 Z. H. Ismail
Z. H. Ismail N. A. Jalaludin
N. A. Jalaludin
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Robot. AI , 18 February 2022
Sec. Robotic Control Systems
Volume 8 - 2021 | https://doi.org/10.3389/frobt.2021.788125
This article is part of the Research Topic Energy Sustainability in Marine Robotics View all 8 articles
In this article, a new form of data assimilation (DA) method namely multiple imputation particle filter with smooth variable structure filter (MIPF–SVSF) is proposed for river state estimation. This method is introduced to perform estimation during missing observation by presenting new sets of data. The contribution of this work is to overcome the missing observation, and at the same time improve the estimation performance. The convergence analysis of the MIPF–SVF is discussed and shows that the method depends on the number of particles and imputations. However, the number of particles and imputations is influenced by the error difference in the likelihood function. By bounding the error, the ability of the method can be improved and the number of particles and computational time are reduced. The comparison between the proposed method with EKF during complete data and multiple imputation particle filter shows the effectiveness of the MIPF–SVSF. The percentage improvement of the proposed method compared to MIPF in terms of root mean square error is between 12 and 13.5%, standard deviation is between 14 and 15%, mean absolute error is between 2 and 7%, and the computational error is reduced between 73 and 90% of the length of time required to perform the estimation process.
The prediction of the river state is important in the hydrology, water resource management, and ecosystem rehabilitation. The knowledge of river flow characteristics is useful for flood forecasting, reservoir operations, and watershed modeling (Sichangi et al., 2018). In flood forecasting, the predicted state is use to produce alerts of the incoming flood to prevent damages to human life, properties and environment (Jain et al., 2018). Besides that, the information from the state estimation is used in controlling the outflows of reservoir during low flows day of river and also rapid flows resulting from dam-break that may cause catastrophy to the environment and massive losses to life and property (Adnan et al., 2017), (Cao et al., 2019). The water flow can also be used in watershed modeling that is used to manage the water by channeling the water from any sources into a single larger body of water such as a larger river (Aswathy et al., 2016). The management and planning of the water source is important for the increasing of the water demand in the next few years due to the increasing population growth, urbanization, industrial use, irrigation needs, and water-intensive agriculture (Tinka et al., 2013). This includes the planning of the water projects, irrigation systems, hydropower system, and optimized utilization of water resources (Adnan et al., 2017). The information of the river discharge (flow) is necessary in the management procedure and the variation of the hydrologic cycle is related to the climate change, land use, and water use (Bjerklie et al., 2018). The river discharge is one of the climate variables by the Global Climate Observing System (Tarpanelli et al., 2019). The prediction of the variables that represent the water flow regime helps in the ecosystem rehabilitation program that seeks to safeguard or restore indigenous ecosystems by manipulating the river flow (Blythe and Schmidt, 2018). The estimation of the river state can be carried out using the data assimilation (DA) method. The DA method is a mathematical technique that combines observation data with the system model and creates the updated model state while maintaining the parameter of the model (Li et al., 2014). The updated model state is defined as the probability density function (pdf) that is based on Bayes’ theorem and known as the new posterior pdf (Smith et al., 2013). The new state is acquired whenever there are new observations and uses them to initiate the next model forecast as reported in a study (He et al., 2014). The DA method is desired to optimally and consistently estimated, even if the noisy readings arrive sequentially in time (Liu and Gupta, 2007). The DA technique is accessible in two classes namely, variational and sequential (Gadsden et al., 2014).
The variational method is based on the optimum theory of control. Optimization is carried out on the associated parameters by minimizing the cost function that influences the model to misfit the information. The examples of this technique are variational data assimilation (VAR), evolutionary data assimilation (EDA), and maximum likelihood ensemble filter (MLEF) (Abaza et al., 2014). The VAR method makes estimates by minimizing the cost function which measures the difference between the model estimate, the observation, and the associated uncertainties. The gradient-based optimization algorithm is used to adjust the model states and parameters of the model and receive the appropriate estimate for the measurement (Kim et al., 2014). Besides that, the EDA utilizes a multi-objective evolutionary strategy to continually develop the set of model states and parameters where the model error and penalty function minimization for each assimilation time step is determined adaptively. This is done to enhance the convergence of parameters and lead to excellent estimation outcomes (Bertino et al., 2003; Solonen et al., 2014). Another type of variational method is the MLEF, which combines the VAR and the ensemble Kalman filter (EnKF). This method maintains the strength of both method and capable to handle nonlinear model dynamics as well as nonlinear observation. However, in some cases the performance of the MLEF may deteriorate due to consistency of the observation (Rafieeinasab et al., 2014). Besides that, the sequential methods use a probabilistic framework and estimate the whole system state sequentially by propagating information only forward in time. This method does not require an adjoint model and makes it easy to adapt with the model (Rigatos, 2012). The sequential-based technique is frequently used in estimation compared to the variational method, since the prior state is updated with the new observation available and the process is performed sequentially (Arulampalam et al., 2002). The examples of this method are extended Kalman filter in (Li et al., 2014), ensemble Kalman filter (EnKF) in (Rafieeinasab et al., 2014), unscented Kalman filter (UKF) (Pintelon et al., 2017), cubature Kalman filter (Liu and Gupta, 2007), and particle filter (PF) (Ugryumova et al., 2015). The EKF is commonly used sequentially DA method due to easy implementation, but depends strongly on the accuracy of the system linearization that is performed using Taylor series expansion (Li et al., 2014). This technique shows excellent efficiency in low nonlinearity and diverges in higher nonlinear cases (Zhang et al., 2015). For a highly nonlinear system, the estimation can be carried out using the EnKF that offers estimation without linearization (Rafieeinasab et al., 2014). This method involves a large sample size to represent the number of samples or ensemble members for precise estimation that can be produced with Monte Carlo method, Latin hypercube sampling, and moment equation (Kang, 2013; Gadsden et al., 2014; Wang et al., 2017). The samples’ mean and covariance are used to perform updating in the estimation process (Rafieeinasab et al., 2014). However, the large sample size may cause for computational demand (Gadsden et al., 2014). Another form of EnKF is the ensemble square root filter (EnSRF) that does not require the observation to be perturbed as the standard implementation of the EnKF. The algorithm of this method has been demonstrated to be as fast as the EnKF and more precise for a specified ensemble size than EnKF (Liu et al., 2017).
The UKF is more appropriate for application for low computational and high accuracy. This method includes the sigma points derived from the unscented transformations (Ding et al., 2015). The sigma points are propagated through the system model and the related weight factor during the estimation process and produce new sets of sigma points, which are subsequently used in the calculation of the projected states (Pintelon et al., 2017). However, this method relies on the precise of prior noise distribution. Wrong prior value can lead to large estimation errors or divergence of errors (Mao et al., 2017). Another type of sequential DA method is the PF, which does not involve system linearization and includes a number of particles during prediction (Hu et al., 2012). Each particle represents the estimated state with its associated likelihood that is determined using the residual between the simulated output and observation (Solonen et al., 2014). Large numbers of particles provide the chance of good estimation, but the computational time will increase. Another factor to consider when using PF is the issue of degeneration and dimensionality curse that can influence the estimation (Ugryumova et al., 2015). All the abovementioned DA methods were implemented in the river state estimation study. The modification of the methods may improve the performance of the method and the result obtained. In a study (Cao et al., 2019), the particle filter is modified by considering the system condition and the particle weighting procedure. The modification has improved the estimation result. Besides that, the modification can also be made by combining two or more methods such as the combination of the PF with smooth variable structure filter (SVSF). The SVSF produce estimated state and state error covariance, which is used to formulate the proposal distribution for the PF to generate particles (Ogundijo et al., 2016). The SVSF is robust to modeling errors and uncertainties (Feng et al., 2011). This method produces better estimated result than the PF only. Besides that, the SVSF also combined with the cubature Kalman filter (CKF). The CKF offers the nearest known approximation to the Bayesian filter in the sense of maintaining second-order information contained in the Gaussian assumption of noisy measurements. This method also does not need Jacobians and therefore applies to a wide range of issues. The accuracy of CKF and the stability of the SVSF ensure good estimation results (Liu and Gupta, 2007).
In this work, the estimated river system flow and stage, and also the velocity of the sensor are inspired from (Tinka et al., 2013) and (Zhang et al., 2014). These values can be obtained using the previously mentioned DA method. However, the missing observation data can be problematic that will affect the estimation process (Ismail and Jalaludin, 2016). The missing data can be handled using modern method or traditional method. The modern method is represented by the maximum likelihood and multiple imputations, while the traditional techniques are deletion and mean imputation techniques (Gadsden et al., 2012). It is noted that the multiple imputation particle filter (MIPF) is introduced to deal with this problem by randomly drawn values known as imputations to replace the missing information and then uses the particle filter to predict nonlinear state as reported in (Habibi, 2007). However, the addition of the new data burdens the estimation process. Therefore, the SVSF is introduced to bound the error difference and assist in the estimation process.
In this article, the convergence analysis of the MIPF–SVSF in estimating the river flow and stage from the initial condition is presented. The article is constructed as follows: the system model, observation model, and the state space model for estimation process are presented in Modelling the Marine River Flow. Problem Formulation briefly explains the effect of the missing observation during estimation. Then, the proposed algorithm for estimation with missing data is described in the Proposed Data Assimilation Approach. The convergence analysis is presented in Convergence Analysis that includes almost sure convergence and convergence of the mean square error. In Results and Discussion, the details on estimation process and numerical simulations are discussed and finally conclusions are presented in Conclusion.
The river flow model can be represented by one or two-dimensional Saint–Venant equations (Tinka et al., 2013) depending on the characteristics of the water flow. If the flow is in one-dimensional, the 1-D Saint–Venant equations is considered. However, if the flow is not one-dimensional, which may happen in flood plains or in large rivers, the 2-D Saint–Venants equation is more suitable to be applied (Litrico and Fromion, 2009). Besides that, the representation of the observation is referring to the movement of the sensor since the Lagrangian sensor is used in this research (Tinka et al., 2013). The combination of the system model and the observation is represented by the state-space model and used in the DA method.
By considering one-dimensional flow of the river without any uncontrolled release of water flow, the system model is represented by 1-D Saint–Venant equations. These two equations coupled are first order hyperbolic partial differential equations (pde) derived from the conservation of mass and momentum. By considering a prismatic channel that have same cross-section throughout the length of channel with no lateral inflow, the equation is represented as (Tinka et al., 2013).
where A is the cross section, Q is the discharge or flow, L is the river reach, T is the free surface width, D is the hydraulic depth, Sf is the friction slope, So is the bed slope, Fg is the gravitational acceleration, hc is the distance of the centroid of the cross section from the free surface, P is the wetted perimeter, and m is the Manning roughness coefficient.
The system observation is represented by the velocity of the flow as measured by the sensors. The relation between the velocity of the sensor and the flow at the corresponding cross-section relies on assumptions made about the profile of the water velocity that considered as the observation model. The profile is the combination of the average velocity in the transverse and vertical direction. In transverse direction, the surface velocity profile is assumed to be quartic, and the von Karman logarithmic profile is assumed in the vertical direction. By considering a particle moving at a distance y from the center line and z from the surface, the relation between the particle’s velocity and the water flow is represented by the following equations (Tinka et al., 2013)
with
where w is the channel width; d is the water depth; Aq, Bq, and Cq are constants; and Kv is the Von Karman log constant.
During estimation process, the system and observation equation is represented as a state-space model that comprises of the parameters of the model, observation, system noise, and measurement noise. The channel is discretized into n cells with each cell and has same length. In the nonlinear system state estimation, the initial conditions and the boundary conditions of the system are required as the inputs. The uncertainties of the model and also the inaccuracies of the inputs measurements are considered as the system noise
where Xt is the state vector at time t
and the input ut contains the boundary conditions, i.e., the upstream flow and downstream stage.
where
where
The Bayesian theorem used by the DA method is represented as follows (Crisan and Doucet, 2002).
where
In this theorem, the observation data
where all parameters are defined in Eq. 14. Based on Eqs 14, 15, the posterior probability is very much depending on the likelihood function
where
In this research, several types of observation namely y and z positions of the sensors, and the velocity of the sensors are considered. The positions of the sensors are used in determining the estimated observation using Eqs 4–8. Next, the obtained estimated velocity is compared with the measured velocity of the sensors and form the likelihood function for this case. Since the likelihood function is important in estimation, the continuous observations from the sensors are desired to secure this function throughout the estimation process. In the event of missing observation data, the likelihood function is affected, and thus limits the ability of the standard DA method. Therefore, the MIPF method is introduced to perform estimation with new input data that replace the missing data. The availability of the observations is checked at each time instance. The missing data are handled by introducing a random indicator variable, Rt,k (Abaza et al., 2014).
Consider the overall observation
The introduction of the new data may affect the error difference between the observation from the new data and the estimated observation. Therefore, the SVSF method that is robust and stable in the estimation process is introduced to handle this problem. The combination of the MIPF and SVSF capable of handling state estimation with missing information and error differences problem.
During missing information, several random observations or imputations is introduced in the estimation process. The imputations are drawn from the proposal function (Chai and Draxler, 2014)
where
where
where
where
where
where
The algorithm of the MIPF–SVSF is the combination of the MIPF and SVSF. The MIPF is functioning to handle the nonlinearity and missing data problem, while the SVSF is used to deal the noise problem. The algorithm of the MIPF–SVSF method is presented as follows:
where
Draw random imputation/observation from proposal function (as in MIPF) from the previously available measurement
where
- Prediction in SVSF involves producing the one step state estimation and the covariance P for particles generation
where
- Updating in SVSF involve updating the state estimation and covariance P for particles generation
where
the saturation function,
- Generate N particles of M imputation by using the previously obtained estimated state,
Determine the important weight of the particles from the previous weight,
The important weight,
Next, the effective sample size,
where
where
where
In order to perform the convergence analysis, the state-space model of the system and observation, and the MIPF–SVSF are reformulated into probability representation.
Let
where
where
where
where
The estimation using MIPF–SVSF is represented by the posterior probability density function that considers both the available observation and the missing observation. The distribution of the overall posterior probability density
where
where
where
By combining Eq. 51 with Eq. 52, the overall posterior probability density can be reformulated into Eq. 53. This equation shows the relationship between the probability density during available observation,
Since the missing observation is very much affecting the probability distribution, the additional knowledge of this problem is covered by introducing the empirical distribution,
where
given
where
Consider the one step prediction error
where
By using the Taylor series expansion around
where
where
that gives
where
where
where
Theorem 1. The one step prediction error covariance,
where
Theorem 2. The filtering error covariance
where
Lemma 1. Given matrices A, H, E, and F with appropriate dimensions such that
Theorem 3: Consider Theorem 1 and Theorem 2 and assume
where
are satisfied.The filter gain for the upper bound
Lemma 2. For
and
Then the solutions for
Satisfy.
Proof. By referring to Lemma 2, rewrite the error covariance matrices as the function of
where
where
which gives
Consider: if
Assumption. The likelihood function
Lemma 3. For any
Then, for any
where
ProofConsider
Let
and, as
Using Minkowski’s inequality
where
Lemma 4. For any
where
Proof: Consider
For the first part of Eq. 90
Using Minkowski’s inequality
Lemma 5. For any
where
Proof: Consider
For the first part of Eq. 95
For the second part of Eq. 94 that refer to Eq. 89
Using Minkowski’s inequality
Lemma 6. For any
There exists a constant
where
ProofConsider the following
By using Minkowski’s inequality
Let
and
That gives
Theorem 4. For all
where
In this section, the estimation of the river flow and stage, and the velocity of the last drifter are presented. Consider the measurements are suffering from the missing data that affect the estimation process. The MIPF–SVSF is proposed to perform the state estimation by applying several numbers of particles and imputations as described in the previous section. The performance of this method is evaluated by finding the root mean square error (RMSE), standard deviation (SD) (Chai and Draxler, 2014), mean absolute error (MAE), and computational time (Liang et al., 2012) between the measured velocity and the estimated velocity. The RMSE, SD, MAE, and computational time of the MIPF–SVSF are compared with the same parameters from forward simulation, EKF during complete data, PF during complete data, and MIPF.
In this research, the measurements from the drifters (Lee et al., 2011) are used in the estimation of the flow, stage, and cross section that are later used to estimate the velocity of the sixth sensor. The estimated sensor velocity is proportional to the velocity of the river flow. During estimation process, the river system is discretized into 60 cells with 5 m interval. The temporal step size is chosen as 1 s. Since the data about the bottom of the river is unavailable, the bed slope is considered as zero.
The estimation is carried out by combining the system and the observation. During no missing data, the estimation is carried out by the PF–SVSF. The MIPF–SVSF is proposed for the state estimation with missing data problem. Consider the observation is suffering from three types of missing data namely missing velocity data, missing position data, and missing combination of velocity and position data at the same time. Whereby each case has 10, 20, and 30% missing data (Ugryumova et al., 2015). During estimation, the missing data is replaced by several number of imputations. The imputations are generated based on the previously available data. For each imputation, the error difference between the estimated measurement by the SVSF, and the observation from the imputation is calculated. This error is bounded by using the smoothing boundary layer vector. The bounded error and the convergence rate are used in producing the SVSF gain to obtain the new state value.
Next, the new state by the SVSF with their covariance are used to generate several particles. The particles and the observation from the imputation is combined to form the likelihood function. From the likelihood function, the important weight of the particles is obtained. The particles and their weight are used to produce estimated state that consists of the flow, stage, and cross-sectional area. The number of estimated states is depending on the number of imputations. The mean of these states is the desired new estimated state by the proposed method. The estimation process is repeated for 400 s with the error difference between the current result and the observation is use in the next estimation cycle. Since the proposed method includes the convergence rate and smoothing boundary layer vector, the error difference between the estimated velocity and the observation is reduced. By reducing the error, the MIPF–SVSF will have less computational time compared to the MIPF.
The estimation process by the DA method includes the merging of the system and the observation. Three types of missing data cases are considered in this research as mentioned earlier. For each case, several numbers of imputations, namely 5, 10, 15, and 20 are injected during estimation with 50 particles. The same number of particles are applied for the whole estimation process due to the good estimation result by the PF using these particles during no missing data. Figure 1 shows the estimated flow and stage by forward simulation, the EKF (no missing data), MIPF and MIPF–SVSF for 30% missing velocity data. The overall flow estimation by the MIPF is smaller than the EKF and forward simulation, while the overall estimation by the MIPF–SVSF is smaller than the other methods. Besides that, the MIPF also produce estimated stage that is bigger than the EKF and the forward simulation. However, the estimated stage by the MIPF–SVSF is bigger than the MIPF. The state estimation by the proposed method seems to be reasonable. Therefore, the performance of the method is evaluated by finding the velocity of the final drifter and compared with the measurement. The velocity of the final drifter is obtained by combining the estimated flow and cross-sectional area at the corresponding cell. Figure 2 shows the velocity of the final drifter predicted by the forward simulation, EKF (no missing data), MIPF, and MIPF–SVSF. The figure shows that the proposed method helps the estimation to converge to the desired value. This can be seen by smaller difference between the estimated and the true state, compared to the other methods.
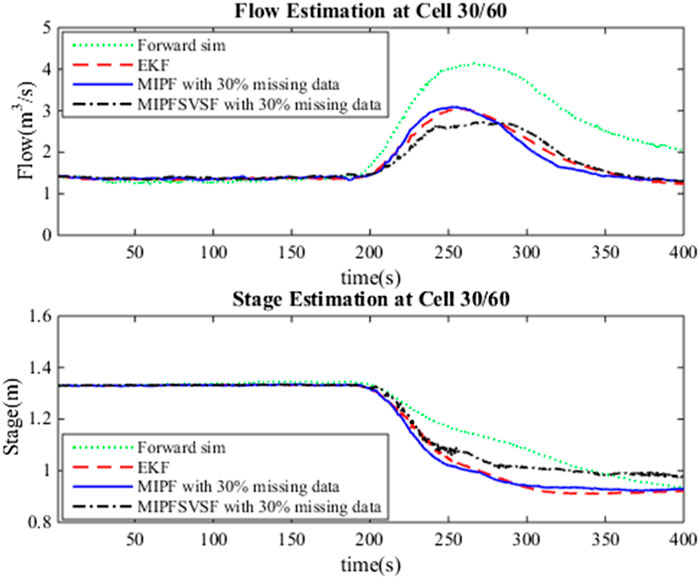
FIGURE 1. Estimated flow and stage at the 30th cell, forward simulation, EKF during no missing data, MIPF with 30% missing data, and MIPF–SVSF with 30% missing data.

FIGURE 2. Estimated velocity of the final drifter using forward simulation, EKF during no missing data, MIPF with 30% missing data, and MIPF-SVSF with 30% missing data.
For further analysis and comparison of the performance of the MIPF–SVSF, the RMSE, the SD, the MAE, and the computational time are determined as in Table 1, Table 2 and Table 3. The performance of the MIPF–SVSF is compared with the MIPF and the PF and the EKF from Table 4. Since the proposed method is the upgraded version of the MIPF, the performance of the MIPF is first examined. By considering all missing data cases, the MIPF is able to produce RMSE, SD, and MAE that is close to the estimation result by the PF during complete data. These show that the external input data successfully fill in the missing part. Besides that, the combination of the SVSF with the MIPF improves the estimation result through smaller RMSE, SD, and MAE compared to the MIPF for all missing data cases. This indicates that the SVSF method successfully bound the error difference in the estimation process. The bounded error also helps to reduce the MIPF–SVSF’s computational time compared to the MIPF through the generation of gain that brought the estimation velocity closer to the observation. The results are represented by bold numbers in Tables 1–3. The selection is made based on the smallest value among variables.
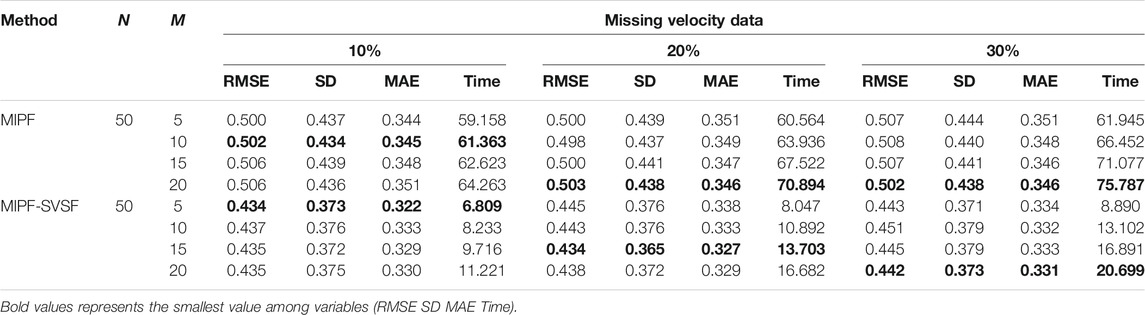
TABLE 1. Performance of the MIPF and MIPF–SVSF during missing velocity data.
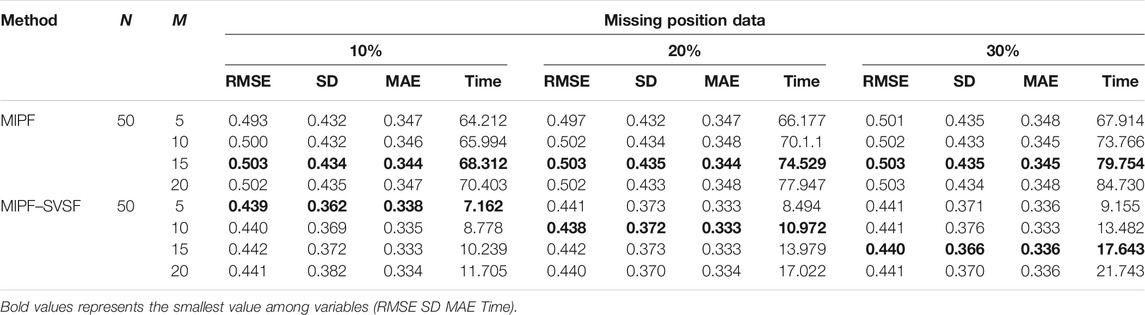
TABLE 2. The performance of the MIPF and MIPF–SVSF during missing position data.
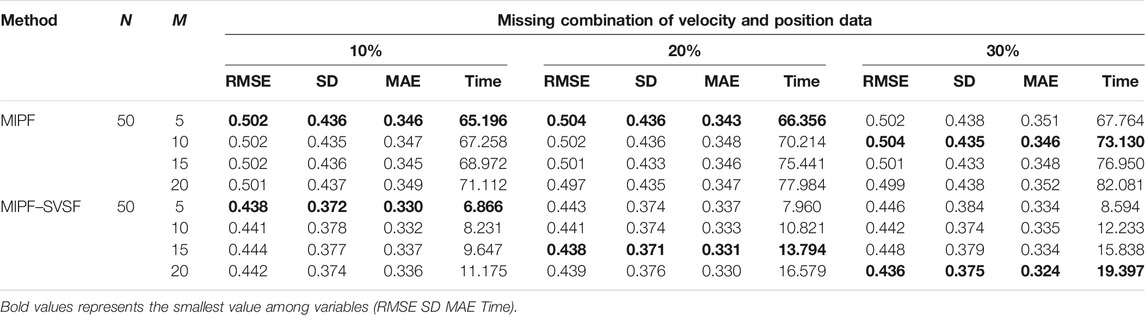
TABLE 3. The performance of the MIPF and MIPF-SVSF during missing combination of position and velocity data.

TABLE 4. The performance of the Forward simulation, EKF, and PF during complete data.
By using 50 particles with different number of imputations, the performance of state estimation by MIPF–SVSF during missing velocity data is shown in Table 1. The result shows that the increasing number of imputations will reduce the RMSE, SD, and MAE. However, too many imputations may diverge the estimation from the true value. This can be seen through the sudden increase of RMSE, SD, and MAE after reduction. Besides that, the number of imputations also related to the percentage of missing data. Whereby the higher percentage of missing observation data require higher number of imputations. The same response is shown during the state estimation with missing position data and missing combination of velocity and position data as shown by Tables 2, 3, respectively. The increasing number of imputations reduces the RMSE, SD, and MAE, and the suitable number of imputations is selected before the divergence of the estimation occurred. For different percentages of missing data, the appropriate number of imputations is considered based on the response from RMSE, SD, and MAE.
In this research, the number of particles is fixed to 50 particles throughout the estimation process. Based on the result represented by bold numbers in Tables 1–3, the MIPF–SVSF has less RMSE, SD, MAE, and computational time compared to the MIPF for all missing data cases. The percentage improvement of the proposed method compared to MIPF in terms of RMSE is between 12 and 13.5%, SD is between 14 and 15%, and MAE is between 2 and 7%. While for the computational time, the percentage of reduction is between 73 and 90%. Therefore, the proposed method still can have small RMSE, SD, MAE and computational time under lower number of particles. Since the number of particles and imputations are related, a smaller number of imputations for MIPF–SVSF compared to the MIPF is enough for good estimation performance.
The MIPF–SVSF is the extension of the MIPF method with the addition of the SVSF. The proposed method introduces several numbers of imputation based on the previously available data to replace the missing data. There are three types of missing data considered in the research, namely, missing velocity data, missing position data, and the missing combination of velocity and position. The convergence analysis of this method shows that the number of particles and imputations depends on the likelihood function that represents error difference between the estimated observation and the imputation data that replaces the missing data. Large error difference requires high number of particles and imputation to converge the estimation to the true state. The SVSF reduces the error difference through the introduction of convergence rate and the smoothing boundary layer vector. These variables are used to generate the particles and their weight and form the estimated state. The performance comparison between MIPF–SVSF and MIPF shows that MIPF–SVSF has better performance than the MIPF in terms of RMSE, SD, MAE and computational time. Besides that, different missing data cases with different percentages of missing data require different combination of particles and imputations. The MIPF–SVSF requires smaller combination of particles and imputation compared to the MIPF for all missing data cases.
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author.
ZI and NJ: Conceptualization; Methodology; Validation; Investigation; Visualization; Writing—original draft. ZI: Formal analysis; Methodology; Validation; Investigation; Visualization; Writing—original draft.
The research has been carried out under program Research Excellence Consortium (JPT (BPKI) 1000/016/018/25 (57)) provided by Ministry of Higher Education Malaysia (MOHE).
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
The author also would like to thank Universiti Teknologi Malaysia (UTM) for work and facilities support.
Abaza, M., Anctil, F., Fortin, V., and Turcotte, R. (2014). Sequential Streamflow Assimilation for Short-Term Hydrological Ensemble Forecasting. J. Hydrol. 519, 2692–2706. doi:10.1016/j.jhydrol.2014.08.038
Adnan, R. M., Yuan, X., Kisi, O., and Anam, R. (2017). Improving Accuracy of River Flow Forecasting Using LSSVR with Gravitational Search Algorithm. Adv. Meteorol. 2017. doi:10.1155/2017/2391621
Arulampalam, M. S., Maskell, S., Gordon, N., and Clapp, T. (2002). A Tutorial on Particle Filters for Online Nonlinear/non-Gaussian Bayesian Tracking. IEEE Trans. Signal. Process. 50 (2), 174–188. doi:10.1109/78.978374
Aswathy, S., Sajikumar, N., and Mehsa, M. (2016). Watershed Modelling Using Control System Concept. Proced. Tech. 24, 39–46. doi:10.1016/j.protcy.2016.05.007
Bertino, L., Evensen, G., and Wackernagel, H. (2003). Sequential Data Assimilation Techniques in Oceanography. Int. Stat. Rev. 71 (2), 223–241. doi:10.1111/j.1751-5823.2003.tb00194.x
Bjerklie, D. M., Birkett, C. M., Jones, J. W., Carabajal, C., Rover, J. A., Fulton, J. W., et al. (2018). Satellite Remote Sensing Estimation of River Discharge: Application to the Yukon River Alaska. J. Hydrol. 561 (April), 1000–1018. doi:10.1016/j.jhydrol.2018.04.005
Blythe, T. L., and Schmidt, J. C. (2018). Estimating the Natural Flow Regime of Rivers with Long-Standing Development: The Northern Branch of the Rio Grande. Water Resour. Res. 54 (2), 1212–1236. doi:10.1002/2017wr021919
Cao, Y., Ye, Y., Liang, L., Zhao, H., Jiang, Y., Wang, H., et al. (2019). A Modified Particle Filter‐Based Data Assimilation Method for a High‐Precision 2‐D Hydrodynamic Model Considering Spatial‐temporal Variability of Roughness: Simulation of Dam‐Break Flood Inundation. Water Resour. Res. 55, 6049–6068. doi:10.1029/2018wr023568
Chai, T., and Draxler, R. R. (2014). Root Mean Square Error (RMSE) or Mean Absolute Error (MAE)? - Arguments against Avoiding RMSE in the Literature. Geosci. Model. Dev. 7 (3), 1247–1250. doi:10.5194/gmd-7-1247-2014
Crisan, D., and Doucet, A. (2002). A Survey of Convergence Results on Particle Filtering Methods for Practitioners. IEEE Trans. Signal. Process. 50 (3), 736–746. doi:10.1109/78.984773
Ding, D., Wang, Z., Alsaadi, F. E., and Shen, B. (2015). Receding Horizon Filtering for a Class of Discrete Time-Varying Nonlinear Systems with Multiple Missing Measurements. Int. J. Gen. Syst. 44 (2), 198–211. doi:10.1080/03081079.2014.973732
Feng, J., Wang, Z., and Zeng, M. (2011). Recursive Robust Filtering with Finite-step Correlated Process Noises and Missing Measurements. Circuits Syst. Signal. Process. 30 (6), 1355–1368. doi:10.1007/s00034-011-9289-6
Gadsden, S. A., Al-Shabi, M., Arasaratnam, I., and Habibi, S. R. (2014). Combined Cubature Kalman and Smooth Variable Structure Filtering: A Robust Nonlinear Estimation Strategy. Signal. Process. 96 (PART B), 290–299. doi:10.1016/j.sigpro.2013.08.015
Gadsden, S. A., Habibi, S. R., and Kirubarajan, T. (2012). The Smooth Particle Variable Structure Filter. Trans. Can. Soc. Mech. Eng. 36 (2), 177–193. doi:10.1139/tcsme-2012-0013
Habibi, S. (2007). The Smooth Variable Structure Filter. Proc. IEEE 95 (5), 1026–1059. doi:10.1109/jproc.2007.893255
He, X., Sithiravel, R., Tharmarasa, R., Balaji, B., and Kirubarajan, T. (2014). A Spline Filter for Multidimensional Nonlinear State Estimation. Signal. Process. 102, 282–295. doi:10.1016/j.sigpro.2014.03.051
Hu, J., Wang, Z., Gao, H., and Stergioulas, L. K. (2012). Extended Kalman Filtering with Stochastic Nonlinearities and Multiple Missing Measurements. Automatica 48 (9), 2007–2015. doi:10.1016/j.automatica.2012.03.027
Ismail, Z. H., and Jalaludin, N. A. (2016). River Flow and Stage Estimation With Missing Observation Data Using Multi Imputation Particle Filter (MIPF) Method. J. Telecommun. Electron. Comput. Eng. (JTEC) 8 (11), 145–150.
Jain, S. K., Mani, P., Jain, S. K., Prakash, P., Singh, V. P., Tullos, D., et al. (2018). A Brief Review of Flood Forecasting Techniques and Their Applications. Int. J. River Basin Manage. 16 (3), 329–344. doi:10.1080/15715124.2017.1411920
Kang, H. (2013). The Prevention and Handling of the Missing Data. Korean J. Anesthesiol. 64 (5), 402–406. doi:10.4097/kjae.2013.64.5.402
Kim, S., Seo, D.-J., Riazi, H., and Shin, C. (2014). Improving Water Quality Forecasting via Data Assimilation – Application of Maximum Likelihood Ensemble Filter to HSPF. J. Hydrol. 519, 2797–2809. doi:10.1016/j.jhydrol.2014.09.051
Lee, H.-C., Lin, C.-Y., Lin, C.-H., Hsu, S.-W., and King, C.-T. (2011). A Low-Cost Method for Measuring Surface Currents and Modeling Drifting Objects. IEEE Trans. Instrum. Meas. 60 (3), 980–989. doi:10.1109/tim.2010.2062730
Li, D. Z., Wang, W., and Ismail, F. (2014). A Mutated Particle Filter Technique for System State Estimation and Battery Life Prediction. IEEE Trans. Instrum. Meas. 63 (8), 2034–2043. doi:10.1109/tim.2014.2303534
Liang, K., Lingfu, K., and Peiliang, W. U. (2012). “Adaptive Gaussian Particle Filter for Nonlinear State Estimation,” in 31st Chinese Control Conference, Hefei, China, July 25-27, 2012, 2146–2150.
Litrico, X., and Fromion, V. (2009). “Modeling of Open Channel Flow,” in Modeling and Control of Hydrosystems. 1st ed. (London, UK: Springer-Verlag), 17–41.
Liu, W.-Q., Wang, X.-M., and Deng, Z.-L. (2017). Robust Centralized and Weighted Measurement Fusion Kalman Estimators for Uncertain Multisensor Systems with Linearly Correlated white Noises. Inf. Fusion 35, 11–25. doi:10.1016/j.inffus.2016.08.002
Liu, Y., and Gupta, H. V. (2007). Uncertainty in Hydrologic Modeling: Toward an Integrated Data Assimilation Framework. Water Resour. Res. 43, 1–18. doi:10.1029/2006wr005756
Mao, J., Ding, D., Song, Y., Liu, Y., and Alsaadi, F. E. (2017). Event-based Recursive Filtering for Time-Delayed Stochastic Nonlinear Systems with Missing Measurements. Signal. Process. 134, 158–165. doi:10.1016/j.sigpro.2016.12.004
Mukherjee, A., and Sengupta, A. (2010). Likelihood Function Modeling of Particle Filter in Presence of Non-stationary Non-gaussian Measurement Noise. Signal. Process. 90 (6), 1873–1885. doi:10.1016/j.sigpro.2009.12.005
Ogundijo, O. E., Elmas, A., and Wang, X. (2016). Reverse Engineering Gene Regulatory Networks from Measurement with Missing Values. J. Bioinform Sys Biol. 2017 (2017), 2. doi:10.1186/s13637-016-0055-8
Pintelon, R., Ugryumova, D., Vandersteen, G., Louarroudi, E., and Lataire, J. (2017). Time-Variant Frequency Response Function Measurement in the Presence of Missing Data. IEEE Trans. Instrum. Meas. 66 (11), 3091–3099. doi:10.1109/tim.2017.2728218
Rafieeinasab, A., Seo, D.-J., Lee, H., and Kim, S. (2014). Comparative Evaluation of Maximum Likelihood Ensemble Filter and Ensemble Kalman Filter for Real-Time Assimilation of Streamflow Data into Operational Hydrologic Models. J. Hydrol. 519, 2663–2675. doi:10.1016/j.jhydrol.2014.06.052
Rigatos, G. G. (2012). A Derivative-free Kalman Filtering Approach to State Estimation-Based Control of Nonlinear Systems. IEEE Trans. Ind. Electron. 59 (10), 3987–3997. doi:10.1109/tie.2011.2159954
Sichangi, A. W., Wang, L., and Hu, Z. (2018). Estimation of River Discharge Solely from Remote-Sensing Derived Data: An Initial Study over the Yangtze River. Remote Sens. 10 (9). doi:10.3390/rs10091385
Smith, P. J., Thornhill, G. D., Dance, S. L., Lawless, A. S., Mason, D. C., and Nichols, N. K. (2013). Data Assimilation for State and Parameter Estimation: Application to Morphodynamic Modelling. Q.J.R. Meteorol. Soc. 139 (671), 314–327. doi:10.1002/qj.1944
Solonen, A., Hakkarainen, J., Ilin, A., Abbas, M., and Bibov, A. (2014). Estimating Model Error Covariance Matrix Parameters in Extended Kalman Filtering. Nonlin. Process. Geophys. 21 (5), 919–927. doi:10.5194/npg-21-919-2014
Tarpanelli, A., Santi, E., Tourian, M. J., Filippucci, P., Amarnath, G., and Brocca, L. (2019). Daily River Discharge Estimates by Merging Satellite Optical Sensors and Radar Altimetry through Artificial Neural Network. IEEE Trans. Geosci. Remote Sensing 57 (1), 329–341. doi:10.1109/tgrs.2018.2854625
Tinka, A., Rafiee, M., and Bayen, A. M. (2013). Floating Sensor Networks for River Studies. IEEE Syst. J. 7 (1), 36–49. doi:10.1109/jsyst.2012.2204914
Ugryumova, D., Pintelon, R., Vandersteen, G., and Member, S. (2015). Frequency Response Function Estimation in the Presence of Missing Output Data. IEEE Trans. Instrum. Meas. 64 (2), 541–553. doi:10.1109/tim.2014.2342431
Wang, S., Fang, H., and Tian, X. (2017). Robust Estimator Design for Networked Uncertain Systems with Imperfect Measurements and Uncertain-Covariance Noises. Neurocomputing 230, 40–47. doi:10.1016/j.neucom.2016.11.035
Zhang, X.-P., Khwaja, A. S., Luo, J.-A., Housfater, A. S., and Anpalagan, A. (2015). Multiple Imputations Particle Filters: Convergence and Performance Analyses for Nonlinear State Estimation with Missing Data. IEEE J. Sel. Top. Signal. Process. 9 (8), 1536–1547. doi:10.1109/jstsp.2015.2465360
Keywords: data assimilation, particle filter, smooth variable structure filter, marine observation, state estimation
Citation: Ismail ZH and Jalaludin NA (2022) An Augmented Multiple Imputation Particle Filter for River State Estimation With Missing Observation. Front. Robot. AI 8:788125. doi: 10.3389/frobt.2021.788125
Received: 01 October 2021; Accepted: 28 December 2021;
Published: 18 February 2022.
Edited by:
Tin Lun Lam, The Chinese University of Hong Kong, ChinaReviewed by:
Nabil Derbel, University of Sfax, TunisiaCopyright © 2022 Ismail and Jalaludin. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Z. H. Ismail, em9vbEB1dG0ubXk=
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.