 Frédéric Chazal
Frédéric Chazal Bertrand Michel
Bertrand Michel- 1Inria Saclay - Île-de-France Research Centre, Palaiseau, France
- 2Ecole Centrale de Nantes, Nantes, France
With the recent explosion in the amount, the variety, and the dimensionality of available data, identifying, extracting, and exploiting their underlying structure has become a problem of fundamental importance for data analysis and statistical learning. Topological data analysis (tda) is a recent and fast-growing field providing a set of new topological and geometric tools to infer relevant features for possibly complex data. It proposes new well-founded mathematical theories and computational tools that can be used independently or in combination with other data analysis and statistical learning techniques. This article is a brief introduction, through a few selected topics, to basic fundamental and practical aspects of tda for nonexperts.
1 Introduction and Motivation
Topological data analysis (tda) is a recent field that emerged from various works in applied (algebraic) topology and computational geometry during the first decade of the century. Although one can trace back geometric approaches to data analysis quite far into the past, tda really started as a field with the pioneering works of Edelsbrunner et al. (2002) and Zomorodian and Carlsson (2005) in persistent homology and was popularized in a landmark article in 2009 Carlsson (2009). tda is mainly motivated by the idea that topology and geometry provide a powerful approach to infer robust qualitative, and sometimes quantitative, information about the structure of data [e.g., Chazal (2017)].
tda aims at providing well-founded mathematical, statistical, and algorithmic methods to infer, analyze, and exploit the complex topological and geometric structures underlying data that are often represented as point clouds in Euclidean or more general metric spaces. During the last few years, a considerable effort has been made to provide robust and efficient data structures and algorithms for tda that are now implemented and available and easy to use through standard libraries such as the GUDHI library1 (C++ and Python) Maria et al. (2014) and its R software interface Fasy et al. (2014a), Dionysus2, PHAT3, DIPHA4, or Giotto5. Although it is still rapidly evolving, tda now provides a set of mature and efficient tools that can be used in combination with or complementarily to other data science tools.
The Topological Data Analysis Pipeline
tda has recently known developments in various directions and application fields. There now exist a large variety of methods inspired by topological and geometric approaches. Providing a complete overview of all these existing approaches is beyond the scope of this introductory survey. However, many standard ones rely on the following basic pipeline that will serve as the backbone of this article:
1. The input is assumed to be a finite set of points coming with a notion of distance—or similarity—between them. This distance can be induced by the metric in the ambient space (e.g., the Euclidean metric when the data are embedded in
2. A “continuous” shape is built on the top of the data in order to highlight the underlying topology or geometry. This is often a simplicial complex or a nested family of simplicial complexes, called a filtration, which reflects the structure of the data on different scales. Simplicial complexes can be seen as higher-dimensional generalizations of neighboring graphs that are classically built on the top of data in many standard data analysis or learning algorithms. The challenge here is to define such structures as are proven to reflect relevant information about the structure of data and that can be effectively constructed and manipulated in practice.
3. Topological or geometric information is extracted from the structures built on the top of the data. This may either result in a full reconstruction, typically a triangulation, of the shape underlying the data from which topological/geometric features can be easily extracted or in crude summaries or approximations from which the extraction of relevant information requires specific methods, such as persistent homology. Beyond the identification of interesting topological/geometric information and its visualization and interpretation, the challenge at this step is to show its relevance, in particular its stability with respect to perturbations or the presence of noise in the input data. For that purpose, understanding the statistical behavior of the inferred features is also an important question.
4. The extracted topological and geometric information provides new families of features and descriptors of the data. They can be used to better understand the data—in particular, through visualization—or they can be combined with other kinds of features for further analysis and machine learning tasks. This information can also be used to design well-suited data analysis and machine learning models. Showing the added value and the complementarity (with respect to other features) of the information provided using tda tools is an important question at this step.
Topological Data Analysis and Statistics
Until quite recently, the theoretical aspects of TDA and topological inference mostly relied on deterministic approaches. These deterministic approaches do not take into account the random nature of data and the intrinsic variability of the topological quantity they infer. Consequently, most of the corresponding methods remain exploratory, without being able to efficiently distinguish between information and what is sometimes called the “topological noise” (see Section 6.2 further in the article).
A statistical approach to TDA means that we consider data as generated from an unknown distribution but also that the topological features inferred using TDA methods are seen as estimators of topological quantities describing an underlying object. Under this approach, the unknown object usually corresponds to the support of the data distribution (or part of it). The main goals of a statistical approach to topological data analysis can be summarized as the following list of problems:
Topic 1: proving consistency and studying the convergence rates of TDA methods.
Topic 2: providing confidence regions for topological features and discussing the significance of the estimated topological quantities.
Topic 3: selecting relevant scales on which the topological phenomenon should be considered, as a function of observed data.
Topic 4: dealing with outliers and providing robust methods for TDA.
Applications of Topological Data Analysis in Data Science
On the application side, many recent promising and successful results have demonstrated the interest in topological and geometric approaches in an increasing number of fields such as material science (Kramar et al., 2013; Nakamura et al., 2015; Pike et al., 2020), 3D shape analysis (Skraba et al., 2010; Turner et al., 2014b), image analysis (Qaiser et al., 2019; Rieck et al., 2020), multivariate time series analysis (Khasawneh and Munch, 2016; Seversky et al., 2016; Umeda, 2017), medicine (Dindin et al., 2020), biology (Yao et al., 2009), genomics (Carrière and Rabadán, 2020), chemistry (Lee et al., 2017; Smith et al., 2021), sensor networks De Silva and Ghrist (2007), or transportation (Li et al., 2019), to name a few. It is beyond our scope to give an exhaustive list of applications of tda. On the other hand, most of the successes of tda result from its combination with other analysis or learning techniques (see Section 6.5 for a discussion and references). So, clarifying the position and complementarity of tda with respect to other approaches and tools in data science is also an important question and an active research domain.
The overall objective of this survey article is two-fold. First, it intends to provide data scientists with a brief and comprehensive introduction to the mathematical and statistical foundations of tda. For that purpose, the focus is put on a few selected, but fundamental, tools and topics, which are simplicial complexes (Section 2) and their use for exploratory topological data analysis (Section 3), geometric inference (Section 4), and persistent homology theory (Section 5), which play a central role in tda. Second, this article also aims at demonstrating how, thanks to the recent progress of software, tda tools can be easily applied in data science. In particular, we show how the Python version of the GUDHI library allows us to easily implement and use the tda tools presented in this article (Section 7). Our goal is to quickly provide the data scientist with a few basic keys—and relevant references—so that he can get a clear understanding of the basics of tda and will be able to start to use tda methods and software for his own problems and data.
Other reviews on tda can be found in the literature, which are complementary to our work. Wasserman (2018) presented a statistical view on tda, and it focused, in particular, on the connections between tda and density clustering. Sizemore et al. (2019) proposed a survey about the application of tda to neurosciences. Finally, Hensel et al. (2021) proposed a recent overview of applications of tda to machine learning.
2 Metric Spaces, Covers, and Simplicial Complexes
As topological and geometric features are usually associated with continuous spaces, data represented as finite sets of observations do not directly reveal any topological information per se. A natural way to highlight some topological structure out of data is to “connect” data points that are close to each other in order to exhibit a global continuous shape underlying the data. Quantifying the notion of closeness between data points is usually done using a distance (or a dissimilarity measure), and it often turns out to be convenient in tda to consider data sets as discrete metric spaces or as samples of metric spaces. This section introduces general concepts for geometric and topological inference; a more complete presentation of the topic is given in the study by Boissonnat et al. (2018).
Metric Spaces
Recall that a metric space (M, ρ) is a set M with a function
i) ρ(x, y) ≥ 0 and ρ(x, y) = 0 if and only if x = y,
ii) ρ(x, y) = ρ(y, x), and
iii) ρ(x, z) ≤ ρ(x, y) + ρ(y, z).
Given a metric space (M, ρ), the set
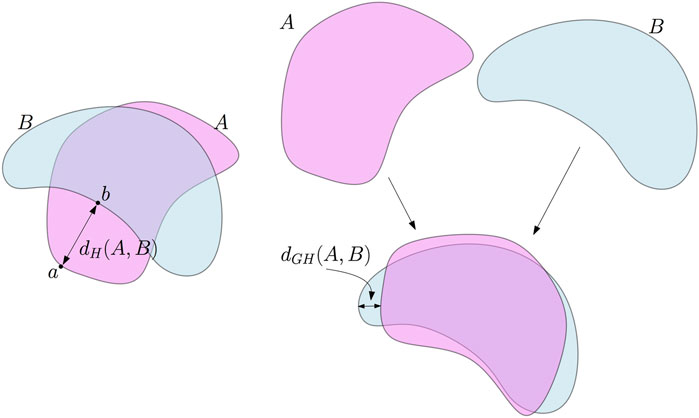
FIGURE 1. Left: the Hausdorff distance between two subsets A and B of the plane. In this example, dH(A, B) is the distance between the point a in A which is the farthest from B and its nearest neighbor b on B. Right: the Gromov–Hausdorff distance between A and B. A can be rotated—this is an isometric embedding of A in the plane—to reduce its Hausdorff distance to B. As a consequence, dGH(A, B) ≤ dH(A, B).
It is a basic and classical result that the Hausdorff distance is indeed a distance on the set of compact subsets of a metric space. From a tda perspective, it provides a convenient way to quantify the proximity between different data sets issued from the same ambient metric space. However, it sometimes occurs that one has to compare data sets that are not sampled from the same ambient space. Fortunately, the notion of the Hausdorff distance can be generalized to the comparison of any pair of compact metric spaces, giving rise to the notion of the Gromov–Hausdorff distance.
Two compact metric spaces, (M1, ρ1) and (M2, ρ2), are isometric if there exists a bijection ϕ: M1 → M2 that preserves distances, that is, ρ2(ϕ(x), ϕ(y)) = ρ1(x, y) for any x, y ∈ M1. The Gromov–Hausdorff distance measures how far two metric spaces are from being isometric.
Definition 1. The Gromov–Hausdorff distance dGH(M1, M2) between two compact metric spaces is the infimum of the real numbers r ≥ 0 such that there exists a metric space (M, ρ) and two compact subspaces C1 and C2 ⊂ M that are isometric to M1and M2and such that dH(C1, C2) ≤ r.
The Gromov–Hausdorff distance will be used later, in Section 5, for the study of stability properties and persistence diagrams.
Connecting pairs of nearby data points by edges leads to the standard notion of the neighboring graph from which the connectivity of the data can be analyzed, for example, using some clustering algorithms. To go beyond connectivity, a central idea in TDA is to build higher-dimensional equivalents of neighboring graphs using not only connecting pairs but also (k + 1)-uple of nearby data points. The resulting objects, called simplicial complexes, allow us to identify new topological features such as cycles, voids, and their higher-dimensional counterpart.
Geometric and Abstract Simplicial Complexes
Simplicial complexes can be seen as higher-dimensional generalization of graphs. They are mathematical objects that are both topological and combinatorial, a property making them particularly useful for tda.
Given a set
The union of the simplices of K is a subset of
Given a set V, an abstract simplicial complex with the vertex set V is a set
The combinatorial description of any geometric simplicial K obviously gives rise to an abstract simplicial complex
Building Simplicial Complexes From Data
Given a data set, or more generally, a topological or metric space, there exist many ways to build simplicial complexes. We present here a few classical examples that are widely used in practice.
A first example is an immediate extension of the notion of the α-neighboring graph. Assume that we are given a set of points
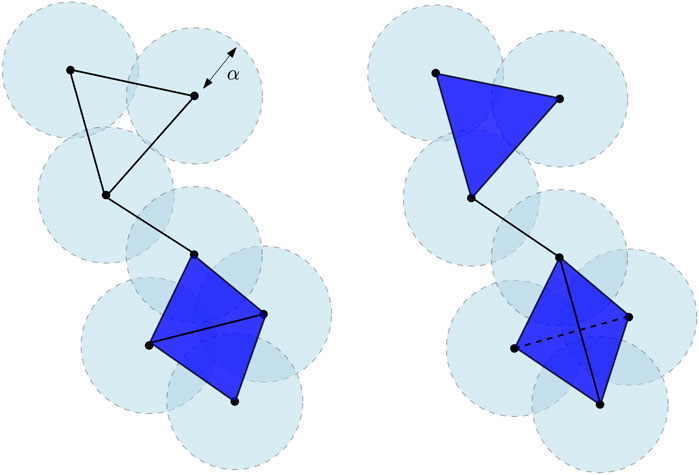
FIGURE 2. Čech complex
Closely related to the Vietoris–Rips complex is the Čech complex
and that if
The Nerve Theorem
The Čech complex is a particular case of a family of complexes associated with covers. Given a cover
Given a cover of a data set, where each set of the cover can be, for example, a local cluster or a grouping of data points sharing some common properties, its nerve provides a compact and global combinatorial description of the relationship between these sets through their intersection patterns (see Figure 3).
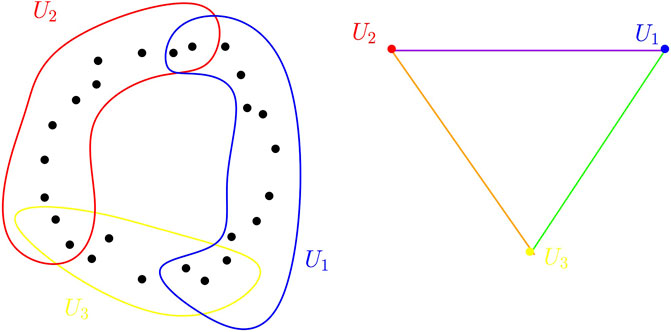
FIGURE 3. Point cloud sampled in the plane and a cover of open sets for this point cloud (left). The nerve of this cover is a triangle (right). Edges correspond to a set of the cover whereas a vertex corresponds to a non-empty intersection between two sets of the cover.
A fundamental theorem in algebraic topology relates, under some assumptions, the topology of the nerve of a cover to the topology of the union of the sets of the cover. To be formally stated, this result, known as the Nerve theorem, requires the introduction of a few notions.
Two topological spaces, X and Y, are usually considered as being the same from a topological point of view if they are homeomorphic, that is, if there exist two continuous bijective maps f: X → Y and g: Y → X such that f°g and g°f are the identity map of Y and X, respectively. In many cases, asking X and Y to be homeomorphic turns out to be too strong a requirement to ensure that X and Y share the same topological features of interest for tda. Two continuous maps f0, f1: X → Y are said to be homotopic if there exists a continuous map H: X × [0, 1] → Y such that for any x ∈ X, H(x, 0) = f0(x) and H(x, 1) = g(x). The spaces X and Y are then said to be homotopy equivalent if there exist two maps, f: X → Y and g: Y → X, such that f°g and g°f are homotopic to the identity map of Y and X, respectively. The maps f and g are then called homotopy equivalent. The notion of homotopy equivalence is weaker than the notion of homeomorphism; if X and Y are homeomorphic, then they are obviously homotopy equivalent, but the converse is not true. However, spaces that are homotopy equivalent still share many topological invariants; in particular, they have the same homology (see Section 4).
A space is said to be contractible if it is homotopy equivalent to a point. Basic examples of contractible spaces are the balls and, more generally, the convex sets in
Theorem 1 (Nerve theorem). Let
It is easy to verify that convex subsets of Euclidean spaces are contractible. As a consequence, if
The Nerve theorem plays a fundamental role in tda; it provides a way to encode the topology of continuous spaces into abstract combinatorial structures that are well suited for the design of effective data structures and algorithms.
3 Using Covers and Nerves for Exploratory Data Analysis and Visualization: The Mapper Algorithm
Using the nerve of covers as a way to summarize, visualize, and explore data is a natural idea that was first proposed for tda in the study by Singh et al. (2007), giving rise to the so-called Mapper algorithm.
Definition 2. Let
The idea of the Mapper algorithm is, given a data set
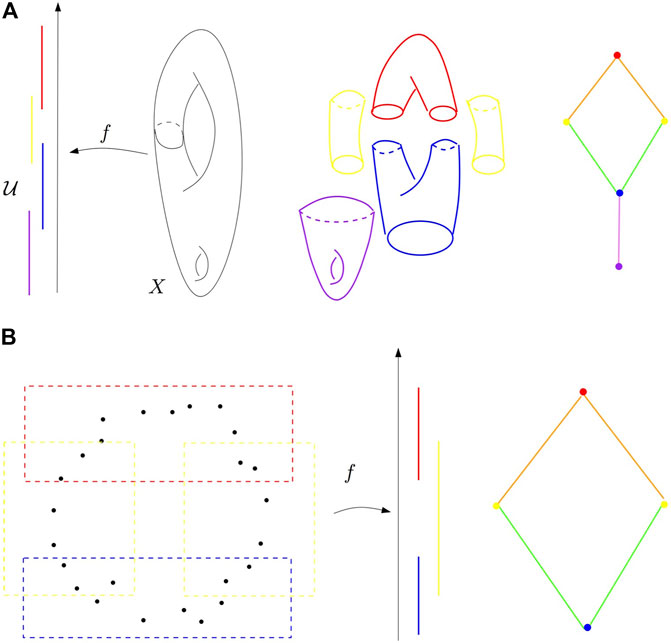
FIGURE 4. (A) Refined pull-back cover of the height function on a surface in
The Mapper algorithm is very simple (see Algorithm 1); but it raises several questions about the various choices that are left to the user and that we briefly discuss in the following.

Algorithm 1. The Mapper algorithm
The Choice of f
The choice of the function f, sometimes called the filter or lens function, strongly depends on the features of the data that one expects to highlight. The following ones are among the ones more or less classically encountered in the literature:
-Density estimates: the Mapper complex may help to understand the structure and connectivity of high-density areas (clusters).
-PCA coordinates or coordinate functions obtained from a nonlinear dimensionality reduction (NLDR) technique, eigenfunctions of graph laplacians may help to reveal and understand some ambiguity in the use of nonlinear dimensionality reductions.
-The centrality function
-For data that are sampled around one-dimensional filamentary structures, the distance function to a given point allows us to recover the underlying topology of the filamentary structures Chazal et al. (2015d).
The Choice of the Cover
When f is a real-valued function, a standard choice is to take
The Choice of the Clusters
The Mapper algorithm requires the clustering of the preimage of the open sets
Theoretical and Statistical Aspects of Mapper
Based on the results on stability and the structure of Mapper proposed in the study by Carrière and Oudot (2017), advances toward a statistically well-founded version of Mapper have been made recently in the study by Carriere et al. (2018). Unsurprisingly, the convergence of Mapper depends on both the sampling of the data and the regularity of the filter function. Moreover, subsampling strategies can be proposed to select a complex in a Rips filtration on a convenient scale, as well as the resolution and the gain for defining the Mapper graph. The case of stochastic and multivariate filters has also been studied by Carrière and Michel (2019). An alternative description of the probabilistic convergence of Mapper, in terms of categorification, has also been proposed in the study by Brown et al. (2020). Other approaches have been proposed to study and deal with the instabilities of the Mapper algorithm in the works of Dey et al. (2016), Dey et al. (2017).
Data Analysis With Mapper
As an exploratory data analysis tool, Mapper has been successfully used for clustering and feature selection. The idea is to identify specific structures in the Mapper graph (or complex), in particular, loops and flares. These structures are then used to identify interesting clusters or to select features or variables that best discriminate the data in these structures. Applications on real data, illustrating these techniques, may be found, for example, in the studies by Carrière and Rabadán (2020), Lum et al. (2013), Yao et al. (2009).
4 Geometric Reconstruction and Homology Inference
Another way to build covers and use their nerves to exhibit the topological structure of data is to consider the union of balls centered on the data points. In this section, we assume that
1.
2. from a practical and algorithmic perspective, topological features of M are inferred from the nerve of the union of balls, using the Nerve theorem.
In this framework, it is indeed possible to compare spaces through isotopy equivalence, a stronger notion than homeomorphism;
4.1 Distance-Like Functions and Reconstruction
Given a compact subset K of
Definition 3 (Hausdorff distance in
In our setting, the considered compact sets are the data set
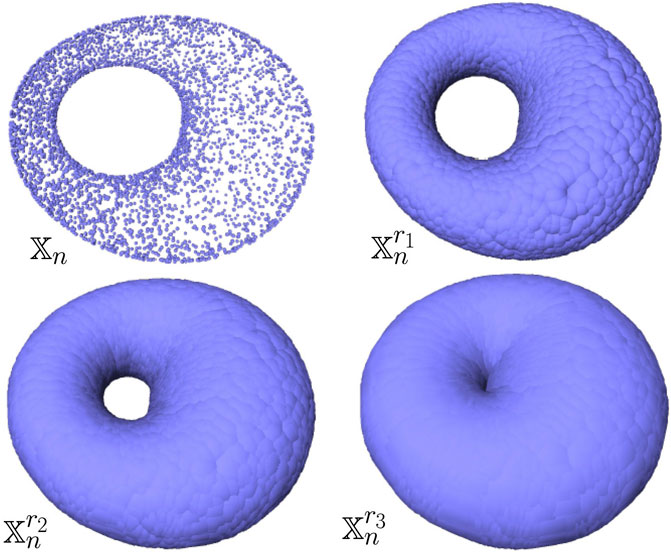
FIGURE 5. Example of a point cloud
These results rely on the one-semiconcavity of the squared distance function
Definition 4. A function
Thanks to its semiconcavity, a distance-like function ϕ has a well-defined, but not continuous, gradient
Definition 5. Let ϕ be a distance-like function and let ϕr = ϕ−1([0, r]) be the r-sublevel set of ϕ.
• A point
• The weak feature size of ϕ at r is the minimum r′ > 0 such that ϕ does not have any critical value between r and r + r′. We denote it by wfsϕ(r). For any 0 < α < 1, the α-reach of ϕ is the maximum r such that ϕ−1((0, r]) does not contain any α-critical point.
The weak feature size wfsϕ(r) (resp. α-reach) measures the regularity of ϕ around its r-level sets (resp. O-level set). When ϕ = dK is the distance function to a compact set
Lemma 1 (isotopy lemma grove (1993)). Let ϕ be a distance-like function and r1 < r2be two positive numbers such that ϕ has no 0-critical point, that is, points x such that ∇ϕ(x) = 0, in the subset ϕ−1([r1, r2]). Then all the sublevel sets ϕ−1([0, r]) are isotopic for r ∈ [r1, r2].
As an immediate consequence of the isotopy lemma, all the sublevel sets of ϕ between r and r + wfsϕ(r) have the same topology. Now the following reconstruction theorem from Chazal et al. (2011b) provides a connection between the topology of the sublevel sets of close distance-like functions.
Theorem 2 (Reconstruction theorem). Let ϕ, ψ be two distance-like functions such that ‖ϕ − ψ‖∞ < ɛ, with reachα(ϕ) ≥ R for some positive ɛ and α. Then, for every r ∈ [4ɛ/α2, R − 3ɛ] and every η ∈ (0, R), the sublevel sets ψrand ϕηare homotopy equivalent when
Under similar but slightly more technical conditions, the Reconstruction theorem can be extended to prove that the sublevel sets are indeed homeomorphic and even isotopic (Chazal et al., 2009c; Chazal et al., 2008).
Coming back to our setting and taking for ϕ = dM and
From a statistical perspective, the main advantage of these results involving the Hausdorff distance is that the estimation of the considered topological quantities boils down to support estimation questions that have been widely studied (see Section 4.3).
4.2 Homology Inference
The above results provide a mathematically well-founded framework to infer the topology of shapes from a simplicial complex built on the top of an approximating finite sample. However, from a more practical perspective, it raises two issues. First, the Reconstruction theorem requires a regularity assumption through the α-reach condition that may not always be satisfied and the choice of a radius r for the ball used to build the Čech complex
Homology in a Nutshell
Homology is a classical concept in algebraic topology, providing a powerful tool to formalize and handle the notion of the topological features of a topological space or of a simplicial complex in an algebraic way. For any dimension k, the k-dimensional “holes” are represented by a vector space Hk, whose dimension is intuitively the number of such independent features. For example, the zero-dimensional homology group H0 represents the connected components of the complex, the one-dimensional homology group H1 represents the one-dimensional loops, the two-dimensional homology group H2 represents the two-dimensional cavities, and so on.
To avoid technical subtleties and difficulties, we restrict the introduction of homology to the minimum that is necessary to understand its usage in the following of the article. In particular, we restrict our information to homology with coefficients in
Let K be a (finite) simplicial complex and let k be a nonnegative integer. The space of k-chains on K, Ck(K) is the set whose elements are the formal (finite) sums of k-simplices of K. More precisely, if {σ1, … , σp} is the set of k-simplices of K, then any k-chain can be written as
If
The boundary of a k-simplex σ = [v0, … , vk] is the (k − 1)-chain
where
In other words, any k-boundary is a k-cycle, that is, Bk(K) ⊆ Zk(K) ⊆ Ck(K). These notions are illustrated in Figure 6.
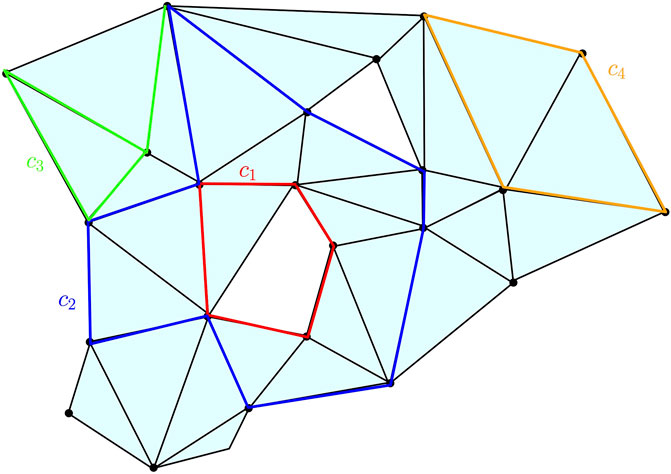
FIGURE 6. Some examples of chains, cycles, and boundaries on a two-dimensional complex K: c1, c2, and c4 are one-cycles; c3 is a one-chain but not a one-cycle; c4 is the one-boundary, namely, the boundary of the two-chain obtained as the sum of the two triangles surrounded by c4. The cycles c1 and c2 span the same element in H1(K) as their difference is the two-chain represented by the union of the triangles surrounded by the union of c1 and c2.
Definition 6 (simplicial homology group and Betti numbers). The kth (simplicial) homology group of K is the quotient vector space
The kth Betti number of K is the dimension βk(K) = dim Hk(K) of the vector space Hk(K).
Figure 7 gives the Betti numbers of several simple spaces. Two cycles, c, c′ ∈ Zk(K), are said to be homologous if they differ by a boundary, that is, if there exists a (k + 1)-chain d such that c′ = c + ∂k+1(d). Two such cycles give rise to the same element of Hk. In other words, the elements of Hk(K) are the equivalence classes of homologous cycles.
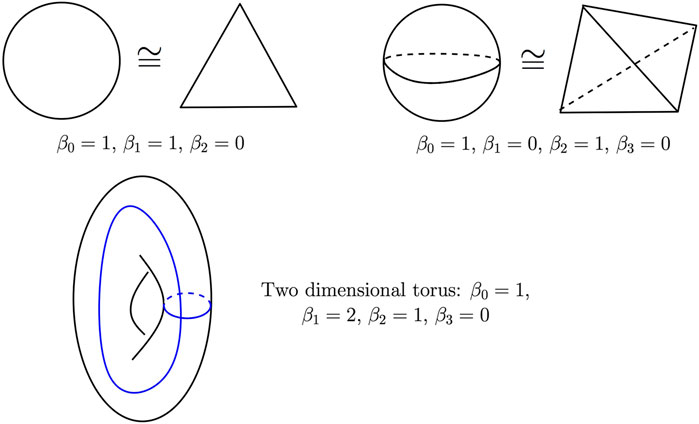
FIGURE 7. Betti numbers of the circle (top left), the two-dimensional sphere (top right), and the two-dimensional torus (bottom). The blue curves on the torus represent two independent cycles whose homology class is a basis of its one-dimensional homology group.
Simplicial homology groups and Betti numbers are topological invariants; if K, K′ are two simplicial complexes whose geometric realizations are homotopy equivalent, then their homology groups are isomorphic and their Betti numbers are the same.
Singular homology is another notion of homology that allows us to consider larger classes of topological spaces. It is defined for any topological space X similarly to simplicial homology, except that the notion of the simplex is replaced by the notion of the singular simplex, which is just any continuous map σ: Δk → X where Δk is the standard k-dimensional simplex. The space of k-chains is the vector space spanned by the k-dimensional singular simplices, and the boundary of a simplex σ is defined as the (alternated) sum of the restriction of σ to the (k − 1)-dimensional faces of Δk. A remarkable fact about singular homology is that it coincides with simplicial homology whenever X is homeomorphic to the geometric realization of a simplicial complex. This allows us, in the sequel of this article, to indifferently talk about simplicial or singular homology for topological spaces and simplicial complexes.
Observing that if f: X → Y is a continuous map, then for any singular simplex σ: Δk → X in X, f °σ: Δk → Y is a singular simplex in Y, one easily deduces that continuous maps between topological spaces canonically induce homomorphisms between their homology groups. In particular, if f is a homeomorphism or a homotopy equivalence, then it induces an isomorphism between Hk(X) and Hk(Y) for any nonnegative integer k. As an example, it follows from the Nerve theorem that for any set of points
As a consequence, the Reconstruction theorem 2 leads to the following result on the estimation of Betti numbers.
Theorem 3. Let
In particular, if M is a smooth m-dimensional submanifold of
From a practical perspective, this result raises three difficulties: first, the regularity assumption involving the α-reach of M may be too restrictive; second, the computation of the nerve of a union of balls requires the use of a tricky predicate testing the emptiness of a finite union of balls; third, the estimation of the Betti numbers relies on the scale parameter r, whose choice may be a problem.
To overcome these issues, Chazal and Oudot (2008) established the following result, which offers a solution to the first two problems.
Theorem 4. Let
where rk
Although this result leaves the question of the choice of the scale parameter r open, it is proven in the study by Chazal and Oudot (2008) that a multiscale strategy whose description is beyond the scope of this article provides some help in identifying the relevant scales on which Theorem 4 can be applied.
4.3 Statistical Aspects of Homology Inference
According to the stability results presented in the previous section, a statistical approach to topological inference is strongly related to the problem of distribution support estimation and level sets estimation under the Hausdorff metric. A large number of methods and results are available for estimating the support of a distribution in statistics. For instance, the Devroye and Wise estimator (Devroye and Wise, 1980) defined on a sample
In the study by Niyogi et al. (2008), it was shown that the homotopy type of Riemannian manifolds with a reach larger than a given constant can be recovered with high probability from offsets of a sample on (or close to) the manifold. This article was probably the first attempt to consider the topological inference problem in terms of probability. The result of the study by Niyogi et al. (2008) was derived from a retract contraction argument and was on tight bounds over the packing number of the manifold in order to control the Hausdorff distance between the manifold and the observed point cloud. The homology inference in the noisy case, in the sense that the distribution of the observation is concentrated around the manifold, was also studied by Niyogi et al. (2008), Niyogi et al. (2011). The assumption that the geometric object is a smooth Riemannian manifold is only used in the article to control in probability the Hausdorff distance between the sample and the manifold and is not actually necessary for the “topological part” of the result. Regarding the topological results, these are similar to those of the studies by Chazal et al. (2009d), Chazal and Lieutier (2008) in the particular framework of Riemannian manifolds. Starting from the result of the study by Niyogi et al. (2008), the minimax rates of convergence of the homology type have been studied by Balakrishna et al. (2012) under various models for Riemannian manifolds with a reach larger than a constant. In contrast, a statistical version of the work of Chazal et al. (2009d) has not yet been proposed.
More recently, following the ideas of Niyogi et al. (2008), Bobrowski et al. (2014) have proposed a robust homology estimator for the level sets of both density and regression functions, by considering the inclusion map between nested pairs of estimated level sets (in the spirit of Theorem 4 above) obtained using a plug-in approach from a kernel estimator.
4.4 Going Beyond Hausdorff Distance: Distance to Measure
It is well known that distance-based methods in tda may fail completely in the presence of outliers. Indeed, adding even a single outlier to the point cloud can change the distance function dramatically (see Figure 8 for an illustration). To answer this drawback, Chazal et al. (2011b) have introduced an alternative distance function which is robust to noise, the distance-to-measure.
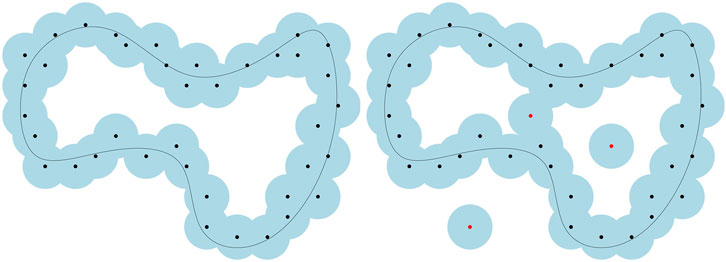
FIGURE 8. Effect of outliers on the sublevel sets of distance functions. Adding just a few outliers to a point cloud may dramatically change its distance function and the topology of its offsets.
Given a probability distribution P in
where B(x, t) is the closed Euclidean ball of center x and radius t. To avoid issues due to discontinuities of the map P → δP,u, the distance-to-measure (DTM) function with parameter m ∈ [0, 1] and power r ≥ 1 is defined by
A nice property of the DTM proved by Chazal et al. (2011b) is its stability with respect to perturbations of P in the Wasserstein metric. More precisely, the map P → dP,m,r is
where Wr is the Wasserstein distance for the Euclidean metric on
In practice, the measure P is usually only known through a finite set of observations
where
The introduction of the DTM has motivated further works and applications in various directions such as topological data analysis (Buchet et al., 2015a), GPS trace analysis (Chazal et al., 2011a), density estimation (Biau et al., 2011), hypothesis testing Brécheteau (2019), and clustering (Chazal et al., 2013), just to name a few. Approximations, generalizations, and variants of the DTM have also been considered (Guibas et al., 2013; Phillips et al., 2014; Buchet et al., 2015b; Brécheteau and Levrard, 2020).
5 Persistent Homology
Persistent homology is a powerful tool used to efficiently compute, study, and encode multiscale topological features of nested families of simplicial complexes and topological spaces. It does not only provide efficient algorithms to compute the Betti numbers of each complex in the considered families, as required for homology inference in the previous section, but also encodes the evolution of the homology groups of the nested complexes across the scales. Ideas and preliminary results underlying persistent homology theory can be traced back to the 20th century, in particular in the works of Barannikov (1994), Frosini (1992), Robins (1999). It started to know an important development in its modern form after the seminal works of Edelsbrunner et al. (2002) and Zomorodian and Carlsson (2005).
5.1 Filtrations
A filtration of a simplicial complex K is a nested family of subcomplexes
In practical situations, the parameter r ∈ T can often be interpreted as a scale parameter, and filtrations classically used in TDA often belong to one of the two following families.
Filtrations Built on Top of Data
Given a subset
Sublevel Sets Filtrations
Functions defined on the vertices of a simplicial complex give rise to another important example of filtration: let K be a simplicial complex with vertex set V and
In practice, even if the index set is infinite, all the considered filtrations are built on finite sets and are indeed finite. For example, when
5.2 Starting With a Few Examples
Given a filtration
Before giving formal definitions, we introduce and illustrate persistent homology on a few simple examples.
Example 1
Let
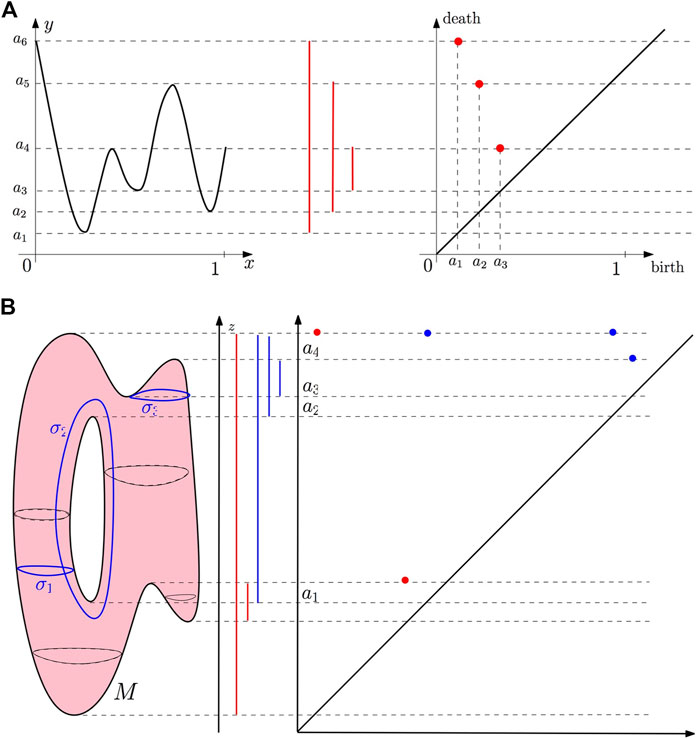
FIGURE 9. (A) Example 1: the persistence barcode and the persistence diagram of a function
Example 2
Let
Example 3
In this last example, we consider the filtration given by a union of growing balls centered on the finite set of points C in Figure 10. Notice that this is the sublevel set filtration of the distance function to C, and thanks to the Nerve theorem, this filtration is homotopy equivalent to the Čech filtration built on the top of C. Figure 10 shows several level sets of the filtration as follows:
a) For the radius r = 0, the union of balls is reduced to the initial finite set of points, each of them corresponding to a zero-dimensional feature, that is, a connected component; an interval is created for the birth for each of these features at r = 0.
b) Some of the balls started to overlap, resulting in the death of some connected components that get merged together; the persistence diagram keeps track of these deaths, putting an end point to the corresponding intervals as they disappear.
c) New components have merged, giving rise to a single connected component and, so, all the intervals associated with a zero-dimensional feature have been ended, except the one corresponding to the remaining components; two new one-dimensional features have appeared, resulting in two new intervals (in blue) starting on their birth scale.
d) One of the two one-dimensional cycles has been filled, resulting in its death in the filtration and the end of the corresponding blue interval.
e) All the one-dimensional features have died; only the long (and never dying) red interval remains. As in the previous examples, the final barcode can also be equivalently represented as a persistence diagram where every interval (a, b) is represented by the point of coordinates (a, b) in
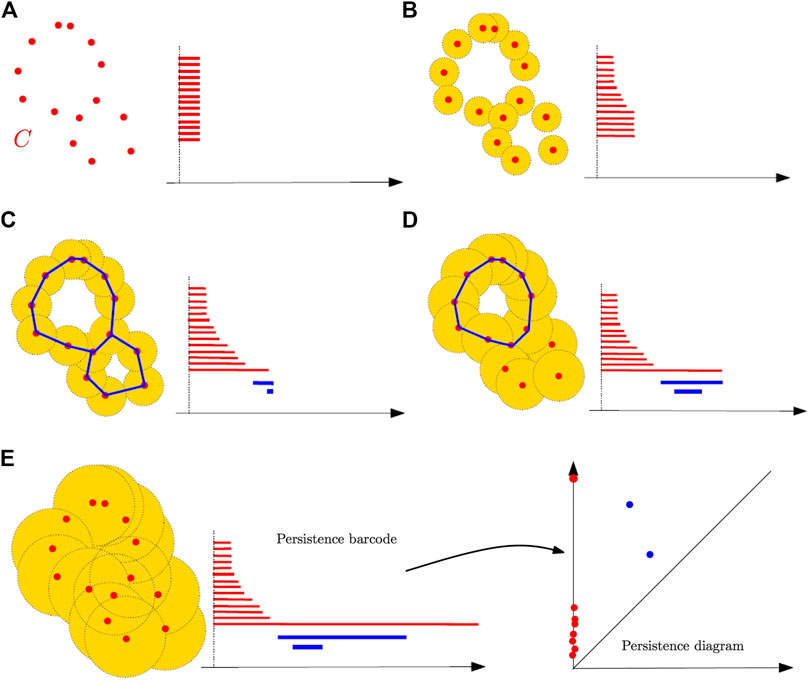
FIGURE 10. The sublevel set filtration of the distance function to a point cloud and the construction of its persistence barcode as the radius of balls increases. The blue curves in the unions of balls represent one-cycles associated with the blue bars in the barcodes. The persistence diagram is finally defined from the persistence barcodes. (A) For the radius r = 0, the union of balls is reduced to the initial finite set of points, each of them corresponding to a zero-dimensional feature, that is, a connected component; an interval is created for the birth for each of these features at r = 0. (B) Some of the balls started to overlap, resulting in the death of some connected components that get merged together; the persistence diagram keeps track of these deaths, putting an end point to the corresponding intervals as they disappear. (C) New components have merged, giving rise to a single connected component and, so, all the intervals associated with a zero-dimensional feature have been ended, except the one corresponding to the remaining components; two new one-dimensional features have appeared, resulting in two new intervals (in blue) starting on their birth scale. (D) One of the two one-dimensional cycles has been filled, resulting in its death in the filtration and the end of the corresponding blue interval. (E) All the one-dimensional features have died; only the long (and never dying) red interval remains. As in the previous examples, the final barcode can also be equivalently represented as a persistence diagram where every interval (a, b) is represented by the point of coordinates (a, b) in
5.3 Persistent Modules and Persistence Diagrams
Persistent diagrams can be formally and rigorously defined in a purely algebraic way. This requires some care, and we only give the basic necessary notions here, leaving aside technical subtleties and difficulties. We refer the readers interested in a detailed exposition to Chazal et al. (2016a).
Let
Definition 7. A persistence module
In many cases, a persistence module can be decomposed into a direct sum of interval modules
where the maps
The following result, from (Chazal et al., 2016a, Theorem 2.8), gives some necessary conditions for a persistence module to be decomposable as a direct sum of interval modules.
Theorem 5. Let
As both conditions above are satisfied for the persistent homology of filtrations of finite simplicial complexes, an immediate consequence of this result is that the persistence diagrams of such filtrations are always well defined.
Indeed, it is possible to show that persistence diagrams can be defined as soon as the following simple condition is satisfied.
Definition 8. A persistence module
Theorem 6 Chazal et al. (2009a), Chazal et al. (2016a). If
The construction of persistence diagrams of q-tame modules is beyond the scope of this article, but it gives rise to the same notion as in the case of decomposable modules. It can be done either by following the algebraic approach based upon the decomposability properties of modules or by adopting a measure theoretic approach that allows us to define diagrams as integer-valued measures on a space of rectangles in the plane. We refer the reader to Chazal et al. (2016a) for more information.
Although persistence modules encountered in practice are decomposable, the general framework of the q-tame persistence module plays a fundamental role in the mathematical and statistical analysis of persistent homology. In particular, it is needed to ensure the existence of limit diagrams when convergence properties are studied (see Section 6).
A filtration
5.4 Persistence Landscapes
The persistence landscape introduced in the study by Bubenik (2015) is an alternative representation of persistence diagrams. This approach aims at representing the topological information encoded in persistence diagrams as elements of a Hilbert space, for which statistical learning methods can be directly applied. The persistence landscape is a collection of continuous, piecewise linear functions
A birth–death pair p = (b, d) ∈ dgm is transformed into the point
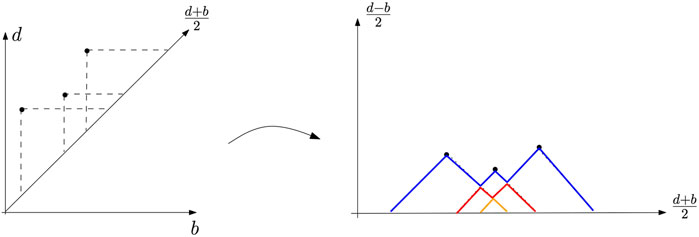
FIGURE 11. Example of a persistence landscape (right) associated with a persistence diagram (left). The first landscape is in blue, the second one in red, and the last one in orange. All the other landscapes are zero.
The persistence landscape λdgm of dgm is a summary of the arrangement of piecewise linear curves obtained by overlaying the graphs of the functions
where kmax is the kth largest value in the set; in particular, 1max is the usual maximum function. Given
The advantage of the persistence landscape representation is two-fold. First, persistence diagrams are mapped as elements of a functional space, opening the door to the use of a broad variety of statistical and data analysis tools for further processing of topological features see Bubenik (2015), Chazal et al. (2015c) and Section 6.3.1. Second, and fundamental from a theoretical perspective, the persistence landscapes share the same stability properties as those of persistence diagrams (see Section 5.7).
5.5 Linear Representations of Persistence Homology
A persistence diagram without its essential part can be represented as a discrete measure on Δ+ = {p = (b, d), b < d < ∞}. With a slight abuse of notation, we can write the following:
where the features are counted with multiplicity and where δ(b,d) denotes the Dirac measure in p = (b, d). Most of the persistence-based descriptors that have been proposed to analyze persistence can be expressed as linear transformations of the persistence diagram, seen as a point process
for some function f defined on Δ and taking values in a Banach space.
In most cases, we want these transformations to apply independently at each homological dimension. For
where dgmk is the persistence diagram of the topological features of dimension k and where fk is defined on Δ and takes values in a Banach space.
Betti Curve
The simplest way to represent persistence homology is the Betti function or the Betti curve. The Betti curve of homological dimension k is defined as
where w is a weight function defined on Δ. In other words, the Betti curve is the number of barcodes at time m. This descriptor is a linear representation of persistence homology by taking f in (5) such that f(b, d) (t) = w(b, d)1t∈[b,d]. A typical choice for the weigh function is an increasing function of the persistence
Persistence Surface
The persistence surface (also called persistence images) is obtained by making the convolution of a diagram with a kernel. It has been introduced in the study by Adams et al. (2017). For
Let
The persistence surface is obviously a linear representation of persistence homology. Typical weigh functions are increasing functions of the persistence.
Other Linear Representations of Persistence
Many other linear representations of persistence have been proposed in the literature, such as the persistence silhouette (Chazal et al., 2015b), the accumulated persistence function (Biscio and Møller, 2019), and variants of the persistence surface (Reininghaus et al., 2015; Kusano et al., 2016; Chen et al., 2017).
Considering persistence diagrams as discrete measures and their vectorizations as linear representation is an approach that has also proven fruitful to studying distributions of diagrams Divol and Chazal (2020) and the metric structure of the space of persistence diagrams Divol and Lacombe (2020) (see Sections 5.6 and Section 6.3).
5.6 Metrics on the Space of Persistence Diagrams
To exploit the topological information and topological features inferred from persistent homology, one needs to be able to compare persistence diagrams, that is, to endow the space of persistence diagrams with a metric structure. Although several metrics can be considered, the most fundamental one is known as the bottleneck distance.
Recall that a persistence diagram is the union of a discrete multi-set in the half-plane above the diagonal Δ and, for technical reasons that will become clear below, of Δ where the point of Δ is counted with infinite multiplicity. A matching (see Figure 12) between two diagrams, dgm1 and dgm2, is a subset m ⊆ dgm1 × dgm2 such that every point in dgm1 \Δ and dgm2 \Δ appears exactly once in m. In other words, for any p ∈ dgm1 \Δ and for any q ∈ dgm2 \Δ, ({p}× dgm2) ∩ m and (dgm1 ×{q}) ∩ m each contains a single pair. The bottleneck distance between dgm1 and dgm2 is then defined by
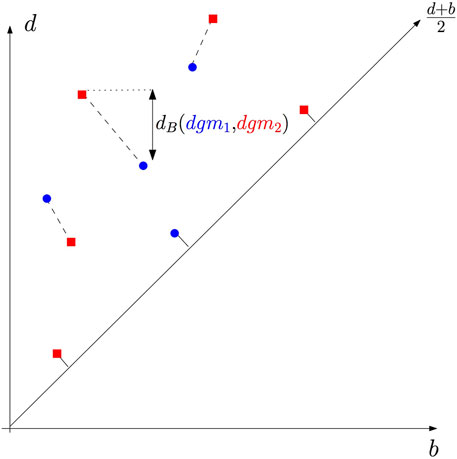
FIGURE 12. Perfect matching and the bottleneck distance between a blue and a red diagram. Notice that some points of both diagrams are matched to points of the diagonal.
The practical computation of the bottleneck distance boils down to the computation of a perfect matching in a bipartite graph for which classical algorithms can be used.
The bottleneck metric is an L∞-like metric. It turns out to be the natural one to express stability properties of persistence diagrams presented in Section 5.7, but it suffers from the same drawbacks as the usual L∞ norms, that is, it is completely determined by the largest distance among the pairs and does not take into account the closeness of the remaining pairs of points. A variant to overcome this issue, the so-called Wasserstein distance between diagrams, is sometimes considered. Given p ≥ 1, it is defined by
Useful stability results for persistence in the Wp metric exist among the literature, in particular the study by Cohen-Steiner et al. (2010), but they rely on assumptions that make them consequences of the stability results in the bottleneck metric. A general study of the space of persistence diagrams endowed with Wp metrics has been considered in the study by Divol and Lacombe (2020), where they proposed a general framework, based upon optimal partial transport, in which many important properties of persistence diagrams can be proven in a natural way.
5.7 Stability Properties of Persistence Diagrams
A fundamental property of persistence homology is that persistence diagrams of filtrations built on the top of data sets turn out to be very stable with respect to some perturbations of the data. To formalize and quantify such stability properties, we first need to be precise with regard to the notion of perturbation that is allowed.
Rather than working directly with filtrations built on the top of data sets, it turns out to be more convenient to define a notion of proximity between persistence modules, from which we will derive a general stability result for persistent homology. Then, most of the stability results for specific filtrations will appear as a consequence of this general theorem. To avoid technical discussions, from now on, we assume, without loss of generality, that the considered persistence modules are indexed by
Definition 9. Let
An important example of a homomorphism of degree δ is the shift endomorphism
Definition 10. Let δ ≥ 0. Two persistence modules
Although it does not define a metric on the space of persistence modules, the notion of closeness between two persistence modules may be defined as the smallest nonnegative δ such that they are δ-interleaved. Moreover, it allows us to formalize the following fundamental theorem (Chazal et al., 2009a; Chazal et al., 2016a).
Theorem 7 (Stability of persistence). Let
Although purely algebraic and rather abstract, this result is an efficient tool to easily establish concrete stability results in TDA. For example, we can easily recover the first persistence stability result that appeared in the literature (Cohen-Steiner et al., 2005).
Theorem 8. Let
where dgmk(f) (resp. dgmk(g)) is the persistence diagram of the persistence module
Proof. Denoting δ = ‖f − g‖∞, we have that for any
Theorem 7 also implies a stability result for the persistence diagrams of filtrations built on the top of data.
Theorem 9. Let
where
As we already noticed in Example 3 of Section 5.2, the persistence diagrams can be interpreted as multiscale topological features of
We now give similar results for the alternative persistence homology representations introduced before. From the definition of the persistence landscape, we immediately observe that λ(k, ⋅) is one-Lipschitz, and thus, stability properties similar to those for persistence diagrams are satisfied for the landscapes.
Proposition 1 (stability of persistence landscapes; Bubenik (2015)). Let dgm and dgm’ be two persistence diagrams (without their essential parts). For any
(i) λ(k, t) ≥ λ(k + 1, t) ≥ 0.
(ii)
A large class of linear representations is continuous with respect to the Wasserstein metric Ws in the space of persistence diagrams and with respect to the Banach norm of the linear representation of persistence. Generally speaking, it is not always possible to upper bound the modulus of continuity of the linear representation operator. However, in the case where s = 1, it is even possible to show a stability result if the weight function takes small values for points close to the diagonal (see Divol and Lacombe (2020), Hofer et al. (2019b)).
Stability Versus Discriminative Capacity of Persistence Representations
The results of the study by Divol and Lacombe (2020) showed that continuity and stability are only possible with weigh functions taking small values for points close to the diagonal. However, in general, there is no specific reason to consider that points close to the diagonal are less important than others, given a learning task. In a machine learning perspective, it is also relevant to design linear representation with general weigh functions, although it would be more difficult to prove the consistency of the corresponding methods without at least the continuity of the representation. Stability is thus important but maybe too strong a requirement for many problems in data sciences. Designing linear representation that is sensitive to specific parts of persistence diagrams rather than globally stable may reveal a good strategy in practice.
6 Statistical Aspects of Persistent Homology
Persistence homology by itself does not take into account the random nature of data and the intrinsic variability of the topological quantity they infer. We now present a statistical approach to persistent homology, in the sense that data are considered to be generated from an unknown distribution. We start with several consistency results for persistent homology inference.
6.1 Consistency Results for Persistent Homology
Assume that we observe n points (X1, … , Xn) in a metric space (M, ρ) drawn i. i. d. from an unknown probability measure μ whose support is a compact set denoted
Let
The finite set
This assumption has been widely used in the literature of set estimation under the Hausdorff distance (Cuevas and Rodríguez-Casal, 2004; Singh et al., 2009). Under this assumption, it can be easily derived that the rate of convergence of
Theorem 10. Chazal et al. (2014)For some positive constants a and b, let
Then, it holds
where the constant C only depends on a and b.
Under additional technical assumptions, the corresponding lower bound can be shown (up to a logarithmic term) (see Chazal et al. (2014)). By applying stability results, similar consistency results can be easily derived under alternative generative models as soon as a consistent estimator of the support under the Hausdorff metric is known. For instance, from the results of the study by Genovese et al. (2012) about Hausdorff support estimation under additive noise, it can be deduced that the minimax convergence rates for the persistence diagram estimation are faster than (log n)−1/2. Moreover, as soon as a stability result is available for some given representation of persistence, similar consistency results can be directly derived from the consistency for persistence diagrams.
Estimation of the Persistent Homology of Functions
Theorem 7 opens the door to the estimation of the persistent homology of functions defined on
6.2 Statistic of Persistent Homology Computed on a Point Cloud
For many applications, in particular when the support of the point cloud is not drawn on or close to a geometric shape, persistence diagrams can be quite complex to analyze. In particular, many topological features are closed to the diagonal. Since they correspond to topological structures that die very soon after they appear in the filtration, these points are generally considered as noise (see Figure 13 for an illustration). Confidence regions of persistence diagrams are rigorous answers to the problem of distinguishing between the signal and the noise in these representations.
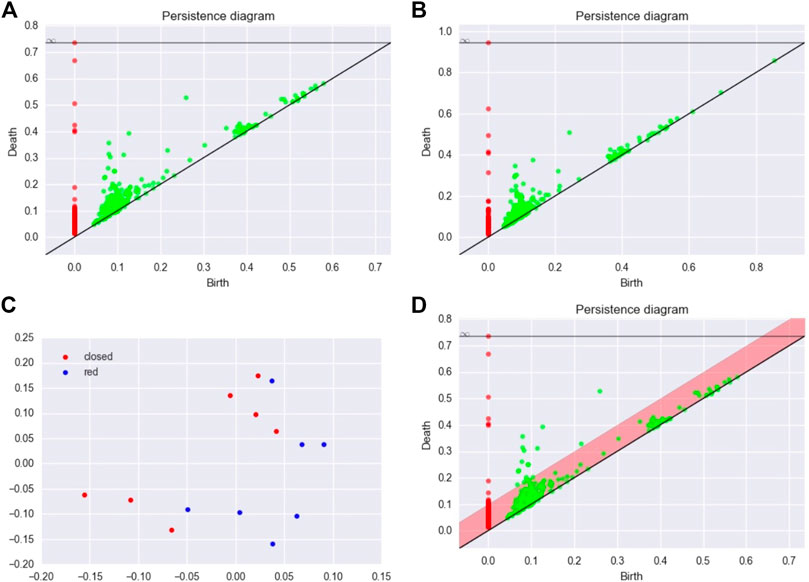
FIGURE 13. (A,B) Two persistence diagrams for two configurations of MBP. (C) MDS configuration for the matrix of bottleneck distances. (D) Persistence diagram and confidence region for the persistence diagram of an MBP.
The stability results given in Section 5.7 motivate the use of the bottleneck distance to define confidence regions. However, alternative distances in the spirit of Wasserstein distances can be proposed too. When estimating a persistence diagram dgm with an estimator
for α ∈ (0, 1). Let Bα be the closed ball of radius α for the bottleneck distance, centered at
Several methods have been proposed in the study by Fasy et al. (2014b) to estimate ηα in different frameworks. These methods mainly rely on stability results for persistence diagrams; confidence sets for diagrams can be derived from confidence sets in the sample space.
Subsampling Approach
This method is based on a confidence region for the support K of the distribution of the sample in the Hausdorff distance. Let
Bottleneck Bootstrap
The stability results often lead to conservative confidence sets. An alternative strategy is the bottleneck bootstrap introduced in the study by Chazal et al. (2016b). We consider the general setting where a persistence diagram
Note that
Bootstrapping Persistent Betti Numbers
As already mentioned, confidence regions based on stability properties of persistence may lead to very conservative confidence regions. Based on the concepts of stabilizing statistics Penrose and Yukich (2001), asymptotic normality for persistent Betti numbers has been shown recently by Krebs and Polonik (2019) and Roycraft et al. (2020) under very mild conditions on the filtration and the distribution of the sample cloud. In addition, bootstrap procedures are also shown to be valid in this framework. More precisely, a smoothed bootstrap procedure together with a convenient rescaling of the point cloud seems to be a promising approach for boostrapping TDA features from point cloud data.
6.3 Statistic for a Family of Persistent Diagrams or Other Representations
Up to now in this section, we were only considering statistics based on one single observed persistence diagram. We now consider a new framework where several persistence diagrams (or other representations) are available, and we are interested in providing the central tendency, confidence regions, and hypothesis tests for topological descriptors built on this family.
6.3.1 Central Tendency for Persistent Homology
Mean and Expectations of Distributions of Diagrams
The space of persistence diagrams being a general metric space but not a Hilbert space, the definition of a mean persistence diagram is not obvious and unique. One first natural approach to defining a central tendency in this context is to consider Fréchet means of distributions of diagrams. Their existence has been proven in the study by Mileyko et al. (2011), and they have also been characterized in the study by Turner et al. (2014a). However, they may not be unique, and they turn out to be difficult to compute in practice. To partly overcome these problems, different approaches have been recently proposed based on numerical optimal transport Lacombe et al. (2018) or linear representations and kernel-based methods Divol and Chazal (2020).
Topological Signatures From Subsamples
Central tendency properties of persistent homology can also be used to compute topological signatures for very large data sets, as an alternative approach to overcome the prohibitive cost of persistence computations. Given a large point cloud, the idea is to extract many subsamples, to compute the persistence landscape for each subsample, and then to combine the information.
For any positive integer m, let X = {x1, … , xm} be a sample of m points drawn from a measure μ in a metric space M and which support is denoted by
and propose to use
Another motivation for this subsampling approach is that it can also be applied when μ is a discrete measure with the support
The average landscape
Theorem 11. [Chazal et al. (2015a)] Let X ∼ μ⊗mand Y ∼ ν⊗m, where μ and ν are two probability measures on M. For any p ≥ 1, we have
where Wp is the pth Wasserstein distance on M.
The result of Theorem 11 is useful for two reasons. First, it tells us that for a fixed m, the expected “topological behavior” of a set of m points carries some stable information about the underlying measure from which the data are generated. Second, it provides a lower bound for the Wasserstein distance between two measures, based on the topological signature of samples of m points.
6.3.2 Asymptotic Normality
As in the previous section, we consider several persistence diagrams (or other representations). The next step after giving central tendency descriptors of persistence homology is to provide asymptotic normality results for these quantities together with bootstrap procedures to derive confidence regions. It is of course easier to show such results for functional representations of persistence. In the studies by Chazal et al. (2015b), Chazal et al. (2015c), following this strategy, confidence bands for landscapes are proposed from the observation of landscapes λ1, … , λN drawn i. i. d. from a random distribution in the space of landscapes. The asymptotic validity and the uniform convergence of the multiplier bootstrap is shown in this framework. Note that similar results can also be proposed for many representations of persistence, in particular by showing that the corresponding functional spaces are Donsker spaces.
6.4 Other Statistical Approaches to Topological Data Analysis
Statistical approaches for tda are seeing an increasing interest and many others have been proposed in recent years or are still subject to active research activities, as illustrated in the following non-exhaustive list of examples.
Hypothesis Testing
Several methods have been proposed for hypothesis testing procedures for persistent homology, mostly based on permutation strategies and for two-sample testing. Robinson and Turner (2017) focused on pairwise distances of persistence diagrams, whereas Berry et al. (2020) studied more general functional summaries. Hypothesis tests based on kernel approaches have been proposed in the study by Kusano (2019). A two-stage hypothesis test of filtering and testing for persistent images was also presented in the study by Moon and Lazar (2020).
Persistence Homology Transform
The representations introduced before are all transformations derived from the persistence diagram computed from a fixed filtration built over a data set. The persistence homology transform introduced in the studies by Curry et al. (2018), Turner et al. (2014b) to study shapes in
Bayesian Statistics for Topological Data Analysis
A Bayesian approach to persistence diagram inference has been proposed in the study by Maroulas et al. (2020) by viewing a persistence diagram as a sample from a point process. This Bayesian method computes the point process posterior intensity based on a Gaussian mixture intensity for the prior.
6.5 Persistent Homology and Machine Learning
Using tda and, more specifically, persistent homology for machine learning is a subject that attracts a lot of information and generated an intense research activity. Although the recent progress in this area goes far beyond the scope of this article, we briefly introduce the main research directions with a few references to help the newcomer to the field to get started.
Topological Data Analysis for Exploratory Data Analysis and Descriptive Statistics
In some domains, tda can be fruitfully used as a tool for exploratory analysis and visualization. For example, the Mapper algorithm provides a powerful approach to exploring and visualizing the global topological structure of complex data sets. In some cases, persistence diagrams obtained from data can be directly interpreted and exploited for better understanding of the phenomena from which the data have been generated. This is, for example, the case in the study of force fields in granular media (Kramar et al., 2013) or of atomic structures in glass (Nakamura et al., 2015) in material science, in the study of the evolution of convection patterns in fluid dynamics (Kramár et al., 2016), and in machining monitoring (Khasawneh and Munch, 2016) or in the analysis of nanoporous structures in chemistry (Lee et al., 2017) where topological features can be rather clearly related to specific geometric structures and patterns in the considered data.
Persistent Homology for Feature Engineering
There are many other cases where persistence features cannot be easily or directly interpreted but present valuable information for further processing. However, the highly nonlinear nature of diagrams prevents them from being immediately used as standard features in machine learning algorithms.
Persistence landscapes and linear representations of persistence diagrams offer a first option to convert persistence diagrams into elements of a vector space that can be directly used as features in classical machine learning pipelines. This approach has been used, for example, for protein binding (Kovacev-Nikolic et al., 2016), object recognition (Li et al., 2014), or time series analysis. In the same vein, the construction of kernels for persistence diagrams that preserve their stability properties has recently attracted some attention. Most of them have been obtained by considering diagrams as discrete measures in
Various other vector summaries of persistence diagrams have been proposed and then used as features for different problems. For example, basic summaries were considered in the study by Bonis et al. (2016) and combined with quantization and pooling methods to address nonrigid shape analysis problems; Betti curves extracted from persistence diagrams were used with one-dimensional convolutional neural networks (CNNs) to analyze time-dependent data and recognize human activities from inertial sensors in the studies by Dindin et al. (2020), Umeda (2017); persistence images were introduced in the study by Adams et al. (2017) and were considered to address some inverse problems using linear machine learning models in the study by Obayashi et al. (2018).
The kernels and vector summaries of persistence diagrams mentioned above are built independently of the considered data analysis or learning task. Moreover, it appears that in many cases, the relevant topological information is not carried by the whole persistence diagram but is concentrated in some localized regions that may not be obvious to identify. This usually makes the choice of a relevant kernel or vector summary very difficult for the user. To overcome this issue, various authors have proposed learning approaches that allow us to learn the relevant topological features for a given task. In this direction, Hofer et al. (2017) proposed a deep learning approach to learn the parameters of persistence image representations of persistence diagrams, while Kim et al. (2020) introduced a neural network layer for persistence landscapes. In the study by Carrière et al. (2020a), the authors introduced a general neural network layer for persistence diagrams that can be either used to learn an appropriate vectorization or directly integrated in a deep neural network architecture. Other methods, inspired from k-means, propose unsupervised methods to vectorize persistence diagrams (Royer et al., 2021; Zieliński et al., 2010), some of them coming with theoretical guarantees (Chazal et al., 2020).
Persistent Homology for Machine Learning Architecture Optimization and Model Selection
More recently, tda has seen new developments in machine learning where persistent homology is no longer used for feature engineering but as a tool to design, improve, or select models (see Carlsson and Gabrielsson (2020), Chen et al. (2019), Gabrielsson and Carlsson (2019), Hofer et al. (2019a), Moor et al. (2020), Ramamurthy et al. (2019), Rieck et al. (2019)). Many of these tools rely on the introduction of loss or regularization functions depending on persistent homology features, raising the problem of their optimization. Building on the powerful tools provided by software libraries such as PyTorch or TensorFlow, practical methods allowing us to encode and optimize a large family of persistence-based functions have been proposed and experimented on (Poulenard et al., 2018; Gabrielsson et al., 2020). A general framework for persistence-based function optimization based on stochastic subgradient descent algorithms with convergence guarantees has been recently proposed and implemented in an easy-to-use software tool (Carriere et al., 2020b). With a different perspective, another theoretical framework to study the differentiable structure of functions of persistence diagrams has been proposed in the study by Leygonie et al. (2021).
7 Topological Data Analysis for Data Sciences With the GUDHI Library
In this section, we illustrate TDA methods using the Python library GUDHI11 (Maria et al., 2014) together with popular libraries such as NumPy (Walt et al., 2011), scikit-learn (Pedregosa et al., 2011), and pandas (McKinney, 2010). This section aims at demonstrating that the topological signatures of TDA can be easily computed and exploited using GUDHI. More illustrations with Python notebooks can be found in the tutorial GitHub12 of GUDHI.
7.1 Bootstrap and Comparison of Protein Binding Configurations
This example is borrowed from Kovacev-Nikolic et al. (2016). In this article, persistent homology is used to analyze protein binding, and more precisely, it compares closed and open forms of the maltose-binding protein (MBP), a large biomolecule consisting of 370 amino acid residues. The analysis is not based on geometric distances in
import numpy as np
import gudhi as gd
import pandas as pd
import seaborn as sns
corr_protein = pd.read_csv(“mypath/1anf.corr_1.txt”, header=None, delim_whitespace=True)
dist_protein_1 = 1− np.abs(corr_protein_1.values)
rips_complex_1 = gd.RipsComplex(distance_matrix=dist_protein_1, max_edge_length=1.1)
simplex_tree_1 = rips_complex_1.create_simplex_tree(max_dimension=2)
diag_1 = simplex_tree_1.persistence()
gd.plot_persistence_diagram(diag_1)
For comparing persistence diagrams, we use the bottleneck distance. The block of statements given below computes persistence intervals and computes the bottleneck distance for zero-homology and one-homology as follows:
interv0_1 = simplex_tree_1.persistence_intervals_in_dimension(0)
interv0_2 = simplex_tree_2.persistence_intervals_in_dimension(0)
bot0 = gd.bottleneck_distance(interv0_1,interv0_2)
interv1_1 = simplex_tree_1.persistence_intervals_in_dimension(1)
interv1_2 = simplex_tree_2.persistence_intervals_in_dimension(1)
bot1 = gd.bottleneck_distance(interv1_1,interv1_2)
In this way, we can compute the matrix of bottleneck distances between the fourteen MBPs. Finally, we apply a multidimensional scaling method to find a configuration in
import matplotlib.pyplot as plt
from sklearn import manifold
mds = manifold.MDS(n_components=2, dissimilarity=“precomputed”)
config = mds.fit(M).embedding_
plt.scatter(config [0:7,0], config [0:7, 1], color=‘red’, label=“closed”)
plt.scatter(config [7:l,0], config [7:l, 1], color=‘blue’, label=“red”)
plt.legend(loc=1)
We now define a confidence band for a diagram using the bottleneck bootstrap approach. We resample over the lines (and columns) of the matrix of distances, and we compute the bottleneck distance between the original persistence diagram and the bootstrapped persistence diagram. We repeat the procedure many times, and finally, we estimate the quantile 95% of this collection of bottleneck distances. We take the value of the quantile to define a confidence band on the original diagram (see Figure 13D). However, such a procedure should be considered with caution because as far as we know, the validity of the bottleneck bootstrap has not been proven in this framework.
7.2 Classification for Sensor Data
In this experiment, the 3D acceleration of 3 walkers (A, B, and C) has been recorded using the sensor of a smartphone14. Persistence homology is not sensitive to the choice of axes, and so no preprocessing is necessary to align the 3 time series according to the same axis. From these three time series, we have picked, at random, sequences of 8 s in the complete time series, that is, 200 consecutive points of acceleration in
alpha_complex_sample = gd.AlphaComplex(points = data_A_sample)
simplex_tree_sample = alpha_complex_sample.create_simplex_tree(max_alpha_square=0.3)
diag_Alpha = simplex_tree_sample.persistence()
From diag_Alpha, we can then easily compute and plot the persistence landscapes (see Figure 14A). For all 300 time series, we compute the persistence landscapes for dimensions 0 and 1, and we compute the first three landscapes for the 2 dimensions. Moreover, each persistence landscape is discretized on 1,000 points. Each time series is thus described by 6,000 topological variables. To predict the walker from these features, we use a random forest (Breiman, 2001), which is known to be efficient in such a high-dimensional setting. We split the data into train and test samples at random several times. We finally obtain an averaged classification error of around 0.95. We can also visualize the most important variables in the random forest (see Figure 14B).
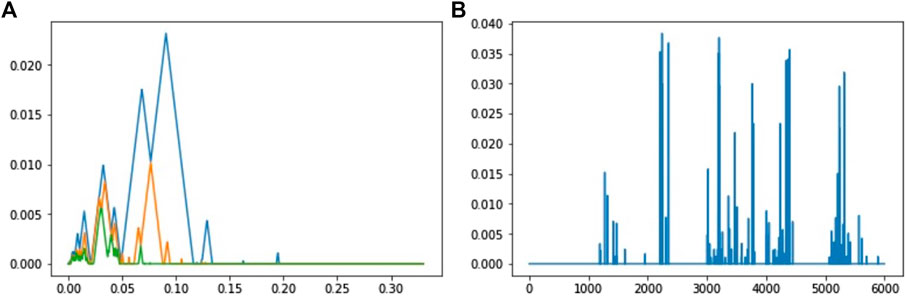
FIGURE 14. (A) First three landscapes for zero-homology of the alpha shape filtration defined for a time series of acceleration of Walker A. (B) Variable importances of the landscape coefficients for the classification of walkers. The first 3,000 coefficients correspond to the three landscapes of dimension 0 and the last 3,000 coefficients to the three landscapes of dimension 1. There are 1,000 coefficients per landscape. Note that the first landscape of dimension 0 is always the same using the Rips complex (a trivial landscape), and consequently, the corresponding coefficients have a zero-importance value.
8 Discussion
In this introductory article, we propose an overview of the most standard methods in the field of topological data analysis. We also provide a presentation of the mathematical foundations of TDA, on the topological, algebraic, geometric, and statistical aspects. The robustness of TDA methods (coordinate invariance and deformation invariance) and the compressed representation of data they offer make their use very interesting for data analysis, machine learning, and explainable AI. Many applications have been proposed in this direction during the last few years. Finally, TDA constitutes an additional possible approach in the data scientist toolbox.
Of course, TDA is suited to address all kinds of problems. Practitioners may face several potential issues when applying TDA methods. On the algorithmic aspects, computing persistence homology can be time and resource consuming. Even if there is still room for improvement, recent computational advances have enabled TDA to be an effective method for data science, thanks to libraries like GUDHI, for example. Moreover, combing TDA using quantization methods, graph simplification, or dimension reduction methods may reduce the computational cost of the TDA algorithms. Another potential problem we can face with TDA is that returning to the data point to interpret the topological signatures can be tricky because these signatures correspond to classes of equivalence of cycles. This can be a problem when there is a need to identify which part of the point cloud “has created” a given topological signature. TDA is in fact more suited to solving data science problems dealing with a family of point clouds, each data point being described by its persistent homology. Finally, the topological and geometric information that can be extracted from the data is not always efficient for solving a given problem in the data sciences alone. Combining topological signatures with other types of descriptors is generally a relevant approach.
Today, TDA is an active field of research, at the crossroads of many scientific fields. In particular, there is currently an intense effort to effectively combine machine learning, statistics, and TDA. In this perspective, we believe that there is still a need for statistical results which demonstrate and quantify the interest of these data science approaches based on TDA.
Author Contributions
All authors listed have made a substantial, direct, and intellectual contribution to the work and approved it for publication.
Funding
This work was partly supported by the French ANR Chair in Artificial Intelligence TopAI.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Acknowledgments
We thank Kovacev-Nikolic et al. (2016) for making their data available.
Footnotes
2http://www.mrzv.org/software/dionysus/
3https://bitbucket.org/phat-code/phat
4https://github.com/DIPHA/dipha
5https://giotto-ai.github.io/gtda-docs/0.4.0/library.html
6As an example, if M is a smooth compact submanifold, then reach0(ϕ) is always positive and known as the reach of M Federer (1959).
7Recall that the symmetric difference of two sets A and B is the set AΔB = (A \ B) ∪ (B \ A).
8Notice that as we are considering coefficients in
9See Villani (2003) for a definition of the Wasserstein distance
10We take here the convention that for r < 0,
11http://gudhi.gforge.inria.fr/python/latest/
12https://github.com/GUDHI/TDA-tutorial
13https://www.researchgate.net/publication/301543862_corr
14The dataset can be downloaded at the link http://bertrand.michel.perso.math.cnrs.fr/Enseignements/TDA/data_acc
References
Aamari, E., Kim, J., Chazal, F., Michel, B., Rinaldo, A., Wasserman, L., et al. (2019). Estimating the Reach of a Manifold. Electron. J. Stat. 13 (1), 1359–1399. doi:10.1214/19-ejs1551
Adams, H., Emerson, T., Kirby, M., Neville, R., Peterson, C., Shipman, P., et al. (2017). Persistence Images: a Stable Vector Representation of Persistent Homology. J. Machine Learn. Res. 18 (8), 1–35.
Anai, H., Chazal, F., Glisse, M., Ike, Y., Inakoshi, H., Tinarrage, R., et al. (2020). “Dtm-based Filtrations,” in Topological Data Analysis (Springer), 33–66. doi:10.1007/978-3-030-43408-3_2
Balakrishna, S., Rinaldo, A., Sheehy, D., Singh, A., and Wasserman, L. A. (2012). Minimax Rates for Homology Inference. J. Machine Learn. Res. - Proc. Track 22, 64–72.
Berry, E., Chen, Y.-C., Cisewski-Kehe, J., and Fasy, B. T. (2020). Functional Summaries of Persistence Diagrams. J. Appl. Comput. Topol. 4 (2), 211–262. doi:10.1007/s41468-020-00048-w
Biau, G., Chazal, F., Cohen-Steiner, D., Devroye, L., and Rodriguez, C. (2011). A Weighted K-Nearest Neighbor Density Estimate for Geometric Inference. Electron. J. Stat. 5, 204–237. doi:10.1214/11-ejs606
Biscio, C. A., and Møller, J. (2019). The Accumulated Persistence Function, a New Useful Functional Summary Statistic for Topological Data Analysis, with a View to Brain Artery Trees and Spatial point Process Applications. J. Comput. Graphical Stat. 28, 671–681. doi:10.1080/10618600.2019.1573686
Bobrowski, O., Mukherjee, S., and Taylor, J. (2014). Topological Consistency via Kernel Estimation. arXiv preprint arXiv:1407.5272.
Boissonnat, J.-D., Chazal, F., and Yvinec, M. (2018). Geometric and Topological Inference, Vol. 57. Cambridge University Press.
Bonis, T., Ovsjanikov, M., Oudot, S., and Chazal, F. (2016). “Persistence-based Pooling for Shape Pose Recognition,” in ProceedingsComputational Topology in Image Context - 6th International Workshop, CTIC 2016. Marseille, France, June 15-17, 2016. 19–29. doi:10.1007/978-3-319-39441-1_3
Brécheteau, C. (2019). A Statistical Test of Isomorphism between Metric-Measure Spaces Using the Distance-To-A-Measure Signature. Electron. J. Stat. 13 (1), 795–849. doi:10.1214/19-ejs1539
Brécheteau, C., and Levrard, C. (2020). A K-Points-Based Distance for Robust Geometric Inference. Bernoulli 26 (4), 3017–3050. doi:10.3150/20-bej1214
Brown, A., Bobrowski, O., Munch, E., and Wang, B. (2020). Probabilistic Convergence and Stability of Random Mapper Graphs. J. Appl. Comput. Topol. 5, 99–140. doi:10.1007/s41468-020-00063-x
Brüel-Gabrielsson, R., Nelson, B. J., Dwaraknath, A., Skraba, P., Guibas, L. J., and Carlsson, G. (2019). A Topology Layer for Machine Learning. arXiv preprint arXiv:1905.12200.
Bubenik, P., Carlsson, G., Kim, P. T., and Luo, Z.-M. (2010). Statistical Topology via morse Theory Persistence and Nonparametric Estimation. Algebraic Methods Stat. Probab. 516, 75–92. doi:10.1090/conm/516/10167
Bubenik, P. (2015). Statistical Topological Data Analysis Using Persistence Landscapes. J. Machine Learn. Res. 16, 77–102.
Buchet, M., Chazal, F., Dey, T. K., Fan, F., Oudot, S. Y., and Wang, Y. (2015a). “Topological Analysis of Scalar fields with Outliers,” in Proc. Sympos. On Computational Geometry.
Buchet, M., Chazal, F., Oudot, S., and Sheehy, D. R. (2015b). “Efficient and Robust Persistent Homology for Measures,” in Proceedings of the 26th ACM-SIAM symposium on Discrete algorithms. SIAM. doi:10.1137/1.9781611973730.13
Cadre, B. (2006). Kernel Estimation of Density Level Sets. J. Multivar. Anal. 97 (4), 999–1023. doi:10.1016/j.jmva.2005.05.004
Carlsson, G., and Gabrielsson, R. B. (2020). “Topological Approaches to Deep Learning,” in Topological Data Analysis (Springer), 119–146. doi:10.1007/978-3-030-43408-3_5
Carlsson, G. (2009). Topology and Data. Bull. Amer. Math. Soc. 46 (2), 255–308. doi:10.1090/s0273-0979-09-01249-x
Carriere, M., Chazal, F., Glisse, M., Ike, Y., and Kannan, H. (2020). A Note on Stochastic Subgradient Descent for Persistence-Based Functionals: Convergence and Practical Aspects. arXiv preprint arXiv:2010.08356.
Carrière, M., Chazal, F., Ike, Y., Lacombe, T., Royer, M., and Umeda, Y. (2020). “Perslay: a Neural Network Layer for Persistence Diagrams and New Graph Topological Signatures,” in International Conference on Artificial Intelligence and Statistics (PMLR), 2786–2796.
Carrière, M., and Michel, B. (2019). Approximation of Reeb Spaces with Mappers and Applications to Stochastic Filters. arXiv preprint arXiv:1912.10742.
Carriere, M., Michel, B., and Oudot, S. (2018). Statistical Analysis and Parameter Selection for Mapper. J. Machine Learn. Res. 19 (12).
Carriere, M., and Oudot, S. (2017). “Sliced Wasserstein Kernel for Persistence Diagrams,” in To Appear in ICML-17.
Carrière, M., and Oudot, S. (2015). Structure and Stability of the 1-dimensional Mapper. arXiv preprint arXiv:1511.05823.
Carrière, M., and Rabadán, R. (2020). “Topological Data Analysis of Single-Cell Hi-C Contact Maps,” in Topological Data Analysis (Springer), 147–162. doi:10.1007/978-3-030-43408-3_6
Chazal, F., Chen, D., Guibas, L., Jiang, X., and Sommer, C. (2011a). Data-driven Trajectory Smoothing. Proc. ACM SIGSPATIAL GIS. doi:10.1145/2093973.2094007
Chazal, F., Cohen-Steiner, D., Glisse, M., Guibas, L., and Oudot, S. (2009a). Proximity of Persistence Modules and Their Diagrams. SCG, 237–246. doi:10.1145/1542362.1542407
Chazal, F., Cohen-Steiner, D., Guibas, L. J., Mémoli, F., and Oudot, S. Y. (2009b). Gromov-hausdorff Stable Signatures for Shapes Using Persistence. Comput. Graphics Forum (proc. SGP 2009) 28, 1393–1403. doi:10.1111/j.1467-8659.2009.01516.x
Chazal, F., Cohen-Steiner, D., and Lieutier, A. (2009d). A Sampling Theory for Compact Sets in Euclidean Space. Discrete Comput. Geom. 41 (3), 461–479. doi:10.1007/s00454-009-9144-8
Chazal, F., Cohen-Steiner, D., and Lieutier, A. (2009c). Normal Cone Approximation and Offset Shape Isotopy. Comp. Geom. Theor. Appl. 42 (6-7), 566–581. doi:10.1016/j.comgeo.2008.12.002
Chazal, F., Cohen-Steiner, D., Lieutier, A., and Thibert, B. (2008). Stability of Curvature Measures. Comput. Graphics Forum (proc. SGP 2009), 1485–1496.
Chazal, F., Cohen-Steiner, D., and Mérigot, Q. (2010). Boundary Measures for Geometric Inference. Found. Comput. Math. 10, 221–240. doi:10.1007/s10208-009-9056-2
Chazal, F., Cohen-Steiner, D., and Mérigot, Q. (2011b). Geometric Inference for Probability Measures. Found. Comput. Math. 11 (6), 733–751. doi:10.1007/s10208-011-9098-0
Chazal, F., de Silva, V., Glisse, M., and Oudot, S. (2016a). The Structure and Stability of Persistence Modules. SpringerBriefs in Mathematics. Springer. doi:10.1007/978-3-319-42545-0
Chazal, F., Fasy, B. T., Lecci, F., Michel, B., Rinaldo, A., and Wasserman, L. (2014a). “Robust Topological Inference: Distance to a Measure and Kernel Distance,” in To Appear in JMLR. .
Chazal, F., Fasy, B. T., Lecci, F., Michel, B., Rinaldo, A., and Wasserman, L. (2015a). “Subsampling Methods for Persistent Homology,” in To appear in Proceedings of the 32 st International Conference on Machine Learning (ICML-15).
Chazal, F., Fasy, B. T., Lecci, F., Rinaldo, A., Singh, A., and Wasserman, L. (2013a). On the Bootstrap for Persistence Diagrams and Landscapes. arXiv preprint arXiv:1311.0376.
Chazal, F., Fasy, B. T., Lecci, F., Rinaldo, A., and Wasserman, L. (2015b). Stochastic Convergence of Persistence Landscapes and Silhouettes. J. Comput. Geom. 6 (2), 140–161.
Chazal, F., Glisse, M., Labruère, C., and Michel, B. (2014b). Convergence Rates for Persistence Diagram Estimation in Topological Data Analysis. Proceedings of Machine Learning Research.
Chazal, F., Guibas, L. J., Oudot, S. Y., and Skraba, P. (2013b). Persistence-based Clustering in Riemannian Manifolds. J. ACM (Jacm) 60 (6), 41. doi:10.1145/2535927
Chazal, F. (2017). “High-dimensional Topological Data Analysis,” in Handbook of Discrete and Computational Geometry. 3rd Ed- To appear. chapter 27. (CRC Press).
Chazal, F., Huang, R., and Sun, J. (2015c). Gromov-Hausdorff Approximation of Filamentary Structures Using Reeb-type Graphs. Discrete Comput. Geom. 53 (3), 621–649. doi:10.1007/s00454-015-9674-1
Chazal, F., Levrard, C., and Royer, M. (2020). Optimal Quantization of the Mean Measure and Application to Clustering of Measures. arXiv preprint arXiv:2002.01216.
Chazal, F., and Lieutier, A. (2008). Smooth Manifold Reconstruction from Noisy and Non-uniform Approximation with Guarantees. Comput. Geom. 40 (2), 156–170. doi:10.1016/j.comgeo.2007.07.001
Chazal, F., Massart, P., and Michel, B. (2016b). Rates of Convergence for Robust Geometric Inference. Electron. J. Statist. 10, 2243–2286. doi:10.1214/16-ejs1161
Chazal, F., and Oudot, S. Y. (2008). “Towards Persistence-Based Reconstruction in Euclidean Spaces,” in Proceedings of the twenty-fourth annual symposium on Computational geometry (New York, NY, USA: SCG ’08ACM), 232–241. doi:10.1145/1377676.1377719
Chen, C., Ni, X., Bai, Q., and Wang, Y. (2019). “A Topological Regularizer for Classifiers via Persistent Homology,” in The 22nd International Conference on Artificial Intelligence and Statistics, 2573–2582.
Chen, Y.-C., Genovese, C. R., and Wasserman, L. (2015). Density Level Sets: Asymptotics, Inference, and Visualization. arXiv preprint arXiv:1504.05438.
Chen, Y.-C., Genovese, C. R., and Wasserman, L. (2017). Density Level Sets: Asymptotics, Inference, and Visualization. J. Am. Stat. Assoc. 112 (520), 1684–1696. doi:10.1080/01621459.2016.1228536
Cohen-Steiner, D., Edelsbrunner, H., Harer, J., and Mileyko, Y. (2010). Lipschitz Functions Have L P -Stable Persistence. Found. Comput. Math. 10 (2), 127–139. doi:10.1007/s10208-010-9060-6
Cohen-Steiner, D., Edelsbrunner, H., and Harer, J. (2005). Stability of Persistence Diagrams. SCG, 263–271. doi:10.1145/1064092.1064133
Cuevas, A., and Rodríguez-Casal, A. (2004). On Boundary Estimation. Adv. Appl. Probab. 36 (2), 340–354. doi:10.1239/aap/1086957575
Curry, J., Mukherjee, S., and Turner, K. (2018). How many Directions Determine a Shape and Other Sufficiency Results for Two Topological Transforms. arXiv preprint arXiv:1805.09782.
De Silva, V., and Carlsson, G. (2004). “Topological Estimation Using Witness Complexes,” in Proceedings of the First Eurographics Conference on Point-Based Graphics (Switzerland, Switzerland: Aire-la-VilleEurographics Association), 157–166. SPBG’04.
Devroye, L., and Wise, G. L. (1980). Detection of Abnormal Behavior via Nonparametric Estimation of the Support. SIAM J. Appl. Math. 38 (3), 480–488. doi:10.1137/0138038
Dey, T. K., Mémoli, F., and Wang, Y. (2016). “Multiscale Mapper: Topological Summarization via Codomain Covers,” in Proceedings of the Twenty-Seventh Annual ACM-SIAM Symposium on Discrete Algorithms (Society for Industrial and Applied Mathematics), 997–1013. doi:10.1137/1.9781611974331.ch71
Dey, T. K., Mémoli, F., and Wang, Y. (2017). Topological Analysis of Nerves, Reeb Spaces, Mappers, and Multiscale Mappers. Proc. Sympos. Comput . Geom.(SoCG). .
Dindin, M., Umeda, Y., and Chazal, F. (2020). “Topological Data Analysis for Arrhythmia Detection through Modular Neural Networks,” in Canadian Conference on Artificial Intelligence (Springer), 177–188. doi:10.1007/978-3-030-47358-7_17
Divol, V., and Chazal, F. (2020). The Density of Expected Persistence Diagrams and its Kernel Based Estimation. J. Comput. Geom. 10 (2), 127–153.
Divol, V., and Lacombe, T. (2020). Understanding the Topology and the Geometry of the Persistence Diagram Space via Optimal Partial Transport. J. Appl. Comput. Topol. 5 (1), 1–53. doi:10.1007/s41468-020-00061-z
Edelsbrunner, H., Letscher, D., and Zomorodian, A. (2002). Topological Persistence and Simplification. Discrete Comput. Geom. 28, 511–533. doi:10.1007/s00454-002-2885-2
Fasy, B. T., Kim, J., Lecci, F., and Maria, C. (2014a). Introduction to the R Package Tda. arXiv preprint arXiv:1411.1830.
Fasy, B. T., Lecci, F., Rinaldo, A., Wasserman, L., Balakrishnan, S., and Singh, A. (2014b). Confidence Sets for Persistence Diagrams. Ann. Stat. 42 (6), 2301–2339. doi:10.1214/14-aos1252
Federer, H. (1959). Curvature Measures. Trans. Amer. Math. Soc. 93, 418. doi:10.1090/s0002-9947-1959-0110078-1
Frosini, P. (1992). “Measuring Shapes by Size Functions,” in Intelligent Robots and Computer Vision X: Algorithms and Techniques (International Society for Optics and Photonics), Vol. 1607, 122–133.
Gabrielsson, R. B., and Carlsson, G. (2019). “Exposition and Interpretation of the Topology of Neural Networks,” in 2019 18th IEEE International Conference On Machine Learning And Applications (ICMLA) (IEEE), 1069–1076. doi:10.1109/icmla.2019.00180
Genovese, C. R., Perone-Pacifico, M., Verdinelli, I., and Wasserman, L. (2012). Manifold Estimation and Singular Deconvolution under Hausdorff Loss. Ann. Statist. 40, 941–963. doi:10.1214/12-aos994
Grove, K. (1993). Critical point Theory for Distance Functions. Proc. Symposia Pure Math. 54. doi:10.1090/pspum/054.3/1216630
Guibas, L., Morozov, D., and Mérigot, Q. (2013). Witnessed K-Distance. Discrete Comput. Geom. 49, 22–45. doi:10.1007/s00454-012-9465-x
Hensel, F., Moor, M., and Rieck, B. (2021). A Survey of Topological Machine Learning Methods. Front. Artif. Intell. 4, 52. doi:10.3389/frai.2021.681108
Hofer, C. D., Kwitt, R., and Niethammer, M. (2019b). Learning Representations of Persistence Barcodes. J. Machine Learn. Res. 20 (126), 1–45.
Hofer, C., Kwitt, R., Niethammer, M., and Dixit, M. (2019a). “Connectivity-optimized Representation Learning via Persistent Homology,”in Proceedings of the 36th International Conference on Machine Learning Vol. 97. Proceedings of Machine Learning Research (PMLR), 2751–2760.
Hofer, C., Kwitt, R., Niethammer, M., and Uhl, A. (2017). Deep Learning with Topological Signatures. arXiv preprint arXiv:1707.04041.
Khasawneh, F. A., and Munch, E. (2016). Chatter Detection in Turning Using Persistent Homology. Mech. Syst. Signal Process. 70-71, 527–541. doi:10.1016/j.ymssp.2015.09.046
Kim, K., Kim, J., Zaheer, M., Kim, J., Chazal, F., and Wasserman, L. (2020). “Pllay: Efficient Topological Layer Based on Persistence Landscapes,” in 34th Conference on Neural Information Processing Systems (NeurIPS)
Kovacev-Nikolic, V., Bubenik, P., Nikolić, D., and Heo, G. (2016). Using Persistent Homology and Dynamical Distances to Analyze Protein Binding. Stat. Appl. Genet. Mol. Biol. 15 (1), 19–38. doi:10.1515/sagmb-2015-0057
Kramar, M., Goullet, A., Kondic, L., and Mischaikow, K. (2013). Persistence of Force Networks in Compressed Granular media. Phys. Rev. E Stat. Nonlin Soft Matter Phys. 87 (4), 042207. doi:10.1103/PhysRevE.87.042207
Kramár, M., Levanger, R., Tithof, J., Suri, B., Xu, M., Paul, M., et al. (2016). Analysis of Kolmogorov Flow and Rayleigh-Bénard Convection Using Persistent Homology. Physica D: Nonlinear Phenomena 334, 82–98. doi:10.1016/j.physd.2016.02.003
Krebs, J. T., and Polonik, W. (2019). On the Asymptotic Normality of Persistent Betti Numbers. arXiv preprint arXiv:1903.03280.
Kusano, G., Fukumizu, K., and Hiraoka, Y. (2017). Kernel Method for Persistence Diagrams via Kernel Embedding and Weight Factor. arXiv preprint arXiv:1706.03472.
Kusano, G., Hiraoka, Y., and Fukumizu, K. (2016). “Persistence Weighted Gaussian Kernel for Topological Data Analysis,” in International Conference on Machine Learning. 2004–2013.
Kusano, G. (2019). On the Expectation of a Persistence Diagram by the Persistence Weighted Kernel. Jpn. J. Indust. Appl. Math. 36 (3), 861–892. doi:10.1007/s13160-019-00374-2
Lacombe, T., Cuturi, M., and Oudot, S. (2018). Large Scale Computation of Means and Clusters for Persistence Diagrams Using Optimal Transport. NeurIPS.
Lee, Y., Barthel, S. D., Dłotko, P., Moosavi, S. M., Hess, K., and Smit, B. (2017). Quantifying Similarity of Pore-Geometry in Nanoporous Materials. Nat. Commun. 8, 15396. doi:10.1038/ncomms15396
Leygonie, J., Oudot, S., and Tillmann, U. (2019). A Framework for Differential Calculus on Persistence Barcodes. arXiv preprint arXiv:1910.00960.
Li, C., Ovsjanikov, M., and Chazal, F. (2014). “Persistence-based Structural Recognition,” in ,2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2003–2010. doi:10.1109/cvpr.2014.257
Li, M. Z., Ryerson, M. S., and Balakrishnan, H. (2019). Topological Data Analysis for Aviation Applications. Transportation Res. E: Logistics Transportation Rev. 128, 149–174. doi:10.1016/j.tre.2019.05.017
Lum, P. Y., Singh, G., Lehman, A., Ishkanov, T., Vejdemo-Johansson, M., Alagappan, M., et al. (2013). Extracting Insights from the Shape of Complex Data Using Topology. Sci. Rep. 3, 1236. doi:10.1038/srep01236
Maria, C., Boissonnat, J.-D., Glisse, M., and Yvinec, M. (2014). “The Gudhi Library: Simplicial Complexes and Persistent Homology,” in International Congress on Mathematical Software (Springer), 167–174. doi:10.1007/978-3-662-44199-2_28
Maroulas, V., Nasrin, F., and Oballe, C. (2020). A Bayesian Framework for Persistent Homology. SIAM J. Math. Data Sci. 2 (1), 48–74. doi:10.1137/19m1268719
McKinney, W. (2010). “Data Structures for Statistical Computing in python,” in Proceedings of the 9th Python in Science Conference (TX: SciPy Austin), Vol. 445, 51–56. doi:10.25080/majora-92bf1922-00a
Mileyko, Y., Mukherjee, S., and Harer, J. (2011). Probability Measures on the Space of Persistence Diagrams. Inverse Probl. 27 (12), 124007. doi:10.1088/0266-5611/27/12/124007
Moon, C., and Lazar, N. A. (2020). Hypothesis Testing for Shapes Using Vectorized Persistence Diagrams. arXiv preprint arXiv:2006.05466.
Moor, M., Horn, M., Rieck, B., and Borgwardt, K. (2020). “Topological Autoencoders,” in International Conference on Machine Learning (PMLR), 7045–7054.
Nakamura, T., Hiraoka, Y., Hirata, A., Escolar, E. G., and Nishiura, Y. (2015). Persistent Homology and many-body Atomic Structure for Medium-Range Order in the Glass. Nanotechnology 26 (30), 304001. doi:10.1088/0957-4484/26/30/304001
Niyogi, P., Smale, S., and Weinberger, S. (2011). A Topological View of Unsupervised Learning from Noisy Data. SIAM J. Comput. 40 (3), 646–663. doi:10.1137/090762932
Niyogi, P., Smale, S., and Weinberger, S. (2008). Finding the Homology of Submanifolds with High Confidence from Random Samples. Discrete Comput. Geom. 39 (1-3), 419–441. doi:10.1007/s00454-008-9053-2
Obayashi, I., and Hiraoka, Y. (2017). Persistence Diagrams with Linear Machine Learning Models. arXiv preprint arXiv:1706.10082.
Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., et al. (2011). Scikit-Learn: Machine Learning in Python. J. Machine Learn. Res. 12 (Oct), 2825–2830.
Penrose, M. D., and Yukich, J. E. (2001). Central Limit Theorems for Some Graphs in Computational Geometry. Ann. Appl. Probab. 11, 1005–1041. doi:10.1214/aoap/1015345393
Petrunin, A. (2007). “Applied Manifold Geometry,” in Surveys in Differential Geometry (Somerville, MA: Int. Press), Vol. XI, 137–483. doi:10.1142/9789812770721_0003
Phillips, J. M., Wang, B., and Zheng, Y. (2014). Geometric Inference on Kernel Density Estimates. arXiv preprint 1307.7760.
Pike, J. A., Khan, A. O., Pallini, C., Thomas, S. G., Mund, M., Ries, J., et al. (2020). Topological Data Analysis Quantifies Biological Nano-Structure from Single Molecule Localization Microscopy. Bioinformatics 36 (5), 1614–1621. doi:10.1093/bioinformatics/btz788
Polonik, W. (1995). Measuring Mass Concentrations and Estimating Density Contour Clusters-An Excess Mass Approach. Ann. Stat. 23, 855–881. doi:10.1214/aos/1176324626
Poulenard, A., Skraba, P., and Ovsjanikov, M. (2018). Topological Function Optimization for Continuous Shape Matching. Comput. Graphics Forum 37, 13–25. doi:10.1111/cgf.13487
Qaiser, T., Tsang, Y.-W., Taniyama, D., Sakamoto, N., Nakane, K., Epstein, D., et al. (2019). Fast and Accurate Tumor Segmentation of Histology Images Using Persistent Homology and Deep Convolutional Features. Med. image Anal. 55, 1–14. doi:10.1016/j.media.2019.03.014
Ramamurthy, K. N., Varshney, K., and Mody, K. (2019). “Topological Data Analysis of Decision Boundaries with Application to Model Selection,” in International Conference on Machine Learning (PMLR), 5351–5360.
Reininghaus, J., Huber, S., Bauer, U., and Kwitt, R. (2015). “A Stable Multi-Scale Kernel for Topological Machine Learning,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 4741–4748. doi:10.1109/cvpr.2015.7299106
Rieck, B. A., Togninalli, M., Bock, C., Moor, M., Horn, M., Gumbsch, T., and Borgwardt, K. (2019). “Neural Persistence: A Complexity Measure for Deep Neural Networks Using Algebraic Topology,” in International Conference on Learning Representations (ICLR 2019) (OpenReview)
Rieck, B., Yates, T., Bock, C., Borgwardt, K., Wolf, G., Turk-Browne, N., et al. (2020). Uncovering the Topology of Time-Varying Fmri Data Using Cubical Persistence. Adv. Neural Inf. Process. Syst. 33.
Robins, V. (1999). Towards Computing Homology from Finite Approximations. Topology Proc. 24, 503–532.
Robinson, A., and Turner, K. (2017). Hypothesis Testing for Topological Data Analysis. J. Appl. Comput. Topol. 1 (2), 241–261. doi:10.1007/s41468-017-0008-7
Roycraft, B., Krebs, J., and Polonik, W. (2020). Bootstrapping Persistent Betti Numbers and Other Stabilizing Statistics. arXiv preprint arXiv:2005.01417
Royer, M., Chazal, F., Levrard, C., Ike, Y., and Umeda, Y. (2021). “Atol: Measure Vectorisation for Automatic Topologically-Oriented Learning,” in International Conference on Artificial Intelligence and Statistics (PMLR)
Barannikov, S. (1994). “The Framed morse Complex and its Invariants,” in Adv. Soviet Math., Vol. 21. Providence, RI: Amer. Math. Soc., 93–115. doi:10.1090/advsov/021/03
Seversky, L. M., Davis, S., and Berger, M. (2016). “On Time-Series Topological Data Analysis: New Data and Opportunities,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, 59–67. doi:10.1109/cvprw.2016.131
Singh, A., Scott, C., and Nowak, R. (2009). Adaptive Hausdorff Estimation of Density Level Sets. Ann. Statist. 37 (5B), 2760–2782. doi:10.1214/08-aos661
Singh, G., Mémoli, F., and Carlsson, G. E. (2007). 8. Tensor Decomposition. SPBG, 91–100. Citeseer. doi:10.1137/1.9780898718867.ch8
Sizemore, A. E., Phillips-Cremins, J. E., Ghrist, R., and Bassett, D. S. (2019). The Importance of the Whole: Topological Data Analysis for the Network Neuroscientist. Netw. Neurosci. 3 (3), 656–673. doi:10.1162/netn_a_00073
Skraba, P., Ovsjanikov, M., Chazal, F., and Guibas, L. (2010). “Persistence-based Segmentation of Deformable Shapes,” in Computer Vision and Pattern Recognition Workshops (CVPRW), 2010 (IEEE Computer Society Conference on), 45–52. doi:10.1109/cvprw.2010.5543285
Smith, A. D., Dłotko, P., and Zavala, V. M. (2021). Topological Data Analysis: Concepts, Computation, and Applications in Chemical Engineering. Comput. Chem. Eng. 146, 107202. doi:10.1016/j.compchemeng.2020.107202
Tsybakov, A. B. (1997). On Nonparametric Estimation of Density Level Sets. Ann. Stat. 25 (3), 948–969. doi:10.1214/aos/1069362732
Turner, K., Mileyko, Y., Mukherjee, S., and Harer, J. (2014a). Fréchet Means for Distributions of Persistence Diagrams. Discrete Comput. Geom. 52 (1), 44–70. doi:10.1007/s00454-014-9604-7
Turner, K., Mukherjee, S., and Boyer, D. M. (2014b). Persistent Homology Transform for Modeling Shapes and Surfaces. Inf. Inference 3 (4), 310–344. doi:10.1093/imaiai/iau011
Umeda, Y. (2017). Time Series Classification via Topological Data Analysis. Trans. Jpn. Soc. Artif. Intell. 32 (3), D–G72_1. doi:10.1527/tjsai.d-g72
van der Walt, S., Colbert, S. C., and Varoquaux, G. (2011). The Numpy Array: a Structure for Efficient Numerical Computation. Comput. Sci. Eng. 13 (2), 22–30. doi:10.1109/mcse.2011.37
Wasserman, L. (2018). Topological Data Analysis. Annu. Rev. Stat. Appl. 5, 501–532. doi:10.1146/annurev-statistics-031017-100045
Yao, Y., Sun, J., Huang, X., Bowman, G. R., Singh, G., Lesnick, M., et al. (2009). Topological Methods for Exploring Low-Density States in Biomolecular Folding Pathways. J. Chem. Phys. 130 (14), 144115. doi:10.1063/1.3103496
Zieliński, B., Lipiński, M., Juda, M., Zeppelzauer, M., and Dłotko, P. (2010). “Persistence Bag-Of-Words for Topological Data Analysis,” in Twenty-Eighth International Joint Conference on Artificial Intelligence (IJCAI-19).
Keywords: topological data analysis, machine learning, geometric inference, topological inference, statistic
Citation: Chazal F and Michel B (2021) An Introduction to Topological Data Analysis: Fundamental and Practical Aspects for Data Scientists. Front. Artif. Intell. 4:667963. doi: 10.3389/frai.2021.667963
Received: 15 February 2021; Accepted: 16 July 2021;
Published: 29 September 2021.
Edited by:
Sriraam Natarajan, The University of Texas at Dallas, United StatesReviewed by:
Ajey Kumar, Symbiosis International (Deemed University), IndiaDevendra Singh Dhami, Darmstadt University of Technology, Germany
Copyright © 2021 Chazal and Michel. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Bertrand Michel, YmVydHJhbmQubWljaGVsQGVjLW5hbnRlcy5mcg==