 Jusheng Liu
Jusheng Liu Chaoran Li
Chaoran Li Ye Huang3,4*
Ye Huang3,4*- 1School of Economics and Management, Shanghai University of Political Science and Law, Shanghai, China
- 2School of Economics and Management, Shanghai University of Sport, Shanghai, China
- 3School of Information Management and Engineering, Shanghai University of Finance and Economics, Shanghai, China
- 4Shanghai Financial Intelligent Engineering Technology Research Center, Shanghai, China
Based on the online patient-physician communication data, this study used natural language processing and machine learning algorithm to construct a medical intelligent guidance and recommendation model. First, based on 16,935 patient main complaint data of nine diseases, this study used the word2vec, long-term and short-term memory neural networks, and other machine learning algorithms to construct intelligent department guidance and recommendation model. Besides, taking ophthalmology as an example, it also used the word2vec, TF-IDF, and cosine similarity algorithm to construct an intelligent physician recommendation model. Furthermore, to recommend physicians with better service quality, this study introduced the information amount of physicians' feedback to the recommendation evaluation indicator as the text and voice service quality. The results show that the department guidance model constructed by long-term and short-term memory neural networks has the best effect. The precision is 82.84%, and the F1-score is 82.61% in the test set. The prediction effect of the LSTM model is better than TextCNN, random forest, K-nearest neighbor, and support vector machine algorithms. In the intelligent physician recommendation model, under certain parameter settings, the recommendation effect of the hybrid recommendation model based on similar patients and similar physicians has certain advantages over the model of similar patients and similar physicians.
1. Introduction
At present, with the development of digital medical health, more and more new technologies are being applied to the medical scene (1–3), for example, online medical, adjuvant therapy, and intelligent minimally invasive surgery (4). Although digital medical health and wise medical care have made some progress, the uneven distribution of medical resources is still a serious challenge in China (5). According to the 2020 statistical bulletin on the development of health services in China, the total number of medical and health institutions in China reached 7.74 billion, and the number of medical visits is still at a high level. From the supply side, by the end of 2020, there are 35,394 hospitals in China. Therefore, the mismatch of medical resources is still serious.
To alleviate the unbalanced distribution of medical resources, the governments implement relevant policies around the 'Internet + medical', these policies impel the platform economy and many online health communities (OHCs) to risen, such as Good Doctor, Chunyu Doctor, 39 Health Network, and Dingxiangyuan. Under these platforms, patients can communicate with the physicians, and the physicians can conduct diagnoses and treatment on the patients (6–9). Although online health communities provide more information and convenience to patients, patients still face great difficulties in selecting the department and the physicians. In fact, due to the asymmetric medical knowledge information between physicians and patients, more patients know their disease symptoms, but do not know how to select a department and a physician, especially older people (10). Thus, how to design intelligent medical guidance and recommendation model is important to most patients.
In OHCs, the communication data between physicians and patients has important value (11). In fact, when the patients consult a physician, the patients will disclose their symptoms to the physician. The data which is disclosed by the patients can reflect the patient's symptoms. According to multiple data from patients, the machine learning algorithm is used to learn the text's meaning and predict the department according to the patient's symptoms. Besides, when the patients find an appropriate department, they cannot find the right physician, because there are many physicians in a department, especially in OHCs. At this moment, it is important to recommend an appropriate physician to the patient. The common practice can be divided into three types: similar patients, similar physicians, and similar patients and physicians. Similar patients mean that if the symptoms between two patients are similar, we can recommend one's physician to the other patient. Similar physicians mean that if one patient consults a physician, we can recommend a similar physician to the next patient. Similar patients and physicians mean that we can combine similar patients and similar physicians and determine the final recommended physician.
At present, concerning the department and physician recommendations, previous studies have explored them from different perspectives (12). In terms of department recommendation, Mullenbach et al. (13) combined the attention mechanism and used LSTM to predict patients' disease types. Mao et al. (14) used the undirected multivariate graph neural network (GNN) to construct a relationship model among patients, departments, and prescriptions to recommend the prescription to the patients. Li and Yu (15) employed the multi-filter residual convolutional neural network to explore the problem of the department recommendation. Besides, with the emergence of a new language model, Wang et al. (16) used the BERT model to explore disease diagnosis and department recommendations.
In terms of physician recommendation, Ju and Zhang (17) combined the patients' geographic location and main complaint text and used the word2vec model and cosine similarity to do a personalized recommendation for patients. Mondal et al. (18) used a multilayer graph and considered the patient's trust in doctors to construct a multilayer network recommendation model, which can use a network to store massive heterogeneous information to achieve the goal of personalized recommendations of physicians to patients. Guo et al. (19) recommended doctors with high academic reputations to patients based on the papers published by doctors, media reports, and fund projects obtained by doctors. Based on the patient preferences and doctor online comments, Yang et al. (20) used the intuitionistic fuzzy sets (IFSs) and Bonferroni means (BM) to solve the interdependence of recommended doctors, and this method can improve the diversity and coverage of recommended doctors. Zhang et al. (21) used a latent dirichlet allocation (LDA) model to extract features of patients' preferences and physicians' characteristics to construct a physician recommendation model. Meng and Xiong (22) used the word2vec and LDA model to indicate the physicians' characteristics, and used the cosine similarity of physicians' characteristics to construct a network and obtain the important doctors based on the vector centrality of a network. Besides, with the development of the algorithm, some researchers use the deep learning algorithm to recommend the physician to patients, such as restricted boltzmann machine (RBM)-convolutional neural network (CNN) method (23) and probabilistic matrix factorization integrated with CNN (PMF-CNN) method (24). Furthermore, Xu et al. (25) also considered the doctors' reputation in the doctor recommendation system.
Throughout the above research, it can be seen that existing research has explored the department and physician recommendation separately. However, there are still some gaps in current research. First, current studies used Chinese context data for research rarely, such as Good Doctor. Second, when people use the method of text classification, they do not pay attention to the semantic relevance of the long text in patients' complaint text. Third, current studies recommend departments or physicians separately, they have not constructed intelligent medical guidance and recommendation model that can recommend departments and physicians. Finally, in terms of the evaluating indicator of recommending physicians, most researchers use precision as a single indicator and do not consider the service quality of recommended physicians.
Based on this, our research constructed intelligent medical guidance and recommendation model based on patient-physician communication data. Distinct from the previous research, this research has several innovations and contributions. First of all, our research constructs an intelligent medical guidance and recommendation model driven by patient-physician communication data. Then, our research uses the LSTM algorithm to deal with the semantic relevance of the long text in patients' complaint text. Finally, our research considers service quality as the evaluating indicator for evaluating the recommended physician. This research will help to resolve the mismatch of patient-physician resources, provide some support for old people who do not select the appropriate departments and doctors, and build a harmonious patient-physician relationship in the future.
The remainder of the article is as follows: Section 2 is the intelligent medical department recommendation model; the intelligent medical physician recommendation model is shown in Section 3; we discuss the main research content in Section 4; besides, the research limitations and future research directions are discussed in Section 5; finally, we summarize the conclusion in Section 6.
2. Intelligent medical department recommendation model
2.1. The process flow of intelligent department guidance
When the patients consult a physician, the patient's complaint text is a kind of description of their symptoms. Classifying the patient's main complaint text can achieve the goal of department recommendation. Therefore, to some degree, intelligent department guidance can be transformed into a text multi-classification problem (26–28). In our research, the data comes from Good Doctor, which is a big online health community in China. We select 16,935 data in Good Doctor randomly and these data belonged to 9 diseases and 8 departments. The diseases contain cataracts, myopia, rhinitis, renal failure, sexual dysfunction, diabetes, abortion, fracture, and infertility. Inside, cataracts and myopia belong to one department named ophthalmology. The process flow of intelligent department guidance is shown in Figure 1.
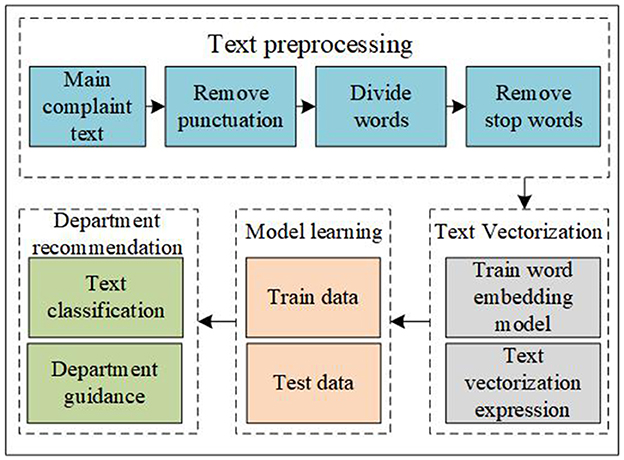
Figure 1. The process flow of intelligent department guidance.
As shown in Figure 1, first, we need to do a pretreatment on the patient's main complaint text. We need to remove punctuation in the main complaint text, divide the sentence into several words, and remove the stop words. At this time, the sentence is divided into several words without stop words. To measure the meaning of the text, we need to make the text vectorized. In this step, due to the professionalism of medical terms, we need to train a word embedding model and use the vector to indicate the text. After that, we need to use some machine learning and deep learning algorithms to train and test the data. Finally, the department guidance can be transformed into a question of text classification. In our data, different patients have different speaking habits, therefore, when patients consult a physician, some patients speak fewer words such as two words and some patients speak many words such as 1,095 words in our research. The average value of the patients' text length is 88.64 and the median is 50. The patient's main complaint text is shown in Table 1.
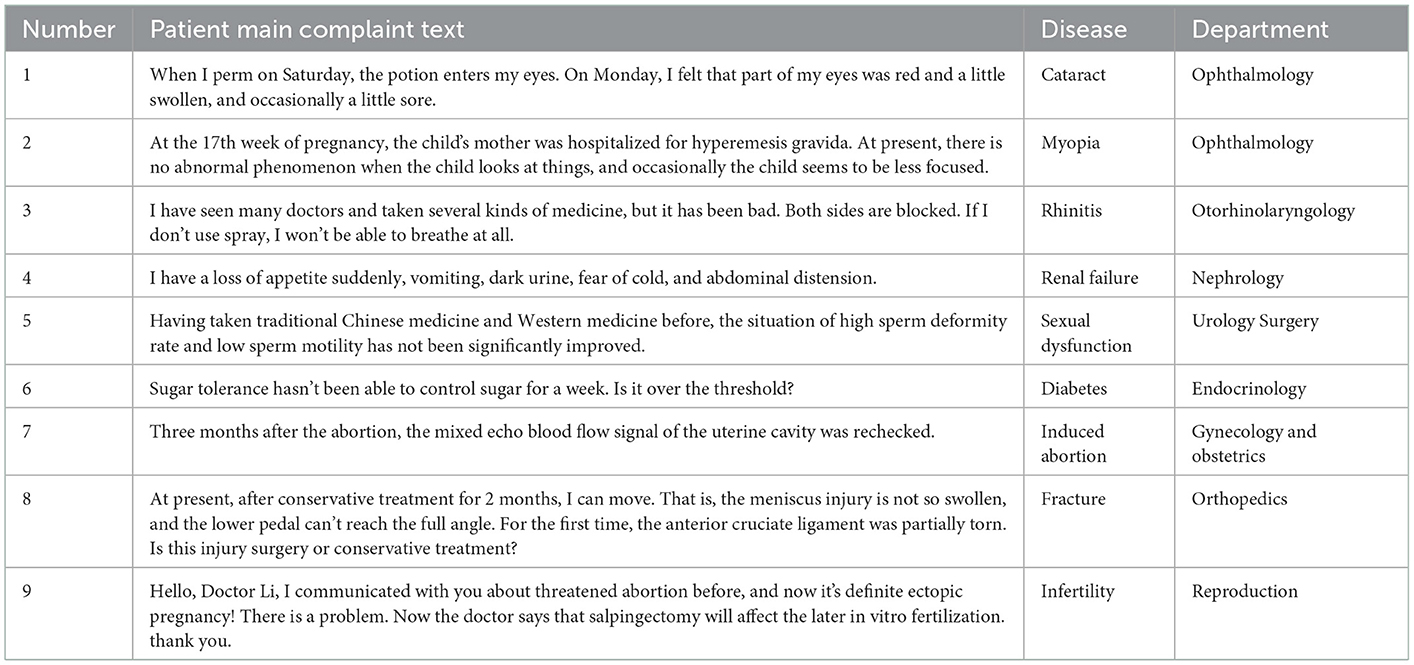
Table 1. Patient's main complaint text.
In the word embedding model, we need to do a text vectorization. In this part, the usual model is the word2vec model. The word2vec model has two forms: skip-grams (29) and continuous bag of words (CBOW) (30). The skip-grams model can infer the semantics of the context by using the semantics of the headword, while the CBOW model can infer the semantics of the headword by using the semantics of the context. The word vector model is shown in Figure 2 (31).
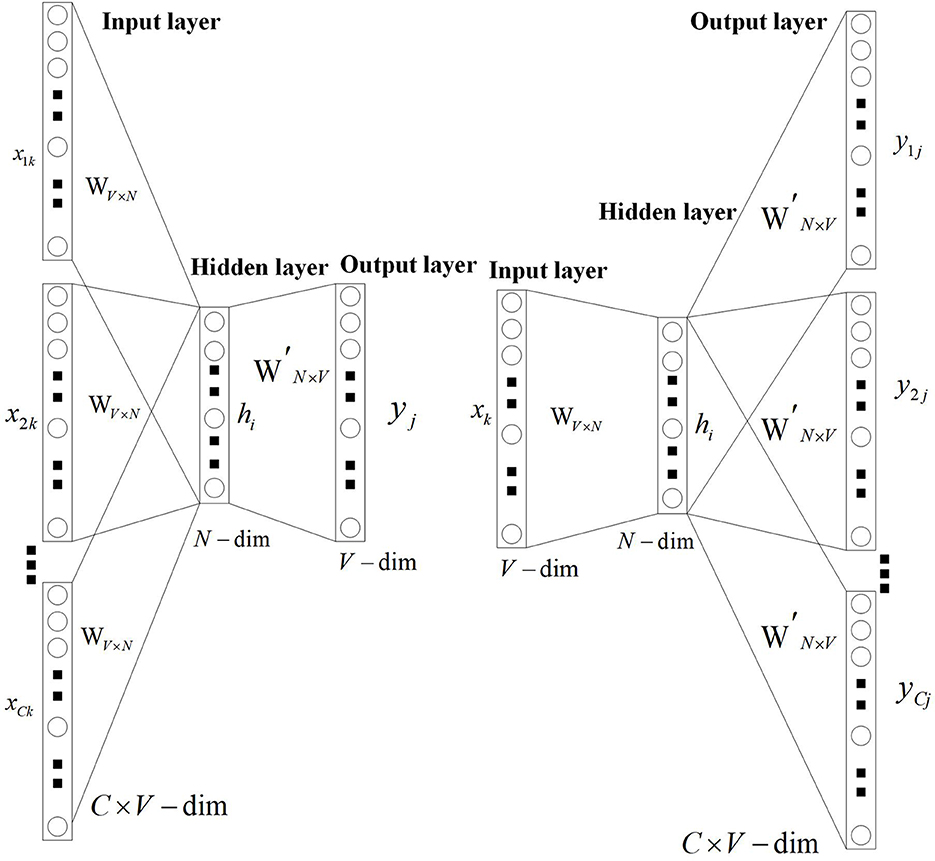
Figure 2. Word vector model.
In our research, to make the word vector model have rich and accurate semantic expression ability, we introduce the patient-physician communication on Good Doctor, medical books, and other corpora to the model. To show the model effect intuitively, we train a 40-dimension Skip-Grams model and selected six diseases to do a test. The six diseases are cataracts, glaucoma, nasal congestion, rhinitis, fracture, and diabetes. The result of the pre-training word vector is shown in Figure 3.
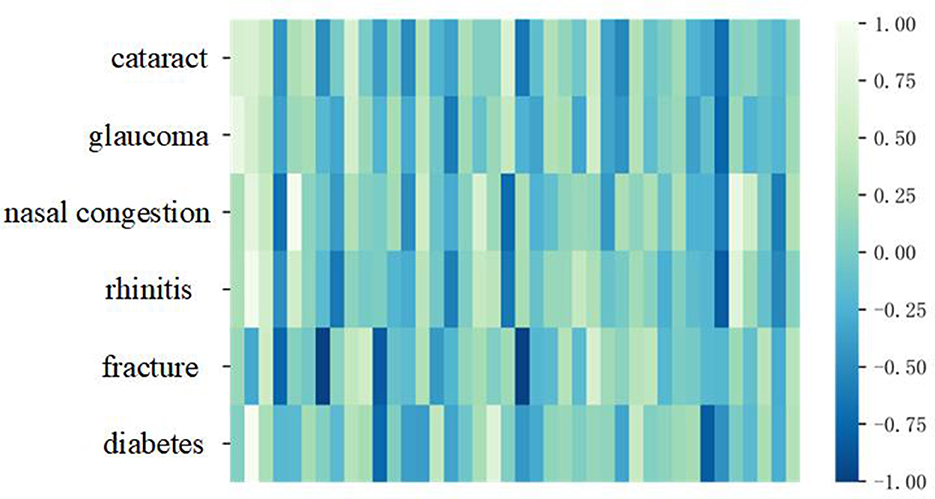
Figure 3. The result of pre-training word vector.
It can be seen from Figure 3, the colors of cataracts and glaucoma, nasal congestion, and rhinitis expressed in vectorization are similar under the same dimension in word vector space, while fractures and diabetes differ greatly in vectorization space expression. This result shows that the pre-trained word vector model is more accurate and effective.
In terms of the dimension of the word vector, we need to determine the appropriate dimension for our model. If the dimension of the word vector is too big, the cost of computers will increase, while the dimension of the word vector is small, the word vector cannot express the meaning of the word well. Thus, it is important to determine the dimension of the word vector. To quickly determine the dimension, we use a classification algorithm named K-Nearest Neighbor (KNN) to determine the final dimension of the word vector. The final result is shown in Figure 4.
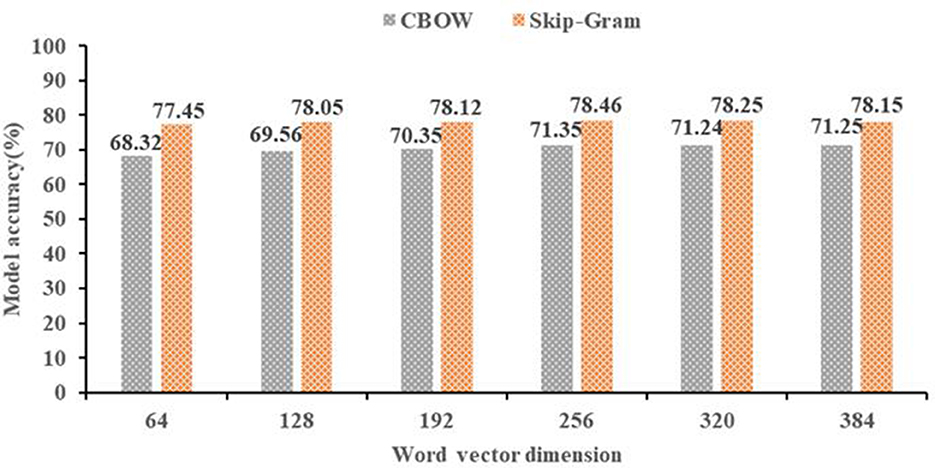
Figure 4. Word vector dimension.
As shown in Figure 4, the horizontal axis is the word vector dimension, the vertical axis is the model accuracy of text classification. We can see that the accuracy of the 256 dimensions in the CBOW model is 71.35%, and the accuracy of the 256 dimensions in the skip-grams model is 78.46%. Therefore, the 256 dimension of the skip-grams model is the best word vector.
After training the word2vec model and determining the dimension of the word vector, it is needed to use deep learning or machine learning algorithm to train and test the data. Because the patients' main complaint text of their symptoms is long, the long short-term memory (LSTM) algorithm can deal with the context semantic relationship well based on its advantage of memory function. Therefore, we select the LSTM algorithm to do the department recommendation. The schematic diagram of the LSTM model is shown in Figure 5 (32).
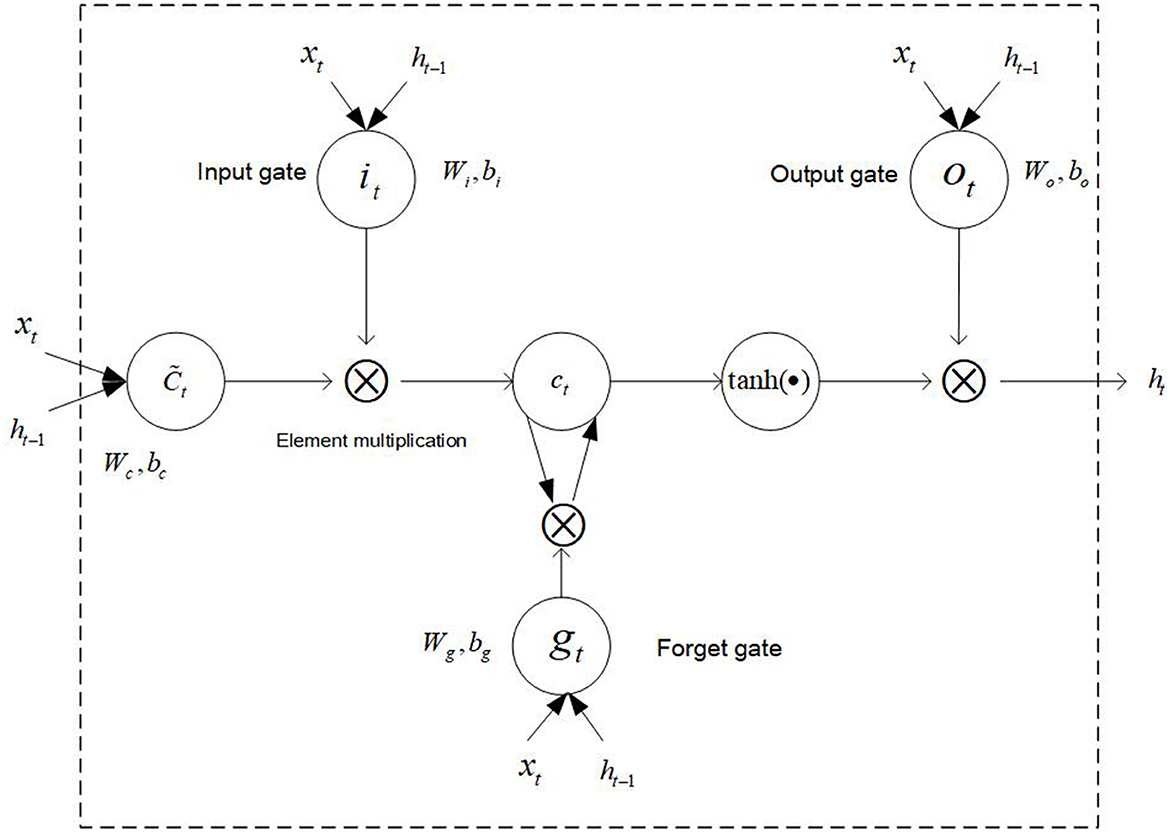
Figure 5. The schematic diagram of the LSTM model.
In LSTM, the information processing flow is as follows: (1) Discard information. The information is discarded and retained by the sigmoid function through the forget gate of LSTM.
Where gt means the proportion of discarded information, σ is the sigmoid function, Wg indicates the weight of the forget gate, and bg is the bias term of the forget gate.
(2) Update information. The retained information is updated through the input gate, and then a new candidate vector is created by a layer and added to the state.
Where it is the weight of the updated door, bt is the bias term of the update gate, tanh is the hyperbolic tangent function, Wc indicates the updating candidate values, bc indicates the updating the bias term of the candidate values, and is the candidate value.
(3) Update the cell status. Multiplying the old state and the discard function gt, further update each status, and the updated status value is Ct.
(4) Determine output status. The sigmoid function can determine which part of the cell state will be output. The cell state will be processed by tanh function, and the processed result will be multiplied by the sigmoid function in gate output to obtain the final output result.
Where Wo is a function that can update the weight, bo can update the bias term of the output value, and ht is the final output value.
During the process of the parameter selection process, different proportions of training data may influence the performance of the model. To select the suitable parameters, this study compares the performance of the LSTM model under the different proportions of training data, the specific result is shown in Figure 6.
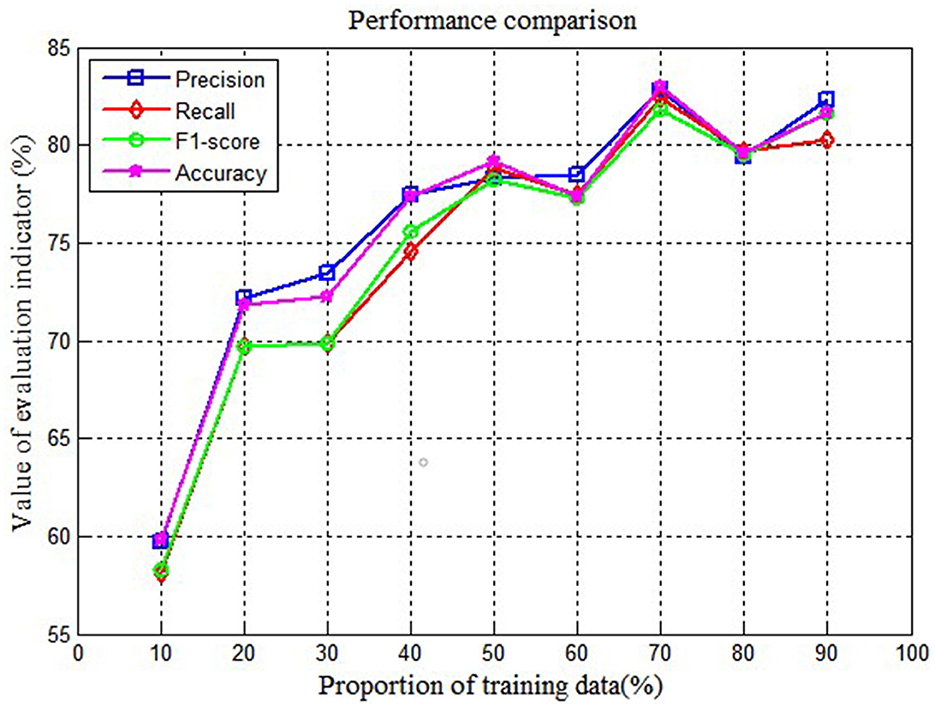
Figure 6. Performance comparison on different proportions of training data.
As shown in Figure 6, it can be found that when the proportion of training data is 70% and the proportion of testing data is 30%, the performance of LSTM is best. Thus, we fix the proportion of training data at 70% and testing data at 30%.
To measure the performance of LSTM in department recommendation, we select machine learning and the deep learning algorithm to do a test. The comparison algorithm contains text CNN (TextCNN), Random Forest, KNN, and SVM algorithms. All algorithms have been dealt with 10-fold cross-validation, and the average result of five times is taken as the final result. Since the LSTM and TextCNN algorithms need to input a matrix, therefore, to keep reasonable input sentence length, the sentence length of LSTM and TextCNN can be set to the median of 75% of all sentence lengths, and the final sentence length is around 110. The input of random forest, KNN, and SVM algorithms is not a matrix, thus the sentence length is not processed. The related parameter settings are shown in Table 2.
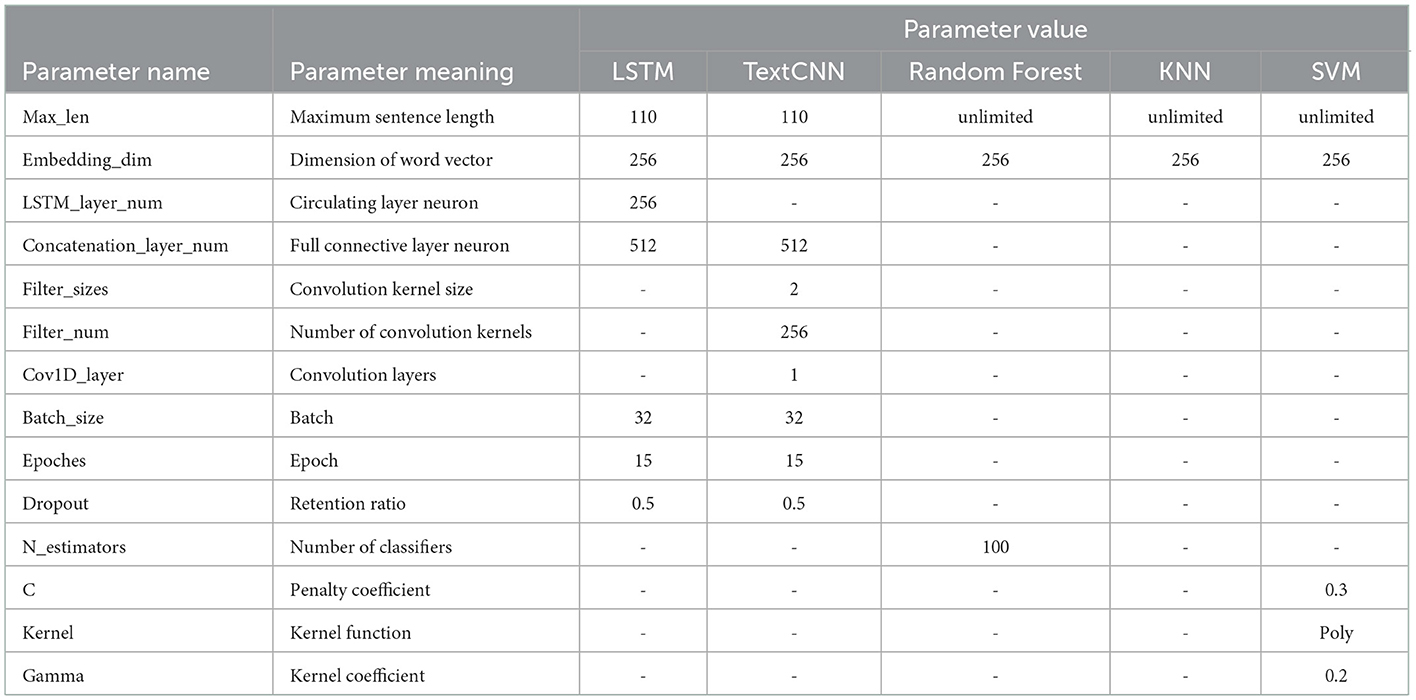
Table 2. The related parameter settings.
2.2. Analysis of the results of the departmental guide recommendations
To verify the classification performance of the model, we selected several indicators to display the results. The specific indicators are shown as follows: When we evaluate the effect of the classification algorithm, we can use precision, recall, f1-score, and accuracy to evaluate the effect of the classification algorithm. Generally, the sample can be classified into positive class (P) and negative class (N). Besides, according to the classifier and actual situation, the sample can be classified into true-positive type (TP), true-negative type (TN), false-positive (FP), and false-negative (FN). This moment, P = TP+PN and N = TN+FP.
(1) Confusion matrix
The confusion matrix is a standard form of accuracy evaluation, which is used to observe the performance of the model in various categories, and calculate the accuracy of the model corresponding to each category. It can reflect the accuracy of model classification effectively and have a good visualization effect in evaluating the classification effect of the model.
(2) Precision
Precision refers to the proportion of samples that are truly positive in the samples that are predicted to be positive, which can indicate the precision of model prediction.
(3) Recall
Recall indicates the probability that the positive class in the sample is predicted correctly and measures the recall rate of the model.
(4) F1-score
As the harmonic average of precision and recall, the F1-score can comprehensively reflect the performance of the model by integrating the indicator advantages of precision and recall.
(5) Accuracy
Accuracy is used to measure the proportion of positive and negative prediction results.
To display the performance of the LSTM model intuitively, we also show the loss graph and accuracy graph in Figures 7, 8. As shown in Figure 7, we can find that training loss and validation loss decrease gradually. Also, the validation loss decreases more gently in the later stages. The above results show that the LSTM model is learning, and there are no underfitting and overfitting situations. Similarly, as shown in Figure 8, when the epoch increases from 1 to 15, training accuracy and validation accuracy increases from 20% to more than 90%. Thus, it can be seen that the LSTM model has a good learning status.
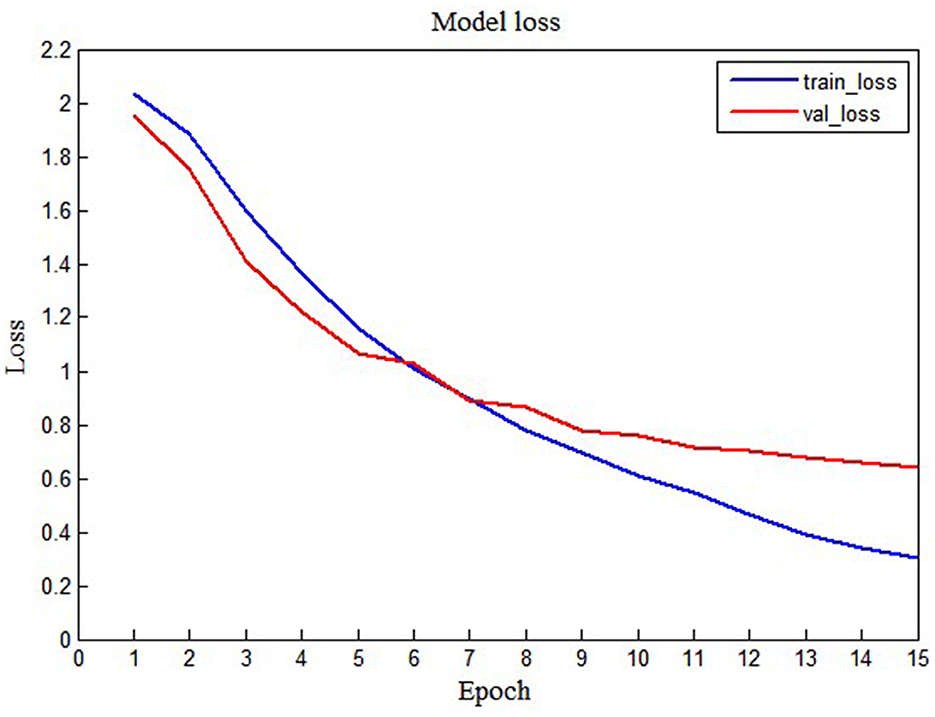
Figure 7. The training loss and validation loss of the LSTM model.
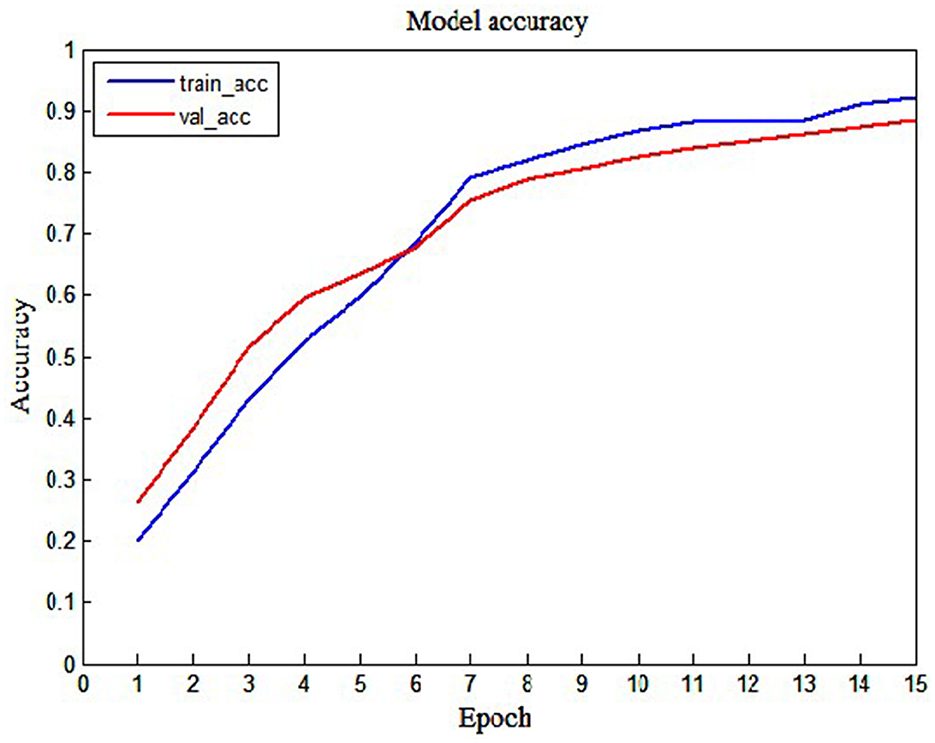
Figure 8. The training accuracy and validation accuracy of the LSTM model.
The normalized confusion matrix of the LSTM model is shown in Figure 9. As shown in Figure 9, we can see that the LSTM model can classify the department well. The precision of Ophthalmology is 0.97 and the precision of the Nephrology is 0.91. The precision of a Gynecologist is 0.63, which is the lowest precision. The reason maybe there is a procedure named abortion which could be classified into the Gynecologist, sometimes it could be classified into Reproduction. Therefore, the precision of a Gynecologist is low.
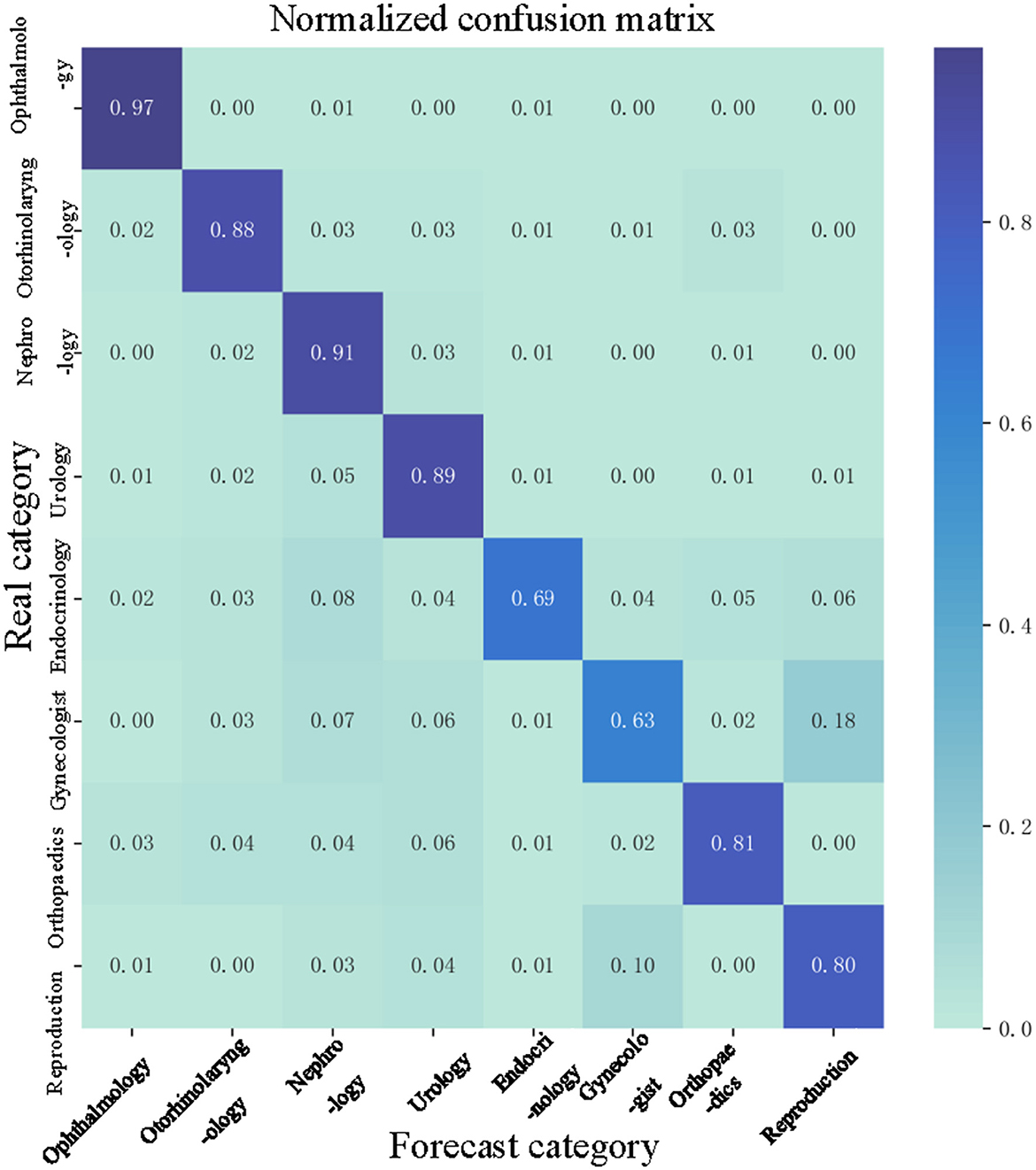
Figure 9. Normalized confusion matrix.
To measure the performance of the LSTM model, we compare the performance of TextCNN, random forest, KNN, and SVM. The specific result is shown in Figure 10.
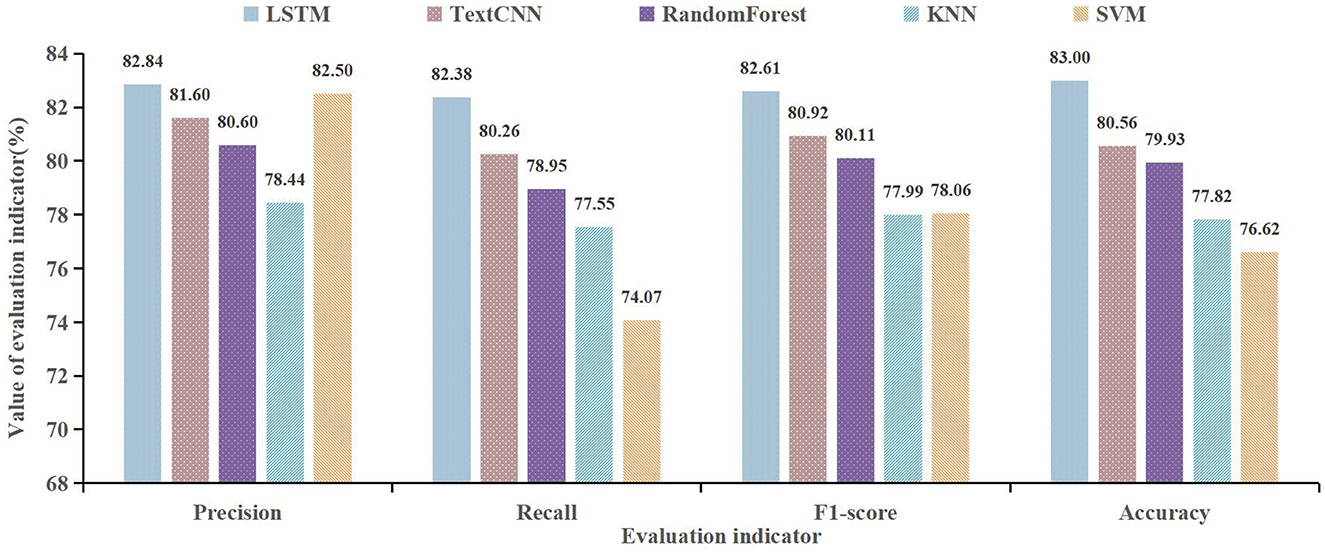
Figure 10. Classification effect of multiple models.
As shown in Figure 10, we can see that the LSTM model shows the best performance on precision, recall, F1-score, and accuracy. The precision of the LSTM is 82.84%, compared with the TextCNN, random forest, KNN, and SVM, it improved by 1.24%, 2.24%, 4.40%, and 0.34%. The F1-score of the LSTM is 82.61%, compared with TextCNN, random forest, KNN, and SVM, it improved by 1.69%, 2.50%, 4.62%, and 4.55%, respectively. Therefore, the LSTM model has a good performance in department recommendations. In terms of LSTM and TextCNN, we consider that their performance will be dependent on the length and context semantic relationship of data. In this research, the patient's main complaint text is long, so the LSTM can deal with the context semantic relationship well, thus, the LSTM model has a better performance than TextCNN. This result reflects the fact that the structure of the algorithm and the way it is optimized can influence the accuracy of the model effectively. Besides, it can be also found that word vector expression, proportions of training data, and model parameters have an influence on the accuracy of the model.
3. Online medical intelligent doctor recommendation model
Based on the department's recommendation, to recommend the appropriate physicians to patients, this study designs an intelligent physician recommendation model further. In our research, we select a department named otorhinolaryngology to carry out the recommendation activity. The data also comes from the Good Doctor, and we use python to crawl diagnosis data and communication data in 63 physicians. One physician can treat multiple patients, and finally, we obtain 1,430 patients' main complaint data and 19,336 communication data. The consulted text from physicians is shown in Table 3.
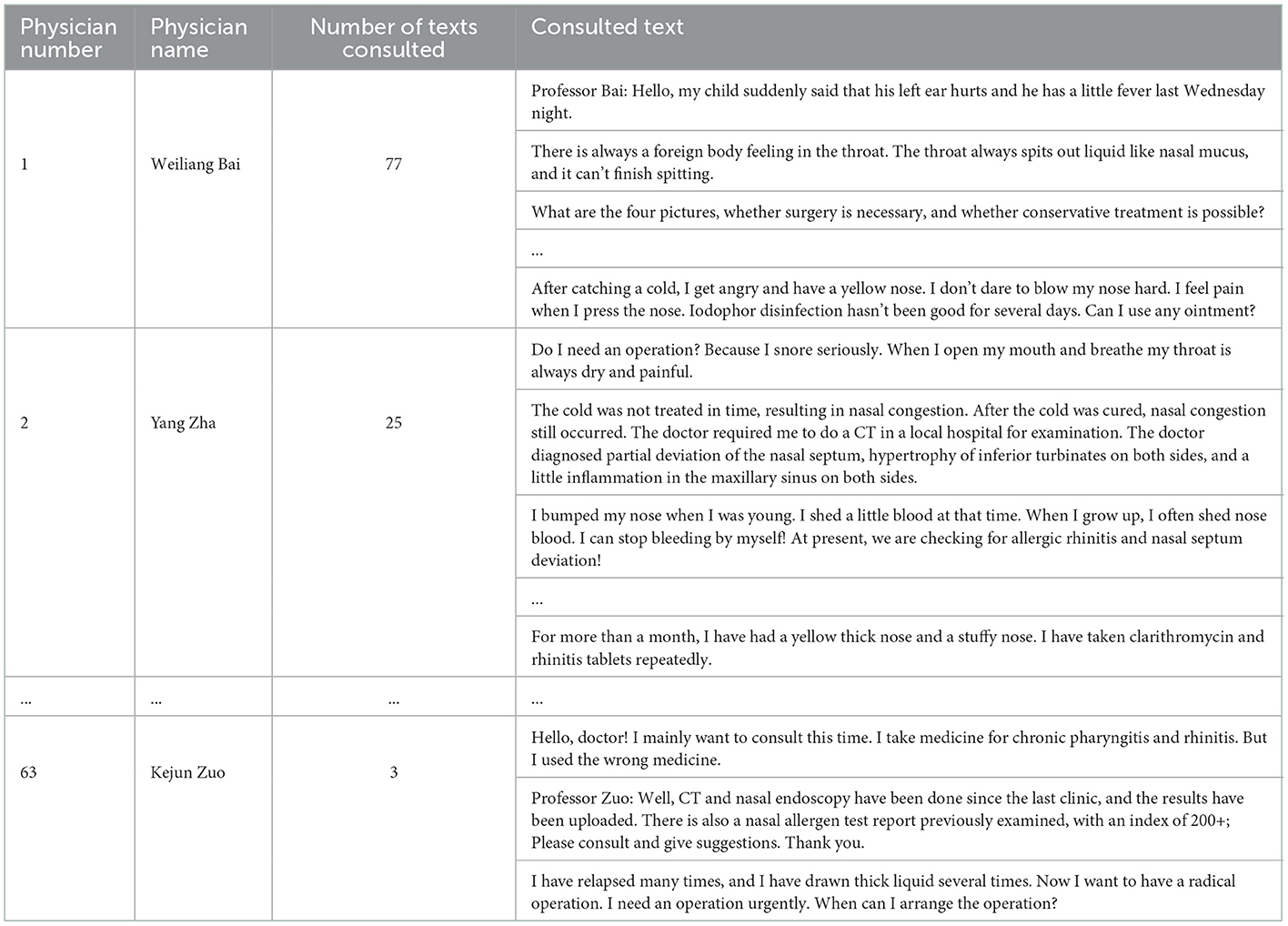
Table 3. The related parameter settings.
The consulted text from patients is shown in Table 4.
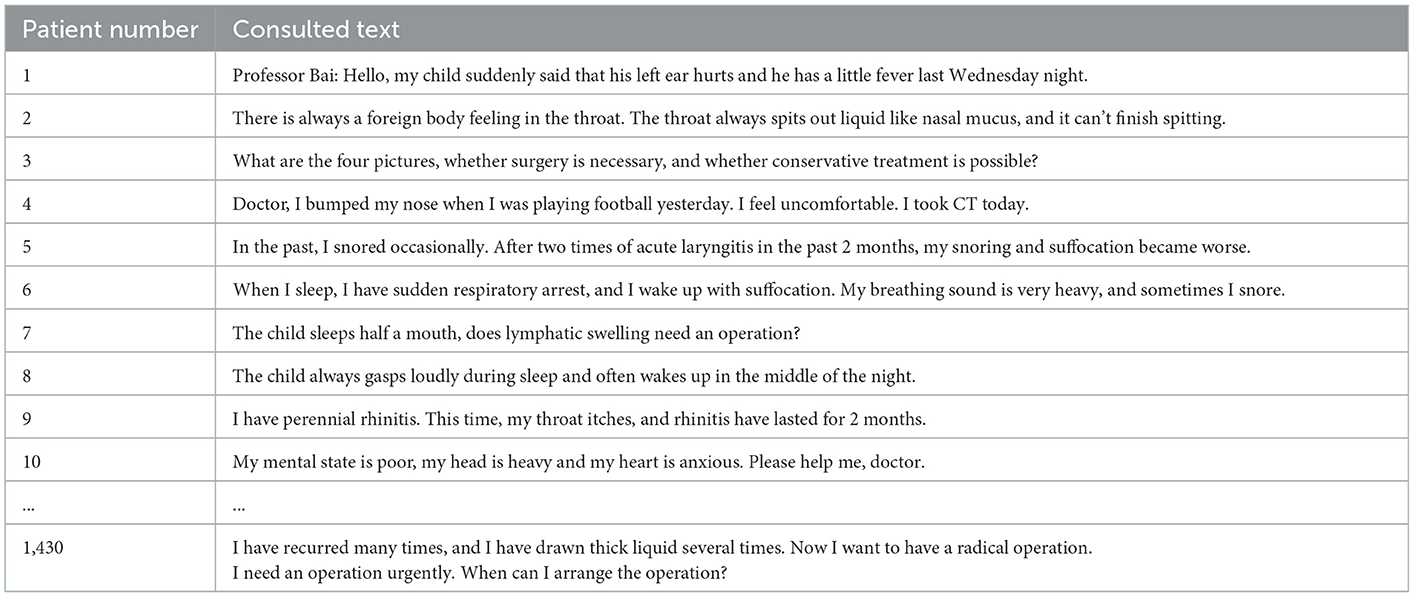
Table 4. Patients' main complaint text.
The patient-physician communication text is shown in Table 5.
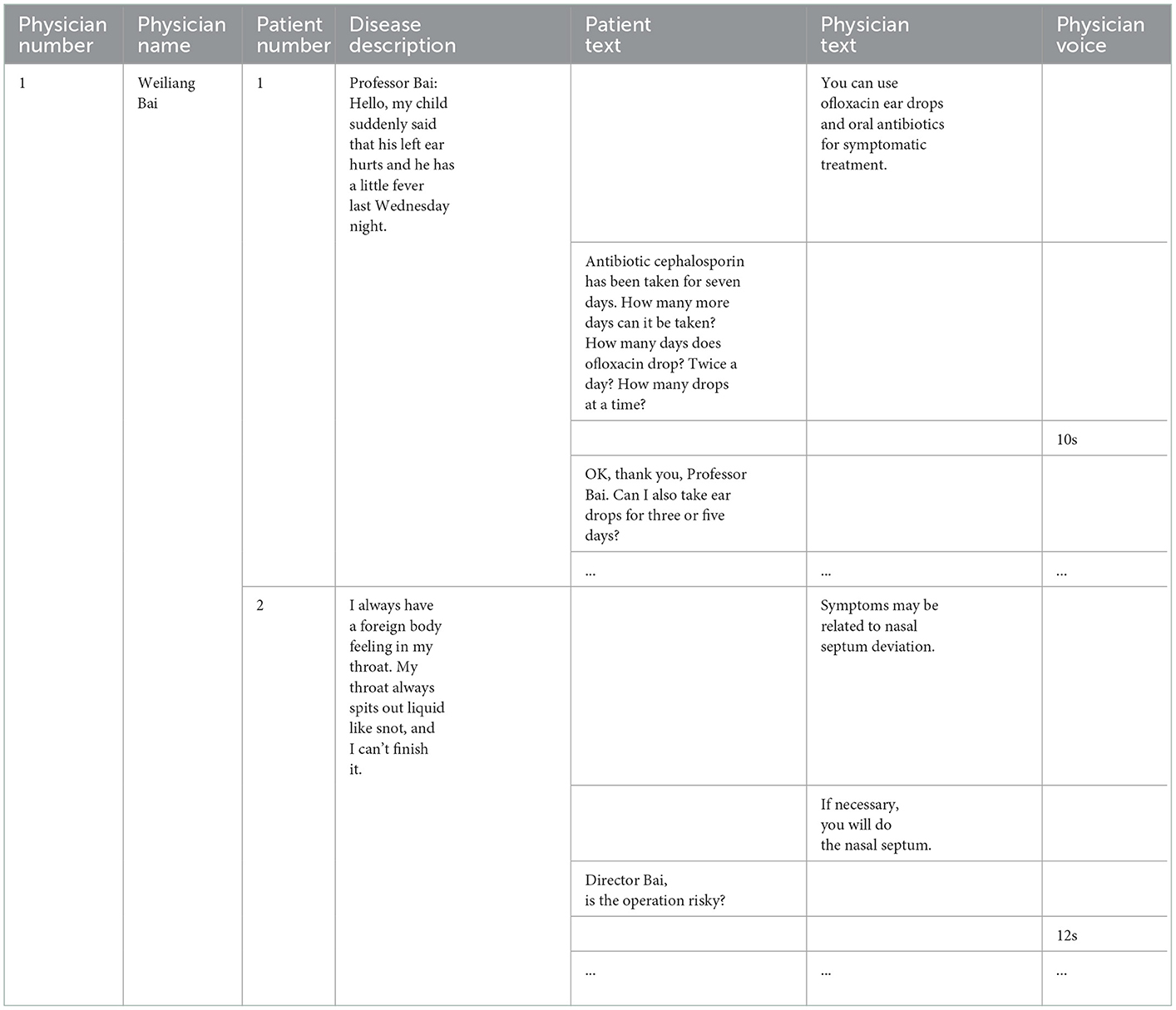
Table 5. Patient-physician communication text.
Based on the above data, this study designs an intelligent physician recommendation model based on patient-physician interaction data. The specific model is shown in Figure 11.
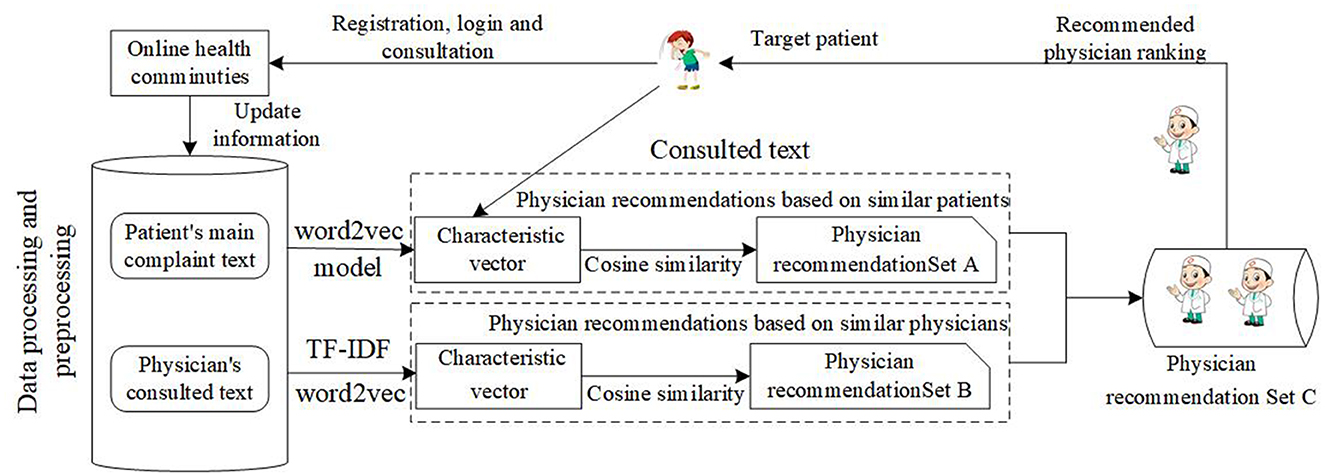
Figure 11. Intelligent physician recommendation process.
As shown in Figure 11, when the patients consult in an online health community, the patient's main complaint text and the physician's consulted text are important data sources. Based on training word vectors, we need to use the word2vec model to vectorize the patients' main complaint text in Table 4, and we also need to use TF_IDF to extract keywords from the physician's consulted text. After that, we need to use the word2vec model to vectorize the keywords from the physician's consulted text. Finally, cosine similarity is employed in the recommendation. The cosine similarity is shown as follows:
Where the u and v indicate patient u and patient v. N(u) and N(v) indicate the word vector set of patient u and patient v. Besides, in the process of the word vector expression, the patient's complained text is composed of several words. In a sentence, each word is defined as w, if there are k words, the sentence can be expressed as di = w1, w2, ..., wk. Furthermore, each word can be mapped to n-dimensional word vectors and can be expressed as vi = vi1, vi2, ..., vin, the patient's complained text is expressed as follows:
3.1. Recommendation model based on similar patients
The vector representation of the patient's main complaint text is shown in Table 6.
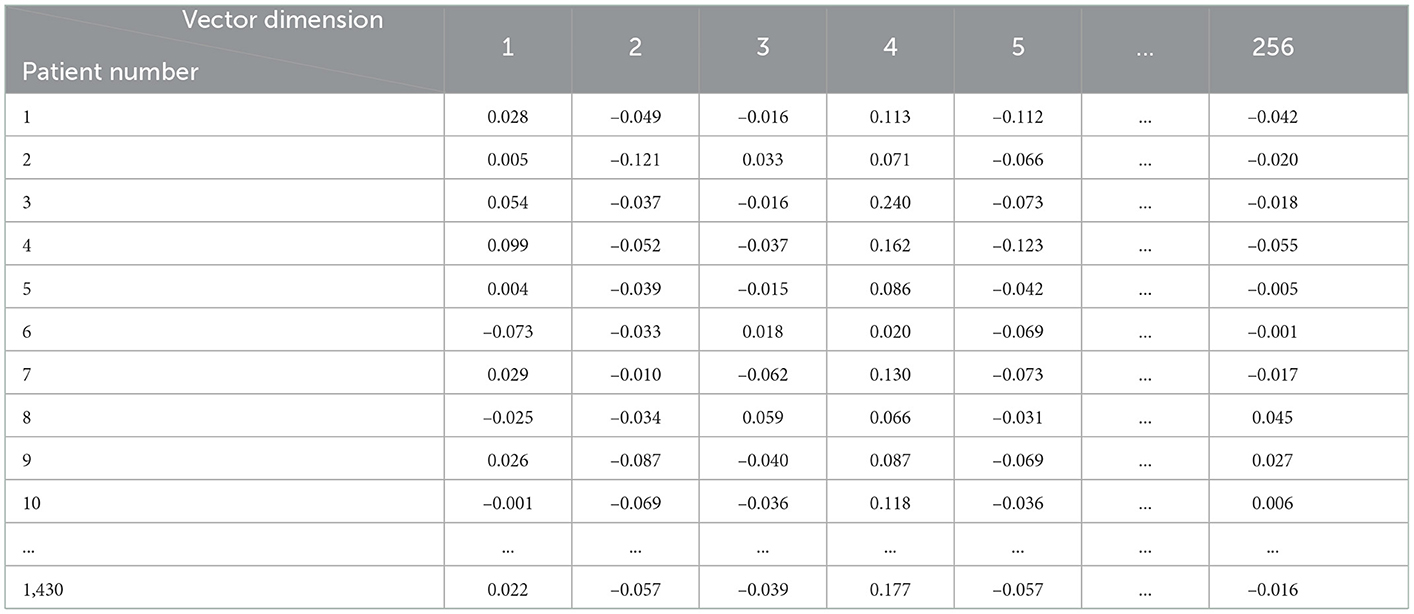
Table 6. The vector representation of the patient's main complaint text.
The cosine similarity of the patient main complaint text is shown in Table 7.

Table 7. The cosine similarity of the patient's main complaint text.
Based on Table 7, we select a patient, for example, a patient numbered 120. We recommend the physician to patient 120. To ensure there is a high similarity of patients, we set the threshold of the cosine similarity to 0.800. If the cosine similarity is larger than 0.800, the physician corresponding to the patient will be recommended in set A. Based on the threshold of the cosine similarity to 0.800, there are 48 physicians will be recommended in set A. The similar patients and physicians of target patient 120 are shown in Table 8.
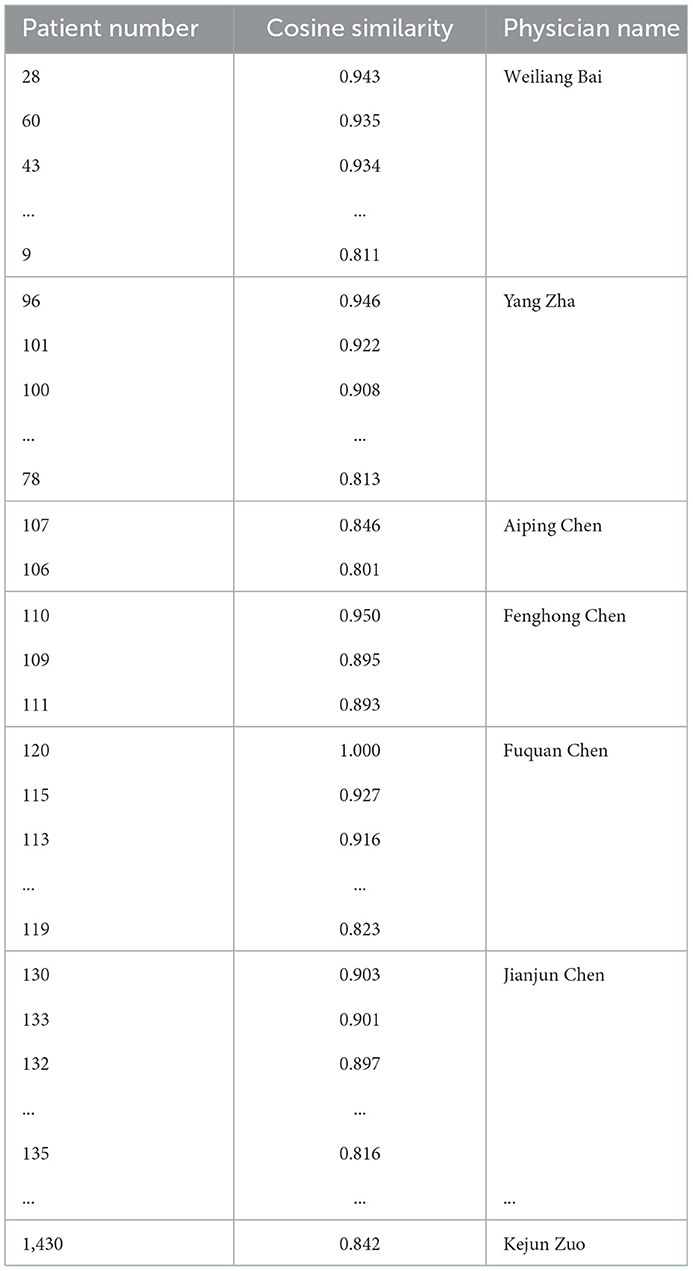
Table 8. Similar patients and physicians of target patient 120.
Based on Table 8, the top 10 physicians are selected as the physician recommendation set based on similar patients. The 120 target patient recommendation results based on similar patients are shown in Table 9.

Table 9. One hundred and twenty target patient recommendation results based on similar patients.
3.2. Recommendation model based on similar physicians
In this section, we will introduce a recommendation model based on similar physicians. When a patient consults a physician, if the physician is similar to the physician consulted before, we can recommend this physician to the patient. Since the physician's consulted text is a set of multiple patients' main complaint texts, we need to use the TF-IDF to extract the key information, such as the keywords. Term frequency-inverse document frequency(TF-IDF) can represent the eigenvalue weight in the spatial vector model and has a wide range of applications in extracting multi-text features. In this algorithm, the TF-IDF of the keyword i in the document j is shown in formula (13):
Where tf(i, j) is the word frequency, it indicates the frequency of keyword i in document j, and idf(i) is the inverse document frequency. The value of tf(i, j) is larger, which indicates that the feature value is more important in the document.
In this research, we use the TF-IDF to extract the key information in multiple texts from physicians' consulted text and use the word2vec algorithm to vectorize the key information from the physician's consulted text. Then, these vectors are arithmetically averaged to obtain the final vector expression. To obtain more information from multiple texts, the number of high-frequency words is set to 15. The extracted keywords are vectorized and further averaged to obtain the vector of the physician's consulted text. The vector of the physician's consulted text is shown in Table 10.
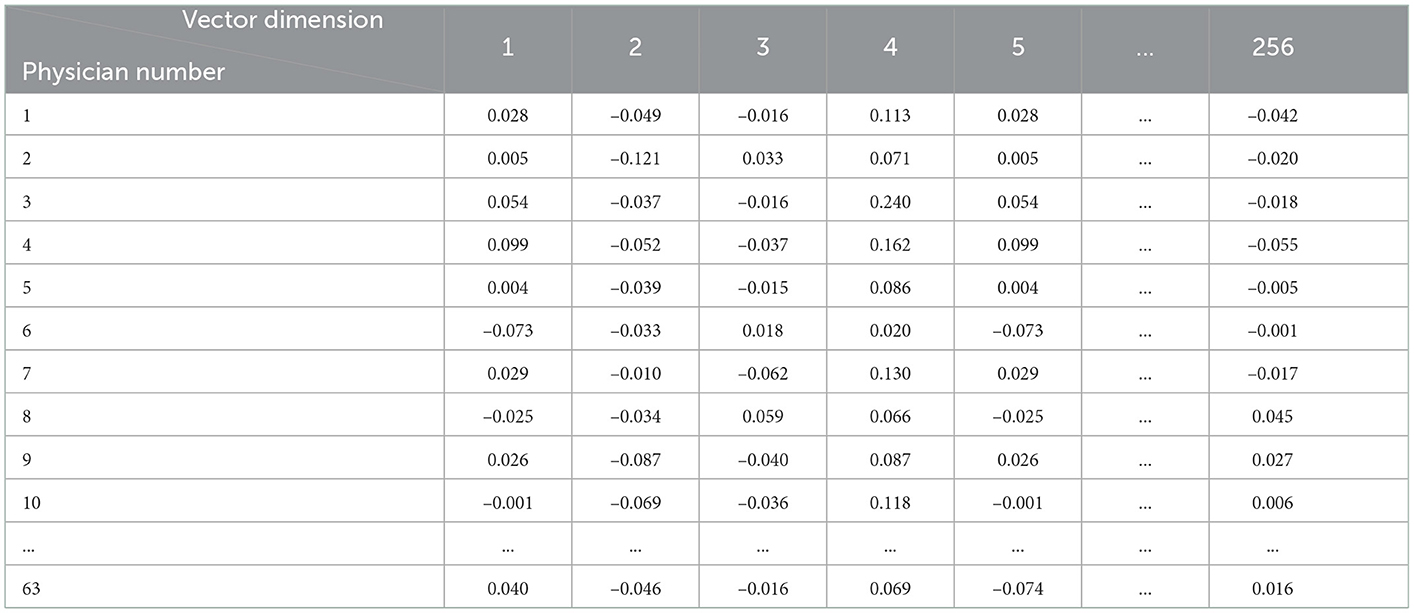
Table 10. The vector of the physician's consulted text.
Based on the vector of the physician's consulted text, this study calculates the cosine similarity of physicians, the results are shown in Table 11.
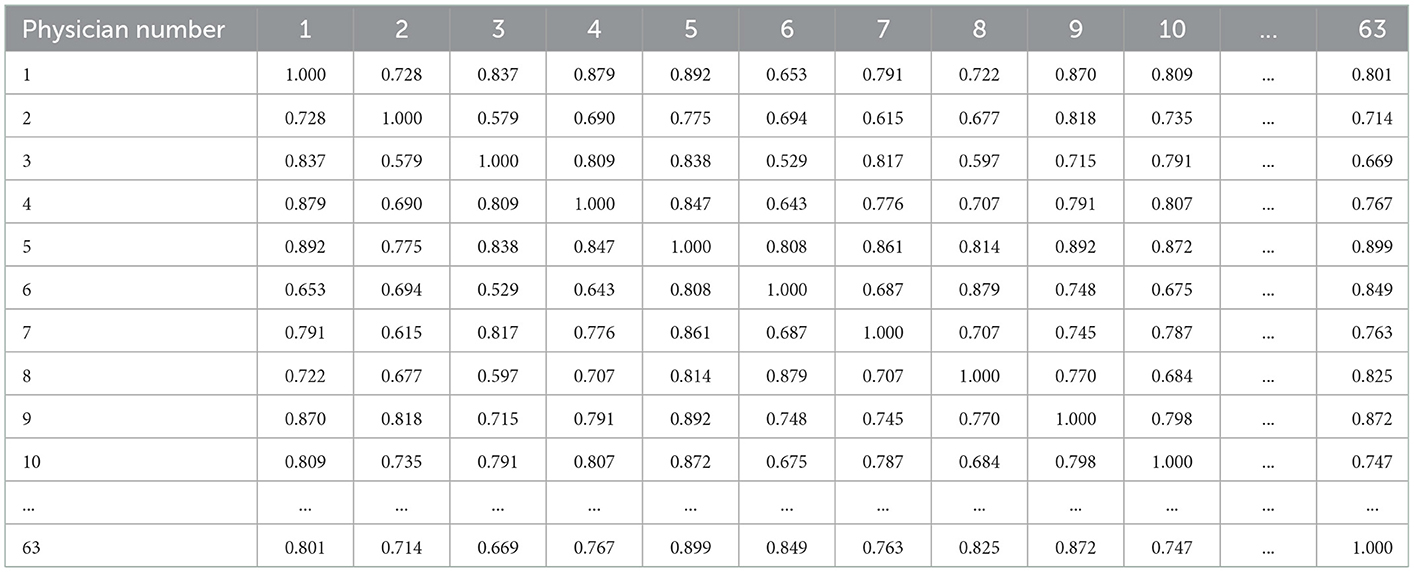
Table 11. The cosine similarity of physicians.
The physician consulted by patient 120 is physician 5, whose name is Fuquan Chen. The 10 physicians are most similar to Fuquan Chen, and the recommended result is shown in Table 12.
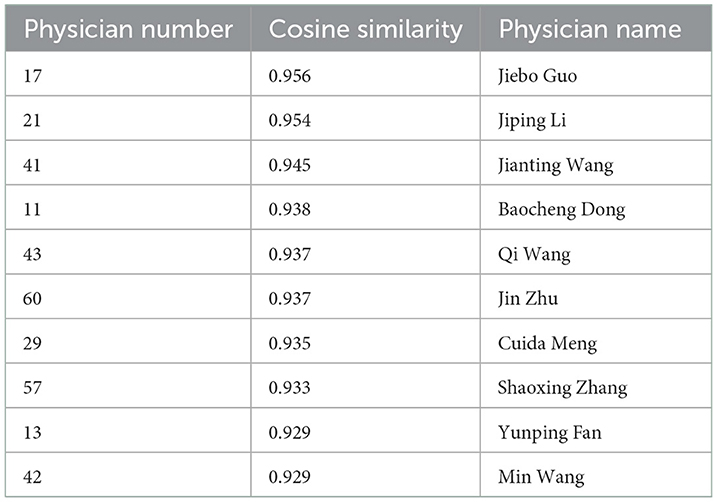
Table 12. One hundred and twenty target patient recommendation results based on similar physicians.
3.3. Recommendation model based on similar physicians
In Sections 3.1, 3.2, the recommended physicians based on similar patients form a recommendation set A, and the recommended physicians based on similar physicians form a recommendation set B. Combining sets A and B, we use the similarity in the recommendation set B to sort the recommendation set A and form a new recommendation set C. The recommendation set C is the final recommendation result. The recommended results based on similar patients and similar physicians are shown in Table 13.
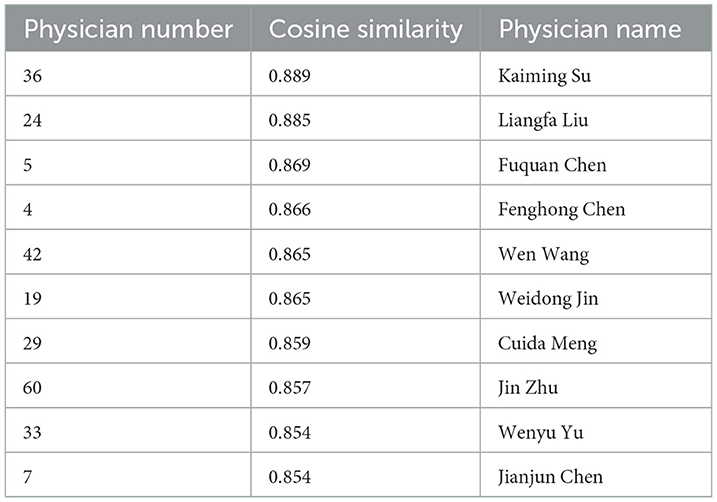
Table 13. Recommended results based the similar patients and similar physicians.
To test the accuracy of the recommended result, we compare the consult information among recommended results. The disease of patient 120 is ‘In September this year, I gave the children nasal endoscopy and found that 3 / 4 of them were blocked. The children breathed with their mouths open at night and snored occasionally!'. The consultation information of the final recommended result is shown in Table 14.
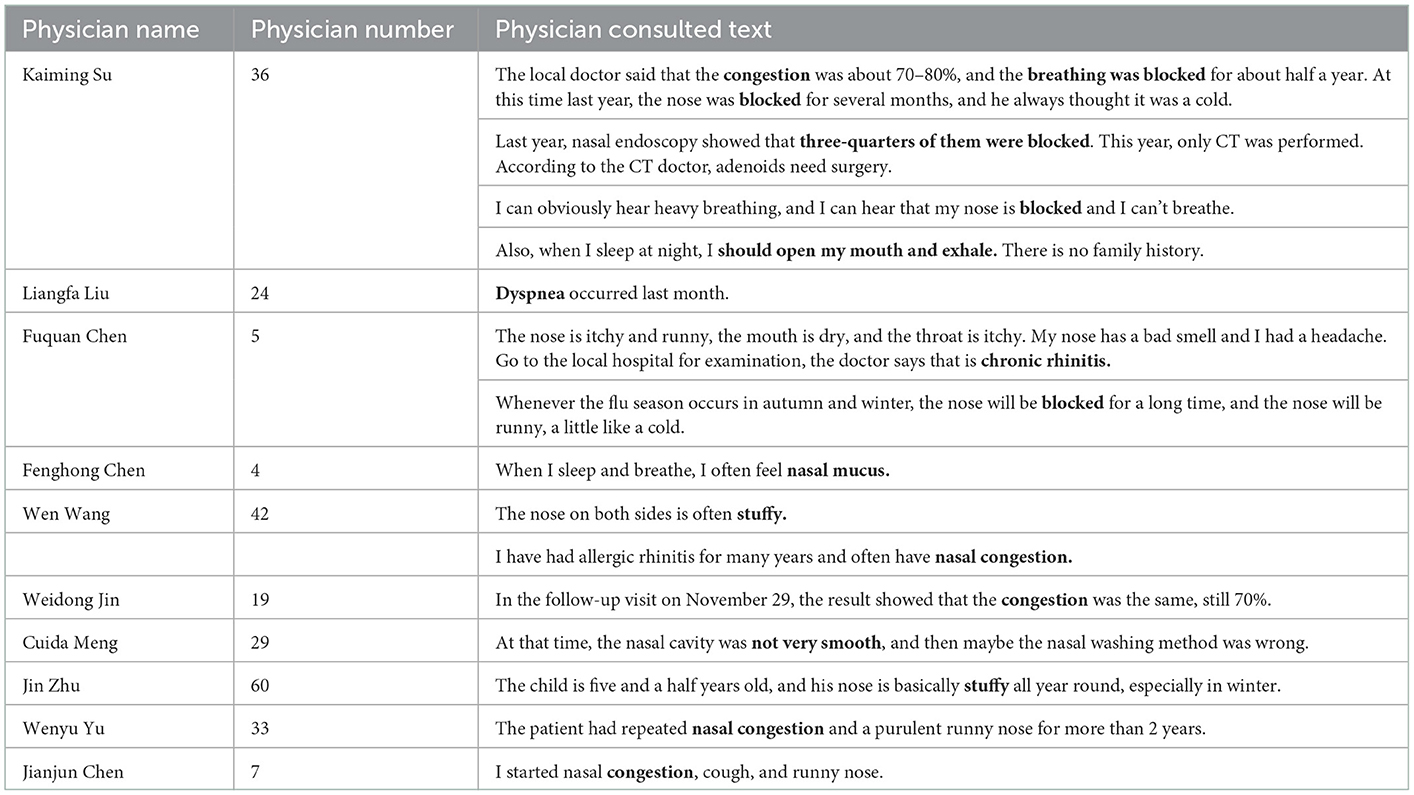
Table 14. Recommended results and diagnosis information of target patient 120.
In Table 14, we can see that the diagnosis information of 10 physicians is similar to the symptoms of patient 120. For example, the diagnosis of physician 36 Kaiming Su contains “breathing was blocked” and “three-quarters of them were blocked”; the diagnosis of physician 42 Wen Wang contains “stuffy,” and “nasal congestion.” This diagnosis information is similar to the symptom of patient 120; therefore, the recommended results are relatively accurate.
3.4. Analysis and evaluation of recommendation results
In this research, there are 1,430 patients and 63 physicians in the research data. The first recommendation model is the recommended model based on similar patients. In this model, we set the similarity threshold to 0.800, if the similarity between other patients and the target patient is greater than or equal to 0.800, the patients will be taken into the similar patients, then the similarity of these patients treated by one physician was averaged. The physicians ranked in the top 10 in the similarity will be taken as the final recommendation results. The second model is the recommendation model based on similar physicians. By calculating the similarity between the remaining 62 physicians and the physician consulted by the target patient, the top 10 physicians were selected as the final recommendation results. The third model is the recommendation model based on similar patients and physicians. In this model, we combined the results of similar patients and physicians to sort further, if the physicians in the model of similar patients are not in the list of the model of similar physicians, the physicians will be deleted and the next physician will fill that position, finally, we can get the final top 10 results.
To build a good evaluation indicator, the evaluation indicator should be composed of three indicators: recommendation precision, text service quality, and voice service quality. If the number of consultation texts that is similar to the patient's consultation text in the recommended physician accounts for 80% or more, the recommendation is deemed to be successful. The recommendation precision is the proportion of the physician who is recommended successfully to the total recommended numbers. In the real life, in addition to the recommendation precision, service quality is also an important indicator. In online health communities, if the physicians speak more text or voice information, the patients will consider that the physician's service is better than the physician who says fewer words or voice, therefore, the text and voice service quality are two important evaluating indicators. The specific calculation method of text and voice service quality is shown as follows: First, we need to calculate the average text and voice length of 63 physicians in our data set. Second, comparing the text length and voice length of recommended physicians with the average of total physicians. If the text and voice length of recommended physicians is larger than the average length, the text and voice service quality is well and the recommended physician in the aspect of text and voice service quality is successful. For example, if 10 physicians are recommended, there are 5 physicians' text length that is larger than the average length of 63 physicians, and the text service quality is 0.5. Similarly, the voice service quality is similar to the text service quality. The final recommendation performance (RP) is a linear weight among recommendation precision, text service quality, and voice service quality. To sign the indicator conveniently, we set the recommendation precision as A, set text service quality as B, and set voice service quality as C. The weight of these factors is τ1, τ2, and τ3. Therefore, the RP is a linear weighted function and it can be expressed as follows:
In the recommendation model, the first factor considered by the patients is the recommendation precision. If the system can recommend a professional and suitable physician to patients, the patients will be satisfied. Then, the text and voice service quality will be considered. Therefore, we can set the weight of the recommendation precision to be larger and set the weight of the text and voice service quality to be smaller. Without losing generality, we set the original weight to τ1 = 0.8, τ2 = 0.1, and τ3 = 0.1. Besides, the similarity threshold and recommended success rate are two important factors that can influence the final recommendation precision and the text and voice service quality. To write conveniently, we set the similarity threshold as β and set the recommended success rate as γ. To test the performance of the three recommendation models, namely recommendation models based on similar patients, recommendation models based on similar physicians, and recommendation models based on similar patients and physicians. Furthermore, we set different parameters under different conditions to examine the performance of the three models. The recommendation performance of the three recommendation models is shown in Table 15.
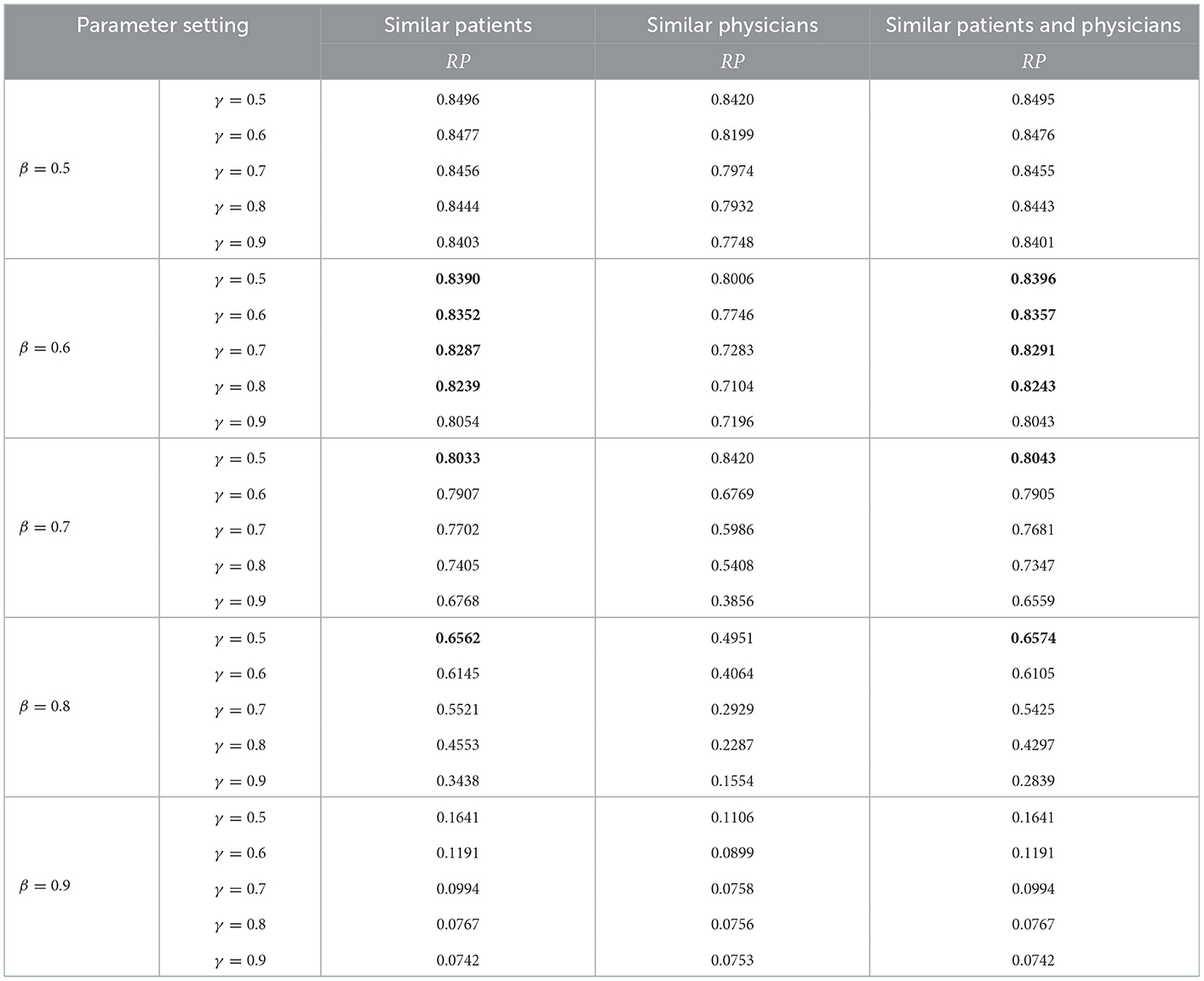
Table 15. Recommendation performance of three recommendation models under different parameters.
As shown in Table 15, under different parameters, the recommendation based on similar patients and physicians have certain advantages. For example, when β = 0.6, γ = 0.5, γ = 0.6, γ = 0.7, γ = 0.8; β = 0.7, γ = 0.5; β = 0.8, γ = 0.5, the performance of the recommendation model based on similar patients and physicians has certain advantages, compared to the recommendation model based on similar patients and the recommendation model based on similar physicians.
4. Discussion
As a novel field of intelligent technology, intelligent medical guidance and recommendation have huge advantages in the medical field (33, 34). At present, previous research has explored the intelligent department recommendation and physician recommendation model separately (35–37), there is spare research exploring the intelligent department guidance and physician recommendation model systematically. Besides, with the development of online health communities, patient-physician communication data have huge value. Based on this, to the best of our knowledge, our research on intelligent medical guidance and recommendation was the earlier research based on patient-physician communication data. In this research, to solve the problem that the patients know the diseases but do not know the department and the patients know the department but do not know how to select a good physician to consult, this study constructs an intelligent medical guidance and recommendation model. The model contains two parts of contents: one is the intelligent department recommendation and the other is the intelligent physician recommendation.
First, in the model of intelligent department recommendations, based on the long text characteristic of patient-physician communication, due to the advantage of processing the context semantic relationship (38), we use the LSTM algorithm to construct an intelligent department recommendation model. Compared with TextCNN, random forest, KNN, and SVM algorithms, the LSTM model has a certain advantage in department recommendation. In terms of a specific indicator, the precision of the LSTM is 82.84% compared with TextCNN, random forest, KNN, and SVM algorithms, it improved by 1.24%, 2.24%, 4.40%, and 0.34%. The F1-score of the LSTM is 82.61% compared with TextCNN, random forest, KNN, and SVM algorithms, it improved by 1.69%, 2.50%, 4.62%, and 4.55%. Therefore, the LSTM model has a good performance in department recommendations.
Second, we use the text analysis method to construct the recommendation model of similar patients and similar physicians. In this part, the TF-IDF, word2vec, and cosine similarity were applied to our research. Based on the patient-physician communication data, we build physician recommendation models based on similar patients, similar physicians, and similar patients and physicians. Distinct from previous studies, with respect to evaluating indicators, in addition to recommendation precision, we introduce the text and voice service quality to the evaluating indicator. Under certain parameters, we found that the performance of recommendation based on similar patients and physicians is better than the recommendation model based on similar patients and similar physicians separately. The model can help patients to find the appropriate physicians to consult.
Third, the intelligent medical guidance and recommendation model is constructed in our research. Although previous studies have explored the intelligent department recommendation and the intelligent physician recommendation separately, few studies designed a systematic intelligent medical guidance and recommendation model that help patients to find the right department and the right doctor. Our research uses text analysis and machine learning to construct an intelligent department recommendation model and an intelligent physician recommendation model. These models can help patients find the appropriate department and physician, especially if it is of great use to the elderly.
5. Limitations and future directions
Although our research explored intelligent medical guidance and recommendation model, there are still some limitations in this research. First, limited by the availability of data, our data comes from a single online health community named Good Doctor, not multiple platforms. The single data sources may make the recommendation efficiency not very high. In the future, we will select more data to train and update the recommendation model.
Second, as a recommendation model, to some degree, our research is confronted with the cold-start problem. In the intelligent department recommendation model, if there are no similar symptoms to the new patient in the database, the recommendation efficiency will be reduced or even unable to recommend. Similarly, in the intelligent physician recommendation model, if the patients have an unusual disease, it is also difficult to make good recommendations to patients. Therefore, in the future, the database needs to be extended by introducing more data to realize an efficient and accurate recommendation.
Third, although we use text analysis and machine learning to construct the recommendation model, the model and method still have some limitations. For example, although we train the word vector model with a medical corpus, our corpus is still small. Future studies can select more medical corpus to express the text precisely. Besides, on the method, we use the LSTM to do a department recommendation. With the development of deep learning, future studies can use more efficient algorithms for department recommendation research, such as the BERT and transformer algorithms.
6. Conclusion
As a new technology, intelligent recommendation brings great convenience to people's life. However, in medical fields, the application of intelligent medical recommendation systems is still less, especially the system based on patient-physician communication data. Due to the fact that there is information asymmetry between doctors and patients, patients know their diseases but do not know how to select an appropriate department to consult, and even though they know which department they do not know select which physician. Based on this, we use text analysis, natural language processing, and machine learning to construct an intelligent department recommendation model and an intelligent physician recommendation model. In the intelligent department recommendation model, considering that the patient's main complaint text is long and has context semantic relevance, we use the LSTM model to construct a department recommendation model. Compared to TextCNN, random forest, KNN, and SVM algorithms, the LSTM algorithm has certain advantages in each evaluation indicator. The precision of LSTM is 82.84% and the F1-score is 82.61% in the test set.
In the intelligent physician recommendation model, considering patient and physician similarities, this study also designs a physician recommendation model based on similar patients and similar physicians. Meanwhile, in terms of evaluation indicators, in addition to the recommendation precision, this study also introduces text service quality and voice service quality to the evaluation indicator. Compared with the recommendation model based on similar patients and the recommendation model based on similar physicians separately, the physician recommendation model based on similar patients and similar physicians have better performance. Overall, this research can give academic circles and hospitals some enlightenment and can provide some references for the reasonable matching between physician and patient resources.
Data availability statement
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
Ethics statement
The data used in the manuscript is publicly available on the website of Good Doctor Online. The data provided by the platform are all anonymous and any information related to personal privacy has been removed.
Author contributions
JL: conceptualization, methodology, writing–original draft, and investigation. CL: methodology, supervision, and validation. YH: methodology and investigation. JH: funding support and validation. All authors contributed to the article and approved the submitted version.
Funding
This work was supported by the Major Program of the National Fund of Philosophy and Social Science of China (Grant No. 18ZDA088), the Shanghai Engineering Research Center of Finance Intelligence (Grant No. 19DZ2254600), the National Natural Science Foundation Project (Grant No. 71871144), the Shanghai Social Science Planning Youth Project (Grant No. 2019EXW001), the Shanghai University of Sport (Grant No. 2022XJ024), and the Shanghai Universities Young Teacher Training Funding Program.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
1. Frank ES, Zhen Y, Han F, Shailesh T, Matthias D. An introductory review of deep learning for prediction models with big data. Front Artif Intell. (2020) 3:00004. doi: 10.3389/frai.2020.00004
2. Zheng S, Yang L, Zhou P, Li H, Liu F, Zhao R. Recommendations and guidance for providing pharmaceutical care services during COVID-19 pandemic: a China perspective. Res Soc Admin Pharm. (2021) 17:1819–24. doi: 10.1016/j.sapharm.2020.03.012
3. Li C, Liu J, Qian G, Wang Z, Han J. Double chain system for online and offline medical data sharing via private and consortium blockchain: a system design study. Front Public Health. (2022) 10:1012202. doi: 10.3389/fpubh.2022.1012202
4. Tridib B, Peter M, Solomon N. Mobile IT in health-the case of short messaging service in an HIV awareness program. Inf Technol Dev. (2018) 24:359–97. doi: 10.1080/02681102.2017.1363029
5. Ye Q, Deng Z, Chen Y, Liao J, Li G, Lu Y. How resource scarcity and accessibility affect patients' usage of mobile health in China: Resource competition perspective. JMIR mHealth uHealth. (2019) 7:e13491. doi: 10.2196/13491
6. Hajli, M. N. (2014). Developing online health communities through digital media. Int. J. Infm. Manag. 34, 311–314. doi: 10.1016/j.ijinfomgt.2014.01.006
7. Liu, S., Xiao, W., Fang, C., Zhang, X., and Lin, J. (2020). Social support, belongingness, and value co-creation behaviors in online health communities. Telemat. Informat. 50:101398. doi: 10.1016/j.tele.2020.101398
8. Guo S, Guo X, Zhang X, Doug V. Doctor-patient relationship strength's impact in an online healthcare community. Inf Technol Dev. (2018) 24:279–300. doi: 10.1080/02681102.2017.1283287
9. Li C, Zhang E, Han J. Adoption of online follow-up service by patients: an empirical study based on the elaboration likelihood model. Comput Hum Behav. (2021) 114:106581. doi: 10.1016/j.chb.2020.106581
10. Juan G DO, Orsolya C, Thomas S. Medical recommender systems based on continuous-valued logic and multi-criteria decision operators, using interpretable neural networks. BMC Med Inform Decis Mak. (2021) 21:1–15. doi: 10.1186/s12911-021-01553-3
11. Liu J, He J, He S, Li C, Yu C, Li Q. Patients' self-disclosure positively influences the establishment of patients' trust in physicians: an empirical study of computer-mediated communication in an online health community. Front Public Health. (2022) 10:823692. doi: 10.3389/fpubh.2022.823692
12. Shi H, Xie P, Hu Z, Zhang M, Xing EP. Towards automated ICD coding using deep learning. arXiv preprint arXiv:171104075. (2017) 1711:04075. doi: 10.18653/v1/P18-1098
13. Mullenbach J, Wiegreffe S, Duke J, Sun J, Eisenstein J. Explainable prediction of medical codes from clinical text. arXiv preprint arXiv:180205695. (2018) 1802:05695. doi: 10.18653/v1/N18-1100
14. Mao C, Yao L, Luo Y. Medgcn: graph convolutional networks for multiple medical tasks. arXiv [Preprint] arXiv: arXiv:190400326. (2019) 1904:00326. doi: 10.1016/j.jbi.2022.104000
15. Li F, Yu H. ICD coding from clinical text using multi-filter residual convolutional neural network. Proc AAAI Conf Artif Intell. (2020) 34:8180–7. doi: 10.1609/aaai.v34i05.6331
16. Wang J, Zhang G, Wang W, Zhang K, Sheng Y. Cloud-based intelligent self-diagnosis and department recommendation service using Chinese medical BERT. J Cloud Comput. (2021) 10:1–12. doi: 10.1186/s13677-020-00218-2
17. Ju C, Zhang S. Doctor recommendation model based on ontology characteristics and disease text mining perspective. Biomed Res Int. (2021) 2021:7431199. doi: 10.1155/2021/7431199
18. Mondal S, Basu A, Mukherjee N. Building a trust-based doctor recommendation system on top of multilayer graph database. J Biomed Inform. (2020) 110:103549. doi: 10.1016/j.jbi.2020.103549
19. Guo L, Jin B, Yao C, Yang H, Huang D, Wang F, et al. Which doctor to trust: a recommender system for identifying the right doctors. J Med Internet Res. (2016) 18:e6015. doi: 10.2196/jmir.6015
20. Yang Y, Hu J, Liu Y, Chen X. Doctor recommendation based on an intuitionistic normal cloud model considering patient preferences. Cogn Comput. (2020) 12:460–78. doi: 10.1007/s12559-018-9616-3
21. Zhang Y, Chen M, Huang D, Wu D, Li Y. iDoctor: personalized and professionalized medical recommendations based on hybrid matrix factorization. Future Gen Comput Syst. (2017) 66:30–5. doi: 10.1016/j.future.2015.12.001
22. Meng Q, Xiong H. A doctor recommendation based on graph computing and LDA topic model. Int J Comput Intell Syst. (2021) 14:808–17. doi: 10.2991/ijcis.d.210205.002
23. Sahoo AK, Pradhan C, Barik RK, Dubey H. DeepReco: deep learning based health recommender system using collaborative filtering. Computation. (2019) 7:25. doi: 10.3390/computation7020025
24. Yan Y, Yu G, Yan X. Online doctor recommendation with convolutional neural network and sparse inputs. Comput Intell Neurosci. (2020) 2020:8826557. doi: 10.1155/2020/8826557
25. Xu C, Wang J, Zhu L, Zhang C, Sharif K. PPMR: a privacy-preserving online medical service recommendation scheme in eHealthcare system. IEEE Internet Things J. (2019) 6:5665–73. doi: 10.1109/JIOT.2019.2904728
26. Chen H, Wu L, Chen J, Lu W, Ding J. A comparative study of automated legal text classification using random forests and deep learning. Inform Process Manag. (2022) 59:102798. doi: 10.1016/j.ipm.2021.102798
27. Zhou Y, Li J, Chi J, Tang W, Zheng Y. Set-CNN: a text convolutional neural network based on semantic extension for short text classification. Knowl Based Syst. (2022) 257:109948. doi: 10.1016/j.knosys.2022.109948
28. Sendhilkumar S, et al. Developing a conceptual framework for short text categorization using hybrid CNN-LSTM based Caledonian crow optimization. Expert Syst Appl. (2023) 212:118517. doi: 10.1016/j.eswa.2022.118517
29. Mikolov T, Chen K, Corrado G, Dean J. Efficient estimation of word representations in vector space. arXiv preprint arXiv:13013781. (2013) 1301:3781. doi: 10.48550/arXiv.1301.3781
30. Le Q, Mikolov T. Distributed representations of sentences and documents. In: International Conference on Machine Learning. Vol. 32 (Beijing) (2014), 1188–1196.
31. Rong X. word2vec parameter learning explained. arXiv preprint arXiv:14112738. (2014) 1411:2738. doi: 10.48550/arXiv.1411.2738
32. Min L, Dong J, Liu J, Gong X. Robust mean-risk portfolio optimization using machine learning-based trade-off parameter. Appl Soft Comput. (2021) 113:107948. doi: 10.1016/j.asoc.2021.107948
33. Luo F, Luo X. Intelligent disease prediagnosis only based on symptoms. J Healthcare Eng. (2021) 2021:9963576. doi: 10.1155/2021/9963576
34. Zhou X, Li Y, Liang W. CNN-RNN based intelligent recommendation for online medical pre-diagnosis support. IEEE/ACM Trans Comput Bio Bioinform. (2020) 18:912–21. doi: 10.1109/TCBB.2020.2994780
35. Abbas K, Afaq M, Ahmed Khan T, Song WC. A blockchain and machine learning-based drug supply chain management and recommendation system for smart pharmaceutical industry. Electronics. (2020) 9:852. doi: 10.3390/electronics9050852
36. Ali F, El-Sappagh S, Islam SR, Kwak D, Ali A, Imran M, et al. A smart healthcare monitoring system for heart disease prediction based on ensemble deep learning and feature fusion. Inf Fusion. (2020) 63:208–22. doi: 10.1016/j.inffus.2020.06.008
37. Li Q, Ling X, Chiang HS, Yang KJ. A medical specialty outpatient clinics recommendation system based on text mining. Int J Grid Utility Comput. (2021) 12:450–6. doi: 10.1504/IJGUC.2021.119568
Keywords: healthcare, recommendation system, natural language processing, text analytics, patient-physician communication data
Citation: Liu J, Li C, Huang Y and Han J (2023) An intelligent medical guidance and recommendation model driven by patient-physician communication data. Front. Public Health 11:1098206. doi: 10.3389/fpubh.2023.1098206
Received: 14 November 2022; Accepted: 04 January 2023;
Published: 26 January 2023.
Edited by:
Md Anisur Rahman, Charles Sturt University, AustraliaReviewed by:
Zhiyang Li, Second Affiliated Hospital of Shantou University Medical College, ChinaMohammad Zavid Parvez, Australian Catholic University, Australia
Copyright © 2023 Liu, Li, Huang and Han. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Chaoran Li,  bGkuY2hhb3JhbkAxNjMuc3VmZS5lZHUuY24=; Ye Huang, aHVhbmcueWVAbWFpbC5zaHVmZS5lZHUuY24=
bGkuY2hhb3JhbkAxNjMuc3VmZS5lZHUuY24=; Ye Huang, aHVhbmcueWVAbWFpbC5zaHVmZS5lZHUuY24=