 Farnaz Sedighin
Farnaz Sedighin Andrzej Cichocki
Andrzej Cichocki- 1Medical Image and Signal Processing Research Center, School of Advanced Technologies in Medicine, Isfahan University of Medical Sciences, Isfahan, Iran
- 2Computational and Data Intensive Science and Engineering Department, Skolkovo Institute of Science and Technology (SKOLTECH), Moscow, Russia
- 3Systems Research Institute, Polish Academy of Science, Warsaw, Poland
Tensor Completion is an important problem in big data processing. Usually, data acquired from different aspects of a multimodal phenomenon or different sensors are incomplete due to different reasons such as noise, low sampling rate or human mistake. In this situation, recovering the missing or uncertain elements of the incomplete dataset is an important step for efficient data processing. In this paper, a new completion approach using Tensor Ring (TR) decomposition in the embedded space has been proposed. In the proposed approach, the incomplete data tensor is first transformed into a higher order tensor using the block Hankelization method. Then the higher order tensor is completed using TR decomposition with rank incremental and multistage strategy. Simulation results show the effectiveness of the proposed approach compared to the state of the art completion algorithms, especially for very high missing ratios and noisy cases.
1 Introduction
Joint analysis of datasets recorded by different sensors is an effective approach for investigating a physical phenomenon. For this propose, the acquired datasets can be recorded in different matrices and jointly analyzed (Ozerov and Févotte, 2009).
By increasing the volume of the recorded data and also the number of the recorded signals, matrices are not any more efficient for analyzing and representing the datasets. For overcoming this limitation, the acquired datasets are represented in tensor formats. Tensors are higher order arrays used in different signal processing applications such as Blind Source Separation (BSS) (Cichocki et al., 2009; Bousse et al., 2016), image in-painting/completion (Liu et al., 2012; Yokota et al., 2016; Wang et al., 2017), time series analysis (Kouchaki et al., 2014; Sedighin et al., 2020) and machine learning (Rabanser et al., 2017; Sidiropoulos et al., 2017).
The acquired datasets can be incomplete or uncertain due to different reasons such as noise, outliers, hardware failure or human error (Liu et al., 2012; Yokota et al., 2016; Wang et al., 2017). Even, sometimes, the resolution of the recorded data is not sufficient due to hardware limitations. In these situations, tensor completion can be very helpful for efficient data analysis.
Tensor completion is an approach for recovering missing or uncertain elements of a data tensor using its available elements (Liu et al., 2012; Yokota et al., 2016; Wang et al., 2017). At the first look, the problem seems to be ill-posed and difficult, but indeed, it can be done using some assumptions for the original data tensor (Gandy et al., 2011; Liu et al., 2012; Bengua et al., 2017).
Generally, tensor completion approaches can be divided into two groups: low rank based approaches (Liu et al., 2012; Bengua et al., 2017) and tensor decomposition based approaches (Yokota et al., 2016, Yokota et al., 2018). However, in some completion methods such as (Yuan et al., 2018b), both of the approaches have been combined.
In low rank based completion approaches, it is assumed that the original tensor is low rank. Under this assumption, the completion is to find the missing elements of a tensor in a way that the completed tensor has low rank approximation (Signoretto et al., 2010; Gandy et al., 2011; Liu et al., 2012; Bengua et al., 2017; Yuan et al., 2018b). In contrast to matrices, there is no unique definition for the tensor rank. One of the basic definitions for the tensor rank is the Canonical Polyadic Decomposition (CPD) rank, which is the number of rank-one tensors after CP decomposition of the original tensor. Estimating the CPD rank of a tensor is difficult, therefore, other alternative definitions such as weighted summation of the ranks of different unfoldings of the data tensor have been proposed (Liu et al., 2012). Algorithms such as Simple Low Rank Tensor Completion (SiLRTC) or High accuracy Low Rank Tensor Completion (HaLRTC) (Liu et al., 2012; Bengua et al., 2017) can be considered as examples for rank minimization based completion algorithms.
In tensor decomposition based approaches, the incomplete tensor is decomposed into several lower order or smaller factor matrices and/or core tensors. These latent factors usually preserve the structural information of the original tensor. Therefore, the completed tensor can be reconstructed using the estimated latent factors. Existing different approaches for tensor decomposition, result in different decomposition based completion approaches. In (Yokota et al., 2016), a completion approach based on CPD has been proposed. In (Yokota et al., 2018), Tucker decomposition has been exploited for tensor completion.
Besides the mentioned tensor decomposition based approaches, recently, new completion methods based on Tensor Train (TT) (Grasedyck et al., 2015; Ko et al., 2018; Yuan et al., 2019) and Tensor Ring (TR) (Wang et al., 2017; Yuan et al., 2018a; Yuan et al., 2018b) decompositions have also been proposed. TT decomposition is an approach for decomposing a tensor into a series of inter-connected third order core tensors (Oseledets, 2011), as (see Figure 1).
where
where
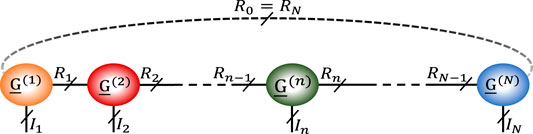
FIGURE 1. General structure for TT and TR decompositions. For the TT decomposition,
In TR decomposition, similar to TT decomposition, a tensor is decomposed into a chain of inter-connected third order core tensors with a notation similar to (Eq. 1), with,
where “tr” denotes the trace operator.
Recently, a promising approach, called Hankelization, has been developed for improving the quality of tensor completion approaches (Yokota et al., 2018; Sedighin et al., 2020). Previously, Hankelization has been used as an initial step for a time series analysis algorithm, called Singular Spectrum Analysis (SSA) (Golyandina et al., 2013; Rahmani et al., 2016; Hassani et al., 2017; Kalantari et al., 2018). Generally speaking, Hankelization is an approach for transferring a lower order dataset to a higher order one by exploiting Hankel matrix structure. In this approach, the initial data is reshaped into a tensor whose slices have Hankel or block Hankel structure. Recall that in a matrix with Hankel structure, all of the elements in each skew diagonal are the same. Hankelization provides possibility of exploiting local correlations of the elements. Due to the Hankel structure, it is expected that the resulting higher order tensor provided by the Hankelization is low rank. This low-rankness in addition to a rank incremental strategy for Tucker model has been used for tensor completion in (Yokota et al., 2018). In (Asante-Mensah et al., 2020), TR decomposition has been used for the completion of Hankelized images. Also in (Sedighin et al., 2020), a new approach for time series completion based on a two-stage Hankelization has been proposed. In this approach, a one way data, i.e., the time series, is first reformatted into a Hankel matrix, and then the resulting Hankel matrix is block Hankelized into a 6-th order tensor using block (patch) Hankelization. In block Hankelization approach, in contrast to classic Hankelization methods, blocks of elements are Hankelized instead of individual elements (Sedighin et al., 2020).
In this paper, we mainly focus on image completion. Using the block Hankelization approach of (Sedighin et al., 2020), the original incomplete tensor (image) is first transformed into a higher order 7-D tensor. Then a TR decomposition has been applied for image completion. Applying TR decomposition for the completion of Hankelized images, or better to say, in the embedded space, has been investigated in few papers such as (Asante-Mensah et al., 2020) and (Sedighin et al., 2021). Similar to many TT and TR completion approaches, determining proper ranks for completion is an important issue, so in this paper, the rank incremental strategy, developed by us in (Sedighin et al., 2021), is used for determining the TR ranks. Moreover, a multistage strategy is developed for further improving the quality of reconstructed images. Multistage strategy has been previously proposed by us in (Sedighin et al., 2020) for time series completion. To best of our knowledge, this is the first time of using multistage strategy for image completion along with adaptive TR decomposition. This is the main difference of the proposed approach with the simulation presented in (Sedighin et al., 2021). The contributions of this paper can be summarized as.
• Applying block Hankelization on each frontal slice of the incomplete image which results in a 7-th order tensor. The block (patch) Hankelization has been applied on each slice of the color image separately, which results in three 6-th order tensors. Then these 6-th order tensors have been combined with each other to produce a 7-th order tensor
• Applying TR decomposition with automatic rank incremental strategy proposed in (Sedighin et al., 2021).
• Developing a multistage strategy for improving the quality of the final reconstructed image.
Extensive simulation results confirmed the quality of the proposed algorithm in image completion, especially for high missing ratios and noisy cases.
The rest of this paper is organized as follows: Notations and preliminaries are presented in Section 2, different TT and TR completion algorithms are briefly reviewed in Section 3. Section 4 is devoted to the Block Hankelization and the proposed algorithm is presented in Section 5. Finally, results and discussion are presented in Section 6 and Section 7, respectively.
2 Notations and Preliminaries
Notations used in this paper are adopted from (Cichocki et al., 2016). It is assumed that vectors, matrices and tensors contain real valued elements. An N‐th order tensor is denoted by a bold underlined capital letter as
Matricization or unfolding of a tensor is reshaping that tensor into a matrix with the same elements. The mode-n matricization of a tensor is defined as
Hadamard (component wise) product of two tensors is denoted by
3 Tensor Train and Tensor Ring Based Completion Algorithms
Tensor Train decomposition has been exploited in many completion algorithms. In (Yuan et al., 2019), two completion algorithms, TT Weighted OPTimization (TT-WOPT) and TT Stochastic Gradient Descent (TT-SGD) have been proposed. The two algorithms are based on the minimization of the following weighted cost function using a gradient descent method:
where
and
A TT based completion algorithm using system identification has been proposed in (Ko et al., 2018). In this approach, the indices of the observed elements are the inputs of a system and the observed values are the outputs. Alternating Least Squares (ALS) and Alternating Directions Fitting (ADF) based approaches have also been proposed in (Grasedyck et al., 2015).
TT rank minimization has been used in many of tensor completion algorithms. Indeed, these algorithms are basically categorized as the rank minimization based approaches, however, since they are using TT rank which is closely related to TT decomposition, we have briefly reviewed them in this section.
In these algorithms, the cost function is defined as (Bengua et al., 2017)
where
TR decomposition has also been used in many completion algorithms. TR-WOPT has been proposed in (Yuan et al., 2018a) and is based on minimizing the cost function similar to (Eq. 4), where
TR-LRF (TR Low Rank Factors) algorithm has been proposed in (Yuan et al., 2018b). This algorithm is based on a combination of rank minimization and TR decomposition approaches, in which the rank minimization has been applied on different matricizations of the core tensors resulting from TR decomposition of the incomplete tensor.
Moreover, in (Yu et al., 2018), a completion algorithm called MTRD has been introduced based on a more balanced matricization of a tensor with TR structure. A new matricization has been defined as
and a is defined as
In (Yu et al., 2019), another completion approach, called TRNNM (TR Nuclear Norm Minimization), based on minimizing the nuclear norm of
4 Block Hankelization
As mentioned earlier, Hankelization is an effective approach in signal processing for exploiting local correlations of pixels or elements. In many of time series completion or forecasting algorithms, Hankelization has been used for transforming a lower order signal into a higher order matrix or tensor (Shi et al., 2020). An illustration for Hankelizing a time series has been shown in Figure 2.
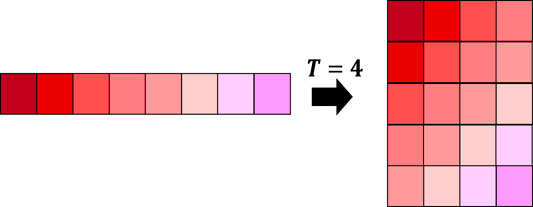
FIGURE 2. Illustration of Hankelization of a one-dimensional signal.
In (Yokota et al., 2018), Hankelization is performed by multiplying a special matrix, called duplication matrix, by each of the modes of the original tensor followed by a tensorization step.
Block (patch) Hankelization using blocks of elements (instead of single elements) has been proposed in (Sedighin et al., 2020). The block Hankelization is also performed by multiplying matrices, called block duplication matrices (shown in Figure 3), by different modes of the original tensor (Sedighin et al., 2020). Each block duplication matrix is of size
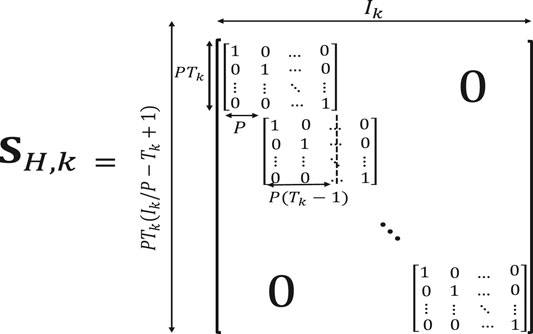
FIGURE 3. Illustration of a block duplication matrix. The lower order tensor is transformed into a higher order tensor by multiplying this matrix into its different modes following by a folding step.
The resulting matrix after multiplication of matrix
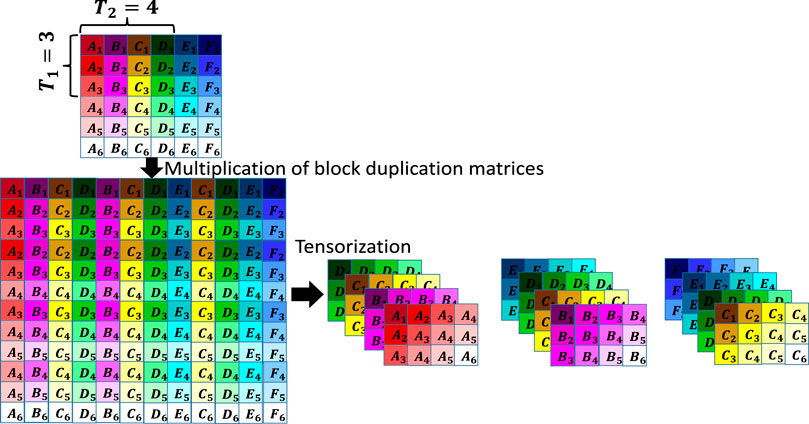
FIGURE 4. Illustration of the block Hankelization. In the first step, the initial matrix is multiplied by two block duplication matrices, and in the second step, the resulting matrix is folded into a 6-th order
5 Proposed Algorithm
As mentioned earlier, the main idea of this paper is to apply TR decomposition on the Hankelized incomplete image. In many TR completion algorithms, the cost function used for completion can be written as
where
where
Similar to (Yokota et al., 2018) and by using a Majorization Minimization approach, minimization of (Eq. 10), can be achieved by minimizing the following auxiliary function
where
where
As mentioned in the introduction, determining the ranks for TT and TR decompositions is a challenging task. In papers such as (Wang et al., 2017; Yuan et al., 2018b), the TR ranks are determined in advance and as inputs for the algorithm. These fixed rank approaches usually fail in reconstruction of the images with high missing ratios. Also, determining proper input ranks is difficult. In papers such as (Yokota et al., 2018; Sedighin et al., 2020), the input ranks are not determined in advance, but are increased gradually during iterations. Experiments show that these adaptive rank approaches are more successful in image completion when missing ratio is high. In this paper, for controlling the TR ranks, i.e., the size of the core tensors, rank incremental approach, presented in detail in (Sedighin et al., 2021), has been exploited. In (Sedighin et al., 2021), sensitivities of the estimation error to each of the core tensors are estimated and the size of the core tensors whose sensitivities are larger than a threshold are increased. However, in contrast to (Sedighin et al., 2021), in this paper, both of the ranks of the selected core tensor are increased. The step for increasing the ranks in each iteration can be 1 or any other natural number. It is also possible not to increase the ranks in some iterations, i.e., changing the rank increasing step to 0. The latter case is mainly applicable for images with high missing ratios.
The estimated
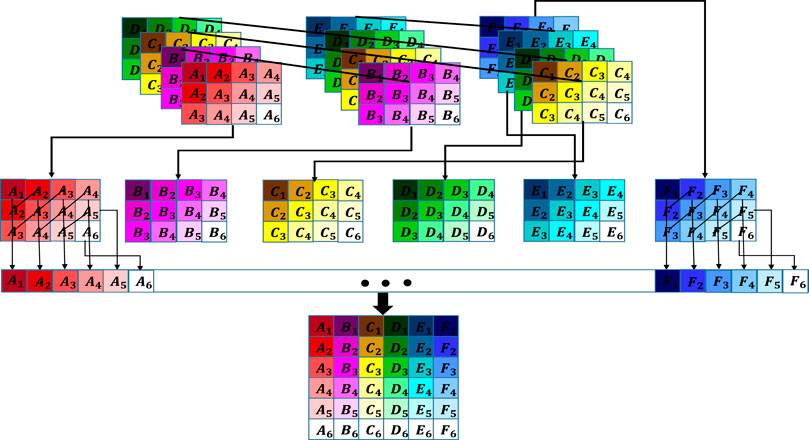
FIGURE 5. Illustration of the de-Hankelization of a block Hankelized dataset. Each colored block is a
The above procedure is repeated until the maximum value of the TR rank vector achieves the limit or the normalized approximation error in the embedded space i.e.,
In this paper, we have employed a multistage strategy to further improve the quality of final results. This is the main difference of this paper with the simulation presented in (Sedighin et al., 2021), which was the result of a single stage algorithm. The main idea and the structure of the multistage strategy have been illustrated in Figure 6. In this approach, the incomplete image is block Hankelized with block size
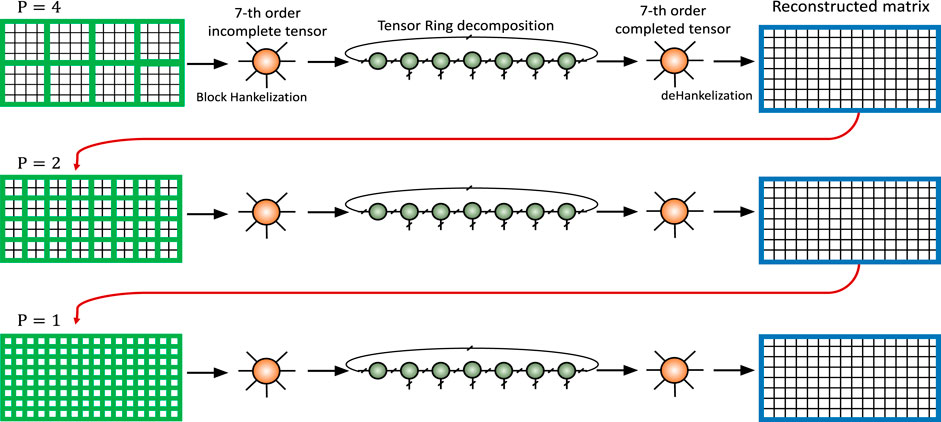
FIGURE 6. Conceptual model for the multistage strategy in the embedded space.
The pseudo code of the proposed algorithm has been listed in Algorithm 1.

Algorithm 1. Pseudo code of the proposed algorithm
6 Results
In this section, the effectiveness of the proposed multistage approach has been investigated and compared with the state of the art algorithms. The proposed algorithm has been compared with the HaLRTC algorithm (Liu et al., 2012) which is a rank minimization based completion algorithm and also with MDT (Yokota et al., 2018), TR-ALS (Wang et al., 2017), TT-WOPT (Yuan et al., 2018a) and TR-LRF (Yuan et al., 2018b), which are tensor decomposition based approaches. We have used standard (typical) color images for our simulations.
In the first simulation, the approaches have been compared for the completion of images with high missing ratios, i.e.,
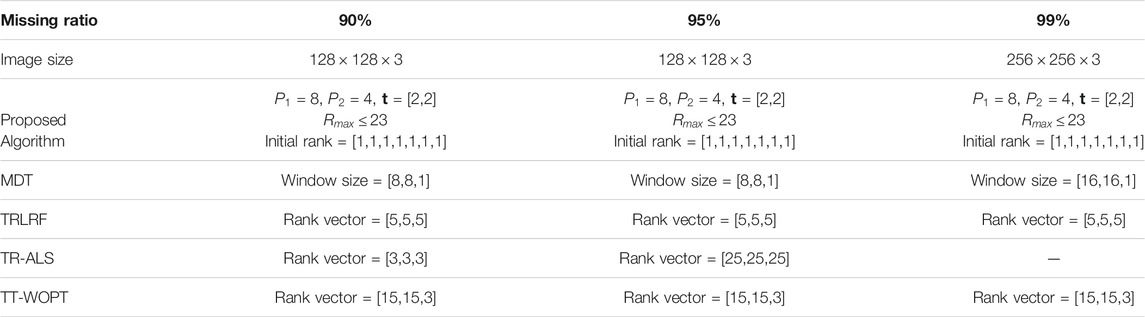
TABLE 1. The initial parameters for each algorithm for the first simulation.

TABLE 2. Comparison of the performance of the algorithms for the reconstruction of images with 90% missing ratio. PSNR, SSIM and normalized approximation error corresponding to each image have been written in brackets.

TABLE 3. Comparison of the performance of the algorithms for the reconstruction of images with

TABLE 4. Comparison of the performance of the algorithms for the reconstruction of images with
In the next simulation, the algorithms have been compared for the completion of structurally missing images. The images with blocks and slices missing elements were completed by the algorithms and the results have been presented in Table 5. The image size of this simulation was
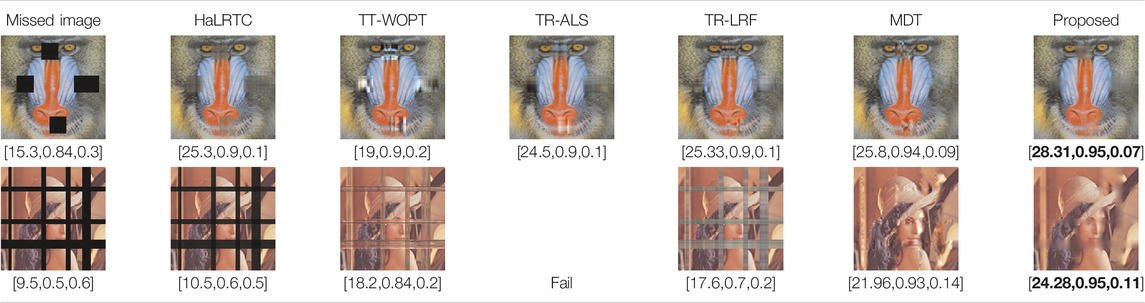
TABLE 5. Comparison of the performance of the algorithms for the reconstruction of images with structural missing elements. PSNR, SSIM and normalized approximation error corresponding to each image have been written in brackets.
In the next simulation, the effectiveness of the multistage strategy has been investigated. For this purpose, one stage algorithms with

TABLE 6. Investigation of the effectiveness of the multistage strategy. Single stage algorithms with
Finally, for investigating the effect of noise on the performance of the proposed algorithm, several incomplete noisy images have been completed by the proposed and the MDT approaches. The size of the images in this simulation was

TABLE 7. Investigation of the effect of noise on the performance of the proposed and MDT algorithms. Images have
7 Discussion
A new approach for image completion in the embedded space by block Hankelization and by exploiting TR decomposition has been proposed and extensively tested. In this approach, the incomplete image has been transformed into a higher order 7-th order tensor using block Hankelizaion and then a TR decomposition with rank incremental strategy and smoothness have been applied for completion. Moreover, a multistage strategy, which has been previously applied by us for time series completion, has been used for increasing the quality of the final completed image. Simulation results and comparisons with the state of the art algorithms indicated the advantage of the proposed algorithm.
Data Availability Statement
The original contributions presented in the study are included in the article/Supplementary Material, further inquiries can be directed to the corresponding author.
Author Contributions
All authors listed have made a substantial, direct, and intellectual contribution to the work and approved it for publication.
Funding
This work was supported by the Ministry of Education and Science of the Russian Federation (Grant 14.756.31.0001).
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Asante-Mensah, M. G., Ahmadi-Asl, S., and Cichocki, A. (2020). Matrix and Tensor Completion Using Tensor Ring Decomposition with Sparse Representation. Machine Learn. Sci. Technology 2 (3). doi:10.1088/2632-2153/abcb4f
Bengua, J. A., Phien, H. N., Tuan, H. D., and Do, M. N. (2017). Efficient Tensor Completion for Color Image and Video Recovery: Low-Rank Tensor Train. IEEE Trans. Image Process. 26, 2466–2479. doi:10.1109/tip.2017.2672439
Bousse, M., Debals, O., and De Lathauwer, L. (2016). A Tensor-Based Method for Large-Scale Blind Source Separation Using Segmentation. IEEE Trans. Signal Process. 65, 346–358. doi:10.1109/TSP.2016.2617858
Cichocki, A., Lee, N., Oseledets, I. V., Phan, A.-H., Zhao, Q., and Mandic, D. (2016). Low-rank Tensor Networks for Dimensionality Reduction and Large-Scale Optimization Problems: Perspectives and Challenges Part 1. arXiv:1609.00893.
Cichocki, A., Zdunek, R., Phan, A. H., and Amari, S. I. (2009). Nonnegative Matrix and Tensor Factorizations: Applications to Exploratory Multi-Way Data Analysis and Blind Source Separation. John Wiley & Sons.
Gandy, S., Recht, B., and Yamada, I. (2011). Tensor Completion and Low-n-Rank Tensor Recovery via Convex Optimization. Inverse Probl. 27, 025010. doi:10.1088/0266-5611/27/2/025010
Golyandina, N., Korobeynikov, A., Shlemov, A., and Usevich, K. (2013). Multivariate and 2D Extensions of Singular Spectrum Analysis with the Rssa Package, 5050. arXiv:1309.
Grasedyck, L., Kluge, M., and Krämer, S. (2015). Variants of Alternating Least Squares Tensor Completion in the Tensor Train Format. SIAM J. Sci. Comput. 37, A2424–A2450. doi:10.1137/130942401
Hassani, H., Kalantari, M., and Yarmohammadi, M. (2017). An Improved SSA Forecasting Result Based on a Filtered Recurrent Forecasting Algorithm. Comptes Rendus Mathematique 355, 1026–1036. doi:10.1016/j.crma.2017.09.004
Huang, H., Liu, Y., Liu, J., and Zhu, C. (2020a). Provable Tensor Ring Completion. Sig. Process. 171, 107486.
Huang, H., Liu, Y., Long, Z., and Zhu, C. (2020b). Robust Low-Rank Tensor Ring Completion. IEEE Trans. Comput. Imaging 6, 1117–1126.
Kalantari, M., Yarmohammadi, M., Hassani, H., and Silva, E. S. (2018). Time Series Imputation via L1 Norm-Based Singular Spectrum Analysis. Fluct. Noise Lett. 17, 1850017. doi:10.1142/s0219477518500177
Ko, C. Y., Batselier, K., Yu, W., and Wong, N. (2018). Fast and Accurate Tensor Completion with Tensor Trains: A System Identification Approach. arXiv:1804.06128.
Kouchaki, S., Sanei, S., Arbon, E. L., and Dijk, D. J. (2015). Tensor Based Singular Spectrum Analysis for Automatic Scoring of Sleep EEG. IEEE Trans. Neural Syst. Rehabil. Eng. 23, 1–9. doi:10.1109/TNSRE.2014.2329557
Liu, J., Musialski, P., Wonka, P., and Ye, J. (2012). Tensor Completion for Estimating Missing Values in Visual Data. IEEE Trans. Pattern Anal. Mach. Intell. 35, 208–220. doi:10.1109/tpami.2012.7
Oseledets, I. V. (2011). Tensor-train Decomposition. SIAM J. Sci. Comput. 33, 2295–2317. doi:10.1137/090752286
Ozerov, A., and Févotte, C. (2009). Multichannel Nonnegative Matrix Factorization in Convolutive Mixtures for Audio Source Separation. IEEE Trans. audio, speech, Lang. Process. 18, 550–563. doi:10.1109/tasl.2009.2031510
Rabanser, S., Shchur, O., and Günnemann, S. (2017). Introduction to Tensor Decompositions and Their Applications in Machine Learning. arXiv:1711.10781.
Rahmani, D., Heravi, S., Hassani, H., and Ghodsi, M. (2016). Forecasting Time Series with Sructural Breaks with Singular Spectrum Analysis, Using a General Form of Recurrent Formula. arXiv:1605.02188.
Sedighin, F., Cichocki, A., and Phan, H. A. (2021). Adaptive Rank Selection for Tensor Ring Decomposition. IEEE J. Selected Top. Signal Process. 15 (3), 454–463. doi:10.1109/jstsp.2021.3051503
Sedighin, F., Cichocki, A., Yokota, T., and Shi, Q. (2020). Matrix and Tensor Completion in Multiway Delay Embedded Space Using Tensor Train, with Application to Signal Reconstruction. IEEE Signal. Process. Lett. 27, 810–814. doi:10.1109/lsp.2020.2990313
Shi, Q., Yin, J., Cai, J., Cichocki, A., Yokota, T., Chen, L., et al. (2020). Block Hankel Tensor ARIMA for Multiple Short Time Series Forecasting. Proceedings of the AAAI Conference on Artificial Intelligence 34, 5758–5766. doi:10.1609/aaai.v34i04.6032
Sidiropoulos, N. D., De Lathauwer, L., Fu, X., Huang, K., Papalexakis, E. E., and Faloutsos, C. (2017). Tensor Decomposition for Signal Processing and Machine Learning. IEEE Trans. Signal. Process. 65, 3551–3582. doi:10.1109/tsp.2017.2690524
Signoretto, M., De Lathauwer, L., and Suykens, J. A. (2010). Nuclear Norms for Tensors and Their Use for Convex Multilinear Estimation. Rep. 10-186 Leuven, Belgium: ESAT-SISTA, KU Leuven.
Wang, W., Aggarwal, V., and Aeron, S. (2017). Efficient Low Rank Tensor Ring Completion. In 2017 IEEE International Conference on Computer Vision (ICCV), Italy, October 22–29, 2017, 5698–5706.
Yang, J., Zhu, Y., Li, K., Yang, J., and Hou, C. (2018). Tensor Completion from Structurally-Missing Entries by Low-TT-Rankness and Fiber-wise Sparsity. IEEE J. Sel. Top. Signal. Process. 12, 1420–1434. doi:10.1109/jstsp.2018.2873990
Yokota, T., Erem, B., Guler, S., Warfield, S. K., and Hontani, H. (2018). Missing Slice Recovery for Tensors Using a Low-Rank Model in Embedded Space. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Utah, June 18–22, 2018, 8251–8259.
Yokota, T., Zhao, Q., and Cichocki, A. (2016). Smooth PARAFAC Decomposition for Tensor Completion. IEEE Trans. Signal. Process. 64, 5423–5436. doi:10.1109/tsp.2016.2586759
Yu, J., Li, C., Zhao, Q., and Zhou, G. (2019). Tensor-Ring Nuclear Norm Minimization and Application for Visual: Data Completion. In 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, May 12–27, 2019, 3142–3146.
Yu, J., Zhou, G., Zhao, Q., and Xie, K. (2018). An Effective Tensor Completion Method Based on Multi-Linear Tensor Ring Decomposition. In 2018 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Honolulu, HI, November 12–15, 2018, 1344–1349.
Yuan, L., Cao, J., Zhao, X., Wu, Q., and Zhao, Q. (2018a). Higher-Dimension Tensor Completion via Low-Rank Tensor Ring Decomposition. In 2018 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Honolulu, HI, November 12–15, 2018, 1071–1076.
Yuan, L., Li, C., Mandic, D., Cao, J., and Zhao, Q. (2018b). Tensor Ring Decomposition With Rank Minimization on Latent Space: An Efficient Approach for Tensor Completion. In Proceedings of the AAAI Conference on Artificial Intelligence, 9151–9158.
Keywords: tensor ring decomposition, image completion, multistage strategy, tensorization, Hankelization
Citation: Sedighin F and Cichocki A (2021) Image Completion in Embedded Space Using Multistage Tensor Ring Decomposition. Front. Artif. Intell. 4:687176. doi: 10.3389/frai.2021.687176
Received: 29 March 2021; Accepted: 29 June 2021;
Published: 13 August 2021.
Edited by:
Jean Kossaifi, Nvidia, United StatesReviewed by:
Riccardo Zese, University of Ferrara, ItalyMeraj Hashemizadeh, Montreal Institute for Learning Algorithm (MILA), Canada
Copyright © 2021 Sedighin and Cichocki. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Farnaz Sedighin, Zi5zZWRpZ2hpbkBhbXQubXVpLmFjLmly