 Gauri Jagatap
Gauri Jagatap Ameya Joshi
Ameya Joshi Animesh Basak Chowdhury
Animesh Basak Chowdhury Siddharth Garg
Siddharth Garg Chinmay Hegde
Chinmay Hegde- Electrical and Computer Engineering, New York University, New York, NY, United States
In this paper we propose a new family of algorithms, ATENT, for training adversarially robust deep neural networks. We formulate a new loss function that is equipped with an additional entropic regularization. Our loss function considers the contribution of adversarial samples that are drawn from a specially designed distribution in the data space that assigns high probability to points with high loss and in the immediate neighborhood of training samples. Our proposed algorithms optimize this loss to seek adversarially robust valleys of the loss landscape. Our approach achieves competitive (or better) performance in terms of robust classification accuracy as compared to several state-of-the-art robust learning approaches on benchmark datasets such as MNIST and CIFAR-10.
1 Introduction
Deep neural networks have led to significant breakthroughs in the fields of computer vision (Krizhevsky et al., 2012), natural language processing (Zhang et al., 2020), speech processing (Carlini et al., 2016), recommendation systems (Tang et al., 2019) and forensic imaging (Rota et al. (2016)). However, deep networks have also been shown to be very susceptible to carefully designed “attacks” (Goodfellow et al., 2014; Papernot et al., 2016; Biggio and Roli, 2018). In particular, the outputs of networks trained via traditional approaches are rather brittle to maliciously crafted perturbations in both input data as well as network weights (Biggio et al., 2013).
Formally put, suppose the forward map between the inputs x and outputs y is modeled via a neural network as y = f(w; x) where w represents the set of trainable weight parameters. For a classification task, given a labeled dataset {xi, yi}, i = 1, … , n where X and Y represents all training data pairs, the standard procedure for training neural networks is to seek the weight parameters w that minimize the empirical risk:
However, the prediction
Several techniques for finding such adversarial perturbations have been put forth. Typically, this can be achieved by maximizing the loss function within a neighborhood around the test point x (Tramèr et al., 2017; Madry et al., 2018):
where
The existence of adversarial attacks motivates the need for a “defense” mechanism that makes the network under consideration more robust. Despite a wealth of proposed defense techniques, the jury is still out on how optimal defenses should be constructed (Athalye et al., 2018).
We discuss several families of effective defenses. The first involves adversarial training (Madry et al., 2018). Here, a set of adversarial perturbations of the training data is constructed by solving a min-max objective of the form:
Wong and Kolter (2018) use a convex outer adversarial polytope as an upper bound for worst-case loss in robust training; here the network is trained by generating adversarial as well as few non-adversarial examples in the convex polytope of the attack via a linear program. Along the same vein include a mixed-integer programming based certified training for piece-wise linear neural networks (Tjeng et al., 2018) and integer bound propagation (Gowal et al., 2019).
The last family of approaches involves randomized smoothing. Here, both training the network as well as the inference made by the network are smoothed out over several stochastic perturbations of the target example (Lecuyer et al., 2019; Cohen et al., 2019; Salman et al., 2019a). This has the effect of optimizing a smoothed-adversarial version of the empirical risk. Randomized smoothing has also been used in combination with adversarial training (Salman et al., 2019b) for improved adversarial robustness under ℓ2 attacks1.
In this paper, we propose a new approach for training adversarially robust neural networks. The key conceptual ingredient underlying our approach is entropic regularization. Borrowing intuition from Chaudhari et al. (2019), instead of the empirical risk (or its adversarial counterpart), our algorithm instead optimizes over a local entropy-regularized version of the empirical risk:
Intuitively, this new loss function can be viewed as the convolution of the empirical risk with a Gibbs-like distribution to sample points from the neighborhoods, X′, of the training data points X that have high loss. Therefore, compared to adversarial training, we have replaced the inner maximization with an expected value with respect to a modified Gibbs measure which is matched to the geometry of the perturbation set.
Since the above loss function is difficult to optimize (or even evaluate exactly), we instead approximate it via Monte Carlo techniques. In particular, we use Stochastic Gradient Langevin Dynamics (Welling and Teh, 2011); in this manner, our approach blends in elements from adversarial training, randomized smoothing, and entropic regularization. We posit that the combination of these techniques will encourage a classifier to learn a better robust decision boundary as compared to prior art (see visualization in Figure 1).
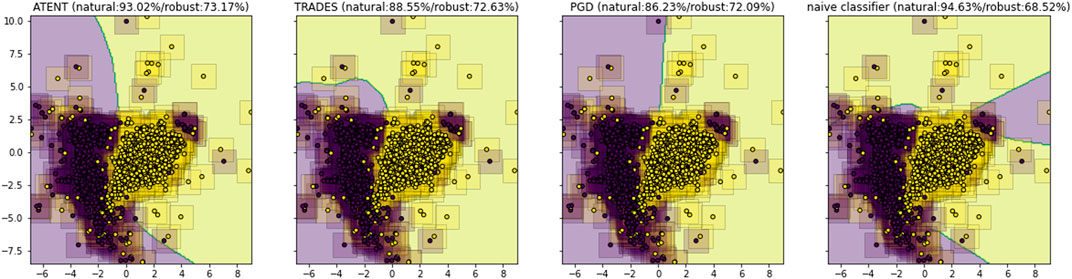
FIGURE 1. TSNE visualization of decision boundaries for a 3-layer neural network trained using different defenses; corresponding natural and robust test accuracies against ℓ∞ attacks for classifying MNIST digits 5 and 8.
To summarize, our specific contributions are as follows:
1. We propose a new entropy-regularized loss function for training deep neural networks (Eq. 2) that is a robust version of the empirical risk.
2. We propose a new Monte Carlo algorithm to optimize this new loss function that is based on Stochastic Gradient Langevin Dynamics. We call this approach Adversarial Training with ENTropy (ATENT).
3. We show that ATENT-trained networks provide improved (robust) test accuracy when compared to existing defense approaches.
4. We combine randomized smoothing with ATENT to show competitive performance with the smoothed version of TRADES.
In particular, we are able to train an ℓ∞-robust CIFAR-10 model to 57.23% accuracy at PGD attack level ϵ = 8/255, which is higher than the latest benchmark defenses based on both adversarial training using early stopping (Salman et al., 2019b) (56.8%) as well as TRADES (56.6%) (Zhang et al., 2019b).
2 Prior Work
Evidence for the existence of adversarial inputs for deep neural networks is by now well established (Carlini N. and Wagner D. A., 2017; Dathathri et al., 2017; Goodfellow et al., 2015; Goodfellow, 2018; Szegedy et al., 2013; Moosavi-Dezfooli et al., 2017). In image classification, the majority of attacks have focused on the setting where the adversary confounds the classifier by adding an imperceptible perturbation to a given input image. The range of the perturbation is pre-specified in terms of bounded pixel-space ℓp-norm balls. Specifically, an ℓp- attack model allows the adversary to search over the set of input perturbations Δp,ϵ = {δ: ‖δ‖p ≤ ϵ} for p = {0, 1, 2, ∞}.
Initial attack methods, including the Fast Gradient Sign Method (FGSM) and its variants (Goodfellow et al., 2014; Kurakin et al., 2016), proposed techniques for generating adversarial examples by ascending along the sign of the loss gradient:
where (xadv − x) ∈ Δ∞,ϵ. Madry et al. (2018) proposed a stronger adversarial attack via projected gradient descent (PGD) by iterating FGSM several times, such that
where p = {2, ∞}. These attacks are (arguably) the most successful available attack techniques reported to date, and serve as the starting point for our comparisons. Both Deep Fool Moosavi-Dezfooli et al., 2016) and Carlini-Wagner (Carlini N. and Wagner D., 2017) construct an attack by finding smallest possible perturbation that can flip the label of the network output.
Several strategies for defending against attacks have been developed. In Madry et al. (2018), adversarial training is performed via the min-max formulation Eq. 1. The inner maximization is solved using PGD, while the outer objective is minimized using stochastic gradient descent (SGD) with respect to w. This can be slow to implement, and speed-ups have been proposed in Shafahi et al. (2019) and Wong et al. (2020). In Li B. et al. (2018); Cohen et al. (2019); Lecuyer et al. (2019); Salman et al. (2019a, Salman et al. (2019b), the authors developed certified defense strategies via randomized smoothing. This approach consists of two stages: the first stage consists of training with noisy samples, and the second stage produces an ensemble-based inference. See Ren et al. (2020) for a more thorough review of the literature on various attack and defense models.
Apart from minimizing the worst case loss, approaches which minimize the upper bound on worst case loss inclu Wong et al., 2018; Tjeng et al. (2018); Gowal et al. (2019). Another breed of approaches use a modified loss function which considers surrogate adversarial loss as an added regularization, where the surrogate is cross entropy (Zhang et al., 2019b) (TRADES), maximum margin cross entropy (Ding et al., 2019) (MMA) and KL divergence (Wang et al., 2019) (MART) between adversarial sample predictions and natural sample predictions.
In a different line of work, there have been efforts towards building neural network networks with improved generalization properties. In particular, heuristic experiments by Hochreiter and Schmidhuber (1997); Keskar et al. (2016); Li H. et al. (2018) suggest that the loss surface at the final learned weights for well-generalizing models is relatively “flat”2. Building on this intuition, Chaudhari et al. (2019) showed that by explicitly introducing a smoothing term (via entropic regularization) to the training objective, the learning procedure weights towards regions with flatter minima by design. Their approach, Entropy-SGD (or ESGD), is shown to induce better generalization properties in deep networks. We leverage this intuition, but develop a new algorithm for training deep networks with better adversarial robustness properties. We also highlight some papers written concurrently in Supplementary Material.
3 Problem Formulation
The task of classification, given a training labelled dataset
We first recap the Entropy SGD (Chaudhari et al., 2019) (see also Supplementary Material). Entropy-SGD considers an augmented loss function of the form
By design, minimization of this augmented loss function promotes minima with wide valleys. Such a minimum would be robust to perturbations in w, but is not necessarily advantageous against adversarial data samples xadv. In our experiments (Section 4) we show that networks trained with Entropy-SGD perform only marginally better against adversarial attacks as compared to those trained with standard SGD.
For the task of adversarial robustness, we instead develop a data-space version of Entropy-SGD. To model for perturbations in the samples, we design an augmented loss that regularizes the data space. Note that we only seek specific perturbations of data x that increase the overall loss value of prediction. In order to formally motivate our approach, we first make some assumptions.
Assumption 1 The distribution of possible adversarial data inputs of the neural network obeys a positive exponential distribution of the form below, where the domain of
and Zw,β is the partition function that normalizes the probability distribution.Note here that cross entropy loss
where
Assumption 2 A modified distribution, (without loss of generality, setting β = 1) with an additional smoothing parameter, assumes the form:
where ZX,w,γ is the partition function that normalizes the probability distribution.Here γ controls the penalty of the distance of the adversary from true data X; if γ → ∞, the sampling is sharp, i.e. p(X′ = X; X, Y, w, γ) = 1 and p(X′ ≠ X; X, Y, w, γ) = 0, which is the same as sampling only the standard loss
which can be seen as a sharp sampling of the loss function at training points X. Now, define the Data-Entropy Loss:
our new objective is to minimize this augmented objective function
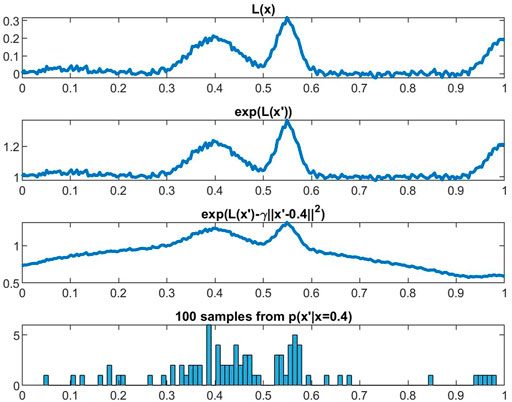
FIGURE 2. Illustration of the sampling procedure in Assumption 2 at fixed weights w. The distribution produces samples x′ from distribution p(x′|x = 0.4), and we compute the average loss over these samples. Effectively, this encourages ATENT to search for w where L(x; w) is relatively flat in the neighborhood of x.
Lemma 3.1 The effective loss
1. β + γ smooth if
2.
If gradient descent is used to minimize the loss in Eq. 4, the gradient update corresponding to the augmented loss function can be computed as follows
Correspondingly, the weights of the network, when trained using gradient descent, using Eq. 5, can be updated as
where η is the step size. The expectation in Eq. 5 is carried out over the probability distribution of data samples X′ as defined in Assumption 2. This can be seen as the adversarial version of the formulation developed in Entropy SGD (Chaudhari et al. (2019)), where the authors use a Gibbs distribution to model an augmented loss function that explores the loss surface at points that are perturbed from the current weights w, denoted by w′ (see Supplementary Material). In contrast, in our approach, we consider loss contributions from perturbations X′ of data points X. This analogue is driven by the fact that the core objective in Chaudhari et al. (2019) is to design a network which is robust to perturbations in weights (generalization), where as the core objective of this paper is to design a network that is robust to perturbations in the inputs (adversarial robustness).The expectation in Eq. 5 is computationally intractable to optimize (or evaluate). However, using the Euler discretization of the Langevin Stochastic Differential Equation (Welling and Teh, 2011), it can be approximated well. Samples can be generated from p(X′) as:
where η′ is the step size for Langevin sampling, ɛ is a scaling factor that controls additive noise. In Langevin dynamics, when one considers a starting point of X′0 then the procedure above yields samples X′1 … X′t that follow the distribution p(X′). Intuitively, the stochastic process X′t is more likely to visit points in the immediate neighborhoods of the entire training dataset X corresponding to high loss values.Observe that X′ and X have the same dimensions and the gradient term in the above equation needs to be computed over n, d-dimensional data points. In practice this can be computationally expensive. Therefore, we discuss a stochastic variant of this update rule, which considers mini-batches of training data instead. Plugging in the distribution in Eq.3, and using the Euler discretization for Langevin Stochastic Differential Equations, the update rule for sampling X′ is
where we have incorporated ZX,wγ in the step size η′. Note that as the number of updates k → ∞, the estimates from the procedure in Eq. 8 converge to samples from the true distribution. p(X′; X, Y, w, γ). We then want to estimate
Algorithm 1 ℓ2-ATENT

Comparison to PGD Adversarial Training: (see also Algorithm 2 Madry et al., 2018 in Supplementary Material, referred as PGD-AT). It is easy to see that the updates of PGD-AT are similar to that of Algorithm 1, consisting broadly of two types of gradient operations in an alternating fashion—1) an (inner) gradient with respect to samples X (or batch-wise samples
constraint being satisfied if ‖X′ − X‖F is minimized, or − ‖X′ − X‖F is maximized).The width of the Gaussian smoothing is adjusted with γ, which is analogous to controlling the projection radius ϵ in the inner-maximization of PGD-AT. Then the second and third terms in Eq. 8 are simply gradient of an ℓ2-regularization term over data space X′ and noise. In this way, ATENT can be re-interpreted as a stochastic formalization of ℓ2-PGD-AT, with noisy controlled updates.Comparison to randomized smoothing: Cohen et al. (2019), describe a defense to adversarial perturbations, in the form of smoothing. A smoothed classifier g, under isotropic Gaussian noise
where
Algorithm 2 ℓ∞-ATENT

Extension to defense against ℓ∞-attacks: It is evident that due to the isotropic structure of the Gibbs measure around each data point, Algorithm 1, ℓ2-ATENT is best suited for ℓ2 attacks. However this may not necessarily translate to robustness against ℓ∞ attacks. For this case, one can use an alternate assumption on the distribution of potential adversarial examples. flushleft
Assumption 3 We consider a modification of the distribution in Assumption 2 to account for robustness against ℓ∞ type attacks:
where ‖⋅‖∞ is the ℓ∞ norm on the vectorization of its argument and ZX,w,γ normalizes the probability.The corresponding Data Entropy Loss for ℓ∞ defenses is: flushleft
This resembles a smoothed version of the loss function with a exponential ℓ∞ kernel along the data dimension to model points in the ℓ∞ neighborhood of X which have high loss. The SGD update to minimize this loss becomes:
where the expectation over p(X′) is computed by using samples generated via Langevin Dynamics:
Plugging in the distribution in Assumption 3 the update rule for sampling X′:
where
where γ is inversely proportional to ϵ (constraint is satisfied if ‖X′ − X‖∞ is minimized, or − ‖X′ − X‖∞ is maximized). This expression can be maximized only if X′ ∈ Δ∞,ϵ of X; however when we take gradients along only one coordinate, this may not be sufficient to drive all coordinates of X′ towards Δ∞,ϵ of X.Similar to the ℓ∞ Carlini Wagner attack (Carlini N. and Wagner D., 2017), we replace the gradient update of the ℓ∞ term, with a clipping based projection oracle. We design an accelerated version of the update rule in Eq. 11, in which we perform a clipping operation, i.e., an ℓ∞ ball projection of the form:
where element-wise projection Pγ(z) = z if |z| < 1/γ and Pγ(z) = 1/γ if |z| > 1/γ. Empirically, we also explored an alternate implementation where the projection takes place in each inner iteration k, however, we find the version in Algorithm 2 to give better results.In both Algorithms 1 and 2, we initialize the Langevin update step with a random normal perturbation δi of benign samples, which is constructed to lie inside within approximately 1/γ radius of the natural samples.
4 Experiments
In this section we perform experiments on a five-layer convolutional model with 3 CNN and 2 fully connected layers, used in Zhang et al. (2019b); Carlini N. and Wagner D. (2017), trained on MNIST. We also train a WideResNet-34-10 on CIFAR10 [as used in Zhang et al. (2019b)] as well as ResNet20. Due to space constraints, we present supplemental results in Supplementary Material. We conduct our experiments separately on networks specifically trained for ℓ2 attacks and those trained for ℓ∞ attacks. We also test randomized smoothing for our ℓ2-ATENT model. Source code is provided in the supplementary material.
Attacks: For ℓ2 attacks, we test PGD-40 with 10 random restarts, and CW2 attacks at radius ϵ2 = 2 for MNIST and PGD-40 and CW2 attacks at ϵ2 = 0.43 (
Defenses: We compare models trained using: SGD (vanilla), Entropy SGD (Chaudhari et al., 2019), PGD-AT (Madry et al., 2018) with random starts [or PGD-AT(E) with random start, early stopping (Rice et al., 2020)], TRADES (Zhang et al., 2019b), MMA (Ding et al., 2019) and MART (Wang et al., 2019). Wherever available, we use pretrained models to tabulate robust accuracy results for PGD-AT, TRADES, MMA and MART as presented in their published versions. Classifiers giving the best and second best accuracies are highlighted in each category. We note here that a good defense mechanism should give better robust accuracies across different attack strategies. Since no single defense strategy outperforms every other defenses across all attacks, we highlight the best two robust accuracies. We find that ATENT obtains either the best or second best robust accuracy against all methods tested. This suggests that ATENT generalizes better than other defense strategies against various attacks.
Smoothing: We also test randomized smoothing (Cohen et al., 2019) in addition to our adversarial training to evaluate certified robust accuracies.
The results were generated using an Intel(R) Xeon(R) W-2195 CPU 2.30 GHz Lambda cluster with 18 cores and a NVIDIA TITAN GPU running PyTorch version 1.4.0.
4.1 MNIST
In Tables 1 and 2, we tabulate the robust accuracy for 5-layer convolutional network trained using the various approaches discussed above for both ℓ2 and ℓ∞ attacks respectively.
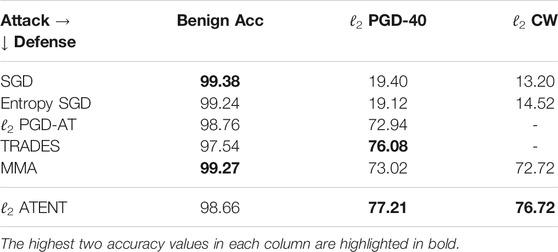
TABLE 1. Robust percentage accuracies of 5-layer convolutional net for MNIST against ℓ2, ϵ = 2 attack.
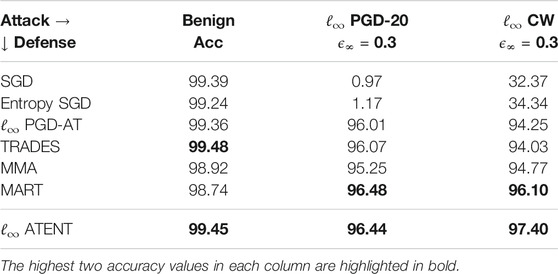
TABLE 2. Robust accuracies (in percentages) of 5-layer convolutional net for MNIST against ℓ∞, ϵ = 0.3 attack.
Training setup: Complete details are provided in Supplementary Material. Our experiments for ℓ2 attack are presented in Table 1. We perform these experiments on a LeNet5 model imported from the Advertorch toolbox (architecture details are provided in the supplement). For ℓ2-ATENT we use a batch-size of 50 and SGD with learning rate of η = 0.001 for updating weights. We set γ = 0.05 and noise
In Table 2, we use a SmallCNN configuration as described in Zhang et al. (2019b) (architecture in supplement). We use a batch-size of 128, SGD optimizer with learning rate of η = 0.01 for updating weights. We set γ = 3.33 and noise
Our experiments on the Entropy-SGD (row 2 in Tables 1 and 2) trained network suggests that networks trained to find flat minima (with respect to weights) are not more robust to adversarial samples as compared to vanilla SGD.
4.2 CIFAR10
Next, we extend our experiments to CIFAR-10 using a WideResNet 34-10 as described in Zhang et al. (2019b); Wang et al. (2019) as well as ResNet-20. For PGD-AT (and PGD-AT (E)), TRADES, and MART, we use the default values stated in their corresponding papers.
Training setup: Complete details in Supplementary Material. Robust accuracies of WRN-34-10 classifer trained using state of art defense models are evaluated at the ℓ∞ attack benchmark requirement of radius ϵ = 8/255, on CIFAR10 dataset and tabulated in Table 3. For ℓ∞-ATENT, we use a batch-size of 128, SGD optimizer for weights, with learning rate η = 0.1 (decayed to 0.01 at epoch 76), 76 total epochs, weight decay of 5 × 10–4 and momentum 0.9. We set γ = 1/(0.0031), K = 10 Langevin iterations,
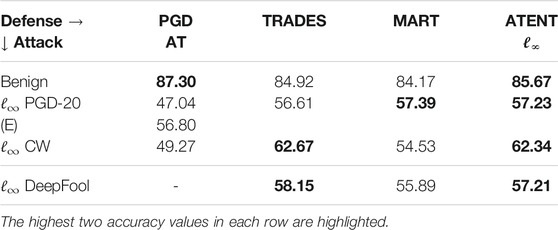
TABLE 3. Robust accuracies of WRN34-10 net for CIFAR10 against ℓ∞ attack of ϵ = 8/255.
Importance of early stopping: Because WRN34-10 is highly overparameterized with approximately 48 million trainable parameters, it tends to overfit adversarially-perturbed CIFAR10 examples. The success of TRADES (and also PGD) in Rice et al. (2020) relies on an early stopping condition and corresponding learning rate scheduler. We strategically search different early stopping points and report the best possible robust accuracy from different stopping points.
We test efficiency of our ℓ2-based defense on both ℓ2 attacks, as well as compute ℓ2 certified robustness for the smoothed version of ATENT against smoothed TRADES (Blum et al., 2020) in Supplementary Table S2 in Supplementary Material. We find that our formulation of ℓ2 ATENT is both robust against ℓ2 attacks, as well as gives a competitive certificate against adversarial perturbations for ResNet20 on CIFAR10.
In Supplementary Material we also demonstrate a fine-tuning approach for ATENT, where we consider a pre-trained WRN34-10 and fine tune it using ATENT, similar to the approach in Jeddi et al. (2020). We find that ATENT can be used to fine tune a naturally pretrained model at lower computational complexity to give competitive robust accuracies while almost retaining the performance on benign data.
4.3 Discussion
We propose a new algorithm for defending neural networks against adversarial attacks. We demonstrate competitive (and often improved) performance of our family of algorithms (ATENT) against the state of the art. We analyze the connections of ATENT with both PGD-adversarial training as well as randomized smoothing. Future work includes extending to larger datasets such as ImageNet, as well as theoretical analysis for algorithm convergence.
Data Availability Statement
The original contributions presented in the study are included in the article/Supplementary Material, further inquiries can be directed to the corresponding authors.
Author Contributions
GJ contributed to probablistic modeling, design of the algorithm and conducted some of the experiments. AJ added to the experimental analysis by designing and performing suitable baseline comparisons. AC performed the initial experimental analysis and researched the code for baseline models. GJ contributed to writing all sections in the first draft of the manuscript. AJ added experimental sections of the manuscript and AC added literature review. SG and CH gave feedback on the problem formulation and suggested papers to be added to literature survey as well as helped design experimental comparisons. All authors contributed to manuscript revision, read, and approved the submitted version.
Funding
This work was supported in part by NSF grant awards CCF-2005804 and CCF-1815101, and NSF/USDA-NIFA award 2021-67021-35329.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations or those of the publisher, the editors, and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Acknowledgments
The authors would like to thank Anna Choromanska for useful initial feedback and Praneeth Narayanamurthy for insightful conceptual discussions.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/frai.2021.780843/full#supplementary-material
Footnotes
1This family of methods has the additional benefit of being certifiably robust: all points within a ball of a given radius around the test point are provably classified with the correct label.
2This is not strictly necessary, as demonstrated by good generalization at certain sharp minima (Dinh et al., 2017).
References
Athalye, A., Carlini, N., and Wagner, D. (2018). Obfuscated Gradients Give a False Sense of Security: Circumventing Defenses to Adversarial Examples.
Biggio, B., Corona, I., Maiorca, D., Nelson, B., Šrndić, N., and Laskov, P. (2013). “Evasion Attacks against Machine Learning at Test Time,” in Joint European conference on machine learning and knowledge discovery in databases (Springer), 387–402. doi:10.1007/978-3-642-40994-3_25
Biggio, B., and Roli, F. (2018). Wild Patterns: Ten Years after the Rise of Adversarial Machine Learning. Pattern Recognition 84, 317–331. doi:10.1016/j.patcog.2018.07.023
Blum, A., Dick, T., Manoj, N., and Zhang, H. (2020). Random Smoothing Might Be Unable to Certify L∞ Robustness for High-Dimensional Images. J. Machine Learn. Res. 21, 1–21.
Carlini, N., Mishra, P., Vaidya, T., Zhang, Y., Sherr, M., Shields, C., et al. (2016). “Hidden Voice Commands,” in 25th {USENIX} Security Symposium ({USENIX} Security 16, 513–530.
Carlini, N., and Wagner, D. A. (2017b). “Towards Evaluating the Robustness of Neural Networks,” in 2017 IEEE Symposium on Security and Privacy (SP). doi:10.1109/sp.2017.49
Carlini, N., and Wagner, D. (2017a). “Towards Evaluating the Robustness of Neural Networks,” in 2017 IEEE Symposium on Security and Privacy (IEEE), 39–57. doi:10.1109/sp.2017.49
Chaudhari, P., Choromanska, A., Soatto, S., LeCun, Y., Baldassi, C., Borgs, C., et al. (2019). Entropy-sgd: Biasing Gradient Descent into Wide Valleys. J. Stat. Mech. Theor. Exp. 2019, 124018. doi:10.1088/1742-5468/ab39d9
Cohen, J., Rosenfeld, E., and Kolter, Z. (2019). “Certified Adversarial Robustness via Randomized Smoothing,” in Proceedings of the 36th International Conference on Machine Learning. Editors K. Chaudhuri, and R. Salakhutdinov, and California Long Beach (Long Beach, CA: Proceedings of Machine Learning Research), USA: PMLR, 97, 1310–1320.
Croce, F., and Hein, M. (2020). “Reliable Evaluation of Adversarial Robustness with an Ensemble of Diverse Parameter-free Attacks,” in International conference on machine learning (PMLR), 2206–2216.
Dathathri, S., Zheng, S., Gao, S., and Murray, R. (2017). “Measuring the Robustness of Neural Networks via Minimal Adversarial Examples,” in Deep Learning: Bridging Theory and Practice, NIPS 2017 workshop, Long Beach, CA 35 (NeurIPS-W).
Ding, G., Sharma, Y., Lui, K., and Huang, R. (2019). “Mma Training: Direct Input Space Margin Maximization through Adversarial Training,” in International Conference on Learning Representations.
Dinh, L., Pascanu, R., Bengio, S., and Bengio, Y. (2017). “Sharp Minima Can Generalize for Deep Nets,” in nternational Conference on Machine Learning, 1019–1028.I.
Fan, Y., Wu, B., Li, T., Zhang, Y., Li, M., Li, Z., et al. (2020). “Sparse Adversarial Attack via Perturbation Factorization,” in Computer Vision–ECCV 2020: 16th European ConferenceProceedings, Part, Glasgow, UK, August 23–28, 2020 (Springer), 35–50. doi:10.1007/978-3-030-58542-6_3XXII 16
Goodfellow, I. J. (2018). Defense against the Dark Arts: An Overview of Adversarial Example Security Research and Future Research Directions. arxiv preprint abs/1806.04169.
Goodfellow, I. J., Shlens, J., and Szegedy, C. (2014). Explaining and Harnessing Adversarial Examples. arXiv preprint arXiv:1412.6572.
Goodfellow, I., Shlens, J., and Szegedy, C. (2015). “Explaining and Harnessing Adversarial Examples,” in ICLR.
Gowal, S., Dvijotham, K., Stanforth, R., Bunel, R., Qin, C., Uesato, J., et al. (2019). “Scalable Verified Training for Provably Robust Image Classification,” in 2019 IEEE/CVF International Conference on Computer Vision (ICCV) (IEEE), 4841–4850. doi:10.1109/iccv.2019.00494
Hochreiter, S., and Schmidhuber, J. (1997). Flat Minima. Neural Comput. 9, 1–42. doi:10.1162/neco.1997.9.1.1
Jeddi, A., Shafiee, M., and Wong, A. (2020). A Simple fine-tuning Is All You Need: Towards Robust Deep Learning via Adversarial fine-tuning. arXiv preprint arXiv:2012.13628.
Jiang, Z., Chen, T., Chen, T., and Wang, Z. (2020). “Robust Pre-training by Adversarial Contrastive Learning,” in NeurIPS.
Joshi, A., Jagatap, G., and Hegde, C. (2021). Adversarial Token Attacks on Vision Transformers. arXiv preprint arXiv:2110.04337.
Keskar, N. S., Mudigere, D., Nocedal, J., Smelyanskiy, M., and Tang, P. T. P. (2016). On Large-Batch Training for Deep Learning: Generalization gap and Sharp Minima. arXiv preprint arXiv:1609.04836.
Krizhevsky, A., Sutskever, I., and Hinton, G. (2012). “Imagenet Classification with Deep Convolutional Neural Networks,” in Advances in Neural Information Processing Systems, 1097–1105.
Kurakin, A., Goodfellow, I., and Bengio, S. (2016). Adversarial Examples in the Physical World. arXiv preprint arXiv:1607.02533.
Lecuyer, M., Atlidakis, V., Geambasu, R., Hsu, D., and Jana, S. (2019). “Certified Robustness to Adversarial Examples with Differential Privacy,” in 2019 IEEE Symposium on Security and Privacy (SP) (IEEE), 656–672. doi:10.1109/sp.2019.00044
Li, B., Chen, C., Wang, W., and Carin, L. (2018a). Certified Adversarial Robustness with Additive Gaussian Noise. arXiv preprint arXiv:1809.03113.
Li, H., Xu, Z., Taylor, G., Studer, C., and Goldstein, T. (2018b). “Visualizing the Loss Landscape of Neural Nets,” in Advances in Neural Information Processing Systems, 6389–6399.
Li, Y., Min, M. R., Lee, T., Yu, W., Kruus, E., Wang, W., et al. (2021). “Towards Robustness of Deep Neural Networks via Regularization,” in Proceedings of the IEEE/CVF International Conference on Computer Vision(ICCV), 7496–7505.
Madry, A., Makelov, A., Schmidt, L., Tsipras, D., and Vladu, A. (2018). “Towards Deep Learning Models Resistant to Adversarial Attacks,” in International Conference on Learning Representations.
Moosavi-Dezfooli, S.-M., Fawzi, A., Fawzi, O., and Frossard, P. (2017). “Universal Adversarial Perturbations,” in IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI (CVPR), 1765–1773.
Moosavi-Dezfooli, S.-M., Fawzi, A., and Frossard, P. (2016). “Deepfool: A Simple and Accurate Method to Fool Deep Neural Networks,” in 2016 IEEE Conference on Computer Vision and Pattern Recognition (Las Vegas, NV: CVPR). doi:10.1109/cvpr.2016.282
Nicolae, M.-I., Sinn, M., Tran, M. N., Buesser, B., Rawat, A., Wistuba, M., et al. (2018). Adversarial Robustness Toolbox v1.2.0. arXiv preprint arXiv:1807.01069.
Papernot, N., McDaniel, P., and Goodfellow, I. (2016). Transferability in Machine Learning: From Phenomena to Black-Box Attacks Using Adversarial Samples. arXiv preprint arXiv:1605.07277.
Paul, S., and Chen, P.-Y. (2021). Vision Transformers Are Robust Learners. arXiv preprint arXiv:2105.07581.
Rauber, J., Brendel, W., and Bethge, M. (2017). Foolbox: A python Toolbox to Benchmark the Robustness of Machine Learning Models. arXiv preprint arXiv:1707.04131.
Ren, K., Zheng, T., Qin, Z., and Liu, X. (2020). Adversarial Attacks and Defenses in Deep Learning. Engineering 6 (3), 346–360. doi:10.1016/j.eng.2019.12.012
Rice, L., Wong, E., and Kolter, Z. (2020). “Overfitting in Adversarially Robust Deep Learning,” in International Conference on Machine Learning (PMLR), 8093–8104.
Rony, J., Granger, E., Pedersoli, M., and Ben Ayed, I. (2021). “Augmented Lagrangian Adversarial Attacks,” in Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 7738–7747.
Rota, P., Sangineto, E., Conotter, V., and Pramerdorfer, C. (2016). “Bad Teacher or Unruly Student: Can Deep Learning Say Something in Image Forensics Analysis,” in 2016 23rd International Conference on Pattern Recognition (ICPR) (IEEE), 2503–2508.
Salman, H., Li, J., Razenshteyn, I., Zhang, P., Zhang, H., Bubeck, S., et al. (2019a). “Provably Robust Deep Learning via Adversarially Trained Smoothed Classifiers,” in Advances in Neural Information Processing Systems, 11289–11300.
Salman, H., Li, J., Razenshteyn, I., Zhang, P., Zhang, H., Bubeck, S., et al. (2019b). Provably Robust Deep Learning via Adversarially Trained Smoothed Classifiers. Adv. Neural Inf. Process. Syst. 32, 11292–11303.
Shafahi, A., Najibi, M., Ghiasi, M. A., Xu, Z., Dickerson, J., Studer, C., et al. (2019). “Adversarial Training for Free,” in Advances in Neural Information Processing Systems, 3353–3364.
Shao, R., Shi, Z., Yi, J., Chen, P.-Y., and Hsieh, C.-J. (2021). On the Adversarial Robustness of Visual Transformers. arXiv preprint arXiv:2103.15670.
Szegedy, C., Zaremba, W., Sutskever, I., Bruna, J., Erhan, D., Goodfellow, I., et al. (2013). Intriguing Properties of Neural Networks. arXiv preprint arXiv:1312.6199.
Tang, J., Du, X., He, X., Yuan, F., Tian, Q., and Chua, T. (2019). “Adversarial Training towards Robust Multimedia Recommender System,” in IEEE Transactions on Knowledge and Data Engineering.
Tjeng, V., Xiao, K., and Tedrake, R. (2018). “Evaluating Robustness of Neural Networks with Mixed Integer Programming,” in International Conference on Learning Representations.
Tramèr, F., Kurakin, A., Papernot, N., Goodfellow, I., Boneh, D., and McDaniel, P. (2017). Ensemble Adversarial Training: Attacks and Defenses. arXiv preprint arXiv:1705.07204.
Wang, Y., Zou, D., Yi, J., Bailey, J., Ma, X., and Gu, Q. (2019). “Improving Adversarial Robustness Requires Revisiting Misclassified Examples,” in International Conference on Learning Representations.
Welling, M., and Teh, Y. (2011). “Bayesian Learning via Stochastic Gradient Langevin Dynamics,” in Proceedings of the 28th International Conference on Machine Learning (Bellevue, Washington D.C: ICML), 681–688.
Wong, E., and Kolter, Z. (2018). “Provable Defenses against Adversarial Examples via the Convex Outer Adversarial Polytope,” in International Conference on Machine Learning (Stockholm, Sweden: PMLR), 5286–5295.
Wong, E., Rice, L., and Kolter, J. Z. (2020). Fast Is Better than Free: Revisiting Adversarial Training.
Wong, E., Schmidt, F., Metzen, J., and Kolter, J. (2018). “Scaling Provable Adversarial Defenses,” in NeurIPS.
Xu, P., Chen, J., Zou, D., and Gu, Q. (2017). Global Convergence of Langevin Dynamics Based Algorithms for Nonconvex Optimization. arXiv preprint arXiv:1707.06618.
Zhang, H., Chen, H., Xiao, C., Gowal, S., Stanforth, R., Li, B., et al. (2019a). “Towards Stable and Efficient Training of Verifiably Robust Neural Networks,” in International Conference on Learning Representations.
Zhang, H., Yu, Y., Jiao, J., Xing, E., El Ghaoui, L., and Jordan, M. (2019b). “Theoretically Principled Trade-Off between Robustness and Accuracy,” in International Conference on Machine Learning, 7472–7482.
Keywords: adversarial learning, robustness, adversarial attack, regularization, neural network training
Citation: Jagatap G, Joshi A, Chowdhury AB, Garg S and Hegde C (2022) Adversarially Robust Learning via Entropic Regularization. Front. Artif. Intell. 4:780843. doi: 10.3389/frai.2021.780843
Received: 21 September 2021; Accepted: 28 October 2021;
Published: 04 January 2022.
Edited by:
Yang Zhou, Auburn University, United StatesCopyright © 2022 Jagatap, Joshi, Chowdhury, Garg and Hegde. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Gauri Jagatap, Z2F1cmkuamFnYXRhcEBueXUuZWR1