 Xiang Shi
Xiang Shi Lihua Zhang
Lihua Zhang Young S. A. Kim
Young S. A. Kim- 1Department of Applied Mathematics and Statistics, Stony Brook University, Stony Brook, NY, USA
- 2Business School of Administration, Zhejiang University of Technology, Hangzhou, China
- 3College of Business, Stony Brook University, Stony Brook, NY, USA
This paper considers the American option pricing problem under the stochastic volatility models. In particular, we introduce the GARCH model with two heavy-tailed distributions: classical tempered stable (CTS) and normal tempered stable (NTS) distribution. Then we apply the Markov chain approach to compute the prices of American style options under these two models. Minimal entropy provides a convenient way to construct equivalent martingale measure (EMM) and allows us to overcome the difficulties in incorporating the Markov chain approximation. The convergence of the approximation is also proved. Both numerical and empirical results are analyzed to show the advantages and drawbacks of our approach.
1. Introduction
It is commonly known that the Black-Scholes model does not describe the real behavior of derivatives very well. The model is not consistent with the observed behavior found in asset returns, such as volatility clustering, skewness and fat tails. Many studies have been conducted to modify Black-Scholes model to incorporate these three empirical features of the asset returns. The α-stable distribution proposed by Mandelbrot [1] is an alternative to the normal distribution for modeling asset returns because it allows for skewness and fat tails. While the α-stable distribution has certain desirable properties, it is not suitable in modeling option prices, because it does not have the second moment or even the first moment. In order to obtain a well-defined model for pricing options, the mean, variance, and exponential moments of the return distribution have to be finite. Therefore, there are many modified distributions proposed for financial modeling based on the α-stable distribution. For example, the classical tempered stable (CTS) distribution [2, 3], normal inverse Gaussian (NIG) distribution [4] and its generalization called normal tempered stable (NTS) distribution [5], the modified tempered stable (MTS) distribution [6] and an extension of the CTS distribution named the KR distribution [7]. These distributions, called the tempered stable distributions, not only can incorporate the fat tails and skewness of asset returns, but also have finite moments for all orders. Furthermore, they are all infinitely divisible, i.e., the random variable can be decomposed to a sequence of i.i.d random numbers from the same family. So each of them uniquely corresponds to a Lévy process. Therefore, by replacing the Brownian motion by these Lévy processes, one can extend Black Scholes model to the so called exponential Lévy models. However, these Lévy exponential models are based on the assumptions that the returns are identically and independently distributed (i.i.d). Therefore, they are not able to explain the volatility clustering phenomena.
GARCH model have been developed to model the asset returns under the assumption of a non- Markovian property, more precisely, the assumption of volatility clustering. In Duan [8, 9], Kallsen[10], Heston [11], and Christoffersen [12] theories have been developed for pricing derivatives contracts using GARCH models. Most of researches assume that the innovations of GARCH are normally distributed. Although one can show that the normal GARCH model has heavier tails than Gaussian white noise, i.e., the kurtosis is greater than 3, it is still not able to fully capture the extreme values and skewness of the return process. To overcome the drawback of normal innovation process, Menn and Rachev [13, 14] introduced an enhanced GARCH model with innovations which follow the smoothly truncated stable distribution. Stentoft [15] proposed a GARCH model with NIG distribution for American option pricing. Kim et al. [7] applied the three tempered stable distributions (CTS, MTS, and KR distributions) to model the residual distribution in the GARCH process, and presented the CTS-GARCH model, MTS-GARCH model, and KR-GARCH model. Kim et al. [16] presented the RDTS-GARCH option pricing model. These models can incorporate the three empirical features of the asset returns pretty well. In this paper, we will consider the two most widely used tempered stable distributions to model the residual distribution: classical tempered stable (CTS) and normal tempered stable (NTS).
However, it is difficult to price American options under the GARCH models with tempered stable distributions. It is widely recognized that the existing methods for pricing American options under GARCH are bivariate tree method and least square simulation method presented by Longstaff and Schwartz [17]. Ritchken and Trevor [18], Duan and Simonato [19] have introduced a modified lattice approach and a Markov chain method, respectively. These methods are applied to price American options under the normal-GARCH model. Rachev et al. [20] applied the least square approach to price American options under different TS-GARCH models. However, the least square method might fail to give accurate results when the option is out of the price [21]. Furthermore, increasing the order of the approximating polynomials may not give a good fit to the price when the returns have heavier tails, i.e., more extreme values.
In this paper, we consider the Markov chain approach presented by Duan and Simonato [19] and apply it to the CTS-GARCH and NTS-GARCH models. The idea of the approach is to discretized the stock price and the volatility, and use a Markov chain to approximate the original process. The fixed partition of the state space simplifies the task of option pricing to a sequence of standard matrix operations.
There are two major difficulties in applying this approach to TS-GARCH models. First, the distribution of the residuals changes over time under the original risk neutral argument of Rachev et al. [20]. Thus, we have to recompute the transition matrix each time which makes the Markov chain approach time-consuming. So we apply the minimal entropy method to determine the risk neutral measure. This method provides a large degree of freedom to construct the model in the risk neutral world. By applying this approach we are allowed to use the same transition matrix when computing the option prices. The second difficulty is how to determine the partition conditions of TS GARCH effectively. The skewness and heavy tails of the tempered stable distributions implies that we need a different way to discretize stock price and volatility in order to make the approximating Markov chain convergent.
The numerical examples shows that the option values computed by the Markov chain method converge to the theoretical value. The computation time of the approach is not as expensive as one might expect since the transition probability matrix is highly sparse. It works well for the TS-GARCH option pricing framework. However, the convergence speed of Markov chain method depends on GARCH parameters. For stocks with relatively higher volatilities, the convergence rate becomes slow even for the normal GARCH model, since we have to increase the range of the stock price and volatilities. It is not strange that the convergence speed under the TS-GARCH model would be slower than the normal GARCH. Nevertheless, the TS-GARCH model captures the stylized facts of the market and therefore provides a better fit to the stock price, see Stentoft [15], Kim et al. [7] and Rachev et al. [20]. In the empirical analysis we illustrate how to apply our approach to compute the American option prices in the real world. Calibrated risk neutral parameters and minimal entropy parameters are computed and compared.
The paper is organized as follows: Section 2 contains the introduction to the GARCH model with the tempered stable distributions. Section 3 presents the Markov chain method under the CTS-GARCH, and NTS-GARCH models. The convergence of the Markov chain method is presented in Section 4. In Section 5, we conduct some numerical experiments and empirical analysis to illustrate our approach. The last section contains the concluding remarks.
2. GARCH Model with Tempered Stable Distributed Innovations
In this section we briefly review the GARCH model with tempered stable innovations introduced by Rachev et al. [20]. Furthermore, we apply the minimal entropy approach to determine the equivalent martingale measure.
2.1. Tempered Stable Distributions
First we introduce two most widely-used tempered stable distributions: the CTS distribution and the NTS distribution.
The CTS distribution with parameter α, C, λ+, λ−, m is defined by its characteristic function:
where C, λ+, λ− > 0, α ∈ (0, 2) \ {1} and m ∈ ℝ. We denote X ~ CTS(α, C, λ+, λ−, m) if the random variable X follows CTS distribution. The parameters m and C are the location and scale parameters respectively. α is the key parameter related to the heavy tail. And λ+ and λ− control the rate of decay on the positive and negative tails respectively. The distribution is symmetric if λ+ = λ−. A Lévy process induced from the CTS distribution is called the classical tempered stable process with parameters (α, C, λ+, λ−, m).
The mean and the variance of the CTS distribution are given by
Therefore, if we set m = 0 and
then X has zero mean and unit variance. In this case, we say that X follows the standard CTS distribution with parameters (α, λ+, λ−) and denoted by X ~ stdCTS(α, λ+, λ−).
Let α ∈ (0, 2), θ, γ > 0 and β, m ∈ ℝ. X is said to follow the normal tempered stable (NTS) distribution, if the characteristic function of X is given by:
We denote an NTS distributed random variable X by X ~ NTS(α, θ, γ, β, m). α and θ control the rate of tail decay; γ and β control the variance; and β determines the skewness. If β > 0, the distribution is skewed to the left. The mean and variance of NTS are given by
If , then we are able to set m = 0 and so that X has zero mean and unit variance. In this case, we say that X follows the standard NTS distribution and denoted by X ~ stdNTS(α, θ, β).
The tempered stable distributions, including CTS and NTS, have heavier tails than Gaussian distribution. On the other hand, their tails are thinner than the α-stable distribution whose tail has a power decay. One can show that the moments of CTS and NTS are all finite. For details we refer to Cont and Tankov [22] and Rachev et al. [20].
2.2. GARCH Option Pricing Model
2.2.1. Under the Market Measure ℙ
In this section we introduce the GARCH model with heavy tailed distributions under the market measure. We do not consider dividends here for simplicity. Let (Ω, {t}t = 0, 1, …, T, ℙ) denote the standard probability space, where t is the sigma algebra represents the information up to time t. We assume that the dynamics of the stock price is given by
where St is the stock price and Xt is the log return at time t. Both μt and σt are predictable which represent conditional mean and conditional variance on t respectively. The well-known GARCH(1,1) process is given by
where α0, α1, and β1 are positive parameters satisfies α1 + β1 < 1 since we want the series to be stationary.
There are different ways to model μt under market measure ℙ. For example, if {εt}t = 1, 2, …, T are i.i.d normally distributed, we can set the conditional mean to be for t = 1, 2, …, T, where r is the risk free interest rate and λ is the market price of risk. Then we are able to construct a risk neutral dynamics in a way similar to Black Scholes model, see Duan [8]. If {εt}t = 1, 2, …, T follows infinitely divisible distribution like CTS or NTS, we can extend Duan's model by setting μt = r + λtσt − g(σt) where g(x): = logE[exp(xεt)]. For tempered stable distributions the moment generating function E[exp(xεt)] may not be well-defined on the real line. In that case, we require to be smaller than a positive number ρ otherwise g(σt) will turn to infinity. So we would rewrite the Equation (1) as:
In practice it is very unlikely that will reach the upper bound ρ. So the properties of GARCH process such as volatility clustering still apply to our modified model.
2.2.2. Under the Risk Neutral Measure ℚ
Now we want to find an equivalent risk neutral measure ℚ so that the dynamics of stock prices St, t = 1, 2, …, T is a martingale, i.e.,
Rachev et al. [20] define the risk neutral measure ℚ to be a product of a sequence of independent measures ℚ1, …, ℚT, such that ξt: = εt + kt is a standard tempered stable distribution under ℚt, where
where is the log moment generating function of ξt. Therefore, we can obtain the risk neutral dynamic of St:
so that
Under this setting, however, the distribution of the innovations ξt varies over time. This makes it very difficult to implement the Markov chain method which we will see later, since we have to recompute the probability transition matrix at each time. Furthermore, it is hard to identify the dynamics of λt under ℙ. We can simply assume it to be a constant, but this assumption would put strong restrictions on the dynamics of the conditional mean under ℙ, that is, we would have only one free parameter in the estimation.
2.2.3. Minimal Entropy Martingale Measure
Luckily, the TS-GARCH model which is a discrete time process with stochastic volatility implies that the market is incomplete, that is, the equivalent martingale measure (EMM) is not unique. In fact, there are several methods to find the “best” EMM of tempered stable distributions. One classical method in selecting an EMM is the Esscher transform presented by Gerber and Shiu [23, 24]. Fujiwara and Miyahara [25] presented the method to find “minimal entropy martingale measure.” Cont and Tankov [22] proffered the “the least-squares calibration with a prior” to find an EMM of the market measure that minimizes the least square error of the model option prices relative to the market option price.
In this paper, we apply the minimal entropy approach which is more flexible than the previous methods. We simply assumes that μt is modeled by the well-known ARMA(1,1) process:
Under the risk neutral measure ℚ, we assume that our model is given by
where is such that the process is a discrete martingale:
is still a GARCH(1,1) process:
where, λ is the market price of risk or the skewness parameter of GARCH, and ξt, t = 1, …, T are i.i.d random variables whose distribution is in the same parametric family of εt. We denote the density function by f(·|η) where η is the vector of parameters. For example, η = (α, λ+, λ−) for standard CTS and η = (α, θ, β) for standard NTS.
Let p and q be the joint density of the two processes, then the Kullback-Leibler divergence or relative entropy between q and p is given by
The density function f of the tempered stable distribution can be calculated via fast Fourier transform (FFT). The expectation in the equation can be computed numerically.
Finally, we calibrate the risk neutral parameters by minimizing the Kullback-Leibler divergence:
3. Markov Chain Method Under the TS-GARCH Models
In this section we introduce the Markov chain method proposed by Duan and Simonato [19], and implement this approach to our TS-GARCH models. And finally we will prove the convergence of Markov chain method under TS-GARCH framework.
3.1. Markov Chain Method
We start with the risk neutral GARCH model introduced in the last section:
Note that the expression is actually a bivariate Markovian system {(St, σt + 1), t = 1, 2, …, T}. We denote the value of the American option at time t by V(St, σt + 1, t). Let f : ℝ+ → ℝ be the payoff function, for call option we have and for put option . Since the bivariate process {(St, σt + 1), t = 1, 2, …, T} is Markovian, then the value of the American option is given by invoking the following dynamic programming:
The Markov property of the bivariate process allows us to approximate the asset price and conditional volatility (St, σt + 1) by a Markov chain.
First let us assume that under the risk neutral measure ℚ the stock price and volatility follows a discrete Markov chain. The stock price St takes m different values: s(1) < s(2) < ⋯ < s(m); and the volatility σt + 1 takes n different values: . So we have overall mn status. Let Π be the mn × mn transition probability matrix for the Markov chain:
where
Although the transition matrix is usually very large, we are able to do matrix operation efficiently since it is a highly sparse. There are two facts to ensure the sparsity of the matrix. First, π(i, j; k, l) would be close to zero when the absolute difference between s(i) and s(k) is too large. Secondly, as we will discuss later, there are at most m non-zero probability for every row of Π even though there are mn entries in each row since σt+1 would be completely determined by St if (St − 1, σt) is given. The sparsity of the transition matrix is a very important property when implementing this method, because it can save storage and computing time. Note that the transition matrix for TS-GARCH is relatively less sparse then normal GARCH due to the heavy tails. But it is still good enough for efficient computing.
However, the distribution of (St, σt + 1) under TS-GARCH model is continuous. To construct a Markov chain for approximating the TS-GARCH process, let {(c(i − 1), c(i)]}i = 1, …, m, {(d(j − 1), d(j)]}j = 1, …, n be two sequences of small disjoint intervals such that s(i) ∈ (c(i − 1), c(i)] and σ(j) ∈ (d(j − 1), d(j)], the transition matrix of the approximating Markov chain is given by:
So the conditional expectation in Equation (2) can be approximated as follows:
Because σt + 1 is uniquely determined by St − 1, St, σt, then j ↦ π(i, j; k, l) is either zero or equal to P(St ∈ (c(i − 1), c(i)]|St − 1 = s(k), σt = σ(l)). In the latter case, simple calculations show that
where
F denotes the cumulative distribution function, and g denotes the log moment generating function of the innovation εt under ℚ. Different with the normal distribution, F does not have a closed form of solution for tempered stable distributions. Similar as the density function which can be computed numerically by FFT, Kim et al. [26] show that we can use one step FFT to obtain F:
where Φ(·) is the characteristic function of εt and θ is a positive number such that |Φ(z)| < ∞ for all z with Im(z) = θ. To compute F, let K and N be large positive integers with N > K and xk = (k − N)∕K, k = 0, 1, 2, …, 2N, then we have
where ω = e − 2 πj∕N and . Then apply FFT to compute this equation and we can obtain the cumulative function of the tempered stable distributions.
Note that we assume that the approximation Markov chain process is time-homogenous since we want the states of stock price and conditional variance take values to be in the same set for every time t. Finally the option value can be approximated as follows:
3.2. Implementing the Markov Chain Approach to TS-GARCH
The basic idea of implementing the Markov chain method to the TS-GARCH model follows Duan and Simonato [19]. First note that the stock price has a trend in the GARCH process under the locally risk neutral measure ℚ, that is, . This contradicts to our assumption that the Markov chain is homogeneous. Therefore, we need to adjust the stock price such that the Markov process based on the adjusted asset price is closer to homogeneous. For example we can set:
where
Thus, the mean of pt will not change with time. Unlike the normal-GARCH in which is a linear function of t if the GARCH process is stationary, the mean of log-price is not linear in TS-GARCH since the log moment generating function g(σt) can not be assumed to be stationary like . Furthermore, computing numerically is time consuming. So instead we set
Note that all we want is that E[pt] dose not vary much through time t = 1, 2, …, T; and that will be in a neighborhood of σ0 in a long term. Since the adjustment factor is deterministic, a compounding factor can be easily incorporated later to recover the pre-adjusted stock price. Then we can set the discrete values for the stock price and its conditional variance. To do this, we define an interval that covers a chosen set of discrete stock prices and variances. For the logarithm of the adjusted stock price, consider an interval around p0: [p0 − Ip, p0 + Ip], Duan and Simonato [19] use the variance of to determine Ip. Since the variance cannot fully describe the diversification of non-symmetric heavy tail distributions, here we use the quantile instead to determine the range of p. Let F be the cumulative distribution function of , whose distribution belongs to the same family of εt due to the infinite divisibility. Then we set and , where
F − 1 is the inverse function of F which is well defined since F is continuous for CTS and NTS. δp(m) is a sequence of decreasing numbers which satisfies the following conditions:
Partition condition. (i) δp(m) → 0 as m → ∞; and (ii) as m → ∞. (iii) 0 < δp(m) ≤ 1.
For example, if the distribution of ξt is α-stable for some α ∈ (0, 2), then it is natural to set , where 0 < ϵ < α. This is because
where C is some positive constant. Here we use the property that the tail of α-stable distribution has a power decay, see Cont and Tankov [22], for details. This implies that as m → ∞. We have similar results for . Thus, must satisfy the second condition. Furthermore, any function of m which decays to zero slower than mϵ − α also satisfiess the partition condition (i) and (ii). For other tempered stable distributions like CTS or NTS, we can still set mϵ − α as an “upper bound” of decay speed of δp(m) since their tails are thinner than the α-stable distribution, that is, the inverse cumulative distribution function F − 1(x) diverges slower than power law as x → 0 or 1.
Similar to pt, we can also set qt to be the logarithm of . Luckily we have the upper bound ρ and lower bound α0 for , so similar as Duan and Simonato [19] we define the upper and lower bound of q:
where δq(n) is some function which satisfies (i) δq(n) → 0 and (ii) δq(1) = 1, and is the weighted average of the initial value and the stationary value , given by :
where τ is a preset value. Note that when n → ∞, q(1) and q(n) converge to log(α) and log(ρ) respectively. When n = 1, which implies the constant volatility, then would be an ideal choice.
Then we simply take the equal-distant partition of the intervals of adjusted price and volatility and obtain a sequence of discrete values p(1) < ⋯ < p(m) and q(1) < ⋯ < q(n). Now consider the m cells for m status of the adjusted price: C(k) = (c(k), c(k + 1)] where c(1) = −∞, c(m) = + ∞, and c(k) = (p(k) + p(k + 1))∕2. Similarly, we have the partition D(k) = (d(k), d(k + 1)] for q, where d(1) = log(α0), d(n) = log(ρ), and d(k) = (q(k) + q(k + 1))∕2. Let
and
Then the transition probability is given by:
If we set
then the probability in Equation (4) can be represented as:
where F is the cumulative distribution function of innovation εt under ℚ.
Note that the above approach might not be the best way to discretize the price and volatility. As long as the ranges of discretized price and volatility increase and the sizes of grids decrease as m and n turns to infinity, we are able to show that the bivariate Markov chain can converge to the objective GARCH process. In the mean time we want to compute the transition matrix only once in order to make the algorithm efficient. So any partitions which meets these criteria may potentially improve the approximation of the Markov chain.
The algorithm is summarized as follows:
1. Compute the discretized adjusted prices and volatilities: p(1), …, p(m) and q(1), …, q(n).
2. Compute the mn × mn transition matrix Π given by Equations (3) and (4).
3. Compute the terminal value:
where is a vector with all ones and ⊗ is the Kronecker product.
4. Given , compute
where max denotes the element-wise maximum for two vectors.
5. If p(k) ≤ log S0 ≤ p(k + 1), then the option price would be the linear interpolation:
3.3. Convergence of the Markov Chain Approach
Duan and Simonato [19] proves the convergence of the Markov chain method under the normal GARCH model. For TS-GARCH model, the proof is similar. There are two major differences between the two models. First, the term in the normal GARCH is replaced by a more general form g(σt). Second, the distribution of εt is skewed and heavy tailed in TS-GARCH. Luckily, these differences does not change the idea of the proof.
In this section we denote the adjusted prices and volatilities of the original GARCH process and the approximating Markov chain by (pt, qt + 1) and , respectively. The distribution function of the Markov chain at time t conditional on the information up to t − 1 is given by ; and the distribution of the object adjusted stock price and volatility is Ft|t − 1:ℝ × [log(α0), log(ρ)] → [0, 1].
Proposition 1. Given the partition condition, converges to Ft|t − 1 as m and n go to infinity.
Proof. First note that the marginal distribution of pt:
where F is the cumulative distribution function of CTS or NTS, is uniformly continuous with respect to x, y ∈ ℝ and z ∈ [log(α0), log(ρ)]. This is because that the distribution function F is uniformly continuous on ℝ, and that is linear with respect to x and y, and g(ez) is continuous on the closed set [log(α0), log(ρ)]. Note that the moment generate functions of CTS and NTS are not defined on ρ, but they have a finite continuous extension on ρ.
Let i*, k*, l* be the integers such that p(i*) ≤ x < p(i* + 1), p(l*) ≤ y < p(l* + 1) and q(k*) ≤ z < q(k* + 1), then the distribution of :
as m, n → ∞. The convergence is uniform, i.e., the rate of convergence dose not depends on the choices of x, y, and z because the uniform continuity.
Now consider the joint distribution of (pt, qt + 1) conditional on pt − 1 = y and qt = z:
where α0 ≤ x2 ≤ ρ. On the other side the joint distribution of the Markov chain conditional on and is given by
Let i*, j* be the integers such that and , then
Since the distribution of conditioning on t − 1 converges uniformly to pt and function H is also uniformly continuous, it is not difficult to show that uniformly as m, n → ∞.
From the proposition and the property of weak convergence we can conclude:
Corollary 1. For any bounded continuous function f : ℝ × [log(α0), log(ρ)] → ℝ,
as m, n → ∞, where k*, l* are the integers such that p(k*) ≤ y < p(k* + 1) and q(l*) ≤ z < q(l* + 1). The convergence is uniform.
Corollary 2. Let be a sequence of bounded continuous function which converges to a bounded continuous function f : ℝ × [log(α0), log(ρ)] → ℝ uniformly, then
as m, n → ∞, where k*, l* are the integers such that p(k*) ≤ y < p(k* + 1) and q(l*) ≤ z < q(l* + 1). The convergence is uniform.
Proof. Since f(m, n) converges to f uniformly, for any ϵ > 0 we have
for all choice of p(k*) and q(l*) if m, n is large enough. On the other side corollary 1 ensures that
for all y and z. Combining the two inequalities we prove the the corollary.
Now consider the American type option with bounded continuous payoff f. The Markov chain method first compute the conditional expectation:
Note that this is a sequence of discrete values. But we are able to construct a continuous extension such that , k = 1, …, m, l = 1, …, n, for each m and n. Then we obtain a sequence of continuous bounded function which converges to the true expectation:
uniformly. Here we assume that GT − 1 is continuous. This implies that the value of the American option given by Markov chain method:
has a continuous extension converges to the true value VT − 1 uniformly for continuous and bounded payoff function f. The corollary 2 allows us to continue doing this and have converges to V0.
However, for call and put options whose payoffs are not bounded we may not have these results. But we are able to use options truncated payoff to approximate call and put, thanks for the dominated convergence theorem. Duan and Simonato [19] loosen the condition by showing if the payoff function is bounded by a integrable function then the European option price computed by Markov chain method converges to the true price. Here we consider the bounded payoff for simplicity. In fact, by discretizing the stock price into a finite set of numbers the Markov chain method assumes that the payoff function is bounded. And by increasing m and n this upper bound will become larger and therefore the value of bounded payoff option would be closer to the value of unbound one.
4. Numerical Examples and Empirical Results
In this section we apply the Markov chain method to compute European and American options under the CTS-GARCH and NTS-GARCH models, respectively. The convergence of the Markov chain method will be illustrated by numerical examples and empirical results.
4.1. Numerical Examples
In this subsection we test the Markov chain method numerically by applying it to pricing American option as well as European option. For simplicity, we set the initial conditional variance to be the stationary variance under the market measure ℙ; that is . The initial stock price is set as S0 = 50, and the annualized risk-free rate is r = 0.025.
The parameters of the GARCH process are set to be . These are the same parameters that Duan and Simonato [19] used in the numerical tests. The facts that α0 ≈ 0 and α1 < β1 correspond to most empirical tests in the literature. We set α = 1.70, λ+ = 1.00, λ− = 0.35 to be the parameters of CTS innovation and α = 1.00, θ = 1.00, β = −0.20 to be the parameters of NTS innovation, so that both distributions are skewed to the left and have heavier tails than normal distribution. These parameters are also chosen based on the empirical observations in Rachev et al. [20].
Tables 1, 3 show the results of the Markov chain approach for American put options. The first column of each table represents the number of m, n. We set m > n in order to get a better approximation of the price process when the size of the Markov chain mn is given. As m, n increases, the Markov chain method would converge to the true result which is proved in Section 3. Columns 2–4, 5–7, 8–10 are the prices of the options with maturity 30, 60, and 90 days respectively. For each maturity we compute the options with strikes 0.9S0, 1.0S0, and 1.1S0, the corresponding columns are marked by the second row. Tables 2, 4 compares the results of the Markov chain approach with the ones of the Monte Carlo with least square approximation. For Monte Carlo method we generate 100,000 scenarios, and the results are given by the last row in Tables 2, 4.
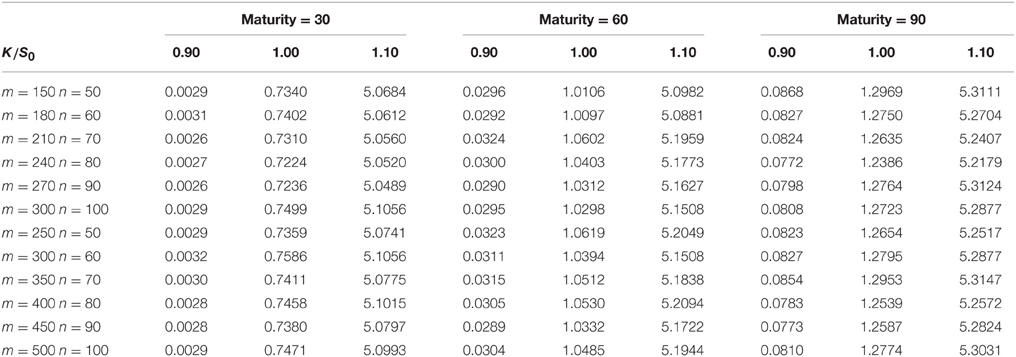
Table 1. American put options in the CTS-GARCH framework.
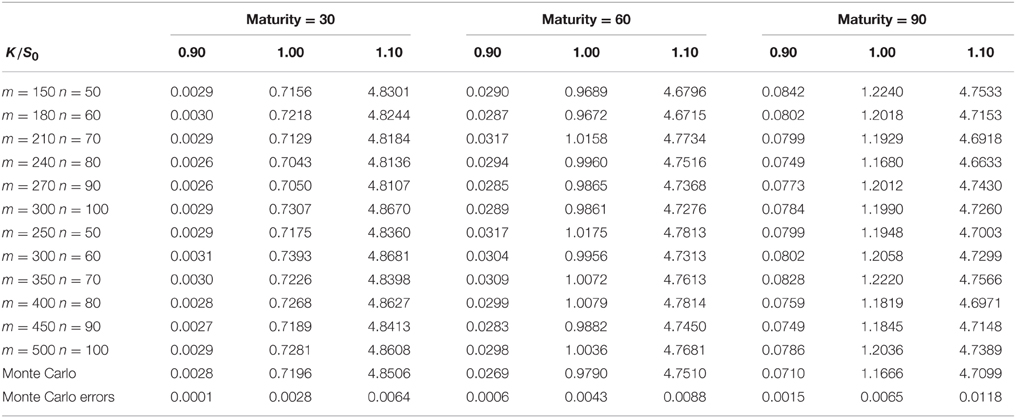
Table 2. European put options in the CTS-GARCH framework.
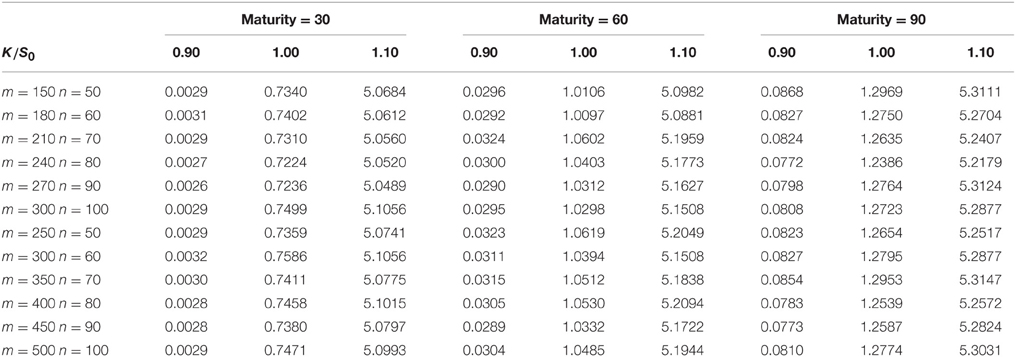
Table 3. American put options in the NTS-GARCH framework.
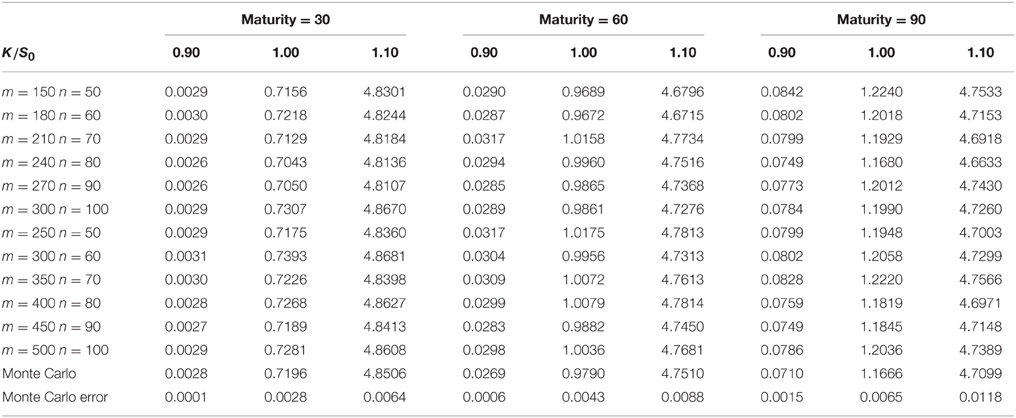
Table 4. European put options in the NTS-GARCH framework.
From these results one can observe that the results of Markov chain method with large m and n and the ones of Monte Carlo correspond roughly in two decimal place. Most of the prices in Tables 1, 3 is greater than the corresponding prices in Tables 2, 4, since the American option is always more expensive than the European option. The convergence of American options is not as fast as the one of European options. This because that small differences in accuracy might change the optimal execution time which would make the price different. We do not compare the American option price with the well known least squares method because the latter is not accurate when the option is out of money. Even for the options which are in the money, the polynomial approximation is only accurate in a small range of stock prices. We would expect more extreme values in GARCH model with heavy tailed distributions. This might make the least square approach more inaccurate.
The fluctuations in the prices are the results of discretizing the stock price and volatility. By comparing the results with the Duan's Normal GARCH model one can find that we need larger m and n to get an acceptable result. This is because we need more grids in a wider interval to approximate the cumulative distribution functions of heavy tailed distributions. In addition, the rate of convergence become slow when the maturity increases. As Duan and Simonato [19] suggested in his paper, the Markov chain method might not be good for options with long maturity.
4.2. Empirical Analysis
In this section, we illustrate the calibration of risk neutral parameters using Markov chain method. As an example, we consider the SPX put option on June 13, 2013 whose moneyness is between 0.9 and 1.1, and whose maturity is 30 days. There are 46 options meet these conditions, the strike price of which ranges from 1480 to 1740. The initial price of S&P 500 index is 1640.42.
The first step is to estimate the parameters under market measure ℙ. The maximum likelihood estimation (MLE) of ARMA(1,1)-GARCH(1,1) with Gaussian innovation is widely known. For non-Gaussian innovations, we can use the quasi maximum likelihood estimator (QMLE). That is, we first estimate the ARMA(1,1)-GARCH(1,1) parameters under Gaussian assumption. Then we will get a sequence of residuals which are assumed to be i.i.d. Finally we use other distributions like CTS or NTS to fit these i.i.d residuals. The convergence of QMLE is studied by Lee and Hansen [27] and Lumsdaine [28]. We select 2 years log daily returns of S&P 500 index as our sample. The data is downloaded from Yahoo finance. The estimated parameters are given by Tables 5–7.

Table 5. ARMA(1,1)-GARCH(1,1) parameters.

Table 6. Standard CTS parameters.

Table 7. Standard NTS parameters.
Then we can compute the risk neutral parameters in two ways. The first way is to minimize the relative entropy between ℙ and ℚ, as described in Section 2.3. The relative entropy is given by Equation (10), which is computed numerically. Here we assume that the GARCH parameters do not change under ℚ. This assumption is widely used in most GARCH option pricing papers, see Duan [8], Stentoft [29], Kim et al. [6] and Rachev et al. [20]. The results of the minimization are shown in Tables 8, 9.

Table 8. Minimal entropy parameters (CTS).

Table 9. Minimal entropy parameters (NTS).
Using these parameters we compute the option price via Markov chain method. We compute the average absolute error (AAE), average percentage error (APE), average relative percentage error (ARPE) and root mean square error (RMSE), which are give by Table 10.

Table 10. Errors of minimal entropy measure.
The second way is to calibrate the risk neutral measure using realized option price, that is, to find the measure which minimizes the errors between model prices and market prices. In this paper we use RMSE to measure the error. The calibrated parameters and their errors are given by Tables 11–13. One can observe that the calibrated risk neutral parameters are different from the minimal entropy parameters.

Table 11. Calibrated parameters (CTS).

Table 12. Calibrated parameters (NTS).
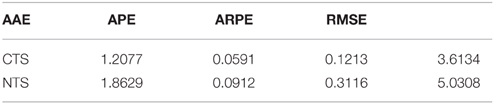
Table 13. Errors of minimal entropy measure.
We find that in both risk neutral measures CTS outperform NTS. However, it is not enough to conclude that CTS is better than NTS based on this specific example. In fact, NTS is usually good in the high dimensional case since it is a subordinated distribution and has a natural multivariate extension. It is also not enough to conclude that minimal-entropy measure is not the real risk neutral measure. The minimal entropy approach is based on the assumption that the risk neutral world is very close to the real one. The calibrated parameters might overfit the model if the option is not volatile. Here we use this method because it provides a convenient way to consider risk neutral model under Markov chain framework. Selecting the best measure in the incomplete market is out of the scope of this paper.
5. Conclusion
In this paper we employ the Markov chain approximation method to compute the value of American-style options under TS-GARCH model. We apply the minimal entropy approach to find the “best” equivalent martingale measure in an incomplete market. This risk neutral measure also allows us to compute the Markov chain method in efficiently. For heavy-tailed distributions, we use the quantile instead of the variance of the distribution to determine the range of the discrete Markov chain. We also consider the rate of tail decay to find the step size of the discretized stock prices. The convergence of the Markov chain approximation for TS-GARCH models can be proved due to the absolute continuity of TS-distribution functions. The Markov chain method is a good alternative for the least square approximation, since the latter one is less accurate when the option is out of the money and when extreme event happens. Furthermore, although the Markov chain approach for TS-GARCH is slower than the one for normal GARCH, TS-GARCH model performs much better than normal GARCH in option pricing since it has more degrees for freedom to capture the heavy-tails in financial markets.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
1. Mandelbrot BB. New methods in statistical economics. J Pol Econ. (1963) 71:421–40. doi: 10.1086/258792
2. Koponen I. Analytic approach to the problem of convergence of truncated lévy flights towards the gaussian stochastic process. Phys Rev E. (1995) 52:1197–9. doi: 10.1103/PhysRevE.52.1197
3. Boyarchenko SI, Levendorskiĭ SZ. Option pricing for truncated lévy processes. Int J Theor Appl Finance. (2000) 3:549–52. doi: 10.1142/S0219024900000541
4. Carr P, Geman H, Madan D, Yor M. The fine structure of asset returns: an empirical investigation. J Bus. (2002) 75:305–32. doi: 10.1086/338705
5. Barndorff-Nielsen OE, Levendorskii S. Feller processes of normal inverse gaussian type. Quant Finance. (2001) 1:318–31. doi: 10.1088/1469-7688/1/3/303
6. Kim YS, Rachev ST, Chung DM, Bianchi ML. The modified tempered stable distribution, GARCH-models and option pricing. Probab Math Stat. (2009) 29:91–117.
7. Kim YS, Rachev ST, Bianchi ML, Fabozzi FJ. Financial market models with lévy processes and time-varying volatility. J Bank Finance. (2008) 32:1363–78. doi: 10.1016/j.jbankfin.2007.11.004
8. Duan JC. The GARCH option pricing model. Math Finance. (1995) 5:13–32. doi: 10.1111/j.1467-9965.1995.tb00099.x
9. Duan JC. Augmented GARCH (p,q) process and its diffusion limit. J Econ. (1997) 79:97–127. doi: 10.1016/S0304-4076(97)00009-2
10. Kallsen J, Taqqu MS. Option Pricing in ARCH-type models. Math Finance. (1998) 8:13–26. doi: 10.1111/1467-9965.00042
11. Heston L, Nandi S. A closed-form GARCH option valuation model. Rev Finacial Stud. (2000) 13:585–625. doi: 10.1093/rfs/13.3.585
12. Christoffersen P, Jacobs K, Ornthanalai C. GARCH option valuation: theory and evidence. J Derivat. (2013) 21:8–41. doi: 10.2139/ssrn.2054859
13. Menn C, Rachev ST. A GARCH option pricing model with α-stable innovations. Eur J Oper Res. (2005) 163:201–09. doi: 10.1016/j.ejor.2004.01.009
14. Menn C, Rachev ST. Smoothly truncated stable distributions, GARCH-models, and option pricing. Math Methods Oper Res. (2009) 69:411–38. doi: 10.1007/s00186-008-0245-6
15. Stentoft L. American option pricing using GARCH models and the normal inverse Gaussian distribution. J Financ. Econom. (2008) 6:540–82. doi: 10.1093/jjfinec/nbn013
16. Kim YS, Rachev ST, Bianchi ML, Fabozzi FJ. Tempered stable and tempered infinitely divisible GARCH models. J Bank Finance (2010) 34:2096–109. doi: 10.1016/j.jbankfin.2010.01.015
17. Longstaff FA, Schwartz ES. Valuing American options by simulation: a simple least-squares approach. Rev Financ Stud. (2001) 14:113–48. doi: 10.1093/rfs/14.1.113
18. Ritchken P, Trevor R. Pricing options under generalized GARCH and stochastic volatility processes. J Finance. (1999) 54:377–402. doi: 10.1111/0022-1082.00109
19. Duan JC, Simonato JG. American option pricing under GARCH by a Markov chain approximation. J Econ Dyn Control. (2001) 25:1689–718. doi: 10.1016/S0165-1889(00)00003-8
20. Rachev ST, Kim YS, Bianchi ML, Fabozzi FJ. Financial Model with Levy Processes and Volatility Clustering. Hoboken, NJ: John Wiley & Sons (2011).
21. Bouchard B, Warin, X. Monte-Carlo valuation of American options: facts and new algorithms to improve existing methods. In: Carmona RA, Del Moral P, Hu P, Oudjane N, editors. Numerical Methods in Finance. Berlin; Heidelberg: Springer (2012). p. 215-255.
24. Gerber FA, Shiu ESW. Actuarial bridges to dynamic hedging and option pricing. Insur Math Econ. (1996) 18:183–531. doi: 10.1016/0167-6687(96)85007-4
25. Fujiwara T, Miyahara Y. The minimal entropy martingale measures for geometric lévy processes. Finance Stoch. (2003) 7:509–31. doi: 10.1007/s007800200097
26. Kim YS, Rachev S, Bianchi ML, Fabozzi FJ. Computing VaR and AVaR in infinitely divisible distributions. Probab Math Stat. (2009) 30:223–45. doi: 10.2139/ssrn.1400965
27. Lee SW, Hansen BE. Asymptotic theory for the GARCH (1, 1) quasi-maximum likelihood estimator. Econom. Theory (1994) 10:29–52. doi: 10.1017/S0266466600008215
28. Lumsdaine RL. Consistency and asymptotic normality of the quasi-maximum likelihood estimator in IGARCH (1, 1) and covariance stationary GARCH (1, 1) models. Econometrica (1996) 64:575–596. doi: 10.2307/2171862
Keywords: tempered stable distribution, GARCH, American options, Markov chain, minimal entropy
Citation: Shi X, Zhang L and Kim YSA (2016) A Markov Chain Approximation for American Option Pricing in Tempered Stable-GARCH Models. Front. Appl. Math. Stat. 1:13. doi: 10.3389/fams.2015.00013
Received: 20 July 2015; Accepted: 10 December 2015;
Published: 08 January 2016.
Edited by:
Sergei Levendorskii, University of Leicester, UKReviewed by:
Jiayao Xie, Ernst & Young, Hong KongOleg Kudryavtsev, Russian Customs Academy Rostov Branch, Russia
Copyright © 2016 Shi, Zhang and Kim. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Xiang Shi, eGlhbmcuc2hpQHN0b255YnJvb2suZWR1