 Fares J. Abu-Dakka
Fares J. Abu-Dakka Matteo Saveriano
Matteo Saveriano
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
REVIEW article
Front. Robot. AI , 21 December 2020
Sec. Robotic Control Systems
Volume 7 - 2020 | https://doi.org/10.3389/frobt.2020.590681
This article is part of the Research Topic Variable Impedance Robot Skills: Control & Learning View all 4 articles
Robots that physically interact with their surroundings, in order to accomplish some tasks or assist humans in their activities, require to exploit contact forces in a safe and proficient manner. Impedance control is considered as a prominent approach in robotics to avoid large impact forces while operating in unstructured environments. In such environments, the conditions under which the interaction occurs may significantly vary during the task execution. This demands robots to be endowed with online adaptation capabilities to cope with sudden and unexpected changes in the environment. In this context, variable impedance control arises as a powerful tool to modulate the robot's behavior in response to variations in its surroundings. In this survey, we present the state-of-the-art of approaches devoted to variable impedance control from control and learning perspectives (separately and jointly). Moreover, we propose a new taxonomy for mechanical impedance based on variability, learning, and control. The objective of this survey is to put together the concepts and efforts that have been done so far in this field, and to describe advantages and disadvantages of each approach. The survey concludes with open issues in the field and an envisioned framework that may potentially solve them.
Day by day realistic applications (e.g., disaster response, services, and logistics applications, etc.) are bringing robots into unstructured environments (e.g., houses, hospitals, museums, and so on) where they are expected to perform complex manipulation tasks. This growth in robot applications and technologies is changing the classical view of robots as caged manipulators in industrial settings. Indeed, robots are now required to directly interact with unstructured environments, which are dynamic, uncertain, and possibly inhabited by humans. This demands to use advanced interaction methodologies based on impedance control.
Classical robotics, mostly characterized by high gain negative error feedback control, is not suitable for tasks that involve interaction with the environment (possibly humans) because of possible high impact forces. The use of impedance control provides a feasible solution to overcome position uncertainties and subsequently avoid large impact forces, since robots are controlled to modulate their motion or compliance according to force perceptions. Note that compliance control (Salisbury, 1980) is only a subset of impedance control to produce compliant motion (Park, 2019) and its tradition definition is “any robot motion during which the end-effector trajectory is modified, or even generated, based on online sensor information” (De Schutter, 1987). Noteworthy, in cases where a robotic system is not providing access to low-level control (e.g., commanding joints torque or motor current), then we model interaction between the robot and the environment using admittance control (Villani and De Schutter, 2016) by translating the contact forces into velocity commands1.
Impedance controller resembles a virtual spring-damper system between the environment and robot end-effector (Hogan, 1985), which allows robots to interact with the environment or humans more safely and in an energy-efficient way. In learning applications, a standard impedance interaction model is defined as
where t = 1, 2, ⋯ , T is the time-step, represents the goal position (or desired trajectory2), and xt is the actual trajectory of the end-effector. are the mass, stiffness, and damping matrices, respectively, for translational motion, while are the moment of inertia, stiffness, and damping matrices, respectively, for rotational motion. ωt is the angular velocity of the end-effector. are rotation matrices and correspond to desired rotation goal and actual orientation profile of the end-effector, respectively. The rotation of Rt into is defined as . and represent the external force and torque applied to the robot end-effector. Figure 1 shows the block scheme of the impedance control for the translational part.
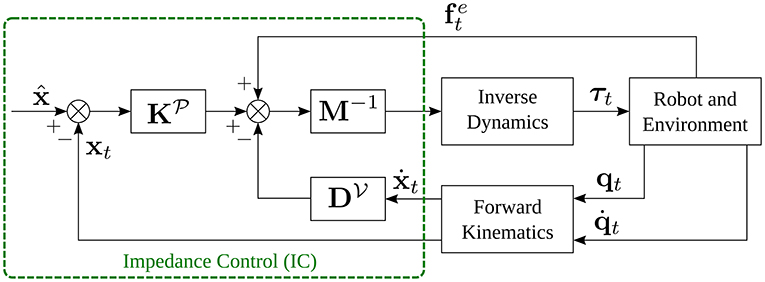
Figure 1. Block scheme of impedance control, obtained assuming that .
Impedance control can be used in Cartesian space to control the end-effector interaction with the environment (Siciliano and Villani, 2001; Albu-Schaffer and Hirzinger, 2002; Lippiello et al., 2007; Caccavale et al., 2008), like in haptic exploration (Eiband et al., 2019), as well as in joint space (Tsetserukou et al., 2009; Li et al., 2011a,b, 2012) to enhance safety. Albu-Schaffer et al. studied Cartesian impedance control with null-space stiffness based on singular perturbation (Albu-Schaffer et al., 2003) and passive approach (Albu-Schäffer et al., 2007). Few years later, research tackled null-space impedance control in multi-priority controllers (Sadeghian et al., 2011; Hoffman et al., 2018) and to ensure the convergence of task-space error. Ott (2008) described Cartesian impedance control and its pros and cons for torque controlled redundant robots.
Impedance control is not only of importance when robots interact with a stiff environment. As mentioned previously, new robot applications are bringing robots to share human spaces that make the contact between them inevitable. In such situations, it is important to ensure the human safety (Goodrich and Schultz, 2008; Haddadin, 2013). Impedance control plays an important role in human-robot interaction. These robots are not supposed to just be in human spaces to do some specific tasks, but also to assist human in many other tasks like lifting heavy objects (e.g., table, box) (Ikeura and Inooka, 1995; Ikeura et al., 2002), objects handover (Bohren et al., 2011; Medina et al., 2016), etc., in human–robot collaboration framework (Bauer et al., 2008).
However, in many tasks robots need to vary their impedance along the execution of the task. As an illustrative example, robots in unstructured environments (homes, industrial floors, or other similar scenarios) may require to turn valves or open doors, etc. Such tasks demand the application of different control forces according to different mass, friction forces, etc. In that sense, sensed forces convey relevant information regarding the control forces needed to perform such manipulation tasks, which can be governed through stiffness variations (Abu-Dakka et al., 2018). Another example, from human–robot cooperative scenario, a robot needs to adapt its stiffness based on its interaction with a human in a cooperative assembly task (Rozo et al., 2013).
From now on the main focus of this survey will be on Variable Impedance Control (VIC) from both control and learning perspectives. To the best of our knowledge, this is the first survey that focuses on control and learning approaches for variable impedance. A thorough search of the relevant literature yielded to the list presented in Table 1.
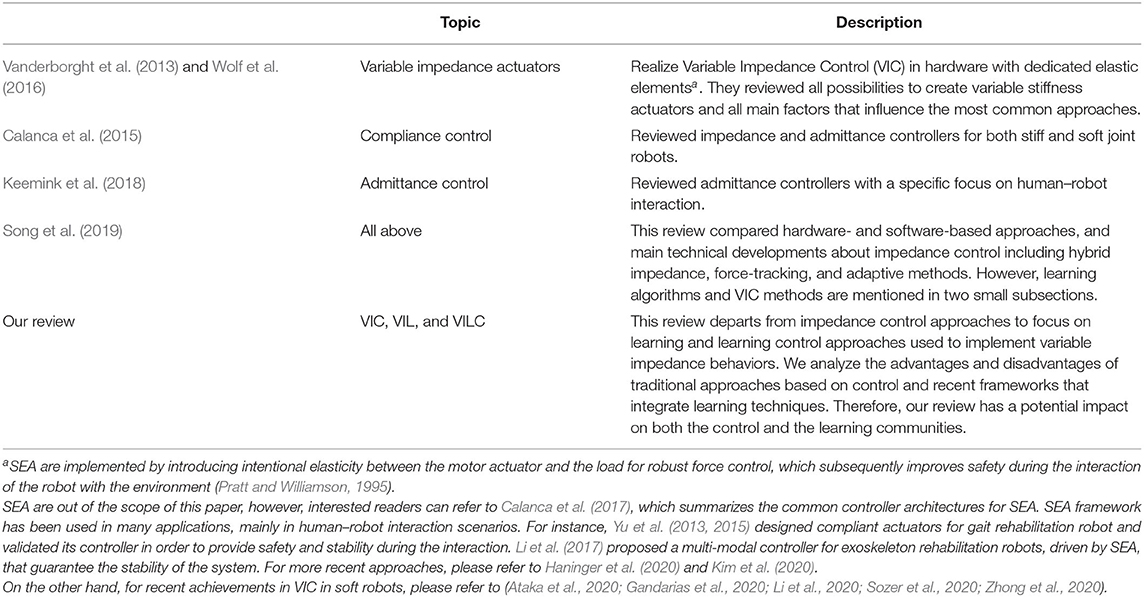
Table 1. Comparison between our review and the current reviews in the literature.
Figure 2 shows the proposed taxonomy that categorize existing approaches in the field. Starting from the root we find the physical concept of mechanical impedance. Mechanical impedance inspired preliminary work on impedance control (Hogan, 1985) where the key idea is to control the impedance behavior of a robotic manipulator to ensure physical compatibility with the environment. In impedance control, we identify two macro groups of approaches, namely those based on constant impedance gains and those based on variable impedance gains. Standard impedance control is a way to actively impose a predefined impedance behavior on a mechanical system. It can be realized both with constant and variable impedance. Standard impedance control3 has been applied to control robots with rigid or elastic joints, both in joint and Cartesian spaces. The stability of a VIC scheme depends on how the impedance gains vary. Therefore, several approaches have been developed to investigate the stability of the controller eventually with a human-in-the-loop. The possibility of varying the impedance has been also investigated from the learning community. Approaches for Variable Impedance Learning (VIL) treat the problem of finding variable impedance gains as a supervised learning problem and exploit human demonstrations as training data (imitation learning). Typically, VIL approaches rely on existing controller to reproduce the learned impedance behavior. On the contrary, Variable Impedance Learning Control (VILC) approaches attempt to directly learn a variable impedance control law. This is typically achieved via imitation, iterative, or reinforcement learning.
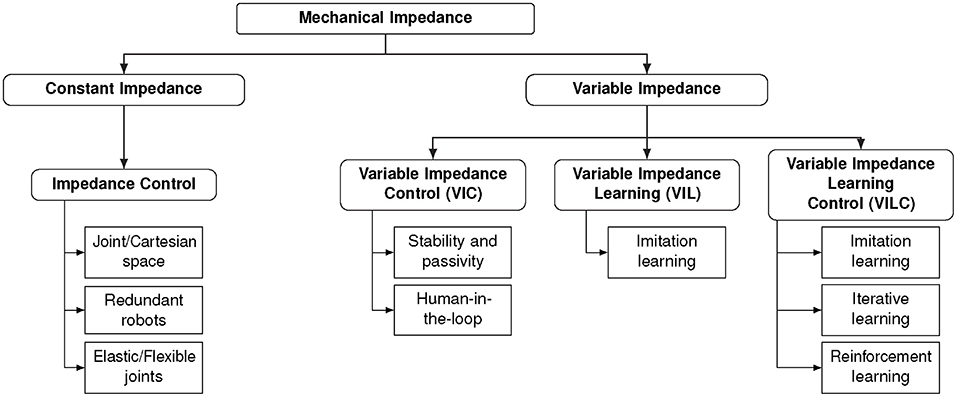
Figure 2. A taxonomy of existing approaches for (variable) impedance learning and control.
The increasing demand for robotic systems to assist human in industry, homes, hospitals, museums, etc., has encouraged roboticists to investigate advanced interaction methods based on impedance control. In tasks that require a robot to interact physically with the environment (possibly human), impedance control provides a dynamic relationship between position and force in order to overcome any position uncertainties and subsequently avoid large impact forces. In the past decades, scholars have been investigated impedance control for a wide range of robot applications, e.g., industry (Jung et al., 2004), agricolture (Balatti et al., 2019), human–robot interaction (Magrini et al., 2015), and rehabilitation (Jamwal et al., 2016). However, since 1995 when Ikeura and Inooka (1995) proposed for the first time the concept of variable impedance control as a method for cooperative systems, researchers started massively to investigate VIC, in many robot applications, due to efficiency, flexibility, and safety that can add to the systems controllers.
In order to write the standard formula for VIC, we need to slightly modify Equations (1) and (2) into
where , , , and are the same quantities defined in section 1. The only difference is the subscript t used to indicate that quantities are varying over time. A block scheme that implements VIC is shown in Figure 3.
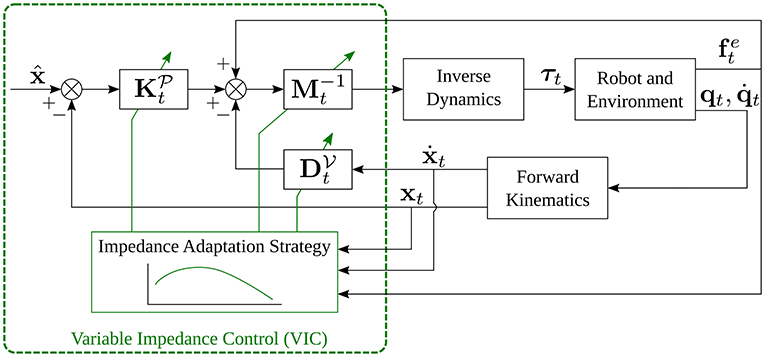
Figure 3. Block scheme of VIC, obtained assuming that .
VIC plays an important role in human–robot cooperation. One of the earliest works was introduced by Ikeura and Inooka (1995) to show the advantages of variable damping control schemes for a master-slave system to perform lifting tasks, which was then extended by introducing variable stiffness (Rahman et al., 1999). In Ikeura and Inooka's system, the damping variation was estimated a priori (through experimental data), either using least-squares (Ikeura and Inooka, 1995) or later by optimizing a suitable cost function (Ikeura et al., 2002). Later, VIC was used to provide a coordination mechanism between robot and human (Al-Jarrah and Zheng, 1997). Tsumugiwa et al. (2002) introduced a variable impedance control based on the human arm stiffness estimation. They varied the virtual damping coefficient of the robot as a function of the estimated stiffness of a human arm, and differential changes in position and force. They used recursive least-squares method to estimate for the stiffness coefficient. They applied signal processing with a digital filtering in order to overcome the influence of the measurement noise and subsequently improve the accuracy. In redundant manipulators, where robots are endowed with the ability to behave naturally as close as possible the desired impedance profile, VIC was used in a cooperative paining task (Ficuciello et al., 2015). Recently, a minimally model-based trajectory tracking VIC controller was proposed (Spyrakos-Papastavridis and Dai, 2020).
When two persons are collaborating or cooperating4 to perform some task (e.g., lift and transport a table), both can sense the intentions of the other partner by sensing the forces transmitted through the object and they act accordingly. However, when a robot is cooperating with a human, it is not obvious for the robot to understand human intention. VIC along with the estimation of human intentions have stimulated researchers efforts in the past couple of decades. Duchaine and Gosselin (2007) estimated human intention by exploiting the time derivative of the applied forces in order to adjust damping parameter in the robot's controller. Recently, Muratore et al. (2019) proposed a multimodal interaction framework that exploits force, motion, and verbal cues for human–robot cooperation. VIC is used to control the physical interaction and the joint stiffness is updated online using the simple adaptation rule
where is the joint stiffness and J is the number of joints. is a small stiffness used to prevent unsafe interaction, et is the joint trajectory tracking error, and α is a positive gain. In practice, the update rule (5) increases the stiffness of the joints with high error letting the robot to track more accurately the desired trajectory.
In rehabilitation, Blaya and Herr (2004) implemented a VIC for an ankle-foot orthosis. However, they did not perform any stability analysis for their system. A VIC controller to provide a continuum of equilibria along the gait cycle has been implemented (Mohammadi and Gregg, 2019). Stability analysis of their controller has been provided based on Lyapunov matrix inequality. Finally, Arnold et al. (2019) proposed to control the ankle joint of a wearable exoskeleton robot to improve the trade-off between performance and stability.
In grasping, Ajoudani et al. (2016) proposed a VIC controller to vary the stiffness based on the friction coefficient, estimated via exploratory action prior grasping, in order to avoid slippage of the grasped object. In manipulation, Johannsmeier et al. (2019) propose a framework that combines skills definition, stiffness adaptation, and adaptive force control. Similarly to Muratore et al. (2019), the stiffness is updated considering the trajectory tracking error. The framework is evaluated on a series of peg-in-hole tasks with low tolerance (< 0.1 mm) showing promising results.
Stability issues of impedance control has been studied from the beginning by Hogan (1985) and later by Colgate and Hogan (1988) where the passivity concept had been introduced. However, stability in VIC is not a trivial problem and has been recently considered in literature. One of the earliest stability analysis of VIC was for a force tracking impedance controller (Lee and Buss, 2008). In their controller, the target stiffness was adapted according to the previous force tracking error resulting in a second-order linear time varying system. Ganesh et al. (2012) implemented a versatile bio-mimetic controller capable of automatic adjustment of the stiffness over a fixed reference trajectory while maintaining stability.
Analyze the stability of an interaction with Lyapunov-based tools becomes hard when the dynamics of the environment are unknown. This is clearly the case of a robot physically interacting with a human operator. In this respect, passivity arises as an intuitive way to investigate stability5. Loosely speaking, the passivity theory introduces a mathematical framework to describe and verify the property of a dynamical system of not producing more energy than it receives.
A passivity-based approach is presented to ensure stability of a time-varying impedance controller (Ferraguti et al., 2013). They ensure the passivity by ensuring that the dissipated energy added to a virtual energy tank is greater than the energy pumped into the system. Their approach depends on the initial and threshold energy levels and on the robot state. Later, Ferraguti et al. extended their approach to time-varying admittance controller in order to adapt the human movements where the passivity analysis took place using port-Hamiltonian representation (Ferraguti et al., 2015). In contrast, Kronander and Billard (2016) proposed state independent stability conditions for VIC scheme for varying stiffness and damping. They used a modified Lyapunov function for the derivation of the stability constraints for both damping and stiffness profiles. This idea of constraining variable impedance matrices to guarantee the stability on variable impedance dynamics before the execution has been expanded later by Sun et al. (2019). Sun et al. (2019) proposed new constraints to on variable impedance matrices that guarantee the exponential stability of the desired impedance dynamics while ensuring the boundedness of the robot's position, velocity, and acceleration in the desired impedance dynamics.
Recently, Spyrakos-Papastavridis et al. (2020) proposed a Passivity-Preservation Control (PPC) that enables the implementation of stable VIC. They also provided joint and Cartesian space versions of the PPC controller to permit intuitive definition of interaction tasks.
Previous works have been devoted to understand how impedance is modulated when humans interact with the environment (Burdet et al., 2001) or to transfer human's impedance-based skills to robots (Ajoudani, 2016). The presence of the human, or human-in-the-loop, introduces a certain level of uncertainty in the system and poses several technical problems for the underlying controller that should guarantee stability of the interaction while effectively supporting the human during the task. In this section, we are covering potential research on VIC approaches from control perspective while having the human in the control loop. However, robot learning capabilities to automatically vary impedance controller parameters to satisfactorily adapt in face of unseen situations while having human-in-the-loop will be covered in section 4.1.
In Ajoudani et al. (2012) introduced the concept of tele-impedance through a technique capable of transferring human skills in impedance (stiffness) regulation to robots (slave) interacting with uncertain environment. Human impedance where estimated in real-time using Electromyography (EMG) to measure signals of eight muscles of human's arm (master). They applied this method to peg-in-hole application based on visual information and without any haptic feedback. Few years later, the authors updated their result in Laghi et al. (2020) by overcoming the loss of transparency by integrating two-channel bilateral architecture with the tele-impedance paradigm.
In control interfaces that include human-in-the-loop, EMG signals have been successfully used to estimate human impedance and subsequently use it as an input “intention estimate” for controlling robots in different tasks, e.g., cooperative manipulation task (Peternel et al., 2016, 2017; DelPreto and Rus, 2019). Peternel et al. (2016, 2017) proposed a multi-modal interface, using EMG and force manipulability measurements of the human arm, to extract human's intention (stiffness behavior) through muscles activities during cooperative tasks. Subsequently, a hybrid force/impedance controller uses the stiffness behavior to perform the task cooperatively with the human.
Rahimi et al. (2018) propose a framework for human–robot collaboration composed of two nested control loops. The outer loop defines a target variable impedance behavior using a feed-forward neural network to adapt the desired impedance in order to minimize the human effort. The inner loop generates an adaptive torque command for the robot such that the unknown robot dynamics follows the target impedance behavior generated in the outer loop. An additive control term, approximated with a neural network whose weights are updated during the execution, is used to cope with the unknown dynamics deriving from the interaction.
Traditionally, robot learning has been concerned about trajectory following tasks (Ouyang et al., 2006). However, the new generation of torque-controlled robots has made it possible to extend learning capabilities to tasks that require variable impedance skills (Abu-Dakka et al., 2018; Abu-Dakka and Kyrki, 2020). Recently, robot learning algorithms have gained great interest for learning, reproducing, and adapting variable impedance parameters and treating them as skill to be learned. The focus in this section is on learning algorithms used to encode variable impedance gains for learning, reproduction, and adaptation, regardless of the effect of these gains on the robot behavior. The latter will be discussed in Section 4. In our taxonomy (see Figure 2), the approaches reviewed in this section belong to the VIL category.
A block scheme that implements VIL is shown in Figure 4. Here, the learning algorithm uses N demonstrations in the form to learn parameterized—with a set of parameters θ—impedance gains. In other words, VIL approaches learn a (nonlinear) mapping ϕ(·) in the form6
where and represent the desired variable stiffness and damping, respectively. At run time, the desired variable impedance gains are retrieved from the current measurements (position, velocity, and force) using the learned model in Equations (6) and (7). As shown in Figure 4, the desired impedance gains are online processes—the gains are saturated or their rate of change is slowed down—to ensure desired closed-loop properties like stable interactions (Ficuciello et al., 2015). Depending on the application, the learned parameters for stiffness and damping may differ or not. The technique used to approximate the nonlinear mappings and distinguishes the different VIL approaches.
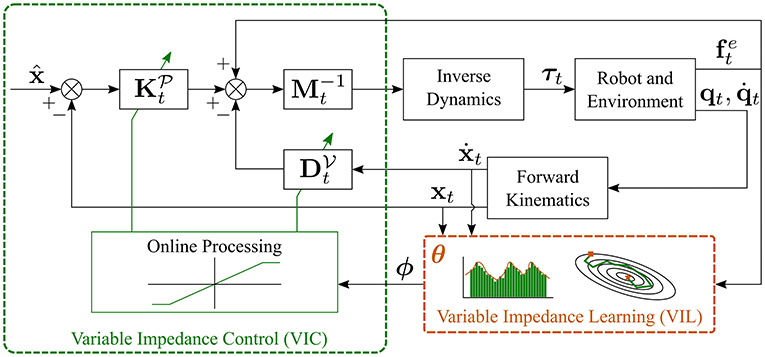
Figure 4. Block scheme of VIL, obtained assuming that .
Training data are typically provided by an expert user, e.g., via kinesthetic teaching as in Kronander and Billard (2014), and are independent from the underlying controller. At run time, the desired variable impedance gains are retrieved from the learned model and a VIC (see section 2) is used to obtain the desired impedance behavior. Note that, in the VIC block in Figure 4, there is no connection between the impedance adaptation strategy and the inertia matrix Mt. This is because most of the approaches for VIL learn only variably stiffness and damping matrices, as described by Equations (6) and (7). On the contrary, several VIC approaches also perform inertia shaping as indicated in Figure 3.
Imitation Learning (IL) or Learning from Demonstration (LfD) methods are tools to give machines the ability to mimic human behavior to perform a task (Hussein et al., 2017; Ravichandar et al., 2020). In this vein, LfD is a userfriendly and intuitive methodology for non-roboticists to teach a new task to a robot. In this case, task-relevant information is extracted from several demonstrations. Standard LfD approaches have focused on trajectory-following tasks, however, recent developments have extended robot learning capabilities to impedance domain (Abu-Dakka et al., 2015, 2018; Abu-Dakka and Kyrki, 2020).
Kormushev et al. (2011) encoded position and force data into a time-driven Gaussian Mixture Model (GMM) to later retrieve a set of attractors in Cartesian space through least-squares regression. Stiffness matrices were estimated using the residuals terms of the regression process. Kronander and Billard (2014) used kinesthetic demonstrations to teach haptic-based stiffness variations to a robot. They estimated full stiffness matrices for given positions using Gaussian Mixture Regression (GMR), which used a GMR that encoded robot Cartesian positions and the Cholesky vector of the stiffness matrix. Saveriano and Lee (2014) follow a similar approach, but exploit the constraints derived by Khansari-Zadeh and Billard (2011) to guarantee the convergence of the trajectory retrieved via GMR. Li et al. (2014) omitted the damping term from the interaction model and used GMM to encode the pose of the end-effector. Then they found the impedance parameters and reference trajectory using optimization techniques. Suomalainen et al. (2019) exploit LfD to learn motion and impedance parameters of two manipulators performing a dual-arm assembly. In their evaluation, they show that adapting the impedance of both robots in both rotation and translation is beneficial since it allows to fulfill the assembly task faster and with less joint motions.
Rozo et al. (2013) proposed a framework to learn stiffness in a cooperative assembly task based on visual and haptic information. They used Task-Parameterized GMM (TP-GMM) (TP-GMM) to estimate stiffness via weighted least-squares (WLS) and the Frobenius norm, where each Gaussian component of the GMM was assigned an independent stiffness matrix. Later, they reformulated their stiffness estimation method as a convex optimization problem, so that optimal stiffness matrices are guaranteed (Rozo et al., 2016).
Although traditional LfD approaches tend to teach manipulation skills to robots from human expert, Peternel and Ajoudani (2017) proposed a learning method based on Dynamic Movement Primitive (DMP) where a novice robot could learn variable impedance behavior from an expert robot through online collaborative task execution.
In IL, multidimensional data are typically stacked into vectors, de facto neglecting the underlying structure of the data. Novel LfD approaches explicitly take into account that training data are possibly generated by certain Riemannian manifolds with associated metrics. Recall that full stiffness and damping matrices are Symmetric Positive Definite (SPD) (Equations 1–7) so that , where is the space of m × m SPD matrices. This implies that impedance gains have specific geometric constraints which need special treatment in the learning algorithms. All aforementioned approaches needed to process impedance matrices before and after the learning takes place. Thus, we need to learn directly variable impedance matrices without any reparameterization.
Abu-Dakka et al. (2018) proposed an LfD framework to learn force-based variable stiffness skills. Both forces and stiffness profiles were probabilistically encoded using tensor-based GMM/GMR (Jaquier and Calinon, 2017) without any prior reparameterization. They compared their results with the traditional Euclidean-based GMM/GMR (Calinon, 2016) after reparameterizing stiffness matrices using Cholesky decomposition. Their results showed that direct learning of SPD data using tensor-based GMM/GMR provides more accurate reproduction than reparameterizing the data and using traditional GMM/GMR. Two years later, Abu-Dakka and Kyrki (2020) reformulated DMPs based on Riemannian metrics, such that the resulting formulation can operate with SPD data in the SPD manifold. Their formulation is capable to adapt to a new goal-SPD-point.
VIL often depends on the underlying control strategy up to the point where defining a clear boundary between the learning algorithm and the controller design becomes impossible. Such approaches belong to the VILC category in Figure 2 and are reviewed in this section.
A block scheme that implements VILC is shown in Figure 5. As for VIL, the learning algorithm uses training data in the form to learn parameterized—with a set of parameters θ—impedance gains. The key difference between VIL and VILC is that in VILC the data collection process itself depends on the underlying control structure. Therefore, the learning and control block are merged in Figure 5, while they are separated in Figure 4. Compared to standard VIC, VILC approaches adopt more complex impedance learning strategies requiring iterative updates and/or robot self-exploration. Moreover, VILC updates also the target pose (or reference trajectory) while typically rely on constant inertia matrices.
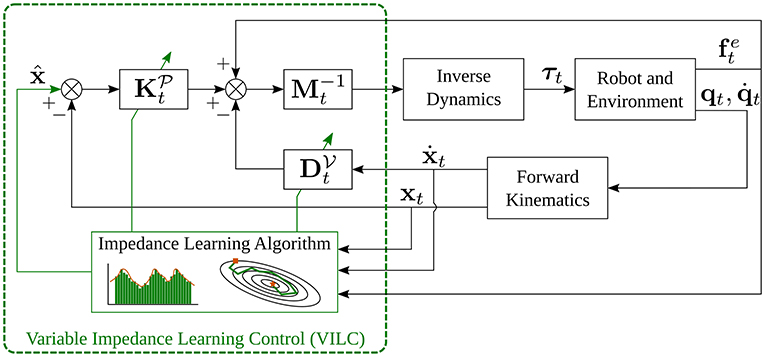
Figure 5. Block scheme of VILC, obtained assuming that .
Some of the imitation learning approaches focus on fitting variable impedance gains from training data independently of the way the resulting behavior is executed on real robots. In our taxonomy, shown in Figure 2, we have categorized these work as methods for impedance learning and reviewed prominent ones in section 3. Nevertheless, approaches for imitation learning exist where learning and control tightly integrate and cannot be decoupled. Prominent approaches are reviewed in this section.
Calinon et al. (2010) propose an active learning control strategy to estimate variable stiffness from the inverse of the observed position covariance encapsulated in a GMM. Their approach is limited to tasks displaying variability in position trajectories across demonstrations, which does not arise in scenarios where the end-effector is constrained to follow a single Cartesian path (e.g., valve-turning tasks). The Integrated MOtion Generator and Impedance Controller (i-MOGIC) proposed by Khansari-Zadeh et al. (2014) derives the robot trajectory and variable impedance gains from a GMM and use them to compute the control input
where G is the number of Gaussian components, are G state dependent mixing coefficients, and are local position and velocity targets, and are full stiffness and damping matrices, and are eventual force (spring) preloads. In this formulation, both the trajectory and the impedance gains depend on the robot's state (position and velocity) and are retrieved at run time using sensed information. The stability of the overall closed-loop system composed of the robot and the i-MOGIC is proved using Lyapunov arguments.
Mathew et al. (2019) implemented an IL-based forward model approach with incremental adaptation capability of a state-dependent, time-independent impedance parameters. Moreover, their approach includes a hybrid force-motion controller that provides compliance in particular directions while adapting the impedance in other directions. Recently, Parent et al. (2020) proposed an approach that takes the advantage of the variability that comes from human demonstrations to adapt the stiffness profile according to the precision required in each phase of motion. Their results show a suitable trade-off between precision and compliance.
Kinesthetic teaching is a well-known approach for imitation learning where the human teacher physically guides the robot to demonstrate the task. Kinesthetic teaching is typically applied “off-line” to collect motion trajectories by compensating the gravitational torque acting on the robot joints that allows for physical guidance. However, some work extend the kinesthetic teaching framework to provide “online” demonstrations that are used to adjust the task execution (Lee and Ott, 2011; Saveriano et al., 2015; Kastritsi et al., 2018; Dimeas et al., 2020).
In this respect, Lee and Ott (2011) exploited a variable stiffness profile to generate different impedance behavior in different parts of the state-space. Close to the reference trajectory the stiffness is high to allow accurate tracking. As the difference between reference and executed trajectories increases, for example because an external force is applied to provide a corrective demonstration, the stiffness smoothly decreases to ease the teaching. Finally, if the tracking error exceeds a certain bound, the stiffness grows again. Overall, the approach allows for a local refinement around a nominal trajectory.
Saveriano et al. (2015) proposed a unified framework for online kinesthetic teaching of motion trajectories for both the end-effector and the null-space. External forces arising from kinesthetic teaching are converted into velocity commands with a standard admittance control. This velocity is added to a stack of tasks with variable priority order and executed using the prioritized inverse kinematics approach by An and Lee (2015). The variable priority order is needed to select the task to execute in case of conflicts, for example when the user tries to distract the end-effector from the nominal trajectory. Kastritsi et al. (2018) used variable stiffness control to allow a human operator to safely interact with the robot during the operation and provide corrective demonstrations, while guaranteeing the overall passivity. They named this incremental learning with human-in-the-loop progressive automation since the robot “progressively” becomes autonomous as the number of iterations grows and the tracking error decreases. The framework has been further extended to adapt periodic movements via human–robot interaction (Dimeas et al., 2020).
An impedance behavior, defined as in Equations (3) and (4), has an intrinsic multi-modal nature since it consists of a reference trajectory and (variable) impedance gains. Peternel et al. (2014, 2018a), Yang et al. (2018), and Wu et al. (2019) designed multi-modal interfaces to let the human to explicitly teach an impedance behavior to the robot. More in details, Peternel et al. (2014) used a marker attached to the hand to measure the position and EMG sensors to capture the muscular activation of the arm, where high values of the EMG signal are mapped into high robot stiffness. Information captured via this multi-modal interface are used in an online learning loop and used to update the parameters of two DMPs, one used to generate the desired trajectory and one the desired stiffness.
Similarly, Yang et al. (2018) used EMG and a master robotic arm to demonstrate variable impedance behaviors to a slave robotic arm. Wu et al. (2019), instead, combined EMG measurements and the forces sensed during kinesthetic teaching into an admittance controller with variable impedance gains. A limitation of these work is that they require a complex setup and a long calibration procedure to achieve good performance. Peternel et al. (2018a) designed a multi-modal interface consisting of a haptic device that measures the arm trajectory and return a force feedback and a potentiometer that the user press to modulate the stiffness. As in their previous work (Peternel et al., 2014), sensed information are used to online estimate the DMPs parameters. The calibration procedure to make the multi-modal interface (Peternel et al., 2014) has been simplified later for easier use (Peternel et al., 2016, 2017). Finally, Peternel et al. (2018b) further extended their control approach for multi-modal interface (Peternel et al., 2016, 2017) by using position and force feedback as well as muscular activity measurements. The latter is used to estimate the human physical fatigue and then teach the robot (based on DMP) to reduce human's fatigue by increasing its contribution to the execution of the cooperative task. As a result, the robot gradually takes over more effort when the human gets tired.
Tuning variable impedance gains can be seen as a repeated learning process where the robot improves its performance at each iteration. The idea of a repeated learning results in two category of approaches, namely those based on iterative learning and those based on Reinforcement Learning (RL). Iterative learning approaches are reviewed in this section, while RL is covered in section 4.3.
A bunch of work (Cheah and Wang, 1998; Gams et al., 2014; Uemura et al., 2014; Abu-Dakka et al., 2015; Kramberger et al., 2018) that propose to iteratively adjust the impedance rely on the Iterative learning control (ILC) framework (Bristow et al., 2006). ILC assumes that the performance of an agent that repeatedly performs the same task can be improved by learning from past executions. In the conventional ILC formulation, the objective is to reduce the trajectory tacking error while rejecting periodic disturbances. This is obtained by adjusting the pre-defined control input with a corrective term that linearly depends on the tracking error, i.e.,
where the subscript r indicates the iteration number, while t a time dependency, ur,t is the control input to adjust, and er,t the trajectory tracking error. The gain γr in Equation (9) is iteratively updated in a way that ensures asymptotic convergence of the tracking error at least if the system to control has a linear dynamic. The conventional ILC described by Equation (9) relies on the trajectory tracking error and it is not directly applicable to VILC. The easiest way to use ILC to reproduce impedance behaviors is to combine it with a properly designed VIC. However, this approach does not allow the robot to learn suitable impedance gains. In order to learn variable impedance gains, the error term in Equation (9) needs to be modified to describe the discrepancy between the desired and the real impedance behavior. Common strategies exploited in VILC to modify the conventional ILC formulation are described as follows.
Recall that the goal of impedance control is to let the robot behave as the second order dynamics specified in Equations (3) and (4). By specifying the desired trajectory and impedance gains, the desired dynamics in Equations (3) and (4) becomes a target impedance behavior and ILC (9) can be used to enforce the convergence of the robot behavior to this target. Cheah and Wang (1998) combined a standard, PD-like controller with a learned feedforward term and a dynamic compensation term. The feedforward term is update with an iterative rule and a proper selection of the compensator gains ensures the convergence of the iterative control scheme to the target behavior. The ILC scheme in Cheah and Wang (1998) relies on a standard impedance controller and requires measurement of interaction forces and a fixed target impedance behavior, i.e., constant gains and a predefined desired trajectory. As a consequence, the interaction may become unstable if the environment changes significantly. This undesirable effect is overcome by the biomimetic controller (Yang et al., 2011) and inspired by experimental observation that humans optimize the arm stiffness to stabilize point-to-point motions (Burdet et al., 2001). In this case, the iterative update rule, not derived from ILC but from human observation, involves both feedforward force and impedance gains. Notably, no force measure is required to implement this iterative control scheme that guarantee stable interactions and error cancellation with a well-defined margin.
There is an intrinsic advantage in adapting the reference trajectory during the motion that is not exploited by Cheah and Wang (1998) and Yang et al. (2011). Indeed, by modulating the desired trajectory, one can let the robot anticipate contacts before they occur. This potentially leads to stable transitions between interaction and free motion phases and allows for adaptation to changing environments. This possibility is investigated by Gams et al. (2014). Gams et al. (2014) proposed to couple two DMPs with an extra force term. The approach is relatively general since the coupling term may represent different reference behaviors including desired contact forces or relative distance between the robot hands. The forcing term is updated from sensory data using an ILC scheme with guaranteed convergence. Varying the joint trajectory as well as the gains of a diagonal stiffness matrix with an ILC rule is exploited by Uemura et al. (2014) to generate energy-efficient motions for multi-joint robots with adjustable elastic elements. The approach has guaranteed convergence properties and can effectively handle boundary conditions like desired initial and goal joint position and velocity.
Abu-Dakka et al. (2015) iteratively modified the desired positions and orientations to match forces and torques acquired from human demonstrations. While Gams et al. (2014) considered only positions, Abu-Dakka et al. (2015) combined unit quaternions, a singularity-free orientation representation, and DMP to represent the full Cartesian trajectory. Moreover, their ILC scheme learns how to slow down the DMP execution such that the force/torque error is minimized. The approach is experimentally validated on challenging manipulation tasks like assembly with low relative tolerances.
As discussed in section 4.1 and Van der Schaft (2000), passivity is a powerful tool to analyze the stability of the interaction with a changing and potentially unknown environment. Kramberger et al. (2018) propose an admittance-based coupling of DMP that allows both trajectory and force tracking in changing environments. The paper introduces the concept of reference power trajectory to describe the target behavior of the system under control—consisting of DMP, robot, and passive environment. Using a power observer, the reference power error is computed and used in an ILC scheme to learn a varying goal of the DMP. As a result, the varying goal reduces the trajectory and force tracking errors while maintaining the passivity of the overall system.
RL is a widely studied topic in the learning and control communities, and it is beyond the scope of this survey to provide an exhaustive description of the topic. For the interested reader, Sutton and Barto (2018) is a good reference to start with RL. Kober et al. (2013), Kormushev et al. (2013), and Deisenroth et al. (2013) described robotic specific problems of RL. Chatzilygeroudis et al. (2020) reviews recent advancement in the field with a particular focus on data-efficient algorithms, while Arulkumaran et al. (2017) focuses on deep learning solutions. Instead, we assume that the reader is already familiar with RL and focus on presenting existing approaches for RL of variable impedance control.
In interaction tasks, variable impedance (or admittance) control can be adopted as a parameterized policy in the form7
where πθ,t is a control policy depending on a set of learnable parameters θ. The parameters θ define the desired trajectory ( and ) as well as the desired impedance (or admittance) behavior ( and ). These parameters can be optimally tuned using approaches from RL (Kim et al., 2010; Buchli et al., 2011; Dimeas and Aspragathos, 2015; Rey et al., 2018; Martín-Martín et al., 2019). Experiments show that adopting such a specialized policy results in increased sample efficiency and overall performance in complex interaction tasks like contact-rich manipulation.
More in details, Kim et al. (2010) used an episodic version of the Natural Actor-Critic algorithm (Peters and Schaal, 2008) to learn a variable stiffness matrix. Their algorithm targets planar 2-link manipulators since the 2 × 2 SPD stiffness matrix is completely represented by 3 scalar values, namely the magnitude, the shape, and the orientation. This keeps the parameter space small and allows for a quick convergence to the optimal stiffness. However, the effectiveness of the approach in realistic cases, e.g., a spatial manipulator with 6 or 7 links, is not demonstrated.
Buchli et al. (2011) used the Policy Improvement with Path Integrals (PI2) algorithm (Theodorou et al., 2010) to search for the optimal policy parameters. A key assumption of PI2 is that the policy representation is linear with respect to the learning parameters. Therefore, Buchli et al. (2011) proposed to represent the desired position and velocity as a DMP (Ijspeert et al., 2013), a policy parameterization that is linear with respect to the learning parameters. For the stiffness, authors exploited a diagonal stiffness matrix and express the variation (time derivative) of each diagonal entry as
where j indicates the jth joint, kθj,t is the stiffness of joint j, ϵj,t is a time-dependant exploration noise, gj is a sum of G Gaussian basis functions, and θj are the learnable parameters for joint j. The stiffness parameterization in Equation (11) is also linear in the parameters and PI2 can be applied to find the optimal policy. It is worth noticing that Buchli et al. (2011) used a diagonal stiffness matrix and one DMP for each motion direction (or joint), allowing the PI2 to optimize the behavior in each direction independently. This has the advantage of reducing the parameter space and, possibly, the training time. However, a diagonal stiffness neglects the mutual dependencies between different motion directions, which may be important depending on the task. Following a similar idea of Buchli et al. (2011) and Rey et al. (2018) parameterized the policy as a nonlinear, time invariant dynamical system using the Stable Estimator of Dynamical Systems (SEDS) (Khansari-Zadeh and Billard, 2011). This is a key difference with the work by Buchli et al. (2011), since DMP introduces an explicit time dependency. The idea of SEDS is to encode a first order dynamics into a GMM
where ξt is a generic state variable, the goal state, 0 < hg(xt) ≤ 1 are G state-dependent mixing coefficients, and the matrices depend on the learned covariance. Using Lyapunov theory (Slotine et al., 1991), authors conclude that the system (12) globally converges to if all the are positive definite8. The PI2 algorithm is modified accordingly to fulfill the SEDS stability requirements during the exploration. Authors also propose to augment the state vector ξ to include position and stiffness, and to encode a variable stiffness profile using Equation (12). A variable impedance controller is then used to perform interaction tasks where the variable, diagonal stiffness matrix and the reference trajectory are retrieved at each time step from the learned dynamical system.
Dimeas and Aspragathos (2015) adopted an admittance control scheme with a constant inertia matrix and null stiffness, and exploits fuzzy Q-learning (Berenji, 1994; Jouffe, 1998) to discover optimal variable damping gains (one for each motion direction). The goal of the learning agent is to minimize the robot jerk (third time derivative of the position) in human–robot co-manipulation tasks. Authors conduct a user study with 7 subjects performing co-manipulation task with a real robot, showing that their approach converges in about 30 episodes to a sub-optimal policy that reduces both time and the energy required to complete the task.
As already mentioned, approaches in Buchli et al. (2011) and Rey et al. (2018) rely on a diagonal stiffness matrix to reduce the parameter space and the corresponding search time. The drawback is that a diagonal stiffness neglects the inter-dependencies between different motion directions. This problem is faced by Kormushev et al. (2010). Kormushev et al. (2010) proposed to learn an acceleration (force) command as a mixture of G proportional-derivative systems
where are G local target, hg,t are time varying mixing coefficients, is a constant damping, and are full stiffness matrices (that authors call coordination matrices since they describe the local dependency across different motion directions). Clearly, the control input ut in (13) realizes a variable impedance control law. The method is applied to the highly dynamic task of flipping a pancake. The work by Luo et al. (2019) follows a different strategy to search for a force control policy. The iterative linear-quadratic-Gaussian approach (Todorov and Li, 2005) is used to find a time-varying linear-Gaussian controller representing the end-effector force. In this case, injecting a Gaussian noise in the control input is beneficial since it helps to reduce the model bias of the RL algorithm (Deisenroth et al., 2015). The generated force is inserted into an hybrid position/force controller that implicitly realize an adaptive impedance behavior, i.e., the robot has high (low) impedance in free (contact) motion. A neural network is trained in a supervised manner to represent and generalize the linear-Gaussian controller, as experimentally demonstrated in four assembly tasks.
In principle, most of (probably all) the approaches developed for robot control can be used to map a learned policy into robot commands. Martín-Martín et al. (2019) presented an interesting comparison between well-known controllers used to map a policy into robot commands. Clearly, the output of the policy depends on the chosen controller. For example, the policy of a joint torque controller outputs the desired torque. In case of a Cartesian variable impedance controller, the policy output are the desired pose, velocity, damping, and stiffness. They compared 5 popular controllers, namely, joint position, velocity, and torque, and Cartesian pose and variable impedance, on 3 tasks (path following, door opening, and surface wiping). The comparison considers the following metrics: (i) sample efficiency and task completion, (ii) energy efficiency, (iii) physical effort (wrenches applied by the robot), (iv) transferability to different robots, and (v) sim-to-real mapping. Their findings show that the Cartesian variable impedance control performs well for all the metrics. Interestingly, a variable impedance control policy is easier to port to another robot and can be almost seamlessly transfer from a simulator to a real robot.
RL methods have great potential and are effective in discovering sophisticated control policy. However, especially for model-free approaches, the policy search can potentially be extremely data inefficient. One possibility is to alleviate this issue is to use a “good” initial policy and locally refine it. Imitating the human impedance behavior is a possibility to initialize the control policy and standard RL techniques or, more effectively, inverse RL approaches can be used to refine the initial policy (Howard et al., 2013). Alternatively, there exists a class of model-based RL approaches that is intrinsically data-efficient (Sutton and Barto, 2018). Loosely speaking a model-free learner uses an approximate dynamic model, learned from collected data, to speed up the policy search.
In the context of VIC, Li et al. (2018, 2019) used Gaussian processes (Williams and Rasmussen, 2006) to learn a probabilistic representation of the interaction dynamics. In order to overcome the measurement noise of the force/torque sensor, Li et al. (2018) designed a Kalman filter to estimate the actual interaction forces. The learned model is used to make long-term reward prediction and optimize the policy using gradient-based optimization as originally proposed by Deisenroth et al. (2015). Gaussian process are extremely sample efficient. However, they do not scale with large datasets and tend to smooth out discontinuities that are typical in interaction tasks. In order to realize sample and computationally efficiency, Roveda et al. (2020) proposed a mode-based RL framework that combines VIC, an ensemble of neural networks to model human–robot interaction dynamics, and an online optimizer of the impedance gains. The ensemble of networks, trained off-line and periodically updated, is exploited to generate a distribution over the predicted interaction that reduces the overfitting and captures uncertainties in the model.
Realizing a safe exploration that avoids undesirable effects during the learning process is a key problem in modern Artificial Intelligent (AI) (Amodei et al., 2016). For RL, this is particularly important in the first stages of the learning when the agent has limited knowledge of the environment dynamics and applies control policies that are potentially far from the optimal one. The aforementioned approaches are promising and they can potentially discover complex variable impedance policies. However, none of them is designed to guarantee a safe exploration. A possible way to guarantee a safe exploration is to identify a set of safe states where the robot is stable (in the sense of Lyapunov) and to prevent the robot to visit unsafe states (Berkenkamp et al., 2017; Chow et al., 2018; Cheng et al., 2019). With the goal of guaranteeing Lyapunov stability during the exploration, Khader et al. (2021) proposed an all-the-time-stability exploration strategy that exploits the i-MOGIC policy parameterization in Equation (8). As detailed in Section 4.1, i-MOGIC allows to learn a VIC with guaranteed Lyapunov stability. As a difference with the SEDS-based approach by Rey et al. (2018), the i-MOGIC parameterization allows to learn full stiffness and damping matrices that encode the synergies between different motion directions. The stability constraints derived by Khansari-Zadeh et al. (2014) are exploited by Khader et al. (2021) to constraint the parameters during the policy updates, guaranteeing a stable exploration.
The idea of using stable dynamical systems to parameterize a control policy is promising, since it allows for a stable exploration. However, it is not clear if an optimal policy can be found in the constrained parameter spaces. At this point, further investigation is required to quantify the limitations introduced by the specific policy parameterizations. A possible solution could be to simultaneously update the policy parameters and the Lyapunov function. This would allow to relax the stability constraints by increasing both the safe set and, as a consequence, the probability of finding an optimal policy.
In this paper, we presented a review for the main learning and control approaches used in variable impedance controllers. Table 2 summarizes the general advantages and disadvantages of these approaches.
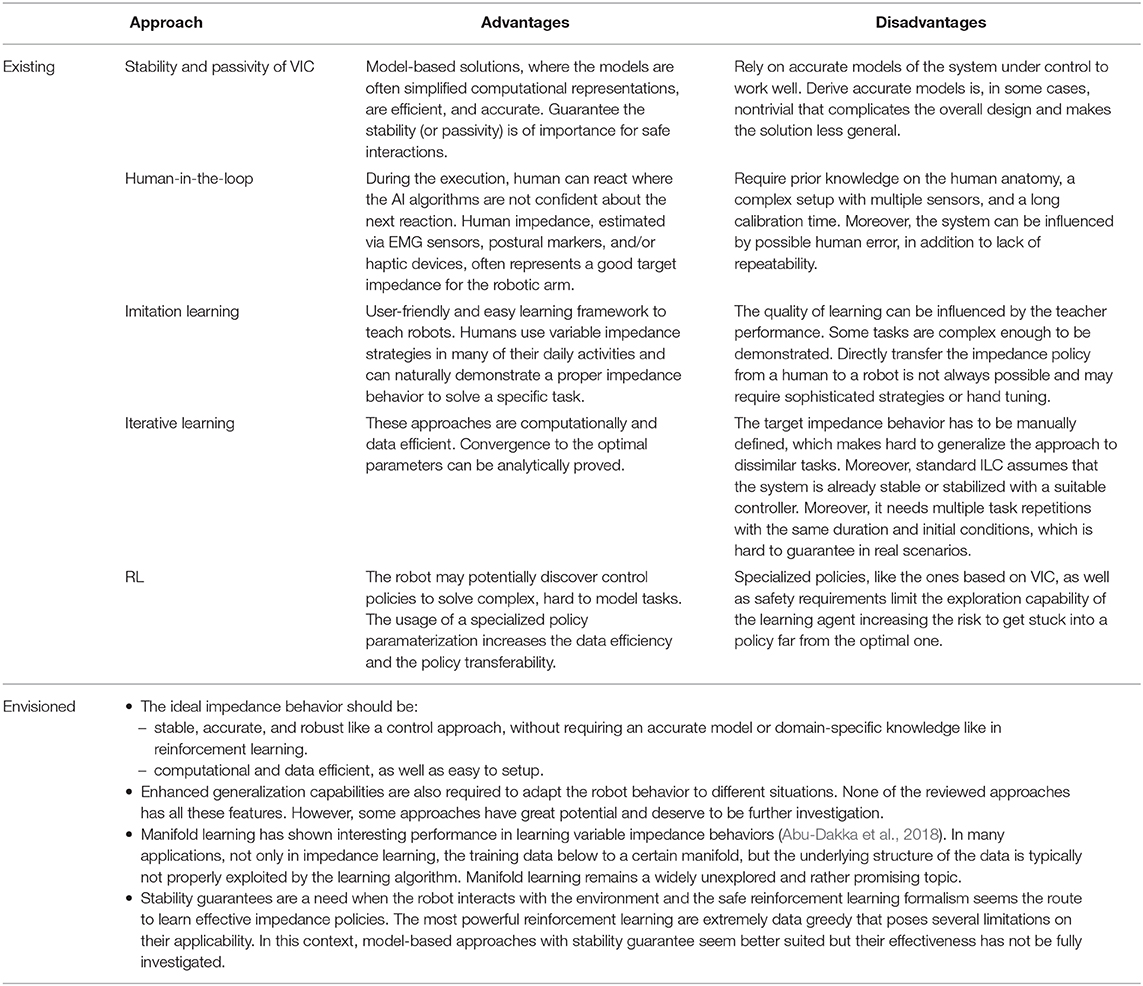
Table 2. A comparison of the main approaches for variable impedance learning and control.
As stated in Table 2, we envision a framework that inherits features from all the different approaches. The ideal framework is to be accurate and robust like a properly designed controller, and, at the same time, flexible, and easy to generalize like a learning approach. However, there are several theoretical and practical difficulties that need to be overcome to realize the envisioned framework.
Theoretical guarantees like stability and robustness become difficult to prove in complex systems like a robot manipulator physically interacting with an unstructured environment. Existing approaches make several simplification assumptions, e.g., interactions with a passive environment, to derive theoretical guarantees. These assumptions significantly restrict the domain of application of developed VIC approaches. In this respect, passivity theory arises as a promising approach given the relatively general working assumptions (see section 2.1). However, the passivity framework, as most control approaches, is model based and sometimes it is hard to come up with a suitable analytical solution without simplification assumptions. It is evident that control alone cannot solve the problem.
Learning-based approaches are designed to work in complex scenarios under minimal assumptions. For instance, many model-free RL approaches only require a reward on the robot's performance to discover a sophisticated and generalizable control policy. This comes at the cost of long training time and possible unsafe robot behaviors. In general, training time and safety are not always an issue for the learning community, but they represent a clear limitation in robotics. Described work on safe and model-based RL (see section 4.3) started to address these issues, but results are still preliminary.
It is evident, from the previous discussion on the limitations of learning and control approaches, that VILC is the route to realize an omni-comprehensive variable impedance framework. However, this poses further challenges to overcome:
• IL is a paradigm for teaching robots how to perform new tasks even by a nonprogrammer teachers/users. In this context, IL approaches extract task-task relevant information (constraints and requirements) from single/several demonstration(s), which can enable adaptive behavior. The approaches presented in section 3 show successful examples of how diverse impedance tasks—e.g., peg-in-the-hole, assembly, etc.—can be learned via human imitation. However, the simple imitation of the task demonstration(s) is prone to failures, especially when physical interaction is required. Possible reasons to fail include9: (i) poor demonstrations provided by inexpert teachers, (ii) inaccurate mapping between human and robot dynamics, and (iii) insufficient demonstrations to generalize a learned task.
To overcome these limitations, one needs to endow robots with the ability to generalize to unseen situations of the task. This generalization can be done by combining demonstration-driven approaches like IL with trial-and-error, reward-driven learning (e.g., RL).
• Policy parameterization is needed to cope with the continuous nature of state and action space in robotics. Moreover, a proper policy representation, like the i-MOGIC used by Rey et al. (2018) and Khader et al. (2021), may lead to desired properties like the all-the-time-stability described in section 4.3, but further investigations are needed to understand if and how a specific policy parameterization limits the learning capabilities of the adopted algorithm.
• Safety of a system is typically ensured by constraining the state-space to a safe (sub-)set. When applied to RL, this limits the robot exploration to a certain safe set that maybe be too conservative to discover interesting policies. Moreover, the safe set is typically hand designed by an expert. A possibility to address this issue is to use a very basic safe set (e.g., a ball around the initial state of the robot), and improve the estimation of the safe set during the learning. Recently, Wabersich and Zeilinger (2018) have proposed a data-driven approach to iteratively increase the safe set. The approach work only for linear systems and the extension to nonlinear ones is, as usual, nontrivial.
• We seek for policies that generalize well and are applicable in a wide range of situations. The generalization capabilities of a learning algorithm often depends on the adopted feature representation. Most of the approaches either use diagonal stiffness and damping matrices or simply vectorize the full matrices to form a training set. However, as discussed in section 3, impedance parameters are SPD matrices and the vectorization simply discards this information. Therefore, a Riemannian manifold represents the natural space from which training data are sampled, and taking the underlying manifold structure often lead to better extracted features that increase the discriminative power and the generalization capabilities of the learning algorithm. Recent work Abu-Dakka et al. (2018) and Abu-Dakka and Kyrki (2020) reformulated the learning problem by taking into account the underlying Riemannian manifold structure and show improved performance compared to standard approaches based on vectorization. Results are promising but too preliminary to definitely assess the generalization capabilities of manifold-based approaches.
Building a safe RL algorithm on top of a manifold representation, like SPD, is, at least in theory, possible. However, at the best of our knowledge, this is still an ongoing research topic and there is no available approach.
Varying the robot impedance during the task execution is a popular and effective strategy to cope with the unknown nature of everyday environments. In this survey, we have analyzed several approaches to adjust impedance parameters considering the task at end. Traditionally, variable impedance behavior were achieved by means of control approaches, namely the variable impedance control. More recently, the learning community has also focused on the problem attempting to learn impedance gains from training data (VIL) or a nonlinear controller with varying impedance (VILC). Each approach has its own advantages and disadvantages that we have summarized in Table 2.
At the current stage, none of the approaches has all the features that a variably impedance behavior requires. Control approaches have solid mathematical foundations that make them robust and efficient, but require a significant amount of prior knowledge. Learning approaches may require less amount of prior information, but they are often data and computationally inefficient. These limitations, as discussed in section 5, reduce the applicability of variable impedance approaches and have heavily burden the spread of robotic solutions in dynamic and unstructured environments.
We believe that manifold and reinforcement learning are the most promising approaches to overcome existing limitations of VILC approaches and have the potential to learn variable impedance behaviors that are effective both in industrial and service scenarios.
FA-D was responsible to review the approaches for impedance control, variable impedance control, and impedance learning. He also have a major contribution in writing the introduction and the final remarks. MS was responsible for the taxonomy used to categorize approaches for variable impedance learning and control. He was also reviewing the approaches used for variable impedance learning control. All authors contributed to the article and approved the submitted version.
This work was partially supported by CHIST-ERA project IPALM (Academy of Finland decision 326304) and partially supported from the Austrian Research Foundation (Euregio IPN 86-N30, OLIVER).
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
1. ^Admittance control maps, in a physically consistent manner, sensed external forces into desired robot velocities. Therefore, it can be considered as the opposite, or the dual, of the impedance control. Unlike impedance control, admittance control performs more accurate execution in non-contact tasks or even in contact with nonstiff (viscous) environments. In practice, the choice between impedance and admittance control often depends on the available robot. It is known that, to realize an impedance controller, one has to directly control the joint torques (or the motor current). However, most of the available robotic platforms are controlled in position or velocity and the roboticists has no access to the force/torque level. This is especially true for industrial robots. In this cases, admittance control is an effective strategy to realize a desired impedance behavior on a position (velocity) controlled robots. The user has to equip the robot with additional sensors, like a force/torque sensor at the end-effector, and convert the measured forces into desired position (velocity) commands.
Ott et al. (2010) proposed a hybrid system that incorporates both controllers in order to achieve: (i) accuracy in free motion and (ii) robust interaction while in contact and free of impacts. Recently, Bitz et al. (2020) investigated the trade-off between agility and stability by proposing a variable damping controller based on user intent. Admittance control is out of the scope of this review and will be partially mentioned. The interested reader is referred to Keemink et al. (2018) for a review on admittance control-based techniques applied to human-robot interaction.
2. ^The reader with a control background will recall that, in impedance control, the interaction model is defined in terms of the error et (e.g., for the position, ) and its derivatives and . The impedance model in Equations (1) and (2) is obtained by assuming , i.e., we aim at reaching the fixed goal defined by and .
3. ^Constant impedance is out of the scope of this paper, however, interested readers are advised to consult (Calanca et al., 2015; Song et al., 2019).
4. ^In literature, authors are using collaboration and cooperation as synonymous. However, by consulting Merriam-Webster, Cooperation means the actions of someone who is being helpful by doing what is wanted or asked, while Collaboration means to work jointly with others or together especially in an intellectual endeavor. Based on this definition, we will distinguish the use of the two words based on the intentions of the tasks. Normally robots are cooperating with human to help him to achieve something but not collaborating with him for a common goal.
5. ^Describe the passivity framework is out of the scope of this review. The interested user is referred to Van der Schaft (2000) for a thorough discussion on passivity theory.
6. ^The mapping for the rotational impedance parameters can be expressed in a similar way.
7. ^The parameterization (10) can be applied in joint or Cartesian spaces and extended to consider the orientation.
8. ^In the original formulation, the matrices are assumed negative definite (Khansari-Zadeh and Billard, 2011). We have slightly modified the system (12) to use positive definite matrices and be consistent with other equations in this survey.
9. ^An exhaustive discussion about pros and cons of IL is beyond the scope of this survey. Therefore, we focus on limitations of IL that particularly affect impedance learning. The interested reader is referred to Ravichandar et al. (2020) for a general discussion about strengths and limitations of IL.
Abu-Dakka, F. J., and Kyrki, V. (2020). “Geometry-aware dynamic movement primitives,” in IEEE International Conference on Robotics and Automation (Paris), 4421–4426. doi: 10.1109/ICRA40945.2020.9196952
Abu-Dakka, F. J., Nemec, B., Jörgensen, J. A., Savarimuthu, T. R., Krüger, N., and Ude, A. (2015). Adaptation of manipulation skills in physical contact with the environment to reference force profiles. Auton. Robots 39, 199–217. doi: 10.1007/s10514-015-9435-2
Abu-Dakka, F. J., Rozo, L., and Caldwell, D. G. (2018). Force-based variable impedance learning for robotic manipulation. Robot. Auton. Syst. 109, 156–167. doi: 10.1016/j.robot.2018.07.008
Ajoudani, A. (2016). Transferring Human Impedance Regulation Skills to Robots. Cham: Springer. doi: 10.1007/978-3-319-24205-7
Ajoudani, A., Hocaoglu, E., Altobelli, A., Rossi, M., Battaglia, E., Tsagarakis, N., et al. (2016). “Reflex control of the Pisa/IIT softhand during object slippage,” in 2016 IEEE International Conference on Robotics and Automation (ICRA) (Stockholm), 1972–1979. doi: 10.1109/ICRA.2016.7487344
Ajoudani, A., Tsagarakis, N., and Bicchi, A. (2012). Tele-impedance: teleoperation with impedance regulation using a body-machine interface. Int. J. Robot. Res. 31, 1642–1656. doi: 10.1177/0278364912464668
Albu-Schaffer, A., and Hirzinger, G. (2002). “Cartesian impedance control techniques for torque controlled light-weight robots,” in IEEE International Conference on Robotics and Automation (Cat. No. 02CH37292), Vol. 1 (Washington, DC), 657–663. doi: 10.1109/ROBOT.2002.1013433
Albu-Schaffer, A., Ott, C., Frese, U., and Hirzinger, G. (2003). “Cartesian impedance control of redundant robots: recent results with the DLR-light-weight-arms,” in IEEE International Conference on Robotics and Automation, Vol. 3 (Taipei), 3704–3709. doi: 10.1109/ROBOT.2003.1242165
Albu-Schäffer, A., Ott, C., and Hirzinger, G. (2007). A unified passivity-based control framework for position, torque and impedance control of flexible joint robots. Int. J. Robot. Res. 26, 23–39. doi: 10.1177/0278364907073776
Al-Jarrah, O. M., and Zheng, Y. F. (1997). “Arm-manipulator coordination for load sharing using variable compliance control,” in Proceedings of International Conference on Robotics and Automation, Vol. 1 (Albuquerque, NM), 895–900. doi: 10.1109/ROBOT.1997.620147
Amodei, D., Olah, C., Steinhardt, J., Christiano, P., Schulman, J., and Mané, D. (2016). Concrete problems in AI safety. arXiv [Preprint]. arXiv:1606.06565.
An, S.-I., and Lee, D. (2015). “Prioritized inverse kinematics with multiple task definitions,” in IEEE International Conference on Robotics and Automation (ICRA) (Seattle, WA), 1423–1430. doi: 10.1109/ICRA.2015.7139376
Arnold, J., Hanzlick, H., and Lee, H. (2019). “Variable damping control of the robotic ankle joint to improve trade-off between performance and stability,” in IEEE International Conference on Robotics and Automation (ICRA) (Montreal, QC), 1699–1704. doi: 10.1109/ICRA.2019.8793869
Arulkumaran, K., Deisenroth, M. P., Brundage, M., and Bharath, A. A. (2017). Deep reinforcement learning: a brief survey. IEEE Signal Process. Mag. 34, 26–38. doi: 10.1109/MSP.2017.2743240
Ataka, A., Abrar, T., Putzu, F., Godaba, H., and Althoefer, K. (2020). Model-based pose control of inflatable eversion robot with variable stiffness. IEEE Robot. Autom. Lett. 5, 3398–3405. doi: 10.1109/LRA.2020.2976326
Balatti, P., Kanoulas, D., Tsagarakis, N. G., and Ajoudani, A. (2019). “Towards robot interaction autonomy: explore, identify, and interact,” in IEEE International Conference on Robotics and Automation (ICRA) (Montreal, QC), 9523–9529. doi: 10.1109/ICRA.2019.8794428
Bauer, A., Wollherr, D., and Buss, M. (2008). Human-robot collaboration: a survey. Int. J. Human. Robot. 5, 47–66. doi: 10.1142/S0219843608001303
Berenji, H. R. (1994). “Fuzzy Q-learning: a new approach for fuzzy dynamic programming,” in IEEE International Fuzzy Systems Conference (Orlando, FL), 486–491. doi: 10.1109/FUZZY.1994.343737
Berkenkamp, F., Turchetta, M., Schoellig, A., and Krause, A. (2017). “Safe model-based reinforcement learning with stability guarantees,” in 31st Conference on Neural Information Processing Systems (NIPS) (Long Beach, CA), 908–918.
Bitz, T., Zahedi, F., and Lee, H. (2020). “Variable damping control of a robotic arm to improve trade-off between agility and stability and reduce user effort,” in IEEE International Conference on Robotics and Automation (ICRA) (Paris), 11259–11265. doi: 10.1109/ICRA40945.2020.9196572
Blaya, J. A., and Herr, H. (2004). Adaptive control of a variable-impedance ankle-foot orthosis to assist drop-foot gait. IEEE Trans. Neural Syst. Rehabil. Eng. 12, 24–31. doi: 10.1109/TNSRE.2003.823266
Bohren, J., Rusu, R. B., Jones, E. G., Marder-Eppstein, E., Pantofaru, C., Wise, M., et al. (2011). “Towards autonomous robotic butlers: lessons learned with the PR2,” in IEEE International Conference on Robotics and Automation (Shanghai), 5568–5575. doi: 10.1109/ICRA.2011.5980058
Bristow, D. A., Tharayil, M., and Alleyne, A. G. (2006). A survey of iterative learning control. IEEE Control Syst. Mag. 26, 96–114. doi: 10.1109/MCS.2006.1636313
Buchli, J., Stulp, F., Theodorou, E., and Schaal, S. (2011). Learning variable impedance control. Int. J. Robot. Res. 30, 820–833. doi: 10.1177/0278364911402527
Burdet, E., Osu, R., Franklin, D. W., Milner, T. E., and Kawato, M. (2001). The central nervous system stabilizes unstable dynamics by learning optimal impedance. Nature 414, 446–449. doi: 10.1038/35106566
Caccavale, F., Chiacchio, P., Marino, A., and Villani, L. (2008). Six-dof impedance control of dual-arm cooperative manipulators. IEEE/ASME Trans. Mechatron. 13, 576–586. doi: 10.1109/TMECH.2008.2002816
Calanca, A., Muradore, R., and Fiorini, P. (2015). A review of algorithms for compliant control of stiff and fixed-compliance robots. IEEE/ASME Trans. Mechatron. 21, 613–624. doi: 10.1109/TMECH.2015.2465849
Calanca, A., Muradore, R., and Fiorini, P. (2017). Impedance control of series elastic actuators: passivity and acceleration-based control. Mechatronics 47, 37–48. doi: 10.1016/j.mechatronics.2017.08.010
Calinon, S. (2016). A tutorial on task-parameterized movement learning and retrieval. Intell. Serv. Robot. 9, 1–29. doi: 10.1007/s11370-015-0187-9
Calinon, S., Sardellitti, I., and Caldwell, D. G. (2010). “Learning-based control strategy for safe human-robot interaction exploiting task and robot redundancies,” in IEEE/RSJ International Conference on Intelligent Robots and Systems (Taipei), 249–254. doi: 10.1109/IROS.2010.5648931
Chatzilygeroudis, K., Vassiliades, V., Stulp, F., Calinon, S., and Mouret, J.-B. (2020). A survey on policy search algorithms for learning robot controllers in a handful of trials. IEEE Trans. Robot. 32, 328–347. doi: 10.1109/TRO.2019.2958211
Cheah, C.-C., and Wang, D. (1998). Learning impedance control for robotic manipulators. IEEE Trans. Robot. Autom. 14, 452–465. doi: 10.1109/70.678454
Cheng, R., Orosz, G., Murray, R. M., and Burdick, J. W. (2019). “End-to-end safe reinforcement learning through barrier functions for safety-critical continuous control tasks,” in AAAI Conference on Artificial Intelligence, Vol. 33 (Honolulu, HI), 3387–3395. doi: 10.1609/aaai.v33i01.33013387
Chow, Y., Nachum, O., Duenez-Guzman, E., and Ghavamzadeh, M. (2018). “A lyapunov-based approach to safe reinforcement learning,” in 32nd Conference on Neural Information Processing Systems (NIPS) (Montreal, QC), 8092–8101.
Colgate, J. E., and Hogan, N. (1988). Robust control of dynamically interacting systems. Int. J. Control 48, 65–88. doi: 10.1080/00207178808906161
De Schutter, J. (1987). “A study of active compliant motion control methods for rigid manipulators based on a generic scheme,” in IEEE International Conference on Robotics and Automation, Vol. 4 (Raleigh, NC), 1060–1065. doi: 10.1109/ROBOT.1987.1087856
Deisenroth, M. P., Fox, D., and Rasmussen, C. E. (2015). Gaussian processes for data-efficient learning in robotics and control. IEEE Trans. Pattern Anal. Mach. Intell. 37, 408–423. doi: 10.1109/TPAMI.2013.218
Deisenroth, M. P., Neumann, G., and Peters, J. (2013). A survey on policy search for robotics. Found. Trends Robot. 2, 1–142. doi: 10.1561/2300000021
DelPreto, J., and Rus, D. (2019). “Sharing the load: human-robot team lifting using muscle activity,” in International Conference on Robotics and Automation (ICRA) (Montreal, QC), 7906–7912. doi: 10.1109/ICRA.2019.8794414
Dimeas, F., and Aspragathos, N. (2015). “Reinforcement learning of variable admittance control for human-robot co-manipulation,” in IEEE/RSJ International Conference on Intelligent Robots and Systems (Hamburg), 1011–1016. doi: 10.1109/IROS.2015.7353494
Dimeas, F., Kastritsi, T., Papageorgiou, D., and Doulgeri, Z. (2020). “Progressive automation of periodic movements,” in International Workshop on Human-Friendly Robotics, eds F. Ferraguti, V. Villani, L. Sabattini, and M. Bonfé (Paris: Springer International Publishing), 58–72. doi: 10.1007/978-3-030-42026-0_5
Duchaine, V., and Gosselin, C. M. (2007). “General model of human-robot cooperation using a novel velocity based variable impedance control,” in Second Joint EuroHaptics Conference and Symposium on Haptic Interfaces for Virtual Environment and Teleoperator Systems (Tsukaba: IEEE), 446–451. doi: 10.1109/WHC.2007.59
Eiband, T., Saveriano, M., and Lee, D. (2019). “Learning haptic exploration schemes for adaptive task execution,” in IEEE International Conference on Robotics and Automation (ICRA) (Montreal, QC), 7048–7054. doi: 10.1109/ICRA.2019.8793934
Ferraguti, F., Preda, N., Manurung, A., Bonfe, M., Lambercy, O., Gassert, R., et al. (2015). An energy tank-based interactive control architecture for autonomous and teleoperated robotic surgery. IEEE Trans. Robot. 31, 1073–1088. doi: 10.1109/TRO.2015.2455791
Ferraguti, F., Secchi, C., and Fantuzzi, C. (2013). “A tank-based approach to impedance control with variable stiffness,” in IEEE International Conference on Robotics and Automation (Karlsruhe), 4948–4953. doi: 10.1109/ICRA.2013.6631284
Ficuciello, F., Villani, L., and Siciliano, B. (2015). Variable impedance control of redundant manipulators for intuitive human-robot physical interaction. IEEE Trans. Robot. 31, 850–863. doi: 10.1109/TRO.2015.2430053
Gams, A., Nemec, B., Ijspeert, A. J., and Ude, A. (2014). Coupling movement primitives: interaction with the environment and bimanual tasks. IEEE Trans. Robot. 30, 816–830. doi: 10.1109/TRO.2014.2304775
Gandarias, J. M., Wang, Y., Stilli, A., García-Cerezo, A. J., Gómez-de-Gabriel, J. M., and Wurdemann, H. A. (2020). Open-loop position control in collaborative, modular variable-stiffness-link (VSL) robots. IEEE Robot. Autom. Lett. 5, 1772–1779. doi: 10.1109/LRA.2020.2969943
Ganesh, G., Jarrassé, N., Haddadin, S., Albu-Schaeffer, A., and Burdet, E. (2012). “A versatile biomimetic controller for contact tooling and haptic exploration,” in IEEE International Conference on Robotics and Automation (Saint Paul, MN), 3329–3334. doi: 10.1109/ICRA.2012.6225057
Goodrich, M. A., and Schultz, A. C. (2008). Human-Robot Interaction: A Survey. Boston, MA: Now Publishers Inc. doi: 10.1561/9781601980939
Haddadin, S. (2013). Towards Safe Robots: Approaching Asimov's 1st Law, 1st Edn. Berlin; Heidelberg: Springer Publishing Company. doi: 10.1007/978-3-642-40308-8
Haninger, K., Asignacion, A., and Oh, S. (2020). “Safe high impedance control of a series-elastic actuator with a disturbance observer,” in IEEE International Conference on Robotics and Automation (ICRA) (Paris), 921–927. doi: 10.1109/ICRA40945.2020.9197402
Hoffman, E. M., Laurenzi, A., Muratore, L., Tsagarakis, N. G., and Caldwell, D. G. (2018). “Multi-priority cartesian impedance control based on quadratic programming optimization,” in IEEE International Conference on Robotics and Automation (ICRA) (Brisbane, QLD), 309–315. doi: 10.1109/ICRA.2018.8462877
Hogan, N. (1985). Impedance control-an approach to manipulation. I-theory. II-Implementation. III-Applications. ASME Trans. J. Dyn. Syst. Measure. Control B 107, 1–24. doi: 10.1115/1.3140701
Howard, M., Braun, D. J., and Vijayakumar, S. (2013). Transferring human impedance behavior to heterogeneous variable impedance actuators. IEEE Trans. Robot. 29, 847–862. doi: 10.1109/TRO.2013.2256311
Hussein, A., Gaber, M. M., Elyan, E., and Jayne, C. (2017). Imitation learning: a survey of learning methods. ACM Comput. Surveys (CSUR) 50, 1–35. doi: 10.1145/3054912
Ijspeert, A. J., Nakanishi, J., Hoffmann, H., Pastor, P., and Schaal, S. (2013). Dynamical movement primitives: learning attractor models for motor behaviors. Neural Comput. 25, 328–373. doi: 10.1162/NECO_a_00393
Ikeura, R., and Inooka, H. (1995). “Variable impedance control of a robot for cooperation with a human,” in IEEE International Conference on Robotics and Automation, Vol. 3 (Nagoya), 3097–3102. doi: 10.1109/ROBOT.1995.525725
Ikeura, R., Moriguchi, T., and Mizutani, K. (2002). “Optimal variable impedance control for a robot and its application to lifting an object with a human,” in 11th IEEE International Workshop on Robot and Human Interactive Communication (Berlin), 500–505. doi: 10.1109/ROMAN.2002.1045671
Jamwal, P. K., Hussain, S., Ghayesh, M. H., and Rogozina, S. V. (2016). Impedance control of an intrinsically compliant parallel ankle rehabilitation robot. IEEE Trans. Indust. Electron. 63, 3638–3647. doi: 10.1109/TIE.2016.2521600
Jaquier, N., and Calinon, S. (2017). “Gaussian mixture regression on symmetric positive definite matrices manifolds: application to wrist motion estimation with SEMG,” in IEEE/RSJ International Conference on Intelligent Robots and Systems (Vancouver, BC), 59–64. doi: 10.1109/IROS.2017.8202138
Johannsmeier, L., Gerchow, M., and Haddadin, S. (2019). “A framework for robot manipulation: skill formalism, meta learning and adaptive control,” in IEEE International Conference on Robotics and Automation (ICRA) (Montreal, QC), 5844–5850. doi: 10.1109/ICRA.2019.8793542
Jouffe, L. (1998). Fuzzy inference system learning by reinforcement methods. IEEE Trans. Syst. Man Cybern. Part C 28, 338–355. doi: 10.1109/5326.704563
Jung, S., Hsia, T. C., and Bonitz, R. G. (2004). Force tracking impedance control of robot manipulators under unknown environment. IEEE Trans. Control Syst. Technol. 12, 474–483. doi: 10.1109/TCST.2004.824320
Kastritsi, T., Dimeas, F., and Doulgeri, Z. (2018). Progressive automation with dmp synchronization and variable stiffness control. IEEE Robot. Autom. Lett. 3, 3789–3796. doi: 10.1109/LRA.2018.2856536
Keemink, A., van der Kooij, H., and Stienen, A. (2018). Admittance control for physical human-robot interaction. Int. J. Robot. Res. 37, 1421–1444. doi: 10.1177/0278364918768950
Khader, S., Yin, H., Falco, P., and Kragic, D. (2021). Stability-guaranteed reinforcement learning for contact-rich manipulation. IEEE Robot. Autom. Lett. 6, 1–8. doi: 10.1109/LRA.2020.3028529
Khansari-Zadeh, S. M., and Billard, A. (2011). Learning stable non-linear dynamical systems with Gaussian mixture models. IEEE Trans. Robot. 27, 943–957. doi: 10.1109/TRO.2011.2159412
Khansari-Zadeh, S. M., Kronander, K., and Billard, A. (2014). Modeling robot discrete movements with state-varying stiffness and damping: a framework for integrated motion generation and impedance control. Proc. Robot. Sci. Syst. X 10:2014. doi: 10.15607/RSS.2014.X.022
Kim, B., Park, J., Park, S., and Kang, S. (2010). Impedance learning for robotic contact tasks using natural actor-critic algorithm. IEEE Trans. Syst. Man Cybern. Part B 40, 433–443. doi: 10.1109/TSMCB.2009.2026289
Kim, T., Yoo, S., Kim, H. S., and Seo, T. (2020). “Position-based impedance control of a 2-dof compliant manipulator for a facade cleaning operation*,” in IEEE International Conference on Robotics and Automation (ICRA) (Paris), 5765–5770. doi: 10.1109/ICRA40945.2020.9197478
Kober, J., Bagnell, J. A., and Peters, J. (2013). Reinforcement learning in robotics: a survey. Int. J. Robot. Res. 32, 1238–1274. doi: 10.1177/0278364913495721
Kormushev, P., Calinon, S., and Caldwell, D. G. (2010). “Robot motor skill coordination with EM-based reinforcement learning,” in IEEE/RSJ International Conference on Intelligent Robots and Systems (Taipei), 3232–3237. doi: 10.1109/IROS.2010.5649089
Kormushev, P., Calinon, S., and Caldwell, D. G. (2011). Imitation learning of positional and force skills demonstrated via kinesthetic teaching and haptic input. Adv. Robot. 25, 581–603. doi: 10.1163/016918611X558261
Kormushev, P., Calinon, S., and Caldwell, D. G. (2013). Reinforcement learning in robotics: applications and real-world challenges. Robotics 2, 122–148. doi: 10.3390/robotics2030122
Kramberger, A., Shahriari, E., Gams, A., Nemec, B., Ude, A., and Haddadin, S. (2018). “Passivity based iterative learning of admittance-coupled dynamic movement primitives for interaction with changing environments,” in IEEE/RSJ International Conference on Intelligent Robots and Systems (Madrid), 6023–6028. doi: 10.1109/IROS.2018.8593647
Kronander, K., and Billard, A. (2014). Learning compliant manipulation through kinesthetic and tactile human-robot interaction. IEEE Trans. Hapt. 7, 367–380. doi: 10.1109/TOH.2013.54
Kronander, K., and Billard, A. (2016). Stability considerations for variable impedance control. IEEE Trans. Robot. 32, 1298–1305. doi: 10.1109/TRO.2016.2593492
Laghi, M., Ajoudani, A., Catalano, M. G., and Bicchi, A. (2020). Unifying bilateral teleoperation and tele-impedance for enhanced user experience. Int. J. Robot. Res. 39, 514–539. doi: 10.1177/0278364919891773
Lee, D., and Ott, C. (2011). Incremental kinesthetic teaching of motion primitives using the motion refinement tube. Auton. Robots 31, 115–131. doi: 10.1007/s10514-011-9234-3
Lee, K., and Buss, M. (2008). Force tracking impedance control with variable target stiffness. IFAC Proc. 41, 6751–6756. doi: 10.3182/20080706-5-KR-1001.01144
Li, C., Zhang, Z., Xia, G., Xie, X., and Zhu, Q. (2018). Efficient force control learning system for industrial robots based on variable impedance control. Sensors 18:2539. doi: 10.3390/s18082539
Li, C., Zhang, Z., Xia, G., Xie, X., and Zhu, Q. (2019). Efficient learning variable impedance control for industrial robots. Bull. Pol. Acad. Sci. Techn. Sci. 67:201–212. doi: 10.24425/bpas.2019.128116
Li, M., Yin, H., Tahara, K., and Billard, A. (2014). “Learning object-level impedance control for robust grasping and dexterous manipulation,” in IEEE International Conference on Robotics and Automation (Hong Kong), 6784–6791. doi: 10.1109/ICRA.2014.6907861
Li, X., Pan, Y., Chen, G., and Yu, H. (2017). Multi-modal control scheme for rehabilitation robotic exoskeletons. Int. J. Robot. Res. 36, 759–777. doi: 10.1177/0278364917691111
Li, Y., Ge, S. S., and Yang, C. (2011a). “Impedance control for multi-point human-robot interaction,” in 8th Asian Control Conference (ASCC) (Kaohsiung), 1187–1192.
Li, Y., Ge, S. S., Yang, C., Li, X., and Tee, K. P. (2011b). “Model-free impedance control for safe human-robot interaction,” in IEEE International Conference on Robotics and Automation (Shanghai), 6021–6026. doi: 10.1109/ICRA.2011.5979855
Li, Y., Ren, T., Chen, Y., and Chen, M. Z. Q. (2020). “A variable stiffness soft continuum robot based on pre-charged air, particle jamming, and origami,” in IEEE International Conference on Robotics and Automation (ICRA) (Paris), 5869–5875. doi: 10.1109/ICRA40945.2020.9196729
Li, Y., Sam Ge, S., and Yang, C. (2012). Learning impedance control for physical robot-environment interaction. Int. J. Control 85, 182–193. doi: 10.1080/00207179.2011.642309
Lippiello, V., Siciliano, B., and Villani, L. (2007). “A position-based visual impedance control for robot manipulators,” in IEEE International Conference on Robotics and Automation (Rome), 2068–2073. doi: 10.1109/ROBOT.2007.363626
Luo, J., Solowjow, E., Wen, C., Ojea, J. A., Agogino, A. M., Tamar, A., et al. (2019). “Reinforcement learning on variable impedance controller for high-precision robotic assembly,” in IEEE International Conference on Robotics and Automation (Montreal, QC), 3080–3087. doi: 10.1109/ICRA.2019.8793506
Magrini, E., Flacco, F., and De Luca, A. (2015). “Control of generalized contact motion and force in physical human-robot interaction,” in IEEE International Conference on Robotics and Automation (Seattle, WA), 2298–2304. doi: 10.1109/ICRA.2015.7139504
Martín-Martíin, R., Lee, M. A., Gardner, R., Savarese, S., Bohg, J., and Garg, A. (2019). “Variable impedance control in end-effector space: an action space for reinforcement learning in contact-rich tasks,” in IEEE/RSJ International Conference on Intelligent Robots and Systems (Macau), 1010–1017. doi: 10.1109/IROS40897.2019.8968201
Mathew, M. J., Sidhik, S., Sridharan, M., Azad, M., Hayashi, A., and Wyatt, J. (2019). “Online learning of feed-forward models for task-space variable impedance control,” in IEEE-RAS 19th International Conference on Humanoid Robots (Toronto, ON), 222–229. doi: 10.1109/Humanoids43949.2019.9035063
Medina, J. R., Duvallet, F., Karnam, M., and Billard, A. (2016). “A human-inspired controller for fluid human-robot handovers,” in IEEE-RAS International Conference on Humanoid Robots (Humanoids) (Cancun), 324–331. doi: 10.1109/HUMANOIDS.2016.7803296
Mohammadi, A., and Gregg, R. D. (2019). Variable impedance control of powered knee prostheses using human-inspired algebraic curves. J. Comput. Nonlin. Dyn. 14:101007–101007-10. doi: 10.1115/1.4043002
Muratore, L., Laurenzi, A., and Tsagarakis, N. G. (2019). “A self-modulated impedance multimodal interaction framework for human-robot collaboration,” in IEEE International Conference on Robotics and Automation (ICRA) (Montreal, QC), 4998–5004. doi: 10.1109/ICRA.2019.8794168
Ott, C. (2008). Cartesian Impedance Control of Redundant and Flexible-Joint Robots. Springer. doi: 10.1109/TRO.2008.915438
Ott, C., Mukherjee, R., and Nakamura, Y. (2010). “Unified impedance and admittance control,” in IEEE International Conference on Robotics and Automation (Anchorage, AK), 554–561. doi: 10.1109/ROBOT.2010.5509861
Ouyang, P., Zhang, W., and Gupta, M. M. (2006). An adaptive switching learning control method for trajectory tracking of robot manipulators. Mechatronics 16, 51–61. doi: 10.1016/j.mechatronics.2005.08.002
Parent, D., Colomé, A., and Torras, C. (2020). “Variable impedance control in Cartesian latent space while avoiding obstacles in null space,” in IEEE International Conference on Robotics and Automation (ICRA) (Paris), 9888–9894. doi: 10.1109/ICRA40945.2020.9197192
Park, J. H. (2019). Compliance/Impedance Control Strategy for Humanoids. Dordrecht: Springer Netherlands. 1009–1028. doi: 10.1007/978-94-007-6046-2_148
Peternel, L., and Ajoudani, A. (2017). “Robots learning from robots: A proof of concept study for co-manipulation tasks,” in IEEE-RAS 17th International Conference on Humanoid Robotics (Humanoids) (Birmingham), 484–490. doi: 10.1109/HUMANOIDS.2017.8246916
Peternel, L., Petrič, T., and Babičc, J. (2018a). Robotic assembly solution by human-in-the-loop teaching method based on real-time stiffness modulation. Auton. Robots 42, 1–17. doi: 10.1007/s10514-017-9635-z
Peternel, L., Petrič, T., Oztop, E., and Babič, J. (2014). Teaching robots to cooperate with humans in dynamic manipulation tasks based on multi-modal human-in-the-loop approach. Auton. Robots 36, 123–136. doi: 10.1007/s10514-013-9361-0
Peternel, L., Tsagarakis, N., and Ajoudani, A. (2016). “Towards multi-modal intention interfaces for human-robot co-manipulation,” in IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) (Daejeon), 2663–2669. doi: 10.1109/IROS.2016.7759414
Peternel, L., Tsagarakis, N., and Ajoudani, A. (2017). A human-robot co-manipulation approach based on human sensorimotor information. IEEE Trans. Neural Syst. Rehabil. Eng. 25, 811–822. doi: 10.1109/TNSRE.2017.2694553
Peternel, L., Tsagarakis, N., Caldwell, D., and Ajoudani, A. (2018b). Robot adaptation to human physical fatigue in human-robot co-manipulation. Auton. Robots 42, 1011–1021. doi: 10.1007/s10514-017-9678-1
Peters, J., and Schaal, S. (2008). Natural actor-critic. Neurocomputing 71, 1180–1190. doi: 10.1016/j.neucom.2007.11.026
Pratt, G. A., and Williamson, M. M. (1995). “Series elastic actuators,” in IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vol. 1 (Pittsburgh, PA), 399–406. doi: 10.1109/IROS.1995.525827
Rahimi, H. N., Howard, I., and Cui, L. (2018). Neural impedance adaption for assistive human-robot interaction. Neurocomputing 290, 50–59. doi: 10.1016/j.neucom.2018.02.025
Rahman, M., Ikeura, R., and Mizutani, K. (1999). “Investigating the impedance characteristic of human arm for development of robots to co-operate with human operators,” in IEEE International Conference on Systems, Man, and Cybernetics, Vol. 2 (Tokyo), 676–681. doi: 10.1109/ICSMC.1999.825342
Ravichandar, H., Polydoros, A. S., Chernova, S., and Billard, A. (2020). Recent advances in robot learning from demonstration. Annu. Rev. Control Robot. Auton. Syst. 3:297–330. doi: 10.1146/annurev-control-100819-063206
Rey, J., Kronander, K., Farshidian, F., Buchli, J., and Billard, A. (2018). Learning motions from demonstrations and rewards with time-invariant dynamical systems based policies. Auton. Robots 42, 45–64. doi: 10.1007/s10514-017-9636-y
Roveda, L., Maskani, J., Franceschi, P., Abdi, A., Braghin, F., Tosatti, L. M., et al. (2020). Model-based reinforcement learning variable impedance control for human-robot collaboration. J. Intell. Robot. Syst. 100, 1–17. doi: 10.1007/s10846-020-01183-3
Rozo, L., Calinon, S., Caldwell, D., Jiménez, P., and Torras, C. (2013). “Learning collaborative impedance-based robot behaviors,” in 27th AAAI Conference on Artificial Intelligence (Bellevue, WA), 1422–1428.
Rozo, L., Calinon, S., Caldwell, D. G., Jimenez, P., and Torras, C. (2016). Learning physical collaborative robot behaviors from human demonstrations. IEEE Trans. Robot. 32, 513–527. doi: 10.1109/TRO.2016.2540623
Sadeghian, H., Villani, L., Keshmiri, M., and Siciliano, B. (2011). “Multi-priority control in redundant robotic systems,” in IEEE/RSJ International Conference on Intelligent Robots and Systems (San Francisco, CA), 3752–3757. doi: 10.1109/IROS.2011.6094609
Salisbury, J. K. (1980). “Active stiffness control of a manipulator in Cartesian coordinates,” in 19th IEEE Conference on Decision and Control Including the Symposium on Adaptive Processes (Albuquerque, NM), 95–100. doi: 10.1109/CDC.1980.272026
Saveriano, M., An, S.-I., and Lee, D. (2015). “Incremental kinesthetic teaching of end-effector and null-space motion primitives,” in IEEE International Conference on Robotics and Automation (ICRA) (Seattle, WA), 3570–3575. doi: 10.1109/ICRA.2015.7139694
Saveriano, M., and Lee, D. (2014). “Learning motion and impedance behaviors from human demonstrations,” in IEEE International Conference on Ubiquitous Robots and Ambient Intelligence (Kuala Lumpur), 368–373. doi: 10.1109/URAI.2014.7057371
Siciliano, B., and Villani, L. (2001). An inverse kinematics algorithm for interaction control of a flexible arm with a compliant surface. Control Eng. Pract. 9, 191–198. doi: 10.1016/S0967-0661(00)00097-6
Slotine, J., Slotine, J., and Li, W. (1991). Applied Nonlinear Control. New Jersey, NJ: Prentice Hall.
Song, P., Yu, Y., and Zhang, X. (2019). A tutorial survey and comparison of impedance control on robotic manipulation. Robotica 37, 801–836. doi: 10.1017/S0263574718001339
Sozer, C., Paternò, L., Tortora, G., and Menciassi, A. (2020). “Pressure-driven manipulator with variable stiffness structure,” in IEEE International Conference on Robotics and Automation (ICRA) (Paris), 696–702. doi: 10.1109/ICRA40945.2020.9197401
Spyrakos-Papastavridis, E., Childs, P. R. N. and Dai, J. S. (2020). Passivity preservation for variable impedance control of compliant robots. IEEE ASME Trans. Mechatron. 25, 2342–2353. doi: 10.1109/TMECH.2019.2961478
Spyrakos-Papastavridis, E. and Dai, J. (2020). Minimally model-based trajectory tracking and variable impedance control of flexible-joint robots. IEEE Trans. Indus. Electron. doi: 10.1109/TIE.2020.2994886
Sun, T., Peng, L., Cheng, L., Hou, Z.-G., and Pan, Y. (2019). Stability-guaranteed variable impedance control of robots based on approximate dynamic inversion. IEEE Trans. Syst. Man Cybern. doi: 10.1109/TSMC.2019.2930582. [Epub ahead of print].
Suomalainen, M., Calinon, S., Pignat, E., and Kyrki, V. (2019). “Improving dual-arm assembly by master-slave compliance,” in IEEE International Conference on Robotics and Automation (ICRA) (Montreal, QC), 8676–8682. doi: 10.1109/ICRA.2019.8793977
Theodorou, E., Buchli, J., and Schaal, S. (2010). A generalized path integral control approach to reinforcement learning. J. Mach. Learn. Res. 11, 3137–3181.
Todorov, E., and Li, W. (2005). “A generalized iterative LQG method for locally-optimal feedback control of constrained nonlinear stochastic systems,” in American Control Conference (Portland, OR), 300–306. doi: 10.1109/ACC.2005.1469949
Tsetserukou, D., Kawakami, N., and Tachi, S. (2009). Isora: humanoid robot arm for intelligent haptic interaction with the environment. Adv. Robot. 23, 1327–1358. doi: 10.1163/156855309X462619
Tsumugiwa, T., Yokogawa, R., and Hara, K. (2002). “Variable impedance control based on estimation of human arm stiffness for human-robot cooperative calligraphic task,” in IEEE International Conference on Robotics and Automation, Vol. 1 (Washington, DC), 644–650. doi: 10.1109/ROBOT.2002.1013431
Uemura, M., Kawamura, S., Hirai, H., and Miyazaki, F. (2014). “Iterative motion learning with stiffness adaptation for multi-joint robots,” in IEEE International Conference on Robotics and Biomimetics (ROBIO) (Bali), 1088–1093. doi: 10.1109/ROBIO.2014.7090477
Van der Schaft, A. J. (2000). L2-Gain and Passivity Techniques in Nonlinear Control, Vol. 2. London: Springer. doi: 10.1007/978-1-4471-0507-7
Vanderborght, B., Albu-Schäffer, A., Bicchi, A., Burdet, E., Caldwell, D. G., Carloni, R., et al. (2013). Variable impedance actuators: a review. Robot. Auton. Syst. 61, 1601–1614. doi: 10.1016/j.robot.2013.06.009
Villani, L., and De Schutter, J. (2016). Force Control. Cham: Springer International Publishing. 195–220. doi: 10.1007/978-3-319-32552-1_9
Wabersich, K. P., and Zeilinger, M. N. (2018). “Linear model predictive safety certification for learning-based control,” in IEEE Conference on Decision and Control (Miami Beach, FL), 7130–7135. doi: 10.1109/CDC.2018.8619829
Williams, C. K., and Rasmussen, C. E. (2006). Gaussian Processes for Machine Learning, Vol. 2. Cambridge, MA: MIT Press. doi: 10.7551/mitpress/3206.001.0001
Wolf, S., Grioli, G., Eiberger, O., Friedl, W., Grebenstein, M., Höppner, H., et al. (2016). Variable stiffness actuators: review on design and components. IEEE/ASME Trans. Mechatron. 21, 2418–2430. doi: 10.1109/TMECH.2015.2501019
Wu, R., Zhang, H., Peng, T., Fu, L., and Zhao, J. (2019). Variable impedance interaction and demonstration interface design based on measurement of arm muscle co-activation for demonstration learning. Biomed. Signal Process. Control 51, 8–18. doi: 10.1016/j.bspc.2019.02.008
Yang, C., Ganesh, G., Haddadin, S., Parusel, S., Albu-Schäffer, A., and Burdet, E. (2011). Human-like adaptation of force and impedance in stable and unstable interactions. IEEE Trans. Robot. 27, 918–930. doi: 10.1109/TRO.2011.2158251
Yang, C., Zeng, C., Fang, C., He, W., and Li, Z. (2018). A dmps-based framework for robot learning and generalization of humanlike variable impedance skills. IEEE/ASME Trans. Mechatron. 23, 1193–1203. doi: 10.1109/TMECH.2018.2817589
Yu, H., Huang, S., Chen, G., Pan, Y., and Guo, Z. (2015). Human-robot interaction control of rehabilitation robots with series elastic actuators. IEEE Trans. Robot. 31, 1089–1100. doi: 10.1109/TRO.2015.2457314
Yu, H., Huang, S., Chen, G., and Thakor, N. (2013). Control design of a novel compliant actuator for rehabilitation robots. Mechatronics 23, 1072–1083. doi: 10.1016/j.mechatronics.2013.08.004
Keywords: impedance control, variable impedance control, variable impedance learning, variable impedance learning control, variable stiffness
Citation: Abu-Dakka FJ and Saveriano M (2020) Variable Impedance Control and Learning—A Review. Front. Robot. AI 7:590681. doi: 10.3389/frobt.2020.590681
Received: 02 August 2020; Accepted: 22 October 2020;
Published: 21 December 2020.
Edited by:
Yongping Pan, National University of Singapore, SingaporeReviewed by:
Sunan Huang, National University of Singapore, SingaporeCopyright © 2020 Abu-Dakka and Saveriano. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Fares J. Abu-Dakka, ZmFyZXMuYWJ1LWRha2thQGFhbHRvLmZp
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.