 Paulo Padrao1†
Paulo Padrao1† Leonardo Bobadilla
Leonardo Bobadilla- 1Knight Foundation School of Computing and Information Sciences, Florida International University, Miami, FL, United States
- 2Institute for Environment, Florida International University, Miami, FL, United States
Prediction and estimation of phenomena of interest in aquatic environments are challenging since they present complex spatio-temporal dynamics. Over the past few decades, advances in machine learning and data processing contributed to ocean exploration and sampling using autonomous robots. In this work, we formulate a reinforcement learning framework to estimate spatio-temporal fields modeled by partial differential equations. The proposed framework addresses problems of the classic methods regarding the sampling process to determine the path to be used by the agent to collect samples. Simulation results demonstrate the applicability of our approach and show that the error at the end of the learning process is close to the expected error given by the fitting process due to added noise.
1 Introduction
The use of autonomous underwater and surface vehicles (AUVs and ASVs) for persistent surveillance in coastal and estuarine environments has been a topic of increasing interest. Examples of studies enabled by these vehicles include the dynamics of physical phenomena, such as ocean fronts, temperature, the onset of harmful algae blooms, salinity profiles, monitoring of seagrass and coral reefs, and fish ecology.
Due to the stochastic nature of these vital environments and the large spatial and temporal scales of significant processes and phenomena, sampling with traditional modalities (e.g., manned boats, buoys) is sparse and predictive models are necessary to augment decision-making to ensure that robotics assets are at the right time and the right place for sampling. However, no single model provides an informed view or representation of these or any other ocean feature that enables intelligent sampling in a principled manner. Therefore, it is critical to forecasting where a robot should sample in the immediate future so that sufficient information is provided on getting to the desired location within a dynamic environment.
Our ideas are inspired by commonly used underwater vehicles in environmental and infrastructure monitoring problems such as the AUV Ecomapper shown in Figure 1. This vehicle can measure water quality parameters, currents, and bathymetric information. However, its mission endurance is limited to a few hours due to its battery constraints, therefore, efficient sampling strategies are needed.

FIGURE 1. YSI-Ecomapper autonomous underwater vehicle.
The contributions of this paper are the following:
1) A novel framework combining classic methods with reinforcement learning to estimate ocean features, which are modeled as spatio-temporal fields.
2) A technique to get a set of informative samples to estimate spatio-temporal fields, which an agent can collect and process.
3) An extension to the classical partial differential equations fitting methods to estimate models incorporating reinforcement learning.
This paper is an expansion of our preliminary work in Padrao et al. (2022) and extends it to include the estimation of ocean features using partial differential equations. The rest of the paper is organized as follows. In Section 2, we review related work to our approach. Section 3 gives the preliminaries needed to build our method and formulate our problem. Section 4 presents the Reinforcement Learning Methods used to solve our approach, and the results are presented in Section 5. Finally, Section 6 concludes our paper and gives direction for future work.
2 Related work
2.1 Oceanic monitoring sampling
Over the last decade, it has become clear that autonomous marine vehicles will revolutionize ocean sampling. Several researchers have investigated approaches for ASVs and AUVs for adaptive ocean sampling Yuh (2000)-Smith et al. (2010c) and fundamental marine sampling techniques for ASVs and AUVs are discussed in Singh et al. (1997). Besides control algorithms for Oceanic Sampling, an alternative approach is to use static sensor placements to maximize information gathering Zhang and Sukhatme (2008).
2.2 Adaptive sampling with marine vehicles
Our work connects also with research on control design for AUVs for adaptive ocean sampling, Yoerger and Slotine (1985); Frazzoli et al. (2002); Low et al. (2009); Rudnick and Perry (2003); Yuh (2000); Frank and Jónsson (2003); Graver (2005); Barnett et al. (1996); Carreras et al. (2000); Ridao et al. (2000); Rosenblatt et al. (2002); Turner and Stevenson (1991); Whitcomb et al. (1999, 1998); McGann et al. (2008b), McGann et al. (2008a), McGann et al. (2008c), Yoerger and Slotine (1985)-McGann et al. (2008c). Applications of ocean sampling techniques for autonomous vehicles are discussed in Singh et al. (1997)-Eriksen et al. (2001). This body of research differs from the proposed research in that we plan to utilize predictive models in the form of Partial Differential Equations (PDE) to enable effective sampling, navigation, and localization within dynamic features.
2.3 Reinforcement learning in marine robotics
Reinforcement learning in marine robotics, especially model-free methods, is an attractive alternative to finding plans for several reasons. First, executing marine robotics experiments and deployments is expensive, time-consuming, and often risky; controllers learned through RL can represent significant time and cost savings and shorten the time to deployment. Second, system identification can sometimes be challenging in marine environments due to several factors such as unmodeled dynamics and environment’s unknowns; for that reason, model-free RL approaches can be an alternative in these scenarios. Examples of approaches that have used RL for ASVs or AUVs include path planning Yoo and Kim (2016), control Cui et al. (2017) and tracking Martinsen et al. (2020).
2.4 Machine learning for partial differential equations
Our ideas are also connected to the use of Machine Learning models in the context of Partial Differential Equations. Due to their usefulness and impact in several domains, there have been efforts to use modern machine learning techniques to solve high dimensional PDEs Han et al. (2018), find appropriate discretizations Han et al. (2018), and control them Farahmand et al. (2017).
3 Preliminaries and problem formulation
3.1 Partial differential equations
Partial differential equations (PDEs) have been used to model water features of interest such as pH, temperature, turbidity, salinity, and chlorophyll-A. Depending on the nature of their motion, they can be modeled through diffusion, advection or a combination of both. It is important to evaluate how they behave given certain initial conditions to understand their evolution in time. We model the ocean features of interest as a scalar field
3.1.1 Advection equation
The advection equation models how a given ocean feature (e.g., algae bloom, oil spill, chemical contaminants, etc.) is transported by a given flow which goes in the direction of
has the solution shown in Evans (1998).
Provided that
3.2 Estimation of the parameters of a PDE
Once we chose a PDE as a model, it is crucial to estimate the parameters of the PDE to get a reliable model. This problem belongs to the family of inverse problems since those parameters are sensitive to the observations and given initial conditions Richard et al. (2019) Antman et al. (2006). Because of this sensitivity, it is computationally expensive to find the PDE parameters. There are optimization-based techniques to solve this problem. These techniques problems balance the fitting parameter to the observations and the model sensitivity to those parameters. One of most used methods is the Tikhonov regularization technique Nair and Roy (2020) Bourgeois and Recoquillay (2018). It comprises solving a regularized optimization problem to get a regularized solution. It can be highly efficient depending on the regularization norm (especially if the L2 norm is used). However, it depends on the regularization constant to achieve good results.
Other approaches to solving the PDE estimation problem take advantage of Bayesian theory Xun et al. (2013). In this case, bayesian learning is connected to regularization since the regularization problem coincides with the maximization of the likelihood of the parameters given the observations Bishop (1995). Therefore, Machine Learning techniques have been proposed to take advantage of the capability of the models to discover hidden relationships between the input data and the final estimation Jamili and Dua (2021). Most of those models use the fact that the samples are given in advance. This work proposes a learning mechanism to select samples that can reasonably estimate the model without exploring the complete domain. This principle has been used in numerical integration problems resulting in several quadrature rules, such that Gauss–Kronrod, Gauss-Legendre, or Newton cotes Kincaid et al. (2009). Those methods have proven to be more efficient since they can give reliable estimations using few points. In this work, we employ an intelligent agent capable of sampling the environment, searching for reliable samples, and using them to compute the parameters of a PDE. Also, this allows estimating the ocean feature behavior in the domain according to Eq. 2.
3.3 Model definition
We modeled the marine environment as a 2-D water layer (representing, for example, the surface) denoted as
To estimate the flow field, we define a scheme of fitting problems based on the known initial conditions of Eq. 1 h(x) and the current samples acquired by the agent. First, we expect to collect samples yi at the location xi and time ti for i = 1, … , n such that the field minimizes the mean square error of the collected samples. Taking advantage of the closed solution described in the homogeneous version of Eq. 1, the fitting error function ef(b) is defined as
where n is the number of collected samples. Next, we define the fitting error ef (x1, … , xn) associated to the locations
The fitting error expressed in Eq. 4 measures how well can the best fitted model prediction of the given samples (i.e., predict yi given xi and a parameter vector b. It is the “best” in the sense that is the minimum achievable error produced by the model given the samples x1, … , xn). Nevertheless, we can notice that if the locations x1, … , xn are wrongly chosen, the fitting error can be low, but its capability of estimating the entire field may lead to over-fitting problems. To handle this issue, we add a new error term based on how well one sample can be predicted using the remaining ones. This is known as cross-validation. In this case, we propose the following cross-validation scheme. For each 1 ≤ i ≤ n let
We define the cross validation error ecv (x1, … , xn) as
and it measures on average how well the samples can fit a model, which is estimating the remaining sample. This avoids the over-fitting problems and allows to measure how reliable are the taken samples. Lastly, we define the total error etotal (x1, … , xn) or just etotal as
This error compound aims to have an equal trade off between the sample estimation measured by ef (x1, … , xn) and the reliability of the samples measured by ecv (x1, … , xn).
The agent is modeled as a rigid body that moves in
Such that f (x, u) is the motion model of the vehicle, o (x, r) is the observation model of the vehicle, and r are additive, zero-mean noise to account for modeling errors and sensor imperfections.
Let
In which (x, y) is the position of the vehicle and ϕ ∈ (−π/4, π/4) is the vehicle’s heading; the forward speed v and the angular velocity of the agent orientation ω can be set directly by the action variables uv and uω, respectively. The kinematic model of the agent
where vx and vy account for the velocity components of the environment (flow field) in x and y directions.
Let
We discretize the action space to obtain a finite subset of
The description of the actions of the agent are summarized in Table 1.

TABLE 1. Description of the actions of the agent.
For the observation model, we assume that the vehicle uses an IMU to measure its heading angle ϕ and has access to GPS at surface level. Also, the vehicle can observe its state with uncertainties due to sensor imperfections and the dynamic nature of the underwater environment. The observation space
The observation model o(x) is represented by
Where
These elements allow us to formulate the following problem.Problem: Given an aquatic environment
4 Methods
Because of the computational effort required to tackle problems with large state spaces, tabular learning methods may be unfeasible Sutton and Barto (2018). As a result, combining approximation solutions of reinforcement learning methods with generalization techniques yields a computationally viable solution for real-world problems.
To update the agent policy based on actions taken, we suggest using SARSA(λ) algorithm in conjunction with a linear function approximation technique based on stochastic semi-gradient descent. The agent is in state
The action-value function approximation is defined as
Where
where α is the step size, and Gt is the return function. Applying linear function approximation, Eq. 15 can be modified to
Where
4.1 Reward function design
In reinforcement learning problems, designing a reward function is not a trivial task, Ng et al. (1999). To avoid spurious exploration, we defined a terminal condition with a fixed number of observations taken to determine when to reset the environment for a new episode. To encourage the agent to minimize the fitting and cross-validation errors within a given number of steps, we provide a reward that is inversely proportional to the sum of the errors at the terminal state. For each episode, the agent collects 20 observations, and the reward function is defined as
where c1 is the ratio between total error at previous and current step and
4.2 Linear methods and feature construction: tile coding
In reinforcement learning systems, feature construction is critical since it values each state of the agent. The main techniques for feature construction of linear methods are polynomial-based, Fourier basis and tile coding Sherstov and Stone (2005). As such, tile coding is a computationally effective feature design technique that divides the state space into divisions called tiles. Each element in the tiling is referred to as a tile. Different tilings are separated by a fixed-size fraction of the tile width Sutton and Barto (2018). If there are n tilings and each tiling has m × m tiles, the feature vector is
for each action in action space.
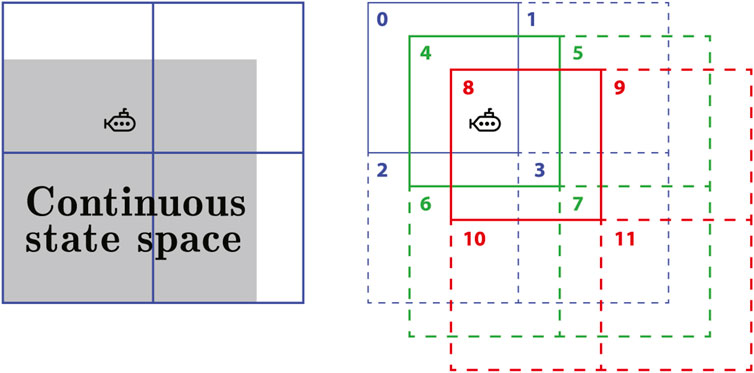
FIGURE 2. An example of tile coding representation of a continuous 2D state space. The agent is a point in the state space to be represented by the active tiles of the three tilings. Active tiles are described by solid lines and have a value of 1. Inactive tiles are described by dashed lines and have a value of 0. Therefore, the feature vector is x(s) = [1, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0].
With tile coding, design issues for discrimination and generalization should be taken into account. The number and size of tiles, for example, affect the granularity of state discrimination, or how far the agent must move in state space to change at least one component of the feature vector. Aside from that, the shape of the tilings and the offset distance between them have an impact on generalization. As an example, if tiles are stretched along one dimension in state space, generalization will extend to states along that dimension as well Sutton and Barto (2018).
4.3 Eligibility traces in reinforcement learning
In problems with large state spaces, the eligibility trace is a technique to promote computational efficiency of reinforcement learning methods. The eligibility trace is a vector
The action-value return function Gt is a function approximation of the n-step return defined as
where γ is the discount rate that regulates the relative importance of near-sighted and far-sighted rewards. Thus, the λ-return
In this way, the update rule for the weight vector in Eq. 16 is modified as follows
where the action-value estimation error δt is defined as
The action-value representation of the eligibility trace is defined as
The complete algorithm for SARSA(λ) is presented in table 1, Sutton and Barto (2018).

Algorithm 1. SARSA(λ) with linear function approximation.
5 Results and discussion
Simulation results are presented in Figure 3. For each simulation, we ran a set of simulations consisting of 400 episodes with 20 steps each to investigate how the agent behaves under the effect of the flow field and the variation of the step size α and the trace decay rate λ. For tile coding, we used eight tilings, each tiling containing 8 × 8 tiles. Thus, the feature vector is
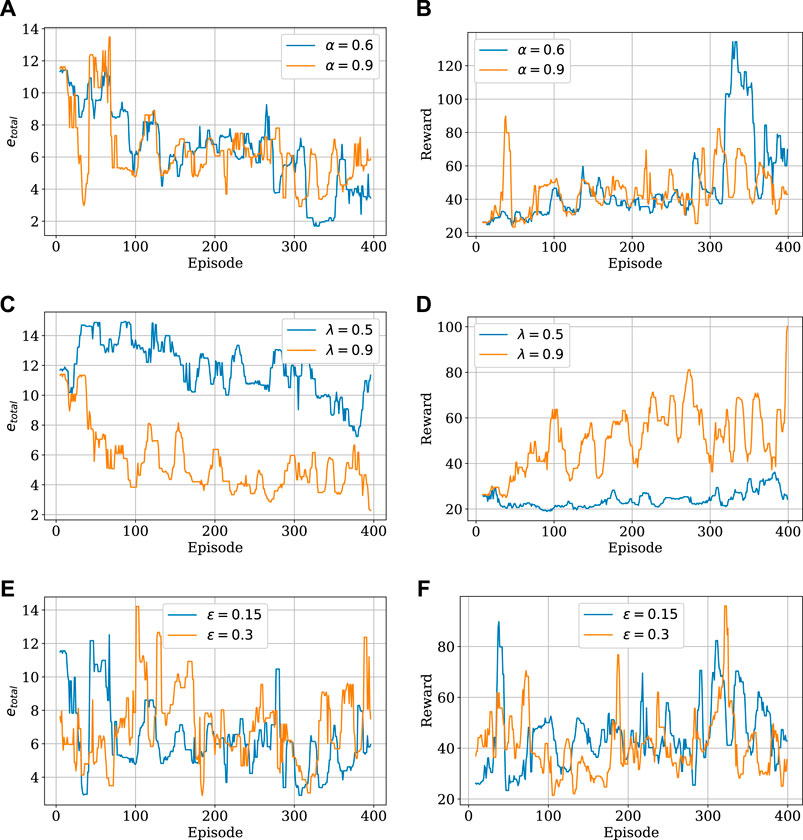
FIGURE 3. Simulation results of the proposed learning framework with the variation of step size α (A,B), trace decay rate λ (C,D), and ϵ-greedy parameter (E,F) with respect to the total number of steps per episode and returns per episode.
h(x) models the initial distribution of the ocean feature. Where a = 100 controls the scale, q = 2 manages the decay rate, ‖ ⋅‖p is the Lp norm defined in
Figures 3A,B shows the total estimation error and agent reward with respect to variation of the step size α. The step size is interpreted as the fraction of the way the agent moves towards the target. Smaller values of the step size α provided an increase in rewards through the episodes and a slight decrease in the estimation error. Additionally, the trace decay rate λ was fixed at 0.9. Figures 3C,D shows the total estimation error and agent reward with respect to variation of trace decay rate λ of the eligibility trace zt in Eq. 25. Larger values of λ resulted in a significant decrease in the estimation error and an increase in rewards. Figures 3E,F shows the total estimation error and agent reward with respect to variation of the ɛ-greedy parameter. Although higher values of the ɛ-greedy parameter can lead to higher exploratory agent behavior, simulation shows similar results with different values of ɛ.
Figure 4 shows different paths taken by the agent in different simulation scenarios. Circles represent level sets of the ocean feature distribution at the end of the simulation. We notice the highest feature concentration location at the center, and the outer circles represent lower ocean feature levels assuming a radial diffusion. Optimal paths have the characteristic of following the ocean feature and crossing its level sets to obtain information at different levels to estimate the entire field.
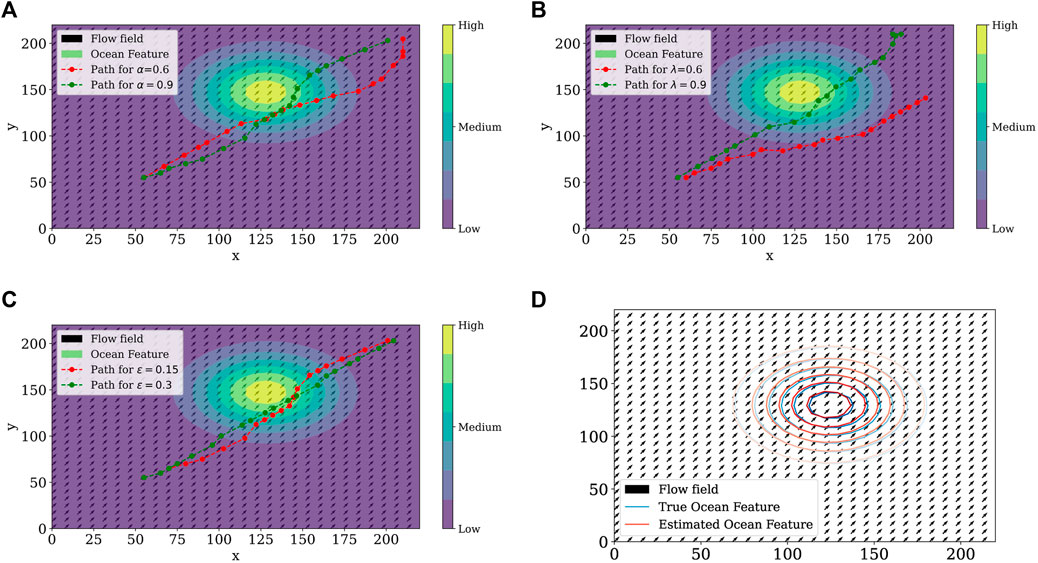
FIGURE 4. Agent path with the variation of step size α (A), trace decay rate λ (B), and ɛ-greedy parameter (C). (D) Difference between the true and the estimated ocean features.
Finally, Figure 4D shows the difference between the estimated and the true ocean feature distributions at the final time. Both of them are similar once the parameters for the true flow field is b = (5,5)⊤ and the estimated is
By the large numbers law. Therefore, etotal = ecv + ef ≈ 2.
To increase the complexity of our simulations, we chose to a double-gyre system; a commonly occurring oceanic feature that is relatively easy to model and analyse Provost and Verron (1987), Wolligandt et al. (2020), Smith et al. (2015), Shadden et al. (2005), Shen et al. (1999). The flow is described by the stream-function
Where fdg (x, t) = a(t)x2 + b(t)x, a(t) = μ sin (ωdgt), b(t) = 100, −,200μ sin (ωdgt) over the domain (0, 200) × (0, 100). In Eq. 28, A describes the magnitude of the velocity vectors, ωdg is the frequency of gyre oscillation, and μ is the amplitude of motion of the line separating the gyres, Shadden et al. (2005). Then the flow field produced the double gyre is the vectorial field v (x, y, t) = ∇ψ(x, y, t).
The PDE (1) considers constant flow fields given by the vector b. For this reason, we need to consider an extension of this equation defined in the bounded domain
Which considers non-constant flow fields, the addition of the diffusion term ρΔf with a small diffusivity coefficient ρ and the homogeneous Neumann boundary conditions with outer normal vector n is due to the numerical difficulties found and reported when the pure advection equation is solved by numerical methods Evans (1998).
Figure 5 illustrates the spread of a given ocean feature through time under the influence of a double-gyre flow field.

FIGURE 5. Spread of a given ocean feature through time under the influence of a double-gyre flow field with A = 10, μ = 0.25, and ωdg = π/5 at (A) t = 0 s (B) t = 5 s (C) t = 10 s.
For the simulation of the reinforcement learning framework and the double-gyre system, we ran a total of 10 episodes with 10 steps each. Although we used tile coding as a computationally effective feature in our reinforcement learning framework, it is still necessary to solve the partial differential equation given in Eq. 29 at each step of each episode. Moreover, to find the fitting and cross-validation errors it is necessary to solve an optimization problem involving the solution of the PDE as a subroutine several times. In order to simulate this computationally intensive optimization algorithm, we took advantage of Florida International University’s Phosphorus, a 20-core Intel(R) Xeon(R) Silver 4114 CPU at 2.20 GHz server, and a Bayesian optimization algorithm intended to handle black box functions which are costly to evaluate. True values for the frequency of gyre oscillation ωdg and the amplitude of gyre motion μ are set to 0.25 and π/5 ≈ 0.6283, respectively. Considering only 10 episodes, the learned values for ωdg and μ were 0.2481 and 0.6344, respectively, with the smallest estimation error in episode 7. Learned parameters are summarized in Table 2 and Figure 6 shows the paths taken by the agent at different episodes while estimating the flow field. The agent follows the contaminant, but careful examination should be made at the gyre separation line once the agent could take an undesired action, resulting in feature mistracking. This behavior is illustrated when we compared paths in Figures 6A,B.
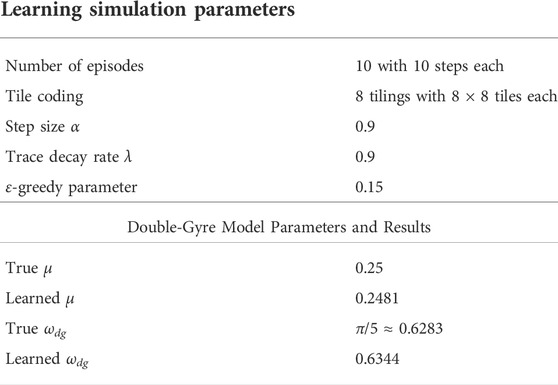
TABLE 2. Learning simulation parameters and results. True and learned double-gyre model parameters over 10 learning episodes.
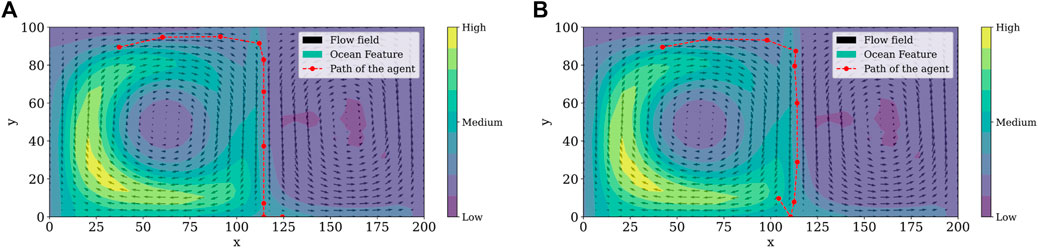
FIGURE 6. Path followed by the agent, double gyre field to estimate the parameters described in Table 2 at different episodes (A) episode 3, (B) episode 7.
6 Conclusion
In this work, we presented a novel method for estimating a spatio-temporal field using informative samples taken by a trained agent. This allowed estimating the distribution of the ocean feature, keeping track of its localization and distribution at each time. It was possible to address the problem of selecting meaning samples such that they help to perform the estimation of the field. Therefore, this develops a different perspective in estimation procedures, which has been addressed using other techniques having pre-defined models to show a priori which samples should be taken.
Moreover, we proposed combining the classical regularization methods used to estimate parameters in partial differential equations with the optimization processes used to carry out those estimates. We merged machine learning techniques, which are more flexible and capable of learning complex patterns from different sources, to choose the sample locations to keep track of and estimate the ocean feature field.
Future work
For future work, we consider the expansion of the proposed method for 3D environments. This can be accomplished by augmenting the vehicle model (state space, action space, observation space) and validating the proposed framework with deployments in aquatic environments such as in the Biscayne Bay area, Florida, United States. Besides that, it is possible to refine our estimation strategies with cooperative agents. A primary direction for future work is to incorporate a combination of heterogeneous agents in order to provide better estimates of the locations of the ocean feature. In this work, we assume known initial conditions for a given linear, constant flow field. A second direction for future work is to investigate how effective the proposed estimation framework is for time-varying flow fields and actual oceanic data from the Regional Ocean Modeling System (ROMS) Shchepetkin and McWilliams (2005). ROMS data set that provides current velocity prediction data consisting of three spatial dimensions (longitude, latitude, and depth) associated with time. Finally, tracking oceanic features, such as the Lagrangian coherent structures (LCS) contributes to a wide range of applications in ocean exploration Hsieh et al. (2012). Therefore, an additional direction of our work is to expand the current work towards an efficient method for LCS tracking using machine learning techniques.
Data availability statement
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
Author contributions
LB and RS contributed to the conception and design of the study. PP and JF performed simulation experiments and wrote the first draft of the manuscript. LB also wrote sections of the manuscript. All authors contributed to manuscript revision, read, and approved the submitted version.
Funding
This work is supported in part by the NSF grants IIS-2034123, IIS-2024733, and the U.S. Dept. Of Homeland Security grant 2017-ST-062000002.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Antman, S. S., Marsden, J. E., Sirovich, L., Hale, J. K., Holmes, P., Keener, J., et al. (2006). Inverse problems for partial differential equations. Second edn. Germany: Springer.
Bachmayer, R., Humphris, S., and Fornari, D. (1998). Oceanographic research using remotely operated underwater robotic vehicles: Exploration. Mar. Technol. Soc. J. 32, 37.
Barnett, D., McClaran, S., Nelson, E., and McDermott, M. (1996). “Architecture of the Texas A&M autonomous underwater vehicle controller,” in Proceedings of Symposium on Autonomous Underwater Vehicle Technology 231–237. doi:10.1109/AUV.1996.532420
Bird, L., Sherman, A., and Ryan, J. P. (2007). “Development of an active, large volume, discrete seawater sampler for autonomous underwater vehicles,” in Proc Oceans MTS/IEEE Conference (Vancouver, Canada), Vancouver, Canada, 04 October 2007. doi:10.1109/OCEANS.2007.4449303
Bishop, C. M. (1995). Training with noise is equivalent to tikhonov regularization. Neural Comput. 7, 108–116. doi:10.1162/neco.1995.7.1.108
Bourgeois, L., and Recoquillay, A. (2018). A mixed formulation of the tikhonov regularization and its application to inverse pde problems. ESAIM Math. Model. Numer. Analysis 52, 123–145. doi:10.1051/m2an/2018008
Carreras, M., Batlle, J., Ridao, P., and Roberts, G. (2000). “An overview on behaviour-based methods for AUV control,” in MCMC2000, 5th IFAC Conference.
Creed, E. L., Kerfoot, J., Mudgal, C., and Barrier, H. (2004). Transition of slocum electric gliders to a sustained operational system. OCEANS ’04: MTTS/IEEE TECHNO-OCEAN ’04 2, 828–833. doi:10.1109/OCEANS.2004.1405565
Creed, E. L., Mudgal, C., Glenn, S., Schofield, O., Jones, C., and Webb, D. C. (2002). Using a fleet of slocum battery gliders in a regional scale coastal ocean observatory. Biloxi, MI, USA: Oceans ’02 MTS/IEEE.
Cui, R., Yang, C., Li, Y., and Sharma, S. (2017). Adaptive neural network control of auvs with control input nonlinearities using reinforcement learning. IEEE Trans. Syst. Man. Cybern. Syst. 47, 1019–1029. doi:10.1109/tsmc.2016.2645699
Davis, R. E., Ohman, M., Rudnick, D., Sherman, J., and Hodges, B. (2008). Glider surveillance of physics and biology in the southern California current system. Limnol. Oceanogr. 53, 2151–2168. doi:10.4319/lo.2008.53.5_part_2.2151
Eriksen, C. C., Osse, T. J., Light, R. D., Wen, T., Lehman, T. W., Sabin, P. L., et al. (2001). Seaglider: A long-range autonomous underwater vehicle for oceanographic research. IEEE J. Ocean. Eng. 26, 424–436. doi:10.1109/48.972073
Farahmand, A.-m., Nabi, S., and Nikovski, D. N. (2017). “Deep reinforcement learning for partial differential equation control,” in American Control Conference (ACC), Seattle, WA, USA, 24-26 May 2017 (IEEE), 3120–3127.
Frank, J., and Jónsson, A. (2003). Constraint-based attribute and interval planning. Constraints 8, 339–364. doi:10.1023/a:1025842019552
Frazzoli, E., Daleh, M., and Feron, E. (2002). Real-time motion planning for agile autonomous vehicles. J. Guid. Control Dyn. 25 (1), 116–129. doi:10.2514/2.4856
Graver, J. (2005). Underwater gliders: Dynamics, control and design (Princeton, NJ: Princeton University). Ph.D. thesis.
Griffiths, G., Jones, C., Ferguson, J., and Bose, N. (2007). Undersea gliders. Feed. Heal. Humans 2, 64–75.
Han, J., Jentzen, A., and Weinan, E. (2018). Solving high-dimensional partial differential equations using deep learning. Proc. Natl. Acad. Sci. U. S. A. 115, 8505–8510. doi:10.1073/pnas.1718942115
Hsieh, M. A., Forgoston, E., Mather, T. W., and Schwartz, I. B. (2012). “Robotic manifold tracking of coherent structures in flows,” in IEEE International Conference on Robotics and Automation, Saint Paul, MN, USA, 14-18 May 2012 (IEEE), 4242–4247. doi:10.1109/ICRA.2012.6224769
Jamili, E., and Dua, V. (2021). Parameter estimation of partial differential equations using artificial neural network. Comput. Chem. Eng. 147, 107221. doi:10.1016/j.compchemeng.2020.107221
Johnson, K. S., and Needoba, J. A. (2008). Mapping the spatial variability of plankton metabolism using nitrate and oxygen sensors on an autonomous underwater vehicle. Limnol. Oceanogr. 53, 2237–2250. doi:10.4319/lo.2008.53.5_part_2.2237
Jones, C., Creed, E. L., Glenn, S., Kerfoot, J., Kohut, J., Mudgal, C., et al. (2005). “Slocum gliders - a component of operational oceanography,” in Autonomous undersea systems institute symposium proceedings.
Kincaid, D., Kincaid, D. R., and Cheney, E. W. (2009). Numerical analysis: Mathematics of scientific computing, vol. 2. Providence, Rhode Island: American Mathematical Soc.
Low, K. H., Dolan, J., and Khosla, P. (2009). “Information-theoretic approach to efficient adaptive path planning for mobile robotic environmental sensing,” in Proceedings of the 19th international conference on automated planning and scheduling (ICAPS-09). arXiv:1305.6129v1.
Martinsen, A. B., Lekkas, A. M., Gros, S., Glomsrud, J. A., and Pedersen, T. A. (2020). Reinforcement learning-based tracking control of usvs in varying operational conditions. Front. Robot. AI 7, 32. doi:10.3389/frobt.2020.00032
McGann, C., Py, F., Rajan, K., Ryan, J. P., and Henthorn, R. (2008a). “Adaptive control for autonomous underwater vehicles,” in AAAI, San Diego, California, USA, 09-12 October 1995 (Chicago, IL: AAAI). doi:10.1109/OCEANS.1995.528563
McGann, C., Py, F., Rajan, K., Thomas, H., Henthorn, R., and McEwen, R. (2008b). “A deliberative architecture for AUV control,” in ICRA (Pasadena, CA: ICRA). doi:10.1109/ROBOT.2008.4543343
McGann, C., Py, F., Rajan, K., Thomas, H., Henthorn, R., and McEwen, R. (2008c). “Preliminary results for model-based adaptive control of an autonomous underwater vehicle,” in Int. Symp. on Experimental Robotics, Athens, July 13-16, 2008 (Athens, Greece: DBLP).
Nair, M. T., and Roy, S. D. (2020). A new regularization method for a parameter identification problem in a non-linear partial differential equation, doi:10.22541/au.159138733.37659934
Ng, A. Y., Harada, D., and Russell, S. (1999). “Policy invariance under reward transformations: Theory and application to reward shaping,” in Proceedings of the Sixteenth International Conference on Machine Learning, June 1999 (Burlington, MA, USA: Morgan Kaufmann), 278–287.
Padrao, P., Dominguez, A., Bobadilla, L., and Smith, R. N. (2022). Towards learning ocean models for long-term navigation in dynamic environments. Chennai: OCEANS 2022, 1–8.
Paley, D. A., Zhang, F., and Leonard, N. E. (2008). Cooperative control for Ocean sampling: The glider coordinated control system. IEEE Trans. Control Syst. Technol. 16, 735–744. doi:10.1109/TCST.2007.912238
Provost, C. L., and Verron, J. (1987). Wind-driven ocean circulation transition to barotropic instability. Dyn. Atmos. Oceans 11, 175–201. doi:10.1016/0377-0265(87)90005-4
Richard, A., Brian, B., and Clifford, T. (2019). Parameter Estimation and inverse problems (candice janco). third edn.
Ridao, P., Yuh, J., Batlle, J., and Sugihara, K. (2000). On AUV control architecture. Kyoto, Japan: IEEE IROS.
Rosenblatt, J., Williams, S., and Durrant-Whyte, H. (2002). A behavior-based architecture for autonomous underwater exploration. Inf. Sci. (N. Y). 145, 69–87. doi:10.1016/s0020-0255(02)00224-4
D. L. Rudnick, and M. Perry (Editors) (2003). Alps: Autonomous and Lagrangian platforms and sensors. Workshop Report, 64. Available at: www.geo-prose.com/ALPS.
Shadden, S., Leigen, F., and Marsden, J. (2005). Definition and properties of Lagrangian coherent structures from finite-time lyapunov exponents in two-dimensional aperiodic flows. Phys. D. Nonlinear Phenom. 212, 271–304. doi:10.1016/j.physd.2005.10.007
Shchepetkin, A. F., and McWilliams, J. C. (2005). The regional oceanic modeling system (ROMS): A split-explicit, free-surface, topography-following-coordinate oceanic model. Ocean. Model.oxf. 9, 347–404. doi:10.1016/j.ocemod.2004.08.002
Shen, J., Medjo, T., and Wang, S. (1999). On a wind-driven, double-gyre, quasi-geostrophic ocean model: Numerical simulations and structural analysis. J. Comput. Phys. 155, 387–409. doi:10.1006/jcph.1999.6344
Sherman, J., Davis, R. E., Owens, W. B., and Valdes, J. (2001). The autonomous underwater glider ”Spray. IEEE J. Ocean. Eng. 26, 437–446. doi:10.1109/48.972076
Sherstov, A. A., and Stone, P. (2005). “Function approximation via tile coding: Automating parameter choice,” in Abstraction, reformulation and approximation. Editors J.-D. Zucker, and L. Saitta (New York: Springer Berlin Heidelberg), 194–205.
Singh, H., Yoerger, D., and Bradley, A. (1997). Issues in auv design and deployment for oceanographic research. Proc. 1997 IEEE Int. Conf. Robotics Automation 3, 1857–1862. doi:10.1109/ROBOT.1997.619058
Singh, S., Sutton, R., and Kaelbling, P. (1995). Reinforcement learning with replacing eligibility traces. Mach. Learn. 22, 123–158. doi:10.1023/A:1018012322525
Smith, R. N., Chao, Y., Li, P. P., Caron, D. A., Jones, B. H., and Sukhatme, G. S. (2010a). Planning and implementing trajectories for autonomous underwater vehicles to track evolving ocean processes based on predictions from a Regional Ocean model. Int. J. Rob. Res. 29, 1475–1497. doi:10.1177/0278364910377243
Smith, R. N., Das, J., Heidarsson, H., Pereira, A., Cetinić, I., Darjany, L., et al. (2010b). \{USC\} \{CINAPS\} builds bridges: Observing and monitoring the \{S\}outhern \{C\}alifornia \{B\}ight. IEEE Robot. Autom. Mag. 17, 20–30. doi:10.1109/mra.2010.935795
Smith, R. N., Das, J., Yi, C., Caron, D. A., Jones, B. H., and Sukhatme, G. S. (2010c). “Cooperative multi-AUV tracking of phytoplankton blooms based on ocean model predictions,” in MTS/IEEE oceans 2010 (Sydney, Australia: IEEE), 1–10.
Smith, R. N., Heckman, C., Sibley, G., and Hsieh, M. A. (2015). “A representative modeling approach to sampling dynamic ocean structures,” in Symposium on marine robotics - broadening horizons with inter-disciplinary science & engineering. A. Pascoal (horta, faial island, azores, Portugal). Editors K. Rajan, and J. Sousa.
Smith, R. N., Schwager, M., Smith, S. L., Jones, B. H., Rus, D., and Sukhatme, G. S. (2011). Persistent ocean monitoring with underwater gliders: Adapting sampling resolution. J. Field Robot. 28, 714–741. doi:10.1002/rob.20405
Sutton, R. S., and Barto, A. G. (2018). Reinforcement learning: An introduction. Cambridge: MIT press.
Turner, R. M., and Stevenson, R. A. G. (1991). Orca: An adaptive, context-sensitive reasoner for controlling AUVs. Proc 7th intnl symp. On unmanned untethered submersible tech. Umhlanga, South Africa: UUST.
Whitcomb, L., Yoerger, D., Singh, H., and Howland, J. (1999). “Advances in underwater robot vehicles for deep ocean exploration: Navigation, control, and survey operations,” in Proceedings of the ninth international symposium of robotics research (London: Springer-Verlag Publications).
Whitcomb, L., Yoerger, D., Singh, H., and Mindell, D. (1998). “Towards precision robotic maneuvering, survey, and manipulation in unstructured undersea environments,” in Robotics research - the eighth international symposium (London: Springer-Verlag Publications), 45–54.
Wolligandt, S., Wilde, T., Roessl, C., and Theisel, H. (2020). A modified double gyre with ground truth hyperbolic trajectories for flow visualization. Comput. Graph. Forum 40, 209–221. doi:10.1111/cgf.14183
Xun, X., Cao, J., Mallick, B., Carroll, R., and Maity, A. (2013). Parameter estimation of partial differential equation models. J. Am. Stat. Assoc. 108, 1009–1020. doi:10.1080/01621459.2013.794730
Yoerger, D., and Slotine, J. (1985). Robust trajectory control of underwater vehicles. IEEE J. Ocean. Eng. 10 (4), 462–470. doi:10.1109/joe.1985.1145131
Yoo, B., and Kim, J. (2016). Path optimization for marine vehicles in ocean currents using reinforcement learning. J. Mar. Sci. Technol. 21, 334–343. doi:10.1007/s00773-015-0355-9
Yuh, J. (2000). Design and control of autonomous underwater robots: A survey. Aut. Robots 8, 7–24. doi:10.1023/a:1008984701078
Keywords: spatio-temporal fields, reinforcement learning, partial differential equations, autonomous navigation, environmental monitoring
Citation: Padrao P, Fuentes J, Bobadilla L and Smith RN (2022) Estimating spatio-temporal fields through reinforcement learning. Front. Robot. AI 9:878246. doi: 10.3389/frobt.2022.878246
Received: 17 February 2022; Accepted: 01 August 2022;
Published: 05 September 2022.
Edited by:
Kostas Alexis, Norwegian University of Science and Technology, NorwayReviewed by:
Elias B. Kosmatopoulos, Democritus University of Thrace, GreeceCaoyang Yu, Shanghai Jiao Tong University, China
Copyright © 2022 Padrao, Fuentes, Bobadilla and Smith. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Leonardo Bobadilla, Ym9iYWRpbGxhQGNzLmZpdS5lZHU=
†These authors have contributed equally to this work and share first authorship