 Qinbing Fu
Qinbing Fu Xuelong Sun
Xuelong Sun Tian Liu
Tian Liu Cheng Hu
Cheng Hu Shigang Yue
Shigang Yue- 1Machine Life and Intelligence Research Centre, School of Mechanical and Electrical Engineering, Guangzhou University, Guangzhou, China
- 2School of Computer Science, University of Lincoln, Lincoln, United Kingdom
Collision prevention sets a major research and development obstacle for intelligent robots and vehicles. This paper investigates the robustness of two state-of-the-art neural network models inspired by the locust’s LGMD-1 and LGMD-2 visual pathways as fast and low-energy collision alert systems in critical scenarios. Although both the neural circuits have been studied and modelled intensively, their capability and robustness against real-time critical traffic scenarios where real-physical crashes will happen have never been systematically investigated due to difficulty and high price in replicating risky traffic with many crash occurrences. To close this gap, we apply a recently published robotic platform to test the LGMDs inspired visual systems in physical implementation of critical traffic scenarios at low cost and high flexibility. The proposed visual systems are applied as the only collision sensing modality in each micro-mobile robot to conduct avoidance by abrupt braking. The simulated traffic resembles on-road sections including the intersection and highway scenes wherein the roadmaps are rendered by coloured, artificial pheromones upon a wide LCD screen acting as the ground of an arena. The robots with light sensors at bottom can recognise the lanes and signals, tightly follow paths. The emphasis herein is laid on corroborating the robustness of LGMDs neural systems model in different dynamic robot scenes to timely alert potential crashes. This study well complements previous experimentation on such bio-inspired computations for collision prediction in more critical physical scenarios, and for the first time demonstrates the robustness of LGMDs inspired visual systems in critical traffic towards a reliable collision alert system under constrained computation power. This paper also exhibits a novel, tractable, and affordable robotic approach to evaluate online visual systems in dynamic scenes.
1 Introduction
The World Health Organisation (WHO) reported that every year, approximately 1.35 millions people worldwide die on road traffic with an increase of 0.11 million over only 5 years ago (WHO, 2018). Collision prevention is an old, but active topic in research communities since it is still obstructing the development of intelligent robots and vehicles. For examples, the internet of vehicles (IoV) systems and technologies are confronting huge challenges from traffic accidents where the emergent strategies from deep learning (Chang et al., 2019) and cloud communication (Zhou et al., 2020) are improving the IoV’s reliability. The unmanned aerial vehicles (UAVs) industries are also reflecting on how to enhance the capability of obstacle detection and avoidance especially when flying through unstructured, dynamic scenes (Albaker and Rahim, 2009). On-road crashes usually occur randomly which are difficult to predict and trace. The typical accident-prone places include intersections, road junctions and highways, etc., where collision prevention is difficult to tackle (Mukhtar et al., 2015).
Therefore, a critically important task is the development of collision avoidance systems with ultimate reliability, which nevertheless is faced with huge challenges (Zehang Sun et al., 2006; Sivaraman and Trivedi, 2013; Mukhtar et al., 2015). The cutting-edge techniques for collision prediction include global positioning system (GPS), active (Radar, Laser, Lidar), and passive (acoustic and optical) sensor strategies, as well as combinations of these with sensor-based algorithms (Zehang Sun et al., 2006; Mukhtar et al., 2015). More specifically, the GPS has been used for predicting real time trajectory of vehicles for collision risk estimation (Ammoun and Nashashibi, 2009). The vision-based techniques have been implemented in passive sensors, i.e., the different kinds of cameras (Sun et al., 2004; Mukhtar et al., 2015). Compared to the active sensors like the Radar, the main advantages of visual ones are lower price and wider coverage of detection range up to 360°, which can provide much richer description about the vehicle’s surroundings including motion analysis (Sabzevari and Scaramuzza, 2016). Compared to the IoV and GPS techniques, the optical methods are not restricted by surrounding infrastructures (Mukhtar et al., 2015). However, the visual approaches bring about pronounced challenges upon fast implementation in real time, and accurate extraction of colliding features from the dynamic visual world mixed with many distractors. A reliable, real-time, energy-efficient collision alert visual system has not yet been demonstrated so far.
Fortunately, nature has been providing us with a lot of inspirations to construct collision sensing visual systems. Robust and efficient collision prediction system is ubiquitous amongst the vast majority of sighted animals. As a source of inspiration, the insects’ dynamic vision systems have been explored as powerful paradigms for collision detection and avoidance with numerous applications in machine vision, as reviewed in (Franceschini, 2014; Serres and Ruffier, 2017; Fu et al., 2018a, Fu et al., 2019b). As a prominent example, locusts can migrate for a long distance in dense swarms containing hundreds to thousands of individuals free of collision (Kennedy, 1951). In the locust’s visual pathways, two lobula giant movement detectors (LGMDs), i.e., the LGMD-1 and the LGMD-2, have been gradually identified and recognised to play crucial roles of collision perception, both of which respond most strongly to approaching objects signalling a direct collision course over other categories of visual movements like translating, receding, etc. (O’Shea and Williams, 1974; O’Shea and Rowell, 1976; Rind and Bramwell, 1996; Simmons and Rind, 1997; Rind and Simmons, 1999; Gabbiani et al., 2002, Gabbiani et al., 2004; Fotowat and Gabbiani, 2011; Rind et al., 2016; Yakubowski et al., 2016). More precisely, the LGMD releases bursts of energy whenever a locust is on a collision course with its cohorts or a predator bird. These energy by neural pulses leads to evasive actions like jumping from the ground while standing, or sliding while flying (Simmons et al., 2010). Surprisingly, the whole process from visual processing to behavioural response takes less than 50 milliseconds (Simmons et al., 2010; Sztarker and Rind, 2014). Therefore, building artificial visual systems that possess the similar robustness and timeliness like the locust’s LGMDs can undoubtedly benefit collision avoidance systems in intelligent robots and vehicles.
Learning from the locust’s LGMDs visual pathways and circuits, there have been many modelling studies to investigate either the LGMD-1 or the LGMD-2 against various visual scenes including online, wheeled mobile robots (Blanchard et al., 2000; Yue and Rind, 2005; Badia et al., 2010; Fu et al., 2016; Fu et al., 2017; Fu et al., 2018b; Isakhani et al., 2018; Fu et al., 2019b), walking robot (Cizek et al., 2017; Cizek and Faigl, 2019), UAVs (Salt et al., 2017, Salt et al., 2019; Zhao et al., 2019), and off-line car driving scenarios, e.g. (Keil et al., 2004; Stafford et al., 2007; Krejan and Trost, 2011; Hartbauer, 2017; Fu et al., 2019a, Fu et al., 2020a). These studies have demonstrated the effectiveness of LGMDs models as quick visual collision detectors for machine vision applications. However, due to high risk and price to replicate extremely dangerous traffic scenarios including many severe crashes, a vacancy is still there to investigate the capability and robustness of LGMDs models for addressing collision challenges from more critical scenarios where many physical collisions will happen. Regarding off-line testing approach, there is currently no comprehensive database covering real crash situations from vehicle-mounted cameras.
To fill these gaps, the recently published robotic platform named “ColCOSΦ” (Sun et al., 2019) can enrich the existing experimenting “toolbox” in the context. The platform can be used to physically implement different multi-robot traffic mimicking real world on-road collision challenges for investigating the proposed visual systems in a practical, affordable manner. More precisely, an artificial pheromones module herein works effectively to optically render different roadmaps involving lanes and signals upon a wide LCD screen acting as the ground of an arena for robots which can pick up these cues with light sensors at bottom. Accordingly, the robots can tightly follow the paths in navigation. Moreover, to focus on investigating the proposed LGMDs inspired visual systems, we apply very basic switch control to separate the states between normal navigation (going forward) and collision avoidance (abrupt braking). Here the more complex motion strategies resembling either the locust’s evasive behaviours or the ground vehicle’s actions are outside the scope of this study.
Therefore, the main contributions of this paper can be summarised as follows:
• This research corroborates the robustness of LGMDs neuronal systems model to timely alert potential crashes in dynamic multi-robot scenes. To sharpen up the acuity of LGMDs inspired visual systems in collision sensing, an original hybrid LGMD-1 and LGMD-2 neural networks model is proposed with non-linear mapping from network outputs to alert firing rate, which works effectively.
• This research complements previous experimentation on the proposed bio-inspired computation approach to collision prediction in more critical, real-physical scenarios.
• This paper exhibits an innovative, tractable, and affordable robotic approach to evaluate online visual systems in different dynamic scenes.
The rest of this article is structured as follows. Section 2 elaborates on the biological background, the formulation of proposed model, and the robotic platform. Section 3 presents the experimental settings on different types of robot traffic systems. Section 4 elucidates the results with analysis. Section 5 discusses on limitations and future works. Section 6 concludes this article.
2 Methods and Materials
2.1 Biological Inspiration
Within this subsection, we firstly introduce the bio-inspiration, i.e., characterisation of the locust LGMD-1 and LGMD-2 visual neurons for the proposed computational modelling and experimenting. Figure 1 illustrates the schematic neural structures: the two neurons are physically close to each other. In general, they have been discovered amongst a group of LGMDs in the locust’s visual brain, a place called “lobula area” (O’Shea and Williams, 1974; O’Shea and Rowell, 1976). The LGMD-1 was first identified as a movement detector, and gradually recognised as a looming (approaching) objects detector, which responds most strongly to direct, rapid approaching objects rather than any other kinds of movements (Rind and Bramwell, 1996). In the same place, the LGMD-2 was also identified as a looming objects detector but with different selectivity to the LGMD-1, that is, the LGMD-2 is only sensitive to darker objects that approach against a relatively brighter background; whilst the LGMD-1 can detect either lighter or darker approaching objects (Simmons and Rind, 1997; Sztarker and Rind, 2014).
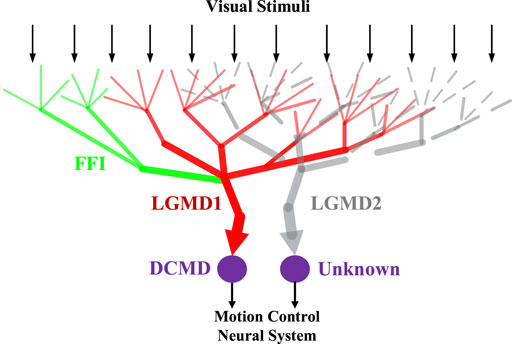
FIGURE 1. Schematic illustration of the LGMD-1 and the LGMD-2 neuromorphology. Visual stimuli are received by the pre-synaptic dendrite structures of both neurons. The feed-forward inhibition (FFI) pathway connects the LGMD-1. The DCMD (descending contra-lateral movement detector) is a one-to-one post-synaptic target neuron to the LGMD-1 conveying spikes to motion control neural system. The post-synaptic partner neuron to the LGMD-2 yet remains unknown.
More precisely, both the looming perception visual neurons show increasing firing rates before the moving object reaching a particular angular size in the field of vision. They are rigorously inhibited at the end of objects approaching, the start of objects receding, and during transient luminance change over a large field of view. Against translating movements at constant speed, they are only activated very briefly. Most importantly, through our previous modelling and bio-robotic research (Fu et al., 2016; Fu et al., 2018b; Fu et al., 2019b), we have found that though with different selectivity, both the neurons could respond strongly to movements with increasing motion intensity, such as fast approaching and accelerating translating objects. Accordingly, all these specific characteristics make the LGMD-1 and LGMD-2 unique neuronal systems to model for addressing collision challenges for intelligent robots and vehicles.
2.2 Model Description
The collision selectivity, which indicates the neuron should respond most strongly to approaching objects over other kinds of movements, is a key feature to be realised in such looming perception neural network models separating their functionality from other categories of motion sensitive neural models (Fu et al., 2019b). Through hundreds of millions of years evolution, the locust’s LGMDs have been tuned with perfect collision selectivity, whereas the current computational models are not. In this regard, we have proposed a few effective methods to implement the different selectivity between the two LGMDs, and to sharpen up the selectivity via the modelling of bio-plausible ON/OFF channels (Fu et al., 2016; Fu et al., 2017; Fu et al., 2019b), and neural mechanisms like spike frequency adaptation (Fu et al., 2017; Fu et al., 2018b), and adaptive inhibition (Fu et al., 2019a; Fu et al., 2020b). However, the collision selectivity of current models still needs to be enhanced especially in complex and dynamic visual scenes.
Moreover, through previous studies, we have found the LGMD-2’s specific selectivity can complement the LGMD-1’s when detecting darker approaching objects, since the LGMD-1 is shortly activated by the recession of darker object whereas the LGMD-2 is not (Fu et al., 2019b). This well matches the situations faced by ground mobile robots and vehicles since most on-road objects are relatively darker than their backgrounds, particularly in daytime navigation. An interesting question thus arises that whether the two neuronal systems can coordinate in sculpting the dark looming selectivity. Accordingly, building upon the two state-of-the-art LGMDs neural network models (Fu et al., 2018b; Fu et al., 2019b), we propose a hybrid visual neural networks model combining the functionality of both the LGMD-1 and the LGMD-2, and investigate the robustness in dynamic visual scene. Compared to related networks, the proposed network features a non-linear unit for the product of spikes elicited by the LGMD-1 and the LGMD-2 neurons to generate the hybrid firing rate. This works effectively to sharpen up the selectivity to darker approaching objects over other motion patterns like recession. Consequently, a potential collision is detected only when both the LGMDs neurons are highly activated in the context. Figure 2 illustrates the schematic structure of the hybrid visual neural networks. The nomenclature is given in Table 1.
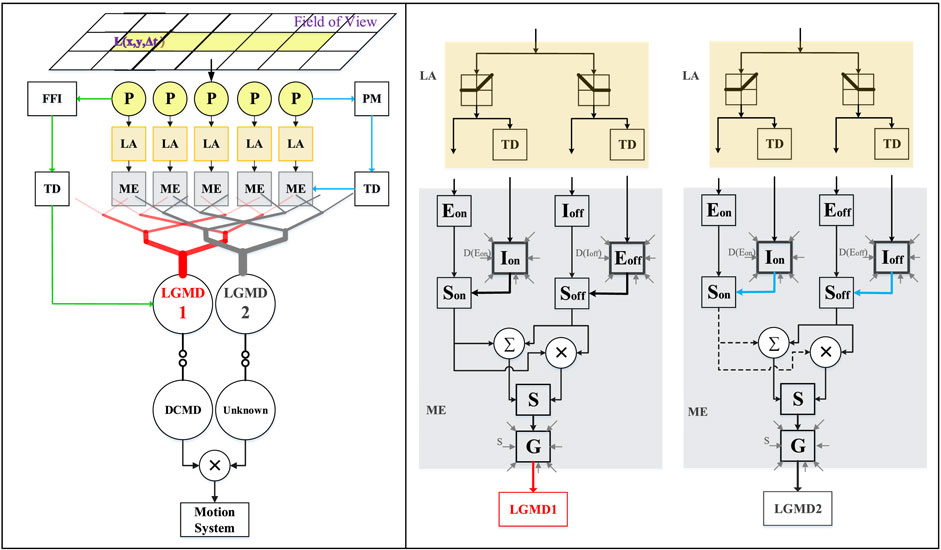
FIGURE 2. Schematic illustration of the proposed feed-forward collision prediction visual neural networks. There are three layers pre-synaptic to the two neurons, the photoreceptor (P), lamina (LA) and medulla (ME) layers. The pre-synaptic neural networks of LGMD-1 and LGMD-2 share the same visual processing in the first two, P and LA layers. The processing yet differs in the third ME layer for the purpose of separating their different selectivity. The ME layer consists of ON/OFF channels wherein the ON channels are rigorously suppressed in the LGMD-2’s circuit (dashed lines). The delayed information is formed by convolving surrounding non-delayed signals in space. The FFI is an individual inhibition pathway to merely the LGMD-1. The PM is a mediation pathway to the medulla layer of the LGMD-2. The two LGMDs pool their pre-synaptic signals respectively to generate spikes that are passed to their post-synaptic neurons. Notably, the non-linearly mapped, hybrid firing rate is the network output deciding the corresponding collision avoidance response.
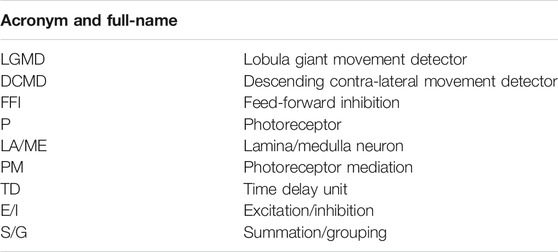
TABLE 1. Nomenclature in the visual neural networks.
2.2.1 Photoreceptors Layer
As shown in Figure 2, the LGMD-1 and the LGMD-2 possess the same visual processing in the first two pre-synaptic layers. The first layer is composed of photoreceptors arranged in a matrix sensing time-varying, single-channel luminance (grey-scale in our case). The photoreceptors compute temporal derivative of every pixel to get motion information. Let
The motion persistence is constituted by np frames.
In addition, the P-layer also indicates the whole-field luminance change with respect to time. This indicator is applied as the FFI in the LGMD-1 neural network, which can be obtained by averaging the overall luminance change at time t. That is,
where C and R denote columns and rows of the visual field in pixels. In addition to that, the FFI goes through a time delay unit (see TD in Figure 2), defined as
τf stands for a time constant and τi is the time interval between consecutive frames of digital signals, both in milliseconds. Notably, here the FFI can directly shut down the LGMD-1 neuron if it overshoots Tffi, i.e., a predefined threshold.
While modelling the LGMD-2, we propose a temporal tuning mechanism, the PM in Figure 2, to adjust local inhibitions in the medulla layer of the LGMD-2. The computations of PM conform to Eqs. 2, 3 which are not restated here.
2.2.2 Lamina Layer
Motion information inevitably induces luminance increment or decrement over time. As shown in Figure 2, the second lamina layer separates the relayed signals into parallel ON and OFF channels, at each node. More precisely, the luminance increment flows into the ON channel, whilst the decrement streams to the OFF channel with a sign-inverting operation. Both the channels retain positive inputs. That is,
[x]+ and [x]− denote max (0, x) and min (x, 0). In addition, a small fraction (α2) of previous signal is allowed to pass through.
2.2.3 Medulla Layer
The medulla layer is the place where different collision selectivity between LGMD-1 and LGMD-2 is shaped. The visual processing thus differs in this layer. First, in the LGMD-1’s medulla, the delayed information varies in different polarity pathways. More precisely, in the ON channels, the local inhibition (Ion1) is formed by convolving surrounding delayed excitations (Eon1). The whole spatiotemporal computation can be defined as the following:
τ1 stands for the latency of excitatory signal. r indicates the radius of convolving area [W1] denotes the convolution kernel in the LGMD-1 that meets the following matrix:
In the LGMD-1’s OFF channels, the delay is nevertheless put forth on the inhibitory signal; the excitation is thus formed by convolving delayed lateral inhibitions. That is,
Here the convolution kernel [W2] is set equally to W1 in Eq. 8.
Second, in the LGMD-2’s medulla, much stronger local inhibitions are put forth in all the ON channels forming a biased-ON pathway in order to achieve its specific selectivity to only darker objects (see dashed lines in Figure 2). More specifically, the generation of local excitation (Eon2) and inhibition (Ion2) in the LGMD-2’s ON channels conforms to the LGMD-1 yet with a different latency τ3. To implement the ‘bias’, the convolution kernel matrix [W3] is increased with self-inhibition as
In the LGMD-2’s OFF pathway, the neural computation is defined as
[W4] fits the following matrix:
As illustrated in Figure 2, following the generation of local ON/OFF excitation and inhibition, there are local summation units in either the medulla layer. For the LGMD-1, the calculation is as the following:
w1 and w2 are the local biases. Note that only the positive S unit signals will pass through to the subsequent circuit. Compared to the LGMD-1, the two local biases are time varying, adjusted by the PM pathway in the LGMD-2. That is,
In both the LGMDs, the polarity summation cells interact with each other in a supra-linear manner as
Cascaded the S unit, a grouping unit is introduced to reduce isolated motion and enhance the extraction of expanding edges of colliding objects in cluttered backgrounds. This is implemented with a passing coefficient matrix [Ce] determined by another convolving process with an equally weighted kernel [Wg]. That is,
ω is a scale parameter computed at every discrete time step. Cω is a constant. ΔC stands for a small real number. Here only the non-negative grouped signals can get through.
2.2.4 LGMD-1 and LGMD-2 Neurons
After the signal processing of pre-synaptic neural networks, the LGMD-1 and LGMD-2 neurons integrate corresponding local excitations from the medulla layer to generate membrane potentials. Here we apply a sigmoid transformation as the neuron activation function. The whole process can be defined as
Subsequently, a spike frequency adaptation mechanism is applied to sculpt the neural response to moving objects threatening collision. The computation is defined as follows:
where α6 is a coefficient indicating the adaptation rate to visual movements calculated by the time constant τs. Generally speaking, such a mechanism reduces neuronal firing rate to stimuli with constant or decreasing intensity, e.g., objects recede or translate at a constant speed; while it has little effect on accelerating motion with increasing intensity like the approaching.
2.2.5 Hybrid Spiking
As the time interval between frames of digital signals is much longer than the reaction time of real visual neurons, we map the membrane potentials exponentially to spikes by an integer-valued function. That is,
where Tspi denotes the spiking threshold and α7 is a scale coefficient affecting the firing rate, i.e., raising it will bring about more spikes within a specified time window.
As illustrated in Figure 2, the elicited spikes are conveyed to their post-synaptic target neurons. Differently from previous modelling on single neuron computation of either the LGMD-1 or the LGMD-2, we herein put forward a non-linear hybrid spiking mechanism aiming at improving the selectivity to darker objects that only threaten direct collision by suppressing the response to other categories of visual stimuli. As a result, the specific selectivity of LGMD-2 well complements the LGMD-1’s where the hybrid spiking frequency will be amplified merely when both neurons are activated. The computation is defined as
Finally, the detection of potential collision threat can be indicated by
nt denotes a short time window in frames. Tcol stands for the collision warning threshold.
2.2.6 Setting Network Parameters
Table 2 elucidates the parameters. In this study, we set up the parameters of neural networks depending on 1) prior knowledges from neuroscience (Rind and Bramwell, 1996; Simmons and Rind, 1997; Rind et al., 2016), 2) previous experience on modelling and experimenting of the LGMD-1 and the LGMD-2 neuron models (Fu et al., 2018b; Fu et al., 2019b), 3) considerations of fast implementation with optimisation as embedded vision systems for online visual processing (Hu et al., 2018). More concretely, the convolutional matrices W1, W2, W3, and W4 are not only based on previous biological and computational studies, but also optimised by “bitwise operation” on the embedded system. There is currently no feedback pathways and learning steps involved in the proposed hybrid neural networks. The parameters given in Table 2 have been systematically investigated in our previous bio-robotic studies with optimisation (Fu et al., 2018b; Fu et al., 2019b; Fu et al., 2017). In addition to that, the very limited computational resources in the micro-robot is restricted for online learning algorithms. Therefore, aligned with previous settings, the emphasis herein is laid on investigating the integration of both LGMDs inspired visual systems in robotic implementation of dynamic visual scenes.

TABLE 2. Setting network parameters.
2.3 Robotic Platform
Within this subsection, we introduce the robotic platform, called ColCOSΦ (Sun et al., 2019), used to simulate different traffic scenarios in this research. As shown in Figure 3, the platform mainly consists of artificial multi-pheromone module, and autonomous micro-mobile robots.
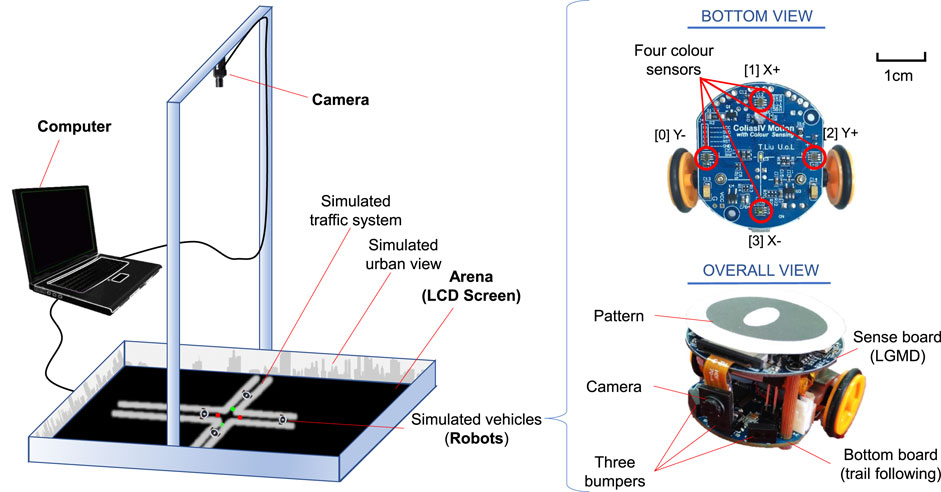
FIGURE 3. Overview of the robotic platform consisting of multiple-pheromone module and micro-mobile robots. The pheromone module is composed of a camera system connecting a computer and a TV arena. The micro-mobile robot comprises a visual sense board implementing the proposed visual systems, and a motion board for route following and emergency braking. Four colour sensors are marked in the bottom view of the robot used for sensing optically rendered pheromone cues displayed upon the LCD screen. The ID-pattern on top of robot is used to run a real time localisation system.
2.3.1 Artificial Pheromones Module
Firstly, the multiple pheromones module was originally developed to conduct the swarm robotic experiments mimicking behaviours of social insects with interactions between multiple pheromones representing different biochemical substances (Sun et al., 2019). More specifically, as illustrated in Figure 3, the module consists of a camera system, a computer, and an arena with an LCD screen acting as the ground. The computer runs a pattern recognition algorithm in real time (Krajník et al., 2014), which is feasible to track and localise many ID-specific patterns with images at 1920 (pixels in width) × 1,080 (pixels in height) from the top-down facing camera, simultaneously, so as to record coordinates of robots with respect to time. In addition, the computer can render the virtual pheromone components, optically, represented by colour tracks or spots on the LCD screen indicating meaningful fields for mobile robots. Here the virtual pheromones are applied to render road maps and signals in the context. As shown in Figure 4, since the nature of pheromone field displayed on the LCD screen is a colour image, different traffic paradigms can be formed in which the roads are drawn by white tracks with boundaries, and the traffic lights and signals are embodied by green/red colour spots with appropriate size on the roads. Accordingly, different traffic sections like intersections, junctions, and even more complex road network can be established with scalability. Figure 4 shows some examples in our experiments. Together with periphery patterned walls (urban skyline), the arena is well constructed for our specific goal of simulating robotic traffic to test the proposed bio-inspired visual systems.
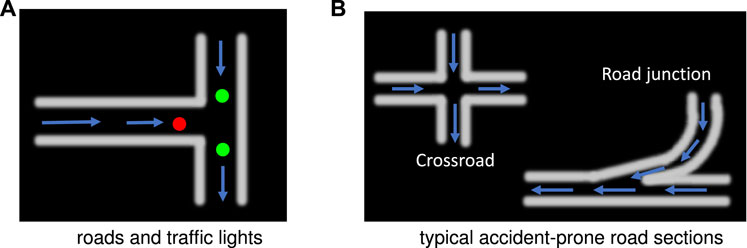
FIGURE 4. Using virtual pheromones to mimic roads and traffic lights: arrows indicate steering directions of robots. The roads are unidirectional.
2.3.2 Micro-Mobile Robot
As illustrated in Figure 3, the autonomous mobile robot used in this study is called Colias-IV (Hu et al., 2018), which includes mainly two components that provide different functions, namely the Colias Basic Unit (CBU), and the Colias Sensing Unit (CSU).
The CBU serves preliminary robot features such as motion, power management and some basic sensing like the bumper infra-red (IR) sensors in Figure 3. The more detailed configuration can be found in our recent paper (Hu et al., 2018), which is not reiterated here. Specifically for the proposed tasks, the CBU is assembled with four colour sensors with high sensitivity on its bottom (see Figure 3). When the robot is running in the arena, these sensors can pick up optical pheromone information on the LCD screen, and then the robot behaviours are adjusted accordingly.
A key factor herein is tightly following the paths. We propose a control strategy that the two-side colour sensors are applied to bind the robot trajectory on the roads, as explained in Figure 5. Moreover, the front and rear light sensors play roles of recognising traffic signals including red (stop) and green (go) lights in the city traffic system, as well as accelerating and decelerating fields in the highway traffic system. More concrete control logic will be presented in the following Section 3.
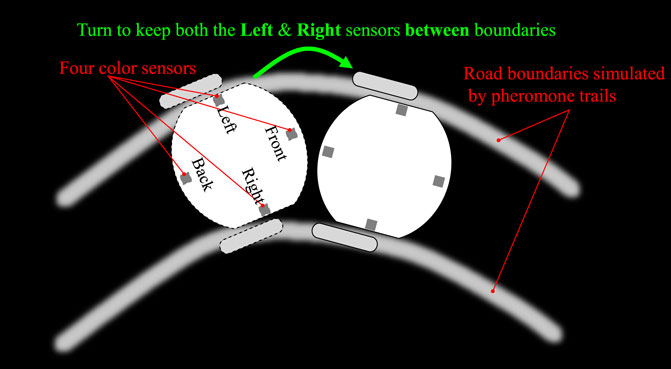
FIGURE 5. Robot route following strategy: keeping two-side colour sensors between road boundaries.
The proposed LGMDs inspired visual systems are implemented for online visual processing. Here the CSU supports this where an ARM Cortex-M4F core micro controller is deployed as the main processor to handle intensive image processing. A monocular camera system with a low voltage CMOS image sensor OV7670 module is utilised in the CSU. With compact size, the camera is capable of operating up to 30 frames per second (fps) in VGA mode with output support for various colour formats. The horizontal viewing angle is approximately 70°. As a trade-off between processing efficiency and image quality, the resolution is configured at 72 × 99 pixels on 30 fps, with output format of 8-bit YUV422. Since the LGMDs only process grey-scale images, the camera setting fits it well, i.e., the proposed image format separates each pixel’s colour channels from the brightness channel; thus no additional colour transformation is required. More details of the CSU can be found in (Hu et al., 2018). Importantly, when assessing the proposed LGMDs inspired visual systems, the optical sensor is applied as the only collision detector.
Furthermore, the micro-robot can communicate with a host computer via a Bluetooth device connecting the CSU (Hu et al., 2018). Here we use it for retrieving the hybrid spiking frequency. With limited processing memory space and transmission ability, a current drawback of the robot is that it cannot send back real-time image views accompanied by motion.
3 Setting Experiments
Within this section, we introduce the experimental settings on multi-robot traffic scenarios. Generally speaking, the proposed LGMDs inspired visual systems are tested in two types of roadmaps: the city ring roads, and the highway. With regard to the primary goal of this research to corroborate the LGMDs’ robustness in critical robot traffic, the roadmaps are designed with accident-prone sections resembling real world circumstances where crash often happens, e.g., the intersection challenge (Colombo and Vecchio, 2012). In addition, we also carry out comparative experiments on different densities of moving agents in the arena, and two collision sensing strategies between the bio-inspired vision and the assembled IR bumper.
Regarding the avoidance, the robot brakes abruptly once detecting potential crash and then resumes moving forward after a short break. Since we herein focus on corroborating the robustness of visual systems, the mechanical control for collision avoidance is out of the scope. Notably, the evasive behaviour matches neither the locust’s jumping/hiding, nor the many on-road situations of ground vehicles. It is also worth to emphasise that there are no human interventions in the autonomous running of multiple mobile robots unless the incidents that robot fails on route following. Each kind of robot traffic lasts for 1 hour. Figures 6, 7 and show the experimental settings from the top-down view. Figure 8 displays some arena inside views in experiments. Algorithm 1 and Algorithm 2 articulate the agent control strategies in the two kinds of traffic systems, respectively.
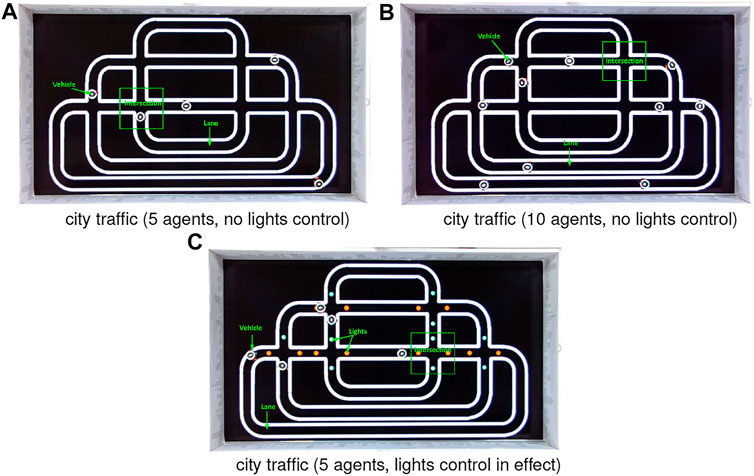
FIGURE 6. Illustration of two kinds of city ring road maps (with and without signals) from the top-down camera’s view including lanes, intersections, robot vehicles and red-green switching lights control at every crossroad. All the robots navigate unidirectionally.
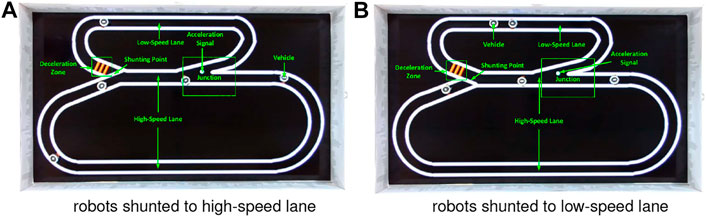
FIGURE 7. Illustration of highway traffic system including two lanes with distinct speed settings. The red signals indicate a deceleration zone as the entrance of low-speed lane. The green spot is an acceleration signal as the exit of low-speed lane. The switcher changes every 6 s. Both the two lanes are unidirectional.

FIGURE 8. Illustration of arena inside views. The surroundings are decorated with urban skyline patterns.
Here we also elucidate the relations between proposed visual systems model and control strategy. First, the model is treasured as internal component of the robot for real-time collision sensing. As presented in Algorithm 1 and Algorithm 2, the model is solely responsible for detecting potential collision; once a danger is alerted (Eq. 29), a corresponding avoidance command is sent to the motion control of robot which is prioritised over any other control logic conducted by environment. Second, the pheromone module herein is applied only to render the external “environment” for multi-robots, in order to construct roads, signals that followed, recognised by robot. Compared to other pheromone based swarm robotic studies, e.g., (Sun et al., 2019; Liu et al., 2020), the pheromones here are not released by engaged robots. More specific traffic set-ups are introduced in the following subsections.
3.1 Setting the City Traffic System
Firstly, the city robot traffic consists of the roadmaps without traffic lights control, and mixed by red (stop) and green (go) spot signals. Both roadmaps include straight and curving roads, and many intersections (see Figure 6). In addition, all the roads are unidirectional loops. As introduced previously, the robot navigation obeys the optical routes where the two boundaries confine its trajectory. In addition to that, the traffic lights also play roles of robot motion control. Algorithm 1 presents this kind of control logic. More concretely, if either the front or rear light sensor detects the red light, the robot will stop for a while until the light switches to green. The robot behaviour is set to go forward as default until potential crash or red light detected. The red and green lights switch every several seconds, constantly. Most importantly, all the robot agents prioritise the reaction to collision alert over traffic lights control.
In the city traffic without lights control, we also investigate the density of mobile robots at two different populations (see Figure 6). The visual scene undoubtedly becomes more complex and dynamic with more robot agents participating in the traffic system. In case of scenarios with lights control, we also set up the traffic that consists of unruly agents in half population to break the red-light control. Therefore, the intersections turn out to be the most dangerous zones resembling real-world intersection challenge (Colombo and Vecchio, 2012).
Algorithm 1: Agent Control Strategy in the City Traffic System.
1 while Power on do
2 Set initial forward speed randomly between 10 ∼ 14 cm/s;
3 if Two-side colour sensors are between road boundaries then
4 Follow route and go forward;
5 if Potential collision sensed then
6 Brake abruptly then stop for approaximately 2 s;
7 else
8 If red light detected by front or rear light sensor then
9 Halt the movement until green light detected;
10 else
11 Move forward and follow path;
12 else
13 Agent is derailed in collision or route following;
14 agent is manually replaced on the path
15 end
3.2 Setting the Highway Traffic System
Compared to the city traffic system that consists of many intersections as critical zones to challenge the proposed LGMDs inspired visual systems, the highway traffic system includes two lanes, i.e., low-speed and high-speed ring roads in loop, a junction where two lanes merge, a shunting mechanism to regularly separate robot vehicles into different lanes, and two light signals as the acceleration and deceleration indicators for agents, as illustrated in Figure 7. As a result, here the road junction and high speed are two leading factors of collision. Algorithm 2 presents this type of control logic. Both the two lanes are also configured as uni-directional with a shunting mechanism to separate robots with equal opportunities to follow either lanes. To change the robot’s speed, two types of signals are rendered by pheromones at the entrance and exit of low-speed lane, respectively (see Figure 7). Accordingly, the robot accelerates to enter the high-speed lane whilst decelerates preceding the low-speed lane.
Algorithm 2: Agent Control Strategy in the Highway Traffic System.
1 Navigation begins at the entrance of low-speed lane
2 Initial forward speed is randomly set between 10 ∼ 14 cm/s
3 While Power on do
4 If Two-side colour sensors are between road boundaries then
5 Follow route and go forward
6 If potential collision sensed then
7 Brake abruptly then stop for approaximately 2 s;
8 resume going forward and following route
9 else
__
10 If Acceleration signal detected by front or rear light sensor then
11 Entrance of high-speed lane reached;
12 Agent forward speed increases to around 21 cm/s within 2 s
13 else
__
14 If Deceleration signal detected by front or rear light sensor then
15 Entrance of low-speed lane reached
16 Agent forward speed decreases back to the origin within 2 s
17 else
__
18 else
19 Agent is derailed in collision or route following
20 Agent is manually replaced on the path
21 end
4 Results and Analysis
Within this section, we present the experimental results with analysis. Firstly, we demonstrate typical events of robot-to-robot interaction in the traffic systems, and visual systems output, i.e., the spike frequency of the hybrid LGMDs neural networks in the three types of investigated robot traffic scenarios. Secondly, the statistical results are given with event density maps. Lastly, we compare the proposed bio-inspired vision with another physical collision sensor in critical robot traffic. A video demo to illustrate our experiments is given in Supplementary Video.
4.1 Metrics
Regarding the statistical results, the overall collision avoidance rate (CAR) herein is used to evaluate the interactions between robot vehicles via the aforementioned localisation system, which is calculated by the following equations:
E and ca stand for the total robot-to-robot events and the collision avoidance with respect to time, respectively. T indicates the total running time of the localisation system in experiments. In this work, stop of the agent indicates a robot-to-robot event, thus:
With regard to the multi-robot localisation system (see Figure 3), an accomplishment of collision avoidance should satisfy the following criterion:
d is the Euclidean distance between robot p at position (xp, yp) and robot q at position (xq, yq) in the two-dimensional image plane, and p, q denote the time-varying coordinates of every two mobile robots given time t. γ = 20 (in pixels) is the predefined distance threshold to decide a successful collision avoidance in the critical robot traffic. Moreover, since the intersections and junctions are the most challenging zones for the robots that resemble the real world on-road situations, we also compare the safe passing rates (PR) on the intersections and junctions (PR1), as well as other road sections including the straight and curving roads (PR2). The calculations are comparable to the CAR with regional information as follows:
EPro1 and EPro2 denote the probability for critical events of interactions between engaged robots at the intersections/junctions and the other road sections, respectively.
4.2 Robot-to-Robot Interactions
To illustrate how the autonomous micro-robots behave in the simulated traffic systems guided by the collision prediction visual systems, some typical robot-to-robot interactions are depicted in Figure 9. It appears that the avoidance behaviours are most likely aroused at some critical moments, for example, two robots meeting at the junction (see Figure 9C), queueing effect by robots on the same lane, yet at different speeds (see Figure 9D). In other normal situations (see Figures 9A,B), the robots navigate smoothly without collision avoidance. Interestingly, when the robot on curving road is facing a nearby-lane oncoming agent, there is usually an alert for a potential crash that well matches the real world driving behaviour (Sivaraman and Trivedi, 2013) (see Figure 9E). In the city traffic system, intersections are the most challenging places for robots to predict imminent crashes. When two vehicles meeting at an intersection, the urgent crossing of one agent in a very short distance could excite both the LGMDs to fire together for a positive alert (see Figure 9F). In this regard, the mimicked red-green light signals can help to alleviate the risk at intersections to a large extent like the real world on-road situations. Here we nevertheless query whether the proposed visual systems, on their own, can cope with such dangerous circumstances without the traffic signal control. The comparative experiments will be carried out in the following subsection.

FIGURE 9. Illustrations of typical traffic phases of robot-to-robot interactions. Each phase is shown by three subsequent snapshots. The trajectories are depicted in colour lines each representing an ID-identified agent. The sites of crash avoidance are marked by green circles.
4.3 Neural Network Response
To articulate the responses of LGMDs hybrid neural networks in different robot traffic scenes, Figure 10 illustrates three sets of model output, that is, the hybrid firing rate. Considering the introduced two types of traffic scenarios, we remotely collected the data from a robot agent interacting with others. It can bee seen from the results that a large number of collision alerts have been signalled by the LGMDs model in the embedded vision of tested robot during navigation. In addition, the neural networks respond much more constantly in the highway traffic system that consists of high-speed robot vehicles and junction.
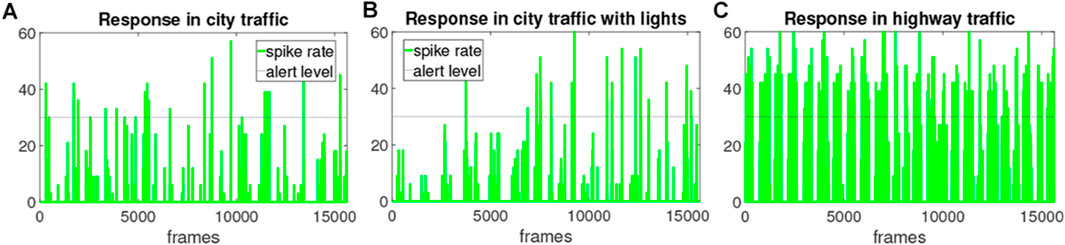
FIGURE 10. The outputs of proposed hybrid neural network model, i.e., the spike rate from a robot agent interacting within three multi-agent traffic systems, each lasting for 8 min: the horizontal dashed line indicates the alert level of firing rate.
4.4 Performance in Critical Robot Traffic
This subsection reports on the performance of the proposed collision prediction visual systems under constrained computation power against different robot traffic challenges. The overall CAR is given in Table 3. The comparative results on specific PR are given in Table 4.

TABLE 3. CAR in multi-robot traffic.

TABLE 4. PR in multi-robot traffic.
4.4.1 Performance in the City Traffic System
In the city traffic system, we carry out systematic and comparative experiments involving several cases. In the first case, the robot traffic has no signal controls at intersections. We also look deeper into the density effect on collision prediction performance. Figure 11 illustrates the event and density maps of all micro-robot agents engaging in the ring road traffic for 1-h implementation.
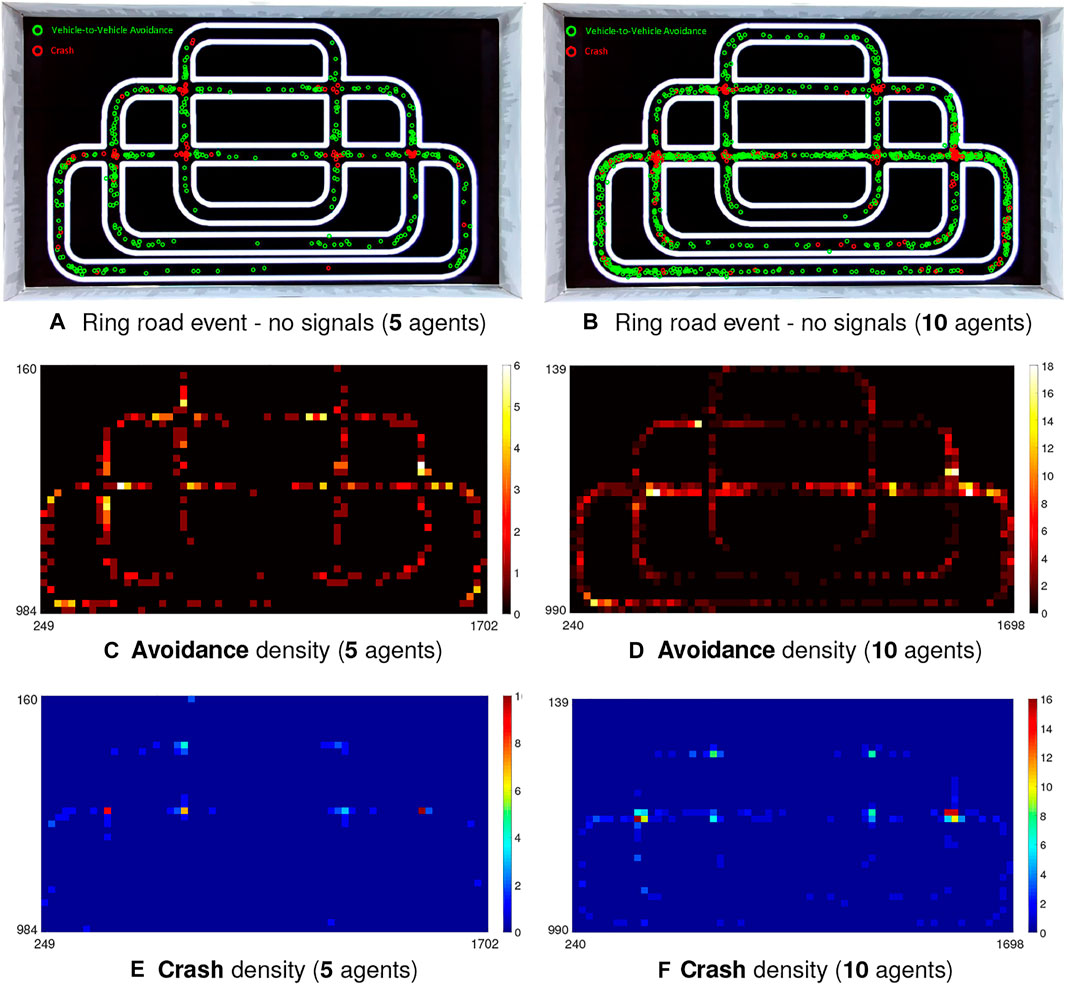
FIGURE 11. Illustration of event and density maps from top-down view of camera including avoidance and crash in the city traffic system at two comparative populations of robot vehicles without light signals at intersections. (A, B) Event maps: red and green circles indicate the positions of crash and avoidance events between robot vehicles, respectively. (C–F) Density maps: X-Y plane denotes the image coordinates.
In the second case, the red and green switching traffic lights are used as the auxiliary signals for robot flows control at intersections. An interesting episode is plotted in this case by mixing unruly robot agents not obeying the law of traffic signals, i.e., red to stop and green to go, that mimic the drivers who always break the traffic rules at intersections leading to immense on-road safety issue. Figure 12 illustrates the corresponding results at this point.
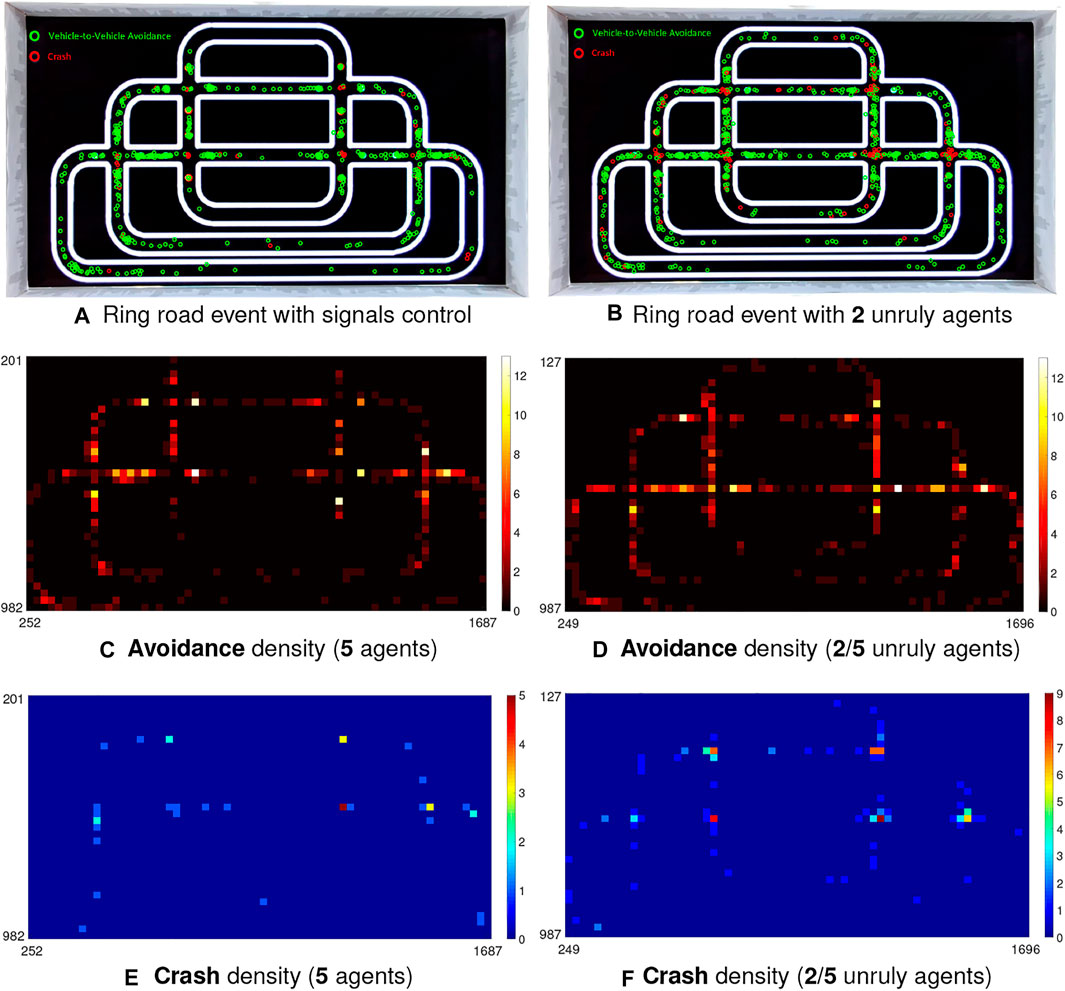
FIGURE 12. Illustration of event and density maps in the city traffic system (5 robot vehicles) with signals control and engaged unruly agents at intersections.
Together with the statistical results in Tables 3, T4, we have the following observations on the experiments of city traffic system:
1) Table 4 shows that more than half critical events take place at intersections in all the imitations of city ring road traffic (see EPro1 in Table 4) indicating that our robot traffic could reflect real world road challenges (Colombo and Vecchio, 2012).
2) Compared to the performance at intersections, the PR is quite higher in the straight and curving road (all above 80%). To be more intuitive, Figures 11, 12 also demonstrate that the crash most frequently occurs at intersections with relatively lower PR, which show higher crash densities there; on the other hand, the PR is fairly higher in other road sections corresponding to higher avoidance densities.
3) The overall CAR peaks in case of the city traffic system with lights, and without unruly agents (92.84%). Compared to that, the CAR reaches valley once lacking red-green signals to relieve the traffic flows at intersections (80.94%).
4) On the aspect of density comparison, there is merely tiny difference on both the CAR and PR of two investigated populations, which reveal that the proposed visual systems perform robustly for collision prediction even in more dynamic environment.
Generally speaking, the proposed bio-inspired hybrid neural networks work effectively and consistently on collision prediction in the city traffic system despite that the intersections are still posing challenges on timely detection-and-avoidance using the visual approach as the only modality. However, we believe this can be improved by increasing the view angle of optical sensor as the current view of frontal camera can only reach approximately 70°. The risk of intersection could also be alleviated by sensor fusion strategy, or other algorithms in intelligent transportation system (Colombo and Vecchio, 2012). With discrepancies amongst forward velocities of multi-robots (refer to the setting in Algorithm 1), the robot vehicles well demonstrate queueing effect guided by the collision prediction systems. On the straight and curving roads, the LGMDs inspired visual systems perform more robustly and consistently on collision alert in comparison with the intersections. Additionally, the robot density in the traffic system dose not greatly affect the overall performance of visual systems, which imply the proposed bio-inspired computation is robust and flexible to more dynamic visual scenes.
4.4.2 Performance in the Highway Traffic System
In the critical highway traffic system, two lanes separate the speed of robots into two ranges, as presented in Section 3. The overall CAR and PR are given in Tables 3, T4. In addition, Figure 13 illustrates the results with event and density maps. Here the most noticeable observation is that in comparison with the city traffic system barring the 10-agents case, more than twofold critical events take place in the highway traffic within the 1-h implementation. Table 4 clearly shows that nearly half (43.2%) critical events concentrate at the junction where the high-speed and low-speed robot flows merge. In spite of that, the overall CAR remains fairly high that is in consistent with the city traffic system without signals control (79.98%); the PR at either the junction (75.29%) or the other road sections (83.55%) is slightly lower than the city traffic results. In general, the LGMDs inspired visual systems are robust to cope with collision prediction in high-speed, dynamic visual scene, in the micro-robot under constrained computation cost.
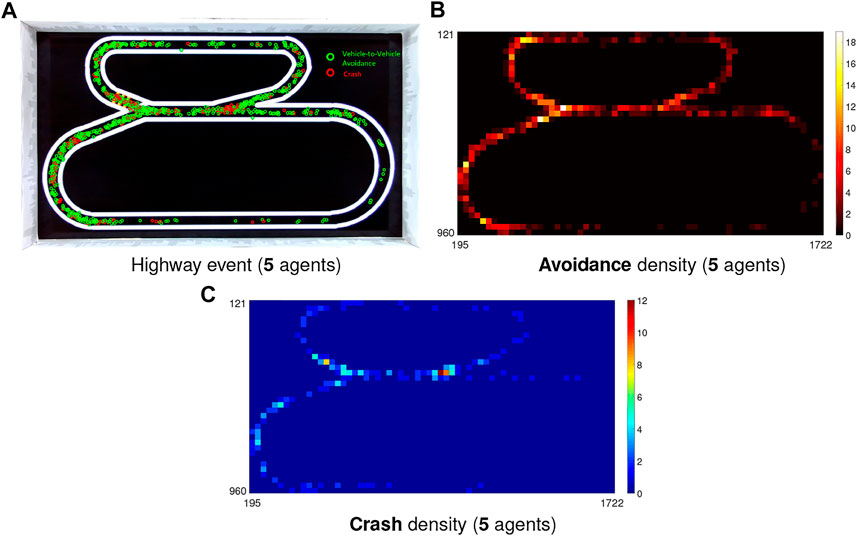
FIGURE 13. Illustration of event and density maps in the highway traffic system.
On the other hand, we also find challenges through the experiments. The event density maps in Figure 13 demonstrate that it is still difficult to address the crash avoidance problems at the junction where the low-speed robot vehicles are accelerating to merge into the high-speed flow. At this point, the robots are required to form a queue to pass the junction free of collision. The similar situations happen at the deceleration zone where the high-speed vehicles are shunted to queue into the low-speed flow. In addition to that, compared to the city traffic results, the PR in other sections is relatively lower, i.e., more crashes between robots occur on the high-speed curving road (see Figure 13C).
4.5 Sensor Comparison
Through the previous experiments, we have shown the effectiveness and robustness of LGMDs inspired visual systems for timely collision prediction in critical robot traffic. The energy efficiency have also been verified via the successful implementation on the micro-robot under extremely constrained computation power. As an alternative, optical approach to collision detection, the proposed bio-inspired computation could be scalable across various platforms and scenarios. In the last type of experiments, we also compare this visual approach with another classic physical sensor strategy–the IR bumper sensors used extensively in robotics for collision sensing and avoidance.
The micro-robot possesses three IR sensors as short-range obstacle sensing technique. Figure 14 compares the detection range between the two physical sensor strategies. It appears that the combination of three bumper sensors has wider coverage in space up to approximately 90° than the monocular camera which could reach only 70°. On the other hand, the optical sensor has much longer sensing distance with respect to the advantage of optical methods. In this kind of experiments, the robot vehicle applies the same braking avoidance behaviour guided by the bumpers. The other experimental setting is in accordance with the earlier experiments. Each type of traffic system implementation lasts for 1 hour, the same duration.
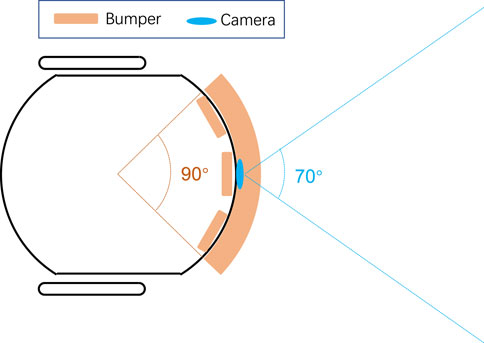
FIGURE 14. Schematic comparison on sensing range of two physical sensor strategies between the combination of three IR bumper sensors and the frontal monocular camera.
Table 5 lists the CAR of IR based technique in the two traffic systems. Though with wider coverage in front, here the CAR of IR based technique is much lower in both types of traffic system (66.81% in city traffic without lights and 48.30% in highway), compared with the performance of LGMDs inspired visual systems (80.94% in city traffic without lights and 79.98% in highway). Compared to the proposed optical approach, the short-range technique can not fulfil the timely crash prediction in the critical robot traffic. The short distance between interactive robots brings about a smaller amount of critical events within an identical time window. Besides that, the CAR is even lower in the highway scenario, which points out that the IR short-range detector is unsuitable to predicting high-speed approaching objects very timely; whilst the proposed approach can signal an impending crash quite earlier. With more abundant features extracted, filtered from the dynamic visual scene, the hybrid LGMDs inspired visual systems are more robust in collision prediction.

TABLE 5. CAR of IR sensors in multi-robot traffic.
5 Discussion
In this section, we discuss further on observed problems through the experiments, and point out corresponding future works. Firstly, we have seen some limitations of the proposed approach for quick collision detection in the context of robot traffic. Some critical conditions are still challenging the proposed LGMDs inspired visual systems. In the city traffic system particularly without signals control, crashes generally take place at intersections (see Figure 11). During the experiments, we have observed that there is a possibility that two robot vehicles are arriving at the intersection, simultaneously. The current approach as frontal collision sensing technique can not well cope with such a problem. On the other hand, crashes are significantly reduced if the robots reached intersection in succession, such as the example shown in Figure 9F; the successful avoidance density is fairly high near the intersections in the city traffic system, as shown in Figures 11, 12. The proposed approach can predict a danger by nearby object crossing the field of vision, very robustly and timely. In this research, a possible restriction is the limited view angle of the monocular camera system in the micro-robot. Therefore, we will develop binocular and panoramic camera systems for future scientific study.
In the highway traffic system, we have noticed that the very high speed movement, i.e., robot velocity over 20 cm/s in the context, is another problem to the LGMDs inspired visual systems embedded in the micro-robot vision. In our previous studies on LGMD-1 (Fu et al., 2018b) and LGMD-2 (Fu et al., 2019b), we have figured out that the LGMDs models demonstrate speed response to approaching object, i.e., the neural networks deliver stronger output against faster approaching object at higher angular velocity. The speed response and looming selectivity of LGMDs models is achieved by the competition between excitation and two kinds of inhibitions–the lateral inhibition, and the FFI. Most importantly, the former inhibition works effectively to sculpt such selectivity when objects expanding on the field of vision before reaching a particular angular size. Otherwise, the FFI (or PM in the LGMD-2) mechanisms could immediately suppress the LGMDs at some critical moments like the end of approaching, the start of receding. Accordingly, the proposed visual systems in the high-speed moving robot have always confronted such difficult situation. This gives reasonable explanation on the higher crash density near the junction where the two lanes merge (see Figure 13). In another word, the high-speed agent could not appropriately predict a crash with the emerged low-speed agent at the junction. In this regard, future effort is in demand to enable the visual systems to well cope with ultra-fast approaching movements.
Regarding the control strategy, as it is not the focus of this research, we have applied very basic switch control between two states, i.e., move and stop, in order to enable the robots to tightly follow paths in all kinds of traffic systems. As a result, the potential crash avoidance is led by abrupt braking which can not fulfil the very complicated, real world emergency actions of vehicles. For example, the deceleration earlier to urgent stop has not been involved in the control of micro-robots. We will incorporate in the robotic motion system more advanced control method, e.g., the fuzzy control, to enrich the robot avoidance reaction corresponding to more realistic behaviours (Sivaraman and Trivedi, 2013).
Secondly, in comparison with previous robot arena experiments on the LGMDs inspired visual systems, in which the robot motion was not confined by specific trajectories (Fu et al., 2017; Fu et al., 2019b), this study strictly binds the robot motion in navigation (see Figure 5, Algorithms 1, 2). The prioritised goal of robot motion is to tightly follow the paths desired by the robot traffic implementation. However, the current motion strategy has the flaw that the robots usually experience yaw rotations in route following. This sometimes results in false positives of collision alert. We will explore new methods in the LGMDs neuronal system model to habituate such visual movements, and also improve the robot route following strategy.
Last but not least, the robot vehicles currently are not fully autonomous in traffic systems. Despite human interventions in merely specific conditions during experiments (e.g., the robot fails in route following or collide with other agents), the human-robot interactions have still influenced the robot traffic implementation, e.g., manually replacing the robot on routes after crash. Accordingly, the different robot traffic systems need to be verified with respect to (Fisher et al., 2021). The safety and functional correctness of the robot traffic reflecting some real world scenes also need to be further validated according to (Webster et al., 2020).
6 Concluding Remarks
This paper has presented a novel study on investigating bio-inspired computation approach to collision prediction in dynamic robot traffic reflecting some real world on-road challenges. To fill the scientific study gap on evaluating online artificial visual systems in dangerous scenarios where physical crashes are prone to happen, we have applied a recently published robotic platform to construct traffic systems including the city roadmap with many intersections, and the highway with junctions. To sharpen up the acuity of collision detection visual systems to darker objects approaching over other categories of movements like recession, we have integrated two LGMDs neuronal models, i.e., the LGMD-1 and LGMD-2 neural networks, as a hybrid model outputting alert firing rate. A potential collision is predicted only when both the LGMDs are highly activated. To focus on investigating the proposed collision prediction visual systems, we have applied the simple bang-bang control to allow the robot to tightly follow paths and brake abruptly corresponding to the avoidance action. The arena experiments have verified the robustness of the proposed approach to timely collision alert for engaged robot vehicles in the traffic systems. This research has complemented the previous experimentation on such bio-inspired visual systems in more critical real-physical scenarios, under extremely constrained computation power. This also has provided an alternative, energy-efficient technique to current collision alert systems. The propose visual systems can be transformed into neuromorphic sensing paradigms which could be prevalent for future autonomous machines.
Data Availability Statement
All datasets generated for this study are included in the article/Supplementary Video.
Author Contributions
QF, XS, TL contributed as the joint first authors. CH configured the micro-robot. All authors contributed to the article and approved the submitted version.
Funding
This research has received funding from the European Union’s Horizon 2020 research and innovation programme under the Marie Sklodowska-Curie Grant Agreement No 778602 ULTRACEPT, the National Natural Science Foundation of China under the Grant No 12031003, and the China Postdoctoral Science Foundation Grant 2020M682651.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/frobt.2021.529872/full#supplementary-material
References
Albaker, B. M., and Rahim, N. A. (2009). “A Survey of Collision Avoidance Approaches for Unmanned Aerial Vehicles,” in 2009 International Conference for Technical Postgraduates, Kuala Lumpur, Malaysia IEEE. doi:10.1109/techpos.2009.5412074
Ammoun, S., and Nashashibi, F. (2009). “Real Time Trajectory Prediction for Collision Risk Estimation between Vehicles,” in IEEE 5th International Conference on Intelligent Computer Communication and Processing, Cluj-Napoca, Romania IEEE. doi:10.1109/iccp.2009.5284727
Bermúdez i Badia, S., Bernardet, U., and Verschure, P. F. M. J. (2010). Non-linear Neuronal Responses as an Emergent Property of Afferent Networks: A Case Study of the Locust Lobula Giant Movement Detector. Plos Comput. Biol. 6, e1000701. doi:10.1371/journal.pcbi.1000701
Blanchard, M., Rind, F. C., and Verschure, P. F. M. J. (2000). Collision Avoidance Using a Model of the Locust Lgmd Neuron. Robotics Autonomous Syst. 30, 17–38. doi:10.1016/s0921-8890(99)00063-9
Chang, W.-J., Chen, L.-B., and Su, K.-Y. (2019). Deepcrash: A Deep Learning-Based Internet of Vehicles System for Head-On and Single-Vehicle Accident Detection With Emergency Notification. IEEE Access. 7, 148163–148175. doi:10.1109/access.2019.2946468
Cizek, P., and Faigl, J. (2019). Self-Supervised Learning of the Biologically-Inspired Obstacle Avoidance of Hexapod Walking Robot. Bioinspiration & Biomimetics. 14, 046002. doi:10.1088/1748-3190/ab1a9c
Cizek, P., Milicka, P., and Faigl, J. (2017). “Neural Based Obstacle Avoidance with CPG Controlled Hexapod Walking Robot,” in Proceedings of the 2017 IEEE International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA (IEEE), 650–656. doi:10.1109/ijcnn.2017.7965914
Colombo, A., and Vecchio, D. D. (2012). “Efficient Algorithms for Collision Avoidance at Intersections,” in Proceedings of the 15th ACM International Conference on Hybrid Systems, Beijing China (Computation and Control), 145–154. doi:10.1145/2185632.2185656
Fisher, M., Mascardi, V., Rozier, K. Y., Schlingloff, B.-H., Winikoff, M., and Yorke-Smith, N. (2021). Towards a Framework for Certification of Reliable Autonomous Systems. Auton. Agent Multi-Agent Syst. 35 (8). doi:10.1007/s10458-020-09487-2
Fotowat, H., and Gabbiani, F. (2011). Collision Detection as a Model for Sensory-Motor Integration. Annu. Rev. Neurosci. 34, 1–19. doi:10.1146/annurev-neuro-061010-113632
Franceschini, N. (2014). Small Brains, Smart Machines: From Fly Vision to Robot Vision and Back Again. Proc. IEEE. 102, 751–781. doi:10.1109/jproc.2014.2312916
Fu, Q., Bellotto, N., Wang, H., Claire Rind, F., Wang, H., and Yue, S. (2019a). “A Visual Neural Network for Robust Collision Perception in Vehicle Driving Scenarios,” in Artificial Intelligence Applications and Innovations, Crete, Greece (Springer International Publishing), 67–79. doi:10.1007/978-3-030-19823-7_5
Fu, Q., Wang, H., Hu, C., and Yue, S. (2019b). Towards Computational Models and Applications of Insect Visual Systems for Motion Perception: A Review. Artif. Life. 25, 263–311. doi:10.1162/artl_a_00297
Fu, Q., Hu, C., Liu, T., and Yue, S. (2017). “Collision Selective LGMDs Neuron Models Research Benefits From a Vision-Based Autonomous Micro Robot,” in Proceedings of the 2017 IEEE/RSJ international conference on intelligent robots and systems (IROS), Vancouver, Canada (IEEE), 3996–4002. doi:10.1109/iros.2017.8206254
Fu, Q., Hu, C., Liu, P., and Yue, S. (2018a). “Towards Computational Models of Insect Motion Detectors for Robot Vision,” in Towards autonomous robotic systems conference, Bristol, United Kingdom. Editors M. Giuliani, T. Assaf, and M. E. Giannaccini (Springer International Publishing), 465–467.
Fu, Q., Hu, C., Peng, J., and Yue, S. (2018b). Shaping the Collision Selectivity in a Looming Sensitive Neuron Model with Parallel on and off Pathways and Spike Frequency Adaptation. Neural Networks. 106, 127–143. doi:10.1016/j.neunet.2018.04.001
Fu, Q., Hu, C., Peng, J., Rind, F. C., and Yue, S. (2020a). A Robust Collision Perception Visual Neural Network with Specific Selectivity to Darker Objects. IEEE Trans. Cybern. 50, 5074–5088. doi:10.1109/TCYB.2019.2946090
Fu, Q., Wang, H., Peng, J., and Yue, S. (2020b). Improved Collision Perception Neuronal System Model With Adaptive Inhibition Mechanism and Evolutionary Learning. IEEE Access. 8, 108896–108912. doi:10.1109/access.2020.3001396
Fu, Q., Yue, S., and Hu, C. (2016). “Bio-inspired Collision Detector With Enhanced Selectivity for Ground Robotic Vision System,” in British machine vision conference, New York, United Kingdom. Editors E. R. H. R C. Wilson, and W. A. P. Smith (BMVA Press), 1–13. doi:10.5244/c.30.6
Gabbiani, F., Krapp, H. G., Hatsopoulos, N., Mo, C.-H., Koch, C., and Laurent, G. (2004). Multiplication and Stimulus Invariance in a Looming-Sensitive Neuron. J. Physiology-Paris. 98, 19–34. doi:10.1016/j.jphysparis.2004.03.001
Gabbiani, F., Krapp, H. G., Koch, C., and Laurent, G. (2002). Multiplicative Computation in a Visual Neuron Sensitive to Looming. Nature. 420, 320–324. doi:10.1038/nature01190
Hartbauer, M. (2017). Simplified Bionic Solutions: A Simple Bio-Inspired Vehicle Collision Detection System. Bioinspir. Biomim. 12, 026007. doi:10.1088/1748-3190/aa5993
Hu, C., Fu, Q., and Yue, S. (2018). “Colias IV: the Affordable Micro Robot Platform With Bio-Inspired Vision,” in Towards autonomous robotic systems conference. Editors M. Giuliani, T. Assaf, and M. E. Giannaccini (Springer International Publishing), 197–208. doi:10.1007/978-3-319-96728-8_17
Isakhani, H., Aouf, N., Kechagias-Stamatis, O., and Whidborne, J. F. (2018). A Furcated Visual Collision Avoidance System for an Autonomous Micro Robot. IEEE Trans. Cogn. Development Syst. 12, 1–11. doi:10.1109/TCDS.2018.2858742
Keil, M. S., Roca-Moreno, E., and Rodriguez-Vazquez, A. (2004). “A Neural Model of the Locust Visual System for Detection of Object Approaches With Real-World Scenes,” in Proceedings of the fourth IASTED international conference on visualization, imaging, and image processing, Marbella, Spain (IASTED), 340–345.
Kennedy, J. S. (1951). The Migration of the Desert Locust (Schistocerca gregaria Forsk.) I. The Behaviour of Swarms. II. A Theory of Long-Range Migrations. Phil. Trans. R. Soc. Lond. B. 235, 163–290. doi:10.1098/rstb.1951.0003
Krajník, T., Nitsche, M., Faigl, J., Vaněk, P., Saska, M., Přeučil, L., et al. (2014). A Practical Multirobot Localization System. J. Intell. Robot Syst. 76, 539–562. doi:10.1007/s10846-014-0041-x
Krejan, A., and Trost, A. (2011). “LGMD-Based Bio-Inspired Algorithm for Detecting Risk of Collision of a Road Vehicle,” in Proceedings of the 2011 IEEE 7th international symposium on image and signal processing and analysis, Dubrovnik, Croatia (IEEE), 319–324.
Liu, T., Sun, X., Hu, C., Fu, Q., Isakhani, H., and Yue, S. (2020). “Investigating Multiple Pheromones in Swarm Robots - A Case Study of Multi-Robot Deployment,” in Proceedings of the 2020 5th International Conference on Advanced Robotics and Mechatronics (ICARM), Shenzhen, China (IEEE), 595–601. doi:10.1109/icarm49381.2020.9195311
Mukhtar, A., Xia, L., and Tang, T. B. (2015). Vehicle Detection Techniques for Collision Avoidance Systems: A Review. IEEE Trans. Intell. Transport. Syst. 16, 2318–2338. doi:10.1109/TITS.2015.2409109
O’Shea, M., and Williams, J. L. (1974). The Anatomy and Output Connection of a Locust Visual Interneurone; the Lobular Giant Movement Detector (LGMD) Neurone. J. Comp. Physiol. 91, 257–266. doi:10.1007/BF00698057
O’Shea, M., and Rowell, C. H. F. (1976). The Neuronal Basis of a Sensory Analyser, the Acridid Movement Detector System. J. Exp. Biol. 68, 289–308. doi:10.1242/jeb.65.2.289
Rind, F. C., and Bramwell, D. I. (1996). Neural Network Based on the Input Organization of an Identified Neuron Signaling Impending Collision. J. Neurophysiol. 75, 967–985. doi:10.1152/jn.1996.75.3.967
Rind, F. C., and Simmons, P. J. (1999). Seeing What Is Coming: Building Collision-Sensitive Neurones. Trends Neurosciences. 22, 215–220. doi:10.1016/s0166-2236(98)01332-0
Rind, F. C., Wernitznig, S., Pölt, P., Zankel, A., Gütl, D., Sztarker, J., et al. (2016). Two Identified Looming Detectors in the Locust: Ubiquitous Lateral Connections Among Their Inputs Contribute to Selective Responses to Looming Objects. Sci. Rep. 6, 35525. doi:10.1038/srep35525
Sabzevari, R., and Scaramuzza, D. (2016). Multi-body Motion Estimation From Monocular Vehicle-Mounted Cameras. IEEE Trans. Robot. 32, 638–651. doi:10.1109/tro.2016.2552548
Salt, L., Howard, D., Indiveri, G., and Sandamirskaya, Y. (2019). Parameter Optimization and Learning in a Spiking Neural Network for Uav Obstacle Avoidance Targeting Neuromorphic Processors. IEEE Trans. Neural Networks Learn. Syst. 31, 3305–3318. doi:10.1109/TNNLS.2019.2941506
Salt, L., Indiveri, G., and Sandamirskaya, Y. (2017). “Obstacle Avoidance With Lgmd Neuron: Towards a Neuromorphic Uav Implementation,” in Proceedings of the 2017 IEEE international symposium on circuits and systems (ISCAS), Baltimore, MD, USA (IEEE), 1–4. doi:10.1109/iscas.2017.8050976
Serres, J. R., and Ruffier, F. (2017). Optic Flow-Based Collision-Free Strategies: From Insects to Robots. Arthropod Struct. Development. 46, 703–717. doi:10.1016/j.asd.2017.06.003
Simmons, P. J., and Rind, F. C. (1997). Responses to Object Approach by a Wide Field Visual Neurone, the LGMD2 of the Locust: Characterization and Image Cues. J. Comp. Physiol. A: Sensory, Neural Behav. Physiol. 180, 203–214. doi:10.1007/s003590050041
Simmons, P. J., Rind, F. C., and Santer, R. D. (2010). Escapes With and Without Preparation: The Neuroethology of Visual Startle in Locusts. J. Insect Physiol. 56, 876–883. doi:10.1016/j.jinsphys.2010.04.015
Sivaraman, S., and Trivedi, M. M. (2013). Looking at Vehicles on the Road: A Survey of Vision-Based Vehicle Detection, Tracking, and Behavior Analysis. IEEE Trans. Intell. Transport. Syst. 14, 1773–1795. doi:10.1109/tits.2013.2266661
Stafford, R., Santer, R. D., and Rind, F. C. (2007). A Bio-Inspired Visual Collision Detection Mechanism for Cars: Combining Insect Inspired Neurons to Create a Robust System. Biosystems. 87, 164–171. doi:10.1016/j.biosystems.2006.09.010
Sun, X., Liu, T., Hu, C., Fu, Q., and Yue, S. (2019). “ColCOS ϕ: A Multiple Pheromone Communication System for Swarm Robotics and Social Insects Research,” in Proceedings of the 2019 IEEE 4th International Conference on Advanced Robotics and Mechatronics (ICARM), Osaka, Japan (IEEE), 59–66. doi:10.1109/icarm.2019.8833989
Sun, Z., Bebis, G., and Miller, R. (2004). “On-Road Vehicle Detection Using Optical Sensors: a Review,” in Proceedings of the 7th International IEEE Conference on Intelligent Transportation Systems, Washington, WA, USA IEEE, 585–590.
Sztarker, J., and Rind, F. C. (2014). A Look Into the Cockpit of the Developing Locust: Looming Detectors and Predator Avoidance. Devel Neurobio. 74, 1078–1095. doi:10.1002/dneu.22184
Webster, M., Western, D., Araiza-Illan, D., Dixon, C., Eder, K., Fisher, M., et al. (2020). A Corroborative Approach to Verification and Validation of Human-Robot Teams. Int. J. Robotics Res. 39, 73–99. doi:10.1177/0278364919883338
[Dataset] WHO (2018). Global Status Report on Road Safety 2018. Available at: https://www.who.int/violence_injury_prevention/road_safety_status/2018/en/.
Yakubowski, J. M., Mcmillan, G. A., and Gray, J. R. (2016). Background Visual Motion Affects Responses of an Insect Motion-Sensitive Neuron to Objects Deviating From a Collision Course. Physiol. Rep. 4, e12801. doi:10.14814/phy2.12801
Yue, S., and Rind, F. C. (2005). “A Collision Detection System for a Mobile Robot Inspired by the Locust Visual System,” in Proceedings of the 2005 IEEE international conference on robotics and automation (ICRA), Barcelona, Spain (IEEE), 3832–3837.
Zehang Sun, Z., Bebis, G., and Miller, R. (2006). On-Road Vehicle Detection: a Review. IEEE Trans. Pattern Anal. Machine Intell. 28, 694–711. doi:10.1109/tpami.2006.104
Zhao, J., Ma, X., Fu, Q., Hu, C., and Yue, S. (2019). An LGMD Based Competitive Collision Avoidance Strategy for Uav. Artif. Intelligence Appl. Innov. 6, 80–91. doi:10.1007/978-3-030-19823-7_6
Keywords: bio-inspired computation, collision prediction, robust visual systems, LGMDs, micro-robot, critical robot traffic
Citation: Fu Q, Sun X, Liu T, Hu C and Yue S (2021) Robustness of Bio-Inspired Visual Systems for Collision Prediction in Critical Robot Traffic. Front. Robot. AI 8:529872. doi: 10.3389/frobt.2021.529872
Received: 27 January 2020; Accepted: 19 July 2021;
Published: 06 August 2021.
Edited by:
Subhadeep Chakraborty, The University of Tennessee, Knoxville, United StatesReviewed by:
Pengcheng Liu, University of York, United KingdomJindong Tan, The University of Tennessee, Knoxville, United States
Copyright © 2021 Fu, Sun, Liu, Hu and Yue. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Qinbing Fu, cWlmdUBsaW5jb2xuLmFjLnVr; Shigang Yue, c3l1ZUBsaW5jb2xuLmFjLnVr
†These authors share first authorship