
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Robot. AI, 11 April 2022
Sec. Biomedical Robotics
Volume 9 - 2022 | https://doi.org/10.3389/frobt.2022.832208
This article is part of the Research TopicHot Topic: Reducing Operating Times and Complication Rates Through Robot-Assisted SurgeryView all 6 articles
 Caspar Gruijthuijsen1†
Caspar Gruijthuijsen1† Luis C. Garcia-Peraza-Herrera2,3*†
Luis C. Garcia-Peraza-Herrera2,3*† Gianni Borghesan1,4
Gianni Borghesan1,4 Dominiek Reynaerts1
Dominiek Reynaerts1 Jan Deprest5
Jan Deprest5 Sebastien Ourselin3
Sebastien Ourselin3 Tom Vercauteren3
Tom Vercauteren3 Emmanuel Vander Poorten1
Emmanuel Vander Poorten1Many keyhole interventions rely on bi-manual handling of surgical instruments, forcing the main surgeon to rely on a second surgeon to act as a camera assistant. In addition to the burden of excessively involving surgical staff, this may lead to reduced image stability, increased task completion time and sometimes errors due to the monotony of the task. Robotic endoscope holders, controlled by a set of basic instructions, have been proposed as an alternative, but their unnatural handling may increase the cognitive load of the (solo) surgeon, which hinders their clinical acceptance. More seamless integration in the surgical workflow would be achieved if robotic endoscope holders collaborated with the operating surgeon via semantically rich instructions that closely resemble instructions that would otherwise be issued to a human camera assistant, such as “focus on my right-hand instrument.” As a proof of concept, this paper presents a novel system that paves the way towards a synergistic interaction between surgeons and robotic endoscope holders. The proposed platform allows the surgeon to perform a bimanual coordination and navigation task, while a robotic arm autonomously performs the endoscope positioning tasks. Within our system, we propose a novel tooltip localization method based on surgical tool segmentation and a novel visual servoing approach that ensures smooth and appropriate motion of the endoscope camera. We validate our vision pipeline and run a user study of this system. The clinical relevance of the study is ensured through the use of a laparoscopic exercise validated by the European Academy of Gynaecological Surgery which involves bi-manual coordination and navigation. Successful application of our proposed system provides a promising starting point towards broader clinical adoption of robotic endoscope holders.
In recent years, many surgical procedures shifted from open surgery to minimally invasive surgery (MIS). Although MIS offers excellent advantages for the patient, including reduced scarring and faster recovery, it comes with challenges for the surgical team. Most notable is the loss of direct view onto the surgical site. In keyhole surgery, the surgeon manipulates long and slender instruments introduced into the patient through small incisions or keyholes. The surgeon relies on endoscopes, also long and slender instruments equipped with a camera and light source, to obtain visual feedback on the scene and the relative pose of the other instruments. The limited field of view (FoV) and depth of field of the endoscope urge an efficient endoscope manipulation method that allows covering all the important features and hereto optimizes the view at all times.
In typical MIS, surgeons cannot manipulate the endoscope themselves as their hands are occupied with other instruments. Therefore, a camera assistant, typically another surgeon takes charge of handling the endoscope. Human camera assistants have a number of shortcomings. An important drawback relates to the cost of the human camera assistant (Stott et al., 2017). Arguably, highly trained clinicians could better be assigned to other surgical duties that require the full extent of their skill set (as opposed to mainly manipulating the endoscope). If made widely feasible, solo MIS surgery would improve cost-effectiveness and staffing efficiency. An additional source of weakness related to human camera assistants is the ergonomic burden associated with assisting in MIS (Wauben et al., 2006; Lee et al., 2009). This may lead to reduced image stability, fatigue, distractions, increased task completion times, and erroneous involuntary movements (Goodell et al., 2006; Platte et al., 2019; Rodrigues Armijo et al., 2020). This problem aggravates for long interventions or when the assistant has to adopt particularly uncomfortable postures. Besides the ergonomic challenges, miscommunication between the surgeon and the assistant may lead to sub-optimal views (Amin et al., 2020).
In order to help or bypass the human camera assistant and to optimize image stability, numerous endoscope holders have been designed in the past (Jaspers et al., 2004; Bihlmaier, 2016; Takahashi, 2020). One can distinguish passive endoscope holders and active or robotic endoscope holders. Passive endoscope holders are mechanical devices that lock the endoscope in a given position until manually unlocked and adjusted. A problem common to passive endoscope holders is that they result in an intermittent operation that interferes with the manipulation task (Jaspers et al., 2004). When surgeons want to adjust the endoscopic view themselves, they will have to free one or both hands to reposition the endoscope. To counter this problem, robotic endoscope holders have been developed. These motorized devices offer the surgeon a dedicated interface to control the endoscope pose. Well-designed robotic endoscope holders do not cause additional fatigue, improve image stability, and increase ergonomics (Fujii et al., 2018). Also, hand-eye coordination issues may be avoided. Overall such robotic endoscope holders may lower the cognitive load of the surgeon and reduce operating room (OR) staff time and intervention cost (Ali et al., 2018). However, despite these advantages and the number of systems available, robotic endoscope holders have not found widespread clinical acceptance (Bihlmaier, 2016). This has been linked to the suboptimal nature of the human interface and consequently the discomfort caused to the surgeon by the increased cognitive load needed to control the camera. Popular robotic endoscope holders use foot pedals, joysticks, voice control, gaze control, and head movements (Kommu et al., 2007; Holländer et al., 2014; Fujii et al., 2018). The context switching between surgical manipulation and these camera control mechanisms seems to hinder the ability of the surgeon to concentrate on the main surgical task (Bihlmaier, 2016).
In this work, we introduce the framework of semantically rich endoscope control, which is our proposal on how robotic endoscope control could be implemented to mitigate interruptions and maximize the clinical acceptance of robotic endoscope holders. We claim that semantically rich instructions that relate to the instruments such as “focus on the right/left instrument” and “focus on a point between the instruments” are a priority, as they are shared among a large number of surgical procedures. Therefore, we present a novel system that paves the way towards a synergistic interaction between surgeons and robotic endoscope holders. To the best of our knowledge, we are the first to report how to construct an autonomous instrument tracking system that allows for solo-surgery using only the endoscope as a sensor to track the surgical tools. The proposed platform allows the surgeon to perform a bi-manual coordination and navigation tasks while the robotic arm autonomously performs the endoscope positioning.
Within our proposed platform, we introduce a novel tooltip localization method based on a hybrid mixture of deep learning and classical computer vision. In contrast to other tool localization methods in the literature, the proposed approach does not require manual annotations of the tooltips, but relies on tool segmentation, which is advantageous as the manual annotation effort could be trivially waived employing methods such as that recently proposed in Garcia-Peraza-Herrera et al. (2021). This vision pipeline was individually validated and the proposed tooltip localization method was able to detect tips in 84.46% of the frames. This performance proved sufficient to allow for a successful autonomous guidance of the endoscope (per user study of the whole robotic system).
We propose a novel visual servoing method for a generalized endoscope model with support for both remote center of motion and endoscope bending. We show that a hybrid of position-based visual servoing (PBVS) and 3D image-based visual-servoing (IBVS) is preferred for robotic endoscope control.
We run a user study of the whole robotic system on a standardized bi-manual coordination and navigation laparoscopic task accredited for surgical training (European Academy of Gynaecological Surgery, 2020). In this study we show that the combination of novel tool localization and visual servoing proposed is robust enough to allow for the successful autonomous control of the endoscope. During the user study experiments (eight people, five trials), participants were able to complete the bi-manual coordination surgical task without the aid of a camera assistant and in a reasonable time (172s on average).
While solo surgery has been demonstrated with simple robotic endoscope control approaches (Takahashi, 2020), we argue that to overcome the usability issues that impede broad clinical adoption of robotic endoscope holders and move towards solo surgery, robotic endoscope control should be performed at the task autonomy level. To efficiently operate in this setting, a robotic endoscope holder should accept a set of semantically rich instructions. These instructions correspond to the commands that a surgeon would normally issue to a human camera assistant. This contrasts with earlier approaches, where the very limited instruction sets (up, down, left, right, zoom in, zoom out) lead to a semantic gap between the robotic endoscopic holder and the surgeon (Kunze et al., 2011). With semantically rich instructions, it would be possible to bridge this gap and restore the familiar relationship between the surgeon and the (now tireless and precise) camera assistant.
A semantically rich instruction set should contain commands that induce context-aware actions. Examples of such are “zoom in on the last suture,” “hold the camera stationary above the liver,” and “focus the camera on my right instrument.” When these instructions are autonomously executed by a robotic endoscope holder, we refer to the control as semantically rich robotic endoscope control. We believe that semantically rich robotic endoscope control can effectively overcome the problem of intermittent operation with endoscopic holders, does not disrupt the established surgical workflow, ensures minimal overhead for the surgeon, and overall maximizes the usability and efficiency of the intervention.
Although instructions that have the camera track an anatomical feature are relevant, autonomous instrument tracking instructions (e.g. “focus the camera between the instruments”) play a prominent role, as they are common to a large number of laparoscopic procedures and form a fundamental step towards solo surgery. Therefore, in this work we focus on semantically rich instructions related to the autonomous instrument tracking (AIT) of a maximum of two endoscopic instruments (one per hand of the operating surgeon, see Figure 1). Particularly, the proposed method implements the instructions “focus on the right/left instrument” and “focus on a point between the instruments.” User interface methods to translate requests expressed by the surgeon (e.g. voice control) to these AIT instructions fall outside the scope of this work.

FIGURE 1. Proposed experimental setup for autonomous endoscope control in a laparoscopic setting. The LASTT model (European Academy of Gynaecological Surgery, 2020) showcased within the box trainer is designed for the simulation of simple surgical tasks with a focus on gynaecological procedures. It is common ground for the practice and evaluation of hand-eye and bi-manual coordination skills.
The remainder of the paper is organized as follows. After describing the related work, the AIT problem is stated in Section 3. The quality of the AIT depends on robust methods to localize one or more surgical instruments in the endoscopic view. Section 4 describes a novel image-processing pipeline that was developed to tackle this problem. Visual servoing methods are described in Section 5. These methods provide the robotic endoscope control with the ability to track the detected instruments autonomously. An experimental user study campaign is set up and described in Section 6 to demonstrate the value of AIT in a validated surgical training task. Section 7 discusses the obtained results and Section 8 draws conclusions regarding the implementation of the AIT instructions proposed in this work.
Robotic endoscope control (REC) allows the surgeon to control the endoscope without having to free their hands. A wide variety of dedicated control interfaces have been developed and commercialized for this purpose, including joystick control, voice control, gaze control and head gesture control (Taniguchi et al., 2010). Despite the apparent differences in these interfaces, established approaches offer the surgeon a basic instruction set to control the endoscope. This set typically consists of six instructions: zoom in/out, move up/down, and move left/right. The basic nature of these instructions makes detailed positioning cumbersome, usually resorting to a lengthy list of instructions. This shifts the surgeon’s focus from handling the surgical instruments towards the positioning of the endoscope, as concurrent execution of those actions is often strenuous and confusing (Jaspers et al., 2004). Moreover, the increased mental workload stemming from simultaneous control of the instruments and the endoscope might adversely affect intervention outcomes (Bihlmaier, 2016). Similar to passive endoscope holders, robotic endoscope holders that offer a basic set of instructions prevent fluid operation and lead to intermittent action.
A number of REC approaches that pursue fully autonomous operation have been proposed as well. A starting point for an autonomous REC strategy is to reposition the endoscope so as to keep the surgical instrument tip centered in the view. Such an approach could work already when only the 2D position of the instrument in the endoscopic image is available (Uecker et al., 1995; Osa et al., 2010; Agustinos et al., 2014; Zinchenko and Song, 2021). In this case, the endoscope zoom level (depth) is left uncontrolled. Some of these methods also require a 3D geometrical instrument model (Agustinos et al., 2014), limiting the flexibility of the system. Approaches such as proposed by Zinchenko and Song (2021) have also suggested to replace the endoscope screen with a head-mounted virtual reality device that facilitates the estimation of the surgeon’s attention focus from the headset’s gyroscope. In this scenario, the autonomous REC strategy aims to reposition the endoscope with the aim of maintaining the weighted center of mass between the instruments’ contour centers and the point of focus in the center of the view. However, it has been shown in works such as (Hanna et al., 1997; Nishikawa et al., 2008) that the zoom level is important for effective endoscope positioning. Other authors tried to circumvent the lack of depth information in 2D endoscopic images by relating the inter-instrument distance to the zoom level (Song et al., 2012; King et al., 2013). This approach is obviously limited to situations where at least two instruments are visible.
When the 3D instrument tip position is available, smarter autonomous REC strategies are possible. In the context of fully robotic surgery, kinematic-based tooltip position information has been used to provide autonomously guided ultrasound imaging with corresponding augmented reality display for the surgeon (Samei et al., 2020). Kinematics have also been employed by Mariani and Da Col et al.(Mariani et al., 2020; Da Col et al., 2021) for autonomous endoscope guidance in a user study on ex vivo bladder reconstruction with the da Vinci Surgical System. In their experimental setup, the system could track either a single instrument or the midpoint between two tools. Similarly, Avellino et al. (2020) have also employed kinematics for autonomous endoscope guidance in a co-manipulation scenario1. In (Casals et al., 1996; Mudunuri, 2010), rule-based strategies switch the control mode between single-instrument tracking or tracking points that aggregate locations of all visible instruments. Pandya et al. argued that such schemes are reactive and that better results can be obtained with predictive schemes, which incorporate knowledge of the surgery and the surgical phase (Pandya et al., 2014). Examples of such knowledge-based methods are (Wang et al., 1998; Kwon et al., 2008; Weede et al., 2011; Rivas-Blanco et al., 2014; Bihlmaier, 2016; Wagner et al., 2021). While promising in theory, in practice, the effort to create complete and reliable models for an entire surgery is excessive for current surgical data science systems. In addition, accurate and highly robust surgical phase recognition algorithms are required, increasing the complexity of this solution considerably.
With regards to the levels of autonomy in robotic surgery, Yang et al. (2017) have recently highlighted that the above strategies aim for very high autonomy levels but take no advantage of the surgeon’s presence. In essence, the surgeon is left with an empty instruction set to direct the endoscope holder. Besides being hard to implement given the current state of the art, such high autonomy levels may be impractical and hard to transfer to clinical practice. Effectively, an ideal camera assistant only functions at the task autonomy level. This is also in line with the recent study by Col et al. (2020), who concluded that it is important for endoscope control tasks to find the right trade-off between user control and autonomy.
To facilitate the autonomous endoscope guidance for laparoscopic applications when the 3D instrument tip position is not available, some authors have proposed to attach different types of markers to the instruments (e.g. optical, electromagnetic). This modification often comes with extra sensing equipment that needs to be added to the operating room.
In Song and Chen (2012), authors proposed to use a monocular webcam mounted on a robotic pan-tilt platform to track two laparoscopic instruments with two colored rings attached to each instrument. They employed the estimated 2D image coordinates of the fiducial markers to control all the degrees of freedom of the robotic platform. However, this image-based visual servoing is not able to attain a desired constant depth to the target tissue (as also shown in our simulation of image-based visual servoing in Section 5.3). In addition, the choice of fiducial markers is also an issue. Over the years, going back at least as far as to (Uenohara and Kanade, 1995), many types of markers have been proposed by the community for tool tracking purposes. For example, straight lines (Casals et al., 1996), black stripes (Zhang and Payandeh, 2002), cyan rings (Tonet et al., 2007), green stripes (Reiter et al., 2011), multiple colour rings for multiple instruments (blue-orange, blue-yellow) (Seong-Young et al., 2005), and multiple colour (red, yellow, cyan and green) bio-compatible markers (Bouarfa et al., 2012). However, although fiducial markers such as colored rings ease the tracking of surgical instruments, attaching or coating surgical instruments with fiducial markers presents serious sterilization, legal and installation challenges (Stoyanov, 2012; Bouget et al., 2017). First, the vision system requires specific tools to work or a modification of the current ones, which introduces a challenge for clinical translation. At the same time, computational methods designed to work with fiducials cannot easily be trained with standard previously recorded interventions. Additionally, to be used in human experiments, the markers need to be robust to the sterilisation process (e.g. autoclave). This poses a manufacturing challenge and increases the cost of the instruments. The positioning of the markers is also challenging. If they are too close to the tip, they might be occluded by the tissue being manipulated. If they are placed back in the shaft, they might be hidden to the camera, as surgeons tend to place the endoscope close to the operating point. Even if they are optimally positioned, fiducials may be easily covered by blood, smoke, or pieces of tissue. In addition to occlusions, illumination (reflections, shadows) and viewpoint changes still remain a challenge for the detection of the fiducial markers.
In contrast to using colored markers, Sandoval et al. (2021) used a motion capture system (MoCap) in the operating room to help the autonomous instrument tracking. The MoCap consisted of an exteroceptive sensor composed of eight high resolution infrared cameras. This system was able to provide the position of the reflective markers placed at the instruments (four markers per instrument) in real time. However, the MoCap increases considerably the cost of the proposed system and complicates the surgical workflow. Instruments need to be modified to add the markers, and the MoCap needs to be installed in the operating room. As any other optical tracking system, it also possesses the risk of occlusions in the line of sight, making it impossible for the system to track the instruments when such occlusions occur. As opposed to all these different markers, the endoscope is necessary to perform the surgery, and the surgeon needs to be able to see the instruments to carry out the intervention, so using the endoscope and its video frames without any instrument modifications to help track the tools is a solution that stems naturally from the existing surgical workflow. This has also been the path followed in the devise of AutoLap™ (Medical Surgery Technologies, Yokneam, Israel) (Wijsman et al., 2018, 2022), which is, to the best of our knowledge, the only robotic laparoscopic camera holder that claims to have incorporated image-based laparoscopic camera steering within its features. However, no technical details are provided in these publications on how it is achieved.
In a typical surgical scenario, a surgeon manipulates two instruments: one in the dominant and one in the non-dominant hand. In such a case, the surgeon might want to focus the camera on one specific instrument, or center the view on a point in between the instruments, depending on their relative importance. AIT strives to automate these tasks, as explained next.
With one instrument present, the proposed AIT objective is to center the instrument tip position s in the FoV, as is illustrated in Figure 2 (top). With two visible instruments, a relative dominance factor wd ∈ [0, 1] can be assigned to the instruments (adjustable via a semantically rich instruction “change dominance factor X% to the right/left”). The AIT controller can then track the virtual average tip position according to
Where sl and sr are the respective tip positions of the left and right instrument as visualized in Figure 2, bottom.
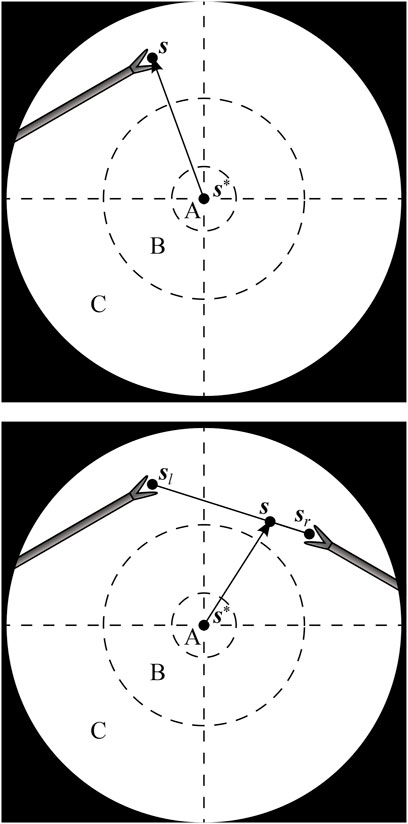
FIGURE 2. Endoscopic view with one instrument tip at position s (top), and two instrument tips at positions sl and sr, combined to a virtual tip position s (bottom). The AIT controller aims to make s coincide with a desired position s*. A, B and C are respectively the target, transition and violation zones of a programmed position hysteresis approach.
If the AIT were implemented to continuously track the virtual tip position s, the view would never come to a standstill, which would be disturbing for the surgeon. As a solution, also suggested in (Bihlmaier, 2016) and Eslamian et al. (2020), a position hysteresis behaviour can be implemented. In this work, a combination of instructions with position hysteresis is implemented based on three zones in the endoscope FoV. As illustrated in Figure 2, target zone A captures the ideal location of the tooltip, and transition zone B represents a tolerated region. Entering a violation zone C triggers re-positioning of the endoscope. Whenever s moves from zone B to zone C, the AIT will be activated. It will then stay active until s reaches zone A. Afterwards, the FoV will be kept stable, until s again crosses the border between zone B and zone C.
This implementation of AIT offers the surgeon instructions to track either instrument, to change the dominance factor, or to stop the tracking by disabling the AIT. Note that this implementation of AIT only specifies two degrees of freedom (DoFs) out of the four available DoFs in typical laparoscopy. The depth DoF is controlled by an additional instruction for the zoom level, i.e., the distance between the camera and the instrument tip. The DoF that rolls the endoscope around its viewing axis is controlled to always enforce an intuitive horizontal orientation of the camera horizon. If desired, a semantically rich instruction could be added to alter this behaviour.
As neither the set of AIT instructions nor any other set of instructions can realistically cover all instructions relevant for semantically rich REC, situations can arise in surgical practice where the capabilities of the robotic endoscope holder are insufficient. In such a case, it is necessary to switch to a comanipulation mode. This kind of switching is already the clinical reality for commercial robotic endoscope holders (Gillen et al., 2014; Holländer et al., 2014) and is particularly relevant when the system is used to support rather than replace the surgical assistant.
This work proposes to embed an easy switching functionality as a system feature. A natural transition from REC to comanipulation mode can be made possible through the use of a mechanically backdrivable robotic endoscope holder. This way, no extra hardware components are needed for switching, neither is it necessary to release the endoscope from the robotic endoscope holder. Instead, the surgeon can simply release one instrument, grab the endoscope and comanipulate it jointly with the robotic endoscope holder. During comanipulation, the human provides the intelligence behind the endoscope motions, while still experiencing support in the form of tremor-eliminating damping and fatigue-reducing gravity compensation. Such an approach broadens the scope of interventions where REC can be realistically applied.
REC based on semantically rich instructions requires the robotic endoscope holder to autonomously execute context-aware tasks. This implies a need to autonomously collect contextual information. The AIT instruction relies on knowledge of the tip position s of the surgical instruments in the endoscopic view. To obtain this information, without the need to alter the employed instruments or surgical workflow, a markerless instrument localization pipeline is developed in this section. Note that the term localization is employed here, instead of the commonly used term tracking, as for the sake of clarity this work reserves tracking for the robotic servoing approaches needed for AIT.
If, in addition to the endoscope, the instruments are also mounted on a robotic system (Weede et al., 2011; Eslamian et al., 2016) or if they are monitored by an external measurement system (Nishikawa et al., 2008; Polski et al., 2009), the position of the instruments can be directly obtained, provided that all involved systems are correctly registered and calibrated. However, in this work, manual handling of off-the-shelf laparoscopic instruments precludes access to such external localization information.
An alternative, which we use in this work, is to exploit the endoscope itself as the sensor. A review on this topic has been published relatively recently by Bouget et al. (2017). In their work Bouget et al. present a comprehensive survey of the last years of research in tool detection and tracking with a particular focus on methods proposed prior to the advent of the deep learning approaches. Recent instrument localization techniques based on Convolutional Neural Networks (CNN) (González et al., 2020; Pakhomov et al., 2020) are currently recognized as the state-of-the-art approaches (Allan et al., 2019; Roß et al., 2021) for such problems. In this work, we leverage our previous experience with CNN-based real-time tool segmentation networks (García-Peraza-Herrera et al., 2016; Garcia-Peraza-Herrera et al., 2017) and embed the segmentation in a stereo pipeline to estimate the location of the tooltips in 3D.
A multi-step image processing pipeline was developed for markerless image-based instrument localization (see Figure 3). As input, the pipeline takes the raw images from a stereo endoscope. As output, it provides the 3D tip positions of the visible instruments. The maximum number of instruments and tips per instrument are required as inputs. In the task performed in our user study, presented in Section 6), a maximum of two instruments with two tips may be present.
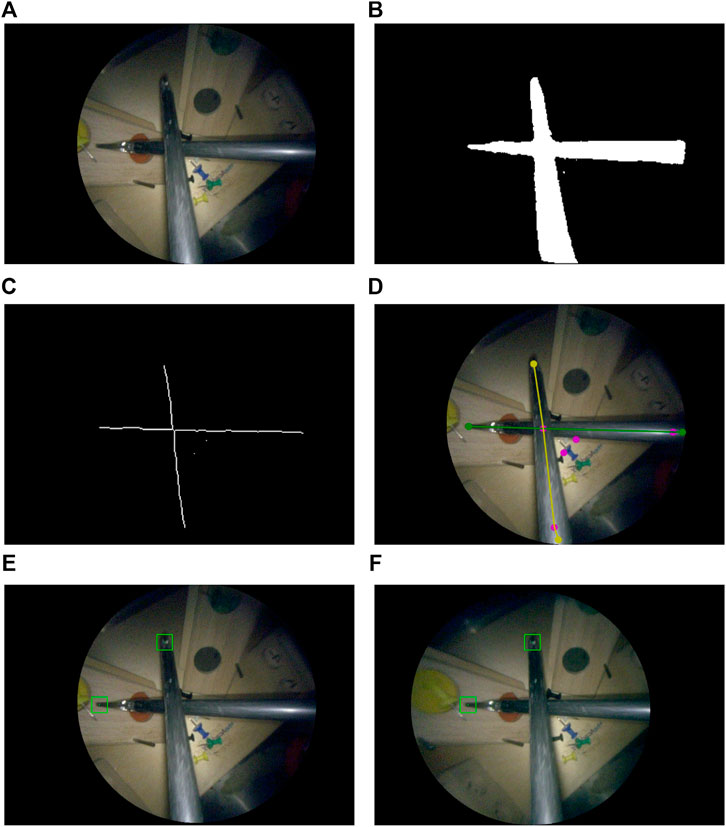
FIGURE 3. Instrument localization pipeline: (A) stereo-rectified right camera input image; (B) predicted tool segmentation; (C) skeletonisation; (D) graph extraction, 2D detection of entrypoints and tips, right and left instrument labelled in green and yellow; (E) left and (F) right stereo-matched tooltips in 2D (bottom row). The pink dots in (D) are graph nodes extracted from the skeleton in (C) but represent neither entrypoints nor tooltips.
The 2D tooltip localization in image coordinates is a key intermediate step in this pipeline. Training a supervised bounding box detector for the tips could be a possible approach to perform the detection. However, to implement the semantically rich AIT presented in Section 3 and Figure 2 we would still need to know whether the detected tips belong to the same or different instruments, and more precisely whether they belong to the instrument handled by the dominant or non-dominant hand. Therefore, we opted for estimating the more informative tool-background semantic segmentation instead. Via processing the segmentation prediction, we estimate how many instruments are in the image, localize the tips, and associate each tip with either the left or right-hand instrument. A downside of using semantic segmentation in comparison to a detector is the increased annotation time required to build a suitable training set. However, recent advances to reduce the number of contour annotations needed to achieve the segmentation such as (Vardazaryan et al., 2018; Fuentes-Hurtado et al., 2019; Garcia-Peraza-Herrera et al., 2021) greatly mitigate this drawback.
In the remaining of this section we first discuss the assumptions made, imaging hardware, and preprocessing steps. Then, we proceed to describe the localization pipeline. The localization method consists of the following steps: binary tool-background segmentation (Section 4.2.3), skeletonization of the segmentation mask (Section 4.2.4), graph extraction from the pixel-wide skeleton (Section 4.2.4), entrynode detection on the graph (Section 4.2.5), leaf node detection on the graph (Section 4.2.6), leaf node to entry node matching (Section 4.2.6), and left/right instrument identification (Section 4.2.8). After matching leaf nodes to entry nodes we have a subgraph for each instrument, and we distinguish between the left/right instrument using the estimated location of each instrument’s entry node (Section 4.2.8).
The implementation of the whole localization pipeline was done in Python, reading the video feed from the framegrabber V4L2 device with OpenCV, and performing the deep learning inference with Caffe (Jia et al., 2014) on an NVIDIA GeForce GTX Titan X GPU.
In our instrument localization pipeline, we assume that the instruments are not completely occluded. Partial occlusions are supported, as long as there is a visible path from the entrypoint to the tip of the instrument. Note that with entrypoint we refer to the point located at the edge of the endoscopic content area where the instrument enters the image. This point is not to be confused with the incision point which is the point on the body wall where the incision is made through which the instrument enters the patient’s body. Now, if the tip is occluded, the tooltip will be estimated on the furthermost point of the shaft. When the entrypoint is completely covered, the instrument will not be detected in the current approach. Methods that exploit knowledge of the incision point could help in such a case (and could be explored in future work as they do not form the core of this work). The current limitations are illustrated in Figure 4. The assumption that instruments have to enter from the edge serves two purposes, 1) as a noise reduction technique for the segmentation, because false positive islands of pixels can be easily discarded, and 2) to detect whether the instrument is held by the right/left hand of the surgeon (as explained in Section 4.2.8). In most cases, the entrypoint of at least one of the instruments will be visible. Therefore, the benefits of the assumption that instruments will not be completely occluded largely outweigh its limitations. The proposal of surgical tool segmentation models that are robust to entrypoint occlusions (Figure 4, right) or complete occlusions is out of the scope of this work.

FIGURE 4. Behaviour and limitations of the instrument localization pipeline in the presence of occlusions. The detected entrypoint and tooltip are indicated by the green and yellow arrow, respectively. In the partially occluded instrument (left), there is a visible path from entrypoint to tip, therefore the instrument is correctly detected. However, when the tip is occluded (center), the tooltip is detected to be on the shaft. If the entrypoint is occluded (right), the instrument is not detected in this stage of the research as tools are expected to enter the scene from the boundary of the content area.
The stereo camera and endoscopy module of choice for this work were the Tipcam1 S 3D ORL (30° view on a 4 mm outer diameter shaft) and Image1 S D3-LINK respectively (both from Karl Storz, Germany). The DVI output of the endoscopy module is plugged into a DVI2PCIe Duo framegrabber (Epiphan, Canada). The endoscopy module produces images at 60 fps and at a resolution of 1920, ×, 1080 pixels, which turns into 1920, ×, 540 as each grabbed image contains a stereo pair with the left frame on even rows and the right frame on odd ones. These images are upsampled in the y-axis so that two images of 1920, ×, 1080 pixels are obtained. Upscaling is chosen (as opposed to downsampling to 960, ×, 540 pixels) to avoid degrading the depth resolution based on x-axis disparity. The left-right cameras are calibrated using a chessboard pattern of 1.1 mm-wide squares (Cognex Glass Calibration Plate Set 320-0015R, Applied Image Inc., NY, United States). Both frames, left and right, are rectified in real-time. Then, the black background of the images is cropped out, keeping just a square crop of the endoscopic circle content area (as shown in Figure 2), which results in an image of 495 × 495 pixels. Finally, the image where the 2D tooltip localization is going to be performed (either the left or right frame can be chosen without loss of generality) is downsampled to 256 × 256 pixels to speed up the subsequent processing steps (i.e. segmentation, graph extraction and 2D tooltip localization). Once the 2D tooltips have been estimated, they are extrapolated to the original image size and the disparity estimation and 3D tooltip reconstruction in Section 4.2.9 is performed on the original upsampled images of 1920, ×, 1080 pixels.
In this work, we trained a CNN to segment instruments in our experimental setup (see Figure 1). While having the necessary characteristics for a bimanual laparoscopic task, the visual appearance of the surgical training model we use is not representative of a real clinical environment. Therefore, we do not propose a new image segmentation approach but rather focus on the downstream computational questions. In order to translate our pipeline to the clinic, a newly annotated dataset containing real clinical images would need to be curated, and the images would need to contain artifacts typical of endoscopic procedures such as blood, partial occlusions, smoke, and blurring. Alternatively, an existing surgical dataset could be used. We have compiled a list of public datasets for tool segmentation2 where the data available includes surgical scenes such as retinal microsurgery, laparoscopic adrenalectomy, pancreatic resection, neurosurgery, colorectal surgery, nephrectomy, proctocolectomy, and cholecystectomy amongst others. The compiled list also includes datasets for similar endoscopic tasks such as tool presence, instrument classification, tool-tissue action detection, skill assessment and workflow recognition, and laparoscopic image-to-image translation. The unlabelled data in these other datasets could also be potentially helpful for tool segmentation.
Next, we provide the details on how we built the segmentation model for our particular proof-of-concept of the robotic endoscope control. The dataset we curated consists of 1110 image-annotation pairs used for training, and 70 image-annotation pairs employed for validation (hyperparameter tuning). These 1110, + ,70 image-annotation pairs were manually selected by the first co-authors so that the chosen images represent well the variety of scenes in the task. They have been extracted from the recording of a surgical exercise in the lab, prior to the user study, and in a different location. There is no testing set at this point because the segmentation is an intermediary step. In Section 7.1, we give more details about our testing set, which is used to evaluate the whole tooltip localization pipeline (as opposed to just the segmentation). The images in each stereo pair do not look the same: there is an observable difference in colour tones between them. Therefore, the data set has an even number of left and right frames such that either of them could be used as input for the surgical tool segmentation. In the training set, 470 images (42%) do not contain any tool. In them, the endoscope just observes the task setting under different viewpoints and lighting conditions (diverse intensities of the light source). The remaining 640 images of the training set, and all images of the validation set, have been manually labelled with delineations of the laparoscopic tools. The U-Net (Ronneberger et al., 2015) architecture showed superior performance in the tool segmentation EndoVis MICCAI challenge (Allan et al., 2019). Therefore, this was the architecture of choice employed for segmentation (32 neurons in the first layer and convolutional blocks composed of Conv + ReLU + BN). A minibatch of four images is used. Default conventional values and common practice was followed for setting the hyperparameters as detailled hereafter. The batch normalization (Ioffe and Szegedy, 2015) momentum was set to 0.1 (default value in PyTorch). Following the U-Net implementation in (Ronneberger et al., 2015), Dropout (Srivastava et al., 2014) was used. In our implementation, Dropout was employed in layers with
Where P is the number of pixels, K = 2 is the number of classes (instrument and background),
Once we have obtained a segmentation prediction from the trained convolutional model, we proceed to convert the segmentation into a graph, which is a stepping stone towards the tooltip detection.
The instrument segmentation prediction is skeletonized via medial surface axis thinning (Lee et al., 1994). The resulting skeleton is converted via the Image-Py skeleton network framework (Xiaolong, 2019) into a pixel skeleton graph G = (V, E) (see Figure 5E), where V is a set of vertices and
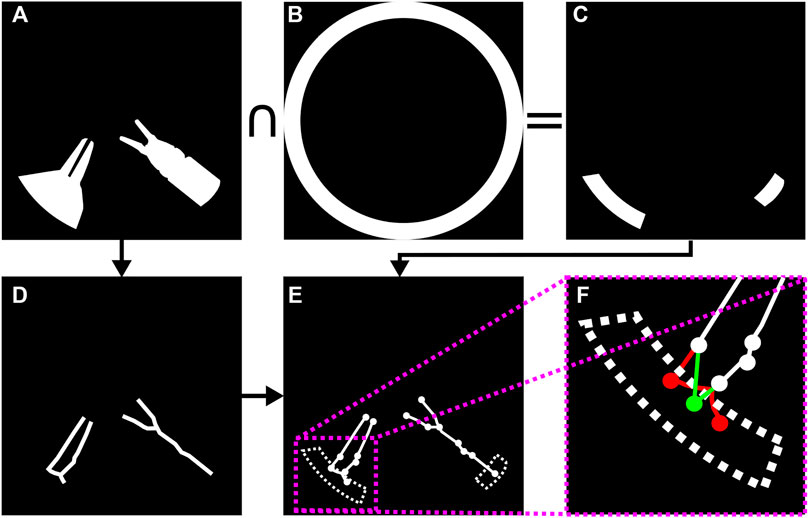
FIGURE 5. Surgical instrument graph construction and entry node extraction: (A) segmentation mask; (B) circle mask used to detect entrypoints; (C) intersection of segmentation mask and circle mask; (D) segmentation mask skeleton obtained according to (Lee et al., 1994); (E) graph obtained from skeleton by means of (Xiaolong, 2019); (F) entrypoint detection. If several graph nodes lie inside the entrypoint mask (in red), they are merged into a new single entry node (in green) whose position attribute is set to the centroid of all the graph nodes inside the dotted area.
As the size of the image is known, a circular segmentation mask (see Figure 5B) is used to detect the graph nodes that could potentially correspond to instrument entrypoints. That is, given G, we populate a set R containing those graph nodes that represent tool entrypoints into the endoscopic image. Those graph nodes contained within the intersection of the circle mask and the tool segmentation mask are collapsed into a single new entry node vc = (n, pc) per instrument, where pc = {xc, yc} is set to the centroid of all nodes captured within the aforementioned intersection. See Figures 5B–F for an example of entry node extraction.
A depth-first search is launched from each entry node to determine all the graph nodes that can be reached from entry nodes. Those that cannot be reached are pruned from the graph.
Let L = {v ∈ V : dG(v) = 1 ∧ v∉R} be the set containing all leaf nodes, where dG(v) = |{u ∈ V: {u, v} ∈ E}|. In this part of the instrument localization pipeline each leaf node in L is paired to an entrypoint node in R. This is solved by recursively traversing G, starting from each leaf. The criteria to decide which node to traverse next is coined in this work as dot product recursive traversal. It is based on the assumption that the correct path from a tip to a corresponding entrypoint is the one with minimal direction changes. The stopping condition is reaching an entry node.
Dot product recursive traversal operates as follows. Let vi, vj ∈ V be two arbitrary nodes, and {vi, vj} the undirected edge connecting them. Assuming vi is previously visited and vj being traversed, the next node v* to visit is chosen following:
Where N(vi) = {w ∈ V: {vi, w} ∈ E}, and A = {vi} is the set of nodes previously traversed. The idea behind (3) is to perform a greedy minimization of direction changes along the path from tooltip to entrypoint (Figure 6A).
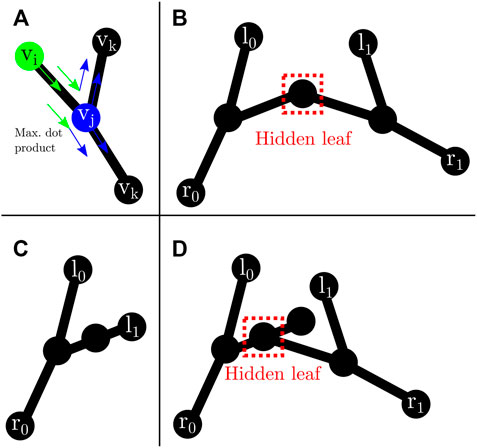
FIGURE 6. Leaf traversal and hidden leaves: (A) graph traversal step. vi (green) represents the previous node. vj (blue) is the current node. vk are possible next nodes. Following (3), the next node will be the one that maximizes the dot product; (B) possible hidden leaf (dashed red box) connected to two nodes; (C) node with two neighbours that does not represent a hidden leaf as both connecting edges are labelled after dot product traversal from l1; (D) possible hidden leaf (dashed red box) with three neighbours.
In the case of two tools present in the image, it is possible to have hidden leaves (Figures 6B,D), defined as graph nodes that represent an overlap between the tip of an instrument and another instrument. This situation can easily occur (Figure 6) in surgical tasks, including the task presented in the experiments from Section 6. There are two possible graph arrangements that can lead to hidden leaves. A node with exactly two (Figure 6B) or three neighbours (Figure 6D). Nonetheless, the number of neighbours alone does not facilitate the discovery of such hidden leaves (and subsequent disentanglement of tools), as it is also possible for a node with exactly two (could be a chain instead) or three (could be a bifurcation instead) neighbours to not be a hidden leaf (see Figure 6C). Hence, extra information is needed. Aiming in this direction, after each successful traversal from a normal leaf to an entry node, all the edges along the path are labelled with the index of the entry node. In addition, all the edges directly connected to an entry node are also labelled.
A node with exactly two or three neighbours whose edges are all labelled with different entry nodes is a hidden leaf. Labelling helps to solve some of the hidden leaf cases. Such leaves can be duplicated, effectively splitting the graph into two, and disentangling the overlapped instruments. After disentanglement, they become normal leaves which can be assigned to an entry node by dot product traversal (3). Although not a hidden leaf, a node with exactly four neighbours whose edges are labelled represents an overlap which can be trivially disentangled. Hidden leaves such as the ones presented in Figures 6B,D cannot be classified with certainty as such just with the graph/skeleton information. As shown in Figure 6, different tool configurations/occlusions could lead to the same graph configuration. As not all the tips can be unambiguously detected, entry nodes that are unmatched after dot product traversal (i.e., they were not reached after launching a traversal from each leaf node to a possible entry node) are paired to the furthest opposing node connected to them.
Although the traversal from tips to entrypoints has been illustrated in this section with one or two instruments (as it is the case in our setup, see Figure 1), the dot product traversal generalizes to setups with more instruments as the assumption that the path from tip to entrypoint is the one with less direction changes still holds.
Noisy skeletons can lead to inaccurate graphs containing more than two leaves matched to the same entry node, or more than two entry nodes connected to leaves. In our framework, unmatched entry nodes are deleted. In addition, due to the nature of our experimental setup, a maximum of two tools with two tips each can be found. Therefore, when more than two leaves are matched to the same entry node, only the two furthest are kept. Analogously, when more than two entry nodes are found and matched to leaves, the two kept are those with the longest chain (from entry node to leaves). That is, a maximum of two disentangled instrument graphs remain after pruning.
In the presence of a single instrument, left/right vertical semi-circles determine whether the instrument is left/right (see Figure 7, right), i.e. if the entrypoint of the tool is located in the right half of the image, it is assumed that the subgraph connected to this entrypoint is the right instrument, and viceversa. Note that this simple method is also generalizable to scenarios with three to five instruments, which are different from the two-instrument solo surgery setting examined in this work (see Figure 8), but still worth mentioning as there are some endoscopic procedures that may involve such number of tools (Abdi et al., 2016).
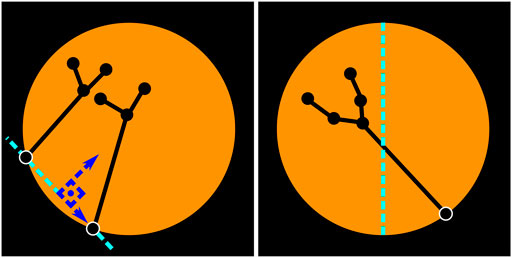
FIGURE 7. Left/right instrument identification. Two-instrument case (left). Single-instrument case (right). The location of the entrypoints is used to identify whether the instruments are left/right. When two instruments are visible, an imaginary vertical line (parallel to the vertical axis of the image) that crosses over the central point of the segment connecting both entrypoints is used to determine if the instrument is left/right. When there is only one instrument, the location of the entrypoint with regards to the vertical axis of the image determines which tool is visible. If the entrypoint resides in the right half, as in the figure above, this is considered to be the right instrument.
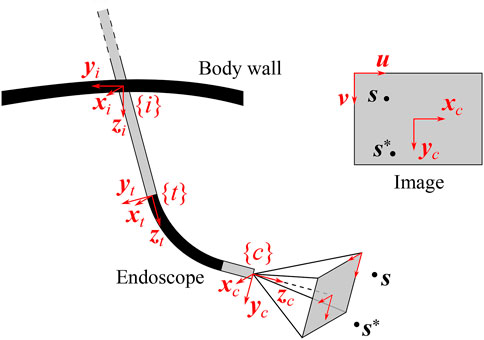
FIGURE 8. Definition of reference frames in a generalized endoscope model. The incision frame {i} is located at the incision point in the body wall, the distal tip frame {t} at the end of the straight endoscope shaft and the camera frame {c} at the end of the endoscope, in the optical center of the camera. The image produced by the endoscope is also shown (upper right insert), along with the projections of the detected feature of interest s and its desired position s*, and with the image coordinate vectors (u, v).
When two instruments are detected (i.e. two entrypoints with their corresponding subgraphs), a line segment connecting the entrypoints of both instruments is assumed to be the viewing horizon. A vertical line that is parallel to the vertical axis of the image and cuts through the central point of the viewing horizon defines whether the entrypoints (and subsequently the instruments) are left/right (see Figure 7, left).
Once the tips of the instruments have been detected and classified as right/left instrument, the disparity for each tooltip in the left and right stereo images is estimated using classical intensity-based template matching. As endoscope images are stereo-rectified, template matching with a sliding window of 64 × 64 pixels running over the same line (and only in one direction) suffices for the stereo matching. Normalized cross-correlation is the cost function of choice. Given the disparity measure for each tooltip, its depth can be reconstructed using the pinhole camera model and conventional epipolar geometry. The 3D reconstruction was performed with an extended Kalman filter (EKF). The EKF is valuable here, because of its capacity to bridge potential measurement gaps and to reduce the noise on the 3D position estimate, which is very sensitive to small disparity variations, as the lens separation of the Tipcam is only 1.6 mm. The details of the EKF are specified in Section 5.2.2.
Although in our proposed experimental setup we use stereovision because we have an stereo-endoscope, many centers still use monoscopic endoscopes. In this case, a method such as that presented by Liu et al. (Liu et al., 2020) could be used to estimate the 3D tip location directly from the 2D endoscopy.
A visual servoing controller determines the relative motion between a camera and an observed target in order to produce the desired camera view upon the target. In the case of AIT, the target is the (virtual) instrument tip position s, defined by (1), and the camera is the endoscope held by the robotic endoscope holder. When working with endoscopes, the visual servoing controller needs to take into account a number of aspects specific for endoscopy, including the presence of the incision point which imposes a geometric constraint and the endoscope geometry. For the online estimation of the incision point, automated routines exist, such as (Dong and Morel, 2016; Gruijthuijsen et al., 2018). This section formalizes visual servoing approaches for REC in MIS.
Two classical approaches exist for visual servoing problems: image-based visual servoing (IBVS) and position-based visual servoing (PBVS) (Chaumette and Hutchinson, 2008). For REC, an extension to these methods is necessary as the camera motion is constrained by the presence of the incision point. In IBVS, this can be done by modifying the interaction matrix, such that it incorporates the kinematic constraint of the incision point (Osa et al., 2010) or such that it describes the mapping between the image space and the joint space of the robotic endoscope holder (Uecker et al., 1995; Zhao, 2014). As these IBVS approaches only act in the image plane, the zoom level can be controlled by a decoupled depth controller (Chen et al., 2018). PBVS approaches can incorporate the incision constraint in an inverse kinematics algorithm that computes the desired robot pose, given the desired endoscopic view (Yu et al., 2013; Eslamian et al., 2016).
Implementations of the above approaches, that the authors are aware of, lack generality: they are formulated for a specific robotic endoscope holder and do not cover oblique-viewing endoscopes, while such endoscopes are commonly used in MIS procedures. Yet, oblique-viewing endoscopes are the most challenging to handle for clinicians (Pandya et al., 2014), and could thus reap most benefits of REC. Generic constraint-based control frameworks, such as eTaSL (Aertbeliën and De Schutter, 2014), could be applied with a generalized endoscope model, like presented below, although they are slower than explicit visual servoing methods.
This section introduces a novel generalized endoscope model for visual servoing that incorporates the incision constraint, as well as the endoscope geometry. Such a model is presented here, along with the ensuing modifications to the classical IBVS and PBVS approaches.
Endoscopes come in different forms and sizes. Rigid endoscopes are typically straight, but can also be pre-bent. The camera can be oriented collinear with the longitudinal axis of the scope or can be positioned at an oblique angle. Some scopes are flexible over their entire length, others contain a proximal rigid straight portion with a distal bendable portion.
Figure 9 visualizes a general endoscope geometry that encompasses all the above configurations, along with the frames of interest. The incision frame {i} is defined at the incision point and is common for all robotic endoscope holders. The z-axis of {i} is the inward-pointing normal of the body wall. A frame {t} is connected to the distal tip of the straight portion of the endoscope shaft, with its z-axis pointing along the shaft axis. In the most general case, the camera frame {c} is located at an offset and rotated with respect to {t}. The offset can reproduce for tip articulation, for stereo camera lens separation. The rotation can account for oblique-viewing endoscopes. As such, this endoscope model can describe complex endoscopes, such as the articulating 3D video endoscope EndoEye Flex 3D (Olympus, Japan) (Figure 10).

FIGURE 9. EndoEye Flex 3D ©Olympus Corporation (Tokyo, Japan).

FIGURE 10. Comparison of the endoscope tip trajectories for different visual servoing approaches for REC. In this simulation, an oblique-viewing 30° endoscope with a 120° FOV was used. Its initial and final pose are drawn. In the final pose, the feature of interest s is in the desired position with respect to the camera. The trajectories are drawn for a case with a small initial depth error (top) and a large initial depth error (bottom).
Starting from this general endoscope model, different visual servoing approaches for REC will be detailed next. The visual servoing approaches strive to determine the endoscope motion that is needed to match the position
The following notation will be used in the subsequent sections: a rotation of angle ξ about the axis i will be denoted by Ri(ξ). For a transformation from a frame {j} to a frame {i}, the notation
The instrument localization pipeline from Section 4.2 yields the tooltip image coordinates ul, vl and the disparity dx. The 3D tooltip position, required for the visual servoing methods, is estimated from these measurement data, through an EKF. The state transition model describes a linear tooltip motion of exponentially decreasing velocity, partially expressed in frames {i} and {c} to limit the non-linearity, and the observation model implements the pinhole camera model:
Where
IBVS aims to determine the camera motion to move the 2D projection of the 3D feature point s to its desired position in the image plane. Assuming a pinhole camera model, the 2D projection sn is obtained by expressing s in normalized camera coordinates:
Classically, the relation between the camera twist
Where
In this equation, it is assumed that the camera has six DoFs, while only three are available for the endoscope control. To incorporate these constraints, the camera twist
Where
The operator [ ]× is the operator for the skew-symmetric matrix. The incision constraint introduces a coupling between the linear tip velocity
With the incision transformation
And the inserted endoscope length
Which maps
As is customary in visual servoing, the error in the normalized image space is expressed as
And the control law enforces an exponential decay of the error:
Characterized by the time constant τ = 1/λ. For a constant
IBVS only seeks to optimize the 2D projected position sn of the target point s in the image plane. As such IBVS alone is insufficient to control the 3D position of the endoscope. A decoupled depth controller can be added to control the third DoF. This was proposed in (Chen et al., 2018) and will be generalized here.
The depth controller acts along the z-axis of the camera frame {c} and uses the kinematic relation between the camera twist
Where
To reduce the depth error ez = z − z*, concurrently with the image-space error en, a similar reasoning as with IBVS can be followed, yielding:
To differentiate between directions, it is possible to define λ as a diagonal matrix, rather than as a scalar.
Instead of decoupling the control in the image plane and the depth control, the 3D feature s can also be used directly to define the 3D motion of the endoscope. This requires a 3D interaction matrix L3D, which can be derived from the kinematic equations of motion for the stationary 3D point s in the moving camera frame {c}:
With
As before, the modified interaction matrix
PBVS identifies the camera pose, with respect to an external reference frame, that produces the desired view upon the 3D feature s and moves the camera towards this pose. As mentioned before, the camera pose is constrained to three DoFs due to the presence of the incision point and the separate horizon stabilization. Finding the desired camera pose, while taking into account its kinematic constraints, involves solving the inverse kinematics for the endoscope as defined in Figure 9.
The forward kinematics of the endoscope can be described as a function of three joint variables (θ1, θ2, l). Based on these variables, any endoscope pose can be reached by applying successive operations in a forward kinematics chains. When these joint variables are set to zero, the endoscope system is in a configuration where the incision frame {i} coincides with the distal tip frame {t}, while the camera frame is offset by
With
The solution of the inverse kinematics can be inserted in the forward kinematics equations to obtain the desired position of the distal endoscope tip
Which straightforwardly leads to the position error of the distal tip, expressed with respect to the incision frame {i}:
When an exponential decaying error is required, the desired endoscope velocity becomes:
And can be expressed in the frame {t} as:
A simulation was implemented to validate all four visual servoing methods for REC: IBVS, IBVS+DC, 3D IBVS and PBVS. Figure 11 presents a visual comparison between them, for a 30° oblique-viewing endoscope with a 120° FoV. In all simulations, s enters the FoV from a side. The visual serviong controller moves the endoscope to center s within its FoV at a given depth z*, or

FIGURE 11. LASTT (European Academy of Gynaecological Surgery, 2020) laparoscopic training model. Inital position of the pins before starting the bi-manual coordination task (left). Procedure to pass a pin from the non-dominant to the dominant hand (right).
From the graphs, it is clear that IBVS differs from the other approaches in that, by construction, it does not attain the desired depth z* in the final endoscope pose. Moreover, IBVS also doesn’t guarantee a constant depth z. Consequently, z will drift towards undesired depths over time. In some configurations, this can be counteracted by separately controlling l to stay constant, but this does not hold for the general case. IBVS alone is thus unsuitable for REC and 3D information about s is a requirement.
Both IBVS+DC and 3D IBVS linearize the visual servoing problem in the camera frame. This enables a desired exponential decay of the targeted errors, but does not produce a well-controlled endoscope motion in Cartesian space. It can be seen from Figure 11 that the trajectories for these methods deviate from the straight trajectory that is accomplished by PBVS, and more so for large initial errors. As space is limited in REC and the environment delicate, the straight trajectory of PBVS appears favourable compared to its alternatives.
IBVS typically yields more accurate visual servoing results than PBVS, because the feedback loop in IBVS-based methods can mitigate camera calibration errors (excluding stereo calibration errors). However, the objective in REC often is to keep s inside a specific region of the endoscopic image (cf. position hysteresis), rather than at an exact image coordinate. The importance of the higher accuracy of IBVS is thus tempered by this region-based control objective: small calibration inaccuracies are acceptable. Therefore, and in contrast to the claims in (Osa et al., 2010), it can be argued that the predictability of a straight visual servoing trajectory outweighs the importance of the visual servoing accuracy. This argumentation points out why PBVS is the preferred approach for REC, especially when large initial errors exist.
If the accuracy of PBVS would need to be enhanced, e.g., when significant calibration errors exist, it is possible to apply a hybrid visual servoing method. PBVS can be used until the initial error drops below a certain threshold and from there, the visual servoing controller gradually switches to an IBVS-based approach for refinement, by applying a weighted combination of the desired tip velocities
To determine the feasibility of the proposed autonomous endoscopy framework, an experimental setup was built (see Figure 1). The mockup surgical setting consisted of a laparoscopic skills testing and training model (LASTT) placed within a laparoscopic box trainer (see Figure 8). A bi-manual coordination exercise was chosen as the target surgical task for the experiments. In this task, a set of pushpins need to be passed between hands and placed in the right pockets. The choice of both laparoscopic trainer and surgical task was clinically motivated. The present study is largely inspired by the surgical scenario occurring during spina bifida Bruner (1999); Meuli and Moehrlen (2014); Kabagambe et al. (2018) surgical procedures (see Figure 12). In this fetal treatment, a surgeon operates while another one guides the endoscope. The LASTT model along with the bi-manual coordination task have been developed by The European Academy for Gynaecological Surgery3 as an initiative to improve quality control, training and education in gynaecological surgery (Campo et al., 2012). Therefore, they are ideal candidates for the feasibility study of the proposed autonomous endoscopy framework.
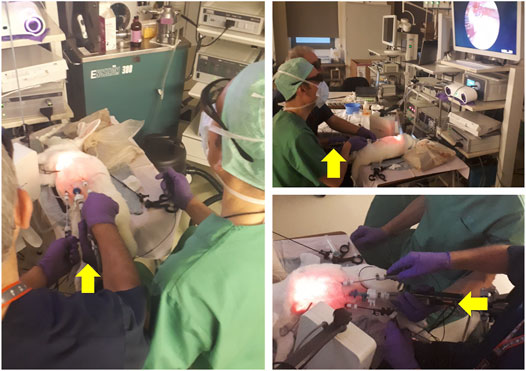
FIGURE 12. Spina bifida intervention performed on an animal model. The surgeon dressed in blue scrubs controls the instruments and manipulates the tissue. The colleague dressed in green guides and holds the endoscope camera during the intervention. The yellow arrows point to the hand of the assistant guiding the camera. As becomes evident in the pictures above, this operating arrangement is not ergonomic, leading to discomfort that increases with the duration of the intervention, and severely limiting the tasks that the surgeon controlling the camera can perform. Picture courtesy of Prof. Jan Deprest.
This task starts by placing a set of coloured pushpins at the base of the LASTT model (see Figure 8, left). There are two pins of each colour. The operator has to pick a pin with the non-dominant hand, pass it to the dominant hand (Figure 8, right), and place it inside the pocket of the same colour. The LASTT task is successfully completed when a pushpin of each of the six colours has been placed in a corresponding pocket, within less than 5 min. If the pin is dropped during the procedure, a second pin of the same colour has to be picked up from the base. If the second pin is also dropped, the test is considered a failure.
As shown in the demonstration video of the bi-manual coordination task with the LASTT model of the European Academy of Gynaecological Surgery4, this exercise cannot be performed with a fixed immobile endoscope due to the reduced field of view of the endoscope, the limited space available for maneuvers within the operating cavity, and the small size of the pins (which resembles small tissue structures). All of these characteristics of the LASTT model mimic the real operating conditions, particularly for gynaecological interventions. Without a robotic endoscope holder, the bi-manual coordination task is performed with one trainee handling the laparoscopic graspers and another trainee acting as the (human) camera assistant. The assistant should hold the endoscope and keep the view centered on what the laparoscopic operator is doing. In our experiments, this human camera assistant is replaced by the Virtuose6D5 (Haption SA, Laval, France) robotic arm. As shown in (Avellino et al., 2020), the dimensions, workspace, and supported payload of this robotic arm are well suited for robotic endoscope control6. The operational workspace is defined as a cube of side 450 mm and is located in the center of the workspace envelope. The extremities of the workspace envelope are bounded by a volume of 1330, ×, 575 × 1020 mm3. The payload supported by the Virtuose6D is 35 N (peak)/10 N (continuous). Additionally, the Virtuose6D features passive gravity compensation, which can be mechanically adjusted to carry up to 8 N. Therefore, although in our setup we are using a stereo-endoscope, this system is also able to hold laparoscopy cameras (e.g. those used in abdominal surgery). In our setup, the robotic arm was holding the Karl Storz Tipcam1, as shown in Figure 1. The Virtuose6D was programmed to respond to semantically rich AIT instructions (Section 3). Additionally, it featured a comanipulation fallback mode (Section 3.2), which it naturally supports owing to its mechanical backdrivability.
A total of eight subjects participated in the study. Two surgeons, two plateau novices, and four novices. The plateau novices were authors of the study, who started out as novices, but familiarized themselves with the system and the task until they reached a plateau in the learning curve. Each participant performed the bi-manual coordination task five times. Before these trials, each participant practised 5–10 min to perform the task while assisted by the robotic endoscope holder.
The autonomous endoscope controller implemented the Hybrid PBVS and 3D IBVS method (Section 5.3.2), switching from PBVS to 3D IBVS when the error ‖en‖ in the normalised image space decreased from 0.6 to 0.3. The target position of the endoscope tip was set to
The position hysteresis approach, which was illustrated in Figure 2, was applied separately in the image plane and along the viewing direction. In the image plane, the target zone A occupied the first 40% of the endoscopic image radius, the transition zone B the next 20%, and the violation zone C the remaining 40%. Along the viewing axis, the target zone was set to 3 cm in both directions of z*. The violation zone started at a distance of 5 cm with respect to z*. The EKF for stereo reconstruction (Section 4.2.9) was used to fill missing data up to 1 s after the last received sample. When the instruments were lost from the view for more than 10 s, the REC switched from the AIT mode to the comanipulation fallback mode, waiting to be manually reset to a safe home position.
When designing the experiments, two preliminary observations were made: 1) the AIT instruction that fixes the tracking target on the tip of the instrument held by the dominant hand was most convenient, and 2) instructions to change the zoom level were not used. The latter observation is easily explained by the nature of the LASTT task, which requires overview rather than close-up inspections. The former observation points out that it is confusing to track a virtual instrument tip in between the real tooltips. While concentrated on the task, participants tend to forget their non-dominant hand and move it out of the view (or in and out of the view without a particular reason). This affected the position of the virtual instrument tip in unexpected ways. In those situations where tracking the non-dominant hand is relevant (e.g., when passing the pin from one hand to another), participants quickly learned to keep the tips together. Hence, tracking the dominant-hand tool was sufficient to provide a comfortable view, and this became the only operation mode that participants used. In fact, as an operator, it was convenient to know that the system is tracking your dominant hand: this is easy to understand and remember. Thus, during all the experiments, the only instruction that was issued was to make the camera track the dominant hand. As all participants were right-handed, s was assigned to the tip of the right-hand tool.
In this section we provide quantitative results on the tooltip tracking accuracy, the responsiveness and usability of the visual servoing endoscopic guidance, and the learning curve of the user study participants.
Given an endoscopic video frame as input, the tooltip localization pipeline produces an estimate of the 2D location of the surgical instrument tips (see Figure 3). The tooltip location in image coordinates is used for the later 3D position reconstruction of the tooltips. Therefore, we first validate the localization pipeline performance independently of the overall task. This includes the instrument segmentation (Section 4.2.3) together with the subsequent tooltip detection steps (Sections 4.2.4–4.2.8).
For the selected bi-manual coordination task of Section 6, two laparoscopic instruments are used. Hence, a maximum of four tips may be encountered in any given endoscopic video frame. Two for the left and two for the right instrument. We define a bounding box around each detected tooltip. The chosen size for the bounding box is 200, ×, 200 pixels (cf. 1080p raw video frames). This corresponds to the size of the instrument distal part at a practical operation depth (Figure 13). A comparison between the bounding box and the image size is shown in Figure 13.
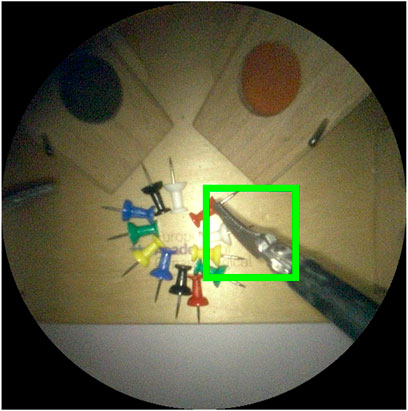
FIGURE 13. Image crop of visible area of 1080p endoscope video frame. The green square is the 200 ×200 pixel bounding box used to evaluate detection performance. An intersection over union ≥ 50% between predicted and ground truth bounding boxes is considered a correct detection.
Following common practice in object detection (Everingham et al., 2015), a
The testing set that we use to report results for the whole tooltip localization pipeline comprises 379 images. These images are evenly sampled video frames extracted at a constant frequency from the recording of the user study experiments, when participants operate the robot (i.e. they are not used during the training or validation of the segmentation model). Our tooltip tracking localization pipeline achieved a tooltip detection precision and recall of 72.45 and 61.89%, respectively. In 84.46% of the video frames, at least one of the present tips was correctly detected.
The responsiveness of the proposed system was also evaluated. To navigate outside the view, participants have to place the tip of the instrument in the violation zone C (see Figure 2 for a description of the zones). When this occurs, the AIT functionality is triggered until the instrument appears in zone A. Figure 14 shows how long it took for the system to recover (entering zone A) after a violation (entering zone C) was detected. As shown in the figure, the control was responsive, taking an average of
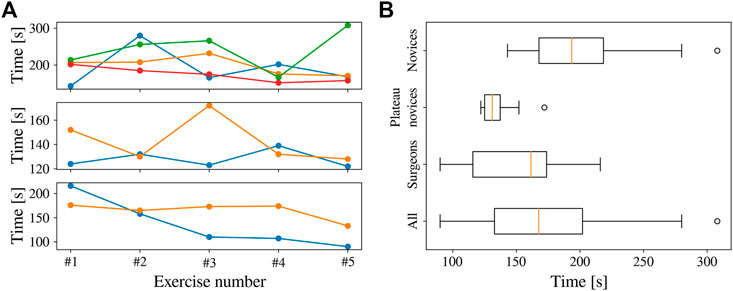
FIGURE 14. Completion time for all the participants in the bi-manual coordination task. (A) Completion time across attempts, with novices (top), plateau novices (centre), and surgeons (bottom). (B) Completion time per group across all trials.
In Figure 14, a number of outliers are present. This occurred when the participants moved their hands too fast for the REC to follow, causing the instruments to entirely disappear from the FoV. On most of these occasions, the participants were able to put the instruments back inside FoV after some time, resuming normal navigation. However, in three instances (of the outliers
When a human trainee is operating the endoscope, it is important for the coordination and the overview of the surgeon that the view remains centred around the instrument. This is also the objective when a human trainee is operating the endoscope. To quantify this aspect, Figure 15 shows the distribution of tip positions for the dominant-hand instrument across all the experiments. The REC indeed manages to keep the tooltip within the boundaries of the target zone A for most of the time. In the 2D image plane, the tip of the instrument was 46%, 23%, and 31% in target, transition, and violation zones, respectively. Similar behaviour was observed along the viewing direction, with a cumulative zone presence of 66%, 22%, and 12%, respectively.
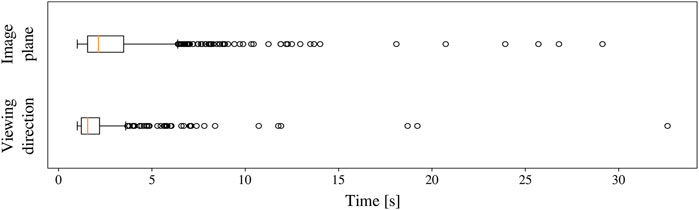
FIGURE 15. Time taken to correct the position of the endoscope after the dominant-hand tooltip entered the violation zone.
The proposed system allowed the user study participants to perform the benchmark surgical task7 with autonomous endoscope guidance within the allocated time. The completion time is shown in Figure 16. The average completion time for the 40 trials was 172 s (only one outlier exceeding 300 s). As shown in the figure, the completion time for the plateau novices was relatively constant. This was not the case for novices and surgeons, where a learning curve can be appreciated despite the initial 5–10 min of practice. The average completion time across participants decreased from 209 s in the first attempt to 144 s in the last exercise. These results indicate that the system provided repeatable behaviour that participants were able to learn.
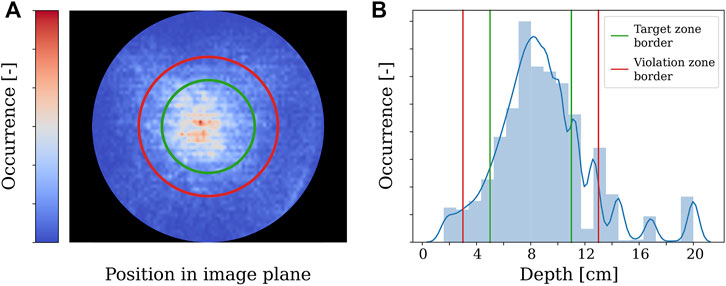
FIGURE 16. Distribution of dominant-hand tooltip presence across all the experiments in the 2D image and viewing direction.
In this work we proposed the use of semantically rich instructions to govern the interaction between a robotic autonomous endoscope holder and the operating surgeon. These are instructions such as “focus on the right tool” or “focus the camera between the instruments.” This opposes previous endoscope holders handled via commands such as “move up” or “zoom in.” Semantically rich instructions are similar to the instructions surgeons would issue to a human camera operator, and can therefore be naturally adopted in clinical practice. Thus, we believe that they may be a powerful tool to increase clinical acceptance.
As a first step towards implementing these instructions within a robotic endoscope holder, we concentrated our efforts on semantically rich instructions related to surgical instruments, which we called autonomous instrument tracking (AIT) instructions. To implement these instructions we built a robotic system capable of executing them without the need for additional sensors besides the endoscope. To the best of our knowledge, we are the first to report how to construct an autonomous instrument tracking system that allows for solo-surgery using only the endoscope as a sensor to track the instruments. Within the proposed system we included a novel tooltip detection method and a new visual servoing approach for a generalized endoscope model with support for remote center of motion and endoscope bending.
We found that our proposed localization method was able to detect tips in 84.46% of the frames, which in combination with our visual servoing approach allowed for a robust autonomous guidance of the endoscope. With regards to the visual servoing method, we found that a hybrid of position-based visual servoing (PBVS) and 3D image-based visual-servoing (IBVS) is preferred for robotic endoscope control.
During our experimental campaign we found that the REC-enabled AIT instructions yielded a predictable behaviour of the robotic endoscope holder that could be quickly understood and learned by the participants. The participants were able to execute a proven bi-manual coordination task within the prescribed completion time while assisted by the robotic endoscope holder. In three of the exercise runs, it was observed that the comanipulation fallback mode was required to solve for situations in which the instruments moved out of the view and the operator was unable to recover them in the view. This comanipulation mode thus ensures that failures in which the robotic endoscope holder has to be abandoned can be dealt with swiftly. An additional instruction to move back the robotic endoscope holder to a safe overview position could be considered as well. Such a safe location could for instance be close to the remote centre of motion (at the incision point). Although for the general case, when flexible instruments are used, care should be paid that such retraction does not cause the bending segment to hinge behind anatomic structures.
Besides the framework evaluation already performed, an in-depth comparison between human and robotic endoscope control remains as future work. Aspects such as time of completion, smoothness of motions, the stability of the image, number of corrections to the target zone, and average position of the instruments in the view remain to be compared. This contrast would quantify the difference in navigation quality between the proposed framework and a human-held endoscope.
While AIT instructions are necessary in most laparoscopic procedures, they are not the only instructions required for a semantic control of the endoscope holder, and it is a limitation of this study that it only focused on them. Therefore, we are positive that this work will pave the way for further developments to enlarge the set of semantically rich instructions.
The inverse kinematics problem (23) can be solved analytically to obtain
Next, l* needs to be extracted from each expression in (fx, fy, fz), yielding respective expressions
Emerges, with a1, b1, c1 constants. Solving this for
The dependence on
With a2, b2, c2 constants. This is a quadratic equation in
The original contributions presented in the study are included in the article/Supplementary Material, further inquiries can be directed to the corresponding author.
LG-P-H and CG have contributed equally to this work and share first authorship.
This work was supported by core and project funding from the Wellcome/EPSRC (WT203148/Z/16/Z; NS/A000049/1; WT101957; NS/A000027/1). This project has received funding from the European Union’s Horizon 2020 research and innovation programme under grant agreement No 101016985 (FAROS project). TV is supported by a Medtronic/Royal Academy of Engineering Research Chair (RCSRF1819∖7∖34).
SO and TV are co-founders and shareholders of Hypervision Surgical Ltd.
The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/frobt.2022.832208/full#supplementary-material
1https://www.youtube.com/watch?v=R1qwKAWFOIk
2https://github.com/luiscarlosgph/list-of-surgical-tool-datasets
3https://esge.org/centre/the-european-academy-of-gynaecological-surgery
4https://europeanacademy.org/training-tools/lastt/
5https://www.haption.com/en/products-en/virtuose-6d-en.html
6https://www.youtube.com/watch?v=R1qwKAWFOIk
7An exemplary video is located in section “Exercise 3: Bi-manual Coordination” at https://europeanacademy.org/training-tools/lastt/
Abdi, E., Burdet, E., Bouri, M., Himidan, S., and Bleuler, H. (2016). In a Demanding Task, Three-Handed Manipulation Is Preferred to Two-Handed Manipulation. Sci. Rep. 6, 21758. doi:10.1038/srep21758
Aertbeliën, E., and De Schutter, J. (2014). “Etasl/Etc: A Constraint-Based Task Specification Language and Robot Controller Using Expression Graphs,” in 2014 IEEE/RSJ International Conference on Intelligent Robots and Systems, 1540–1546. doi:10.1109/iros.2014.6942760
Agustinos, A., Wolf, R., Long, J. A., Cinquin, P., and Voros, S. (2014). “Visual Servoing of a Robotic Endoscope Holder Based on Surgical Instrument Tracking,” in 5th IEEE RAS/EMBS International Conference on Biomedical Robotics and Biomechatronics (Sao Paulo, Brazil: IEEE), 13–18. doi:10.1109/BIOROB.2014.6913744
Ali, J. M., Lam, K., and Coonar, A. S. (2018). Robotic Camera Assistance: The Future of Laparoscopic and Thoracoscopic Surgery? Surg. Innov. 25, 485–491. doi:10.1177/1553350618784224
Allan, M., Shvets, A., Kurmann, T., Zhang, Z., Duggal, R., Su, Y. H., et al. (2019). 2017 Robotic Instrument Segmentation Challenge. Arxiv. Available at: http://arxiv.org/abs/1902.06426.
Amin, M. S. A., Aydin, A., Abbud, N., Van Cleynenbreugel, B., Veneziano, D., Somani, B., et al. (2020). Evaluation of a Remote-Controlled Laparoscopic Camera Holder for Basic Laparoscopic Skills Acquisition: a Randomized Controlled Trial. Surg. Endosc. 35, 4183–4191. doi:10.1007/s00464-020-07899-5
Avellino, I., Bailly, G., Arico, M., Morel, G., and Canlorbe, G. (2020). “Multimodal and Mixed Control of Robotic Endoscopes,” in Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems (New York, NY: ACM), 1–14. doi:10.1145/3313831.3376795
Bengio, Y. (2012). “Practical Recommendations for Gradient-Based Training of Deep Architectures,” in Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics) 7700 LECTU, 437–478. doi:10.1007/978-3-642-35289-8_26
Bihlmaier, A. (2016). “Endoscope Robots and Automated Camera Guidance,” in Learning Dynamic Spatial Relations (Wiesbaden: Springer Fachmedien Wiesbaden), 23–102. doi:10.1007/978-3-658-14914-7_2
Bouarfa, L., Akman, O., Schneider, A., Jonker, P. P., and Dankelman, J. (2012). In-vivoreal-time Tracking of Surgical Instruments in Endoscopic Video. Minimally Invasive Ther. Allied Tech. 21, 129–134. doi:10.3109/13645706.2011.580764
Bouget, D., Allan, M., Stoyanov, D., and Jannin, P. (2017). Vision-based and Marker-Less Surgical Tool Detection and Tracking: a Review of the Literature. Med. Image Anal. 35, 633–654. doi:10.1016/j.media.2016.09.003
Bruner, J. P. (1999). Fetal Surgery for Myelomeningocele and the Incidence of Shunt-dependent Hydrocephalus. JAMA 282, 1819. doi:10.1001/jama.282.19.1819
Campo, R., Molinas, C. R., De Wilde, R. L., Brolmann, H., Brucker, S., Mencaglia, L., et al. (2012). Are You Good Enough for Your Patients? the European Certification Model in Laparoscopic Surgery. Facts Views Vis. Obgyn 4, 95–101. Available at: http://www.ncbi.nlm.nih.gov/pubmed/24753896http://www.pubmedcentral.nih.gov/articlerender.fcgi?artid=PMC3987500.
Casals, a., Amat, J., and Laporte, E. (1996). “Automatic Guidance of an Assistant Robot in Laparoscopic Surgery,” in Proceedings of IEEE International Conference on Robotics and Automation (IEEE), 895–900. doi:10.1109/ROBOT.1996.503886
Chaumette, F., and Hutchinson, S. (2008). Visual Servoing and Visual Tracking. Handbook of Robotics 2008, 563–583. doi:10.1007/978-3-540-30301-5_25
Chen, P.-J., Lin, M.-C., Lai, M.-J., Lin, J.-C., Lu, H. H.-S., and Tseng, V. S. (2018). Accurate Classification of Diminutive Colorectal Polyps Using Computer-Aided Analysis. Gastroenterology 154, 568–575. doi:10.1053/j.gastro.2017.10.010
Col, T. D., Mariani, A., Deguet, A., Menciassi, A., Kazanzides, P., and De Momi, E. (2020). “Scan: System for Camera Autonomous Navigation in Robotic-Assisted Surgery,” in 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2996–3002. doi:10.1109/iros45743.2020.9341548
Da Col, T., Caccianiga, G., Catellani, M., Mariani, A., Ferro, M., Cordima, G., et al. (2021). Automating Endoscope Motion in Robotic Surgery: A Usability Study on da Vinci-Assisted Ex Vivo Neobladder Reconstruction. Front. Robot. AI 8. doi:10.3389/frobt.2021.707704
Dong, L., and Morel, G. (2016). “Robust Trocar Detection and Localization during Robot-Assisted Endoscopic Surgery,” in 2016 IEEE International Conference on Robotics and Automation (ICRA), 4109–4114. doi:10.1109/icra.2016.7487602
Eslamian, S., Reisner, L. A., King, B. W., and Pandya, A. K. (2016). Towards the Implementation of an Autonomous Camera Algorithm on the da Vinci Platform. Stud. Health Technol. Inform. 220, 118–123. Available at: http://www.ncbi.nlm.nih.gov/pubmed/27046563.
Eslamian, S., Reisner, L. A., and Pandya, A. K. (2020). Development and evaluation of an autonomous camera control algorithm on the da vinci surgical system. Int. J. Med. Robot 16, e2036. doi:10.1002/rcs.2036
European Academy of Gynaecological Surgery (2020). LASTT. Available at: https://europeanacademy.org/training-tools/lastt/.
Everingham, M., Eslami, S. M. A., Van Gool, L., Williams, C. K. I., Winn, J., and Zisserman, A. (2015). The Pascal Visual Object Classes Challenge: A Retrospective. Int. J. Comput. Vis. 111, 98–136. doi:10.1007/s11263-014-0733-5
Fuentes-Hurtado, F., Kadkhodamohammadi, A., Flouty, E., Barbarisi, S., Luengo, I., and Stoyanov, D. (2019). EasyLabels: Weak Labels for Scene Segmentation in Laparoscopic Videos. Int. J. CARS 14, 1247–1257. doi:10.1007/s11548-019-02003-2
Fujii, K., Gras, G., Salerno, A., and Yang, G.-Z. (2018). Gaze Gesture Based Human Robot Interaction for Laparoscopic Surgery. Med. Image Anal. 44, 196–214. doi:10.1016/j.media.2017.11.011
Garcia-Peraza-Herrera, L. C., Fidon, L., D'Ettorre, C., Stoyanov, D., Vercauteren, T., and Ourselin, S. (2021). Image Compositing for Segmentation of Surgical Tools without Manual Annotations. IEEE Trans. Med. Imaging 40, 1450–1460. doi:10.1109/TMI.2021.3057884
Garcia-Peraza-Herrera, L. C., Li, W., Fidon, L., Gruijthuijsen, C., Devreker, A., Attilakos, G., et al. (2017). “ToolNet: Holistically-Nested Real-Time Segmentation of Robotic Surgical Tools,” in 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) (IEEE), 5717–5722. doi:10.1109/IROS.2017.8206462
García-Peraza-Herrera, L. C., Li, W., Gruijthuijsen, C., Devreker, A., Attilakos, G., Deprest, J., et al. (2017). “Real-Time Segmentation of Non-rigid Surgical Tools Based on Deep Learning and Tracking,” in CARE workshop, held in conjunction with MICCAI 2016, 84–95. doi:10.1007/978-3-319-54057-3_8
Gillen, S., Pletzer, B., Heiligensetzer, A., Wolf, P., Kleeff, J., Feussner, H., et al. (2014). Solo-surgical Laparoscopic Cholecystectomy with a Joystick-Guided Camera Device: a Case-Control Study. Surg. Endosc. 28, 164–170. doi:10.1007/s00464-013-3142-x
González, C., Bravo-Sánchez, L., and Arbelaez, P. (2020). ISINet: An Instance-Based Approach for Surgical Instrument Segmentation. MICCAI 2020, 595–605. doi:10.1007/978-3-030-59716-0_57
Goodell, K. H., Cao, C. G. L., and Schwaitzberg, S. D. (2006). Effects of Cognitive Distraction on Performance of Laparoscopic Surgical Tasks. J. Laparoendoscopic Adv. Surg. Tech. 16, 94–98. doi:10.1089/lap.2006.16.94
Gruijthuijsen, C., Dong, L., Morel, G., and Poorten, E. V. (2018). Leveraging the Fulcrum point in Robotic Minimally Invasive Surgery. IEEE Robot. Autom. Lett. 3, 2071–2078. doi:10.1109/lra.2018.2809495
Hanna, G. B., Shimi, S., and Cuschieri, A. (1997). Influence of Direction of View, Target-To-Endoscope Distance and Manipulation Angle on Endoscopic Knot Tying. Br. J. Surg. 84, 1460–1464. doi:10.1111/j.1365-2168.1997.02835.x
Holländer, S. W., Klingen, H. J., Fritz, M., Djalali, P., and Birk, D. (2014). Robotic Camera Assistance and its Benefit in 1033 Traditional Laparoscopic Procedures: Prospective Clinical Trial Using a Joystick-Guided Camera Holder. Surg. Technol. Int. 25, 19–23. Available at: http://www.ncbi.nlm.nih.gov/pubmed/25419950.
Ioffe, S., and Szegedy, C. (2015). Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. Arxiv.
Jaspers, J. E. N., Breedveld, P., Herder, J. L., and Grimbergen, C. A. (2004). Camera and Instrument Holders and Their Clinical Value in Minimally Invasive Surgery. Surg. Laparosc. Endosc. Percutaneous Tech. 14, 145–152. doi:10.1097/01.sle.0000129395.42501.5d
Jia, Y., Shelhamer, E., Donahue, J., Karayev, S., Long, J., Girshick, R., et al. (2014). Caffe: Convolutional Architecture for Fast Feature Embedding. arXiv preprint arXiv:1408.5093.
Kabagambe, S. K., Jensen, G. W., Chen, Y. J., Vanover, M. A., and Farmer, D. L. (2018). Fetal Surgery for Myelomeningocele: A Systematic Review and Meta-Analysis of Outcomes in Fetoscopic versus Open Repair. Fetal Diagn. Ther. 43, 161–174. doi:10.1159/000479505
King, B. W., Reisner, L. A., Pandya, A. K., Composto, A. M., Ellis, R. D., and Klein, M. D. (2013). Towards an Autonomous Robot for Camera Control during Laparoscopic Surgery. J. Laparoendoscopic Adv. Surg. Tech. 23, 1027–1030. doi:10.1089/lap.2013.0304
Kommu, S. S., Rimington, P., Anderson, C., and Rané, A. (2007). Initial Experience with the EndoAssist Camera-Holding Robot in Laparoscopic Urological Surgery. J. Robotic Surg. 1, 133–137. doi:10.1007/s11701-007-0010-5
Kunze, L., Roehm, T., and Beetz, M. (2011). “Towards Semantic Robot Description Languages,” in 2011 IEEE International Conference on Robotics and Automation (IEEE), 5589–5595. doi:10.1109/ICRA.2011.5980170
Kwon, D.-S., Ko, S.-Y., and Kim, J. (2008). “Intelligent Laparoscopic Assistant Robot through Surgery Task Model: How to Give Intelligence to Medical Robots,” in Medical Robotics. I-Tech Education and Publishing, 197–218. doi:10.5772/5249
Lee, G., Lee, T., Dexter, D., Godinez, C., Meenaghan, N., Catania, R., et al. (2009). Ergonomic Risk Associated with Assisting in Minimally Invasive Surgery. Surg. Endosc. 23, 182–188. doi:10.1007/s00464-008-0141-4
Lee, T. C., Kashyap, R. L., and Chu, C. N. (1994). Building Skeleton Models via 3-D Medial Surface Axis Thinning Algorithms. CVGIP: Graphical Models Image Process. 56, 462–478. doi:10.1006/cgip.1994.1042
Liu, X., Sinha, A., Ishii, M., Hager, G. D., Reiter, A., Taylor, R. H., et al. (2020). Dense Depth Estimation in Monocular Endoscopy with Self-Supervised Learning Methods. IEEE Trans. Med. Imaging 39, 1438–1447. doi:10.1109/TMI.2019.2950936
Mariani, A., Colaci, G., Da Col, T., Sanna, N., Vendrame, E., Menciassi, A., et al. (2020). An Experimental Comparison towards Autonomous Camera Navigation to Optimize Training in Robot Assisted Surgery. IEEE Robot. Autom. Lett. 5, 1461–1467. doi:10.1109/LRA.2020.2965067
Meuli, M., and Moehrlen, U. (2014). Fetal Surgery for Myelomeningocele Is Effective: a Critical Look at the Whys. Pediatr. Surg. Int. 30, 689–697. doi:10.1007/s00383-014-3524-8
Mudunuri, A. V. (2010). Autonomous Camera Control System for Surgical Robots. Ph.D. thesis (Detroit, MI, USA: Wayne State University).
Nishikawa, A., Nakagoe, H., Taniguchi, K., Yamada, Y., Sekimoto, M., Takiguchi, S., et al. (2008). How Does the Camera Assistant Decide the Zooming Ratio of Laparoscopic Images? Analysis and Implementation. MICCAI 2008, 611–618. doi:10.1007/978-3-540-85990-1_73
Osa, T., Staub, C., and Knoll, A. (2010). “Framework of Automatic Robot Surgery System Using Visual Servoing,” in 2010 IEEE/RSJ International Conference on Intelligent Robots and Systems (IEEE), 1837–1842. doi:10.1109/IROS.2010.5650301
Pakhomov, D., Shen, W., and Navab, N. (2020). “Towards Unsupervised Learning for Instrument Segmentation in Robotic Surgery with Cycle-Consistent Adversarial Networks,” in 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) (IEEE), 8499–8504. doi:10.1109/iros45743.2020.9340816
Pandya, A., Reisner, L., King, B., Lucas, N., Composto, A., Klein, M., et al. (2014). A Review of Camera Viewpoint Automation in Robotic and Laparoscopic Surgery. Robotics 3, 310–329. doi:10.3390/robotics3030310
Platte, K., Alleblas, C. C. J., Inthout, J., and Nieboer, T. E. (2019). Measuring Fatigue and Stress in Laparoscopic Surgery: Validity and Reliability of the star-track Test. Minimally Invasive Ther. Allied Tech. 28, 57–64. doi:10.1080/13645706.2018.1470984
Polski, M., Fiolka, A., Can, S., Schneider, A., and Feussner, H. (2009). “A New Partially Autonomous Camera Control System,” in World Congress on Medical Physics and Biomedical Engineering, 276–277. doi:10.1007/978-3-642-03906-5_75
Rahman, M. A., and Wang, Y. (2016). “Optimizing Intersection-Over-Union in Deep Neural Networks for Image Segmentation,” in Advances in Visual Computing, 234–244. doi:10.1007/978-3-319-50835-1_22
Reiter, A., Goldman, R. E., Bajo, A., Iliopoulos, K., Simaan, N., and Allen, P. K. (2011). “A Learning Algorithm for Visual Pose Estimation of Continuum Robots,” in IROS (IEEE), 2390–2396. doi:10.1109/iros.2011.6094947
Rivas-Blanco, I., Estebanez, B., Cuevas-Rodriguez, M., Bauzano, E., and Munoz, V. F. (2014). “Towards a Cognitive Camera Robotic Assistant,” in 5th IEEE RAS/EMBS International Conference on Biomedical Robotics and Biomechatronics (IEEE), 739–744. doi:10.1109/BIOROB.2014.6913866
Rodrigues Armijo, P., Huang, C.-K., Carlson, T., Oleynikov, D., and Siu, K.-C. (2020). Ergonomics Analysis for Subjective and Objective Fatigue between Laparoscopic and Robotic Surgical Skills Practice Among Surgeons. Surg. Innov. 27, 81–87. doi:10.1177/1553350619887861
Ronneberger, O., Fischer, P., and Brox, T. (2015). U-net: Convolutional Networks for Biomedical Image Segmentation. MICCAI 2015, 234–241. doi:10.1007/978-3-319-24574-4_28
Roß, T., Reinke, A., Full, P. M., Wagner, M., Kenngott, H., Apitz, M., et al. (2021). Comparative Validation of Multi-Instance Instrument Segmentation in Endoscopy: Results of the ROBUST-MIS 2019 challenge. Med. Image Anal. 70, 101920. doi:10.1016/j.media.2020.101920
Samei, G., Tsang, K., Kesch, C., Lobo, J., Hor, S., Mohareri, O., et al. (2020). A Partial Augmented Reality System with Live Ultrasound and Registered Preoperative MRI for Guiding Robot-Assisted Radical Prostatectomy. Med. Image Anal. 60, 101588. doi:10.1016/j.media.2019.101588
Sandoval, J., Laribi, M. A., Faure, J.-P., Breque, C., Richer, J.-P., and Zeghloul, S. (2021). Towards an Autonomous Robot-Assistant for Laparoscopy Using Exteroceptive Sensors: Feasibility Study and Implementation. IEEE Robot. Autom. Lett. 6, 6473–6480. doi:10.1109/lra.2021.3094644
Seong-Young, K., Kim, J., Kwon, D. S., and Lee, W. J. (2005). “Intelligent Interaction between Surgeon and Laparoscopic Assistant Robot System,” in ROMAN 2005. IEEE International Workshop on Robot and Human Interactive Communication, 60–65. doi:10.1109/ROMAN.2005.1513757
Song, C., Gehlbach, P. L., and Kang, J. U. (2012). Active Tremor Cancellation by a "Smart" Handheld Vitreoretinal Microsurgical Tool Using Swept Source Optical Coherence Tomography. Opt. Express 20, 23414–23421. doi:10.1364/oe.20.023414
Song, K.-T., and Chen, C.-J. (2012). “Autonomous and Stable Tracking of Endoscope Instrument Tools with Monocular Camera,” in 2012 IEEE/ASME International Conference on Advanced Intelligent Mechatronics (AIM) (IEEE), 39–44. doi:10.1109/AIM.2012.6266023
Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I., and Salakhutdinov, R. (2014). Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Machine Learn. Res. 15, 1929–1958.
Stott, M. C., Barrie, J., Sebastien, D., Hammill, C., and Subar, D. A. (2017). Is the Use of a Robotic Camera Holder Economically Viable? A Cost Comparison of Surgical Assistant versus the Use of a Robotic Camera Holder in Laparoscopic Liver Resections. Surg. Laparosc. Endosc. Percutaneous Tech. 27, 375–378. doi:10.1097/SLE.0000000000000452
Takahashi, M. (2020). “Solo Surgery with VIKY: Safe, Simple, and Low-Cost Robotic Surgery,” in Handbook of Robotic and Image-Guided Surgery. Editor M. H. Abedin-Nasab (Amsterdam, Netherlands: Elsevier), 79–88. doi:10.1016/B978-0-12-814245-5.00005-0
Taniguchi, K., Nishikawa, A., Sekimoto, M., Kobayashi, T., Kazuhara, K., Ichihara, T., et al. (2010). “Classification, Design and Evaluation of Endoscope Robots,” in Robot Surgery (London, UK: InTech), 1–24. doi:10.5772/6893
Tonet, O., Thoranaghatte, R., Megali, G., and Dario, P. (2007). Tracking Endoscopic Instruments without a Localizer: a Shape-Analysis-Based Approach. Comp. Aided Surg. 12, 35–42. doi:10.1080/10929080701210782
Uecker, D. R., Lee, C., Wang, Y. F., and Wang, Y. (1995). Automated Instrument Tracking in Robotically Assisted Laparoscopic Surgery. J. Image Guid. Surg. 1, 308–325. doi:10.1002/(sici)1522-712x(1995)1:6<308::aid-igs3>3.0.co;2-e
Uenohara, M., and Kanade, T. (1995). Vision-based Object Registration for Real-Time Image Overlay. Comput. Biol. Med. 25, 249–260. doi:10.1016/0010-4825(94)00045-R
Vardazaryan, A., Mutter, D., Marescaux, J., and Padoy, N. (2018). Weakly-Supervised Learning for Tool Localization in Laparoscopic Videos. LABELS 2018, 169–179. doi:10.1007/978-3-030-01364-6_19
Wagner, M., Bihlmaier, A., Kenngott, H. G., Mietkowski, P., Scheikl, P. M., Bodenstedt, S., et al. (2021). A Learning Robot for Cognitive Camera Control in Minimally Invasive Surgery. Surg. Endosc. 2021, 1–10. doi:10.1007/s00464-021-08509-8
Wang, Y.-F., Uecker, D. R., and Wang, Y. (1998). A New Framework for Vision-Enabled and Robotically Assisted Minimally Invasive Surgery. Comput. Med. Imaging Graphics 22, 429–437. doi:10.1016/S0895-6111(98)00052-4
Wauben, L. S. G. L., van Veelen, M. A., Gossot, D., and Goossens, R. H. M. (2006). Application of Ergonomic Guidelines during Minimally Invasive Surgery: a Questionnaire Survey of 284 Surgeons. Surg. Endosc. 20, 1268–1274. doi:10.1007/s00464-005-0647-y
Weede, O., Monnich, H., Muller, B., and Worn, H. (2011). “An Intelligent and Autonomous Endoscopic Guidance System for Minimally Invasive Surgery,” in 2011 IEEE International Conference on Robotics and Automation (IEEE), 5762–5768. doi:10.1109/ICRA.2011.5980216
Wijsman, P. J. M., Broeders, I. A. M. J., Brenkman, H. J., Szold, A., Forgione, A., Schreuder, H. W. R., et al. (2018). First Experience with the AUTOLAP SYSTEM: an Image-Based Robotic Camera Steering Device. Surg. Endosc. 32, 2560–2566. doi:10.1007/s00464-017-5957-3
Wijsman, P. J. M., Molenaar, L., Voskens, F. J., van’t Hullenaar, C. D. P., and Broeders, I. A. M. J. (2022). Image-based Laparoscopic Camera Steering versus Conventional Steering: a Comparison Study. J. Robotic Surg.. doi:10.1007/s11701-021-01342-0
Xiaolong, Y. (2019). Image-Py Skeleton Network Module. Available at: https://github.com/Image-Py/sknw.
Yang, G.-Z., Cambias, J., Cleary, K., Daimler, E., Drake, J., Dupont, P. E., et al. (2017). Medical Robotics-Regulatory, Ethical, and Legal Considerations for Increasing Levels of Autonomy. Sci. Robot. 2, eaam8638. doi:10.1126/scirobotics.aam8638
Yu, L., Wang, Z., Sun, L., Wang, W., and Wang, T. (2013). “A Kinematics Method of Automatic Visual Window for Laparoscopic Minimally Invasive Surgical Robotic System,” in 2013 IEEE International Conference on Mechatronics and Automation (IEEE), 997–1002. doi:10.1109/ICMA.2013.6618051
Zhang, X., and Payandeh, S. (2002). Application of Visual Tracking for Robot-Assisted Laparoscopic Surgery. J. Robotic Syst. 19, 315–328. doi:10.1002/rob.10043
Zhao, Z. (2014). “Real-time 3D Visual Tracking of Laparoscopic Instruments for Robotized Endoscope Holder,” in Proceeding of the 11th World Congress on Intelligent Control and Automation (IEEE), 6145–6150. doi:10.1109/WCICA.2014.7053773
Keywords: minimally invasive surgery, endoscope holders, endoscope robots, endoscope control, visual servoing, instrument tracking
Citation: Gruijthuijsen C, Garcia-Peraza-Herrera LC, Borghesan G, Reynaerts D, Deprest J, Ourselin S, Vercauteren T and Vander Poorten E (2022) Robotic Endoscope Control Via Autonomous Instrument Tracking. Front. Robot. AI 9:832208. doi: 10.3389/frobt.2022.832208
Received: 09 December 2021; Accepted: 17 February 2022;
Published: 11 April 2022.
Edited by:
Daniele Cafolla, Mediterranean Neurological Institute Neuromed (IRCCS), ItalyReviewed by:
Juan Sandoval, University of Poitiers, FranceCopyright © 2022 Gruijthuijsen, Garcia-Peraza-Herrera, Borghesan, Reynaerts, Deprest, Ourselin, Vercauteren and Vander Poorten. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Luis C. Garcia-Peraza-Herrera, bHVpc19jLmdhcmNpYV9wZXJhemFfaGVycmVyYUBrY2wuYWMudWs=
†These authors have contributed equally to this work and share first authorship
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.