 Shane D. McLean1
Shane D. McLean1 Paul Pop
Paul Pop Silviu S. Craciunas
Silviu S. Craciunas
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Robot. AI , 04 January 2022
Sec. Robotic Control Systems
Volume 8 - 2021 | https://doi.org/10.3389/frobt.2021.762227
Modern Advanced Driver-Assistance Systems (ADAS) combine critical real-time and non-critical best-effort tasks and messages onto an integrated multi-core multi-SoC hardware platform. The real-time safety-critical software tasks have complex interdependencies in the form of end-to-end latency chains featuring, e.g., sensing, processing/sensor fusion, and actuating. The underlying real-time operating systems running on top of the multi-core platform use static cyclic scheduling for the software tasks, while the communication backbone is either realized through PCIe or Time-Sensitive Networking (TSN). In this paper, we address the problem of configuring ADAS platforms for automotive applications, which means deciding the mapping of tasks to processing cores and the scheduling of tasks and messages. Time-critical messages are transmitted in a scheduled manner via the timed-gate mechanism described in IEEE 802.1Qbv according to the pre-computed Gate Control List (GCL) schedule. We study the computation of the assignment of tasks to the available platform CPUs/cores, the static schedule tables for the real-time tasks, as well as the GCLs, such that task and message deadlines, as well as end-to-end task chain latencies, are satisfied. This is an intractable combinatorial optimization problem. As the ADAS platforms and applications become increasingly complex, such problems cannot be optimally solved and require problem-specific heuristics or metaheuristics to determine good quality feasible solutions in a reasonable time. We propose two metaheuristic solutions, a Genetic Algorithm (GA) and one based on Simulated Annealing (SA), both creating static schedule tables for tasks by simulating Earliest Deadline First (EDF) dispatching with different task deadlines and offsets. Furthermore, we use a List Scheduling-based heuristic to create the GCLs in platforms featuring a TSN backbone. We evaluate the proposed solution with real-world and synthetic test cases scaled to fit the future requirements of ADAS systems. The results show that our heuristic strategy can find correct solutions that meet the complex timing and dependency constraints at a higher rate than the related work approaches, i.e., the jitter constraints are satisfied in over 6 times more cases, and the task chain constraints are satisfied in 41% more cases on average. Our method scales well with the growing trend of ADAS platforms.
Advanced Driver Assistance Systems (ADAS), present in more and more modern consumer vehicles, perform complex functions that range from driver assistance, e.g., automated or assisted parking, lane changing, etc., to fully autonomous driving. In modern ADAS systems, there is a drive towards moving functions from hardware to software and the architecture from distributed to centralized, allowing modularization within an integrated hardware platform that can be cooperatively used and centrally managed (Niedrist, 2018). This drive has multiple advantages, like reusability and portability, but presents several challenges, especially in terms of real-time, testing, and safety (Gietelink et al., 2006). The fusion of multiple software functions of different criticality levels onto the same hardware platform has to be done in a composable manner with guaranteed temporal and spatial isolation without sacrificing real-time capabilities. This mixed-criticality paradigm applied to the automotive domain requires new concepts in terms of safety-critical temporal and spatial isolation, new scheduling results and configurations tools, as well as analysis methods for SIL certification (c.f. (Hammond et al., 2015; Niedrist, 2018)).
Generally, integrated ADAS platforms are composed of heterogeneous multi-core CPUs and Systems-on-chip (SoCs) of different performance and safety levels that are interlinked by a (real-time) communication network (Sommer et al., 2013; Becker et al., 2016b). In such integrated platforms, the ADAS functions have complex timing requirements and feature a complex interdependence between sensors, control software, and actuators. For example, one function for driver assistance collects sensor data from both cameras and distance sensors (ultrasonic, LIDAR) into a sensor fusion layer which transmits the data via the time-aware communication backbone to control algorithms that activate, e.g., the emergency brake system. This succession of function execution and message transmission creates a temporal dependency chain, which has to comply with a set of timing requirements in terms of latency. In order to guarantee both the interdependence and real-time behavior of tasks and their messages, the safety-critical ADAS functions and their communication frames have to be scheduled appropriately. Moreover, other less critical systems, like infotainment, are also integrated into the same platform and must not interfere with the real-time behavior of critical functions.
The scheduling of task sets with dependencies has been a well-studied topic within the real-time community. Task schedules with inter-task dependencies are computed in (Chetto et al., 1990) by modifying the offsets and deadlines of the individual tasks and then using EDF to schedule the new task set (Buttazzo, 2011). In (Choi and Agrawala, 2000) the notion of absolute and relative timing constraints (i.e., events are temporally dependent on each other) for source and sink task requirements are introduced. Furthermore, the authors present a scheduling approach for uniprocessor systems with complex timing constraints such as jitter requirements. In (Fohler, 1994) the authors compute static schedules for tasks that communicate through bounded delay protocols like TDMA or TTP using dependency graphs. The work in (Tindell and Clark, 1994) presents an analysis of the schedulability of tasks that communicate using the TDMA protocol. In (Abdelzaher and Shin, 1999) an optimal task schedule for communicating tasks is generated using a branch-and-bound approach. A similar approach is introduced in (Peng et al., 1997) with modified optimization criteria. (Craciunas et al., 2014) presents a similar heuristic scheduling approach to ours which uses EDF simulation to create static schedules for tasks with communication and precedence dependencies but in contrast to our work, the results only apply for dependencies between tasks with equal periods. The temporal dependencies between tasks presented in the prior work described above are not as complex as the ones arising from the ADAS task chains where not only task periods can be different, but the correctness of the chain dependency is related to individual task jobs. Multi-rate tasks and complex precedence constraints have been analyzed in (Forget et al., 2011, 2017; Mubeen and Nolte, 2015). Additionally, in (Isović and Fohler, 2000), a two-step approach for distributed systems is introduced, which is based on an offline computation and an online EDF mechanism for scheduling tasks with complex constraints like jitter and job-level precedence requirements.
In the context of ADAS, the complex task chain requirements have been addressed in terms of computing the worst-case end-to-end latency of multi-rate chains, c.f. (Becker et al., 2017), depending on the available system information, e.g., scheduling algorithm or task offsets. Our approach is different in that it generates schedules that already adhere to the task chain requirements, which does not necessitate a further analysis since the schedule construction guarantees the real-time requirements. In (Rajeev et al., 2010), the authors present a model-checking-based method to compute worst-case response times and end-to-end latencies of tasks that have chain dependency and communication constraints. In (Becker et al., 2016a), the authors introduce a task chain latency analysis that does not require information about the concrete scheduling algorithm. (Verucchi et al., 2020) use an existing list-scheduling algorithm but apply it on a directed acyclic graph (DAG), which is constructed from multi-rate task sets such that complex precedence and timing constraints are captured and satisfied.
In (Lukasiewycz et al., 2012) a modular framework for ILP-based scheduling of time-triggered distributed automotive systems is presented, where both bus access and operating system schedules are created. The end-to-end latency of chains only applies single-rate dependency chains, and the method suffers from an exponential increase in runtime with increasing the number of tasks and messages. An extension that adds an incremental step in order to reduce the runtime complexity of the schedule generation has been proposed in (Sagstetter et al., 2014), where the focus is on integrating locally optimized schedules into a globally non-optimal solution. In terms of the communication backbone, the scheduling problem for TSN networks has been addressed in, e.g., (Craciunas et al., 2016; Serna Oliver et al., 2018) for fully deterministic communication needs, including latency and jitter requirements without taking into account the schedule of the communicating tasks. Furthermore, the combined task and message scheduling problem has also been thoroughly studied for other types of networks, e.g., TTEthernet (Craciunas and Serna Oliver, 2016), shared registers (Becker et al., 2016a), or the Universal Communication Model (Pop et al., 2003).
In our earlier work (McLean et al., 2020) we considered that the communication backbone is done via Peripheral Component Interconnect Express (PCIe), and we have used a periodic real-time task model in which the worst-case execution time (WCET) of a task changes based on the core speed and the communication is modeled as overhead at the end of task instance execution. This paper extends our work to consider the IEEE 802.1 Time-Sensitive Networking (TSN) deterministic Ethernet standard for the communication. TSN is becoming a de-facto standard in several areas, e.g., industrial, automotive, avionics, space, with a broad industry adoption and several vendors developing TSN switches. This paper presents a heuristic-based scheduling algorithm for ADAS platforms that considers the different dimensions of timing and dependency requirements and is designed with scalability in mind. The optimization approaches are based on metaheuristics (Simulated Annealing and Genetic Algorithm), which take into account not only the timing constraints but also design goals, such as function allocation on computing units. We consider both PCIe and TSN for the communication. Future work may also include the LET model (Biondi and Di Natale, 2018) which is becoming increasingly popular in the automotive domain since it can provide deterministic communication behavior.
To the best of our knowledge, this is the first work to propose a heuristic-based solution to the combined scheduling problem in ADAS platforms that requires a solution for the task-to-core assignment, static task schedule generation, and the scheduling of TSN messages sent by the tasks, which respects both task and complex task chain timing constraints.
We start by introducing the platform and application models in Section 2 followed by a description of the scheduling problem in Section 3. We introduce the algorithm in Section 4 followed by an experimental evaluation in Section 5 and conclude the paper in Section 6.
The modern integrated ADAS hardware platform features a multi-core multi-SoC embedded ECU with a variety of CPUs and Graphics Processing Units (GPUs) running at different speeds, which are interconnected through either a deterministic Ethernet backbone, such as TSN (IEEE, 2016b) or TTEthernet (Steiner et al., 2011), or through PCIe. RazorMotion (TTTech Computertechnik AG, 2018), for example, features a Renesas RH850P/1H-C ASIL D MCU with lockstep cores running at 240 MHz and two Renesas R-Car H3 ASIL B SoCs with four Cortex A57, four Cortex A53, one Cortex R7, one IMP-X5, and one IMG PowerVR GX6650 GPU.
Figure 1 presents a high-level view of the ADAS platform, which is similar to the platform described in (Marija Sokcevic, 2020). Each host can run a different operating system depending on the safety and performance requirements. Each such OS can have a different scheduling policy, ranging from fixed-priority (AUTOSAR (Bunzel, 2011)) to table-driven or dynamic priority scheduling (typically in safety RTOSes). However, there is a growing tendency to use a table-driven static schedule execution due to the compositionality and isolation properties (Lukasiewycz et al., 2012; Sagstetter et al., 2014; Mehmed et al., 2017; Ernst et al., 2018), i.e., tasks that are already scheduled are not influenced by new tasks being added to the system. In order to provide a common execution environment and hardware abstraction, a middleware layer, e.g., the MotionWise (TTTech Computertechnik AG, 2018) layer, is running on top of each operating system. The middleware layer also ensures portability of software functions to be located according to their execution and safety requirements (Niedrist, 2018). Moreover, the middleware layer provides the capability to execute tasks according to a table-driven pre-computed schedule independent of the underlying OS dispatching mechanisms, which ensures temporal isolation (Mehmed et al., 2017). Hence, in this paper, we focus on creating static schedules for the table-driven dispatching mechanism of such ADAS systems.
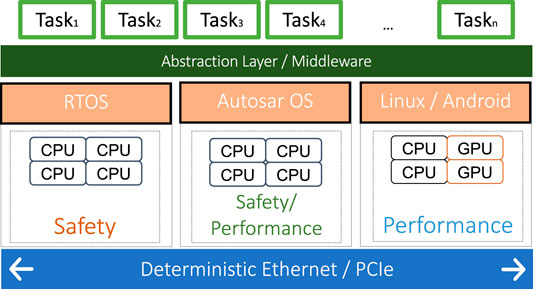
FIGURE 1. High-level platform model.
Tasks performing software functions of different criticality levels communicate with each other both on- and off-chip through different means. On-chip communication is usually done through buffers, message passing, or shared memory, while off-chip communication is achieved either through PCIe or TSN. The safety-critical communication also has to adhere to stringent timing requirements and has to be aligned to the execution schedule of the real-time tasks. For example, when PCIe is used, a message sending cost has to be taken into account when scheduling the respective communicating tasks. When using time-aware switched Ethernet technologies like TSN, the schedule of the messages has to be aligned to the execution of the tasks, and the end-to-end latency requirements comprising both task execution and message transmission have to be met.
We model an ADAS platform as a graph
Time-Sensitive Networking (IEEE, 2016b) addresses the need to have more determinism and real-time capabilities over standardized Ethernet networks. To achieve this, TSN defines a series of amendments to the IEEE 802.1Q standard, as well as stand-alone mechanisms and protocols (e.g., 802.1ASrev). TSN has already seen adoption in the industrial domain and is becoming increasingly relevant in the automotive domain. The main mechanisms out of the TSN ecosystem that we consider in this paper are the clock synchronization protocol IEEE 802.1ASrev (IEEE, 2016a), which provides a synchronized clock reference, and the timed-gate functionality of IEEE 802.1Qbv (IEEE, 2015) bringing scheduled communication capabilities on the egress ports of devices. The timed-gate mechanism is essentially a shaping gate that forwards selected message streams from each egress queue according to the transmission schedule encoded in so-called Gate-Control Lists (GCL). A TSN stream is defined by a payload size, a talker (sender), one or more listeners (receivers), and optional timing requirements in terms of jitter and latency. The global schedule synthesis has been studied in (Craciunas et al., 2016; Dürr and Nayak, 2016; Pop et al., 2016; Serna Oliver et al., 2018) focusing on enforcing deterministic transmission, temporal isolation, and compositional system design for critical streams with end-to-end latency requirements.
A communication link is modeled as a directed edge is represented by two vertices
On top of this platform, many different software functions implemented by different vendors must be integrated and deployed. It is crucial that software functions (which may be tested independently) can be integrated with other software functions compositionally. The system is composed of applications (called tasks or runnables) that are either pre-assigned to cores or must be assigned by the scheduling algorithm. Tasks have real-time requirements, both in terms of execution (offset, deadline, jitter) as well as temporal dependencies arising from task chains (defined below). We model the applications as a set of n periodic tasks, Γ = {τi∣1 ≤ i ≤ n}, similar to the model in (Liu and Layland, 1973). A task τi is defined by the tuple (σi, ri, ϕi, Ci, Ti, Di) with σi representing the core, Ci denoting the worst-case execution time (WCET), Ti the period, ri the earliest release time, ϕi the initial offset/displacement of task arrival times and Di the relative deadline of the task under the assumption that Di ≤ Ti. Each real-time task τi yields an infinite set of instances (jobs) τi,k, k = 1, 2, … (Buttazzo, 2011, p. 80). Tasks can be preempted at any time instant on a timeline with macrotick granularity given by the underlying OS capabilities.
If a task τi is pre-assigned to a core, then its core σi will be given. Otherwise, we decide their assignment to a specific core, in that the σi of a task τi can take any value from a finite set of core values
The scheduling allows preemption, i.e., a schedule table can be constructed such that a task is interrupted by another task and then resumes its execution. Currently, tasks cannot migrate at run time after they have been assigned to a core, but in the future, we envision that task migration, when done correctly with respect to the deterministic timing behavior, will allow even better resource utilization.
Tasks may exchange messages. A message is modeled as a flow (stream)
Each task may have implicit timing constraints arising from the task definition and explicit design parameters related to arrival offsets and/or deadline requirements. Hence, a task must execute periodically with the given period Ti, and in each period, it must finish its worst-case execution Ci within the defined deadline Di, starting after the earliest release time ri. In addition, tasks may also have jitter requirements, i.e., constraints on the variance of execution of consecutive period instances (Buttazzo, 2011, p. 81-82), due to control loop considerations (Di Natale and Stankovic, 2000). We denote the jitter requirements of a task τi with Ji and the observed jitter ji, i.e., the maximal deviation of both starting and finishing times for any two consecutive task instances are bounded by Ji.
Other timing requirements are related to message passing between tasks, where the communication latency has to be considered. The most complex set of timing requirements come from the so-called task (or event) chains (c.f. (Becker et al., 2016a)). A task chain specifies that at least one instance of every task in the given task chain list has to be executed in the specified order within a given maximum end-to-end reaction latency. These chains also have a priority, pi, which can be used for optimization criteria. Since the tasks in the chain can be on different hosts/cores, the communication needs have to be included in the end-to-end latency considerations. In a PCIe backbone, the latencies between communicating tasks are modeled and enforced as an additional delay after executing the sending tasks. In the case of TSN, the frame schedule must be aligned to the task execution to ensure that the messages are sent after the sending task has been executed and before the receiving task starts. Please note that tasks in the chains may have different activation patterns and periodicity, i.e., we are considering multi-rate chains (c.f. (Becker et al., 2017)).
We give a simple example of a task chain in Figure 2 composed of 4 tasks, a source (τ1), two processing tasks (τ2, τ3) and a sink (τ4) with periods of 20 ms, 20 ms, 10 ms and 20 ms, respectively. The critical communication between τ1 and τ2 is done off-chip through the TSN network over two switches (SW1 and SW2) since τ1 and τ2 are running on different SoCs. For the purposes of this illustration, tasks τ2, τ3, and τ4 are located on the same core, and the communication is assumed to be in 0-time. From each instance of the source, there needs to be a succession of instances of the other tasks in the right order such that the latency is not exceeded. It is allowed that an instance of the processing or sink tasks merges multiple signals. In the example, the sink merges the signal from two execution instances of the processing task τ3. The communication frames from τ1 to τ2 have to be scheduled in such a way that the message is forwarded through the switches and arrives at τ2 before the respective instance of τ2 executes. The latency of the communication needs to be also included in the total end-to-end latency.
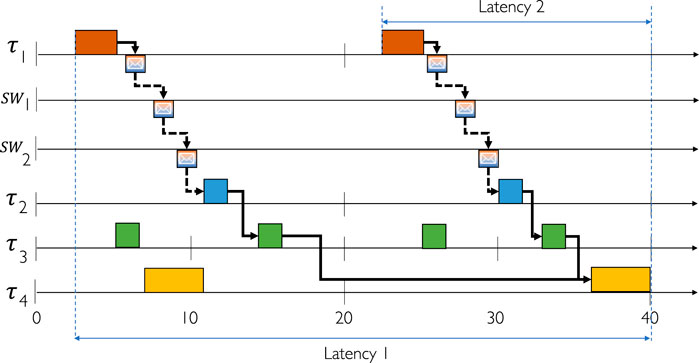
FIGURE 2. Task chain example with TSN communication.
Let
where hpi is the hyperperiod of the chain ℵi calculated as the least common multiple of the periods of the tasks in the respective chain and interfering tasks.1 and start(τi,j) and end(τi,j) denote the start and end of the execution of the job τi,j, respectively.
If there is communication over the TSN network between any two tasks in the chain, the TSN network schedule needs to reflect several correctness conditions. Firstly, the correctness conditions from (Craciunas et al., 2016) for generating GCL schedules need to be fulfilled in order to have correct and deterministic frame transmission over IEEE 802.1Qbv TSN devices. In addition to the technological constraints of standard full-duplex Ethernet networks, a deterministic timing of frames is enforced in (Craciunas et al., 2016) through so-called frame/flow isolation constraints. In the timed-gate mechanism of IEEE 802.1Qbv, the transmission schedule applies to the entire traffic class (as opposed to individual frames like in, e.g., TTEthernet). Therefore, the queue state has to be known and deterministic in order to ensure that the right frames are sent at the right time. Hence, the isolation conditions in (Craciunas et al., 2016) enforce that a correct GCL schedule isolates frames of different flows either in the space domain by placing them in different egress queues or in the time domain, preventing frames of different flows from being in the same queue at the same time. Secondly, implementation or network-specific correctness conditions need to be fulfilled. Here we mention the synchronization error and the microtick of the timeline. The synchronization protocol defined in IEEE 802.1As-rev ensures a common clock reference; however, individual clocks may still have a bounded time differential towards the clock reference. The maximum of all the individual bounded clock errors is called the network precision (δ). Furthermore, the (hardware) realization of the required state machines defined in, e.g., IEEE 802.1Qbv implementing the TAS mechanism also has a certain overhead, resulting in a minimum mandatory spacing of scheduled events (called microtick or link granularity). The microtick or link granularity defines the fastest rate at which schedule events can be processed by the TSN hardware and hence, the granularity of the TSN scheduling timeline. Thirdly, the GCL schedule and, more specifically, the schedule offsets of the frame transmission need to be aligned to the task schedule. For example, a message transmitted between two tasks within a chain has to be scheduled for sending after the execution of the sending task and has to arrive before the receiving task executes. Additionally, the communication latency, which adds to the chain’s overall end-to-end latency, has to be within the given latency requirements.
For a given mapping M, we denote the schedule table with
The scheduling algorithm needs to find an assignment of unassigned tasks to cores such that the tasks are schedulable on each assigned core concerning their timing constraints (offsets, deadlines, and jitter) as well as concerning the task chain requirements. Moreover, since there is communication either between individual tasks or between tasks in a task chain, the scheduling algorithm also needs to find a schedule for the deterministic communication backbone that respects the required maximum latencies.
As an input to our problem we have 1) the ADAS platform
The presented in the previous section is a combination of the problems in (Pop et al., 2016) and (McLean et al., 2020). Both problems are complex scheduling problems, and the decision problem associated with them have been thoroughly investigated in the literature. (Sinnen, 2007) and (Garey and Johnson, 1979) prove it to be in the NP-complete class by reducing it to the known 3-PARTITION and PARTITION problems. With the assumption that P ≠ NP, the scheduling problem cannot be solved efficiently by a polynomial-time algorithm. In our initial investigation of the problem, we have implemented a solution using Optimization Modulo Theories (OMT), which is an extension of Satisfiability Modulo Theories (SMT), based on the work in (Craciunas and Serna Oliver, 2016). However, the OMT/SMT approach has not been able to find solutions due to the complexity of the problem. The increasing complexity of ADAS platforms renders such mathematical programming approaches, including Integer Linear Programming (ILP) (Craciunas and Serna Oliver, 2016), infeasible in practice. It is expected that ADAS platforms, which already have the complexity of an entire in-vehicle electronics system (TTTech Computertechnik AG, 2018), will grow to a scale of thousands of functions with hundreds of complex event chain requirements. For such intractable problems, researchers have proposed the use of problem-specific heuristics and metaheuristics (Burke and Kendall, 2005), as an alternative to exact optimization methods which have exponential running times. Several metaheuristic approaches have been presented in the literature (Burke and Kendall, 2005), and the challenge is to identify the right metaheuristic for our problem. Metaheuristics aim to find a good quality solution in a reasonable time but do not guarantee that an (optimal) solution will always be found. Based on the review of the related work, we have decided to implement a combination of heuristics for scheduling, based on List Scheduling (Sinnen, 2007) and a simulation of the Earliest Deadline First (EDF) (Craciunas and Serna Oliver, 2016) scheduling algorithm. For the mapping, we have decided to compare the Simulated Annealing (SA) and Genetic Algorithm (GA) metaheuristics, which have been shown in the literature to be a promising approach for task mapping problems.
An overview of our optimization strategy is illustrated in Figure 3. The metaheuristics (SA or GA) decide the mapping M via an iterative search which generates neighboring solutions from the current solution, see “SA or GA search procedure” box in the figure, see the details in Section 4.2. The schedule
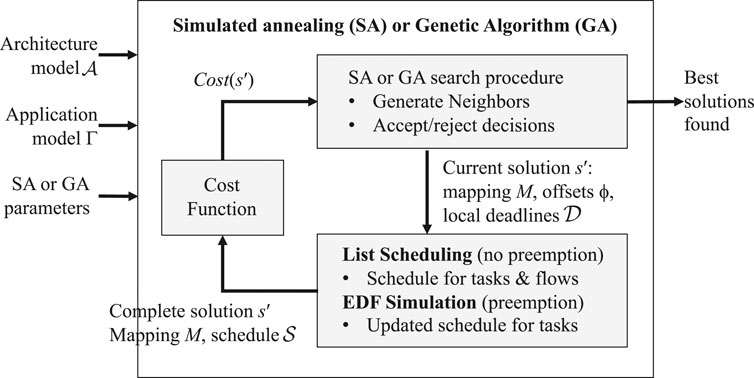
FIGURE 3. Solution overview.
We use an LS-based heuristic to jointly schedule the flows and the tasks involved in communication, presented in Section 4.3. Once the communicating tasks and flows are scheduled, we use an Earliest Deadline First (EDF)-based scheduling heuristic to add the tasks not involved in communication across cores and optimize the schedule, also by introducing design-time “preemption”, i.e., task splitting, see Section 4.4. We then check if the schedule adheres to the timing requirements imposed by the jitter and task chain constraints. The EDF scheduling heuristic introduces design-time task preemption by simulating at design time an EDF scheduling policy parameterized by task offsets and local deadlines. The heuristics receive as an input the mapping of tasks to cores. The LS heuristic is controlled by the tasks and flow offsets (ϕi ≥ 0), which are the earliest times a task can be started, or a flow can be sent. The EDF heuristic is controlled by both the offsets and local deadlines
The mapping and the controlling parameters (offsets, deadlines) for the scheduling heuristics are determined by the metaheuristics, as part of their search procedure. We have developed two metaheuristics, one based on Simulated Annealing (SA), see Section 4.2.1 and one based on a Genetic Algorithm (GA), see Section 4.2.2. Both metaheuristics modify the mapping of tasks M, the task and flow offsets (ϕi ≥ 0), and deadlines
The cost function (Cost), defined in Eq. 2, captures both a minimization objective with respect to the end-to-end latency of task chains and penalties representing constraint violations given by the application. The function has two cases, 1) a value if the solution configuration meets all the timing constraints and 2) a combination of static and dynamic penalties if one or more timing constraints are violated.
During the search, the metaheuristics do not reject the invalid solutions. Instead, we “penalize” an invalid solution by increasing its cost function value to be larger than the values for valid solutions in the hope of driving the search towards valid solutions. A solution is invalid if one of the three constraints is violated: 1) There is a task or flow which does not meet its deadline, i.e., the worst-case response time fi of a task τi is larger than its deadline Di (or the worst-case delay of a flow is larger than its deadline). 2) There is a chain ℵi which has an end-to-end latency li that is greater than its allowed latency Li. 3) There is a task τi which has a jitter ji greater than maximum allowed jitter Ji, see the notations in Section 2.4. We capture each of these constraint violations using a separate penalty term, which is zero if the constraint is not violated: 1) ρD for deadline violations, 2) ρℵ for chain latency violations and 3) ρJ for jitter violations. Hence, if the sum of these penalty terms is zero then the solution is valid, i.e., all constraints are satisfied and thus all penalty terms are zero. We capture this situation with a test defined by χ(s) = ρℵ + ρD + ρJ > 0. χ(s) is true if the solution is valid, i.e., case (1) in Eq. 2, and false if the solution is invalid, corresponding to case (2).
Let us first discuss case (1) when the solution is valid. In this case, the value of the cost function which has to be minimized is defined as the average weighted distance of the measured end-to-end latency li over the imposed constraint Li, of all task chains. Basically, the smaller the chain latencies, the smaller the term. When we sum up
Let us consider the example in Figure 4 where we have three tasks and one chain on a single core. The details are given next to the figure, with the note that the allowed end-to-end latency of the chain L1 is 20, and its priority pi is 1.0. Figure 4A shows a valid solution, whereas Figure 4B an invalid one. For Figure 4A we have l1 = 20, hence the cost function is
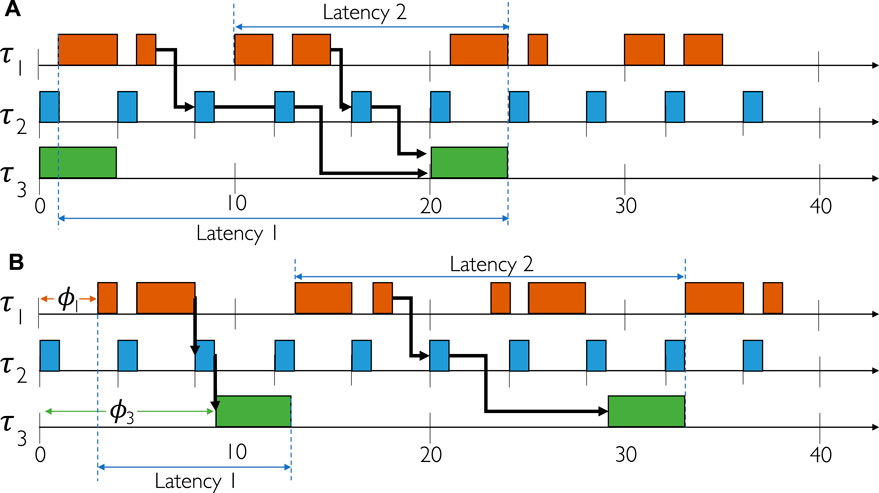
FIGURE 4. Schedule optimization. (A) End-to-end task chain latencies not satisfied. (B) End-to-end task chains latencies satisfied.
The values of these penalty functions are dynamic, i.e., a larger value is used bigger constraint violations. We first define the ρℵ from Eq. 3 in detail and then discuss the other two penalties, which are similarly constructed. The relative importance of these penalties are determined by the weights w2, w3 and w3. ρℵ in Eq. 3, measures the weighted average of end-to-end violation. The violation of a chain ℵi is defined as the difference between its highest observed chain latency li and its end-to-end constraint Li.
If li is smaller or equal to Li then the chain constraint is satisfied and the term is zero. We discuss here the case when the constraint is not satisfied, i.e., li > Li. When li > Li the max operator will return li − Li. To normalize the penalty value, we clamp any observed violation li − Li to the interval [0, Li] using the min operator and divide by Li, hence the term in the summation will be in the interval [0, 1]. We divide the sum with the number of chains
Likewise, the additional deadline and jitter costs (ρD and ρJ) is listed by Eqs. 4, 5, respectively. Here ρD measures the weighted average of deadline violations with a violation range clamped in the interval [0, Di]. The deadline violation of a task or flow i is denoted as the difference between the maximal relative finishing time of all of i’s instances fi and the relative deadline Di.
Finally, ρJ measures the weighted average of jitter violations. We define the jitter violation of a task τi as the difference between the maximal observed jitter ji and the threshold Ji. The violation range is then clamped in the interval [0, Ji].
In Eqs. 2–5, we list w1, w2, w3 and w4 as static weights designed to capture the importance of the respective violation with the following constraints: w2 ≥ w1, w3 ≥ w1, w4 ≥ w1. The constants were determined based on manual experimentation and observations, with w1 through w4 set to 10,000, 40,000, 10,000, and 60,000, respectively. Please note that there are no optimal values for the weights, since they have to be adapted to the application domain, criticality definitions and design goals of the respective use-case.
The SA and GA metaheuristics aim to iteratively optimize solutions by randomly changing existing solutions s to create new solutions s′ and evaluate them by using the cost function. They take as input the platform model
We first describe a Simulated Annealing (SA)-based metaheuristic approach, which uses an EDF-based heuristic to solve the task scheduling problem. Simulated Annealing is a heuristic method that aims to optimize solutions by randomly selecting a candidate solution in the neighborhood of the current one (Burke and Kendall, 2005). The SA algorithm accepts a new neighbor solution if it is better than the current one. Moreover, a worse solution can be accepted with a certain probability given by the cost function Cost and the cooling scheme defined by an initial temperature, ts and a cooling rate cr, specifying the rate at which the temperature drops with each iteration.
A new candidate solution s′ (also called neighbor) is generated starting from the current solution s by performing design transformations (also called moves) on s. We use three moves, described in the following. AdjustDeadline adjusts the deadline of a single randomly selected task. Only tasks that failed at complying with the jitter constraints are potential candidates for this move. Note that the deadlines in
The function that generates neighbor solutions is implemented as a simple state machine, allowing moves mentioned earlier to be chosen randomly. Various probability assignments for these moves were tried, and, based on observations from performed experiments, a uniform distribution has been chosen for all actions.
GA is a multi-objective optimization heuristic inspired by evolutionary biology (Deb et al., 2000). We 1) encode each solution (chromosome) as an array where each entry (gene) contains information on the mapping, offset and deadline of a task/flow and 2) randomly initialize N individuals. We then 3) evolve some selected candidates by using 4) recombination and 5) mutation. Finally, 6) the evolved candidates with better fitness will replace the parent population. As mentioned, GA is a multi-objective metaheuristic. This means that the fitness is captured with several cost function values, i.e., ρℵ for chains, ρD for deadlines and ρJ for jitter constraints, see the discussion in Section 4.1. This is in contrast to SA, which collapses all these terms into a single cost function value, as defined in Eq. (2). Steps 3) to 6) are repeated until the allotted time is exhausted.
Several crossover operators have been proposed in the literature, and we have implemented: uniform order-based crossover (OX), (OX) using 2-point and using 1-point approaches (Syswerda, 1991), Partially-Mapped Crossover (Goldberg and Lingle, 1985), Cycle-Based Crossover (Goldberg and Lingle, 1987) and Alternating-Position Crossover (Larranaga et al., 1997). Based on our experiments, we have decided to employ a standard uniform crossover. Regarding mutation, for each gene in the chromosome, we compare a randomly generated number with a “probability of mutation”, and if this number is smaller, then this position is mutated. The probability of mutation has been determined using ParamILS (Hutter et al., 2009) as discussed in Section 5. To select parents, we sort the “population” using the “non-dominated” sorting method from (Deb et al., 2000). Half the population is kept as parents, and to create new individuals, two random parents are picked until all individuals have been created.
One approach to the task and flow scheduling problem is to solve the problems separately and then fit them together. This is a reasonable approach when the two sub-problems do not form a circular dependency. In our case, however, the two scheduling problems are closely linked together. Let us consider the example in Figure 5, where we have a topology of three end systems (ES1 to ES3) and one switch (SW1). We have four tasks τA, τB, τC, and τD with precedence constraints [τA ≺ τB ≺ τC ≺ τD] that form a chain. τA needs to be executed on ES1, τB on ES2 and τC and τD on ES3. Task τA sends a message to τB, and τB sends a message to τC. For illustration purposes, the task WCETs and the transmission times of message frames on links are a single time unit, and network precision and macrotick are ignored. The period of all tasks is 8 time units, and the chain latency is also 8 time units.

FIGURE 5. Scheduling approaches, (A) is a schedule where flows 1 and 2 are scheduled before taking tasks into account, (B) is the optimized scenario where task and flows are scheduled concurrently.
If the messages are scheduled first, then the solution of the flow would look as shown in Figure 5A. This schedule minimizes the flow latencies, but since task τB must receive message 1 and send message 2, the schedule contains a lot of idle time; hence, the chain latency becomes 13 time units. Note that messages 1 and 2 scheduled at the beginning of the schedule are sent by tasks τA and τB from the previous period. The same issue exists if the tasks are scheduled without any knowledge of the network. However, if both task scheduling and message scheduling are optimized concurrently, then an optimized solution, shown in Figure 5B, can be produced. This reduces the chain latency substantially to 8 time units from 13 in Figure 5A, meeting thus the task chain latency constraint.
In this section, we propose a joint flow and task scheduling heuristic based on List Scheduling (LS) (Sinnen, 2007). LS is a widely used task scheduling heuristic that is known to obtain good quality solutions when determining static schedules for tasks on multiprocessors. We have re-purposed LS for jointly scheduling flows and tasks. Our LS is inspired by the individual flow scheduling heuristic from (Raagaard and Pop, 2017), which uses variants of ASAP (As Soon As Possible) and ALAP (As Late As Possible) scheduling. Both of these are a special case of the List Scheduling heuristic (Sinnen, 2007). Our LS is more general, scheduling both flows and tasks. This LS can use offset and ordering parameters to control the placement of frames, which is not considered in (Raagaard and Pop, 2017).
LS receives as input the architecture
Algorithm 1 ScheduleFlow (θ, ϕ). Schedules a flow θ as soon as possible (ASAP), considering its offset ϕ given by the metaheuristic. All frames in the flow have initialized lower and upper bounds to − ∞, ∞, respectively.

Similar to (Raagaard and Pop, 2017), LS starts with an empty timeline and iteratively schedules one flow at a time. The metaheuristic specifies the order in which flows are chosen. Similar to (Raagaard and Pop, 2017), the flows are chosen according to their deadlines since flows with tight deadlines are the hardest to schedule and therefore should be picked first. The tie-breaker for the ordering is given by the flow period. Each flow is scheduled using the ScheduleFlow procedure in Algorithm 1 such that the end-to-end latency is minimized. The termination condition for the LS is that either a schedule has been found for all flows or the current iteration does not produce a feasible schedule with respect to the flow deadline.We now examine the steps of Algorithm 1 in more detail. In step 1 frames are retrieved in the order given by Eq. 7, see Section 4.3.3 for an explanation of how the next frame is determined. In step 3, the frame offset ϕ is set to the earliest time in a feasible region, greater than the lower bound, determined in step 2. Section 4.3.2 and Section 4.3.1 present how we define and determine the feasible regions and the lower bound, respectively. If the algorithm reaches a state where a frame cannot be scheduled, e.g., there is not enough space, then it needs to find another solution. This search is done by backtracking: In step 4 backtracking is done by increasing the lower bound to the latest available time which is less than the frame offset found in step 3, then rescheduling the previous frame, see Section 4.3.4.
The lower bound for the LS algorithm, inspired by (Raagaard and Pop, 2017), is calculated using Eq. 6.
When a flow is scheduled, each frame will block those queues and the network links where it is scheduled. The feasible region for a frame, similar to (Raagaard and Pop, 2017), is a set of intervals where the frame can be scheduled without violating the feasibility of the existing partial schedule. The algorithm relies on feasible regions to find out where the frames can be scheduled without interfering with other frames. Since frames can have different periods, this complicates the search for space where the frame can be scheduled.
We introduce two operations that the feasible region implement, i.e., queue blocking, and searching for the feasible region of a frame. Blocking is used when a frame is scheduled in a known feasible region, and searching is used when the algorithm is searching for an appropriate place for a frame. Blocking happens at most once for every flow scheduled, while searching can happen several times, depending on how hard it is to schedule a frame. In order to minimize the time in search, the following method of constructing the feasible regions is used.
If a frame
Algorithm 2 BlockQueues

Step 4 of Alg. 2 does the queue blocking. It takes a start, end, and a frame, and blocks the frame’s queue and link in that interval, where mod is the modulo operator. If start > end, then the queue is blocked in the intervals [0, end[ and [start, QT], where QT is the period of the queue. An example of the blocking is illustrated in Figure 6, where we show on a link [va, vb] how the feasible region of a frame instance θi,m is blocked. Let us assume that an earlier frame in the same queue and link had a period of 10 ms and our frame’s period is θi,m.T = 15 ms. Both frames have an offset of 2 ms and their transmission times are 1 ms. Frame instance θi,m cannot use the time slots where the earlier frame has been scheduled, at every 10 ms, the first row in Figure 6. In addition, we also need to block those times where, if θi,m is scheduled periodically with a period of 15, runs the risk of conflicting with the other frame with a period of 10. For example, θi,m cannot be scheduled at time 7, because its next occurrence at 7 + 15 = 22 would conflict with the other frame that periodically is scheduled every 10 ms with an offset of 2, i.e., 2 + 10 + 10 = 22. The second row in Figure 6 shows the times blocked by Algorithm 2 for our example with two frames.

FIGURE 6. Blocking times of a frame with a period of 15 ms considering another frame with a period of 10 ms over their hyperperiod.
The LS heuristic schedules the frames in the order specified by Eq. 7:
where LCL is the last “virtual link” (core), FNL is the first network link, NL is the next link, bLNL is true when frame is on the last network link, and bLS is true if the frame is the last frame in the flow. The NextFrame function is valid for all frames except the last “virtual frame”, where NextLink is not defined.
LS starts from the first “virtual frame” (sender task), and goes through each frame and ends with the last “virtual frame” (receiving task). The idea is to allow backtracking only to change the last scheduled frame. We illustrate an ordering in Figure 7, where the order is indicated in parenthesis inside the rectangles representing tasks and frames. In Figure 7 we have a setup where a task τ1 on ES1 modeled as a “virtual frame” on the “virtual link” [ES1, ES1] sends a flow Φ1 of size 3xMTU, which hence has to be split in three frames θ1.1, θ1.2 and θ1.3, to a task τ2 on ES2.
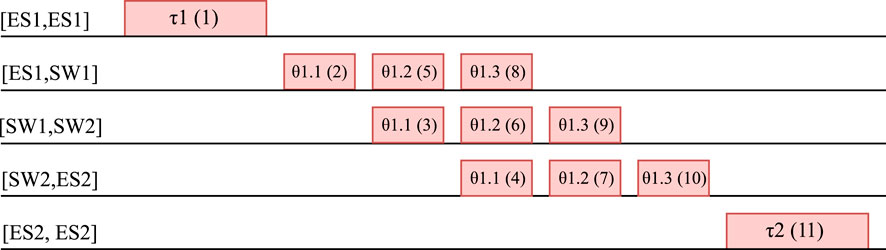
FIGURE 7. How tasks and flow frames are scheduled together. The order is indicated by the number in parenthesis.
Figure 7 shows the order in which Eq. 7 will visit the frames. Note that by using this order and converting tasks to “virtual frames” on “virtual links” we can treat the tasks and frames together and schedule them jointly. Thus, the frames τ1 and τ2 on “virtual links” [ES1, ES1] and [ES2, ES2], respectively, are “virtual frames” (tasks), hence they are scheduled as tasks without concern for MTU-size limits. However, the flow Φ1 has to be split into frames θ1.1 to θ1.3, which are then scheduled as frames on the physical links. The idle times in the schedule in Figure 7 between each frame are due to the link granularity and synchronization, which have been considered for this example.
When the LS heuristic schedules a frame instance θi,m, it sets the upper bound of the frame instance
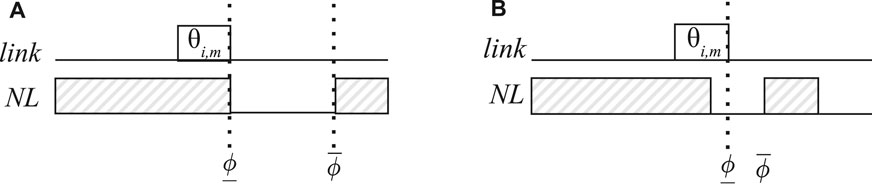
FIGURE 8. Visualization of lower bound and upper bounds. The hatched areas are already filled by other frames, such that the non-hatched areas form the feasible region. (A) Case where the next frame can be scheduled in the feasible region. (B) Case where there is not enough space is available to schedule the frame and backtracking will be used to move the frame forward.
Case (1) is when we have enough space to send
The List Scheduling heuristic from Section 4.3 has scheduled all the flows and the corresponding communicating tasks, resulting in a partial schedule
Algorithm 3 EDFScheduleSynthesis

We start by assigning all tasks to their respective cores (step 1 in Algorithm 3). All tasks without a task mapping will be mapped according to a best-fit strategy with respect to utilization, i.e., balancing the processor and core utilization. We run the simulation for a length l (set in step 2), after which the schedule will repeat itself. l is defined by 2 ⋅hyperperiod + MaxOffset, where hyperperiod is determined as the Least Common Multiple of all tasks in Γ and the MaxOffset is the maximum over all offsets ϕi (Leung and Merrill, 1980). The iteration over the simulation length l is done in the steps 6–12. The current time is captured by cycle, and we advance the time to the next event that needs to be simulated.The EDF simulation is performed per core σ (step 10), and we use a queue Qσ containing all cores from all processors, ordered by the earliest event that needs to be simulated. To start the simulation, steps 3–5 add cores to the queue Qσ, by visiting all the cores in the architecture
We have evaluated the proposed solutions in for both network setups, PCIe in Section 5.1 and TSN in Section 5.2. We have used both realistic test cases and synthetic test cases. The synthetic test cases were generated using a tool developed for this purpose (McLean et al., 2019), which derives the desired task properties from the realistic test cases. The test case generation tool was extended to add TSN flows based on the work from (Craciunas and Serna Oliver, 2016). All experiments were conducted on a High Performance Computing (HPC) cluster, with each node configured with 2xIntel Xeon Processor 2660v3 (10 cores, 2.60 GHz) and 128 GB memory. Both SA and GA run on one node at a time.
The choice of parameters for the metaheuristics has been done using ParamILS (Hutter et al., 2009), which performs a stochastic search in the parameter space. ParamILS works by giving it a list of possible values for each parameter to be tuned. The list of values was initially chosen on a broad scale, and then if runs seemed to converge, the range was narrowed. Because the different test case sizes have varying difficulty, parameter tuning was done separately for the different test case sizes. For each type of test case, 10 parallel runs were launched with differing seeds so that more solutions could be discovered (Hutter et al., 2012).
As a first experiment, we were interested in determining our proposed SA’s ability to find near-optimal solutions. We have implemented an exhaustive search that finds the optimal solution; however, we could only do that for small task sets of less than 10 tasks considering an architecture with two cores. Our SA was able to find the same optimal solution in less than 10 s. In the following sets of experiments, determining the efficacy of SA was achieved through a combination of synthetic and realistic test scenarios, benchmarked against two other heuristics: Greedy, presented as the initial solution for the metaheuristics in Section 4.2 and Genetic Algorithm (GA).
We were then interested in determining if using an SA meta-heuristic combined with EDF-simulation is a viable solution for finding feasible schedules when confronted with very large task sets. Thus, we have used five test cases, ranging from 100 to 500% in scale, i.e., for ADAS1x100% the application contains 151 tasks and 31 chains using a model of the architecture discussed in section 2, whereas with ADAS1x200% the architecture would double the number of processors, tasks and task chains. The results are presented in Table 1, with each row representing the results of a task case. A test case is a scenario consisting of 30 synthetically generated task sets, with each undergoing 30 trials (runs of SA and GA on the same test case). Thus a single test case, e.g., ADAS1x100%, would conduct 900 trials for each algorithm. As the experiment progresses through each case, the algorithms were given additional time due to an inherent increased complexity of the problem (see the Time column).

TABLE 1. Evaluation results on synthetic test cases.
For each algorithm (Greedy, SA, and GA), we show in the table, under the Sched. columns, the percentage of cases (out of the 30 trials) for which the algorithms determine schedulable solutions (all deadline constraints are satisfied; 1 means 100%). The columns labeled Chains have the percentage of chains out of the total chains, for which the respective algorithm was able to satisfy the end-to-end constraints. Similarly, Jitter denotes the percentage of jitter constraints satisfied. These values are presented in terms of minimum, average and maximum considering the 30 runs. Note that the Greedy algorithm is not stochastic and always outputs the same result.
As we can see from Table 1, the Greedy approach has comparatively the worst performance in terms of complying with the constraints. We also see that SA can find schedulable solutions (in terms of deadlines, chains, and jitter constraints) within the allotted time, even when the problem size increases. We see that SA has a drop in finding feasible schedules (from 100% in column Chains. for ADAS1x100%, to 63% for ADAS1x500%, and cannot meet the jitter constraints for some of the two largest test cases). We estimate that this is caused by a combination of increased difficulty of the task sets and their constraints, as well the crude method for estimating the time allotted. We observed that both SA and GA obtain similar quality results, with SA being slightly better for smaller test cases and GA doing slightly better for larger test cases. Both metaheuristics (SA and GA) are clearly superior to the mapping heuristic, such as Greedy, when presented with very large task sets.
For the following evaluation, we were interested in the ability of SA to handle realistic test cases. Thus, we have used three test cases, ADAS1 to ADAS3, which are variants of an anonymized realistic task set currently in use in a series-production vehicle. All test cases have 151 tasks and 31 task chains, but with varying jitter, earliest activation, and macrotick constraints. The experiment was set up such that 30 trials were conducted with SA for each test case; the time limit used is in minutes. As we can see from Table 2, SA can find feasible solutions for all test cases. As the test cases get progressively more difficult from ADAS1 to ADAS3, in terms of timing constraints that need to be satisfied, SA retains its ability to find solutions within the allotted time, albeit at a slightly lower rate. By comparison, we see that the percentage of resolved constraints for the Greedy algorithm decreases similarly and fails on all accounts to find feasible schedules that meet all the constraints. We have also implemented an approach from the related work (Verucchi et al., 2020), called DAG, which constructs a Directed Acyclic Graph (DAG) from the input task set. The constructed DAG can handle the multiple periods of tasks in the task set and encodes the chain constraints. Such a DAG is built on the fly by our approach when constructing a solution. The DAG approach does not consider “preemption”, i.e., the tasks will not be split when scheduled, and uses List Scheduling instead of EDF for scheduling the DAG. As we can see, the DAG approach from related work is similar to our Greedy approach and significantly under-performs compared to our SA metaheuristic. In addition, it results in fewer jitter constraints satisfied, compared to our Greedy.

TABLE 2. Evaluation results on realistic test cases.
In this section, we considered that the communication is done via a TSN backbone. We have used synthetic test cases, for which we generated various TSN networks. We have used three different types of graphs with varying degrees of connectivity. The topologies (mesh, ring, and tree) are shown in Figure 9.
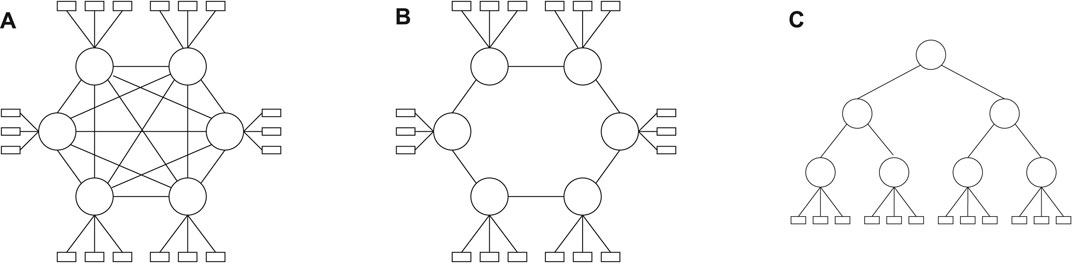
FIGURE 9. Topologies used for experiments. In each topology, a switch has 3 end systems attached (for tree: Leaf nodes only). (A) Mesh topology. (B) Ring topology. (C) Tree topology with depth = 2.
The number of end systems, switches, and chains are given in Table 3, similar to the setup used in (Craciunas and Serna Oliver, 2016), except for the number of chains. For each end system, 16 tasks are created, 8 which communicate and 8 which do not. Each communicating task sends a message to another communicating task. Thus, there will be |ES|⋅ 4 flows in the network. The utilization is set to be 50% for each end system, 25% of which corresponds to communicating tasks and 75% to the rest. Task WCETs are chosen such that they are divisible with the macrotick and fit within the assigned utilization. Message lengths are chosen at random between 84 and 1,542 Bytes. The macrotick of the end systems is set to 250 μs, and the granularity of the links are set to 1 μs. The speed of links from end systems to switches is set to 100 Mbps and to 1 Gbps between switches.
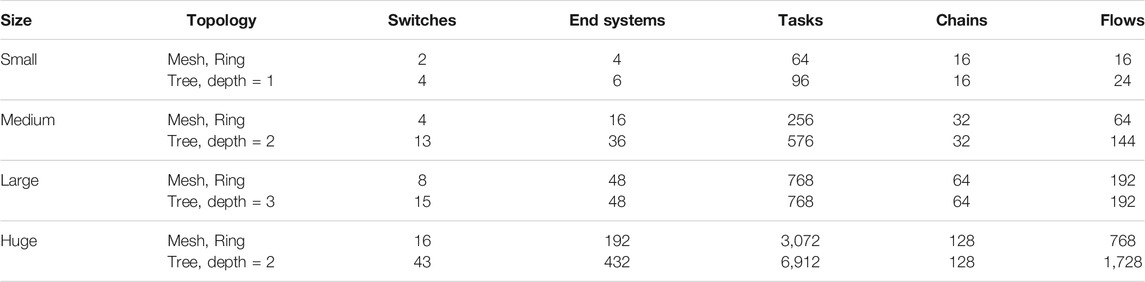
TABLE 3. Number of switches, end systems and chains for each topology and size of test case.
We have used three sets of randomly chosen periods, all in milliseconds, P1 = {10, 20, 25, 50, 100}, P2 = {10, 30, 100}, and P3 = {50, 75}. We use the shortest paths for routes. The chains are generated with a maximum task length of 15, and a minimum of 2, and lengths are chosen from a uniform random distribution. Two consecutive tasks in a chain must either be on the same end system or be communicating via the TSN network. In order to compare the performance between the two metaheuristics, 10 runs were performed on each of the test cases for a total of 360 runs for each of the metaheuristics. The time given for each size is as follows. 300 s for small test cases, 1,200 s for medium, 4,800 s for large, and 19,200 s for the largest test cases, called “huge”.
Figure 10 shows on the y-axis the percentage of test cases solved for each size and topology. The results are grouped per topology, mesh, ring, and tree, and for each topology, we use different sets of periods, P1 to P3. A test case is “solved” if all the requirements are satisfied. On the y-axis, 1 means that 100% of the requirements were satisfied, whereas 0 means that no requirements could be satisfied. On the x-axis, we show the type of test case, small, medium, large, and huge. As we can see, our GA and SA solutions can successfully solve all the test cases, except for some of the “huge” test cases, especially in the tree topologies, where a few requirements could not be satisfied. In those situations, GA performs better than SA. When considering the cost of the solutions (the value of Eq. 2), we noticed that SA is better than GA in terms of the cost function for small, medium, and large test cases. However, in the huge test cases, GA not only is able to find feasible solutions more consistently but is also able to find solutions of lower cost.
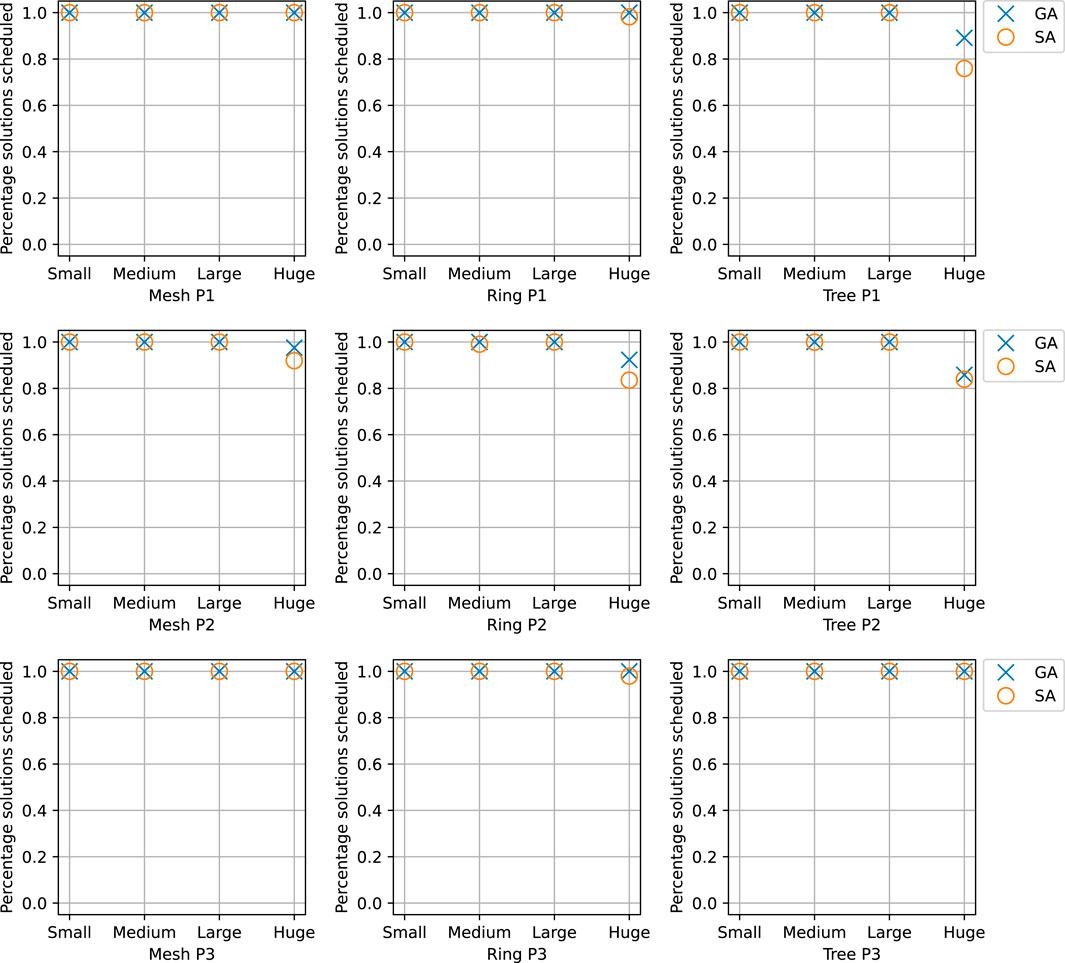
FIGURE 10. Comparison of SA and GA in terms of percentage of solved solutions, i.e., all the tasks and flows are successfully scheduled and the constraints, e.g., chain latencies, are satisfied.
Finally, we were also interested in our approaches’ ability to find a feasible solution as fast as possible. That is, we wanted to determine what is the earliest time when all the requirements are satisfied. Once such a solution is found, the metaheuristics continue the optimization until the time limit is reached. Hence, we modified SA and GA to return once a feasible solution was found. The runtime results are shown in Figure 11. The figure shows that when SA can find a feasible solution for a test case, it generally finds it faster than GA. However, there are situations where GA outperforms SA.
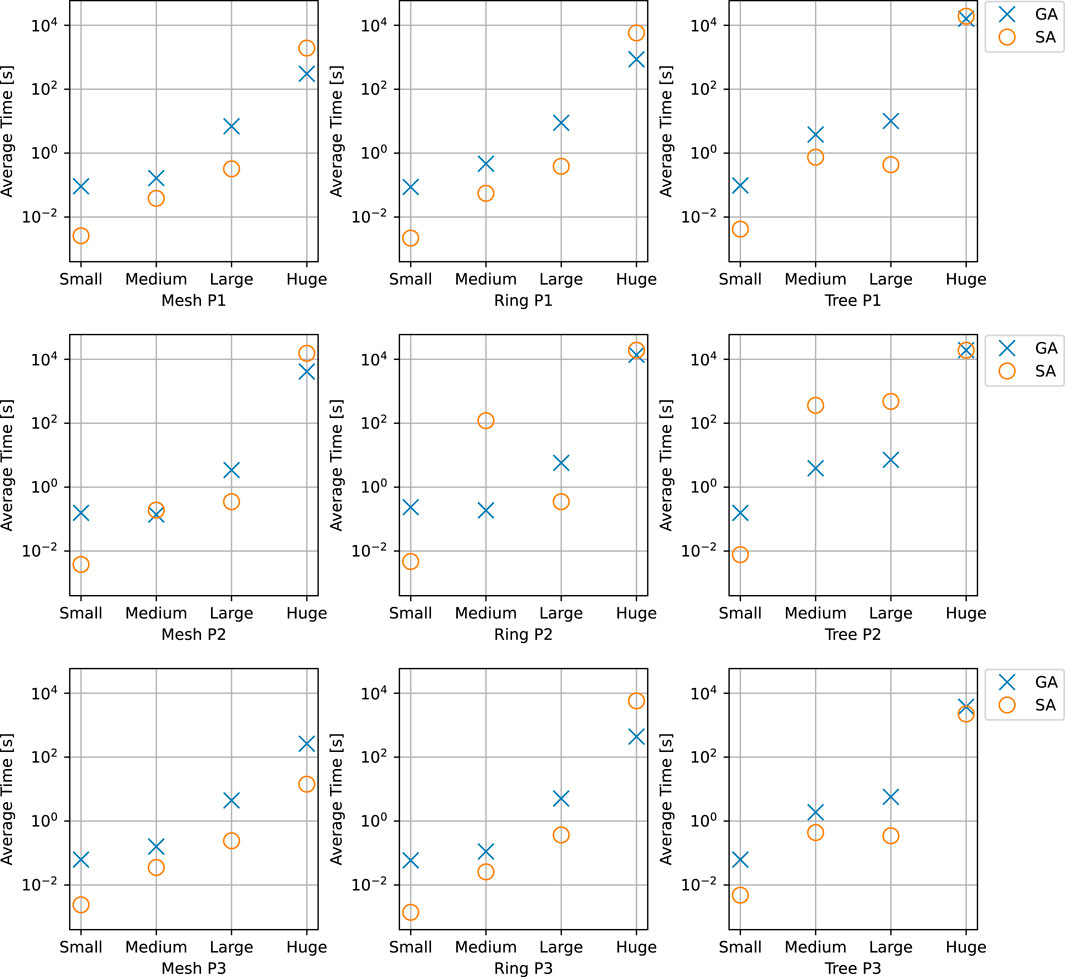
FIGURE 11. Comparison of SA and GA runtimes when searching for the first feasible solution.
In this paper, we have considered safety-critical ADAS applications mapped on modern multi-processor platforms. The applications are modeled as a set of communicating software tasks with complex timing requirements, e.g., jitter, deadlines, and end-to-end latency bounds on task chains. We have proposed an optimization strategy that, given the application and platform models, determines a mapping of tasks to the cores of the platform and a static schedule of tasks on each core, such that the timing constraints are satisfied. We have also considered a realistic communication backbone implemented using the IEEE 802.1 Time-Sensitive Networking standard, and our optimization derives the schedule tables for the TSN messages.
Our optimization strategy uses metaheuristics (Simulated Annealing and Genetic Algorithm) to explore the solution space, combined with a scheduling heuristic to jointly solve the task and message scheduling problem. The experimental evaluation on several realistic and synthetic test cases has demonstrated that our proposed strategy is able to find solutions that meet the timing constraints at a higher rate than traditional approaches and scales with the growing trend of ADAS platforms.
Our evaluation has shown that SA is superior in finding feasible solutions fast and with a lower cost function value compared to GA, whereas GA outperforms SA for very large TSN-based test cases where. As future work, we want to implement a hybrid multi-objective metaheuristic (Blum and Roli, 2008) that combines SA and GA and considers several optimization objectives, such as reducing the number of task preemptions in order to reduce context switch overhead and reducing the number of switch queues used by the TSN messages.
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
All authors listed have made a substantial, direct, and intellectual contribution to the work and approved it for publication.
The research presented throughout this paper has partially received funding from the European Community’s Horizon 2020 programme under the UP2DATE project (grant agreement 871465).
Author SC was employed by the company TTTech Computertechnik AG.
The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors, and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
This paper is an extended version of (McLean et al., 2020) based on original technical material contained in a thesis of the first author (McLean, 2019) which is archived as a technical report (McLean et al., 2019) and extended with material included in a thesis of the second author (Hansen, 2020).
1I.e., tasks that execute on the same core as the tasks in the chain
Abdelzaher, T. F., and Shin, K. G. (1999). Combined Task and Message Scheduling in Distributed Real-Time Systems. IEEE Trans. Parallel Distrib. Syst. 10, 1179–1191. doi:10.1109/71.809575
Aichouch, M., Prévotet, J.-C., and Nouvel, F. (2013). “Evaluation of the Overheads and Latencies of a Virtualized RTOS,” in 2013 8th IEEE International Symposium on Industrial Embedded Systems (IEEE), 81–84. doi:10.1109/sies.2013.6601475
Barzegaran, M., Cervin, A., and Pop, P. (2020). Performance Optimization of Control Applications on Fog Computing Platforms Using Scheduling and Isolation. IEEE Access 8, 104085–104098. doi:10.1109/access.2020.2999322
Becker, M., Dasari, D., Mubeen, S., Behnam, M., and Nolte, T. (2017). End-to-end Timing Analysis of Cause-Effect Chains in Automotive Embedded Systems. J. Syst. Architecture 80, 1. doi:10.1016/j.sysarc.2017.09.004
Becker, M., Dasari, D., Mubeen, S., Behnam, M., and Nolte, T. (2016a). “Synthesizing Job-Level Dependencies for Automotive Multi-Rate Effect Chains,” in 2016 IEEE 22nd International Conference on Embedded and Real-Time Computing Systems and Applications (IEEE), 159–169. doi:10.1109/rtcsa.2016.41
Becker, M., Dasari, D., Nicolic, B., Akesson, B., Nelis, V., and Nolte, T. (2016b). “Contention-free Execution of Automotive Applications on a Clustered many-core Platform,” in 2016 28th Euromicro Conference on Real-Time Systems (IEEE), 14–24. doi:10.1109/ecrts.2016.14
Biondi, A., and Di Natale, M. (2018). “Achieving Predictable Multicore Execution of Automotive Applications Using the LET Paradigm,” in 2018 IEEE Real-Time and Embedded Technology and Applications Symposium (IEEE), 240–250. doi:10.1109/rtas.2018.00032
Blum, C., and Roli, A. (2008). “Hybrid Metaheuristics: an Introduction,” in Hybrid Metaheuristics (Springer), 1–30. doi:10.1007/978-3-540-78295-7_1
Bunzel, S. (2011). AUTOSAR - the Standardized Software Architecture. Informatik Spektrum 34, 79–83. doi:10.1007/s00287-010-0506-7
Buttazzo, G. C. (2011). Hard Real-Time Computing Systems: Predictable Scheduling Algorithms and Applications (Real-Time Systems Series). Springer-Verlag.
Chetto, H., Silly, M., and Bouchentouf, T. (1990). Dynamic Scheduling of Real-Time Tasks under Precedence Constraints. J. Real-Time Syst. 2, 181–194. doi:10.1007/bf00365326
Choi, S., and Agrawala, A. K. (2000). “Scheduling of Real-Time Tasks with Complex Constraints,” in Performance Evaluation: Origins and Directions (IEEE), 253–282. doi:10.1007/3-540-46506-5_11
Craciunas, S. S., and Oliver, R. S. (2016). Combined Task- and Network-Level Scheduling for Distributed Time-Triggered Systems. Real-time Syst. 52, 161–200. doi:10.1007/s11241-015-9244-x
Craciunas, S. S., Serna Oliver, R., Chmelik, M., and Steiner, W. (2016). “Scheduling Real-Time Communication in IEEE 802.1Qbv Time Sensitive Networks,” in Proc. 24th International Conference on Real-Time Networks and Systems (IEEE), 183–192. doi:10.1145/2997465.2997470
Craciunas, S. S., Serna Oliver, R., and Ecker, V. (2014). “Optimal Static Scheduling of Real-Time Tasks on Distributed Time-Triggered Networked Systems,” in Proceedings of the 2014 IEEE Emerging Technology and Factory Automation (IEEE), 1–8. doi:10.1109/etfa.2014.7005128
Deb, K., Agrawal, S., Pratap, A., and Meyarivan, T. (2000). “A Fast Elitist Non-dominated Sorting Genetic Algorithm for Multi-Objective Optimization: NSGA-II,” in Proceedings of the International Conference on Parallel Problem Solving from Nature (IEEE), 849–858. doi:10.1007/3-540-45356-3_83
Di Natale, M., and Stankovic, J. A. (2000). Scheduling Distributed Real-Time Tasks with Minimum Jitter. IEEE Trans. Comput. 49, 303–316. doi:10.1109/12.844344
Dürr, F., and Nayak, N. G. (2016). “No-wait Packet Scheduling for IEEE Time-Sensitive Networks (TSN),” in Proceedings of the 24th International Conference on Real-Time Networks and Systems (IEEE), 203–212.
Ernst, R., Kuntz, S., Quinton, S., and Simons, M. (2018). The Logical Execution Time Paradigm: New Perspectives for Multicore Systems (Dagstuhl Seminar 18092). Dagstuhl Rep. 8, 122–149.
Fohler, G. (1994). Flexibility in Statically Scheduled Real-Time Systems. Ph.D. Thesis, Technisch- Naturwissenschaftliche Fakultät. Vienna, Austria: Technische Universität Wien.
Forget, J., Boniol, F., and Pagetti, C. (2017). “Verifying End-To-End Real-Time Constraints on Multi-Periodic Models,” in Proceedings IEEE Emerging Technology and Factory Automation (IEEE), 1–8. doi:10.1109/etfa.2017.8247612
Forget, J., Grolleau, E., Pagetti, C., and Richard, P. (2011). “Dynamic Priority Scheduling of Periodic Tasks with Extended Precedences,” in Proceedings IEEE Emerging Technology and Factory Automation (IEEE), 1–8. doi:10.1109/etfa.2011.6059015
Garey, M. R., and Johnson, D. S. (1979). Computers and Intractability: A Guide to the Theory of NP-Completeness. W. H. Freeman.
Gietelink, O., Ploeg, J., Schutter, B. D., and Verhaegen, M. (2006). Development of Advanced Driver Assistance Systems with Vehicle Hardware-In-The-Loop Simulations. Vehicle Syst. Dyn. 44, 1. doi:10.1080/00423110600563338
Goldberg, D. E., and Lingle, R. (1987). “A Study of Permutation Crossover Operators on the TSP,” in Proceeding of the Second International Conference on Genetic Algorithms and Their Applications. Editor J. J. Grefenstette (Hillsdale, New Jersey: Lawrence Erlbaum), 224–230.
Goldberg, D. E., and Lingle, R. (1985). “Alleles, Loci and the TSP,” in Proceeding of the First International Conference on Genetic Algorithms and Their Applications. Editor J. J. Grefenstette (Hillsdale, New Jersey: Lawrence Erlbaum), 154–159.
Hammond, M., Qu, G., and Rawashdeh, O. A. (2015). “Deploying and Scheduling Vision Based Advanced Driver Assistance Systems (ADAS) on Heterogeneous Multicore Embedded Platform,” in 2015 9th International Conference on Frontier of Computer Science and Technology (IEEE), 172–177. doi:10.1109/fcst.2015.69
Hansen, E. A. J. (2020). Configuration of Computer-Platforms for Autonomous Driving ApplicationsMaster’s Thesis. Kongens Lyngby, Denmark: Technical University of Denmark.
Hutter, F., Hoos, H. H., and Leyton-Brown, K. (2012). “Parallel Algorithm Configuration,” in International Conference on Learning and Intelligent Optimization (IEEE), 55–70. doi:10.1007/978-3-642-34413-8_5
Hutter, F., Hoos, H. H., Leyton-Brown, K., and Stützle, T. (2009). ParamILS: An Automatic Algorithm Configuration Framework. J. Artif. Intell. Res. 36, 267–306.
IEEE (2016a). 802.1AS-Rev - Timing and Synchronization for Time-Sensitive Applications. IEEE. Available at: https://www.ieee802.org/1/pages/802.1as.html (Accessed 08 19, 2021).
IEEE (2015). 802.1Qbv-2015 - IEEE Standard for Local and Metropolitan Area Networks – Bridges and Bridged Networks - Amendment 25: Enhancements for Scheduled Traffic. IEEE. Available at: https://ieeexplore.ieee.org/servlet/opac?punumber=8613093 (Accessed 08 19, 2021).
IEEE (2016b). Official Website of the 802.1 Time-Sensitive Networking Task Group. IEEE. Available at: https://1.ieee802.org/tsn/(Accessed 06 11, 2019).
Isović, D., and Fohler, G. (2000). “Efficient Scheduling of Sporadic, Aperiodic, and Periodic Tasks with Complex Constraints,” in Proceedings IEEE Real-Time Systems Symposium (IEEE), 207–216.
Larranaga, P., Kuijpers, C., Poza, M., and Murga, R. (1997). Decomposing Bayesian Networks. Triangulation of the Moral Graph with Genetic Algorithms. Stat. Comput. 7, 19–34.
Leung, J. Y.-T., and Merrill, M. L. (1980). A Note on Preemptive Scheduling of Periodic, Real-Time Tasks. Inf. Process. Lett. 11, 115–118. doi:10.1016/0020-0190(80)90123-4
Liu, C. L., and Layland, J. W. (1973). Scheduling Algorithms for Multiprogramming in a Hard-Real-Time Environment. J. Acm 20, 46–61. doi:10.1145/321738.321743
Lukasiewycz, M., Schneider, R., Goswami, D., and Chakraborty, S. (2012). “Modular Scheduling of Distributed Heterogeneous Time-Triggered Automotive Systems,” in 17th Asia and South Pacific Design Automation Conference (IEEE), 665–670. doi:10.1109/aspdac.2012.6165039
Dataset Marija Sokcevic (2020). Partitioned Complexity. Available at: https://www.tttech-auto.com/expert_insight/expert-insights-partitioned-complexity/(Accessed 06 15, 2021).
McLean, S. D., Craciunas, S. S., Hansen, E. A. J., and Pop, P. (2020). “Mapping and Scheduling Automotive Applications on ADAS Platforms Using Metaheuristics,” in 2020 25th IEEE International Conference on Emerging Technologies and Factory Automation (IEEE), 329–336. doi:10.1109/etfa46521.2020.9212029
McLean, S. D. (2019). Mapping and Scheduling of Real-Time Tasks on Multi-Core Autonomous Driving platformsMaster’s Thesis. Kongens Lyngby, Denmark: Technical University of Denmark.
McLean, S. D., Pop, P., and Craciunas, S. S. (2019). Mapping and Scheduling of Real-Time Tasks on Multi-Core Autonomous Driving Platforms. Kongens Lyngby, Denmark: Tech. rep., Technical University of Denmark.
Mehmed, A., Steiner, W., and Rosenblattl, M. (2017). “A Time-Triggered Middleware for Safety-Critical Automotive Applications,” in Presented at the 22nd International Conference on Reliable Software Technologies—Ada-Europe (IEEE).
Mubeen, S., and Nolte, T. (2015). “Applying End-To-End Path Delay Analysis to Multi-Rate Automotive Systems Developed Using Legacy Tools,” in 2015 IEEE World Conference on Factory Communication Systems (IEEE), 1–4. doi:10.1109/wfcs.2015.7160585
Niedrist, G. (2018). “Deterministic Architecture and Middleware for Domain Control Units and Simplified Integration Process Applied to ADAS,” in Fahrerassistenzsysteme 2016 (Wiesbaden: Springer Fachmedien Wiesbaden), 235–250. doi:10.1007/978-3-658-21444-9_15
Peng, D.-T., Shin, K. G., and Abdelzaher, T. F. (1997). Assignment and Scheduling Communicating Periodic Tasks in Distributed Real-Time Systems. IIEEE Trans. Softw. Eng. 23, 745–758. doi:10.1109/32.637388
Pop, P., Raagaard, M. L., Craciunas, S. S., and Steiner, W. (2016). Design Optimisation of Cyber‐physical Distributed Systems Using IEEE Time‐sensitive Networks. IET Cyber-phys. Syst. 1, 86–94. doi:10.1049/iet-cps.2016.0021
Pop, T., Eles, P., and Peng, Z. (2003). “Schedulability Analysis for Distributed Heterogeneous Time/event Triggered Real-Time Systems,” in 15th Euromicro Conference on Real-Time Systems (IEEE), 257–266.
Raagaard, M. L., and Pop, P. (2017). Optimization Algorithms for the Scheduling of IEEE 802.1 Time-Sensitive Networking (TSN). Kongens Lyngby, Denmark: Tech. rep., Technical University of Denmark.
Rajeev, A. C., Mohalik, S., Dixit, M. G., Chokshi, D. B., and Ramesh, S. (2010). “Schedulability and End-To-End Latency in Distributed ECU Networks: Formal Modeling and Precise Estimation,” in Proceedings of the Tenth ACM International Conference on Embedded Software (IEEE), 129–138.
Sagstetter, F., Andalam, S., Waszecki, P., Lukasiewycz, M., Stähle, H., Chakraborty, S., et al. (2014). “Schedule Integration Framework for Time-Triggered Automotive Architectures,” in Proceedings of the 51st Annual Design Automation Conference (IEEE), 1–6. doi:10.1145/2593069.2593211
Serna Oliver, R., Craciunas, S. S., and Steiner, W. (2018). “IEEE 802.1Qbv Gate Control List Synthesis Using Array Theory Encoding,” in 2018 IEEE Real-Time and Embedded Technology and Applications Symposium (IEEE), 13–24. doi:10.1109/rtas.2018.00008
Sommer, S., Camek, A., Becker, K., Buckl, C., Zirkler, A., Fiege, L., et al. (2013). “RACE: A Centralized Platform Computer Based Architecture for Automotive Applications,” in 2013 IEEE International Electric Vehicle Conference (IEVC) (IEEE), 1–6. doi:10.1109/ievc.2013.6681152
Steiner, W., Bauer, G., Hall, B., and Paulitsch, M. (2011). “TTEthernet: Time-Triggered Ethernet,” in Time-Triggered Communication (Boca Raton, United States: CRC).
Syswerda, G. (1991). “Schedule Optimization Using Genetic Algorithms,” in Handbook of Genetic Algorithms (New York: Van Nostrand Reinhold), 332–349.
Tindell, K., and Clark, J. (1994). Holistic Schedulability Analysis for Distributed Hard Real-Time Systems. Microprocess. Microprogram 40, 1. doi:10.1016/0165-6074(94)90080-9
Dataset TTTech Computertechnik AG (2018). Automated Driving Offering. Available at: https://www.tttech-auto.com/products/automated-driving/.
Verucchi, M., Theile, M., Caccamo, M., and Bertogna, M. (2020). “Latency-aware Generation of Single-Rate Dags from Multi-Rate Task Sets,” in 2020 IEEE Real-Time and Embedded Technology and Applications Symposium (IEEE), 226–238. doi:10.1109/rtas48715.2020.000-4
Keywords: automotive applications, task scheduling, task preemption, time-sensitive networking, TSN, IEEE 802.1Qbv
Citation: McLean SD, Juul Hansen EA, Pop P and Craciunas SS (2022) Configuring ADAS Platforms for Automotive Applications Using Metaheuristics. Front. Robot. AI 8:762227. doi: 10.3389/frobt.2021.762227
Received: 21 August 2021; Accepted: 14 October 2021;
Published: 04 January 2022.
Edited by:
Dakshina Dasari, Robert Bosch, GermanyReviewed by:
Risat Pathan, University of Gothenburg, SwedenCopyright © 2022 McLean, Juul Hansen, Pop and Craciunas. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Paul Pop, cGF1cG9AZHR1LmRr
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.