
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Signal Process., 05 April 2022
Sec. Signal Processing Theory
Volume 2 - 2022 | https://doi.org/10.3389/frsip.2022.794469
This article is part of the Research TopicWomen in Signal ProcessingView all 12 articles
 Kavya Gupta1,2*
Kavya Gupta1,2* Fateh Kaakai2Beatrice Pesquet-Popescu2Jean-Christophe Pesquet1
Fateh Kaakai2Beatrice Pesquet-Popescu2Jean-Christophe Pesquet1 Fragkiskos D. Malliaros1
Fragkiskos D. Malliaros1The stability of neural networks with respect to adversarial perturbations has been extensively studied. One of the main strategies consist of quantifying the Lipschitz regularity of neural networks. In this paper, we introduce a multivariate Lipschitz constant-based stability analysis of fully connected neural networks allowing us to capture the influence of each input or group of inputs on the neural network stability. Our approach relies on a suitable re-normalization of the input space, with the objective to perform a more precise analysis than the one provided by a global Lipschitz constant. We investigate the mathematical properties of the proposed multivariate Lipschitz analysis and show its usefulness in better understanding the sensitivity of the neural network with regard to groups of inputs. We display the results of this analysis by a new representation designed for machine learning practitioners and safety engineers termed as a Lipschitz star. The Lipschitz star is a graphical and practical tool to analyze the sensitivity of a neural network model during its development, with regard to different combinations of inputs. By leveraging this tool, we show that it is possible to build robust-by-design models using spectral normalization techniques for controlling the stability of a neural network, given a safety Lipschitz target. Thanks to our multivariate Lipschitz analysis, we can also measure the efficiency of adversarial training in inference tasks. We perform experiments on various open access tabular datasets, and also on a real Thales Air Mobility industrial application subject to certification requirements.
Artificial neural networks are at the core of recent advances in Artificial Intelligence. One of the main challenges faced today, especially by companies designing advanced industrial systems, is to ensure the safety of new generations of products using these technologies. Neural networks have been shown to be sensitive to adversarial perturbations (Szegedy et al., 2013). For example, changing a few pixels of an image may lead to misclassification of the image by a Deep Neural Network (DNN), which emphasizes the potential lack of stability of such architectures. DNNs being sensitive to adversarial examples, can thus be fooled, in an intentional manner (security issue) or in undeliberate/accidental manner (safety issue), which raises a major stability concern for safety-critical systems which need to be certified by an independent certification authority prior to any entry into production/operation. DNN-based solutions are hindered with such issue due to their complex nonlinear structure. Attempts towards verification of neural networks have been made for example in (Katz et al., 2017; Weng et al., 2019). It has been proven in (Tsipras et al., 2018b) that there exists a trade-off between the prediction performance and the stability of neural networks.
In the last years, the number of works devoted to the stability issue of neural networks has grown in manifolds. In these works, the terms “stability”, “robustness” or “local robustness” are used interchangeably with the same meaning which is formally defined in this paper as the extent to which a neural network can continue to operate correctly despite small perturbations in its inputs. The stability criterion considered here highlights the fact that these small perturbations in the inputs do not produce high variations of the outputs. Many approaches have been proposed, some dedicated to specific architectures (e.g., networks using only ReLU activation functions) and grounded on more or less empirical techniques. We can break down broadly these techniques into three categories:
• Purely computational approaches which consist in attacking a neural network and observing its response to such attacks,
• methods based on (often clever) heuristics for testing/promoting the stability of a neural net,
• studies that aim at establishing mathematical proofs of stability.
These three kinds of strategies are useful for building and certifying effectively robust neural networks. However, the techniques based on mathematical proofs of stability are generally preferred by industrial safety experts since they enable a safe-by-design approach that is more efficient than a robustness verification activity done a posteriori with a necessarily bounded effort. Among the possible mathematical approaches, we focus in this article on those relying upon the analysis of the Lipschitz properties of neural networks. Such properties play a fundamental role in the understanding of the internal mechanisms governing these complex nonlinear systems. Besides, they make few assumptions on the type of non-linearities used and are thus valid for a wide range of networks. Nevertheless, they generate a number of challenges both from a theoretical and numerical standpoints.
Since DNNs are sensitive to small specific perturbations, providing a quantitative estimation of the stability of such architectures is of paramount importance for safe and secure product development in domains such as aeronautics, ground transportation, autonomous vehicles, energy, and healthcare. One metric to assess the stability of neural networks to adversarial perturbations is the Lipschitz constant, which upper bounds the ratio between output variations and input variations for a given metric. More generally, in deep learning theory, novel generalization bounds critically rely on the Lipschitz constant of the neural network (Bartlett et al., 2017). One of the main limitations of the Lipschitz constant, defined in either global or local context, is that it only provides a single parameter to quantify the robustness of a neural network. Such a single-parameter analysis does not facilitate the understanding of potential sources of instability. In particular, it may be insightful to identify the inputs which have the highest impact in terms of sensitivity. In the context of tabular data mining, the inputs often have quite heterogeneous characteristics. Some of them are categorical data, often encoded in a specific way [e.g., one-hot encoder (Hancock and Khoshgoftaar, 2020)] and among them, one can usually distinguish those which are unsorted (like labels identifying countries) or those which are sorted (like severity scores in a disease). So, it may appear useful to analyze in a specific manner each type of inputs of a NN and even sometimes to exclude some of these inputs (e.g., unsorted categorical data for which the notion of small perturbation may be meaningless) from the performed sensitivity analysis.
The contributions of the work are summarized below:
• A multivariate analysis of the Lipschitz properties of NNs is performed by generating a set of partial Lipschitz constants. This opens a new dimension to studying the stability of NNs.
• Our sensitivity analysis allows us to capture the behaviour of an individual input or group of inputs.
• The results of this analysis are displayed by a new graphical representation termed as a Lipschitz star.
• Using the proposed analysis, we also study quantitatively the effect of spectral normalization constraint and adversarial training on the stability of NNs.
• We showcase our results on various open-source datasets along with a real industrial application in the domain of Air Traffic Management.
In the next section we give a detailed description of the state-of-the-art related to the quantification of the Lipschitz constant in neural networks. Section 3 gives our proposed method pertaining to sensitivity of inputs and introduction to Lipschitz stars. Section 4 provides an analytical evaluation for our approach with synthetic datasets. The next section gives detailed results on three open source datasets and a real safety critical industrial dataset. The last section concludes our paper.
An m-layered feedforward network can be modelled by the following recursive equations:
where, at the ith layer,
Since the seminal work in (Szegedy et al., 2013), it is known that instability in the outputs of the neural networks may arise. This issue, often referred to as the stability with respect to adversarial noise, tends to be more severe when the training set is small. However, it may even happen with large datasets such as ImageNet. As shown in (Goodfellow et al., 2015), the problem is mainly related to the choice of the weight matrices. One way of quantifying the stability of the system is to calculate a Lipschitz constant of the network.
A Lipschitz constant of a function T is an upper bound on the ratio between the variations of the output values and the variations of input arguments of a function T. Thus, it is a measure of sensitivity of the function with respect to input perturbations. This means that, if
then θ is a Lipschitz constant of T. Note that, the same notation is used here for the norms on
where
The first upper-bound on the Lipschitz constant of a neural network was derived by analyzing the effect of each layer independently and considering a product of the resulting spectral norms (Goodfellow et al., 2015). This leads to the following Trivial Upper Bound:
Although easy to compute, this upper bound turns out be over-pessimistic. In (Virmaux and Scaman, 2018), the problem of computing the exact Lipschitz constant of a differentiable function is pointed out to be NP-hard. A first generic algorithm (AutoLip) for upper bounding the Lipschitz constant of any differentiable function is proposed. This bound however reduces to Eq. 4 for standard feedforward neural networks. Additionally, the authors proposed an algorithm, called SeqLip, for sequential neural networks, which shows significant improvement over AutoLip. A sequential neural network is a network for which the activation operators are separable in the sense that, for every i ∈ (1, … , m),
where the activation function
where
which shows that
In Combettes and Pesquet (2020b) various bounds on the Lipschitz constant of a feedforward network are derived by assuming that, for every i ∈ (1, … , m) the activation operator Ri is αi-averaged with
We thus see that the smaller αi, the more “stable” Ri is. In the limit case when α1 = 1, Ri is non-expansive and, when αi = 1/2, Ri is said to be firmly nonexpansive. An important subclass of firmly nonexpansive operators is the class of proximity operators of convex functions which are proper and lower-semicontinuous. Let
The proximity operator is a fundamental tool in convex optimization. As shown in (Combettes and Pesquet, 2020a), the point is that most of the activation functions (e.g., sigmoid, ReLu, leaky ReLU, ELU) currently used in neural networks are the proximity operators of some proper lower-semicontinuous convex functions. This property is also satisfied by activation operators which are not separable, like softmax or the squashing function used in capsule networks. The few activation operators which are not proximity operators (e.g., convex combinations of a max pooling and an average pooling) can be viewed as over-relaxations of proximity operators and correspond to a value of the averaging parameter greater than 1/2.
Based on these averaging assumptions, a first estimation of the Lipschitz constant is given by
where
for every k ∈ (1, … , m−1),
and for every
When, for every i ∈ (1, … , m−1), Ri is firmly nonexpansive, the expression simplifies as
If, for every i ∈ (1, … , m−1), Ri is separable2, a second estimation is provided which reads
We thus see that, when α1 = … = αm−1 = 1/2, we recover Eq. 7 without making any assumption on the differentiability of the activation functions. This estimation is more accurate than the previous one in the sense that
It is proved in (Combettes and Pesquet, 2020b) that, if the network is with non-negative weights, that is
Another interesting result which is established in (Combettes and Pesquet, 2020b) is that similar results hold if other norms than the Euclidean norm are used to quantify the perturbations on the input and the output. For example, for a given i ∈ (1, … , m), for every p ∈ (1, + ∞), we can define the following norm:
If (p, q) ∈ (1,+∞)2, the input space
where ‖ ⋅‖p,q is the subordinate Lp,q matrix norm induced by the two previous norms. The ability to use norms other than the Euclidean one may be sometimes more meaningful in practice (especially for the ℓ1 or the sup norm). However, computing such a subordinate norm is not always easy (Lewis, 2010).
The work in (Fazlyab et al., 2019) focuses on neural networks using separable activation operators. It assumes that the activation function ρi used at a layer i ∈ (1, … , m) is slope-bounded, i.e., there exist nonnegative parameters ϒmin and ϒmax such that
As said by the authors, most activation functions satisfy this inequality with ϒmin = 0 and ϒmax = 1. In other words, the above inequality means that ρi is an increasing function and nonexpansive. But a known result (Combettes and Pesquet, 2008, Proposition 1.4) states that a function ρi satisfies these properties if and only if it is the proximity operator of some proper lower-semicontinuous convex function. So it turns out that we recover similar assumptions to those made in (Combettes and Pesquet, 2020a).
Let us thus assume that ϒmin = 0, ϒmax = 1, and m ≥ 2. A known property is that Ri is firmly nonexpansive if and only if
The point is that, if Ri is a separable operator, this inequality holds in a more general metric associated with a matrix
where
For every
Summing for the first m−1 layers yields
On the other hand, ϑm > 0 is a Lipschitz constant of the neural network T if
For the latter inequality to hold, it is thus sufficient to ensure that
This inequality can be rewritten in matrix form as
with
In the case of a network having just one hidden layer, which is mainly investigated in (Fazlyab et al., 2019), the above matrix reduces to
Condition Eq. 28 is satisfied, for every (x0, … , xm−1) and (y0, … , ym−1) if and only if
It is actually sufficient that this positive semidefiniteness constraint be satisfied for any matrices
where C is the closed convex set
Although there exists efficient SDP solvers, the method remains computationally intensive. A solution to reduce its computational complexity at the expense of a lower accuracy consists of restricting the optimization of the metric matrices Q1, … , Qm−1 to a subset of
One limitation of this method is that it is tailored to the use of the Euclidean norm.
Remark 1. In (Fazlyab et al., 2019), it is claimed that Eq. 23 is valid for every metric matrix
where
The approach in (Latorre et al., 2020) applies to neural networks having a single output (i.e., Nm = 1)3. The authors mention that their approach is restricted to differentiable activation functions, but it is actually valid for any separable firmly nonexpansive activation operators. Indeed, when Nm = 1, the Lipschitz constant in Eq. 19 reduces to
where p∗ ∈ (1, + ∞) is the dual exponent of p (such that 1/p + 1/p∗ = 1). Recall that p ∈ (1, + ∞) is the exponent of the ℓp-norm equipping the input space. This shows that ϑm is equal to
where, for every
Function Φ is a multivariate polynomial of the components of its vector arguments. Therefore, if the unit ball associated with the ℓp norm can be described via polynomial inequalities, which happens when
A comparison of the state-of-the-art and proposed approach is presented in Table 1.

TABLE 1. Comparison of state-of-the-art Lipschitz estimation approaches vs the proposed one.
To extend the theoretical results presented above on the evaluation of neural network stability through their Lipschitz regularity, we present in this section a new approach based on a suitable weighting operation performed in the computation of Lipschitz constants. This enables a multivariate sensitivity analysis of the neural network stability for individual inputs or groups of inputs. We will start by motivating this weighting from a statistical standpoint. Then we will define it in a more precise manner, before discussing its resulting mathematical properties.
For tractability, assume that the perturbation at the network input is a realization of a zero-mean Gaussian distributed random vector
for every
where Γ is the gamma function and γ the lower (unnormalized) incomplete gamma function.
On the other hand, let us assume that the maximum standard deviation σmax of the components of
Let us focus our attention on perturbations in Cη. By doing so, we impose some norm-bounded condition, which may appear more realistic for adversarial perturbations. Then, we will be interested in calculating
By making the variable change
where
On the other hand, based on the first-order approximation in Eq. 40, T(x + z) is approximately Gaussian with mean T(x) and covariance matrix T′(x)ΣT′(x)⊤. As
Based on the previous motivations, we propose to employ a weighted norm to define a Lipschitz constant of the network as follows:
Definition 1. Let Ω be an N0 × N0 symmetric positive definite real-valued matrix. We say that ${\theta}_{m}^{\upOmega}$ is an Ω-weighted norm Lipschitz constant of T as described in Figure 1 if
The above definition can be extended to non Euclidean norms by making use of exponents (p, q) ∈ (1,+∞)2 and by replacing inequality Eq. 44 with
By changes of variable, this inequality can also be rewritten as.
Therefore, we see that calculating
Although all our derivations were based on the fact that Ω is positive definite, from the latter expression we see that, by continuous extension,

FIGURE 1. m-layered feedforward neural network architecture. For the ith-layer, Wi is the linear weight operator, bi the bias vector, and Ri the activation operator.
In this section, we will be interested in a specific family of weighted norms associated with the set of matrices
defined, for every nonempty subset
where
If we come back to the statistical interpretation in Section 3.1,
The next proposition lists the main properties related to the use of such weighted norms for calculating Lipschitz constants. The proofs of these results are given in Supplementary Appendix S2.
Proposition 1. Let (p, q) ∈ (1,+∞)2. For every nonempty subset
1) As ϵ → 0,
2)
3) Let
4) Function
5) Let
6) Let
We have
7) Let
We have
8) Let
Let us comment on these results. According to Property (i) in the limit case when ϵ → 0, only the inputs with indices in
To highlight the need for advanced sensitivity analysis tools in the design of neural networks, we first study simple synthetic examples of polynomial systems for which we can calculate explicitly the partial Lipschitz constants. We generate input-output data for the defined systems, and train a fully connected model using a standard training, i.e., without any constraints. We compare this approach with a training subject to a spectral norm constraint on the layers.
Spectral Normalization: For safety critical tasks, Lipschitz constant and performance targets can be specified as engineering requirements, prior to network training. A Lipschitz target can be defined by a safety analysis of the acceptable perturbations for each output knowing the input range and it constitutes a current practice in many industries. Imposing this Lipschitz target can be done either by controlling the Lipschitz constant for each layer or for the whole network depending on the application at hand. Such a work for controlling the Lipschitz constant has been presented in (Serrurier et al., 2021) using Hinge regularization. In our experiments, we train networks while using a spectral normalization technique (Miyato et al., 2018) which has been proved to be effective in controlling Lipschitz properties in GANs. Given an m layer fully connected architecture and a Lipschitz target L, we can constrain the spectral norm of each layer to be less than
For each training, we study the effect of input variables on the stability of the networks. As proposed in Section 3.3, for a given group of inputs with indices in
Partial Lipschitz constant values
We consider regression problems where the data is synthesized by a second-order multivariate polynomial. The system to be modelled is thus described by the following function:
where
The explicit values of the partial Lipschitz constant on this domain can be derived as follows. We first calculate the gradient of f
where, for every k ∈ (1, … , N0), ∂kf denotes the partial derivative w.r.t. the k-th variable given by
For every
where, for every diagonal matrix
Since the partial derivatives in Eq. 57 are affine functions of the variables
In our numerical experiments, we consider a toy example corresponding to N0 = 3 and
where
and, consequently,
By looking at the seven possible binary values of (ɛ1, ɛ2, ɛ3) ≠ (0, 0, 0), we thus calculate the Lipschitz constant of f with respect to each group of inputs. For example,
• if ɛ1 = 1, ɛ = 0, ɛ3 = 0, we calculate
• if ɛ1 = ɛ2 = 1, ɛ3 = 0, we calculate
• if ɛ1 = ɛ2 = ɛ3 = 1, we calculate
These Lipschitz constants allow us to evaluate the intrinsic dynamics of the system, that is how it responds when its inputs vary.
Our interest will be now to evaluate how this dynamics is modified when the system is modelled by a neural network. To do so, three systems are studied by choosing γ ∈ (0, 1/10, 1) and M = 50. We generate 5,000 data samples from each system, the input values being drawn independently from a random uniform distribution. While training the neural networks, the dataset is divided with a ratio of 4:1 into training and testing samples. The input is normalized using its mean and standard deviation, while the output is max-normalized. We build neural networks for approximating the systems using two hidden layers (m = 3) with a number of hidden neurons equal to 30 in each layer and ReLU activation functions. The training loss is the mean square error.
For different values of γ, we report the values of the partial Lipschitz constants in Tables 2, 3, 4. The variable
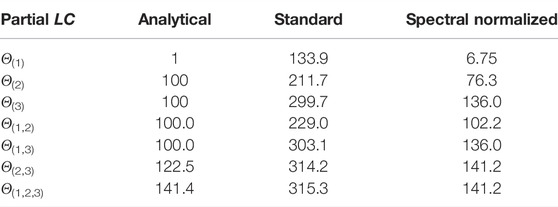
TABLE 2. Comparison of Lipschitz constant values when γ = 0. Test performance for standard training: NMSE = 0.007, NMAE = 0.005, for spectral normalization: NMSE = 0.011, NMAE = 0.009.
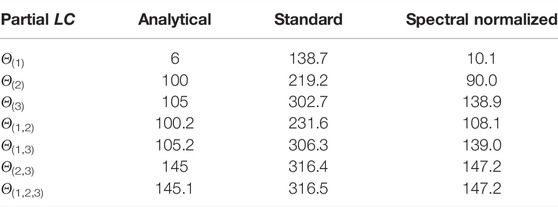
TABLE 3. Comparison of Lipschitz constant values when γ = 1/10. Test performance for standard training: NMSE = 0.006, NMAE = 0.005, for spectral normalization: NMSE = 0.009, NMAE = 0.007.
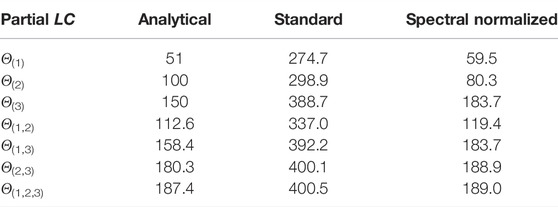
TABLE 4. Comparison of Lipschitz constant values when γ = 1. Test performance for standard training: NMSE = 0.006, MAE = 0.005, for spectral normalization: NMSE = 0.014, NMAE = 0.009.
Comments on the results:
• In general, ξ3 impacts the output of this system the most, and (ξ2, ξ3) mainly account for the global dynamics of the system.
• With standard training, we see that there exists a significant increase of the sensitivity with respect to the input variations, so making the neural network vulnerable to adversarial perturbations.
• By using spectral normalization, it is possible to constrain the global Lipschitz constant of the system to be close to the analytical global value while keeping a good accuracy. One may however notice an increase of the sensitivity to ξ1 and ξ3, and a decrease of the sensitivity to ξ2 with respect to the original system.
• For all the three models, the values obtained with neural networks follow the same trend, for different groups of inputs, as those observed with the analytical values.
• Although the Lipschitz constant of the neural networks is computed on the whole space and the one of the system on (−50,50)3, our Lipschitz estimates appear to be consistent without resorting to a local analysis.
These observations emphasize the importance of controlling the Lipschitz constant of neural network models through specific training strategies. In addition, we see that evaluating the Lipschitz constant with respect to groups of inputs allow us to have a better understanding of the behaviour of the models.
In this section, we have discussed the proposed method for synthetic datasets. In the next section, the sensitivity analysis will be made on widely used open source datasets and an industrial dataset.
We study four regression problems involving tabular datasets to showcase our proposed multivariate analysis of the stability of neural networks. Tabular data take advantage of heterogeneous sources of information coming from different sensors or data collection processes. We apply our methods on widely used tabular datasets: 1) Combined Cycle Power Plant dataset 5 which has 4 attributes with 9,568 instances; 2) Auto MPG dataset 6 consists of 398 instances with 7 attributes; 3) Boston Housing dataset 7 consists of 506 instances with 13 attributes. For Combined Power Plant and Auto MPG datasets, we solve a regression problem with a single output, whereas for Boston Housing dataset we consider a two-output regression problem with “price” and “ptratio” as the output variables. The attributes in the dataset are a combination of continuous and categorical. The datasets are divided with a ratio of 4:1 between training and test data.
Thales Air Mobility industrial application represents the prediction of the Estimated Time En-route (ETE), meaning the time spent by an aircraft between the take-off and landing, considering a number of variables as described in Table 5. The application is important in air traffic flow management, which is an activity area where safety is critical. The purpose of the proposed sensitivity analysis is thus to help engineers in building safe by design models complying with given safety stability targets. The dataset consists of 2,219,097 training, 739,639 validation, and 739,891 test samples.
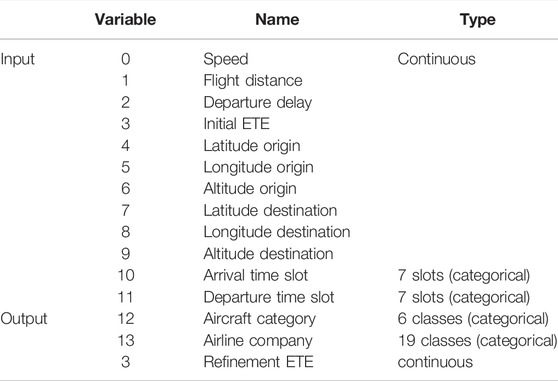
TABLE 5. Input and output variables description for the Thales Air Mobility industrial application dataset.
For all the models, we build fully connected networks with ReLU8 activation function on all the hidden layers, except the last one. The models are trained on Keras with Tensorflow backend. The initializers are set to Glorot uniform. The network architecture of the different models, number of layers, and neurons are tabulated in Table 6. Combined Cycle Power Plant dataset with (10, 6) network architecture is trained with two hidden layers having 10 and 6 hidden neurons, respectively. For Thales Air Mobility industrial application [10 × (30)] implies that the neural network has 10 hidden layers with 30 neurons each.

TABLE 6. Network Architecture and training setup for different datasets.
In this section we study the effect of input variables on the stability of the networks. More specifically, we study the effect of input variations on the stability of the networks by quantifying
As shown by Proposition 1, varying the ϵ parameter is also insightful since it allows us to measure how the network behaves when input perturbations are gradually more concentrated on a given subset of inputs.
Although our approach can be applied to groups of inputs, for simplicity in this section, we will focus on the case when the sets
For each dataset, we first perform a standard training when designing the network. To facilitate comparisons, the Lipschitz star of the network trained in such standard manner is presented as the first subplot of all the figures in the paper. Next, we show the variation in terms of input sensitivity, when 1) a Lipschitz target is imposed, and 2) when an adversarial training of the networks is performed. The network architecture remains unchanged, for all our experiments and each dataset, as indicated in Section 5.1. All the Lipschitz constants for each value of ϵ are calculated using LipSDP-Neuron (Fazlyab et al., 2019). Since an increased stability may come at the price of a loss of accuracy (Tsipras et al., 2018a), we also report the performance of the networks on test datasets in terms of MAE (Mean Absolute Error) for each of the Lipschitz star plot.
Spectral norm constrained training is performed as explained in Section 4.1. The results are shown for our three datasets in Figures 2–5. On these plots, we can observe a shrinkage of the Lipschitz stars following the reduction of the target Lipschitz value. Interestingly, improving stability does not affect significantly the performance of the networks. Let us comment on the last use case in light of the obtained results.
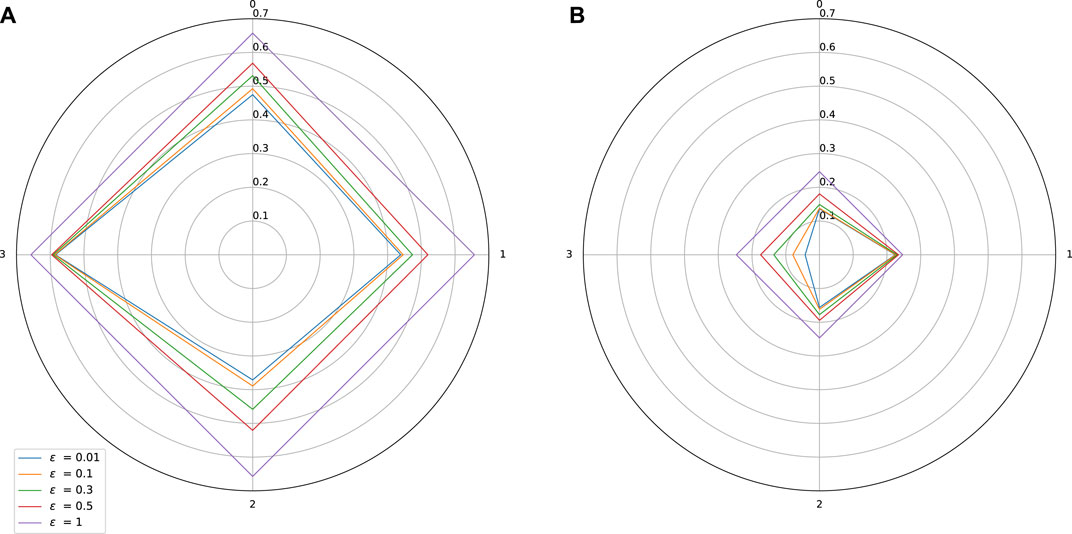
FIGURE 2. Sensitivity w.r.t. to each input on Combined Cycle Power Plant dataset. Influence of a spectral normalization constraint. (A) Standard training: Lipschitz constant = 0.66, MAE = 0.007, (B) With spectral normalization: Lipschitz constant = 0.25, MAE = 0.0066.
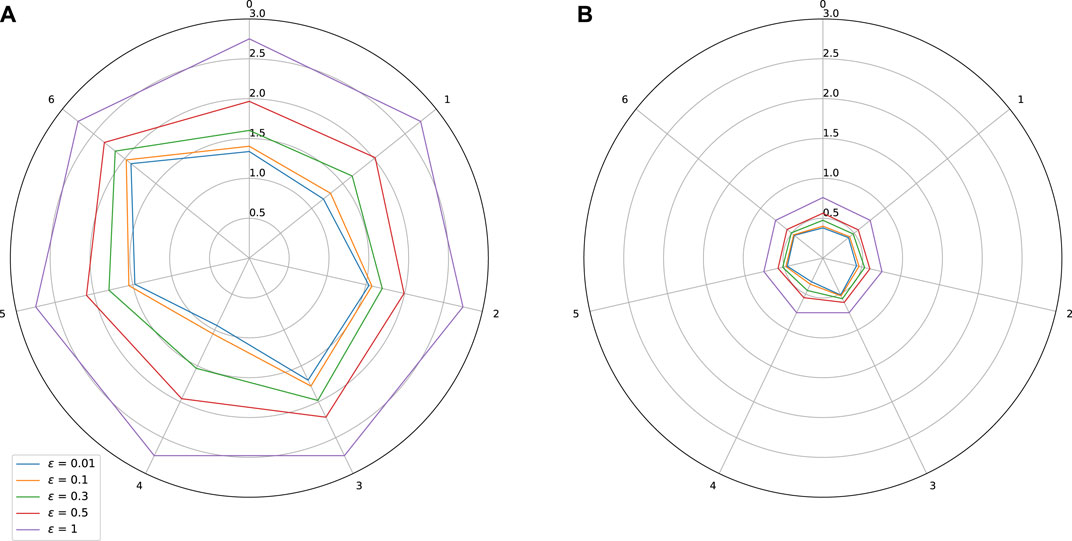
FIGURE 3. Sensitivity w.r.t. to each input on Auto MPG dataset. Influence of a spectral normalization constraint. (A) Standard training: Lipschitz constant = 2.75, MAE = 0.05, (B) With spectral normalization: Lipschitz constant = 0.76, MAE = 0.04.
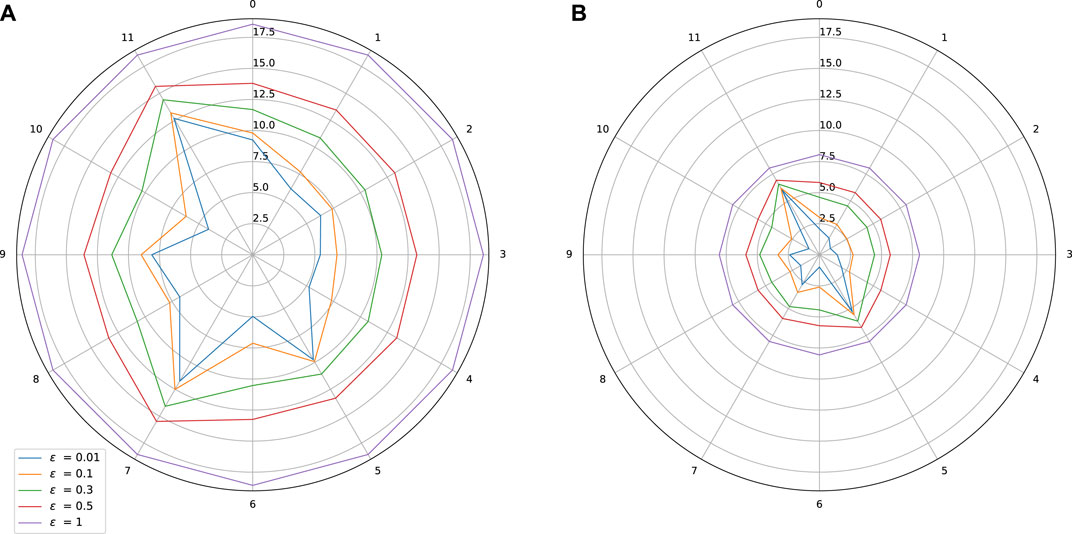
FIGURE 4. Sensitivity w.r.t. to each input on Boston Housing dataset. Influence of a spectral normalization constraint. (A) Standard training: Lipschitz constant = 18.56, MAE(y1) = 2.45, MAE(y2) = 1.41, (B) With spectral normalization: Lipschitz constant = 8.06, MAE(y1) = 2.96, MAE(y2) = 1.35.
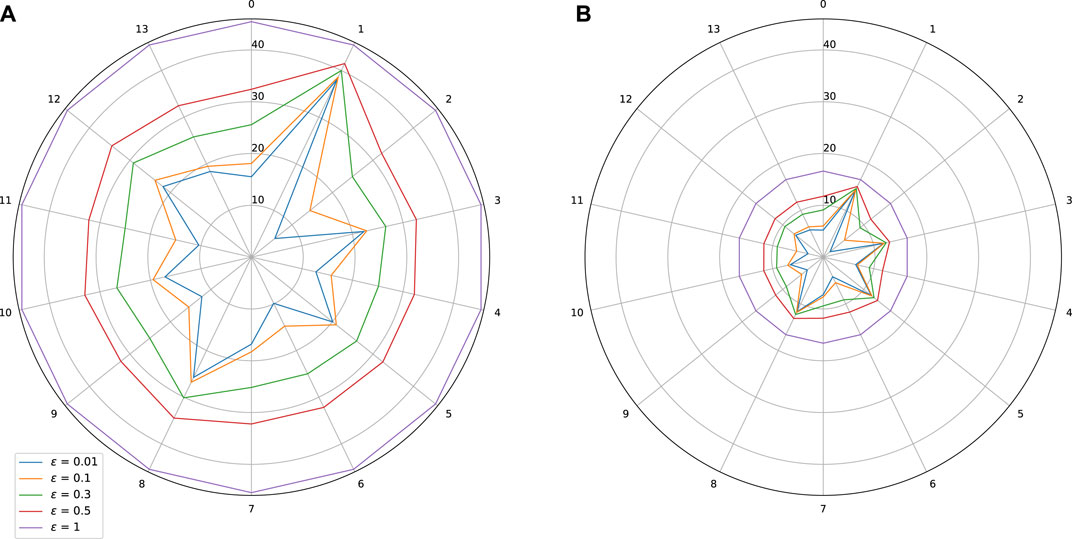
FIGURE 5. Sensitivity w.r.t. to each input on Thales Air Mobility industrial application. Influence of a spectral normalization constraint. (A) Standard training: Lipschitz constant = 45.46, MAE = 496.37 (s), (B) With spectral normalization constraint: Lipschitz constant = 16.62, MAE = 478.88 (s).
Comments on the Thales Air Mobility industrial application From the star plots, it is clear that the various variables have a quite different effect on the Lipschitz behavior of the network. This is an expected outcome since these variables carry a different amount of information captured by learning. From Figure 5 we observe that variables 1—Flight Distance and 3—Initial ETE play a prominent role, while variables 5—Longitude Origin, and 8—Longitude Destination are also sensitive. Some plausible explanations for these facts are mentioned below.
• Flight distance: The impact of a change of this input can be significant since because of air traffic management separation rules, the commercial aircrafts cannot freely increase their speed to minimize the impact of a longer flight distance.
• Initial ETE: Modifying this input is equivalent to changing the initial conditions, which will have a significant impact. It is possible, in the worst case scenario, to accumulate other perturbations coming from other coupled inputs and parameters (e.g., weather conditions) and this is probably the reason why the partial Lipschitz constant is very high, and close to the global Lipschitz constant.
• Longitude origin and destination parameters: These parameters are related to different continents and even countries of the origin and destination airports and probably with different qualities of air traffic equipment.
Generating adversarial attacks and performing adversarial training constitute popular methods in designing robust neural networks. However, these techniques have received less attention for regression tasks, since most of the works deal with classification tasks (Goodfellow et al., 2015; Kurakin et al., 2018; Eykholt et al., 2018). Also, most of the existing works in the deep learning literature are for standard signal/image processing problems, whereas there are only few works handling tabular data (Zhang et al., 2016; Ke et al., 2018). One noticeable exception is (Ballet et al., 2019) which investigates problems related to adversarial attacks for classification tasks involving tabular data. Since our applications are related to regression problems for which few existing works are directly applicable, we designed a specific adversarial training method. More specifically, for a given amplitude of the adversarial noise and for each sample in the training set, we generate the worst attack based on the spectral properties of the Jacobian of the network, computed by backpropagation at this point. At each epoch of the adversarial training procedure, we solve the underlying minmax problem (Tu et al., 2019). More details on the generation of adversarial attacks for regression attacks can be found in (Gupta et al., 2021).
The generated adversarial attacks from the trained model at the previous epoch are successively concatenated to the training set for the next training epoch, much like in standard adversarial training practices using FGSM (Goodfellow et al., 2015) and Deepfool (Moosavi-Dezfooli et al., 2016) attacks. While generating adversarial attacks on tabular data, some of the variables may be more susceptible to attacks than others. The authors of (Ballet et al., 2019) take care of this aspect by using a feature importance vector. They also only attack the continuous variables, disregarding categorical ones while generating attacks. For the Power plant and Boston Housing datasets, we attack all the four input variables, while on the MPG dataset, we attack only the continuous variables. For the industrial dataset, we generate attacks for the five most sensitive input variables. We also tried attacking all the variables of the dataset but this was not observed to be more efficient. The results in form of Lipschitz star are given in Figures 6–9.
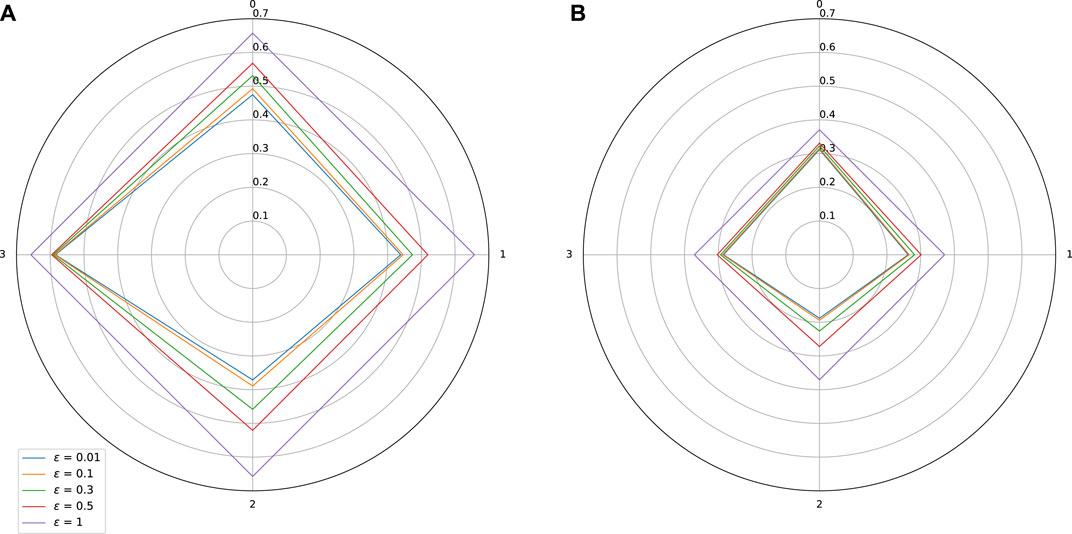
FIGURE 6. Sensitivity w.r.t. to each input on Combined Cycle Power Plant dataset. Effect of adversarial training. (A) Standard training: Lipschitz constant = 0.657, MAE = 0.007, (B) Adversarial training: Lipschitz constant = 0.37, MAE = 0.0068.
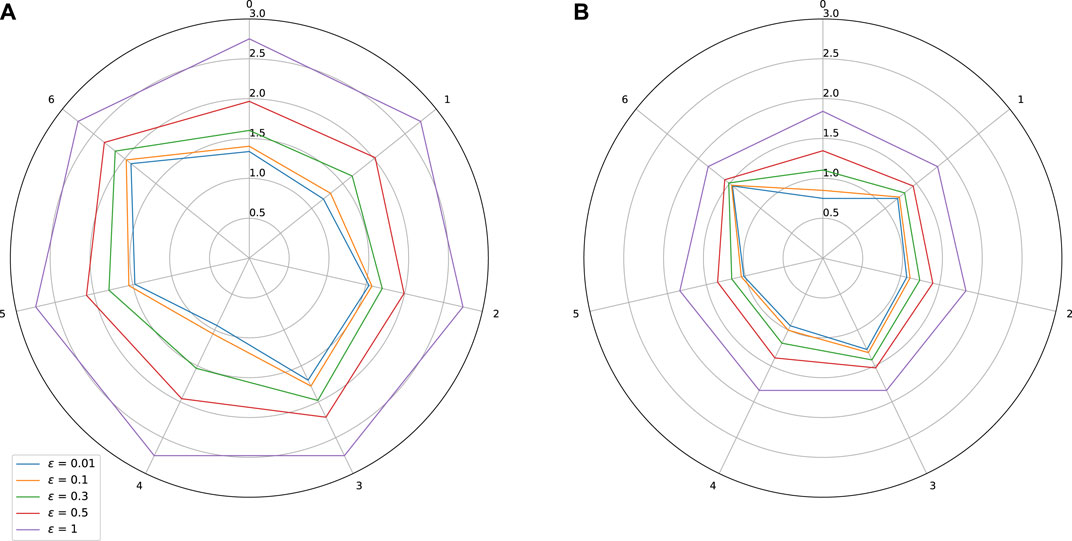
FIGURE 7. Sensitivity w.r.t. to each input on Auto MPG dataset. Effect of adversarial training. (A) Standard training: Lipschitz constant = 2.75, MAE = 0.05, (B) Adversarial training: Lipschitz constant = 1.84, MAE = 0.042.
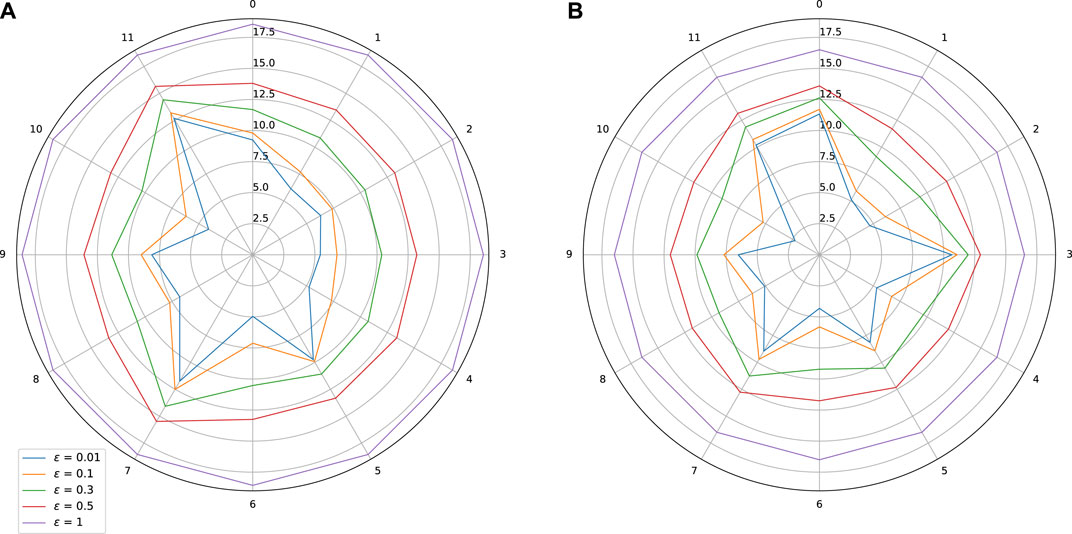
FIGURE 8. Sensitivity w.r.t. to each input on Boston Housing dataset. Effect of adversarial training. (A) Standard training: Lipschitz = 18.56, MAE(y1) = 2.45, MAE(y2) = 1.41, (B) Adversarial training: Lipschitz constant = 16.50, MAE(y1) = 2.35 MAE(y2) = 1.32.
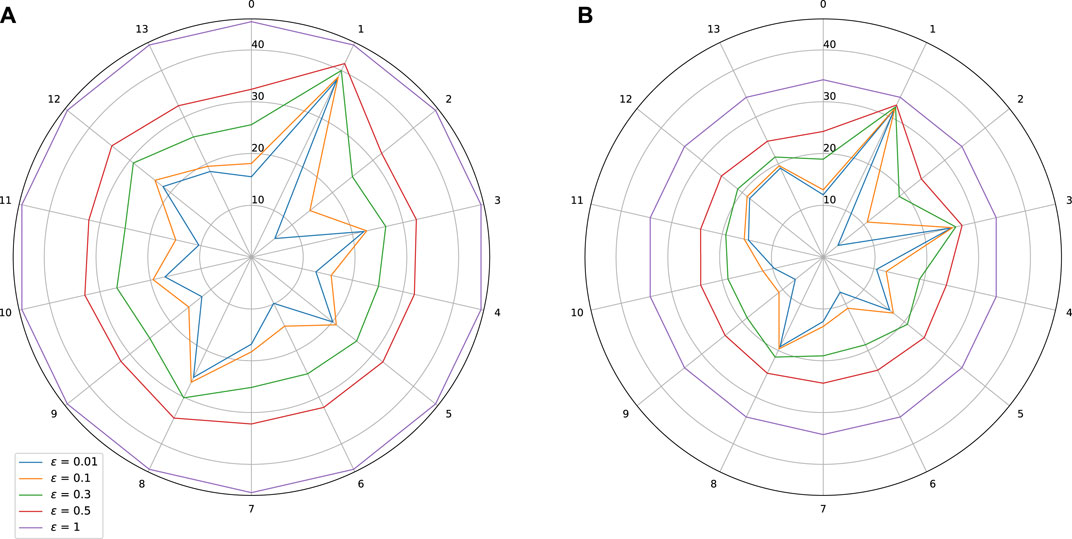
FIGURE 9. Sensitivity w.r.t. to each input on Thales Air Mobility industrial application. Effect of adversarial training. (A) Standard training: Lipschitz = 45.47, MAE = 496.37 (s), Adversarial training. (B) Lipschitz = 34.26, MAE = 494.7 (s).
As expected, adversarial training leads to a shrinkage of the star plots, which indicates a better control on the stability of the trained models, while also improving slightly the MAE. In the test we did, we observe however that our adversarial training procedure is globally less efficient than the spectral normalization technique.
We now consider the case when the set
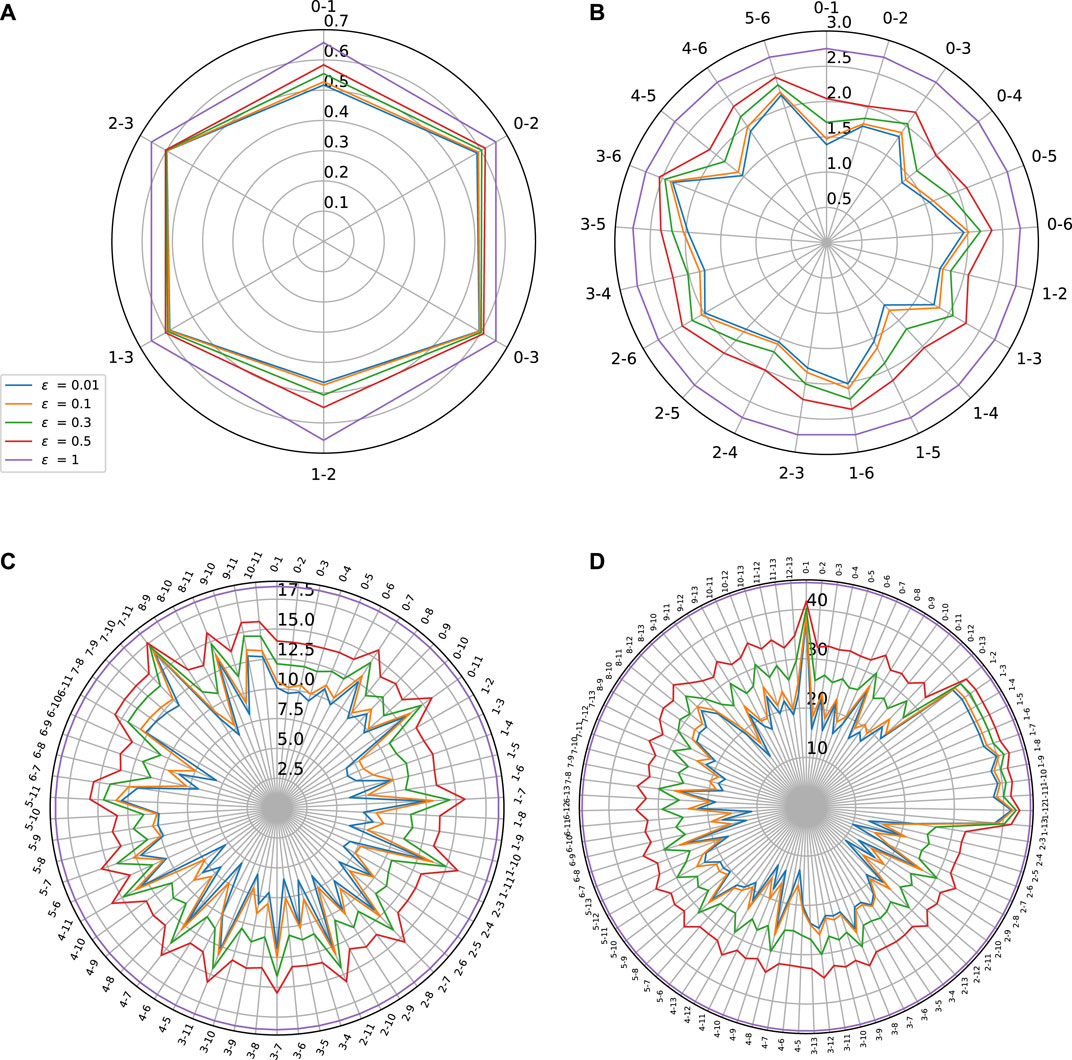
FIGURE 10. Sensitivity w.r.t to pair of variables on (A) Combined Power Plant dataset (B) Auto MPG Dataset (C) Boston Housing dataset and (D) Thales Air Mobility industrial application.
As shown by Figure 10, this Lipschitz star representation can be useful for displaying the influence of groups of variables instead of single ones. This may be of high interest when the number of inputs is large, especially if they can be grouped into variables belonging to a given class having a specific physical meaning (e.g., electrical variables versus mechanical ones). Such Lipschitz star representation might however not be very insightful for identifying the coupling that may exist between the variables within a given group. For example, it may happen that, considered together, two variables yield an increased sensitivity than the sensitivity of each of them individually. The reason why we need to find a better way for highlighting these coupling effects is related to Proposition 3(v) which states that, for every
This property means that, when considering a pair of inputs, the one with the highest partial Lipschitz constant will “dominate” the other. To circumvent this difficulty and make our analysis more interpretable, we can think of normalizing the Lipschitz constant in a suitable manner. Such a strategy is a common practice in statistics when, for example, the covariance of a pair of variables is normalized by the product of their standard deviations to define their correlation factor. Once again, we can take advantage of the properties established in Proposition 3 to provide us a guideline to perform this normalization. In addition to Eq. 63, according to Property (viii),
The two previous inequalities suggest to normalize the Lipschitz constant for pairs of inputs by defining
Indeed, when ϵ is close to zero, Eqs 63–65 show that
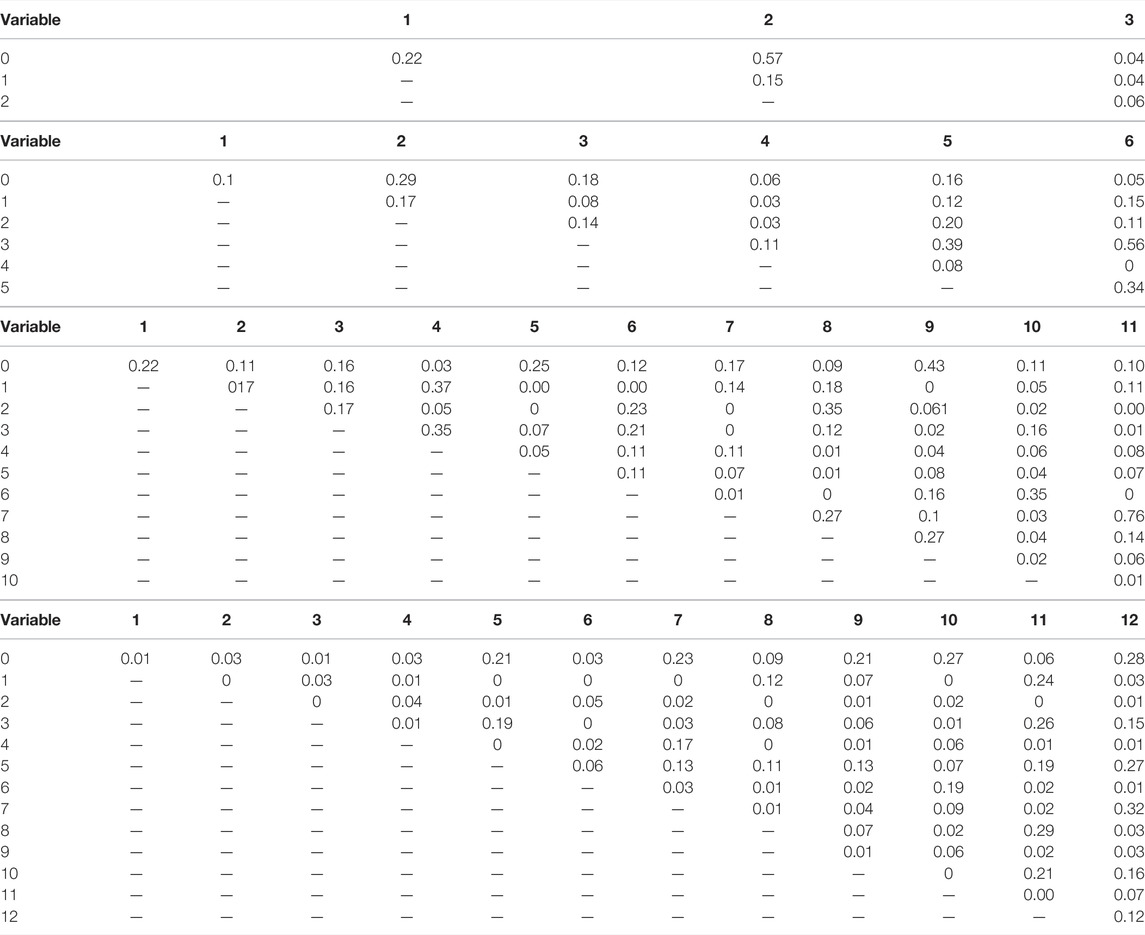
TABLE 7. Second order normalized coupling matrix with ϵ = 0.001 on (A) Combined Power Plant Dataset (B) Auto MPG Dataset (C) Boston Housing Dataset and (D) Thales Air Mobility industrial application.
We summarize some important observations/properties concerning the stability of the NNs which can be drawn from training on different datasets and leveraging the quantitative tools we have proposed in this article.
a) Combined Power Plant Dataset
• “3—Exhaust Vacuum” is the most sensitive variable out of the four variables.
• We observe for any variable coupled with “3” gives a higher partial Lipschitz constant.
• From Table 7A, we see that the effect is mostly caused by the sensitivity of “3” and there is no gain when coupled with other variables. Hence, “3” dominates the overall sensitivity of the NN.
• On the other hand, we observe that, “0” when coupled with “1” and “2” becomes more sensitive as evidenced by the gain in Table 7A.
b) Auto MPG Dataset
• Variable “6—Origin” and “3—Weight” are the most sensitive variables.
• The values of partial Lipschitz constant peak when the other variables are coupled with “3” or “6”.
• From Table 7B, we see that most of the values coupled with either “3” or “6” are close to zero, except when “3” and “6” are coupled together. Also, we see an exception when “5” is coupled with either “3” or “6”. This suggests that altogether “3”, “5”, and “6” have a higher impact on the stability of the network.
c) Boston Housing Dataset
• Variable “7—DIS” and “11—LSTAT” are the most sensitive variables.
• We observe a high partial Lipschitz constant when coupling any variables with “7” or “11”.
• From Table 7C, we see that all the values for both “7” and “11” coupled with other variables are close to zero, except when “7” and “11” are jointly considered. Hence, “7” and “11” dominate the sensitivity of the NN.
• We observe from the table of normalized values, that “2–9” have a higher impact on the sensitivity of the NN when coupled. Similar observation can be made for pairs “2–8”,“1–4”,“3–4”.
d) Thales Air Mobility industrial application
• Variable “1—Flight distance”,“3—Initial ETE”, and “8—Longitude Destination” are the most sensitive variables.
• We see peaks in the partial Lipschitz constant values when these highly sensitive variables are coupled with other variables.
• But when analyzing the normalized tables, it becomes clear that the gain is mostly due to these sensitive variables.
• We also observe from Table 7D, an increased sensitivity of “0” when coupled with other variables “5”, “7”, “10”, “11”, and “13”.
We have proposed a new multivariate analysis of the Lipschitz regularity of a neural network. Our approach, whose theoretical foundations are given in Section 3, allows the sensitivity with respect to any group of inputs to be highlighted. We have introduced a new “Lipschitz star” representation which is helpful to display how each input or group of inputs contributes to the global Lipschitz behaviour of a network. The use of these tools has been illustrated on four regression use cases involving tabular data. The improvements brought by two robust training methods (training subject to Lipschitz bounds and adversarial training) have been measured. More generally the proposed methodology is applicable to various machine learning tasks to build “safe-by-design” models where heterogeneous/multimodal/multi-omic data can be used.
The industrial dataset presented in this article is not readily available because the dataset is internal to Thales. Further inquiries should be directed to a2F2eWEuZ3VwdGExMDBAZ21haWwuY29t. All other datasets are readily available from the following: https://archive.ics.uci.edu/ml/datasets/Combined+Cycle+Power+Plant; https://archive.ics.uci.edu/ml/datasets/auto+mpg; https://www.cs.toronto.edu/∼delve/data/boston/bostonDetail.html.
KG—Doctoral student handling the processing of the datasets, coding of the tools proposed, optimization of the results and writing of the article. FK—Thales advisor of the doctoral student. Responsible for procuring industrial datasets and technical advises on the experimentation and better utilization of tools, editing of the article. BP-P—Thales advisor of the doctoral student. Responsible for procuring industrial datasets and technical advises on the experimentation.and better utilization of tools, editing of the article. J-CP—Academic advisor responsible mathematical proofs of the work presented in the article and writing of the article. FM—Academic advisor responsible for editing the article.
Doctoral thesis of KG is funded by l’Association Nationale de la Recherche et de la Technologie (ANRT) and Thales LAS France under CIFRE convention. Part of this work was supported by the ANR Research and Teaching Chair in Artificial Intelligence, BRIDGEABLE.
KG, FK and BP-P were employed by the company Thales LAS France.
The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/frsip.2022.794469/full#supplementary-material
1More generally, a function ρi,k can be applied to each component ξi,k but this situation rarely happens in standard neural networks.
2The result remains valid if different scalar activation functions are used in a given layer.
3This can be extended to multiple output network, if the output space is equipped with the ℓ+∞ norm.
4Recall that this interpretation is valid when p = 2 in Eq. 47.
5https://archive.ics.uci.edu/ml/datasets/Combined+Cycle+Power+Plant.
6https://archive.ics.uci.edu/ml/datasets/auto+mpg.
7https://www.cs.toronto.edu/∼delve/data/boston/bostonDetail.html.
8We present the results only for ReLU, but we tested our approach with other activation functions such as tanh as well and found the trends in sensitivity of inputs to be similar.
Ballet, V., Renard, X., Aigrain, J., Laugel, T., Frossard, P., and Detyniecki, M. (2019). Imperceptible Adversarial Attacks on Tabular Data. NeurIPS 2019 Workshop on Robust AI in Financial Services: Data, Fairness, Explainability, Trustworthiness and Privacy (Robust AI in FS 2019). Available at https://hal.archives-ouvertes.fr/hal-03002526.
Bartlett, P. L., Foster, D. J., and Telgarsky, M. J. (2017). “Spectrally-normalized Margin Bounds for Neural Networks,” in Advances in Neural Information Processing Systems, 6240–6249.
Chen, T., Lasserre, J.-B., Magron, V., and Pauwels, E. (2020). Semialgebraic Optimization for Lipschitz Constants of ReLU Networks. Adv. Neural Inf. Process. Syst. 33, 19189–19200.
Combettes, P. L., and Pesquet, J.-C. (2020a). Deep Neural Network Structures Solving Variational Inequalities. Set-Valued Variational Anal. 28, 1–28. doi:10.1007/s11228-019-00526-z
Combettes, P. L., and Pesquet, J.-C. (2020b). Lipschitz Certificates for Layered Network Structures Driven by Averaged Activation Operators. SIAM J. Math. Data Sci. 2, 529–557. doi:10.1137/19m1272780
Combettes, P. L., and Pesquet, J.-C. (2008). Proximal Thresholding Algorithm for Minimization over Orthonormal Bases. SIAM J. Optim. 18, 1351–1376. doi:10.1137/060669498
Eykholt, K., Evtimov, I., Fernandes, E., Li, B., Rahmati, A., Xiao, C., et al. (2018). “Robust Physical-World Attacks on Deep Learning Visual Classification,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 1625–1634. doi:10.1109/cvpr.2018.00175
Fazlyab, M., Robey, A., Hassani, H., Morari, M., and Pappas, G. (2019). “Efficient and Accurate Estimation of Lipschitz Constants for Deep Neural Networks,” in Advances in Neural Information Processing Systems, 11423–11434.
Goodfellow, I. J., Shlens, J., and Szegedy, C. (2015). Explaining and Harnessing Adversarial Examples. International Conference on Learning Representations. Available at http://arxiv.org/abs/1412.6572.
Gupta, K., Pesquet, J.-C., Pesquet-Popescu, B., Malliaros, F., and Kaakai, F. (2021). An Adversarial Attacker for Neural Networks in Regression Problems. IJCAI Workshop on Artificial Intelligence Safety (AI Safety). Available at http://ceur-ws.org/Vol-2916/paper_17.pdf.
Hancock, J. T., and Khoshgoftaar, T. M. (2020). Survey on Categorical Data for Neural Networks. J. Big Data 7, 1–41. doi:10.1186/s40537-020-00305-w
Katz, G., Barrett, C., Dill, D. L., Julian, K., and Kochenderfer, M. J. (2017). “Reluplex: An Efficient SMT Solver for Verifying Deep Neural Networks,” in International Conference on Computer Aided Verification (Springer), 97–117. doi:10.1007/978-3-319-63387-9_5
Ke, G., Zhang, J., Xu, Z., Bian, J., and Liu, T.-Y. (2018). TabNN: A Universal Neural Network Solution for Tabular Data.
Kurakin, A., Goodfellow, I. J., and Bengio, S. (2018). Adversarial Examples in the Physical World. Artificial Intelligence Safety and Security. Chapman and Hall/CRC, 99–112.
Latorre, F., Rolland, P. T. Y., and Cevher, V. (2020). Lipschitz Constant Estimation of Neural Networks via Sparse Polynomial Optimization. 8th International Conference on Learning Representations.
Lewis, A. D. (2010). A Top Nine List: Most Popular Induced Matrix Norms. Available at https://mast.queensu.ca∼andrew/notes/pdf/2010a.pdf.
Miyato, T., Kataoka, T., Koyama, M., and Yoshida, Y. (2018). Spectral Normalization for Generative Adversarial Networks. International Conference on Learning Representations. Available at https://openreview.net/forum?id=B1QRgziT-.
Moosavi-Dezfooli, S.-M., Fawzi, A., and Frossard, P. (2016). “Deepfool: a Simple and Accurate Method to Fool Deep Neural Networks,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (IEEE), 2574–2582. doi:10.1109/cvpr.2016.282
Pauli, P., Koch, A., Berberich, J., Kohler, P., and Allgower, F. (2022). Training Robust Neural Networks Using Lipschitz Bounds. IEEE Control. Syst. Lett. 6, 121–126. doi:10.1109/LCSYS.2021.3050444
Serrurier, M., Mamalet, F., González-Sanz, A., Boissin, T., Loubes, J.-M., and del Barrio, E. (2021). “Achieving Robustness in Classification Using Optimal Transport with Hinge Regularization,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (IEEE), 505–514. doi:10.1109/cvpr46437.2021.00057
Szegedy, C., Zaremba, W., Sutskever, I., Bruna, J., Erhan, D., Goodfellow, I. J., et al. (2013). “Intriguing Properties of Neural Networks,” in 2nd International Conference on Learning Representations, Banff, AB, April 14–16, 2014. Available at https://dblp.org/rec/journals/corr/SzegedyZSBEGF13.bib.
Tsipras, D., Santurkar, S., Engstrom, L., Turner, A., and Madry, A. (2018a). Robustness May Be at Odds with Accuracy. International Conference on Learning Representations. Available at https://openreview.net/forum?id=SyxAb30cY7.
Tsipras, D., Santurkar, S., Engstrom, L., Turner, A., and Madry, A. (2018b). There Is No Free Lunch in Adversarial Robustness (But There Are Unexpected Benefits). arXiv preprint arXiv:1805.12152 2 (3).
Tu, Z., Zhang, J., and Tao, D. (2019). Theoretical Analysis of Adversarial Learning: A Minimax Approach. Advances in Neural Information Processing Systems 32.
Virmaux, A., and Scaman, K. (2018). “Lipschitz Regularity of Deep Neural Networks: Analysis and Efficient Estimation,” in Advances in Neural Information Processing Systems, 3835–3844.
Weng, L., Chen, P.-Y., Nguyen, L., Squillante, M., Boopathy, A., Oseledets, I., et al. (2019). “Proven: Verifying Robustness of Neural Networks with a Probabilistic Approach,” in International Conference on Machine Learning (Long Beach, CA: PMLR), 6727–6736.
Yang, Y.-Y., Rashtchian, C., Zhang, H., Salakhutdinov, R. R., and Chaudhuri, K. (2020). A Closer look at Accuracy vs. Robustness. Advances in Neural Information Processing Systems. 33, 8588–8601.
Keywords: lipschitz, neural networks, stability, adversarial attack, sensitivity, safety, tabular data
Citation: Gupta K, Kaakai F, Pesquet-Popescu B, Pesquet J- and Malliaros FD (2022) Multivariate Lipschitz Analysis of the Stability of Neural Networks. Front. Sig. Proc. 2:794469. doi: 10.3389/frsip.2022.794469
Received: 13 October 2021; Accepted: 31 January 2022;
Published: 05 April 2022.
Edited by:
Hagit Messer, Tel Aviv University, IsraelReviewed by:
Zhenyu Liao, Huazhong University of Science and Technology, ChinaCopyright © 2022 Gupta, Kaakai, Pesquet-Popescu, Pesquet and Malliaros. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Kavya Gupta, a2F2eWEuZ3VwdGExMDBAZ21haWwuY29t
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.