 Haoyuan Chen
Haoyuan Chen Nuobei Shi1,2
Nuobei Shi1,2 Raymond Lee
Raymond Lee- 1Guangdong Provincial Key Laboratory of Interdisciplinary Research and Application for Data Science, Beijing Normal University-Hong Kong Baptist University United International College, Zhuhai, China
- 2Department of Computer Science, Faculty of Science, Hong Kong Baptist University, Hong Kong, China
- 3School of Applied Science and Civil Engineering, Beijing Institute of Technology, Zhuhai, China
Introduction: Online question-and-answer (Q&A) platforms are frequently replete with extensive human resource support. This study proposes a novel methodology of a customized large language model (LLM) called Chaotic LLM-based Educational Q&A System (CHAQS) to navigate the complexities associated with intelligent Q&A systems for the educational sector.
Methods: It uses an expansive dataset comprising over 383,000 educational data pairs, an intricate fine-tuning process encompassing p-tuning v2, low-rank adaptation (LRA), and strategies for parameter freezing at an open-source large language model ChatGLM as a baseline model. In addition, Fuzzy Logic is implemented to regulate parameters and the system's adaptability with the Lee Oscillator to refine the model's response variability and precision.
Results: Experiment results showed a 5.12% improvement in precision score, an 11% increase in recall metric, and an 8% improvement in the F1 score as compared to other models.
Discussion: These results suggest that the CHAQS methodology significantly enhances the performance of educational Q&A systems, demonstrating the effectiveness of combining advanced tuning techniques and fuzzy logic for improved model precision and adaptability.
Introduction
Contents depend on domain specialists to annotate data and establish a robust reference framework for inquiries and answers in classical education. Question-and-answer (Q&A) online platforms, such as Piazza or EdStem, effectively provide answers to students' queries related to course contents, assignments, and administrative procedures (Thinnyun et al., 2021). However, the volume of queries from students at the end of each semester has generated extensive human resource support, in particular to the computer science discipline, where enrollment rates have experienced an unprecedented surge (Thinnyun et al., 2021). In 2015, Jill Watson AI by GeorgiaTech signified an ontology framework with a Q&A pair database to alleviate the loads associated with manual question–answering processes (Goel et al., 2021), but it is restricted to logistical or syllabus-related nature queries involving substantial maintenance and development resources.
Large language models (LLMs), such as ChatGPT (Goel et al., 2021), ChatGLM (Du et al., 2022), and LLaMA2-Chat (Touvron et al., 2023), have exemplified intelligent education to deliver personalized and timely responses in recent years but lack reliability in the educational context. Hence, this study uses a novel methodology of a customized LLM called Chaotic LLM-based Educational Q&A System (CHAQS) by using a vast corpus of educational data to fine-tune an open-source LLM model, ChatGLM3-6b (Du et al., 2022). Meanwhile, Fuzzy Logic with a chaotic Lee Oscillator (Lee, 2004, 2020) dynamically modulates answer generation parameters of the system, such as temperature and top_p. It uses its dynamic inherent properties enabling adjustment mechanisms to not only generate nuanced and contextually relevant answers within the educational domain but also diverse inquiries and delivering response flexibility. Experiment results showed that it achieved satisfactory performance in Bidirectional Encoder Representations from Transformers (BERT) F1, precision, and recall score evaluation metrics.
The contributions of this study are as follows:
• Build a specialized educational domain LLM for answering questions.
• Use Fuzzy Logic to dynamically adjust output parameters of the model, such as top_p and temperature.
• Propose a Q&A system combining Fuzzy Logic with Lee Oscillator for response flexibility.
• Compare the benchmark model to indicate significant improvements in F1, precision, and recall metrics.
Related work
Large language models
LLMs, such as ChatGPT (Goel et al., 2021), ChatGLM (Du et al., 2022), and LLaMA2-Chat (Touvron et al., 2023), signified transformation across various industries enhancing user experiences through many applications but are restricted to specialized domains. These include as follows: OceanGPT focuses on oceanography to leverage vast datasets for research and conservation efforts on marine ecosystems (Bi et al., 2023) and Chatlaw navigates the intricacies of legal language, statutes, and case laws for legal professionals (Cui et al., 2023). HuatuoGPT focuses on medical diagnostics and patient care to provide insights and understanding of complex medical conditions (Zhang et al., 2023). FinGPT analyzes market trends, financial reporting, and investment strategies for finance sectors (Deng and Yu, 2023).
Additionally, ArtGPT interprets artistic contents to facilitate creative processes, providing insights into the history and theory to correlate with technology and creative arts (Yuan et al., 2023). Furthermore, a MathGPT solves complex mathematical problems with interpretations (Rane, 2023).
Each of these models exemplifies the concerted effort to modify LLM capabilities to specific domains, navigating the inherent complexities of the applicability of diverse fields and artificial intelligence.
It is noteworthy that the effects of LLMs on educational domains have shifted to interactive and personalized learning environments, which highlighted the profound implications of chat-based Q&A systems on educational engagement and efficacy (Deng and Yu, 2023). Other educational chatbots, such as Ada (Xie and Pentina, 2022) and the Replika AI platform (Xie and Pentina, 2022), further exemplify LLMs' adaptabilities for academic support and emotional engagement with students. Furthermore, fine-tuning of LLMs for nuanced teacher responses in BEA 2023 Shared Task underscores the continuous efforts on model refinement (Zhao et al., 2020; Dan et al., 2023).
Fine-tuning techniques, such as adapter tuning to pattern-exploiting training (PET; Schick and Schütze, 2021), prefix and prompt tuning, P-tuning (Liu et al., 2022b), P-tuning V2 (Liu et al., 2022a), and low-rank adaptation (LoRA; Hu et al., 2022), have improved model customization with minimal adjustments to the underlying parameters enhancing the adaptability and efficiency of LLMs specific domains.
Lee Oscillator
Lee Oscillator (Lee, 2004) is a chaotic neural oscillator that simulates the dynamic behavior of neurons and information processing. It exhibits better gradual transitions, shifting from chaotic to non-chaotic states smoothly as compared to traditional neural oscillators. The calculation formula is as follows:
where u(t), v(t), s(t), and z(t) are the state variables of excitatory, inhibitory, input, and output neurons, respectively; f is the sigmoid function; a1, a2, b1, and b2 are the weight parameters for these constitutive neurons; θu and θv are the thresholds for excitatory and inhibitory neurons; I(t) is the external input stimulus; and k is the decay constant.
Hence, this study uses ChatGLM3-6b as a baseline model and integrates a Chaotic LLM-based Educational Q&A System to dynamically modify model parameters. It aims to refine response quality and contextual relevance generated by educational Q&A systems to address the specific needs of students and educators with flexibility and precision. Figure 1 shows the overall framework of CHAQS.
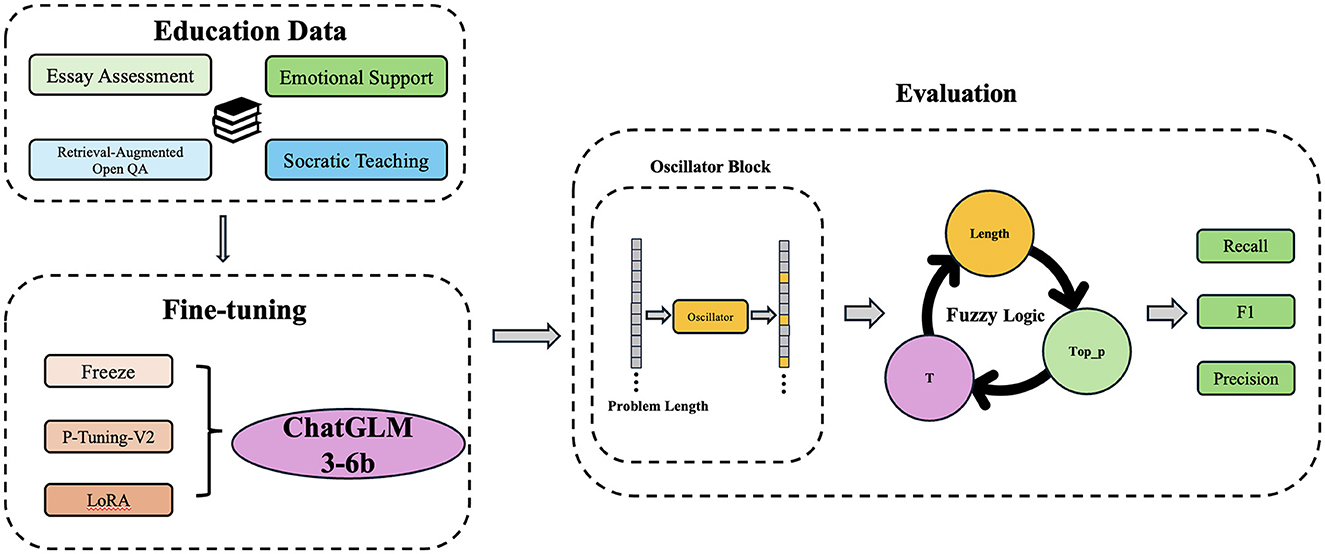
Figure 1. Framework of Chaotic LLM-based Educational Q&A System (CHAQS).
Methodology
Proposed LLM-based educational Q&A system (CHAQS)
This section uses different fine-tuning techniques, such as P-tuning v2, LoRA, and freeze, to fine-tune the baseline model ChatGM3-6b prior to Fuzzy Logic and Lee Oscillator integration.
P-tuning v2 fine-tuning technique is built upon P-tuning, to introduce dynamic prompt generation using a neural network to create context-aware prompts based on the input text. This allows flexible and effective task adaptation.
LoRA proposes an alternative adaptation strategy by introducing low-rank matrices that modify the self-attention and feed-forward layers of transformer models. This allows selective and efficient parameter updates to enhance model performance with minimal computational cost.
LoRA's modification of a transformer layer's weight matrix W' is described in Equation 5:
where W is the original weight matrix and B is the low-rank matrix learned during training. This approach provides a balance between adaptation flexibility and computational efficiency.
Freeze fine-tuning technique allows the remaining unfrozen parts to adapt to the specifics of a new task. It balances between frozen and trainable parameters and assists in maintaining the model's robustness while ensuring task-specific adaptability.
Hence, the baseline model ChatGLM3-6b uses the specific educational dataset by the above fine-tuning techniques prior to Fuzzy Logic and Lee Oscillator integration.
Chaotic Fuzzy Logic Augmented Q&A System
Figure 2 shows a Chaotic LLM-based Educational Q&A System (CHAQS) structure. It consists of two parts, namely, Fuzzy Logic and Lee Oscillator, to optimize the answer generation process of the model after fine-tuning techniques are used to the baseline model ChatGLM3-6b. It also combines question texts to dynamically adjust model parameters, such as top_p and temperature. Chaotic Fuzzy Logic Augmented Q&A System procedure are listed in Algorithm 1.
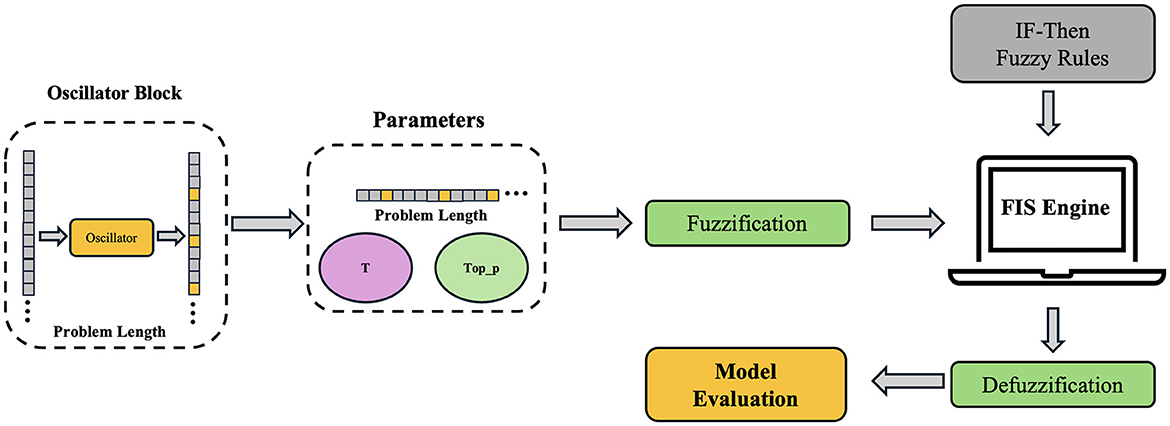
Figure 2. Structure of Chaotic Fuzzy Logic Augmented Q&A System.

Algorithm 1. Chaotic Fuzzy Logic for adjusting educational Q&A system.
The top_p is a parameter of text generation strategy called “nucleus sampling,” and its basic idea is to randomly select the next word from a subset of vocabulary with the highest probabilities, where the cumulative probability of the subset reaches at least the threshold p. This approach aims to balance between diversity and coherence of the generated text by considering only the vocabulary whose cumulative probabilities reach a specific percentage, thereby avoiding an over-representation of high-frequency words while reducing the likelihood of generating irrelevant or illogical text. Moreover, the top_p mathematical representation is as follows: Let V be the vocabulary, for a given threshold p, find the smallest subset V′⊆V such that , where P(w) is the model output probability for word w. When generating the next word, sampling is performed from the set V′ according to its probability distribution.
The Temperature parameter is different from the parameter top_p. This parameter is used to control the randomness and creativity in the generated text by LLMs, adjusting the probabilities of predicted words in the output layer of the system. The original probability distribution calculated by the softmax layer is given as follows in Equation 6:
where Xi is the logit corresponding to the i-th element and V is the total number of elements. Moreover, p(Xi) is the resulting probability of the i-th element after applying the softmax function.
With the introduction of the Temperature parameter (T), the formula becomes Equation 7:
To incorporate Fuzzy Logic into the system, the first step involves fuzzification of variables. Here, the length of the question text in the dataset as a variable is selected to define fuzzy membership functions accordingly. The set of fuzzymembership functions is as follows in Equation 8:
Referring to the case study of Fuzzy Logic Introduction (Lee, 2019), we classified the question length into three types: short, medium, and long. After that, as shown in Figure 3, we analyzed and visualized the question length distribution of this educational dataset. During the preliminary analysis, we observed that some significant breakpoints could be set as thresholds. For example, we identified that setting the thresholds at 0.35 and 0.65 effectively classified examples in this dataset, ensuring that our system can distinctly differentiate between the categories, thereby enhancing the ability of the model to generate contextually appropriate responses.
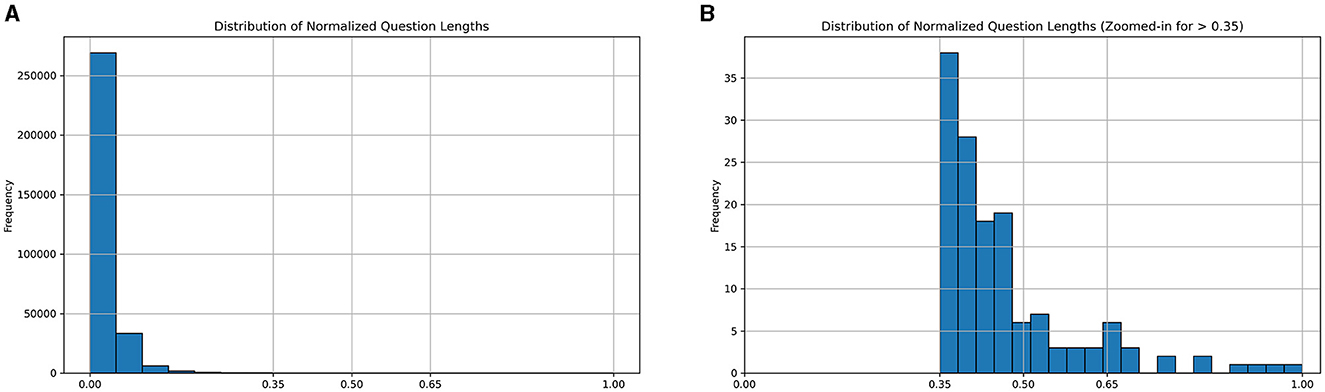
Figure 3. Histograms of the distributions of normalized question lengths. (A) Distribution of normalized question lengths. (B) Distribution of normalized question lengths (Zoomed-in for >0.35).
This categorization is crucial for the Fuzzy Logic system, allowing for a fuzzification process of problem length beyond mere numerical values. This fuzzy membership function enables the system to handle the inherently fuzzy nature of problem length classification, where the boundaries between categories are not rigid but gradual.
After defining the problem_length function, the top_p and temperature parameters generated by the model are fuzzified. These two parameters are categorized into the following terms: low, medium, and high, and their membership functions are defined as follows in Equations 9 and 10:
Here, Lee Oscillator is integrated to dynamically modify the problem length parameters as follows (Equation 11):
The calculation formula of the Lee Oscillator function Lee() is stated in Equations 1–4.
It is necessary to establish fuzzy rules for the system upon Lee Oscillator implementation to process the problem length. The length of the problem is used as a feature to adjust the top_p and temperature parameters of the system in its output answers, making diversified responses across different question lengths. Figure 4 shows the fuzzy rules setting of our system.
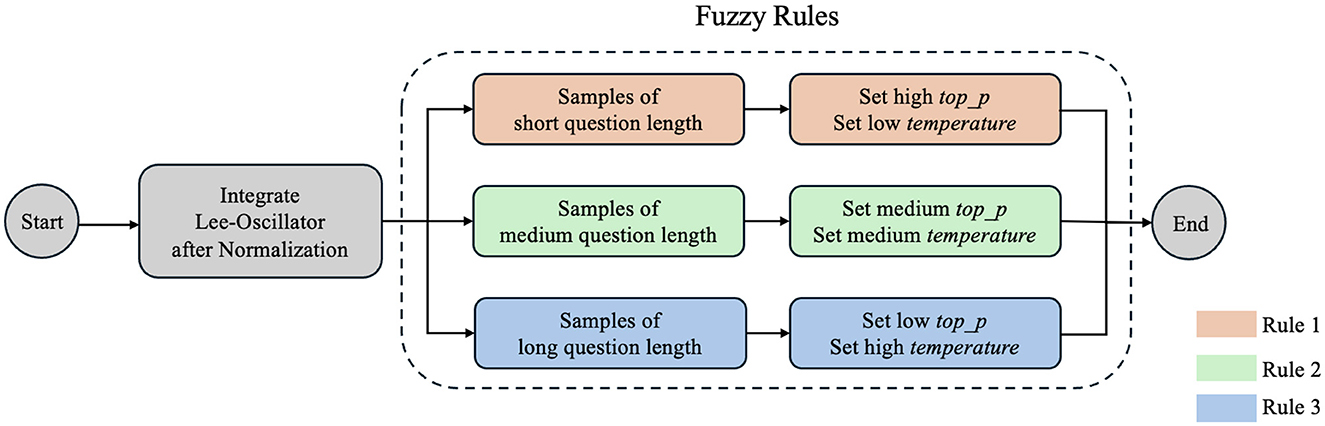
Figure 4. Fuzzy rules setting of CHAQS.
These Fuzzy Logic rules allow for varying levels of diversity and randomness in responses based on the length of the question.
As for short questions (Rule 1), a lack of information is often encountered. To introduce a suitable level of diversity in generated answers, the top_p parameter is set to a high range, allowing the model to explore a broader vocabulary space. At the same time, the temperature parameter is set to a low range to maintain the coherence of answers to reduce randomness, the Rule 1 is defined in Equation 12.
For medium-length questions (Rule 2), they generally provide sufficient background information so that the system does not require a high degree of creativity to provide reasonable answers. Therefore, the top_p parameter is set to a medium range, encouraging the model to focus on vocabulary and concepts already mentioned in the question text. However, to prevent the generated answers from being monotonous, the temperature parameter is set to a medium range to introduce a certain degree of innovation the Rule 2 is defined in Equation 13.
For longer questions (Rule 3), since the question itself usually provides sufficient information, the top_p value is set to a low range to limit the vocabulary space of the model when predicting answers, encouraging it to focus on words closely related to the question text; at the same time, to avoid generating trivial or repetitive content, the temperature parameter is set to a high range to introduce creativity and unexpected elements in answers the Rule 3 is defined in Equation 14.
Experiments
Data description
The dataset used in the experiments is an English data version compiled by Dan et al. (2023). It contains numerous instructions and dialogue data, discussions related to role-playing, creative writing, and code-related topics and is organized by “problem” and “solution” fields to define the problem and resolution for each educational sample, as shown in Table 1.
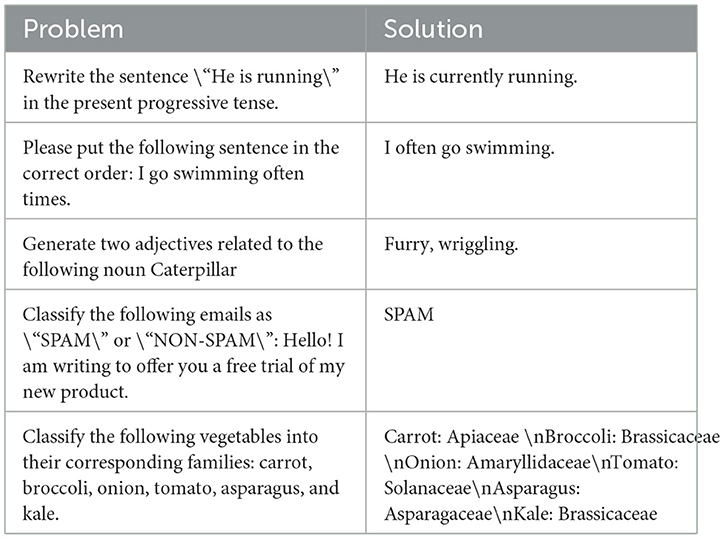
Table 1. Subset of the dataset samples.
Figure 5 shows histograms of dataset example length distributions. It is instrumental in determining the optimal maximum sequence length parameter for subsequent fine-tuning of the baseline model ChatGLM3-6b. It can identify a suitable parameter to accommodate the majority of data by examining sample length distribution in the educational dataset, ensuring that the baseline model ChatGLM3-6b is effectively fine-tuned on representative samples to avoid unneeded computational costs from excessive long sequences.
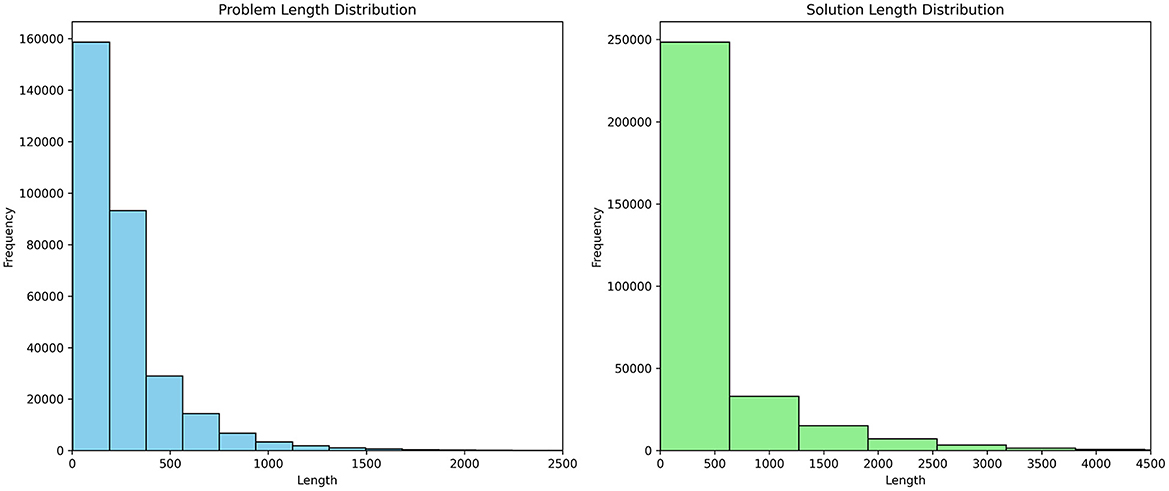
Figure 5. Histograms of the distributions of dataset example length.
Evaluation metrics
BERT score
We use BERT F1, precision, and recall score as evaluation metrics. BERT score (Zhang et al., 2019) is a metric to evaluate output quality in text generation tasks, such as machine translation or text summarization. It calculates the similarity between the predicted text and the reference text and uses a pre-trained BERT model (or other similar transformer models) to extract text embeddings and compute similarity scores accordingly. BERT score consists of three main steps: embedding, similarity calculation, and aggregation, which is calculated as follows:
• Embedding: The process is to translate words from reference texts, which are often referred to as standard texts, and the candidate texts are referred to as model answer texts into high-dimensional vector space Er and Ec, respectively.
• Similarity Calculation: The similarity between each pair of words is calculated in the reference text for the candidate text. Cosine similarity is used to calculate between Er and Ec as shown in Equation 15:
• Aggregation: The similarity score for the entire text is calculated. For Precision (P), the score for each candidate word Wc is the score of its highest similarity with words Wr in the reference text, as described in Equation 16. For Recall (R), the score for each reference word Wr is the score of its highest similarity with words Wc in the candidate text, as shown in Equation 17. Then, these scores are averaged to calculate the overall precision and recall, where the F1 score is the harmonic mean of precision and recall, as defined in Equation 18.
Bilingual evaluation understudy
To verify the effectiveness of our system from multiple aspects, we also use bilingual evaluation understudy (BLEU; Papineni et al., 2002), to evaluate the quality of answers. It measures the similarity between the predicted text and the reference text by comparing n-grams. BLEU consists of three main steps: n-gram extraction, precision calculation, brevity penalty, and aggregation, which is calculated as follows:
• 1.N-Gram Extraction: N-gram extraction extracting n-grams from both the reference texts and the candidate texts.
• Precision Calculation: The precision of n-grams of the candidate text is calculated compared to the reference text. The precision for each n-gram length n is given by Equation 19.
Countclip(n−gram) is the clipped count of a particular n-gram in the candidate translation. Countref(n−gram) is the maximum count of a particular n-gram in the reference translation. Count(n−gram) is the total count of the n-gram in the candidate generation without clipping.
• Brevity penalty (BP): This process is designed to avoid favoring shorter generations. The BP calculation is defined in Equation 20.
where c is the length of the candidate text and r is the length of the reference text.
• Aggregation: The final BLEU score is computed in Equation 21.
where wn is the weight for n-grams.
Human evaluation
We also choose a human evaluation approach to evaluate our system comprehensively. A total of 10 evaluators participated in this part, reviewing 100 educational answers for each model. A previous study on the evaluation of LLM generation (Shen et al., 2023; Evans et al., 2024; Yang et al., 2024) considers various factors, such as coherence, consistency, fluency, and relevance. As for our educational domains, mathematical computing and problem-solving tasks are also included in the dataset. To assess the ability of the system in these tasks, we added an additional factor, accuracy, so our human evaluation includes five factors:
• Coherence: Apply coherence to evaluate whether the contents flow logically.
• Consistency: Evaluate whether the answer remains as contradictory statements.
• Fluency: Assess the readability of the answer.
• Relevance: Determines the relevance between the answer and the reference text.
• Accuracy: Checks the accuracy of the answer in some specific mathematical questions.
Each factor scores on a scale of 0–2, where 0 represents the answer is bad or false, 2 represents a suitable and accurate answer, and 1 represents an unclear partially incorrect answer. Therefore, each sample can achieve a maximum score of 10. The final human evaluation scores in the experimental table are calculated. First, the scores for all five factors are summarized for each sample. Then, the average of these total scores for all samples is computed, and this averaged score represents the final evaluation for each model.
Baseline model
ChatGLM3-6b (Du et al., 2022) is selected as the open-source baseline model and fine-tuned with the dataset using techniques such as Freeze P-tuning-v2 (Liu et al., 2022b), and LoRA (Hu et al., 2022). CHAQS is used for the output of the model to provide quality responses.
Experimental settings and hyperparameters
The hardware implementation is based on eight NVIDIA V100 Tensor Core GPUs, each with a 32 GB VRAM Graphics Card, using deep learning framework PyTorch 1.13.1+cu117, numpy 1.21.6, and pandas 1.3.5 for model fine-tuning. The specific hyperparameter settings of the experiment are shown in Table 2.
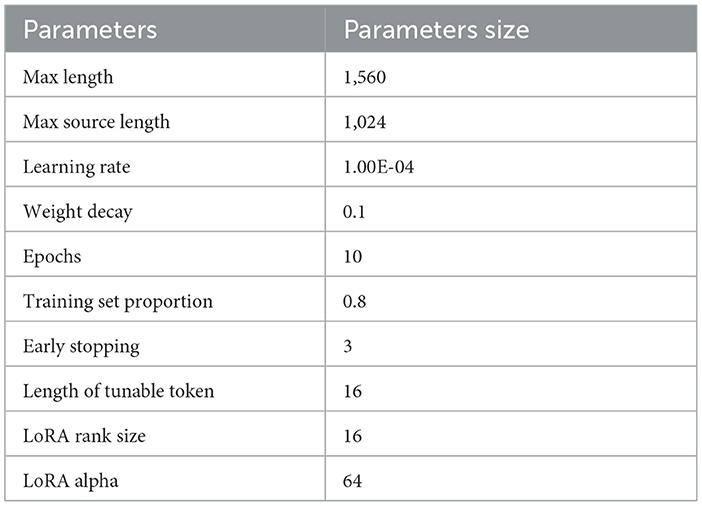
Table 2. Hyperparameter settings.
Model comparison
BERT F1, recall, precision scores, BLEU, and human evaluation are selected as evaluation metrics for the experiment. Here, Lee Oscillator parameter bifurcation behavior under different external input stimuli is used to capture the remarkable feature of the oscillator (Lee, 2004), and the specific oscillator parameter settings are presented in Table 3.
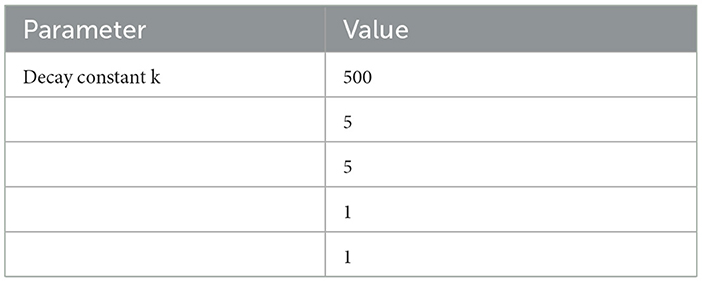
Table 3. Oscillator parameter settings.
Using ChatGLM3-6b as the baseline model with different fine-tuning techniques on educational data, LoRA, Freeze, and P-tuning-v2 are used as stated previously. Subsequently, chaotic characteristics are introduced into various fine-tuned models by incorporating Fuzzy Logic and Lee Oscillator. The comparison of fine-tuning techniques is presented in Table 4.
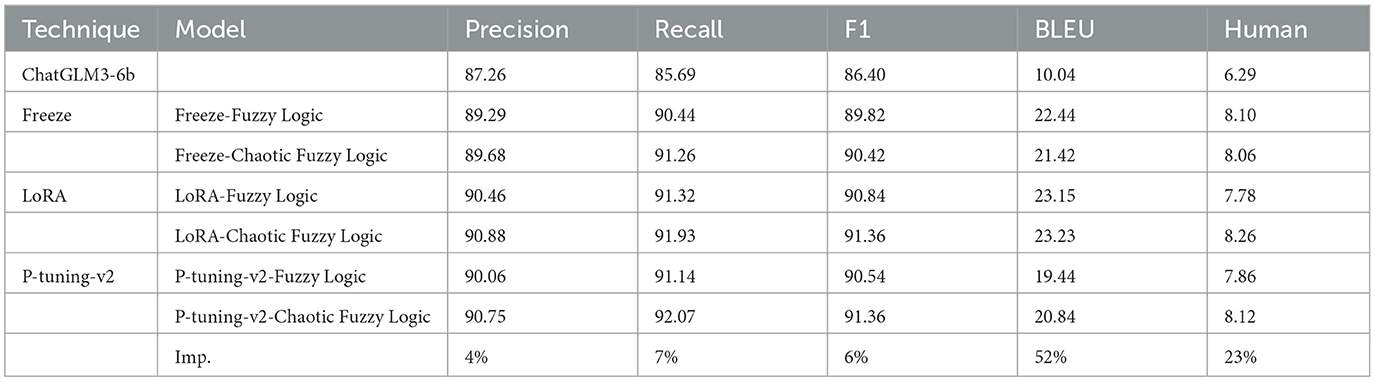
Table 4. Model comparison with fine-tuning techniques.
It showed that CHAQS has significant improvements across various metrics. It is evident that the fine-tuned model using the P-tuning-v2 technique has achieved BERT precision scores, recall scores, and F1 scores at 90.75, 92.07, and 91.36, respectively. It achieved improvements at 4, 7, and 6% compared to the baseline model, ChatGLM3-6b, which showed that it can enhance model performance, and our system also exhibited excellent performance according to both BLEU metric and human evaluation standards.
Moreover, CHAQS is compared with LLMs at a similar scale as a benchmark. These include (1) Qwen-7B-Chat (Bai et al., 2023), by Alibaba Cloud, is a model with 7 billion parameters, which enhances performance based on the Qwen-7B using an alignment mechanism; (2) Baichuan2-7B-Chat (Yang et al., 2023), by Baichuan Intelligence, is trained on 2.6 trillion tokens of high-quality corpus with commendable results on multiple authoritative English and multilingual general and domain benchmarks; (3) Llama-2-7B-Chat (Touvron et al., 2023), based on the Llama architecture with 7 billion parameters, is a model that has fine-tuned with human instructions based on the Llama-2-7B; (4) XVERSE-7B-Chat, by Shenzhen Yuanxiang Technology, is a mainstream decoder-only standard transformer network structure with a wide range of applications; (5) Yi-6B-Chat model, by (AI et al., 2024) 01.AI, is one of the open-source LLMs using 6 billion parameters and trained on 3 trillion bytes multilingual corpus; and (6) BlueLM-7B-Chat (Tack et al., 2023), by Vivo AI Global Research Institute, is a large-scale pre-trained language model that exhibits strong competitiveness among open-source models of similar scale.
It showed that CHAQS has significant improvements over other state-of-the-art models on the dataset in terms of BERT precision, recall, and F1 scores, as shown in Table 5. This highlights its effectiveness in this educational dataset. It also showed that there is an average increase of 5.12% in the precision score, an average increase of 11% in the recall metric, and an improvement of 8% in the F1 score compared with other models, and our system also exhibited excellent performance according to both BLEU metrics and human evaluation.
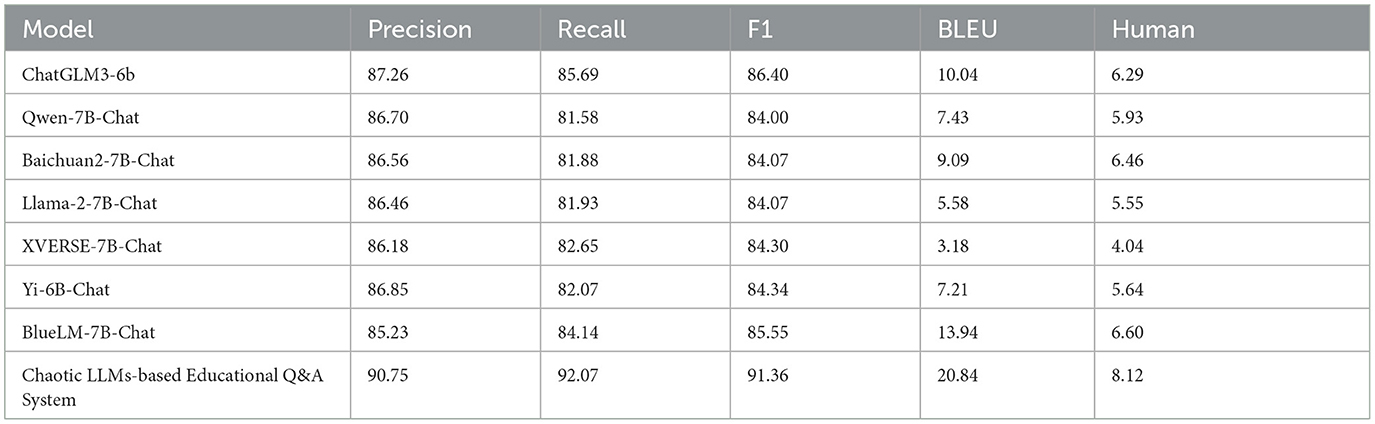
Table 5. State-of-the-art model comparison.
Ablation study
Figures 6, 7 show the ablation study result of CHAQS. To highlight the impact of our method, we also compared it with other settings after P-tuning V2 and LoRA. We used different parameter settings, such as both temperature and top_p (p) set to 0 or 1, and referred to the OpenAI API (Goel et al., 2021), setting the temperature to 0.7 and the top_p to 1.0.
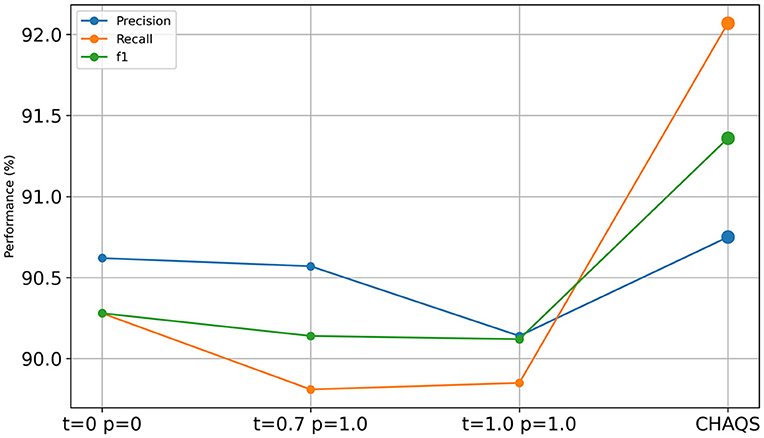
Figure 6. Ablation study of P-tuning v2 CHAQS.
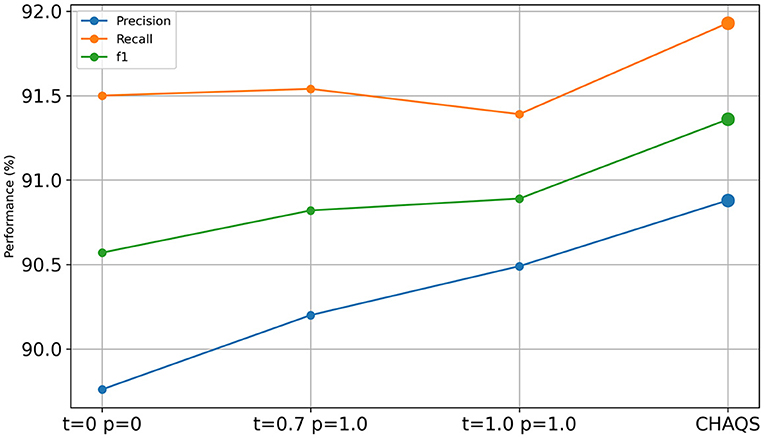
Figure 7. Ablation study of LoRA CHAQS.
In addition, we also apply our CHAQS to llama2-7b-Chat (Touvron et al., 2023) using LoRA fine-tuning techniques, to validate the generality of our method, as shown in Table 6.
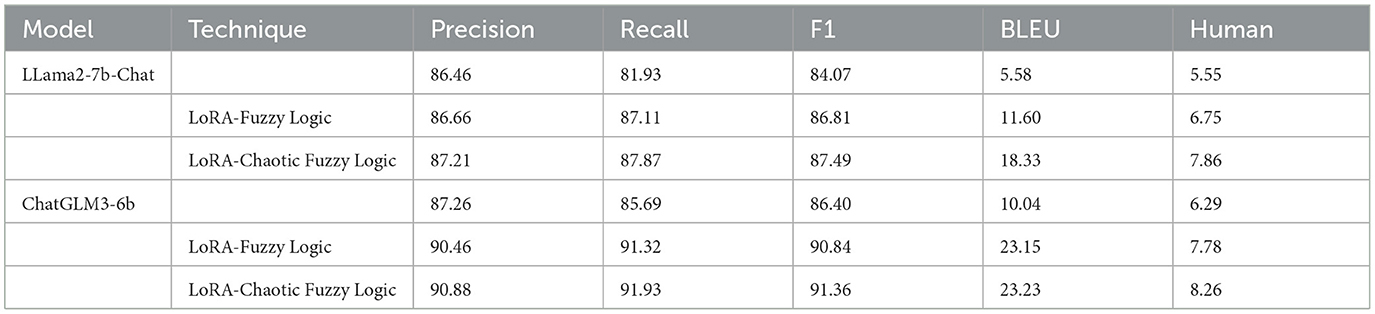
Table 6. A comparison between llama2-7b-chat and chamglm3-6b.
Case studies
There are three representative tasks selected to evaluate the performance and quality of the system: Task 1 determines relevance to a target, Task 2 converts given text into lemma form called lemmatization, and Task 3 analyzes a given text with candidate choices to select the most appropriate emotion. The comparison between CHAQS and ChatGLM3-6b answers from the test dataset is presented in Table 7.
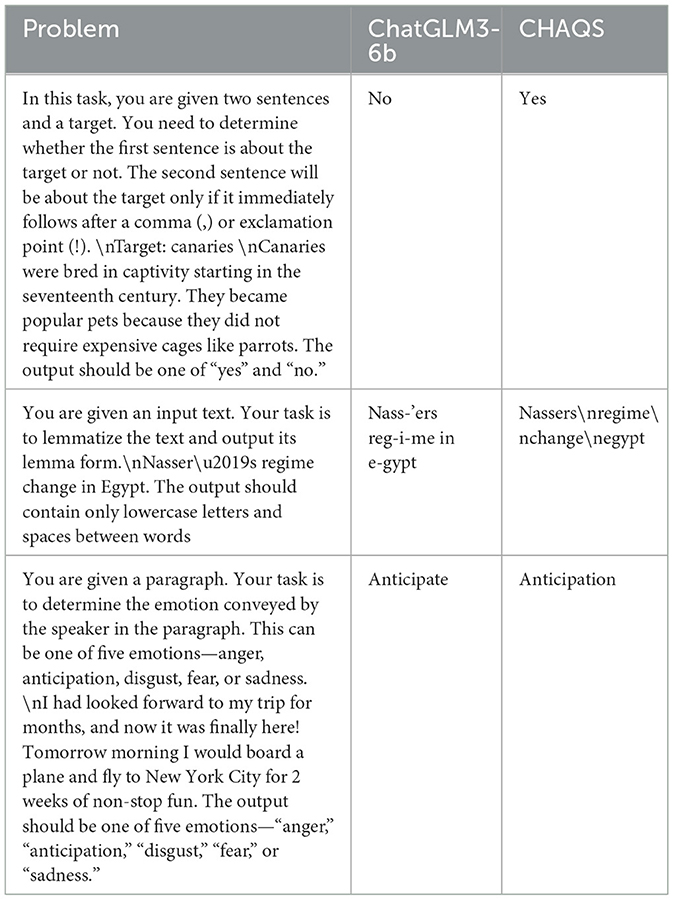
Table 7. Model generation comparison.
It showed that CHAQS provided more accurate and task-appropriate answers. For instance, in Task 1, it is considered that the first sentence was related to the target “Canaries” accurately. In Task 2, CHAQS performed text lemmatization accurately and avoided incorrect hyphens and retention of separators. In Task 3, CHAQS also identified the emotion and selected the lemma form “anticipation” instead of “anticipate” accurately.
To highlight the impact of our method, we also compared it with other settings. For example, in Table 8, we used different parameter settings, such as both temperature and top_p (p) set to 0 or 1, and referred to the OpenAI API (Goel et al., 2021), setting the temperature to 0.7 and the top_p to 1.0.

Table 8. A comparison of different parameter settings.
As shown in Table 8, we selected representative questions to illustrate the diversity of responses in the system. For example, Problem 4 required generating a more complex sentence, and our CHAQS system produced the only sentence in the past tense. Regarding Problem 5, our CHAQS system provided a more detailed answer, not only offering a clear and concise definition of anger but also specifying its nature (annoyance, displeasure, and hostility). For Problem 6, which involves natural language inference to determine the relationship between a given premise and a hypothesis, our system not only provided the correct answer but also explained the process more clearly and accurately by pointing out that the car with the number 27 is unrelated to the problem requirements.
Conclusion and future works
This study is focused on developing CHAQS that integrates with the LLM ChatGLM3-6b after fine-tuning with educational data. The approach is diverged from depending on commercial models and prompt-engineering practices via API calls opting for open-source models. Experiment results showed that CHAQS can significantly enhance the performance of LLM by using various fine-tuning techniques, integrating Fuzzy Logic and oscillators in the educational domain. When compared with various benchmark models, such as ChatGLM3-6b and Llama-2-7B-Chat, the system resulted in significant improvements in BERT precision, recall, and F1 scores, highlighting its effectiveness and potential for educational applications.
There are three representative tasks selected, namely, target relevance, lemmatization, and emotion analysis. It also showed that the system provided accurate answers compared with the benchmark model.
Nevertheless, there are limitations in the system. Fine-tuning parameters are required to improve response quality and coherence. Since the system is restricted by computational resources, it can only fine-tune small-scale open-source LLMs and is required to perform at other large-scale LLMs that have more than 10 billion parameters in various domains and tasks for evaluation. Hence, future studies can explore multi-turn Q&A, integrate OCR functions to process image-based educational data, and evaluate other approaches, such as assessments by experts or LLMs.
Data availability statement
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
Author contributions
HC: Conceptualization, Formal analysis, Investigation, Methodology, Project administration, Software, Writing – original draft. NS: Data curation, Validation, Visualization, Writing – original draft. LC: Funding acquisition, Project administration, Writing – review & editing. RL: Funding acquisition, Resources, Writing – review & editing.
Funding
The author(s) declare financial support was received for the research, authorship, and/or publication of this article. This study was supported in part by the Guangdong Provincial Key Laboratory IRADS (2022B1212010006 and R0400001-22) and Key Laboratory for Artificial Intelligence and Multi-Model Data Processing of the Department of Education of Guangdong Province, and Guangdong Province F1 project grant on Curriculum Development and Teaching Enhancement on Quantum Finance Course: UICR0400050-21CTL.
Acknowledgments
The authors thank Beijing Normal University-Hong Kong Baptist University United International College and the IRADS Laboratory for the provision of a computer facility to conduct this research. Additionally, we acknowledge the use of the ChatGLM3-6B large language model developed by THUDM, for assistance in the experimental part. The specific model used was ChatGLM3-6B.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
AI, 01., Young, A., Chen, B., Li, C., Huang, C., Zhang, G., et al. (2024). Yi: Open Foundation Models by 01.AI. arXiv preprint arXiv:2403.04652. doi: 10.48550/arXiv.2403.04652
Bai, J., Bai, S., Chu, Y., Cui, Z., Dang, K., Deng, X., et al. (2023). Qwen Technical Report. arXiv preprint arXiv:2309.16609. doi: 10.48550/arXiv.2309.16609
Bi, Z., Zhang, N., Xue, Y., Ou, Y., Ji, D., Zheng, G., et al. (2023). OceanGPT: A Large Language Model for Ocean Science Tasks. arXiv preprint arXiv:2310.02031. doi: 10.48550/arXiv.2310.02031
Cui, J., Li, Z., Yan, Y., Chen, B., and Yuan, L. (2023). ChatLaw: Open-Source Legal Large Language Model with Integrated External Knowledge Bases. arXiv preprint arXiv:2306.16092. doi: 10.48550/arXiv.2306.16092
Dan, Y., Lei, Z., Gu, Y., Li, Y., Yin, J., Lin, J., et al. (2023). EduChat: A Large-Scale Language Model-based Chatbot System for Intelligent Education. arXiv preprint arXiv:2308.02773. doi: 10.48550/arXiv.2308.02773
Deng, X., and Yu, Z. (2023). A meta-analysis and systematic review of the effect of chatbot technology use in sustainable education. Sustainability 15:2940. doi: 10.3390/su15042940
Du, Z., Qian, Y., Liu, X., Ding, M., Qiu, J., Yang, Z., et al. (2022). GLM: general language model pretraining with autoregressive blank infilling. Proc. 60th Annu. Meet. Assoc. Comput. Linguist. 1, 320–335. doi: 10.18653/v1/2022.acl-long.26
Evans, J., D'Souza, J., and Auer, S. (2024). Large language models as evaluators for scientific synthesis. arXiv preprint arXiv:2407.02977. doi: 10.48550/arXiv.2407.02977
Goel, A., Sikka, H., and Gregori, E. (2021). Agent smith: teaching question answering to Jill Watson. arXiv preprint arXiv:2112.13677. doi: 10.48550/arXiv.2112.13677
Hu, E. J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., et al. (2022). “LoRA: Low-Rank Adaptation of Large Language Models,” in International Conference on Learning Representations (ICLR). doi: 10.48550/arXiv.2106.09685
Lee, R. S. T. (2004). A transient-chaotic autoassociative network (TCAN) based on Lee Oscillators. IEEE Trans. Neural Netw. 15, 1228–1243. doi: 10.1109/TNN.2004.832729
Lee, R. S. T. (2019). Quantum Finance: Intelligent Forecast and Trading Systems. Singapore: Springer Singapore.
Lee, R. S. T. (2020). Chaotic type-2 transient-fuzzy deep neuro-oscillatory network (CT2TFDNN) for worldwide financial prediction. IEEE Trans. Fuzzy Syst. 28, 731–745. doi: 10.1109/TFUZZ.2019.2914642
Liu, X., Ji, K., Fu, Y., Tam, W., Du, Z., Yang, Z., et al. (2022a). “P-tuning: prompt tuning can be comparable to fine-tuning across scales and tasks,” in Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) (Stroudsburg, PA: Association for Computational Linguistics), 61–68.
Liu, X., Ji, K., Fu, Y., Tam, W., Du, Z., Yang, Z., and Tang, J. (2022b). “P-Tuning v2: Prompt tuning can be comparable to fine-tuning universally across scales and tasks,” in Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics, Vol. 2 (Dublin: Association for Computational Linguistics), 61–68. doi: 10.18653/v1/2022.acl-short.8
Papineni, K., Roukos, S., Ward, T., and Zhu, W.-J. (2002). “BLEU: a method for automatic evaluation of machine translation,” in Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics (Philadelphia, PA: Association for Computational Linguistics), 311–318.
Rane, N. (2023). Enhancing mathematical capabilities through ChatGPT and similar generative artificial intelligence: roles and challenges in solving mathematical problems. SSRN Electron. J. 2023:4603237. doi: 10.2139/ssrn.4603237
Schick, T., and Schütze, H. (2021). “Exploiting cloze-questions for few-shot text classification and natural language inference,” in Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume (Stroudsburg, PA: Association for Computational Linguistics), 255–269.
Shen, C., Cheng, L., Nguyen, X.-P., You, Y., and Bing, L. (2023). “Large language models are not yet human-level evaluators for abstractive summarization,” in Findings of the Association for Computational Linguistics: EMNLP 2023, eds. H. Bouamor, J. Pino, and K. Bali (Singapore: Association for Computational Linguistics), 4215–4233.
Tack, A., Kochmar, E., Yuan, Z., Bibauw, S., and Piech, C. (2023). “The BEA 2023 shared task on generating AI teacher responses in educational dialogues,” in Proceedings of the 18th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2023) (Stroudsburg, PA: Association for Computational Linguistics), 785–795.
Thinnyun, A., Lenfant, R., Pettit, R., and Hott, J. R. (2021). “Gender and engagement in CS courses on piazza,” in Proceedings of the 52nd ACM Technical Symposium on Computer Science Education (New York, NY: ACM), 438–444.
Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., et al. (2023). Llama 2: Open Foundation and Fine-Tuned Chat Models. arXiv preprint arXiv:2307.09288. doi: 10.48550/arXiv.2307.09288
Xie, T., and Pentina, I. (2022). “Attachment theory as a framework to understand relationships with social chatbots: a case study of Replika,” in Proceedings of the 55th Hawaii International Conference on System Sciences, 2046–2055. doi: 10.24251/HICSS.2022.258
Yang, A., Xiao, B., Wang, B., Zhang, B., Bian, C., Yin, C., et al. (2023). Baichuan 2: Open Large-scale Language Models.
Yang, S., Yuan, Z., Li, S., Peng, R., Liu, K., and Yang, P. (2024). GPT-4 as Evaluator: Evaluating Large Language Models on Pest Management in Agriculture. arXiv preprint arXiv:2403.11858. doi: 10.48550/arXiv.2403.11858
Yuan, Z., Wang, X., Wang, K., and Sun, L. (2023). ArtGPT-4: Towards Artistic-Understanding Large Vision-Language Models With Enhanced Adapter. arXiv preprint arXiv:2305.07490. doi: 10.48550/arXiv.2305.07490
Zhang, H., Chen, J., Jiang, F., Yu, F., Chen, Z., Li, J., et al. (2023). HuatuoGPT, Towards Taming Language Model to Be a Doctor. arXiv preprint arXiv:2305.15075. doi: 10.48550/arXiv.2305.15075
Zhang, T., Kishore, V., Wu, F., Weinberger, K. Q., and Artzi, Y. (2019). “BERTScore: Evaluating Text Generation With BERT,” in Proceedings of the International Conference on Learning Representations (ICLR) 2020. doi: 10.48550/arXiv.1904.09675
Keywords: education, large language model, Lee Oscillator, Fuzzy Logic, AI-based QA system
Citation: Chen H, Shi N, Chen L and Lee R (2024) Enhancing educational Q&A systems using a Chaotic Fuzzy Logic-Augmented large language model. Front. Artif. Intell. 7:1404940. doi: 10.3389/frai.2024.1404940
Received: 21 March 2024; Accepted: 23 July 2024;
Published: 08 August 2024.
Edited by:
Lili Mou, University of Alberta, CanadaCopyright © 2024 Chen, Shi, Chen and Lee. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Raymond Lee, cmF5bW9uZHNodGxlZSYjeDAwMDQwO3VpYy5lZHUuY24=