 S. M. Nahid Mahmud
S. M. Nahid Mahmud Scott A. Nivison2
Scott A. Nivison2 Rushikesh Kamalapurkar
Rushikesh Kamalapurkar- 1School of Mechanical and Aerospace Engineering, Oklahoma State University, Stillwater, OK, United States
- 2Munitions Directorate, Air Force Research Laboratory, Eglin AFB, FL, United States
Reinforcement learning has been established over the past decade as an effective tool to find optimal control policies for dynamical systems, with recent focus on approaches that guarantee safety during the learning and/or execution phases. In general, safety guarantees are critical in reinforcement learning when the system is safety-critical and/or task restarts are not practically feasible. In optimal control theory, safety requirements are often expressed in terms of state and/or control constraints. In recent years, reinforcement learning approaches that rely on persistent excitation have been combined with a barrier transformation to learn the optimal control policies under state constraints. To soften the excitation requirements, model-based reinforcement learning methods that rely on exact model knowledge have also been integrated with the barrier transformation framework. The objective of this paper is to develop safe reinforcement learning method for deterministic nonlinear systems, with parametric uncertainties in the model, to learn approximate constrained optimal policies without relying on stringent excitation conditions. To that end, a model-based reinforcement learning technique that utilizes a novel filtered concurrent learning method, along with a barrier transformation, is developed in this paper to realize simultaneous learning of unknown model parameters and approximate optimal state-constrained control policies for safety-critical systems.
1 Introduction
Due to advantages such as repeatability, accuracy, and lack of physical fatigue, autonomous systems have been increasingly utilized to perform tasks that are dull, dirty, or dangerous. Autonomy in safety-critical applications such as autonomous driving and unmanned flight relies on the ability to synthesize safe controllers. To improve robustness to parametric uncertainties and changing objectives and models, autonomous systems also need the ability to simultaneously synthesize and execute control policies online and in real time. This paper concerns reinforcement learning (RL), which has been established as an effective tool for safe policy synthesis for both known and uncertain dynamical systems with finite state and action spaces [see, e.g., Sutton and Barto (1998); Doya (2000)].
RL typically requires a large number of iterations due to sample inefficiency [see, e.g., Sutton and Barto (1998)]. Sample efficiency in RL can be improved via model-based reinforcement learning (MBRL); however, MBRL methods are prone to failure due to inaccurate models [see, e.g., Kamalapurkar et al. (2016a,b, 2018)]. Online MBRL methods that handle modeling uncertainties are motivated by complex tasks that require systems to operate in dynamic environments with changing objectives and system models. Accurate models of the system and the environment are generally not available due to sparsity of data. In the past, MBRL techniques under the umbrella of approximate dynamic programming (ADP) have been successfully utilized to solve reinforcement learning problems online with model uncertainty [see, e.g., Modares et al. (2013); Kiumarsi et al. (2014); Qin et al. (2014)]. ADP utilizes parametric methods such as neural networks (NNs) to approximate the value function and the system model online. By obtaining an approximation of both the value function and the system model, a stable closed-loop adaptive control policy can be developed [see, e.g., Vamvoudakis et al. (2009); Lewis and Vrabie (2009); Bertsekas (2011); Bhasin et al. (2012); Liu and Wei (2014)].
Real-world optimal control applications typically include constraints on states and/or inputs that are critical for safety [see, e.g., He et al. (2017)]. ADP was successfully extended to address input constrained control problems in Modares et al. (2013) and Vamvoudakis et al. (2016). The state-constrained ADP problem was studied in the context of obstacle avoidance in Walters et al. (2015) and Deptula et al. (2020), where an additional term that penalizes proximity to obstacles was added to the cost function. Since the added proximity penalty in Walters et al. (2015) was finite, the ADP feedback could not guarantee obstacle avoidance, and an auxiliary controller was needed. In Deptula et al. (2020), a barrier-like function was used to ensure unbounded growth of the proximity penalty near the obstacle boundary. While this approach results in avoidance guarantees, it relies on the relatively strong assumption that the value function is continuously differentiable over a compact set that contains the obstacles in spite of penalty-induced discontinuities in the cost function.
Control Barrier Function (CBF) is another approach to guarantee safety in safety-critical systems [see e.g., Ames et al. (2017)], with recent applications to the safe reinforcement learning problems [see e.g., Choi et al. (2020); Cohen and Belta (2020); Marvi and Kiumarsi (2021)]. Choi et al. (2020) have addressed the issue of model uncertainty in safety-critical control with an RL-based data-driven approach. A drawback of this approach is that it requires a nominal controller that keeps the system stable during the learning phase, which may not be always possible to design. In Marvi and Kiumarsi (2021), the authors develop a safe off-policy RL scheme which trades-off between safety and performance. In Cohen and Belta (2020), the authors develop a safe RL scheme in which the proximity penalty approach from Deptula et al. (2020) is cast into the framework of CBFs. While the control barrier function results in safety guarantees, the existence of a smooth value function, in spite of a nonsmooth cost function, needs to be assumed. Furthermore, to facilitate parametric approximation of the value function, the existence of a forward invariant compact set in the interior of the safe set needs to be established. Since the invariant set needs to be in the interior of the safe set, the penalty becomes superfluous, and safety can be achieved through conventional Lyapunov methods.
This paper is inspired by a safe reinforcement learning technique, recently developed in Yang et al. (2019), based on the idea of transforming a state and input constrained nonlinear optimal control problem into an unconstrained one with a type of saturation function, introduced in Graichen and Petit (2009), and Bechlioulis and Rovithakis (2009). In Yang et al. (2019), the state constrained optimal control problem is transformed using a barrier transformation (BT), into an equivalent, unconstrained optimal control problem. A learning technique is then used to synthesize the feedback control policy for the unconstrained optimal control problem. The controller for the original system is then derived from the unconstrained approximate optimal policy by inverting the barrier transformation. In Greene et al. (2020), the restrictive persistence of excitation requirement in Yang et al. (2019) is softened using model-based reinforcement learning (MBRL), where exact knowledge of the system dynamics is utilized in the barrier transformation.
One of the primary contributions of this paper is a detailed analysis of the connection between the transformed dynamics and the original dynamics, which is missing from results such as Yang et al. (2019), Greene et al. (2020), and Yang et al. (2020). While the stability of the transformed dynamics under the designed controllers is established in results such as Yang et al. (2019), Greene et al. (2020), and Yang et al. (2020), the implications of the behavior of the transformed system on the original system are not examined. In this paper, it is shown that the trajectories of the original system are related to the trajectories of the transformed system via the barrier transformation as long as the trajectories of the transformed system are complete.
While the transformation in Yang et al. (2019) and Greene et al. (2020) results in verifiable safe controllers, it requires exact knowledge of the system model, which is often difficult to obtain. Another primary contribution of this paper is the development of a novel filtered concurrent learning technique for online model learning, and its integration with the barrier transformation method, to yield a novel MBRL solution to the online state-constrained optimal control problem under parametric uncertainty. The developed MBRL method learns an approximate optimal control policy in the presence of parametric uncertainties for safety critical systems while maintaining stability and safety during the learning phase. The inclusion of filtered concurrent learning makes the controller robust to modeling errors and guarantees local stability under a finite (as opposed to persistent) excitation condition.
In the following, the problem is formulated in Section 2 and the BT is described and analyzed in Section 3. A novel parameter estimation technique is detailed in Section 4 and a model-based reinforcement learning technique for synthesizing feedback control policy in the transformed coordinates is developed in Section 5. In Section 6, a Lypaunov-based analysis is utilized to establish practical stability of the closed-loop system resulting from the developed MBRL technique in the transformed coordinates, which guarantees that the safety requirements are satisfied in the original coordinates. Simulation results in Section 7 demonstrate the performance of the developed method and analyze its sensitivity to various design parameters, followed by a comparison of the performance of the developed MBRL approach to an offline pseudospectral optimal control method. Strengths and limitations of the developed method are discussed in Section 8, along with possible extensions.
2 Problem Formulation
2.1 Control Objective
Consider a continuous-time affine nonlinear dynamical system
where
The objective is to design a controller u for the system in (1) such that starting from a given feasible initial condition x0, the trajectories x(⋅) decay to the origin and satisfy xi(t) ∈ (ai, Ai), ∀t ≥ 0, where i = 1, 2, … , n and ai < 0 < Ai. While MBRL methods such as those detailed in Kamalapurkar et al. (2018) guarantee stability of the closed loop, state constraints are typically difficult to establish without extensive trial and error. To achieve the stated objective, an MBRL framework (see Figure 1) is developed in this paper, where a BT is used to guarantee satisfaction of state constraints.
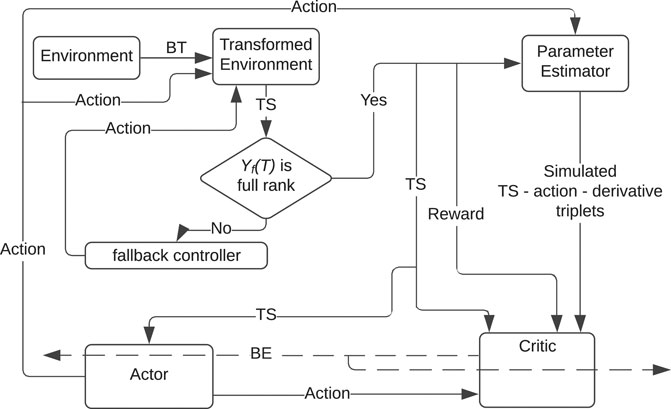
FIGURE 1. The developed BT MBRL framework. The control system consists of a model-based barrier-actor-critic-estimator architecture. In addition to the transformed state-action measurements, the critic also utilizes states, actions, and the corresponding state derivatives, evaluated at arbitrarily selected points in the state space, to learn the value function. In the figure, BT: Barrier Transformation; TS: Transformed State; BE: Bellman Error.
3 Barrier Transformation
3.1 Design
Let the function
Define
Define
Consider the BF based state transformation
where
The dynamics of the transformed state can then be expressed as
where F (s) := y(s)θ,
Continuous differentiability of b−1 implies that F and G are locally Lipschitz continuous. Furthermore, f (0) = 0 along with the fact that b−1 (0) = 0 implies that F (0) = 0. As a result, for all compact sets
3.2 Analysis
In the following lemma, the trajectories of the original system and the transformed system are shown to be related by the barrier transformation provided the trajectories of the transformed system are complete [see, e.g., Page 33 of Sanfelice (2021)]. The completeness condition is not vacuous, it is not difficult to construct a system where the transformed trajectories escape to infinity in finite time, while the original trajectories are complete. For example, consider the system
Lemma 1. If t ↦ Φ(t, b(x0), ξ) is a complete Carathéodory solution to (7), starting from the initial condition b(x0), under the feedback policy (s, t)↦ζ(s, t) and t↦Λ(t, x0, ξ) is a Carathéodory solution to (1), starting from the initial condition x0, under the feedback policy (x, t)↦ξ(x, t), defined as ξ(x, t) = ζ(b(x), t), then Λ(⋅, x0, ξ) is complete and
Proof. See Lemma 1 in the Supplementary Material.
Note that the feedback ξ is well-defined at x only if b(x) is well-defined, which is the case whenever x is inside the barrier. As such, the main conclusion of Lemma 1 also implies that Λ(⋅, x0, ξ) remains inside the barrier. It is thus inferred from Lemma 1 that if the trajectories of (7) are bounded and decay to a neighborhood of the origin under a feedback policy (s, t)↦ζ(s, t), then the feedback policy
To achieve BT MBRL in the presense of parametric uncertainties, the following section develops a novel parameter estimator.
4 Parameter Estimation
The following parameter estimator design is motivated by the subsequent Lyapunov analysis, and is inspired by the finite-time estimator in Adetola and Guay (2008) and the filtered concurrent learning (FCL) method in Roy et al. (2016). Estimates of the unknown parameters,
where
where β1 is a symmetric positive definite gain matrix and
Equations 7–12 constitute a nonsmooth system of differential equations
where
Lemma 2. If ‖Yf‖ is non-decreasing in time then (13) admits Carathéodory solutions.
Proof. see Lemma 2 in Supplementary Material.
Note that (9), expressed in the integral form
where
and the fact that s(τ) − s0 − Gf(τ) = Y(τ)θ, can be used to conclude that Xf(t) = Yf(t)θ, for all t ≥ 0. As a result, a measure for the parameter estimation error can be obtained using known quantities as
The filter design is thus motivated by the fact that if the matrix
Assumption 3. There exists a time instance T > 0 such that Yf(T) is full rank.
Note that the minimum eigenvalue of Yf is trivially non-decreasing for t ≥ t3 since Yf(t) is constant ∀t ≥ t3. Indeed, for t4 ≤ t5 ≤ t3,
Assumption 4. A fallback controller
If a fallback controller that satisfies Assumption 4 is not available, then, under the additional assumption that the trajectories of (7) are exciting over the interval [0, T), such a controller can be learned online, while maintaining system stability, using model-free reinforcement learning techniques such as Bhasin et al. (2013); Vrabie and Lewis (2010), and Modares et al. (2014).
5 Model-Based Reinforcement Learning
Lemma 1 implies that if a feedback controller that practically stabilizes the transformed system in (7) is designed, then the same feedback controller, applied to the original system by inverting the BT, also achieves the control objective stated in Section 2.1. In the following, a controller that practically stabilizes (7) is designed as an estimate of the controller that minimizes the infinite horizon cost.
over the set
Assuming that an optimal controller exists, let the optimal value function, denoted by
where uI and
where
Remark 6. In the developed method, the cost function is selected to be quadratic in the transformed coordinates. However, a physically meaningful cost function is more likely to be available in the original coordinates. If such a cost function is available, it can be transformed from the original coordinates to the barrier coordinates using the inverse barrier function, to yield a cost function that is not quadratic in the state. While the analysis in this paper addresses the quadratic case, it can be extended to address the non-quadratic case with minimal modifications as long as s↦r(s, u) is positive definite for all
5.1 Value Function Approximation
Since computation of analytical solutions of the HJB equation is generally infeasible, especially for systems with uncertainty, parametric approximation methods are used to approximate the value function V∗ and the optimal policy u∗. The optimal value function is expressed as
where
The basis functions are selected such that the approximation of the functions and their derivatives is uniform over the compact set
Since the ideal weights, W, are unknown, an actor-critic approach is used in the following to estimate W. To that end, let the NN estimates
where the critic weights,
5.2 Bellman Error
Substituting (23) and (24) into (19) results in a residual term,
Traditionally, online RL methods require a persistence of excitation (PE) condition to be able learn the approximate control policy [see, e.g., Modares et al. (2013); Kamalapurkar et al. (2016a); Kiumarsi et al. (2014)]. Guaranteeing PE a priori and verifying PE online are both typically impossible. However, using virtual excitation facilitated by model-based BE extrapolation, stability and convergence of online RL can be established under a PE-like condition that, while impossible to guarantee a priori, can be verified online by monitoring the minimum eigenvalue of a matrix in the subsequent Assumption 7 [see, e.g., Kamalapurkar et al. (2016b)]. Using the system model, the BE can be evaluated at any arbitrary point in the state space. Virtual excitation can then be implemented by selecting a set of states
where,
where
where, Fk := F(sk), ϵk := ϵ(sk), σk := σ(sk),
5.3 Update Laws for Actor and Critic Weights
The actor and the critic weights are held at their initial values over the interval [0, T) and starting at t = T, using the instantaneous BE
with
where the controller ψ was introduced in Assumption 4. The following verifiable PE-like rank condition is then utilized in the stability analysis.
Assumption 7. There exists a constant
Since ωk is a function of the weight estimates
6 Stability Analysis
In the following theorem, the stability of the trajectories of the transformed system, and the estimation errors
Theorem 8. Provided Assumptions 3, 4, and 7 hold, the gains are selected large enough based on (46) - (49) in Supplementary Material, and the weights
Proof. See Theorem 8 in Supplementary Material.
Using Lemma 1, it can then be concluded that the feedback control law
applied to the original system in (1), achieves the control objective stated in Section 2.1.
7 Simulation
To demonstrate the performance of the developed method, two simulation results, one for a two-state dynamical system, and one for a four-state dynamical system corresponding to a two-link planar robot manipulator, are provided.2
7.1 Two State Dynamical System
The dynamical system is given by
where
The state x =
7.1.1 Results for the Two State System
As seen from Figure 2, the system state stays within the user-specified safe set while converging to the origin. The results in Figure 3 indicate that the unknown weights for both the actor and critic NNs converge to similar values. As demonstrated in Figure 4 the parameter estimation errors also converge to a small neighborhood of the origin.
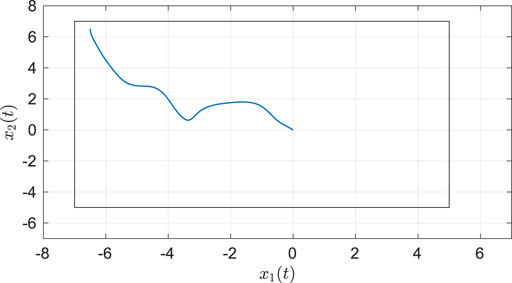
FIGURE 2. Phase portrait for the two-state dynamical system using MBRL with FCL in the original coordinates. The boxed area represents the user-selected safe set.
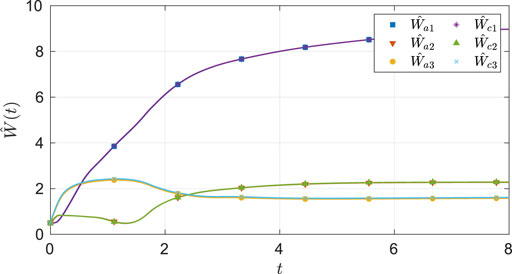
FIGURE 3. Estimates of the actor and the critic weights under nominal gains for the two-state dynamical system.
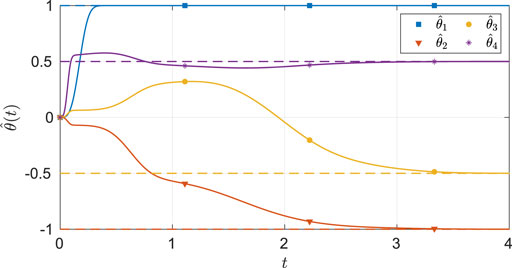
FIGURE 4. Estimates of the unknown parameters in the system under the nominal gains for the two-state dynamical system. The dash lines in the figure indicates the ideal values of the parameters.
Since the ideal actor and critic weights are unknown, the estimates cannot be directly compared against the ideal weights. To gauge the quality of the estimates, the trajectory generated by the controller

TABLE 1. Comparison of costs for a single barrier transformed trajectory of (35), obtained using the optimal feedback controller generated via the developed method, and obtained using pseudospectral numerical optimal control software.
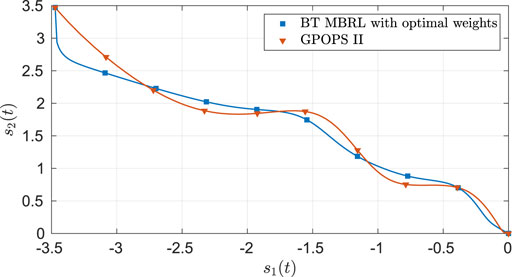
FIGURE 5. Comparison of the optimal trajectories obtained using GPOPS II and using BT MBRL with FCL and fixed optimal weights for the two-state dynamical system.
7.1.2 Sensitivity Analysis for the Two State System
To study the sensitivity of the developed technique to changes in various tuning parameters, a one-at-a-time sensitivity analysis is performed. The parameters kc1, kc2, ka1, ka2, β, and v are selected for the sensitivity analysis. The costs of the trajectories, under the optimal feedback controller obtained using the developed method, are presented in Table 2 for five different values of each parameter. The parameters are varied in a neighborhood of the nominal values (selected through trial and error) kc1 = 0.3, kc2 = 5, ka1 = 180, ka2 = 0.0001, β = 0.03, and v = 0.5. The value of β1 is set to be diag(50, 50, 50, 50). The results in Table 2 indicate that the developed method is robust to small changes in the learning gains.
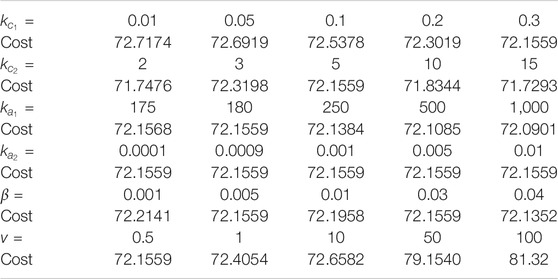
TABLE 2. Sensitivity Analysis for the two state system.
7.2 Four State Dynamical System
The four-state dynamical system corresponding to a two-link planar robot manipulator is given by
where
with s2 = sin(x2), c2 = cos(x2), p1 = 3.473, p2 = 0.196, and p3 = 0.242. The state x =
7.2.1 Results for the Four State System
As seen from Figure 6, the system state stays within the user specified safe set while converging to the origin. As demonstrated in Figures 7 and 8, the actor and the critic weights converge, and estimates of the unknown parameters in the system model converge to their true values. Since the true actor and critic weights are unknown, the learned optimal controller is compared with an offline numerical optimal controller. The results of the comparison (see Table 3) indicate that the two solution techniques generate slightly different trajectories in the state space (see Figure 9) and that the total cost resulting from the learned controller is higher. We hypothesize that the difference in costs can be attributed to the exact basis for value function approximation being unknown.
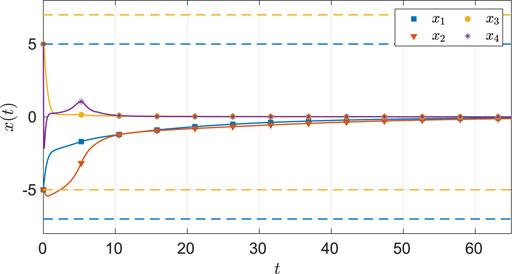
FIGURE 6. State trajectories for the four-state dynamical system using MBRL with FCL in the original coordinates. The dash lines represent the user-selected safe set.
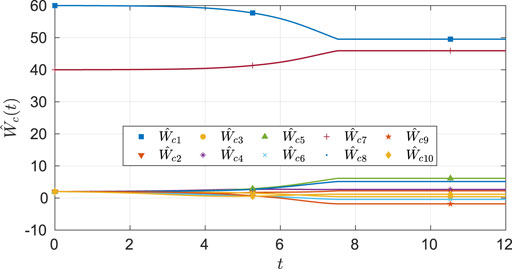
FIGURE 7. Estimates of the critic weights under nominal gains for the four-state dynamical system.
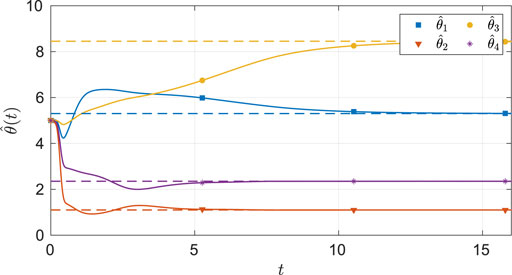
FIGURE 8. Estimates of the unknown parameters in the system under the nominal gains for the four-state dynamical system. The dash lines in the figure indicates the ideal values of the parameters.

TABLE 3. Costs for a single barrier transformed trajectory of (37), obtained using the developed method, and using pseudospectral numerical optimal control software.
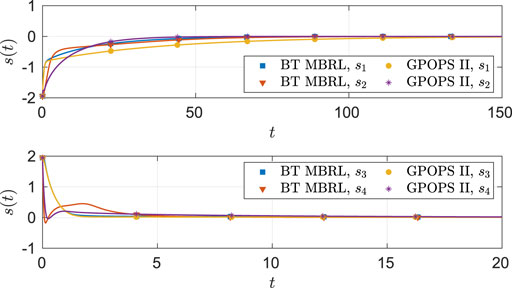
FIGURE 9. Comparison of the optimal angular position (top) and angular velocity (bottom) trajectories obtained using GPOPS II and BT MBRL with fixed optimal weights for the four-state dynamical system.
In summary, the newly developed method can achieve online optimal control thorough a BT MBRL approach while estimating the value of the unknown parameters in the system dynamics and ensuring safety guarantees in the original coordinates during the learning phase.
The following section details a one-at-a-time sensitivity analysis and study the sensitivity of the developed technique to changes in various tuning parameters.
7.2.2 Sensitivity Analysis for the Four State System
The parameters kc1, kc2, ka1, ka2, β, and v are selected for the sensitivity analysis. The costs of the trajectories under the optimal feedback controller, obtained using the developed method, are presented in Table 4 for five different values of each parameter.
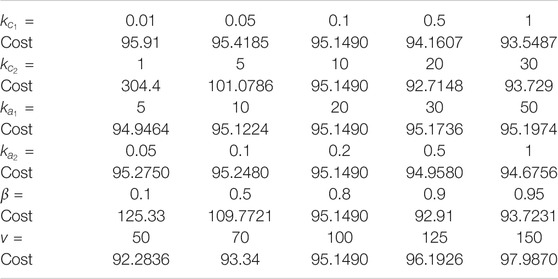
TABLE 4. Sensitivity Analysis for the four state system.
The parameters are varied in a neighborhood of the nominal values (selected through trial and error) kc1 = 0.1, kc2 = 10, ka1 = 20, ka2 = 0.2, β = 0.8, and v = 100. The value of β1 is set to be diag(100, 100, 100, 100).
The results in Tables 2 and 4, indicate that the developed method is not sensitive to small changes in the learning gains. While reduced sensitivity to gains simplifies gain selection, as indicated by the local stability result, the developed method is sensitive to selection of basis functions and initial guesses of the unknown weights. Due to high dimensionality of the vector of unknown weights, a complete characterization of the region of attraction is computationally difficult. As such, the basis functions and the initial guess were selected via trial and error.
8 Conclusion
This paper develops a novel online safe control synthesis technique which relies on a nonlinear coordinate transformation that transforms a constrained optimal control problem into an unconstrained optimal control problem. A model of the system in the transformed coordinates is simultaneously learned and utilized to simulate experience. Simulated experience is used to realize convergent RL under relaxed excitation requirements. Safety of the closed-loop system, expressed in terms of box constraint, regulation of the system states to a neighborhood of the origin, and convergence of the estimated policy to a neighborhood of the optimal policy in transformed coordinates is established using a Lyapunov-based stability analysis.
While the main result of the paper states that the state is uniformly ultimately bounded, the simulation results hint towards asymptotic convergence of the part of the state that corresponds to the system trajectories, x (⋅). Proving such a result is a part of future research.
Limitations and possible extensions of the ideas presented in this paper revolve around two key issues: (a) safety, and (b) online learning and optimization. The barrier function used in the BT to address safety can only ensure a fixed box constraint. A more generic and adaptive barrier function, constructed, perhaps, using sensor data is a subject for future research.
For optimal learning, parametric approximation techniques are used to approximate the value functions in this paper. Parametric approximation of the value function requires selection of appropriate basis functions which may be hard to find for the barrier-transformed dynamics. Developing techniques to systematically determine a set of basis functions for real-world systems is a subject for future research.
The barrier transformation method to ensure safety relies on knowledge of the dynamics of the system. While this paper addresses parametric uncertainties, the BE method could potentially result in a safety violation due to unmodeled dynamics. In particular, the safety guarantees developed in this paper rely on the relationship (Lemma 1) between trajectories of the original dynamics and the transformed system, which holds in the presence of parametric uncertainty, but fails if a part of the dynamics is not included in the original model. Further research is needed to establish safety guarantees that are robust to unmodeled dynamics (for a differential games approach to robust safety, see Yang et al. (2020)).
Data Availability Statement
The original contributions presented in the study are included in the article/Supplementary Material, further inquiries can be directed to the corresponding author.
Author Contributions
NM: Conceptualization, Methodology, Validation, Resources, Investigation, Numerical experiment, Formal analysis, Writing—Original Draft; SN: Writing—Reviewing; ZB: Writing—Reviewing; RK: Conceptualization, Formal analysis- Reviewing and Editing; Writing—Reviewing and Editing, Supervision.
Funding
This research was supported, in part, by the Air Force Research Laboratories under award number FA8651-19-2-0009. Any opinions, findings, or recommendations in this article are those of the author(s), and do not necessarily reflect the views of the sponsoring agencies.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/frobt.2021.733104/full#supplementary-material
Footnotes
1For applications with bounded control inputs, a non-quadratic penalty function similar to Eq. 17 of Yang et al. (2020) can be incorporated in (17).
2The source code for these simulations is available at https://github.com/scc-lab/publications-code/tree/master/2021-Frontiers-BT-MBRL.
References
Adetola, V., and Guay, M. (2008). Finite-time Parameter Estimation in Adaptive Control of Nonlinear Systems. IEEE Trans. Automat. Contr. 53, 807–811. doi:10.1109/tac.2008.919568
Ames, A. D., Xu, X., Grizzle, J. W., and Tabuada, P. (2017). Control Barrier Function Based Quadratic Programs for Safety Critical Systems. IEEE Trans. Automat. Contr. 62, 3861–3876. doi:10.1109/TAC.2016.2638961
Bechlioulis, C. P., and Rovithakis, G. A. (2009). Adaptive Control with Guaranteed Transient and Steady State Tracking Error Bounds for Strict Feedback Systems. Automatica 45, 532–538. doi:10.1016/j.automatica.2008.08.012
Bertsekas, D. P. (2011). Dynamic Programming and Optimal Control. 3rd edition, II. Belmont, MA: Athena Scientific.
Bhasin, S., Kamalapurkar, R., Johnson, M., Vamvoudakis, K. G., Lewis, F. L., and Dixon, W. E. (2012). “An Actor-Critic-Identifier Architecture for Adaptive Approximate Optimal Control,” in Reinforcement Learning and Approximate Dynamic Programming for Feedback Control. Editors F. L. Lewis, and D. Liu (Piscataway, NJ, USA: Wiley and IEEE Press), 258–278. IEEE Press Series on Computational Intelligence. doi:10.1002/9781118453988.ch12
Bhasin, S., Kamalapurkar, R., Johnson, M., Vamvoudakis, K. G., Lewis, F. L., and Dixon, W. E. (2013). A Novel Actor-Critic-Identifier Architecture for Approximate Optimal Control of Uncertain Nonlinear Systems. Automatica 49, 89–92. doi:10.1016/j.automatica.2012.09.019
Choi, J., Castañeda, F., Tomlin, C., and Sreenath, K. (2020). “Reinforcement Learning for Safety-Critical Control under Model Uncertainty, Using Control Lyapunov Functions and Control Barrier Functions,” in Proceedings of Robotics: Science and Systems, Corvalis, Oregon, USA, July 12–16, 2020. doi:10.15607/RSS.2020.XVI.088
Cohen, M. H., and Belta, C. (2020). “Approximate Optimal Control for Safety-Critical Systems with Control Barrier Functions,” in Proceedings of the IEEE Conference on Decision and Control, Jeju, Korea (South), 14–18 Dec. 2020, 2062–2067. doi:10.1109/CDC42340.2020.9303896
Deptula, P., Chen, H.-Y., Licitra, R. A., Rosenfeld, J. A., and Dixon, W. E. (2020). Approximate Optimal Motion Planning to Avoid Unknown Moving Avoidance Regions. IEEE Trans. Robot. 36, 414–430. doi:10.1109/TRO.2019.2955321
Doya, K. (2000). Reinforcement Learning in Continuous Time and Space. Neural Comput. 12, 219–245. doi:10.1162/089976600300015961
Graichen, K., and Petit, N. (2009). Incorporating a Class of Constraints into the Dynamics of Optimal Control Problems. Optim. Control. Appl. Meth. 30, 537–561. doi:10.1002/oca.880
Greene, M. L., Deptula, P., Nivison, S., and Dixon, W. E. (2020). Sparse Learning-Based Approximate Dynamic Programming with Barrier Constraints. IEEE Control. Syst. Lett. 4, 743–748. doi:10.1109/LCSYS.2020.2977927
Greene, M. L., Deptula, P., Kamalapurkar, R., and Dixon, W. E. (2021). “Mixed Density Methods for Approximate Dynamic Programming,” in Handbook of Reinforcement Learning and Control. Studies in Systems, Decision and Control. Editors K. G. Vamvoudakis, Y. Wan, F. Lewis, and D. Cansever (Cham, Switzerland: Springer International Publishing), 325, 139–172. chap. 5. doi:10.1007/978-3-030-60990-0_5
He, W., Li, Z., and Chen, C. L. P. (2017). A Survey of Human-Centered Intelligent Robots: Issues and Challenges. Ieee/caa J. Autom. Sin. 4, 602–609. doi:10.1109/jas.2017.7510604
Kamalapurkar, R., Rosenfeld, J. A., and Dixon, W. E. (2016a). Efficient Model-Based Reinforcement Learning for Approximate Online Optimal Control. Automatica 74, 247–258. doi:10.1016/j.automatica.2016.08.004
Kamalapurkar, R., Walters, P., and Dixon, W. E. (2016b). Model-based Reinforcement Learning for Approximate Optimal Regulation. Automatica 64, 94–104. doi:10.1016/j.automatica.2015.10.039
Kamalapurkar, R., Walters, P., Rosenfeld, J., and Dixon, W. (2018). “Reinforcement Learning for Optimal Feedback Control: A Lyapunov-Based Approach,” in Communications and Control Engineering. Cham, Switzerland: Springer International Publishing. doi:10.1007/978-3-319-78384-0
Kiumarsi, B., Lewis, F. L., Modares, H., Karimpour, A., and Naghibi-Sistani, M.-B. (2014). Reinforcement -Learning for Optimal Tracking Control of Linear Discrete-Time Systems with Unknown Dynamics. Automatica 50, 1167–1175. doi:10.1016/j.automatica.2014.02.015
Lewis, F. L., and Vrabie, D. (2009). Reinforcement Learning and Adaptive Dynamic Programming for Feedback Control. IEEE Circuits Syst. Mag. 9, 32–50. doi:10.1109/mcas.2009.933854
Liu, D., and Wei, Q. (2014). Policy Iteration Adaptive Dynamic Programming Algorithm for Discrete-Time Nonlinear Systems. IEEE Trans. Neural Netw. Learn. Syst. 25, 621–634. doi:10.1109/TNNLS.2013.2281663
Marvi, Z., and Kiumarsi, B. (2021). Safe Reinforcement Learning: A Control Barrier Function Optimization Approach. Int. J. Robust Nonlinear Control. 31, 1923–1940. doi:10.1002/rnc.5132
Modares, H., Lewis, F. L., and Naghibi-Sistani, M.-B. (2013). Adaptive Optimal Control of Unknown Constrained-Input Systems Using Policy Iteration and Neural Networks. IEEE Trans. Neural Netw. Learn. Syst. 24, 1513–1525. doi:10.1109/tnnls.2013.2276571
Modares, H., Lewis, F. L., and Naghibi-Sistani, M.-B. (2014). Integral Reinforcement Learning and Experience Replay for Adaptive Optimal Control of Partially-Unknown Constrained-Input Continuous-Time Systems. Automatica 50, 193–202. doi:10.1016/j.automatica.2013.09.043
Patterson, M. A., and Rao, A. V. (2014). GPOPS-II: A MATLAB Software for Solving Multiple-Phase Optimal Control Problems Using hp-Adaptive Gaussian Quadrature Collocation Methods and Sparse Nonlinear Programming. ACM Trans. Math. Softw. 41, 1–37. doi:10.1145/2558904
Qin, C., Zhang, H., and Luo, Y. (2014). Online Optimal Tracking Control of Continuous-Time Linear Systems with Unknown Dynamics by Using Adaptive Dynamic Programming. Int. J. Control. 87, 1000–1009. doi:10.1080/00207179.2013.863432
Roy, S. B., Bhasin, S., and Kar, I. N. (2016). “Parameter Convergence via a Novel PI-like Composite Adaptive Controller for Uncertain Euler-Lagrange Systems,” in Proceedings of the IEEE Conference on Decision and Control, Las Vegas, NV, USA, 12–14 Dec. 2016, 1261–1266. doi:10.1109/cdc.2016.7798439
Sutton, R. S., and Barto, A. G. (1998). Reinforcement Learning: An Introduction. Cambridge, MA, USA: MIT Press.
Vamvoudakis, K., Vrabie, D., and Lewis, F. L. (2009). “Online Policy Iteration Based Algorithms to Solve the Continuous-Time Infinite Horizon Optimal Control Problem,” in IEEE Symp. Adapt. Dyn. Program. Reinf. Learn., Nashville, TN, USA, 30 March–2 April 2009, 36–41. doi:10.1109/adprl.2009.4927523
Vamvoudakis, K. G., Miranda, M. F., and Hespanha, J. P. (2016). Asymptotically Stable Adaptive-Optimal Control Algorithm with Saturating Actuators and Relaxed Persistence of Excitation. IEEE Trans. Neural Netw. Learn. Syst. 27, 2386–2398. doi:10.1109/tnnls.2015.2487972
Vrabie, D., and Lewis, F. (2010). “Online Adaptive Optimal Control Based on Reinforcement Learning,” in Optimization and Optimal Control: Theory and Applications. Editors A. Chinchuluun, P. M. Pardalos, R. Enkhbat, and I. Tseveendorj (New York, NY: Springer New York), 309–323. doi:10.1007/978-0-387-89496-6_16
Walters, P., Kamalapurkar, R., and Dixon, W. E. (2015). “Approximate Optimal Online Continuous-Time Path-Planner with Static Obstacle Avoidance,” in Proceedings of the IEEE Conference on Decision and Control, Osaka, Japan, 15–18 Dec. 2015 (Osaka, Japan, 650–655. doi:10.1109/cdc.2015.7402303
Yang, Y., Yin, Y., He, W., Vamvoudakis, K. G., Modares, H., and Wunsch, D. C. (2019). “Safety-aware Reinforcement Learning Framework with an Actor-Critic-Barrier Structure,” in Proceedings of the American Control Conference, Philadelphia, PA, USA, 10–12 July 2019, 2352–2358. doi:10.23919/acc.2019.8815335
Yang, Y., Ding, D.-W., Xiong, H., Yin, Y., and Wunsch, D. C. (2020). Online Barrier-Actor-Critic Learning for H∞ Control with Full-State Constraints and Input Saturation. J. Franklin Inst. 357, 3316–3344. doi:10.1016/j.jfranklin.2019.12.017
Nomenclature
RL Reinforcement Learning
MBRL Model-based Reinforcement Learning
ADP Approximate Dynamic Programming
NN Neural Network
BF Barrier Function
BT Barrier Transformation
CL Concurrent Learning
FCL Filtered Concurrent Learning
PE Persistence of Excitation
FE Finite Excitation
TS Transformed State
BE Bellman Error
HJB Hamilton-Jacobi-Bellman
VI Value Iteration
PI Policy Iteration.
Keywords: safe learning, barrier transformation, model-based reinforcement learning, control theory, parameter estimation, nonlinear systems
Citation: Mahmud SMN, Nivison SA, Bell ZI and Kamalapurkar R (2021) Safe Model-Based Reinforcement Learning for Systems With Parametric Uncertainties. Front. Robot. AI 8:733104. doi: 10.3389/frobt.2021.733104
Received: 29 June 2021; Accepted: 27 September 2021;
Published: 16 December 2021.
Edited by:
Yongping Pan, National University of Singapore, SingaporeReviewed by:
Mohamed Hamdy, University of Menoufia, EgyptSayan Basu Roy, Indraprastha Institute of Information Technology Delhi, India
Copyright © 2021 Mahmud, Nivison, Bell and Kamalapurkar. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Rushikesh Kamalapurkar, rushikesh.kamalapurkar@okstate.edu