 Christian Mücher1,2*
Christian Mücher1,2*- 1Chair of Statistics and Econometrics, University of Freiburg, Freiburg, Germany
- 2Graduate School of Decision Sciences, University of Konstanz, Konstanz, Germany
This paper uses Long Short Term Memory Recurrent Neural Networks to extract information from the intraday high-frequency returns to forecast daily volatility. Applied to the IBM stock, we find significant improvements in the forecasting performance of models that use this extracted information compared to the forecasts of models that omit the extracted information and some of the most popular alternative models. Furthermore, we find that extracting the information through Long Short Term Memory Recurrent Neural Networks is superior to two Mixed Data Sampling alternatives.
1. Introduction
The volatility, the time-varying centered second moment of a financial asset, is crucial to measure, forecast, and evaluate financial risk. There exist many ways of modeling and forecasting volatility separable into two main groups: Models based on (squared) daily returns and models based on the Realized Volatility (RV) estimator. In the first group, volatility is treated as a latent variable and estimated from the model. Famous examples in this regard are, on the one hand, (G)ARCH models (Engle, 1982; Bollerslev, 1986) and their various extensions that treat volatility as conditionally observable. On the other hand, Stochastic Volatility models (Taylor, 1986; Ruiz, 1994) treat conditional volatility as random variables and rely on filtering techniques for estimation and forecasting. While the vast models in this group capture stylized properties of financial data such as volatility clustering, long-memory, and asymmetric reactions of volatility to positive and negative shocks, they generally perform worse in forecasting volatility compared to the models of the second group (Andersen et al., 2004; Sizova, 2011).
The availability of high-frequency (HF), intraday returns and the introduction of RV as an estimator of integrated volatility over a day (Andersen et al., 2001a,b; Barndorff-Nielsen and Shephard, 2002a,b) lead to the second group of models. Since the RV ex-post gives a consistent volatility estimate, the main focus of models in the second group is forecasting. Andersen et al. (2001a,b), and Barndorff-Nielsen and Shephard (2002a) find that RV and the logarithm of RV exhibit long memory. Their autocorrelation functions show a hyperbolic decay, meaning that past shocks have a very long influence on the system of RV. Therefore, the authors propose forecasting volatility via fractional integrated autoregressive moving average (ARFIMA) models to account for the long memory. The most prominent alternative to ARFIMA models for forecasting volatility based on RV is the Heterogeneous Autoregressive Model (HAR) by Corsi (2009). The HAR model approximates the long memory in the data through RV's daily, weekly, and monthly averages. These averages are used in a linear model as explanatory variables to predict volatility. Corsi (2009) finds that the HAR model performs better than the ARFIMA models in forecasting volatility. The HAR model is popular because of its good performance and ease of implementation (the HAR can be estimated by simple OLS regression). There exist many extensions of the HAR model in the literature, such as the HAR with jumps model of Andersen et al. (2007), the Semivariance HAR of Patton and Sheppard (2015), or the HARQ of Bollerslev et al. (2016). However, the standard HAR model, both for the level and the logarithm of RV, still is a challenging benchmark to beat in applications on real financial data.
Artificial Neural Networks (ANNs) have become more and more popular over the last decade, and various fields apply them for classification, prediction, and modeling tasks. Cybenko (1989) and Hornik et al. (1989) show the capability of Feed Forward Neural Networks (FNNs), fully connected ANNs with one hidden layer, to approximate any continuous function on a compact set arbitrarily well. Furthermore, Schäfer and Zimmermann (2006) show that Recurrent Neural Networks (RNNs) can approximate any open, dynamic system arbitrarily well. The popularity of ANNs is, on the one hand, due to these theoretical results. On the other hand, ANNs have been among the winning algorithms for various classification and forecasting competitions over the past years. RNNs combine the ability of ANNs to capture complex non-linear dependencies in the data with capturing temporal relationships. Long Short Term Memory (LSTM) RNNs (Hochreiter and Schmidhuber, 1997) are a type of RNN specifically designed to capture long memory in data. Their capacity to capture non-linear, long-term dependencies in the data make them the perfect candidates for modeling volatility.
This paper aims to use LSTMs to non-linearly transform the HF returns of a financial asset, observed within a day, into a daily, scalar variable and to use this variable to forecast volatility. Non-linear transformations of the HF returns are not novel since the RV estimator (the sum of the squared HF returns of a day) is also a non-linear transformation, but a particular one. We investigate whether volatility forecasts solely constructed from the ANN-based transformation of the HF returns are different from forecasts obtained through the past RVs. While the ANN transformation is very flexible in the functional form, the resulting sequence might not capture the long persistence in the volatility, as the RV estimator does. However, the flexibility of the functional form might capture other information that is useful to predict volatility and that the RV estimator does not take into account. Examples of such information are the sign of the HF returns or patterns of HF returns occurring over a day. We thus combine the two approaches and investigate whether the resulting model exhibits a superior forecasting performance compared to the models that rely on each measure alone.
An alternative approach to transforming the HF returns is the Mixed Data Sampling (MIDAS) approach of Ghysels et al. (2004). In MIDAS, the transformation happens through a weighted sum of the HF returns. The weights are obtained non-linearly, e.g., by an Almon or a Beta Lag Polynomial (Ghysels et al., 2004). We introduce a novel type of MIDAS model that obtains those weights through an LSTM cell. In MIDAS applications, however, the construction of the transformed HF measure is linear.
Though, as mentioned earlier, the RV estimator is also a transformation of the HF returns, throughout the paper, we will use the term transformed HF returns or transformed measure to refer to the scalar variable obtained through either the ANN transformation or the MIDAS transformation.
We compare the forecasting performance of models that use either one of the transformed measures to forecast volatility with each other and with models that construct the forecasts relying solely on information from past RV, such as the HAR model. We can thus answer whether the transformation can extract at least the same information as the past RV. We further compare these models' forecasts with those obtained from models that combine the RV information with the transformed measures, allowing us to investigate whether the transformed measures contain information supplementary to the RV. Lastly, we can compare the different transformation methods to determine whether the non-linearity introduced through ANNs performs differently from the MIDAS approaches.
The remainder of this paper is structured as follows: section 2 gives an overview of the literature in volatility forecasting with ANNs. Section 3 introduces the LSTM RNN, and section 4 explains the different transformations of the HF returns. It first describes the non-linear transformation through LSTMs and then shows the two MIDAS approaches. Section 5 elaborates on using the transformed HF returns to generate volatility forecasts. We further introduce the benchmark models to which we compare our proposed methodology. Finally, we present the results of our empirical application in section 6, and section 7 concludes.
2. Literature Review
A vast area of finance applies ANNs. For example, White (1988), among others, uses ANNs to predict stock returns while Gu et al. (2020) use ANNs for asset pricing and Sadhwani et al. (2021) apply ANNs for mortgage risk evaluation. ANNs are further applied to model and forecast financial risk. The literature in this field reflects the two main branches of volatility modeling and forecasting mentioned in section 1: models based on daily (squared) returns and models based on realized measures estimated from the HF returns. An early contribution to the literature of volatility modeling and forecasting through daily squared returns is Donaldson and Kamstra (1997). The authors introduce a semi nonparametric non-linear GARCH model based on ANNs and show superior performance to other GARCH type alternatives. Franke and Diagne (2006) show that ANNs yield non-parametric estimators of the conditional variance function of an asset when trained with daily returns as inputs and squared returns as targets. Their results have been applied by Giordano et al. (2012) and generalized for the Multi-Layer-Perceptron (MLP), fully connected ANNs with multiple hidden layers, by Franke et al. (2019). Arnerić et al. (2014) exploit the non-linear Autoregressive Moving Average (ARMA) structure of a Jordan type RNN (Jordan, 1997) and the ARMA representation of the GARCH model to introduce the Jordan GARCH(1,1) model. Their model shows superior performance in out-of-sample root mean squared error (RMSE). Alternative approaches use the output of GARCH models, potentially combined with other explanatory variables, as inputs to an MLP (see e.g., Hajizadeh et al., 2012; Kristjanpoller et al., 2014).
The literature on forecasting volatility via ANNs through realized measures consists of two main fields. The first field uses ANNs to relax the linearity of the HAR model by feeding the lagged daily, weekly, and monthly averages of RV to MLPs. The evidence in this branch is mixed. Rosa et al. (2014) find improvements in the forecasting performance of the non-linear HAR model, while Vortelinos (2017) concludes that the ANN HAR model is not predicting volatility better than the linear HAR. He argues that the MLP cannot capture the long-term dependencies in the RV. Baruník and Křehlík (2016) find mixed evidence of the ANN HAR model for the volatility of energy market prices. Their ANN-based model produces more accurate forecasts than the linear model for some forecasting horizons and some markets. Arnerić et al. (2018) find that an MLP fitted to the HAR inputs can outperform the linear benchmark. In addition, they find that including jump measures in the analysis further improves the forecasting performance. Christensen et al. (2021) find superior forecasting performance of their MLP HAR model over the linear HAR. Further, they find that the model's performance improves when additional firm-specific and macroeconomic indicators are added. Li and Tang (2021) apply an MLP to a large set of variables such as realized and MIDAS measures and option Implied Variances. They find that the resulting model outperforms the linear benchmark. The performance improves further through an ensemble learning algorithm that combines the outputs of other linear and non-linear machine learning techniques, such as penalized regression and random forests, with the output from the ANN model.
The second field in the literature utilizes RNNs to capture, in addition to non-linearity, long-term dependencies in the data. Miura et al. (2019) examine the volatility of cryptocurrencies finding that a ridge regression yields the best out of sample forecasting results, followed by LSTM RNNs. Baştürk et al. (2021) apply LSTM RNNs to the past measure of RV and the negative part of past daily returns to jointly forecast the volatility and the Value at Risk (VaR) of a financial asset. The authors find superior forecasting performance of the LSTM network for the VaR forecasts. However, their approach cannot produce improved volatility forecasts compared to the linear alternatives.
A recent contribution to both branches of this literature is Bucci (2020), who compares the forecasting performance of various ANN structures to standard benchmarks from the financial econometrics literature such as the HAR model and ARFIMA models. He further investigates how adding macroeconomic and financial indicators as exogenous explanatory variables improves the model's forecasting performance. The target variable in his analysis is the monthly log square root of the RV. He finds that the long memory type ANNs such as the LSTM network outperform the financial econometrics literature's classical models. Furthermore, these models outperform the ANNs that do not account for long memory in the data. This result holds for various forecasting horizons.
Finally, Rahimikia and Poon (2020a) and Rahimikia and Poon (2020b) propose a HAR model augmented by an ANN applied to HF limited order book information and news sentiment data. In both papers, the authors find a superior forecasting performance of their model compared to the HAR benchmark. Their approach of augmenting the HAR model by transformed HF data is similar to the idea of this paper. In parts of our application, we augment models for LF measures such as the HAR with transformed HF information. The difference is that we consider the HF returns and not other auxiliary HF information. Further, we also consider models that use only the information from the transformed HF returns for the forecast.
3. Long Short Term Memory
LSTM RNNs are a specific type of RNN structures that overcome the problem that classical RNNs face. Specifically, the limited capacity of such networks to learn long-term relationships due to vanishing or exponentially increasing gradients (Hochreiter, 1991; Bengio et al., 1994). The cornerstone of LSTMs is the long memory cell denoted by Cτ. A candidate value of which, is a non-linear transformation (using the hyperbolic tangent activation function tanh1) of a linear combination of the τ-th periods' input vector values vτ and the previous periods' output value yτ−1 plus an intercept
Next, the values of the forget fτ and the input iτ gate are computed. These are obtained by applying the sigmoid activation function σ(·)2 to a linear combination of the input vector values vτ and the previous periods' output value yτ−1 plus an intercept.
The memory cell value is computed by
i.e., it combines the previous periods' cell value and the current periods' candidate cell value. Since the sigmoid function returns values on the interval (0, 1), fτ denotes the share to be “forgotten” from the previous cell state and iτ the share of the proposal state to be added to the new cell state. The output of the LSTM cell yτ is generated by applying the tanh function to the memory cell values and multiplying the result by the value of the output gate oτ
where the latter is obtained in the same manner as the values of fτ and iτ
The output gate gives the share of the activated cell values to return as the output of the memory cell. LSTM cells thus are dynamic systems wherein interacting layers drive the hidden state dynamics. This interaction enables the LSTM cell to account for a high degree of non-linearity and to capture long-term dependencies in the data.
4. Transformation of the High-Frequency Returns
Denote by rt,j the t-th days' j-th log-return. We have j = 1, …, M equidistantly sampled returns within day t. The increments between two intraday returns determine the number of intraday observations. For returns sampled every 5 minutes within a normal trading day at the New York Stock Exchange, we obtain 78 intraday high-frequency returns. We will denote the vector of the intraday returns on day t by rt,1 : M. We aim to apply a transformation to rt,1 : M that returns a scalar value which we will refer to as the transformed measure. The transformation depends on parameter vector θHF. We present three different methods to obtain the transformed measure in the following.
4.1. Non-linear Transformation
The LSTM architecture described earlier can be used for a non-linear transformation of the HF returns. In its' simplest form, we use the sequence of the M intraday returns as input to the LSTM cell, and the output of the cell at time M, yt,M, as the transformed value. We thus iterate through the LSTM equations over the j = 1, …, M intraday returns at day t
and set , where θHF contains the LSTM cell weights and intercepts. Through the interaction of the three gates and the non-linear activation of the proposal state and the actual state, the LSTM cell allows for a high degree of non-linearity while also capturing long memory in the data. Both the cell input (rt,j) and output (yt,j) at within day lag j are scalars. The parameter vector θHF of the model using one LSTM cell thus contains 12 parameters: Four 2 × 1 weight vectors and four intercepts. To increase the degree of non-linearity, we further use a network that consists of one hidden layer of LSTM cells and use the outputs of these cells as inputs to another LSTM cell returning a scalar value.
4.2. MIDAS Transformations
Denote by the weights associated with the j-th intraday return on day t. The weights are determined by the elements of θHF. While the weights may be obtained in a non-linear manner, the resulting transformed measure
is a weighted sum and thus linear.
In a Beta Lag MIDAS model (labeled Beta MIDAS hereafter), the weight associated with the j-th lag is obtained by
where is the probability density function (pdf) of the Beta distribution. In this case, the parameter vector contains the Beta distribution parameters. While only depending on two parameters, the weights obtained from the normalized Beta pdf are capable to capture complex non-linear functional forms.
An alternative way to obtain the weights associated with the j-th observation is to use the lag values as inputs to an LSTM cell. In this case, the input to the LSTM cell is rj = j with j = 1, 2, …, M. The corresponding output (yj) lies on the interval between (−1, 1). Note that in this case, rj and yj do not depend on t since they only vary within the day but not over the days. To transform the output at within day lag j (yj) into a weight, we apply the exponential function and normalize the values, i.e.,
yielding weights that lie in the interval (0, 1) and sum up to one. This transformation is similar to the Beta MIDAS, where the Beta pdf values associated with j/M are normalized such that they sum up to one. Same as above, the parameter vector θHF of the LSTM MIDAS model contains 12 parameters.
5. Volatility Forecasting
This paper aims to forecast the daily volatility of a financial asset. Consider the price process of a financial asset Pt, determined by the stochastic differential equation
where μt and σt denote the drift and the instantaneous or spot volatility process, respectively, and Wt is a standard Brownian motion. The integrated variance from day t − 1 to t is then defined as
The integrated variance yields a direct measure of the discrete time return volatility (Andersen et al., 2004), but the series is latent, and we can not observe it directly. However, we can estimate the integrated variance ex-post through the RV estimator defined as
i.e., the sum of the M squared intraday HF returns. Our goal is to assess how the information obtained from applying the different transformations of the HF returns explained earlier helps predict one step ahead volatility. To answer this, we consider different scenarios.
First, we vary the input variables used to predict volatility, considering three different settings. We start by combining the transformed measure (for readability, we omit the dependence of the transformed measure on θHF from here on) with past information on the RV. Next, we assess how this combination fares compared to using each stream of information on itself, i.e., using only the information obtained from the transformation and using only the past information on RV. Finally, when using the information on the transformed measure, we again differentiate between two settings: In the first, we only use the most recent (the past days) value of the transformed measure. In the second, we account for dynamics in the transformed measure and use the values of multiple past days. The contributions of Andersen et al. (2001a) and Andersen et al. (2001b) as well as models like the HAR and the work by, e.g., Audrino and Knaus (2016), show that it is necessary to account for the long memory in the volatility. In the setting where we use multiple past values of the transformed measure, we therefore apply an LSTM cell to the sequence of transformed measures. This means that for τ = 1, …, t, we iterate over
and set , where contains the corresponding LSTM cell weights and intercepts. Using an LSTM cell circumvents the problem of lag order selection through either information criteria or shrinkage methods. The LSTM cell takes into account the whole sequence of by storing the necessary information in the memory cell. Figure 1 depicts the underlying idea.
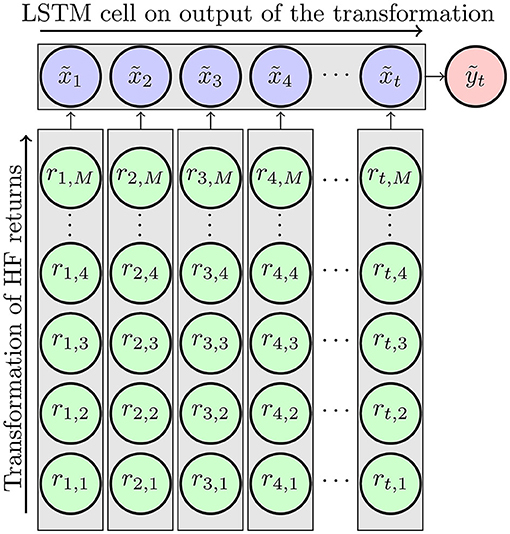
Figure 1. Method depicted. The HF returns are transformed in the vertical direction, meaning that for each day 1, …, t the same type of transformation is applied to the HF returns of that day. The result is a sequence of τ = 1, …, t transformed measures to which an LSTM cell is horizontally applied.
We then linearly combine the output ỹt (for readability, we omit the dependence of ỹt on from here on) with the other LF measures under consideration. This results in the following, case dependent, transformed HF information input variable
We consider two settings, where we linearly combine the information from the past RV with that of the transformed HF returns and add an intercept. Herein, in resemblance to the classical HAR model, we first use past, daily, weekly, and monthly averages of the natural logarithm of RV (referred to as log RV hereafter). Denote the logarithm of RV at day t by ln RVt i.e.,
Weekly and monthly averages of log RV are then defined by
and
Second, we use the output of an LSTM cell applied to the sequence of the past log RVs.
This results in the, case dependent, low frequency information input variable and
The HAR model is the most commonly used benchmark in volatility forecasting. However, its' implicit lag order selection (it is a restricted AR(22) model) is not necessarily validated in real data applications (Audrino and Knaus, 2016). As mentioned earlier, we circumvent the trouble of lag order selection since we apply an LSTM cell to the LF inputs. The LSTM cell can capture the long-term dynamics. Alternatively, one could fit an autoregressive model of order p on the RV, add the lags of the transformed measure as additional explanatory variables, and perform lag order selection via Information Criteria or shrinkage methods. However, we leave these two alternatives for further research.
We take the exponential of these linear combinations to guarantee the positiveness of the generated forecast. The output of the model thus is generated by
where θ is a vector collecting all parameters. βLF contains either the parameters associated with the daily, weekly, and monthly averages of log RV or the parameters associated with the output of the LSTM cell applied to the sequence of log RV. βHF is the parameter of the scalar measure obtained from the transformation of the HF returns, and c is an intercept. The model that only uses the transformed HF returns for the forecast corresponds to restricting βLF = 0. This comparison allows for a very detailed analysis of the source of potential gains in the forecasting performance:
1. We can assess whether there are significant differences in the forecasting performances of the models that only use the transformed measure as inputs to those that combine them with the LF variables. It is thus possible to inspect whether or not the sequence of transformed HF returns captures the information included in the past RV.
2. We can investigate whether it is necessary to consider the entire information in the transformed measure or whether the most recent information suffices.
3. We can compare the different transformation methods, assessing the differences between the linear MIDAS type transformations and the non-linear transformations.
4. We can examine whether using the classical HAR inputs with a fixed lag order of 22 is enough or whether using an LSTM cell on the past RV values, which is less restrictive in terms of the lag order selection, is fruitful.
5.1. Benchmark Models
We apply a variety of benchmark models, four models of the HAR family and an ARFIMA(p,d,q) model. Our proposed methodology ensures the positiveness of the volatility predictions by construction (see Equation 30). However, when fitting the benchmark models to the level of RV, the forecasts are not guaranteed to be positive. We thus implement each benchmark model once for the level of RV and once for the log of RV to allow for a fair comparison. In the latter case, the forecasts are bias corrected (Granger and Newbold, 1976), i.e.,
where is the forecast error variance estimated from the residuals.
Following the suggestion of Andersen et al. (2003), we start by fitting an ARFIMA model
for xt = RVt and xt = ln RVt, where εt is a Gaussian white noise with zero mean and variance σ2. Φ(L) and Θ(L) are lag polynomials of degrees p and q, respectively whose roots lie outside the unit circle.
Next, we implement benchmark models from the HAR family, starting with the classical HAR model (Corsi, 2009) in levels
and in logs
For all HAR family models, the error term εt is assumed to be a white noise process with 𝔼[εt] = 0 and 𝕍. Following Andersen et al. (2007), we include the CHAR model as the second benchmark. The CHAR model is based on the jump robust Bi-Power Variation (BPV) measure of Barndorff-Nielsen and Shephard (2004), defined as
where is the expectation of the absolute value of a standard normal random variable. The CHAR model then replaces the daily, weekly, and monthly averages of RV on the right hand side of the HAR model with the corresponding averages of BPV, i.e., for levels
and for logs
An alternative model that accounts for jumps is the HAR with jumps (HAR-J) model (Andersen et al., 2007). The HAR-J model adds the jump measure Jt = max(RVt − BPVt, 0) or, when modeling log RV, ln (1 + Jt), as an additional explanatory variable to the HAR model. However, in our application, the HAR-J model in levels produces negative volatility predictions in two cases. For the log case the average losses of the HAR-J model are very similar to those from the HAR model. We thus omit the results from the HAR-J model, though the differences are statistically significant. They are available from the authors upon request. The next benchmark model is the Semivariance-HAR (SHAR) model by Patton and Sheppard (2015), which builds on the semi-variation measure of Barndorff-Nielsen et al. (2010) differentiating between variation associated with positive and negative intraday returns. The estimators are defined as
and
where 𝕀 is the indicator function and . The SHAR model uses this decomposition of RVt such that for levels
and for logs
The last benchmark from the HAR family is the HARQ model of Bollerslev et al. (2016). The HARQ model uses the Realized Quarticity (RQ) estimator of Barndorff-Nielsen and Shephard (2002a) to correct for measurement error in the RV estimator. The HARQ model for levels is
and for logs.
6. Application
We use the 5 minutes log-returns (M = 78 intraday observations per trading day) of IBM from January, 02, 2001 till December 28, 2018 (T = 4, 482 days). We use the first 80% of the data (till May 27, 2015) as the in-sample data and the last 20% as the out-of-sample data. In order to obtain forecasts from each model introduced earlier, the QLIKE loss (Patton, 2011) between the forecast yt(θ) and the next periods RV, RVt+1 is minimized, i.e., the objective is to find
where the QLIKE loss function is defined as
The QLIKE is a better choice when forecasting volatility than the mean squared error since it considers that the variable of interest is positive. We implement all models (except the benchmark models) in Python using Keras (Chollet, 2015) with the TensorFlow (Abadi et al., 2015) backend. This workflow comes with a comprehensive set of functions, allowing custom types of neural networks. We implement, e.g., the Beta MIDAS model as a specific case of an MLP that takes a 2 × 1 vector of ones as inputs and has a diagonal weight matrix coinciding with the parameters φ1 and φ2 of the Beta pdf. The layer then returns an M × 1 vector of weights associated with the standardized Beta pdf as described earlier. We estimate the parameters of all models under consideration (except the Benchmark models) by Stochastic Gradient Descent (SGD). Since SGD introduces an implicit regularization of the parameters (Soudry et al., 2018) this methodology should allow for a fair comparison of the forecasting results of the different models.
We train by Adaptive Moments SGD (ADAM, Kingma and Ba, 2014) with a batch size (length of a randomly selected sample selected for one SGD parameter update) of 128. Keras computes the gradient of RNNs by Truncated Back Propagation Through Time (Rumelhart et al., 1986); truncated in the manner that the computation of the gradient considers only a limited amount of past lags. The horizon of truncation is referred to as lookback and does not change the fact that the RNN considers the whole sequence of inputs when producing the forecast after training. We set the lookback equal to 128. We standardize the input data and divide the target data (the one step ahead RV) by its' standard deviation. We do not demean the target data to ensure positivity. We store the standard deviations to re-scale the resulting predictions in each forecasting step.
We use an expanding window scheme for forecasting: We start training for 1,000 epochs (one epoch means the algorithm went through the whole sample once) on the first 80% of the data and use the trained network and the newly available information to make a one step ahead prediction. Then, the model is re-trained for another 100 epochs for each one step ahead prediction with the previous iterations parameter values as starting values, resulting in 897 out of sample forecasts. To make training more feasible, we employ early stopping criteria. These interrupt the training before the target number of epochs is hit, given that there was no improvement of the training error over several specified past epochs. The term patience refers to this specified number of epochs. We set the minimum, absolute change of the training loss to be considered an improvement to 10−6, the initial training step patience to 500, and the patience in the re-training steps to 50. The code runs on an NVIDIA Tesla V100 GPU on the bwHPC Cluster.
We estimate the HAR family benchmark models by OLS and the ARFIMA models using R's fracdiff (Maechler, 2020) and forecast (Hyndman and Khandakar, 2008) packages. On the in-sample data, an ARFIMA(5,d,2) model provides the best fit for the level of RV and an ARFIMA (0,d,1) for the logarithm of RV.
6.1. Forecast Evaluation
We compare the forecasting performance of our presented model with varying inputs and the benchmark models for both levels and logs using different loss measures. First, we compare the average QLIKE loss of the different models. Next, we report the square root of the average squared error loss (the RMSE). We further compute Value at Risk (VaR) and Expected Shortfall (ES) forecasts based on the volatility forecasts. The VaR is the p-th quantile of the return distribution and the ES is the expected value of the return, given that the return is smaller than the VaR. We compute the daily log returns rt as the sum of the intraday returns of day t, which is equivalent to the log return based on the difference between the log closing and opening prices. Table 1 reports descriptive statistics of the daily returns (rt), the RV estimated from 5 minutes log-returns (RVt), and the standardized returns for the whole sample, the in- and the out-of-sample period.
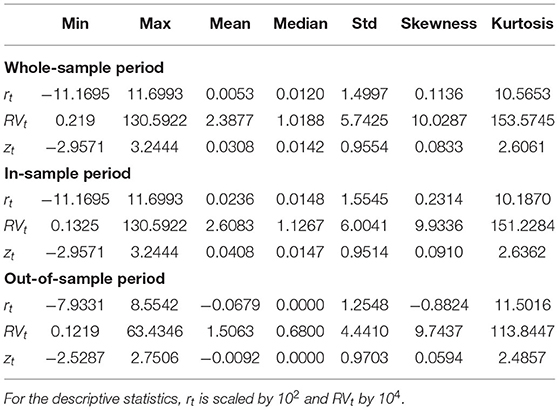
Table 1. Descriptive statistics.
After standardizing the daily returns, their skewness and kurtosis are close to those of a standard normal distribution. For the out-of-sample period, we can not reject the H0 of a Kolmogorov-Smirnov test that the standardized returns are standard normally distributed (p-value = 0.646). For the whole sample (p-value = 0.018) and the in-sample period (p-value = 0.011) we reject this hypothesis at the 5% level. These results are reasonable since the out-of-sample period does not contain the financial crisis. We thus use the normal distribution to compute forecasts of VaR and ES. We also compute forecasts of VaR and ES using the standardized Student-t distribution, where, similar to Brownlees and Gallo (2010), for each iteration in the expanding window, we estimate the degrees of freedom based on the information available up to time t. All estimated degrees of freedom are larger than 100, indicating no need to account for fat tails. Further, the statistical analysis results and the ranking of the models do not change compared to the case of the normal distribution. We thus do not report the Student-t distribution results here. They are available from the authors on request.
To evaluate the performance of the models in forecasting VaR and ES, we use the asymmetric piece-wise linear loss function of Gneiting (2011) for the VaR and the zero-homogeneous loss function of Fissler and Ziegel (2016) for the VaR and the ES jointly.3 Using the short notation r = rt, and , these loss functions are
and.
6.2. Results
Table 2 reports the results of the out-of-sample losses introduced above for the different models. It further shows which models are in the Model Confidence Set (MCS) of Hansen et al. (2011) at the 10% level. We use the arch library of Sheppard et al. (2021) to compute the MCS p-values. In addition, we report the results of Binomial tests,4 where we test each model against the other models in Supplementary Figures 1–6. The table consists of two main blocks, again consisting of multiple blocks as indicated by the horizontal lines. The first main block contains the results for the ANN models, where the first two rows show the results for the models that do not use the transformed measure as additional input (indicated by the superscript O), i.e., the models corresponding to the restriction βHF = 0. The first model is a non-linear HAR estimated by SGD. Non-linear since we use the exponential of a linear combination of daily, weekly, and monthly averages of log RV on the right-hand side. The second row shows the results of modeling the long memory in RV not via the restricted AR(22) character of the HAR model but an LSTM cell applied to the log RV.
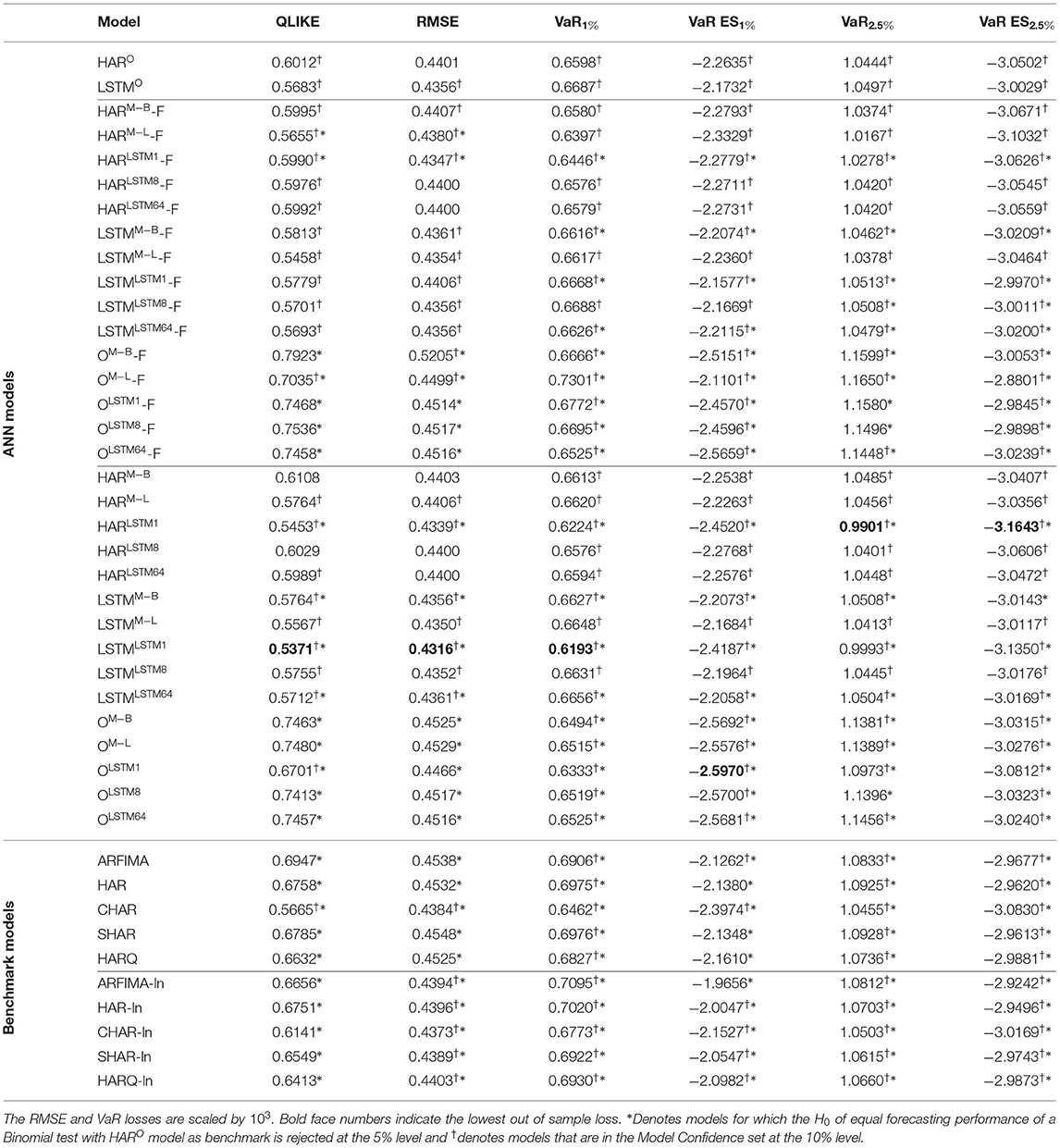
Table 2. Out of sample losses.
Next, follow the models that use the information from the transformed measure. The superscript indicates the type of transformation: The superscript O indicates no transformation, the superscripts M-B and M-L indicate the Beta and LSTM MIDAS transformation, respectively, and the superscript LSTM plus a number indicates the non-linear, LSTM based transformation. The number indicates the number of LSTM cells in the hidden layer in this case.
The model's name indicates the type of low-frequency information: HAR refers to the daily, weekly, and monthly averages, and LSTM refers to an LSTM cell applied to the sequence of log RV. They reflect choosing and respectively. The name O refers to only using the information from the transformed measure, i.e., it corresponds to the restriction βLF = 0. Here we have two blocks again. The first reporting models that apply an LSTM cell to the sequence of the transformed measure. These models thus take into account the full information in the sequence of the transformed measure, indicated by -F in the model name. The second block refers to models that only use the most recent value of the transformed measure. The two blocks thus correspond to the choice of and , respectively. The last block shows the results of the benchmark models, where we differentiate between them being applied for the level of RV and to the logarithm of RV (indicated by -ln in the model name). We transform the forecasts using the bias correction mentioned earlier for the latter case.
We first consider whether using only the transformed measure for forecasting volatility is fruitful. Table 2 clearly shows that the models that only rely on the transformed measure (labeled O plus the superscript corresponding to the transformation used) are the worst-performing models within their respective blocks in terms of the QLIKE and the squared error loss. These models perform comparably or worse than the alternatives for the VaR loss and the joint loss of VaR and ES. The only exception is when jointly evaluating forecasts of VaR and ES at p = 1%. In this case, these models are the best performing ones, and among them, the model that uses the non-linear transformation via one LSTM cell performs best. The differences in the forecasting performance of the only transformed measure models to those that also use the information on past RV (HAR and LSTM plus superscript) are significant in terms of a binomial test for equal forecasting performance at the 1% level, as Figure 2 shows. Figure 2A of the figure displays the test decision when comparing the models that combine the HAR inputs with ỹt against the model that only uses ỹt (O plus superscript). The x-axis labels specify the type of transformation used to obtain the transformed measure. Figure 2B shows the results for only using the most recent information in the transformed measure, i.e., combining the HAR inputs with vs. solely using . Figures 2C,D show the results for the case where the HAR inputs are replaced by the output of an LSTM cell applied to the sequence of log RV. All p-values are smaller than 0.01 in all cases. For the QLIKE and the squared error loss, we can conclude that none of the transformations can extract enough information from the HF returns to replace the information on past RV for forecasting volatility. When forecasting the VaR and ES, these models yield results comparable to those of the other models. They outperform the alternative models only for the joint evaluation of the VaR and the ES at the 1% level.
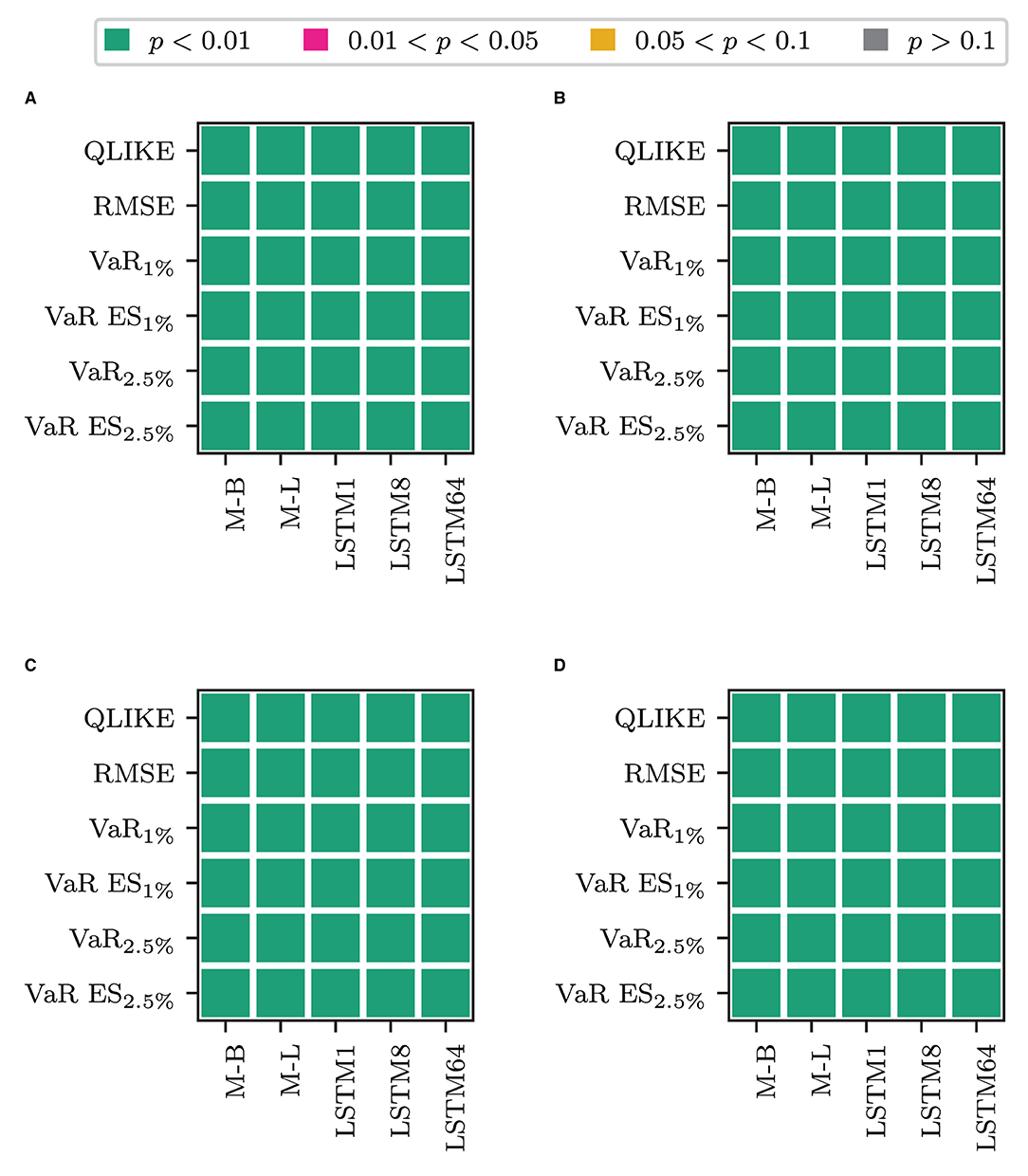
Figure 2. Results for a Binomial test of equal forecasting performance between the models that use only the transformed measure and their counterpart that use it in combination. (A) HAR-F vs. O-F. (B) HAR vs. O. (C) LSTM-F vs. O-F. (D) LSTM vs. O.
Next, we address whether the -F models (the models that use the output of an LSTM cell applied to the sequence of the transformed measure) yield any differences in the forecasting performance compared to the models that only use the most recent information from the transformation. Figure 3 shows the testing results for differences between a model that only uses the most recent information in the transformed measure against its' -F counterpart. At the 5% level, regardless of the LF input they are combined with, we see no significant differences in the forecasting performance of the MIDAS Beta, the LSTM8, and the LSTM64 transformation models compared to their -F counterparts. However, these differences are significant for the LSTM MIDAS and the LSTM1 transformation. When we only use the transformed measure, the LSTM MIDAS transformation model with full information produces lower average OLIKE and squared error losses. In contrast, the model that only uses the most recent information produces lower average losses when jointly evaluating VaR and ES. For the LSTM1 transformation, the model that only uses the most recent information yields the lower average loss for all loss functions. Combining the transformed measure with other LF information yields the following pattern: For the LSTM MIDAS transformation, where the differences are significant, the -F model gives the lower average losses. For the LSTM1 transformation, using only the most recent information yields lower average losses.
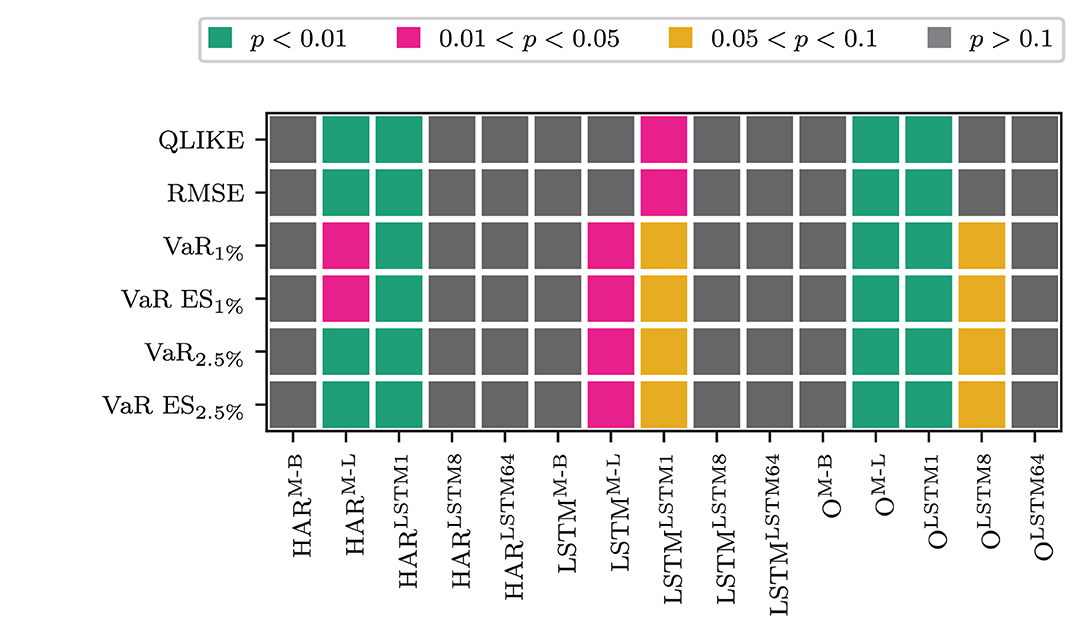
Figure 3. Results for a Binomial test of equal forecasting performance between the full information (ỹt) and the recent information () models.
Whether there are significant differences in the forecasting performance between the models that use ỹt and the models that use is thus case dependent. There are no significant differences for most models and transformations. For the LSTM MIDAS, it depends on whether it is used alone or in combination. In the former case, the -F models produce lower losses when the differences are significant. Using the -F models yields the lower QLIKE and squared error in the latter case. However, using produces lower VaR and ES losses. For the non-linear transformation through one LSTM cell, only applying the transformation to the most recent HF returns yields lower average losses. It seems that, in this case, the more distant information in the HF returns gets accounted for by the RV. However, the most recent HF returns contain information that the lagged RV does not yet capture.
When we use the LSTM MIDAS transformation, it is necessary to use the sequential information in the transformed measure. An alternative explanation for this could be that the -F model introduces additional non-linearity into the transformed measure by applying an LSTM cell to its' sequence. While in the LSTM MIDAS case is constructed linearly as a weighted sum, ỹt is a non-linear transformation of the sequence of that linear measure. So the better forecasting performance of the model that uses ỹt for the LSTM MIDAS transformation could be due to that non-linearity. However, the transformation of the HF returns through one LSTM cell is already the output of a non-linear function. Since only the most recent transformed measure is informative for this transformation, it appears that there are no gains from introducing more non-linearity through an LSTM cell on the sequence of transformed measures. Comparing these two against each other, we see that models that use only the most recent non-linear transformed measure produce lower losses than the models that use the LSTM cell applied to the LSTM MIDAS transformation. These differences are significant at the 1% level for all losses (see Supplementary Figures 1–6). Thus, the non-linearity within the transformed measure seems to produce more helpful information for forecasting volatility than introducing non-linearity to the transformed measure obtained from the linear method.
Next, we address whether combining the transformed measure with the other LF inputs yields significant gains in forecasting compared to only using the LF inputs. Figure 4 displays the test results. Figures 4A,B show the test results for combining the HAR model inputs with the transformed measures against the model that does not use the transformation. The x-axis labels again indicate the type of transformation. Figure 4A shows the results for the -F models and Figure 4B for the models that only use the most recent information. The lower part of the figure, Figures 4C,D, display the corresponding results when replacing the HAR inputs with the output of an LSTM cell applied to the sequence of log RV. Combining any of the LF inputs with the LSTM1 transformation yields statistically different forecasts to the models that omit the transformed measure, in any case, and for all losses. In the case of the HAR model inputs, the combined model yields lower losses in both cases. For the LSTM input, the -F model performs worse, whereas the model that only uses the most recent HF information yields lower losses. For the other transformations, the results are case-dependent. When combined with the HAR inputs, the LSTM MIDAS model yields significantly different QLIKE and RMSE losses in the full information case. The HARM−L-F model yields the lower QLIKE and RMSE losses in these two cases. The differences are not statistically different at the 5% level in the remaining cases. The non-linear transformation with 64 LSTM cells yields statically different results for all losses but the QLIKE and the squared error loss in the full information case. Its' losses are lower than the comparison model in these cases. When using the recent information only the non-linear transformation with 64 LSTM cells does not deliver significantly different results. However, in the full information case, the Beta MIDAS transformation for the VaR and ES for p = 1% and p = 2.5% yields losses significantly different from the comparison model's (at the 5% level). In these cases, the Beta MIDAS transformation model yields slightly better results.
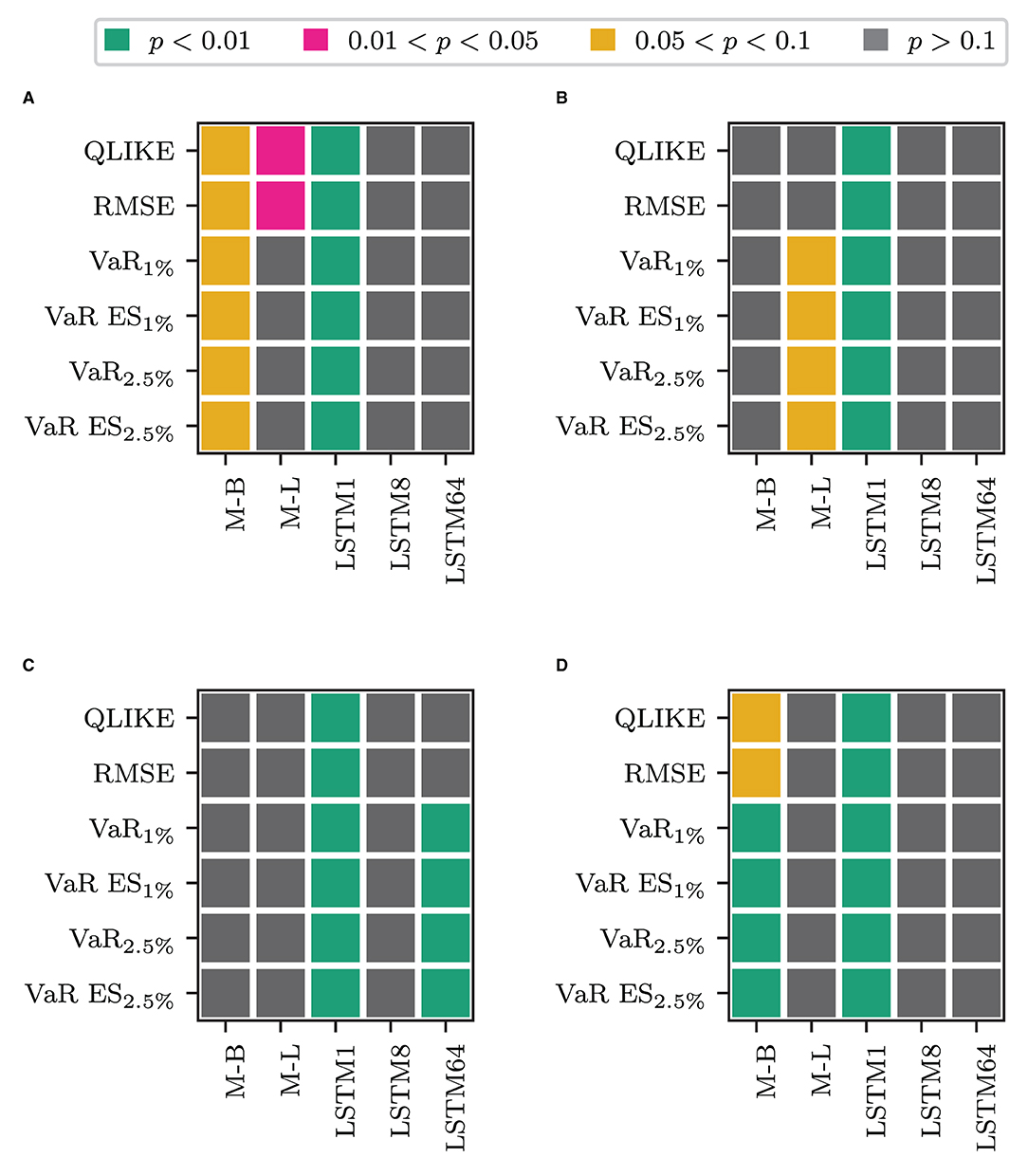
Figure 4. Results for a Binomial test of equal forecasting performance between the models combine the transformed measure and their counterpart that does not use the transformed measure. (A) HAR-F vs. HARO. (B) HAR vs. HARO. (C) LSTM-F vs. LSTMO. (D) LSTM vs. LSTMO.
Next, we consider whether there are differences in the forecasting performances of the models depending on whether we use the HAR inputs or the output of an LSTM cell applied to past log RV. Table 2 reports a rejection of the H0 of the Binomial test for equal forecasting performance concerning the HARO model at the 5% level with an asterisk. From the table, we see that for the LSTMO model, we can not reject the H0 for any of the loss measures. Thus there are no significant differences between the ANN model that only uses the HAR model inputs and the ANN model that uses an LSTM cell on past log RVs. One difference is that the LSTMO model is in the MCS at the 10% level for all losses, whereas the HARO model is not in the 10% MCS for the squared error loss. For the remaining models that use the transformed measure, the test results are displayed in Figure 5.
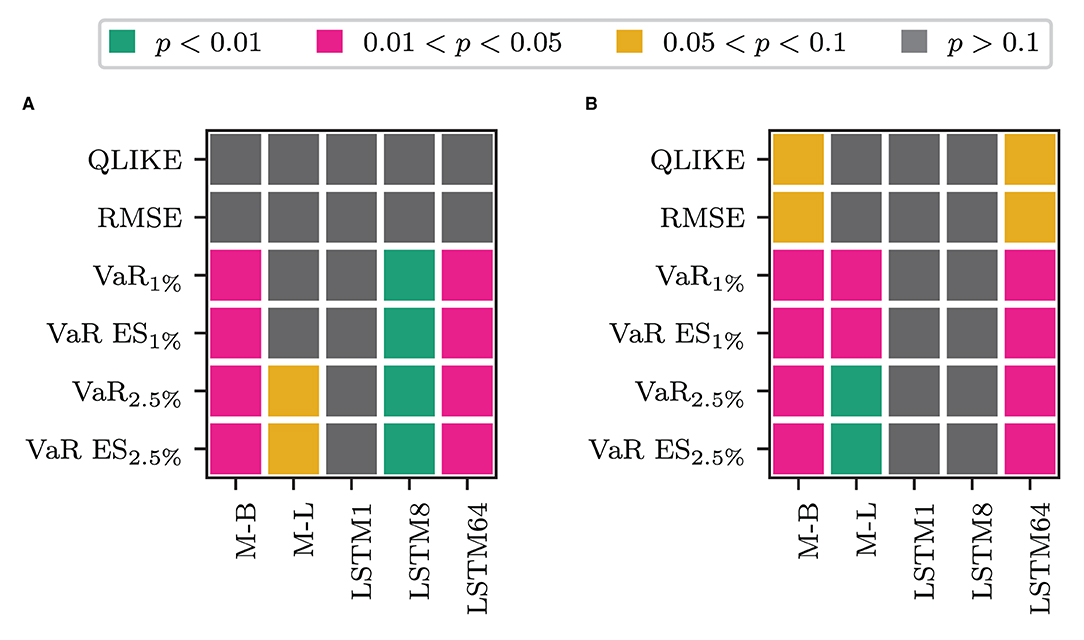
Figure 5. Results for a Binomial test of equal forecasting performance between the models that combine the transformed measure with the HAR inputs and their counterpart that uses the LSTM cell applied to log RV. (A) HAR-F vs LSTM-F. (B) HAR vs LSTM.
According to the figure, we can not reject the H0 at the 5% level for the QLIKE and the squared error loss. For the VaR and ES losses, we reject the H0 at the 5% level for the Beta MIDAS, the LSTM8, and the LSTM64 transformations when using ỹt. In this case, the models that use the HAR inputs perform better than those using the LSTM input. When using , we reject for the Beta and LSTM MIDAS models and the LSTM64 models considering the VaR and ES losses. In all except one case, the models that use the HAR inputs yield the lower out of sample loss. The only exception is the LSTM MIDAS model for the VaR2.5%. In this case, the LSTM inputs are performing marginally better. Overall, it appears that the HAR model inputs can approximate the long memory in the data to an extent comparable to that of an LSTM cell. However, we want to stress that we did not hunt for an optimal LSTM network architecture for this task. The purpose of the LSTM cell in this application is simply to circumvent the implicit lag order selection of the HAR model. A network of LSTM cells applied to the sequence of log RV as in Bucci (2020) might yield more consistent improvements in the forecasting performance than the HAR model inputs. It is interesting to see that the daily, weekly, and monthly averages used in the HAR model are not only comparable to ARFIMA models in the extent they account for long memory (Corsi, 2009), but also to an LSTM cell.
Among the benchmark models, the CHAR model is performing best. It produces the lowest out of sample loss among the benchmark models for the level and the log of RV. Furthermore, it produces lower losses for all except the RMSE loss in levels than in logs. It is the only benchmark model in the 10% MCS for all losses and it produces lower QLIKE and RMSE losses than the HARO model, i.e., the HAR model estimated by SGD. These differences are significant at the 5% level. Also, for the other losses except for the VaR2.5%, it yields lower losses than the HARO. This is in line with Rahimikia and Poon (2020a), who also find that the CHAR is performing best among the HAR family models. Apart from the CHAR model, the remaining benchmark models cannot perform better than any of the ANN models except those that only use the transformed measure.
We come to a short intermediate conclusion:
1. We found that using only the transformed measure to forecast RV results in higher out-of-sample forecast losses than models that combine the transformed measure with information on past log RV. This holds especially true for the QLIKE and the RMSE error loss. The only exception is the loss of jointly evaluating the VaR and ES at p = 1%.
2. We found that when using linear means to construct the transformed measure, it is crucial to consider the sequential information in the transformed measure. However, this might be due to non-linearity induced through the LSTM cell that we apply to the transformed measure. Therefore, it is sufficient only to use the most recent information when constructing the transformed measure non-linearly. In most cases, this yields better forecasting performance.
3. The non-linear transformation through one LSTM cell seems superior to the other transformations throughout the statistical analysis. The models performing best are those that use this transformation. Further, we have the most statistical evidence for differences in the forecasting performance for these models. We will further investigate this in the following.
4. For the QLIKE and the RMSE loss, there are no statistical differences in the performance of the models that use the HAR inputs and the models that use an LSTM cell applied to log RV. The daily, weekly, and monthly averages of log RV appear to be sufficient to account for the long memory in the data. Especially when combined with the LSTM1 transformed measure, this also holds for all other losses.
This short wrap-up leads to two hypotheses. First, the non-linear transformation through one LSTM cell is superior to all other transformations. Second, the models that combine the transformed measure from such a non-linear transformation with the information on past log RV perform better than all other models. These two models are the two best ranked models for each loss measure, except the joint evaluation of VaR1% and ES1%. We cannot reject that these two models perform equally well for any of the losses (see Supplementary Figures 1–6).
Investigating these hypotheses results in non-pairwise comparisons of the models. Further, the hypotheses are uni-directional, i.e., we are interested in whether these models perform better than the competitors. Thus we can not use a Binomial Test for equal forecasting performance but instead use the test for superior predictive ability (SPA test) of Hansen (2005). We use the arch library of Sheppard et al. (2021) to perform the SPA test. When computing the p-values, we use a block bootstrap with the number of bootstrap resamplings set to 1000 and the block length set to 5. The results are not sensitive to the choice of these two values. We also computed the p-values with resamplings set to 3,000, 5,000, 7,000, 9,000 and block lengths of 10, 15, 20, …, 95, 100. The results did not change by much. The SPA test tests whether the expected loss difference between the loss of a candidate and a set of alternative models is smaller or equal to zero. A rejection of the null hypothesis thus means that there is a model among the alternatives performing significantly better than the candidate model.
We start by reporting the p-values of a sequence of SPA tests where we use the LSTM1 transformation models as candidates against the models that use the other transformations. The p-values displayed in Table 3 show that, at the 5% level, we can not reject the H0 of the SPA test in any case. Thus, at the 5% level, the non-linear transformation by one LSTM cell gives forecasting losses smaller or equal to those of all alternative transformations used. This holds for any loss function. At the more conservative 10% level, for the models that use the full information on the transformed measure (upper part of the table) and the joint loss of VaR and ES at 2.5%, we reject the H0. Thus, for this loss, at least one transformation works better. Overall, however, this evidence supports the first hypothesis of the non-linear transformation through one LSTM cell performing best.
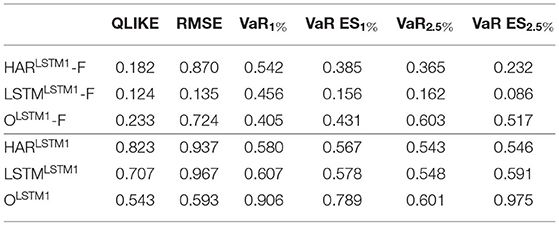
Table 3. p-values of SPA tests for the LSTM1 against the alternative transformations.
To assess the second hypothesis, we use all models excluding the HARLSTM1 and LSTMLSTM1 as the set of alternatives. We then apply the SPA test for each of these two models as candidates. Table 4 displays the p-values of those tests. Again, we see that the null hypothesis that no alternative model performs better than any of the two models under consideration can not be rejected for any loss function. Among the considered models, including the benchmarks for logs and levels, no model performs significantly better than the HARLSTM1 and the LSTMLSTM1.
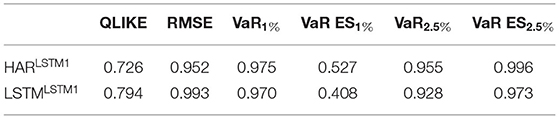
Table 4. p-values of SPA tests for HARLSTM1 and LSTMLSTM1 against the remaining models.
7. Conclusion
This paper aims to forecast the daily volatility utilizing information extracted from the intraday high-frequency (HF) returns through Long Short Term Memory (LSTM) Recurrent Neural Networks (RNN). These structures are flexible in the degree of non-linearity they allow for and capture long persistence in the data. Our method extracts a non-linear, scalar transformation of the HF returns (referred to as transformed HF measure). We use this measure to make one step ahead predictions of the daily volatility. We vary the degree of non-linearity by testing different numbers of LSTM cells in the RNN and find no merits in using more than one LSTM cell for the non-linear transformation. For comparison, we implement two Mixed Data Sampling (MIDAS) approaches to construct the transformation of the HF returns. The MIDAS models obtain weights associated with the HF return and build the transformation as a weighted sum. The first MIDAS model generates weights associated with the lag of an intraday return through an LSTM cell (LSTM MIDAS). The second is an Artificial Neural Network (ANN) implementation of the Beta Lag Polynomial MIDAS (Beta MIDAS) (Ghysels et al., 2004).
To account for dynamics and long memory in the volatility series, we apply an LSTM cell to the sequence of transformed measures. However, we also compare settings where we only use the most recent information from the transformed measure. The reason is that the information from the HF returns might only be “new” for a short time. Further in the past, it is probably incorporated by the RV estimator. We compare the forecasting performance of models solely based on the transformed HF measure to those of models that only use the information from the past Realized Volatility (RV). Namely, the HAR model and a model that applies an LSTM cell to the sequence of past RVs. The HAR model is one of the most popular models to approximate long memory in the volatility series. LSTM RNNs can account for complex non-linear dependencies in the data and capture long-term dependencies. Our comparison assesses whether the proposed transformation can extract the same or more information from the HF returns than the RV estimator. Finally, we combine the information from the transformed measure and the information from the RV for the forecast. We can thus investigate whether our proposed transformations extract information from the HF returns that is supplementary to the RV information when forecasting volatility.
In an expanding window forecasting exercise on data on the IBM stock, we compare the performance of the models in forecasting out-of-sample volatility. We further compute Value at Risk (VaR) and Expected Shortfall (ES) forecasts based on the volatility forecast. We perform a thorough statistical analysis to identify the source of the improved forecasting performance. Our results on the data set under consideration are four-fold:
First, they show that making volatility forecasts based solely on the transformed HF measure is not fruitful. Neither of the transformations can produce a measure that accounts for the long persistence in the volatility. This result is independent of whether we account for dynamics in the transformed measure or only take the most recent value for the forecast. Interestingly, when jointly evaluating the VaR1% and ES1% forecasts based on the volatility forecasts, those models perform better than the alternatives. However, for the 2.5% VaR and ES, their performance is again worse or comparable to the alternatives. When forecasting volatility, the transformations we propose are thus unable to extract the same information from the high-frequency returns as the RV estimator. Since the RV estimator ex-post is a consistent estimator of the volatility of a day, it is crucial to take this information into account for the forecasting task. Maybe more complex non-linear ANN structures could extract the same amount of information from the HF returns. However, in our eyes, it is more fruitful to facilitate the forecasting task for the method by using the RV information.
Second, there is no difference in using the sequence of the transformed measure or only the most recent value for most cases. There are significant differences only for the LSTM MIDAS transformation and the non-linear transformation based on one LSTM cell. The LSTM MIDAS transformation excels when we account for dynamics in the transformed measure. In contrast, the non-linear transformation excels when only using the most recent information. Though puzzling at first, this finding is quite intuitive. The LSTM MIDAS builds the transformed measure as a weighted sum. The transformation is thus linear. However, the linearity is insufficient to extract additional information from the HF returns. Therefore the model that only uses the most recent transformed measure, in this case, performs no different than the model that does not use the information. However, we account for dynamics in the sequence of transformed measures by applying an LSTM cell to it. While this circumvents the trouble of lag order selection, it introduces non-linearity in the transformed measure, which likely results in better models' better performance. When we use an LSTM cell to transform the HF returns non-linearly, there are no additional gains from accounting for dynamics in the measure. Accounting for dynamics leads to worse forecasting performance in some cases. We thus conclude that the transformed measure must be non-linear for the transformation to extract additional information from the HF returns. However, allowing for dynamics in the non-linearly obtained transformed measure does not add any additional gains. This coincides with our previous findings indicating that the additional information in the HF returns gets picked up by the RV estimator further in the past. In the short run, though, this information is helpful for the prediction of volatility.
Third, we add to the literature by finding another prove for the improved forecasting performance of ANN models compared to the linear HAR model benchmark. Our models that do not include the transformed measure, i.e., only use either the HAR model inputs or apply an LSTM cell to the sequence of RV, perform significantly differently from the classical HAR model, both estimated in logs and levels. The simple non-linearity we induce through modeling the exponential of the linear combination of past daily, weekly, and monthly averages of the logarithm of RV already is sufficient to outperform the classical linear HAR for both logs and levels. Our results thus add to the evidence provided by, e.g., Rosa et al. (2014) and Arnerić et al. (2018). We also apply an LSTM cell to the sequence of the logarithm of RV as an alternative to the HAR inputs. The LSTM cell allows for a high degree of non-linearity, and it captures long memory in the data. We find no significant differences between the LSTM and the HAR input models when predicting volatility in most cases. Our findings thus indicate that, for the simple structures we use, the HAR inputs capture the long persistence in the volatility series equally well as the LSTM cell on the data set under consideration. To some extent, this contradicts the findings of Bucci (2020) who finds that gated recurrent ANNs such as LSTM RNNs outperform ANNs that do not account for long memory in the data. However, the author forecasts the logarithm of the square root of monthly RV and not, as in this case, the level of daily RV. When constructing VaR and ES forecasts based on the volatility forecasts, we find significant differences in the performance of the HAR and the LSTM input models, where for these quantities, the HAR input models show better performance.
Fourth, the statistical analysis of the forecasting results pointed toward two hypotheses. First, the non-linear transformation through one LSTM cell is superior to all alternative transformations that we suggest, especially when only accounting for the most recent information in the transformed measure. Through a sequence of tests for superior predictive ability (SPA tests), we find that the non-linear transformation through one LSTM cell outperforms the alternatives. When only considering the most recent HF information, this result holds under conservative choices for the significance level. However, this result only holds for less conservative choices for the significance level (5%) for the setting where we account for dynamics in the transformed measure. So the non-linear transformation through one LSTM cell outperforms the MIDAS alternatives and the alternatives that allow for higher degrees of non-linearity by using a network of LSTM cells. This is very convenient since it circumvents the challenging task of finding the optimal network architecture for the transformation. Second, combining this transformed measure with the information on the past RV yields superior forecasting performance to all other models under consideration. Another sequence of SPA tests shows that the models that augment the information from the log RV with the most recent transformation from one LSTM cell significantly outperform all alternative models, including the benchmarks. When augmented by the most recent transformation from one LSTM cell, there are no significant differences between the model that uses an LSTM on past log RV and the model that uses the HAR. So also in this case, the HAR models' lagged daily, weekly, and monthly averages are approximating the long persistence in the volatility equally well as the LSTM cell.
Our analysis thus directs to a new type of HAR model that augments the classical HAR by a non-linear transformation of the HF returns within a day. These results are in line with the findings of Rahimikia and Poon (2020a), who also find that their proposed HAR model augmented by HF limited order book and news sentiment data shows superior forecasting performance. However, the information we utilize for the augmentation does not stem from an auxiliary source such as news feeds but from the same information used to construct the RV estimator. Our resulting models can outperform some of the most popular benchmark models in the literature, such as ARFIMA models, the HAR, the CHAR, and the HARQ model. A natural extension of the presented work would be to use Bi-Power Variation and Realized Quarticity measures as additional inputs for the forecasting task. One could then assess, whether in this case, there are also gains in the forecasting performance through augmenting this model with the non-linear transformation of the HF returns through one LSTM cell.
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
Author Contributions
CM contributed to the conceptualization of the idea, implemented the code, and wrote the manuscript.
Conflict of Interest
The author declares that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Acknowledgments
We want to thank Gerhard Fechteler, Eric Ghysels, Lyudmila Grigoryeva, Roxana Halbleib, Ekaterina Kazak, Ingmar Nolte, Winfried Pohlmeier, the members of the Chair of Econometrics at the Department of Economics at the University of Konstanz, Germany, and two anonymous referees, for helpful comments. All remaining errors are ours. We acknowledge support by the state of Baden-Württemberg through bwHPC. The author acknowledges financial support from the German federal state of Baden-Württemberg through a Landesgraduiertenstipendium.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/frai.2021.787534/full#supplementary-material
Footnotes
1. ^The hyperbolic tangent function applied to value x is tanh(x) = [exp (x) − exp (−x)]/[exp (x) + exp (−x)]. It is a sigmoid function rescaled to the interval (−1, 1).
2. ^The sigmoid function applied to value x is defined as σ(x) = 1/[1 − exp (−x)].
3. ^There exists no strictly consistent loss function for the ES alone (Gneiting, 2011).
4. ^The Binomial test tests whether positive and negative sign changes in the loss differential of two models are equally likely. It is also known as the Diebold Mariano Sign test.
References
Abadi, M., Agarwal, A., Barham, P., Brevdo, E., Chen, Z., Citro, C., et al. (2015). TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. Available online at: tensorflow.org.
Andersen, T. G., Bollerslev, T., and Diebold, F. X. (2007). Roughing it up: including jump components in the measurement, modeling, and forecasting of return volatility. Rev. Econ. Stat. 89, 701–720. doi: 10.1162/rest.89.4.701
Andersen, T. G., Bollerslev, T., Diebold, F. X., and Ebens, H. (2001a). The distribution of realized stock return volatility. J. Finan. Econ. 61, 43–76. doi: 10.1016/S0304-405X(01)00055-1
Andersen, T. G., Bollerslev, T., Diebold, F. X., and Labys, P. (2001b). The distribution of realized exchange rate volatility. J. Am. Stat. Assoc. 96, 42–55. doi: 10.1198/016214501750332965
Andersen, T. G., Bollerslev, T., Diebold, F. X., and Labys, P. (2003). Modeling and forecasting realized volatility. Econometrica 71, 579–625. doi: 10.1111/1468-0262.00418
Andersen, T. G., Bollerslev, T., and Meddahi, N. (2004). Analytical evaluation of volatility forecasts. Int. Econ. Rev. 45, 1079–1110. doi: 10.1111/j.0020-6598.2004.00298.x
Arnerić, J., Poklepović, T., and Aljinović, Z. (2014). Garch based artificial neural networks in forecasting conditional variance of stock returns. Croat. Oper. Res. Rev. 329–343. doi: 10.17535/crorr.2014.0017
Arnerić, J., Poklepović, T., and Teai, J. W. (2018). Neural network approach in forecasting realized variance using high-frequency data. Bus. Syst. Res. 9, 18–34. doi: 10.2478/bsrj-2018-0016
Audrino, F., and Knaus, S. D. (2016). Lassoing the HAR model: a model selection perspective on realized volatility dynamics. Econ. Rev. 35, 1485–1521. doi: 10.1080/07474938.2015.1092801
Barndorff-Nielsen, O. E., Kinnebrock, S., and Shephard, N. (2010). “Measuring downside risk - realized semivariance,” in Volatility and Time Series Econometrics: Essays in Honor of Robert F. Engle, eds T. Bollerslev, J. Russel, and M. Watson (London, UK: Oxford University Press), 117–136. doi: 10.1093/acprof:oso/9780199549498.003.0007
Barndorff-Nielsen, O. E., and Shephard, N. (2002a). Econometric analysis of realized volatility and its use in estimating stochastic volatility models. J. R. Stat. Soc. Ser. B 64, 253–280. doi: 10.1111/1467-9868.00336
Barndorff-Nielsen, O. E., and Shephard, N. (2002b). Estimating quadratic variation using realized variance. J. Appl. Econ. 17, 457–477. doi: 10.1002/jae.691
Barndorff-Nielsen, O. E., and Shephard, N. (2004). Power and bipower variation with stochastic volatility and jumps. J. Financ. Econ. 2, 1–37. doi: 10.1093/jjfinec/nbh001
Baruník, J., and Křehlík, T. (2016). Combining high frequency data with non-linear models for forecasting energy market volatility. Expert Syst. Appl. 55, 222–242. doi: 10.1016/j.eswa.2016.02.008
Baştürk, N., Schotman, P. C., and Schyns, H. (2021). A Neural Network With Shared Dynamics for Multi-Step Prediction of Value-At-Risk and Volatility. doi: 10.2139/ssrn.3871096
Bengio, Y., Simard, P., and Frasconi, P. (1994). Learning long-term dependencies with gradient descent is difficult. IEEE Trans. Neural Netw. 5, 157–166. doi: 10.1109/72.279181
Bollerslev, T. (1986). Generalized autoregressive conditional heteroscedasticity. J. Econ. 31, 307–327. doi: 10.1016/0304-4076(86)90063-1
Bollerslev, T., Patton, A. J., and Quaedvlieg, R. (2016). Exploiting the errors: a simple approach for improved volatility forecasting. J. Econ. 192, 1–18. doi: 10.1016/j.jeconom.2015.10.007
Brownlees, C. T., and Gallo, G. M. (2010). Comparison of volatility measures: a risk management perspective. J. Financ. Econ. 8, 29–56. doi: 10.1093/jjfinec/nbp009
Bucci, A. (2020). Realized volatility forecasting with neural networks. J. Financ. Econ. 18, 502–531. doi: 10.1093/jjfinec/nbaa008
Chollet, F. (2015). Keras. Available online at: https://keras.io/
Christensen, K., Siggaard, M., and Veliyev, B. (2021). A Machine Learning Approach to Volatility Forecasting. CREATES Research Paper 2021-03, 3.
Corsi, F. (2009). A simple approximate long-memory model of realized volatility. J. Financ. Econ. 7, 174–196. doi: 10.1093/jjfinec/nbp001
Cybenko, G. (1989). Approximation by superpositions of a sigmoidal function. Math. Control Signals Syst. 2, 303–314. doi: 10.1007/BF02551274
Donaldson, R., and Kamstra, M. (1997). An artificial neural network-garch model for international stock return volatility. J. Empir. Finance 4, 17–46. doi: 10.1016/S0927-5398(96)00011-4
Engle, R. (1982). Autoregressive conditional heteroskedasticity with estimates of the variance of United Kingdom inflation. Econometrica 50, 987–1007. doi: 10.2307/1912773
Fissler, T., and Ziegel, J. F. (2016). Higher order elicitability and osband's principle. Ann. Stat. 44, 1680–1707. doi: 10.1214/16-AOS1439
Franke, J., and Diagne, M. (2006). Estimating market risk with neural networks. Stat. Decis. 24, 233–253. doi: 10.1524/stnd.2006.24.2.233
Franke, J., Hardle, W. K., and Hafner, C. M. (2019). “Neural networks and deep learning,” in Statistics of Financial Markets: An Introduction (Cham: Springer), 459–495. doi: 10.1007/978-3-030-13751-9_19
Ghysels, E., Santa-Clara, P., and Valkanov, R. (2004). The Midas Touch: Mixed Data Sampling Regression Models.
Giordano, F., La Rocca, M., and Perna, C. (2012). “Nonparametric estimation of volatility functions: Some experimental evidences,” in Mathematical and Statistical Methods for Actuarial Sciences and Finance, eds C. Perna and M. Sibillo (Milano: Springer Milan), 229–236. doi: 10.1007/978-88-470-2342-0_27
Gneiting, T. (2011). Making and evaluating point forecasts. J. Am. Stat. Assoc. 106, 746–762. doi: 10.1198/jasa.2011.r10138
Granger, C. W., and Newbold, P. (1976). Forecasting transformed series. J. R. Stat. Soc. Ser. B 38, 189–203. doi: 10.1111/j.2517-6161.1976.tb01585.x
Gu, S., Kelly, B., and Xiu, D. (2020). Empirical asset pricing via machine learning. Rev. Financ. Stud. 33, 2223–2273. doi: 10.1093/rfs/hhaa009
Hajizadeh, E., Seifi, A., Zarandi, M. F., and Turksen, I. (2012). A hybrid modeling approach for forecasting the volatility of s&p 500 index return. Expert Syst. Appl. 39, 431–436. doi: 10.1016/j.eswa.2011.07.033
Hansen, P. R. (2005). A test for superior predictive ability. J. Bus. Econ. Stat. 23, 365–380. doi: 10.1198/073500105000000063
Hansen, P. R., Lunde, A., and Nason, J. M. (2011). The model confidence set. Econometrica 79, 453–497. doi: 10.3982/ECTA5771
Hochreiter, S. (1991). Untersuchungen zu Dynamischen Neuronalen Netzen. Diploma, Technische Universität München, 91(1).
Hochreiter, S., and Schmidhuber, J. (1997). Long short-term memory. Neural Comput. 9, 1735–1780. doi: 10.1162/neco.1997.9.8.1735
Hornik, K., Stinchcombe, M., and White, H. (1989). Multilayer feedforward networks are universal approximators. Neural Netw. 2, 551–560. doi: 10.1016/0893-6080(89)90020-8
Hyndman, R. J., and Khandakar, Y. (2008). Automatic time series forecasting: the forecast package for R. J. Stat. Softw. 26, 1–22. doi: 10.18637/jss.v027.i03
Jordan, M. I. (1997). “Chapter 25: Serial order: A parallel distributed processing approach,” in Neural-Network Models of Cognition, Vol. 121 of Advances in Psychology, eds J. W. Donahoe and V. P. Dorsel (North-Holland), 471–495. doi: 10.1016/S0166-4115(97)80111-2
Kingma, D. P., and Ba, J. (2014). Adam: a method for stochastic optimization. arXiv preprint arXiv:1412.6980.
Kristjanpoller, W., Fadic, A., and Minutolo, M. C. (2014). Volatility forecast using hybrid neural network models. Expert Syst. Appl. 41, 2437–2442. doi: 10.1016/j.eswa.2013.09.043
Li, S. Z., and Tang, Y. (2021). Forecasting Realized Volatility: An Automatic System Using Many Features and Many Machine Learning Algorithms. Available Online at: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3776915
Maechler, M. (2020). fracdiff: Fractionally Differenced ARIMA aka ARFIMA(P,d,q) Models. R Package Version 1.5-1.
Miuro, R., Pichl, L., and Kaizoji, T. (2019). “Artificial neural networks for realized volatility prediction in cryptocurrency time series,” in Advances in Neural Networks ISNN 2019, eds H. Lu, H. Tang, and Z. Wang (Cham: Springer), 165–172. doi: 10.1007/978-3-030-22796-8_18
Patton, A. J. (2011). Volatility forecast comparison using imperfect volatility proxies. J. Econ. 160, 246–256. doi: 10.1016/j.jeconom.2010.03.034
Patton, A. J., and Sheppard, K. (2015). Good volatility, bad volatility: signed jumps and the persistence of volatility. Rev. Econ. Stat. 97, 683–697. doi: 10.1162/REST_a_00503
Rahimikia, E., and Poon, S.-H. (2020a). Big data approach to realised volatility forecasting using HAR model augmented with limit order book and news. Available Online at: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3684040
Rahimikia, E., and Poon, S.-H. (2020b). Machine learning for realised volatility forecasting. Available Online at: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3707796
Rosa, R., Maciel, L., Gomide, F., and Ballini, R. (2014). “Evolving hybrid neural fuzzy network for realized volatility forecasting with jumps,” in 2014 IEEE Conference on Computational Intelligence for Financial Engineering & Economics (CIFEr) (London, UK), 481–488. doi: 10.1109/CIFEr.2014.6924112
Ruiz, E. (1994). Quasi-maximum likelihood estimation of stochastic volatility modles. J. Econ. 63, 289–306. doi: 10.1016/0304-4076(93)01569-8
Rumelhart, D. E., Hinton, G. E., and Williams, R. J. (1986). Learning representations by back-propagating errors. Nature 323, 533–536. doi: 10.1038/323533a0
Sadhwani, A., Giesecke, K., and Sirignano, J. (2021). Deep learning for mortgage risk. J. Financ. Econ. 19, 313–368. doi: 10.1093/jjfinec/nbaa025
Schafer, A. M., and Zimmermann, H. G. (2006). “Recurrent neural networks are universal approximators,” in Artificial Neural Networks – ICANN 2006, eds D. S. Kollias, A. Stafylopatis, W. Duch, and E. Oja (Berlin: Springer), 632–640.
Sheppard, K., Khrapov, S., Lipták, G., Capellini, R., Fortin, A., Judell, M., et al. (2021). Bashtage/Arch: Release 5.1.0.
Sizova, N. (2011). Integrated variance forecasting: model based vs. reduced form. J. Econ. 162, 294–311. doi: 10.1016/j.jeconom.2011.02.004
Soudry, D., Hoffer, E., Nacson, M. S., Gunasekar, S., and Srebro, N. (2018). The implicit bias of gradient descent on separable data. J. Mach. Learn. Res. 19, 2822–2878. Available Online at: http://jmlr.org/papers/v19/18-188.html
Vortelinos, D. I. (2017). Forecasting realized volatility: HAR against principal components combining, neural networks and garch. Res. Int. Bus. Finance. 39, 824–839. doi: 10.1016/j.ribaf.2015.01.004
Keywords: neural networks, forecasting, high-frequency data, realized volatility, mixed data sampling, long short term memory
Citation: Mücher C (2022) Artificial Neural Network Based Non-linear Transformation of High-Frequency Returns for Volatility Forecasting. Front. Artif. Intell. 4:787534. doi: 10.3389/frai.2021.787534
Received: 30 September 2021; Accepted: 27 December 2021;
Published: 11 February 2022.
Edited by:
Massimiliano Caporin, University of Padua, ItalyReviewed by:
Jan-Alexander Posth, Zurich University of Applied Sciences, SwitzerlandArindam Chaudhuri, Samsung R & D Institute, India
Copyright © 2022 Mücher. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Christian Mücher, Y2hyaXN0aWFuLm11ZWNoZXJAdndsLnVuaS1mcmVpYnVyZy5kZQ==