 Juan Equiza-Goñi
Juan Equiza-Goñi- Facultad de Ciencias Económicas y Empresariales, Universidad de Navarra, Pamplona, España
Objectives: During the COVID-19 pandemic, surveillance systems worldwide underestimated mortality in real time due to longer death reporting lags. In Spain, the mortality monitor “MoMo” published downward biased excess mortality estimates daily. I study the correction of such bias using polynomial regressions in data from January to March 2021 for Spain and the Comunitat Valenciana, the region with the highest excess mortality.
Methods: This adjustment for real-time statistics consisted of (1) estimating forthcoming revisions with polynomial regressions of past revisions, and (2) multiplying the daily-published excess mortality by these estimated revisions. The accuracy of the corrected estimates compared to the original was measured by contrasting their mean absolute errors (MAE) and root mean square errors (RMSE).
Results: Applying quadratic and cubic regressions improved the first communication of cumulative mortality in Spain by 2–3%, on average, and the flow in registered deaths by 20%. However, for the Comunitat Valenciana, those corrections improved the first publications of the cumulative mortality by 36–45%, on average; their second publication, by 23–30%; and the third, by 15–21%. The flow of deaths registered each day improved by 62–63% on their first publication, by 19–36% on the second, and by 12–17% on the third.
Conclusion: It is recommended that MoMo's estimates for excess mortality be corrected from the effect of death reporting lags by using polynomial regressions. This holds for the flows in each date and their cumulative sum, as well as national and regional data. These adjustments can be applied by surveillance systems in other countries.
Introduction
MoMo is the monitoring system of daily mortality for all causes in Spain. It was developed in 2004 and belongs to the European network of surveillance systems EuroMOMO. Since January 2020, daily mortality data is collected by almost 4,000 computerized civil registries, including all regions and representing 93% of the Spanish population. Since the COVID-19 pandemic reached Spain, the National Center of Epidemiology—Institute of Health Carlos III (Centro Nacional de Epidemiología—Instituto de Salud Carlos III, CNE-ISCII) has been issuing reports (1) on the evolution of excess mortality registered by MoMo as well as publishing daily data online on the observed mortality (2). The logic behind the publication of this information is that the statistic for excess mortality is also a good way of estimating and communicating to the public the number of deaths caused by COVID-19 [see, for example, Cerda Thomas (3), or, more recently, Adam (4)].
According to MoMo, Spain witnessed the fourth episode of excess mortality between 4 January and 13 February1. Despite the absence of lockdowns during this period and the experience acquired in previous COVID-19 surges, the number of deaths published in the first quarter of 2021 was still influenced by the aggravated reporting lag documented during similar episodes. Equiza-Goñi (5, 6) showed that the statistics of cumulative excess mortality in Spain in March–May and September–December of 2020 were downward biased due to death reporting lags. Akhmetzhanov (7) and Rosenbaum et al. (8) documented the same problem in all-cause excess mortality figures in the United States2.
By contrast, González Morán et al. (9) and Leon et al. (10) stressed the need for real-time information to monitor the pandemic. Aroca (11) and Vestergaard and Mølbak (12) underlined the importance of effectively communicating it to the public. Naudé and Vinuesa (13) and Malecki et al. (14) summarized some of the challenges that this communication implied and provided some recommendations. Carvalho et al. (15) suggested that nowcasting techniques must be applied to Brazilian mortality data to achieve more up-to-date monitoring. Gutierrez et al. (16) provided empirical evidence of the effect of death reporting lags on individuals' beliefs and behavior in Mexico, and, consequently, on COVID-19 transmission.
In this line of research, Equiza-Goñi (5, 6) proposed and evaluated the performance of estimating polynomial regressions based on past revisions of real-time data to correct the effect of death reporting lags. Based on data from 2020, both studies found that quadratic and cubic regression-based corrections applied to mortality estimates in their first publication improved them notably, setting them closer to their definitive values. Although using cubic regressions brought the corrected mortality estimates slightly closer to their definitive values than quadratic regressions, those estimates that were adjusted using quadratic regressions were more robust to the presence of holidays in the sample (6). Extending previous work, the present study evaluates this methodology in new data from 2021 using not only aggregated national but also regional Spanish mortality estimates. Moreover, this is measured for the cumulative sum of deaths and, in a further step, for the flow reported for each date. As a novel measure, to gauge the full benefits of this methodology, estimates beyond their first publication were also corrected.
The main goal of this study is, thus, to evaluate the accuracy of extrapolating observed past revisions through polynomial regressions to correct the widespread negative bias derived from death reporting lags in real-time mortality estimates during the pandemic. For this purpose, I used a sample of Spanish data published by MoMo during the first quarter of 2021.
Methodology
Equiza-Goñi (5) described and evaluated a methodology to correct the effect of death reporting lags in real-time excess mortality estimates published by MoMo. This method was followed in this study to adjust daily data published in January–March 2021. Note that MoMo uses the model in León-Gómez et al. (17) to define excess mortality as the difference between the observed and expected numbers of deaths. A similar procedure was followed by León-Gómez et al. (18) for all of Spain, or by Ochoa Sangrador et al. (19) for the case of the Spanish region “Comunidad Autónoma de Castilla y León”. However, there are other models for estimating excess mortality that could be applied, for example, Vanella et al. (20).
First, I obtained the excess mortality time series estimates3 for all of Spain and each of its autonomous regions or “Comunidades Autónomas” (CC.AA.) that were published daily by MoMo in the period 11 January to 31 March 2021. Note that, for each date of this period, MoMo published updated estimates for the complete daily history of mortality observed since 2015. I excluded publications before 2021 because these were not provided by MoMo between 5 and 10 January 2021. Given that I use both aggregated data for Spain and their CC.AA, my work is aligned with studies on previous episodes of excess mortality in the current pandemic using both national data [Fouillet et al. (22); Vestergaard et al. (23); regarding the first “wave”, and Nørgaard et al. (24); Grabowski et al. (25); in the context of the second] and regional level data [Morfeld et al. (26); Modig et al. (27); or, more recently, Konstantinoudis et al. (28)].
Second, based on the data released between 11 January and 31 March, I computed the intensity of daily revisions for the time series of excess mortality accumulated since 8 December 20204. Revisions for each date of the time series are calculated as the ratio between the estimates published 1 day and the corresponding ones reported for the same dates the day before. For example, on 14 January, the excess mortality accumulated up to 13 January was published at 2,790 deaths. By contrast, the sum of deaths for that period had been 2,213 as of 13 January, which is the first release extending the series of mortality up to that date. This means that on 14 January, the cumulative excess mortality estimate that was firstly published the day before was revised by 126% (or, simply, 1.26). Thus 1.26 is an example of an observed revision performed 1 day after (the first) publication. The data published on 14 January also reported that the cumulative excess mortality up to 12 January came to 2,736 deaths. However, the data as of 13 January provided a cumulative excess mortality for that period of 2,319 deaths. Since the excess mortality for that period was first published on 12 January, I conclude that between 13 and 14 January-−2 days after the first publication—the sum of deaths for that period was revised by 118%. Thus, 1.18 is an example of a revision performed 2 days after (first) publication.
Third, I corrected the excess mortality estimates in the sample: both the series of cumulative excess deaths, and the flows of deaths registered daily. The corrections of the former were extrapolations into the future of the past, already observed, revisions. I started correcting publications on 18 January, and thus had the releases dated 11–18 January as the initial sample of revisions, and thereafter, it was gradually extended as an increasing window. The extrapolations were based on quadratic and cubic regressions estimated with the data on revisions that I had computed5. The corrected flows, however, were the first differences of the cumulative excess mortality estimates already adjusted using polynomial regressions. I also imposed in all cases that the adjustments (i.e., the extrapolated revisions) had to be ratios greater or equal to one (i.e., published estimates can only be revised upwards). Moreover, the vertex or inflection point of the fitted curve would necessarily take the value of 1 in the vertical axis; and only the decreasing part of the curve is considered relevant.
Figure 1 shows an example: the estimated 1-day and 2-day after-publication adjustments for the 18 January data release. The thick blue dots show the revisions performed between 12 and 18 January of cumulative mortality estimates 1 day after their first publication (i.e., of those first published on 11–17 January). The red asterisks show, instead, the revisions performed on 12–18 January of cumulative mortality estimates 2 days after their first publication (i.e., of those first published on 10–16 January). Note that the values corresponding to 14 January are both mentioned in the previous paragraph: 1.26 and 1.18. The blue and red dashed lines are the quadratic regressions estimated to predict the 1-day and 2-day after-publication revisions, respectively. The revision carried out on the excess of mortality first published on 18 January, the day after is predicted by extrapolating the regression based on observed 1-day after revisions to 19 January obtaining 1.026. Similarly, the revision 2 days after the first publication for the 18 January estimate is forecasted by extrapolating the regression based on observed 2-day after-revisions on 20 January. Given that the fitted curve has its vertex on 19 January, the revision forecasted for 20 January is necessarily equal to 1.00. The blue and red dotted lines are the predicted revisions based on cubic regressions, instead: 1.035 for 19 January as a 1-day after-revision, and 1.00 for 20 January as a 2-day after-revision6. Similarly, if estimated revisions 3, 4, 5… up to 14 days after, and multiplied all of them by the cumulative excess mortality first published up to 18 January, I would obtain my corrected estimate of excess mortality for that date and release.
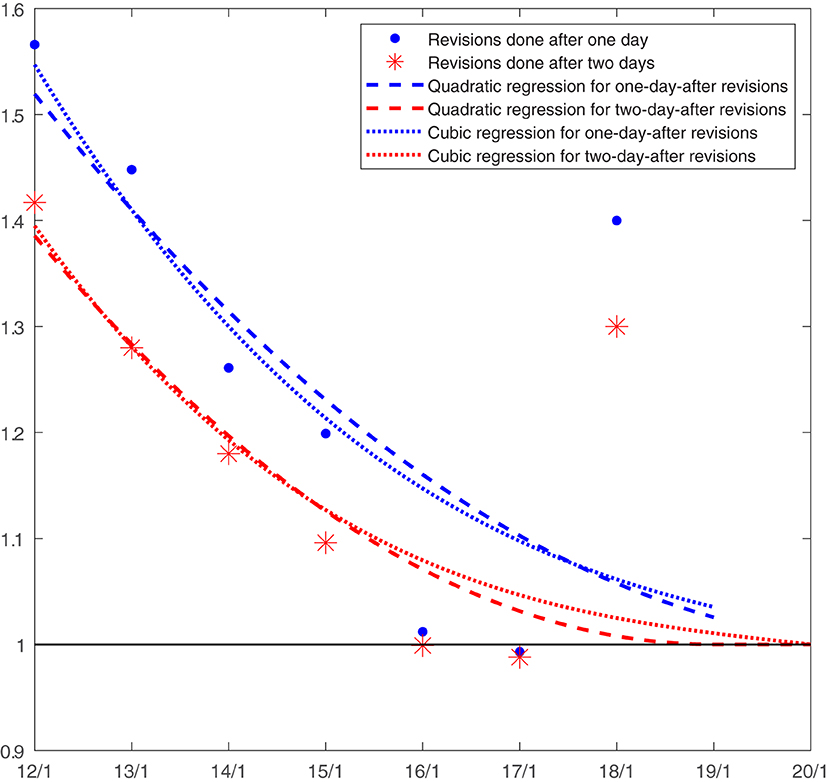
Figure 1. Estimation of the 1-day-after and 2-day-after publication revisions for the 18 January release. Source: author own calculations.
Finally, I compared the accuracy of the real-time estimates (either published by MoMo or already corrected using this methodology) with respect to their definitive values. For this purpose, I used the well-known criteria: mean absolute error (MAE) and (square) root of the mean squared error (RMSE), both frequently used measures of the difference between predicted and observed values. I compared the published and corrected estimates not only in their first publication but also in the posterior ones.
Results
Figure 2 shows the time series published between 12 January and 31 March for the cumulative excess mortality in Spain (blue solid line) as well as the first estimates published each day during that period (dotted orange line)7. Given that the former (i.e., the revised series published at the end of the first quarter of 2021) became stable and close to the latter (i.e., the estimates published in real time) by 19 February, Figure 2 shows only the subsample ending on 26 February 2021. It can be seen that these real-time estimates were downward biased because of death reporting lags. This delay implied that the excess mortality estimated daily was, on average, 91% of its definitive value (assuming the latter to be the series published at the end of the first quarter).
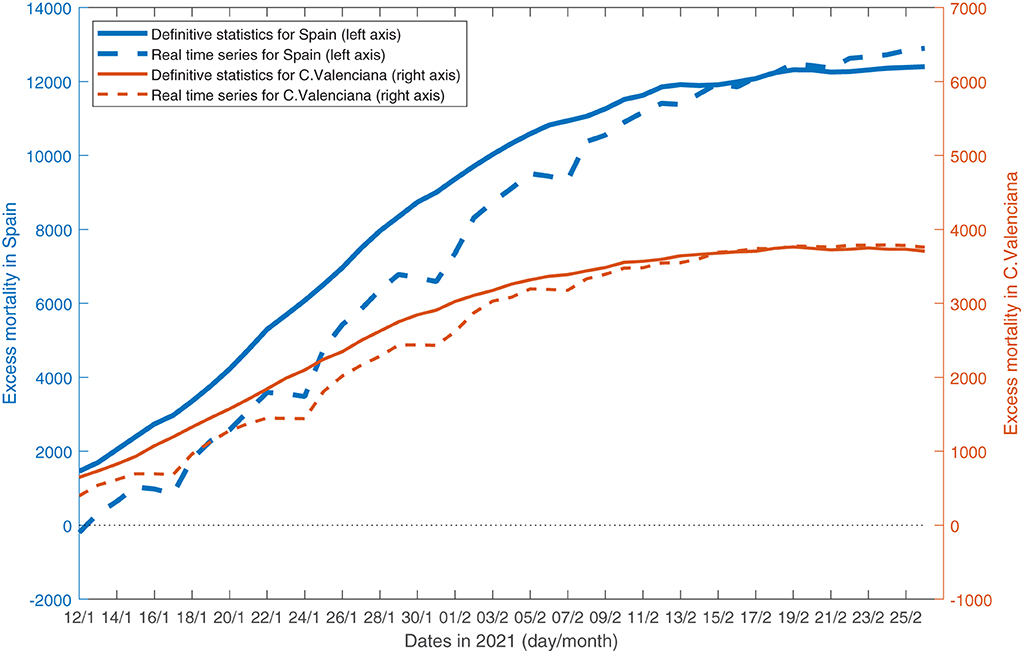
Figure 2. Cumulative excess mortality in Spain and the C. valenciana on 12 January to 26 February 2021. Source: datasets retrieved daily by the author in that period from https://momo.isciii.es/panel_momo/.
Using polynomial regressions to correct Spanish real-time excess mortality estimates in their first release resulted in values that represented, on average, 92% of the already revised estimates published at the end of the quarter. In particular, the first column in Table 1 shows that the mean absolute error (MAE) of the corrected estimates divided by the MAE of the original estimates released in their first publication (“After 0 days”) is equal to 0.98. Similarly, the ratio between the (square) root mean squared error (RMSE) of corrected and original firstly published estimates is 0.98. Summing up, correcting these first publications using quadratic regressions implied an improvement in these by measures close to 2% (with respect to the original, non-corrected, estimates). Below, in the same column, I show that cubic regressions also implied an improvement of about 3%.
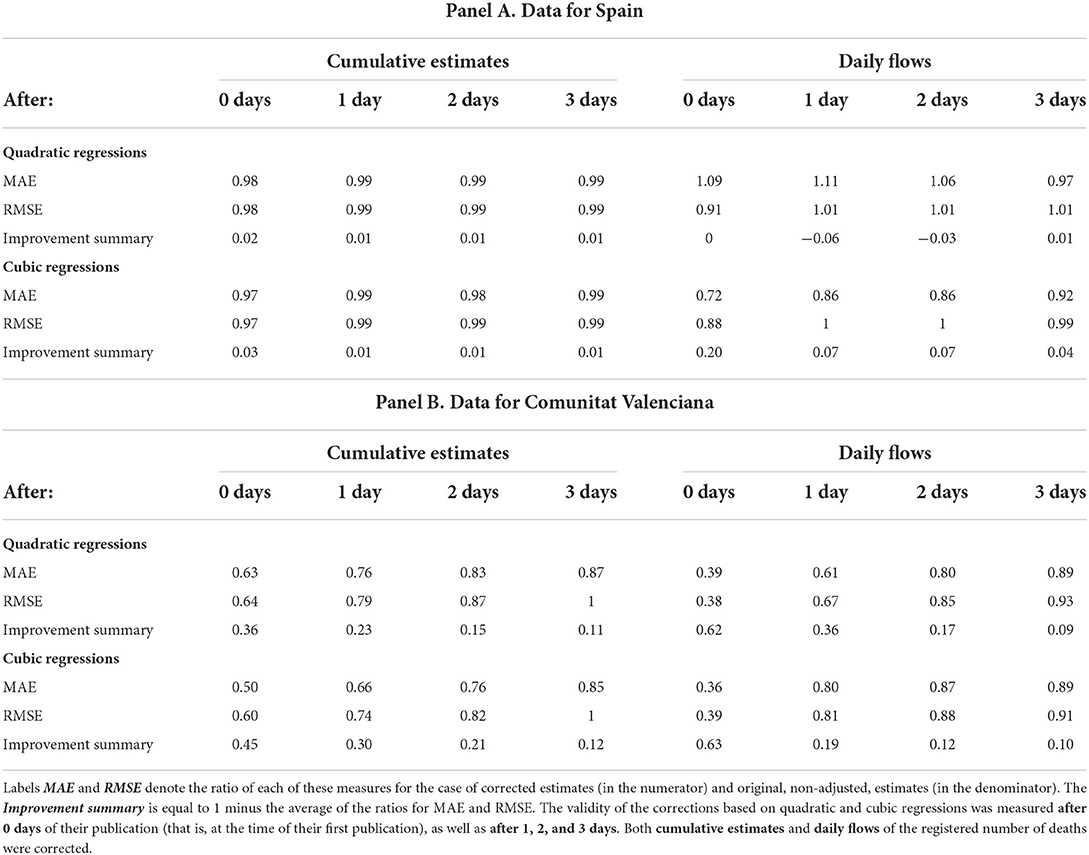
Table 1. Measures of accuracy for corrected mortality estimates on 18 January to 26 February 2021.
The next three columns in Table 1 show that the corrections based on both regressions (quadratic and cubic) improved by about 1% the official statistics that had been already revised once, twice, and three times (days) after their first publication. In the next columns, on the right, I show the ratios concerning the number of deaths registered each day (the flows) in contrast to the cumulative excess mortality already discussed. We can see that the cubic model corrections applied to the first published estimates brought them 20% closer, on average, to their definitive values; and 7% closer 2 or 3 days after publication. The corrections based on quadratic regressions did not improve real time statistics.
The aggregated data for Spain, however, hides a large heterogeneity between regions or CC.AA. Table 2 shows for each region the total number of deaths registered during the first quarter of 2021 and the difference with respect to the expected mortality, i.e., the excess mortality. In the third column, I show the ratio between this excess mortality and the total number of deaths. For example, 10% of total mortality registered for Spain as a whole between 1 January and 31 March 2021 was actually in excess with respect to the usual figure. However, this percentage is lower in many CC.AA. (e.g., Asturias, with 7%; or Galicia, with 2%) and it is even negative in a few cases (e.g., Canarias, −6%, or Navarra, −5%). The Comunitat Valenciana, in contrast, suffered excess mortality of about 22% of its total number of registered deaths.
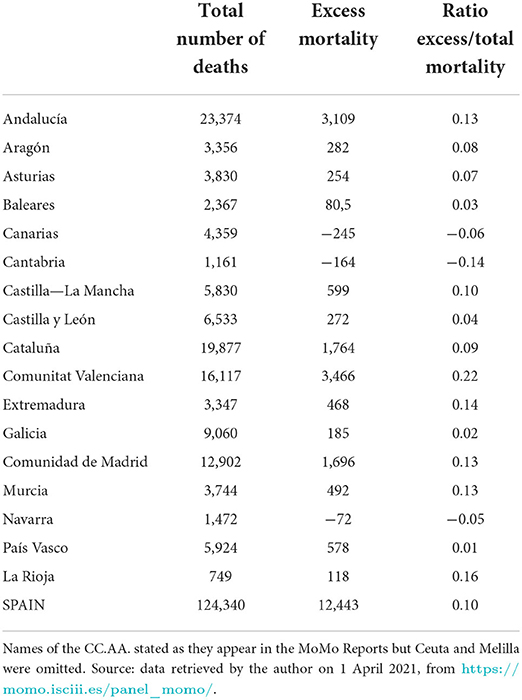
Table 2. Total number of deaths and registered excess mortality from 1 January to 31 March 2021.
Figure 2 also shows the cumulative excess mortality in the Comunitat Valenciana between 12 January and 26 February 2021. Note that there is also a difference between the historical series (thin solid blue line) and the estimates published in real time (thin dotted orange line). In fact, on average, the preliminary statistics on excess mortality published daily represented around 94% of their definitive values, that is, those already revised and published at the end of the first quarter of 2021.
Table 2 shows that the Comunitat Valenciana was the “autonomous region” with the highest cumulative excess mortality as a share of its total number of deaths in the first quarter of 2021. The second half of Table 1 reports the benefits of applying quadratic and cubic regressions to correct the mortality estimates published by MoMo for this region8. Interestingly, the statistics published first in real time for the regional cumulative excess mortality became 36 and 45% closer to their definitive values after they were corrected using 2nd- and 3rd-grade polynomials. Previously, it was mentioned that the first publication of these mortality estimates was, on average, 94% of their revised values; now, after being corrected they represented, on average, 98–99% of their definitive values.
The three columns that follow in the second half of Table 1 show that both types of regressions generate improvements of about 23–30% and 15–21% in real-time estimates that had already been revised once and twice (1 and 2 days) after their first publication, respectively9. In the columns on the right reporting ratios for daily mortality flows, we can see that the corrections brought their originally published values 62–63% closer to their definitive values. In the following days, when these estimates had already been revised once or twice, the corrections yielded improvements of about 19–36% and 12–17%, respectively. Summing up, the regression-based adjustments refined very significantly the publications of the statistics for this region at least up to their third revision.
Discussion
Table 1 shows that using quadratic and cubic models to correct the effect of reporting lags in excess mortality estimates at the national level brought them slightly closer to their definitive values. By comparison, Equiza-Goñi (5, 6) reported improvements of about 18–25 and 6–13% in the periods 15 April to 25 May 25 and 1 September to 25 December 2020, respectively. This different performance could be explained by the smaller share of the most recent excess mortality on the total number of registered deaths (10%) compared to the two previous excess mortality episodes (39 and 15%, respectively). Moreover, Table 2 documents a ratio of excess mortality relative to total mortality much higher for the Comunitat Valenciana than for the rest of the CC.AA. According to the second half of Table 1, the real-time statistics for this autonomous region did become notably closer to their definitive values after the polynomial corrections had been applied.
Therefore, Table 1 shows that the polynomial corrections used in national-level data seem to be much more relevant in regional data, plausibly because there is a relatively important excess mortality. At least, that is clearly the case for the Comunitat Valenciana. Moreover, Table 1 also shows that the correction of the negative bias caused by reporting lags has persistent effects, being beneficial even when the real-time estimates have been revised repeatedly. In addition, it can be observed that most of the improvement in the cumulative excess mortality estimates is due to bringing the data of the last, most recent, flows of registered deaths closer to their definitive values. In fact, MoMo states in the files documenting their real-time online dataset or “dashboard” that the number of deaths reported in the most recent days previous to the date of publication might be susceptible to modification in the days that followed (29). My work shows that those revisions can be effectively forecasted days in advance using polynomial regressions, and thus bringing MoMo's preliminary estimates of these flows closer to their actual values. This information can be especially useful to achieve updated monitoring of the pandemic, thus complementing the other commonly used indicators, such as the daily number of cases and hospital or ICU admission rates.
Finally, Table 1 reports that the corrections based on cubic regressions generally improved the statistics published in real time more than by corrections using quadratic regressions. This is not surprising given that the second-order polynomial is embedded in the cubic model (i.e., a restricted polynomial). Equiza-Goñi (6) found, however, the opposite result and claimed that it was due to the presence of several holidays between 1 September and 25 December 2021. The problem was that holidays implied longer reporting lags for reasons unrelated to the number of deaths and the time since their first publication. The higher flexibility of the cubic model compared to the quadratic regression resulted in the estimates from Equiza-Goñi (6) being more sensitive to these outliers (i.e., unusual revisions for common values of excess mortality and days past since publication). Given that in the timespan covered in this study, only March 19 was a holiday in the Comunitat Valenciana, the higher performance of cubic over quadratic regressions is aligned with the discussion in Equiza-Goñi (6). Thus, the best corrections would result from using quadratic regressions in the presence of a relevant number of holidays in the sample, while using cubic regressions in their absence.
In summary, it is recommended that MoMo's daily statistics on excess mortality be corrected by applying revisions predicted by polynomial models that have already been estimated with data from past revisions. In this way, using quadratic and cubic regressions helps mitigate the negative bias observed in real-time estimates due to death reporting lags. Other recent studies (30, 31) consider this delay as one of the main obstacles to the correct interpretation of COVID-19 data. Sarnaglia et al. (32) or Guglielmi et al. (33), for example, suggest other methodologies to reduce the problems generated by reporting lags in counting the number of infectious cases. This work suggests that, in the pandemic, the estimates of mortality that are currently reported by surveillance systems worldwide, and by MoMo and EuroMOMO in particular, could be complemented by publishing also these adjusted measures. In such a manner, these systems will not simply acknowledge that in periods of extraordinary mortality reporting lags could worsen but, in addition, provide public health practitioners estimates in which foreseeable revisions have already been implemented. Also, the real-time communication to the public of mortality statistics that are not systematically downward biased will raise awareness about public health risks and incentivize more responsible behavior.
Moreover, as noted, estimates corrected using the cubic model are generally closer to their definitive values if the estimating sample does not include holidays; otherwise, using quadratic estimates seems a more robust option. Therefore, a mixed strategy combining both quadratic and cubic extrapolations would be desirable, depending on whether holidays constitute a significant part of the sample period. All corrected estimates are nonetheless preliminary and, thus, should be subjected to a critical reading (34). For instance, even though this study adds further evidence of the improvements achieved through polynomial extrapolations, adjusted real-time estimates would still be remarkably revised. Moreover, at times, the corrections recommended by this research would result in inflated mortality estimates that, arguably, would generate an unnecessary alarm. Overall, the advantages of more accurate mortality real-time data could easily compensate for some possible drawbacks. Further work could also test these methodological recommendations and their benefits in sample periods of excess mortality due to extreme temperatures or the flu.
Data availability statement
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author.
Author contributions
Author contributed to the article and approved the submitted version.
Acknowledgments
Jokin de Irala (ICS-Universidad de Navarra, Facultad de Medicina), Jesús López (ICS-Universidad de Navarra), and José Luis Pinto (Universidad de Navarra).
Conflict of interest
The author declares that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Footnotes
1. ^The media have often named that period as “the third wave”, thus ignoring the second episode that happened in the summer of 2020 and, fortunately, translated only into a moderate mortality.
2. ^Surveillance systems in the U.S.A. and Europe share many characteristics, specifically, they all rely on largely computerized processes. However, U.S. and EuroMOMO data are published weekly while the Spanish MoMo system is reporting data daily.
3. ^Balak et al. (21) studies the estimation and prediction of the cumulative number of COVID-19 cases.
4. ^The chosen starting date of the accumulation period is flexible and implies only slight differences in the results.
5. ^In line with Equiza-Goñi (5, 6), using polynomials of order 1 yielded little or no improvement, thus this article focuses on presenting only the benefits of using quadratic and cubic regressions.
6. ^In the case of 2-day after-revisions, the fitted cubic curve has precisely an inflexion point on 20 January.
7. ^The accumulation period for excess mortality shown in Figure 2 starts on 1 January. When applying polynomials, I used figures of excess mortality accumulated since 8 December, 2020, to avoid the negative sum resulting from figures published up to 18 January.
8. ^I normalized the size of the cumulative excess mortality of the Comunitat Valenciana to be equal to that of Spain by accumulating it from an earlier date than 8 December. Thus, the different size of excess mortality does have an impact on the results; that is, all differences are due to the relatively bigger revisions (longer reporting lags) observed in the region compared to Spain.
9. ^Not shown in Table 2, these corrections generated improvements of about 11–13% and 8–9% in real time estimates that had already been revised three and four times after their first publication, respectively.
References
1. Informes MoMo 2020—Instituto de Salud Carlos III. Available online at: www.isciii.es/QueHacemos/Servicios/VigilanciaSaludPublicaRENAVE/EnfermedadesTransmisibles/MoMo/Paginas/Informes-MoMo-2020.aspx (accessed October 22, 2022).
2. Dashboard MoMo—Instituto de Salud Carlos III. Available online at: momo.isciii.es/public/momo/dashboard/momo_dashboard.html#nacional (accessed October 15, 2021).
3. Cerda Thomas R. Exceso de mortalidad durante la pandemia de COVID-19, revisión narrativa. Revista médica de Chile. (2020) 148:1647–51. doi: 10.4067/S0034-98872020001101647
4. Adam D. The pandemic's true death toll: millions more than official counts. Nature. (2022) 601:312–5. doi: 10.1038/d41586-022-00104-8
5. Equiza-Goñi J. Correcciones para las cifras diarias de mortalidad acumulada en España durante la pandemia de COVID-19. Revista Española de Salud Pública. (2021) 95:7. Available online at: https://www.sanidad.gob.es/biblioPublic/publicaciones/recursos_propios/resp/revista_cdrom/VOL95/ORIGINALES/RS95C_202104048.pdf (accessed October 22, 2022).
6. Equiza-Goñi J. Comunicación diaria de cifras corregidas de mortalidad en España durante la segunda ola de pandemia COVID-19. Revista Española de Comunicación en Salud. (2022) 13:78–86. doi: 10.20318/recs.2022.6328
7. Akhmetzhanov AR. Estimation of delay-adjusted all-cause excess mortality in the USA: March–December 2020. Epidemiol Infect. (2021) 149:e156. doi: 10.1017/S0950268821001527
8. Rosenbaum JE, Stillo M, Graves N, Rivera R. Timeliness of provisional United States mortality data releases during the COVID-19 pandemic: delays associated with electronic death registration system and weekly mortality. J Public Health Policy. (2021) 42:536–49. doi: 10.1057/s41271-021-00309-7
9. González Morán F, Muñoz Criado I, Vanaclocha H. La información en tiempo real: una herramienta necesaria en vigilancia epidemiológica. Gaceta Sanitaria. (2008) 22:162–7. doi: 10.1157/13119327
10. Leon DA, Shkolnikov VM, Smeeth L, Magnus P, Pechholdová M, Jarvis CI. COVID-19: a need for real-time monitoring of weekly excess deaths. Lancet. (2020) 395:e81. doi: 10.1016/S0140-6736(20)30933-8
11. Aroca Jácome R. Los pronósticos matemáticos son hipótesis: consideración de la incertidumbre en la presentación de datos sobre la pandemia por COVID 19. Revista Española de Comunicación en Salud. (2020) 1:339–346. doi: 10.20318/recs.2020.5476
12. Vestergaard LS, Mølbak K. Timely monitoring of total mortality associated with COVID-19: informing public health and the public. Eurosurveillance. (2020) 25:2001591. doi: 10.2807/1560-7917.ES.2020.25.34.2001591
13. Naudé W, Vinuesa R. Data deprivations, data gaps and digital divides: Lessons from the COVID-19 pandemic. Big Data Soc. (2021) 8:20539517211025545. doi: 10.1177/20539517211025545
14. Malecki KM, Keating JA, Safdar N. Crisis communication and public perception of COVID-19 risk in the era of social media. Clin Infect Dis. (2021) 72:697–702. doi: 10.1093/cid/ciaa758
15. Carvalho CAD, Carvalho VAD, Campos MAG, Oliveira BLCAD, Diniz EM, Santos AMD, et al. Delay in death reporting affects timely monitoring and modeling of the COVID-19 pandemic. Cadernos de Saúde Pública. (2021) 37:292320. doi: 10.1590/0102-311x00292320
16. Gutierrez E, Rubli A, Tavares T. Information and behavioral responses during a pandemic: evidence from delays in COVID-19 death reports. J Develop Econ. (2022) 154:102774. doi: 10.1016/j.jdeveco.2021.102774
17. León-Gómez I, Delgado-Sanz C, Jiménez-Jorge S, Flores V, Simón F, Gómez-Barroso D, et al. Exceso de mortalidad relacionado con la gripe en España en el invierno de 2012. Gaceta Sanitaria. (2015) 29:258–65. doi: 10.1016/j.gaceta.2015.01.011
18. León-Gómez I, Mazagatos C, Delgado-Sanz C, Frías L, Vega-Piris L, Rojas-Benedicto A, et al. The impact of COVID-19 on mortality in spain: monitoring excess mortality (MoMo) and the surveillance of confirmed COVID-19 deaths. Viruses. (2021) 13:2423. doi: 10.3390/v13122423
19. Ochoa Sangrador C, Garmendia Leiza JR, Pérez Boillos MJ, Pastrana Ara F, Lorenzo Lobato MDP, Andrés de Llano JM. Impacto de la COVID-19 en la mortalidad de la comunidad autónoma de Castilla y León. Gaceta Sanitaria. (2022) 35:459–64. doi: 10.1016/j.gaceta.2020.04.009
20. Vanella P, Basellini U, Lange B. Assessing excess mortality in times of pandemics based on principal component analysis of weekly mortality data—the case of COVID-19. Genus. (2021) 77:1–36. doi: 10.1186/s41118-021-00123-9
21. Balak N, Inan D, Ganau M, Zoia C, Sönmez S, Kurt B, et al. A simple mathematical tool to forecast COVID-19 cumulative case numbers. Clin Epidemiol Global Health. (2021) 12:100853. doi: 10.1016/j.cegh.2021.100853
22. Fouillet A, Pontais I, Caserio-Schönemann C. Excess all-cause mortality during the first wave of the COVID-19 epidemic in France, March to May 2020. Eurosurveillance. (2020) 25:2001485. doi: 10.2807/1560-7917.ES.2020.25.34.2001485
23. Vestergaard LS, Nielsen J, Richter L, Schmid D, Bustos N, Braeye T, et al. Excess all-cause mortality during the COVID-19 pandemic in Europe–preliminary pooled estimates from the EuroMOMO network, March to April 2020. Eurosurveillance. (2020) 25:2001214. doi: 10.2807/1560-7917.ES.2020.25.26.2001214
24. Nørgaard SK, Vestergaard LS, Nielsen J, Richter L, Schmid D, Bustos N, et al. Real-time monitoring shows substantial excess all-cause mortality during second wave of COVID-19 in Europe, October to December 2020. Eurosurveillance. (2021) 26:2002023. doi: 10.2807/1560-7917.ES.2021.26.7.2100191
25. Grabowski J, Witkowska N, Bidzan L. Letter to the editor: excess all-cause mortality during second wave of COVID-19–the polish perspective. Eurosurveillance. (2021) 26:2100117. doi: 10.2807/1560-7917.ES.2021.26.7.2100117
26. Morfeld P, Timmermann B, Groß JV, Lewis P, Cocco P, Erren TC. COVID-19: heterogeneous excess mortality and “burden of disease” in Germany and Italy and their states and regions, January–June 2020. Front Public Health. (2021) 9:477. doi: 10.3389/fpubh.2021.663259
27. Modig K, Ahlbom A, Ebeling M. Excess mortality from COVID-19: weekly excess death rates by age and sex for Sweden and its most affected region. Eur J Public Health. (2021) 31:17–22. doi: 10.1093/eurpub/ckaa218
28. Konstantinoudis G, Cameletti M, Gómez-Rubio V, Gómez IL, Pirani M, Baio G, et al. Regional excess mortality during the 2020 COVID-19 pandemic in five European countries. Nat Commun. (2022) 13:1–11. doi: 10.1038/s41467-022-28157-3
29. Gobierno de España. Estrategia de diagnóstico, vigilancia y control en la fase de transición de la pandemia de covid-19 indicadores de seguimiento, actualizado a 12 de mayo de 2020. Spain: Gobierno de España (2020). Available online at: www.semg.es/images/2020/Coronavirus/20200512_COVID19_Estrategia_vigilancia_y_control_e_indicadores.pdf (accessed October 31, 2022).
30. Backhaus A. Common pitfalls in the interpretation of COVID-19 data and statistics. Intereconomics. (2020) 55:162–6. doi: 10.1007/s10272-020-0893-1
31. Struelens MJ, Vineis P. COVID-19 research: challenges to interpret numbers and propose solutions. Front Public Health. (2021) 9:345. doi: 10.3389/fpubh.2021.651089
32. Sarnaglia AJ, Zamprogno B, Molinares FAF, de Godoi LG, Monroy NAJ. Correcting notification delay and forecasting of COVID-19 data. J Math Anal Appl. (2021) 514:125202. doi: 10.1016/j.jmaa.2021.125202
33. Guglielmi N, Iacomini E, Viguerie A. Identification of time delays in COVID-19 data. arXiv preprint arXiv:2111.13368 (2021). Available online at: https://arxiv.org/pdf/2111.13368.pdf (accessed October 31, 2022).
34. Santillán-García A. Lectura crítica de la evidencia científica en época de pandemia, herramienta para la seguridad de la información epidemiológica. Enfermería en Cardiología: Revista Científica e Informativa de la Asociación Española de Enfermería en Cardiología. (2020) 81:6–11. Available online at: https://enfermeriaencardiologia.com/media/acfupload/627287a20e383_Enferm-Cardiol.-2020-27-81-6-11_1.pdf (accessed October 22, 2022).
Keywords: public health surveillance, mortality, COVID-19, nowcasting, health communication
Citation: Equiza-Goñi J (2022) Real-time mortality statistics during the COVID-19 pandemic: A proposal based on Spanish data, January–March, 2021. Front. Public Health 10:950469. doi: 10.3389/fpubh.2022.950469
Received: 22 May 2022; Accepted: 24 October 2022;
Published: 08 November 2022.
Edited by:
Reza Lashgari, Shahid Beheshti University, IranReviewed by:
José María Martín-Olalla, Sevilla University, SpainRavi Philip Rajkumar, Jawaharlal Institute of Postgraduate Medical Education and Research (JIPMER), India
Copyright © 2022 Equiza-Goñi. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Juan Equiza-Goñi, jequizag@unav.es