 Danilo Gaspar
Danilo Gaspar Luciano L. Mendes
Luciano L. Mendes Tales C. Pimenta
Tales C. Pimenta- 1Research and Development Department, Hitachi Kokusai Linear, Santa Rita do Sapucaí, Brazil
- 2Radiocommunications Reference Center, Instituto Nacional De Telecomunições–Inatel, Santa Rita do Sapucaí, Brazil
- 3Electrical Engineering Department, Universidade Federal De Itajubá–Unifei, Itajubá, Brazil
The advent of the fifth generation (5G) of mobile networks has introduced several new use cases that are pushing mobile networks in environments that are typically supported by wired technologies. The initial discussions around the sixth generation (6G) of mobile networks signalizes that different approaches are needed to address all contrasting requirements, where multiple-input multiple-output (MIMO) technique stands as a key technology for most future wireless systems. In this review, we present an introduction on classical linear estimators and coherent detectors along with an innovative and accurate complexity formulation within a common framework, allowing a fair comparison and providing an initial guideline for researchers that are looking for a general view of the main techniques available for spatial multiplexing (SM)-MIMO detection and estimation.
1 Introduction
Since the first generation (1G) of mobile communication in the 1980s until today, the field of digital communication has tremendously evolved both in capacity and reliability (Giordani et al., 2020). The emerging fifth generation (5G) is driving mobile communication systems towards an unprecedented evolution in terms of flexibility, data rate and latency, enabling wireless networks to support applications that are typically backed by wired technologies. The scenarios for the sixth generation (6G) are even harder to achieve considering the foreseen increase in flexibility, while supporting conflicting requirements for several applications in different verticals, besides higher data rates, higher coverage, higher frequency bands and extreme low latency. It is clear that future mobile networks cannot rely on a single radio access network to fulfill all these requirements. Different approaches are needed to address all requirements, but multiple-input multiple-output (MIMO) schemes represent a key technology for most future wireless systems. For example, in the agribusiness scenario, high data rates are necessary to transmit multi-spectral videos in infrared, ultraviolet and visible light in real time from drone to the cloud. In industry 4.0, very low latency is necessary for controlling robots and synchronizing autonomous actions with humans on the plant floor. MIMO can provide the necessary bandwidth, reducing the frame duration and increasing the robustness for data with a very short life span. Communication systems employing MIMO techniques present significant advantages when compared with traditional SISO architectures, i.e., mitigating fading effects by creating spatial diversity or exploiting channel scattering to achieve higher data rates by spatial multiplexing means. MIMO systems with detection schemes that can harvest diversity and multiplexing gains are able to improve the throughput, increase coverage and reduce the outage probability at the same time. Although the mentioned advantages are appealing features in the future mobile communication context, they are accompanied by demanding drawbacks such as uncorrelated transmission channels requirement, in order to avoid weak conditioned channel matrices, high signaling coordination on MIMO channel estimation, considering each individual transmitting antenna and higher complexity for the network nodes. The challenges imposed by the mobile communication channels require complex processes on the receiver side to recover the information with a desired quality of service (QoS). Among these processes, the estimation and detection algorithms tailored for mobile communications deserve special attention, since the interest on these techniques is growing constantly with the adoption of new schemes, such as MIMO, reconfigurable intelligent surfaces (RIS) (Tapio et al., 2021) and new waveforms (Zhang et al., 2017).
In the digital communications context, the estimation process is associated with choosing a hypothesis from an uncountable infinite set of hypotheses, according to some predefined criteria. One interesting example in communication systems is the channel estimation, where an estimate of the channel impulse response or the channel frequency response must be obtained on the receiver side with minimal mean-squared error (MSE). On the other hand, the detection procedure relates to making a decision from a countably finite set of hypotheses following, again, some established criterion. Another interesting example in the digital communication system is the discrete data detection. In this case, the detector must decide in favor of one of the M possible data symbols from a discrete sample space (or constellation) using the maximum likelihood or the minimum distance criteria (Gallager, 2008). The detectors and estimators analyzed in this paper are used to recover data in the downlink of mobile networks, where the base station (BS) and the user equipment (UE) employ orthogonal frequency division multiplexing (OFDM) with multiple transmit and receive antennas for space multiplexing. The channel is assumed to be frequency-selective and time-variant, with coherence time larger than the symbol block length and coherence bandwidth larger than one subcarrier.
Since these topics are widely studied, the number of different techniques available in the literature can be overwhelming. Hence, this paper aims for presenting an introduction on two critical tasks of mobile communication physical layer (PHY), which are: a) the linear estimation algorithms, suitable for channel state information (CSI) estimation and equalization and; b) detection and non-linear estimators schemes, in order to surpass the limitations of linear estimators in certain applications, i.e., spatial multiplexing (SM)-MIMO (Foschini, 1996). The analysis of beamforming MIMO and non-coherent detectors are beyond the scope of this intro work and can be addressed in (Ahmed et al., 2018; Mahmoud and El-Mahdy, 2021) for the interested reader. Other studies are also available in the literature as follows.
An extensive survey on detection algorithms related to massive MIMO can be found in (Albreem et al., 2019), where well-known linear detectors, including linear equalizers and suitable iterative methods as alternatives to avoid matrix inversion, are characterized according to its performance and complexity profiles. This reference also chronologically lists pertinent publications on MIMO subject. Similarly, in (Albreem et al., 2021a), low complexity linear detectors employing different numerical solutions for the large matrix inversion problem are evaluated, comparing its respective estimated computational cost and resource utilization in a system level deployment.
Still related to this topic, a recent overview on precoding techniques for massive MIMO is conducted (Albreem et al., 2021b). The idea behind precoding is to simplify the detection task on the receiver terminal, transferring its complexity to the transmission side, at the BS, which is in charge of precoding the transmitted information, employing suitable and eventually heavy digital pre-processing. This work also lists features, advantages, challenges and research opportunities related to massive MIMO. Moreover, it discusses and summarizes different precoding algorithms such as linear and non-linear precoders, RIS based precoder and machine learning deep neural network precoding. It concludes that, although linear precoders suffer from performance deterioration under certain scenarios, they still play a crucial role in the transmitter design due to their relative simplicity. This conclusion reinforces the importance of linear estimation concepts discussed here.
In (Jang et al., 2021; Pereira de Figueiredo, 2022), machine learning is pointed out as an important enabling technology for applications such as MIMO, massive MIMO and beamspace MIMO in the millimeter wave. It is notable that machine learning is gathering special attention from the academic community thanks to its potential to replace statistical driven solvers by generalist and adaptive learning-based techniques. Machine learning based MIMO detectors can even outperform the classic approaches when the channel statistical behavior does not match the model considered in the design of the model-driven detectors. Crucial tasks as channel estimation and detection (Ye et al., 2018), resource management (Hussain et al., 2020) and other optimization problems (Dahrouj et al., 2021) are being revisited under the machine learning perspective and, undoubtedly, will play an important role in 6G (Kaur et al., 2021; Sarkar and Debnath, 2021).
An accessible overview encompassing the state-of-the-art solutions to the detection problem is available in (Larsson, 2009). Prominent linear equalizers and detectors are investigated in (Kobayashi et al., 2014), presenting bit error rate (BER) performance analysis and computational complexity comparison under the assumption of different channel correlation scenarios.
In (Jalden and Ottersten, 2005), the sphere detector (SD) is examined, presenting the respective complexity in terms of the number of visited nodes, culminating in the definition of lower and upper bounds for the computational cost given the channel matrix dimension, constellation size and signal-to-noise ratio (SNR).
In this review article, regarding estimators and equalizers, we concentrate in the linear minimum mean squared error (LMMSE) estimator and its low cost iterative variances (Sayed, 2003; Proakis, 2007) as feasible alternatives to address the large matrix inversion problem. Moreover, the component-wise conditionally unbiased (CWCU)-LMMSE (Lang and Huemer, 2015) is considered as an appropriate equalization method featured by an additional weighting process leading to a constrained unbiased estimation. We also present detailed derivations for these estimators and its respective MSE, allowing the reader to investigate the estimation error performance along the Bayesian Cramer-Rao bound (BCRB) as a an absolute reference. Besides this analysis, computational complexity is formulated and further evaluated, seeking to identify which techniques present reasonable performance and affordable computational cost.
Regarding the detector, we focus on the renowned and relevant detection methods for the spatial multiplexing multiple-input multiple-output (SM-MIMO) applications, encompassing the Maximum Likelihood Detector (MLD), the minimum mean squared error (MMSE)- ordering successive interference cancellation (OSIC) (Hampton, 2013), the SD (Hassibi and Vikalo, 2005) and the iterative MMSE- Parallel Interference Cancellation (PIC) detector (Bensaad et al., 2013), presenting a compiled reviewing about these techniques together with each algorithm description. Furthermore, respective computational cost is derived, allowing one to conduct a complexity comparison alongside a performance analysis through a Monte Carlo BER simulation.
One of the main contributions of this tutorial work relies on.
• gathering and compiling the principles of classical estimators and detectors, in a uniform and accessible way, supported by detailed description of the procedures of each analyzed technique;
• performing a complexity comparison among the techniques in terms of float-point operations (FLOPs) under a common framework, allowing a fairly analysis and providing an interesting reference for researchers starting in this field.
In order to achieve these goals, the remaining of this manuscript is structured as follows: Section 2 presents a simplified model to linearly describe a generic and orthogonal digital communication PHY that will be used as a reference along this paper. Section 3 brings the background on complexity analysis of algorithms employed in estimation and detection problems. In Sections 4 and Sections 5, in this order, we present the main techniques for linear estimation and detection, their derivations, and estimated complexity. Section 6 presents numerical examples and performance analysis of the techniques described in Sections 4 and Sections 5, but tailored to specific applications on low order SM-MIMO, such as equalization and detection. Finally, Section 7 presents the conclusions by highlighting the main findings and results achieved in this paper.
Notation: Matrices and vectors are written in boldface uppercase and lowercase as X and x, respectively. A random variable observation is represented as a sub-indexed lowercase xi. The notation
2 System model for the digital communication PHY
This section introduces the concept of an orthogonal multicarrier digital communication PHY as a linear model, which is employed in following sections of this paper.
In a broad sense, a digital communication PHY is responsible for: a) adapting the digital information to a waveform that is transmitted to one or more receivers through a communication channel, and; b) for retrieving the information on the receiver side from the distorted and noisy version of the transmitted signal. Both transmitter and receiver are designed based on the communication channel characteristics as noise and fading statistics, average scattering pattern, coherence time, coherence bandwidth and the impairments introduced by the transmitter’s and receiver’s RF front-end, among others. Specifically for a modern mobile communication system, the PHY must deal with double-dispersive MIMO channels, where each path between one transmitting and one receiving antenna is modeled as a time-variant and frequency-selective impulse response. We consider a scheme employing n transmitting antennas and m receiving antennas as a generalization of the mobile communication system, as it embraces more simplified arrangements, e.g., the usual soft-input soft-output (SISO) when m = n = 1. It is worth to mention that, assuming a SM-MIMO case, when m = n ≥ 2, inter-antenna interference (IAI) takes place once each receiving antenna might collect signals from more than one transmitting antennas. In this case, the detection method should be carefully chosen to take the trade-off between performance and complexity into account. Figure 1 illustrates a simplified wireless communication system assuming this scenario.At the transmitter side, the Bit Encoding block receives the data bit sequences and protects them by applying randomization, forward error correction (FEC) (Ryan and Lin, 2009) and interleaving, aiming to increase the system robustness against the adverse effects of the mobile channel. The resulting coded bits are then fed to the Waveform Modulator block, where different techniques may be used, e.g., symbol modulation and multicarrier techniques, leading to specific waveforms tailored for mobile MIMO channels. The channel block introduces time and frequency fading and it combines the transmitted signals at each receiving antenna, besides adding the additive white Gaussian noise (AWGN). On the receiver side, the Waveform Demodulation block is responsible for performing the time and frequency synchronization, waveform demodulation, antenna decoupling and data symbol estimation, while the Bit Decoding block is responsible for correcting the bit errors that might be introduced by the channel. In SISO iterative detection, the Bit Decoding performs soft demapping in order to obtain soft coded bit sequences, in the form of Log-Likelihood Ratios (LLRs), carrying a sort of confidence measurement about the bit sequence. The LLRs are fed backwards to Waveform Demodulation block as a-priori information, subscripted
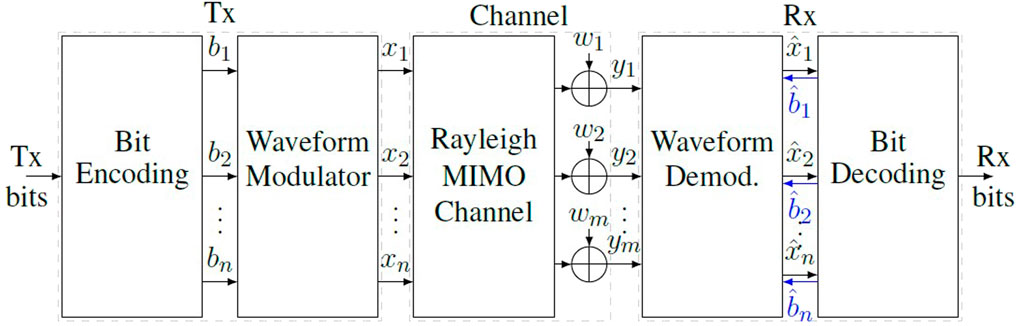
FIGURE 1. Simplified block diagram of a generic and communication system.
It is worth to clarify that, despite of its importance in the communication research field, the availability of studies involving channel coding techniques are wide and easily found in literature, thus, beyond the scope of this work. Instead, this work relies on available algorithms in (Glavieux and Vaton, 2007; Ryan and Lin, 2009), such as Convolutional Codes (CCs) and A-Posteriori Probability (APP) decoding.
Next, we describe the matricial notation for the orthogonal multicarrier MIMO, since this scheme is one of the most popular solution for the air interface in mobile communication systems.
2.1 Orthogonal multicarrier MIMO PHY
Consider the system from Figure 1, where n × m antennas may be employed, resulting in n × m paths between the transmitter and receiver. The channel impulse response (CIR) between the jth transmitting antenna and the ith receiving antenna with L taps is represented by
Assuming that an uncoded and non-precoded OFDM is employed as multi-carrier modulation scheme to transmit n parallel streams of Ns Quadrature Amplitude Modulation (QAM) symbols, mapped into Kon active subcarriers from a total of K. Let
where
At the receiver side, the received signal from the ith antenna at instant t can be represented as
where i = 1…m and
Assuming perfect time and frequency synchronization, the demodulated signal from the ith receive antenna is
where
In (4),
Introducing 1) and 4) into 3) yields to
where
From (5), the received signal for the kth subcarrier at the ith receive antenna is
where k = 1…Kon is the subcarrier index and
where
Indeed, 7) can be seen as a system factorization, where the orthogonal multicarrier detection problem splits into Kon subsystems with dimension m × n, m ≥ n. In general, for linear estimators employing matrix inversion, the expected complexity order is Konm3. It is easy to note that, for high order MIMO applications, where dozens or even hundreds of antennas are used, not only solving the entire system requires prohibitive computational cost but also other challenging aspects arise, e.g., high signaling coordination on MIMO channel estimation, considering each transmitting antenna. It is worth to mention that, for systems exploring diversity gain and employing a sufficiently high number of receiving antennas, an especial situation named channel hardening takes place, where the resulting fading channel behaves as deterministic (Gunnarsson et al., 2020). In this sense, a simple linear detector, e.g., the zero-forcing (ZF) detector, approaches the MLD performance while granting a significant simplification in the system implementation.
From now on, suppressing the subcarrier index in (7), for notation simplicity, yields to a linear model representation of the orthogonal multicarrier MIMO PHY, for a given subcarrier, that is widely used in next sections.
2.2 Linear model
Taking into account that the coding and decoding blocks can be seen as independent and separated functions, the linear model that represents the communication chain of the orthogonal system is given by
where
According to Section 2.1, the proposed model consists in a CP protected orthogonal multicarrier scheme resulting in a equivalent block-fading channel from subcarrier perspective, where each element of H is a flat fading scaling factor associated with each m × n path between all transmit and receiving antennas. The probability density function (PDF) of the random elements of H and w are assumed to be complex Gaussian.
For the linear model in (8), and also assuming that x and y are independent and identically distributed (iid), the cross covariance and the covariance matrices can be described in terms of the independent random variable (RV) as
and
These matrices are, in general, part of the linear estimation solution and are also present in the associated error covariance matrix of the estimator, which is a common parameter for performance analysis.
3 Definitions on complexity evaluation
Before describing the linear estimation and detection techniques, we present a comprehensive review on the algorithms complexity analysis in order to allow a comparison among techniques.
Table 1 summarizes the amount of FLOPs demanded on common matrix algebra (Hunger, 2007) and the implicit Householder QR factorization (HQR) (Trefethen and Bau, 1997). In this context,
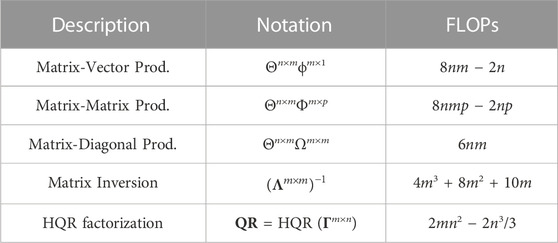
TABLE 1. Common matrix algebra computational complexity.
Moreover, Table 2 presents some useful finite sum identities (Rosen, 2010), which were widespread applied on the complexity formulation for the investigated techniques.

TABLE 2. Useful finite sum identities.
4 Linear estimation techniques
In this subsection, we describe the most relevant techniques on linear estimation that are commonly used in digital communications systems, such as synchronization, channel estimation, and equalization.
4.1 Linear minimum mean squared error estimator
The LMMSE is a simple implementation of the classic MMSE estimator that presents low complexity and sub-optimal performance once it is constrained to be linear. The LMMSE estimator (Huemer et al., 2017; Albreem et al., 2021a) for a random vector
where Al and bl are, respectively, a coefficient matrix and an offset vector that minimizes the MSE for the linear estimation of x. Sub-index l is used as an identification for the LMMSE estimator. The MSE matrix stores the covariance among the desired random vector and its estimation as
where
The parameters Al and bl, s.t.
which is detailed in Supplementary Appendix SA, yielding to
and
Notice that for a zero mean parameter μx, (15) reduces to a null vector. Introducing (14) and (15) in (11) results in
Applying the expectation operator on (16), allows us to verify that the LMMSE estimator is globally unbiased, as
The associated computational complexity of (16), in terms of FLOPs, is
It is worth to mention that, for the specific case when n = m and H is diagonal, the operations in (16) involves only diagonal matrices, reducing the overall complexity to Ol (47n).
The error covariance matrix of the LMMSE estimator is given by
whose diagonal represents the estimation error variance on
4.2 Steepest-descent estimator
The steepest-descent (STPD) is an iterative procedure that can be applied to LMMSE and other estimators non-subject only to MMSE performance criteria. In particular, applying the STPD procedure to the LMMSE allows to reduce its overall complexity, once no matrix inversion is necessary. As a result, the STPD scheme can achieve the same MSE performance as the LMMSE. Consider the STPD linear estimator for (8) as
where As and bs are, respectively, the final coefficient matrix and an offset vector that recursively converges to the MMSE criteria for the linear estimation of x. The sub-index s denotes the STPD linear estimator. The parameter
where t is an iteration index and δ is the step-size parameter which defines the behavior of the recursive algorithm. This is a crucial parameter and should be chosen carefully to guarantee a reasonable trade-off between convergence speed and stability (Sayed, 2003). The parameter
which allows to express (19) at iteration t as
and finally, the instantaneous MSE
As
The complexity of computing (22), in terms of FLOPs, is
Notice that Os refers to the computational effort per iteration. For the diagonal case, when n = m and H is diagonal, the complexity per iteration reduces to Os(42n). In the next subsection, a popular algorithm based on STPD is presented as an option to further reduce the complexity and does not require previous knowledge on the exact signal statistics.
4.3 Least mean squares estimator
The least mean squares (LMS) is a widely employed adaptive algorithm solution involving unconstrained optimization problems in linear estimation. It is based on stochastic-gradient method that is obtained from steepest-descent implementation with a suitable approximation (Sayed, 2003). This approach dismiss the need to know the exact signal statistics and also performs its role through an iterative learning and tracking mechanism.
Retrieving from (9), (10) and (20), the LMS recursion can be rewritten, replacing those statistic parameters by its instantaneous approximations, leading to
where
and
Typically, the mean of the observable RVs are not known a priori and, in order to calculate blms, it is necessary to employ some estimation method, as the local-mean estimator (LME) (Lin and Unbehauen, 1991), then estimate the mean information. It is also worth to highlight that, although it is not necessary to know exact values of Cxy, Cyy, μx and μy, it is mandatory to grant access to xt and yt while processing the recursion. In practical applications, such as channel estimation and equalization, this requirement can be addressed employing a training sequence, also known as pilot symbol, whenever the estimation procedure demands an update (Sayed, 2003; Guimarães, 2010). Thus, the LMS parameters can be defined as
and
where
where ζ = (Mw − 1)/Mw is the real valued parameter that depends on the moving average window of length Mw. Finally, the LMS estimator is given by
The instantaneous estimation error is obtained directly from xt and
and, as the algorithm converges, its magnitude decays.
Analyzing (28), while approaching the convergence state, the update term also decays and, under some conditions, i.e., the choice of a stable-convergent update coefficient, the final coefficient matrix is approximately given by
By replacing (34) into (32) and taking the expectation of (33), we can obtain the expected MSE matrix of the LMS algorithm as
Eq. 35 is equivalent to the LMMSE MSE matrix from (18), which is, in practical applications, a lower bound for the LMS MSE performance.
The complexity to compute (32) for each LMS iteration is
which already includes the estimator update task, incorporating the computational cost from (28) and (29). As these equations depend only on the instantaneous observations of the vectors xt and yt, even when the transformation matrix H is diagonal, this condition does not reduces the complexity, once the instantaneous approximations
4.4 Component-wise conditionally unbiased LMMSE estimator
The CWCU-LMMSE is a constrained linear and conditionally unbiased version of MMSE estimator, where the conditional expectation of each estimated component
where Ac and bc are, respectively, the coefficient matrix and the offset vector that minimizes the MSE with the additional constraint
and
where Al is the coefficient matrix of the LMMSE estimator and
are the real valued elements of the weighting diagonal matrix
The diagonal matrix D can also be obtained performing
Applying (38), (39) and (41) in (37) allows us to represent the CWCU-LMMSE estimator as
whose computational complexity in terms of FLOPs can be obtained from (17), taking into account the weighting diagonal matrix D, yielding to
For the case when n = m and H is diagonal, the complexity decreases to Oc(82n). The error co-variance matrix of the CWCU-LMMSE estimator is described in Supplementary Appendix SC and it is given by
4.5 Maximum a-posteriori estimator
The maximum a-posteriori (MAP) estimator is an useful approach to incorporate prior information into the data estimation problem. The MAP estimator is based on posterior probability maximization and it is close related to MAP hypothesis testing (Yates and Goodman, 2005). Although the MAP estimator could, in some cases, result in optimum estimates, like the MSE, it can be cumbersome (or even prohibited) to determine the exactly posterior probability function. In general, the MAP estimate of the RV X given the observation Y = y is
where fX∣Y (x∣y) is the conditional distribution function of X given Y = y.
Retrieving the definition of the complex Gaussian random vectors x and y from Section 2.2, which are connected through the linear model in (8), its conditional PDF is given by the bi-variate complex Gaussian distribution (Andersen et al., 1995) as
where det (⋅) is the determinant operator,
and
Analyzing (47), it is clear that its maximum probability occurs when its exponent is null, hence, when
Finally, replacing 9) and (10) in (50) leads to
which, in this specific case, resolves to the LMMSE estimator in (16). Hence, its computational complexity is equivalent to (17),
while the error covariance matrix corresponds to (18) and is given by
4.6 Bayesian Cramér-Rao bound on estimators
The BCRB defines a physical lower bound for MSE performance, which is helpful to classify whether a given estimator attains the BCRB criteria.
Since all our information is embodied in the observed data and, eventually, in our prior knowledge about the unknown parameter, the estimation accuracy depends directly on its PDFs (Kay, 1993).
The BCRB is defined as a lower bound for the MSE matrix and it is related to the inverse of the Bayesian Fisher information matrix (BFIM) IB (Trees and Bell, 2007), which means that
where the matrix inequality means that
From the linear model in (8), replacing the corresponding PDFs
and
in (55), allows to define the BCRB as
5 Detection techniques
In this section we present the MLD as a reference for the performance and complexity analysis once, considering the use of multiple antennas on transmitting and receiving simultaneous streams, is able to achieve optimal performance, minimizing the BER although showing an unfeasible complexity depending on system parameters. As a countermeasure for the prohibitive computational cost, we also review two known detection techniques, one sub-optimal and one close optimal, both with affordable complexity.
5.1 Maximum likelihood detector
As presented in Section 2, the detection task at the receiver is basically a decision process applied on the received signal in order to recover the transmitted message.
Retrieving the system model presented in (8), with m ≥ n, we admit now that x holds a sequence of discrete symbols from an alphabet
where
Algorithm 1. ML Detector.
Result:
1: ρ2 = ∞
2: for k ← 1 to Mn do
3:
4: if
5:
6:
7: end if
8: end for
In the Algorithm 1,
Supposing an alphabet with 16 distinct elements and n = 8, the MLD needs a total of 4.29 × 109 hypothesis tests in order to detect
5.2 MMSE with ordering successive interference cancellation detector
The MMSE-OSIC is a non-linear estimator that attempts to improve interference cancellation in applications such as SM-MIMO, i.e., Bell Laboratories layer space-time (BLAST) variances (Hampton, 2013).
This method basically starts organizing the rows of the received sequence y and the full-rank channel matrix H in ascending order of SNR. Afterwards, starting from the last row, which holds the symbol with higher SNR, decides by the most likely transmitted information at layer ℓ through ML detection. The estimated symbol from layer ℓ = n is then used, together with CSI, to remove its interference in the foregone layer ℓ = n − 1, prior to ML detection. This procedure is repeated until all layers ℓ = n − 1, …, 1 have been processed. Finally, original ordering is reestablished undoing the initial sort operation. The idea to organize the received sequence according to SNR is to avoid error propagation, possibility that might occur in case we start the successive interference cancellation (SIC) algorithm with an arbitrary low SNR signal (Golden et al., 1999).
The ordained received vector and CSI can be obtained performing
and
where P is a m × m binary permutation matrix, built based on SNR estimation for each y element. It has exactly one entry of 1 in each row and each column, with 0s elsewhere. For example, sorting a vector in ascending order according to a given estimated SNR sequence, e.g., (Zhang et al., 2017; Giordani et al., 2020; Tapio et al., 2021), would require a left multiplication by
where Ai is the ith row of a linear equalization matrix, e.g., the LMMSE equalizer from (14).
Hereafter, the SIC at layer ℓ is accomplished by interference cancellation and equalization through
followed by ML detection
In (64),
In (65), the sub-indexed term
Algorithm 2. MMSE-OSIC.
Result:
1: yo = Py
2: Ho = PH
3: for ℓ ← n to 1 do
4: j = [1, …, ℓ]
5:
6:
7: end for
Analysing Algorithm 2 and applying the summation identity
5.3 Sphere detector
The SD (Fincke and Pohst, 1985) is an algorithm to address the non-deterministic polynomial-time (NP) hard integer least squares (ILS) problem and achieve optimal MLD performance with an average polynomial complexity (Hassibi and Vikalo, 2005).
The principle of SD is to reduce the exhaustive search procedure over all possible code words carried out by the MLD. This is accomplished restricting the search only on hypothesis where the distance from one possible code word are within a predefined radius of a high-dimensional sphere, where each hypothesis can be seen as a path with sequentially interconnected points in a finite tree structure. Whenever a path segment reaches a cumulative distance that exceeds the sphere radius, this segment and all subsequent points are discarded, yielding to a variable complexity reduction (Larsson, 2009).
In this way, depending only on the radius parameter ρ, a trade off between performance and complexity can be trimmed. If ρ is chosen sufficiently high and kept constant, all paths might be checked and the SD behaves like the MLD. If ρ is too small, this can result in non-eligible paths. In this situation, the procedure can be repeated with an increased radius. A practical approach is to initialize ρ = ∞ or based on a code word given by a low complexity technique (Dehghani Soltani et al., 2014), e.g., the ZF or MMSE detectors (Proakis, 2007) and update the radius whenever a better hypothesis is found during the search procedure.
We start introducing the HQR factorization (Koudougnon et al., 2011) expressed as QR = HQR(H) for the full-rank channel matrix H and admitting m ≥ n, where Q ∈ Cm×m is an orthonormal matrix s.t. QHQ = Im and R ∈ Cm×n is an upper-triangular matrix. Left multiplying the received vector from (8) by QH yields to
Since Q is orthonormal, the noise distribution of
which can be addressed through a point-sequence search algorithm (Agrell et al., 2002). This structure resembles a spanning tree, with a root node located at the top layer ℓ = n, spanning to M nodes in the immediately next layer ℓ = n − 1. In this way, each node from an upper layer connects to M nodes in subsequent beneath layer. Each layer connection or path section is defined here as a segment. A series of segments connecting a root node to one of the Mn nodes at the final layer ℓ = 1 forms one distinct path among Mn possibilities. The total amount of nodes, ηSD, in a given spanning tree structure has a close relation with the SD complexity and can be obtained as
The SD executes a top-down search along the tree while compute the squared node distance
where ℓ = n, n − 1, …, 1 is the layer index and
Algorithm 3 describes the SD mechanism to find
Algorithm 3. Sphere Detector.
Result:
1: QR = HQR(H)
2:
3: ρ2 = ∞
4: ℓ = n
5: function SD(ℓ)
6: for s ← 1 to M do
7:
8:
9: if
10: if (ℓ == 1) then
11:
12:
13: else
14: SD (ℓ − 1)
15: end if
16: end if
17: end for
18: end function
The task of finding an exact expression for the complexity of the SD is not trivial once it depends not only on the transmission channel matrix dimension but also on the sphere radius, which is, in turn, a function of the SNR. Indeed, the SD FLOPs account is a random variable with expected polynomial complexity although, in the worst case scenario, it can reach exponential complexity (Hassibi and Vikalo, 2005). Considering the worst case, where all nodes of every segment are visited, the resulting complexity is given by
where OHQR is the complexity of the HQR factorization at line 1 of the Algorithm 3, given by Table 1, and the term
With the aid of the identities given in Table 2, an upper bound for the SD algorithm complexity is obtained as
where the last term on (73) is the predominant computational cost associated with the recursive SD(ℓ) function.
In a first glance, the worst case scenario for the SD algorithm exhibits higher complexity when compared with the MLD. This happens due the fact that every visited node requires the computation of the squared partial distances
There are also some slight variants of the SD algorithm that seeks to achieve a reduced (Arfaoui et al., 2016) or even fixed complexity (Larsson, 2009) at the cost of sub-optimal performance. In (Burg et al., 2005), some suitable approximations and simplifications are admitted, leading to implementations with affordable complexities.
5.4 Iterative MMSE-PIC detector
This method relies on two concepts, parallel interference cancellation and SISO channel decoding (Studer et al., 2011), exchanging refined information between these two domains in a iterative form. Differently from SIC, where data symbols are individually detected removing the interference caused by already decided symbols, the PIC estimates all data elements sharing the same radio resource jointly. The PIC performs a detection on the jth element xj of x assuming that all its other elements, denoted by
where
with
Figure 2 illustrates the block diagram for the proposed iterative SISO MMSE-PIC detector. Its entry point considers, under the assumption of perfect synchronization and channel state information at the receiver (CSIR), the demodulated signal vector y, the equivalent MIMO CFR and the corresponding AWGN variance
where
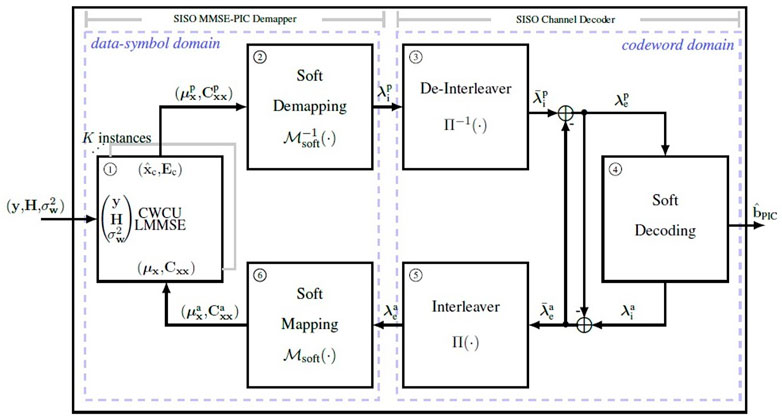
FIGURE 2. Block diagram of the Iterative MMSE-PIC detector.
The soft channel decoding is responsible for recovering the transmitted bit information from demapper estimates, obeying the code constraints. Usually, soft decoding applies algorithms able to exactly compute or approximate the APP of the information bits or, more generally, a reliability measure about each information bit. Hence, soft decoding results decoded LLRs, required in order to output re-encoded LLRs
The extrinsic information gained during codeword domain processing, denoted by
and
This encloses the iterative MMSE-PIC loop, allowing to start a new iteration considering the a-priory information gained from soft decoding. Along successive iterations, both demapper and decoder procedures self benefit from exchanged refined information between each other. Algorithm 4 summarizes the required tasks for each iteration.
Algorithm 4. Iterative MMSE-PIC Detector.
Result:
1: for all k subcarriers do % K parallel instances, suppressed indexes
2:
3: end for
4:
5:
6:
7:
8:
9:
10:
With respect to computational effort comparison, it is reasonable to consider the estimation processes at line 2, detaining the majority complexity executing Algorithm 4. Since demapping and decoding are, in general, common tasks in every digital communication system, it is sufficient to express the MMSE-PIC detector complexity per iteration by
The estimation stage employs up to K parallel instances of the CWCU-LMMSE estimator to solve each m × n linear systems, corresponding to the number of active subcarriers. Retrieving (44), the complexity order of Algorithm 4 is mainly dictated by a cubic behavior on the employed MIMO dimension. In order to further reduce the computational cost involved in MMSE-PIC detection, approximated estimators that avoid costly matrix inversion can be considered (Matthé et al., 2018; Zhang and Kim, 2019; Park, 2022).
5.5 Genie-aided detector
The MLD energy efficiency is commonly taken as reference for performance analysis involving alternative detectors. According to Section 5.1, the computational effort required to evaluate the ML detection is, in general, unfeasible, depending on system order, even for simulation purpose. In order to overpass this demanding condition, we can consider employing an hypothetical Genie-Aided Detector (GAD).
The GAD access additional transmission side information carried to the detector through a non-dispersive and unitary gain parallel channel, representing the genie (Eriksson et al., 1995). In the receiver side, upon decision of the transmitted data, the ED ϱR between the detected information
Algorithm 5. Genie-Aided Detector.
Initialize:
1: total_frames = 0;
2: frame_error = 0;
For each iteration results: FERML
3: total_frames = total_frames + 1;
4:
5:
6: if
7: frame_error = frame_error + 1;
8:
9: end if
The GAD description encloses this section and finally allows to evaluate the aforementioned concepts, involving the estimation and detection techniques.
6 Simulation results
In order to demonstrate the properties of the investigated estimators and detectors, we propose three numerical examples. The first one seeks to evaluate and compare the resulting MSE on the estimation of four different RVs, each one considering a specific scenario, chosen to allow an easy visualization of its characteristic biasedness. The second example focus on the uncoded and non-iterative detection task considering a hypothetical SM-MIMO system, where a Monte Carlo simulation is conducted for the BER performance evaluation. The complexity comparison is performed, in both examples, analyzing the involved computational effort as a function of its respective cost sensitive parameters. The third example evaluates the iterative MMSE-PIC and compare its FER performance w.r.t. an overestimated and hypothetical SISO MLD with the help of a GAD.
6.1 Numerical example of linear estimation
Consider a linear system as in (8) with m = 4 and n = 4, where each element of the observable random vector y is
The elements of H, x and w are mutually independent, where
The proposed transformation matrix H = diag ([1, 0.5, 1, 0.5]) was built in order to allow the investigation of the MSE in some specific cases, varying from unitary transform coefficient and lower noise energy to low scaling factor with high noise energy. Table 3 outlines the proposed cases of study.
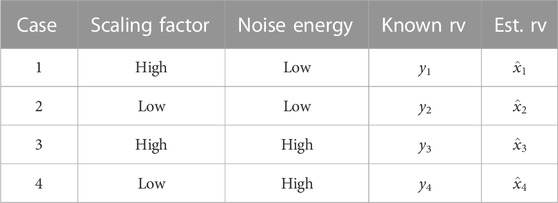
TABLE 3. Proposed cases for the performance analysis.
Figures 3–5 shown the intensity charts of the relative frequencies for each estimates in the complex plane. High incidence values are marked in red, while low occurrence values are plotted in blue. The × markers indicate possible values assumed by the discrete RVs xj.In the top right quadrant, we have the intensity color plot for the RV x1, corresponding to the proposed case 1 from Table 3 and, in counterclockwise direction, the remaining quadrants illustrate the resulting estimation of x2, x3 and x4, respectively, related to cases 2, 3 and 4, in this order. The plot from Figure 3 reproduces the results for the LMMSE estimator and are equivalently obtained when employing STPD or MAP estimators. Figure 4 and Figure 5 show the relative frequencies obtained by the LMS estimation and the CWCU-LMMSE estimator, respectively.
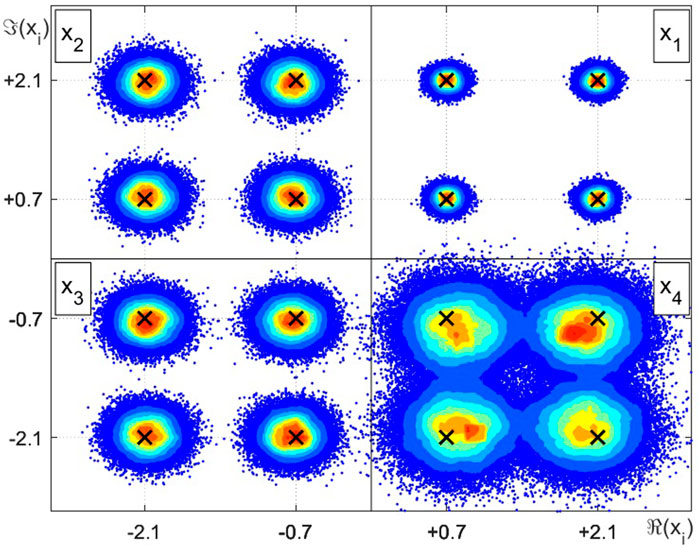
FIGURE 3. Intensity chart for the complex random variables estimation example employing LMMSE, STPD or MAP.
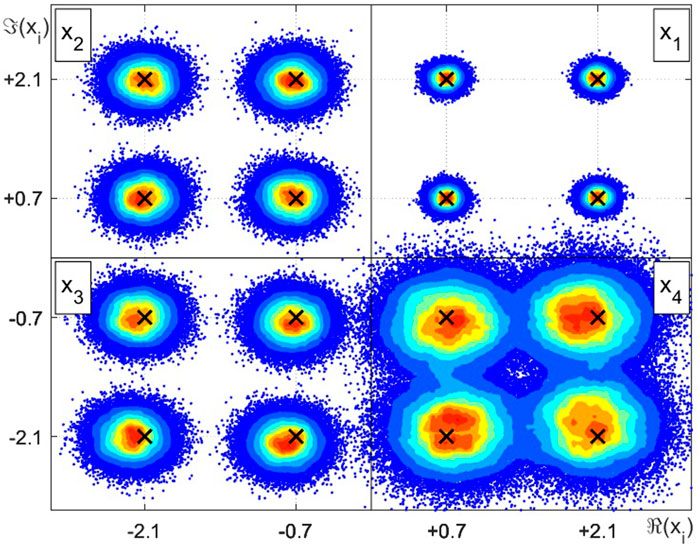
FIGURE 4. Intensity chart for the complex random variables estimation example employing LMS.
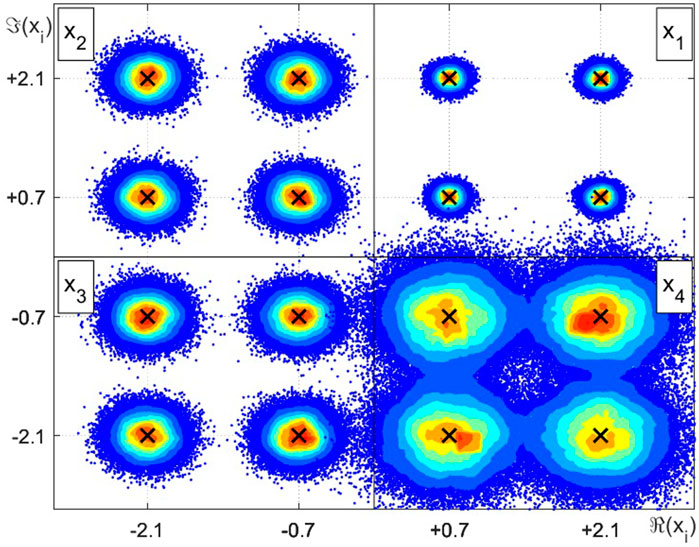
FIGURE 5. Intensity chart for the complex random variables estimation example employing CWCU LMMSE.
For the case 1, where the scaling factor equals one and the SNR is high, all estimators perform equally in terms of the MSE. This result is also observed for cases 2 (low scaling factor and high SNR) and case 3 (high scaling factor and low SNR). For case 4, with low scaling factor and low SNR, the MSE increases in relation to the other cases. In this situation, one can observe that the LMMSE, STPD and MAP estimators, whose restriction relies only on the linearity constraint, achieve the smallest MSE. The exception is the LMS estimator, which shows an poorer performance, mainly because of its built-in approximations. The CWCU-LMMSE estimator cannot outperform the LMMSE estimator in a MSE sense since it has additional constraints. However, the CWCU-LMMSE estimator features its inherent conditional unbiased property, which is evidenced in study case 4, whose result can be visualized at Figure 5. The CWCU-LMMSE has its estimates centered around the true RV events, since this estimator holds the established constraints. In contrast, the LMMSE based estimators introduce a small bias towards the prior mean,
Table 4 summarizes the most relevant results for the performance analysis of the estimators considered in this review. Columns 2, 3 and 4 from Table 4 present the diagonal components of the coefficient matrix A, the elements of the offset vector b and the diagonal elements of the resulting MSE matrix E, respectively. Each element corresponds, from left to right, to the proposed cases 1 to 4, in this order. The last column shows the required computational cost in FLOPs on estimating

TABLE 4. Linear estimation result summary.
Figure 6 illustrates the convergence behavior for the iterative STPD and LMS methods in terms of the instantaneous squared error estimation and, as expected, it decays along successive iterations. In this example, the error decreases rapidly in the first iterations, and few more are necessary to reach a stable convergence state.Figure 7 represents the amount of FLOPs as a function of the dimensions of the m × n non-diagonal transformation matrix. The STPD and the LMS iterative methods are the less costly algorithms, since no matrix inversion is involved and their complexity accounts only the amount of FLOPs per iteration. However, in practical applications, these algorithms requires no more than few iterations to converge, as exemplified by Figure 6. The LMMSE and the MAP estimators are equivalent and show intermediary complexity, while the CWCU-LMMSE is the most complex algorithm because it employs an additional weighting operation.
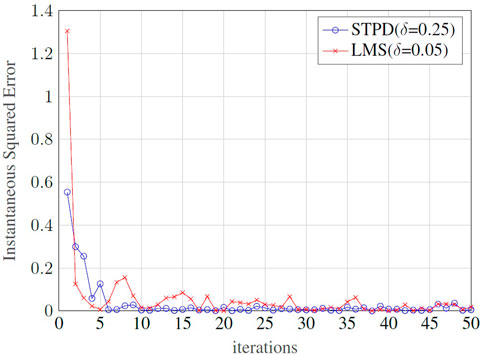
FIGURE 6. STPD and LMS convergence behavior for the proposed example.

FIGURE 7. FLOP counting for the presented linear estimators.
In Figure 8, one can visualize the MSE of the linear estimators against the BCRB. Parameter α is the noise energy and parameter β is the transformation matrix gain, where Cww = αIn and H = βIn, for n = 4. The LMMSE and the MAP estimators attain the BCRB and are considered optimal in a Bayesian sense. The iterative STPD and LMS methods are, at least in theory, lower bounded by the LMMSE performance once they depend on further convergence aspects of the algorithms. As expected, the CWCU-LMMSE does not attain the BCRB and it shows low performance in terms of MSE, especially in cases with intense noise enhancement (high α and low β).
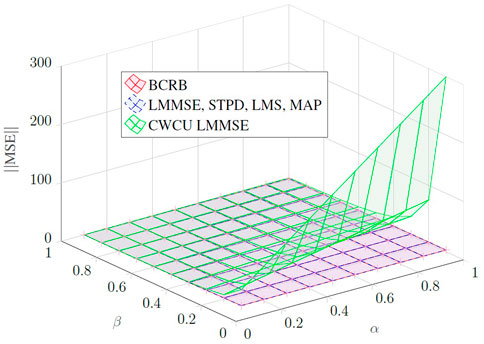
FIGURE 8. MSE versus BCRB for the investigated linear estimators.
6.2 Numerical example of non-iterative and uncoded detection in a digital communication system
In this subsection, an n × m SM-MIMO digital communication system based on the model presented in Section 2 is considered. We adopted n = m = 4 antennas for both the transmitter and receiver, such that n different data streams are transmitted simultaneously. Furthermore, no channel coding neither iterative detection are used, these are the reasons why we excluded the MMSE-PIC from this analysis. The system uses a 16-QAM to map bits into symbols, which are transmitted through a time-varying and frequency selective channel employing an orthogonal multicarrier scheme, i.e., CP protected OFDM. Assuming a symbol length with K = 64 samples, a CP with NCP = 16 samples, which is larger than the maximum channel delay profile. In this case, the channel coherence bandwidth is wider than the bandwidth of a subcarrier and the channel frequency response can be considered to be a flat Rayleigh channel per subcarrier. We also assume perfect symbol time and carrier frequency synchronization and that the CSIR is available. The simulation parameters are given in Table 5.
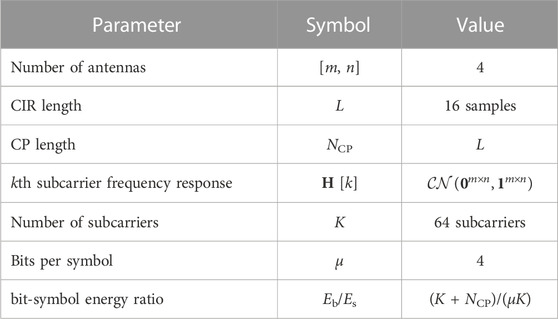
TABLE 5. Parameters for the non-iterative and uncoded system simulation.
Figure 9 illustrates some selected energy efficiency Monte Carlo simulation results. It relates the BER versus the Eb/N0 ratio for the main presented estimation and detection techniques. The so called MMSE process performs a LMMSE equalization over the received and demodulated symbols, which can be applied in this case, since the system model is linear. The denominated CWCU-LMMSE further employs a diagonal weighting on the LMMSE equalization matrix, as demonstrated in Section 4. Then, right after equalization, ML detection is used to find the most probable transmitted sequence. According to (63), an equalization matrix is required to estimate the SNR in the MMSE-OSIC described in Algorithm 2. In this example, we used the aforementioned equalization matrices, the LMMSE and its weighted CWCU-LMMSE version. Besides these detectors, we present the results for the SD, described by Algorithm 3 The MLD, described by Algorithm 1, has also been implemented as a benchmark for the techniques considered in this paper.
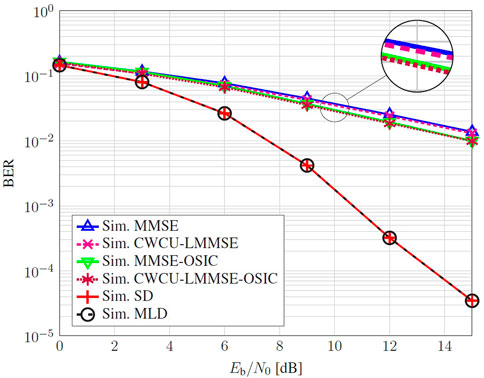
FIGURE 9. Monte Carlo simulation of an uncoded 16-QAM employing a 4 × 4 SM-MIMO-OFDM in time-varying and frequency selective channel.
The detectors exploiting the diagonal weighting, namely CWCU-LMMSE and CWCU-LMMSE-OSIC, show a slight improvement in the BER performance when compared with the corresponding MMSE and MMSE-OSIC, in this order. This small improvement is a result of a better fitting of the CWCU-LMMSE equalized signal on the constellation grid prior to detection. This characteristic holds for the Rayleigh flat-fading channel, where the symbols after CWCU LMMSE equalization remains unbiased, while the symbols equalized by the LMMSE tends to introduce a small bias towards the expected value of the discrete RV set, which, for a symmetric equiprobable QAM constellation, is zero. On the other hand, for AWGN channel, both equalizers performs equally in terms of BER (Lang and Huemer, 2015). The SD achieves a performance that is equivalent to the one observed for the MLD and over-performing all previous detectors.
In Figure 10, we analyze the SD complexity for the proposed example in terms of the average number of visited nodes at each layer. We notice that this parameters is not so dependent on the SNR as the average amount of visited nodes slight decays with the Eb/N0. Furthermore, bottom layers are more commonly visited once the tree search structure exponentially expands towards the underneath layers. From the average number of visited nodes and (72), we obtain the average complexity in FLOPs. This is an important parameter once it allows to compare the upper bound of the SD complexity, given by (73), its average computational cost, and the MLD complexity given by (60). This behavior can be seen graphically in Figure 11, that brings the complexity growth, in log scale, of the presented detection methods, in terms of FLOPs counting as a function of the constellation size M, while assuming n = m. Among the presented detectors, the MMSE-OSIC has the lowest and restrained computational cost once that (66) follows a cubic expansion rate with the number of receive antennas. This behavior can be extended for the iterative MMSE-PIC considering the linear dependency on the number of iterations. We can also infer, as described in (73) and (60), an exponential growth in the worst case scenario for the SD and for the MLD, respectively. The average complexity of SD for the proposed example is also pointed in the graph, which confirms that, in average, the SD achieves the MLD performance at an smaller complexity (approximately 4 Oosic in this example), although it can still reach exponential computational cost.
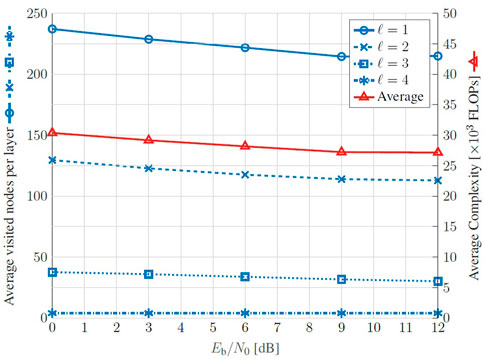
FIGURE 10. SD complexity analysis for the simulated parameters.
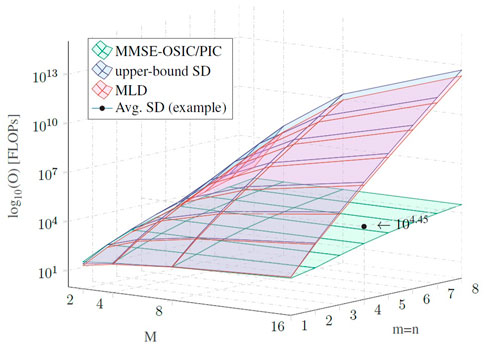
FIGURE 11. FLOP complexity comparison for the main evaluated detection methods.
It is easy to see that both SD and MLD algorithms, although optimal in terms of BER performance compared with the OSIC approach, exhibits prohibitive complexity when the modulation order or the number of antennas increases, which is the case of high order communication systems, such as massive MIMO (Albreem et al., 2019). In these cases, different solutions, in general some slight variances of the presented methods, as those already cited in Section 1, or even new proposals that might emerge from that, should also be considered.
6.3 Numerical example of iterative detection in a digital communication system
This example focus on the iterative MMSE-PIC detector, described in Section 5.4, employing a convolutional code aiming error correction capability. In order to provide an optimal reference for energy efficient comparison, we consider the GAD to emulate a SISO MLD, resulting in a hypothetical FER lower bound. We also present the results for the non-iterative detectors MMSE-OSIC and SD, both employing intra-frame interleaving, hard demapping and hard channel decoding. The simulation employs the same parameters used in the uncoded example with supplementary information given by Table 6.
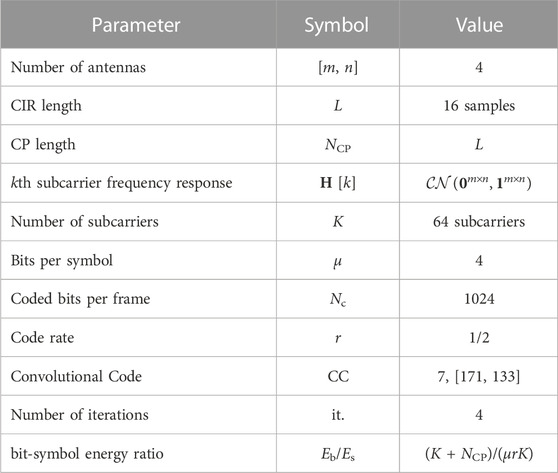
TABLE 6. Supplementary parameters for the iterative detection simulation.
Figure 12 illustrates the BER behavior for the same channel coding parameters, accenting the difference between non-iterative hard detectors and an iterative soft approach. The MMSE-OSIC poorly performs as a result of error propagation and single iteration execution. The conventional SD, although able to close achieves the ML criteria, are also still far away from the iterative MMSE-PIC once its detection is based only on the constellation constraint. It is worth to mention the availability of SISO-SD in literature (Studer and Bölcskei, 2010; Witte et al., 2010) that approaches the optimal performance in SM-MIMO applications. In this work, we replace this intricate detector by the so called genie detection.
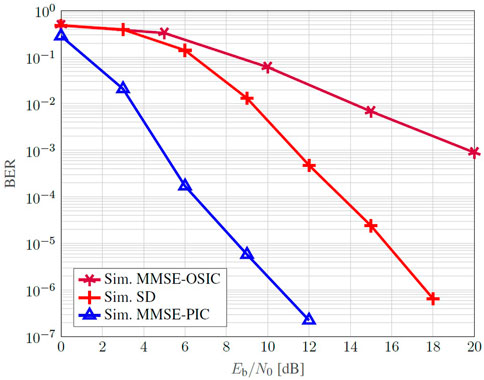
FIGURE 12. BER Monte Carlo simulation of a coded 16-QAM employing a 4 × 4 SM-MIMO-OFDM in time-varying and frequency selective channel.
In Figure 13, we analyze the FER performance w.r.t. a reference lower bound given by the GAD, based on the detected codeword from the MMSE-PIC. Whenever a bit error is detected in a codeword, the simulation accounts for a frame error. Once again, both non-iterative MMSE-OSIC and SD are positioned on the right of the iterative MMSE-PIC, this last one exhibiting a close to optimal result. This demonstrates that, among all detectors analyzed, the MMSE-PIC shows a prominent performance not only in terms of energy efficiency but also in complexity meaning, comparable to the cubic order of the MMSE-OSIC.
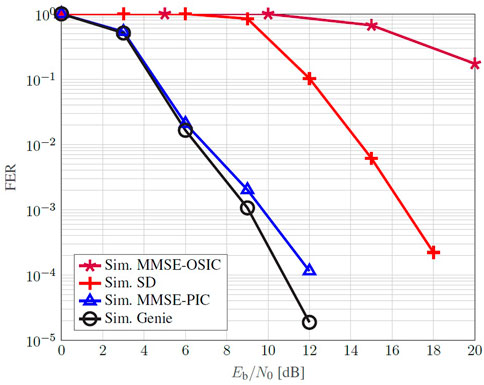
FIGURE 13. FER Monte Carlo simulation of a coded 16-QAM employing a 4 × 4 SM-MIMO-OFDM in time-varying and frequency selective channel.
7 Conclusion
In this review, linear estimators based on the classical LMMSE was discussed, including its intricate derivations, generally omitted even in textbooks. These detailed descriptions might be helpful on proposing new estimators or low complexity approximations. Regarding on complexity, a substantiated computing method is employed, based on FLOP counting for diverse involved operations, which can be a useful tool on the evaluation and comparison of different procedures. Moreover, the proposition of a BCRB permits to use an absolute reference for the MSE analysis. Although the CWCU-LMMSE MSE diverges from the BCRB in cases with potential for noise enhancement, this result does not reflect in the BER, being attributed to its unbiasedness characteristic, yielding to a better constellation grid fitting prior to detection. Note that, in similar situations, the LMMSE would also require a re-scaling in order to fit the constellation grid. In the case of the CWCU-LMMSE, this process is inherent.
With respect to detectors, those visited in this work were described through easy implementable algorithms and analysed in terms of its energy efficiency and computing cost. Although both MLD and SD achieves optimal performance, its intrinsic exponential complexity implies harsh restrictions on practical MIMO applications, s.t. small constellation sizes and few simultaneous data streams, limited by the number of transmit and receive antennas. Although the MMSE-OSIC presents affordable complexity, its performance is far from optimal. In contrast, the iterative MMSE-PIC associates expressive results, being able to closely achieves optimal performance with a computational cost comparable to the MMSE-OSIC. The iterative MMSE-PIC poses as a feasible alternative to SM-MIMO, even for massive MIMO applications, especially considering recent researches that seeks to reduce the complexity on the system solution problem, employing suitable approximations to the matrix inversion (Park, 2022).
In summary, in order to achieve the challenging and contrasting requirements of future mobile communication, different radio access techniques, among them the SM-MIMO scheme, will be a fundamental tool. In this sense, the presented tutorial contributes with a common framework that allows a fair comparison among the settled studied solutions and provides an initial guideline for researchers that are looking for a general view of the main techniques available for SM-MIMO detection and estimation.
Future works on these topics might also embrace the use of iterative estimators, specially some mixture of the STPD or the LMS with the CWCU-LMMSE weighting diagonal, in order to attain unbiasedness and avoid costly matrix inversion while keeping a channel tracking mechanism, jointly with parallel interference cancellation methods applied on non-orthogonal waveforms in SM-MIMO applications, with potential to harvest diversity while achieving multiplexing gain at the same time. Moreover, artificial intelligence is a prominent alternative to replace the statistical-based solvers discussed here by more generalist algorithms.
Author contributions
DG carried out the background research, manuscript development and simulation analysis. LM conceived the study, participated in its design, coordination and helped to write the manuscript. TP helped with the writing of the manuscript and also reviewing it. All authors read and approved the final manuscript.
Funding
This work was partially supported by the Brazil 6G project funded by RNP/MCTIC Grant No. 01245.010604/2020-14, by the SAMURAI project funded by FAPESP Grant No. 20/05127-2 and by CNPq Grand No. 303282/2021-5.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/frcmn.2023.968370/full#supplementary-material
References
Agrell, E., Eriksson, T., Vardy, A., and Zeger, K. (2002). Closest point search in lattices. IEEE Trans. Inf. Theory 48, 2201–2214. doi:10.1109/TIT.2002.800499
Ahmed, I., Khammari, H., Shahid, A., Musa, A., Kim, K. S., De Poorter, E., et al. (2018). A survey on hybrid beamforming techniques in 5g: Architecture and system model perspectives. IEEE Commun. Surv. Tutorials 20, 3060–3097. doi:10.1109/COMST.2018.2843719
Albreem, M. A., Juntti, M., and Shahabuddin, S. (2019). Massive MIMO detection techniques: A survey. IEEE Commun. Surv. Tutorials 21, 3109–3132. doi:10.1109/COMST.2019.2935810
Albreem, M. A., Alsharif, M. H., and Kim, S. (2020). A low complexity near-optimal iterative linear detector for massive MIMO in realistic radio channels of 5G communication systems. Entropy 22, 388. doi:10.3390/e22040388
Albreem, M. A., Salah, W., Kumar, A., Alsharif, M. H., Rambe, A. H., Jusoh, M., et al. (2021). Low complexity linear detectors for massive MIMO: A comparative study. IEEE Access 9, 45740–45753. doi:10.1109/ACCESS.2021.3065923
Albreem, M. A., Habbash, A. H. A., Abu-Hudrouss, A. M., and Ikki, S. S. (2021). Overview of precoding techniques for massive MIMO. IEEE Access 9, 60764–60801. doi:10.1109/ACCESS.2021.3073325
Anastasopoulos, A. (2003). Sequence error probability lower bounds for joint detection and estimation. IEEE Trans. Commun. 51, 347–351. doi:10.1109/TCOMM.2003.809718
Andersen, H. H., Højbjerre, M., Sørensen, D., and Eriksen, P. S. (1995). The multivariate complex normal distribution. New York, NY: Springer.
Arfaoui, M. A., Ltaief, H., Rezki, Z., Alouini, M. S., and Keyes, D. (2016). Efficient sphere detector algorithm for massive MIMO using GPU hardware accelerator. Procedia Comput. Sci. 80, 21696–21808. doi:10.1016/j.procs.2016.05.377
Bai, L., and Choi, J. (2014). Low complexity MIMO detection. New York, United States: Springer Publishing Company. Incorporated.
Bensaad, A., Bensaad, Z., Soudini, B., and Beloufa, A. (2013). SISO MMSE-PIC detector in MIMO-OFDM systems. Int. J. Mod. Eng. Res. 3 (5), 2840–2847.
Burg, A., Borgmann, M., Wenk, M., Zellweger, M., Fichtner, W., and Bolcskei, H. (2005). VLSI implementation of MIMO detection using the sphere decoding algorithm. IEEE J. Solid-State Circ. 40, 1566–1577. doi:10.1109/JSSC.2005.847505
Colavolpe, G., Ferrari, G., and Raheli, R. (2001). Extrinsic information in iterative decoding: A unified view. IEEE Trans. Commun. 49, 2088–2094. doi:10.1109/26.974255
Dahrouj, H., Alghamdi, R., Alwazani, H., Bahanshal, S., Ahmad, A. A., Faisal, A., et al. (2021). An overview of machine learning-based techniques for solving optimization problems in communications and signal processing. IEEE Access 9, 74908–74938. doi:10.1109/ACCESS.2021.3079639
Dehghani Soltani, M., Alimadadi, M., and Amindavar, H. (2014). “A hybrid method to reduce the complexity of k-best sphere decoding algorithm,” in 2014 22nd Iranian Conference on Electrical Engineering (ICEE), 1765–1770. doi:10.1109/IranianCEE.2014.6999824
Eriksson, H., Odling, P., Koski, T., and Borjesson, P. (1995). “A genie-aided detector with a probabilistic description of the side information,” in Proceedings of 1995 IEEE International Symposium on Information Theory, 332. doi:10.1109/ISIT.1995.550319
Fincke, U., and Pohst, M. (1985). Improved methods for calculating vectors of short length in a lattice. Math. Comput. 44, 463–471. doi:10.2307/2007966
Foschini, G. J. (1996). Layered space-time architecture for wireless communication in a fading environment when using multi-element antennas. Bell Labs Tech. J. 1, 41–59. doi:10.1002/bltj.2015
Gallager, R. G. (2008). Principles of digital communication. Cambdridge, MA: Cambridge University Press. doi:10.1017/CBO9780511813498
Giordani, M., Polese, M., Mezzavilla, M., Rangan, S., and Zorzi, M. (2020). Toward 6g networks: Use cases and technologies. IEEE Commun. Mag. 58, 55–61. doi:10.1109/MCOM.001.1900411
Glavieux, A., and Vaton, S. (2007). Convolutional codes. Paris, France: John Wiley & Sons, 129–196. doi:10.1002/9780470612422.ch3
Golden, G., Foschini, C., Valenzuela, R., and Wolniansky, P. (1999). Detection algorithm and initial laboratory results using V-BLAST space-time communication architecture. Electron. Lett. 35 (2), 14–16. doi:10.1049/el:19990058
Guimarães, D. A. (2010). Digital transmission: A simulation-aided introduction with VisSim/comm. Heidelberg, Germany: Springer-Verlag Berlin Heidelberg. doi:10.1007/978-3-642-01359-1
Gunnarsson, S., Flordelis, J., Van Der Perre, L., and Tufvesson, F. (2020). channel hardening in massive MIMO: Model parameters and experimental assessment. IEEE Open J. Commun. Soc. 1, 501–512. doi:10.1109/OJCOMS.2020.2987704
Hagenauer, J., and Hoeher, P. (1989). “A Viterbi algorithm with soft-decision outputs and its applications,” in 1989 IEEE Global Telecommunications Conference and Exhibition ’Communications Technology for the 1990s and Beyond’, 1680–1686. doi:10.1109/GLOCOM.1989.64230
Hampton, J. R. (2013). Introduction to MIMO communications. Cambridge, MA: Cambridge University Press. doi:10.1017/CBO9781107337527
Hassibi, B., and Vikalo, H. (2005). On the sphere-decoding algorithm i. expected complexity. IEEE Trans. Signal Process. 53, 2806–2818. doi:10.1109/TSP.2005.850352
Huemer, M., Lang, O., and Hofbauer, C. (2017). Component-wise conditionally unbiased widely linear MMSE estimation. Signal Process. 133, 227–239. doi:10.1016/j.sigpro.2016.10.018
Hunger, R. (2007). Floating point operations in matrix-vector calculus. Munich, Germany: Munich University of Technology, Inst. for Circuit Theory and Signal Processing.
Hussain, F., Hassan, S. A., Hussain, R., and Hossain, E. (2020). Machine learning for resource management in cellular and IoT networks: Potentials, current solutions, and open challenges. IEEE Commun. Surv. Tutorials 22, 1251–1275. doi:10.1109/COMST.2020.2964534
Jalden, J., and Ottersten, B. (2005). On the complexity of sphere decoding in digital communications. IEEE Trans. Signal Process. 53, 1474–1484. doi:10.1109/TSP.2005.843746
Jang, J. Y., Park, C. Y., Shin, B. S., and Song, H. K. (2021). Combined deep learning and SOR detection technique for high reliability in massive MIMO systems. IEEE Access 9, 148976–148987. doi:10.1109/ACCESS.2021.3125002
Kaur, J., Khan, M. A., Iftikhar, M., Imran, M., and Emad Ul Haq, Q. (2021). Machine learning techniques for 5G and beyond. IEEE Access 9, 23472–23488. doi:10.1109/ACCESS.2021.3051557
Kay, S. M. (1993). Fundamentals of statistical signal processing: Estimation theory. Hoboken, NJ: Prentice-Hall.
Kobayashi, R. T., Ciriaco, F., and Abrão, T. (2014). “Performance and complexity analysis of sub-optimum MIMO detectors under correlated channel,” in 2014 International Telecommunications Symposium (ITS), 1–5. doi:10.1109/ITS.2014.6948035
Koudougnon, H., Saadane, R., and Belkasmi, M. (2011). “Sphere decoding based on QR decomposition in STBC,” in 2011 International Conference on Multimedia Computing and Systems, 1–5. doi:10.1109/ICMCS.2011.5945624
Lang, O., and Huemer, M. (2015). CWCU LMMSE estimation under linear model assumptions. Linz, Austria: Elsevier, 537–545. doi:10.1007/978-3-319-27340-2_67
Larsson, E. (2009). MIMO detection methods: How they work [lecture notes]. IEEE Signal Process. Mag. 26, 91–95. doi:10.1109/MSP.2009.932126
Lin, J., and Unbehauen, R. (1991). “A method to improve the performance of the LMS adaptive filter in processing signals of non-zero mean with sharp changes,” in 1991 IEEE International Symposium on Circuits and Systems (ISCAS), 556–559.
Mahmoud, O., and El-Mahdy, A. (2021). “Performance evaluation of non-coherent dpsk signal detection algorithms in massive mimo systems,” in 2021 Telecoms Conference (ConfTELE), 1–5. doi:10.1109/ConfTELE50222.2021.9435427
Matthe, M., Zhang, D., and Fettweis, G. (2016). “Iterative detection using MMSE-PIC demapping for MIMO-GFDM systems,”. European Wireless in 2016; 22th European Wireless Conference, 1–7.
Matthé, M., Zhang, D., and Fettweis, G. (2018). Low-complexity iterative mmse-pic detection for mimo-gfdm. IEEE Trans. Commun. 66, 1467–1480. doi:10.1109/TCOMM.2017.2782339
Mopuri, S., and Acharyya, A. (2017). Low-complexity methodology for complex square-root computation. IEEE Trans. Very Large Scale Integration (VLSI) Syst. 25, 3255–3259. doi:10.1109/TVLSI.2017.2740343
Park, S. (2022). Low-complexity lmmse-based iterative soft interference cancellation for mimo systems. IEEE Trans. Signal Process. 70, 1890–1899. doi:10.1109/TSP.2022.3165311
Pereira de Figueiredo, F. A. (2022). An overview of massive MIMO for 5G and 6G. IEEE Lat. Am. Trans. 20, 931–940. In portuguese. doi:10.1109/TLA.2022.9757375
Prandoni, P., and Vetterli, M. (2008). Signal processing for communications. Communication and information sciences. Lausanne, Switzerland: EPFL Press.
Rosen, K. H. (2010). Handbook of discrete and combinatorial mathematics. Second Edition. London, United Kingdom: Chapman & Hall/CRC.
Ryan, W., and Lin, S. (2009). Channel codes: Classical and modern. Cambridge, MA: Cambridge University Press. doi:10.1017/CBO9780511803253
Sarkar, S., and Debnath, A. (2021). “Machine learning for 5G and beyond: Applications and future directions,” in 2021 Second International Conference on Electronics and Sustainable Communication Systems (ICESC), 1688–1693. doi:10.1109/ICESC51422.2021.9532728
Studer, C., and Bölcskei, H. (2010). Soft–input soft–output single tree-search sphere decoding. IEEE Trans. Inf. Theory 56, 4827–4842. doi:10.1109/TIT.2010.2059730
Studer, C., Fateh, S., and Seethaler, D. (2011). ASIC implementation of soft-input soft-output MIMO detection using MMSE parallel interference cancellation. IEEE J. Solid-State Circ. 46, 1754–1765. doi:10.1109/JSSC.2011.2144470
Tapio, V., Hemadeh, I., Mourad, A., Shojaeifard, A., and Juntti, M. (2021). Survey on reconfigurable intelligent surfaces below 10 GHz. EURASIP J. Wirel. Commun. Netw. 2021, 175. doi:10.1186/s13638-021-02048-5
Trees, H. L. V., and Bell, K. L. (2007). Bayesian bounds for parameter estimation and nonlinear filtering/tracking. Hoboken, NJ: Wiley-IEEE Press. doi:10.5555/1296178
Witte, E. M., Borlenghi, F., Ascheid, G., Leupers, R., and Meyr, H. (2010). “A scalable vlsi architecture for soft-input soft-output single tree-search sphere decoding,” in IEEE Transactions on Circuits and Systems II: Express Briefs, 706–710. doi:10.1109/TCSII.2010.2056014
Yates, R. D., and Goodman, D. J. (2005). Probability and stochastic processes. 2nd ed. edn. Hoboken, NJ: John Wiley & Sons.
Ye, H., Li, G. Y., and Juang, B. H. (2018). Power of deep learning for channel estimation and signal detection in OFDM systems. IEEE Wirel. Commun. Lett. 7, 114–117. doi:10.1109/LWC.2017.2757490
Zhang, M., and Kim, S. (2019). Evaluation of mmse-based iterative soft detection schemes for coded massive mimo system. IEEE Access 7, 10166–10175. doi:10.1109/ACCESS.2018.2889728
Zhang, D., Matthé, M., Mendes, L. L., and Fettweis, G. (2017). A study on the link level performance of advanced multicarrier waveforms under MIMO wireless communication channels. IEEE Trans. Wirel. Commun. 16, 2350–2365. doi:10.1109/TWC.2017.2664820
Glossary
1G first generation
5G fifth generation
6G sixth generation
APP A-Posteriori Probability
AWGN additive white Gaussian noise
BCRB Bayesian Cramer-Rao bound
BER bit error rate
BLAST Bell Laboratories layer space-time
BFIM Bayesian Fisher information matrix
BS base station
CC Convolutional Code
CFLOP complex float-point operation
CFR channel frequency response
CIR channel impulse response
CP cyclic prefix
CSI channel state information
CSIR channel state information at the receiver
CWCU component-wise conditionally unbiased
DFT discrete Fourier transform
ED Euclidean distance
FEC forward error correction
FER frame error rate
FLOP float-point operation
GAD Genie-Aided Detector
HQR Householder QR factorization
IAI inter-antenna interference
ILS integer least squares
iid independent and identically distributed
ISI intersymbol interference
LLR log-likelihood ratio
LME local-mean estimator
LMS least mean squares
LMMSE linear minimum mean squared error
MAP maximum a-posteriori
MIMO multiple-input multiple-output
ML maximum likelihood
MLD Maximum Likelihood Detector
MSE mean squared error
MMSE minimum mean squared error
OSIC ordering successive interference cancellation
MSE mean-squared error
NP non-deterministic polynomial-time
OFDM orthogonal frequency division multiplexing
OSIC ordering successive interference cancellation
PDF probability density function
PHY physical layer
PIC Parallel Interference Cancellation
QAM Quadrature Amplitude Modulation
QoS quality of service
RIS reconfigurable intelligent surfaces
RV random variable
SD sphere detector
SIC successive interference cancellation
SISO soft-input soft-output
SM spatial multiplexing
SM-MIMO spatial multiplexing multiple-input multiple-output
SNR signal-to-noise ratio
SOVA Soft output Viterbi Algorithm
STPD steepest-descent
UE user equipment
ZF zero-forcing
Keywords: estimation, iterative detection, spatial multiplexing, MIMO, sphere detector, interference cancellation, complexity
Citation: Gaspar D, Mendes LL and Pimenta TC (2023) A review on principles, performance and complexity of linear estimation and detection techniques for MIMO systems. Front. Comms. Net 4:968370. doi: 10.3389/frcmn.2023.968370
Received: 13 June 2022; Accepted: 01 February 2023;
Published: 28 February 2023.
Edited by:
Tran Trung Duy, Posts and Telecommunications Institute of Technology (PTIT), VietnamReviewed by:
Byungju Lee, Incheon National University, Republic of KoreaAgbotiname Lucky Imoize, University of Lagos, Nigeria
Copyright © 2023 Gaspar, Mendes and Pimenta. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Danilo Gaspar, ZGdhc3BhckBsaW5lYXIuY29tLmJy