
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Robot. AI, 19 March 2021
Sec. Robotic Control Systems
Volume 8 - 2021 | https://doi.org/10.3389/frobt.2021.621820
This article is part of the Research TopicEnergy Sustainability in Marine RoboticsView all 8 articles
 Tauhidul Alam1*
Tauhidul Alam1* Abdullah Al Redwan Newaz2
Abdullah Al Redwan Newaz2 Leonardo Bobadilla3Wesam H. Alsabban4
Leonardo Bobadilla3Wesam H. Alsabban4 Ryan N. Smith5
Ryan N. Smith5 Ali Karimoddini2
Ali Karimoddini2Ocean ecosystems have spatiotemporal variability and dynamic complexity that require a long-term deployment of an autonomous underwater vehicle for data collection. A new generation of long-range autonomous underwater vehicles (LRAUVs), such as the Slocum glider and Tethys-class AUV, has emerged with high endurance, long-range, and energy-aware capabilities. These new vehicles provide an effective solution to study different oceanic phenomena across multiple spatial and temporal scales. For these vehicles, the ocean environment has forces and moments from changing water currents which are generally on the order of magnitude of the operational vehicle velocity. Therefore, it is not practical to generate a simple trajectory from an initial location to a goal location in an uncertain ocean, as the vehicle can deviate significantly from the prescribed trajectory due to disturbances resulted from water currents. Since state estimation remains challenging in underwater conditions, feedback planning must incorporate state uncertainty that can be framed into a stochastic energy-aware path planning problem. This article presents an energy-aware feedback planning method for an LRAUV utilizing its kinematic model in an underwater environment under motion and sensor uncertainties. Our method uses ocean dynamics from a predictive ocean model to understand the water flow pattern and introduces a goal-constrained belief space to make the feedback plan synthesis computationally tractable. Energy-aware feedback plans for different water current layers are synthesized through sampling and ocean dynamics. The synthesized feedback plans provide strategies for the vehicle that drive it from an environment’s initial location toward the goal location. We validate our method through extensive simulations involving the Tethys vehicle’s kinematic model and incorporating actual ocean model prediction data.
Ocean ecosystems are complex and have high variability in both time and space. Consequently, ocean scientists must collect data over long periods to obtain a synoptic view of ocean ecosystems and understand their spatiotemporal variability. To support data collection, autonomous underwater vehicles (AUVs) are increasingly being used for studying different oceanic phenomena such as oil spill mapping (Kinsey et al., 2011), harmful algal blooms (Das et al., 2010), phytoplankton and zooplankton communities (Kalmbach et al., 2017), and coral bleaching (Manderson et al., 2017). These AUVs can be classified into two categories: 1) propeller-driven vehicles, such as the Dorado class, which can move fast and gather numerous sensor observations but are limited in deployment time to multiple hours; and 2) minimally-actuated vehicles such as drifters, profiling floats, and gliders that move slower, but can remain on deployment for tens of days to multiple weeks.
A new generation of the long-range autonomous underwater vehicles (LRAUVs), i.e., Tethys, combines the advantages of both minimally-actuated and propeller-driven AUVs (Hobson et al., 2012). These LRAUVs can move quickly for hundreds of kilometers, float with water currents, and carry a broad range of data collection sensors. They can also control their buoyancy for changing depths in the water and the angle at which they move through the water. By mixing modalities, an LRAUV can be deployed in the water for weeks at a time and navigate challenging ocean current conditions for long periods. Two instances of deployed Tethys AUVs are shown in Figure 1. A planning and control technique for this vehicle is critical to increase its autonomy and generate mission trajectories during long-range operations. The execution of a planned trajectory for this vehicle is also challenging due to ocean currents’ variability and uncertainty. Thus, it is not practical to generate a simple navigation trajectory from an initial location to a goal location in a dynamic ocean environment because the vehicle can deviate from its trajectory due to motion noise and cannot estimate its state accurately in underwater environments due to sensor noise.

FIGURE 1. Two instances of a Tethys-class vehicle deployed in the ocean (MBARI, 2009).
To address these challenges, we consider the use of feedback motion planning for an LRAUV by combining its kinematic modeling and an ocean dynamic model while also incorporating motion and sensor uncertainties. A feedback plan is calculated over each ocean current layer in an underwater environment for a vehicle inspired by our previous work (Alam et al., 2020) so that the vehicle can adapt its trajectory from any deviated state in the presence of any noise or modeling errors. Furthermore, this feedback plan is crucial when the vehicle state is not fully observable from sensor readings. For such vehicles with partially observable states, a Partially Observable Markov Decision Process (POMDP) provides a standard mathematical model for vehicle motion planning under uncertainties. The two major factors make solving our problem particularly difficult: 1) for the POMDP formulation, finding the optimal solution is formally hard (NP-hard or PSPACE-hard), and 2) our objective is to compute stochastic energy-aware feedback plans using ocean dynamics in contrast to other prior POMDP feedback planning methods that calculate the stochastic shortest path. A large body of existing research focuses on the stochastic shortest path problem without considering energy constraints. However, it may be unrealistic to assume that the vehicle has unlimited resources in many applications. A more realistic model would consider that an autonomous vehicle has limited stored energy, which continually depletes as it operates. Here, we address this constraint and propose an extension to the POMDP framework that includes energy awareness. Although energy awareness should take into account an initial energy condition, the efficiency of actuation, and the drag effect, our method mostly utilizes ocean currents in our calculations.
In this article, we present a method to synthesize feedback plans for an LRAUV in an underwater environment under motion and sensor uncertainties. First, we develop an ocean dynamic model from ocean current prediction data. Second, a goal-constrained belief space is introduced to make the feedback plan synthesis computationally tractable. Finally, energy-aware feedback plans for several water current layers are synthesized by utilizing sampling and the ocean dynamic model.
A preliminary version of this article appeared in (Orioke et al., 2019). This article is fundamentally different in that it extends (Orioke et al., 2019) by incorporating motion uncertainty and sensor uncertainty coupled with energy awareness from the water flow of an underwater environment within a modified POMDP framework.
The feedback mission control of autonomous underwater vehicles in dynamic and spatiotemporal aquatic environments has attracted a great deal of interest. A feedback trajectory tracking scheme was developed for an AUV in a dynamic oceanic environment with modeled and unmodeled uncertainties (Sanyal and Chyba, 2009). An informative feedback plan was generated for AUVs to visit essential locations by estimating Kriging errors from spatiotemporal fields (Reis et al., 2018). An obstacle avoidance method (Kawano, 2006) is presented, where an MDP-based re-planner considers only the geometrical properties of obstacles and the dynamics and kinematics of an AUV to find and track its target path. An adaptive mission plan for an AUV according to its available resources, such as battery and memory usage, is proposed to add or remove locations for data collection tasks in underwater environments (Harris and Dearden, 2012).
A finite-state automata-based supervisory feedback control (Xu and Feng, 2009) is presented for obstacle avoidance by an AUV. A temporal plan is calculated in (Cashmore et al., 2014) for AUV mission control that optimizes the time taken to complete a single inspection tour. A feedback and replanning framework (Cashmore et al., 2014) is integrated along with the temporal plan in the Robot Operating System (ROS). Sampling Based Model Predictive Control (SBMPC) (Caldwell et al., 2010) is utilized to simultaneously generate control inputs and feasible trajectories for an AUV in the presence of nonlinear constraints.
Open-loop trajectory design methods (Chyba et al., 2009; Smith et al., 2010) drive an AUV from a given initial location to the desired goal location, minimizing a cost in terms of energy and time taken by the vehicle. The implementation of open-loop trajectories for AUVs works well in environments without any model uncertainties. In our previous work (Alam et al., 2018a, 2020), we have proposed an open-loop approach for solving the problem of deploying a set of minimally-actuated drifters for persistent monitoring of an aquatic environment. In our another work (Alam et al., 2018b), we predicted the localized trajectory of a drifter for a sequence of compass observations during its deployment in a marine environment. We presented a closed-loop approach (Alam et al., 2018b) when an AUV has a considerable unpredictability of executing its action in a dynamic marine environment. Moreover, the previous studies (Bellingham et al., 2010; Hobson et al., 2012) on the Tethys AUV described the mission and other capabilities of the vehicle. However, there is no work on the development of a planning algorithm for controlling the vehicle.
Various types of rewards modification in POMDPs have been investigated in previous research efforts (Lee et al., 2018; Kim et al., 2019). Typically, the reward function in POMDPs is designed to solve the stochastic shortest path problem, where the goal is to compute a feedback plan that reaches a target state from a known initial state by maximizing the expected total reward. From a motion planning point of view, the reward can be replaced by a cost, where the goal is to minimize the expected total cost. In both cases, the sequence of rewards or costs, however, can be aggregated by considering the discounted reward (cost) or the average reward (cost).
A point-based algorithm to calculate approximate POMDP solutions is presented combining the full and partial observable components of an AUV’s state to reduce the dimension of its belief space (Ong et al., 2009). An efficient point-based POMDP algorithm for AUV navigation (Kurniawati et al., 2008) exploiting the optimally reachable states is developed to improve computational efficiency. A point-based POMDP approach (Kurniawati and Patrikalakis, 2013) is presented, where the original solution is updated by modifying a set of sample beliefs. The planning for hydrothermal vent mapping problems using information from plume detections is modeled as a POMDP utilizing the reachable states as the current state of an AUV (Saigol et al., 2009). In this work, an information likelihood algorithm is proposed turning the POMDP into an information state MDP. An online POMDP solver (Kurniawati and Yadav, 2016) based on an adaptive belief tree is proposed to improve the existing solution and update the solution when replanning is needed in dynamic environments.
To the best of our knowledge, this is the first work for synthesizing energy-aware feedback plans from a POMDP solution for an underwater vehicle using water flow under motion and sensor uncertainties. In our work, we utilize an LRAUV’s sensor readings to control its mission operation, taking into account its several drifting and actuation capabilities.
In this section, we describe a representation of an underwater environment and motion and observation (sensing) models for our vehicle with relevant definitions. Then, we formulate our problem of interest.
First, we consider a 3-D environment where a workspace is an ocean environment denoted as
Definition 3.1 (Workspace). The workspace is defined as
Second, in our vehicle motion model, we incorporate noise and uncertainty in the vehicle’s movement to account for the modeling error and unmodeled dynamics.
Definition 3.2 (Motion Model). The state space for the vehicle is defined as
The motion model
where
Third, it is assumed that our vehicle can observe its positions and the goal location with uncertainties due to imperfect sensor readings and the dynamic nature of an underwater environment.
Definition 3.3 (Observation Model). Let Y be the observation space, which is the set of all possible sensor observations
where
It is challenging to plan in an uncertain, stochastic environment when there are motion and observation uncertainties in a vehicle model. To formulate this planning problem, it is necessary to connect hidden states and observations of our vehicle. A generic model in this context is Partially Observable Markov Decision Processes (POMDPs).
Definition 3.4 (POMDP). A POMDP is defined by a tuple
• X is a finite set of states.
• U is a finite set of actions, available to the vehicle.
•
•
• Y is a finite set of observations for the vehicle.
•
•
Due to sensor noise, observations of our vehicle provide only partial information over the states. Planning with partial information can be framed as a search problem in a belief space. Let B be the belief space.
Definition 3.5 (Belief). A belief state
in which the next belief state depends only on the current belief state, action, and observation.
Typically, the POMDP solution can be found by solving the equivalent belief MDP where every belief is a state.
Definition 3.6 (Belief MDP). An equivalent belief MDP is defined by a tuple
• B is the set of belief states over the POMDP states.
• U is a finite set of actions, available to the vehicle as for the original POMDP.
• τ is the belief state transition function.
•
•
A feedback plan is called a solution to a belief MDP problem if it causes the goal state to be reached from every belief state in B. Let
Definition 3.7 (Feedback Plan). A feedback plan π is defined as a function over the belief space
The value function of a feedback plan π is computed from the expected discounted reward at the current belief state b as follows:
where γ is the discount factor, and
In our 3-D workspace
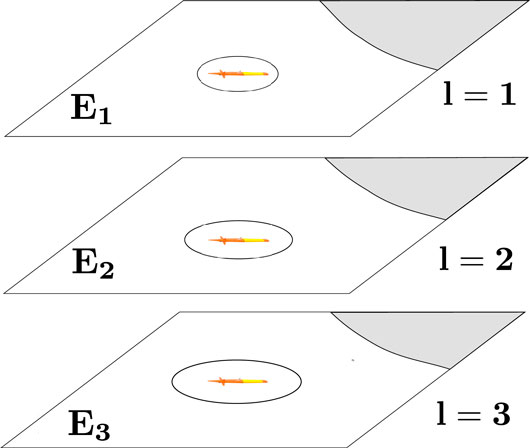
FIGURE 2. Localization uncertainty of a vehicle increases as it goes down along different water current layers.
When the vehicle is uncertain about its state due to sensor noise and has also motion uncertainty, it is crucial to compute a feedback plan that maps every belief state to an action. In computing a feedback plan, we take the environmental water flow into account as an ocean dynamic model. We assume that this ocean dynamic model and the reward function are known a-priori. Our reward function is strictly positive, monotonically increasing toward the goal belief state, and additive. Unlike many prior POMDP feedback planning algorithms that compute the stochastic shortest path, our goal is to compute the stochastic energy-aware path using the ocean dynamic model. Due to the curse of dimensionality of the belief space, it is computationally intractable to synthesize feedback plans for multiple water current layers concurrently. Therefore, we assume that a high-level planner provides an intermediate goal at each water current layer. This motivates us to formulate the following problem to synthesize water current layer-wise feedback plans for our vehicle.
Problem Statement: Given an ocean environment
In this section, we detail an energy-aware feedback planning method that utilizes sampling and the ocean dynamic model for solving the problem formulated in Section 3.
We utilize the Regional Ocean Modeling System (ROMS) (Shchepetkin and McWilliams, 2005) predicted oceanic current data in the Southern California Bight (SCB) region, CA, USA, as illustrated in Figure 3A, which is contained within
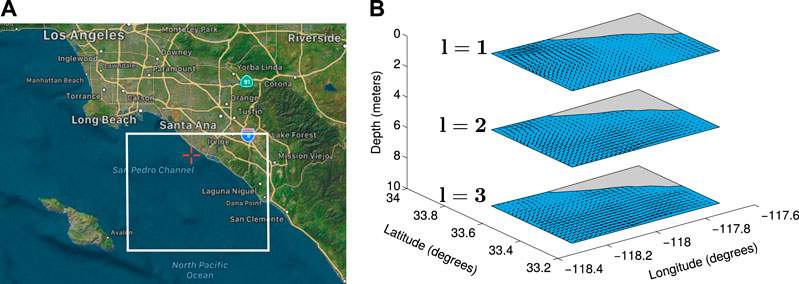
FIGURE 3. (A) The area of interest in the SCB region, California. (B) Flow fields generated from ROMS oceanic current prediction data.
The four dimensions of 4-D ROMS current prediction data are longitude, latitude, depth, and time. The ROMS current prediction data are given at depths from 0 m to 125 m and with 24 h forecast for each day. Each ROMS current velocity prediction is given at depths from 0 m to 4,000 m, with a 12-h hindcast, a 12-h nowcast, and a 48-h forecast each day. The first 24-h comprising hindcasts and nowcasts of each day are the most accurate ocean current prediction in the ROMS model. In our work, we utilize a concatenation of the earliest 24-h of each prediction for each day for 30 days of predictions. The three components of oceanic currents are northing current (α), easting current (β), and vertical current (λ). These components are given based on the four dimensions (time, depth, longitude, and latitude).
We create flow fields at several water current layers from the ROMS ocean current prediction data. Ocean current prediction data for a specific time and at a particular water current layer can be represented as a flow field. Let the flow field on a location q at a particular water current layer of the environment
where i and j are unit vectors along the latitude and longitude axes, respectively.
The vertical component of the ocean current
It is computationally expensive to compute a feedback plan for a given goal belief state
where
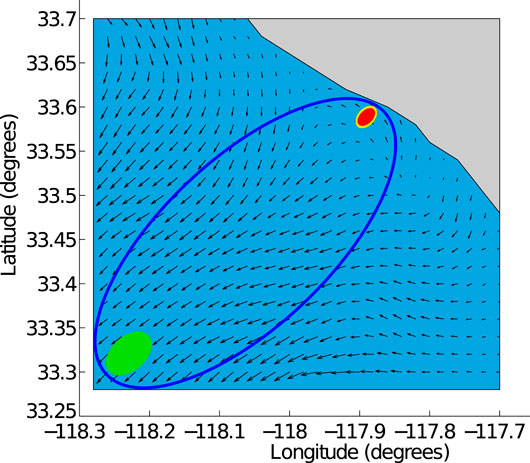
FIGURE 4. The blue elliptical goal-constrained belief space
We develop our energy-aware feedback planning algorithm based on the Partially Observable Monte Carlo Planning (POMCP) algorithm (Silver and Veness, 2010). The POMCP algorithm assumes that the optimal plan can be synthesized by aggregating rewards of the available actions from each state using the Monte-Carlo Tree Search (MCTS) algorithm. It is an approximate method that does not consider energy awareness, but it is known to extract near-optimal policies in finding the stochastic shortest path where optimal rewards depend on the distance from the goal state. Furthermore, the POMCP algorithm allows us to utilize the domain knowledge. In our work, we use the domain knowledge of the reachable belief space
To overcome the challenges associated with solving belief space planning, we first define a set of discrete actions and a set of discrete outcomes. For an LRAUV planning to reach a goal location, we consider nine actions that include actions toward eight compass directions, i.e., N, NE, E, SE, S, SW, W, NW along with drift (idle). The outcomes of actions could be three observations, i.e., goal, intermediate, and outside. In other words, the goal observation refers to the vehicle reaches to the goal location, the intermediate observation refers to it moves toward the goal location, and the outside observation refers to it goes beyond the goal-constrained belief space. Since the outcome of any action is not deterministic, the LRAUV must consider all three observations when simulating an action. For a given state x, Algorithm 1 provides a set of preferred actions

Algorithm 1. Preferred_Action (

Algorithm 2. Search (
Algorithm 3 simulates an action and keeps track of its outcome. We refer to a complete simulated trial as a rollout where we keep track of actions and their outcomes as history h. To plan with energy-awareness, we incorporate the ocean dynamic model F in Algorithm 4 as a prior to the simulator

Algorithm 3. Rollout (

Algorithm 4. Preferred_Action (
In this section, we examine a Tethys-like LRAUV’s kinematic model and evaluate its navigation solution in an underwater environment under motion and sensing uncertainties. The experiments are conducted on a Unix/Linux computer with Intel Core i7 4.5 GHz processor and 32 GB memory.
The vehicle motion is noisy due to the inherent dynamic nature of water flow of the underwater environment. The vehicle observation model suffers uncertainty in measuring distances and locations in sensor-denied, such as GPS, underwater environments. We modeled our vehicle motion and observation models under Gaussian noise. This setup also makes our Tethys navigation problem a POMDP problem.
Let
We incorporate water flow fields as prior knowledge in our motion model for the vehicle. In other words, the next transition state of the vehicle is influenced by the water flow field of a current layer as well as its actions. The unicycle motion and observation models for the vehicle can be expressed as
in which A is the state transition matrix of dimension
The importance of incorporating water flow fields as the ocean dynamics in our motion model is that a Tethys-like vehicle is deployed to navigate through the water flow. However, the vehicle can leverage pressure, velocity, and acceleration of flow fields at times to perform a drifting action and save energy in its long-term mission. It is also important to note that motion and sensor noises provide motion and observation uncertainties but flow fields can be utilized for performing a passive action (drift) with no actuation and thus saving energy.
The updated observation model with energy awareness from the ocean dynamics can be expressed as
in which the energy awareness
where ϕ is the angular velocity and ψ is the linear velocity of the flow field.
A simulated Tethys-like LRAUV with the above kinematics model can take nine actions that include actions toward eight compass directions, i.e., N, NE, E, SE, S, SW, W, NW along with drift (idle). The task for the vehicle is to reach a designated goal state with an energy-aware trajectory by utilizing water currents as much as possible. In our simulation, when LRAUV takes an action, the outcome of that action could be any of three observations, i.e., goal, intermediate, and outside.
To incorporate the water flow pattern in our simulation, we used the ROMS (Shchepetkin and McWilliams, 2005) predicted ocean current data observed in the SCB region. The 3-D ocean environment was taken into account as a simulated environment for the Tethys movements having six 2-D ocean surfaces at six different water current layers or depths (e.g., 0 m, 5 m, 10 m, 15 m, 20 m, and 25 m). Each 2-D ocean current layer is tessellated into a grid map. Each tessellated water current layer is a
The feedback plan synthesis using the MCTS algorithm depends not only on the distance between initial and goal locations but also on the ocean dynamics. In our experiments during the rollout step of the MCTS algorithm, we use 50 trials for each action over an approximated belief state. We then employ the particle filter to evaluate the rollout outcomes with respect to the goal location. When selecting the next best action using Algorithm 3, we utilize a simple PID controller to follow the high-level action.
We implement our energy-aware feedback planning algorithm for many water current layers from our ROMS ocean current prediction data. We obtain a set of feedback plans as an output from our layer-wise feedback plan synthesis. Figure 5 illustrates the executed trajectories of the vehicle applying the synthesized feedback plans for the same pair of given initial and goal locations. For these experiments, we use longitude and latitude coordinates to represent the vehicle locations. We first set the vehicle’s initial location at
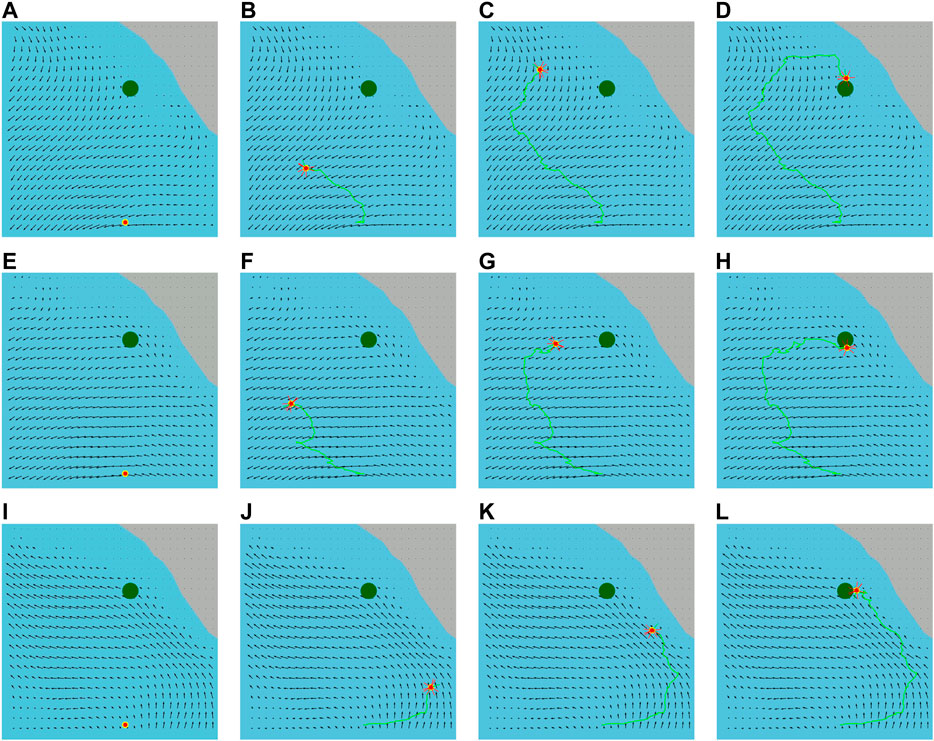
FIGURE 5. Executed trajectories delineated with the green lines of the vehicle (red circle) from its initial location to the goal location (green circle) applying the synthesized feedback plans for the first water current layer (surface layer) in (A)–(D) and for the third water current layer in (E)–(H) and for the sixth water current layer in (I)–(L). The red lines around the vehicle represent a set of preferred actions of a belief state.

TABLE 1. Comparison of executed trajectory lengths using synthesized feedback plans for several water current layers along with plan synthesis times for a number of hours.
We also execute trajectories applying the synthesized feedback plan for the same water current layer for the varying pairs of initial and goal locations that are illustrated in Figure 6. We observe that the trajectories of our feedback plans are not straight lines. This is because our energy-aware feedback plan chooses an action using the ocean dynamics in Algorithm 4. Therefore, the actions are selected to facilitate drifting through water currents, as mentioned in Section 4.3.
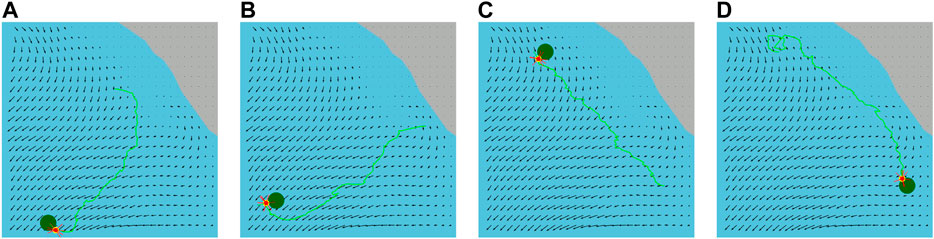
FIGURE 6. Executed trajectories (green lines) of the vehicle (red circles) from its varying initial locations to different goal locations (green circles) applying the synthesized feedback plan on the water surface layer.
This article presents an energy-aware feedback planning method for an LRAUV utilizing its kinematic model in an underwater environment under motion and sensor uncertainties. First, we generated flow fields for several water current layers from a concatenated ROMS ocean current prediction data to introduce the ocean dynamic model. Our method then synthesizes energy and computationally efficient feedback plans on goal-constrained belief spaces for many water current layers using the ocean dynamic model and sampling. Our simulation results of the execution of synthesized feedback plans demonstrated our method’s practical and potential application. There are several exciting directions to follow up on this research.
Our POMDP solution uses nine actions (eight neighboring cells and drift) for planning, which fits the scales of the ROMS resolutions (kilometers) and allows us to treat the LRAUV as a unicycle vehicle. We believe that our method can be easily generalized to incorporate modeling AUV dynamics in shorter spatial scales. We are currently using our planner, but a realistic AUV simulator (Manhães et al., 2016), could be used as a black box to generate the next states. Paring our planner with a physically realistic simulation will help us avoid complicated system identification issues and extend our methodology’s range of applications. Additionally, we would like to incorporate an initial amount of available energy, the actuator efficiency, and the drag effect in our energy model.
One desirable feature of AUV deployments in many scenarios is avoiding constant resurfacing due to energy, stealth, and collision safety constraints. The vehicle can collide with ships and jeopardize its mission. We are currently extending our framework to incorporate dynamic obstacles on the surface, representing, for example, boats and other vessels. We are interested in the short term to generalize this idea to other external motion fields that can be used by autonomous vehicles to use their resources efficiently. Aerial platforms such as blimps and balloons (Das et al., 2003; Wolf et al., 2010) can provide another exciting study case for our ideas.
The original contributions presented in the study are included in the article/Supplementary Material, further inquiries can be directed to the corresponding author.
The first two authors have an equal contribution to this manuscript. Other authors have contributed to develop ideas and write the article.
This work is supported in part by the Louisiana Board of Regents Contract Number LEQSF(2020-21)-RD-A-14 and by the U.S. Department of Homeland Security under Grant Award Number 2017-ST-062000002. This work is also supported in part by the Office of Naval Research Award Number N000141612634, and by the National Science Foundation awards IIS-2034123, IIS-2024733, and the MRI Award Number 1531322.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Alam, T., Reis, G. M., Bobadilla, L., and Smith, R. N. (2020). A data-driven deployment and planning approach for underactuated vehicles in marine environments. IEEE J. Oceanic Eng. 99, 1–17. doi:10.1109/JOE.2020.2999695
Alam, T., Reis, G. M., Bobadilla, L., and Smith, R. N. (2018a). A data-driven deployment approach for persistent monitoring in aquatic environments. In Proceedings of the IEEE International Conference on Robotic Computing (IRC), Laguna Hills, CA, January 31–February 2, 2018, 147–154. doi:10.1109/IRC.2018.00030
Alam, T., Reis, G. M., Bobadilla, L., and Smith, R. N. (2018b). An underactuated vehicle localization method in marine environments. In Proceedings of the MTS/IEEE OCEANS Charleston, Charleston, SC, October 22–25, 2018, 1–8. doi:10.1109/OCEANS.2018.8604762
Bellingham, J. G., Zhang, Y., Kerwin, J. E., Erikson, J., Hobson, B., Kieft, B., et al. (2010). Efficient propulsion for the Tethys long-range autonomous underwater vehicle. In Proceedings of the IEEE/OES Autonomous Underwater Vehicles, Monterey, CA, September 1–3, 2010. 1–7. doi:10.1109/AUV.2010.5779645
Caldwell, C. V., Dunlap, D. D., and Collins, E. G. (2010). Motion planning for an autonomous underwater vehicle via sampling based model predictive control. In Proceedings of the MTS/IEEE OCEANS Seattle, Seattle, WA, September 20–23, 2010, 1–6. doi:10.1109/OCEANS.2010.5664470
Cashmore, M., Fox, M., Larkworthy, T., Long, D., and Magazzeni, D. (2014). AUV mission control via temporal planning. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, May 31–June, 2014, 6535–6541. doi:10.1109/ICRA.2014.6907823
Chyba, M., Haberkorn, T., Singh, S. B., Smith, R. N., and Choi, S. K. (2009). Increasing underwater vehicle autonomy by reducing energy consumption. Ocean Eng. 36, 62–73. doi:10.1016/j.oceaneng.2008.07.012
Das, J., Rajany, K., Frolovy, S., Pyy, F., Ryany, J., Caronz, D. A., et al. (2010). Towards marine bloom trajectory prediction for AUV mission planning. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Anchorage, AK, May 3–7, 2010, 4784–4790. doi:10.1109/ROBOT.2010.5509930
Das, T., Mukherjee, R., and Cameron, J. (2003). Optimal trajectory planning for hot-air balloons in linear wind fields. J. Guidance, Control Dyn. 26, 416–424. doi:10.2514/2.5079
Harris, C., and Dearden, R. (2012). Contingency planning for long-duration AUV missions. In Proceedings of the IEEE/OES Autonomous Underwater Vehicles (AUV), Southampton, UK, September 24–27, 2012, 1–6. doi:10.1109/AUV.2012.6380747
Hobson, B. W., Bellingham, J. G., Kieft, B., McEwen, R., Godin, M., and Zhang, Y. (2012). Tethys-class long range AUVs-extending the endurance of propeller-driven cruising AUVs from days to weeks. In Proceedings of the IEEE/OES Autonomous Underwater Vehicles Symposium (AUV), Southampton, UK, September 24–27, 2012, 1–8. doi:10.1109/AUV.2012.6380735
Kalmbach, A., Girdhar, Y., Sosik, H. M., and Dudek, G. (2017). Phytoplankton hotspot prediction with an unsupervised spatial community model. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, May 30–June 5, 2021, 4906–4913.
Kawano, H. (2006). Real-time obstacle avoidance for underactuated autonomous underwater vehicles in unknown vortex sea flow by the MDP approach. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Beijing, China, October 9–15, 2006, 3024–3031. doi:10.1109/IROS.2006.282239
Kim, S.-K., Thakker, R., and Agha-Mohammadi, A.-A. (2019). Bi-directional value learning for risk-aware planning under uncertainty. IEEE Robot. Autom. Lett. 4, 2493–2500. doi:10.1109/lra.2019.2903259
Kinsey, J. C., Yoerger, D. R., Jakuba, M. V., Camilli, R., Fisher, C. R., and German, C. R. (2011). Assessing the deepwater horizon oil spill with the sentry autonomous underwater vehicle. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), San Francisco, CA, September 25–30, 2011, 261–267.
Kurniawati, H., Hsu, D., and Lee, W. S. (2008). Sarsop: efficient point-based POMDP planning by approximating optimally reachable belief spaces. In Proceedings of the Robotics: Science and Systems (RSS). Cambridge, MA: MIT Press. doi:10.15607/rss.2008.iv.009
Kurniawati, H., and Patrikalakis, N. M. (2013). Point-based policy transformation: adapting policy to changing POMDP models. In Proceedings of Algorithmic Foundations of Robotics (WAFR) X, Berlin, Germany: Springer. 493–509. doi:10.1007/978-3-642-36279-8_30
Kurniawati, H., and Yadav, V. (2016). An online POMDP solver for uncertainty planning in dynamic environment. in Proceedings of the International Symposium on Robotics Research (ISRR), Puerto Varas, Chile, December 11–14, 2017, 611–629. doi:10.1007/978-3-319-28872-7_35
Lee, J., Kim, G.-H., Poupart, P., and Kim, K.-E. (2018). Monte-Carlo tree search for constrained POMDPs. in Proceedings of the Advances in Neural Information Processing Systems (NIPS), Denver, CO, December 3–8, 2018, 7923–7932.
Manderson, T., Li, J., Dudek, N., Meger, D., and Dudek, G. (2017). Robotic coral reef health assessment using automated image analysis. J. Field Robotics 34, 170–187. doi:10.1002/rob.21698
Manhães, M. M. M., Scherer, S. A., Voss, M., Douat, L. R., and Rauschenbach, T. (2016). UUV simulator: a gazebo-based package for underwater intervention and multi-robot simulation. in Proceedings of the MTS/IEEE OCEANS-Monterey, Monterey, CA, September 19–23, 2016. 1–8.
MBARI, (2009). Autonomous underwater vehicles. Available at: https://www.mbari.org/at-sea/vehicles/autonomous-underwater-vehicles/. (Accessed October 10, 2020).
Ong, S. C., Png, S. W., Hsu, D., and Lee, W. S. (2009). POMDPs for robotic tasks with mixed observability. In Proceedings of the Robotics: Science and Systems (RSS), June 28-July 1, 2009, Seattle, WA. doi:10.15607/RSS.2009.V.026
Orioke, O. S., Alam, T., Quinn, J., Kaur, R., Alsabban, W. H., Bobadilla, L., et al. (2019). Feedback motion planning for long-range autonomous underwater vehicles. in Proceedings of the MTS/IEEE OCEANS-Marseille, France, Paris, June 17–20, 2019. 1–6.
Papadimitriou, C. H., and Tsitsiklis, J. N. (1987). The complexity of Markov decision processes. Mathematics OR 12, 441–450. doi:10.1287/moor.12.3.441
Reis, G. M., Alam, T., Bobadilla, L., and Smith, R. N. (2018). Feedback-based informative AUV planning from Kriging errors. in Proceedings of the IEEE/OES Autonomous Underwater Vehicles (AUV), Porto, Portugal, November 6–9, 2018. doi:10.1109/auv.2018.8729814
Saigol, Z. A., Dearden, R., Wyatt, J. L., and Murton, B. J. (2009). Information-lookahead planning for AUV mapping. In Proceedings of International Joint Conference on Artificial Intelligence (IJCAI), Pasadena, CA, July 11–17, 2009. 1831–1836.
Sanyal, A. K., and Chyba, M. (2009). Robust feedback tracking of autonomous underwater vehicles with disturbance rejection. In Proceedings of the American Control Conference (ACC), St. Louis, MO, June 10–12, 2009. 3585–3590.
Shchepetkin, A. F., and McWilliams, J. C. (2005). The Regional Oceanic Modeling System (ROMS): a split-explicit, free-surface, topography-following-coordinate oceanic model. Ocean Model. 9, 347–404. doi:10.1016/j.ocemod.2004.08.002
Silver, D., and Veness, J. (2010). Monte-Carlo planning in large POMDPs. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Vancouver, BC, Canada, December 6–9, 2010. 2164–2172.
Smith, R. N., Chao, Y., Li, P. P., Caron, D. A., Jones, B. H., and Sukhatme, G. S. (2010). Planning and implementing trajectories for autonomous underwater vehicles to track evolving ocean processes based on predictions from a regional ocean model. Int. J. Robotics Res. 29, 1475–1497. doi:10.1177/0278364910377243
Wolf, M. T., Blackmore, L., Kuwata, Y., Fathpour, N., Elfes, A., and Newman, C. (2010). Probabilistic motion planning of balloons in strong, uncertain wind fields. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Anchorage, AK, USA, May 3–7, 2010. 1123–1129. doi:10.1109/ROBOT.2010.5509135
Keywords: feedback planning, energy-aware, long-range autonomous underwater vehicles, predictive ocean model, kinematic model, state uncertainty model
Citation: Alam T, Al Redwan Newaz A, Bobadilla L, Alsabban WH, Smith RN and Karimoddini A (2021) Towards Energy-Aware Feedback Planning for Long-Range Autonomous Underwater Vehicles. Front. Robot. AI 8:621820. doi: 10.3389/frobt.2021.621820
Received: 27 October 2020; Accepted: 11 January 2021;
Published: 19 March 2021.
Edited by:
Fumin Zhang, Georgia Institute of Technology, United StatesReviewed by:
Elias Kosmatopoulos, Democritus University of Thrace, GreeceCopyright © 2021 Alam, Al Redwan Newaz, Bobadilla, Alsabban, Smith and Karimoddini. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Tauhidul Alam, dGFsYW1AbHN1cy5lZHU=
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.