
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Microbiomes , 03 June 2024
Sec. Omics and Bioinformatics for Microbiomes
Volume 3 - 2024 | https://doi.org/10.3389/frmbi.2024.1366948
 Jie Zhou1
Jie Zhou1 Jiang Gui1Weston D. Viles2Haobin Chen1
Jiang Gui1Weston D. Viles2Haobin Chen1 Siting Li1
Siting Li1 Juliette C. Madan3
Juliette C. Madan3 Modupe O. Coker3,4
Modupe O. Coker3,4 Anne G. Hoen1,3*
Anne G. Hoen1,3*Introduction: The microbial interactions within the human microbiome are complex, and few methods are available to identify these interactions within a longitudinal microbial abundance framework. Existing methods typically impose restrictive constraints, such as requiring long sequences and equal spacing, on the data format which in many cases are violated.
Methods: To identify microbial interaction networks (MINs) with general longitudinal data settings, we propose a stationary Gaussian graphical model (SGGM) based on 16S rRNA gene sequencing data. In the SGGM, data can be arbitrarily spaced, and there are no restrictions on the length of data sequences from a single subject. Based on the SGGM, EM -type algorithms are devised to compute the L1-penalized maximum likelihood estimate of MINs. The algorithms employ the classical graphical LASSO algorithm as the building block and can be implemented efficiently.
Results: Extensive simulation studies show that the proposed algorithms can significantly outperform the conventional algorithms if the correlations among the longitudinal data are reasonably high. When the assumptions in the SGGM areviolated, e.g., zero inflation or data from heterogeneous microbial communities, the proposed algorithms still demonstrate robustness and perform better than the other existing algorithms. The algorithms are applied to a 16S rRNA gene sequencing data set from patients with cystic fibrosis. The results demonstrate strong evidence of an association between the MINs and the phylogenetic tree, indicating that the genetically related taxa tend to have more/stronger interactions. These results strengthen the existing findings in literature.
Discussion: The proposed algorithms can potentially be used to explore the network structure in genome, metabolome etc. as well.
Microorganisms thrive in communities in large numbers. They interact with their host and with one another in various ways, such as commensalism, synergism, competition, parasitism, and predation. This complex set of interactions can be depicted in the form of microbial interaction networks (MINs) (Faust and Raes, 2012). Traditionally, such interactions have been inferred using culture-based methods, which can only accommodate a small number of microbial strains (Gause, 1934; Staley and Konopka, 1985; Harcombe, 2010). Since most microbes cannot be cultivated, the estimated interactions under laboratory conditions could be misleading. Underpinned by advances in next-generation sequencing (NGS) technologies, a complete microbiome profile can be measured at a relatively low cost, allowing researchers to investigate microbial interactions in situ. However, the complexities of these high-throughput data, such as their high dimensionality, zero inflation, and compositional nature, pose substantial challenges to identifying MINs (Faust and Raes, 2012). Currently, the primary way to infer MINs is the pairwise method, in which the cooccurrence or mutual exclusion pattern of two species is compared using measures such as Pearson or Spearman correlation (Qin et al., 2010; Zhou et al., 2010; Arumugam et al., 2011; Barberan et al., 2012). An emerging method is based on conditional independence, i.e., the conditional joint distribution of two taxa given all the other microbiome members. Conditional independence is conceptually superior to the pairwise method since it removes the effects of all the other taxa when measuring the relationship between the two taxa of interest (Kurtz et al., 2015; Chen et al., 2017; Viles et al., 2021). Furthermore, if the data follow a normal distribution, then the precision matrix, i.e., the inverse of the covariance matrix, directly reflects the conditional independence relationship among microbes. With such an appealing interpretation, precision matrices have become the ideal tools for exploring the structure of MINs (Fang et al., 2017; Yoon et al., 2019; Yuan et al., 2019; Jiang et al., 2020; Tian et al., 2023).
In particular, the authors in (Kurtz et al., 2015) proposed a conditional independence-based pipeline named SParse InversE Covariance Estimation for Ecological Association Inference (SPIEC-EASI) to estimate MINs. In SPIEC-EASI, L1-penalized maximum likelihood estimation of the precision matrix is employed to identify high-dimensional MINs. Mathematically, the L1-penalized maximum likelihood estimation of the precision matrix has been studied extensively in the literature (Yuan and Lin, 2007; Avella-Medina et al., 2018; Wang and Jiang, 2020). Algorithms have been proposed to compute such estimates, e.g., graphical LASSO (Friedman et al., 2008; Friedman et al., 2019) and the neighborhood method (Meinshansen and Bühlmann, 2006). In SPIEC-EASI, graphical LASSO computes the precision matrix recursively based on the coordinate descent algorithm. In contrast, the neighborhood method computes the neighborhood of each node and then combines these neighborhoods to form an estimate of the network. However, a prerequisite of SPIEC-EASI is that the data should be independent. Although independence is a reasonable assumption if the data are cross-sectional, in many other cases, data sets are longitudinal, in which multiple observations are made on the same subject. In such studies, the observations from the same subject are typically correlated and violate the assumption of SPIEC-EASI. There have been studies to estimate the network from the correlated data. The time series models, e.g., vector autoregression, have been employed to address the correlation between observations within the same cluster (Bach and Jordan, 2004; Qiu et al., 2016; Chen et al., 2017; Epskamp et al., 2018; He et al., 2022). In particular, the authors in (He et al., 2022) used autoregression in the proposed ARZIMM model to characterize the longitudinal absolute abundance data for the microbiome study. However, time series methods require the data for each subject to be long enough and equally spaced, which is not usually satisfied in reality. Functional data analysis has also been used to decipher the conditional correlation for high-dimensional data (Zhu et al., 2016; Li and Solea, 2018; Qiao et al., 2019; Solea and Li, 2020). For example, for electroencephalogram (EEG) data (Qiao et al., 2019), proposed a functional graphical model to estimate a network of brain reactions, and (Solea and Li, 2020) proposed the copula Gaussian graphical model for a network of functional magnetic resonance imaging (fMRI) data. Functional data analysis based methods require the data to be densely spaced and the sample size to be large. The requirements inherited in these existing methods are often violated for longitudinal data sets in human microbiome studies.
In this paper, we consider the estimation of MINs from irregularly spaced longitudinal 16S rRNA gene sequencing data. The SPIEC-EASI pipeline can be seen as a special case of the proposed algorithms. The inferences are considered under three conditions. In the first condition, we assume that all subjects share an autocorrelation parameter τ during the trial. For this case, we propose a model named the homogeneous SGGM to characterize MINs. For the homogeneous SGGM, a recursive graphical LASSO algorithm is proposed to compute the L1-penalized maximum likelihood estimate (MLE) of the network. In the second condition, the homogeneous SGGM is extended to the heterogeneous SGGM, allowing different subjects to have their own autocorrelation parameter. For the heterogeneous SGGM, an expectation-maximization (EM)-type algorithm is devised to compute the L1-penalized MLE of the network. In the third condition, the autocorrelation parameters are further allowed to depend on covariates such as sex and race. We show how the algorithm in condition two can be adapted to accommodate the extension. Extensive simulation studies are conducted to compare the proposed algorithms with existing algorithms, including the SPIEC-EASI pipeline and the GGMselect algorithm family (Giraud et al., 2012). The comparisons are conducted under different scenarios, aiming to investigate the robustness of the algorithms to violations of the assumptions of the SGGM. This is necessary since the 16S rRNA gene sequencing data are highly irregular and may fail to exactly satisfy the premises of the proposed models and algorithms. For all the scenarios considered, the proposed algorithms exhibit better performance for network selection than that of other existing algorithms.
In the final part, the proposed models are employed to study a longitudinal gut microbiome data set from a cohort with cystic fibrosis in New Hampshire (Madan et al., 2012). To validate the proposed algorithms, with the estimated MINs, we measure the correlation between the estimated MINs and the corresponding phylogenetic tree. A permutation test is proposed to determine the significance of such a correlation. The results demonstrate strong evidence for the positive correlation between the MINs and the phylogenetic tree, indicating that genetically related taxa also tend to have more/stronger interactions. These findings strengthen the discoveries that have been reported in other studies (Chaffron et al., 2010; Eiler et al., 2012) and provide an empirical basis for using phylogenetic trees as a tool to explore microbial interactions in future studies (Chung et al., 2022).
The paper is organized as follows. In the Materials and methods section, we introduce stationary Gaussian graphical models (SGGMs) and three related inference algorithms. In the Results section, we compare the performance of the proposed algorithms with that of the conventional methods under different scenarios and demonstrate the superiority of the proposed algorithm. We then considered the gut microbiome of subjects with cystic fibrosis. The homogeneous version of the proposed algorithm is employed to identify the MINs of the microbiome. The plausibility of the estimated MINs is discussed. The Discussion section includes a brief review of the models.
Let denote observations of some transformed abundance data of a microbiome with p taxa from subject i at time tk (1 ≤ i ≤ m, 1 ≤ k ≤ ni) so thatkit is appropriate to assume that , where and . The precision matrix is defined as Ω = Σ−1. Then, the nip vector represents all the observations on subject i, and vector y represents the observations on all the m subjects with . For the correlations between the observations, we assume that the observations from different subjects are independent, i.e., for . For observations from the 1 same subject, we assume where D = diag(σ1,···,σp) with diagonal elements of Σ, while is the correlation matrix between and for which the following form is assumed:
The symbol in (Equation 1) stands for the Hadamard product of matrices and R. Here, R is the correlation matrix with respect to covariance matrix Σ, while matrix defines the dampening rates at which the components of decrease as time goes from to . For example, is the dampening rate of correlation to correlation . Theoretically, dampening rates can vary from taxon to taxon and depend on the time points as long as the resulting matrix Hik1k2 is positive definite. However, in this paper, for subject i, we assume that the components of have the same dampening rate. Furthermore, they depend on time points only through the distance between to , i.e., for some decreasing function 0 ≤ gi(·) ≤ 1. Motivated by studies on the longitudinal regression model (Diggle et al., 2002), we assume function gi(·) has the form of . For p = 0, we have , which is referred to as the uniform correlation and can be used to model the spatial correlation. For example, specimens may be collected at different body sites from the same subjects, for which the uniform correlation seems to be a reasonable assumption. On the other hand, the cases of p > 0 can be used to model the irregularly spaced temporal correlation, which typically decreases as the time span increases. In particular, functions and have been used in the marginal regression model for low-dimensional longitudinal data. Here, the parameters τis, which are referred to as autocorrelation parameters, measure the dampening rates that are shared by all the components of .
Without loss of generality, we always employ the correlation function in the following and assume that the observations have been centered so that μ = 0. Let Σi denote the covariance matrix of the observation vector yi. The density function of y is then given by
Since the number of unknown parameters in Ω is much larger than the sample size in the context of the gut microbiome, the maximum likelihood estimate of Ω is unidentifiable, and sparsity is typically assumed in the literature. To this end, penalized maximum likelihood estimation (MLE) is usually adopted, e.g., the SPIEC-EASI model in (Kurtz et al., 2015). The SPIEC-EASI pipeline employes the L1-penalty to achieve the sparsity of Ω for cross-sectional observations. Here, we adopt the same strategy for longitudinal data and use the minimizer of the following L1-penalized negative log-likelihood function as the estimate of network Ω
We refer to model (Equations 2, 3) the stationary Gaussian graphical model (SGGM). Here, stationarity stems from the fact that the same network Ω is shared by all the subjects and at all time points. If the data are independent observations, then (3) can be solved by the graphical LASSO algorithm (Friedman et al., 2008) or the neighborhood method (Meinshansen and Bühlmann, 2006), and SGGM is just reduced to the SPIEC-EASI model. However, since the data are longitudinal and can correlate to each other, the performance of the SPIEC-EASI pipeline is not guaranteed when solving (3).
Notably, in model (2, 3), we assume the same correlation dampening rate τi for all the taxa in the microbiome of subject i. This assumption is motivated by the characteristics of the gut microbiome, where the taxa are typically influenced by the same perturbation sources, such as diet change and disease development. However, even if this assumption is violated and different taxa have different dampening rates, model (2, 3) can still be used as a working model for identifying the network structure, in which τi can be regarded as the mean dampening rate of the whole microbiome. In such cases, models (2, 3) still outperform the SPIEC-EASI pipeline, and the latter ignores the correlation structure of longitudinal data. We demonstrate this point through simulation studies in Section 3.1.
In the following sections, we propose three algorithms to identify the network Ω in (3) based on different dampening rate τi models. An algorithm for the homogeneous SGGM is first considered, and two extensions are proposed that allow the algorithms to deal with cohorts of heterogeneous subjects. These algorithms integrate the graphical LASSO algorithm with other algorithms, e.g., the EM algorithm, to find the penalized maximum likelihood estimator of Ω.
In this section, we consider identifying Ω under the assumption .
Thus, it is assumed that correlations between observations at different time points dampen at the same rate for each subject in the cohort. From the density function (2), the log-likelihood function for is given by
up to a constant. Here, ⊗ stands for the Kronecker product. We use the formulas and . Note that with formula , the last term in (Equation 4) can be rewritten as
where and . By substituting (Equation 5) into (4), we have
where . Here, we use to emphasize that matrix is a function of unknown parameter τ. With (Equation 6) in hand, the sparse network can be achieved by minimization the L1-penalized negative log-likelihood function (3), i.e.,
for given tuning parameter λ > 0. The minimization problem (Equation 7) can be solved through a block coordinate descent procedure. First note that for a given τ, the solution of Ω can be obtained through the following minimization:
which has the same form as the GGM for independent data when the empirical covariance matrix is given by . Consequently, the graphical LASSO algorithm can be used to compute the sparse estimate of Ω in (Equation 8). On the other hand, given Ω, the minimization of (7) with respect to τ does not involve any L1 penalty term and consequently can be carried out through the maximization of the likelihood function (6) with respect to τ. The conventional Newton algorithm can be used in this step. This process continues until convergence is achieved. This algorithm will be referred to as homogeneous longitudinal graphical LASSO (LGLASSO), for which the details are summarized in the following table.

Algorithm 1 Identify the network based on the homogeneous SGGM.
In the homogeneous SGGM, we assume that a single correlation parameter τ applies to all the subjects. In real data analysis, this parameter may vary across subjects. In this section, we consider network identification without assuming . Instead, we assume that the parameters τi’s are independent random variables from the exponential distribution . Consequently, the joint density function for is
from which the likelihood function for Σ and α is given by
With (Equations 9, 10) in hand, the sparse estimate for the network can then be obtained by minimizing the following L1-penalized negative log-likelihood function:
where . Since no explicit form for is available, the expectation-maximization (EM) algorithm is proposed here to find the solution to (11) (Dempster et al., 1977). Since we are considering the negative log-likelihood function in (11), the maximization in the EM algorithm will be replaced by the minimization. The correlation parameters will be taken as the so-called missing data. Recall in the first step of the EM algorithm that the conditional distribution of missing data τ given y, Σ = Σ0, α = α0 has to be derived from (2) and (9) as follows:
For (12), the expectation of the complete log-likelihood function for (y, τ) to (12) has to be computed. Given the joint density function (9) of (y, τ), the expectation of its logarithmic transformation can be shown to be
where in which is defined in the previous section. In the second step of the EM algorithm, the minimum point of the Q function in (13) has to be computed. This, again, is implemented through a block coordinate descent algorithm. First, for fixed Ω, it is straightforward to show that the minimum of the Q function with respect to α is attained at
i.e., the reciprocal of the sample mean of the conditional expectation of τi with respect to density (12). Then, for a given α in (Equation 14), the minimization of (13) with respect to Ω is equivalent to
which can be solved through the graphical LASSO algorithm. The difficult part of this algorithm is to find the expectation , which may not have an explicit form given that is a nonlinear function of τ and the complex form of density function g(τ); therefore, this expectation will be computed through a Monte Carlo method. This algorithm will be referred to as the heterogeneous longitudinal graphical LASSO, for which the details are summarized in the following table. Given initial values α0 and Ω0, tuning parameter λ and error tolerance e > 0, the following algorithm is applied.
In the previous section, we assumed that is constant across the subjects. In this section, we further relax this constraint, and α can be a function of the covariates. Specifically, we assume , where αi has the following form:

Algorithm 2 Identify the network based on the heterogeneous SGGM.
Here, represents covariates such as sex and race, and represents unknown parameters. The model (Equations 9–15) and Algorithm 2 in the previous section can then be revised straightforwardly to accommodate the current regression model (Equation 16). Specifically, first replace the parameter α in (Equations 9, 10) by . Then, the conditional distribution of missing data is given by
Based on (Equation 17), the L1-penalized likelihood estimation of the MIN (11) is then given by
For the same reason, we need to use the EM algorithm to solve the optimization problem (Equation 18). The conditional distribution of missing value is given by (12), with α0 replaced by , from which the Q function is given by
Given the penalized Q function (Equation 19), the current estimate of the network Ω and parameter α, defined as the minimum point of Q, can be computed by the block coordinate descent algorithm. However, unlike (14), in the current case, the estimate of α does not admit an explicit form. We have to use numerical methods such as Newton algorithms to find the minimizer of the Q function (19). Specifically, we solve the following problem by using the BFGS algorithms:

Algorithm 3 Identify the network based on the covariate-adjusted SGGM.
Using in (Equation 20), the estimate of the MIN Ω is given by the solution of Equation (15) through the graphical LASSO algorithm. The algorithm is summarized in the following.
Remark: (1) All three algorithms described above leverage the graphical LASSO algorithm to achieve efficiency even though graphical LASSO itself is devised for independent data. (2) Note that correlation τi for subject i is a random variable. The forecast of τi, is given by the expectation of distribution (12), which is one of the outputs in Algorithms 2 and 3. (3) The proposed algorithms can generate a solution path for a given sequence of tuning parameters λ. To select the optimal network Ω from the candidate networks, model selection criteria can be used, e.g., Akaike information criterion (AIC), Bayesian information criterion (BIC), or cross-validation (CV). In the numerical studies in the next section, we use the extended BIC (EBIC) that is dedicated to the graphical model to select λ (Foygel and Drton, 2010).
In this section, we compare the proposed algorithms, which are referred to as longitudinal graphical LASSO (LGLASSO) algorithms, with other existing network selection methods. These methods include graphical LASSO (Friedman et al., 2008; Friedman et al., 2019), neighborhood (Meinshansen and Bühlmann, 2006), GGMselectC01 and GGMselect-LA algorithms (Giraud et al., 2012; Bouvier et al., 2022). The graphical LASSO and neighborhood algorithms have been used in the SPIEC-EASI pipeline in (Kurtz et al., 2015) to select MINs and both are based on the L1-penalty. On the other hand, the GGMselect algorithm family provides different ways to construct and select the candidate models, e.g., GGMselectC01 employs the estimation procedure in (Wille and Bühlmann, 2006) to construct the candidate models, while GGMselect-LA uses the Fisher random variable to define the criterion for network selection. We demonstrate that the proposed longitudinal graphical LASSO algorithms can outperform these existing algorithms for simulated high-dimensional longitudinal microbiome data.
Let TP,P,FP,N,TN be the numbers of true positive edges, real positive edges, false-positive edges, null edges, and true null edges, respectively. In the following, we use the true/false positive rate (TPR/FPR) to measure the performance of each algorithm. They are defined as TPR = TP/P, FPR = FP/N. Also, for the conventional indices sensitivity/specificity, we have sensitivity = TPR, specificity = TN/N
The simulations consist of three scenarios. In the first scenario, we consider cases where the data follow the SGGM in Sections 2.2 and 2.3. Recall that the SGGM assumes that all the taxa in the microbiome share a common dampening rate τi for subject i. We refer to such microbiomes as having a homogeneous community. In the second scenario, we consider the microbiomes that violate such homogeneity, i.e., having heterogeneous communities. In scenario three, we consider the left-censored microbiome data, which aims to test the robustness of the SGGM with respect to zero inflation. The zero-inflation phenomena are widely observed in 16S rRNA gene sequencing experiments and violate the assumptions of the SGGM. Both the homogeneous and heterogeneous versions of LGLASSO in Sections 2.2 and 2.3 are investigated in each scenario. We use the receiver operating characteristic (ROC) curve to show the superiority of our algorithms over the graphical LASSO and the neighborhood algorithms in all scenarios. In the case of the heterogeneous LGLASSO, we also use (TPR,FPR) to compare the performances of the algorithms in which the networks are selected through the extended BIC (EBIC). The methods of GGMselect-C01 and GGNselect-LA have their own model selection approaches for network selection. The EBIC for the Gaussian graphic model is given by
where ln is the log-likelihood function, n is the sample size, G is the network of interest, |G| is the number of edges in G, p is the number of nodes, and T is the tuning parameter. In (Equation 21), we choose a typical value T = 2 for model selection.
Since homogeneity/heterogeneity involves both microbial community and LGLASSO algorithms, we will use more specific names, homogeneous-subject LGLASSO (heterogenoussubject LGLASSO), to refer to the algorithm to avoid confusion in the following sections.
In a homogeneous microbial community, for each subject, all taxa in the microbiome share a common correlation-dampening rate. Based on whether the subjects share dampening rates, we have the homogeneous-subject LGLASSO in Section 2.2 and heterogeneous-subject LGLASSO in Sections 2.3 and 2.4, respectively. We first consider the former case. Specifically, we consider networks with p = 80 nodes shared by all m = 10 subjects. The precision matrix corresponding to this network is generated through the R package BDgraph (Mohammadi and Wit, 2019) with an edge density equal to 0.1. For subject i (1 ≤ i ≤ m), there are ni observations where ni follows Poisson distribution with the mean value of 10. The spaces between two consecutive time points tij and ti(j+1) are generated by max{Δij, 0.5}, where Δij follows a Poisson distribution with a mean value of 1. Then, the data for subject i are generated with the real autocorrelation parameter in Algorithm 1 given by τ.
First, the homogeneous-subject LGLASSO, graphical LASSO, and neighborhood algorithms are carried out for the simulated data set, from which their respective solution paths are computed. For each path, the connection probability pij for any given node pair (Vi,Vj) is then computed as the proportion of networks that have (Vi,Vj) connected among all the networks on the path. The processes are replicated 50 times, and the final estimate for pij is the average of these 50 estimates of pij. With these pij (1 ≤ i ≤ j ≤ 80) in hand, the ROC curve is computed based on the R package pROC (Robin et al., 2011) and displayed in Figure 1 under the two indicated situations τ = 0.14,0.018. In both cases, the proposed homogeneous-subject LGLASSO algorithm outperforms the graphical LASSO and the neighborhood algorithms. The differences between these ROC curves are more evident for τ = 0.018 than τ = 0.14. We interpret this phenomenon as the proposed LGLASSO can better handle the correlated longitudinal data than other algorithms.
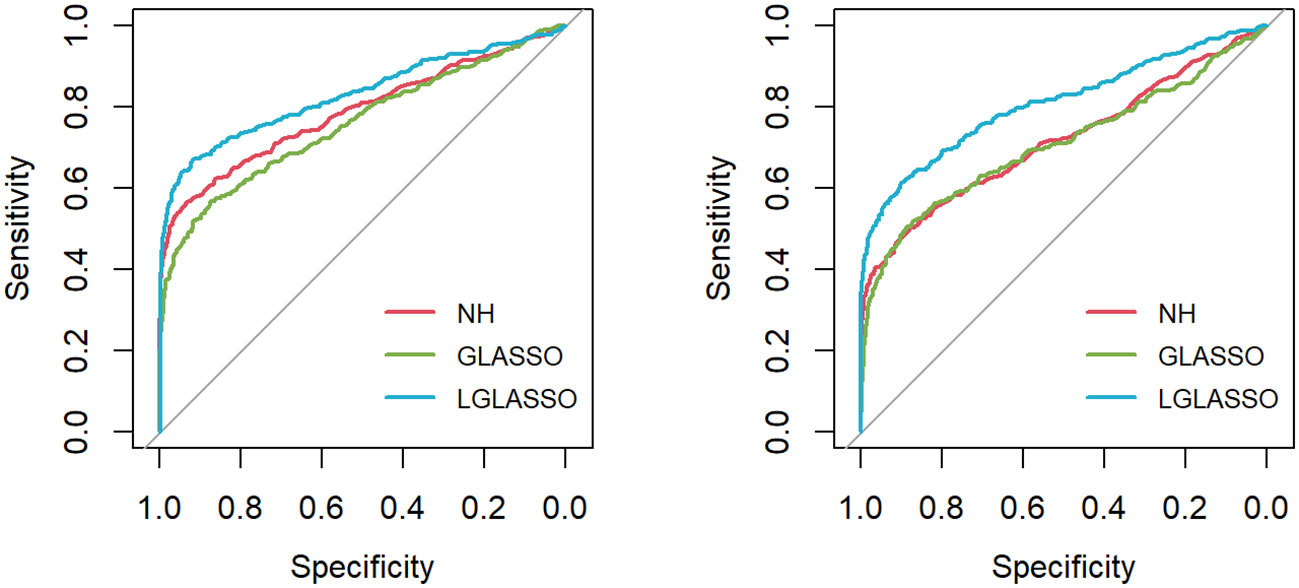
Figure 1 ROC curves for the homogeneous-subject LGLASSO, graphical LASSO, and neighborhood algorithms. The data are generated based on the homogeneous SGGM in Section 2.2. The dampening rates for the left and right plots are τ = 0.36,0.018, respectively.
Next, we consider the heterogeneous-subject LGLASSO and covariate-adjusted LGLASSO algorithms proposed in Sections 2.3 and 2.4, respectively. For ease of exposition, we consider the heterogeneous-subject LGLASSO as a special covariateadjusted LGLASSO in which vector 1 is the only covariate. As in Scenario 1, we still consider a network with p = 80 nodes and an edge density equal to 0.1. For each subject of m = 10 subjects, the spaces between consecutive observations are generated similarly. Since the dampening rate τ is an exponential random variable in the heterogeneous-subject LGLASSO, we generate random samples as the individual τis from the following two settings, Eτ = 0.14,0.018. Then with the same replication scheme as above, the ROC curves are computed and plotted in Figure 2. Similar to the case of homogeneous-subject LGLASSO, these ROC curves also demonstrate the superiority of heterogeneous-subject LGLASSO over other methods, especially for the higher correlation case Eτ = 0.018.
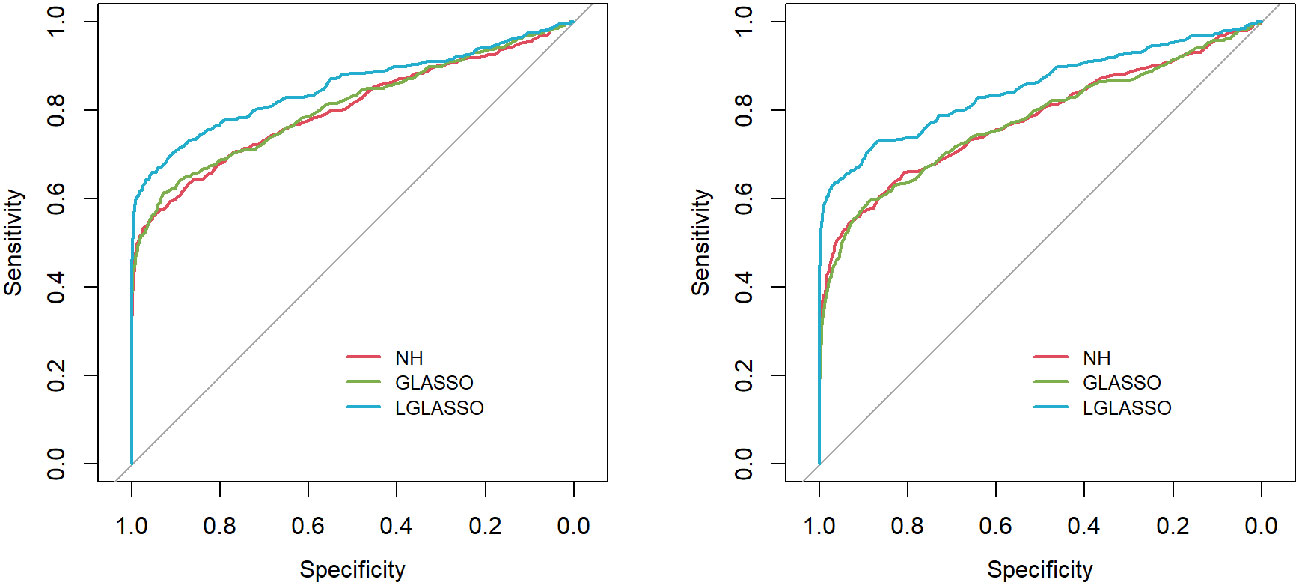
Figure 2 ROC curves for the heterogeneous-subject LGLASSO, graphical LASSO, and neighborhood algorithms. The data are generated based on the heterogeneous SGGM in Section 2.3. The average dampening rates for the left and right plots are Eτ = 0.14,0.018, respectively.
We then employ the EBIC (21) to select the optimal model from the solution path. Specifically, two covariates x1 and x2 are introduced in which x1 ∼ N(0,1) and P(x2 = 0) = P(x2 = 1) = 0.5. The three settings for their coefficients (α1, α2) in Equation (16) are (α1, α2) = (0,0), (0.5, 0.5),(1,1) while the intercept is always α0 = 4. Note that with (α1, α2) = (0,0), the covariates have no effect on the dampening rate, and therefore, the model reduces to the heterogeneous-subject LGLASSO in Section 2.3. For each simulated data set, the pairs (TPR,FPR) can be computed. The process is replicated 50 times and the averages of these 50 (TPR,FPR) are listed in Table 1. Note that for GGMselect-C01 and GGMselect-LA listed in Table 1, we used their own model selection method instead of the EBIC. From Table 1, we can see that the proposed LGLASSO algorithm obtains the highest TPR and lowest FPR in most cases. In other words, with the EBIC as the model selection method, the heterogeneous-subject LGLASSO algorithms still have the best performance among the algorithms considered.
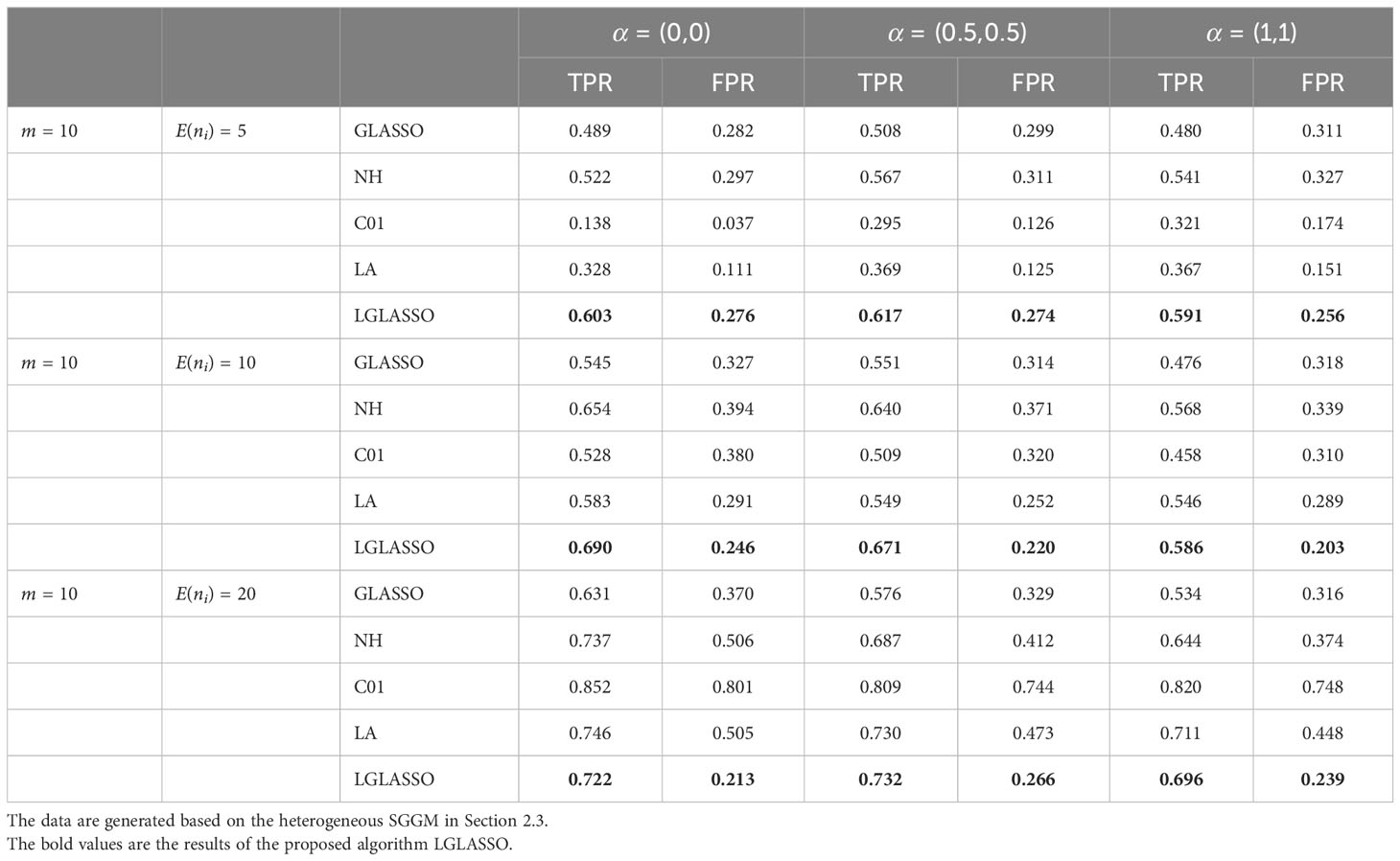
Table 1 Performance comparison of heterogeneous-subject LGLASSO (LGLASSO), graphical LASSO (GLASSO), neighborhood (NH) algorithm, GGMselect-C01 (C01), and GGMselect-LA (LA).
In Section 2.1, we mentioned that the taxa from the same subject are supposed to share the same correlation-dampening rate. In this section, we show by simulation that even if the microbiome fails to satisfy this assumption, the proposed algorithm can still outperform the conventional methods. Specifically, in the heterogeneous microbial community, the taxa have different correlation-dampening rates for each subject. For ease of exposition, we consider a simple situation where the microbiome consists of two subcommunities, A and B, which have different correlation-dampening rates τA and τB, respectively. Furthermore, we assume that these two communities are independent of each other, i.e., the taxa in community A (B) can correlate with one another; however, they are independent of the taxa in community B (A).
Specifically, for p = 80 taxa, we assume the first 40 taxa are in community A, and the other 40 taxa are in community B. As in Scenario 1, we first investigate the performance of the homogeneous-subject LGLASSO algorithm. For m = 10, Eni = 10, τA = 0.018, with a given τB, the data for communities A and B are generated by the same method as that in Scenario 1. Since we assume these two communities are independent, the complete data set is simply a combination of the data sets from communities A and B. Three solution paths for the homogeneous-subject GLASSO, graphical LASSO, and neighborhood algorithms are then computed based on the combined data set from which the estimates of the connection probability pijs are computed the same way as in Scenario 1. Based on these pijs, the ROC curves are plotted in Figure 3 for the three settings, τB = 0.36,0.049, and 0.018. Obviously, for heterogenous communities, the proposed homogeneous-subject LGLASSO still outperforms the other two methods, especially when the correlation is higher (i.e., τB = 0.018)
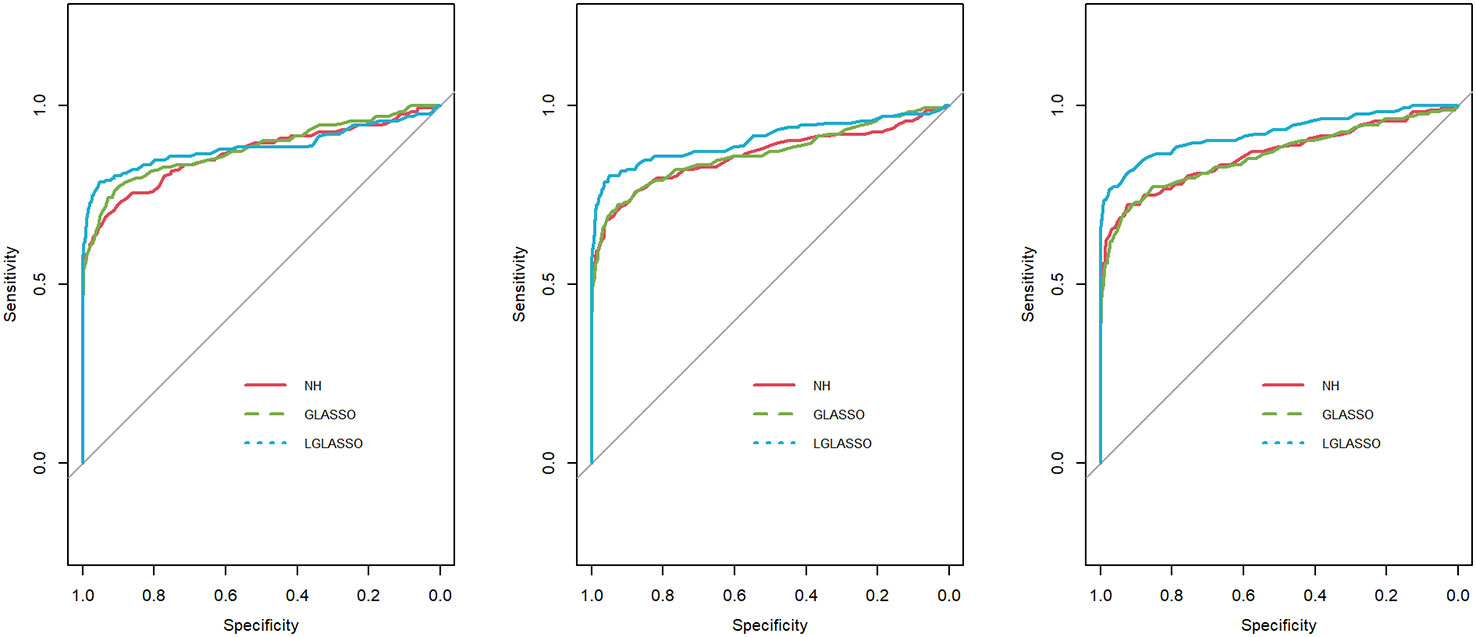
Figure 3 ROC curves for the homogeneous-subject LGLASSO, graphical LASSO, and neighborhood algorithms. The data are generated from homogeneous SGGM with a heterogeneous microbiome. The dampening rates, from left to right, are (τA,τB) = (0.018,0.36), (0.018,0.049), and (0.018,0.018), respectively.
Next, we consider the performance of the heterogeneous-subject LGLASSO. The data are generated from heterogeneous subjects with heterogeneous microbial communities. For ease of exposition, we focus on the heterogeneous-subject model in Section 2.3, and the covariate-adjusted model in Section 2.4 is omitted here. Specifically, for subject i, the corresponding microbiome consists of two microbial communities that have correlation dampening rates τiA and τiB (1 ≤ i ≤ m) and satisfy τiA ∼ exp(α1), τiB ∼ exp(α2). The parameter settings for (EτiA, EτiB) include the following three cases: (EτiA, EτiB) = (0.036,0.36),(0.036,0.14),(0.036,0.049). For each (α1, α2) pair, 10 random samples are generated for (τiA,τiB) from the corresponding exponential distributions, which are used as the real autocorrelation parameters for the 10 subjects. With (τiA,τiB), ni measurements for subject i are then generated in the same way as in Figure 3 with Eni = 10. With these data, the heterogeneous-subject LGLASSO, graphical LASSO, and neighborhood algorithms are carried out, and the resulting ROC curves are presented in Figure 4. These ROC curves demonstrate that with heterogeneous communities and heterogeneous subjects, the proposed algorithm LGLASSO still outperforms graphical LASSO and neighborhood methods when the correlations between data are reasonably high.
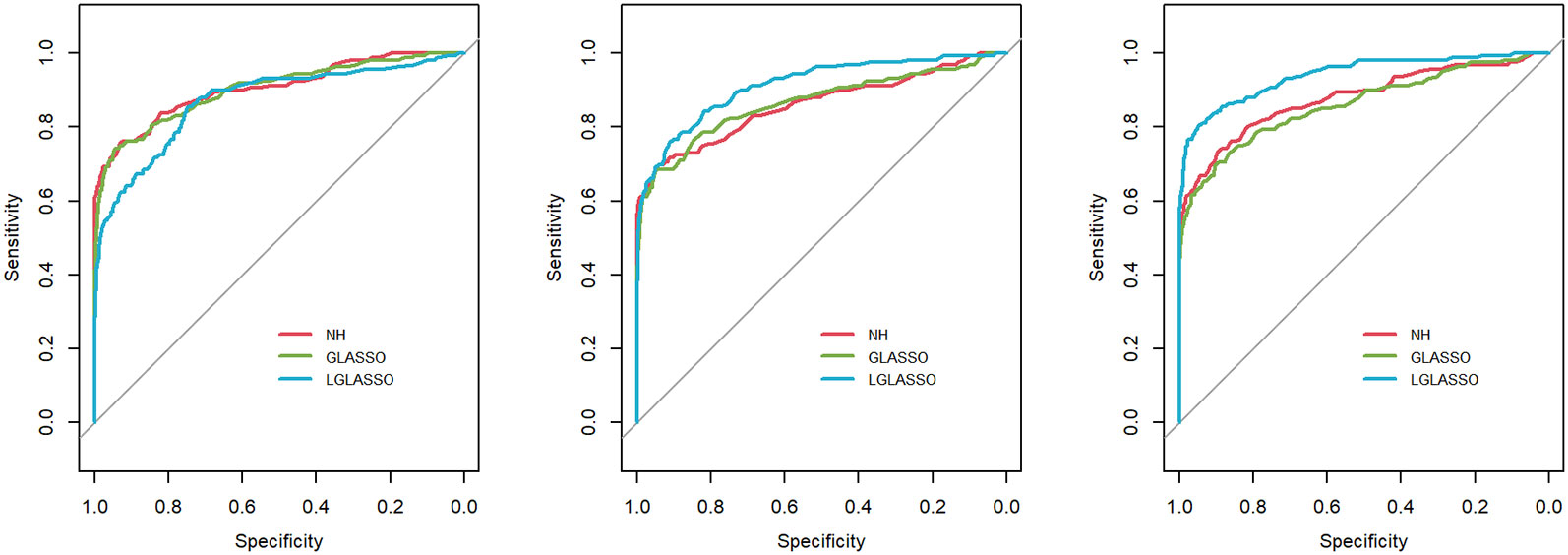
Figure 4 ROC curves for the heterogeneous-subject LGLASSO, graphical LASSO, and neighborhood algorithms. The data are generated from heterogeneous SGGM with a heterogeneous microbiome. The average dampening rates, from left to right, are (EτiA, EτiB) = (0.036,0.36), (0.036,0.14), and (0.036,0.049), respectively.
In this section, we consider the performance of the algorithms when the data generated from the SGGM are left-censored. Left-censored data represent the transformed zero-inflated relative abundance of 16S rRNA gene sequences. An example of such transformations is shown in Section 3.2 in the real data analysis. Here, we investigate the influence of zero inflation on the performance of the proposed algorithms. As in Scenario 1, we consider left-censored homogeneous-subject LGLASSO with m = 10, Eni = 10 (1 ≤ i ≤ m) and τ = 0.018. Under this setting, the data are first generated in the same way as in Scenario 1. Using the generated data, we consider the following censoring scheme: given 0< q1< 1, for each taxon, all observations with values less than quantile yq1 are replaced by yq1 with a probability of q2. This censoring scheme is motivated by the observation that the smaller the relative abundance is, the higher the probability is that this taxon is missed by the sequencing experiments. Here, we consider six combinations of (q1, q2), i.e., (0.1,0.3),(0.1,0.5),(0.1,0.7),(0.4,0.3),(0.4,0.5),(0.4,0.7). For each of these combinations, the ROC curves corresponding to the respective solution paths of the homogeneous-subject LGLASSO, graphical LASSO, and the neighborhood algorithms are shown in Figure 5. Obviously, even though the proposed homogeneous-subject LGLASSO algorithm outperforms the other algorithms, zero inflation can significantly affect its performance, and the advantage of LGLASSO diminishes when the proportion of zero is high. The same investigations are carried out for the heterogeneous-subject LGLASSO. The procedure is the same as the above homogeneous case except that the dampening rate is random with Eτi = 0.018 for (1 ≤ i ≤ m). The resulting ROC curves are depicted in Figure 6, from which we can see a similar pattern as the ones in Figure 5.
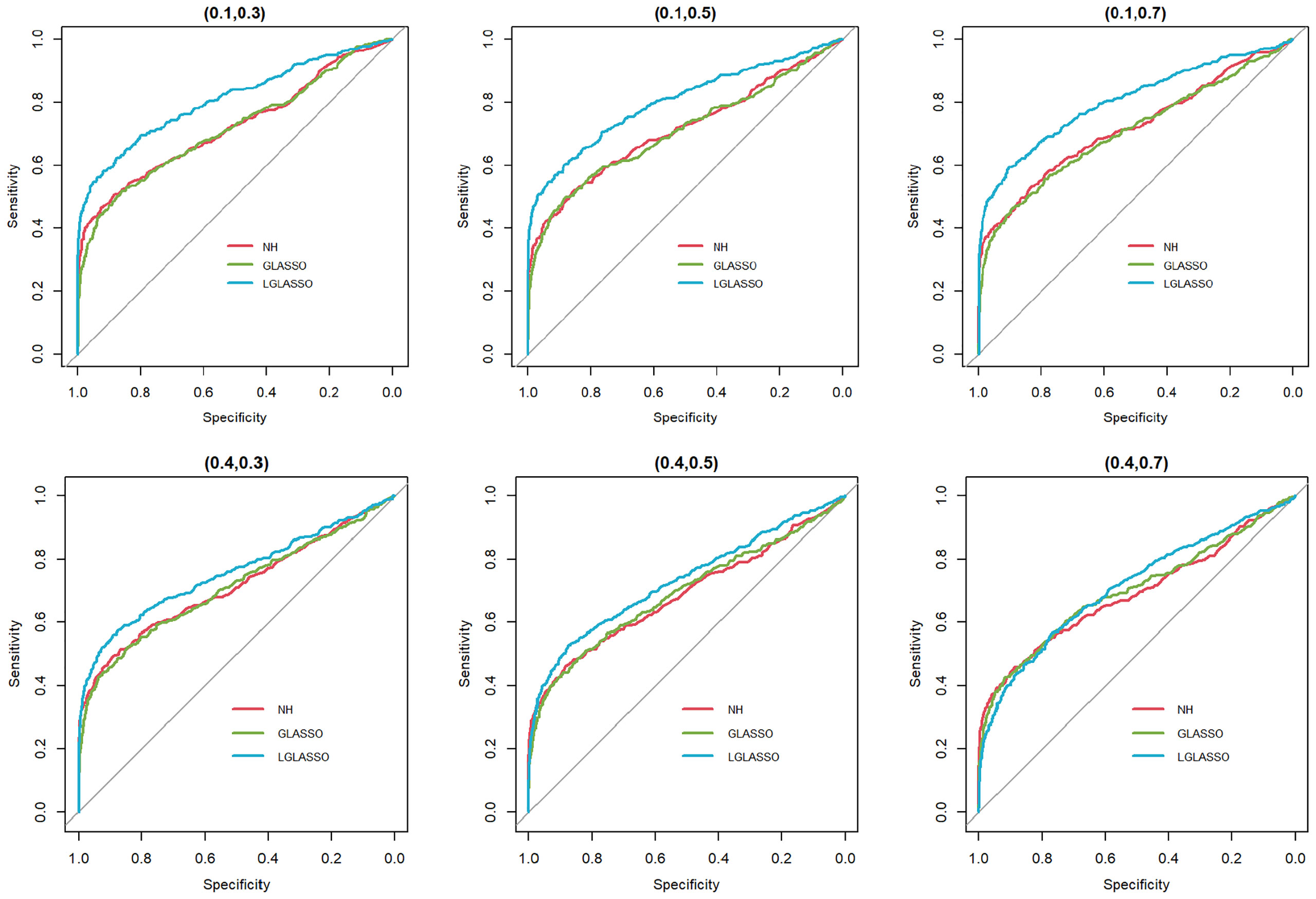
Figure 5 ROC curves for the homogeneous-subject LGLASSO, graphical LASSO, and neighborhood algorithms. The data are generated from a left-censored homogeneous SGGM model. The first number in parentheses is the quantile, and the second is the probability, which are the parameters for data censoring.
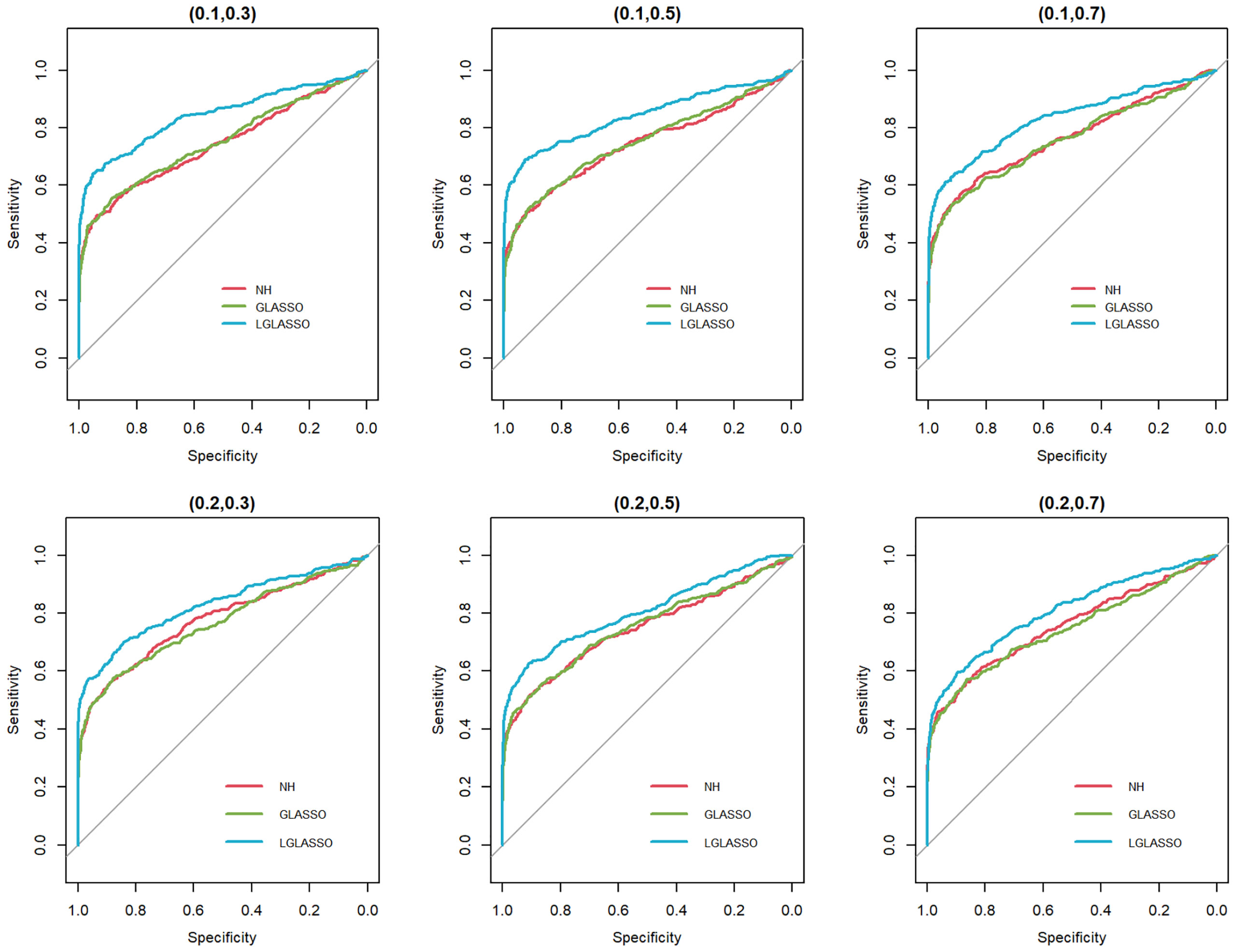
Figure 6 ROC curves for the heterogeneous-subject LGLASSO, graphical LASSO, and neighborhood algorithms. The data are generated from a left-censored heterogeneous SGGM model. The first number in parentheses is the quantile, and the second is the probability, which are the parameters for data censoring.
In this section, a longitudinal data set from a cohort of children with cystic fibrosis was investigated using the homogeneous version of the proposed algorithm in Section 2.2. Specifically, stool samples from thirty-eight children were collected from children aged 6 months to 51 months old (Madan et al., 2012). The number of observations from each child ranged from 2 to 17. Each observation consisted of the abundance of 16,383 amplicon sequence variants (ASVs) of the 16S rRNA gene. These sequences were then collapsed to the genus level using the R package DADA2 (Callahan et al., 2016). The sequences that had no genus-level information were dropped. Then, all the taxa with a proportion of nonzero observations less than 10% were combined, which was referred to as the composite taxon. There were 83 total remaining taxa. The observations of zeros for each of these 83 taxa were replaced by the minimum abundance of that taxon divided by 10. The log-ratio transformation was then carried out to obtain the relative abundance, in which the composite taxon was used as the reference. Similar log-ratio transformations have been used and justified in empirical studies (Kurtz et al., 2015; Greenacre et al., 2021).
The application of the homogeneous model in Section 2.2 to the transformed data yielded the estimated network, which is displayed in Figure 7. Based on the modularity maximization algorithm (Newman, 2006; Blondel et al., 2008), five communities were identified in the estimated network, which is listed in Table 2.
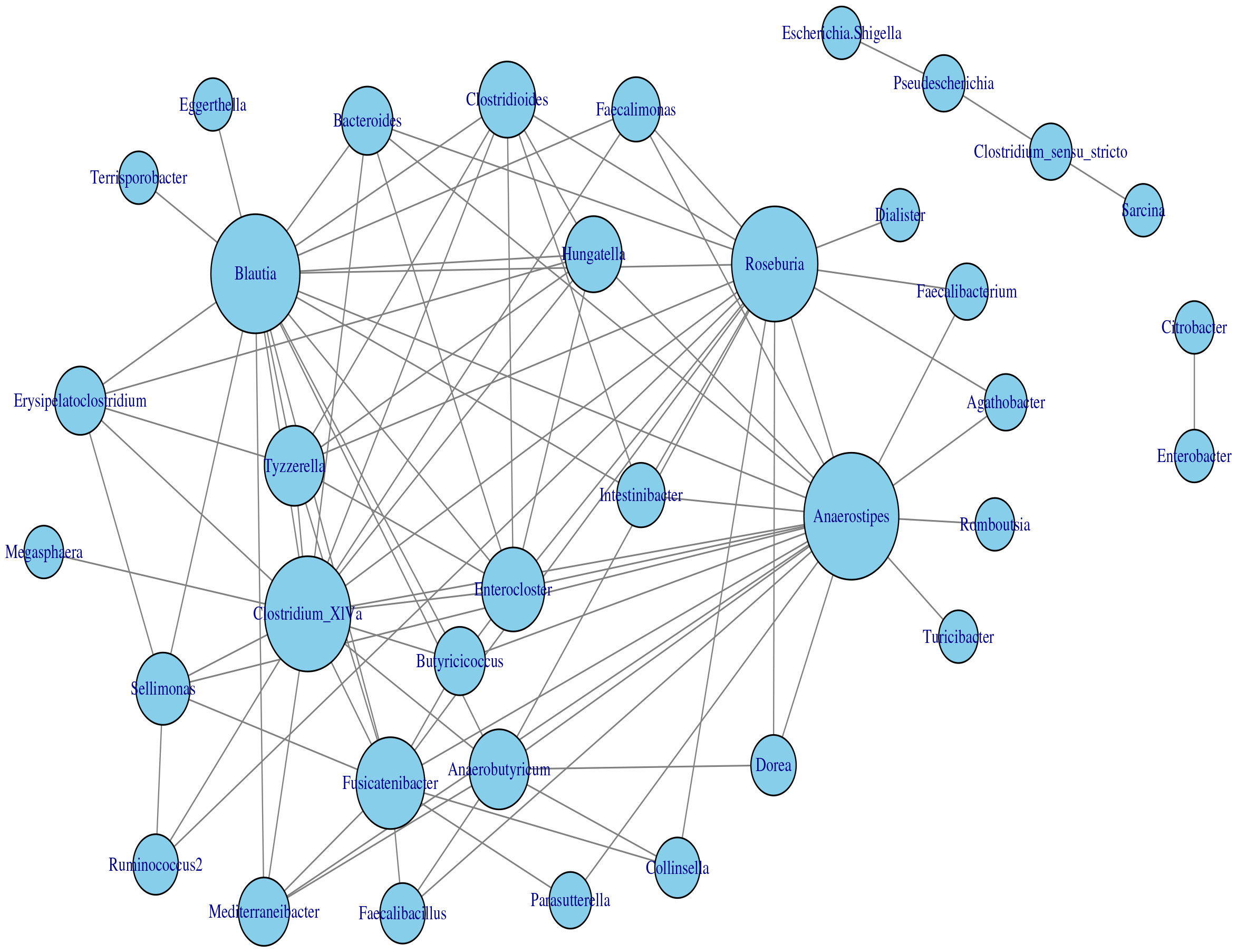
Figure 7 Microbial interaction network generated with the homogeneous LGLASSO based on the gut microbiome abundance data in Section 3.2.

Table 2 Five communities selected by maximizing the modularity of the estimated MIN in Figure 7.
To show that the estimated network can reveal the true structure of the underlying network, we investigated the relationship between the estimated network and the phylogenetic tree of the 82 taxa (the composite network was excluded here). The phylogenetic tree constructed from the same data set is presented in Figure 8 and demonstrates the evolutionary relationship among these taxa. Our underlying hypothesis is that microbial taxa that are closer in terms of evolutionary history also have more/stronger interactions in the human body. To validate this hypothesis, the null hypothesis is set as follows: the estimated network in Figure 7 is independent of the phylogenetic tree in Figure 8. Correlation between the estimated network and phylogenetic tree is employed to test this hypothesis. In particular, we computed the distances between two taxa in the estimated network and the phylogenetic tree. Here, the distance between taxa A and B is defined as the length of the shortest path from A to B in the estimated network (phylogenetic tree). If no paths exist between two taxa in the network (phylogenetic tree), that pair will be excluded from the following computations. Let d1 and d2 be the distance vectors for all possible pairs of taxa from the estimated network and phylogenetic tree, respectively. The correlation between d1 and d2 is used to measure the relatedness between the network and phylogenetic tree. This correlation was determined to be r0 = 0.333 for the tuning parameter selected by the EBIC.
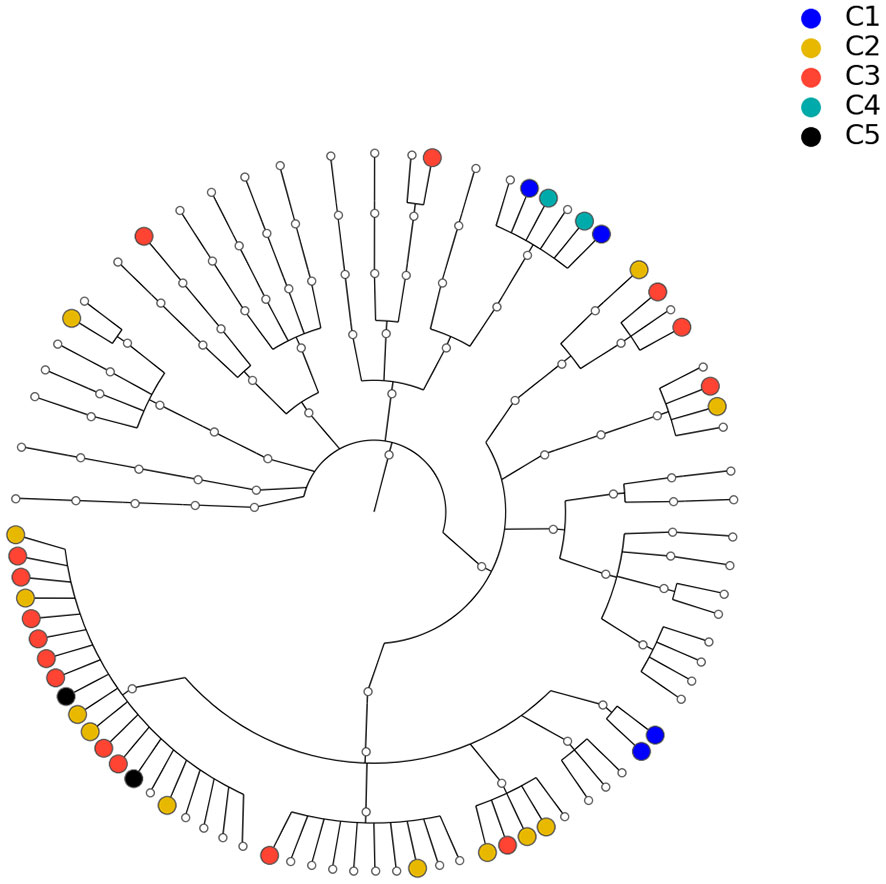
Figure 8 Phylogenetic tree for the 82 microbial taxa in Section 3.2. Dots with different colors correspond to different communities listed in Table 2.
To understand the significance of r0 against the null hypothesis, we use the permutation method to estimate the null distribution. Specifically, we keep the structure of the estimated network unchanged and permute the order of the 82 taxa m = 5000 times on the estimated network. be the distance vectors of the network for the ith permutation. Then, the correlations , which collectively depict the null distribution, can be derived. Given r(i), the p value of r0 is smaller than 1/5000, which means that the correlation between the estimated network and phylogenetic tree is statistically significant, i.e., the data support the hypothesis that microbial taxa with closer evolution histories tend to have more/stronger interactions.
It should be noted that some related findings have been reported in the literature. In (Chaffron et al., 2010), the authors performed a global meta-analysis of previously sampled microbial lineages in the environment. They found that genomes from coexisting taxa tended to be more similar than expected by chance, both with respect to pathway content and genome size. The studies in (Eiler et al., 2012) also revealed that ecological coherence is often dependent on taxonomic relatedness. These studies employed coefficient-based methods such as Fisher’s exact test to infer the interaction of taxa. This can lead to a misleading conclusion. It is known that the correlation between two taxa, A and B, may be induced by their correlation with a third taxon C, even though A and B are independent if C is fixed. In the current study, the interaction between the taxa is defined based on the conditional correlation coefficient, which by its definition eliminates the possible spurious correlation between taxa A and B induced by taxon C. Therefore, by using abundance instead of cooccurrence information and boosted by the proposed methods, we reach a more convincing and robust conclusion than existing ones in the literature.
The results above are derived with the fixed tuning parameter selected by the EBIC. The correlations between the estimated MIN and phylogenetic tree are actually robust with respect to the tuning parameter. To demonstrate this point, let us consider the networks generated from other tuning parameter choices. Specifically, for each of the 40 tuning parameters ranging from λ = 7 to 13, the same homogeneous model and the permutation test are carried out. The estimated and permuted correlations are displayed in Figure 9 in the form of a boxplot. From left to right, the boxplots in Figure 9 correspond to the tuning parameters increasing from 7 to 13. The dots linked by the line represent the correlations between the estimated MINs and the phylogenetic tree, while others correspond to the correlations computed from the permuted MINs. The most prominent feature of Figure 9 is that for all 40 cases, the observed correlations between the MINs and the phylogenetic tree are positive; in the first half of the boxplots, the estimated correlations are also significant. It should be noted that even though the estimated correlations in the second half of the boxplots do not appear significant, it does not mean that the edges in these estimated networks do not reflect the true structure. Instead, the insignificance may stem from the fact that the second half of the networks are sparser. A sparse network will generate shorter vectors d1, d2, which in turn increase the variability of the correlation estimates.
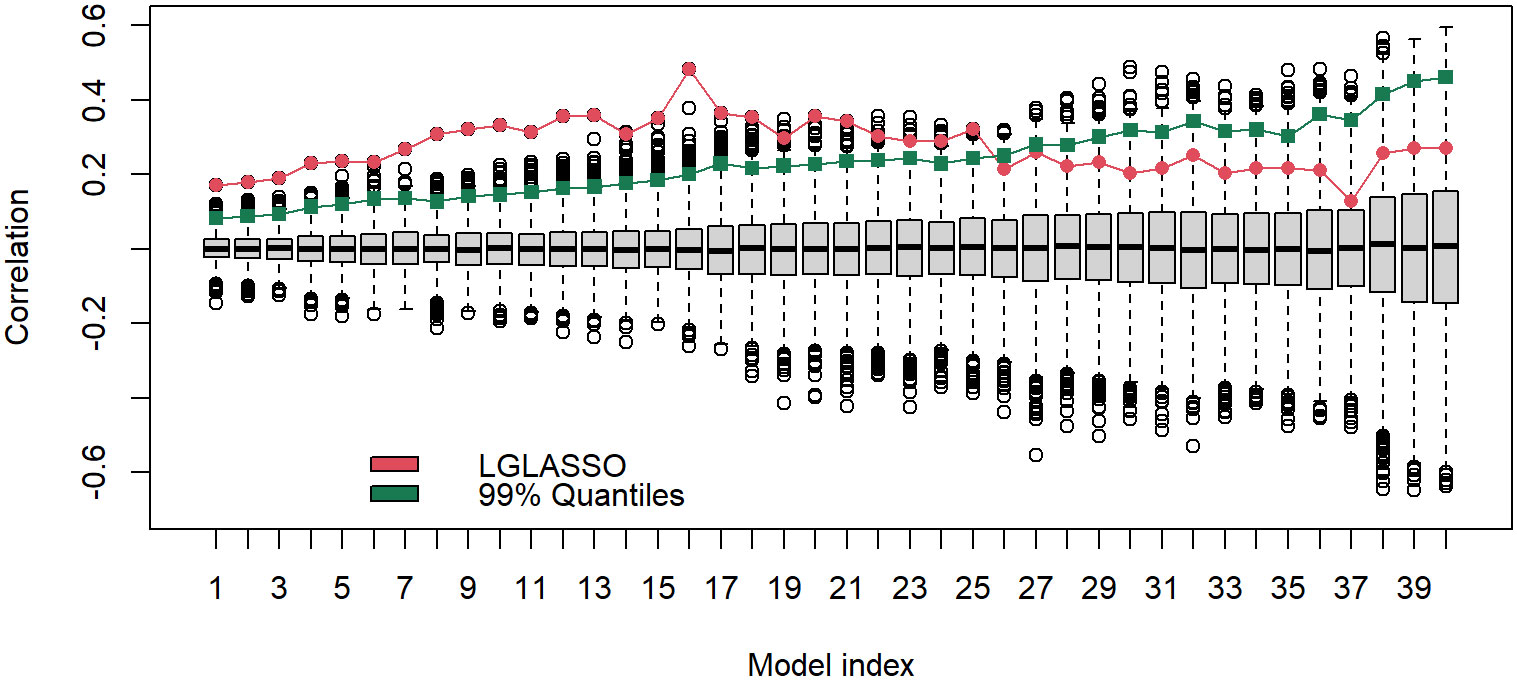
Figure 9 Boxplots of correlations between the networks and phylogenetic tree that correspond to, from left to right, the tuning parameters λ increasing from 7 to 13. For a given boxplot, the red dot represents the correlations from the original estimated networks, and the black dots represent correlations computed from 5000 permutations of the estimated network. The green dot represents the 1% upper quantile of the 5000 permutation correlations.
Finally, let us compare the results of the proposed algorithm with those of the SPIECEASI algorithm in (Kurtz et al., 2015). Though in the original form of the SPIEC-EASI algorithm, the centered log-ratio transformation was employed for the relative abundances of the taxa, we use the additive log-ratio transformation here. Note that the SPIEC-EASI algorithm includes both graphical LASSO and neighborhood algorithms. We restrict ourselves to networks with edges between 20 and 1300, which we believe cover all biologically meaningful cases. First, we compute the solution path for each algorithm. For the networks on each solution path, their correlations with the phylogenetic tree are calculated. Figure 10 displays the correlations for the three solution paths corresponding to the three algorithms. It is evident that for most of the solution paths, the networks generated through the proposed algorithm have higher correlations with the phylogenetic tree than those generated through the SPIEC-EASI algorithms. The correlations at the beginning parts of the three paths appear to be comparable. We attribute this to the fact that the networks at the beginning parts are much sparser, leading to a smaller sample size when computing the correlations. A smaller sample size can blur the comparison of different algorithms, as shown in Figure 9. In other words, if we assume that the phylogenetic tree represents the true structure of the MIN, then the proposed algorithms have greater power in the identification of the MIN than that of the SPIEC-EASI algorithm.
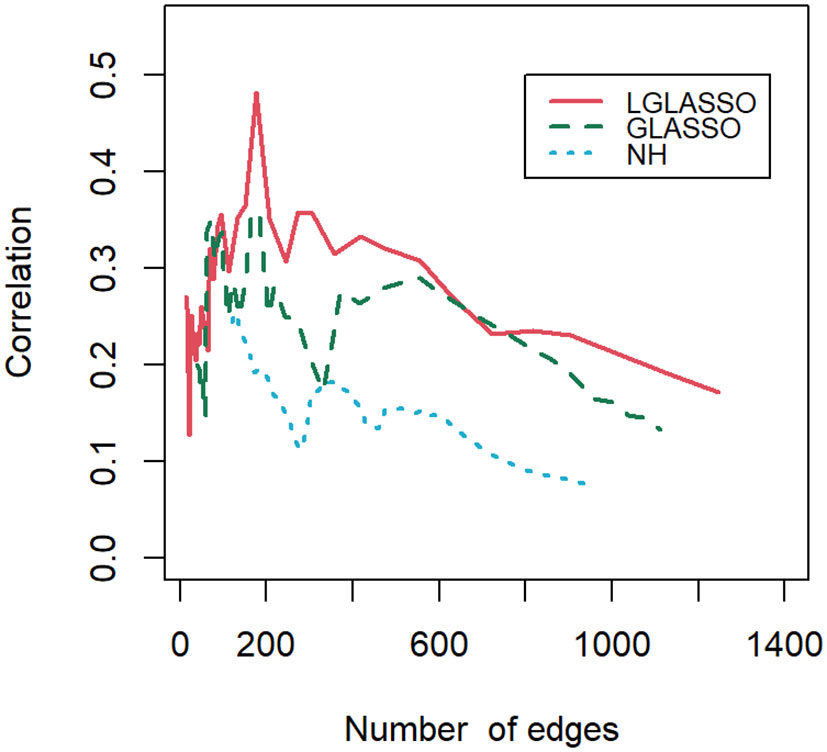
Figure 10 Correlations between the phylogenetic tree and networks selected by the LGLASSO, GLASSO, and NH methods for a sequence of tuning parameters.
Identifying microbial interaction networks is critical for understanding the causal relationship among taxa. However, it remains a challenging problem since observations of the microbiome have many distinct features, such as high dimensionality, zero inflation, and composition. In this study, we study network identification based on irregularly spaced longitudinal 16S rRNA gene sequencing data. For microbial abundance data, the correlations between different time points are typically omitted in practice due to technical difficulties. In this study, a model named SGGM is proposed to characterize the correlations in the longitudinal microbial abundance data. Efficient inference algorithms for estimating microbial interaction networks are devised based on the SGGM. Through the use of simulated data, our model and algorithms show that they have more power to identify microbial interaction networks than conventional methods, where the correlations are just omitted. Furthermore, the algorithms demonstrate their robustness when the data do not follow the SGGM strictly, e.g., heterogeneous microbial communities and zero inflation. The proposed method is employed to study the microbiomes from a cohort with cystic fibrosis disease. The relationship between the microbial interaction networks and the phylogenetic tree is revealed, strengthening previous literature results. It is also necessary to highlight the limitations of SGGM and the related LGLASSO algorithms. First, SGGM only models the stationary process, i.e., the microbial correlation structure remains the same during the data collection process. This may or may not be a valid assumption for a specific situation. For example, the subjects may get vaccinated during the data collection period, which may affect how the constituent microbes interact with each other. If this is the case, SGGM should not be used. Second, SGGM assumes a constant dampening rate τ for all the taxa in the microbiome within the same subject. We only studied the robustness of the LGLASS algorithms with respect to τ under very simple cases, i.e., two independent sub-microbial communities with different dampening rates. In reality, things can get very involved. For example, the whole community may have multiple sub-communities, and each of them has its own dampening rate, e.g., community A evolves with a high frequency, community B evolves with a medium frequency, community C evolves with a low frequency, and communities A, B, and C are related to each other in some way. In such cases, it should be cautious to use SGGM to identify the underlying network. Some form of cross-validation is recommended in such situations.
The original contributions presented in the study are included in the article/supplementary material. Further inquiries can be directed to the corresponding author. The proposed algorithms are available in the R package lglasso, which can be accessed at https://github.com/jiezhou-2/lglasso. The code for reproducing the simulation results in Section 3.1 can be found at https://jiezhou-2.github.io/lglasso_data_analysis/index.html. For access to the cystic fibrosis data used in Section 3.2, please contact the corresponding author at QW5uZS5HLkhvZW5AZGFydG1vdXRoLmVkdQ==.
JZ: Conceptualization, Formal analysis, Investigation, Methodology, Software, Validation, Visualization, Writing – original draft, Writing – review & editing. JG: Conceptualization, Formal analysis, Funding acquisition, Investigation, Methodology, Supervision, Writing – review & editing. WV: Conceptualization, Methodology, Writing – review & editing. HC: Investigation, Writing – review & editing. SL: Writing – review & editing. JM: Data curation, Funding acquisition, Project administration, Writing – review & editing. MC: Conceptualization, Resources, Writing – review & editing. AH: Conceptualization, Formal analysis, Funding acquisition, Investigation, Methodology, Project administration, Supervision, Writing – original draft, Writing – review & editing.
The author(s) declare financial support was received for the research, authorship, and/or publication of this article. This work is supported by the NIH NIGMS grants P20GM125498, P20GM130454, R01LM012723 and NIAID grant U19AI145825.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Arumugam M., Raes J., Pelletier E., Le Paslier D., Yamada T., Mende D. R., et al. (2011). Enterotypes of the human gut microbiome. Nature 473, 174–180. doi: 10.1038/nature09944
Avella-Medina M., Battey H. S., Fan J., Li Q. (2018). Robust estimation of high-dimensional covariance and precision matrices. Biometrika 105, 271–284. doi: 10.1093/biomet/asy011
Bach F. R., Jordan M. I. (2004). Learning graphical models for stationary time series. IEEE Trans. Signal process. 52, 2189–2199. doi: 10.1109/TSP.2004.831032
Barberan A., Bates S. T., Casamayor E. O., Fierer N. (2012). Using network analysis to explore co-occurrence patterns in soil microbial communities. ISME J. 6, 343–351. doi: 10.1038/ismej.2011.119
Blondel V. D., Guillaume J.-L., Lambiotte R., Lefebvre E. (2008). Fast unfolding of communities in large networks. J. Stat. Mech. 2008 (10), P10008. doi: 10.1088/1742-5468/2008/10/P10008
Bouvier A., Giraud C., Huet S., Verzelen N. GGMselect: Gaussian Graphs Models Selection, 2022, version: 0.1-12.5 (CRAN). Available at: https://CRAN.R-project.org/package=GGMselect.
Callahan B. J., McMurdie P. J., Rosen M. L., Han A. W., Johnson A. J. A., Holmes S. P. (2016). DADA2: High-resolution sample inference from Illumina amplicon data. Nat. Methods 13, 581–583. doi: 10.1038/nmeth.3869
Chaffron S., Rehrauer H., Pernthaler J., Von Mering C. (2010). A global network of coexisting microbes from environmental and whole-genome sequence data. Genome Res. 20, 947–959. doi: 10.1101/gr.104521.109
Chen I., Kelkar Y. D., Gu Y., Zhou J., Qiu X., Wu H. L. (2017). Highdimensional linear state space models for dynamic microbial interaction networks. PloS One 12 (11), e0187822. doi: 10.1371/journal.pone.0187822
Chung H. C., Gaynanova I., Ni Y. (2022). Phylogenetically informed Bayesian truncated copula graphical models for microbial association networks. Ann. Appl. Stat. 16 (4), 2437–2457. doi: 10.1214/21-AOAS15
Dempster A. P., Laird N. M., Rubin D. B. (1977). Maximum likelihood from incomplete data via the EM algorithm. J. R Stat. Soc. Ser. B Methodol. 39, 1–22. doi: 10.1111/j.2517-6161.1977.tb01600.x
Diggle P., Diggle D., Diggle P. J., Heagerty P., Liang K.-Y., Zeger S., et al (2002). Analysis of Longitudinal Data (London: Oxford University Press). doi: 10.1093/oso/9780198524847.001.0001
Eiler A., Heinrich F., Bertilsson S. (2012). Coherent dynamics and association networks among lake bacterioplankton taxa. ISME J. 6, 330–342. doi: 10.1038/ismej.2011.113
Epskamp S., Waldorp L. J., Mõttus R., Borsboom D. (2018). The gaussian graphical model in cross-sectional and time-series data. Multivariate Behav. Res. 53, 453–480. doi: 10.1080/00273171.2018.1454823
Fang H., Huang C., Zhao H., Deng M. (2017). gCoda: conditional dependence network inference for compositional data. J. Comput. Biol. 24, 699–708. doi: 10.1089/cmb.2017.0054
Faust K., Raes J. (2012). Microbial interactions: from networks to models. Nat. Rev. Microbiol. 10, 538–550. doi: 10.1038/nrmicro2832
Foygel R., Drton M. (2010). Extended Bayesian Information Criteria for Gaussian Graphical Models. In: Advances in Neural Information Processing Systems (Curran Associates, Inc). Available online at: https://papers.nips.cc/paper/2010/hash/072b030ba126b2f4b2374f342be9ed44-Abstract.html (Accessed November 21, 2021).
Friedman J., Hastie T., Tibshirani R. (2008). Sparse inverse covariance estimation with the graphical LASSO. Biostatistcs 9, 432–441. doi: 10.1093/biostatistics/kxm045
Friedman J., Hastie T., Tibshirani R. (2019). Graphical Lasso: Estimation of Gaussian Graphical Models Version: 1.11. Available online at: https://CRAN.R-project.org/package=glasso.
Gause G. F. (1934). The Struggle for Existence (New York: Williams and Wilkins). doi: 10.5962/bhl.title.4489
Giraud C., Hue S., Verzelen N. (2012). Graph selection with GGMselect. Stat. Appl. Genet. Mol. Biol. 11 (3). doi: 10.1515/1544-6115.1625
Greenacre M., Martínez-Alvaró M., Blasco A. (2021). Compositional data analysis of microbiome and any-omics datasets: A validation of the additive logratio transformation. Front. Microbiol. 12. doi: 10.3389/fmicb.2021.727398
Harcombe W. (2010). Novel cooperation experimentally evolved between species. Evolution 64, 2166–2172. doi: 10.1111/j.1558-5646.2010.00959.x
He L., Wang C., Hu J., Gao Z., Falcone E., Holland S. M., et al. (2022). ARZIMM: A novel analytic platform for the inference of microbial interactions and community stability from longitudinal microbiome study. Front. Genet. 13. doi: 10.3389/fgene.2022.777877
Jiang D., Sharpton T., Jiang Y. (2020). Microbial interaction network estimation via bias-corrected graphical lasso. Stat Biosci. 13, 329–350. doi: 10.1007/s12561-020-09279-y
Kurtz Z. D., Müller C. L., Miraldi E. R., Littman D. R., Blaser M. J., Bonneau R. A. (2015). Sparse and compositionally robust inference of microbial ecological networks. PloS Comput. Biol. 11, e1004226. doi: 10.1371/journal.pcbi.1004226
Li B., Solea E. (2018). A nonparametric graphical model for functional data with application to brain networks based on fMRI. J. Am. Stat. Assoc. 113, 1637–1655. doi: 10.1080/01621459.2017.1356726
Madan J. C., Koestler D. C., Stanton B. A., Davidson L., Moulton L. A., Housman M. L., et al. (2012). Serial analysis of the gut and respiratory microbiome in cystic fibrosis in infancy: interaction between intestinal and respiratory tracts and impact of nutritional exposures. mBio 3, e00251–e00212. doi: 10.1128/mBio.00251-12
Meinshansen N., Bühlmann P. (2006). High dimensional graphs and variable selection with lasso. Ann. Stat 34, 1436–1462. doi: 10.1214/009053606000000281
Mohammadi R., Wit E. (2019). BDgraph: an R package for bayesian structure learning in graphical models. J. Stat. Softw. 89, 1–30. doi: 10.18637/jss.v089.i03
Newman M. E. J. (2006). Modularity and community structure in networks. Proc. Natl. Acad. Sci. 103, 8577–8582. doi: 10.1073/pnas.0601602103
Qiao X., Guo S., Gareth J. M. (2019). Functional graphical models. J. Am. Stat. Assoc. 114, 525. doi: 10.1080/01621459.2017.1390466
Qin J., Li R., Raes J., Arumugam M., Burgdorf K. S., Manichanh C., et al. (2010). A human gut microbial gene catalogue established by metagenomic sequencing. Nature 464, 59–65. doi: 10.1038/nature08821
Qiu H., Han F., Liu H., Caffo B. (2016). Joint estimation of multiple graphical models from high dimensional time series. J. R Stat. Soc. Ser. B Stat. Methodol. 78, 487–504. doi: 10.1111/rssb.12123
Robin X., Turck N., Hainard A., Tiberti N., Lisacek F., Sanchez J., et al. (2011). pROC: an open-source package for R and S+ to analyze and compare ROC curves. BMC Bioinf. 12, 77. doi: 10.1186/1471-2105-12-77
Solea E., Li B. (2020). Copula gaussian graphical models for functional data. J. Am. Stat. Assoc. 117 (538), 781–793. doi: 10.1080/01621459.2020.1817750
Staley J. T., Konopka A. E. (1985). Measurement of in situ activities of nonphotosynthetic microorganisms in aquatic and terrestrial habitats. Annu. Rev. Microbiol. 39, 321–346. doi: 10.1146/annurev.mi.39.100185.001541
Tian C., Jiang D., Hammer A., Sharpton T., Jiang Y. (2023). Compositional graphical lasso resolves the impact of parasitic infection on gut microbial interaction networks in a zebrafish model. J. Am. Stat. Assoc. 118, 1500–1514. doi: 10.1080/01621459.2022.2164287
Viles W. D., Madan J. C., Li H., Karagas M. R., Hoen A. G. (2021). Information content of high-order association of the human gut microbiota network. Ann. Appl. Stat. 15, 1788–1807. doi: 10.1214/21-AOAS1449
Wang C., Jiang B. (2020). An efficient ADMM algorithm for high dimensional precision matrix estimation via penalized quadratic loss. Comput. Stat Data Anal. 142, 106812. doi: 10.1016/j.csda.2019.106812
Wille A., Bühlmann P. (2006). Low-order conditional independence graphs for inferring genetic networks. Stat. Appl. Genet. Mol. Biol. 5. Art. 1, 34 pp. (electronic). doi: 10.2202/1544-6115.1170
Yoon G., Gaynanova I., Muller C. L. (2019). Microbial networks in SPRING-Semiparametric rank-based correlation and partial correlation estimation for quantitative microbiome data. Front. Genet. 10, 516. doi: 10.3389/fgene.2019.00516
Yuan H., He S., Deng M. (2019). Compositional data network analysis via lasso penalized D-trace loss. Bioinformatics 35, 3404–3411. doi: 10.1093/bioinformatics/btz098
Yuan M., Lin Y. (2007). Model selection and estimation in the Gaussian graphical model. Biometrika 94, 19–35. doi: 10.1093/biomet/asm018
Zhou J., Deng Y., Luo F., He Z., Tu Q., Zhi X. (2010). Functional molecular ecological networks. mBio 1, e00169–e00110. doi: 10.1128/mBio.00169-10
Keywords: Gaussian graphical model, microbial interaction network, EM algorithm, longitudinal data, relative abundance
Citation: Zhou J, Gui J, Viles WD, Chen H, Li S, Madan JC, Coker MO and Hoen AG (2024) Identifying stationary microbial interaction networks based on irregularly spaced longitudinal 16S rRNA gene sequencing data. Front. Microbiomes 3:1366948. doi: 10.3389/frmbi.2024.1366948
Received: 07 January 2024; Accepted: 30 April 2024;
Published: 03 June 2024.
Edited by:
Muhammad Ali, Trinity College Dublin, IrelandReviewed by:
Nar Singh Chauhan, Maharshi Dayanand University, IndiaCopyright © 2024 Zhou, Gui, Viles, Chen, Li, Madan, Coker and Hoen. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Anne G. Hoen, YW5uZS5nLmhvZW5AZGFydG1vdXRoLmVkdQ==
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.