 Kexin Han
Kexin Han Yongqiang Dai
Yongqiang Dai Huan Liu1
Huan Liu1 Junjie Hu
Junjie Hu
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
TECHNOLOGY AND CODE article
Front. Vet. Sci., 01 April 2025
Sec. Veterinary Clinical, Anatomical, and Comparative Pathology
Volume 12 - 2025 | https://doi.org/10.3389/fvets.2025.1396799
Introduction: Subclinical mastitis in dairy cows carries substantial economic, animal welfare, and biosecurity implications. The identification of subclinical forms of the disease is routinely performed through the measurement of somatic cell count (SCC) and microbiological tests. However, their accurate identification can be challenging, thereby limiting the opportunities for early interventions. In this study, an enhanced neural backpropagation (BP) network model for predicting somatic cell count is introduced. The model is based on TBESO (Multi-strategy Boosted Snake Optimizer) and utilizes monthly Dairy Herd Improvement (DHI) data to forecast the status of subclinical mastitis in cows.
Materials and methods: The Monthly Dairy Herd Improvement (DHI) data spanning from January 2022 to July 2022 (full dataset) was partitioned into both the training and testing datasets. TBESO addresses the challenge associated with erratic initial weights and thresholds in the BP neural network, impacting training outcomes. The algorithm employs three strategies to rectify issues related to insufficient population diversity, susceptibility to local optimization, and reduced accuracy in snake optimization. Additionally, six alternative regression prediction models for subclinical mastitis in dairy cows are developed within this study. The primary objective is to discern models by exhibiting higher predictive accuracy and lower error values.
Results: The evaluation of the TBESO-BP model in the test phase reveals a coefficient of determination R2 = 0.94, a Mean Absolute Error (MAE) of 2.07, and a Root Mean Square Error (RMSE) of 5.33. In comparison to six alternative models, the TBESO-BP model demonstrates superior accuracy and lower error values.
Discussion: The TBESO-BP model emerges as a precise tool for predicting subclinical mastitis in dairy cows. The TBESO algorithm notably enhances the efficacy of the BP neural network in regression prediction, ensuring elevated computational efficiency and practicality post-improvement.
Mastitis stands out as the most costly and prevalent ailment affecting dairy cows, leading to a substantial decline in milk yield and impacting lactation function. The consequence often involves the culling of affected cows, resulting in a significant financial setback for dairy farms (1). Research indicates that mastitis in dairy cows accounts for approximately 38% of the total direct expenditure associated with common production diseases on dairy farms (2). Notably, subclinical mastitis, being 40 times more prevalent than clinical mastitis and challenging to detect, accentuates its pronounced economic impact (3). Consequently, the imperative lies in the development and utilization of efficient models for the prediction and diagnosis of subclinical mastitis. Presently, the primary methods employed for detecting subclinical mastitis on farms include somatic cell count (SCC) (4), the California mastitis test (5), milk pH testing (6), milk conductivity testing (7), milk enzyme analysis (5) and pathogen diagnosis (8). Despite offering reasonable accuracy in indicating subclinical mastitis, these methods are often associated with a substantial workload and extended intervals between tests. Due to their inherent limitations, these methods are unlikely to meet the farm’s demand for accurate prediction of subclinical mastitis (9).
Due to its widespread adoption and scientific nature, Dairy Herd Improvement (DHI) data has emerged as the primary method and tool for scientifically managing cattle herds in various developed dairy-producing countries, including Canada, the United States, the Netherlands, Sweden, Japan, and others (10). When the SCCs exceeds 100,000 cells/mL, it can serve as a warning indicator for subclinical mastitis (11). To augment the robustness and early prediction capability of subclinical mastitis diagnosis, this study proposes the incorporation of predictive factors unrelated to SCC, such as milk quality parameters, along with the integration of longitudinal monitoring of SCC (12). This methodology not only enhances the diagnostic capabilities but also serves as an optimal data input channel for machine learning systems. Specifically, it contributes to the creation of models focused on the timely identification of subclinical mastitis.
In recent years, the agricultural landscape has witnessed a rapid evolution in information technology, leading to the mainstream adoption of big data on farms. Numerous studies have explored diverse methods and applications aimed at developing predictive and prescriptive decision support tools. Researcher Nazira Mammadova and colleagues (13) proposed a classification prediction method for somatic cell count (SCC) in dairy cows based on Support Vector Machines. Baştan A et al. (14) conducted a study involving 439 pregnant cows, employing multivariate linear regression analysis and a backward stepwise method to predict the incidence of mastitis. Zhou X et al. (15) utilized eight machine learning algorithms to forecast mastitis in dairy cows, based on 14-dimensional data obtained from automatic monitoring systems and milking systems. They validated the consistency of these variables as predictors of cow diseases within automatic system monitoring. However, these methods may only forecast using data from the few days preceding the disease’s onset, and there is no significant disparity in precision and predictive worth among various models (8). Additionally, certain methods require distinct chemical identification, posing challenges for implementation on most dairy farms and limiting their potential as universally applicable predictive models.
Hence, the primary objective of this study is to develop a precise regression prediction model using neural networks, grounded in monthly Dairy Herd Improvement (DHI) data. However, given the nonlinear gradient optimization nature inherent in neural network regression prediction, challenges such as encountering local minima and the influence of randomness in initial weights and thresholds during training may surface. To address these issues, intelligent optimization algorithms have demonstrated commendable efficacy (16).
The Snake Optimization Algorithm (SO), introduced by Hashim F A et al., is a recent advancement in the domain of intelligent optimization (17). Inspired by the foraging behavior of snakes, this algorithm simulates the path selection and movement strategies of snakes. It has been applied to optimization problems such as predicting non-stationary channels (18), ship radiation denoising (19), and multidimensional microgrid energy management (20). The Snake Optimization Algorithm exhibits excellent efficacy in managing continuous nonlinear problems, offering an innovative approach to tackling the nonlinear gradient optimization issues in neural networks. Nevertheless, obstacles remain, such as disparities in the ability to explore and exploit, as well as limitations like sluggish convergence rate and mediocre optimization precision (18).
Based on the research findings mentioned above, this study proposes a novel regression prediction model, called TBESO-BP, for estimating SCC in dairy cows. TBESO-BP model based on TBESO (Multi-strategy Boosted Snake Optimizer) optimized BP neural network to offer a more efficient prognostic instrument for the prevention and management of subclinical mastitis in dairy cows. Furthermore, this study aspires to be a valuable reference and source of inspiration for addressing regression prediction challenges in diverse fields.
In tackling the prediction and diagnosis challenges associated with mastitis in dairy cows, this study implemented a systematic approach to data collection and analysis. The subsequent sections outline the data sources, data processing methods, and approaches employed in establishing predictive models. Through the utilization of these data and methods, the objective is to furnish a more effective and accurate tool for predicting mastitis in dairy cows.
The experimental data utilized in this study originated from a dairy farm in Gansu Province, China, encompassing all lactating cows on the farm. The dairy farm is equipped with modern agricultural data collection facilities, ensuring comprehensive and meticulously maintained data. These facilities provide optimal conditions for conducting numerical analysis of Dairy Herd Improvement (DHI).
The experiment spans from January 2022 to July 2022, with a sampling frequency of once per month. The dataset comprises 25,155 DHI measurement records from 4,015 lactating cows on the farm. This judicious sampling frequency ensures accuracy while avoiding the complexity of frequent sampling, thereby preserving predictive accuracy (21).
Initially, data cleaning was conducted on the original 25,155 Dairy Herd Improvement (DHI) records spanning from January to July 2022. Adhering to the criteria defined in the Chinese Holstein cattle production performance determination technical specification (NY/T. 1450–2007) for abnormal data, entries were removed based on criteria such as fat percentage > 7% or < 2%, protein percentage > 5% or < 2%, 305-day milk yield <2,000 kg, lactation days <5 days, lactation days >405 days, and data without records of calving. Subsequently, preliminary feature selection involved eliminating redundant columns like ‘subtotal’ and ‘average with total,’ addressing missing values, and removing redundant feature columns and empty rows, including ‘calving date,’ ‘calving interval (days),’ ‘group number,’ ‘birth date,’ and ‘sampling date,’ while ensuring data integrity through backup.
Following the initial data selection, 24,835 valid records were obtained. These records include time-related indicators such as “Month” and other features like “Parity (calves),” “Lactation days (days),” and “Milk yield (Kg).” A correlation analysis was performed using a correlation heatmap, leading to the removal of features with high correlations (correlation coefficient > 0.66) (22), such as “305 milk yield (Kg),” “WHI,” and “Total fat (%).” All accessible data and code used for data analysis have been uploaded in the GitHub repository.
With the data now prepared, a model was constructed to explore the relationships between these selected features and the target variable. This model aims to quantify the predictive impact of each feature, incorporating temporal aspects to capture potential temporal effects. The target variable is the SCC of the current month. During model training and evaluation, the predicted values for the month will be compared with the actual values to validate the model parameters and its performance. The following sections detail the methodology for model evaluation and criteria for assessing prediction accuracy. The finalized selection of features and the target variable for prediction are outlined in Table 1. The dataset contains 19,591 remaining valid records.
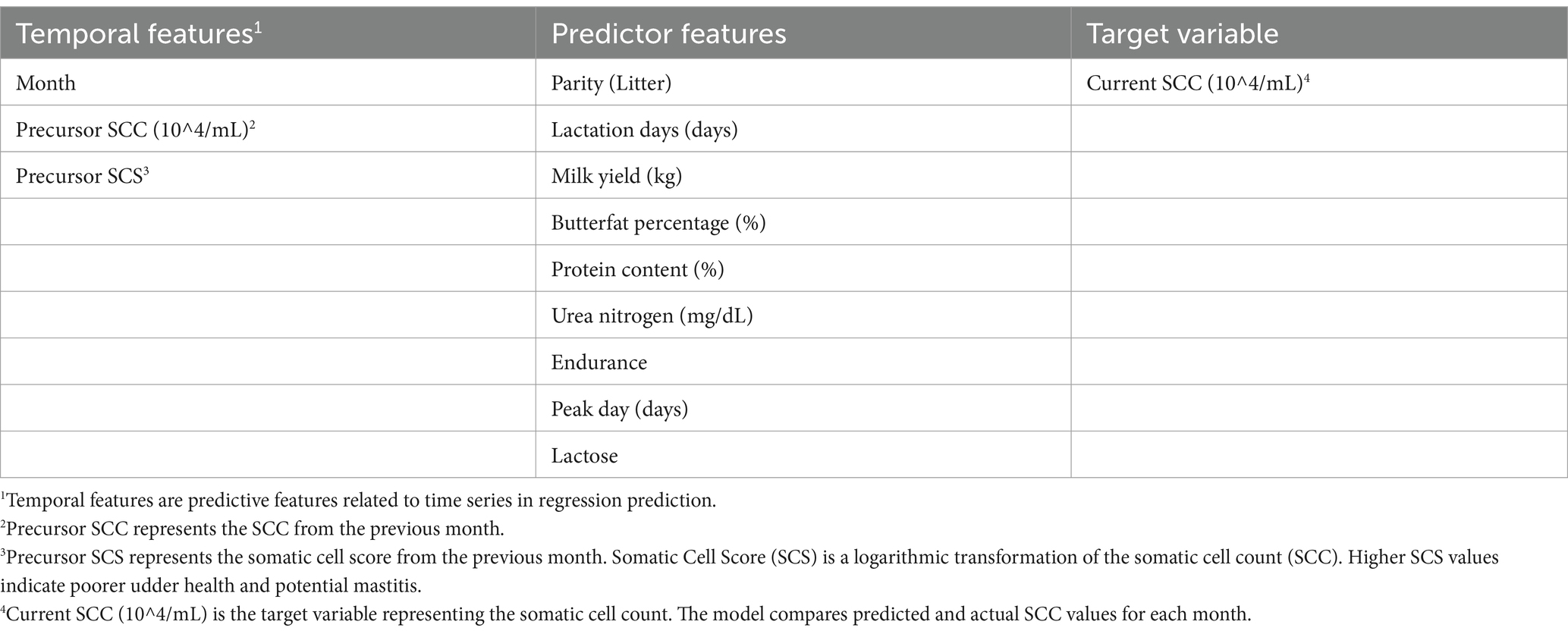
Table 1. The selected temporal features, predictor features and target variable.
For accurate regression predictions in subclinical mastitis diagnosis, a robust modeling approach is essential. This study explores the use of a Backpropagation (BP) neural network, a nonlinear regression model capable of capturing complex relationships between variables. The BP neural network model consists of an input layer, a hidden layer, and an output layer. For each layer in the neural network, the input is first weighted, a bias is added, and then passed through an activation function to obtain the output. The detailed explanation and mathematical formulations are provided in the Supplementary materials.
When the input data X is an n × m matrix, where n is the number of data samples and m is the number of features for each sample, the network computes a predicted output . Choose a , to calculate its predicted output as Equation 1:
Where is predicted output for -th sample, is the -th features for -th sample, is the weight between the -th hidden neuron and the -th output neuron, is the weight between the -th feature and the -th hidden neuron, is the bias term for the -th hidden neuron, is the bias term for the -th output layer neuron, represents the number of hidden neurons and , are the non-linear activation function, see details in the Supplementary Equations 1–4.
To minimize the prediction error, the BP adjusts the weights during training based on a loss function, the study chooses the Mean Squared Error (MSE) as the loss function as Equation 2:
where represents the difference between the true value and the predicted value on the test set for a specific data sample.
The gradient descent method is commonly used by updating network parameters based on the gradient information of the error function, gradually reducing the error. But gradient descent can converge slowly if the rate is too small or overshoot if it’s too large. In this study, to better adapt and fit Dairy Herd Improvement (DHI) data and to improve the accuracy of the prediction model, an enhanced optimization algorithm is utilized to replace the gradient descent method of selecting the weights and bias of the BP neural network. In other words, transforming the issue of selecting the neural network’s weights and thresholds into an optimization problem. That means the higher the fitness value obtained by the optimization algorithm, the smaller the corresponding loss function value, resulting in a better prediction as Equation 3:
The prediction model is evaluated in terms of both accuracy and error to assess its performance. The standard evaluation criteria are outlined in Table 2, as follows:

Table 2. The standard evaluation criteria and their formulas.
The initial four indicators serve to quantify prediction errors. Mean Absolute Error (MAE) represents the average of absolute errors, Root Mean Squared Error (RMSE) assesses the deviation between observed and true values and Mean Absolute Percentage Error (MAPE) measures the expected value of relative error loss. R2 evaluates the percentage of variability in the target variable explained by the model’s explanatory variables, with a higher value indicating better performance, approaching 1.
To ensure the scientific validity of the experimental results, the final outcomes were averaged over 10 independent runs. The experiments were conducted in a Windows 11 environment with an Intel(R) Core (TM) i9-14900K CPU running at 3.20GHz, 64.0GB of memory, and all model codes were implemented using MATLAB R2024a, and the following model comparison chart corresponds to this configuration.
For this study, comparative experiments were conducted to evaluate the following three BP model variations: the classic BP model (23), AHL-BP (Improved BP with Auto Hiding Learning) (24), PSO-BP (Particle Swarm Optimization-based BP model) (25), and the SO-BP (Snake Optimizer Generalized Regression Neural Network model) (17).
In the comparative experiments, the population size was set to 100, and the maximum number of iterations was set to 50 for both PSO-BP and SO-BP, as these are population-based swarm intelligence optimization algorithms. The population size represents the total number of individuals in the population, which plays a key role in balancing exploration and exploitation. Therefore, was chosen to balance computational efficiency with maintaining sufficient diversity to avoid local optima, based on experimentation and the complexity of the problem. The lower boundary and upper boundary were set to −1 and 1, respectively.
The radar chart below compares the performance of these four models on the training and testing datasets using RMSE, MAPE, MAE, and R2 metrics in Figure 1. Here, lower values for RMSE, MAPE, and MAE indicate better model accuracy, while higher R2 values signify better fit quality. In this radar chart, each axis represents a different evaluation metric, with larger areas indicating superior overall performance.
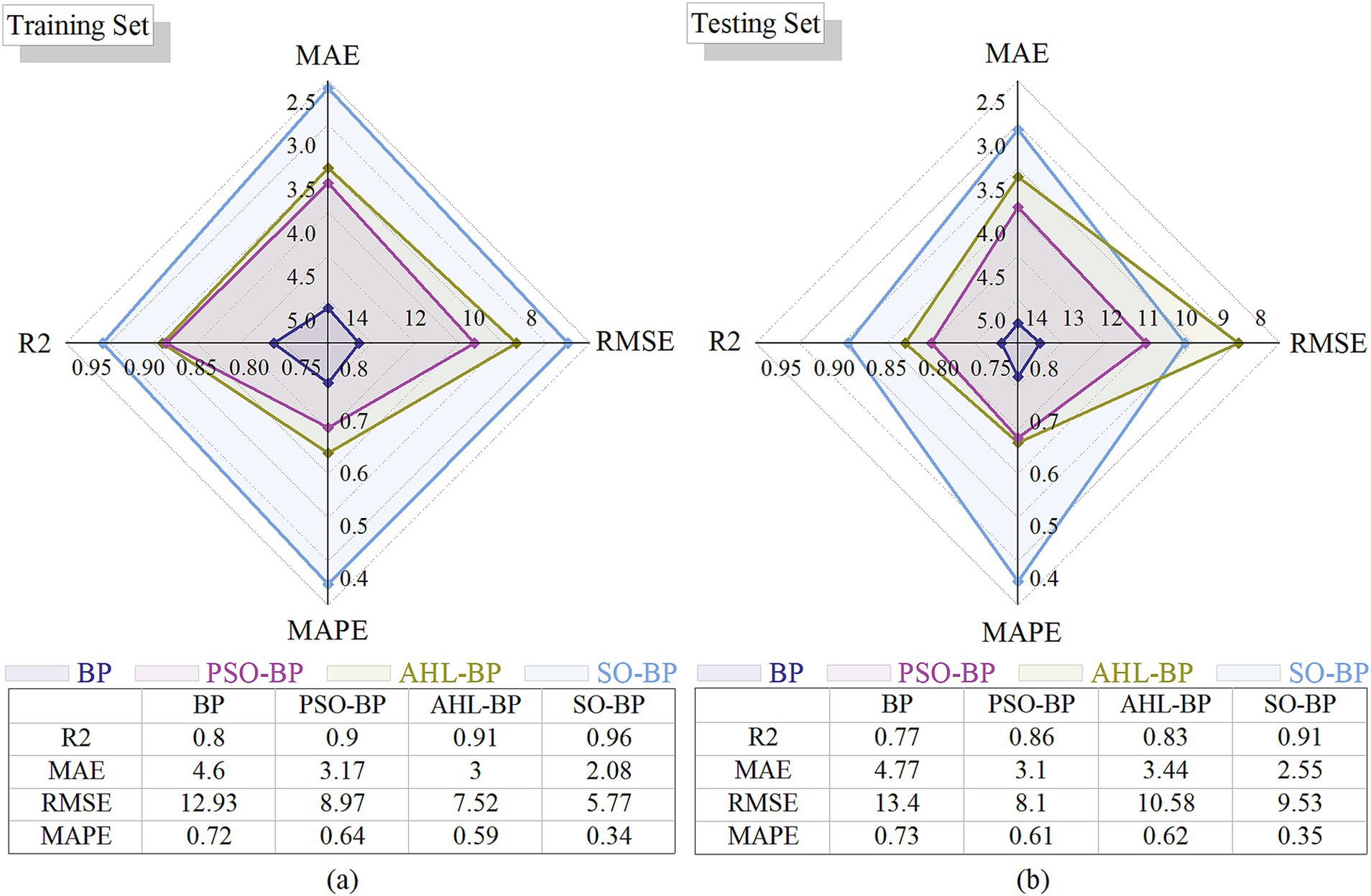
Figure 1. Radar charts of performance comparison (a) Training set; (b) Testing set.
As shown in Figure 1, the SO-BP model has the largest area, thus outperforming the other models, which is why the snake optimization algorithm (SO) was selected as the primary improvement approach.
SO effectively tackles single-objective optimization by adjusting its global exploration and local exploitation phases based on the iteration count (17), but its initial exploration focus can lower convergence rates, and later exploitation may risk local optima trapping.
To address these limitations, The Multi-strategy Boosted Snake Optimizer (TBESO) for enhanced prediction accuracy of subclinical mastitis in cows incorporates Tent Chaotic Mapping (TCM), Bidirectional Search (BDS), and Elite Reverse Learning (EOBL), enhancing SO’s adaptability for complex optimization challenges.
The TBESO algorithm enhances performance in four stages (3.2.1–3.2.4). Firstly, in the initialization stage (3.2.1), Tent chaotic mapping (TCM) is introduced to generate the initial population, increasing population diversity. In the exploration stage (3.2.2), Bidirectional Search (BDS) is employed to update foraging positions, accelerating the convergence of TBESO. In the exploitation stage (3.2.3), the snake population updates individual positions through fighting and mating. Finally, in the population updating stage (3.2.4), the Elite reverse learning (EOBL) mechanism is introduced to further optimize the population, expanding the search range of TBESO and preventing it from getting trapped in local optima.
TBESO uses a chaotic mapping approach (26) in this step, unlike the original Snake Optimization algorithm. This random and convenient technique preserves population diversity. It helps Snake Optimization avoid local traps and explore globally. Random snakes are dispersed uniformly.
The definition of the Tent chaotic mapping algorithm is as Equation 4:
Here, represents the position of the -th snake at iteration , is the updated position of the -th snake at the next iteration, represents a threshold parameter that divides the function into two conditional segments, here takes a value of 1.999, and is the iteration step, representing the number of updates applied to the position.
The Tent chaotic mapping generates a uniformly distributed population, with a population size of . After generating the initial population, the population is divided into male and female groups, with representing the number of males and representing the number of females as Figure 2b.
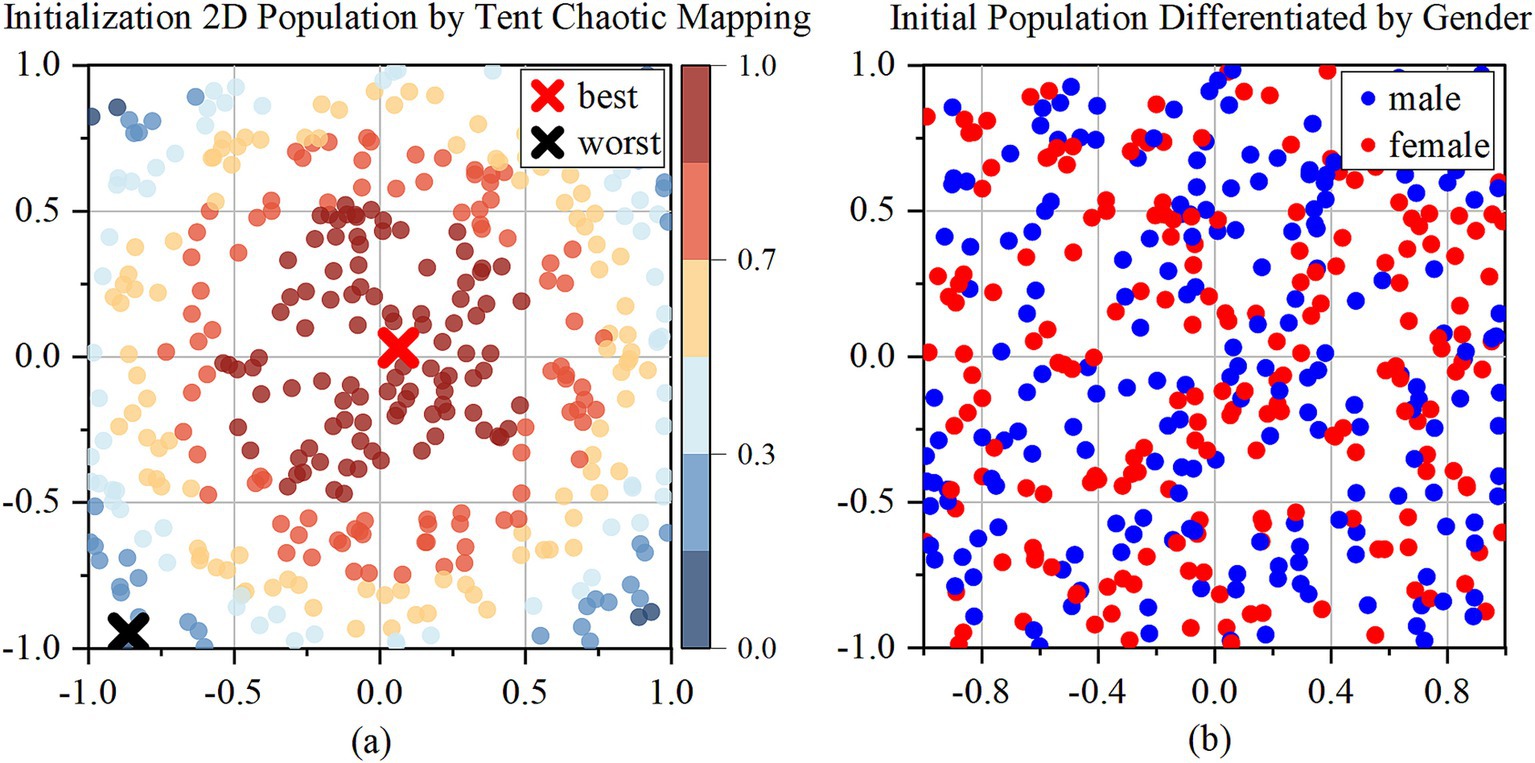
Figure 2. Initialization of 2D population by Tent chaotic mapping. (a) 2D initialization population; (b) Initial population differentiated by gender.
To demonstrate the evolution of candidate solutions over the iterations, the study visualizes the population distribution in Supplementary materials. The population distribution of the TBESO is examined after 25 iterations in a two-dimensional space. The population size () is set to 400, with the upper boundary () and lower boundary () defined as 1 and −1, respectively and the following population distribution chart corresponds to this configuration. Additionally, an ablation experiment using the CEC 2017 benchmark suite is conducted to assess the effectiveness of the TBESO algorithm under various conditions. Specific details of this ablation experiment can be found in the Supplementary materials.
In Figure 2a, which depicts the initial population generated by Tent chaotic mapping, the blue points are farther from the origin. Figure 2b distinguishes male and female populations using red and blue points.
The food quality determines whether the snake population enters the foraging stage (exploration stage) or the mating and reproduction mode (exploitation stage). Additionally, Snake behavior is also affected by temperature when food is abundant.
Defining Food quantity can be obtained using the Equation 5:
Where refers to the current iteration and refers to the maximum number iterations. The constant is set to a specific value, in this case, .
If (Threshold = 0.25), indicating insufficient food, the snake population will update its positions through two methods. One is random updating, which is similar to the original Snake Optimization algorithm. The other is adopting a bidirectional search strategy. The position update will choose the method that produces a higher fitness value between the two.
Random updating as Equations 6, 7:
In the provided context, and denote the randomly chosen positions of male and female individuals, respectively, where is a random scalar generated from a uniform distribution in the range (0,1). The constant is a constant and equals 0.05, and , are the lower and upper bounds of the problem, respectively. The ± symbol represents the flag direction operator (diversity factor), which randomly chooses between increasing or decreasing the solution’s position, enabling more effective exploration of the solution space. Additionally, and represent the ability of males and females to search for food, and they can be calculated as Equations 8, 9:
Where and are the fitness of and of -th individuals at iteration in male and female group, respectively.
The bidirectional search algorithm simultaneously initiates two independent searches, with one progressing forward from the start and the other moving backward from the target. The principle of Bidirectional search is to guide individuals iteratively, moving them away from the worst individual while simultaneously approaching the best individual (Figure 3).
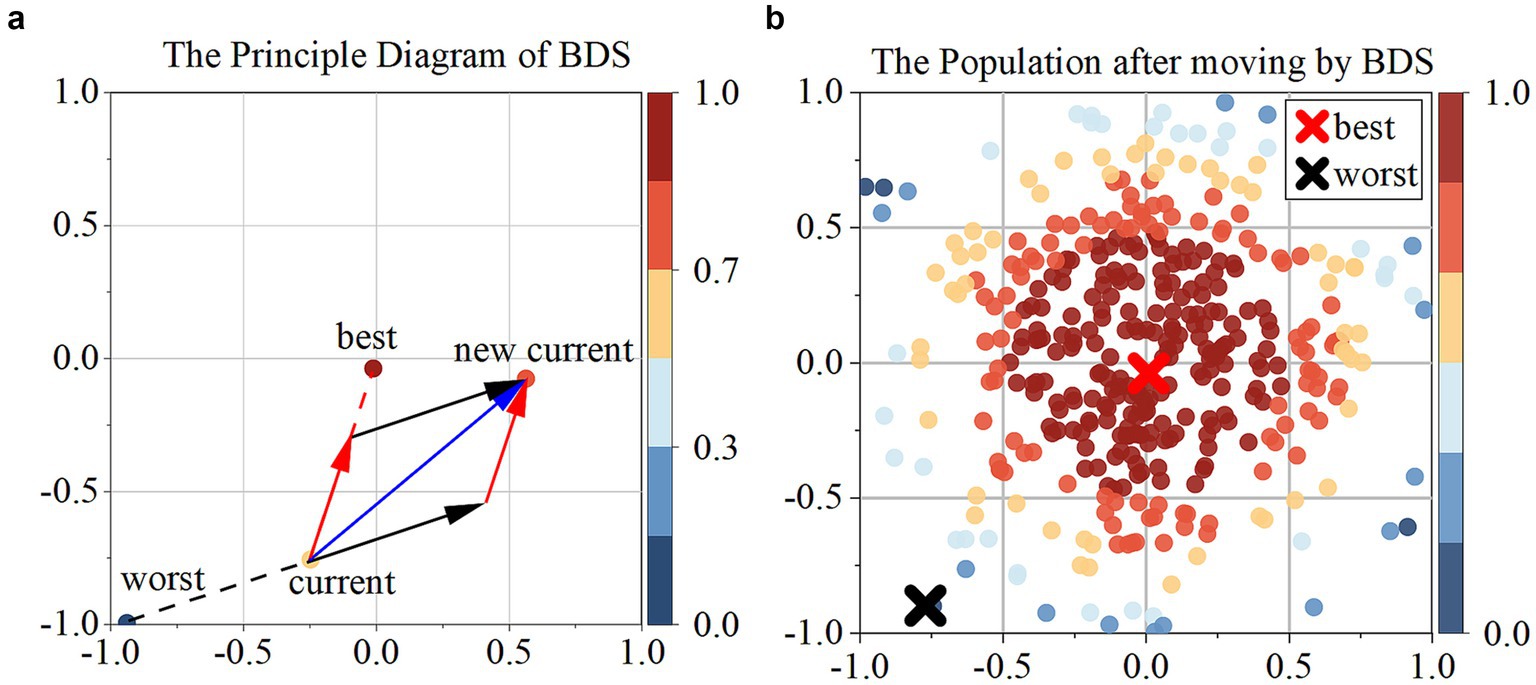
Figure 3. (a) Presents the principal diagram of BDS; (b) the population after moving by BDS.
In this context, deep blue individuals represent the worst individual (), deep red individuals represent the best individual (), black arrows represent the vector ( moving away from the worst individual, with the Equations 10, 11:
Where and represent the best and worst female individuals, and and represent the best and worst male individuals. and are two randomly generated random numbers from uniform distribution in the interval (0, 1).
If (Threshold = 0.25) represents sufficient food. In the presence of abundant food, the behaviors of the snake population are influenced by temperature. When the temperature is high and food is plentiful, the snake population will move toward food and consume the existing resources. However, only when the temperature is low and there is sufficient food will be mating, and reproduction occur.
The Temperature can be defined using the Equation 12:
1. When , indicating high temperature, the snake population will move to the food only as Equation 13:
Where is the position of individual (male or female), is the position of the best individuals among and , which is also the best one in the whole population, and guides the entire population during the optimization process, and .
2. When , in low temperature, the snake will be in the fight mode or mating mode randomly. The probability of choosing fighting mode is when , while mating mode is selected when . Here, is a random number drawn from a uniform distribution in the range (0, 1).
In the fighting mode, each male will fight to get the best female, and each female will try to select the best male as Equations 14, 15:
Where refers to-th male position, refers to the positions of the best individual in female group, and are the fighting ability of male, female agents, respectively. and can be calculated from the Equations 16, 17:
In the mating mode, the mating occurs between each pair related to the availability of food quantity Equations 18, 19:
Where are the position of -th agent in male and female group and refers to the mating ability of male and female, respectively, and they can be calculated as Equations 20, 21:
During the mating process in the search space, a female snake may lay eggs. The (in the pseudocode) represents a randomly selected value of either 1 or −1 and simulates the process of laying eggs (generating new solutions) and hatching (replacing poor solutions with potentially better ones), thereby promoting exploration of the search space. If equals 1, select worst male and female and replace them as Equations 22, 23:
Where are the worst individuals in male and female group. Here, , are the lower and upper bounds of the problem, respectively.
After the exploitation stage, to address the issue of poor local development capability in the Snake Optimization algorithm, TBESO introduces the Elite Reverse Learning strategy (27). This strategy leverages the characteristic that elite individuals contain more effective information than general individuals. It creates a reverse population using elite individuals to increase population diversity. The best individual from the new population is then selected for the next generation iteration, utilizing the neighborhood space of elite individuals and enhancing local development capability, as Figure 4.
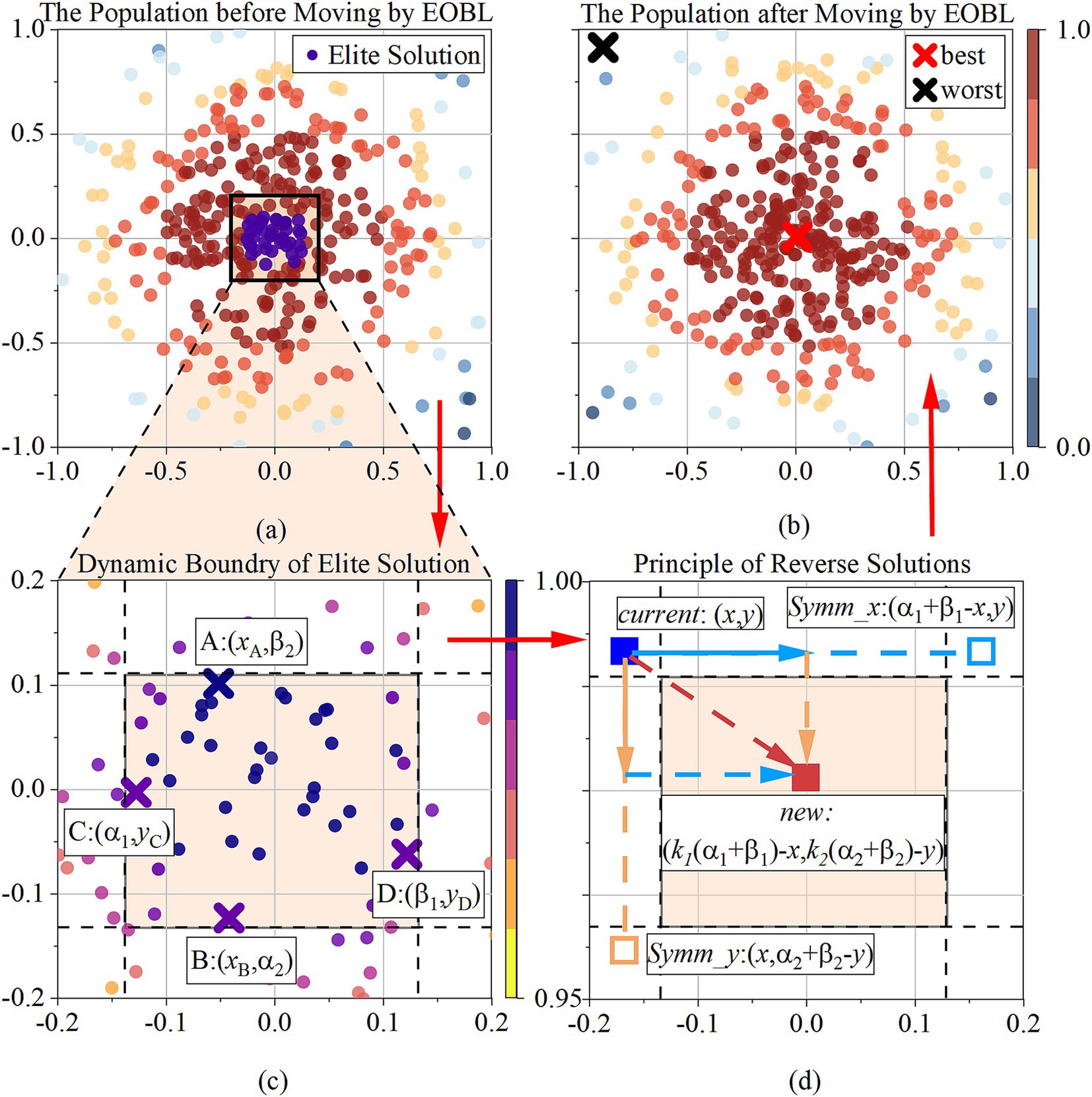
Figure 4. (a) The population before moving by EOBL; (b) the population before moving by EOBL; (c) presents how the dynamic boundary of elite solution is determined; (d) presents how the reverse solution is determined; The sequence is (a), (c), (d), (b), along the red arrow.
The elite solution is the best solution in the current population based on their fitness values, depicted as the colored square in the Figures 4a,c. Its definition as , where represents the index of each elite solution within the group of elites, and . is the total number of elite solutions. The study determined it as which is the number of populations. represents the specific dimension within an elite solution vector, indexed by , where is the total number of dimensions.
Given a current solution represents the -th individual in Figure 4d, where and denote the dynamic boundaries in the elite group, representing the maximum and minimum values in dimension , expressed as , . The elite reverse solution of the -th individual is in Figure 4d, as Equation 24:
where is a random scalar generated from a uniform distribution in the range (0,1).
Dynamic boundaries overcome the drawback of fixed boundaries in preserving search experience, enabling the reverse solution of elites to be in a narrow and dynamic search space, facilitating algorithm convergence. If the dynamic boundary operation causes to cross the boundary and become an infeasible solution, it can be reset using a randomly generated method, as Equation 25:
where is a random scalar generated from a uniform distribution in the range (0,1), and represents lower boundary upper boundary for dimension, respectively.
The calculation updates the solution within a symmetric range around the elite individual, introducing randomness in both the x-axis and y-axis directions (). This promotes diversity in search, helping to explore multiple regions of space and avoid local optima. If the new solution is better, it will replace the current one, ensuring continuous improvement and refinement of the best solutions over iterations. Figure 4b shows the population distribution after being updated by the EOBL.
Combining the Tent chaotic mapping, bidirectional search strategy, and elite reverse learning strategy mentioned above, the pseudocode for the TBESO algorithm is as follows. Here, represents the population size, is the initial population generated by the Tent chaotic mapping algorithm, represents the maximum number of iterations, and are the lower and upper bounds of the optimization problem, is the dimension of the problem, represents food quality, represents the current temperature, is a random number drawn from a uniform distribution in the range (0, 1), represents a randomly selected value of either 1 or −1 (Algorithm 1).

ALGORITHM 1. Procedure of the proposed TBESO algorithm.
The pseudocode is as follows:
Upon acquiring TBESO, the procedure selects neural network initial weights () and thresholds (). The model compares the total sum of the discrepancies between the anticipated values generated by the neural network and the actual values. This loss represents the TBESO iterative optimization fitness function.
Once TBESO reaches the defined objective conditions, the related weights and thresholds are regarded as the starting optimal values for the backpropagation (BP) neural network. This method reduces absolute disparities to improve model performance and forecast accuracy. Figure 5 shows that iteratively selecting BP neural network initial weights and thresholds improves model performance.
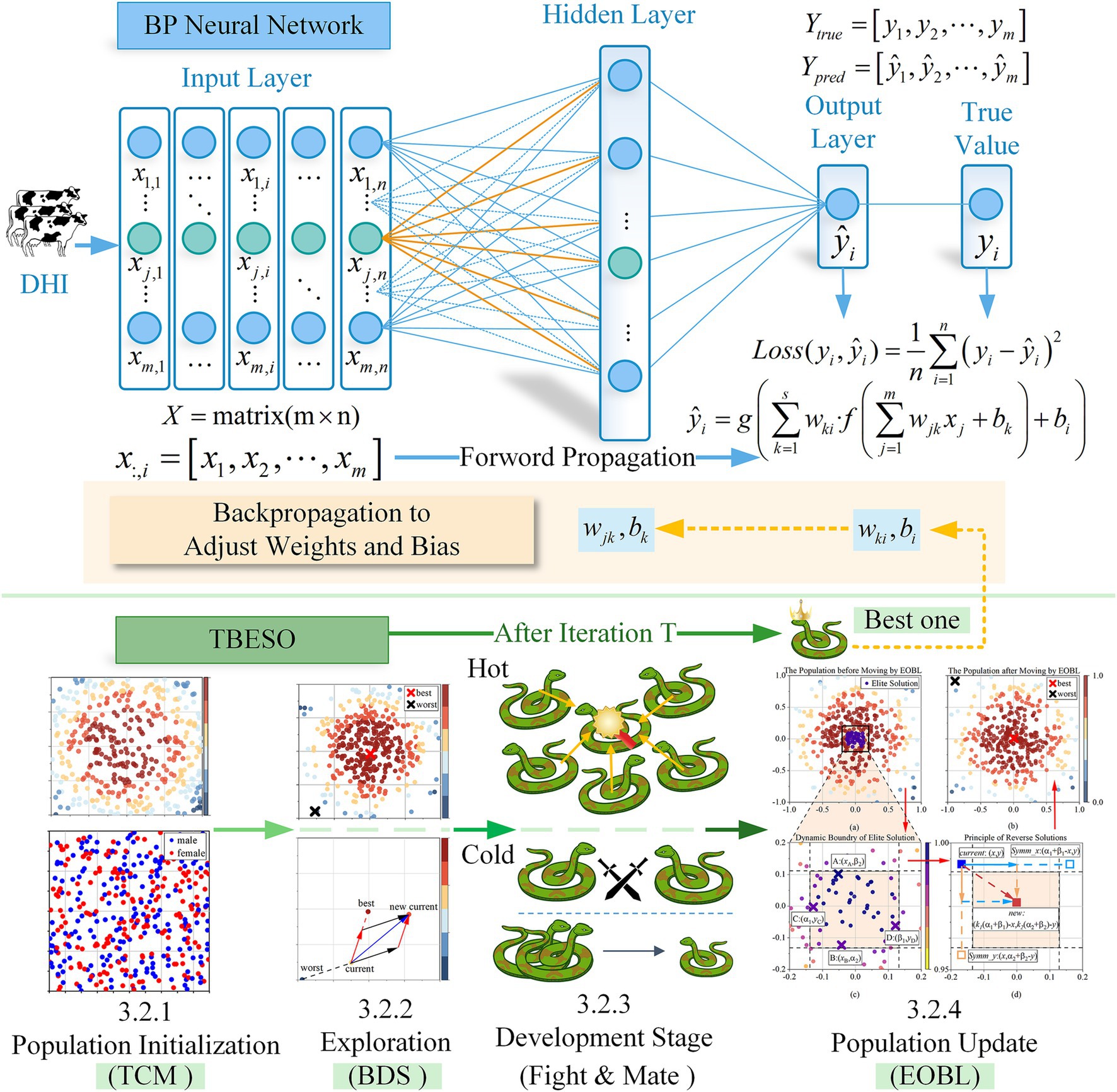
Figure 5. The process of TBESO-BP model.
To evaluate the SO-BP, BEESO-BP [Improved BP based on Multi-strategy Boosted Snake-Inspired Optimizer (27), which proposed by researchers Gang Hu and Rui Yang], and the TBESO-BP were compared for predicting the number of cow somatic cells, we conducted comparative experiments using the same environment and parameters as previously described. Each model was tested with a population size of 100 and 50 maximum iterations, and results were averaged over 10 independent runs.
These radar charts were used in Figure 6 to compare each model’s results across four performance metrics: R2, MAE, RMSE, and MAPE. The radar chart provides an intuitive visualization of model strengths and weaknesses across these axes, highlighting which models performed best in specific areas. A larger area within the radar chart indicates a superior overall performance of the model, as it reflects higher predictive accuracy (R2) and lower error metrics (MAE, RMSE, and MAPE).
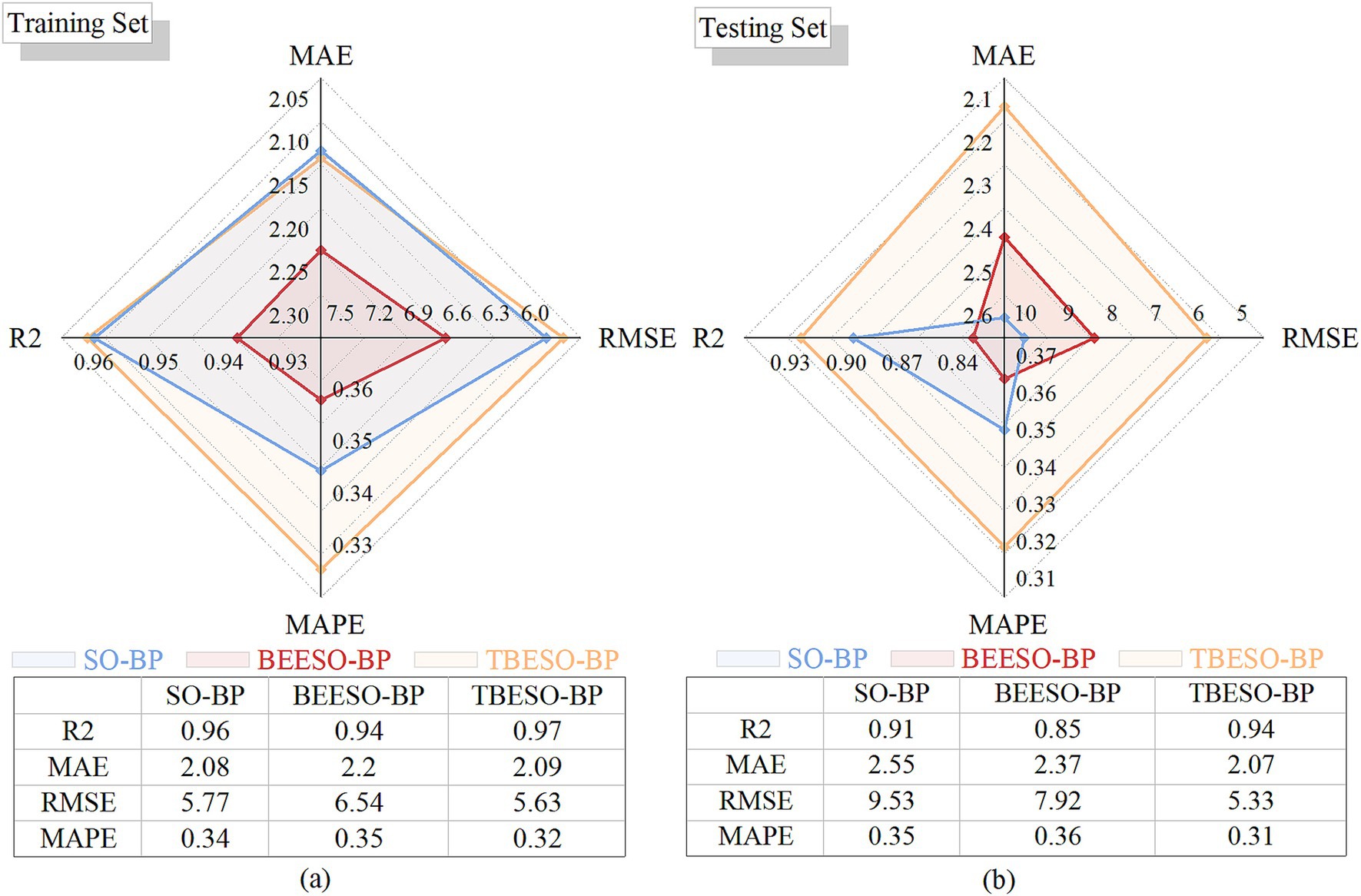
Figure 6. Radar charts of performance comparison. (a) Training set; (b) Testing set.
Figure 6a shows that in the training set, the TBESO-BP model achieves an R-squared of 96.60%, with MAE, RMSE, and MAPE values of 2.09, 5.63, and 32.05%, respectively slightly outperforming both the SO-BP and BEESO-BP models.
Similarly, Figure 6b illustrates the TBESO-BP model’s performance on the testing set, achieving an R-squared of 93.97% and error metrics of 2.07 (MAE), 5.04 (RMSE), and 31.36% (MAPE), again surpassing the SO-BP and BEESO-BP models.
To analyze and compare the predictive performance and efficiency of each model, including BP, PSO-BP, AHL-BP, SO-BP, BEESO-BP, and the proposed TBESO-BP, we evaluate performance metrics such as MAE, RMSE, MAPE and R2, as shown in Figures 1, 6. These figures allow for an easy comparison of model efficiency and accuracy. Smaller values for MAE, RMSE, and MAPE indicate better performance, while a higher R2 suggests improved fitting accuracy. Each of these metrics directly correlates with practical performance, highlighting the strengths and weaknesses of the models in applications.
The comparison results entail the six regression prediction models, with the evaluation of error quantification standards such as MAE, RMSE, MAPE, and the assessment of correctness quantification using R2. The predicted performances of the six models differ and are studied as follows:
Upon evaluating R2 for accuracy in Figures 1, 6, all six models show R2 values exceeding 76.57% on both training and test sets, indicating generally robust predictive performance. However, the TBESO-BP model stands out with a test R2 of 93.97%, outperforming other models by 22.72, 48.60, 12.86, 3.09, and 10.96% compared to BP, AHL-BP, PSO-BP, SO-BP, and BEESO-BP, respectively. This highlights that the TBESO-BP model demonstrates exceptional accuracy in predicting somatic cell count.
Upon evaluating error quantification standards MAE, RMSE, and MAPE in Figures 1, 6, the TBESO-BP model outperforms the other models, with smaller errors across both the training and test sets. On the test set, TBESO-BP achieves reductions of 56.60% in MAE, 56.46% in RMSE, and 40.29% in MAPE compared to the BP model. Additionally, compared to other models such as AHL-BP, PSO-BP, SO-BP, and BEESO-BP, TBESO-BP demonstrates improvements across all metrics, reducing MAE by 33.23, 40.00, 18.82, and 14.49%, respectively.
Lower MAE in TBESO-BP model indicates that its predictions are closer to actual values, which is crucial for predicting SCC, a key indicator for subclinical mastitis. Accurate predictions of SCC are essential for effective farm management and timely intervention decisions. Furthermore, the smaller MAPE of TBESO-BP highlights its ability to maintain accurate predictions, even in situations with large variations in data ranges. The smaller RMSE highlights the model’s ability to remain consistent and less influenced by a few extreme data samples.
When selecting an appropriate prediction model, it is essential to consider not only error metrics like MAE, RMSE, R2, and MAPE but also the model’s runtime. In practical applications, the runtime can significantly impact tasks with high real-time demands. Therefore, by analyzing the runtime of each model, we gain further insights into their suitability for different use cases. Figure 7 presents the comparison of the mean duration of the six models as follows:
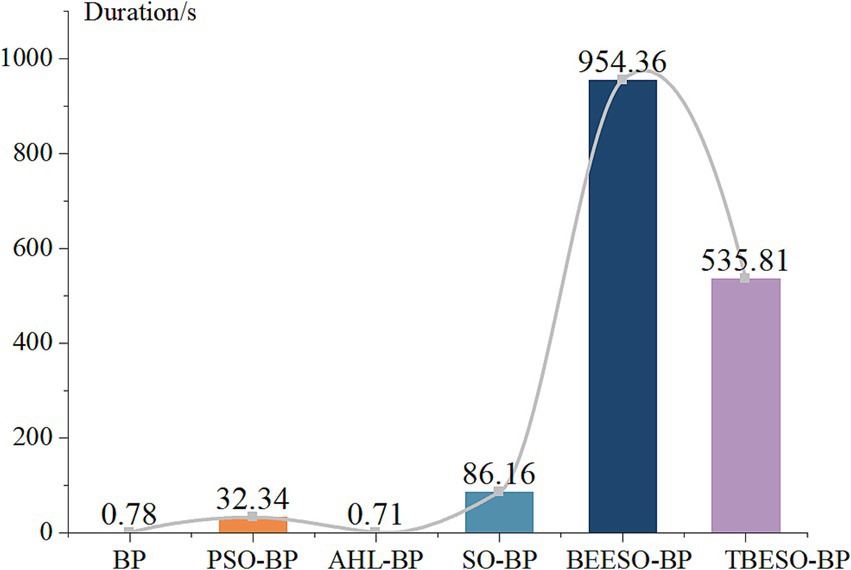
Figure 7. Mean duration comparison plot of 6 models.
Figure 7 reveals that the classic BP, AHL-BP, and PSO-BP models have durations all below 33 s, with values exceeding 8. The lowest R-squared is for BP at 76.57% according to Figures 1b, 6b, while the highest is for AHL-BP at 85.74%. In contrast, the SO-BP, BEESO-BP, and TBESO-BP models have durations exceeding 85 s, with error values all below 100. The TBESO-BP model has the lowest error value at only 30.67 and all three models have R-squared above 84.68%, with TBESO-BP being the highest at 93.97%. This indicates that overall prediction duration increases with improved prediction performance. In practical applications, the choice of the prediction model should be based on the specific usage scenario.
In summary, among the six comparative prediction models, the AHL-BP is better suited for scenarios with lower accuracy requirements and higher real-time demands. For example, in disease warning software, it can provide real-time fuzzy warnings for potential subclinical mastitis in cows when cow information is updated, allowing for timely preventive measures. On the other hand, the TBESO-BP model is better suited for scenarios with higher accuracy requirements and lower real-time demands. For instance, after entering cow information, it can accurately predict SCCs for subclinical mastitis in cows, facilitating a more precise assessment of the severity of the condition.
To analyze the models’ predictive accuracy in the context of subclinical mastitis in dairy cows, Figure 8 illustrates the real versus predicted values of somatic cell counts (SCCs) for each of the six models across 30 test samples. The x-axis represents the sample sequence, and the y-axis shows SCC values in units of 104/ml. The TBESO-BP model’s predictions are shown as a blue line, and the true SCC values are marked in red line. Other models’ predictions are represented by scatter plots for comparison.
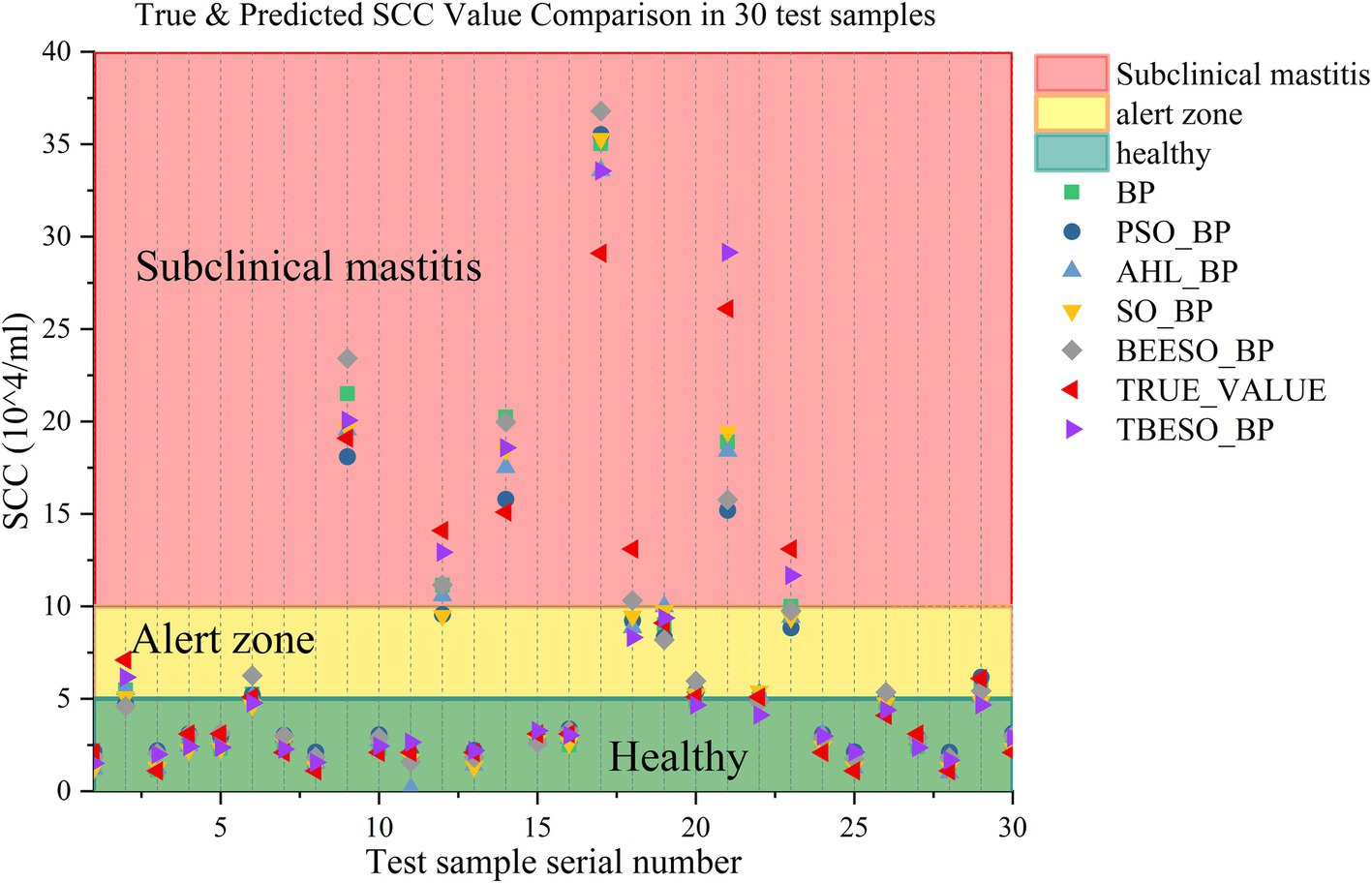
Figure 8. True & predicted SCC value comparison in 30 test samples.
In this chart, the colored background conveys health status based on SCC thresholds: green represents the healthy range (SCC ≤ 50,000/ml), yellow indicates a cautionary range, and red marks the subclinical mastitis diagnostic threshold (SCC > 100,000/ml) (28). The chart effectively highlights the TBESO-BP model’s capability to predict SCC values, crucial for accurate early detection and intervention.
Figure 8 demonstrates that the TBESO-BP model’s predictions align more closely with the actual SCC values than those of the other models, highlighting its superior accuracy. Notably, in this sample set, SCC values for samples 9, 12, 14, 17, 21 and 23 fall within the red background area, indicating probably are subclinical mastitis. Samples 2, 6, 19, and 29 are situated in the yellow caution zone, while the remaining samples are within the green, healthy range.
The capabilities of these models enable them to accurately predict SCCs and growth trends in cows, providing real-time health information for breeders and farm managers, which is crucial for subclinical mastitis warning. This holds significant implications:
1. Early Detection and Prevention: Through regression prediction models, potential diseased cows can be identified in the early stages of disease development, allowing for timely intervention, improving treatment success rates, and avoiding vaccine wastage.
2. Precision Warning System: Utilizing regression prediction models, we can construct a more precise warning system with abundant data. This enables breeders to make more accurate decisions based on individual characteristics and health status of each cow, effectively reducing the incidence and impact of subclinical mastitis.
3. Resource Optimization: Regression prediction models assist farm owners or breeders in more efficiently allocating resources. Targeted interventions can prevent unnecessary treatment and additional expenses, optimizing resource utilization while enhancing cow health.
4. Data-Driven Decision-Making: By employing regression prediction models, historical and real-time data can better support decision-making in livestock management. This contributes to the scientific and predictable management of livestock, making the industry more stable and sustainable.
5. Scientific Research and Innovation: Regression prediction models provide researchers with a high-quality data source for in-depth studies on pathogenesis, influencing factors, and preventive measures of subclinical mastitis in dairy cows. This data-driven approach fosters innovation and development in relevant fields.
In conclusion, this study not only validates the effectiveness of the six prediction models for SCC prediction but also introduces a new and more accurate regression prediction model, TBESO-BP, for health management in dairy farming. This will contribute to improving breeding efficiency, optimizing resource utilization, and enhancing the production and welfare of dairy cows.
In addressing the challenges of accuracy and quantitative prediction in traditional methods for predicting subclinical mastitis in dairy cows, this study proposes a Body SCC Prediction Model based on Improved Snake Optimization Algorithm and Backpropagation (TBESO-BP). The model incorporates tent chaotic mapping, elite reverse learning, and bidirectional search strategies to enhance the population diversity, convergence speed, and local development capability of the snake optimization algorithm. Using TBESO, the initial weights and thresholds of the BP neural network are optimized, and the predictions of six models are objectively evaluated using five evaluation indicators.
The results demonstrate that the TBESO-BP model proposed in this paper exhibits high accuracy and stability in predicting subclinical mastitis in dairy cows. The optimized TBESO algorithm partially addresses issues such as lack of population diversity and susceptibility to local optima in the original algorithm, making it applicable to other problems.
Furthermore, in practical applications, the choice of a suitable prediction model should align with the specific prediction goals. The six comparative models in this study all demonstrate good prediction accuracy. The BP neural network with adaptive hidden layers is more suitable for real-time fuzzy warnings with lower precision requirements but higher immediacy. On the other hand, the TBESO-BP model, which provides accurate predictions of SCCs, is beneficial for assessing the specific condition of subclinical mastitis in dairy cows, particularly in scenarios where higher accuracy is needed without overly prioritizing immediacy. These research findings not only offer new reference points for the prevention and treatment of subclinical mastitis in dairy cows but also provide an accurate and reliable predictive tool.
Publicly available datasets were analyzed in this study. This data can be found here: https://github.com/Otherisland/SubclinicalMastitisPrediction-TBESO-BP.
Ethical approval was not required for the study involving animals in accordance with the local legislation and institutional requirements because this study is exclusively centered on data analysis, utilizing non-public yet anonymized datasets. The research does not involve experimental interventions on humans or animals, and no sensitive information is processed. The data used in this study are obtained from non-public sources but have been thoroughly anonymized to ensure confidentiality. Given the non-experimental nature of the research, absence of direct involvement with human or animal subjects, and the utilization of anonymized datasets, ethical approval is deemed unnecessary. This study adheres to strict data protection protocols to uphold privacy and confidentiality standards. The owner of the dairy farm provided informed consent for the use of the data and for the participation of their animals in this study.
KH: Conceptualization, Data curation, Formal analysis, Investigation, Methodology, Software, Writing – original draft, Writing – review & editing. YD: Conceptualization, Data curation, Formal analysis, Investigation, Writing – review & editing. HL: Writing – review & editing. JH: Writing – review & editing. LL: Writing – review & editing. ZW: Writing – review & editing. LW: Writing – review & editing.
The author(s) declare that financial support was received for the research and/or publication of this article. This work was supported by the Natural Science Foundation of Gansu Province (25JRRA355); and Innovation Fund for Higher Education of Gansu Province (2022B-107).
This work was supported by “Basic research innovation group” under Grant No.21JR7RA858.
LL was employed by Gansu Nongken Tianmu Dairy Co., Ltd.
The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
The Supplementary material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fvets.2025.1396799/full#supplementary-material
1. Marques-Bastos, SLS, Coelho, MLV, De Sousa Santos, IN, Moreno, DSA, Barrias, ES, De Mendonça, JFM, et al. Effects of the natural antimicrobial peptide aureocin A53 on cells of Staphylococcus aureus and Streptococcus agalactiae involved in bovine mastitis in the excised teat model. World J Microbiol Biotechnol. (2023) 39:5. doi: 10.1007/s11274-022-03443-w
2. Bochniarz, M, Szczubiał, M, Brodzki, P, Krakowski, L, and Dąbrowski, R. Serum amyloid a as an marker of cow’s mastitis caused by Streptococcus sp. Comp Immunol Microbiol Infect Dis. (2020) 72:101498. doi: 10.1016/j.cimid.2020.101498
3. Wang, L, Haq, SU, Shoaib, M, He, J, Guo, W, Wei, X, et al. Subclinical mastitis in small-holder dairy herds of Gansu Province, Northwest China: prevalence, bacterial pathogens, antimicrobial susceptibility, and risk factor analysis. Microorganisms. (2024) 12:2643. doi: 10.3390/microorganisms12122643
4. Fernandes, L, Guimaraes, I, Noyes, NR, Caixeta, LS, and Machado, VS. Effect of subclinical mastitis detected in the first month of lactation on somatic cell count linear scores, milk yield, fertility, and culling of dairy cows in certified organic herds. J Dairy Sci. (2021) 104:2140–50. doi: 10.3168/jds.2020-19153
5. Kandeel, SA, Megahed, AA, Ebeid, MH, and Constable, PD. Evaluation of 3 esterase tests for the diagnosis of subclinical mastitis at dry-off and freshening in dairy cattle. J Dairy Sci. (2019) 102:1402–16. doi: 10.3168/jds.2017-14345
6. Ali, A, Mir, MUR, Ganie, SA, Mushtaq, S, Bukhari, SI, Alshehri, S, et al. Milk-compositional study of metabolites and pathogens in the milk of bovine animals affected with subclinical mastitis. Molecules. (2022) 27:8631. doi: 10.3390/molecules27238631
7. Burmańczuk, A, Hola, P, Wojciechowska, B, Kowalski, C, and Grabowski, T. Validation of relationship between milk resistance and daily yield of dairy cows.
8. Ebrahimi, M, Mohammadi-Dehcheshmeh, M, Ebrahimie, E, and Petrovski, KR. Comprehensive analysis of machine learning models for prediction of sub-clinical mastitis: deep learning and gradient-boosted trees outperform other models. Comput Biol Med. (2019) 114:103456. doi: 10.1016/j.compbiomed.2019.103456
9. Bobbo, T, Matera, R, Pedota, G, Manunza, A, Cotticelli, A, Neglia, G, et al. Exploiting machine learning methods with monthly routine milk recording data and climatic information to predict subclinical mastitis in Italian Mediterranean buffaloes. J. Dairy Sci. (2023) 106:1942–52. doi: 10.3168/jds.2022-22292
10. van den Borne, BHP, Vernooij, JCM, Lupindu, AM, van Schaik, G, Frankena, K, Lam, TJGM, et al. Relationship between somatic cell count status and subsequent clinical mastitis in Dutch dairy cows. Prev Vet Med. (2011) 102:265–73. doi: 10.1016/j.prevetmed.2011.07.013
11. Sumon, SMMR, Parvin, MS, Ehsan, MA, and Islam, MT. Relationship between somatic cell counts and subclinical mastitis in lactating dairy cows. Vet World. (2020) 13:1709–13. doi: 10.14202/vetworld.2020.1709-1713
12. Ebrahimie, E, Mohammadi-Dehcheshmeh, M, Laven, R, and Petrovski, K. Rule discovery in milk content towards mastitis diagnosis: dealing with farm heterogeneity over multiple years through classification based on associations. Animals. (2021) 11:1638. doi: 10.3390/ani11061638
13. Mammadova, N, and Keskin, İ. Application of the support vector machine to predict subclinical mastitis in dairy cattle. Sci World J. (2013) 2013:1–9. doi: 10.1155/2013/603897
14. Baştan, A, Salar, S, Cengi̇, ZM, Darbaz, İ, Demi̇rel, MA, and Özen, D. The prediction of the prevalence and risk factors for subclinical heifermastitis in Turkish dairy farms. Turk J Vet Anim Sci. (2015) 39:682–7. doi: 10.3906/vet-1501-80
15. Zhou, X, Xu, C, Wang, H, Xu, W, Zhao, Z, Chen, M, et al. The early prediction of common disorders in dairy cows monitored by automatic systems with machine learning algorithms. Animals. (2022) 12:1251. doi: 10.3390/ani12101251
16. Moayedi, H, Nguyen, H, and Kok, FL. Nonlinear evolutionary swarm intelligence of grasshopper optimization algorithm and gray wolf optimization for weight adjustment of neural network. Eng Comput. (2021) 37:1265–75. doi: 10.1007/s00366-019-00882-2
17. Hashim, FA, and Hussien, AG. Snake optimizer: a novel meta-heuristic optimization algorithm. Knowl Based Syst. (2022) 242:108320. doi: 10.1016/j.knosys.2022.108320
18. Liu, Q, Wang, P, Sun, J, Li, R, and Li, Y. Wireless Channel prediction of GRU based on experience replay and Snake optimizer. Sensors. (2023) 23:6270. doi: 10.3390/s23146270
19. Li, Y, Xiao, L, Tang, B, Liang, L, Lou, Y, Guo, X, et al. A denoising method for ship-radiated noise based on optimized variational mode decomposition with snake optimization and dual-threshold criteria of correlation coefficient. Math Probl Eng. (2022) 2022:1–21. doi: 10.1155/2022/8024753
20. Alamir, N, Kamel, S, Megahed, TF, Hori, M, and Abdelkader, SM. Energy management of multi-microgrid considering demand response using snake optimizer In: 2022 23rd international Middle East power systems conference (MEPCON). Cairo, Egypt: IEEE (2022). 1–6.
21. Pakrashi, A, Ryan, C, Guéret, C, Berry, DP, Corcoran, M, Keane, MT, et al. Early detection of subclinical mastitis in lactating dairy cows using cow-level features. J Dairy Sci. (2023) 106:4978–90. doi: 10.3168/jds.2022-22803
22. Zhou, H, Wang, X, and Zhu, R. Feature selection based on mutual information with correlation coefficient. Appl. Intell. (2022) 52:5457–74. doi: 10.1007/s10489-021-02524-x
23. Rumelhart, DE, Hinton, GE, and Williams, RJ. Learning representations by back-propagating errors. Nature. (1986) 323:533–6. doi: 10.1038/323533a0
24. Zhang, Y, Cui, N, Feng, Y, Gong, D, and Hu, X. Comparison of BP, PSO-BP and statistical models for predicting daily global solar radiation in arid Northwest China. Comput Electron Agric. (2019) 164:104905. doi: 10.1016/j.compag.2019.104905
25. Li, J, Dong, X, Ruan, S, and Shi, L. A parallel integrated learning technique of improved particle swarm optimization and BP neural network and its application. Sci. Rep. (2022) 12:19325. doi: 10.1038/s41598-022-21463-2
26. Li, Y, Han, M, and Guo, Q. Modified whale optimization algorithm based on tent chaotic mapping and its application in structural optimization. KSCE J Civ Eng. (2020) 24:3703–13. doi: 10.1007/s12205-020-0504-5
27. Hu, G, Yang, R, Abbas, M, and Wei, G. BEESO: multi-strategy boosted Snake-inspired optimizer for engineering applications. J Bionic Eng. (2023) 20:1791–827. doi: 10.1007/s42235-022-00330-w
Keywords: subclinical mastitis, snake optimization, regression prediction, neural network, Dairy Herd Improvement
Citation: Han K, Dai Y, Liu H, Hu J, Liu L, Wang Z and Wei L (2025) TBESO-BP: an improved regression model for predicting subclinical mastitis. Front. Vet. Sci. 12:1396799. doi: 10.3389/fvets.2025.1396799
Edited by:
Muhammad Shoaib, Yangzhou University, ChinaReviewed by:
Freddy Fikse, Swedish University of Agricultural Sciences, SwedenCopyright © 2025 Han, Dai, Liu, Hu, Liu, Wang and Wei. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Yongqiang Dai, ZHlxQGdzYXUuZWR1LmNu
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.