 Giovanni Maccarrone
Giovanni Maccarrone Giacomo Morelli
Giacomo Morelli Sara Spadaccini
Sara Spadaccini
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Artif. Intell. , 15 October 2021
Sec. AI in Finance
Volume 4 - 2021 | https://doi.org/10.3389/frai.2021.757864
This article is part of the Research Topic Explainable Artificial Intelligence models and methods in Finance and Healthcare View all 5 articles
This paper compares the predictive power of different models to forecast the real U.S. GDP. Using quarterly data from 1976 to 2020, we find that the machine learning K-Nearest Neighbour (KNN) model captures the self-predictive ability of the U.S. GDP and performs better than traditional time series analysis. We explore the inclusion of predictors such as the yield curve, its latent factors, and a set of macroeconomic variables in order to increase the level of forecasting accuracy. The predictions result to be improved only when considering long forecast horizons. The use of machine learning algorithm provides additional guidance for data-driven decision making.
The real Gross Domestic Product (GDP) is a single, omni-comprehensive measure of the economic activity that considers the total value of goods and services produced in the economy. It is considered by academics, investors, and regulators as a proxy for the wealth of the economy and an informative indicator that drives the decision-making processes (Provost and Fawcett, 2013). This makes the forecast of the GDP a relevant issue. Indeed, it is of interest to target national economic policies as well as in other fields, from non-performing loans (Bouheni et al., 2021) to natural disaster (Atsalakis et al., 2020).
When the research question is the forecast of periods of growth or recession a popular methodology is to decompose the GDP in cyclical and trend components relying on appropriate filters. A growth (recession) means that the value of the cycle component is positive (negative) for a given period. However, within this approach it is only possible to assess the growth (or recession) losing the quantitative information on the prediction. This is instead achieved through the regression methodology. That it is the approach we follow, such choice being driven by the limitations encountered in the decomposition of the GDP in cyclical and trend components (Luginbuhl and Koopman, 2004).
The aim of this paper is to show among a set of different models and forecasting strategies which performs better. Classical time series analysis or machine learning? One-step-ahead or multi-step-ahead forecast? Including macro-economic variables or just the self-explanatory GDP values? How does our model respond to periods of economic turbulence? These are the research questions we aim to provide an answer.
Several approaches have been proposed in the literature to forecast the GDP. Indeed, the macroeconomic literature that investigates this topic through the time series approach mainly use different specifications of VAR (Ang et al., 2006; Brave et al., 2019; Koop et al., 2020), and forecasting improvements can be achieved relying on appropriate Bayesian shrinkage procedures, as highlighted in Bańbura et al. (2010). Regarding the potential economic indicators that are used as predictors of the GDP, many authors converge on the use of the yield curve that contains information about future economic activity (Giannone et al., 2008; Yiu and Chow, 2010). Estrella and Hardouvelis (1991) find that especially the slope of the yield curve can predict cumulative variations in real GDP for up to 4 years into the future. A similar study is carried out by Bernard and Gerlach (1998) in eight countries finding that, although there are substantial differences across the countries, the slope of the yield provides information about the possibility of future recessions, whereas Ang et al. (2006) find that nominal short rates outperform the slope of the yield curve in forecasting GDP growth. Other studies (Koop, 2013; Schorfheide and Song, 2015) use instead a set of macroeconomic variables to predict the U.S. GDP. Drawing from this strand of literature, e.g., Estrella and Mishkin (1996), Koop (2013), Diebold et al. (2006), we use the yield curve as well as its latent factors and a set of macroeconomic variables, namely Consumer Price Index, Unemployment rate, Federal Fund rates, and Manufacturing Capacity Utilization.
Chauvet and Potter (2013) offer a comparison between reduced form, autoregressive, VAR, and Markow switching models and find that simple time series autoregressive process of order two [AR (2)] outperforms other models in the forecast of the U.S. GDP. Baffigi et al. (2002) provide an example of the use of ARIMA for the U.E. GDP prediction. Lunde and Torkar (2020) exploit more than 120 predictors and then perform a principal component analysis (PCA) to reduce the number of variables. Despite the inclusion of different sources of information in their set-up, the PCA does not provide the economic interpretation of the results.
In this paper, we propose models with macro-economic variables and other models that take advantage of the self-explanatory information of the GDP relying on both classical time series analysis as well as on a machine learning algorithm. In particular, we forecast the U.S. GDP with ARX, SARIMAX and Linear Regression to include additional information such as real and financial measures of economic activity, and use AR and SARIMA as a benchmark for time series analysis. We also exploit the K-Nearest Neighbour (KNN) machine learning methodology. Our goal is to achieve forecasts with high accuracy and with high degree of explainability that is a best practice for building trust between machine learning and decision-makers, as pointed out in Bellotti et al. (2021). The idea is that the decision-maker should adopt the machine learning as a powerful instrument and should employ it with awareness without regarding it as a “black-box.”
Many studies explore the potential of machine learning in the field of forecasting. Stone (1977) shows the consistency property of the non-parametric KNN estimator. The model is widely used for classification tasks such as object identification and, due to the easy implementation and explainability, it is also used in applications such as missing data imputation (Bertsimas et al., 2021) and reduction of training set (Wauters and Vanhoucke, 2017) being able to better identify similar objects. The KNN can identify repeated patterns within the time series and for this reason is applied to financial time series modeling as in Ban et al. (2013). Al-Qahtani and Crone (2013) use KNN for forecasting U.K. electricity demand and find that KNN outperforms better forecasts than other benchmark models. Rodríguez-Vargas (2020) finds that KNN outperforms also two competitors machine learning models, the random forest and the extreme gradient boosting, in terms of accuracy for predicting the inflation. In general, KNN has been referenced as one of the top ten algorithms in data mining (Wu et al., 2008). Moreover, KNN is especially suitable for cases in which there is not an high number of past observations, i.e., very little past information. As pointed out in Wauters and Vanhoucke (2017), artificial intelligence methods require a minimum number of observation to work properly whereas for the KNN this limitation is not so strict even though a minimum number of observation is required (Diebold and Nason, 1990). We therefore employ the KNN model as it offers a simple methodology based on distance metrics to exploit past information.
A compelling way to predict real economic variables is offered by the nowcasting literature, which aims to predict their values in the very short term. When the objective is to study the prediction at horizons lower than a quarter, given quarterly data available for GDP, it is possible to use a consistent two step estimator, as in Doz et al. (2011), that provides the policymaker with an early estimate of the next quarter including auxiliary exogenous predictors available at a lower frequency. Moreover, this framework can be empowered with alternative variables to boost the economic knowledge. For instance, Spelta and Pagnottoni (2021) use nowcasting to assess the impact of mobility restrictions on the economic activity during the pandemic. In particular, they study the trade-off between economic sacrifices and health outcomes in terms of timely policy suggestions. Foroni et al. (2020) explicitly focus on the forecast and nowcast of COVID-19 recession and recovery studying the GDP growth and showing an interesting similarity with the great recession.
We analyze two different forecasting strategies: the one-step-ahead and the multi-step-ahead forecasts (Marcellino et al., 2006; Hu et al., 2020). The former is more reliable and accurate by construction, however it results to be less informative for macroprudential policies. In the multi-step-ahead strategy proposed, we forecast the U.S. GDP up to 12 quarters in advance. This information is potentially extremely valuable although much more challenging.
Finally, we evaluate the performance in terms of mean square error. In particular, we are interested in studying the trade-off between two different aspects: the accuracy of the estimates even when considering a period of economic turbulence, and the forecasting horizon.
The rest of the paper is organized as follows: Section 2 introduces the model specifications and the empirical strategy, Section 3 illustrates the empirical analysis, Section 4 reports the results and Section 5 concludes.
Closely related to the GDP forecast is the ability to understand whether the forecasted value is associated with growth or recession for the economy. It can be achieved through a classification framework that defines a binary target variable starting from the time series of the GDP. An appealing approach to detect recessions is to decompose the GDP in trend and cyclical components. Among the techniques used, the filters are the most employed in literature. A well-known technique is the Hodrick and Prescott (1997) filter, also known as H-P filter, which through an appropriate parametrized minimization problem generates the GDP cycle component. Once the cycle component has been detected from the time series, it is then transformed into a binary variable that assumes value equal to 1 (recession) whenever the cyclical component is lower than zero and 0 (growth) otherwise. Nevertheless, the use of this approach has been criticized. Hamilton (2018) proposes a regression filter as an alternative. Even if such regression filter overcomes the drawbacks of the H-P filter, it results to suffer some limitations, as discussed in Schüler (2018). Another procedure as in Bernard and Gerlach (1998) and Estrella and Hardouvelis (1991) is to set the GDP equal to unit during the quarters of recession indicated by the National Bureau of Economic Research (NBER).1 Applying the H-P filter to our data, we have encountered the limitations of this filter on the right tail. In Figure 1 each line represents a different size of the test set when splitting the entire time series into train and test sets. The red line shows the value of the cycle when the test set contains the 4 quarters of 2020, the green line does the job for 2 years (8 quarters) and so on. The feature that clearly emerges is that the values obtained through the filter are affected by the size of the test set. Using the test set with the last 4 and 8 quarters, the H-P filter assigns to the third quarter of 2020 a positive value. This means that the classification procedure on the filter generates those quarters as periods of growth (rather than recessions). As a result, the policymaker waste resources since the model is being fitted on unreliable data. When the test size is long enough, the filter provides the policymaker with appropriate values. Notice that the value obtained comparing the binary outcome derived from the H-P filter and the NBER data, that is the one for which the two time series match is 12 quarters in our example. We also control for the Subprime recession. Similarly, more than 4 quarters are required by H-P filter to match the NBER recession period for the second quarter of 2009, as shown in Figure 2. Since H-P filter cannot be considered reliable on the tails, the classification approach does not represent a trustworthy model for predicting growth (recession). Furthermore, another drawback of the classification is the loss of the quantitative information: the decision maker is provided with signal of growth or recession without any kind of information related to the magnitude of the event. We point out that neglecting such quantitative specification comes at a cost as the resulting classification will rely on biased trend-cycle decomposition and, therefore, be misleading. Instead, using predictions based on the actual value of the GDP, the benefit for the policymaker is to capture the intensity of the variation. In this way, the entity of the growth (recession) of the GDP assumes a real value that can be fundamental to address medium-term economic policies. In contrast to the cyclical indicator, this type of information gives the policymaker a wider set of possible actions than a binary pair (growth or recession), to better calibrate the reaction to expected changes in the GDP. For instance, the Federal Reserve System (FRS) may be interested in the GDP growth forecast with the aim to set the interest rate against any inflationary threats. On the one hand, when the forecast is based on classification, the only strategy the FRS can apply is to lower or raise the interest rate without knowledge of the value which is needed to set the policy. On the other hand, a quantitative information about the prediction of the GDP growth allows the FRS to optimally set the interest rate, following classical policies such as the Taylor rule (Taylor, 1993) or other rules, to respond to variation of the GDP. For all these reasons, we forecast the GDP with regression techniques.
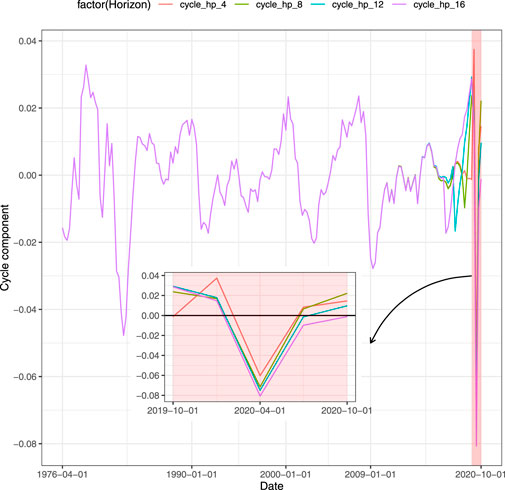
FIGURE 1. Cycle decomposition of GDP, sensitiveness to different horizons until last quarter of 2020.
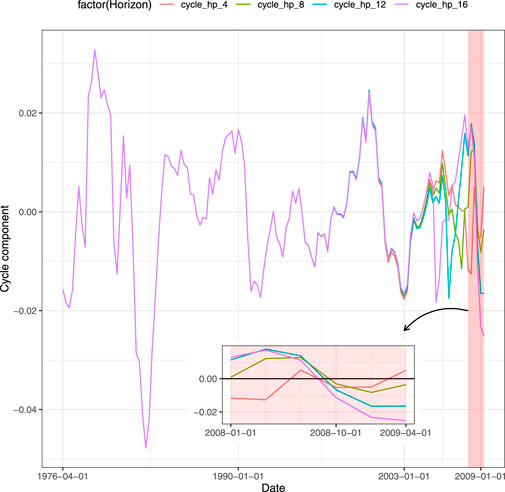
FIGURE 2. Cycle decomposition of GDP, sensitiveness to different horizons until second quarter of 2009.
We explore different forecasting models to predict the United States GDP: KNN, AR, SARIMA, ARX, SARIMAX, and a particular specification of the classical linear regression model (LR). Let ti, i ∈ {1, 2, 3, 4} represents the ti − th quarter of year T ∈ {1976, 1977, … , 2020}, so that t ∈ {1, … , 179} is the number of total quarters. Define
KNN. The KNN is a machine learning algorithm useful to solve both classification and regression problems (Wu et al., 2008) based on learning by analogy. We apply the KNN methodology to forecast univariate time series. The rationale behind the use of KNN for time series forecasting is that a time series may contain repetitive patterns. The i−th data point (target) can be described by a vector of n covariates
When predicting a new data point, the algorithm finds the k observed targets with covariates’ values (the x lagged quarters) closer to it. Then, it assigns to the new data point the average of the k’s target values. We use tsfknn library on the software R for the implementation (Martínez et al., 2019).
AR. The purely autoregressive process of order p, AR(p) satisfies the equation:
where {ɛt} is a white noise with E (ɛt) = 0,
ARX. The ARX model is an extension of AR that includes the time series of covariates x′k,t:
SARIMA. The seasonal ARIMA (p, d, q) × (P,D,Q)S, or SARIMA, is a process that takes simultaneously into account two features of the observed time series: the correlation between consecutive values modelled by standard ARIMA and the correlation between observations that are far from each other that captures the seasonality. Formally, the ARIMA part of the model is defined as:
where p is the autoregressive order of the process with coefficients ϕi and q is the order of the moving average process with coefficients θi. Notice that in a standard ARIMA process bt is white noise, whereas here it is not due to the existence of unexplained correlation that we model as follows:
where D represents the degree of the integration, P and Q are the seasonal orders of the autoregressive and moving average processes with coefficients Φi and Θi, respectively, S is the seasonality, and
SARIMAX. The SARIMAX model is an extension of SARIMA that includes the time series of covariates x′k,t:
Linear Regression. We specify the classical LR model as follows:
where the dependent variable
We propose two different forecasting strategies with the aim of studying the accuracy of the GDP predictions when we include all the available information at present time. We also assess the magnitude of the precision for different forecasting horizons.
The one-step-ahead forecasting strategy computes the forecast for one quarter ahead. This implies that the train set, that is the data used for the forecast, is reduced by one observation that corresponds to the forecasting horizon, which is our test set, and covariates have one period lag. We run the prediction of the GDP for each quarter of the period from the first quarter of 2019 to the last of 2020. In each forecast the test set moves back by one quarter and the train becomes one quarter shorter. It is important to highlight that the chosen out-of-sample forecasting horizon includes both 1 year of normal times (2019) and 1 year affected by the Sars-COVID-19 pandemic (2020). The forecasting methodology works as follow:
In the multi-step-ahead forecasting strategy predictions are run over the horizon that increases at each forecast. In this set up, the end point of the test period is set fixed to the last quarter of 2020 and the starting point moves back by one quarter each forecast. Both GDP and covariates enter the models with a lag equal to the forecasting horizon. The forecasting methodology works as follow:
The maximum length of the forecasting horizon here considered is 12 quarters from the first quarter of 2018 to the last of 2020.
We measure the economic activity with the seasonally adjusted real U.S. GDP expressed in quarterly frequency and in log scale. The data span the period from second quarter of 1976 to fourth quarter of 2020, for an overall of 179 observations, and are available from the database of the Federal Reserve Bank of Saint Louis, Federal Reserve Economic Data, FRED.
Interest rates and proxies. Both short-term and long-term U.S. federal government interest rates are used in our study. Short-term interest rates are obtained from Treasury-Bills with maturities 3 and 6 months; long-term interest rates are from the U.S. government bonds with maturities of 2, 3, 5, 7 and 10 years. Drawing on Diebold et al. (2006) and Ang et al. (2006), we exploit an alternative representation of the yield curve through its latent factors, namely the level, slope, and curvature to capture the economic information contained in it. The level is computed taking the average of short-, medium- and long-term bonds; in our study we use the interest rates at 3 months, 2 and 10 years. The slope is the result of the difference between the shortest- and the longest-term yield, 3 months and 10 years. The curvature is estimated computing the double product of the medium-term yield minus the shortest- and the longest-term yield.
Macroeconomic variables. We extend the analysis introducing key observable macroeconomic variables. Following the existing literature (Ang et al., 2006; Diebold et al., 2006; Koop, 2013; Schorfheide and Song, 2015) we select the Consumer Price Index, Manufacturing Capacity Utilization, and Unemployment Rate to illustrate real economic activity whereas the Federal Funds rates proxies the monetary policy. The Manufacturing Capacity Utilization and the Consumer Price Index are differentiated to make the series stationary.
KNN. Performing a grid search we find that optimal value of k is 2 for both forecasting strategies.
AR. We use stepwise procedure in order to choose the optimal autoregressive value of p, minimizing the AIC value.
ARX. The same methodology of AR has been applied to ARX.
SARIMA. With quarterly GDP data the seasonal period of the series is s = 4. Therefore, (11) becomes:
The orders p, d, q and P, D, Q are chosen performing stepwise search to minimize the AIC selection criterion.
SARIMAX. By (11), (7) becomes:
Linear Regression. We fit a linear regression for each scenario and forecasting strategy. In the one-step-ahead forecasts the covariates have one period lag. In the multi-step-ahead the covariates have a lag equal to the length of the forecasting horizon, which increases at each forecast.
We include a set of covariates x′n,t in LR, ARX and SARIMAX and study six different scenarios:
Scenario 1 = {Yield Curve};
Scenario 2 = {Yield Curve, Macro-variables};
Scenario 3 = {Macro-variables};
Scenario 4 = {Proxies};
Scenario 5 = {Macro-variables,Proxies};
Scenario 6 (Full) = {Yield Curve, Macro-variables, Proxies},
where the covariates for the yield curve are Treasury-Bills with maturities 3 and 6 months and 2, 3, 5, 7 and 10 years. Macro variables are Consumer Price Index, Manufacturing Capacity Utilization, Unemployment rate, and the Federal Funds rate. The proxies are the level, slope and curvature.
The KNN model achieves the best forecasting results with respect to SARIMA and AR, specifications that do not include covariates, as reported in Table 1.

TABLE 1. Average MSE for all periods.
Other models that provide good forecasts are models that include covariates, namely SARIMAX, LR and ARX. We notice that both SARIMAX and LR tend to overestimate the GDP predictions. We also investigate the average of the predictions obtained with the two models (Mean LR-SARIMAX):
Table 2 reports the average MSE. Among all the models, KNN provides the best forecasts. SARIMAX and ARX are able to better predict the GDP one-step-ahead when interest rates (Scenario 1) and proxies (Scenario 4) are considered as covariates. This finding remains true also when forecasting with the multi-step-ahead strategy.
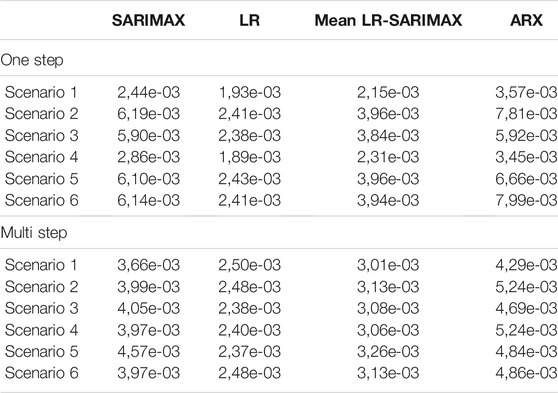
TABLE 2. Comparison of average MSE in the two strategies considered: one-step- vs. multi-step-ahead.
Overall, the one-step-ahead predictions with Scenarios 1 and 4 are the most accurate, whereas the multi-step-ahead forecast with macro variables (Scenario 3) contributes to improve the predictions the most. The Mean LR-SARIMAX performs equally likely as the SARIMAX.
Table 3 displays the prediction accuracy for the forecasting horizon of Scenario 4 (proxies). Figure 3 shows the accuracy, in terms of MSE, that fitted models achieve in each forecast horizon in the one-step-ahead strategy. The clear pattern that emerges is the change in the best performing model due to the COVID-19 shock. Specifically, models with the autoregressive component perform better before the second quarter of 2020 while the other models result to better respond to COVID-19. On the one hand, the KNN provides the best out-of-sample prediction for the second quarter of 2020 that corresponds to the beginning of the pandemic outbreak. On the other hand, SARIMAX is more accurate in normal periods as it achieves the lowest forecast error for the first quarter of 2019. The same holds for both AR and ARX which are the most accurate in the second quarter of 2019. SARIMA is the best performing model for the fourth quarter of 2019.
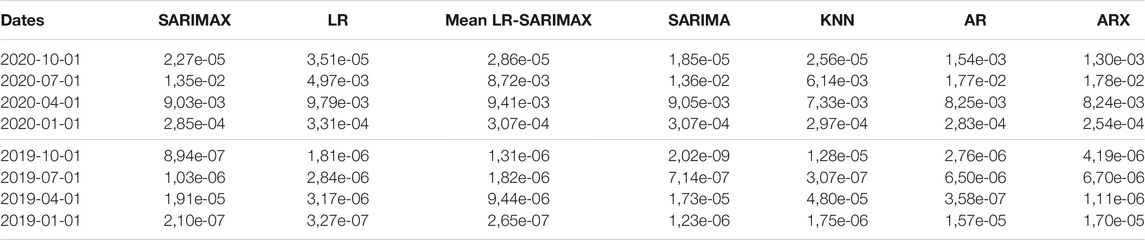
TABLE 3. MSE One-step-ahead forecast, Scenario 4.
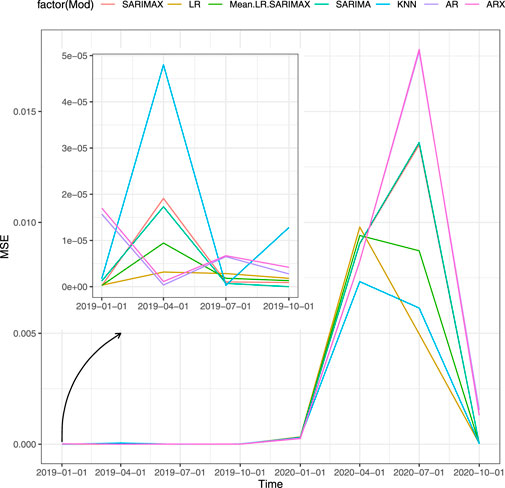
FIGURE 3. MSE of the models for one-step-ahead, Scenario 4, sensitiveness to the pandemic shock.
The second best forecasting model is the LR. As shown in Figure 3, it performs well on the whole forecasting horizon. Looking at single scenarios that include the LR outperforms the other models, confirming the forecasting-power of the yield curve in predicting the GDP.
Table 4 shows the results of the second type of forecasting strategy for the Scenario 5 (proxies and macro variables). Figure 4 shows the MSE of the models for each forecasting horizon. The change occurs also for the multi-step-ahead strategy and the time series models loss the most in terms of performance after the second quarter of 2020. The best overall performance is achieved by the LR with this specification. We highlight that such set of covariates performs better than other combinations, namely Scenario 1, 2, 3, 4, and 6. The average MSE with Scenario 5 is the lowest among models with and without covariates. This result holds true for both periods of stability and crisis. A possible justification lies in the fact that the LR does not include the autoregressive term of the GDP that may affect the prediction performance. Indeed, the macro variables may be more reactive improving the prediction compared to autoregressive models.
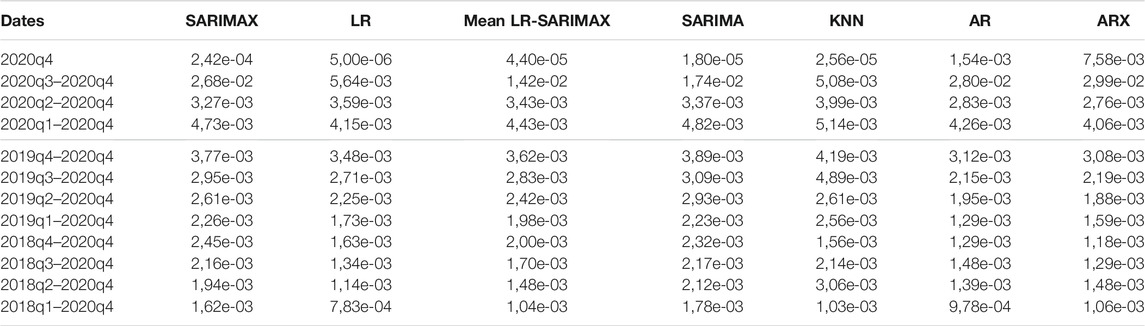
TABLE 4. MSE multi-step-ahead forecast, Scenario 5.
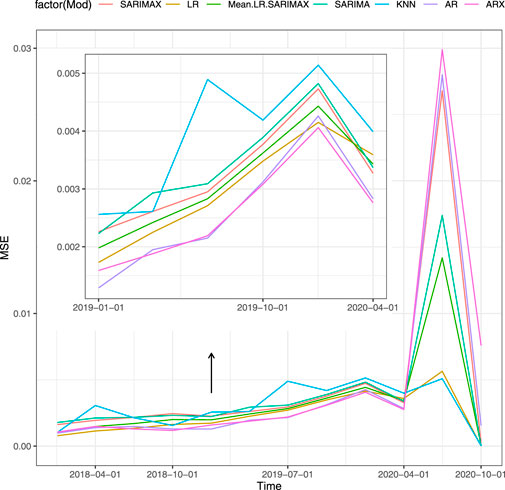
FIGURE 4. MSE of the models for multi-step-ahead, Scenario 5, sensitiveness to the pandemic shock.
In this article, we provide a comparison of the predictive ability of time series, linear regression, and machine learning models to forecast the U.S. GDP. We discuss the benefit for the policymaker of a regression approach compared to the classification to address medium-term policies. Moreover, we evaluate two different strategies of forecasting, one-step-ahead and multi-step-ahead, considering the self-explanatory power of GDP and the importance of financial and macro-economic variables as predictors. On the one hand, the machine learning KNN achieves the best performance for the one-step-ahead strategy, providing evidence that in the subsequent horizon the exploitation of repetitive patterns in the GDP increases the forecast. On the other hand, it loses predictive power when the forecast is performed for a longer horizon. SARIMA performs poorly in the one-step-ahead and multi-step-ahead strategies. Including covariates, SARIMAX obtains a lower error in the one-step-ahead strategy especially with the Treasury-Bills with maturities 3 and 6 months and 2, 3, 5, 7 and 10 years (Scenario 1). ARX achieves the best forecasting performance in one-step-ahead with proxies (Scenario 4) and yield curve (Scenario 1). Considering the multi-step-ahead accuracy, the yield curve has proved to be the best predictor to be paired with this model. Surprisingly, the LR achieves the best performance in the multi-step-ahead forecast using proxies for the yield curve and macro variables (Scenario 5). Moreover, it achieves the second-best performance in the one-step-ahead strategy using only the proxies as predictors and confirming the strong predictive power of the yield curve for the GDP. In general, we find that a switch occurs in terms of forecasting performances, both for one and multi-step-ahead (see Figures 3, 4), between models which have the autoregressive component and models without it. Before the cutoff, the pandemic outbreak in our study, time series models perform better but after that event LR and KNN outperform the other approaches. The results of our analysis suggest the use of the KNN model for one-step-ahead forecasts and that of LR with the use of financial variables for multi-step-ahead forecasts. We propose to overcome the trade-off between accuracy in the estimates and the forecasting horizon, considering the two forecasting strategies which are not mutually exclusive. Indeed, the benefit of a continuous forecasting of both one-step-ahead and multi-step-ahead allows the decision-maker to have two useful instruments: on the one hand the multi-step provides a long-term vision for planning in advance investments, monetary policy, etc., on the other hand the one-step-ahead might tip the scale for possible refinement around the decision taken. There are many possible avenues for future works. A desirable address is to develop a model that includes the international bond yield curve (Byrne et al., 2019), macro variables, and the GDP of countries the United States trade with.
The data analyzed in this study are freely available at the Federal Reserve Bank of Saint Louis, Federal Reserve Economic Data (FRED) website, https://fred.stlouisfed.org/. The interested reader may use the provided link to FRED to explore the data. Any further inquiries can be directed to the corresponding author.
GMa, GMo and SS conceptualized the topic, performed the literature review, drafted, edited and reviewed the article and approved the manuscript for submission. GMa and SS implemented the code.
Author SS was employed by company Enel Global Services S.r.l.
The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
1NBER considers as recessions two consecutive quarters of negative GDP growth
Al-Qahtani, F. H., and Crone, S. F. (2013). “Multivariate K-Nearest Neighbour Regression for Time Series Data A Novel Algorithm for Forecasting uk Electricity Demand,” in The 2013 international joint conference on neural networks (IJCNN) (IEEE), 1–8.
Ang, A., Piazzesi, M., and Wei, M. (2006). What Does the Yield Curve Tell Us about Gdp Growth? J. Econom. 131, 359–403. doi:10.1016/j.jeconom.2005.01.032
Atsalakis, G. S., Bouri, E., and Pasiouras, F. (2020). Natural Disasters and Economic Growth: a Quantile on Quantile Approach. Ann. Operations Res. 5, 1–27. doi:10.1007/s10479-020-03535-6
Baffigi, A., Golinelli, R., and Parigi, G. (2002). Real-time GDP Forecasting in the Euro Area, Vol. 456. Princeton, NJ: Citeseer.
Ban, T., Zhang, R., Pang, S., Sarrafzadeh, A., and Inoue, D. (2013). “Referential Knn Regression for Financial Time Series Forecasting,” in International Conference on Neural Information Processing (Springer), 601–608. doi:10.1007/978-3-642-42054-2_75
Bańbura, M., Giannone, D., and Reichlin, L. (2010). Large Bayesian Vector Auto Regressions. J. Appl. Econom. 25, 71–92.
Bellotti, A., Brigo, D., Gambetti, P., and Vrins, F. (2021). Forecasting Recovery Rates on Non-Performing Loans With Machine Learning. Int. J. Forecast. 37, 428–444. doi:10.1016/j.ijforecast.2020.06.009
Bernard, H., and Gerlach, S. (1998). Does the Term Structure Predict Recessions? the International Evidence. Int. J. Fin. Econ. 3, 195–215. doi:10.1002/(sici)1099-1158(199807)3:3<195:aid-ijfe81>3.0.co;2-m
Bertsimas, D., Orfanoudaki, A., and Pawlowski, C. (2021). Imputation of Clinical Covariates in Time Series. Mach Learn. 110, 185–248. doi:10.1007/s10994-020-05923-2
Bouheni, F. B., Obeid, H., and Margarint, E. (2021). Nonperforming Loan of European Islamic Banks Over the Economic Cycle. Ann. Operations Res., 1–36. doi:10.1007/s10479-021-04038-8
Brave, S. A., Butters, R. A., and Justiniano, A. (2019). Forecasting Economic Activity With Mixed Frequency Bvars. Int. J. Forecast. 35, 1692–1707. doi:10.1016/j.ijforecast.2019.02.010
Byrne, J. P., Cao, S., and Korobilis, D. (2019). Decomposing Global Yield Curve Co-Movement. J. Banking Finance. 106, 500–513. doi:10.1016/j.jbankfin.2019.07.018
Chauvet, M., and Potter, S. (2013). Forecasting Output. Handbook Econ. Forecast. 2, 141–194. doi:10.1016/b978-0-444-53683-9.00003-7
Diebold, F. X., and Nason, J. A. (1990). Nonparametric Exchange Rate Prediction? J. Int. Econ. 28, 315–332. doi:10.1016/0022-1996(90)90006-8
Diebold, F. X., Rudebusch, G. D., and Boragˇan Aruoba, S. (2006). The Macroeconomy and the Yield Curve: a Dynamic Latent Factor Approach. J. Econom. 131, 309–338. doi:10.1016/j.jeconom.2005.01.011
Doz, C., Giannone, D., and Reichlin, L. (2011). A Two-step Estimator for Large Approximate Dynamic Factor Models Based on Kalman Filtering. J. Econom. 164, 188–205. doi:10.1016/j.jeconom.2011.02.012
Estrella, A., and Hardouvelis, G. A. (1991). The Term Structure as a Predictor of Real Economic Activity. J. Finance 46, 555–576. doi:10.1111/j.1540-6261.1991.tb02674.x
Estrella, A., and Mishkin, F. S. (1996). “The Yield Curve as a Predictor of Recessions in the united states and Europe,” in The Determination of Long-Term Interest Rates and Exchange Rates and the Role of Expectations (Basel: Bank for International Settlements).
Foroni, C., Marcellino, M., and Stevanovic, D. (2020). Forecasting the Covid-19 Recession and Recovery: Lessons From the Financial Crisis. Int. J. Forecast. doi:10.1016/j.ijforecast.2020.12.005
Giannone, D., Reichlin, L., and Small, D. (2008). Nowcasting: The Real-Time informational Content of Macroeconomic Data. J. Monetary Econ. 55, 665–676. doi:10.1016/j.jmoneco.2008.05.010
Hamilton, J. D. (2018). Why You Should Never Use the Hodrick-Prescott Filter. Rev. Econ. Stat. 100, 831–843. doi:10.1162/rest_a_00706
Hodrick, R. J., and Prescott, E. C. (1997). Postwar U.S. Business Cycles: An Empirical Investigation. J. Money, Credit Banking. 29, 1–16. doi:10.2307/2953682
Hu, Z., Ge, Q., Li, S., Boerwinkle, E., Jin, L., and Xiong, M. (2020). Forecasting and Evaluating Multiple Interventions for Covid-19 Worldwide. Front. Artif. Intell. 3, 41. doi:10.3389/frai.2020.00041
Koop, G., McIntyre, S., Mitchell, J., and Poon, A. (2020). Reconciled Estimates of Monthly GDP in the US. Warwick, United Kingdom: Economic Statistics Centre of Excellence.
Koop, G. M. (2013). Forecasting with Medium and Large Bayesian Vars. J. Appl. Econ. 28, 177–203. doi:10.1002/jae.1270
Luginbuhl, R., and Koopman, S. J. (2004). Convergence in European GDP Series: a Multivariate Common Converging Trend-Cycle Decomposition. J. Appl. Econ. 19, 611–636. doi:10.1002/jae.785
Lunde, A., and Torkar, M. (2020). Including News Data in Forecasting Macro Economic Performance of China. Comput. Manag. Sci. 17, 585–611. doi:10.1007/s10287-020-00382-5
Marcellino, M., Stock, J. H., and Watson, M. W. (2006). A Comparison of Direct and iterated Multistep Ar Methods for Forecasting Macroeconomic Time Series. J. Econom. 135, 499–526. doi:10.1016/j.jeconom.2005.07.020
Martínez, F., Frías, M. P., Charte, F., and Rivera, A. J. (2019). Time Series Forecasting With Knn in R: the Tsfknn Package. R. J. 11, 229. doi:10.32614/rj-2019-004
Provost, F., and Fawcett, T. (2013). Data Science and its Relationship to Big Data and Data-Driven Decision Making. Big data. 1, 51–59. doi:10.1089/big.2013.1508
Rodríguez-Vargas, A. (2020). Forecasting Costa Rican Inflation With Machine Learning Methods. Latin Am. J. Cent. Banking. 1, 100012. doi:10.1016/j.latcb.2020.100012
Schorfheide, F., and Song, D. (2015). Real-Time Forecasting With a Mixed-Frequency Var. J. Business Econ. Stat. 33, 366–380. doi:10.1080/07350015.2014.954707
Schüler, Y. (2018). On the Cyclical Properties of Hamilton’s Regression Filter. Discussion Papers 03/2018. Amsterdam: Deutsche Bundesbank.
Spelta, A., and Pagnottoni, P. (2021). Mobility-based Real-Time Economic Monitoring Amid the Covid-19 Pandemic. Sci. Rep. 11, 13069–13115. doi:10.1038/s41598-021-92134-x
Stone, C. J. (1977). Consistent Nonparametric Regression. Ann. Stat. 5, 595–620. doi:10.1214/aos/1176343886
Taylor, J. B. (1993). Discretion Versus Policy Rules in Practice. Carnegie-Rochester Conf. Ser. Public Pol. 39, 195–214. doi:10.1016/0167-2231(93)90009-l
Wauters, M., and Vanhoucke, M. (2017). A Nearest Neighbour Extension to Project Duration Forecasting With Artificial intelligence. Eur. J. Oper. Res. 259, 1097–1111. doi:10.1016/j.ejor.2016.11.018
Wu, X., Kumar, V., Ross Quinlan, J., Ghosh, J., Yang, Q., Motoda, H., et al. (2008). Top 10 Algorithms in Data Mining. Knowl Inf. Syst. 14, 1–37. doi:10.1007/s10115-007-0114-2
Keywords: k nearest neighborhood, machine learning, time series, GDP, forecasting strategies
Citation: Maccarrone G, Morelli G and Spadaccini S (2021) GDP Forecasting: Machine Learning, Linear or Autoregression?. Front. Artif. Intell. 4:757864. doi: 10.3389/frai.2021.757864
Received: 12 August 2021; Accepted: 20 September 2021;
Published: 15 October 2021.
Edited by:
Emanuela Raffinetti, University of Pavia, ItalyReviewed by:
Thomas Edward Leach, University of Pavia, ItalyCopyright © 2021 Maccarrone, Morelli and Spadaccini. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Giacomo Morelli, Z2lhY29tby5tb3JlbGxpQHVuaXJvbWExLml0
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.