 Siew Ann Cheong1,2*
Siew Ann Cheong1,2* Yann Wei Lee3†
Yann Wei Lee3† Ying Ying Li4†
Ying Ying Li4† Jia Qing Lim4†
Jia Qing Lim4† Jiok Duan Jadie Tan3†
Jiok Duan Jadie Tan3† Xin Ping Joan Teo4†
Xin Ping Joan Teo4†- 1Division of Physics and Applied Physics, School of Physical and Mathematical Sciences, Nanyang Technological University, Singapore, Singapore
- 2Complexity Institute, Nanyang Technological University, Singapore, Singapore
- 3Nanyang Girls High School, Singapore, Singapore
- 4River Valley High School, Singapore, Singapore
Financial markets are complex systems where information processing occurs at multiple levels. One signature of this information processing is the existence of recurrent sequences. In this paper, we developed a procedure for finding these sequences and a process of statistical significance testing to identify the most meaningful ones. To do so, we downloaded daily closing prices of the Dow Jones Industrial Average component stocks, as well as various assets like stock market indices, United States government bonds, precious metals, commodities, oil and gas, and foreign exchange. We mapped each financial instrument to a letter and their upward movements to words, before testing the frequencies of these words against a null model obtained by reshuffling the empirical time series. We then identify market leaders and followers from the statistically significant words in different cross sections of financial instruments, and interpret actionable trends that can be traded upon.
1 Introduction
In his seminal 1970 paper, Fama introduced the notion of an efficient market, within which the prices of securities fully reflect all information from the past, as well as future expectations on their returns [1]. In his paper, the empirical evidence Fama cited as supporting this efficient market hypothesis is zero (or close to zero) serial correlation. However, if financial markets are truly efficient, then it would be impossible for traders to profit beyond the fundamental values of the securities. Naturally, the only trading strategy that makes sense in an efficient market would be buy-and-hold. This brings us then to the elephant in the room: why are there so many hedge funds (according to https://www.investopedia.com/terms/h/hedgefund.asp, more than 10,000 of them) in the world, and why are so many of them making money? Fundamentally, all hedge funds engage in some form of technical trading [2–4], frequently dismissed by financial economists as not founded on firm principles. The profitability of technical trading was first investigated by Lukac et al. [5] and Brock et al. [6]. Testing 12 technical trading rules for 12 commodities between 1978 and 1984, Lukac et al. found that seven rules produced significant gross returns, while four rules produced significant net returns and significant risk-adjusted returns, after taking into account transportation and storage costs. Testing the commonly used moving average and trading range break rules on the Dow Jones index from 1897 to 1986, Brock et al. found these technical trading rules generating significant positive returns, especially from buy signals. Later, Levich and Thomas [7], Parisi and Vasquez [8], Kwon and Kish [9], also showed that technical trading can be significantly profitable, for currency futures contracts between 1976 and 1990, for many stocks on the Chilean stock market between 1989 and 1998, and for the New York Stock Exchange value-weighted index over the period 1962 to 1996, respectively.
When the technical trading rules were tested within shorter subperiods in Refs. [7] and [9], their profitabilities were found to be lower for the last sub-periods, 1986 to 1990 and 1985 to 1996, respectively. Kwon and Kish suspected that this was due to the market becoming more efficient after computerization. But as they pondered this, a wave of criticism on technical trading started, led by the papers by Ready [10] and Bajgrowicz and Scaillet [11]. In these papers, as well as those by Fang et al. [12] and Taylor [13], technical trading rules found to be profitable in the earlier periods in Ref. [6] were tested for later periods, and found to have lost their magic. Taylor, who examined the performance of momentum-based technical trading rules over the cross section of Dow Jones Industrial Average component stocks between 1928 and 2012, found the profitability of these technical trading rules evolving slowly over time, but are most profitable between the mid-1960s to the mid-1980s. This phenomenon was also observed for the performance of hedge funds. For example, earlier studies by Ackermann et al. and Liang reported stellar performances of 9.2–16.1% annual return for 906 hedge funds between January 1994 and December 1995) [14], and monthly returns ranging from
Ultimately, through the literature survey above, we see that machine learning is also not exhaustive. It finds the best, but not all that are profitable. Also, technical trading rules discovered through machine learning (including those using artificial neural networks [19–21]) do not necessarily perform better than those learned by human traders. Here let us address the question why technical trading rules have only short-lived successes, from the context of information processing by complex systems. For example, a typical language like English contains more than 100,000 words, using which we construct sentences containing about 20 words. However, an overwhelming majority of the
Financial markets are also complex systems, in which participants are constantly learning how to process the complex information coursing through the system. As they do so, they add to the complex information in the system. Therefore, efficient or not, we expect hidden rules and recurrent sequences to be present in financial markets. However, as financial agents act on the market, they are themselves acted upon. As such, no agent or strategy can dominate forever, even though a previously-dominant strategy may return to dominance time and again. This explains why technical trading rules can be profitable (because exploitable information always exists in the market), and why their profitabilities are short-lived (because they generate information that can be exploited by other technical trading rules). Therefore, when a group of technical trading rules become unprofitable, another group of technical trading rules become profitable. This tells us that to hunt for this shifting information, we should look not only for correlations in time, but also correlations in space, across different instruments and different asset classes. So far, technical trading focuses on temporal patterns representing high-order serial correlations in individual instruments, but spatio-temporal patterns involving multiple instruments should also exist, and can be exploited for technical trading. Surprisingly, after a broad survey of the literature, we found no previous studies on technical trading based on spatio-temporal patterns. In fact, when we search Google Scholar using “pattern recognition” and “multivariate time series”, we end up with two hits. In the 2011 conference paper by Spiegel et al. [24], time series segmentation was first used to define features in the individual time series, before these features were used to define patterns across the small number of car accelerator sensor time series. In their 2016 paper [25], Fontes and Pereira used a three-step method involving subsequence matching and fuzzy clustering, followed by PCA to analyze sensor time series cross section from a gas turbine for monitoring and fault prediction.
In this paper, we take the natural next step to test the feasibility of technical trading using spatio-temporal patterns over the cross section of Dow Jones Industrial Average component stocks, as well as over cross sections of multiple asset classes including commodities, bonds, FOREX rates, indices, metals, and oil and gas. To find these recurrent spatio-temporal patterns, all these existing works relied on time series segmentation to first convert a real-valued time series into a symbolic time series. This is computationally heavy, so instead of time series segmentation, we describe in Section 2 how we collected and cleaned our data, and how we map a specific choice of price movements to spatio-temporal cross sections of strings with lengths up to 5 days and comprising up to 10 alphabets. Ultimately, with this symbolic mapping all temporal patterns can be mapped to strings of alphabets. However, even after this simplification the extraction of actionable information on financial markets is not a trivial task, firstly because we have no prior knowledge what these signals would look like, and must thus analyze movements within the system, identify recurrent sequences that appear, and use these to infer the rules of information processing within financial markets. Such an analysis has been carried out in various fields to analyze various complex systems [26–30], and we ourselves have done so for natural languages [31] and teaching practices [32]. Secondly, the very many signals overlap in time to mask each other, and more importantly, participants hide their intentions as they trade. This leads to the financial markets becoming so “noisy” that one can guess price movements correctly only slightly more than 50% of the time (although Kelly showed in 1956 that this is sufficient to ensure a positive return betting on an outcome [33]). This second problem also occurs for our gene expression machinery, or the information processing machinery of other complex systems. Fortunately, network science has made great strides in systematically and independently identifying spatial motifs [34–36], which are collections of nodes that are co-activated much more frequently than we expected from random and uncorrelated activation of nodes, or temporal motifs [37, 38], which are sequences of nodes that are activated one after another. Spatial motifs can be very large, and we need a lot of data to be confident that they are not products of random fluctuations. Similarly, temporal motifs can be very long, making the space of sequences to search through very large indeed. As far as we know, there have been no efforts to develop methods for identifying spatio-temporal motifs, consisting of different cross sections of nodes at different lags. Therefore, in Section 2, we describe how to unpack spatio-temporal sequences into collections of temporal sequences, and thereafter test these empirical sequences against null models to identify sequences that are repeated more frequently than by chance. We then report in Section 3 that in general, there are no actionable serial correlations for single instruments, but many recurrent multiple-instrument spatio-temporal sequences exist, which allow one to design trading strategies around them. Finally, we tested the feasibility of these trading strategies in Section 4, before summarizing our findings in Section 5.
2 Data and Methods
2.1 Data
We downloaded two sets of time series data in the form of comma-separated values (CSV) files. The first set (see Supplementary Table S1) comprised daily prices of the 30 component stocks of the Dow Jones Industrial Average (DJI). These belong to the 30 largest publicly-owned United States companies, which are prominent brand names many people are familiar with. We used the maximum time period for each stock, so that we can compare them across the longest possible time period. The second set (see Supplementary Table S2) comprised daily prices of three to five instruments each from six different asset classes, including stock indices, precious metals, commodities, government bonds, energy materials, and foreign exchange. The 26 instruments in this second data set were selected primarily because data was readily available, and also because they are easily recognizable.
We then imported these CSV files into Python for cleaning. First, we removed empty cells or cells that contain errors, before saving the cleaned data as two separate numpy files. The first file contains the dates in International Organization for Standardization (ISO) format, while the second file contains the corresponding closing prices. For missing prices over weekends or public holidays, we set them equal to the prices of the previous days. As such, a financial instrument can only increase continuously for at most 5 days, as closing prices over the weekends are set to those on Friday.
2.2 Compiling Lists of Spatio-Temporal Sequences
To avoid having to deal with the full complexity of financial markets, but still be able to discover statistically significant patterns within the data, we map the day-to-day price change time series to symbolic sequences from a small alphabet. There are many ways this can be done, depending on what trading strategy we would like to adopt. For example, if we would like to watch for 2 days of positive price changes, and buy the instruments that are most likely to also experience positive price changes in the next one, two, or three days, we would choose to map the price changes to letters of an alphabet (one letter for each instrument), only when the price changes are positive. This example is illustrated in Figure 1A. Alternatively, if we would like to sell an instrument whose price is most likely to fall after 2 days of gain in the prices of two other instruments, we can map positive price changes to uppercase letters ‘A’, ‘B’, ‘C’, …, and negative price changes to lowercase letters ‘a’, ‘b’, ‘c’, ….
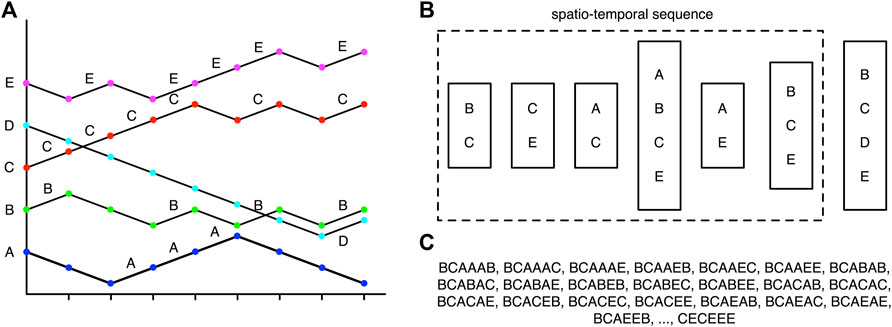
FIGURE 1. (A) The price time series of five financial instruments, mapped to the alphabets ‘A’, ‘B’, ‘C’, ‘D’, ‘E’. When the price of an instrument rises, the corresponding letter is added to the spatial cross section. (B) For days
In Figure 1B, we show how we organize the symbolic sequences of the cross section of instruments into spatio-temporal sequences. A spatio-temporal sequence consists of spatial cross sections like (‘B’, ‘C’), (‘C’, ‘E’), (‘A’, ‘C’), (‘A’, ‘B’, ‘C’, ‘E’), (‘A’, ‘E’), (‘B’, ‘C’, ‘E’) at successive times. Spatial cross sections at different times need not be the same in size, like (‘B’, ‘C’) and (‘A’, ‘B’, ‘C’, ‘E’) for example. Spatio-temporal sequences also need not be equally long in time. For example, the spatio-temporal sequence (‘B’, ‘C’) → (‘C’, ‘E’) → (‘A’, ‘C’) → (‘A’, ‘B’, ‘C’, ‘E’) → (‘A’, ‘E’) → (‘B’, ‘C’, ‘E’) has a temporal length of 6. This spatio-temporal sequence stops here, because in the time series cross section, no instrument has an increasing price on day 7. The spatial cross section (‘B’, ‘C’, ‘D’, ‘E’) on day 8 then represents the start of the next spatio-temporal sequence, which may have a different temporal length. Going through the time series cross section
2.3 Null Model and Test of Statistical Significance
In general, when we expand the spatio-temporal sequences into temporal sequences, and count the number of times they appear, some temporal sequences will be frequent, while others will be rare. However, a frequent temporal sequence may be less informative than a rare temporal sequence, if the former contains many highly-frequent symbols. In other words, these frequent temporal sequences can occur by chance, because their symbols are so common. Therefore, the frequencies of different temporal sequences must be tested against appropriate null models, to ensure at the very least that they are not likely to be obtained by chance.
Depending on what information we are interested in, we can construct different null models. In Section 3.1, we will show that the probability of empirically finding positive price movements in an instrument for r consecutive days is
A simple null model that preserves spatial cross correlations, but contains no temporal correlations, can be obtained by reshuffling the empirical spatio-temporal sequences, as shown in Figure 2. If this reshuffling is done within individual spatio-temporal sequences, we also preserve the distribution of lengths. With this null model, and some additional care, it is even possible to perform statistical testing at the level of spatio-temporal sequences. However, we chose for simplicity to perform statistical testing at the level of temporal sequences. A temporal sequence is a simple word (string of symbols), like ‘BCA’, ‘BCABA’, and so on. To do the test, we extract all possible words that can be generated from the list of spatio-temporal sequences. For example, for (‘B’, ‘C’) → (‘C’, ‘E’) → (‘A’, ‘C’), we can generate the words ‘BCA’, ‘BCC’, ‘BEA’, ‘BEC’, ‘CCA’, ‘CCC’, ‘CEA’, ‘CEC’. We then count the number of times each word appears after this unpacking of the spatio-temporal sequences. These are our empirical frequencies.
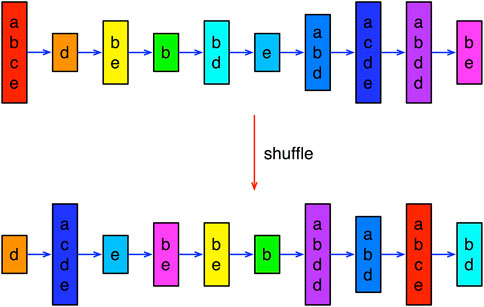
FIGURE 2. Shuffling a length-10 spatio-temporal sequence with spatial cross sections of different sizes, to obtain a null-model ensemble of length-10 spatio-temporal sequences.
Next, we shuffle the empirical spatio-temporal sequences
Since we sampled the null model
3 Results
3.1 1-Letter Words
When we analyze each of the 56 instruments independently, by emitting a single letter when the price increases, we are looking at bull runs of different durations in their time series. We show the distributions of durations for stocks in the first data set in Supplementary Figure S1, and those for instruments in the second data set in Supplementary Figure S2. Plotted on a linear-log scale, these graphs are all close to being linear, suggesting that the distributions are exponential. Such an exponential distribution arises very naturally if we assume that the price increase on one day is uncorrelated with a price increase on any other day. Therefore, if the probability of a price increase is p, the probability of finding a bull run over r days is simply
This result should not surprise us, since it is just an unconventional way to present a very well known observation in finance, namely the serial correlation or autocorrelation is nearly zero [41]. This also means that there is no signal for a trader to act on, when the 1-letter word lengths are so distributed, beyond betting on the probability p of getting a price increase on a given day, regardless of the number of days of price increases prior to it. According to Fama and others after him, the market is thus “efficient” [1].
3.2 2-Letter Words
However, this does not mean that there is no actionable price movement information in the financial markets. In fact, trying to understand this information by looking at the price movement of a single instrument is like trying to understand the first sentence of this paragraph by looking at the distribution {_,_, _, ‘a’, ‘a’, _, _, _, ‘aa’, _, _, ‘a’, _, _, ‘aa’, ‘a’} of the letter ‘a’ appearing in the words. If we use two letters, say ‘a’ and ‘e’, the distribution {‘ee’, _, ‘e’, _, ‘ea’, ‘a’, ‘ee’, _, _, ‘aae’, ‘e’, ‘ee’, ‘a’, _, ‘e’, ‘aa’, ‘ae’} is now more informative (though still not enough for us to comprehend the sentence). The distribution {‘ee’, ‘i’, ‘e’, _, ‘ea’, ‘a’, ‘ee’, ‘i’, _, ‘aiae’, ‘ie’, ‘ee’, ‘iai’, ‘i’, ‘e’, ‘iaia’, ‘ae’} becomes even more informative if we include one more letter (‘i’). In this subsection, let us demonstrate (as a proof of concept) how we can extract more information from the distribution of 2-letter words. To do this, let us examine two pairs of instruments, (A = HD, B = TRV) and (A = platinum, B = USD-EUR), which are chosen because individually, their distributions of 1-letter words are the least informative (in that the probability of finding a word with length-r is closest to the product of independently finding r length-1 words).
For the HD-TRV pair, we used data between Sep 22, 1981 and Mar 7, 2018. Going through the 9,194 closing prices, we found 1,019 trading days when there were no price increases in either HD or TRV. The rest of the trading days are partitioned into 1,974 spatio-temporal sequences. The shortest of these spatio-temporal sequences are {(A)}, {(B)}, and {(A, B)}, which are the three possible spatial cross-sections. The longest spatio-temporal sequence is length-22 (price increases over multiple holidays and weekends). We focused on the 1,676 spatio-temporal sequences length-5 and shorter. These unpack into 4,213 temporal sequences, with the distribution shown in Table 1. As expected, after statistical testing at the level of
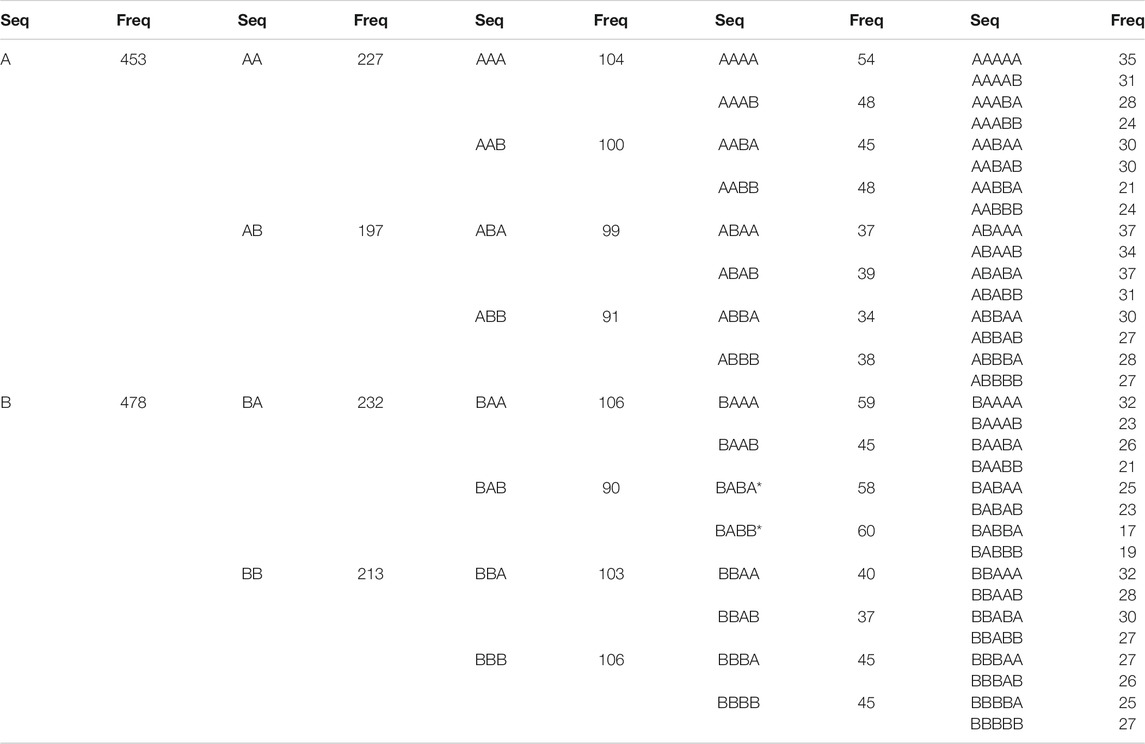
TABLE 1. Empirical frequencies of 2-letter temporal sequences of up to length-5, corresponding to price increases in HD and TRV. In this table, an asterix indicates statistical significance at the level of
For the platinum-USD-EUR pair, we used data between Dec 27, 1979 and Mar 13, 2018. Going through the 9,922 prices, we found 639 trading days when there were no price increases in either platinum or USD-EUR. The rest of the trading days were partitioned into 1,884 spatio-temporal sequences, and the longest spatio-temporal sequence is length-27 (price increases over multiple holidays and weekends). Focusing on the 1,449 spatio-temporal sequences length-5 and shorter, we find that these unpack into 3,185 temporal sequences, with the distribution shown in Table 2. In this case, we find BA occurring more frequently than expected from the null model, at the
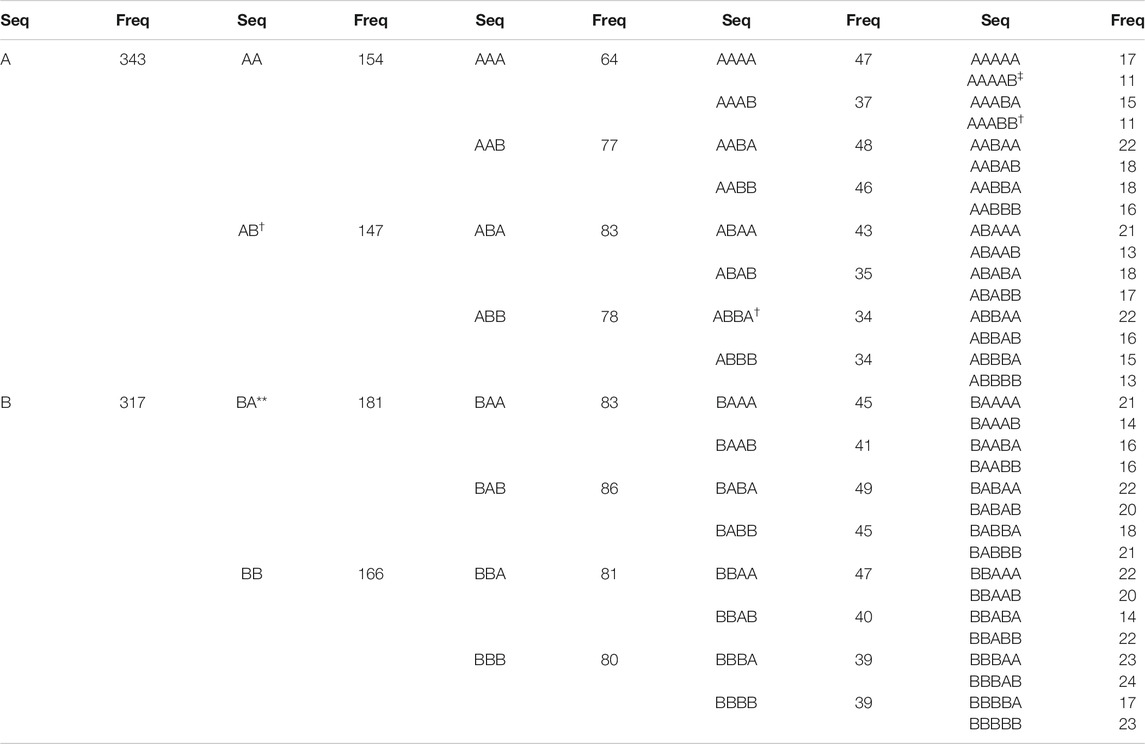
TABLE 2. Empirical frequencies of 2-letter temporal sequences of up to length-5, corresponding to price increases in platinum and USD-EUR. In this table, an empirical frequency that is significantly higher than expected from the null model is indicated by an asterix (
3.3 5-Letter Words
In Section 3.2, we illustrated how we can better understand the information contained in an English sentence by going from one-letter sequences to two-letter sequences, and how the information extraction improved with three-letter sequences. In this subsection, let us show that this is also true for financial markets, by going to a cross section of five stocks, (A) GE, (B) CSCO, (C) HD, (D) JPM, (E) MMM, using prices between Feb 16, 1990 and Mar 8, 2018. Out of the 10,248 trading days, there are 2,225 days on which there are no price increases in any of the five stocks. From the remaining 8,023 trading days, we found 1,987 spatio-temporal sequences of lengths between 1 and 5. After unpacking, we obtained 158,106 temporal sequences.
Out of
For this cross section of five stocks, we also found a very interesting statistic: of the 183
Finally, we find 11 of the
we find that six prefixes match, and their empirical frequencies are close to each other. Therefore, we can write these 12 length-5 motifs as
and then further as
In doing so, we are repacking the 12 length-5 temporal motifs back into a spatio-temporal motif.
3.4 10-Letter Words
Ultimately, there are tens of thousands of stocks on the New York Stock Exchange and other US exchanges, so the 30 DJI component stocks, or even the 500 S&P 500 component stocks cannot provide a comprehensive picture on all information flowing through these stock markets. If we go beyond stock markets, to include assets from other financial markets (commodities, oil and gas, bonds, foreign exchange, …), it is clear a cross section of five instruments represents not even the tip of an iceberg. It is thus tempting to consider cross sections of many more instruments. However, as we have seen from Section 3.2 and Section 3.3, while the numbers of spatio-temporal sequences remain comparable, the numbers of temporal sequences that we unpack going from a two-letter alphabet to a five-letter alphabet increased 50-fold. If we now go from a five-letter alphabet to a 10-letter alphabet, the numbers of temporal sequences is expected to increase another 30-fold, to approximately
At the same time, the information we can extract from financial markets become richer when we use larger alphabets. To illustrate this, and also highlight new problems encountered, let us analyze two large cross sections of instruments in this subsection: 1) a cross section of 10 DJI component stocks, and 2) a cross section of nine mixed assets. In the first cross section, (A) GE, (B) CSCO, (C) HD, (D) JPM, (E) MMM, (F) MRK, (G) UTX, (H) BA, (I) VZ, (J) XOM, we used prices between Feb 16, 1990 and Mar 8, 2018. Out of 10,248 trading days, we found 1,863 days on which there were no price increases in any of the stocks. For the rest of the trading days, price increases were organized into 1,738 spatio-temporal sequences up to length-5. For 10 stocks, there are 111,110 unique temporal sequences. Out of these, 3,580 temporal sequences are statistically significant at the
for
for
where
Because of the number of
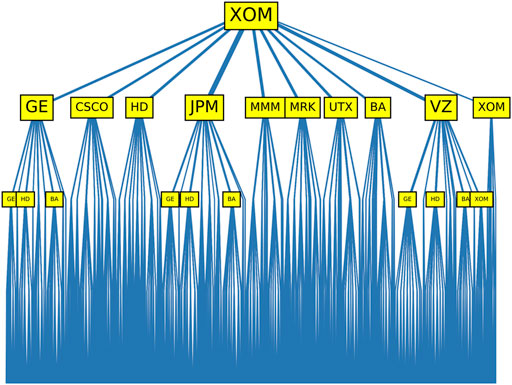
FIGURE 3. Tree diagram of dynamical motifs rooted in (J) XOM (price increase on the first day). In this figure, we label all ten stocks with price increases on the second day, but use a larger font for (A) GE, (D) JPM, and (I) VZ, to indicate that price increases in these stocks are followed by the largest numbers of dynamical motifs. For price increases on the third day, we label only those stocks following XOM and GE/JPM/VZ, and are themselves followed by the most dynamical motifs. Except for (J) XOM following VZ, we find consistently (A) GE, (C) HD, and (H) BA following price increases on the second day. This is also true for the branches we did not highlight, as well as for the fourth day.
The second cross section we feature here consists of indices and precious metals, namely (A) gold, (B) silver, (C) palladium, (D) S&P 500, (E) Hang Seng, (F) platinum, (G) Dow Jones, (H) Nikkei, and (I) NASDAQ. We used prices between Apr 2, 1990 and Jan 28, 2018. Of the 10,164 trading days, we find 1,604 days on which there were no price increases in any of the assets. For the rest of the trading days, price increases were organized into 1,607 spatio-temporal sequences up to length-5. For the nine assets, 9,145 temporal sequences are statistically significant at the
We also found the 9,145
Unlike for the cross section of 10 DJI stocks, in this cross section of nine mixed assets, length-4 sequences outnumber length-5 sequences. For the length-4 sequences,
while
None of the assets are particularly strong leaders or strong followers. For the length-5 sequences, from the distribution
we find the strong leaders are (A) gold, (D) S&P 500, (G) Dow Jones, (I) NASDAQ, while the weak leaders are (B) silver, (E) Hang Seng, (H) Nikkei. Gold is well known to be a leading indicator of inflation [42, 43], so it would not be surprising for gold to also lead smaller-scale market movements. Using the Hilbert transform to complexify the return time series of major global indices, Vodenska et al. showed convincingly that FOREX markets lead equity markets, and the US equity market is one of the leaders of other equity markets [44]. Finally, from the distribution
we see that (C) palladium, (E) Hang Seng are strong followers, while (A) gold, (F) platinum are weak followers. As expected, (A) gold being a strong leader is a weak follower, whereas (E) Hang Seng being a weak leader is a strong follower. Surprisingly, (C) palladium is a strong follower, even though it is not weak as a leader. Similarly, (F) platinum is one of the weakest followers, even though it is not the strongest of leaders.
The tree diagrams for length-5
4 Feasibility
After identifying the dynamical motifs, let us check whether they can be traded profitably. We do this for length-5 motifs, which are the most informative. First, let us explain how a simple trading strategy can be developed using one specific
For this length-5 motif, we find that over the period Feb 16, 1990 to Mar 8, 2018, the price increase sequence XOM → VZ → BA appeared 964 times, while the price increase sequence XOM → VZ → BA → MMM appeared 477 times. Buying MMM 964 times at the end of day 3 and selling it at the of day 4, we compute for each transaction the fractional return
for the price increase sequence XOM → VZ → BA that started on day t. The normalized histogram for these 964 fractional returns is shown in Figure 4. Similarly, of the 477 times the price increase sequence XOM → VZ → BA → MMM appeared, price increase in XOM followed 236 times. If we wait for the price increase sequence XOM → VZ → BA → MMM to appear, buy XOM at the end of day 4, and sell it at the end of day 5, we find the fractional return
for the price increase sequence XOM → VZ → BA that started on day t. The normalized histogram for these 477 fractional returns is also shown in Figure 4.
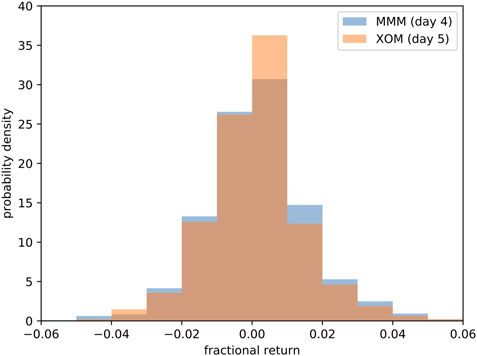
FIGURE 4. Probability densities of the fractional returns for trading MMM on day 4 and XOM on day 5 based on the
The average fractional returns are 0.0012 for MMM, and 0.0007 for XOM. These are positive, but puny. More importantly, over the roughly 28-year period, we would have traded only
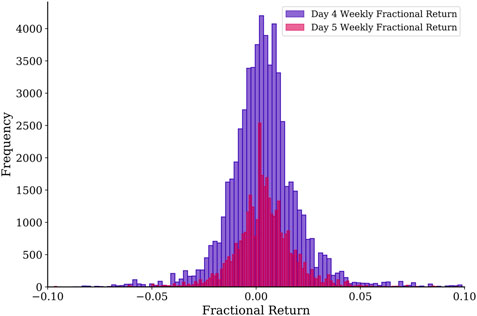
FIGURE 5. Distributions of fractional returns for trading on day 4 and day 5 of
If we trade multiple motifs in the same week, then our prospects would be different. This is because we may fail to profit from some motifs, but still succeed in other motifs. Therefore, we should first average the fractional return over all motifs we trade in a given week, before compiling the histogram of 424 weekly average fractional returns shown in Figure 6. Unlike for the fractional return of individual transactions, when we trade all possible motifs and average the fractional returns over them, we find that we almost never lose money in any week. The average of the average fractional return per week is 0.0035 on day 4 and 0.0042 on day 5, the same as when we average over the distributions of fractional returns. However, since we now know the average fractional return per week is (almost) always positive, we can compound them to get an average fractional return of 0.0077 per week, or an average fractional return of 0.4004 per annum!
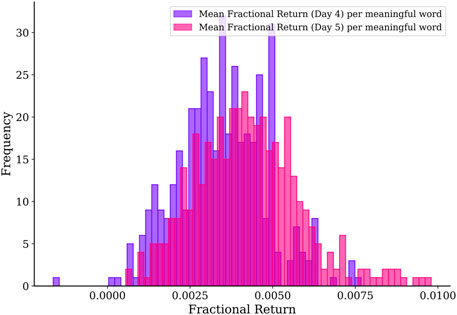
FIGURE 6. Distributions of weekly average fractional returns for trading on day 4 and day 5 of all
Another way to understand this profitability is in terms of
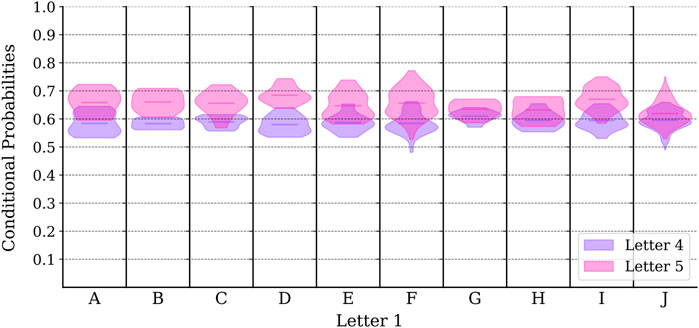
FIGURE 7. Distributions of conditional probabilities for price increases on day 4 and day 5 for all
Before we conclude, let us also test the feasibility of our simple trading strategy for the
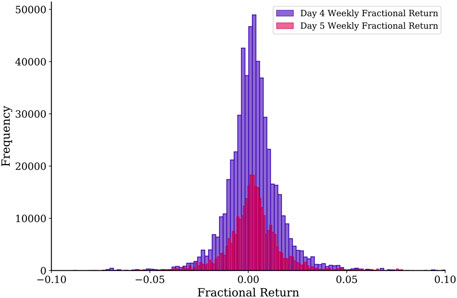
FIGURE 8. Histograms of the fractional returns for day 4 and day 5 trading based on
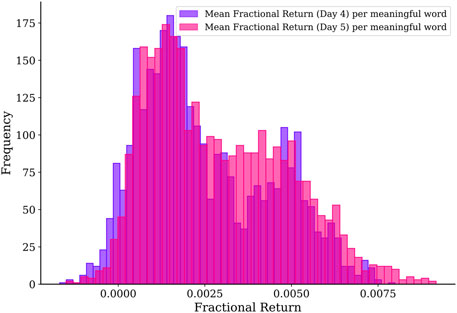
FIGURE 9. Histograms of the weekly average fractional returns for day 4 and day 5 trading based on all
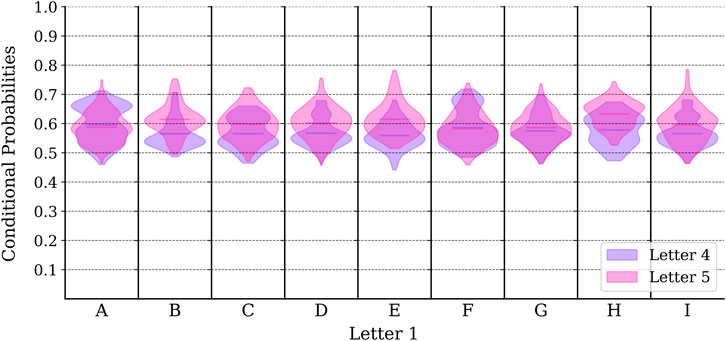
FIGURE 10. Histograms of the conditional probabilities for day 4 and day 5 trading based on all
We also investigated a second cross section of DJI stocks, as well as a second and third cross sections of mixed assets. The distributions of fractional returns, weekly average fractional returns, and conditional probabilities of these cross sections are shown in Supplementary Figures S8 and S9.
5 Conclusions and Outlook
In this paper, we explained how information processing by self-organized functions in complex systems lead to the existence of recurrent activity sequences or dynamical motifs. In financial markets, which are also complex systems, past and expected information that gets incorporated into prices must therefore be in the form of recurrent sequences. Thus far, technical traders have exploited temporal patterns corresponding to high-order serial correlations of individual instruments, but actionable spatio-temporal patterns (also called dynamical motifs) must also exist. To identify these dynamical motifs
We tested the above procedure on the 30 DJI component stocks, as well as 26 instruments from various asset classes, to find the absence of serial correlations that traders can exploit, if they are traded individually. We then tested the procedure on two pairs of instruments, to find two length-4 dynamical motifs for (HD, TRV) that are statistically significant at the
In this study, we identified dynamical motifs consisting of price increases over five consecutive days from daily prices. For 616 length-5 motifs in the cross section of 10 DJI component stocks, we could execute 96,000 trades over 28 years, or about 3,400 trades per year. For 9,145 length-5 motifs in the cross section of nine mixed assets, we could execute about 877,300 trades, or about 31,300 trades per year. To get better returns, a trader would want to trade more frequently. This can be done by going to higher-frequency data, and use the high-frequency motifs identified for trading. We do not know how well such a strategy will perform, but imagine it doing better, since in high-frequency data, autocorrelations and cross correlations do not have time to die out, and therefore motifs would become easier to identify, and are also statistically more significant. In this paper, we also mapped all price increases in an instrument to a single letter. If we do not have many instruments, it is possible (and perhaps desirable) to use two letters per instrument, so that one would represent a small increase, while the other would represent a large increase. Alternatively, we can map the price increases in an instrument to more than one instance of the letter. For example, an increase of 0–1% can be mapped to A, an increase of 1–2% to AA, and an increase of 2–5% to AAA. Traders can then choose to act only if a large price increase is expected. Other variations are also possible.
As a final caveat, let us say that like for purely temporal patterns of single instruments, the profitabilities of spatio-temporal patterns containing multiple instruments are also expected to be short-lived, because once a spatio-temporal pattern becomes dominant it can be exploited by other spatio-temporal patterns. In Figure 11 we show the frequencies of two length-5 motifs (at the
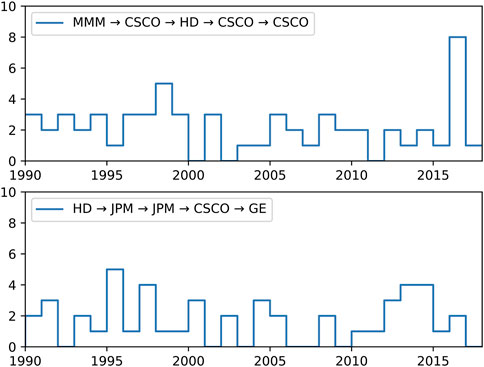
FIGURE 11. The number of times two length-5 motifs ((top) MMM → CSCO → HD → CSCO → CSCO, and (bottom) HD → JPM → JPM → CSCO → GE) in the cross section of five DJI component stocks (A) GE, (B) CSCO, (C) HD, (D) JPM, (E) MMM, appear for each year between Feb 16, 1990 and Mar 8, 2018.
Data Availability Statement
The datasets presented in this study can be found in online repositories. The names of the repository/repositories and accession number(s) can be found in the article/Supplementary Material.
Author Contributions
SC conceived the study, wrote some of the Python programs, and wrote the manuscript. YWL, YYL, JL, JT, and XT downloaded the data sets and wrote the rest of the Python programs. All authors analyzed the results and reviewed the manuscript.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
YWL, YYL, JL, JT, and XT thank the Singapore Ministry of Education Science Mentorship Program for the opportunity to participate in this study.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fams.2021.641595/full#supplementary-material.
References
1. Fama, EF. Efficient Capital Markets: A Review of Theory and Empirical Work. J Finance (1970). 25:383–417. doi:10.2307/2325486
2. Brown, DP, and Jennings, RH. On Technical Analysis. Rev Financ Stud (1989). 2:527–51. doi:10.1093/rfs/2.4.527
3. Park, CH, and Irwin, SH. What Do We Know About the Profitability of Technical Analysis? J Econ Surv (2007). 21:786–826. doi:10.1111/j.1467-6419.2007.00519.x
4. Nazário, RT, e Silva, JL, Sobreiro, VA, and Kimura, H. A Literature Review of Technical Analysis on Stock Markets. Q Rev Econ Finance (2017). 66:115–26. doi:10.1016/j.qref.2017.01.014
5. Lukac, LP, Brorsen, BW, and Irwin, SH. A Test of Futures Market Disequilibrium Using Twelve Different Technical Trading Systems. Appl Econ (1988). 20:623–39. doi:10.1080/00036848800000113
6. Brock, W, Lakonishok, J, and LeBaron, B. Simple Technical Trading Rules and the Stochastic Properties of Stock Returns. J Finance (1992). 47:1731–64. doi:10.2307/2328994
7. Levich, RM, and Thomas, LR. The Significance of Technical Trading-Rule Profits in the Foreign Exchange Market: A Bootstrap Approach. J Int Money Finance (1993). 12:451–74. doi:10.1016/0261-5606(93)90034-9
8. Parisi, F, and Vasquez, A. Simple Technical Trading Rules of Stock Returns: Evidence From 1987 to 1998 in Chile. Emerg Mark Rev (2000). 1:152–64. doi:10.1016/S1566-0141(00)00006-6
9. Kwon, KY, and Kish, RJ. Technical Trading Strategies and Return Predictability: NYSE. Appl Financ Econ (2002). 12:639–53. doi:10.1080/09603100010016139
10. Ready, MJ. Profits From Technical Trading Rules. Financ Manage (2002). 31:43–61. doi:10.2307/3666314
11. Bajgrowicz, P, and Scaillet, O. Technical Trading Revisited: False Discoveries, Persistence Tests, and Transaction Costs. J Financ Econ (2012). 106:473–91. doi:10.1016/j.jfineco.2012.06.001
12. Fang, J, Jacobsen, B, and Qin, Y. Predictability of the Simple Technical Trading Rules: An Out-of-Sample Test. Rev Financ Econ (2014). 23:30–45. doi:10.1016/j.rfe.2013.05.004
13. Taylor, N. The Rise and Fall of Technical Trading Rule Success. J Bank Finance (2014). 40:286–302. doi:10.1016/j.jbankfin.2013.12.004
14. Ackermann, C, McEnally, R, and Ravenscraft, D. The Performance of Hedge Funds: Risk, Return, and Incentives. J Finance (1999). 54:833–74. doi:10.1111/0022-1082.00129
15. Liang, B. On the Performance of Hedge Funds. Financ Anal J (1999). 55:72–85. doi:10.2139/SSRN.89490
16. Fung, W, Hsieh, DA, Naik, NY, and Ramadorai, T. Hedge Funds: Performance, Risk, and Capital Formation. J Finance (2008). 63:1777–803. doi:10.1111/j.1540-6261.2008.01374.x
17. Allen, F, and Karjalainen, R. Using Genetic Algorithms to Find Technical Trading Rules. J Financ Econ (1999). 51:245–71. doi:10.1016/S0304-405X(98)00052-X
18. Fernández-Rodríguez, F, González-Martel, C, and Sosvilla-Rivero, S. On the Profitability of Technical Trading Rules Based on Artificial Neural Networks: Evidence from the Madrid Stock Market. Econ Lett (2000). 69:89–94. doi:10.1016/S0165-1765(00)00270-6
19. Kimoto, T, Asakawa, K, Yoda, M, and Takeoka, M. Stock Market Prediction System with Modular Neural Networks. In: Proceedings of the 1990 International Joint Conference on Neural Networks (IJCNN 1990); 1990 June 17–21; San Diego, CA. New York, NY: IEEE. (2009). p. 1–6.
20. Zhang, Y, and Wu, L. Stock Market Prediction of S&P 500 via Combination of Improved BCO Approach and BP Neural Network. Expert Syst Appl (2009). 36:8849–54. doi:10.1016/j.eswa.2008.11.028
21. Guresen, E, Kayakutlu, G, and Daim, TU. Using Artificial Neural Network Models in Stock Market Index Prediction. Expert Syst Appl (2011). 38:10389–97. doi:10.1016/j.eswa.2011.02.068
22. Wise, J, Roush, R, and Fowler, S. Concepts of Biology. Scotts Valley, CA: CreateSpace Independent Publishing Platform (2013).
23. Tymoczko, JL, Berg, JM, Stryer, L, and Gatto, G. Biochemistry: A Short Course. Austin, TX: Macmillan Learning (2019).
24. Spiegel, S, Gaebler, J, Lommatzsch, A, De Luca, E, and Albayrak, S. Pattern Recognition and Classification for Multivariate Time Series. In: Proceedings of the Fifth International Workshop on Knowledge Discovery from Sensor Data; August 21, 2011, San Diego, CA. New York, NY: ACM (2011). p. 34–42.
25. Fontes, CH, and Pereira, O. Pattern Recognition in Multivariate Time Series – A Case Study Applied to Fault Detection in a Gas Turbine. Eng Appl Artif Intell (2016). 49:10–8. doi:10.1016/j.engappai.2015.11.005
26. Zhang, YQ, Li, X, Xu, J, and Vasilakos, AV. Human Interactive Patterns in Temporal Networks. IEEE Trans Syst Man Cybern Syst (2015). 45:214–22. doi:10.1109/TSMC.2014.2360505
27. Hulovatyy, Y, Chen, H, and Milenković, T. Exploring the Structure and Function of Temporal Networks With Dynamic Graphlets. Bioinformatics (2015). 31:i171–80. doi:10.1093/bioinformatics/btv227
28. Xuan, Q, Fang, H, Fu, C, and Filkov, V. Temporal Motifs Reveal Collaboration Patterns in Online Task-Oriented Networks. Phys Rev E (2015). 91:052813. doi:10.1103/PhysRevE.91.052813
29. Paranjape, A, Benson, AR, and Leskovec, J. Motifs in Temporal Networks. In: Proceedings of the Tenth ACM International Conference on Web Search and Data Mining (WSDM 2017); 2017 Feb 6–10; Cambridge, UK. New York, NY: ACM (2017). p. 601–10.
30. Liu, P, Benson, AR, and Charikar, M. Sampling Methods for Counting Temporal Motifs. In: Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining; 2019 Feb 11–15; Melbourne, Australia. New York, NY: ACM (2019). p. 294–302.
31. Goh, WP, Luke, KK, and Cheong, SA. Functional Shortcuts in Language Co-Occurrence Networks. PLoS ONE (2018). 13:0203025. doi:10.1371/Fjournal.pone.0203025
32. Goh, WP, Kwek, D, Hogan, D, and Cheong, SA. Complex Network Analysis of Teaching Practices. Eur Phys J Data Sci (2014). 3:34. doi:10.1140/epjds/s13688-014-0034-9
33. Kelly, JL. A New Interpretation of Information Rate. In: LC McClean, EO Thorp, and WT Ziemba, editors. The Kelly Capital Growth Investment Criterion. Singapore: World Scientific (2011). p. 25–34.
34. Milo, R, Shen-Orr, S, Itzkovitz, S, Kashtan, N, Chklovskii, D, and Alon, U. Network Motifs: Simple Building Blocks of Complex Networks. Science (2002). 298:824–7. doi:10.1126/science.298.5594.824
35. Shen-Orr, SS, Milo, R, Mangan, S, and Alon, U. Network Motifs in the Transcriptional Regulation Network of Escherichia coli. Nat Genet (2002). 31:64–8. doi:10.1038/ng881
36. Wernicke, S, and Rasche, F. FANMOD: A Tool for Fast Network Motif Detection. Bioinformatics (2006). 22:1152–3. doi:10.1093/bioinformatics/btl038
37. Kovanen, L, Karsai, M, Kaski, K, Kertész, J, and Saramäki, J. Temporal Motifs in Time-Dependent Networks. J Stat Mech Theor Exp. (2011). P11005. doi:10.1088/1742-5468/2011/11/P11005
38. Kovanen, L, Kaski, K, Kertész, J, and Saramäki, J. Temporal Motifs Reveal Homophily, Gender-Specific Patterns, and Group Talk in Call Sequences. Proc Natl Acad Sci U S A (2013). 110:18070–5. doi:10.1073/pnas.1307941110
39. Dunn, OJ. Multiple Comparisons Among Means. J Am Stat Assoc (1961). 56:52–64. doi:10.1080/01621459.1961.10482090
40. Šidák, Z. Rectangular Confidence Regions for the Means of Multivariate Normal Distributions. J Am Stat Assoc (1967). 62:626–33. doi:10.1080/01621459.1967.10482935
41. Chakraborti, A, Toke, IM, Patriarca, M, and Abergel, F. Econophysics Review: I. Empirical Facts. Quant Finance (2011). 11:991–1012. doi:10.1080/14697688.2010.539248
42. Moore, GH. Gold Prices and a Leading Index of Inflation. Challenge (1990). 33:52. doi:10.1016/S0148-6195(97)00034-9
43. Mahdavi, S, and Zhou, S. Gold and Commodity Prices as Leading Indicators of Inflation: Tests of Long-Run Relationship and Predictive Performance. J Econ Bus (1997). 49:475–89. doi:10.1016/S0148-6195(97)00034-9
44. Vodenska, I, Aoyama, H, Fujiwara, Y, Iyetomi, H, and Arai, Y. Interdependencies and Causalities in Coupled Financial Networks. PloS One (2016). 11:0150994. doi:10.1371/journal.pone.0150994
45. Kato, K. Weekly Patterns in Japanese Stock Returns. Manage Sci (1990). 36:1031–43. doi:10.1287/mnsc.36.9.1031
46. Becker, KG, Finnerty, JE, and Tucker, AL. The Intraday Interdependence Structure Between US and Japanese Equity Markets. J Financ Res (1992). 15:27–37. doi:10.1111/j.1475-6803.1992.tb00784.x
Keywords: financial markets, serial correlations, complex systems, information processing, recurrent sequences
Citation: Cheong SA, Lee YW, Li YY, Lim JQ, Tan JDJ and Teo XPJ (2021) Identifying Actionable Serial Correlations in Financial Markets. Front. Appl. Math. Stat. 7:641595. doi: 10.3389/fams.2021.641595
Received: 14 December 2020; Accepted: 29 March 2021;
Published: 26 April 2021.
Edited by:
Sou Cheng Choi, Illinois Institute of Technology, United StatesReviewed by:
Halim Zeghdoudi, University of Annaba, AlgeriaJiajia Li, Pacific Northwest National Laboratory (DOE), United States
Copyright © 2021 Cheong, Lee, Li, Lim, Tan and Teo. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Siew Ann Cheong, Y2hlb25nc2FAbnR1LmVkdS5zZw==
†These authors have contributed equally to this work