 Qijie Lai1
Qijie Lai1 Chao Yang
Chao Yang- 1Department of Infrastructure, Guangdong Power Grid Corporation, Guangzhou, China
- 2Yunfu Power Supply Bureau, Guangdong Power Grid Corporation, Yunfu, China
- 3School of Automation, Guangdong University of Technology, Guangzhou, China
Efficient data collection and sharing play a crucial role in power infrastructure construction. However, in an outdoor remote area, the data collection efficiency is reduced because of the sparse distribution of base stations (BSs). Unmanned aerial vehicles (UAVs) can perform as flying BSs for mobility and line-of-sight transmission features. In this paper, we propose a multiple temporary UAV-assisted data collection system in the power infrastructure scenario, where multiple temporary UAVs are employed to perform as relay or edge computing nodes. To improve the system performance, the task processing model selection, communication resource allocation, UAV selection, and task migration are jointly optimized. We designed a QMIX-based multi-agent deep reinforcement learning algorithm to find the final optimal solutions. The simulation results show that the proposed algorithm has better convergence and lower system costs than the current existing algorithms.
1 Introduction
With the rapid economic development, more electric power infrastructures have been built rapidly, which causes more cases of outdoor power line erection, distribution station construction, and other types of facilities (Kumar et al., 2017). The South China Power Grid, along with other companies, has initiated comprehensive power infrastructure management measures. They utilize advancements from the Internet of Things (IoT), communication networks, and artificial intelligence technologies to oversee the power infrastructure processes to enhance the safety protocols for the construction workers and maintain the quality standards of the projects rigorously. The holistic strategy marks significant progress in integrating modern technology with traditional power systems, reflecting an evolving landscape in infrastructure management. Along with the process, a large amount of onsite data need to be collected and fused for processing (L’Abbate, 2023; Stoupis et al., 2023). For example, in order to construct a digital twin (DT) for outdoor power infrastructure construction systems, the ground nodes with sensing devices need to share information with other nodes continuously. In particular, the shared information is not only associated with the ground nodes but also with the environment and the construction workers. However, the various types of data to be processed and the complex construction environment make the data collection of outdoor power infrastructure extremely difficult.
Due to the superior mobility, ease of deployment, and direct line-of-sight (LoS) communication advantages, unmanned aerial vehicles (UAVs) are increasingly utilized as relay or edge computing nodes in data collection networks (Jayakody et al., 2020; Rahman et al., 2022), specifically in power infrastructure contexts. Notably, in addition to those that are strategically deployed, there exist multiple UAVs undertaking separate missions, such as package delivery, target tracking, and environmental monitoring, often operating in areas encompassing the power infrastructure facilities. A significant portion of the computational and communication resources on these incidental UAVs are typically idle. Engaging these UAVs in infrastructure monitoring initiatives could profoundly enhance the network communicative efficiency and computational capacity. However, it is critical that these UAVs are primarily dedicated to their original assignments; their operations are designed and hard to be changed.
Currently, in the UAV-assisted IoT, UAVs function as relay nodes (Rahman et al., 2022; Jayakody et al., 2020; Zhang et al., 2018) or edge computing nodes (Jeong et al., 2018; Liu et al., 2020) primarily, with particular emphasis on their flight trajectories, energy consumption, and task offloading strategies. For instance, Jeong et al. (2018) optimized UAV communication resource allocation and trajectory planning to minimize the overall system energy consumption, ensuring service quality. Conversely, Liu et al. (2020) introduced an edge computing framework utilizing a fleet of UAVs as relay nodes. The task offloading and UAV flight planning are optimized jointly to meet the users’ computational demands and latency sensitivities. Addressing the issue of base station (BS) edge servers in power infrastructure networks occasionally failing to satisfy the users’ computational needs, Hu et al. (2019) and Peng et al. (2020) advocated for deploying UAVs equipped with edge computing servers to overwhelmed areas; the proposed strategy can mitigate resource scarcity in roadside units during peak periods effectively. Zhang et al. (2022) established a UAV-assisted edge vehicular network computing structure with energy harvesting. UAVs aid vehicles in executing onboard task computations. Employing wireless power transfer (WPT) technology, UAVs harvest energy from base stations and vehicles. The UAV speed, computation, and communication resource allocation are jointly optimized to enhance UAV data-processing efficiency. Ng et al. (2020) utilized UAVs as relay nodes to improve the efficiency of the interactions between Internet of Vehicles (IoV) components and the federated learning (FL) server in the IoV with an FL edge computing server, thereby enhancing FL precision. However, the primary objective is to escalate UAV profitability, and the results indicate that the system stability also needs be enhanced. Furthermore, Liu et al. (2022) proposed the strategic deployment of UAVs within edge vehicular networking contexts, aiming to cater to network-connected autonomous vehicles that exhibit intensive computational and communication resource requests; the allocation of UAV communication and computational resources is optimized to maximize the system accessible resource capacity. Sun et al. (2023b) optimized the schedules among UAVs to ensure the shortest response time in the UAVs with edge computing services that cover the IoV users for data collection. Moreover, the communication bandwidth allocation and flying trajectory are jointly optimized by Wang et al. (2023b). Lyu et al. (2019) and Peng et al. (2020) confronted the disparity between fluctuating vehicle densities and the static establishment of roadside unit (RSU), and the flexible UAV deployment strategy is proposed to equilibrate network Quality of service (QoS) and UAV deployment frequency.
However, in power infrastructure scenarios, the ground nodes (such as wind generator and wire tower) have several types of tasks that need to be processed. Because the UAV can function as both the relay and edge computing node, it can select a suitable task processing model based on the mobility of the UAV and the task computing resource requests. The UAV can select a suitable task processing model. In addition, when a single UAV acts as a relay node or edge computing node, its resources are not sufficient, and it is difficult to handle intensive task processing requests in complex outdoor scenarios. A UAV swarm composed of multiple UAVs can solve this problem effectively. Compared with the single-UAV scenario, the design of the multiple UAV-assisted edge network optimization strategy also needs to consider the problems of relay selection and task migration. Thus, it is necessary to select the appropriate node in the data uploading phase and the selection of the task migration node when the ground node is moving away from the communication range of the UAV, where the current task is located. In this paper, we propose a UAV selection, communication resource allocation, and task migration joint optimal strategy based on a multi-agent deep reinforcement learning algorithm via QMIX (Rashid et al., 2018), and the main optimization objective is to minimize the cost of the ground users under the task completion delay constraint. The main contributions of this paper are summarized as follows:
1) We construct a temporary UAV-assisted data collection system model in the power infrastructure scenario, and multiple UAVs are employed to function as relay or edge computing nodes.
2) We formulate a joint optimization method to minimize the system cost, where the task processing model, communication resource allocation, UAV selection, and task migration are jointly optimized.
3) We present a QMIX-based multi-agent deep reinforcement learning algorithm to find the final optimal solutions.
Moreover, several simulation examples are presented to show that the proposed UAV-assisted data collection method can reduce the task-completion delay and the system cost. The rest of this paper is organized as follows: the system model is proposed in Section 2; Section 3 describes the joint problem solution via the QMIX-based algorithm; Section 4 presents multiple simulations and discusses the simulation results; and finally, the conclusion of the paper is presented in Section 5.
2 System model
Figure 1 illustrates the system model of the multiple temporary UAV-assisted data collection network. We consider a power infrastructure scenario in the wild, as shown in Figure 1; several ground nodes (including wind generator and wire tower) have a high demand for task transmission to build a DT system for the reconstruction of the infrastructure scenario to improve the management quality. Multiple temporary UAVs pass the power gird construction site, and the temporary passing UAVs have their own missions; the available resources of a single UAV are not enough, and multiple UAVs can cooperative to finish the data collection efficiently. They form a UAV network and can function as both the relay and edge computing nodes. To obtain enough information to improve the advanced decision-making system accuracy, the ground nodes in the infrastructure scenario need to continuously share information with other nodes through the edge network, and the tasks are collected by relying on their own sensing devices. The information is not only associated with the ground nodes but also with the environment and the construction workers. The decision-making center cannot change the flying trajectory and other parameters, and we set that the ground nodes should pay when they use the UAVs for data collection. The energy consumption and available varying computation resources are not considered in this paper. The main symbols used are summarized in Table 1.
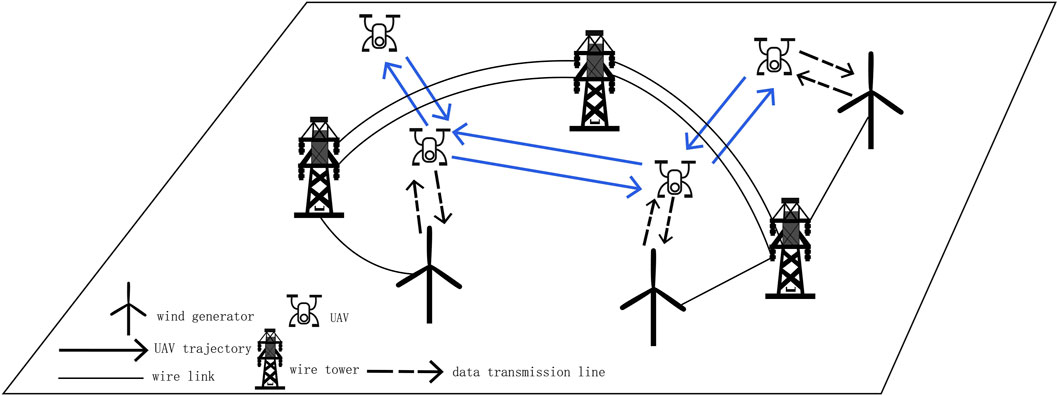
Figure 1. Multi-temporary unmanned aerial vehicle (UAV)-assisted data collection system model.
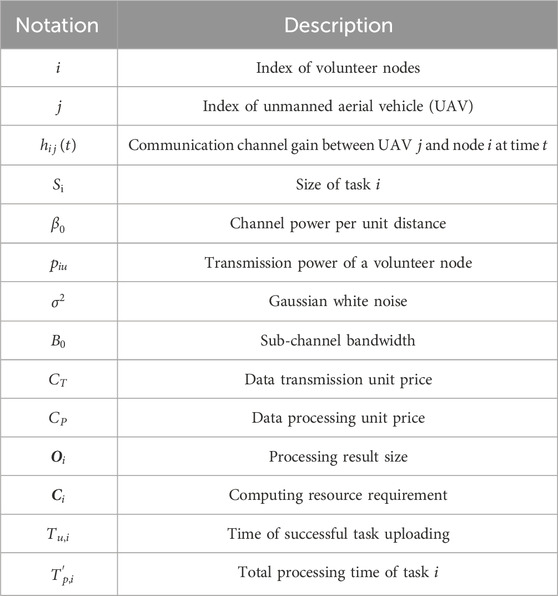
Table 1. Main symbols.
When a task node collects information, it first sends out an information task via the common orthogonal frequency-division multiplexing access (OFDMA) technology (Xia et al., 2021), and then, a volunteer node receives the task. After receiving the task, the volunteer node immediately packages its own collected real-time information and sends it directly back to the task node via wireless communication or to the UAV, which then acts as a relay node to forward the data to the task node. For clarity in the discussion, we assign numbers to both the task nodes and volunteer nodes. The task node is numbered as 0, while the volunteer nodes are designated as
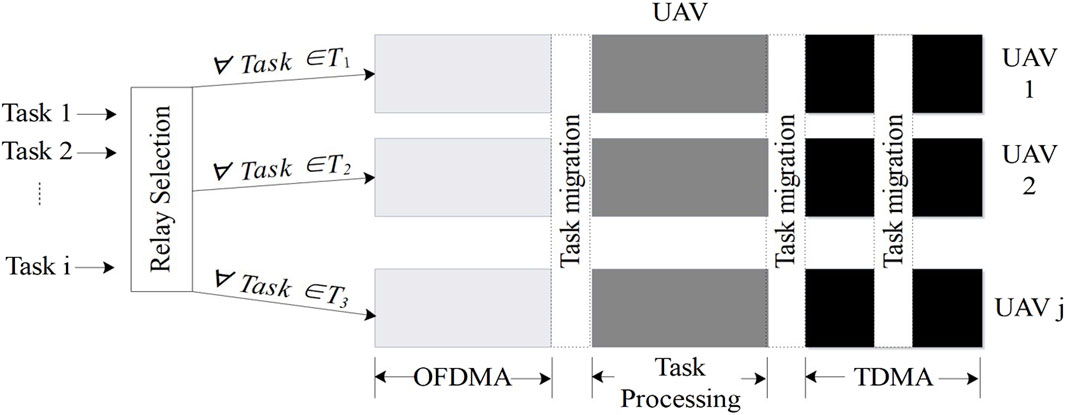
Figure 2. Multi-temporary UAV data transmission model.
In the single-UAV scenario, there are no idle UAV nodes available for selection, eliminating the need for volunteer nodes to make relay choices when uploading data. However, with multiple UAVs, volunteer nodes must identify and select an appropriate UAV as a relay node before data transmission to ensure the completion of the data collection task as effectively as possible. The UAV is denoted by

Table 2. Task migration process in different situations.
2.1 Delay calculation
2.1.1 Scenarios with no migration needed
UAVs can function as aerial platforms, establishing LoS links with ground nodes; thus, we utilize the free space path loss (FSPL) model to characterize the communication channel between the UAVs and the ground nodes (Hossein Motlagh et al., 2016). The communication channel gain between UAV
where
where
where
After the data processing phase, the processing results are sent to the task node immediately. We consider the Time Division Multiple Address (TDMA) technology so that the task in the current transmission has all the available channels currently. The data download rate can be expressed as follows:
The size of the processed results after the completion of task
where
2.1.2 Scenarios containing task migration
Task migration is accomplished through communication links between the UAVs (Huang et al., 2021), for which the channel rate is expressed as follows:
As shown in Figure 3, task migration can occur at any stage. For scenario 2, where the task migration occurs during the task uploading phase, the starting and ending times for migration are set as
In addition,
For situation 3, the total processing time of task
In addition,
where
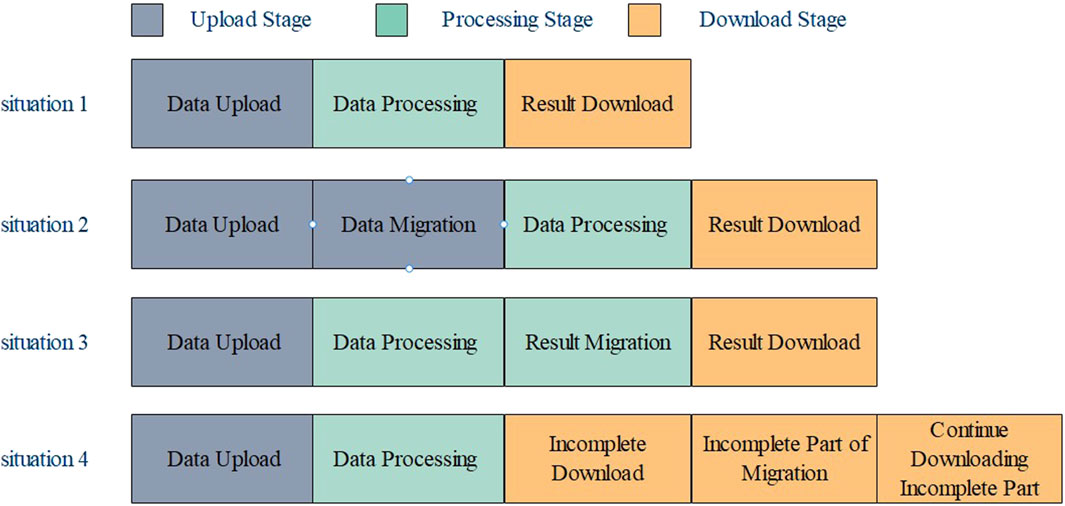
Figure 3. Task migration in different situations.
For scenario 4, the total time consumed during the result download phase, denoted as
where
In addition,
The total time
where
The time taken to complete all the tasks in a cycle is as follows:
2.2 Cost calculation
The total system costs are divided into communication costs and computational costs.
When task migration is included, the cost also includes the expenses incurred for task migration. The main costs incurred during task migration are communication costs, which can be expressed as follows:
Then,
It is important to highlight that
Among these,
2.3 Optimized problem description
According to the description of the above system model, we establish the joint optimization problem. Under the premise of satisfying the task delay constraints, channel resource constraints, and decision space constraints, the relay selection decision variable
P1:
Subject to:
C1:
C2:
C3:
C4:
C5:
C6:
C7:
where
3 QMIX-based solution algorithm
Since the states of all temporary UAVs at the next moment are only associated with the state of the current moment, they are independent of the states corresponding to the last moments. Therefore, the decision-making problem in this paper satisfies the Markovian properties. In the proposed multi-temporary UAV-assisted data collection network scenario, multiple temporary UAVs interact with the environment at the same time, and the uncertain behaviors among the UAVs will cause significant instability to the system. At the same time, limited by the means of information acquisition, it is difficult for the UAVs to obtain an accurate and real-time overall state of the environment in a large airspace. The decision-making center cannot control the temporary UAVs. Therefore, the relay selection and mission migration problem can be solved by the QMIX-based multi-agent deep reinforcement learning algorithm. In addition, the solution is described as a partially observable Markov decision process (POMDP) (Peng et al., 2020; Hossein Motlagh et al., 2016), which contains the following important parts.
3.1 Global states and locally observable states
To reduce the data transmission time and improve the real-time and accuracy of the data, the UAV can only obtain the immediate positional and directional information of other UAVs, while its trajectory information needs to be obtained by itself internally.
Here,
3.2 Movement
Relay selection and migration target selection are both carried out for UAVs assuming that there are N UAVs in the system. The action of the agent
It can be expressed as follows:
When a unique maximum element
•
•
•
then, the joint action
•
•
•
then, the joint action
3.3 Incentive
In multi-agent reinforcement learning, the design of the reward function significantly differs from that in single-agent reinforcement learning. We consider the design of the reward function from a global perspective, which is expressed as follows:
In the formula,
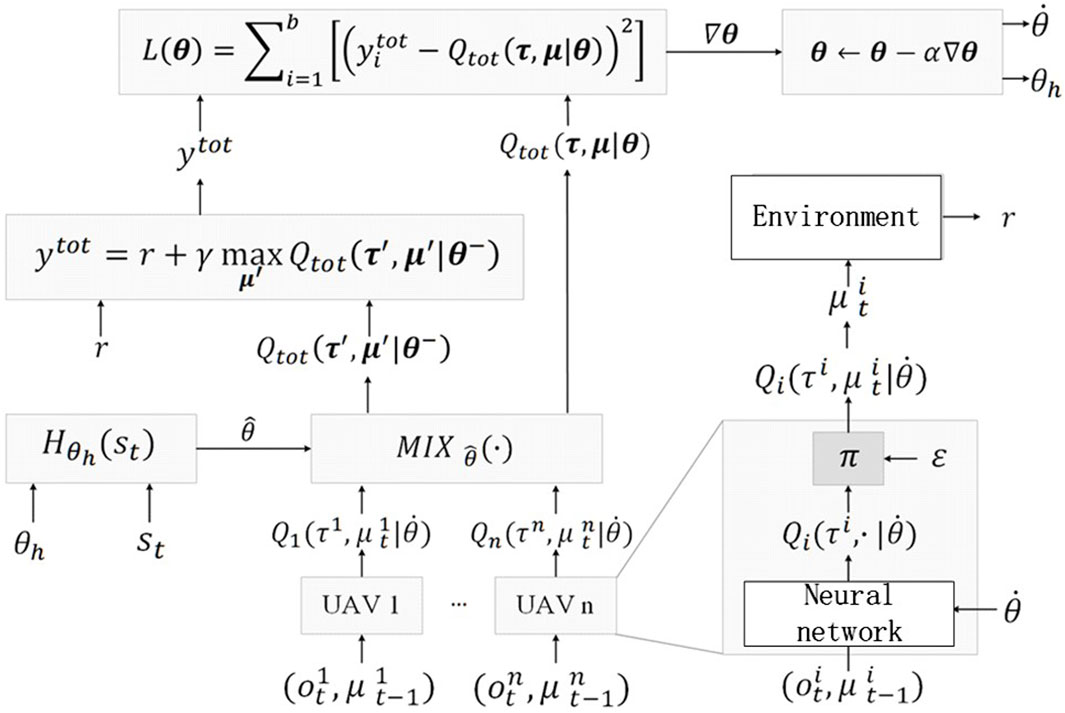
Figure 4. Framework of the QMIX-based selection strategy on relay and migration target.
As shown in Figure 4, QMIX is a novel value-based multi-agent reinforcement learning method. Each UAV makes the decisions with its own environment and sends the decisions to the mix network. The form of the QMIX fusion function is not directly assumed but is estimated through a neural network. Hence, the total action value function
where
where N represents the space of the agent indexes within the system. To ensure the monotonicity of
Algorithm 1.QMIX-based solution algorithm.
1 Initialize the experience pool, setting the upper and lower storage limits as
2 Initialize the real neural network parameters for agents
3 For
4 Initialize the state
5 Initialize an empty list
6 While
7
8 For
9 Under the global state
10 Based on its local state
11 End for
12 Combine the actions
13 Execute the joint action
14 Store the sequence
15 If the time step counter
16 Randomly draw a batch of historical sequence segments from the experience pool.
17 Each segment contains complete historical information from the initial state to the terminal state
18 For
19 Combine
20 Agent
21 Agent
22 End for
23 The hypernetwork takes the global state
24 All
25 All max
26 Compute the loss function
27 Reset the time step counter
28 End if
29 If the time step counter
30
31 Reset the time step counter
32 End if
33 Complete the global state transition, set
34 End while
35 Store the historical sequence list
36 End for
4 Simulation analysis
4.1 Parameter settings
In the simulation, we consider a power infrastructure data collection network environment assisted by multiple temporary UAVs. The maximum one-hop communication distance between the nodes is set to 30 m. In addition, the UAVs are configured with a communication radius of 300 m and a flight altitude of 50 m. Their starting locations and flight direction are given randomly. The CPU speed of the UAV is set to 1∼3 GHz (GC = 109 cycles; GHz = GC/s), the raw data are set between 2 and 10 Mb, and the computational demand-to-data size ratio of the task ranges from 1 GC/Mb to 2 GC/Mb. The number of ground volunteer nodes is set to 30, which is denoted as I = 30. The starting location is given randomly, while the starting locations of the task nodes are known. The latency requirement of the task satisfies
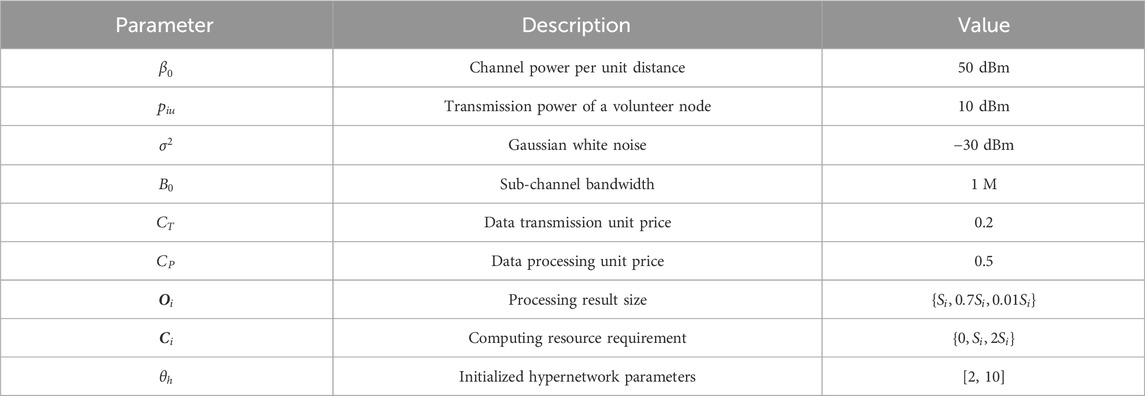
Table 3. Parameters.
The simulation experiments are conducted from two aspects. On one hand, the convergence of the proposed algorithm is evaluated. On the other hand, the performances of the proposed algorithm and the comparative strategies under different operating conditions are observed by modifying variables such as the number of temporary UAVs
4.2 Analysis of results
In this paper, the multi-agent deep reinforcement learning algorithm (QMIX) is used to find the optimal relay node selection and task migration target. The proposed algorithm is denoted as the QMIX-based selection strategy on relay and migration target (QSSRMT), and we design three groups of comparative schemes, which are as follows:
1) ISSRMT (Zhu et al., 2021): independent learning approach-based selection strategy on relay and migration target algorithm.
2) DSSRMT (Xia et al., 2021): deep Q-learning-based selection strategy on relay and migration target algorithm.
3) VSSRMT (Sunberg et al., 2016): value function decomposition method-based selection strategy on relay and migration target algorithm.
Figure 5 shows the reward variation curves for the number of UAVs
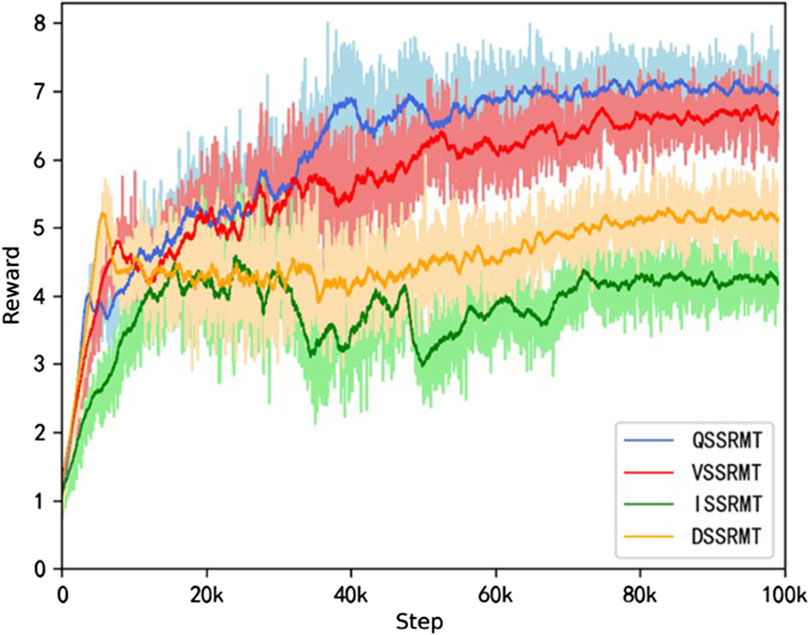
Figure 5. Reward curve of different algorithms.
Figure 6 shows the cost curves of various algorithms under the condition of UAV computational speed
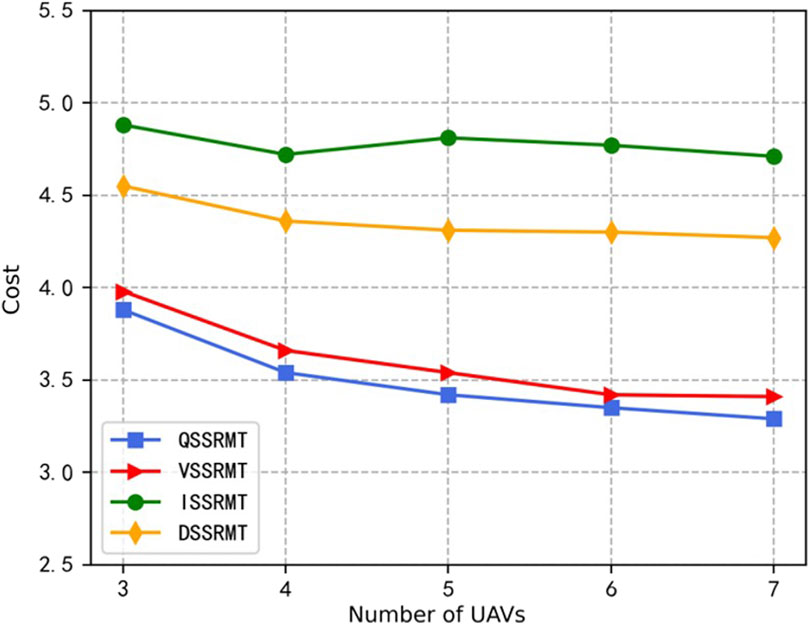
Figure 6. Relationship between the cost and number of UAVs.
Figure 7 illustrates the relationships between the system cost and different UAV transmission power levels. From the figure, we can find that as the UAV transmission power increases, there is a significant reduction in the average cost of task processing. The main reason is that the magnitude of the UAV transmission power influences the transmission rate of the communication link quality between the UAV and the ground nodes directly. As discerned from Eqs 1, 2, the larger the UAV transmission power, the higher the transmission rate of the downloading communication links. When the download rate is higher, the fine-grained task computation mode struggles to offer additional time-saving advantages; yet, it remains a more costly option. Under these conditions, adopting model 1 to simply package the data and then send them to the users directly becomes a more cost-effective choice.
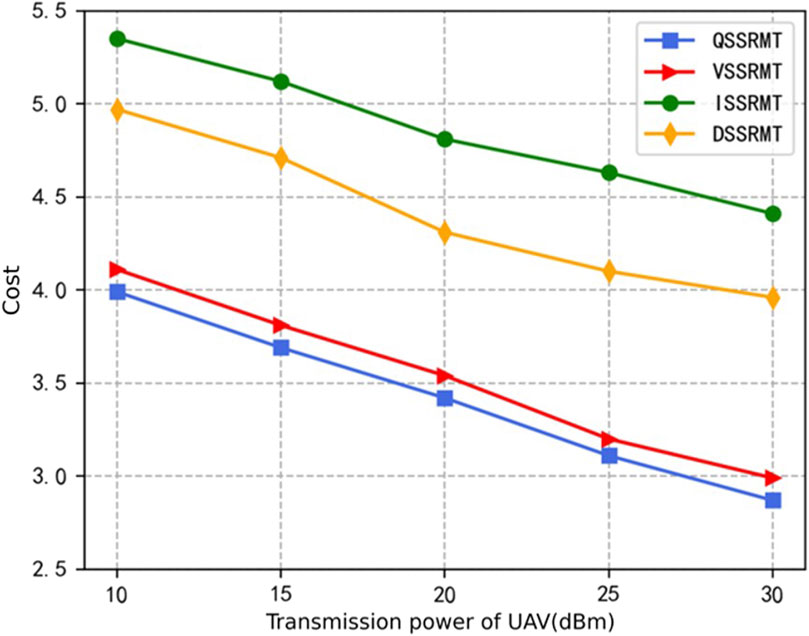
Figure 7. Relationship between the cost and transmission power of UAVs.
Figure 8 shows the relationships between the average system cost and different UAV computational capacities. From the figure, we can find that when the UAV computational capacity is between 1 and 2 GHz, an increase in computational power leads to a rapid decrease in the average task cost. However, when the computational capacity exceeds 2 GHz, further increases have a negligible effect on the task processing cost. The enhancement in UAV computational capacity can reduce the time consumed for task processing, thereby decreasing the probability of task failure to a certain extent. However, once the task processing time is reduced to a certain level, it no longer remains the primary factor contributing to task failure. In other words, when the UAV has sufficient computational capacity, further reductions in task processing time no longer affect the task completion success rate significantly. Figure 9 shows the relationship between the average system cost and different numbers of ground nodes I; we set that the data size and latency requirement of the generation tasks of each node are the same. From the figure, we can find that when the number of ground volunteer nodes increases, the whole system cost increases; because more tasks need be processed, the system delays, and the cost increases. The performance of the proposed QMIX-based QSSRMT is evidently the best when compared with the other three algorithms.
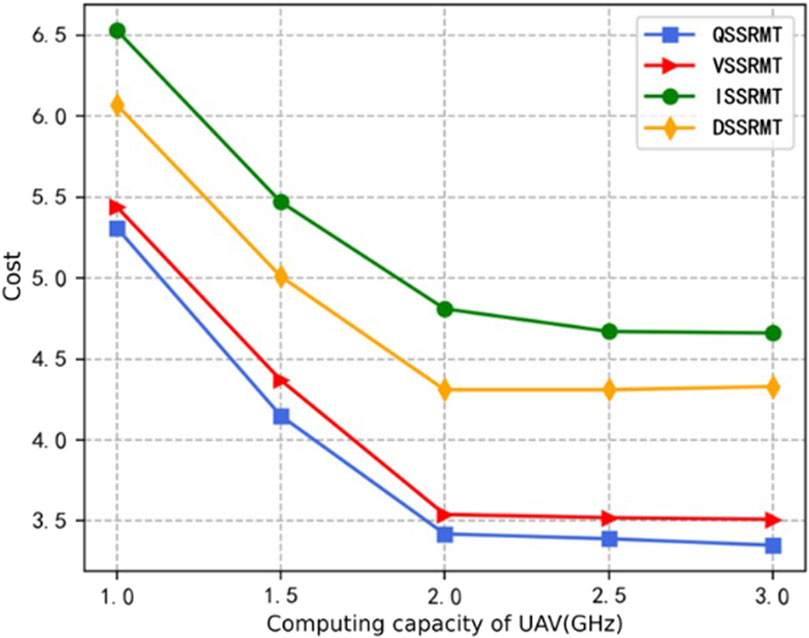
Figure 8. Relationship between the cost and UAV computing capacity.
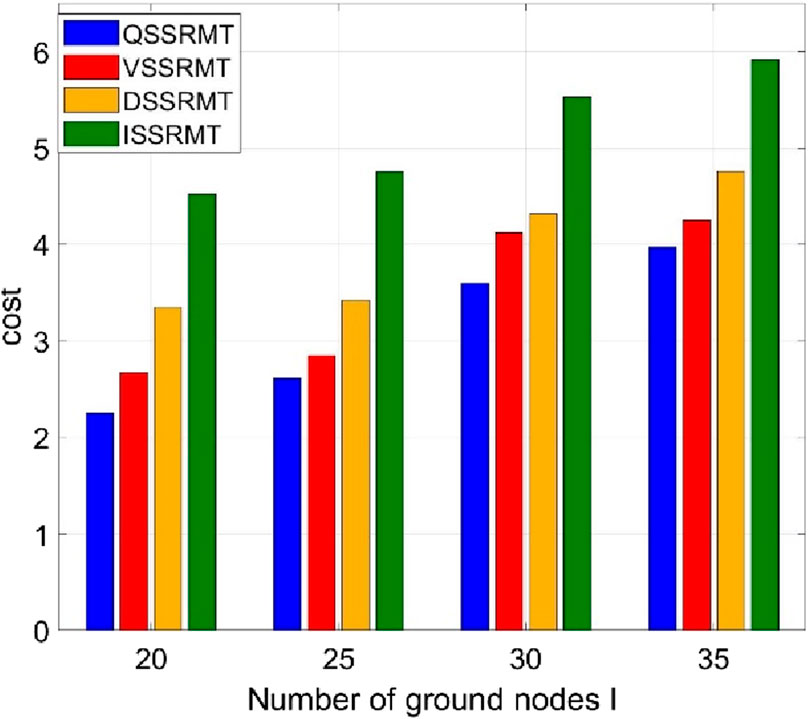
Figure 9. Relationship between the cost and number of ground nodes I.
5 Conclusion
In this paper, we investigate an efficient data collection and sharing strategy in outdoor data collection for power infrastructure networks aided by multiple temporary UAVs. A multi-constraint integer nonlinear optimization problem is established that jointly optimizes relay selection, channel allocation, task processing mode decision, and migration target selection. We propose a decision-making scheme via a QMIX-based multi-agent deep reinforcement learning method to accomplish the joint solutions of relay selection and migration target selection issues. Simulation experiments validate the effectiveness of the proposed strategies based on QMIX. For future work, we will investigate the cooperative data collection scheme by taking into account the UAVs and vehicles on the ground simultaneously for improving the efficiency.
Data availability statement
The original contributions presented in the study are included in the article/Supplementary Material; further inquiries can be directed to the corresponding author.
Author contributions
QL: data curation, software, and writing–original draft. RX: software and writing–original draft. ZY: methodology, resources, and writing–review and editing. GW: formal analysis, investigation, methodology, and writing–review and editing. ZH: data curation, software, and writing–review and editing. CY: supervision and writing–review and editing.
Funding
The author(s) declare that no financial support was received for the research, authorship, and/or publication of this article.
Conflict of interest
Authors QL, RX, and ZY were employed by Guangdong Power Grid Corporation. Authors GW and ZH were employed by Yunfu Power Supply Bureau, Guangdong Power Grid Corporation.
The remaining author declares that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors, and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Hossein Motlagh, N., Taleb, T., and Arouk, O. (2016). Low-altitude unmanned aerial vehicles-based Internet of things services: comprehensive survey and future perspectives. IEEE Internet Things J. 3 (6), 899–922. doi:10.1109/jiot.2016.2612119
Hu, S., Zhao, X., Ren, Y., and Xu, D. (2021). “Decentralized formation tracking and disturbance suppression for collaborative UAVs transportation,” in 2021 40th Chinese Control Conference (CCC), Shanghai, China, July, 2021, 5535–5539.
Hu, X., Wong, K. K., Yang, K., and Zheng, Z. UAV-assisted relaying and edge computing: scheduling and trajectory optimization. IEEE Trans. Wirel. Commun., 2019, 18(10):4738–4752. doi:10.1109/twc.2019.2928539
Huang, W., Guo, H., and Liu, J. (2021). “Task offloading in UAV swarm-based edge computing: grouping and role division,” in 2021 IEEE Global Communications Conference (GLOBECOM), Madrid, Spain, December, 2021, 1–6.
Jayakody, D. N. K., Perera, T. D. P., Ghrayeb, A., and Hasna, M. O. (2020). Self-energized UAV-assisted scheme for cooperative wireless relay networks. IEEE Trans. Veh. Technol. 69 (1), 578–592. doi:10.1109/tvt.2019.2950041
Jeong, S., Simeone, O., and Kang, J. (2018). Mobile edge computing via a UAV-mounted cloudlet: optimization of bit allocation and path planning. IEEE Trans. Veh. Technol. 67 (3), 2049–2063. doi:10.1109/tvt.2017.2706308
Kumar, N., Vasilakos, A. V., and Rodrigues, J. J. P. C. (2017). A multi-tenant cloud-based DC nano Grid for self-sustained smart buildings in smart cities. IEEE Commun. Mag. 55 (3), 14–21. doi:10.1109/mcom.2017.1600228cm
L Abbate, C. (2023). A modern communications platform to enable the modern Grid: a utility-grade wireless broadband network. IEEE Power Energy Mag. 21 (5), 18–26. doi:10.1109/mpe.2023.3288589
Liu, B., Zhang, W., Chen, W., Huang, H., and Guo, S. (2020). Online computation offloading and traffic routing for UAV swarms in edge-cloud computing. IEEE Trans. Veh. Technol. 69 (8), 8777–8791. doi:10.1109/tvt.2020.2994541
Liu, Y., Zhou, J., Tian, D., Sheng, Z., Duan, X., Qu, G., et al. (2022). Joint communication and computation resource scheduling of a UAV-assisted mobile edge computing system for platooning vehicles. IEEE Trans. Intelligent Transp. Syst. 23 (7), 8435–8450. doi:10.1109/tits.2021.3082539
Lyu, F., Yang, P., Shi, W., Wu, H., Wu, W., Cheng, N., et al. (2019). “Online UAV scheduling towards throughput QoS guarantee for dynamic IoVs,” in ICC 2019 - 2019 IEEE Internation-al Conference on Communications (ICC), Shanghai, China, May, 2019, 1–6.
Ng, J. S., Bryan Lim, W. Y., Dai, H. N., Xiong, Z., Huang, J., Niyato, D., et al. (2020). “Communication-efficient federated learning in UAV-enabled IoV: a joint auction-coalition approach,” in GLOBECOM 2020 - 2020 IEEE Global Communications Conference, Taipei, Taiwan, December, 2020, 1–6.
Peng, H., Ye, Q., and Shen, X. (2020). Spectrum management for multi-access edge computing in autonomous vehicular networks. IEEE Trans. Intelligent Transp. Syst. 21 (7), 3001–3012. doi:10.1109/tits.2019.2922656
Pokhrel, S. R., Jin, J., and Vu, H. L. (2019). Mobility-aware multipath communication for unmanned aerial surveillance systems. IEEE Trans. Veh. Technol. 68 (6), 6088–6098. doi:10.1109/tvt.2019.2912851
Rahman, S., Akter, S., and Yoon, S. (2022). OADC: an obstacle-avoidance data collection scheme using multiple unmanned aerial vehicles. Appl. Sci. 12 (22), 11509. doi:10.3390/app122211509
Rashid, T., Samvelyan, M., de Witt, C. S., Farquhar, G., Foerster, J., and Whiteson, S.QMIX (2018). “Monotonic value function factorisation for deep multi-agent reinforcement learning,” in 2018 35th International Conference on Machine Learning (ICML), Stockholm, SWEDEN, July, 2018.
Stoupis, J., Rodrigues, R., Razeghi-Jahromi, M., Melese, A., and Xavier, J. I. (2023). Hierarchical distribution Grid intelligence: using edge compute, communications, and IoT technologies. IEEE Power Energy Mag. 21 (5), 38–47. doi:10.1109/mpe.2023.3288596
Sun, L., Wan, L., Wang, J., Lin, L., and Gen, M. (2023a). Joint resource scheduling for UAV-enabled mobile edge computing system in Internet of vehicles. IEEE Trans. Intelligent Transp. Syst. 24, 15624–15632. Accepted. doi:10.1109/tits.2022.3224320
Sun, L., Wan, L., Wang, J., Lin, L., and Gen, M. (2023b). Joint resource scheduling for UAV-enabled mobile edge computing system in Internet of vehicles. IEEE Trans. Intelligent Transp. Syst. 24 (12), 15624–15632. doi:10.1109/tits.2022.3224320
Sunberg, Z. N., Kochenderfer, M. J., and Pavone, M. (2016). “Optimized and trusted collision avoidance for unmanned aerial vehicles using approximate dynamic programming,” in 2016 IEEE International Conference on Robotics and Automation (ICRA), Stock-holm, Sweden, May, 2016, 1455–1461.
Wang, J., Zhang, X., He, X., and Sun, Y. (2023a). Bandwidth allocation and trajectory control in UAV-assisted IoV edge computing us-ing multiagent reinforcement learning. IEEE Trans. Reliab. 72, 599–608. Accepted. doi:10.1109/tr.2022.3192020
Wang, J., Zhang, X., He, X., and Sun, Y. (2023b). Bandwidth allocation and trajectory control in UAV-assisted IoV edge computing using multiagent reinforcement learning. IEEE Trans. Reliab. 72 (2), 599–608. doi:10.1109/tr.2022.3192020
Xia, Z., Du, J., Jiang, C., Wang, J., Ren, Y., and Li, G. (2021). “Multi-UAV cooperative target tracking based on swarm intelligence,” in ICC 2021-IEEE International Conference on Communications, Montreal, QC, Canada, June, 2021, 1–6.
Zhang, S., Zhang, H., He, Q., Bian, K., and Song, L. Joint trajectory and power optimization for UAV relay networks. IEEE Commun. Lett., vol. 22, no. 1, pp. 161–164. 2018.doi:10.1109/lcomm.2017.2763135
Zhang, Z., Xie, X., Xu, C., and Wu, R. (2022). “Energy harvesting-based UAV-assisted vehicular edge computing: a deep reinforcement learning approach,” in 2022 IEEE/CIC International Conference on Communications in China (ICCC Workshops), Sanshui, Foshan, China, August, 2022, 199–204.
Keywords: data collection, unmanned aerial vehicle, task migration, multi-agent deep reinforcement learning, QMIX
Citation: Lai Q, Xie R, Yang Z, Wu G, Hong Z and Yang C (2024) Efficient multiple unmanned aerial vehicle-assisted data collection strategy in power infrastructure construction. Front. Comms. Net 5:1390909. doi: 10.3389/frcmn.2024.1390909
Received: 24 February 2024; Accepted: 13 May 2024;
Published: 10 June 2024.
Edited by:
Oluwakayode Onireti, University of Glasgow, United KingdomReviewed by:
Kosta Dakic, The University of Sydney, AustraliaAttai Ibrahim Abubakar, University of Glasgow, United Kingdom
Copyright © 2024 Lai, Xie, Yang, Wu, Hong and Yang. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Chao Yang, Y2h5YW5nNTEzQGdkdXQuZWR1LmNu