 Stefano Teso
Stefano Teso Öznur Alkan2
Öznur Alkan2- 1CIMeC and DISI, University of Trento, Trento, Italy
- 2Optum, Dublin, Ireland
- 3Machine Learning Group, Department of Computer Science, TU Darmstadt, Darmstadt, Germany
- 4IBM Research, Dublin, Ireland
Explanations have gained an increasing level of interest in the AI and Machine Learning (ML) communities in order to improve model transparency and allow users to form a mental model of a trained ML model. However, explanations can go beyond this one way communication as a mechanism to elicit user control, because once users understand, they can then provide feedback. The goal of this paper is to present an overview of research where explanations are combined with interactive capabilities as a mean to learn new models from scratch and to edit and debug existing ones. To this end, we draw a conceptual map of the state-of-the-art, grouping relevant approaches based on their intended purpose and on how they structure the interaction, highlighting similarities and differences between them. We also discuss open research issues and outline possible directions forward, with the hope of spurring further research on this blooming research topic.
1. Introduction
The fields of eXplainable Artificial Intelligence (XAI) and Interactive Machine Learning (IML) have traditionally been explored separately. On the one hand, XAI aims at making AI and Machine Learning (ML) systems more transparent and understandable, chiefly by equipping them with algorithms for explaining their own decisions (Guidotti et al., 2018b; Holzinger et al., 2022; Ras et al., 2022). Such explanations are instrumental for enabling stakeholders to inspect the system's knowledge and reasoning patterns. However stakeholders only participate as passive observers and have no control over the system or its behavior. On the other hand, IML focuses primarily on communication between machines and humans, and it is specifically concerned with eliciting and incorporating human feedback into the training process via intelligent user interfaces (Ware et al., 2001; Fails and Olsen, 2003; Amershi et al., 2014; He et al., 2016; Wang, 2019; Michael et al., 2020). Despite covering a broad range of techniques for in-the-loop interaction between humans and machines, most research in IML does not explicitly consider explanations of ML models.
Recently, a number of works have sought integrating techniques from XAI within the IML loop. The core observation behind this line of research is that, interacting through explanations is an elegant and human-centric solution to the problem of acquiring rich human feedback, and therefore leads to higher-quality AI and ML systems, in a manner that is effective and transparent for both users and machines. In order to accomplish this vision, these works leverage either machine explanations obtained using techniques from XAI, human explanations provided as feedback by sufficiently expert annotators, or both, to define and implement a suitable interaction protocol.
These two types of explanations play different roles. By observing the machine's explanations, users have the opportunity of building a better understanding of the machine's overall logic, which not only has the potential to facilitate trust calibration (Amershi et al., 2014), but also supports and amplifies our natural capacity of providing appropriate feedback (Kulesza et al., 2015). Machine explanations are also key for identifying imperfections and bugs affecting ML models, such as reliance on spurious correlations of features that are not causally related with the desired outcome (Lapuschkin et al., 2019; Geirhos et al., 2020; Schramowski et al., 2020). At the same time, human explanations are a very rich source of supervision for models (Camburu et al., 2018) and are also very natural for us to provide. In fact, explanations tap directly into our innate learning and teaching abilities (Lombrozo, 2006; Mac Aodha et al., 2018) and are often spontaneously provided by human annotators when given the chance (Stumpf et al., 2007). Machine explanations and human feedback can also be combined to build interactive model editing and debugging facilities, because—once aware of limitations or bugs in the model—users can indicate effective improvements and supply corrective feedback (Kulesza et al., 2015; Teso and Kersting, 2019).
The goal of this paper is to provide a general overview and perspective of research on leveraging explanations in IML. Our contribution is two-fold. First, we survey a number of relevant approaches, grouping them based on their intended purpose and how they structure the interaction. Our second contribution is a discussion of open research issues, on both the algorithmic and human sides of the problem, and possible directions forward. This paper is not meant as an exhaustive commentary of all related work on explainability or on interactivity. Rather, we aim to offer a conceptual guide for practitioners to understand core principles and key approaches in this flourishing research area. In contrast to existing overviews on using explanations to guide learning algorithms (Hase and Bansal, 2022), debug ML models (Lertvittayakumjorn and Toni, 2021), and transparently recommend products (Zhang and Chen, 2020), we specifically focus on human-in-the-loop scenarios and consider a broader range of applications, highlighting the variety of mechanisms and protocols for producing and eliciting explanations in IML.
This paper is structured as follows. In Section 2 we discuss a general recipe for integrating explanations into interactive ML, recall core principles for designing successful interaction strategies, and introduce a classification of existing approaches. Then we discuss key approaches in more detail, organizing them based on their intended purpose and the kind of machine explanations they leverage. Specifically, we survey methods for debugging ML models using saliency maps and other local explanations in Section 3, for editing models using global explanations (e.g., rules) in Section 4, and for learning and debugging ML models with concept-level explanations in Section 5. Finally, we outline remaining open problems in Section 6 and related topics in 7.
2. Explanations in interactive machine learning
Interactive Machine Learning (IML) stands for the design and the implementation of algorithms and user interfaces in order to engage users to actually build ML models. As suggested by Ware et al. (2001), this stands in contrast to standard procedures, in which building a model is a fully automated process and domain experts have little control beyond data preparation. Research in IML explores ways to learn and manipulate models through an intuitive human-computer interface (Michael et al., 2020) and encompasses a variety of learning and interaction strategies. Perhaps the most well-known IML framework is active learning (Settles, 2012; Herde et al., 2021), which tackles learning high-performance predictors in settings in which supervision is expensive. To this end, active learning algorithms interleave acquiring labels of carefully selected unlabeled instances from an annotator and model updates. As another brief example, consider a recommender solution in a domain like movies, videos, or music, where the user can provide explicit feedback through rating the recommended items (He et al., 2016). These ratings can then be infused to the recommendation model's decision making process so as to tailor the recommendations toward end users interests.
In IML, users are encouraged to shape the decision making process of the model, so it is important for users to build a correct mental model of the “intelligent agent,” which will then allow them to seamlessly interact with it. Conversely, since user feedback and involvement are so central, uninformed feedback risks wasting annotation effort and ultimately compromising model quality. Not all approaches to IML are equally concerned with user understanding. For instance, in active learning the machine is essentially a black-box, with no information being disclosed about what knowledge it has acquired and what effect feedback has on it (Teso and Kersting, 2019). Strategies for interactive customization of ML models, like the one proposed by Fails and Olsen (2003), are less opaque, in that users can explore the impact of their changes and tune their feedback accordingly. Yet, the model's logic can only be (approximately) reconstructed from changes in behavior, making it hard to anticipate what information should be provided to guide the model in a desirable direction (Kulesza et al., 2015). Following Kulesza et al. (2015), we argue that proper interaction requires transparency and an understanding of the underlying model's logic. And it is exactly here that explanations can be used to facilitate this process.
2.1. A general approach for leveraging explanations in interaction
In order to appreciate the potential roles played by explanations, it is instructive to look at explanatory debugging (Kulesza et al., 2010), the first framework to explicitly leverage them in IML, and specifically at EluciDebug (Kulesza et al., 2015), its proof-of-concept implementation.
EluciDebug is tailored for interactive customization of Naïve Bayes classifiers in the context of email categorization. To this end, it presents users with explanations that illustrate the relative contributions of the model's prior and likelihood toward the class probabilities. In particular, its explanations convey what words the model uses to distinguish work emails from personal emails and how much they impact its decisions. In a second step, the user has the option of increasing or decreasing the relevance of certain input variables toward the choice of certain classes by directly adjusting the model weights. Continuing with our email example, the user is free to specify relevant words that the system is currently ignoring and irrelevant words that the system is wrongly relying on. This very precise form of feedback contrasts with traditional label-based strategies, in which the user might, e.g., tell the system that a message from her colleague about baseball is a personal (rather than work-related) communication, but has no direct control over what inputs the system decides to use. The responsibility of choosing what examples (e.g., wrongly classified emails) to provide feedback on is left to the user, and the interaction continues until she is happy with the system's behavior. EluciDebug was shown to help users to better understand the system's logic and to more quickly tailor it toward their needs (Kulesza et al., 2015).
EluciDebug highlights how explanations contribute to both understanding and control, two key elements that will reoccur in all approaches we survey. We briefly unpack them in the following.
2.2. Understanding
By observing the machine's explanations, users get the opportunity of building a better understanding of the machine's overall logic. This is instrumental in uncovering limitations and flaws in the model (Vilone and Longo, 2021). As a brief example, consider a recommender solution in a domain like movies, videos, or music, where the users are presented with explanations in the form of a list of features that are found to be most relevant to the users' previous choices (Tintarev and Masthoff, 2007). Upon observing this information, users can see the assumptions the underlying recommender has made for their interests and preferences. It might be the case that the model made incorrect assumptions for the users' preferences possibly due to some changes of interests which is not explicitly available in the data. In such a scenario, explanations provide a perfect ground for understanding the underlying model's behavior.
Explanations are also instrumental for identifying models that rely on confounds in the training data, such as watermarks in images, that happen to correlate with the desired outcome but that are not causal for it (Lapuschkin et al., 2019; Geirhos et al., 2020). Despite achieving high accuracy during training, these models generalize poorly to real-world data where the confound is absent. Such buggy behavior can affect high-stakes applications like COVID-19 diagnosis (DeGrave et al., 2021) and scientific analysis (Schramowski et al., 2020), and cannot be easily identified using standard evaluation procedures without explanations. Ideally, the users would develop a structural mental model that gives them a deep understanding of how the model operates, however a functional understanding is often enough for them to be able to interact (Sokol and Flach, 2020b). The ability of disclosing issues with the model, in turn, may facilitate trust calibration (Amershi et al., 2014). This is especially true in interactive settings as here the user can witness how the model evolves over time, another important factor that contributes to trust (Waytz et al., 2014; Wang et al., 2016).
2.3. Control
Understanding supports and amplifies our natural capacity of providing appropriate feedback (Kulesza et al., 2015): once bugs and limitations are identified, interaction with the model enables end-users to modify the algorithm in order to correct those flaws. Bi-directional communication between users and machines together with transparency enables directability, that is, the ability to rapidly assert control or influence when things go astray (Hoffman et al., 2013). Clearly, control is fundamental if one plans to take actions based on a model's prediction, or to deploy a new model in the first place (Ribeiro et al., 2016). At the same time, directability also contributes to trust allocation (Hoffman et al., 2013). The increased level of control can also help to achieve significant gains in the end user's satisfaction.
Human feedback can come in many forms, and one of these forms is explanations, either from scratch or by using the machine's explanations as a starting point (Teso and Kersting, 2019). This type of supervision is very informative: a handful of explanations are oftentimes worth many labels, substantially reducing the sample complexity of learning (well-behaved) models (Camburu et al., 2018). Importantly, it is also very natural for human to provide as explanations lie at the heart of human communication and tap directly into our innate learning and teaching abilities (Lombrozo, 2006; Mac Aodha et al., 2018). In fact, Stumpf et al. (2007) showed that when given the chance to provide free-form annotations, users had no difficulty providing generous amounts of feedback.
2.4. Principles
To ground the exchange of explanations between an end user and a model, Kulesza et al. (2010) presented a set of key principles around explainability and correctability. Although the principles are discussed in the context of explanatory debugging, they apply to all the approaches that are presented in this paper. These include: (1) Being iterative, so as to enable end-users to build a reasonable and informed model of the machine's behavior. (2) Presenting sound, faithful explanations that do not over-simplify the model's reasoning process. (3) Providing as complete a picture of the model as possible, without omitting elements that play an important role in its decision process. (4) Avoiding to overwhelming the user, as this complicates understanding and feedback construction. (5) Ensuring that explanations are actionable, making them engaging for users to attend to, thus encouraging understanding while enabling users to adjust them to their expertise. (6) Making user changes easily reversible. (7) Always honoring feedback, because when feedback is disregarded users may stop bothering to interact with the system. (8) Making sure to effectively communicate what effects feedback has on the model. Clearly there is a tension behind these principles, but they nonetheless are useful in guiding the design of explanation-based interaction protocols. As we will discuss in Section 6, although existing approaches attempt to satisfy one or more of these desiderata, no general method yet exists that satisfies all of them.
2.5. Dimensions of explanations in interactive machine learning
Identifying interaction and explainability as two key capabilities of a well performing and trustworthy ML system, motivates us to layout this overview on leveraging explanations in interactive ML. The methods we survey tackle different applications using a wide variety of strategies. In order to identify common themes and highlight differences, we organize them along four dimensions:
Algorithmic goal: We identify three high-level scenarios. One is that of using explanation-based feedback, optionally accompanied by other forms of supervision, to learn an ML model from scratch. Here, the machine is typically in charge of asking appropriate questions, feedback may be imperfect, and the model is updated incrementally as feedback is received. Another scenario is model editing, in which domain experts are in charge of inspecting the internals of a (partially) trained model (either directly if the model is white-box or indirectly through its explanations) and can manipulate them to improve and expand the model. Here feedback is typically assumed high-quality and used to constrain the model's behavior. The last scenario is debugging, where the focus is on fixing issues of misbehaving (typically black-box) models and the machine's explanations are used to both spot bugs and elicit corrective feedback. Naturally, there is some overlap between goals. Still, we opt to keep them separate as they are often tackled using different algorithmic and interaction strategies.
Type of machine explanations: The approaches we survey integrate four kinds of machine explanations: input attributions (IAs), example attributions (EAs), rules, and concept attributions (CAs). IAs identify those input variables that are responsible for a given decision, and as such they are local in nature. EAs and CAs are also local, but justify decisions in terms of relevant training examples and high-level concepts, respectively. At the other end of the spectrum, rules are global explanations in that they aim to summarize, in an interpretable manner, the logic of a whole model. These four types of explanations are illustrated in Figure 1 and described in more detail in the next sections.
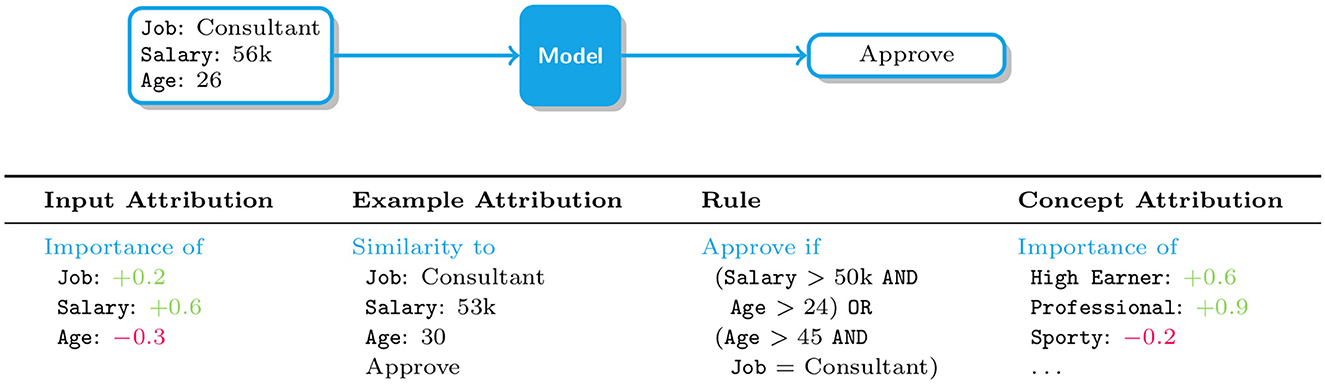
Figure 1. Illustration of how various kinds of explanations support human understanding in the context of loan requests. From left to right: input attributions and example attributions (discussed in Section 3), rules (discussed in Section 4), and concept attributions (discussed in Section 5).
Type of human feedback and incorporation strategy: Algorithmic goal and choice of machine explanations act as a determiner for the types of interactions that can happen, in turn affecting two other important dimensions, namely the type of feedback that can be collected and the way the machine can consume this feedback (Narayanan et al., 2018). Feedback ranges from updated parameter values, as in EluciDebug, to additional data points, to gold standard explanations supplied by domain experts. Incorporation strategies go hand-in-hand, and range from updating the model's parameters as instructed to (incrementally) retraining the model, perhaps including additional loss terms to incorporate explanatory feedback. All details are given in the following sections.
The methods we survey are listed in Table 1. Notice that the two most critical dimensions, namely algorithmic goal and type of machine explanations, are tightly correlated: learning approaches tend to rely on local explanations and editing approaches on rules, while debugging approaches employ both. For this reason, we chose to structure the next three sections by explanation type. One final remark before proceeding. Some of the approaches we cover rely on choosing specific instances or examples to be presented to the annotator. Among them, some rely on machine-initiated interaction, in the sense that they leave this choice to the machine (for instance, methods grounded on active learning tend to pick specific instances that the model is uncertain about Settles, 2012), while others rely on human-initiated interaction and expect the user to pick instances of interest from a (larger) set of options. We do not group approaches based on this distinction, so as to keep our categorization manageable. The specific type of interaction used will be made clear in the following sections on a per-method basis.
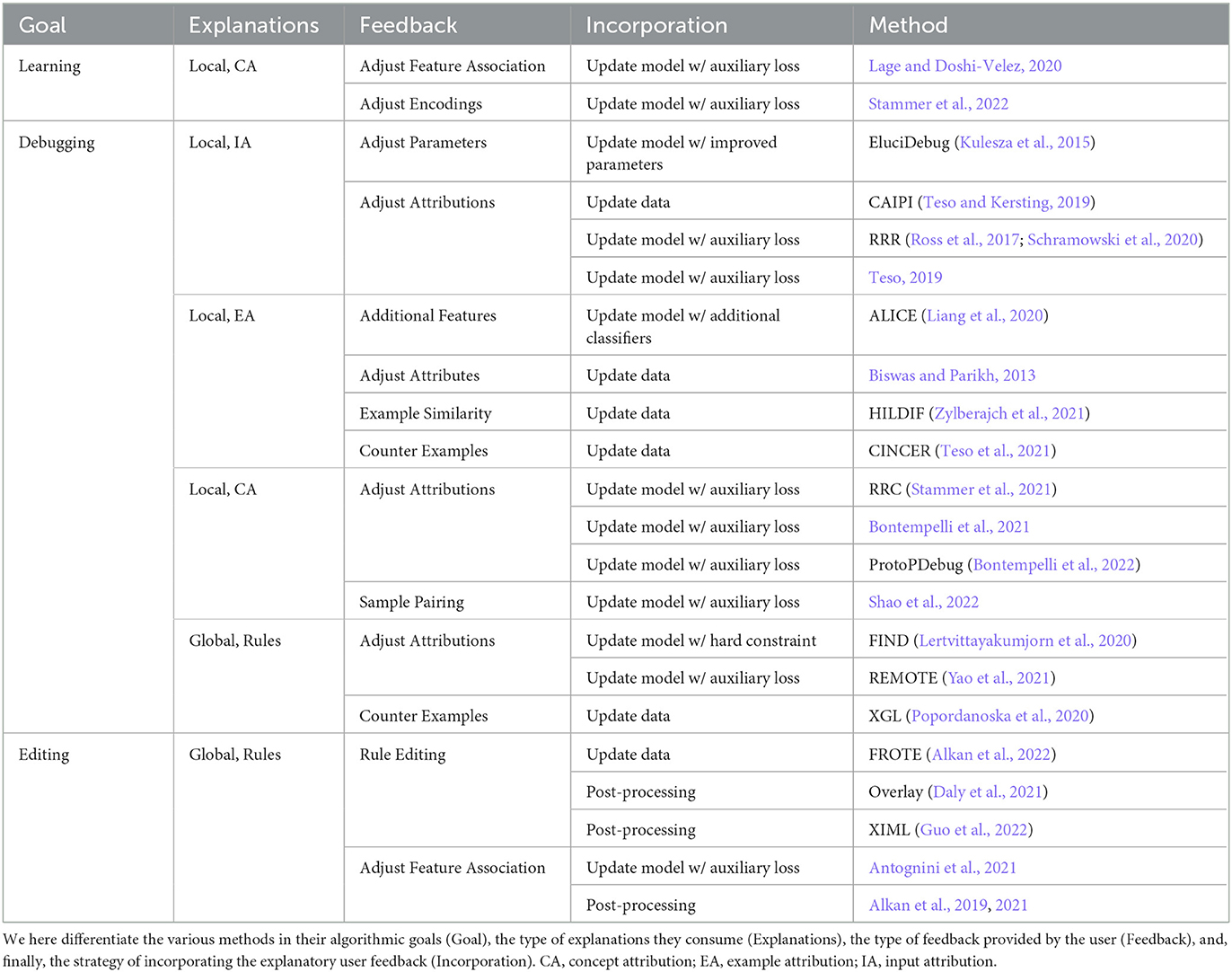
Table 1. Table of methods covered in this overview.
3. Interacting via local explanations
In this section, we discuss IML approaches that rely on local explanations to carry out interactive model debugging. Despite sharing some aspects with EluciDebug (Kulesza et al., 2015), these approaches exploit modern XAI techniques to support state-of-the-art ML models and explore alternative interaction protocols. Before reviewing them, we briefly summarize those types of local explanations that they build on.
3.1. Input attributions and example attributions
Given a classifier and a target decision, local explanations identify a subset of “explanatory variables” that are most responsible for the observed outcome. Different types of local explanations differ in what variables they consider and in how they define responsibility.
Input attributions, also known as saliency maps, convey information about relevant vs. irrelevant input variables. For instance, in loan request approval an input attribution might report the relative importance of variables like Job, Salary and Age of the applicant, as illustrated in Figure 1, and in image tagging that of subsets of pixels, as shown in Figure 2, left. A variety of attribution algorithms have been developed. Gradient-based approaches like Input Gradients (IGs) (Baehrens et al., 2010; Simonyan et al., 2014), GradCAM (Selvaraju et al., 2017), and Integrated Gradients (Sundararajan et al., 2017) construct a saliency map by measuring how sensitive the score or probability assigned by the classifer to the decision is to perturbations of individual input variables. This information is read off from the gradient of the model's output with respect to its input, and as such it is only meaningful if the model is differentiable and the inputs are continuous (e.g., images). Sampling-based approaches like LIME (Ribeiro et al., 2016) and SHAP (Štrumbelj and Kononenko, 2014; Lundberg and Lee, 2017) capture similar information (Garreau and Luxburg, 2020), but they rely on sampling techniques that are applicable also to non-differentiable models and to categorical and tabular data. For instance, LIME distills an interpretable surrogate model using random samples labeled by the black-box predictor and then extracts input relevance information from the surrogate. Despite their wide applicability, these approaches tend to be more computationally expensive than gradient-based alternatives (Van den Broeck et al., 2021) and, due to variance inherent in the sampling step, in some cases their explanations may portray an imprecise picture of the model's decision making process (Teso, 2019; Zhang et al., 2019). One last group of approaches focus on identifying the smallest subset of input variables whose value, once fixed, ensures that the model's output remains the same regardless of the value taken by the remaining variables (Shih et al., 2018; Camburu et al., 2020; Wang et al., 2020), and typically come with faithfulness guarantees. Although principled, these approaches however have not yet been used in explanatory interaction.
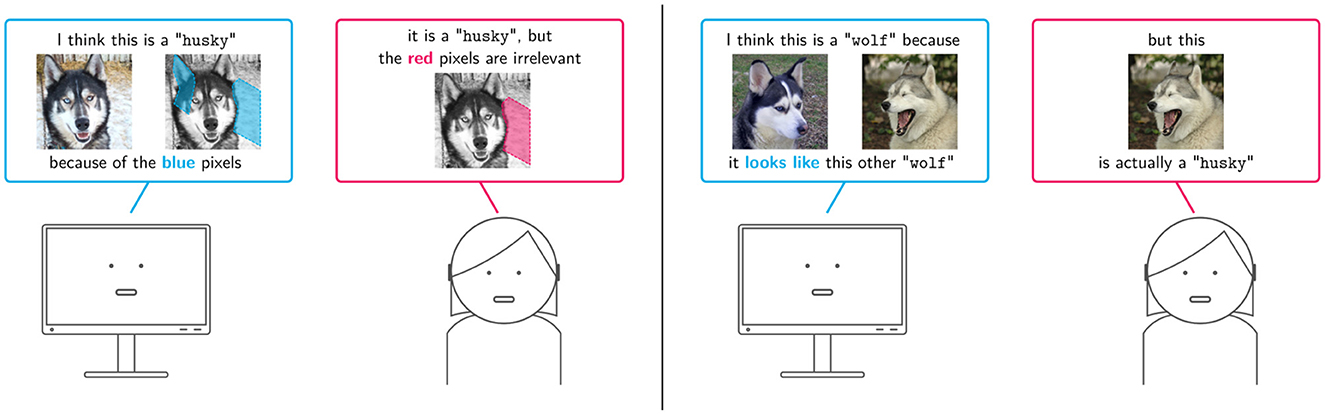
Figure 2. Illustration of two explanation strategies based on local explanations. (Left) The machine explains its predictions by highlighting relevant input variables—in this case, relevant pixels—and the user replies with an improved attribution map. (Right) The machine justifies its predictions in terms of training examples that support them, and the user either corrects the associated label. In both cases, the data and model are aligned to the user's feedback.
Example attributions, on the other hand, explain a target decisions in terms of those training examples that most contributed to it, and are especially natural in settings, like medical diagnosis, in which domain experts are trained to perform case-based reasoning (Bien and Tibshirani, 2011; Kim et al., 2014; Chen et al., 2019). For instance, in Figure 1 a loan application is approved by the machine because it is similar to an previously approved application and in Figure 2, right a mislabeled training image fools the model into mispredicting a husky dog as a wolf. For same classes of models, like nearest neighbor classifiers and prototype-based predictors, example relevance can be easily obtained. For all other models, it can in principle be evaluated by removing the example under examination from the training set and checking how this changes the models' prediction upon retraining. This naïve solution however scales poorly, especially for larger models for which retraining is time consuming. A more convenient alternative are Influence Functions (IFs), which offer an efficient strategy for approximating example relevance without retraining (Koh and Liang, 2017), yielding a substantial speed-up. Evaluating IFs is however non-trivial, as it involves inverting the Hessian of the model, and can be sensitive to factors such as model complexity (Basu et al., 2021) and noise (Teso et al., 2021). This has prompted researchers to develop more scalable and robust algorithms for IFs (Guo et al., 2021) as well as alternative strategies to estimate example relevance (Yeh et al., 2018; Khanna et al., 2019).
3.2. Interacting via input attributions
One line of work on integrating input attributions and interaction is eXplanatory Interactive Learning (XIL) (Teso and Kersting, 2019; Schramowski et al., 2020). In the simplest case, XIL follows the standard active learning loop (Settles, 2012), except that whenever the machine queries the label of a query instance, it also presents a prediction for that instance and a local explanation for the prediction. Contrary to EluciDebug, which is designed for interpretable classifiers, in XIL the model is usually a black-box, e.g., a support vector machine or a deep neural network, and explanations are extracted using input attribution methods like LIME (Teso and Kersting, 2019) or GradCAM (Schramowski et al., 2020). At this point, the annotator supplies a label for the query instance—as in regular active learning—and, optionally, corrective feedback on the explanation. The user can, for instance, indicate what input variables the machine is wrongly relying on for making its prediction. Consider Figure 2, left: here the query instance depicts a husky dog, but the model wrongly classifies it as a wolf based on the presence of snow in the background (in ), which happens to correlate with wolf images in the training data. To correct for this, the user indicates that the snow should not be used for prediction (in ).
XIL then aligns the model based on this corrective feedback. CAIPI (Teso and Kersting, 2019), the original implementation of XIL, achieves this using data augmentation. Specifically, CAIPI makes a few copies of the target instance (e.g., the husky image in Figure 2) and then randomizes the input variables indicated as irrelevant by the user while leaving the label unchanged, yielding a small set of synthetic examples. These are then added to the training set and the model is retrained. Essentially, this teaches the model to classify the image correctly without relying on the randomized variables. Data augmentation proved effective at debugging shallow models for text classification and other tasks (Teso and Kersting, 2019; Slany et al., 2022) and at reducing labeling effort (Slany et al., 2022), at the cost of requiring extra space to store the synthetic examples.
A more refined version of CAIPI (Schramowski et al., 2020) solves this issue by introducing two improvements: LIME is replaced with GradCAM (Selvaraju et al., 2017), thus avoiding sampling altogether, and the model is aligned using a generalization of the right for the right reasons (RRR) (Ross et al., 2017) modified to work with GradCAM. Essentially, the RRR loss penalizes the model proportionally to the relevance that its explanations assign to inputs that have been indicated as irrelevant by the user. Combining it with a regular loss for classification (e.g., the categorical cross-entropy loss) yields an end-to-end differentiable training pipeline that can be optimized using regular back-propagation. This in turn leads to shorter training times, especially for larger models, without the need for extra storage space. This approach was empirically shown to successfully avoid Clever Hans behavior in deep neural networks used for hyperspectral analysis of plant phenotyping data (Schramowski et al., 2020).
Several alternatives to the RRR loss have been developed. The Contextual Decomposition Explanation Penalization (CDEP) (Rieger et al., 2020) follows the same recipe, but it builds on Contextual Decomposition (Singh et al., 2018), an attribution technique that takes relationships between input variables into account. The approach of Yao et al. (2021) enables annotators to dynamically explore the space of feature interactions and fine-tune the model accordingly. The Right for Better Reasons (RBR) loss (Shao et al., 2021) improves on gradient-based attributions by replacing input gradients with their influence function (Koh and Liang, 2017), and it was shown to be more robust to changes in the model and speed up convergence. Human Importance-aware Network Tuning (HINT) (Selvaraju et al., 2019) takes a different route in that it rewards the model for activating on inputs deemed relevant by the annotator. Finally, Teso (2019) introduced a ranking loss designed to work with partial and possibly sub-optimal explanation corrections. These methods have recently been compared in the context of XIL by Friedrich et al. (2022). There, the authors introduce a set of benchmarking metrics and tasks and conclude that the “no free lunch” theorem (Wolpert and Macready, 1997) also holds for XIL, i.e., no method exceeds on all evaluations.
ALICE (Liang et al., 2020) also augments active learning, but it relies on contrastive explanations. In each interaction round, the machine selects a handful of class pairs, focusing on classes that the model cannot discriminate well, and for each of them asks an annotator to provide a natural language description of what features enable them to distinguish between the two classes. It then uses semantic parsing to convert the feedback into rules and integrates it by “morphing” the model architecture accordingly.
FIND is an alternative approach for interactively debugging models for natural language processing tasks (Lertvittayakumjorn et al., 2020). What sets it apart is that interaction is framed in terms of sets of local explanations. FIND builds on the observation that, by construction, local explanations fail to capture how the model behaves in regions far away from the instances for which the user receives explanations. This, in turn, complicates acquiring high-quality supervision and allocating trust (Wu T. et al., 2019; Popordanoska et al., 2020). FIND addresses this issue by extracting those words and n-grams that best characterize each latent feature acquired by the model, and then visualizing the relationship between words and features using a word cloud. The characteristic words are obtained using layer-wise relevance propagation (Bach et al., 2015), a technique akin to input gradients, to all examples in the training set. Based on this information, the user can turn off those latent features that are not relevant for the predictive task. For instance, if a model has learned a latent feature that strongly correlates with a polar word like “love” and uses it to categorize documents into non-polar classes such as spam and non-spam, FIND allows to instruct the model to no longer rely on this feature. This is achieved by introducing a hard constraint directly into the prediction process. Other strategies for overcoming the limits of explanation locality are discussed in Section 4.
3.3. Interacting via example attributions
Example attributions also have a role to play in interactive debugging. Existing strategies aim to uncover and correct cases where a model relies on “bad” training examples for its predictions, but target different types bugs and elicit different types of feedback. HILDIF (Zylberajch et al., 2021) uses a fast approximation of influence functions (Guo et al., 2021) to identify examples in support of a target prediction and then asks a human-in-the-loop to verify whether the their level of influence is justified. It then calibrates the influence of these examples on the model via data augmentation. Specifically, HILDIF tackles NLP tasks and it augments those training examples that are most relevant, as determined by the user, by replacing words by synonyms, effectively boosting their relative influence compared to the others. In this sense, the general idea is reminiscent of XIL, although viewed from the lens of example influence rather than attribute relevance.
A different kind of bug occurs when a model relies on mislabeled examples, which are frequently encounteded in applications, especially when interacting with (even expert) human annotators (Frénay and Verleysen, 2014). CINCER (Teso et al., 2021) offers a direct way to deal with this issue in sequential learning tasks. To this end, in CINCER the machine monitors incoming examples and asks a user to double-check and re-label those examples that look suspicious (Zeni et al., 2019; Bontempelli et al., 2020). A major issue is that the machine's skepticism may be wrong due to—again—presence of mislabeled training examples. This begs the question: is the machine skeptical for the right reasons? CINCER solves this issue by identifying those training examples that most support the model's skepticism using IFs, giving the option of relabeling the suspicious incoming example, the influential examples, or both. This process is complementary to HILDIF, as it enables stakeholders to gradually improve the quality of the training data itself, and—as a beneficial side-effect—also to calibrate its influence on the model.
3.4. Benefits and limitations
Some of the model alignment strategies employed by the approaches overviewed in this section were born for offline alignment task (Ross et al., 2017; Ghaeini et al., 2019; Selvaraju et al., 2019; Hase and Bansal, 2022). A major issue of this setting is that it is not clear where the ground-truth supervision comes from, as most existing data sets do not come with dense (e.g., pixel- or word-level) relevance annotations. In interactive the settings we consider, this information is naturally provided by a human annotator. Another important advantage is that in interactive settings users are only required to supply feedback tailored for those buggy behaviors exhibited by the model, dramatically reducing the annotation burden. The benefits and potential drawbacks of explanatory interaction are studied in detail by Ghai et al. (2021).
4. Interacting via global explanations
All explanations discussed so far are local, in the sense that they explain a given decision f(x) = y of a specific input x. Local explanations enable the user to build a mental model of individual predictions, however bringing together the information gleaned by examining a number of individual predictions may prove challenging to get an overall understanding of a model. Lifting this restriction immediately gives regional explanations, which are guaranteed to be valid in a larger, well-defined region around x. For instance, the explanations output by decision trees are regional in this sense. Global explanations aim to describe the behavior of f across all of its domain (Guidotti et al., 2018b) providing an approximate overview of the model (Craven and Shavlik, 1995; Deng, 2019). One approach is to train a directly interpretable model such as a decision tree or a rule set, using the same training data optimized for the interpretable model to behave similarly to the original model. This provides a surrogate white-box model of f which can then be used as an approximate global map of f (Guidotti et al., 2018b; Lundberg et al., 2020). Other approaches start with local or regional explanations and merge them to provide a global explainer (Lundberg et al., 2020; Setzu et al., 2021).
4.1. Rule-based explanations
An example rule-based explanation on the loan request approval could be “Approve if Salary>50k AND Age>24,” as shown in Figures 1, 3. Rule-based explanations decompose the models predictions into simple atomic elements either via decision trees, rule lists or rule sets. While decision trees are similar to rule lists and sets in terms of how they logically represent the decision processes, it is not always the case that decision trees are interpretable from a user perspective, particularly when the number of nodes are large (Narayanan et al., 2018). As a result, for explanations to facilitate user interaction, the size and complexity of the number of rules and clauses need to be considered.

Figure 3. Illustration of rule-based explanation feedback. (Left) Rule-based explanations shown to the user to support the prediction. (Right) The input instance does not satisfy any rules to support approve, so the clauses the input instance violates can be shown so the user can validate whether those reasons should be upheld.
LORE (Guidotti et al., 2018a) is an example of a local rule-based explainer, which builds an interpretable predictor by first generating a balanced set of neighbor instances of a given data instance through an ad-hoc genetic algorithm, and then building a decision tree classifier out of this set. From this classifier, a local explanation is then extracted, where the local explanation is a pair of logical rules, corresponding to the path in the tree and a set of counterfactual rules, explaining which conditions need to be changed for the data instance to be assigned the inverted class label by the underlying ML model. Both LIME (Ribeiro et al., 2016), and Anchors (Ribeiro et al., 2018) are other examples which uses a similar intuition such that, even if the decision boundary for the black box ML model can be arbitrarily complex over the whole data space for a given data instance, there is a high chance that the decision boundary is clear and simple in the neighborhood of a data point which can be captured by an interpretable model. Nanfack et al. learn a global decision rules explainer using a co-learning approach to distill the knowledge of a blackbox model into the decision rules (Nanfack et al., 2021).
Rule-based surrogates have the advantage of being interpretable however, in order to achieve coverage, the model must add rules to cover increasingly narrow slices which can in turn negatively impact interpretability. BRCG (Dash et al., 2018) and GLocalX (Setzu et al., 2021) trade-off fidelity with interpretability along with compactness of the rules to produce a rule-based representation of the model, which makes them more appropriate as the basis for user feedback.
4.2. Interacting via rule-based explanations
Rule-based explanations are logical representations of a machine learning model's decision making process which have the benefit of being interpretable to the user. This logical representation can then be modified by end users or domain experts, and these edits bring the advantage that the expected behavior is more predictable to the end user. Another key advantage of rule-based surrogate models is that, they provide a global representation of the underlying model rather than local explanations which make it more difficult for a user to build up an overall mental model of the system. Additionally, if the local explanations presented to the user to learn and understand the machine learning model are not well distributed, they may create a biased view of the model, potentially leading users to trust a model that for some regions has inaccurate logic.
Lakkaraju et al. (2016) produce decision sets where the decision set effectively becomes the predictive model. Popordanoska et al. supports user feedback by generating a rule-based system from data that the user may modify which is then used as a rule-based executable model (Popordanoska et al., 2020).
Daly et al. (2021) present an algorithm which brings together a rule-based surrogate derived by Dash et al. (2018) and an underlying machine learning model to support user provided modifications to existing rules in order to incorporate user feedback in a post-processing approach. Similar to CAIPI (Teso and Kersting, 2019; Schramowski et al., 2020) predictions and explanations are presented to experts, however the explanations are rule-based. The user can then specify changes to the labels and rules by adjusting the clauses of the explanation. For example, the user can modify a value such as change Age = 26 to Age = 30, remove a clause such as Gender = male or add a clause such as an additional feature requirement such as Employed = true. The modified labels and clauses are stored together with transformations that map between original and feedback rules as an Overlay or post-processing approach to the existing model. In a counterfactual style approach, the transformation function is applied to relevant new instances presented to the system in order to understand if the user adjustment influences the final prediction. One advantage of the combined approach is that the rule-based surrogate does not need to encode the full complexity of the model as the underlying prediction still comes from the ML model. The rule-based explanations are used as the source of feedback to provide corrections to key variables. Results showed this approach can support updates and edits to an ML model without retraining as a “band-aid,” however once the intended behavior diverges too much from the underlying model, results deteriorate. Alkan et al. (2022) similarly use rules as the unit for feedback where the input training data is pre-processed in order to produce an ML model that aligns with the user provided feedback rules. The FROTE algorithm generates synthetic instances that reflect both the feedback rules as well as the existing data and has the advantage of encoding the user feedback into the model. As with the previous solution, the advantage is the rules do not need to reflect the entire model, but can focus on the regions where feedback or correction is needed. The results showed that the solution can support modifications to the ML model even when they diverge quite significantly from that of the existing model. Ratner et al. (2017) combines data-sources to produce weak labels and one source of labels they consider are user provided rules or labeling functions which can then be tuned. A recent work (Guo et al., 2022) explored an explanation-driven interactive machine learning (XIML) system with the Tic-Tac-Toe game as a use case to understand how an XIML mechanism effects users' satisfaction with the underlying ML solution. A rule based explainer, BRCG (Dash et al., 2018), is used for generating explanations, and authors experimented on different modalities to support user feedback through visual or rule-based corrections. They conducted a user study in order to test the effect of allowing users to interact with the rule-based system through creating new rules or editing or removing existing rules. The results of the user study demonstrated that allowing interactivity within the designed XIML system leads to increased satisfaction for the end users.
4.3. Benefits and limitations
An important advantage of leveraging rules to enable user feedback is that, editing a clause can impact many different data points which can aid in reducing the cognitive load for the end user and making the changes more predictable. When modifying a Boolean clause, the feedback and the intended consequences are clearer in comparison to alternative techniques such as re-weighting feature importance or a training data point. However, one challenge with rule based methods is that, feedback can be conflicting in nature, therefore some form of conflict resolution is needed to be implemented in order to allow experts to resolve collisions (Alkan et al., 2022). Additionally, rules can be probabilistic and eliciting such probabilities from experts can be difficult.
An additional challenge is that, most of the existing rule-based solutions only build upon original features in the data. However, recent work has started to consider this direction for example (Alaa and van der Schaar, 2019) produces a symbolic equation as a white-box model and (Santurkar et al., 2021) supports editing concept based rules for image classification. In the next section, let us therefore continue with a branch of work that potentially allows for interactions on a local and global level via concept-based explanations.
5. Interacting using concept-based explanations
An advantage of input attributions is that they can be extracted from any black-box model without the need for retraining, thus leaving performance untouched. Critics of these approaches, however, have raised a number of important issues (Rudin, 2019). Perhaps the most fundamental ones, particularly from an interaction perspective, are the potential lack of faithfulness of post-hoc explanations and that input-based explanations are insufficient to accurately capture the reasons behind a model's decision, particularly when these are abstract (Stammer et al., 2021; Viviano et al., 2021). Consider an input attribution highlighting a red sports car: does the model's prediction depend on the fact that a car is present, that it is a sports car, or that it is red? This lack of precision can severely complicate interaction and revision.
A possible solution to this issue is to make use of white-box models, which—by design—admit inspecting their whole reasoning process. Models in this category include, e.g., shallow decision trees (Angelino et al., 2017; Rudin, 2019) and sparse linear models (Ustun and Rudin, 2016) based on human-understandable features. These models, however, do not generally support representation learning and struggle with sub-symbolic data.
A more recent solution are concept-based models (CBMs), which combine ideas from white and black-box models to achieve partial, selective interpretability. Since it is difficult—and impractical—to make every step in a decision process fully understandable, CBMs generally break down this task into two levels of processing: a bottom level, where one module (typically black-box) is used for extracting higher-level concept vectors cj(x), with j = 1, …, k, from raw inputs, and a more transparent, top level module in which a decision y = f(c1(x), …, ck(x)) is made based on the concepts alone. Most often, the top layer prediction is obtained by performing a weighted aggregation of the extracted concepts. Figure 1 provides an example of such concept vectors extracted from the raw data in the context of loan requests. Such concept vectors are often of binary form, e.g. a person applying for a loan is either considered a professional or not. The explanation finally corresponds to importance values on these concept vectors.
CBMs combine two key properties. First, the prediction is (roughly) independent from the inputs given the concept vectors. Second, the concepts are chosen to be as human understandable as possible, either by designing them manually or through concept learning, potentially aided by additional concept-level supervision. Taken together, these properties make it possible to faithfully explain a CBMs predictions based on the concept representation alone, thus facilitating interpretability without giving up on representation learning. Another useful feature of CBMs is that they allow for test-time interventions to introspect and revise a model's decision based on the individual concept activations (Koh et al., 2020).
Research on CBMs has explored different representations for the higher-level concepts, including (i) autoencoder-based concepts obtained in an unsupervised fashion and possibly constrained to be independent and dissimilar from each other (Alvarez-Melis and Jaakkola, 2018). (ii) prototype representations that encode concrete training examples or parts thereof (Chen et al., 2019; Hase et al., 2019; Barnett et al., 2021; Nauta et al., 2021b; Rymarczyk et al., 2021), (iii) concepts that are explicitly aligned to concept-level supervision provided upfront (Chen et al., 2020; Koh et al., 2020), (iv) white-box concepts obtained by interactively eliciting feature-level dependencies from domain experts (Lage and Doshi-Velez, 2020).
The idea and potential of symbolic, concept-based representations is also found in neuro-symbolic models, although this branch of research was developed from a different standpoint than interpretability alone. Specifically, neuro-symbolic models have recently gained increased interest in the AI community (Garcez et al., 2012; Yi et al., 2018; d'Avila Garcez et al., 2019; Wagner and d'Avila Garcez, 2021) due to their advantages in terms of performance, flexibility and interpretability. The key idea is that these approaches combine handling of sub-symbolic representations with human-understandable, symbolic latent representations. Although it is still an open debate on whether neuro-symbolic approaches are ultimately preferable over purely subsymbolic or symbolic approaches, several recent works have focused on the improvements and richness of neuro-symbolic explanations in the context of understandability and the possibilities of interaction that go beyond the approaches of the previous sections. Notably, the distinction between CBMs and neuro-symbolic models can be quite fuzzy, with CBMs possibly considered as one category of neuro-symbolic AI (Sarker et al., 2021; Yeh et al., 2021).
Although research on concept-level and neuro-symbolic explainability is a flourishing branch of research, it remains quite recent and only selected works have incorporated explanations in an interactive setting. In this section we wish to provide details on these works, but also mention noteworthy works that show potential for leveraging explanations in human machine interactions.
5.1. Interacting with concept-based models
Like all machine learning models, CBMs are also prone to erroneous behavior and may require revision and debugging by human experts (Bahadori and Heckerman, 2021). The special structure of CBMs poses challenges that are specific to this setting. A major issue that arises in the context of CBMs is that not only the weights used in the aggregation of the concept activations can be faulty and require adjustment, but the concepts themselves—depending on how they are defined or acquired—can be insufficient, incorrect, or uninterpretable (Lage and Doshi-Velez, 2020; Kambhampati et al., 2022).
These two steps have mostly been tackled separately. Figure 4 gives a brief sketch of this where a human user can guide a model in learning the basic set of concepts from raw images (Figure 4, left), but also provide feedback on the concept aggregations, e.g. in case relevant concepts are ignored for the final class prediction (Figure 4, right).
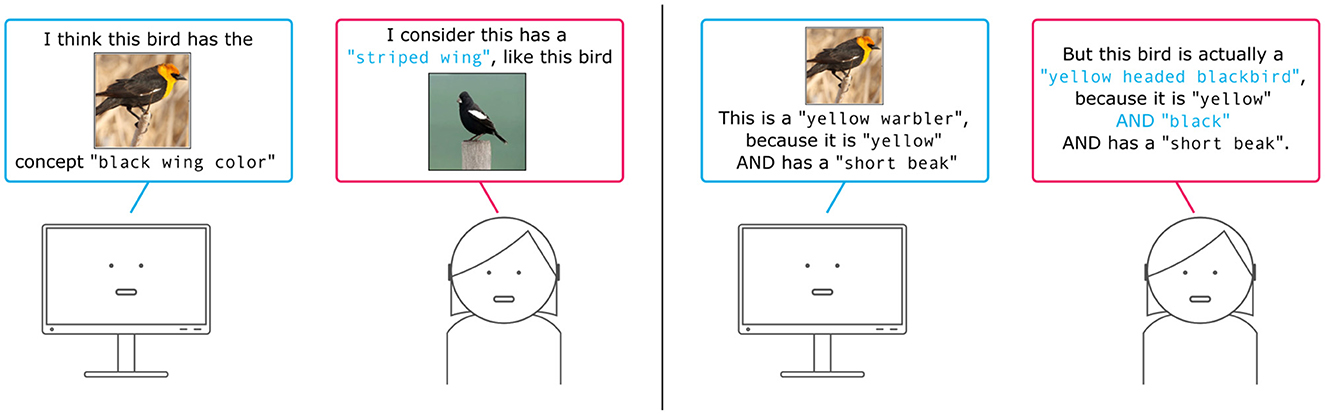
Figure 4. Illustration of providing feedback on concept learning and concept aggregation strategies. (Left) In concept learning a model learns a set of basic concepts that are present in the dataset. Hereby it learns to grounding specific features of the dataset on symbolic concept labels. (Right) Given a set of known basic concepts a model could falsely aggregate the concept activations leading to a false final prediction. Users can provide feedback on the concept explanations.
Several works have tackled interactively learning concepts. For instance, Lage and Doshi-Velez (2020) focus on human-machine concept alignment, and propose an interactive loop in which a human expert directly guides concept learning. Specifically, the machine elicits potential dependencies between inputs and concepts by asking questions like, e.g., “does the input variable lorazepam contribute to the concept depression?.” This is reminiscent of FIND (Lertvittayakumjorn et al., 2020), but the queried dependencies are chosen by the machine so to be as informative as possible. In their recent work, Stammer et al. (2022) propose to use prototype representations for interactively learning concepts and thereby grounding features of image data to discrete (symbolic) concept representations. via these introspectable encodings a human user can guide the concept learning by directly giving feedback on the prototype activations or by providing paired samples that possess specific concepts which the model should learn. The sample pairing feedback is reminiscent of Shao et al. (2022) who proposed debiasing generative models via weak supervision. Bontempelli et al. (2022) on the other hand propose debugging part-prototype networks via interactive supervision on the learned part-prototypes using a simple interface in which the user can determine signal that concept is valid or not valid for a particular precision using a single click. They also remark that this kind of concept-level feedback on concepts generalizes is very rich, in that it naturally generalizes to all instances that feature those concepts, facilitating debugging from few interaction rounds.
Other works focus on the concept aggregation step. For instance, Teso (2019) applied explanatory interactive learning to self-explainable neural networks, enabling end-users to fine-tune the aggregation weights (Alvarez-Melis and Jaakkola, 2018). An interesting connection to causal learning is made by Bahadori and Heckerman (2021), who present an alternative and principled approach for debiasing CBMs from confounders. These two strategies, however, assume the concepts to be given and fixed, which is often not the case.
Finally, Bontempelli et al. (2021) outline a unifying framework for debugging CBMs that clearly distinguishes between bugs in the concept set and bugs in the aggregation step, and advocate a multi-step procedure that encompasses determining where the source of the error lies and providing corrective supervision accordingly.
5.2. Interacting with neuro-symbolic models
Neuro-symbolic models, similar to CBMs, also support communicating with users in terms of symbolic, higher-level concepts as well as more general forms of constraints and knowledge. There are different ways in which these symbols can be presented and the interaction can be structured.
Ciravegna et al. (2020), propose to integrate deep learning with expressive human-driven first-order logic (FOL) explanations. Specifically, a neural network maps to a symbolic concept space and is followed by an additional network that learns to create FOL explanations from the latent concept space. Thanks to this direct translation into FOL explanations, it is in principle easy to integrate prior knowledge from expert users as constraints onto the model.
On the other hand Stammer et al. (2021) focus more on human-in-the-loop learning. With their work, the authors show that receiving explanations on the level of the raw input—as done by standard approaches presented in the previous sections—can be insufficient for removing Clever Hans behavior, and show how this problem can be solved by integrating and interacting with rich, neuro-symbolic explanations. Specifically, the authors incorporate a right for the right reason loss (Ross et al., 2017) on a neural reasoning module which receives multi-object concept activations as input. The approach allows for concept-level explanations, and user feedback is cast in terms of relational logic statements.
The benefits of symbolic explanations and feedback naturally extend from supervised learning and computer vision domains, as in the previous works, to settings like planning (Chakraborti et al., 2019) and, most recently, reinforcement learning (RL). In particular, in the context of deep RL, Guan et al. (2021) provide coarse symbolic feedback in the form of object-centric image regions to accompany binary feedback on an agent's proposed actions. Another interesting use of symbolic explanations in RL is that of Zha et al. (2021), in which an RL agent learns to better understand human demonstrations by grounding these in human-aligned symbolic representations.
5.3. Benefits and limitations
The common underlying motivation of all these approaches is the potential of symbolic communication to improve both precision and bandwidth of explanatory interaction between (partially sub-symbolic) AI models and human stakeholders. A recent paper by Kambhampati et al. (2022) provides an excellent motivation on the importance of this property as well as important remaining challenges. The main challenge of concept-based and neuro-symbolic models lies in identifying a set of basic concepts or symbols (Yeh et al., 2021) and grounding a model's latent representations on these. Though recent works, e.g. Lage and Doshi-Velez (2020) and Stammer et al. (2022), have started to tackle this it remains an important issue to solve particularly for real world data.
6. Open problems
Despite recent progress on integrating explanations and interaction, many unresolved problems remain. In this section, we outline a selection of urgent open issues and, wherever possible, suggest possible directions forward, with the hope of spurring further research on this important topic.
6.1. Handling human factors
Machine explanations are only effective insomuch as they are understood by the person at the receiving end. Simply ensuring algorithmic transparency, which is perhaps the major focus in current XAI research, gives few guarantees, because understanding strongly depends on human factors such as mental skills and familiarity with the application domain (Sokol and Flach, 2020b; Liao and Varshney, 2021). As a matter of fact, factual but ill-designed machine guidance can actively harm understanding (Ai et al., 2021).
Perhaps the most critical element for successful explanation-based interaction requires is that the user and the machine to agree on the semantics of the explanations they exchange. This is however problematic, partly because conveying this information to users is non-trivial, and partly because said semantics are often unclear or brittle to begin with, as discussed in Sections 6.2, 6.3. The literature does provide some guidance on what classes of explanations may be better suited for IML. Existing studies suggest that people find it easier to handle explanations that express concrete cases (Kim et al., 2014) and that have a counterfactual flavor (Wachter et al., 2017), and that breaking larger computations into modules facilitates simulation (Lage et al., 2019), but more work is needed to implement and evaluate these suggestions in the context of explanation-based IML. Moreover, settings in which users have also to manipulate or correct the machine's explanations, like interactive debugging, impose additional requirements. Another key issue is that of cognitive biases. For instance, human subjects tend to pay more attention to affirmative aspects of counterfactuals (Byrne, 2019), while AIs have no such bias. Coping with these human factors requires to design appropriate interaction and incorporation strategies, and it is necessary for correct and robust operation of explanation-based IML.
We also remark that different stakeholders inevitably need different kinds of explanations (Miller, 2019; Liao and Varshney, 2021). A promising direction of research is to enable users to customize the machine's explanations to their needs (Sokol and Flach, 2020b; Finzel et al., 2021). Challenges on this path include developing strategies for eliciting the necessary feedback and assisting users in exploring the space of alternatives.
6.2. Semantics and faithfulness
Not all kinds of machine explanations are equally intelligible and not all XAI algorithms are equally reliable. For instance, some gradient-based attribution techniques fail to satisfy intuitive properties (like implementation invariance Sundararajan et al., 2017) or ignore information at the top layers of neural networks (Adebayo et al., 2018), while sampling-based alternatives may suffer from high variance (Teso, 2019; Zhang et al., 2019). This is further aggravated by the fact that explanation techniques are not robust: slight changes in input, model, or hyper-parameters of the explainer, can yield very different explanations (Artelt et al., 2021; Ferrario and Loi, 2022b; Virgolin and Fracaros, 2023). A number of other issues have been identified in the literature (Hooker et al., 2019; Kindermans et al., 2019; Adebayo et al., 2020; Kumar et al., 2020; Sixt et al., 2020). The semantics of transparent models is also not always well-defined. For instance, the coefficients of linear models are often viewed as capturing feature importance in an additive manner (Ribeiro et al., 2016), but this interpretation is only valid as long as the input features are independent, which is seldom the case in practice. Decision tree-based explanations have also received substantial scrutiny (Izza et al., 2020).
Another critical element is faithfulness. The reason is that bugs identified by unfaithful explanations may be artifacts in the explanation rather than actual issues with the model, meaning that asking users to correct them is not only deceptive, but also uninformative for the machine and ultimately wasteful (Teso and Kersting, 2019). The distribution of machine explanations is equally important for ensuring faithfulness: individually faithful local explanations that fail to cover the whole range of machine behaviors may end up conveying an incomplete (Lertvittayakumjorn et al., 2020) and deceptively optimistic (Popordanoska et al., 2020) picture of the model's logic to stakeholders and annotators.
Still, some degree of unfaithfulness is inevitable, for both computational and cognitive reasons. On the one hand, interaction should not overwhelm the user (Kulesza et al., 2015). This entails presenting a necessarily simplified picture of the (potentially complex) inference process carried out by the machine. On the other hand, extracting faithful explanations often comes at a substantial computational cost (Van den Broeck et al., 2021), which is especially problematic in interactive settings where excessive repeated delays in the interaction can estrange the end-user. Alas, more light-weight XAI strategies tend to rely on approximations and leverage less well-defined explanation classes.
6.3. Abstraction and explanation requirements
Many attribution methods are restricted to measuring relevance of individual input variables or training examples. In stark contrast, explanations used in human–human communication convey information at a more abstract, conceptual level, and as such enjoy improved expressive power. An important open research question is how to enable machines to communicate using such higher-level concepts, especially in the context of the approaches discussed in Section 5.
This immediately yields the issue of obtaining a relevant, user-understandable symbolic concept space (Kambhampati et al., 2022; Rudin et al., 2022). This is highly non-trivial. In many cases it might not be obvious what the relevant higher-level concepts should be, and more generally it is not clear what properties should be enforced on these concepts—when learned from data—so to encourage interpretability. Existing candidates include similarity to concrete examples (Chen et al., 2019), usage of generative models (Karras et al., 2019), and enforcing disentanglement among concepts (Schölkopf et al., 2021; Stammer et al., 2022). One critical challenge is that imperfections in the learned concepts may compromise the predictive power of a model as well as the semantics of explanations while being hard to spot (Hoffmann et al., 2021; Kraft et al., 2021; Mahinpei et al., 2021; Margeloiu et al., 2021; Nauta et al., 2021a), calling for the development of concept-level debugging strategies (Bontempelli et al., 2021). Additionally, assuming a basic set of concepts has been identified, it seems likely that this set will not be sufficient and should allow for expanding (Kambhampati et al., 2022).
On the broader topic of explanation requirements, Liao and Varshney (2021) discuss many different aspects that XAI brings, such as the diverse explainability needs of stakeholders due to the no “one-fits-all” solutions from the collection of XAI algorithms, and pitfalls of XAI in the sense that there can be a gap between algorithmic explanations that several XAI works provide and the actionable understanding that these solutions can facilitate. One important statement that is highlighted in Liao and Varshney (2021) is that, closing the gap between technicality of XAI and the user's engagement with the explanations requires considering possible user interactions with XAI, and operationalizing human-centered perspectives in XAI algorithms.
This latter point also requires developing evaluation methods that better consider the actual user needs in the downstream usage contexts. This further raises the question of whether “good” explanations actually exist and how one can quantify these. One interesting direction forward is to consider explanation approaches in which a user can further query an initial model's explanation similar to how humans provide additional (detailed) queries in case the initial explanation is confusing or insufficient.
6.4. Modulating and manipulating trust
In light of the ethical concern of deploying ML models in more real-world applications, the field of trustworthy ML has grown, which studies and pursues desirable qualities such as fairness, explainability, transparency, privacy and robustness (Varshney, 2019; Angerschmid et al., 2022). Both explainability and robustness may have the potential to promote reliability and trust, and can ensure that humans intelligence complements AI (Holzinger, 2021). As discussed by Liao and Varshney (2021), explainability has moved beyond providing details to comprehend the ML models being developed, and it has rather become an essential requirement for people to trust and adopt AI and ML solutions.
However, the relationship between (high-quality) explanations and trust is not straightforward (Ferrario and Loi, 2022a). One reason is that explanations are not the only contributing factor (Wang et al., 2018). However, while user studies support the idea that explanations enable stakeholders to reject trust in misbehaving models, the oft stated claim that explanations help to establish trust into deserving models enjoys less empirical support. This is related to a trend, observed in some user studies, that participants may put too much trust in AI models to begin with Schramowski et al. (2020), thus making the effects of additional explanations less obvious. Understanding also plays a role. Failure to understand an explanation may drive users to immediately and unjustifiably distrust the system (Honeycutt et al., 2020) and, rather surprisingly, in some cases the mere fact of being exposed to the machine's internal reasoning may induce a loss of trust (Honeycutt et al., 2020). More generally, the link between interaction and trust is under-explored.
Another important issue that explanations can be intentionally manipulated by malicious parties so to persuade stakeholders into potentially trusting unfair or buggy systems (Dombrowski et al., 2019; Heo et al., 2019; Anders et al., 2020). This is a serious concern for the entire enterprise of explainable AI and therefore for explanatory interaction. Despite initial efforts on making explanations robust against such attacks, more work is still needed to guarantee safety for models used in practice.
6.5. Annotation effort and quality
Explanatory supervision comes with its own set of challenges. First and foremost, just like other kinds of annotations, corrections elicited from human supervisors are bound to be affected by noise, particularly when interacting with non-experts (Frénay and Verleysen, 2014). Since explanations potentially convey much more information than simple labels, the impact of noise is manifold. One option to facilitate ensuring high-quality supervision is that of providing human annotators with guidance, cf. Cakmak and Thomaz (2014), but this cannot entirely prevent annotation noise. In order to cope with this, it is critical to develop learning algorithms that are robust to noisy explanatory supervision. An alternative is to leverage interactive strategies for enabling users to identify and rectify mislabeled examples identified by the machine (Zeni et al., 2019; Teso et al., 2021). Any successfull design will also have to take into account performativity, that is, the fact that predictions can interact with the surrounding environment in a way that modifies the target of the learning procedure, requiring strategic reasoning to anticipate the impact of predictions (Perdomo et al., 2020). For instance, in our context, explanation algorithms that adapt to the user's abilities could modify those abilities, possibly complicating understanding of future explanations and interaction. Studies on this phenomenon are, however, entirely missing.
Some forms of explanatory supervision—for instance, pixel-level relevance annotations—require higher effort on the annotator's end. This extra cost is often justified by the larger impact that explanatory supervision has on the model compared to pure label information, but in most practical application effort is constrained by a tight budget and must be kept under control. Analogously to what is normally done in interactive learning (Settles, 2012), doing so involves developing querying strategies that only eliciting explanatory supervision when strictly necessary (e.g.,when label information is not enough) and to efficiently identify the most informative queries. To the best of our knowledge, this problem space is completely unexplored.
6.6. Benchmarking and evaluation
Evaluating and benchmarking current and novel approaches that integrate explanations and interaction is particularly challenging. There are several reasons for this. One reason is the effort in providing extensive user studies, where many recent studies tend to focus on simulated user interactions for evaluations. The difficulties for this are not just the participant organization and proper study design itself (which can lead to many pitfalls if not properly devised), but also from the engineering perspective a swift user feedback integration is not immediate in all studies. Thus, in many cases additional engineering and an extensive user study remain necessary before real-world deployment.
Further reasons are the individual use case of a method, but also the possibly high variance in user's feedback which make it challenging to assess a methods properties with one task and study alone. A very important branch for future research is thus to develop more standardized benchmarking tasks and metrics for evaluating such methods, where Friedrich et al. (2022) provide an initial set of important evaluation metrics and tasks for future research on XIL.
7. Related topics
Research on integrating interaction and explanations builds on and is related to a number of different topics. The main source of inspiration is the vast body of knowledge on explainable AI, which has been summarized in several overviews and surveys (Adadi and Berrada, 2018; Gilpin et al., 2018; Guidotti et al., 2018b; Montavon et al., 2018; Carvalho et al., 2019; Sokol and Flach, 2020a; Belle and Papantonis, 2021; Liao and Varshney, 2021; Ras et al., 2022). A major difference to this literature is that in XAI the communication between machine and user stops after receiving the machine's explanations.
Recommender systems are another area where explanations have found wide applicability, with a large number of approaches being proposed and applied in real-world systems in recent years. Compatibly with our discussion, explanations has been shown to improve transparency (Sinha and Swearingen, 2002; Tintarev and Masthoff, 2015) and trustworthiness (Zhang and Curley, 2018) of recommendations, to help users make better decisions, and to enable users to provide feedback to the system by correcting any incorrect assumptions that the recommender has made for their interests (Alkan et al., 2019). With critiquing-based recommenders, users can critique the presented suggestions and provide their preferences (Chen and Pu, 2012; Wu G. et al., 2019; Antognini et al., 2021). Here we focus on parallel advancements made in interactive ML, and refer the reader to Zhang and Chen (2020) for a comprehensive review of explainable recommender systems.
The idea of using explanations as supervision in ML can be traced back to explanation-based learning (DeJong and Mooney, 1986; Mitchell et al., 1986), where the goal is to extract logical concepts by generalizing from symbolic explanations, although the overall framework is not restricted to purely logical data.
Another major source of inspiration are approaches for offline explanation-based debugging, a topic has recently received substantial attention, especially in natural language processing community (Lertvittayakumjorn and Toni, 2021). This topic encompasses, for instance, learning from annotator rationales (Zaidan et al., 2007), i.e., from snippets of text appearning in a target sentence that support a particular decision, and that effectively the same role as input attributions. Recent works have extended this setup to complex natural language inference tasks (Camburu et al., 2018). Another closely related topic is learning from feature-level supervision, which has been used to complement standard label supervision for learning higher quality predictors (DeCoste and Schölkopf, 2002; Raghavan et al., 2006; Raghavan and Allan, 2007; Druck et al., 2008, 2009; Attenberg et al., 2010; Settles, 2011; Small et al., 2011). These earlier approaches assume (typically complete) supervision about attribute-level relevance to be provided in advance, independently from the model's explanations, and focus on shallow models. More generally, human explanations can be interpreted as encoding prior knowledge and thus used guide the learning process toward better aligned models faster (Hase and Bansal, 2022). This perspective overlaps with and represents a special case of informed ML (Beckh et al., 2021; von Rueden et al., 2021).
Two other areas where explanations have been used to inform the learning process are explanation-based distillation and regularization. The aim of distillation is to compress a larger model into a smaller one for the purpose of improving efficiency and storage costs. It was shown that paying attention to the explanations of the source model can tremendously (and provably) improve the sample complexity of distillation (Milli et al., 2019), hinting at the potential of explanations as a rich source of supervision. Regularization instead aims at encouraging models to produce more simulatable (Wu et al., 2018, 2020) or faithful explanations (Plumb et al., 2020) by introducing an additional penalty into the learning process. Here, however, no explanatory supervision is involved.
Two types of explanations that we have not delved into are counterfactuals and attention. Counterfactuals identify changes necessary for achieving alternative and possibly more desirable outcomes (Wachter et al., 2017), for instance what should be changed in a loan application in order for it to be approved. They have become popular in XAI as a mean to help stakeholders to form actionable plans and control the system's behavior (Lim, 2012; Karimi et al., 2021), but have recently shown promise as a mean to design novel interaction strategies (Kaushik et al., 2019; Wu et al., 2021; De Toni et al., 2022). Attention mechanisms (Bahdanau et al., 2015; Vaswani et al., 2017) also offer insight into the decision process of neural networks and, although their interpretation is somewhat controversial (Bastings and Filippova, 2020), they are a viable alternative to gradient-based attributions for integrating explanatory feedback into the model in an end-to-end manner (Mitsuhara et al., 2019; Heo et al., 2020).
Finally, another important aspect that we had to omit is causality (Pearl, 2009), which is perhaps the most solid foundation for imbuing cause-effect relationships within ML models (Chattopadhyay et al., 2019; Xu et al., 2020), and conversely the ability to identify causal relationships between inputs and predictions constitutes a fundamental step toward explaining model predictions (Holzinger et al., 2019; Geiger et al., 2021). Work on causality in interactive ML is however sparse at best.
8. Conclusion
This overview provides a conceptual guide on current research on integrating explanations into interactive machine learning for the purpose of establishing a rich bi-directional communication loop between machine learning models and human stakeholders in a way that is beneficial to all parties involved. Explanations make it possible for users to better understand the machine's behavior, spot possible limitations and bugs in its reasoning patterns, establish control over the machine, and arguably modulate trust. At the same time, the machine obtains high-quality, informed feedback in exchange. We categorized existing approaches along four dimensions, namely algorithmic goal, type of machine explanations involved, human feedback received, and incorporation strategy, facilitating the identification of links between different approaches as well as respective strengths and limitations. In addition, we identified a number of open problems impacting the human and machine sides of explanatory interaction and highlighted noteworthy paths of future, with the goal of spurring further research into this novel and promising approach, helping to bridge the gap toward human-centric machine learning and AI.
Author contributions
All authors listed have made a substantial, direct, and intellectual contribution to the work and approved it for publication.
Funding
The research of ST was partially supported by TAILOR, a project funded by EU Horizon 2020 research and innovation programme under GA No. 952215.
Acknowledgments
The authors are grateful to Giovanni De Toni and Emanuele Marconato for providing feedback on preliminary drafts of the manuscript.
Conflict of interest
ÖA was employed by Optum. ED was employed by IBM Research.
The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Adadi, A., and Berrada, M. (2018). Peeking inside the black-box: a survey on explainable artificial intelligence (XAI). IEEE Access 6, 52138–52160. doi: 10.1109/ACCESS.2018.2870052
Adebayo, J., Gilmer, J., Muelly, M., Goodfellow, I., Hardt, M., and Kim, B. (2018). “Sanity checks for saliency maps,” in International Conference on Neural Information Processing Systems (Montréal, QC), 9525–9536.
Adebayo, J., Muelly, M., Liccardi, I., and Kim, B. (2020). “Debugging tests for model explanations,” in International Conference on Neural Information Processing Systems (Vancouver, BC), 700–712.
Ai, L., Muggleton, S. H., Hocquette, C., Gromowski, M., and Schmid, U. (2021). Beneficial and harmful explanatory machine learning. Mach. Learn. 110, 695–721. doi: 10.1007/s10994-020-05941-0
Alaa, A. M., and van der Schaar, M. (2019). “Demystifying black-box models with symbolic metamodels,” in International Conference on Neural Information Processing Systems, Vol. 32. (Vancouver, BC).
Alkan, Ö., Daly, E. M., Botea, A., Valente, A. N., and Pedemonte, P. (2019). “Where can my career take me? harnessing dialogue for interactive career goal recommendations,” in International Conference on Intelligent User Interfaces, 603–613.
Alkan, Ö., Mattetti, M., Daly, E. M., Botea, A., Vejsbjerg, I., and Knijnenburg, B. (2021). IRF: A Framework for Enabling Users to Interact with Recommenders through Dialogue. ACM Human Comput. Interact. 5, 1–25. doi: 10.1145/3449237
Alkan, Ö., Wei, D., Mattetti, M., Nair, R., Daly, E., and Saha, D. (2022). FROTE: feedback rule-driven oversampling for editing models. Mach. Learn. Syst. 4, 276–301.
Alvarez-Melis, D., and Jaakkola, T. S. (2018). “Towards robust interpretability with self-explaining neural networks,” in International Conference on Neural Information Processing Systems (Montréal, QC), 7786–7795.
Amershi, S., Cakmak, M., Knox, W. B., and Kulesza, T. (2014). Power to the people: the role of humans in interactive machine learning. AI Mag. 35, 105–120. doi: 10.1609/aimag.v35i4.2513
Anders, C., Pasliev, P., Dombrowski, A.-K., Müller, K.-R., and Kessel, P. (2020). “Fairwashing explanations with off-manifold detergent,” in International Conference on Machine Learning, 314–323.
Angelino, E., Larus-Stone, N., Alabi, D., Seltzer, M. I., and Rudin, C. (2017). Learning certifiably optimal rule lists for categorical data. J. Mach. Learn. Res. 18, 1–78. doi: 10.1145/3097983.3098047
Angerschmid, A., Zhou, J., Theuermann, K., Chen, F., and Holzinger, A. (2022). Fairness and explanation in AI-informed decision making. Mach. Learn. Knowl. Extract. 4, 556–579. doi: 10.3390/make4020026
Antognini, D., Musat, C., and Faltings, B. (2021). “Interacting with explanations through critiquing,” in International Joint Conference on Artificial Intelligence, 515–521.
Artelt, A., Vaquet, V., Velioglu, R., Hinder, F., Brinkrolf, J., Schilling, M., et al. (2021). “Evaluating robustness of counterfactual explanations,” in 2021 IEEE Symposium Series on Computational Intelligence (SSCI) (Orlando, FL: IEEE), 01–09.
Attenberg, J., Melville, P., and Provost, F. (2010). “A unified approach to active dual supervision for labeling features and examples,” in Joint European Conference on Machine Learning and Knowledge Discovery in Databases (Berlin; Heidelberg: Springer), 40–55.
Bach, S., Binder, A., Montavon, G., Klauschen, F., Müller, K.-R., and Samek, W. (2015). On pixel-wise explanations for non-linear classifier decisions by layer-wise relevance propagation. PLoS ONE 10, e0130140. doi: 10.1371/journal.pone.0130140
Baehrens, D., Schroeter, T., Harmeling, S., Kawanabe, M., Hansen, K., and Müller, K.-R. (2010). How to explain individual classification decisions. J. Mach. Learn. Res. 11, 1803–1831.
Bahadori, M. T., and Heckerman, D. (2021). “Debiasing concept-based explanations with causal analysis,” in International Conference on Learning Representations.
Bahdanau, D., Cho, K., and Bengio, Y. (2015). “Neural machine translation by jointly learning to align and translate,” in International Conference on Learning Representations.
Barnett, A. J., Schwartz, F. R., Tao, C., Chen, C., Ren, Y., Lo, J. Y., et al. (2021). A case-based interpretable deep learning model for classification of mass lesions in digital mammography. Nat. Mach. Intell. 3, 1061–1070. doi: 10.1038/s42256-021-00423-x
Bastings, J., and Filippova, K. (2020). “The elephant in the interpretability room: why use attention as explanation when we have saliency methods?” in BlackboxNLP Workshop on Analyzing and Interpreting Neural Networks for NLP (Association for Computational Linguistics), 149–155.
Basu, S., Pope, P., and Feizi, S. (2021). “Influence functions in deep learning are fragile,” in International Conference on Learning Representations.
Beckh, K., Müller, S., Jakobs, M., Toborek, V., Tan, H., Fischer, R., et al. (2021). Explainable machine learning with prior knowledge: an overview. arXiv preprint arXiv:2105.10172. doi: 10.48550/arXiv.2105.10172
Belle, V., and Papantonis, I. (2021). Principles and practice of explainable machine learning. Front. Big Data 4, 688969. doi: 10.3389/fdata.2021.688969
Bien, J., and Tibshirani, R. (2011). Prototype selection for interpretable classification. Ann. Appl. Stat. 5, 2403–2424. doi: 10.1214/11-AOAS495
Biswas, A., and Parikh, D. (2013). “Simultaneous active learning of classifiers and attributes via relative feedback,” in Conference on Computer Vision and Pattern Recognition (Portland, OR: IEEE), 644–651.
Bontempelli, A., Giunchiglia, F., Passerini, A., and Teso, S. (2021). “Toward a unified framework for debugging gray-box models,” in The AAAI-22 Workshop on Interactive Machine Learning.
Bontempelli, A., Teso, S., Giunchiglia, F., and Passerini, A. (2020). “Learning in the wild with incremental skeptical gaussian processes,” in International Joint Conference on Artificial Intelligence.
Bontempelli, A., Teso, S., Tentori, K., Giunchiglia, F., and Passerini, A. (2022). “Concept-level debugging of part-prototype networks,” in International Conference on Learning Representations.
Byrne, R. M. J. (2019). “Counterfactuals in explainable artificial intelligence (XAI): evidence from human reasoning,” in International Joint Conference on Artificial Intelligence, 6276–6282.
Cakmak, M., and Thomaz, A. L. (2014). Eliciting good teaching from humans for machine learners. Artif. Intell. 217, 198–215. doi: 10.1016/j.artint.2014.08.005
Camburu, O.-M., Giunchiglia, E., Foerster, J., Lukasiewicz, T., and Blunsom, P. (2020). The struggles of feature-based explanations: shapley values vs. minimal sufficient subsets. arXiv preprint arXiv:2009.11023. doi: 10.48550/arXiv.2009.11023
Camburu, O.-M., Rocktäschel, T., Lukasiewicz, T., and Blunsom, P. (2018). “e-SNLI: natural language inference with natural language explanations,” in International Conference on Neural Information Processing Systems (Montréal, QC), 9560–9572.
Carvalho, D. V., Pereira, E. M., and Cardoso, J. S. (2019). Machine learning interpretability: a survey on methods and metrics. Electronics 8, 832. doi: 10.3390/electronics8080832
Chakraborti, T., Sreedharan, S., Grover, S., and Kambhampati, S. (2019). “Plan explanations as model reconciliation-an empirical study,” in International Conference on Human-Robot Interaction, 258–266.
Chattopadhyay, A., Manupriya, P., Sarkar, A., and Balasubramanian, V. N. (2019). “Neural network attributions: a causal perspective. In International Conference on Machine Learning, pages 981–990.
Chen, C., Li, O., Tao, D., Barnett, A., Rudin, C., and Su, J. K. (2019). This looks like that: deep learning for interpretable image recognition. Adv. Neur. Infm. Process. Syst. 32, 1–12. Available online at: https://proceedings.neurips.cc/paper/2019/file/adf7ee2dcf142b0e11888e72b43fcb75-Paper.pdf
Chen, L., and Pu, P. (2012). Critiquing-based recommenders: survey and emerging trends. User Model User-adapt Interact. 22, 125–150. doi: 10.1007/s11257-011-9108-6
Chen, Z., Bei, Y., and Rudin, C. (2020). Concept whitening for interpretable image recognition. Nat. Mach. Intell. 2, 772–782. doi: 10.1038/s42256-020-00265-z
Ciravegna, G., Giannini, F., Gori, M., Maggini, M., and Melacci, S. (2020). “Human-driven fol explanations of deep learning,” in International Joint Conference on Artificial Intelligence, 2234–2240.
Craven, M., and Shavlik, J. (1995). “Extracting tree-structured representations of trained networks,” in International Conference on Neural Information Processing Systems, Vol. 8, 24–30.
Daly, E. M., Mattetti, M., Alkan, Ö., and Nair, R. (2021). User driven model adjustment via boolean rule explanations. AAAI Conf. Artif. Intell. 35, 5896–5904. doi: 10.1609/aaai.v35i7.16737
Dash, S., Gunluk, O., and Wei, D. (2018). “Boolean decision rules via column generation,” in International Conference on Neural Information Processing Systems, Vol. 31 (Montréal, QC), 4655–4665.
d'Avila Garcez, A. S., Gori, M., Lamb, L. C., Serafini, L., Spranger, M., and Tran, S. N. (2019). “Neural-symbolic computing: an effective methodology for principled integration of machine learning and reasoning,” in FLAP, Vol. 6.
De Toni, G., Viappiani, P., Lepri, B., and Passerini, A. (2022). Generating personalized counterfactual interventions for algorithmic recourse by eliciting user preferences. arXiv preprint arXiv:2205.13743. doi: 10.48550/arXiv.2205.13743
DeCoste, D., and Schölkopf, B. (2002). Training invariant support vector machines. Mach. Learn. 46, 161–190. doi: 10.1023/A:1012454411458
DeGrave, A. J., Janizek, J. D., and Lee, S.-I. (2021). AI for radiographic COVID-19 detection selects shortcuts over signal. Nat. Mach. Intell. 2021, 1–10. doi: 10.1038/s42256-021-00338-7
DeJong, G., and Mooney, R. (1986). Explanation-based learning: an alternative view. Mach. Learn. 1, 145–176. doi: 10.1007/BF00114116
Deng, H. (2019). Interpreting tree ensembles with intrees. Int. J. Data Sci. Anal. 7, 277–287. doi: 10.1007/s41060-018-0144-8
Dombrowski, A.-K., Alber, M., Anders, C., Ackermann, M., Müller, K.-R., and Kessel, P. (2019). Explanations can be manipulated and geometry is to blame.
Druck, G., Mann, G., and McCallum, A. (2008). “Learning from labeled features using generalized expectation criteria,” in Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (Singapore), 595–602.
Druck, G., Settles, B., and McCallum, A. (2009). “Active learning by labeling features,” in Conference on Empirical Methods in Natural Language Processing, 81–90.
Fails, J. A., and Olsen Jr, D. R. (2003). “Interactive machine learning,” in International Conference on Intelligent User Interfaces, 39–45.
Ferrario, A., and Loi, M. (2022a). “How explainability contributes to trust in AI,” in ACM Conference on Fairness, Accountability, and Transparency (FAccT '22), Seoul, (Republic of Korea. ACM, New York, NY), 1457–1466. doi: 10.1145/3531146.3533202
Ferrario, A., and Loi, M. (2022b). The robustness of counterfactual explanations over time. IEEE Access 10, 82736–82750. doi: 10.1109/ACCESS.2022.3196917
Finzel, B., Tafler, D. E., Scheele, S., and Schmid, U. (2021). “Explanation as a process: user-centric construction of multi-level and multi-modal explanations,” in Künstliche Intelligenz (Cham: Springer), 80–94.
Frénay, B., and Verleysen, M. (2014). Classification in the presence of label noise: a survey. Trans. Neural Netw. Learn. Syst. 25, 845–869. doi: 10.1109/TNNLS.2013.2292894
Friedrich, F., Stammer, W., Schramowski, P., and Kersting, K. (2022). A typology to explore and guide explanatory interactive machine learning. arXiv preprint arXiv:2203.03668.
Garcez, A. S. D., Broda, K. B., and Gabbay, D. M. (2012). Neural-Symbolic Learning Systems: Foundations and Applications. Springer Science &Business Media.
Garreau, D., and Luxburg, U. (2020). “Explaining the explainer: a first theoretical analysis of LIME,” in International Conference on Artificial Intelligence and Statistics (Palermo), 1287–1296.
Geiger, A., Lu, H., Icard, T., and Potts, C. (2021). “Causal abstractions of neural networks,” in International Conference on Neural Information Processing Systems, 9574–9586.
Geirhos, R., Jacobsen, J.-H., Michaelis, C., Zemel, R., Brendel, W., Bethge, M., et al. (2020). Shortcut learning in deep neural networks. Nat. Mach. Intell. 2, 665–673. doi: 10.1038/s42256-020-00257-z
Ghaeini, R., Fern, X., Shahbazi, H., and Tadepalli, P. (2019). “Saliency learning: teaching the model where to pay attention,” in Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Vancouver, BC), 4016–4025.
Ghai, B., Liao, Q. V., Zhang, Y., Bellamy, R., and Mueller, K. (2021). Explainable active learning (XAL) toward ai explanations as interfaces for machine teachers. ACM Human Comput. Interact. 4, 1–28. doi: 10.1145/3432934
Gilpin, L. H., Bau, D., Yuan, B. Z., Bajwa, A., Specter, M., and Kagal, L. (2018). “Explaining explanations: an overview of interpretability of machine learning,” in International Conference on Data Science and Advanced Analytics, 80–89.
Guan, L., Verma, M., Guo, S., Zhang, R., and Kambhampati, S. (2021). “Widening the pipeline in human-guided reinforcement learning with explanation and context-aware data augmentation,” in International Conference on Neural Information Processing Systems.
Guidotti, R., Monreale, A., Ruggieri, S., Pedreschi, D., Turini, F., and Giannotti, F. (2018a). Local rule-based explanations of black box decision systems. arXiv preprint arXiv:1805.10820. doi: 10.48550/arXiv.1805.10820
Guidotti, R., Monreale, A., Ruggieri, S., Turini, F., Giannotti, F., and Pedreschi, D. (2018b). A survey of methods for explaining black box models. ACM Comput. Surveys 51, 1–42. doi: 10.1145/3236009
Guo, H., Rajani, N., Hase, P., Bansal, M., and Xiong, C. (2021). “FastIF: scalable influence functions for efficient model interpretation and debugging,” in Conference on Empirical Methods in Natural Language Processing, 10333–10350.
Guo, L., Daly, E. M., Alkan, Ö., Mattetti, M., Cornec, O., and Knijnenburg, B. (2022). “Building trust in interactive machine learning via user contributed interpretable rules,” in International Conference on Intelligent User Interfaces.
Hase, P., and Bansal, M. (2022). “When can models learn from explanations? a formal framework for understanding the roles of explanation data,” in Proceedings of the First Workshop on Learning with Natural Language Supervision, 29–39.
Hase, P., Chen, C., Li, O., and Rudin, C. (2019). Interpretable image recognition with hierarchical prototypes. Conf. Hum. Comput. Crowdsourcing 7, 32–40. doi: 10.1609/hcomp.v7i1.5265
He, C., Parra, D., and Verbert, K. (2016). Interactive recommender systems: a survey of the state of the art and future research challenges and opportunities. Expert. Syst. Appl. 56, 9–27. doi: 10.1016/j.eswa.2016.02.013
Heo, J., Joo, S., and Moon, T. (2019). “Fooling neural network interpretations via adversarial model manipulation,” in International Conference on Neural Information Processing Systems, Vol. 32 (Vancouver, BC), 2925–2936.
Heo, J., Park, J., Jeong, H., Kim, K. J., Lee, J., Yang, E., et al. (2020). “Cost-effective interactive attention learning with neural attention processes,” in International Conference on Machine Learning, 4228–4238.
Herde, M., Huseljic, D., Sick, B., and Calma, A. (2021). A survey on cost types, interaction schemes, and annotator performance models in selection algorithms for active learning in classification. IEEE Access 9, 166970–166989. doi: 10.1109/ACCESS.2021.3135514
Hoffman, R. R., Johnson, M., Bradshaw, J. M., and Underbrink, A. (2013). Trust in automation. IEEE Intell Syst. 28, 84–88. doi: 10.1109/MIS.2013.24
Hoffmann, A., Fanconi, C., Rade, R., and Kohler, J. (2021). This looks like that... does it? shortcomings of latent space prototype interpretability in deep networks. arXiv preprint arXiv:2105.02968. doi: 10.48550/arXiv.2105.02968
Holzinger, A. (2021). “The next frontier: Ai we can really trust,” in Machine Learning and Principles and Practice of Knowledge Discovery in Databases-International Workshops of ECML PKDD 2021, Proceedings, Communications in Computer and Information Science (Switzerland: Springer), 427–440.
Holzinger, A., Langs, G., Denk, H., Zatloukal, K., and Müller, H. (2019). Causability and explainabilty of artificial intelligence in medicine. Wiley Interdisc. Rev. Data Min. Knowl. Disc. 9, e1312. doi: 10.1002/widm.1312
Holzinger, A., Saranti, A., Molnar, C., Biecek, P., and Samek, W. (2022). Explainable AI Methods - A Brief Overview. Cham: Springer International Publishing.
Honeycutt, D., Nourani, M., and Ragan, E. (2020). Soliciting human-in-the-loop user feedback for interactive machine learning reduces user trust and impressions of model accuracy. Conf. Hum. Comput. Crowdsourcing 8, 63–72. doi: 10.1609/hcomp.v8i1.7464
Hooker, S., Erhan, D., Kindermans, P., and Kim, B. (2019). “A benchmark for interpretability methods in deep neural networks,” in International Conference on Neural Information Processing Systems (Vancouver, BC), 9734–9745.
Izza, Y., Ignatiev, A., and Marques-Silva, J. (2020). On explaining decision trees. arXiv preprint arXiv:2010.11034. doi: 10.48550/arXiv.2010.11034
Kambhampati, S., Sreedharan, S., Verma, M., Zha, Y., and Guan, L. (2022). “Symbols as a lingua franca for bridging human-ai chasm for explainable and advisable AI systems,” in Proceedings of Thirty-Sixth AAAI Conference on Artificial Intelligence (AAAI).
Karimi, A.-H., Schölkopf, B., and Valera, I. (2021). “Algorithmic recourse: from counterfactual explanations to interventions,” in Conference on Fairness, Accountability, and Transparency, 353–362.
Karras, T., Laine, S., and Aila, T. (2019). “A style-based generator architecture for generative adversarial networks,” in Conference on Computer Vision and Pattern Recognition, 4401–4410.
Kaushik, D., Hovy, E., and Lipton, Z. (2019). “Learning the difference that makes a difference with counterfactually-augmented data,” in International Conference on Learning Representations.
Khanna, R., Kim, B., Ghosh, J., and Koyejo, S. (2019). “Interpreting black box predictions using fisher kernels,” in International Conference on Artificial Intelligence and Statistics (Naha, Okinawa), 3382–3390.
Kim, B., Rudin, C., and Shah, J. A. (2014). “The bayesian case model: a generative approach for case-based reasoning and prototype classification,” in International Conference on Neural Information Processing Systems, 1952–1960.
Kindermans, P.-J., Hooker, S., Adebayo, J., Alber, M., Schütt, K. T., Dähne, S., et al. (2019). “The (un) reliability of saliency methods,” in Explainable AI: Interpreting, Explaining and Visualizing Deep Learning (Long Beach, CA: Springer), 267–280.
Koh, P. W., and Liang, P. (2017). “Understanding black-box predictions via influence functions,” in International Conference on Machine Learning (Sydney), 1885–1894.
Koh, P. W., Nguyen, T., Tang, Y. S., Mussmann, S., Pierson, E., Kim, B., et al. (2020). “Concept bottleneck models,” in International Conference on Machine Learning, 5338–5348.
Kraft, S., Broelemann, K., Theissler, A., Kasneci, G., Esslingen am Neckar, G., AG, S. H., et al. (2021). “SPARROW: Semantically coherent prototypes for image classification,” in The 32nd British Machine Vision Conference (BMVC).
Kulesza, T., Burnett, M., Wong, W.-K., and Stumpf, S. (2015). “Principles of explanatory debugging to personalize interactive machine learning,” in International Conference on Intelligent User Interfaces (New York, USA), 126–137. doi: 10.1145/2678025.2701399
Kulesza, T., Stumpf, S., Burnett, M., Wong, W.-K., Riche, Y., Moore, T., et al. (2010). “Explanatory debugging: supporting end-user debugging of machine-learned programs,” in Symposium on Visual Languages and Human-Centric Computing (Madrid), 41–48.
Kumar, I. E., Venkatasubramanian, S., Scheidegger, C., and Friedler, S. (2020). “Problems with shapley-value-based explanations as feature importance measures,” in International Conference on Machine Learning, 5491–5500.
Lage, I., Chen, E., He, J., Narayanan, M., Kim, B., Gershman, S. J., et al. (2019). Human evaluation of models built for interpretability. AAAI Conf. Hum. Comput. Crowdsourcing 7, 59–67. doi: 10.1609/hcomp.v7i1.5280
Lage, I., and Doshi-Velez, F. (2020). Learning interpretable concept-based models with human feedback. arXiv preprint arXiv:2012.02898. doi: 10.48550/arXiv.2012.02898
Lakkaraju, H., Bach, S. H., and Leskovec, J. (2016). “Interpretable decision sets: ajoint framework for description and prediction,” in International Conference on Knowledge Discovery and Data Mining (San Francisco, CA), 1675–1684. doi: 10.1145/2939672.2939874
Lapuschkin, S., Wäldchen, S., Binder, A., Montavon, G., Samek, W., and Müller, K.-R. (2019). Unmasking clever hans predictors and assessing what machines really learn. Nat. Commun. 10, 1–8. doi: 10.1038/s41467-019-08987-4
Lertvittayakumjorn, P., Specia, L., and Toni, F. (2020). “Find: human-in-the-loop debugging deep text classifiers,” in Conference on Empirical Methods in Natural Language Processing, 332–348.
Lertvittayakumjorn, P., and Toni, F. (2021). Explanation-based human debugging of nlp models: a survey. Trans. Assoc. Comput. Linguist. 9, 1508–1528. doi: 10.1162/tacl_a_00440
Liang, W., Zou, J., and Yu, Z. (2020). “Alice: active learning with contrastive natural language explanations,” in Conference on Empirical Methods in Natural Language Processing (Association for Computational Linguistics), 4380–4391.
Liao, Q. V., and Varshney, K. R. (2021). Human-centered explainable ai (xai): from algorithms to user experiences. arXiv preprint arXiv:2110.10790. doi: 10.48550/arXiv.2110.10790
Lim, B. Y. (2012). Improving understanding and trust with intelligibility in context-aware applications (Ph.D. thesis). Carnegie Mellon University: Pittsburgh, PA, United States.
Lombrozo, T. (2006). The structure and function of explanations. Trends Cogn. Sci. 10, 464–470. doi: 10.1016/j.tics.2006.08.004
Lundberg, S. M., Erion, G., Chen, H., DeGrave, A., Prutkin, J. M., Nair, B., et al. (2020). From local explanations to global understanding with explainable ai for trees. Nat. Mach. Intell. 2, 56–67. doi: 10.1038/s42256-019-0138-9
Lundberg, S. M., and Lee, S.-I. (2017). “A unified approach to interpreting model predictions,” in International Conference on Neural Information Processing Systems, 4768–4777.
Mac Aodha, O., Su, S., Chen, Y., Perona, P., and Yue, Y. (2018). “Teaching categories to human learners with visual explanations,” in Conference on Computer Vision and Pattern Recognition, 3820–3828.
Mahinpei, A., Clark, J., Lage, I., Doshi-Velez, F., and Pan, W. (2021). Promises and pitfalls of black-box concept learning models. arXiv preprint arXiv:2106.13314. doi: 10.48550/arXiv.2106.13314
Margeloiu, A., Ashman, M., Bhatt, U., Chen, Y., Jamnik, M., and Weller, A. (2021). Do concept bottleneck models learn as intended? arXiv preprint arXiv:2105.04289. doi: 10.48550/arXiv.2105.04289
Michael, C. J., Acklin, D., and Scheuerman, J. (2020). On interactive machine learning and the potential of cognitive feedback. arXiv preprint arXiv:2003.10365. doi: 10.48550/arXiv.2003.10365
Miller, T. (2019). Explanation in artificial intelligence: Insights from the social sciences. Artif. Intell. 267, 1–38. doi: 10.1016/j.artint.2018.07.007
Milli, S., Schmidt, L., Dragan, A. D., and Hardt, M. (2019). “Model reconstruction from model explanations,” in Conference on Fairness, Accountability, and Transparency, 1–9.
Mitchell, T. M., Keller, R. M., and Kedar-Cabelli, S. T. (1986). Explanation-based generalization: a unifying view. Mach. Learn. 1, 47–80. doi: 10.1007/BF00116250
Mitsuhara, M., Fukui, H., Sakashita, Y., Ogata, T., Hirakawa, T., Yamashita, T., et al. (2019). Embedding human knowledge into deep neural network via attention map. arXiv preprint arXiv:1905.03540. doi: 10.48550/arXiv.1905.03540
Montavon, G., Samek, W., and Müller, K.-R. (2018). Methods for interpreting and understanding deep neural networks. Digit. Signal Process. 73, 1–15. doi: 10.1016/j.dsp.2017.10.011
Nanfack, G., Temple, P., and Frénay, B. (2021). “Global explanations with decision rules: a co-learning approach,” in Conference on Uncertainty in Artificial Intelligence, 589–599.
Narayanan, M., Chen, E., He, J., Kim, B., Gershman, S., and Doshi-Velez, F. (2018). How do humans understand explanations from machine learning systems? an evaluation of the human-interpretability of explanation. arXiv preprint arXiv:1802.00682. doi: 10.48550/arXiv.1802.00682
Nauta, M., Jutte, A., Provoost, J., and Seifert, C. (2021a). “This looks like that, because... explaining prototypes for interpretable image recognition,” in Joint European Conference on Machine Learning and Knowledge Discovery in Databases (Springer), 441–456.
Nauta, M., van Bree, R., and Seifert, C. (2021b). “Neural prototype trees for interpretable fine-grained image recognition,” in Conference on Computer Vision and Pattern Recognition (Nashville, TN: IEEE), 14933–14943.
Parkash, A., and Parikh, D. (2012). “Attributes for classifier feedback,” in European Conference on Computer Vision (Springer), 354–368.
Perdomo, J., Zrnic, T., Mendler-Dünner, C., and Hardt, M. (2020). “Performative prediction,” in International Conference on Machine Learning, 7599–7609.
Plumb, G., Al-Shedivat, M., Cabrera, Á. A., Perer, A., Xing, E., and Talwalkar, A. (2020). “Regularizing black-box models for improved interpretability,” in International Conference on Neural Information Processing Systems, Vol. 33. (Vancouver, BC).
Popordanoska, T., Kumar, M., and Teso, S. (2020). Machine guides, human supervises: interactive learning with global explanations. arXiv preprint arXiv:2009.09723. doi: 10.48550/arXiv.2009.09723
Raghavan, H., and Allan, J. (2007). “An interactive algorithm for asking and incorporating feature feedback into support vector machines,” in Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (Amsterdam: Association for Computing Machinery), 79–86.
Raghavan, H., Madani, O., and Jones, R. (2006). Active learning with feedback on features and instances. J. Mach. Learn. Res. 7, 1655–1686.
Ras, G., Xie, N., van Gerven, M., and Doran, D. (2022). Explainable deep learning: a field guide for the uninitiated. J. Artif. Intell. Res. 73, 329–397. doi: 10.1613/jair.1.13200
Ratner, A., Bach, S. H., Ehrenberg, H., Fries, J., Wu, S., and Ré, C. (2017). “Snorkel: rapid training data creation with weak supervision,” in Proceedings of the VLDB Endowment. International Conference on Very Large Data Bases, Vol. 11 (NIH Public Access), 269.
Ribeiro, M. T., Singh, S., and Guestrin, C. (2016). ““why should I trust you?”: explaining the predictions of any classifier,” in International Conference on Knowledge Discovery and Data Mining (San Francisco, CA), 1135–1144.
Ribeiro, M. T., Singh, S., and Guestrin, C. (2018). Anchors: high-precision model-agnostic explanations. Conf. Artif. Intell. 32, 11491. doi: 10.1609/aaai.v32i1.11491
Rieger, L., Singh, C., Murdoch, W., and Yu, B. (2020). “Interpretations are useful: penalizing explanations to align neural networks with prior knowledge,” in International Conference on Machine Learning, 8116–8126.
Ross, A. S., Hughes, M. C., and Doshi-Velez, F. (2017). “Right for the right reasons: training differentiable models by constraining their explanations,” in International Joint Conference on Artificial Intelligence, 2662–2670.
Rudin, C. (2019). Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead. Nat. Mach. Intell. 1, 206–215. doi: 10.1038/s42256-019-0048-x
Rudin, C., Chen, C., Chen, Z., Huang, H., Semenova, L., and Zhong, C. (2022). Interpretable machine learning: fundamental principles and 10 grand challenges. Stat. Surv. 16, 1–85. doi: 10.1214/21-SS133
Rymarczyk, D., Struski, Ł., Tabor, J., and Zieliński, B. (2021). “Protopshare: prototypical parts sharing for similarity discovery in interpretable image classification,” in ACM SIGKDD Conference on Knowledge Discovery and Data Mining (Sinagpore: Association for Computing Machinery), 1420–1430.
Santurkar, S., Tsipras, D., Elango, M., Bau, D., Torralba, A., and Madry, A. (2021). “Editing a classifier by rewriting its prediction rules,” in International Conference on Neural Information Processing Systems, Vol. 34.
Sarker, M. K., Zhou, L., Eberhart, A., and Hitzler, P. (2021). Neuro-Symbolic Artificial Intelligence. AI Communications 34, 197–209. doi: 10.3233/AIC-210084
Schölkopf, B., Locatello, F., Bauer, S., Ke, N. R., Kalchbrenner, N., Goyal, A., et al. (2021). Toward causal representation learning. Proc. IEEE 109, 612–634. doi: 10.1109/JPROC.2021.3058954
Schramowski, P., Stammer, W., Teso, S., Brugger, A., Herbert, F., Shao, X., et al. (2020). Making deep neural networks right for the right scientific reasons by interacting with their explanations. Nat. Mach. Intell. 2, 476–486. doi: 10.1038/s42256-020-0212-3
Selvaraju, R. R., Cogswell, M., Das, A., Vedantam, R., Parikh, D., and Batra, D. (2017). “Grad-CAM: visual explanations from deep networks via gradient-based localization,” in International Conference on Computer Vision, 618–626.
Selvaraju, R. R., Lee, S., Shen, Y., Jin, H., Ghosh, S., Heck, L., et al. (2019). “Taking a hint: leveraging explanations to make vision and language models more grounded,” in International Conference on Computer Vision (Venice: IEEE), 2591–2600.
Settles, B. (2011). “Closing the loop: fast, interactive semi-supervised annotation with queries on features and instances,” in Conference on Empirical Methods in Natural Language Processing (Edinburgh), 1467–1478.
Settles, B. (2012). Active learning: Synthesis Lectures on Artificial Intelligence and Machine Learning. Long Island, NY: Morgan and Clay Pool.
Setzu, M., Guidotti, R., Monreale, A., Turini, F., Pedreschi, D., and Giannotti, F. (2021). Glocalx-from local to global explanations of black box ai models. Artif. Intell. 294, 103457. doi: 10.1016/j.artint.2021.103457
Shao, X., Skryagin, A., Schramowski, P., Stammer, W., and Kersting, K. (2021). Right for better reasons: training differentiable models by constraining their influence function. Conf. Artif. Intell. 2021, 17148. doi: 10.1609/aaai.v35i11.17148
Shao, X., Stelzner, K., and Kersting, K. (2022). Right for the right latent factors: debiasing generative models via disentanglement. arXiv preprint arXiv:2202.00391.
Shih, A., Choi, A., and Darwiche, A. (2018). “A symbolic approach to explaining bayesian network classifiers,” in International Joint Conference on Artificial Intelligence, 5103–5111.
Simonyan, K., Vedaldi, A., and Zisserman, A. (2014). “Deep inside convolutional networks: Visualising image classification models and saliency maps,” in International Conference on Learning Representations.
Singh, C., Murdoch, W. J., and Yu, B. (2018). “Hierarchical interpretations for neural network predictions,” in International Conference on Learning Representations.
Sinha, R. R., and Swearingen, K. (2002). “The role of transparency in recommender systems,” in Conference on Human Factors in Computing Systems, 830–831.
Sixt, L., Granz, M., and Landgraf, T. (2020). “When explanations lie: why many modified bp attributions fail,” in International Conference on Machine Learning, 9046–9057.
Slany, E., Ott, Y., Scheele, S., Paulus, J., and Schmid, U. (2022). “CAIPI in practice: towards explainable interactive medical image classification,” in Artificial Intelligence Applications and Innovations. IFIP WG 12.5 International Workshops, 389–400.
Small, K., Wallace, B. C., Brodley, C. E., and Trikalinos, T. A. (2011). “The constrained weight space svm: learning with ranked features,” in International Conference on International Conference on Machine Learning, 865–872.
Sokol, K., and Flach, P. (2020a). “Explainability fact sheets: a framework for systematic assessment of explainable approaches,” in Conference on Fairness, Accountability, and Transparency (Barcelona), 56–67.
Sokol, K., and Flach, P. (2020b). “One explanation does not fit all,” in KI-Künstliche Intelligenz (Bristol), 1–16.
Stammer, W., Memmel, M., Schramowski, P., and Kersting, K. (2022). “Interactive disentanglement: Learning concepts by interacting with their prototype representations,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (IEEE), 10317–10328.
Stammer, W., Schramowski, P., and Kersting, K. (2021). “Right for the right concept: Revising neuro-symbolic concepts by interacting with their explanations,” in Conference on Computer Vision and Pattern Recognition, 3619–3629.
Štrumbelj, E., and Kononenko, I. (2014). Explaining prediction models and individual predictions with feature contributions. Knowl. Inf. Syst. 41, 647–665. doi: 10.1007/s10115-013-0679-x
Stumpf, S., Rajaram, V., Li, L., Burnett, M., Dietterich, T., Sullivan, E., et al. (2007). “Toward harnessing user feedback for machine learning,” in International Conference on Intelligent User Interfaces (Honolulu), 82–91.
Sundararajan, M., Taly, A., and Yan, Q. (2017). “Axiomatic attribution for deep networks,” in International Conference on Machine Learning (Sydney), 3319–3328.
Teso, S. (2019). “Toward faithful explanatory active learning with self-explainable neural nets,” in Workshop on Interactive Adaptive Learning, 4–16.
Teso, S., Bontempelli, A., Giunchiglia, F., and Passerini, A. (2021). “Interactive label cleaning with example-based explanations,” in International Conference on Neural Information Processing Systems.
Teso, S., and Kersting, K. (2019). “Explanatory interactive machine learning,” in Conference on AI, Ethics, and Society, 239–245.
Tintarev, N., and Masthoff, J. (2007). “Effective explanations of recommendations: user-centered design,” in Proceedings of the 2007 ACM conference on Recommender Systems (Minneapolis, MN), 153–156.
Tintarev, N., and Masthoff, J. (2015). Explaining Recommendations: Design and Evaluation. Cham: Springer.
Ustun, B., and Rudin, C. (2016). Supersparse linear integer models for optimized medical scoring systems. Mach. Learn. 102, 349–391. doi: 10.1007/s10994-015-5528-6
Van den Broeck, G., Lykov, A., Schleich, M., and Suciu, D. (2021). On the tractability of SHAP explanations. Proc. AAAI Conf. Artif. Intell. 35, 6505–6513. doi: 10.1609/aaai.v35i7.16806
Varshney, K. R. (2019). Trustworthy machine learning and artificial intelligence. XRDS Crossroads ACM Mag. Stud. 25, 26–29. doi: 10.1145/3313109
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., et al. (2017). “Attention is all you need,” in International Conference on Neural Information Processing Systems (Long Beach, CA), 6000–6010.
Vilone, G., and Longo, L. (2021). Notions of explainability and evaluation approaches for explainable artificial intelligence. Inf. Fusion 76, 89–106. doi: 10.1016/j.inffus.2021.05.009
Virgolin, M., and Fracaros, S. (2023). On the robustness of sparse counterfactual explanations to adverse perturbations. Artif. Intell. 316, 103840. doi: 10.1016/j.artint.2022.103840
Viviano, J. D., Simpson, B., Dutil, F., Bengio, Y., and Cohen, J. P. (2021). “Saliency is a possible red herring when diagnosing poor generalization,” in International Conference on Learning Representations.
von Rueden, L., Mayer, S., Beckh, K., Georgiev, B., Giesselbach, S., Heese, R., et al. (2021). Informed machine learning - a taxonomy and survey of integrating prior knowledge into learning systems. IEEE Trans. Knowl. Data Eng. 2021, 3079836. doi: 10.1109/TKDE.2021.3079836
Wachter, S., Mittelstadt, B., and Russell, C. (2017). Counterfactual explanations without opening the black box: Automated decisions and the gdpr. Harv. JL & Tech. 31, 841. doi: 10.2139/ssrn.3063289
Wagner, B., and d'Avila Garcez, A. (2021). “Neural-symbolic integration for fairness in AI,” in CEUR Workshop, Vol. 2846.
Wang, E., Khosravi, P., and Van den Broeck, G. (2020). “Towards probabilistic sufficient explanations,” in Extending Explainable AI Beyond Deep Models and Classifiers Workshop at ICML (XXAI).
Wang, G. (2019). Humans in the loop: the design of interactive AI systems. J. Artif. Intell. Res. 64, 243–252. doi: 10.1613/jair.1.11345
Wang, N., Pynadath, D. V., and Hill, S. G. (2016). “Trust calibration within a human-robot team: comparing automatically generated explanations,” in 2016 11th ACM/IEEE International Conference on Human-Robot Interaction (HRI) (Christchurch: IEEE), 109–116.
Wang, N., Pynadath, D. V., Rovira, E., Barnes, M. J., and Hill, S. G. (2018). “Is it my looks? or something i said? the impact of explanations, embodiment, and expectations on trust and performance in human-robot teams,” in International Conference on Persuasive Technology, 56–69.
Ware, M., Frank, E., Holmes, G., Hall, M., and Witten, I. H. (2001). Interactive machine learning: letting users build classifiers. Int. J. Hum. Comput. Stud. 55, 281–292. doi: 10.1006/ijhc.2001.0499
Waytz, A., Heafner, J., and Epley, N. (2014). The mind in the machine: Anthropomorphism increases trust in an autonomous vehicle. J. Exp. Soc. Psychol. 52, 113–117. doi: 10.1016/j.jesp.2014.01.005
Wolpert, D. H., and Macready, W. G. (1997). No free lunch theorems for optimization. IEEE Trans. Evolut. Comput. 1, 67–82. doi: 10.1109/4235.585893
Wu, G., Luo, K., Sanner, S., and Soh, H. (2019). “Deep language-based critiquing for recommender systems,” in Conference on Recommender Systems, 137–145.
Wu, M., Hughes, M., Parbhoo, S., Zazzi, M., Roth, V., and Doshi-Velez, F. (2018). Beyond sparsity: tree regularization of deep models for interpretability. Conf. Artif. Intell. 32, 11501. doi: 10.1609/aaai.v32i1.11501
Wu, M., Parbhoo, S., Hughes, M., Kindle, R., Celi, L., Zazzi, M., et al. (2020). Regional tree regularization for interpretability in deep neural networks. Conf. Artif. Intell. 34, 6413–6421. doi: 10.1609/aaai.v34i04.6112
Wu, T., Ribeiro, M. T., Heer, J., and Weld, D. S. (2021). “Polyjuice: generating counterfactuals for explaining, evaluating, and improving models,” in Annual Meeting of the Association for Computational Linguistics.
Wu, T., Weld, D. S., and Heer, J. (2019). Local decision pitfalls in interactive machine learning: an investigation into feature selection in sentiment analysis. Trans. Comput. Hum. Interact. 26, 1–27. doi: 10.1145/3319616
Xu, G., Duong, T. D., Li, Q., Liu, S., and Wang, X. (2020). Causality learning: a new perspective for interpretable machine learning. arXiv preprint arXiv:2006.16789. doi: 10.48550/arXiv.2006.16789
Yao, H., Chen, Y., Ye, Q., Jin, X., and Ren, X. (2021). Refining neural networks with compositional explanations. arXiv preprint arXiv:2103.10415. doi: 10.48550/arXiv.2103.10415
Yeh, C., Kim, B., and Ravikumar, P. (2021). “Human-centered concept explanations for neural networks,” in Neuro-Symbolic Artificial Intelligence: The State of the Art, volume 342 of Frontiers in Artificial Intelligence and Applications, eds H. Pascal and S. M. Kamruzzaman (IOS Press), 337–352.
Yeh, C.-K., Kim, J. S., Yen, I. E., and Ravikumar, P. (2018). “Representer point selection for explaining deep neural networks,” in International Conference on Neural Information Processing Systems, 9311–9321.
Yi, K., Wu, J., Gan, C., Torralba, A., Kohli, P., and Tenenbaum, J. (2018). “Neural-symbolic VQA: disentangling reasoning from vision and language understanding,” in International Conference on Neural Information Processing Systems (Montréal, QC), 1039–1050.
Zaidan, O., Eisner, J., and Piatko, C. (2007). “Using “annotator rationales” to improve machine learning for text categorization,” in Conference of the North American Chapter of the Association for Computational Linguistics (New York, NY: Association for Computational Linguistics), 260–267.
Zeni, M., Zhang, W., Bignotti, E., Passerini, A., and Giunchiglia, F. (2019). Fixing mislabeling by human annotators leveraging conflict resolution and prior knowledge. Interact. Mobile Wearable Ubiquitous Technol. 3, 32. doi: 10.1145/3314419
Zha, Y., Guan, L., and Kambhampati, S. (2021). Learning from ambiguous demonstrations with self-explanation guided reinforcement learning. arXiv preprint arXiv:2110.05286.
Zhang, J., and Curley, S. P. (2018). Exploring explanation effects on consumers' trust in online recommender agents. Int. J. Hum. Comput. Interact. 34, 421–432. doi: 10.1080/10447318.2017.1357904
Zhang, Y., and Chen, X. (2020). Explainable recommendation: A survey and new perspectives. Foundat. Trends®Inf. Retrieval 14, 1–101. doi: 10.1561/9781680836592
Zhang, Y., Song, K., Sun, Y., Tan, S., and Udell, M. (2019). “Why should you trust my explanation?” understanding uncertainty in LIME explanations,” in AI for Social Good Workshop at ICML'19.
Keywords: human-in-the-loop, explainable AI, interactive machine learning, model debugging, model editing
Citation: Teso S, Alkan Ö, Stammer W and Daly E (2023) Leveraging explanations in interactive machine learning: An overview. Front. Artif. Intell. 6:1066049. doi: 10.3389/frai.2023.1066049
Received: 10 October 2022; Accepted: 01 February 2023;
Published: 23 February 2023.
Edited by:
Costantino Grana, University of Modena and Reggio Emilia, ItalyReviewed by:
Andreas Holzinger, Medical University Graz, AustriaAndrea Ferrario, ETH Zürich, Switzerland
Copyright © 2023 Teso, Alkan, Stammer and Daly. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Stefano Teso, 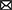 c3RlZmFuby50ZXNvQHVuaXRuLml0
c3RlZmFuby50ZXNvQHVuaXRuLml0