 Yuexu ZhaoQiwei Liu*
Yuexu ZhaoQiwei Liu*- College of Economics, Hangzhou Dianzi University, Hangzhou, China
Based on the epidemic data of COVID-19 in 50 states of the United States (the US) from December 2021 to January 2022, the spatial and temporal clustering characteristics of COVID-19 in the US are explored and analyzed. First, the retrospective spatiotemporal analysis is performed by using SaTScan 9.5, and 17 incidence areas are obtained. Second, the reliability of the results is tested by the circular distribution method in the time latitude and the clustering method in the spatial latitude, and it is confirmed that the retrospective spatiotemporal analysis accurately measures in time and reasonably divides regions according to the characteristics in space. Empirical results show that the first-level clustering area of the epidemic has six states with an average relative risk of 1.28 and the second-level clustering area includes 18 states with an average relative risk of 0.86. At present, the epidemic situation in the US continues to expand. It is necessary to do constructive work in epidemic prevention, reduce the impact of epidemic, and effectively control the spread of the epidemic.
Introduction
Coronavirus disease 2019 (COVID-19) refers to the new coronavirus infection in 2019 caused by acute respiratory infectious diseases in the majority of patients; some of them will develop as severe cases and even results in death. Since the large-scale outbreak of new corona pneumonia in 21 January 2020, the economy in the US has been gradually affected. Besides, the epidemic is a public emergency that all countries in the world have to face. As one of the most serious epidemic countries, the US has accumulated 74,741,586 new coronavirus cases as on 31 January 2022, and there is a certain aggregation tendency in time and space. Scan statistic is a method to test whether there is an aggregation of diseases, and detect whether the abnormal increase of diseases in time and space is caused by random variation. It has been widely used in infectious diseases, cardiovascular diseases, and other fields as a spatial statistical method in epidemic statistics.
In 1965, Joseph (1) proposed the concept of scan statistic. Kulldorff et al. (2–5) proposed the spatial scan statistic, and applied scan statistic to analyze the breast cancer mortality in the US. For example, they utilized the dynamic variable scanning window to detect the leukemia data in northern New York, and used the log-likelihood ratio to determine the cluster with the highest degree of aggregation. They also proposed many statistical models of spatiotemporal scanning, such as retrospective space-time scan statistic in Bernoulli model or Poisson model, prospective space-time scan statistic, space-time rearrangement scan statistic, and elliptical spatial scan statistic in periodic geographic disease monitoring. As the research goes further, Jung et al. (6, 7) proposed ordinal model scan statistic in 2007, which had excellent performance compared with Bernoulli scan statistic for binary classification of prostate cancer data. Huang et al. (8, 9) proposed the spatial scan statistic based on the exponential model for the male survival data with prostate cancer in the US in 2007; this method could be applied to the survival data and pure spatial data. In order to study the spatial heterogeneity continuously measured in the population data, the weighted normal spatial scan statistic was proposed and applied to the two-stage lung cancer survival research in 2009. Barbara (10) found that Cutl's method was more effective than Kulldorff's scan statistic for irregular shape spatiotemporal clusters, and for cylindrical spatiotemporal clusters; these two methods had similar results. Li et al. (11) analyzed the fund sustainability. Yin (12) carried out the research on application in early warning of infectious diseases, and graded the data of provinces and cities. Ma et al. (13) selected the optimal spatial scale through the number of signals in the monitoring of infectious diseases. So far, scan statistic has been widely used in disease prevention, including tuberculosis, schistosomiasis, and hand, foot, and mouth disease.
The majority of the abovementioned studies explore the spatial aggregation of various infectious diseases. COVID-19 is a highly contagious disease, which has seriously affected people's lives since its outbreak, and has a great threat to people's health. Hohl et al. (14) used the daily new coronavirus case data provided by the John Hopkins University at the county level, and applied SaTScan to conduct a prospective space-time analysis, and detected the active clusters in various provinces and cities in the US. To avoid using prospective space-time scan statistic to identify emergence of COVID-19 disease groups, Beard et al. (15) proposed the COVID-19 monitoring method, which was based on spatiotemporal event sequence similarity. Hohl et al. (16) used prospective Poisson space-time scan statistic to detect daily clusters of COVID-19 at successive county levels in 48 states and Washington DC, which was helpful to facilitate decision-making and public health resource allocation. Pei et al. (17) found that the epidemic distribution had obvious space-time heterogeneity, and the spatial-temporal transmission had typical network characteristics.
In this paper, we will study the spatial aggregation of COVID-19 in the US from the following aspects. First, we construct a dynamic scanning window, calculate the relative risk to measure the intensity of aggregation, and utilize the scan statistical analysis through SaTScan9.5 based on the retrospective spatiotemporal analysis method. Second, we analyze the rational treatment of SaTScan9.5, and innovatively use circular distribution method (time latitude) and cluster analysis method (spatial latitude) to test the reliability of spatiotemporal scanning results. Through horizontal comparison, it is found that spatiotemporal scan analysis not only accurately measures in time but also reasonably divides regions according to characteristics in space. Finally, we take into account the data and how the COVID-19 pandemic changes on the ground, locating the gathering area and span period on time. At the same time, according to the scanning results, it not only provides an important theoretical basis for the relevant epidemic prevention work, but also has crucial importance for the establishment of an early warning system for the corresponding disease, ultimately playing a positive role in strengthening prevention and resolving the risk of major diseases in the world.
Methodology
Retrospective spatiotemporal analysis needs to build a scanning window to judge the number of diseases inside and outside the window. Since the scanning statistics involve time and space, the scanning window is in the form of a cylinder; the height of the cylinder represents the time, and the bottom area of the cylinder represents the area. The location and size of the scan window are dynamic, as it is unknown when and where the COVID-19 outbreak will occur.
In the analysis process, a position is randomly selected as the scanning center, and then, the cylindrical scanning window changes continuously. The cluster of geographic size of the scanning window ranges between zero and a predefined upper limit. There are several ways to determine the value of upper bound, for example, one can take the percentage of number of people at risk of disease or radius value of circle as the upper bound. In this article, we use the former method. The time length of the scan window specifies the maximum time frame according to the percentage of the entire study cycle or the specific number of days.
To determine the possibility of aggregation, the actual number of patients and the number of regional populations are calculated to obtain the theoretical number of patients, and the log-likelihood ratio (LLR) is constructed by using the actual and theoretical number of patients inside and outside the window; the relative risk () is calculated to evaluate the strength of aggregation. Since the scanning window undergoes a dynamic change, numerous scanning windows will be generated during the scanning process. For controlling the false-positive rate at a certain level, the window with the largest LLR is selected as the clustering area among all scanning windows. The statistical significance of LLR is tested by Monte Carlo stochastic simulation method.
We then give hypothesis test as follows:
Null Hypothesis (H0): The spatial and temporal distribution of newly confirmed cases of COVID-19 in the US is completely random;
Alternative Hypothesis (H1): The spatial and temporal distribution of newly confirmed cases of COVID-19 in the US is not completely random.
Assuming that the number of cases in window A is nA, the population is mA, E(A) is the expected number of cases in the scanning window based on the original assumption and adjusted by covariates, the total number of cases in the total region is nT, the total population is mT, and the expected number of cases is E(T), then
The probability density function of specific points observed at region x is as follows:
where p is the ratio of actual incidence to expected incidence in window A, q is the ratio of actual incidence to expected incidence outside window A, and the probability of any specific point is independent of all other points, one can also refer to Tang et al. (18) and Yang (19).
If p > q, the likelihood function LR(A, p, q) is denoted by:
Otherwise, the likelihood function LR0(based on invalid hypothesis) is
Test statistic for spatiotemporal scan λ is defined as follows:
According to Equations (4) and (5), we have
In formula (7), I(·) is a characteristic function. The ratio of the actual incidence to the expected incidence in window A is greater than the ratio of the actual incidence to the expected incidence outside window A. The is a measure of how risk within a cylinder differs from risk outside.
Next, we use Monte Carlo random method to simulate the p value of LLR to determine whether the aggregation is statistically significant. First, we simulate c random datasets, calculate the maximum LLR for each dataset, and rank it with the real LLR from big to small. If the real value rank is R, then we have
If p < 0.05, we reject the original assumption. The relative risk of each aggregation is as follows:
Empirical analysis
Source of the data
This paper selects 50 states from the US for research. The data of the COVID-19 mainly came from the data of the New York Times, including the date of diagnosis, the current area, and the source of infection of patients with COVID-19. Demographic data mainly came from the US 2020 census data, the basic geographic information data of each state were derived from Google satellite map data, and the latitude and longitude coordinates mainly chose the state capital as the center position.
The variant data are derived from the Centers for Disease Control and Prevention (CDC) study that tracks the proportion of variants estimated from weekly random sampling in the Department of Health and Human Services region followed by gene sequencing tests across the region, which we use to estimate the number of variant infections in the state over a week with new cases per day.
Parameter setting
We use the retrospective spatiotemporal analysis method, and choose the discrete Poisson model. The scanning time is set to be from 1 December 2021 to 31 January 2022, and the time interval is 1 day. As COVID-19 is highly contagious, the population with a ceiling of 50% in the space window is at risk, and the maximum circle size file is set at 30% of the population, rather than 30% of the regular population, and the regional overlap is set at zero. Referring to a large number of relevant literatures, combined with the actual situation, it is known that the outbreak of COVID-19 is fast, and the incubation period is short. Besides, the inaction of the US government to manage the outbreak makes the cycle longer. The daily pattern of COVID-19 changes rapidly, so the minimum time cluster is set to 1 day. In the test window, the number of Monte Carlo random simulation is set to 999.
Description analysis
In the population distribution, the US COVID-19 has nothing to do with gender, and included patients mainly in the age group of 44 to 59 years. In terms of time distribution, the US had the largest number of new cases on 10th January, with 1,420,374 cases. On 3rd, 18th, and 24th January, more than 1 million new cases were added daily with 1,003,751, 1,173,885, and 1,025,999 cases, respectively. In terms of the overall trend, the outbreak in the early stages of each state is relatively serious, and the number of confirmed cases has experienced a short lag and rapid growth. From Figure 1, we can see that the overall epidemic situation has not been effectively controlled, so the number of confirmed cases has increased cumulatively, having a certain increasing tendency. In the regional distribution, cases were mainly concentrated in the east and west of the US, and California has the largest number of confirmed cases, followed by New York.
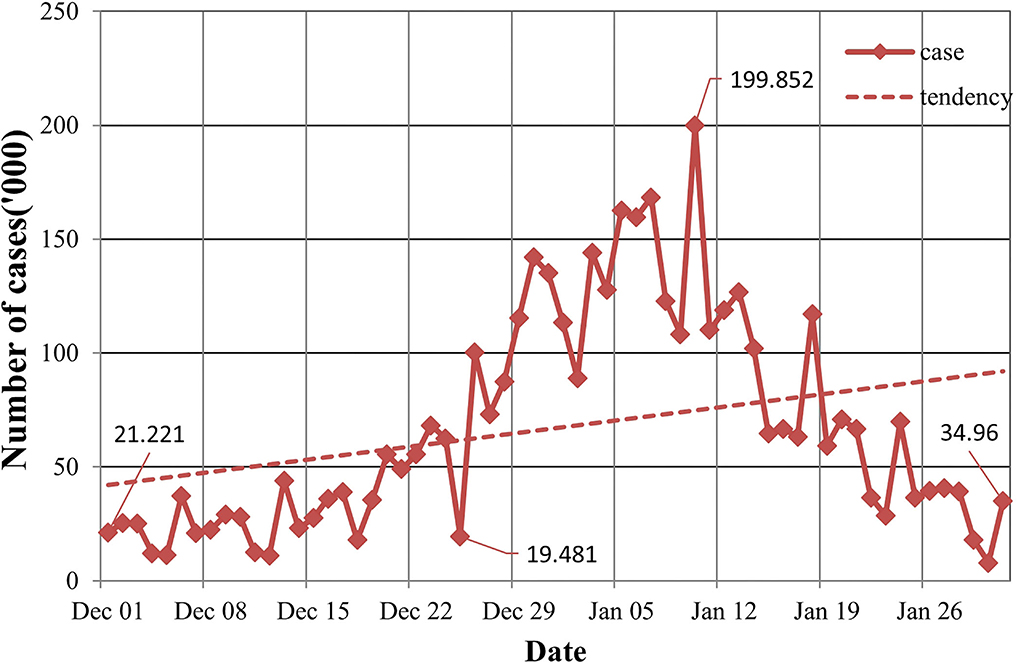
Figure 1. The number of COVID-19 cases.
Space-time analysis
A retrospective spatiotemporal analysis is carried out in the US. After SaTScan 9.5 is run, 17 clustering areas are obtained and arranged from large to small according to the log-likelihood ratio, and we obtain p < 0.01. The clustering areas are tested by the aboriginality test. The specific data are summarized in Table 1.
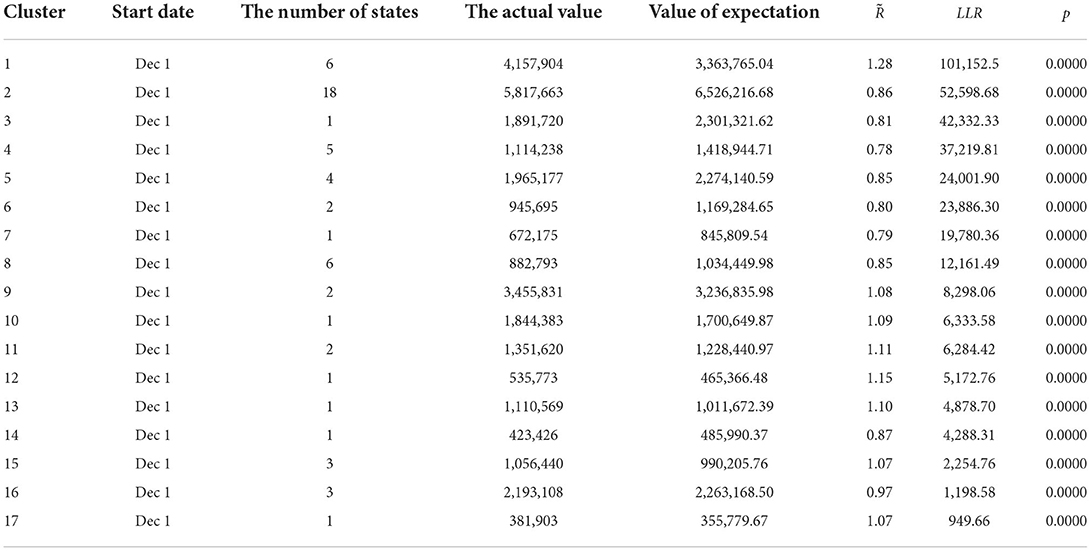
Table 1. Retrospective spatiotemporal analysis.
The cluster areas are mainly concentrated in Connecticut, Rhode Island, New York, Massachusetts, New Hampshire, and New Jersey from 1 December 2021 to 31 January 2022. The log-likelihood ratio is 101,152.56, and the aggregation is the highest, with a relative risk of 1.28. It also shows that the aggregation of COVID-19 in the six places during this period is strong. From 1 December 2021 to 31 January 2022, 18 states, such as Colorado, become the second agglomeration, with a log-likelihood ratio of 52,598.68 and a relative risk of 0.86. Texas from 1 December 2021 to 31 January 2022 is one of the three types of gathering areas, with a log-likelihood ratio of 42,332.33 and a relative risk of 0.81.
Combined with the daily incidence of each state, it can be observed that the starting time of the gathering area is just the time for the sudden increase of the confirmed cases of COVID-19 in the region, and the end time is the time for the growth rate of the confirmed cases to begin to decline. Combined with Table 2, the incidence of the four states involved, Rhode Island, New York, Massachusetts, and New Jersey, accounts for the top five regions of the incidence of COVID-19 in the US, and New York is the city with the second largest number of confirmed cases. Although Massachusetts and New Hampshire have fewer confirmed cases than New York, they are geographically close to New York, where the epidemic is relatively serious.
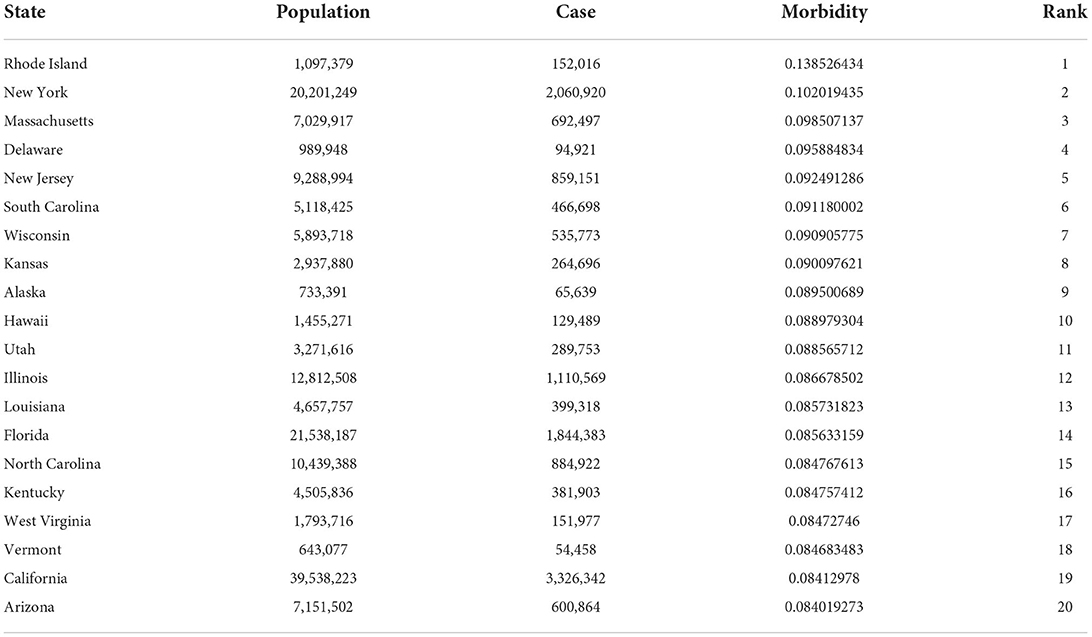
Table 2. Numbers of cases and morbidities in the top 20 states.
Circular distribution analysis
Since the research time is 62 days, we divide 360° evenly over each day, then 1 day is equivalent to 5.81°, and 1 h is equivalent to 0.21°. To avoid the infinite calculation, the calculation time of each day is 8:00 a.m., that is, the one-third corresponding degree of 1 day is taken as the degree of the day. By the spatiotemporal scanning analysis, we obtain 17 clustering areas, and take the first three clustering areas as example. In order to compare the following analysis results to previous ones, we combine the daily newly confirmed cases according to the clusters. The r, r0, and p-values of Rayleigh test are obtained through calculation, as summarized in Table 3.
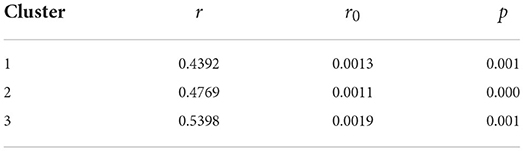
Table 3. Results of circular distribution analysis.
The peak day and peaks of each cluster are summarized in Table 4.

Table 4. Peak day and peak period of incidence of COVID-19 in each cluster area.
Clustering analysis
Hierarchical cluster analysis method is commonly used in classification research. This method can overcome the shortcomings of qualitative classification. According to the index characteristics of the classification object, the total feature similarity is divided into a class. In this case, the cumulative confirmed cases, the regional population, and the incidence rate are used as the indicators of each region, and imported into R software for standardization. The deviation square and clustering analysis are used to divide them into four categories. Since the latitude and longitude coordinates are involved in the spatiotemporal scanning analysis, the central coordinates of the capital are added to the index, as shown in Figure 2. Due to the mess up of text and pictures as displayed in the diagram, it should be replaced with a geographical code (US-01), as shown in Table 5.
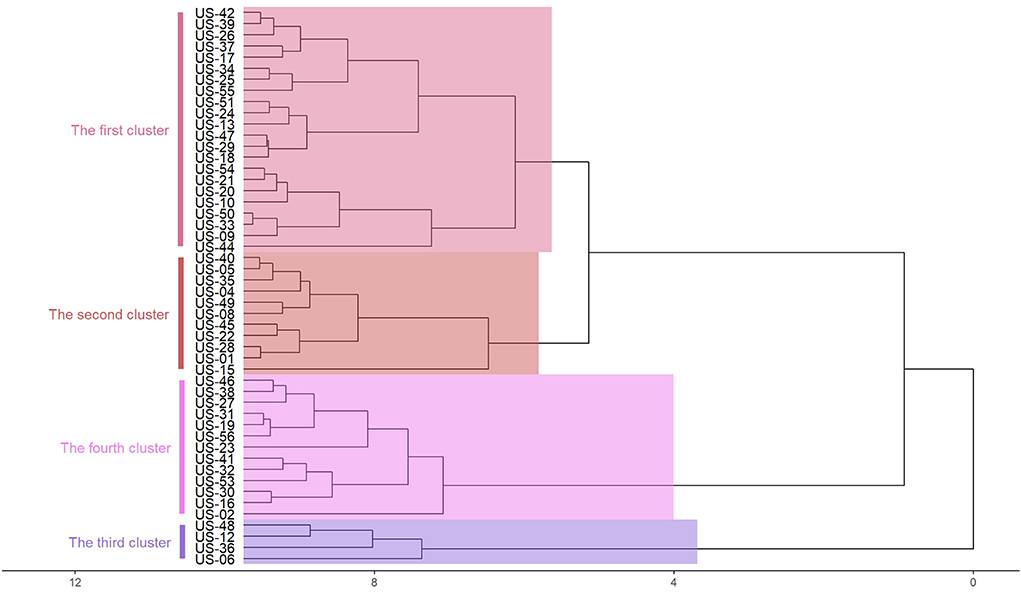
Figure 2. Coordinated hierarchical cluster analysis.

Table 5. Correspondence tables of states.
From Figure 2, we can see that there are highly correlated with geographical location. The same category of states are adjacent states, and the case information is not reflected. Therefore, the clustering method cannot well-balance the relationship between the number of cases and their geographical locations.
Results comparison
The peak periods calculated by spatial-temporal scanning analysis are compared with those calculated by circular distribution method, as shown in Table 6. Combined with the actual situation, the peak period of the disease obtained by the circular distribution method is similar to the epidemic situation of COVID-19 in the region. The peak period of the disease obtained by the spatial-temporal scanning method is longer than that of the circular distribution method, and the time is generally advanced. Spatiotemporal scanning analysis can send early warning signals for COVID-19, which is a kind of fulminant and fast infectious disease, and has a higher practical value for disease prevention and control.

Table 6. Comparison of STSA and CDA.
The clustering areas obtained by spatiotemporal scanning analysis are compared with the classification results obtained by the system clustering method, as shown in Table 7. In the Spatiotemporal Scanning Analysis (STSA), Hierarchical Cluster Analysis (HCA), and Coordinated Hierarchical Cluster Analysis (CHCA), US-44 (Rhode Island), US-25 (Massachusetts), US-09 (Connecticut), US-34 (New Jersey), and US-33 (New Hampshire) are classified into the first category, while US-36 (New York) is classified into the first category by spatiotemporal scanning. Combined with the actual situation, it can be seen that the results have a great relationship with the cumulative confirmed cases. After adding the coordinate index, the results are highly correlated with the geographical location, and the case information is weakened. The spatiotemporal scanning method makes good use of the information of regional population, case information, geographical location, and other information to give a reasonable clustering area. In terms of disease prevention and control, spatiotemporal scanning method can better provide theoretical basis for its adaptation to local conditions.
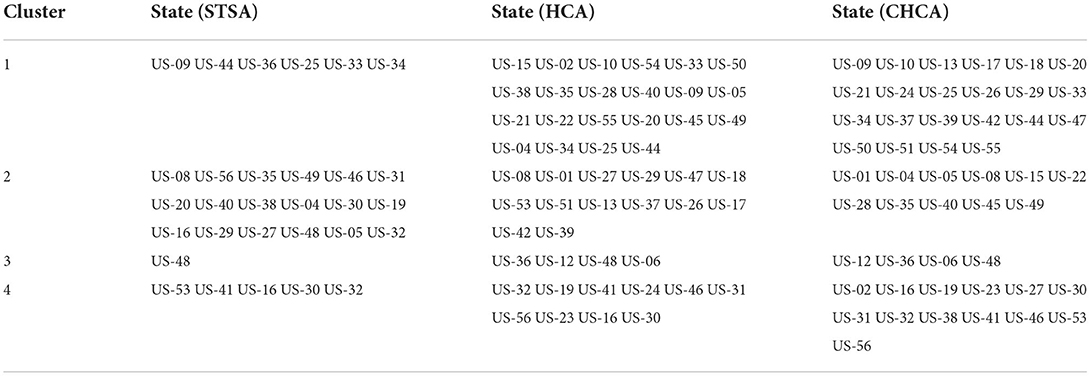
Table 7. Comparison of STSA and (C)HCA.
Through the abovementioned comparative analysis, it can be seen that the circular distribution method and the space-time scan method have a certain overlap interval in the peak period of disease onset, and the clustering analysis method is certainly similar with its regional aggregation. However, the spatiotemporal scanning method can provide early warning and make better use of geographical factors to determine disease outbreak areas in detail, which is more instructive for the early warning and prevention and control of COVID-19.
The spatiotemporal scanning method can provide more objective grouping basis for the further model establishment of related research. According to the epidemic law of different regions, different groups can be included in different covariate modeling. The qualitative and quantitative research on the influencing factors of COVID-19 will provide an important basis for the development of effective epidemic prevention measures by health institutions such as disease control centers in the region by analyzing the incidence characteristics of patients with COVID-19 in different regions and at different times, and combining the economic level, population flow, medical conditions, and other factors in the region.
Omicron variation
In the study of infectious diseases, we cannot ignore the situation of some variants. Based on the time node selected in this paper, the first Omicron case was reported in the US on 1 December, so we are paying attention to Omicron at this stage. Next, we need to know more about Omicron. In fact, Omicron has a significant growth advantage over Delta, leading to rapid spread in the community with higher levels of incidence than previously seen in this pandemic. With the sharp increase of cases and the scarcity of medical resources, we should also give importance to its dissemination.
From Figure 3, we can see that the B.167.2 (Delta) accounted for 99.25% on 4 December, while B.1.1.529 (Omicron) accounted for a low proportion. After 2 weeks, the proportion of Omicron increased rapidly, reaching 40.64%, while the corresponding Delta decreased to 58.08%. After another week, the proportion of Omicron exceeded Delta, becoming the largest variant of infection. After the following 5 weeks, the proportion reached 95.31%. Within 2 months, Omicron became the mutant with the largest proportion of infection, and its propagation speed was very fast.
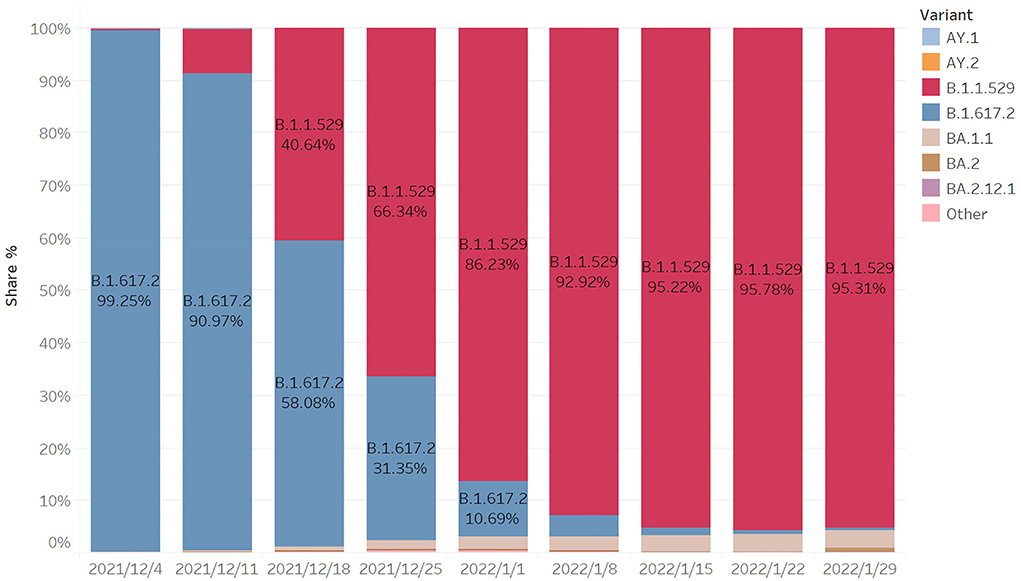
Figure 3. Proportion of COVID-19 variants.
Based on the CDC's tracking data of variants and the prediction of the proportion of variants, we calculate the number of variants per week in different regions according to the new cases per day and the proportion of variants per week in the corresponding region. The following figure clearly shows the cumulative number of Omicron cases in the last week. In order to show the map integrally, US-02 and US-15 have changed the actual location in the map. According to the number clustering, the map is divided into four categories. We can find the features in Figure 4.
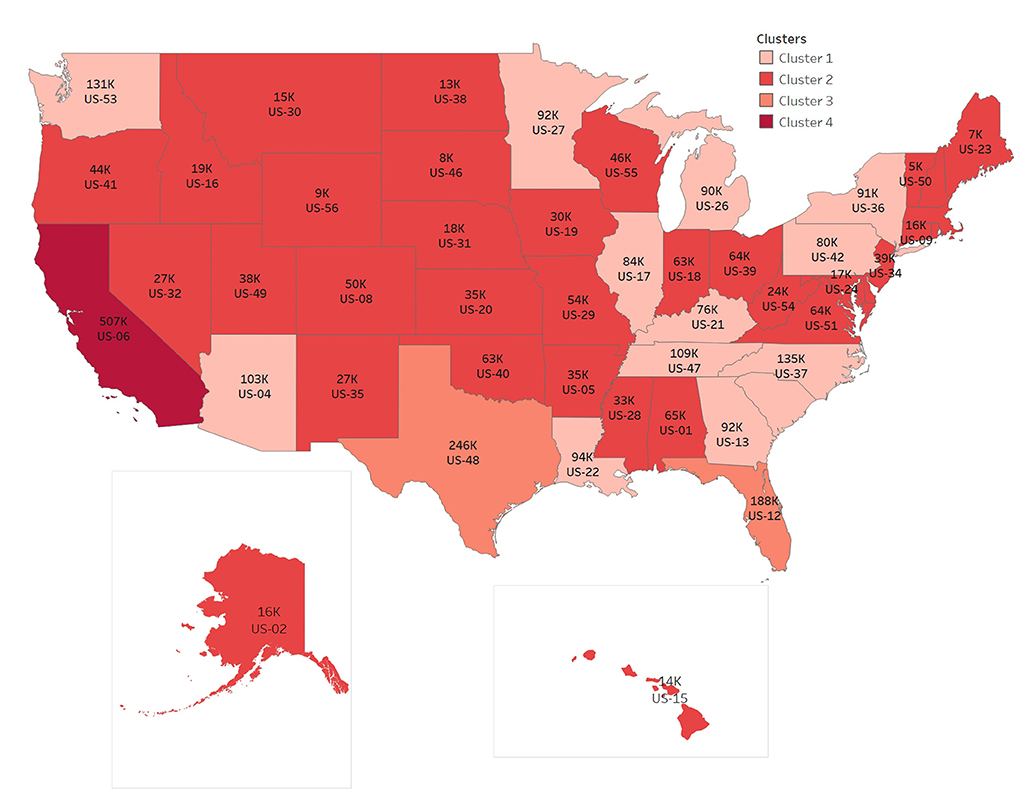
Figure 4. Distribution of Omicron cases from Jan 25 to Jan 31, 2022.
The numbers of items in clusters 1–4 are 18, 29, 2, 1, respectively, and the cluster centers are 89,703, 24,703, 217,010, 507,330 respectively, in Figure 4. The number of Omicron cases increases rapidly in 2 months, with the largest number of cases in one state, US-06, accumulating to 507,330 per week, and also with the largest number in neighboring states.
To summarize, it can be clearly seen that the rate of infection of Omicron increased rapidly, and there is a trend of diffusion from the middle to the surrounding. Population flow is one of the reasons for the rapid spread of virus. The reality of the spread from densely populated cities to other cities can also be observed from the distribution map of Omicron cases.
Conclusion
In this paper, a retrospective spatiotemporal analysis of confirmed cases of COVID-19 in 50 states of the US is carried out. The first cluster is Connecticut, Rhode Island, New York, Massachusetts, New Hampshire, and New Jersey. The second cluster comprises 18 states, and the three types of gathering area is Texas. Through observation, it can be seen that the geographical location of the capital belonging to the same type of gathering area is relatively close. There is minimal difference between the gathering time and the peak time of newly confirmed cases daily, and the incidence of prominent gathering areas is higher. The reliability test of space-time scan results show that space-time scan has the advantages of accurate measurement in time and reasonable division of regions according to characteristics in space. On the basis of making full use of the existing time and spatial information, a spatiotemporal scanning analysis accurately locates the clustering area, timing and quantifying the corresponding clustering area, and evaluating the risk degree of the region, as we know that a high level of economic development and perfect medical conditions have played a positive role in the recovery of patients. From the analysis of this paper, spatiotemporal scanning analysis has greatly improved the timeliness and effectiveness of early warning of diseases, and can provide scientific basis for early prevention and control of diseases.
Data availability statement
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author.
Author contributions
YZ conceived and designed the study. QL analyzed the data. YZ and QL contributed to the writing of the manuscript. All authors contributed to the article and approved the submitted version.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
1. Naus J. The distribution of the size of the maximum cluster of points on a line. J Am Stat Assoc. (1965) 60:532–8. doi: 10.2307/2282688
2. Kulldorff M. Prospective time periodic geographical disease surveillance using a scan statistic. J Royal Statist Soc. (2001) 164:61–72. doi: 10.2307/2680534
3. Kulldorff M, Heffernan R, Hartman J, et al. A space-time permutation scan statistic for the early detection of disease outbreaks. PLoS Med. (2005) 2:e59. doi: 10.1371/journal.pmed.0020059
4. Kulldorff M, Huang L, Pickle L, Duczmal L. An elliptic spatial scan statistic. Stat Med. (2006) 25:3929–43. doi: 10.1002/sim.2490
5. Kulldorff M, Mostashari F, Duczmal L, Katherine Yih W, Kleinman K, Platt R. Multivariate scan statistic for disease surveillance. Stat Med. (2007) 26:1824–33. doi: 10.1002/sim.2818
6. Jung I, Kulldorff M, Klassen A. A. spatial scan statistic for ordinal data. Stat Med. (2007) 26:1594–607. doi: 10.1002/sim.2607
7. Jung I, Kulldorff M, Richard OJ. A spatial scan statistic for multinomial data. Stat Med. (2010) 29:1910–8. doi: 10.1002/sim.3951
8. Huang L, Kulldorff M, Gregorio D. A spatial scan statistic for survival data. Biometrics. (2007) 63:109–18. doi: 10.1111/j.1541-0420.2006.00661.x
9. Huang L, Tiwari RC, Zou Z, Kulldorff M, Feuer EJ. Weighted normal spatial scan statistic for heterogeneous population data. J Am Stat Assoc. (2009) 104:886–98. doi: 10.1198/jasa.2009.ap07613
10. Wieckowska B, Górna I, Trojanowski M, Pruciak A, Stawińska-Witoszyńska B. Searching for space-time clusters: the CutL method compared to Kulldorff's scan statistic. Geospatial Health. (2019) 14:314–20. doi: 10.4081/gh.2019.791
11. Li D, Fang Z, Yu Y. Scan statistic: a new method to detect the persistence of fund performance. Operat Res Manag. (2006) 15:82–7. doi: 10.3969/j.issn.1007-3221.2006.01.018
12. Yin F. Application of Spatio-Temporal Scan Statistic in Early Warning of Infectious Diseases. Chengdu: Sichuan University (2007).
13. Ma Y, Li X, Zhang Y. Spatial scale selection of scan statistic in infectious disease surveillance. Modern Prevent Med. (2011) 38:1601–4.
14. Hohl A, Delmelle EM, Desjardins MR, Lan Y. Daily surveillance of COVID-19 using the prospective space-time scan statistic in the United States. Spat Spatiotemporal Epidemiol. (2020) 34:100354. doi: 10.1016/j.sste.2020.100354
15. Xu FY, Beard K. A comparison of prospective space-time scan statistic and spatiotemporal event sequence based clustering for COVID-19 surveillance. PLoS ONE. (2021) 16:e0252990. doi: 10.1371/journal.pone.0252990
16. Hohl A, Delmelle E, Desjardins M. Rapid detection of COVID-19 clusters in the United States using a prospective space-time scan statistic: an update. SIGSPATIAL Special. (2020) 12:27–33. doi: 10.1145/3404111.3404116
17. Pei T, Wang X, Song C, Liu Y, Huang Q, Shu H, et al. Research progress on spatiotemporal analysis and modeling of COVID-19 epidemic. J Geo-Inform Sci. (2021) 23:188–210. doi: 10.12082/dqxxkx.2021.200434
Keywords: the spatiotemporal analysis, COVID-19, scan statistic, spatial aggregation, Omicron
Citation: Zhao Y and Liu Q (2022) Analysis of distribution characteristics of COVID-19 in America based on space-time scan statistic. Front. Public Health 10:897784. doi: 10.3389/fpubh.2022.897784
Received: 16 March 2022; Accepted: 18 July 2022;
Published: 10 August 2022.
Edited by:
Omar El Deeb, Lebanese American University, LebanonReviewed by:
Keun Hwa Lee, Hanyang University, South KoreaSilvia – Giono Cerezo, Instituto Politécnico Nacional (IPN), Mexico
Copyright © 2022 Zhao and Liu. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Qiwei Liu, qiweiliu@hdu.edu.cn