 Ameer Hamza1
Ameer Hamza1 Muhammad Attique Khan1*
Muhammad Attique Khan1* Shui-Hua Wang2Majed Alhaisoni3Meshal Alharbi4
Shui-Hua Wang2Majed Alhaisoni3Meshal Alharbi4 Hany S. Hussein5,6
Hany S. Hussein5,6 Hammam Alshazly7Ye Jin Kim8Jaehyuk Cha8*
Hammam Alshazly7Ye Jin Kim8Jaehyuk Cha8*- 1Department of Computer Science, HITEC University, Taxila, Pakistan
- 2Department of Mathematics, University of Leicester, Leicester, United Kingdom
- 3Computer Sciences Department, College of Computer and Information Sciences, Princess Nourah Bint Abdulrahman University, Riyadh, Saudi Arabia
- 4Department of Computer Science, College of Computer Engineering and Sciences, Prince Sattam Bin Abdulaziz University, Al-Kharj, Saudi Arabia
- 5Electrical Engineering Department, College of Engineering, King Khalid University, Abha, Saudi Arabia
- 6Electrical Engineering Department, Faculty of Engineering, Aswan University, Aswan, Egypt
- 7Faculty of Computers and Information, South Valley University, Qena, Egypt
- 8Department of Computer Science, Hanyang University, Seoul, South Korea
The COVID-19 virus's rapid global spread has caused millions of illnesses and deaths. As a result, it has disastrous consequences for people's lives, public health, and the global economy. Clinical studies have revealed a link between the severity of COVID-19 cases and the amount of virus present in infected people's lungs. Imaging techniques such as computed tomography (CT) and chest x-rays can detect COVID-19 (CXR). Manual inspection of these images is a difficult process, so computerized techniques are widely used. Deep convolutional neural networks (DCNNs) are a type of machine learning that is frequently used in computer vision applications, particularly in medical imaging, to detect and classify infected regions. These techniques can assist medical personnel in the detection of patients with COVID-19. In this article, a Bayesian optimized DCNN and explainable AI-based framework is proposed for the classification of COVID-19 from the chest X-ray images. The proposed method starts with a multi-filter contrast enhancement technique that increases the visibility of the infected part. Two pre-trained deep models, namely, EfficientNet-B0 and MobileNet-V2, are fine-tuned according to the target classes and then trained by employing Bayesian optimization (BO). Through BO, hyperparameters have been selected instead of static initialization. Features are extracted from the trained model and fused using a slicing-based serial fusion approach. The fused features are classified using machine learning classifiers for the final classification. Moreover, visualization is performed using a Grad-CAM that highlights the infected part in the image. Three publically available COVID-19 datasets are used for the experimental process to obtain improved accuracies of 98.8, 97.9, and 99.4%, respectively.
Introduction
The coronavirus has recently spread throughout the world as a new infection. Coronavirus is typically spread by animals or humans (1, 2). It is discovered to be transmitted by bats as a result of animal transmission. Coronavirus also replicates in the human body with several other common coronaviruses, including 229E: Alpha, NL63: Alpha, OC43: Beta, and HKU1: Beta (3). The coronavirus disease outbreak was dubbed the coronavirus global pandemic or COVID-19 pandemic by the World Health Organization (WHO) in March 2020 (4). The disease known as COVID-19 is caused by a virus (SARS-CoV-2). Lung diseases range in severity from a common cold to a potentially fatal illness. Coronavirus illnesses were frequently accompanied by respiratory system diagnoses. Individuals may occasionally contract minor, self-limiting infections with severe consequences, such as influenza. Symptoms of respiratory problems, fatigue, and a sore throat include fever, cough, and breathing difficulties (5). The majority of researchers have emphasized the need for COVID-19-specific diagnostic methods, medications, or vaccinations to prevent its spread (6). Because of its higher sensitivity and specificity in terms of observations, the reverse transcription-polymerase chain reaction (RT-PCR) is the current gold standard for diagnosing COVID-19 (7).
Visual indicators could be used as an alternative strategy for quickly screening infected individuals (8). This infection's most prevalent symptom is respiratory sickness. For chest radiography, images (X-rays of the chest) are thought to be the most reliable visual signal. Radiologists examine these images physically to identify visual patterns that indicate the presence of COVID-19 (9). Even though traditional diagnosis has improved over time, it is still vulnerable to medical staff errors. It is also more expensive because each patient requires a diagnostic test kit. Medical-based imaging procedures, such as CXR and CT scans, are much faster, safer, and more widely available for screening (10). For COVID-19 screening, CXR image screening is superior to CT scans because it is more accessible and less expensive (11, 12). However, it may take some time to manually diagnose the virus using X-ray scans. If there is little or no prior knowledge and expertise about the infection and its characteristics, it may result in several inaccuracies and human-made mistakes. As a result, there is a compelling need to automate such operations on a large scale, and it should be accessible to all, so that treatment can become more effective, precise, and timely (13).
Previous research has used computer vision (CV) and artificial intelligence (AI) methods involving deep learning (DL) algorithms; specifically, CNNs have been validated as a realistic method for analyzing medical images (14, 15). A deep learning technique called a convolutional neural network was previously utilized to accurately identify pneumonia in CXR images of a patient's chest (16–18). The researchers introduced several CNN models for classification tasks, including ResNet50 (19), AlexNet (20), InceptionV3 (21), and a few others (22). Computer vision researchers have used pre-trained deep learning models in medical imaging, particularly for COVID-19 diagnosis and classification (23, 24).
Loey et al. (25) presented a Bayesian-based optimization DCNN model to classify coronavirus illness by using CXR images. The presented approach tuned the hyperparameters of DCNN models and extracted the high-level features. The data used in the experimental process were large in size and achieved 96% accuracy. This approach is limited by its high computing time due to the Bayesian optimization because it takes too much iteration during the training process. Yoo et al. (26) employed a hybrid technique model on CXR images by classifying the coronavirus using a decision tree classifier and deep learning. The created method achieved 95% accuracy. Wang et al. (27) designed a deep learning model-based transfer learning approach to identify the coronavirus. CXR images were utilized for this method. COVID-19 and healthy images were 565,537, respectively. The created deep learning technique gained 96.7% accuracy. They extracted high-level features and ML-based classifiers to create an efficient technique for improving the sensitivity of DCNN models. Chowdhury et al. (28) implemented a novel framework based on a CNN. They used a multiclass dataset that included COVID-19, pneumonia, and the healthy class. They constructed a CNN in the parallel pipeline and supplied crucial elements for the classification method. The suggested approach attained an accuracy of 96.9%, which was superior to the current techniques. Khan and Aslam (29) utilized the DCNN networks such as ResNet, DenseNet, and VGGNet and performed transfer learning concepts for training the models on the Chest X-ray dataset. The dataset includes 195 COVID-19 images and 862 normal images. On the selected dataset, the provided method achieved an accuracy of 99%. Che Azemin et al. (30) designed a ResNet CNN based on a deep learning algorithm to diagnose COVID-19 from CXR images. They considered the binary class problem—COVID-19 and healthy classes. The selected dataset was utilized for the training of the CNN model through transfer learning. The trained model achieves 72% accuracy, which is higher than the recent methods. Khan et al. (31) presented a DL and explainable AI-based framework for COVID-19 classification from CXR images. Transfer learning was utilized to train pre-trained deep models on enhanced images, and features were merged for greater information. Following that, the Whale–Elephant herding method is used to choose the best features, which are then classified using the ELM classifier. Few other techniques such as meta-classifier with deep learning approach for COVID-19 classification (32), novel CNN approach called CNN-COVID (33), optimization algorithm called novel crow swarm (34), and multi-agent deep reinforcement learning (35).
The models in the preceding studies were retrained using the transfer learning concept, which involves freezing the weights of a few layers to save computational time. They also used fixed hyperparameters like learning rate, momentum, mini-batch size, epoch count, etc. When there is a lot of variation in the results due to different hyperparameter values, this method is inefficient. In this work, we proposed a multimodal Bayesian hyperparameter optimization method for the training of deep learning models for COVID-19 classification. Moreover, an explainable AI-based diagnosis has been performed. Our major participation in this work is as follows:
• A multi-filter fusion-based hybrid technique is proposed for contrast enhancement that increases the local and global information of an image.
• Bayesian optimization is employed on deep learning models for the optimization of hyperparameters that helps in the better training of selected data.
• High-level features are extracted by both models and fused by a novel slicing-based serial fusion.
• Grad-CAM visualization is performed on the final classification, resulting in the colored visualization of the COVID-19, pneumonia, and tuberculosis-infected regions.
The manuscript is organized as follows. The proposed methodology such as multi-filters fusion-based hybrid contrast enhancement technique, Bayesian optimization of hyperparameters of DCCN models, deep transfer learning, feature extraction, fusion, and Grad-CAM for explainable AI, is presented in Section Proposed methodology. The findings of the proposed approach are shown in Section Experimental results and analysis, and Section Conclusion presents the conclusion.
Proposed methodology
The proposed methodology for the COVID-19 classification and explainable AI-based diagnosis is presented here. In the proposed method, multi-filter contrast enhancement and deep transfer learning with Bayesian optimization are employed. Figure 1 shows the proposed architecture based on Bayesian optimization and features fusion for COVID-19 classification. This figure illustrates that, in the first phase, data augmentation is performed on the selected datasets using a multi-filter contrast enhancement method and a few additional filters. Two pre-trained models, namely, EfficientNet-B0 and MobileNet-V2, are modified and trained using deep transfer learning and optimized the hyperparameters by employing Bayesian optimization. Features are extracted from both optimized models and fusion is performed by utilizing a new method named, slicing-based serial fusion. Finally, the samples are subjected to Grad-CAM analysis in order to pinpoint the source of the infection.

Figure 1. Proposed classification architecture for COVID-19 utilizing deep transfer learning and Bayesian optimization.
Contrast enhancement
Enhancing contrast is one of the most important and useful steps to enhance the vital objects in the images (36). Another goal of this step is to enhance the overall image quality. Medical image identification and interpretation mainly rely on image enhancement methods (37). When segmentation is performed, poor contrast is always detected incorrectly. In the classification process, the enhanced images can extract more important features than the feature extraction through the original images. In this work, the images of the selected datasets have low contrast and poor quality. These problems may lead us to misclassification. Therefore, we designed a multi-filter technique by utilizing the fusion of different filters. First, top-hat and bottom-hat filtering are implemented and combined with information. After that, intensity values are adjusted by using a mathematical formula.
Consider, the COVID-19 datasets 𝔻 having k images 𝔻∈ℝk, where each image represented by and (h, w) ∈ ℝ. Each sample has resized into . Suppose that the kernel σ with a value of 13. The top-hat is based on • opening operation and the bottom-hat is based on ▪ closing operation. So, the top-hat and bottom-hat filtering are derived as:
where f′(h, w) represents the fused image of top-bottom filtering. In the next step, the adjust filter is employed on the resultant images from the top-hat and bottom-hat filters. Adjust filter boosts an image's lightness by transforming the points of the input pixels' intensities to new ones, with the mean amount of data absorbed in the low and high intensities being about 1.5%. The symbol p is the pixel value of the image, the gamma (γ) is a variable, which evaluates the form of the procedure among the coordinating coefficients (q, f) and (r, e).
where Fk(h, w) is the final enhanced image, visually illustrated in Figure 2.
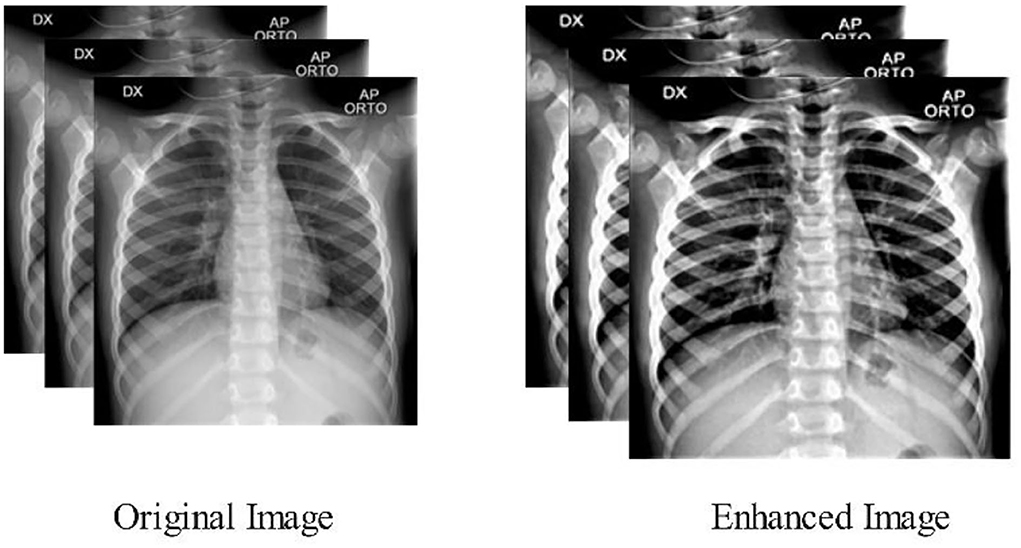
Figure 2. Samples enhanced images of multi-filters fusion technique.
Dataset collection and description
This study adopts an experimental technique that makes use of three publicly accessible datasets: COVID-GAN and COVID-Net small chest x-ray (https://www.kaggle.com/yash612/covidnet-mini-and-gan-enerated-chest-xray), COVID-19 radiography (https://www.kaggle.com/datasets/tawsifurrahman/covid19-radiography-database). CXR (pneumonia, COVID-19, TB) (https://www.kaggle.com/datasets/jtiptj/chest-xray-pneumoniacovid19tuberculosis). There are three classes in COVID-GAN and COVID-Net small chest x-ray datasets. COVID-19 radiography and CXR (pneumonia, COVID-19, and tuberculosis) consist of four classes. The original images are shown in Figure 3. These datasets are highly imbalanced as shown in Table 1. For balancing the dataset, we set 6,000 images in each class for all the datasets by utilizing data augmentation. Using the augmented dataset, 50% of images have been utilized for the training, while the rest of the 50% were used for the testing. In the data augmentation process, three primary functions are used: flip-left, rotate 90, and flip-right. The augmented images are visually shown in Figure 4.
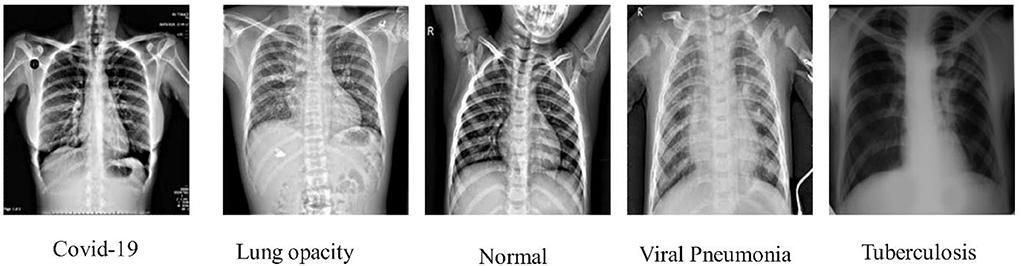
Figure 3. sCXR instances for the classification of COVID-19 and other infections.

Table 1. Complete explanation of selected datasets.
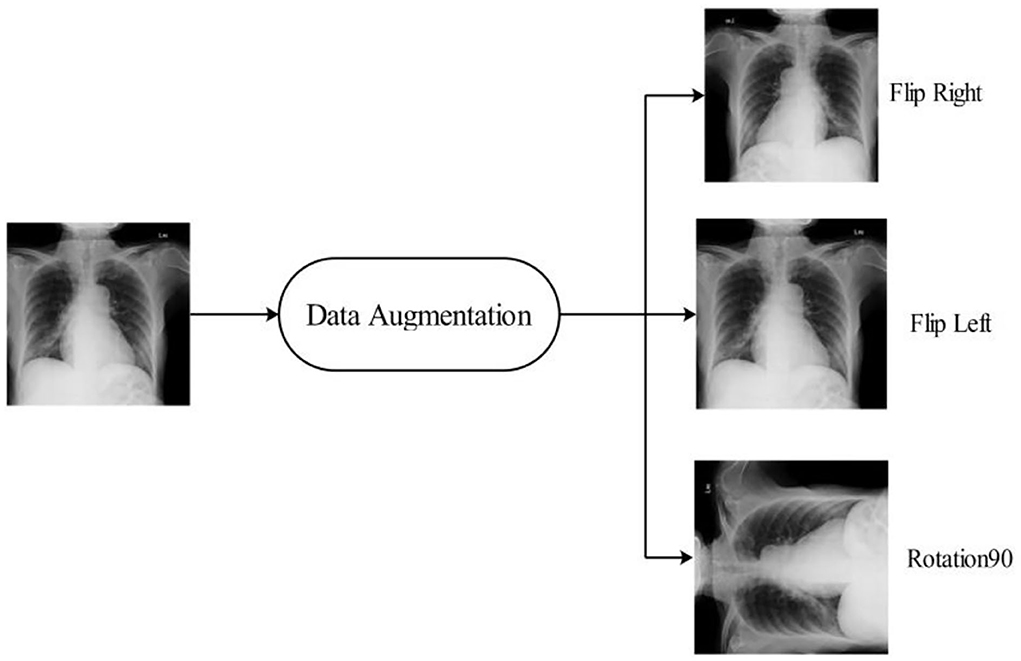
Figure 4. Sample images after data augmentation.
EfficientNet deep features
The EfficientNet model, which ranks among the top models, achieved 84.4% accuracy on ImageNet for the classification task with a parameter size of 5.3 M (38). Deep learning architectures are intended to find simple but efficient solutions. By uniformly increasing depth, breadth, and resolution while reducing model size, EfficientNet outperforms competitor state-of-the-art models. The first step in the compound scaling technique is to find a grid that identifies whether distinct scaling dimensions of the baseline network connect to one another within the limits of a constrained set of resources. The optimal scaling factor for height, breadth, and resolution may be determined using this procedure. These coefficients are then added to the original network to make the final network the appropriate size (17).
The main building block for EfficientNet-B0 is the asymmetrical bottleneck MB Conv. Blocks in MB Conv consist of an expansion layer followed by a compression layer. Later, it was possible to connect bottlenecks directly while connecting a much smaller number of channels. When compared to conventional layers, the computational cost of this design's deep separable convolutions is around k2, where k is the kernel size that determines the width and height of the 2D convolution window (39). In this work, we utilized the EfficientNet-B0 model for the features extraction. The model was originally trained on 1,000 classes and accepts the input size of 224 × 224 × 3. We fine-tuned the FC Layer with the new FC Layer which consists of COVID-19 classes. The updated model was trained by utilizing deep transfer learning and BO. The detail of Bayesian optimization (BO) is provided below. The objective of BO was to find the best hyperparameters for EfficientNet-B0 which gives the minimum error rate and increase the accuracy. The hyperparameters are selected dynamically via BO. The high-level features extracted from the average global pooling layer after the model has been trained on selected COVID-19 datasets and obtained a feature vector of size N × 1,280. Visually, the process of fine-tuning and deep transfer learning is shown in Figure 5.
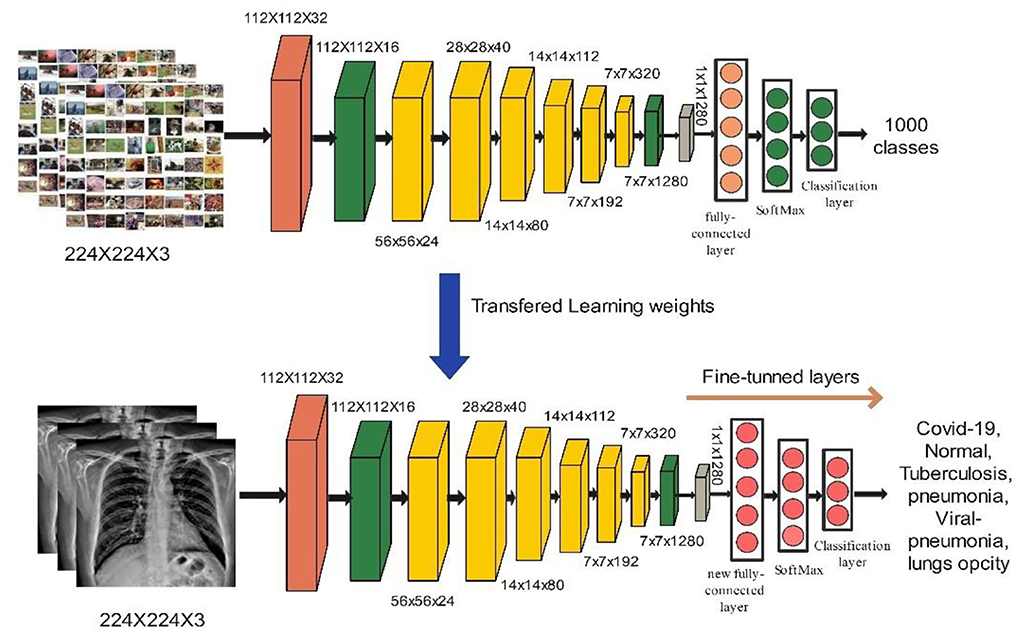
Figure 5. Visually representation of modified building block of efficient Net b0.
MobileNet-V2 deep features
MobileNet-V2 employs depth-wise separable convolutions (DSCs) for portability and to solve the problem of data loss in non-linear layers inside convolution blocks. MobileNet-V2 has 5.3 million parameter values (40). The building block of MobileNet-V2 is shown in Figure 6. We used the MobileNet-V2 model in our proposed work for deep feature extraction. The model was pre-trained on the ImageNet dataset, which has 1,000 classes, and it takes input sizes of 224 × 224 × 3. The FC Layer was replaced with a new FC layer. As described in Section Hyperparameters optimization using BO, the updated model was trained using deep transfer learning, and the hyperparameters were optimized using BO. The trained model was utilized for the feature extraction. The activation is performed on global average pool (GAP) layer and retrieved features have a dimension of N × 1280. Visually, the process of deep transfer learning is shown in Figure 6.
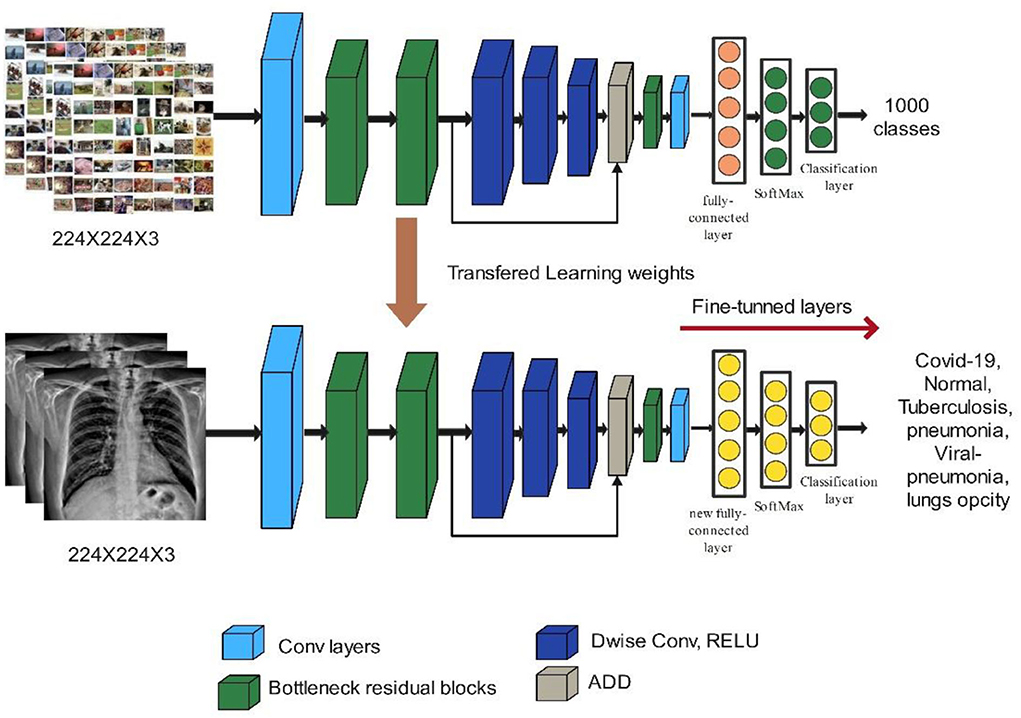
Figure 6. Modified building block of MobileNet-V2.
Hyperparameters optimization using BO
When using deep learning architectures, we need to adjust all of the hyperparameters in order to obtain classification accuracy. The selection of hyperparameters has a significant impact on the accuracy of the correct prediction (41). The goal of optimizing hyperparameters is to choose the values that get the best validation results. The hyperparameter optimization is calculated as:
where f(x) is the objective score to minimize error rate when compared to the validation set, and x is the set of hyperparameters with a value in the domain where hyperparameter optimization evaluation is more expensive. It takes longer to train and is nearly impossible to achieve by hand with deep neural network models with many hyperparameters. BO has been used in simulations and machine learning models. To improve model performance, computer vision-based approaches use feed-forward network architectures to adjust hyperparameters. It simplifies the time-taking task of optimizing a number of parameters (42). Deep learning models need particular hyperparameter (HP) tuning. These parameters can be manually or automatically set. Although manual optimization produces adequate results, it is highly dependent on expertise and lacks consistency, making it less than ideal. HPs can be modified automatically by random and grid searches; however, some ineffectual sites may be unavoidable due to the inability to gain knowledge from previous searches. BO has garnered a lot of attention in parameter modification because of its distinct advantages. BO differs from other approaches in that it takes into account historical parameter information by updating the prior with Gaussian progress (GP). Also, BO has a very low number of iterations and a very fast convergence time. The BO method may also avoid local optimality when dealing with non-convex situations. The strong convergence and robustness of BO make it an excellent choice for optimizing HPs (43, 44). In our work, we utilized Bayesian optimization for a deep convolutional neural network to optimize the hyperparameters for achieving the minimum error of models. Section Depth, learning rate, momentum, and L2Regularization are the optimization parameters. The ranges of these parameters are shown in Table 2.

Table 2. Hyperparameters ranges for Bayesian optimization.
Proposed feature fusion
Feature fusion is an important step in which multi-directional information is combined to get a better output. As shown in Figure 1, features are extracted from two pre-trained models; therefore, fusion is important to combine the only important information (36). We proposed a novel feature fusion technique called slicing-based serial fusion in our study.
Consider, the first vector , which has a dimension of N × 1280, and the size of second vector , which also has a dimension of N × 1280 and is obtained by selected models EfficientNet-B0 and MobileNet-V2, respectively. Suppose is fused feature vector having dimension N × K. We selected a mid-point based on any from the selected vectors, which are computed as follows:
where m represents the mid-point of vector and N represents the total number of images used for feature extraction. Based on the m-value, and are divided into slices. The slices equation is calculated as:
where and represent the slicing that contains half and half of the features of vector , and and represent the slicing that contains half and half of the features of vector . The structure of slicing vectors is visually shown in Figure 7.
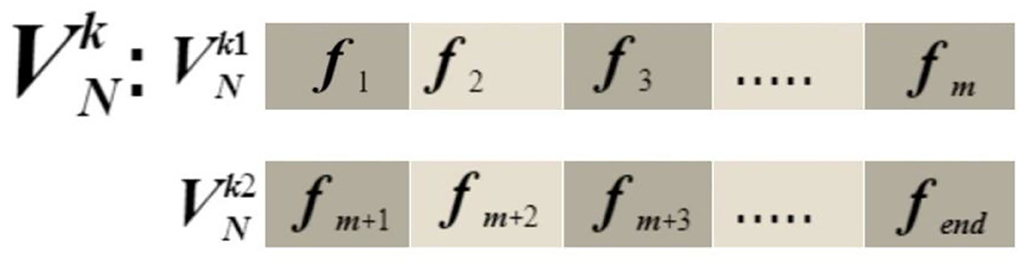
Figure 7. Structure of slicing vectors.
After slicing both vectors, the information is aggregated in the initial fused vector . The sliced vectors are fused in this sequence , respectively.
The output vector are attained with dimensions N × 2560 but these features are mixed with each other by utilizing the slicing technique. In the next phase, features are refined further using a Kurtosis-based function. We tried to select the important features in the fused vector using this function.
Based on this equation, we obtained a final vector having dimension N × 1422. This resultant vector is fed to machine learning classifiers for final classification.
Experimental results and analysis
For the experimental process, the datasets are split 50:50, indicating that 50% of the images are used to train the models and the remaining 50% are utilized for the testing process. The entire experimental process is carried out using 10-fold cross-validation. The static hyperparameters that are used during the training of deep models are epochs and mini-batch sizes having values 200 and 16, respectively. Moreover, the initial learning rate, stochastic gradient descent, momentum, L2Regularization, and section depth are optimized by utilizing Bayesian optimization. Multiple classifiers are used in this work for the classification results, including a support vector machine, wide neural network, ensemble subspace discriminant, and linear regression kernel. The classifier's performance parameters are sensitivity, precision, false positive rate, F1-score, accuracy, and computation time. Moreover, Grad-CAM analysis is conducted for further verification of the infected COVID-19 region in the image. All the simulations are conducted in MATLAB2022a executing on a workstation from MSI's GL75 Leopard series equipped with an 8 GB NVIDIA GTX graphics card, 512 SSD, and an Intel Core i7 10th generation processor.
COVID-19 radiography database results
Modified EfficientNet-B0 features
In this experiment, features are extracted from modified EfficientNet-B0. This model was trained through BO and transfer learning on the augmented dataset. Table 3 shows the classification accuracy of this updated model on the COVID-19 radiography dataset. In this table, it is noted that the QSVM classifier has a higher accuracy of 97.2% than the other classifiers listed. This classifier has a sensitivity rate of 97.12%, a precision rate of 97.15%, and an F1-score of 97.13%. Additionally, these values are determined for the remaining classifiers. During the classification process, the computation time of all classifiers is also recorded, with the wide neural network consuming the least time 18.004 (s) and the SVM kernel classifier taking the most time (688.63) (s).
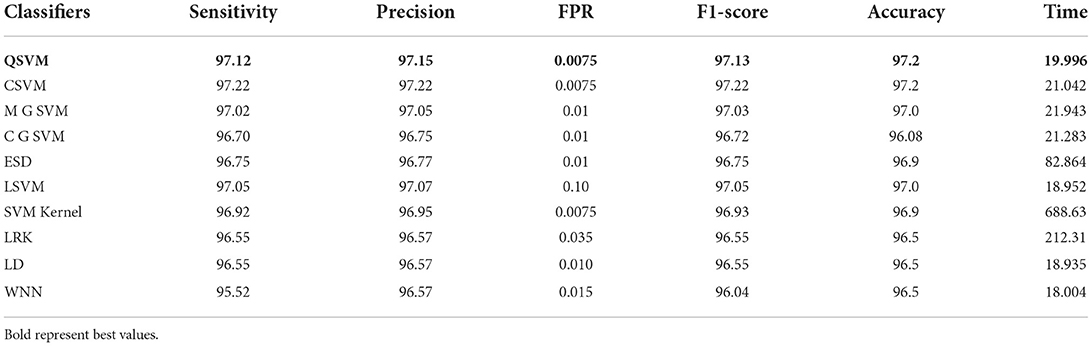
Table 3. Classification accuracy of modified EfficientNet-B0 Bayesian optimization features on COVID-19 radiography dataset.
Modified MobileNet-V2 features
From this experiment, the modified MobileNet-V2 model is fine-tuned and trained using BO on the COVID-19 radiography dataset. Table 4 shows the classification results of this experiment. From this table, the ESD classifier has an accuracy of 94.2% that is better than the other classifiers, listed in this table. This classifier has a 94.25% sensitivity rate, 94.28% precision rate, and F1-score is 94.28%. The numerical outcomes support the conclusion that the ESD outperforms the other classifiers. These values are also generated for the experiment's remaining classifiers. In this experiment, the amount of time for each classifier is noted and the linear discriminant classifier required the least amount of time of 15.743 s. In contrast, the LRK classifier was executed in 127.41 s, the highest of all the classifiers.
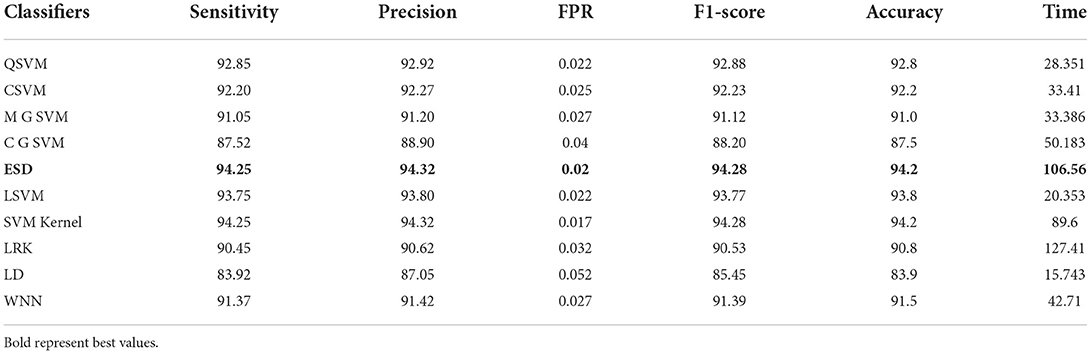
Table 4. Classification accuracy of modified MobileNet-v2 Bayesian optimization features on COVID-19 radiography dataset.
Proposed fused results
In this experiment, the proposed fusion approach is opted and fused the features of both optimized models. The fused vector is passed to the classifiers, which yielded the best accuracy of 98.8% on QSVM, which is higher than in experiments 1 and 2. Table 5 shows the detailed results of this experiment. QSVM has a sensitivity rate of 98.57%, a precision rate of 98.57%, and an F1-score of 98.57%. In addition, a QSVM confusion matrix is shown in Figure 8. This statistic indicates that the correct prediction rate for each class exceeds 97%. Also observed is the computing time of each classifier, with the linear SVM classifier executing faster than the others. This classifier's execution time is 38.901 s, while the longest execution time is 454.86 seconds (s). Comparing Tables 3, 4, it is observed that the fusion process improves accuracy, but time is increased due to the addition of extra features.
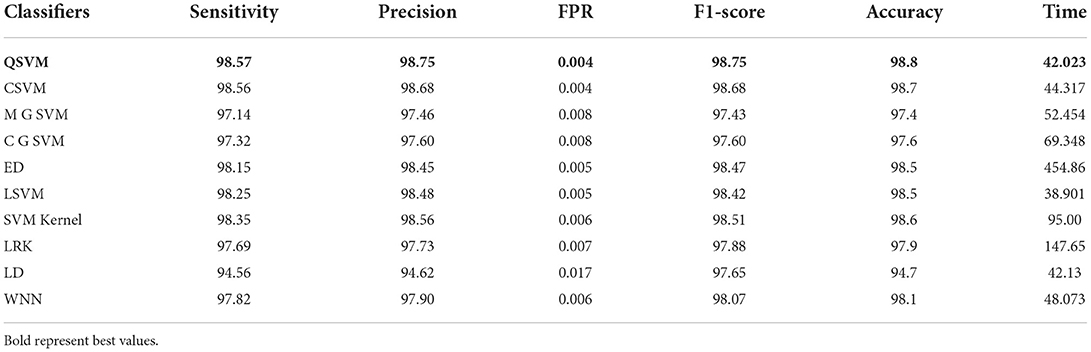
Table 5. Classification results of proposed slicing-based serial fusion technique on COVID-19 radiography database.
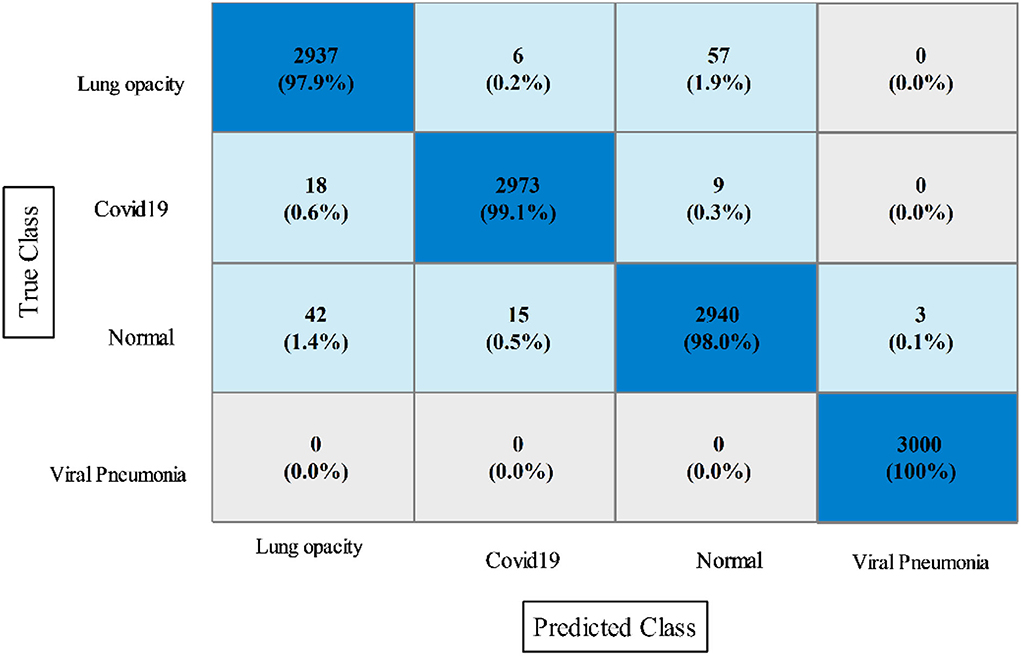
Figure 8. Confusion matrix of quadratic SVM utilizing the proposed slicing-based serial fusion technique on the COVID-19 radiography dataset.
COVID-GAN and COVID-Net mini chest X-ray dataset
In this section, the results of the COVID-GAN and COVID-Net Mini Chest X-Ray dataset have been presented. In the first phase, features are extracted from the modified EfficientNet-B0 model. This model was trained through BO and transfer learning on the augmented dataset. Table 6 shows the classification accuracy of this model and obtained the 97.4% on Cubic SVM. The sensitivity, precision, and F1-score are 97.13, 97.26, and 97.15%, respectively. The classification computational time for all classifiers in this phase experiment is also recorded; the Quadratic SVM classifier has the shortest execution time of 14.318 (s) and the longest execution time of 128.74 (s). In the next phase, features are extracted through the modified MobileNet-V2 model. Features are passed to the classifiers and obtained the maximum accuracy of 93.5% on Cubic SVM, as shown in Table 7. This table shows that the sensitivity rate for Cubic SVM is 93.35%, the precision rate is 93.46%, and the F1-score is also 93.47%. All classifiers' processing times are also noted down, and it is noted that modified EfficientNet-Bo features work better than modified MobileNet-V2 features.
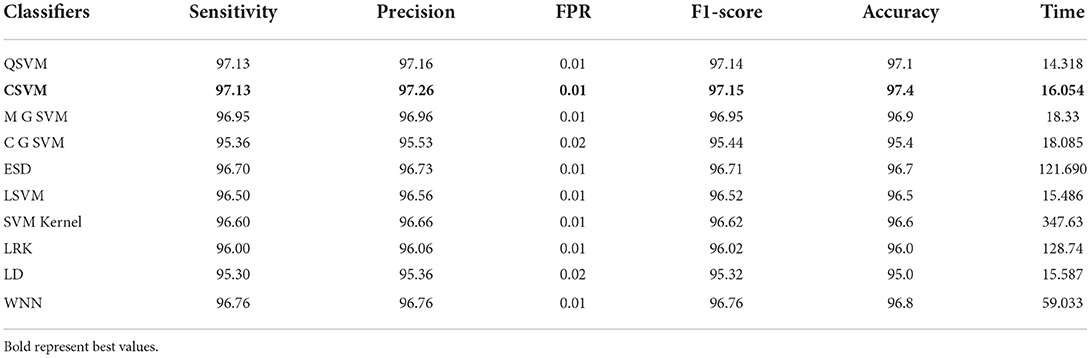
Table 6. Proposed modified EfficientNet-B0 Bayesian optimized features results on COVID-GAN and COVID-Net mini chest X-ray dataset.
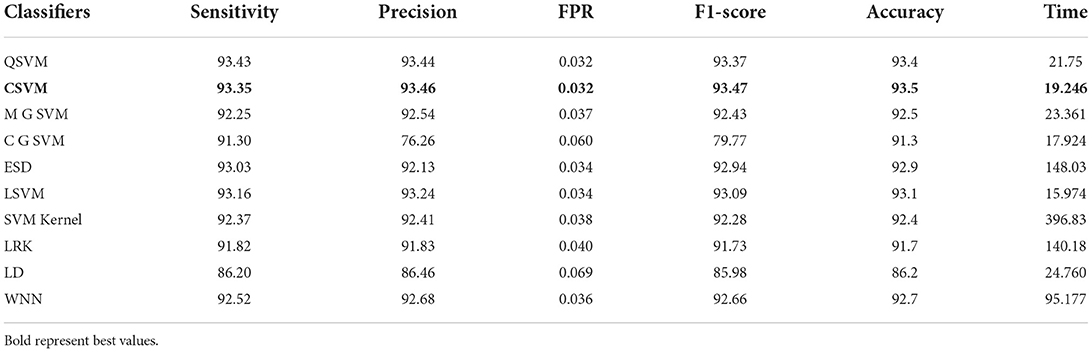
Table 7. Proposed method modified MobileNet-V2 utilizing Bayesian optimization results on COVID-GAN and COVID-Net mini chest X-ray dataset.
In the final step, fusion is performed using the proposed approach, and results are shown in Table 8. According to the data in this table, the Cubic SVM classifier has the highest accuracy of 97.9%, which is higher than the previous two steps (Tables 6, 7). The sensitivity and precision rates are also improved−97.26 and 97.36%, respectively. A confusion matrix, as shown in Figure 9, can be used to confirm the performance of CSVM. In comparison to the previous two experiments on this dataset, accuracy improves significantly after the fusion of features of both optimized trained models. Also, it is noted that the time is increased after the proposed fusion step.
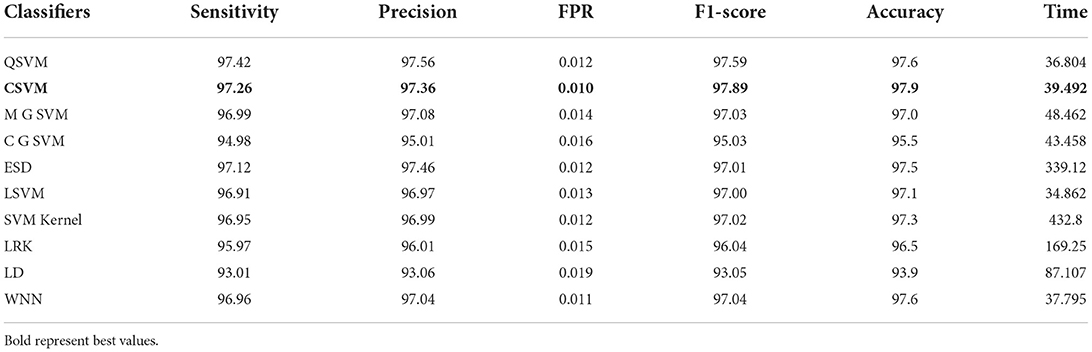
Table 8. Proposed slicing-based serial fusion results on COVID-GAN and COVID-Net mini chest X-ray dataset.
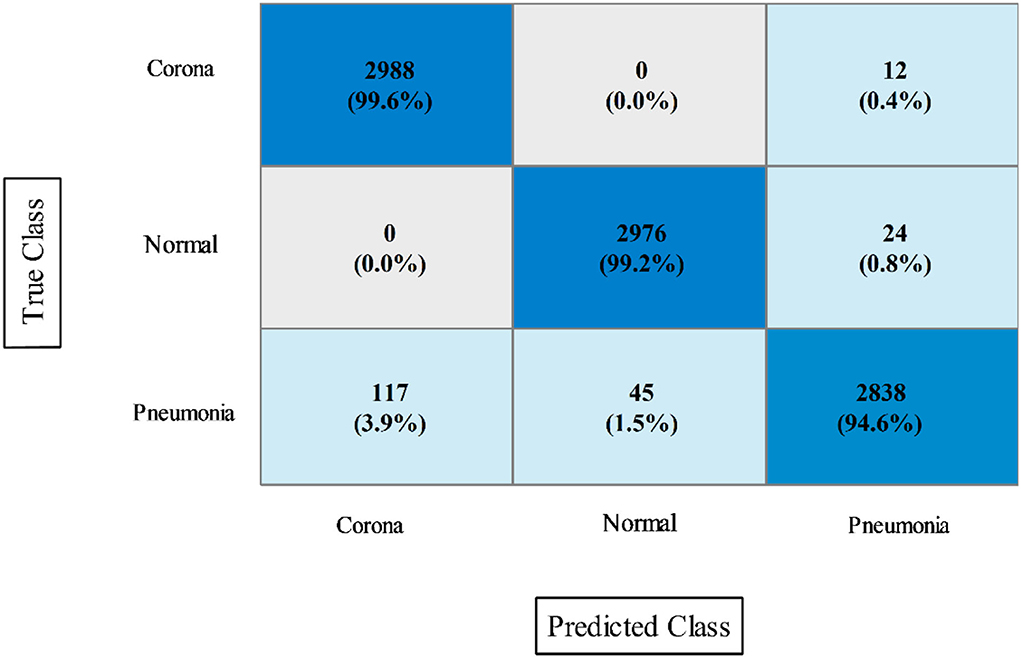
Figure 9. Confusion matrix of CSVM after proposed features fusion for COVID-GAN and COVID-Net mini chest X-ray dataset.
Chest X-ray (pneumonia, COVID-19, and tuberculosis)
The results of this dataset are shown in Tables 9–11. Table 9 shows the results after the feature extraction through a modified EfficientNet-B0 model that was trained through BO. For these features, quadratic SVM gives a better accuracy of 98.80%. The linear SVM has the least execution time of 21.394 (s), whereas the SVM Kernel classifier has the highest execution time is 3,497.8 (s). Table 10 shows the classification results of modified MobileNet-V2 features. In this table, the QSVM obtained the best accuracy of 97.0%. The F1-score is 97.05, the sensitivity rate is 96.02, and the precision rate is 96.6%. The computational time of this model is a little high than the modified Efficientnet-B0 features. Finally, fusion is improved, and the outcomes are shown in Table 11. From this table, the wide neural network classifier has the highest accuracy of 99.4%. Other measures of this classifier are calculated as well, including an F1-score of 99.38%, a sensitivity rate of 99.63%, and a precision rate of 99.79%. The confusion matrix of this classifier is also shown in Figure 10. Based on this figure, the sensitivity rate can be verified. After the fusion process, computational time increases but significantly improves accuracy.
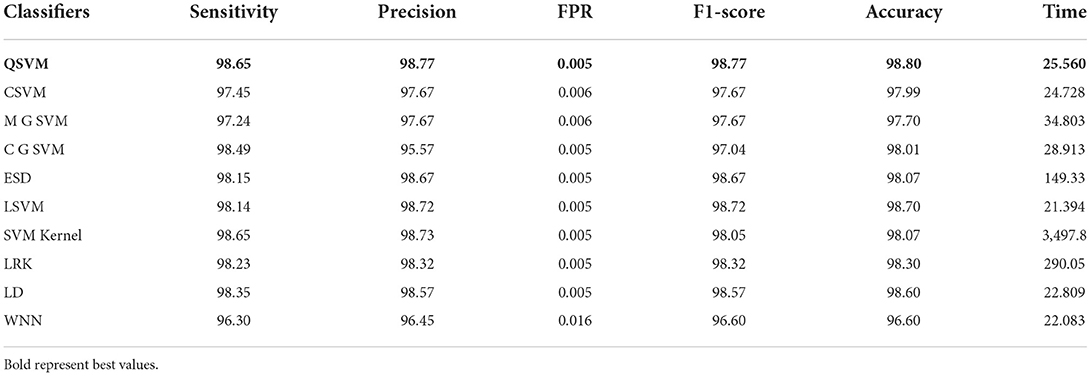
Table 9. Proposed modified EfficientNet-B0 Bayesian optimized features results on chest X-ray dataset.
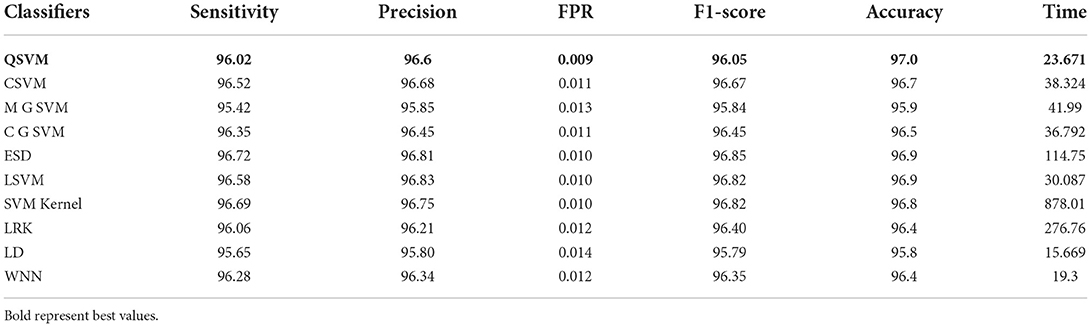
Table 10. Proposed modified MobileNet-V2 Bayesian optimized features results on chest X-ray dataset.
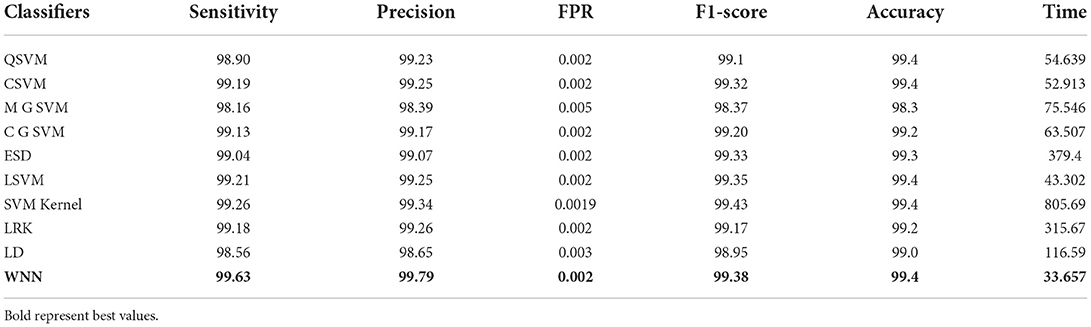
Table 11. Proposed slicing-based serial feature fusion results on chest X-ray dataset.
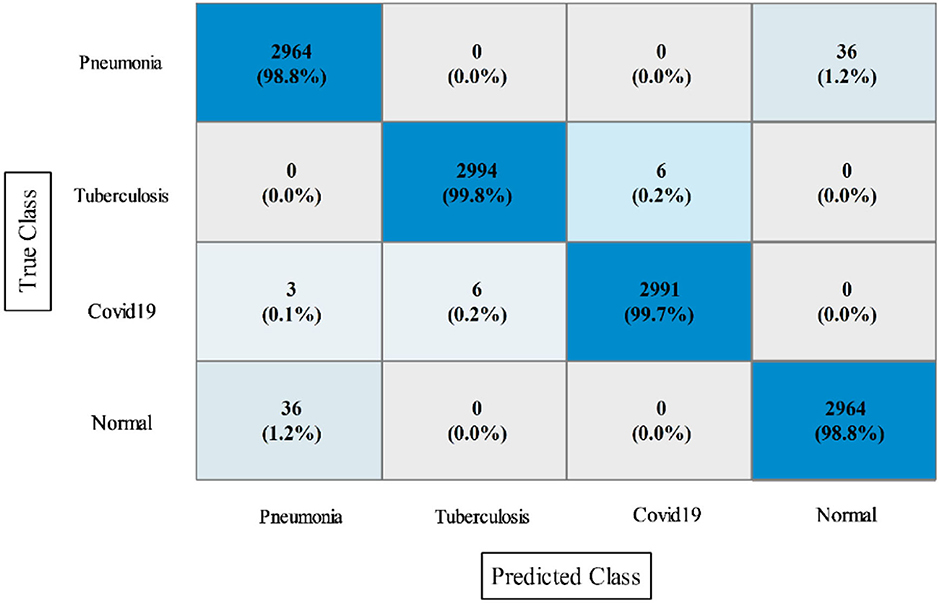
Figure 10. Confusion matrix of WNN for the proposed fusion on the chest X-ray dataset.
Grad-CAM visualization and comparison
Grad-CAM is a CAM generalization that offers a localization map on the image based on the selected layer. In our work, we utilized global average pooling convolutional (GAP) feature maps that are directly fed into SoftMax (45). Grad-CAM needs to acquire a localization map that discriminates based on social status. Grad-CAM in deep convolutional neural networks, after a convolutional layer has been trained, its feature mappings β are used to calculate the layer's gradient of gc. Weights are calculated using global average pooled interpretations of these gradients.
where weights are represented by that defines the feature map k for a specific class c and serves as a partial linearization of the deep network downstream of β. It is not necessary for gc to be a class score; alternatively, it might be anything that can be triggered in a different way. Our Grad-CAM heat map, like CAM, is a weighted combination of feature maps, but we then refine the findings using a ReLU:
This generates the primitive heat map that is normalized for visualization. In our article, we utilized the Grad-CAM for the analysis of the selected models. The Grad-CAM creates a heap map of the infected area of the lungs in the CXR images. A few resultant samples are shown in Figure 11. Finally, Table 12 shows a comprehensive evaluation of many computerized methods. This table contains a large number of newly introduced strategies that all use deep learning and Bayesian optimization concepts. Recently, the maximum accuracy has reached 99.3% by (46). In contrast, the suggested framework obtained a high degree of accuracy, as shown in Table 12. This shows the improvement of the proposed method.
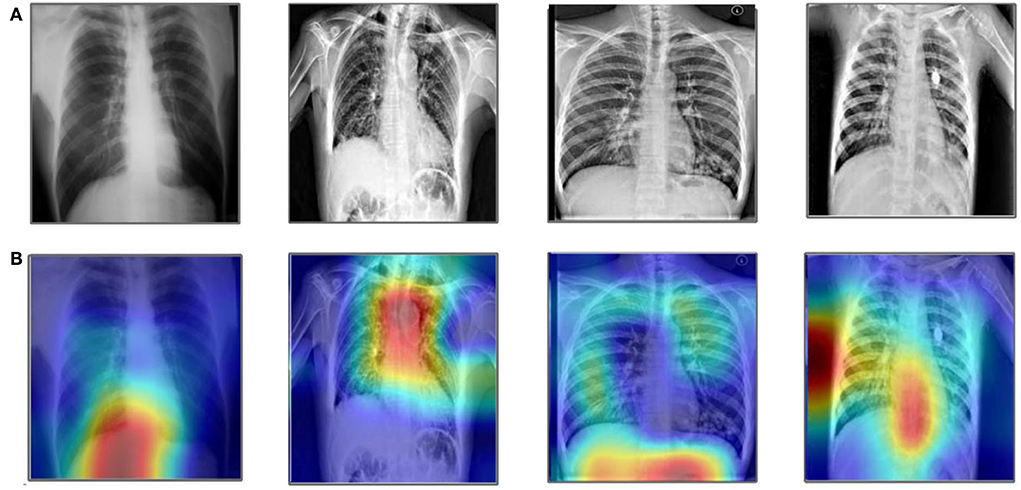
Figure 11. Sample images of Grad-Cam-based analysis. (A) Original images and (B) Grad-CAM analysis.

Table 12. Comparison of the proposed method to existing techniques.
Conclusion
This article presents an automated COVID-19 classification technique based on the hyperparameter optimization of pre-trained deep learning models via BO. Initially, contrast is increased to improve the visual quality of the input images, which are later used to train selected pre-trained models. Transfer learning is used to fine-tune and train both models. BO was used to optimize the hyperparameters of selected pre-trained models during training. Following that, features are extracted and fused using a proposed slicing-based approach. Three publicly available datasets were used in the experiment, and the accuracy was higher than with previous techniques. Based on the findings, we concluded that the proposed contrast-enhanced approach improved training capability, allowing for the later extraction of important features. Furthermore, the BO-based hyperparameters selection trained selected models more effectively than static initialization. Furthermore, the proposed fusion method improved classification accuracy. The computational time of the classification accuracy that was increased after the fusion process is the work's limitation. In future, feature selection methods will be prioritized in order to reduce the dimension of fused data.
Data availability statement
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author/s.
Author contributions
All authors listed have made a substantial, direct, and intellectual contribution to the work and approved it for publication.
Funding
This work was supported by the Human Resources Program in Energy Technology of the Korea Institute of Energy Technology Evaluation and Planning (KETEP), granted financial resources from the Ministry of Trade, Industry & Energy, Republic of Korea (No. 20204010600090).
Acknowledgments
The authors extend their appreciation to the Deanship of Scientific Research at King Khalid University for supporting this work through Research Groups Project under Grant No. RGP.2/16/43. The authors also like to thank HITEC University.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
1. Alshazly H, Linse C, Barth E, Martinetz T. Explainable COVID-19 detection using chest CT scans and deep learning. Sensors. (2021) 21:455. doi: 10.3390/s21020455
2. Shui-Hua W, Khan MA, Govindaraj V, Fernandes SL, Zhu Z, Yu-Dong Z. Deep rank-based average pooling network for COVID-19 recognition. Comp Mater Cont. (2022) 2797–2813. doi: 10.32604/cmc.2022.020140
3. Bhuyan HK, Chakraborty C, Shelke Y, Pani SK. COVID-19 diagnosis system by deep learning approaches. Expert Syst. (2022) 39:e12776. doi: 10.1111/exsy.12776
4. Subramanian N, Elharrouss O, Al-Maadeed S, Chowdhury M. A review of deep learning-based detection methods for COVID-19. Comput Biol Med. (2022) 143:105233. doi: 10.1016/j.compbiomed.2022.105233
5. Kogilavani SV, Prabhu J, Sandhiya R, Kumar MS, Subramaniam U, Karthick A, et al. COVID-19 detection based on lung Ct scan using deep learning techniques. Comput Math Methods Med. (2022) 2022:7672196. doi: 10.1155/2022/7672196
6. Krull A, Vičar T, Prakash M, Lalit M, Jug F. Probabilistic Noise2Void: unsupervised content-aware denoising. Front Comput Sci. (2020) 2:5. doi: 10.3389/fcomp.2020.00005
7. Jahanshahi AA, Dinani MM, Madavani AN Li J, Zhang SX. The distress of Iranian adults during the Covid-19 pandemic - More distressed than the Chinese and with different predictors. Brain Behav Immun. (2020) 87:124–5. doi: 10.1016/j.bbi.2020.04.081
8. World Health Organization. Weekly Epidemiological Update on COVID-19. (2021). Available online at: https://www.who.int/; https://www.who.int/publications/m (accessed September 14, 2022).
9. Chung M, Bernheim A, Mei X, Zhang N, Huang M, Zeng X, et al. CT imaging features of 2019 novel coronavirus (2019-nCoV). Radiology. (2020) 295:202–7. doi: 10.1148/radiol.2020200230
10. Alshazly H, Linse C, Abdalla M, Barth E, Martinetz T. COVID-Nets: deep CNN architectures for detecting COVID-19 using chest CT scans. PeerJ Comp Sci. (2021) 7:e655. doi: 10.7717/peerj-cs.655
11. Zhang J, Xie Y, Pang G, Liao Z, Verjans J, Li W, et al. Viral pneumonia screening on chest X-ray images using confidence-aware anomaly detection. IEEE Trans Med Imaging. (2020) 40:879–90. doi: 10.1109/TMI.2020.3040950
12. Oh Y, Park S, Chul Ye K. Deep learning COVID-19 features on CXR using limited training data sets. IEEE Trans Med Imaging. (2020) 39:2688–700. doi: 10.1109/TMI.2020.2993291
13. Shin H-C, Roth HR, Gao M, Lu L, Xu Z, Nogues I, et al. Deep convolutional neural networks for computer-aided detection: CNN architectures, dataset characteristics and transfer learning. IEEE Trans Med Imaging. (2016) 35:1285–98. doi: 10.1109/TMI.2016.2528162
14. Nogues I, Yao J, Mollura D, Summers RM. Deep Convolutional Neural Networks for Computer-Aided Detection: CNN Architectures, Dataset Characteristics and Transfer Learning. IEEE (2016).
15. Kini AS, Gopal Reddy AN, Kaur M, Satheesh S, Singh J, Martinetz T, et al. Ensemble deep learning and internet of things-based automated COVID-19 diagnosis framework. Contrast Media Mol Imaging (2022). doi: 10.1155/2022/7377502
16. Litjens G, Kooi T, Bejnordi BE, Setio AAA, Ciompi F, Ghafoorian M, et al. A survey on deep learning in medical image analysis. Med Image Anal. (2017) 42:60–88. doi: 10.1016/j.media.2017.07.005
18. Lakhani P, Sundaram BJR. Deep learning at chest radiography: automated classification of pulmonary tuberculosis by using convolutional neural networks. Radiology. (2017) 284:574–82. doi: 10.1148/radiol.2017162326
19. He K, Zhang X, Ren S, Sun J. Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. (2016). p. 770–8.
20. Russakovsky O, Deng J, Su H, Krause J, Satheesh S, Ma S, et al. Imagenet large scale visual recognition challenge. Int J Comput Vis. (2015) 115:211–52. doi: 10.1007/s11263-015-0816-y
21. Szegedy C, Vanhoucke V, Ioffe S, Shlens J, Wojna Z. Rethinking the inception architecture for computer vision. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. (2016). p. 2818–26.
22. Iandola FN, Han S, Moskewicz MW, Ashraf K, Dally WJ, Keutzer K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and < 0.5 MB model size. arXiv. (2016) 1–13. doi: 10.48550/arXiv.1602.07360
23. Hamza A, Attique Khan M, Wang S, Alqahtani A, Alsubai S, Binbusayyis A, et al. COVID19 Classification using Chest X-Ray images: a framework of CNN-LSTM and improved max value moth flame optimization. Front Public Health. 2795:1–20. doi: 10.3389/fpubh.2022.948205
24. Syed HH, Khan MA, Tariq U, Armghan A, Alenezi F, Khan JA, et al.. A rapid artificial intelligence-based computer-aided diagnosis system for COVID-19 classification from CT images. Behav Neurol. (2021). doi: 10.1155/2021/2560388
25. Loey M, El-Sappagh S, Mirjalili S. Bayesian-based optimized deep learning model to detect COVID-19 patients using chest X-ray image data. Comput Biol Med. (2022) 142:05213. doi: 10.1016/j.compbiomed.2022.105213
26. Yoo SH, Geng H, Chiu TL Yu SK, Cho DC, Heo J, et al. Deep learning-based decision-tree classifier for COVID-19 diagnosis from chest X-ray imaging. Front Med. (2020) 7:427. doi: 10.3389/fmed.2020.00427
27. Wang D, Mo J, Zhou G, Xu L, Liu Y. An efficient mixture of deep and machine learning models for COVID-19 diagnosis in chest X-ray images. PLoS ONE. (2020) 15:e0242535. doi: 10.1371/journal.pone.0242535
28. Chowdhury NK, Rahman MM, Kabir MA. PDCOVIDNet: a parallel-dilated convolutional neural network architecture for detecting COVID-19 from chest X-ray images. Health Inf Sci Syst. (2020) 8:27. doi: 10.1007/s13755-020-00119-3
29. Khan IU, Aslam N. A deep-learning-based framework for automated diagnosis of COVID-19 using X-ray Images. Information. (2020) 11:419. doi: 10.3390/info11090419
30. Che Azemin MZ, Hassan R, Mohd Tamrin MI, Md Ali AM. COVID-19 deep learning prediction model using publicly available radiologist-adjudicated chest X-ray images as training data: preliminary findings. Int J Biomed Imaging. (2020) 2020:8828855. doi: 10.1155/2020/8828855
31. Khan MA, Azhar M, Ibrar K, Alqahtani A, Alsubai S, Binbusayyis A, et al. COVID-19 classification from chest X-ray images: a framework of deep explainable artificial intelligence. Comp Intell Neurosci. (2022). doi: 10.1155/2022/4254631
32. Ravi V, Narasimhan H, Chakraborty C, Pham TD. Deep learning-based meta-classifier approach for COVID-19 classification using CT scan and chest X-ray images. Multimedia Syst. (2022) 28:1401–15. doi: 10.1007/s00530-021-00826-1
33. De Sousa PM, Carneiro PC, Oliveira MM, Pereira GM, da Costa Junior CA, de Moura LV, et al. COVID-19 classification in X-ray chest images using a new convolutional neural network: CNN-COVID. Res Biomed Eng. (2022) 38:87–97. doi: 10.1007/s42600-020-00120-5
34. Mohammed MA, Al-Khateeb B, Yousif M, Mostafa SA, Kadry S, Abdulkareem KH, et al.. Novel crow swarm optimization algorithm and selection approach for optimal deep learning COVID-19 diagnostic model. Comp Intell Neurosci. (2022). doi: 10.1155/2022/1307944
35. Allioui H, Mohammed MA, Benameur N, Al-Khateeb B, Abdulkareem KH, Garcia-Zapirain B, et al. A multi-agent deep reinforcement learning approach for enhancement of COVID-19 CT image segmentation. J Pers Med. (2022) 12:309. doi: 10.3390/jpm12020309
36. Khan MA, Alhaisoni M, Tariq U, Hussain N, Majid A, Damaševičius R, et al. COVID-19 case recognition from chest CT images by deep learning, entropy-controlled firefly optimization, and parallel feature fusion. Sensors. (2021) 21:7286. doi: 10.3390/s21217286
37. Kaur R, Kaur S. Comparison of contrast enhancement techniques for medical image. In: 2016 Conference on Emerging Devices and Smart Systems (ICEDSS). (2016). p. 155−9.
38. Atila Ü, Uçar M, Akyol K, Uçar E. Plant leaf disease classification using EfficientNet deep learning model. Ecol Inform. (2021) 61:101182. doi: 10.1016/j.ecoinf.2020.101182
39. Sandler M, Howard A, Zhu M, Zhmoginov A, Chen LC. Mobilenetv2: inverted residuals and linear bottlenecks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. (2018). p. 4510–20.
40. Dong K, Zhou C, Ruan Y, Li Y. MobileNetV2 model for image classification. In: 2020 2nd International Conference on Information Technology and Computer Application (ITCA). (2020). p. 476–80.
41. Victoria AH, Maragatham G. Automatic tuning of hyperparameters using Bayesian optimization. Evol Syst. (2021) 12:217–23. doi: 10.1007/s12530-020-09345-2
42. Joy TT, Rana S, Gupta S, Venkatesh S. Hyperparameter tuning for big data using Bayesian optimisation. In: 2016 23rd International Conference on Pattern Recognition (ICPR). (2016). p. 2574−9.
43. Abbasimehr H, Paki R. Prediction of COVID-19 confirmed cases combining deep learning methods and Bayesian optimization. Chao, Solit Fract. (2021) 142:110511. doi: 10.1016/j.chaos.2020.110511
44. Snoek J, Larochelle H, Adams RP. Practical bayesian optimization of machine learning algorithms. Adv Neural Inf Process Syst. (2012) 25:1–16.
45. Zhou B, Khosla A, Lapedriza A, Oliva A, Torralba A. Learning deep features for discriminative localization. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. (2016). p. 2921−9.
46. Canayaz M, Sehribanoglu S, Özdag R, Demir M. COVID-19 diagnosis on CT images with Bayes optimization-based deep neural networks and machine learning algorithms. Neural Comp Appl. (2022) 34:5349–65. doi: 10.1007/s00521-022-07052-4
47. Nour M, Cömert Z, Polat K. A novel medical diagnosis model for COVID-19 infection detection based on deep features and Bayesian optimization. Appl Soft Comput. (2020) 97:106580. doi: 10.1016/j.asoc.2020.106580
Keywords: corona virus, multi-filters contrast enhancement, deep learning, Bayesian optimization, hyperparameters, fusion
Citation: Hamza A, Attique Khan M, Wang S-H, Alhaisoni M, Alharbi M, Hussein HS, Alshazly H, Kim YJ and Cha J (2022) COVID-19 classification using chest X-ray images based on fusion-assisted deep Bayesian optimization and Grad-CAM visualization. Front. Public Health 10:1046296. doi: 10.3389/fpubh.2022.1046296
Received: 16 September 2022; Accepted: 12 October 2022;
Published: 04 November 2022.
Edited by:
Yu-Dong Zhang, University of Leicester, United KingdomReviewed by:
Mazin Mohammed, University of Anbar, IraqAmir Faisal, Sumatra Institute of Technology, Indonesia
Priti Bansal, Netaji Subhas University of Technology, India
Copyright © 2022 Hamza, Attique Khan, Wang, Alhaisoni, Alharbi, Hussein, Alshazly, Kim and Cha. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Muhammad Attique Khan, YXR0aXF1ZS5raGFuQGhpdGVjdW5pLmVkdS5waw==; Jaehyuk Cha, Y2hhamhAaGFueWFuZy5hYy5rcg==