 Alessandro Betti
Alessandro Betti Giuseppe Boccignone
Giuseppe Boccignone Lapo Faggi
Lapo Faggi Marco Gori
Marco Gori Stefano Melacci
Stefano Melacci
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
HYPOTHESIS AND THEORY article
Front. Artif. Intell. , 01 December 2021
Sec. Machine Learning and Artificial Intelligence
Volume 4 - 2021 | https://doi.org/10.3389/frai.2021.768516
This article is part of the Research Topic Symmetry as a Guiding Principle in Artificial and Brain Neural Networks View all 11 articles
Symmetries, invariances and conservation equations have always been an invaluable guide in Science to model natural phenomena through simple yet effective relations. For instance, in computer vision, translation equivariance is typically a built-in property of neural architectures that are used to solve visual tasks; networks with computational layers implementing such a property are known as Convolutional Neural Networks (CNNs). This kind of mathematical symmetry, as well as many others that have been recently studied, are typically generated by some underlying group of transformations (translations in the case of CNNs, rotations, etc.) and are particularly suitable to process highly structured data such as molecules or chemical compounds which are known to possess those specific symmetries. When dealing with video streams, common built-in equivariances are able to handle only a small fraction of the broad spectrum of transformations encoded in the visual stimulus and, therefore, the corresponding neural architectures have to resort to a huge amount of supervision in order to achieve good generalization capabilities. In the paper we formulate a theory on the development of visual features that is based on the idea that movement itself provides trajectories on which to impose consistency. We introduce the principle of Material Point Invariance which states that each visual feature is invariant with respect to the associated optical flow, so that features and corresponding velocities are an indissoluble pair. Then, we discuss the interaction of features and velocities and show that certain motion invariance traits could be regarded as a generalization of the classical concept of affordance. These analyses of feature-velocity interactions and their invariance properties leads to a visual field theory which expresses the dynamical constraints of motion coherence and might lead to discover the joint evolution of the visual features along with the associated optical flows.
Deep learning has revolutionized computer vision and visual perception. Amongst others, the great representational power of convolutional neural networks and the elegance and efficiency of Backpropagation have played a crucial role (Krizhevsky et al., 2012). By and large, there is a strong scientific recognition of their capabilities, which is very well deserved. However, an important but often overlooked aspect is that natural images are swamped by nuisance factors such as lighting, viewpoint, part deformation and background. This makes the overall recognition problem much more difficult (Lee and Soatto, 2011; Anselmi et al., 2016). Typical CNNs architectures, not structurally modelling these possible variations, require a large amount of data with high variability to gain satisfying generalization skills. Some recent works have addressed this aspect focusing on the construction of invariant (Gens and Domingos, 2014; Anselmi et al., 2016) or equivariant (Cohen and Welling, 2016) features with respect to a priori specified symmetry groups of transformations. We argue that, when relying on massively supervised learning, we have been working on a problem that is—from a computational point of view—remarkably different and likely more difficult with respect to the one offered by Nature, where motion is in fact in charge for generating visual information. Motion is what offers us an object in all its poses. Classic translation, scale, and rotation invariances can clearly be obtained by appropriate movements of a given object (Betti et al., 2020). However, the experimentation of visual interaction due to motion goes well beyond the need for these invariances and it includes the object deformation, as well as its obstruction. Could not be the case that motion is in fact nearly all we need for learning to see? Current deep learning approaches based on supervised images mostly neglect the crucial role of temporal coherence, ending up into problems where the extraction of visual concepts can only be based on spatial regularities. Temporal coherence plays a fundamental role in extracting meaningful visual features (Mobahi et al., 2009; Zou et al., 2011; Wang and Gupta, 2015; Pan et al., 2016; Redondo-Cabrera and Lopez-Sastre, 2019) and, more specifically, when dealing with video-based tasks, such as video compression (Bhaskaran and Konstantinides, 1997). Some of these video-oriented works are specifically focused on disentangling content features (constant within the selected video clip) from pose and motion features (that codify information varying over time) (Denton and Birodkar, 2017; Villegas et al., 2017; Hsieh et al., 2018; Tulyakov et al., 2018; Wang et al., 2020). The problem of learning high-level features consistent with the way objects move was also faced in Pathak et al. (2017) in the context of unsupervised object foreground versus background segmentation.
In this vein, we claim that feature learning arises mostly from motion invariance principles that turn out to be fundamental for detecting the object identity as well as characterizing interactions between features themselves. To understand that, let us start considering a moving object in a given visual scene. The object can be thought of as made up of different material points, each one with its own identity that does not change during the object motion. Consequently, the identity of the corresponding pixels has also to remain constant along their apparent motion on the retina. We will express this idea in terms of feature fields (i.e. functions of the given pixel and the specific time instant) that are invariant along the trajectories defined by their conjugate velocity fields, extending, in turn, the classical brightness invariance principle for the optical flow estimation (Horn and Schunck, 1981). Visual features and the corresponding optical flow fields make up an indissoluble pair linked by the motion invariance condition that drives the entire learning process. Each change in the visual features affects the associated velocity fields and vice versa. From a biological standpoint, recent studies have suggested that the ventral and dorsal pathways may not be as independent as originally thought (Milner, 2017). Following this insight, we endorse the joint discovery of visual features and the related optical flows, pairing their learning through a motion invariance constraint. Motion information does not only confer object identity, but also its affordance. As defined by Gibson in his seminal work (Gibson, 1966, 1979), affordances essentially characterize the relation between an agent and its environment and, given a certain object, correspond to the possible actions that can be executed upon it. A chair, for example, offers the affordance of seating a human being, but it can have other potential uses. In other words, the way an agent interacts with a particular object is what defines its affordance, and this is strictly related to their relative motion. Extending and generalizing this classic notion of affordance to visual features, we will define the notion of affordance field, describing the interaction between pairs of visual features. Essentially, these interactions are defined by the relative motion of the features themselves so that the corresponding affordance fields will be required to be invariant with respect to such relative motion. Hence, in the rest of the paper, we will use the term affordance in this broader sense.
This paper is organized as follows. Section 2 is focused on classical methods for optical flow estimation. In this case, the brightness is given by the input video and the goal is to determine the corresponding optical flow through the brightness invariance condition. Typical regularization issues, necessary to specify a unique velocity field, are also addressed. Section 3 is devoted to extend the previous approach to visual features. This time, features are not given in advance but are jointly learnt together with the corresponding velocity fields. Features and velocities are tied by the motion invariance principle. After that, the classical notion of affordance by Gibson (1966), Gibson (1979) is introduced and extended to the case of visual features. Even in this case motion invariance (with respect to relative velocities) plays a pivotal role in defining the corresponding affordance fields. At the end of Section 3 regularization issues are also considered and a formulation of learning of the visual fields is sketched out, together with the description of a possible practical implementation of the proposed ideas through deep neural networks. Finally, Section 4 draws some conclusions.
The fundamental problem of optical flow estimation has been receiving a lot of attention in computer vision. In spite of the growing evidence of performance improvement (Fischer et al., 2015; Ilg et al., 2017; Zhai et al., 2021), an in-depth analysis on the precise definition of the velocity to be attributed to each pixel is still questionable (Verri, 1987; Verri and Poggio, 1989; Aubert and Kornprobst, 2006). While a simple visual inspection of some recent top level optical flow estimation systems clearly indicates remarkable performance, the definition of “optical flow” is difficult and quite slippery. Basically, we need to associate each pixel with its velocity. When considering the temporal quantization, any sound definition of such a velocity does require to know where any pixel moves on the next frame. How can we trace any single pixel? Clearly, any such pixel corresponds to a “point” of an “object” in the visual environment and the fundamental requirement to fulfill is that of tracking the point of the object.
An enlightening answer to this question was given by Horn and Shunck in a seminal paper published at the beginning of the eighties (Horn and Schunck, 1981). The basic assumption is the local-in-time constancy of the brightness intensity function I: Ω × [0, T] → [0, 1] where Ω is a subset of
Assuming smoothness we can approximate this condition to the first order taking into account only infinitesimal temporal distances and obtain at t = t0:
where
Assumption Eq. 1 is reasonable when there are no occlusions and changes of the light source are assumed to be “small.” Of course, in real world applications of computer vision these scenarios are not always met. On the other hand, it is clear that the optical flow u could be derived from an invariance condition of the type Eq. 1 applied to different and possibly more “stable” visual features rather than to the brightness itself. As shown in Figure 1, this would give a different optical flow with respect to the one defined through the brightness invariance condition (Figure 1C). For example, a feature responding to the entire barber’s pole, that is standing still, would have an associated optical flow that is null everywhere (Figure 1D). Still, we have to keep in mind that in both cases the resulting optical flow is different from the 2-D motion field (defined as the projection on the image plane of the 3-D velocity of the visual scene, see e.g. Aubert and Kornprobst (2006)) shown in Figure 1B.
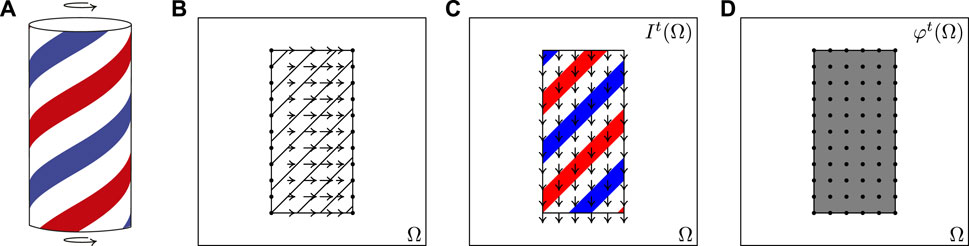
FIGURE 1. Barber’s pole example. (A) The 3-D object spinning counterclockwise. (B) The 2-D projection of the pole and the projected velocity on the retina Ω. (C) The brightness of the image and its optical flow pointing downwards. (D) A feature map that responds to the object and its conjugate (zero) optical flow.
This indeed is the main motivation to couple the problem of feature extraction together with motion invariance constraints and the derivation of robust and meaningful optical flows associated to those visual features.
Before going on to lay out the theory for the extraction of motion invariant visual features, we need to recall some facts about the optical flow condition Eq. 2. Given a video stream described by its brightness intensity I as it is defined as in Section 1, the problem of finding for each pixel of the frame spatial support at each time instant the velocity field u(x, t) satisfying
is clearly ill posed since a scalar equation is not sufficient to properly constrain the two components of u. Locally, we can unequivocally determine only the component of u along ∇I.
Although many methods have been proposed to overcome this issue (see for example the work of Aubert and Kornprobst (2006)), that is usually referred to as the aperture problem, here we are interested in the class of approaches that aims at regularizing the optical flow:
where AI is a functional that enforces constraint Eq. 3, hence a standard choice is
S imposes smoothness and H may be used to condition the extraction of the flow over spatially homogeneous regions. Depending on the regularity assumptions on I and the properties that we want to impose on the solution of this regularized problem (namely if we want to admit solutions that preserve discontinuities or not) the exact form of S and the form and presence of HI may vary. For example, in the original approach proposed in Horn and Schunck (1981) we find:
Note that since we are interested in extracting the optical flow for any frame of a video, namely the field u(x, t), it is useful for any function
Notice that the brightness might not necessarily be the ideal signal to track. Since the brightness can be expressed as a weighed average of the red R, green G, and blue B components, one could think of tracking each single color component of the video signal by using the same invariance principle stated by Eq. 3. It could in fact be the case that one or more of the components R, G, B are more invariant in the sense of Eq. 3 during the motion of the corresponding material point, see Figure 2. In that case, in general, each color can be associated with corresponding optical flows vR, vG, vB that might differ. In doing so, instead of tracking the brightness, one can track the single colors. Instead, under the assumption that each color component has the same optical flow v = vR = vG = vB we have.
where v ⋅∇(R,G,B)′≔(v ⋅∇R,v ⋅∇G,v ⋅∇B)′. It is worth mentioning that the simultaneous tracking of different channels might contribute to a better positioning of the problem since, in general, rank∇(R, G, B)′ = 2 and the system Eq. 8 admits an unique solution.1 One can think of the color components as features that, unlike classical convolutional spatial features, are temporal features.
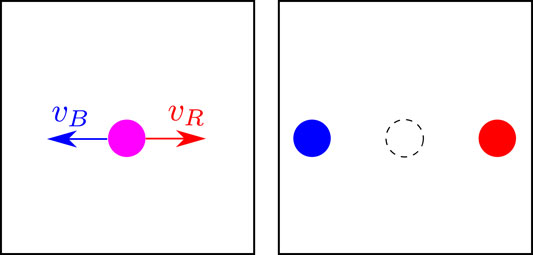
FIGURE 2. Tracking of different color components in a synthetic example. In this case, each color component is associated to a specific velocity field.
Before proceeding further, let us underline that some other optical flow methods try to directly solve the brightness invariance condition Eq. 1 without differentiating it. This is the case, for example, of the Gunnar Farnebäck’s algorithm (Farnebäck, 2003): the basic idea here is to approximate the brightness of the input images through polynomial expansions with variable coefficients, and the brightness invariance condition Eq. 1 is then solved under this assumption. Figure 3 shows the optical flows extracted by the Horn-Schunck and Farnebäcks methods in the barber’s pole case.

FIGURE 3. Barber’s pole optical flow (sub-sampled). (A) Horn–Schunck method (Horn and Schunck, 1981) with smoothing factor coefficient = 1 (B) Gunnar Farnebäck’s algorithm (Farnebäck, 2003) in the quadratic expansion case.
In the next section, we will discuss how to use a very similar approach, based on the consistency of features along apparent motion trajectories on the frame spatial support, to derive visual features φi along with the corresponding conjugate optical flows
As we have already anticipated in the previous sections, the optical flow extracted by imposing an invariance condition like the one in Eq. 3 strongly depends on the features on which we are imposing that invariance; hence it should be not surprising that different sets of features could give rise to different optical flows. This can be easily understood by considering the barber’s pole example in Figure 1. The related classical optical flow is depicted in Figure 1C, see also Figure 3, and it is different from the projection of the 3-D velocities on the frame spatial support Figure 1B (the resulting optical flow is an optical illusion indeed). Let us now assume the existence of a visual feature φr characterizing the red stripes, that is φr(x, t) = 1 iff (x, t) is inside a stripe. As the barber’s pole rotates, the conjugate velocity
This example clearly explains how different velocity fields can be associated to different visual features, but we still have to go one step further. Until now, mimicking the case of the classical optical flow estimation given the corresponding input brightness, we have described the construction of velocity fields starting from visual features whose existence was a priori assumed. Recent studies have suggested that the ventral and dorsal pathways may not be as independent as originally thought. Evidence for contributions from ventral stream systems to the dorsal stream indicates a crucial role in mediating complex and flexible visuomotor skills. Meanwhile, complementary evidence points to a role for posterior dorsal-stream visual analysis in certain aspects of 3-D perceptual function in the ventral stream (but see Milner, 2017 for a review). As pointed out by Milner (2017) potential cross-stream interactions might take three forms:
1) Independent processing: computations along the separate pathways proceed independently and in parallel and reintegrate at some final stage of processing within a shared target brain region; this might be achieved via common projections to the lateral prefrontal cortex or superior temporal sulcus (STS);
2) Feedback: processing along the two pathways is modulated by the existence of feedback loops which transmit information from downstream brain regions, including information processed along the complementary stream; feedback is likely to involve projections to early retinotopic cortical areas.
3) Continuous cross-talk: information is transferred at multiple stages and locations along the two pathways.
The three forms need not be mutually exclusive and a resolution of the problems of visual integration might involve a combination of such possibilities (Milner, 2017).
Yet, from a learning standpoint, the cross-talk mode is intriguing for setting some minimal conditions for an agent (either biological or artificial) in order to develop visual capabilities. Following this biological insight, we endorse the indissoluble conjunction of features and velocities and, consequently, their joint discovery based on the motion invariance condition.
where we are considering d different visual features. Locally, this equation means that, at each pixel x of the frame spatial support and specific time instant t, features φi are preserved along the trajectories defined by the corresponding velocity fields
Like for the brightness, in general, the invariance condition Eq. 9 generates an ill-posed problem. In particular, when the moving object has a uniform color, we can notice that brightness invariance holds for virtually infinite trajectories. Likewise, any of the features φ is expected to be spatially smooth and nearly constant in small portions of the frame spatial support, and this restores the ill-posedness of the classical problem of determining the optical flow that has been addressed in the previous section. Unlike brightness invariance, in the case of visual features the ill-posedness of the problem has a double face. Just like in the classic case of estimating the optical flow, vφ is not uniquely defined (the aperture problem). On top of that, now the corresponding feature φ is not uniquely defined, too. We will address regularization issues in Section 3.3 where, including additional information other than coherence on motion trajectories, we will make the learning process well-posed. Of course, the regularization process will also involve a term similar to the one invoked for the optical flow v, see Eq. 6, that will be imposed on vφ. Given what we have discussed so far, we can also expect the presence of some regularization term concerning the features themselves and their regularity. Finally, these terms will be complemented with an additional “prediction” index necessary to avoid trivial features’ solutions (we postpone its description to Section 3.3).
The basic notion at the core of this section is that
where Γ = Ω × [0, T] and μ is an appropriately weighted Lebesgue measure on
As already noticed, when we consider color images, what is done in the case of brightness invariance can be applied to the separated components R,G,B. Interestingly, for a material point of a certain color, given by a mixture of the three components, we can establish the same brightness invariance principle, since those components move with the same velocity. Said in other words, there could be group of different visual features φi, i = 1, …, m that share the same velocity (vi = v) and are consistent with it, that is ∂tφi + v ⋅∇φi = 0 ∀i = 1, …, m. Thus, we can promptly see that any feature φ of span(φ1, …, φm) is still conjugated with v; we can think of span(φ1, …, φm) as a functional space conjugated with v.
Let us now consider the feature group
where
Feature groups, that are characterized by their common velocity, can give rise to more structured features belonging to the same group. This can promptly be understood when we go beyond linear spaces and consider for a set of indices
Evaluating ∂tη + v ⋅∇η we obtain indeed
and we conclude that if
Any learning process that relies on the motion of a given object can only aspire to discover the identity of that object, along with its characterizing visual features such as pose and shape. The motion invariance process is in fact centered around the object itself and, as such, it does reveal its own features in all possible expositions that are gained during motion. Humans, and likely most animals, also conquer a truly different understanding of visual scenes that goes beyond the conceptualization with single object identities. In the early Sixties, James J. Gibson coined the notion of affordance in (Gibson, 1966), even though a more refined analysis came later in (Gibson, 1979). In his own words: “The affordances of the environment are what it offers the animal, what it provides or furnishes, either for good or ill. The verb to afford is found in the dictionary, the noun affordance is not. I have made it up. I mean by it something that refers to both the environment and the animal in a way that no existing term does. It implies the complementarity of the animal and the environment.” Considering this animal-centric view, we gain the understanding that affordance can be interpreted as what characterizes the “interaction” between animals and their surrounding environment. In more general terms, the way an agent interacts with a particular object is what defines its affordance, and this is strictly related to their relative motion. In the last decades, computer scientists have also being working on this general idea, trying to quantitatively implement it in the fields of computer vision and robotics (Ardón et al., 2020; Hassanin et al., 2021). As far as visual affordance is concerned, that is, extracting affordance information from still images and videos, different cognitive tasks have been considered so far, as for example affordance recognition and affordance segmentation, see (Hassanin et al., 2021) for a recent review.
In the spirit of the previous section, we will consider a more abstract notion of affordance, characterizing the interaction between different visual features along with their corresponding conjugate velocity fields. We will focus our attention on actions that are perceivable from single pictures2 and on the related local notion of affordance, that will be defined by some function characterizing the interaction between feature φj and feature φi when considering the pixel x at the specific time instant t. As we will see, the principle of motion invariance can be extended to naturally define (explicitly or implicitly) this generalized notion of affordance. A natural choice is to consider what we will denote as the affordance field ψij as a function of space and time. To implicitly codify the interaction between features i and j, ψij(x, t) has to be constrained by some relation of the form
where a1, …, a7 are scalars. Considering the case in which the motion field associated to feature φj is everywhere null, the affordance field ψij will codify a property only related to φi itself and strictly related to its identity, that has to be invariant with respect to vi. Thus, from this observation, we can infer a1 = a2 = a3 = a4 = 0 and a5 = a6 so that the above constraint becomes:
where bj = a7/a5. Requiring bj = −1 this constraint assumes a very reasonable physical meaning, that is the motion invariance of the affordance field ψij in the reference of feature φj. Within this choice, the affordance field is conjugated with the velocity vi − vj indeed, which is in fact the relative velocity of feature φi in the reference of feature φj. Considering points at the border of φi, this can lead to slightly expand ψij outside the region defined by φi itself, as shown in Figure 4. In the case vi = 0, the motion consistency is forced “backward” along the pixels’ trajectories defined by − vj. In the case bj = 1 Eq. 15 becomes symmetric under permutations instead so that ψij and ψji will be developed exploiting the same constraint. This will likely result in the same affordance feature unless some other factor (let us think for example to different initializations in neural architectures) breaks that symmetry. From the classic affordance perspective this is not a desirable property as we can easily understand considering, for example, a knife that is used to slice bread: the affordance transmitted by the knife to the bread would be strictly related to the possibility of being cut or sliced, that is clearly a property that could not be attached to the knife.
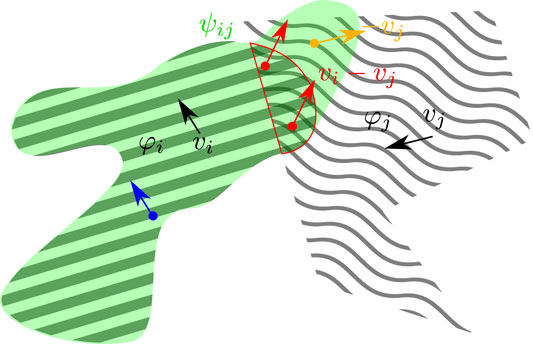
FIGURE 4. Illustration of Eq. 15 with bj = − 1. The two considered features φi (diagonal lines), φj (wavy lines) translate over the frame spatial support with uniform velocities vi, vj. The green area represents where ψij is on, while the red border identifies the region where φi and φj overlap. On the overlapping region the velocity fields of the two features are both present and here the affordance field ψij(x, t) is constrained to be consistent along the direction vi − vj (red arrows). Outside and on the left of the red border, the consistency term in Eq. 15 essentially collapses to the feature identity constraint Eq. 9 defined by the invariance motion property with respect to vi (blue arrow). Finally, in those region where vi = 0, motion consistency of ψij is required along − vj (orange arrow).
Another viable and different alternative to codify the interaction between features may be the one of directly evaluating the affordance as function of the feature fields and their respective velocities:
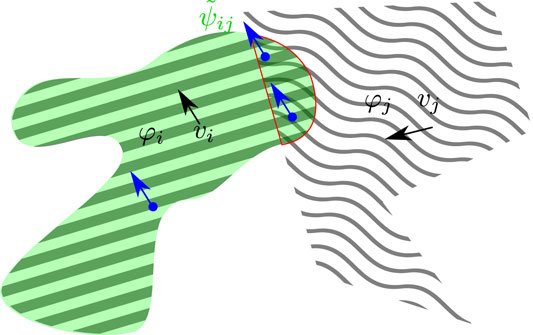
FIGURE 5. Illustration of Eq. 16. The two considered features φi (diagonal lines), φj (wavy lines) translate over the frame spatial support with uniform velocities vi, vj. The green area represents where
Given the possible great variability of velocity fields in a visual scene, let us underline that within this second approach some problems in the learning of the affordance function
Given a certain visual environment we can easily realize that, as time goes by, object interactions begin obeying statistical regularities and the interactions of feature φi with the others become very well defined. Hence, the notion of ψij can be evolved towards the inherent affordance ψi of feature φi, which is in fact a property associated with φi while living in a certain visual environment. For example, thinking in terms of the classic notion of affordance, when considering a knife the related inherent affordance property is gained by being manipulated, in a certain way, by a virtually unbounded number of different people. Based on Eq. 15 (bj = −1) we define the inherent feature affordance as the function ψi(x, t) which satisfies.
Let us note that the above formula can also be interpreted as the motion invariance property of ψi with respect to the velocity
• The pairing of φi and ψi relies on the same optical flow which comes from φi. This makes sense, since the inherent affordance is a feature that is expected to gain abstraction coming from the interactions with other features, whereas the actual optical flow can only come from identifiable entities that are naturally defined by φi.
• The inherent affordance features still bring with them a significant amount of redundant information. This can be understood when considering especially high level features that closely resemble objects. For example, while we may have many different chairs in a certain environment, one would expect to have only a single concept of chair. On the opposite, ψ assigns many different affordance variables that are somewhat stimulated by a specific identifiable feature. This corresponds to thinking of these affordance features as entities that are generated by a corresponding identity feature.
• The collection of visual fields
In order to abstract the notion of affordance even further we can, for instance, proceed as follows: for each κ = 1,…, n we can consider another set of fields
In this way the variables χκ do not depend, unlike for ψ, on a particular vi, which contributes to lose the link with its firing feature. Moreover, they need to take into account, during their development, multiple motion fields which results in a motion invariant property with respect to the average velocity
Once the set of the χκ is given, a method to select the most relevant affordances could simply be achieved through a linear combination. In other words, a subselection of χ1, …, χn can be performed by considering for each l = 1, …, nχ < n the linear combinations
where
We have already discussed the ill-posed definition of features conjugated with their corresponding optical flow. Interestingly, we have also shown that a feature group
Let us assume that we are given n feature groups ϕi, i = 1, …n, each one composed of mi single features (mi-dimensional feature vector)
Here, the notation
Important additional information comes from the need of exhibiting the human visual skill of reconstructing pictures from our symbolic representation. At a certain level of abstraction, the features that are gained by motion invariance possess a certain degree of semantics that is needed to interpret the scene. However, visual agents are also expected to deal with actions and react accordingly. As such, a uniform cognitive task that visual agents are expected to carry out is that of predicting what will happen next, which is translated into the capability of guessing the next incoming few frames in the scene. We can think of a predictive computational scheme based on the φi codes
Of course, as the visual agent gains the capability of predicting what will come next, it means that the developed internal representation based on features ϕ cannot correspond with the mentioned trivial solution. Interestingly, it looks like visual perception does not come alone: the typical paired skill of visual prediction that animals exhibit helps regularizing the problem of developing invariant features. Clearly, the φ = cφ which satisfies motion invariance is no longer acceptable since it does not reconstruct the input. This motivates the involvement of prediction skills typical of action that, again, seems to be interwound with perception.
Having described all the regularization terms necessary to the well-posedness of the learning problem, we can introduce the following functional.
where A(ϕ, v) is the direct generalization to feature groups of Eq. 10, that is
Basically, the minimization is expected to return the pair (ϕ, v), whose terms should nominally be conjugated. The case in which we reduce to consider only the brightness, that is when the only ϕ is I, corresponds with the classic problem of optical flow estimation. Of course, in this case the term R is absent and the problem has a classic solution. Another special case is when there is no motion, so as the integrand in the definition Eq. 10 of A is simply null ∀i = 1, …, n. In this case, the learning problem reduces to the unsupervised extraction of features ϕ.
The learning of ψi can be based on a formulation that closely resembles what has been done for φi, for which we have already considered the regularization issues. In the case of ψi we can get rid of the trivial constant solution by minimizing.
which comes from the p-norm translation (Gori and Melacci, 2013; Gnecco et al., 2015) of the logic implication φi ⇒ ψi. Here we are assuming that φi, ψi range in [0, 1], so as whenever φi gets close to 1, it forces the same for ψi. This yields a well-posed formulation thus avoiding the trivial solution.
As far as the χ are concerned, like for ψ, we ask for the minimization of
that comes from the p-norm translation of the logic implication ψκ ⇒ χκ. While this regularization term settles the value of χκ on the corresponding ψκ, notice that the motion invariance condition (18) does not assume any privilege with respect to the firing feature ψκ.
In the previous sections we discussed invariance properties of visual features that lead to model the processes of computational vision as transport equations on the visual fields, see Eqs 9, 15, 17, 18. Some of those properties are based on the concept of consistency under motion, others lead to a generalization of the concept of affordance. In this section we will discuss how the features φ, ψ and χ, along with the velocity fields vφ, can be represented in terms of neural networks that operate on a visual stream and how the above theory can be interpreted in a classical framework of machine learning.
The first step we need to perform consists in moving to a discretized frame spatial support
It should be noted that, within this framework, the learning problem for the fields φ, χ, η and vφ, that is based on the principles described in this paper and that is defined by the optimization problem of the form described in Eq. 23, becomes a finite-dimensional learning problem on the weights of the neural models.
Thus, learning will be affected by the structure (i.e. the architecture) of the network that we choose. Recent successes of deep learning within the realm of computer vision suggest that natural choices for Φ would be Deep Convolutional Neural Networks (DCNN). More precisely, the features extracted at level ℓ of a DCNN can be identified with a group of Φi; in this way we are establishing a hierarchy between features that, in turn, suggests a natural way in which we could perform the grouping operation that we discussed in Section 3.1. In this way, features that are at the same level of a CNN share the same velocity (see Figure 6). In the case of velocities, CNN-based architectures like the one employed by FlowNet (see Fischer et al. (2015)) have been already proven to be suitable to model velocity fields.
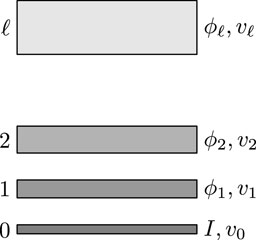
FIGURE 6. Different visual features along with the corresponding velocity fields.
It is also important to bear in mind that the choice of a specific neural architecture has strong repercussions on the way the invariance conditions are satisfied. For instance, let us consider the case of Convolutional Networks together with the fundamental condition expressed by Eq. 9. In this case, since CNN are equivariant under translations, any feature that tracks a uniformly translating motion of the brightness will automatically satisfy Eq. 9 with the same velocity of the translation of the input.
In this paper we have proposed motion invariance principles that lead to discover identification features and more abstract features that are somewhat inspired to the notion of affordance. Those principles are expressed by motion invariance equations that characterize the interesting visual field interactions. The conjunction with features φ leads to believe that those features and their own velocities represent an indissoluble pair. Basically, the presence of a visual feature in the frame spatial support corresponds with its own optical flow, so as they must be jointly detectable. Apparently, in case of a visual agent without relative movement with respect to an object, this sounds odd. What if the object is fixed? Interestingly, foveate animals always experiment movement in the frame of reference of their eyes, and something similar can be experimented in computers by the simulation of focus of attention Zanca et al. (2019), Faggi et al. (2020). Hence, apart from the case of saccadic movements, foveate animals, like haplorhine primates, are always in front of motion, and conjugation of features with the corresponding optical flow does not result in trivial conditions.
The overall field interaction of features and velocities leads to compose a more abstract picture, since in the extreme case of features that represent objects, as already pointed out, we see the emergence of the classic notion of affordance. Interestingly, the described mechanisms of field interaction go well beyond the connection with such a high-level cognitive notion. We can promptly realize that it is impossible to understand whether the discussed field interactions come from different objects or if they are in fact generated within the same object. Overall, the discussed field interactions represent a natural mechanism for transmitting information from the video by local mechanisms.
It has been shown that in order to get a well-posedness of the motion invariance problems of Eqs 9, 15, 17, 18 we need to involve appropriate regularization. In particular, the development of visual features φ requires the correspondent minimization of Eq. 21, that somewhat indicates the need of involving action together with perception. Indeed, visual perception coupled with gaze shifts should be considered the Drosophila of perception-action loops. Among the variety of active behaviors the organism can fluently engage to purposively act upon and perceive the world (e.g, moving the body, turning the head, manipulating objects), oculomotor behavior is the minimal, least energy, unit. The history of these ideas has been recently reviewed in Bajcsy et al. (2018). At that time, such computational approaches were pervaded by the early work of Gibson (1950) who proposed that perception is due to the combination of the environment in which an agent exists and how that agent interacts with it. He was primarily interested in optic flow that is generated on the frame spatial support when moving through the environment (as when flying) realizing that it was the path of motion itself that enabled the perception of specific elements, while disenabling others. That path of motion was under the control of the agent and thus the agent chooses how it perceives its world and what is perceived within it Bajcsy et al. (2018). The basic idea of Gibson’s view was that of the exploratory behaviour of the agent. It is worth noting that despite of the pioneering work of Aloimonos et al. (1988), Ballard (1991), and Bajcsy and Campos (1992), gaze dynamics has been by and large overlooked in computer vision. The current state of affairs is that most effort is spent on salience modelling Borji (2021), Borji and Itti (2013) as a tool for predicting where/what to look at (the tacit though questionable assumption is that, once suitably computed, salience would be predictive of gaze). Interestingly enough, and rooted in the animate vision approach, Ballard set out the idea of predictive coding Rao and Ballard (1999):
We describe a model of visual processing in which feedback connections from a higher-to a lower-order visual cortical area carry predictions of lower-level neural activities, whereas the feedforward connections carry the residual errors between the predictions and the actual lower level activities. When exposed to natural images, a hierarchical network of model neurons implementing such a model developed simple cell-like receptive fields. A subset of neurons responsible for carrying the residual errors showed endstopping and other extra-classical receptive field effects. These results suggest that rather than being exclusively feedforward phenomena, nonclassical surround effects in the visual cortex may also result from cortico-cortical feedback as a consequence of the visual system using an efficient hierarchical strategy for encoding natural images.
This idea has gained currency in recent research covering many fields from theoretical cognitive neuroscience (e.g., Knill and Pouget, 2004; Ma et al., 2006) to philosophy Clark (2013). Currently, the most influential approach in this perspective has been proposed by Friston (e.g., Feldman and Friston, 2010; Friston, 2010) who considered a variational approximation to Bayesian inference and prediction (free energy minimization, minimization of action functionals, etc).
The principles on visual feature flow introduced in this paper might also have an impact in computer vision, since one can reasonably believe that the proposed invariances might overcome one of the major current limitation of supervised learning paradigms, namely the need of a huge amount of labeled examples. This being said, deep neural networks, along with their powerful approximation capabilities, could provide us with the ideal computational structure to complete the theoretical framework here proposed.
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author.
All authors listed have made a substantial, direct, and intellectual contribution to the work and approved it for publication.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
This work was partially supported by the PRIN 2017 project RexLearn (Reliable and Explainable Adversarial Machine Learning), funded by the Italian Ministry of Education, University and Research (grant no. 2017TWNMH2).
1Under the assumption
2For example, we can understand that a person is sitting on or standing up from a chair just considering a still image.
3Here we are overloading the symbols φ, vφ and I in order to avoid a cumbersome notation. In the previous sections φ, vφ and I are functions defined over the spatio-temporal cylinder Ω × [0, T], here they are instead regarded as vector-valued functions of time only.
Aloimonos, J., Weiss, I., and Bandyopadhyay, A. (1988). Active Vision. Int. J. Comput. Vis. 1, 333–356. doi:10.1007/bf00133571
Anselmi, F., Leibo, J. Z., Rosasco, L., Mutch, J., Tacchetti, A., and Poggio, T. (2016). Unsupervised Learning of Invariant Representations. Theor. Comput. Sci. 633, 112–121. doi:10.1016/j.tcs.2015.06.048
Ardón, P., Pairet, È., Lohan, K. S., Ramamoorthy, S., and Petrick, R. (2020). Affordances in Robotic Tasks–A Survey. arXiv preprint arXiv:2004.07400.
Aubert, G., and Kornprobst, P. (2006). Mathematical Problems in Image Processing: Partial Differential Equations and the Calculus of Variations, Vol. 147. New York City, NY: Springer Science & Business Media.
Bajcsy, R., and Campos, M. (1992). Active and Exploratory Perception. CVGIP: Image Understanding 56, 31–40. doi:10.1016/1049-9660(92)90083-f
Bajcsy, R., Aloimonos, Y., and Tsotsos, J. K. (2018). Revisiting Active Perception. Auton. Robot 42, 177–196. doi:10.1007/s10514-017-9615-3
Betti, A., Gori, M., and Melacci, S. (2020). Learning Visual Features under Motion Invariance. Neural Networks 126, 275–299. doi:10.1016/j.neunet.2020.03.013
Bhaskaran, V., and Konstantinides, K. (1997). Image and Video Compression Standards: Algorithms and Architectures. Boston, MA: Springer.
Borji, A., and Itti, L. (2013). State-of-the-art in Visual Attention Modeling. IEEE Trans. Pattern Anal. Mach. Intell. 35, 185–207. doi:10.1109/tpami.2012.89
Borji, A. (2021). Saliency Prediction in the Deep Learning Era: Successes and Limitations. IEEE Trans. Pattern Anal. Mach. Intell. 43, 679–700. doi:10.1109/TPAMI.2019.2935715
Clark, A. (2013). Whatever Next? Predictive Brains, Situated Agents, and the Future of Cognitive Science. Behav. Brain Sci. 36, 181–204. doi:10.1017/s0140525x12000477
Cohen, T., and Welling, M. (2016). “Group Equivariant Convolutional Networks,” in International conference on machine learning (PMLR), New York City, NY, June 20–22, 2016, 2990–2999.
Denton, E., and Birodkar, V. (2017). Unsupervised Learning of Disentangled Representations from Video. Advances in Neural Information Processing Systems. Editors I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett (Red Hook, NY: Curran Associates, Inc.) 30. Available at https://proceedings.neurips.cc/paper/2017/file/2d2ca7eedf739ef4c3800713ec482e1a-Paper.pdf
Faggi, L., Betti, A., Zanca, D., Melacci, S., and Gori, M. (2020). Wave Propagation of Visual Stimuli in Focus of Attention. CoRR. arXiv preprint arXiv:2006.11035.
Farnebäck, G. (2003). “Two-frame Motion Estimation Based on Polynomial Expansion,” in Scandinavian Conference on Image Analysis, Halmstad, Sweden, June 29–July 2, 2003 (Springer), 363–370. doi:10.1007/3-540-45103-x_50
Feldman, H., and Friston, K. J. (2010). Attention, Uncertainty, and Free-Energy. Front. Hum. Neurosci. 4, 215. doi:10.3389/fnhum.2010.00215
Fischer, P., Dosovitskiy, A., Ilg, E., Häusser, P., Hazırbaş, C., Golkov, V., et al. (2015). Flownet: Learning Optical Flow with Convolutional Networks. Proceedings of the IEEE International Conference on Computer Vision, 2758–2766.
Friston, K. (2010). The Free-Energy Principle: a Unified Brain Theory? Nat. Rev. Neurosci. 11, 127–138. doi:10.1038/nrn2787
Gens, R., and Domingos, P. M. (2014). Deep Symmetry Networks. Adv. Neural Inf. Process. Syst. 27, 2537–2545. doi:10.5555/2969033.2969110
Gibson, J. J. (1966). The Senses Considered as Perceptual Systems, Vol. 2. Boston, MA: Houghton Mifflin Boston.
Gibson, J. J. (1979). The Ecological Approach to Visual Perception. Boston, MA: Houghton Mifflin Comp.
Gnecco, G., Gori, M., Melacci, S., and Sanguineti, M. (2015). Foundations of Support Constraint Machines. Neural Comput. 27, 388–480. doi:10.1162/neco_a_00686
Gori, M., and Melacci, S. (2013). Constraint Verification with Kernel Machines. IEEE Trans. Neural Netw. Learn. Syst. 24, 825–831. doi:10.1109/tnnls.2013.2241787
Hassanin, M., Khan, S., and Tahtali, M. (2021). Visual Affordance and Function Understanding. ACM Comput. Surv. 54, 1–35. doi:10.1145/3446370
Horn, B. K. P., and Schunck, B. G. (1981). Determining Optical Flow. Artif. Intell. 17, 185–203. doi:10.1016/0004-3702(81)90024-2
Hsieh, J.-T., Liu, B., Huang, D.-A., Li, F.-F., and Niebles, J. C. (2018). Learning to Decompose and Disentangle Representations for Video Prediction. NeurIPS, 514–524. Available at http://papers.nips.cc/paper/7333-learning-to-decompose-and-disentangle-representations-for-video-prediction.
Ilg, E., Mayer, N., Saikia, T., Keuper, M., Dosovitskiy, A., and Brox, T. (2017). “Flownet 2.0: Evolution of Optical Flow Estimation with Deep Networks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, honolulu, HI, July 21–26, 2017, 2462–2470. doi:10.1109/cvpr.2017.179
Knill, D. C., and Pouget, A. (2004). The Bayesian Brain: the Role of Uncertainty in Neural Coding and Computation. Trends Neurosci. 27, 712–719. doi:10.1016/j.tins.2004.10.007
Krizhevsky, A., Sutskever, I., and Hinton, G. E. (2012). Imagenet Classification with Deep Convolutional Neural Networks. Adv. Neural Inf. Process. Syst. 25, 1097–1105.
Lee, T., and Soatto, S. (2011). Video-based Descriptors for Object Recognition. Image Vis. Comput. 29, 639–652. doi:10.1016/j.imavis.2011.08.003
Ma, W. J., Beck, J. M., Latham, P. E., and Pouget, A. (2006). Bayesian Inference with Probabilistic Population Codes. Nat. Neurosci. 9, 1432–1438. doi:10.1038/nn1790
Milner, A. D. (2017). How Do the Two Visual Streams Interact with Each Other? Exp. Brain Res. 235, 1297–1308. doi:10.1007/s00221-017-4917-4
Mobahi, H., Collobert, R., and Weston, J. (2009). “Deep Learning from Temporal Coherence in Video,” in Proceedings of the 26th Annual International Conference on Machine Learning, Montreal, QC, June 14–18, 2009, 737–744. doi:10.1145/1553374.1553469
Pan, Y., Li, Y., Yao, T., Mei, T., Li, H., and Rui, Y. (2016). “Learning Deep Intrinsic Video Representation by Exploring Temporal Coherence and Graph Structure,” in IJCAI, New York City, NY, July 9–15, 2016, (Citeseer), 3832–3838.
Pathak, D., Girshick, R., Dollár, P., Darrell, T., and Hariharan, B. (2017). “Learning Features by Watching Objects Move,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, July 21–26, 2017, 2701–2710. doi:10.1109/cvpr.2017.638
Rao, R. P. N., and Ballard, D. H. (1999). Predictive Coding in the Visual Cortex: a Functional Interpretation of Some Extra-classical Receptive-Field Effects. Nat. Neurosci. 2, 79–87. doi:10.1038/4580
Redondo-Cabrera, C., and Lopez-Sastre, R. (2019). Unsupervised Learning from Videos Using Temporal Coherency Deep Networks. Comput. Vis. Image Understanding 179, 79–89. doi:10.1016/j.cviu.2018.08.003
Tulyakov, S., Liu, M.-Y., Yang, X., and Kautz, J. (2018). “Mocogan: Decomposing Motion and Content for Video Generation,” in Proceedings of the IEEE conference on computer vision and pattern recognition, Salt Lake City, UT, June 18–23, 2018, 1526–1535. doi:10.1109/cvpr.2018.00165
Verri, A., and Poggio, T. (1989). Motion Field and Optical Flow: Qualitative Properties. IEEE Trans. Pattern Anal. Machine Intell. 11, 490–498. doi:10.1109/34.24781
Verri, A. (1987). “Against Quantititive Optical Flow,” in Proc. First Int’l Conf. Computer Vision, London, UK, June 8–11, 1987 (London, 171–180).
Villegas, R., Yang, J., Hong, S., Lin, X., and Lee, H. (2017). Decomposing Motion and Content for Natural Video Sequence Prediction. ICLR. arXiv preprint arXiv:1706.08033.
Wang, X., and Gupta, A. (2015). “Unsupervised Learning of Visual Representations Using Videos,” in Proceedings of the IEEE international conference on computer vision, Santiago, Chile, December 7–13, 2015, 2794–2802. doi:10.1109/iccv.2015.320
Wang, Y., Bilinski, P., Bremond, F., and Dantcheva, A. (2020). “G3an: Disentangling Appearance and Motion for Video Generation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, June 13–19, 2020, 5264–5273. doi:10.1109/cvpr42600.2020.00531
Zanca, D., Melacci, S., and Gori, M. (2019). Gravitational Laws of Focus of Attention. IEEE Trans. Pattern Anal. Mach Intell. 42, 2983–2995. doi:10.1109/TPAMI.2019.2920636
Zhai, M., Xiang, X., Lv, N., and Kong, X. (2021). Optical Flow and Scene Flow Estimation: A Survey. Pattern Recognit. 114, 107861. doi:10.1016/j.patcog.2021.107861
Keywords: affordance, convolutional neural networks, feature flow, motion invariance, optical flow, transport equation
Citation: Betti A, Boccignone G, Faggi L, Gori M and Melacci S (2021) Visual Features and Their Own Optical Flow. Front. Artif. Intell. 4:768516. doi: 10.3389/frai.2021.768516
Received: 31 August 2021; Accepted: 25 October 2021;
Published: 01 December 2021.
Edited by:
Andrea Tacchetti, DeepMind Technologies Limited, United KingdomReviewed by:
Raffaello Camoriano, Italian Institute of Technology (IIT), ItalyCopyright © 2021 Betti, Boccignone, Faggi, Gori and Melacci. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Lapo Faggi, bGFwby5mYWdnaUB1bmlmaS5pdA==
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.