain graph which is partitioned into two equal-size clusters and which consist of consecutive nodes. The edges connecting nodes within the same cluster have weight 1, while the single edge connecting nodes from different clusters has weight 1/2.
It will be convenient to define, for a given partition , its boundary as the set of edges which connect nodes and from different clusters, i.e., with . With a slight abuse of notation, we will use the same symbol also to denote the set of nodes which are connected to a node from another cluster.
The TV of a clustered graph signal of the form (Equation 4) can be upper bounded as
Thus, for a partition with small weighted boundary , the associated clustered graph signals (Equation 4) have small TV ||x[·]||TV due to Equation (5).
The signal model (Equation 4), which also has been used in Sharpnack et al. [23] and Wang et al. [24], is closely related to the stochastic block model (SBM) [30]. Indeed, the SBM is obtained from Equation (4) by choosing the coefficients uniquely for each cluster, i.e., . Moreover, the SBM provides a generative (stochastic) model for the edges within and between the clusters .
We highlight that the clustered signal model (Equation 4) is somewhat dual to the model of band-limited graph signals [1, 4–7, 17, 19]. The model of band-limited graph signals is obtained by the subspaces spanned by the eigenvectors of the graph Laplacian corresponding to the smallest (in magnitude) eigenvalues, i.e., the low-frequency components. Such band-limited graph signals are smooth in the sense of small values of the Laplacian quadratic form [31]
Here, we used the vector representation x = (x[1], …, x[N])T of the graph signal x[·] and the graph Laplacian matrix L ∈ ℝN×N defined element-wise as
A band-limited graph signal x[·] is characterized by a clustering (within a small bandwidth) of their graph Fourier transform (GFT) coefficients [22]
with the orthonormal eigenvectors of the graph Laplacian matrix L. In particular, by the spectral decomposition of the psd graph Laplacian matrix L (cf. Equation 7), we have L = UΛUH with U = (u1, …, uN) and the diagonal matrix Λ having (in decreasing order) the non-negative eigenvalues λl of L on its diagonal.
In contrast to band-limited graph signals, a clustered graph signal of the form (Equation 4) will typically have GFT coefficients which are spread out over the entire (graph) frequency range. Moreover, while band-limited graph signals are characterized by having a sparse GFT, a clustered graph signal of the form (Equation 4) has a dense (non-sparse) GFT in general. On the other hand, while a clustered graph signal of the form (Equation 4) has sparse signal differences , the signal differences of a band-limited graph signal are dense (non-sparse).
Let us illustrate the duality between the clustered graph signal model (Equation 4) and the model of band-limited graph signals (cf. [7, 17]) by considering a dataset representing a finite length segment of a time series. The data graph underlying this time series data is chosen as a chain graph (cf. Figure 2), consisting of N = 100 nodes which represent the individual time samples. The time series is partitioned into two clusters , each cluster consisting of 50 consecutive nodes (time samples). We model the correlations between successive time samples using edge weight Wi, j = 1 for data points i, j belonging to the same cluster and a smaller weight Wi, j = 1/2 for the single edge {i, j} connecting the two clusters and .
A clustered graph signal (time series) (cf. Equation 4) defined over is characterized by very sparse signal differences . Indeed the signal difference x0[i] − x0[j] of the clustered graph signal x0[·] is non-zero only for the single edge {i, j} which connects and . In stark contrast, the GFT of x0[·] is spread out over the entire (graph) frequency range (cf. Figure 3), i.e., the graph signal x0[·] does not conform with the band-limited signal model.
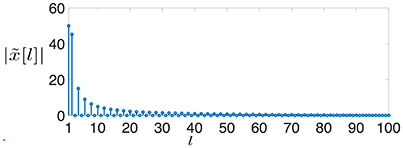
Figure 3. The magnitudes of the GFT coefficients (cf. Equation 8) of a clustered graph signal x0[·] defined over a chain graph (cf. Figure 2).
On the other hand, we illustrate in Figure 4 a graph signal xBL[·] with GFT coefficients (cf. Equation 8) for l = 1, 2 and otherwise. Thus, the graph signal is clearly band-limited (it has only two non-zero GFT coefficients) but the signal differences xBL[i] − xBL[j] across the edges are clearly non-sparse.
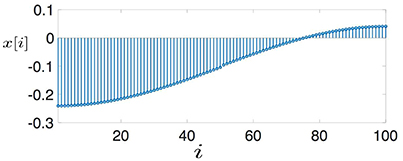
Figure 4. A band-limited graph signal defined over a chain graph with N = 100.
Given a dataset with data graph , we aim at recovering a graph signal from its noisy values
provided on a (small) sampling set
Typically M ≪ N, i.e., the sampling set is a small subset of all nodes in the data graph .
The recovered graph signal should incur only a small empirical (or training) error
Note that the definition (Equation 11) of the empirical error involves the ℓ1-norm of the deviation between recovered and measured signal samples. This is different from the error criterion used in the ordinary Lasso, i.e., the squared-error loss [32]. The definition (Equation 11) is beneficial for applications with measurement errors ei (cf. Equation 9) having mainly small values except for a few large outliers [18, 33]. However, by contrast to plain Lasso, the error function in Equation (11) does not satisfy a restricted strong convexity property [34], which might be detrimental for the convergence speed of the resulting recovery methods (cf. Section 4).
In order to recover a clustered graph signal with a small TV (cf. Equation 5) from the noisy signal samples it is sensible to consider the recovery problem
This recovery problem amounts to a convex optimization problem [35], which, as the notation already indicates, might have multiple solutions (which form a convex set). In what follows, we will derive conditions on the sampling set such that any solution of Equation (12) allows to accurately recover clustered a graph signal x[·] of the form (Equation 4).
Any graph signal obtained from Equation (12) balances the empirical error with the TV in an optimal manner. The parameter λ in Equation (12) allows to trade off a small empirical error against the amount to which the resulting signal is clustered, i.e., having a small TV. In particular, choosing a small value for λ enforces the solutions of Equation (12) to yield a small empirical error, whereas choosing a large value for λ enforces the solutions of Equation (12) to have small TV. Our analysis in section 3 provides a selection criterion for the parameter λ which is based on the location of the sampling set (cf. Equation 10) and the partition underlying the clustered graph signal model (Equation 4). Alternatively, for sufficiently large sampling sets one might choose λ using a cross-validation procedure [13].
Note that the recovery problem (Equation 12) is a particular instance of the generic nLasso problem studied in Hallac et al. [12]. There exist efficient convex optimization methods for solving the nLasso problem (Equation 12) (cf. [36] and the references therein). In particular, the alternating method of multipliers (ADMM) has been applied to the nLasso problem in Hallac et al. [12] to obtain a scalable learning algorithm which can cope with massive heterogeneous datasets.
The accuracy of graph signal recovery methods based on the nLasso problem (Equation 12), depends on how close the solutions of Equation (12) are to the true underlying graph signal . In what follows, we present a condition which guarantees any solution of Equation (12) to be close to the underlying graph signal x[·] if it is clustered of the form (Equation 4).
A main contribution of this paper is the insight that the accuracy of nLasso methods, aiming at solving Equation (12), depends on the topology of the underlying data graph via the existence of certain flows with demands [37]. Given a data graph , we define a flow on it as a mapping which assigns each directed edge (i, j) the value h[(i, j)], which can be interpreted as the amount of some quantity flowing through the edge (i, j) [37]. A flow with demands has to satisfy the conservation law
with a prescribed demand d[i] for each node . Moreover, we require flows to satisfy the capacity constraints
Note that the capacity constraint (Equation 14) applies only to intra-cluster edges and does not involve the boundary edges . The flow values h(i, j) at the boundary edges take a special role in the following definition of the notion of resolving sampling sets.
Definition 1. Consider a dataset with data graph which contains the sampling set . The sampling set resolves a partition with constants K and L if, for any bi, j ∈ {0, 1} with , there exists a flow h[·] on (cf. Equations 13, 14) with
for every boundary edge and demands (cf. Equation 13) satisfying
This definition requires nodes of a resolving sampling set to be sufficiently well connected with every boundary edge . In particular, we could think of injecting (absorbing) certain amounts of flow into (from) the data graph at the sampled nodes. At each sampled node , we can inject (absorb) a flow of level at most K (cf. Equation 16). The injected (absorbed) flow has to be routed from the sampled nodes via the intra-cluster edges to each boundary edge such that it carries a flow value L · Wi, j. Clearly, this is only possible if there are paths of sufficient capacity between sampled nodes and boundary edges available.
The definition of resolving sampling sets is quantitive as it involves the numerical constants K and L. Our main result stated below is an upper bound on the estimation error of nLasso methods which depends on the value of these constants. It will turn out that resolving sampling sets with a small values of K and large values of L are beneficial for the ability of nLasso to recover the entire graph signal from noisy samples observed on the sampling set. However, the constants K and L are coupled via the flow h[·] used in Definition 1, e.g., the constant K always has to satisfy
Thus, the minimum possible value for K depends on the values of the edge weights Wi, j of the data graph. Moreover, the minimum possible value for L depends on the precise connectivity of sampled nodes with the boundary edges . Indeed, Definition 1 requires to route (by satisfying the capacity constraints, Equation 14), an amount of flow given by LWi, j from a boundary edge to the sampled nodes in .
In order to make (the somewhat abstract) Definition 1 more transparent, let us state an easy-to-check sufficient condition for a sampling set such that it resolves a given partition .
Lemma 2. Consider a partition of the data graph which contains the sampling set . If each boundary edge with , is connected to sampled nodes, i.e., and with , , and weights Wm,i, Wn,j ≥ LWi, j, then the sampling set resolves the partition with constants L and
In Figure 1C we depict a data graph consisting of two clusters . The data graph contains the sampling set which resolves the partition with constants K = L = 4 according to Lemma 2.
The sufficient condition provided by Lemma 2 can be used to guide the choice for the sampling set . In particular Lemma 2 suggests to sample more densely near the boundary edges which connect different clusters. This rationale allows to cope with applications where the underlying partition is unknown. In particular, we could use highly scalable local clustering methods (cf. [38]) to find the cluster boundaries and then select the sampled nodes in their vicinity. Another approach to cope with lack of information about is based on using random walks to identify the subset of nodes with a large boundary which are sampled more densely [39].
We now state our main result which is that solutions of the nLasso problem (Equation 12) allow to accurately recover the true underlying clustered graph signal x[·] (conforming with the partition (cf. Equation 4) from the noisy measurements (Equation 9) whenever the sampling set resolves the partition .
Theorem 3. Consider a clustered graph signal x[·] of the form (Equation 4), with underlying partition of the data graph into disjoint clusters . We observe the noisy signal values y[i] at the samples nodes (cf. Equation 9). If the sampling set resolves the partition with parameters K > 0, L > 1, any solution of the nLasso problem (Equation 12) with λ: = 1/K satisfies
Thus, if the sampling set is chosen such that it resolves the partition (cf. Definition 1), nLasso methods (cf. Equation 12) recover a clustered graph signal x[·] (cf. Equation 4) with an accuracy which is determined by the level of the measurement noise e[i] (cf. Equation 9).
Let us highlight that the knowledge of the partition underlying the clustered graph signal model (Equation 4) is only needed for the analysis of nLasso methods leading to Theorem 3. In contrast, the actual implementation methods of nLasso methods based on Equation (12) does not require any knowledge of the underlying partition. What is more, if the true underlying graph signal x[·] is clustered according to Equation (4) with different signal values al for different clusters , the solutions of the nLasso Equation (12) could be used for determining the clusters which constitute the partition .
We also note that the bound (Equation 19) characterizes the recovery error in terms of the semi-norm which is agnostic toward a constant offset in the recovered graph signal . In particular, having a small value of does in general not imply a small squared error as there might be an arbitrarily large constant offset contained in the nLasso solution .
However, if the error is sufficiently small, we might be able to identify the boundary edges of the partition underlying a clustered graph signal of the form (Equation 4).
Indeed, for a clustered graph signal of the form (Equation 4), the signal difference x[i] − x[j] across edges is non-zero only for boundary edges . Lets assume the signal differences of x[·] across boundary edges are lower bounded by some positive constant η > 0 and the nLasso error satisfies . As can be verified easily, we can then perfectly recover the boundary of the partition as precisely those edges for which . Given the boundary , we can recover the partition and, in turn, average the noisy observations y[i] over all sampled nodes belonging to the same cluster. This simple post-processing of the nLasso estimate is summarized in Algorithm 1.

Algorithm 1. Post-Processing for nLasso.
Lemma 4. Consider the setting of Theorem 3 involving a clustered graph signal x[·] of the form (Equation 4) with coefficients al satisfying for l ≠ l′ with a known positive threshold η > 0. We observe noisy signal samples y[i] (cf. Equation 9) over the sampling set with a bounded error e[i] ≤ ϵ. If the sampling set resolves the partition with parameters K > 0, L > 1 such that
then the signal delivered by Algorithm 1 satisfies
In order to illustrate the theoretical findings of section 3 we report the results of some illustrative numerical experiments involving the recovery of clustered graph signals of the form (Equation 4) from a small number of noisy measurements (Equation 9). To this end, we implemented the iterative method ADMM [16] to solve the nLasso (Equation 12) problem. We applied the resulting semi-supervised learning algorithm to two synthetically generated data sets. The first data set represents a time series, which can be represented as a graph signal over a chain graph. The nodes of the chain graph, which represent the discrete time instants are partitioned evenly into clusters of consecutive nodes. A second experiment is based on data sets generated using a recently proposed generative model for complex networks.
Our first experiment, is based on a graph signal defined over a chain graph (cf. Figure 2) with N = 105 nodes , connected by N − 1 undirected edges. The nodes of the data graph are partitioned into N/10 equal-sized clusters , l = 1, …, N/10, each constituted by 10 consecutive nodes. The intrinsic clustering structure of the chain graph matches the partition via the edge weights Wi, j. In particular, the weights of the edges connecting nodes within the same cluster are chosen i.i.d. according to (i.e., the absolute value of a Gaussian random variable with mean 2 and variance 1/4). The weights of the edges connecting nodes from different clusters are chosen i.i.d. according to .
We then generate a clustered graph signal x[·] of the form (Equation 4) with coefficients al ∈ {1, 5}, where the coefficients al and of consecutive clusters and are different. The graph signal x[·] is observed via noisy samples y[i] (cf. Equation 9 with ) obtained for the nodes belonging to a sampling set . We consider two different choices for the sampling set, i.e., and . Both choices contain the same number of nodes, i.e., . The sampling set contains neighbors of cluster boundaries and conforms to Lemma 2 with constants K = 5.39 and L = 2 (which have been determined numerically). In contrast, the sampling set is obtained by selecting nodes uniformly at random from and thereby completely ignoring the cluster structure of .
The noisy measurements y[i] are then input to an ADMM implementation for solving the nLasso problem (Equation 12) with λ = 1/K. We run ADMM for a fixed number of 300 iterations and using ADMM-parameter ρ = 0.01 [16]. In Figure 5 we illustrate the recovered graph signals (over the first 100 nodes of the chain graph) , obtained from noisy signal samples over either sampling set or .
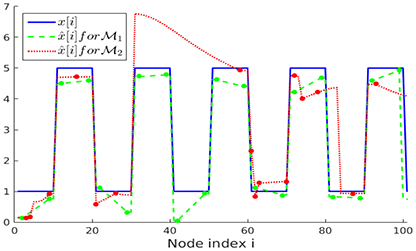
Figure 5. Clustered graph signal x[·] along with the recovered graph signals obtained from noisy signal samples set (Lemma 2) and (random).
As evident from Figure 5, the recovered signal obtained when using the sampling set , which takes the partition into account, better resembles the original graph signal x[·] than when using the randomly selected sampling set . The favorable performance of is also reflected in the empirical normalized mean squared errors (NMSE) between the real and recovered graph signals, which are and , respectively.
We have repeated the above experiment with the same parameters but considering noiseless initial samples y[i] for both sampling sets and . The recovered graph signals for the first 100 nodes of the chain are presented in Figure 6. It can be observed that the recovery starting from the sampling set (conforming to the partition ) perfectly resembles the original graph signal x[·], as expected according to our upper bound in Equation (19). The NMSE obtained after running ADMM for 300 iterations for solving the nLasso problem (Equation 12) are and , respectively.
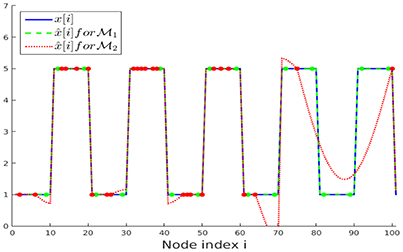
Figure 6. Clustered graph signal x[·] along with the recovered graph signals obtained from noiseless signal samples over sampling set (Lemma 2) and (random). The noiseless signal samples y[i] = x[i] are marked with dots.
In this second experiment, we generate a data graph using the generative model introduced by Lancichinetti et al. [40], in what follows referred to as LFR model. The LFR model aims at imitating some key characteristics of real-world networks such as power law distributions of node degrees and community sizes. The data graph contains a total of N = 105 nodes which are partitioned into 1,399 clusters, . The nodes of are connected by a total of 9.45·105 undirected edges .
The edge weights Wi, j, which are also provided by the LFR model, conform to the cluster structure of , i.e., inter-cluster edges with have larger weights compared to intra-cluster edges with and . Given the data graph and partition we generate a clustered graph signal according to Equation (4) as with coefficients aj randomly chosen i.i.d. according to a uniform distribution .
We then try to recover the entire graph signal x[·] by solving the nLasso problem (Equation 12) using noisy measurements y[i], according to Equation (9) with i.i.d. measurement noise , obtained at the nodes in a sampling set . As in section 4.1, we consider two different choices and for the sampling set which both contain the same number of nodes, i.e., . The nodes in sampling set are selected according to Lemma 2, i.e., by choosing nodes which are well connected (close) to boundary edges which connect different clusters of the partition . In contrast, the sampling set is constructed by selecting nodes uniformly at random, i.e., the partition is not taken into account.
In order to construct the sampling set , we first sorted the edges of the data graph in ascending order according to their edge weight Wi, j. We then iterate over the the edges according to the list, starting with the edge having smallest weight, and for each edge we select the neighboring nodes of i and j with highest degree and add them to , if they are not already included there. This process continues until the sampling set has reached the prescribed size of 104. Using Lemma 2, we then verified numerically that the sampling set resolves with constants K = 142.6 and L = 2 (cf. Definition 1).
The measurements y[i] collected for each sampling sets and are fed into the ADMM algorithm (using parameters ρ = 1/100) for solving the nLasso problem (Equation 12) with λ = 1/K. The evolution of the NMSE achieved by the ADMM output for an increasing number the iterations is shown in Figure 7. According to Figure 7 the signal recovered from the sampling set approximates the true graph signal x[·] more closely compared to when using the sampling set . The NMSE achieved after 300 iterations of ADMM is and , respectively.
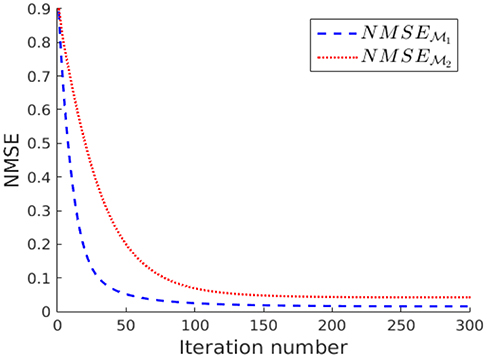
Figure 7. Evolution of the NMSE achieved by increasing number of nLasso-ADMM iterations when using sampling set or , respectively.
Finally, we compare the recovery accuracy of nLasso to that of plain label propagation (LP) [41], which relies on a band-limited signal model (cf. section 2.1). In particular, LP quantifies signal smoothness by the Laplacian quadratic form (Equation 6) instead of the total variation (Equation 1), which underlies nLasso (Equation 12). The signals recovered after running the LP algorithm for 300 iterations for the two sampling sets and incur an NMSE of and , respectively. Thus, the signals recovered using nLasso are more accurate compared to LP, as illustrated in Figure 8. However, our results indicate that LP also benefits by using the sampling set whose construction is guided by our theoretical findings (cf. Lemma 2).
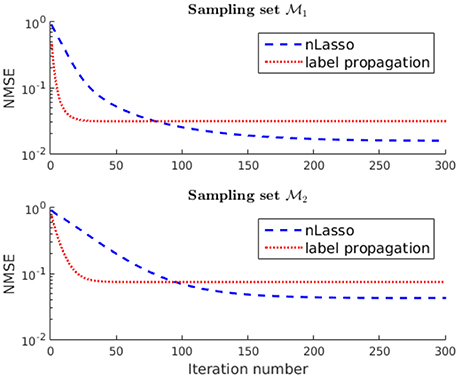
Figure 8. Evolution of the NMSE achieved by increasing number of nLasso-ADMM iterations and LP iterations. Both algorithms are fed with the same signal samples obtained either over sampling set or , respectively.
The high-level idea behind the proof of Theorem 3 is to adapt the concept of compatibility conditions for Lasso type estimators [32]. This concept has been championed for analyzing Lasso type methods [32]. Our main technical contribution is to verify the compatibility condition for a sampling set which resolves the partition underlying the signal model (Equation 4) (cf. Lemma 6 below).
As an intermediate step toward proving Theorem 3, we adopt the compatibility condition [42], which has been introduced to analyze Lasso methods for learning sparse signals, to the clustered graph signal model (Equation 4). In particular, we define the network compatibility condition for sampling graph signals with small total variation (cf. Equation 1).
Definition 5. Consider a data graph whose nodes are partitioned into disjoint clusters . A sampling set is said to satisfy the network compatibility condition, with constants K, L > 0, if
for any graph signal .
It turns out that any sampling set which resolves the partition with constants K and L (cf. Definition 1) also satisfies the network compatibility condition (Equation 22) with the same constants.
Lemma 6. Any sampling set which resolves the partition with parameters K, L > 0 satisfies the network compatibility condition with parameters K, L.
Proof: Let us consider an arbitrary but fixed graph signal . Since the sampling set resolves the partition there exists a flow h[e] on with (cf. Definition 1)
Moreover, due to Equation (15), we have the important identity
which holds for all boundary edges . This yields, in turn,
Since = ∂∪(\∂), we can develop (Equation 25) as
which verifies (Equation 22). □
The next result shows that if the sampling set satisfies the network compatibility condition, any solution of the nLasso (Equation 12) allows to accurately recover a clustered graph signal (cf. Equation 4).
Lemma 7. Consider a clustered graph signal x[·] of the form (Equation 4) defined on the data graph whose nodes are partitioned into the clusters . We observe the noisy signal values y[i] at the sampled nodes (cf. Equation 9). If the sampling set satisfies the network compatibility condition with constants L > 1, K > 0, then any solution of the nLasso problem (Equation 12), for the choice λ: = 1/K, satisfies
Proof: Consider a solution of the nLasso problem (Equation 12) which is different from the true underlying clustered signal x[·] (cf. Equation 4). We must have (cf. Equation 9)
since otherwise the true underlying signal x[·] would achieve a smaller objective value in Equation (12) which, in turn, would contradict the premise that is optimal for the problem (Equation 12).
Let us denote the difference between the solution of Equation (12) and the true underlying clustered signal x[·] by . Since x[·] satisfies Equation (4),
Applying the decomposition property of the semi-norm || · ||TV to Equation (28) yields
Therefore, using Equation (29) and the triangle inequality,
Since , Equation (31) yields
i.e., for sufficiently small measurement noise e[i], the signal differences of the recovery error cannot be concentrated across the edges within the clusters . Moreover, using
the inequality Equation (31) becomes
Thus, since the sampling set satisfies the network compatibility condition, we can apply Equation (22) to yielding
Inserting Equation (35) into Equation (34), with λ = 1/K, yields
Combining Equations (32) and (36) yields
□
Combine Lemma 6 with Lemma 7.
Given a known cluster structure of the data graph, we introduced the notion of resolving sampling sets. A sampling set resolves a cluster structure if there exists a sufficiently large network flow between the sampled nodes, with prescribed flow values over boundary edges which connect different clusters. Loosely speaking, this requires to choose the sampling set mainly in the boundary regions between different clusters in the data graph. Thus, we can leverage efficient clustering methods for identifying the cluster boundary regions in order to find sampling sets which resolve the intrinsic cluster structure of the network structure underlying a dataset.
The verification if a particular sampling set resolves a given partition requires to consider all possible sign patterns for the boundary edges, which is intractable for large graphs. An important avenue for follow-up work is the investigation if resolving sampling sets can be characterized easily using probabilistic models for the underlying network structure and sampling sets. Moreover, we plan to extend our analysis to nLasso methods using other loss functions, e.g., the squared error loss and also the logistic loss function in the context of classification problems.
Parts of the work underlying this paper have been presented in Mara and Jung [43]. A preprint of this manuscript is available under https://arxiv.org/abs/1704.02107 [44].
AJ initiated the research and provided first proofs for the main results. NT helped with proof reading and pointing to some typos in the proofs. AM took care of the numerical experiments.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The authors are grateful to Madelon Hulsebos for a careful proof-reading of an early manuscript. Moreover, the constructive comments of reviewers are appreciated sincerely. This manuscript is available as a pre-print at the following address: https://arxiv.org/abs/1704.02107. Copyright of this pre-print version rests with the authors.
1. Sandryhaila A, Moura JMF. Classification via regularization on graphs. In 2013 IEEE Global Conference on Signal and Information Processing. Austin, TX (2013). p. 495–8. doi: 10.1109/GlobalSIP.2013.6736923
2. Chen S, Sandryhaila A, Moura JMF, Kovačević J. Signal recovery on graphs: variation minimization. IEEE Trans Signal Process. (2015) 63:4609–24. doi: 10.1109/TSP.2015.2441042
4. Chapelle O, Schölkopf B, Zien A, (eds.). Semi-Supervised Learning. Cambridge, MA: The MIT Press (2006). doi: 10.7551/mitpress/9780262033589.001.0001
5. Zhou D, Schölkopf B. A regularization framework for learning from graph data. In: ICML Workshop on Statistical Relational Learning and Its Connections to Other Fields, vol. 15. Banff (2004). p. 67–8.
6. Gadde A, Anis A, Ortega A. Active semi-supervised learning using sampling theory for graph signals. In: Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. KDD '14 (2014). p. 492–501. doi: 10.1145/2623330.2623760
7. Ando RK, Zhang T. Learning on graph with laplacian regularization. In: Advances in Neural Information Processing Systems. Vancouver, BC (2007).
8. Belkin M, Niyogi P, Sindhwani V. Manifold regularization: a geometric framework for learning from labeled and unlabeled examples. J Mach Lear Res. (2006) 7:2399–434.
9. Sandryhaila A, Moura JMF. Big data analysis with signal processing on graphs: representation and processing of massive data sets with irregular structure. IEEE Signal Process Mag. (2014) 31:80–90. doi: 10.1109/MSP.2014.2329213
10. Shuman DI, Narang SK, Frossard P, Ortega A, Vandergheynst P. The emerging field of signal processing on graphs: extending high-dimensional data analysis to networks and other irregular domains. IEEE Signal Process Mag. (2013) 30:83–98. doi: 10.1109/MSP.2012.2235192
11. Narang SK, Gadde A, Ortega A. Signal processing techniques for interpolation in graph structured data. In: 2013 IEEE International Conference on Acoustics, Speech and Signal Processing (2013). p. 5445–9. doi: 10.1109/ICASSP.2013.6638704
12. Hallac D, Leskovec J, Boyd S. Network Lasso: clustering and optimization in large graphs. In: Proceedings of SIGKDD (2015). p. 387–96. doi: 10.1145/2783258.2783313
13. Hastie T, Tibshirani R, Friedman J. The Elements of Statistical Learning. Springer Series in Statistics. New York, NY: Springer (2001).
14. Hastie T, Tibshirani R, Wainwright M. Statistical Learning with Sparsity. The Lasso and its Generalizations. Boca Raton FL: CRC Press (2015).
15. Yamada M, Koh T, Iwata T, Shawe-Taylor J, Kaski S. Localized lasso for high-dimensional regression. In: Proceedings of the 20th International Conference on Artificial Intelligence and Statistics. Fort Laud-erdale, FL (2017). p. 325–33.
16. Boyd S, Parikh N, Chu E, Peleato B, Eckstein J. Distributed Optimization and Statistical Learning via the Alternating Direction Method of Multipliers. vol. 3 of Foundations and Trends in Machine Learning. Hanover, MA: Now Publishers (2010).
17. Romero D, Ma M, Giannakis GB. Kernel-based reconstruction of graph signals. IEEE Trans Signal Process. (2017) 65:764–78. doi: 10.1109/TSP.2016.2620116
18. Tsitsvero M, Barbarossa S, Lorenzo PD. Signals on graphs: uncertainty principle and sampling. IEEE Trans Signal Process. (2016) 64:4845–60. doi: 10.1109/TSP.2016.2573748
19. Chen S, Varma R, Sandryhaila A, Kovačević J. Discrete signal processing on graphs: sampling theory. IEEE Trans Signal Process. (2015) 63:6510–23. doi: 10.1109/TSP.2015.2469645
20. Chen S, Varma R, Singh A, Kovačević J. Signal recovery on graphs: fundamental limits of sampling strategies. IEEE Trans Signal Inform Process Over Netw. (2016) 2:539–54. doi: 10.1109/TSIPN.2016.2614903
21. Segarra S, Marques AG, Leus G, Ribeiro A. Reconstruction of graph signals through percolation from seeding nodes. IEEE Trans Signal Process. (2016) 64:4363–78. doi: 10.1109/TSP.2016.2552510
22. Wang X, Liu P, Gu Y. Local-set-based graph signal reconstruction. IEEE Trans Signal Process. (2015) 63:2432–44. doi: 10.1109/TSP.2015.2411217
23. Sharpnack J, Rinaldo A, Singh A. Sparsistency of the Edge Lasso over Graphs. AIStats (JMLR WCP). La Palma (2012).
24. Wang YX, Sharpnack J, Smola AJ, Tibshirani RJ. Trend filtering on graphs. J Mach Lear Res. (2016) 17:1–41. Available online at: http://jmlr.org/papers/v17/15-147.html
25. Golub GH, Van Loan CF. Matrix Computations. 3rd Edn. Baltimore, MD: Johns Hopkins University Press (1996).
27. Cui S, Hero A, Luo ZQ, Moura JMF, (eds.). Big Data Over Networks. Cambridge, UK: Cambridge University Press (2016).
28. Zhu X, Rabbat M. Graph spectral compressed sensing for sensor networks. In: Proceedings of IEEE ICASSP 2012. Kyoto (2012). p. 2865–8.
33. Chambolle A, Pock T. An introduction to continuous optimization for imaging. Acta Numer. (2016) 25:161–319. doi: 10.1017/S096249291600009X
34. Agarwal A, Negahban S, Wainwright MJ. Fast global convergence of gradient methods for high-dimensional statistical recovery. Ann Stat. (2012) 40:2452–82. doi: 10.1214/12-AOS1032
36. Zhu Y. An augmented ADMM algorithm with application to the generalized lasso problem. J Comput Graph Stat. (2017) 26:195–204. doi: 10.1080/10618600.2015.1114491
38. Spielman DA, hua Teng S. A local clustering algorithm for massive graphs and its application to nearly-linear time graph partitioning. arXiv:0809.3232 (2008).
39. Basirian S, Jung A. Random walk sampling for big data over networks. In: Proceedings of International Conference on Sampling Theory and Applications. Tallinn (2017).
40. Lancichinetti A, Fortunato S, Radicchi F. Benchmark graphs for testing community detection algorithms. Phys Rev E (2008) 78:046110. doi: 10.1103/PhysRevE.78.046110
41. Zhu X, Ghahramani Z. Learning from Labeled and Unlabeled Data with Label Propagation. Technical Report CMU-CALD-02-107, Carnegie Mellon University (2002).
42. van de Geer SA, Bühlmann P. On the conditions used to prove oracle results for the Lasso. Electron J Stat. (2009) 3:1360–92. doi: 10.1214/09-EJS506
Keywords: compressed sensing, big data, semi-supervised learning, complex networks, convex optimization, clustering
Citation: Jung A, Tran N and Mara A (2018) When Is Network Lasso Accurate? Front. Appl. Math. Stat. 3:28. doi: 10.3389/fams.2017.00028
Received: 09 October 2017; Accepted: 28 December 2017;
Published: 19 January 2018.
Edited by:
Juergen Prestin, University of Lübeck, GermanyReviewed by:
Katerina Hlavackova-Schindler, University of Vienna, AustriaCopyright © 2018 Jung, Tran and Mara. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Alexander Jung, YWxleGFuZGVyLmp1bmdAYWFsdG8uZmk=
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.