 Mengting Li
Mengting Li Xiangyu Lu2,3†
Xiangyu Lu2,3† Rongsheng Tong
Rongsheng Tong Xingwei Wu
Xingwei Wu- 1Personalized Drug Therapy Key Laboratory of Sichuan Province, Department of Pharmacy, Sichuan Provincial People's Hospital, University of Electronic Science and Technology of China, Chengdu, China
- 2Chinese Academy of Sciences Sichuan Translational Medicine Research Hospital, Chengdu, China
- 3The Second Department of Hepatobiliary Surgery, Sichuan Academy of Medical Sciences and Sichuan Provincial People's Hospital, University of Electronic Science and Technology of China, Chengdu, China
- 4School of Pharmacy, Chengdu Medical College, Chengdu, China
- 5Endocrine Department, Sichuan Provincial People's Hospital, Chengdu, China
Background: Medication adherence is the main determinant of effective management of type 2 diabetes, yet there is no gold standard method available to screen patients with high-risk non-adherence. Developing machine learning models to predict high-risk non-adherence in patients with T2D could optimize management.
Methods: This cross-sectional study was carried out on patients with T2D at the Sichuan Provincial People's Hospital from April 2018 to December 2019 who were examined for HbA1c on the day of the survey. Demographic and clinical characteristics were extracted from the questionnaire and electronic medical records. The sample was randomly divided into a training dataset and a test dataset with a radio of 8:2 after data preprocessing. Four imputing methods, five sampling methods, three screening methods, and 18 machine learning algorithms were used to groom data and develop and validate models. Bootstrapping was performed to generate the validation set for external validation and univariate analysis. Models were compared on the basis of predictive performance metrics. Finally, we validated the sample size on the best model.
Results: This study included 980 patients with T2D, of whom 184 (18.8%) were defined as medication non-adherence. The results indicated that the model used modified random forest as the imputation method, random under sampler as the sampling method, Boruta as the feature screening method and the ensemble algorithms and had the best performance. The area under the receiver operating characteristic curve (AUC), F1 score, and area under the precision-recall curve (AUPRC) of the best model, among a total of 1,080 trained models, were 0.8369, 0.7912, and 0.9574, respectively. Age, present fasting blood glucose (FBG) values, present HbA1c values, present random blood glucose (RBG) values, and body mass index (BMI) were the most significant contributors associated with risks of medication adherence.
Conclusion: We found that machine learning methods could be used to predict the risk of non-adherence in patients with T2D. The proposed model was well performed to identify patients with T2D with non-adherence and could help improve individualized T2D management.
Introduction
Diabetes mellitus (DM) is a common chronic disease with disordered metabolism and hyperglycemia. Type 2 diabetes (T2D) accounts for more than 90% of diabetic cases (1, 2). As morbidity and prevalence continue to rise worldwide, T2D greatly increases healthcare costs and imposes a tremendous economic burden on society and public health systems (3, 4). Total healthcare costs for diabetics are estimated ~$2.1 trillion by 2030 (5).
Pharmacotherapy is one of the most commonly used treatment modalities for controlling the progression of chronic diseases, especially diabetes. In most cases, the benefits of high adherence to medications have been well-determined in diabetes (6–8). The extent to which patients follow prescribed treatments determines the outcome. However, poor adherence to oral hypoglycemic drugs is common in patients with T2D (9). As reported, between a third and a half of drugs prescribed for patients with T2D were not taken as recommended, and estimates varied widely depending on the population studied (10–13). Evidence suggested that non-adherence was an important contributor associated with poor glycemic control and other negative health outcomes, such as the increased risk of hospitalization and complications (14, 15). In a decade, studies indicated that telephone calls, text messages, and educational interventions played an important role in improving adherence to medication (16–18). However, for patients with good compliance, additional interventions are a waste of healthcare resources that are already limited. Thus, the early detection of patients with a high risk of poor adherence to medication is the premise of these effective interventions.
So, we considered whether it is possible to identify patients with a high risk of poor medication adherence early and provide individualized methods to improve their compliance. In our previous study, we reported predictive models of the risks of medication adherence in patients with T2D (19), and the area under the receiver operating characteristic curve (AUC) of the ensemble model was 0.866. The results confirmed that machine learning could be used to predict the risk of drug non-adherence in patients with T2D. Thus, in this study, we used a larger sample size, more variables, more data preprocessing algorithms, and machine learning algorithms to develop models that could more accurately predict medication adherence in patients with T2D.
Methods
Data sources and participants
The cross-sectional study was conducted at the Sichuan Provincial People's Hospital from 1 April 2018 to 31 December 2019. We performed a face-to-face questionnaire interview and filled out questionnaires according to the responses of the patients who participated in the survey. Participants were selected according to the following criteria: (1) diagnosed as patients with T2D; (2) examined HbA1c on the day of the questionnaire; (3) interested to take part in the survey and provide information to the investigators, as well as signed the informed consent forms; (4) received hypoglycemic agency treatment; and (5) over 18 years of age. Ethics approval was obtained through the Ethics Committee of the Sichuan Provincial People's Hospital (approval # 2018-53).
Data collection and outcome definition
The data in this study were collected from electronic medical records (EMRs) and face-to-face questionnaires. Clinical laboratory results, such as HbA1c value and fasting blood glucose (FBG) value, were collected according to EMRs. Body mass index (BMI) was calculated using the following formula: BMI = weight (kg)/height2 (m2). Information on self-glycemic monitoring, diet, exercise, and mental state were provided by patients in face-to-face questionnaires. The questionnaire consists of four parts. The first part is about basic characteristics, including age, nationalities, waistline, occupation, marital status, and so on. The second part is related to self-glycemic monitoring, containing regular measurements frequency of FBG, measurement interval between previous and present, etc. The third part was about exercise, diet, and mental state. The last part was treatment regimen and medication adherence, in which we recorded the duration of the treatment regimen, type and dose of insulin used, etc. The adherence status, which was determined as the outcome variable, was defined according to the proportion of days covered (PDC). PDC higher than 80% was regarded as good medication compliance (20, 21).
Data preprocessing
Data were preprocessed by removing (1) the variables with missing values >90%, (2) the variables with a single value occupying >90%, and (3) the variables with coefficients of variation < 0.01. After the above steps, the data were further processed.
Data partition and dataset building
The data were randomly divided into two subsets (namely, training set and test set) at a ratio of 8:2, which would be used to train and test models, respectively.
Missing data were inevitable in practice. In case of questionable data or missing data in the part of the questionnaire, patients were contacted via telephone for certainty or addition. However, the clinical characteristics of the patients comprised several missing values, such as FBG and postprandial blood glucose (PBG). Missing data were filled in using four imputing methods, including not imputing (marked as Not), simple imputing, random forest, and modified random forest.
Due to the imbalanced data of medication adherence, five sampling methods were applied, including not sampling (marked as Not), Synthetic Minority Oversampling Technique (SMOTE), Borderline SMOTE, Random Over Sampler, and Random Under Sampler.
Three variable selection methods were considered in this study, including no screening (marked as Not), Boruta, and LassoCV. The importance of variables was evaluated according to the output of Boruta and LassoCV (variable importance scores). A high score suggested that the variable could improve predictive accuracy.
Thus, a total of 60 datasets were derived from the training set and set up by using four imputing methods, five sampling methods, and three feature screening methods.
Model development
In this process, several machine learning algorithms were trained for binary classification and applied to develop predictive models, including AdaBoost, Extreme Gradient Boosting (XGBoost), gradient boosting, Bagging, Bernoulli Naive Bayes, Gaussian Naive Bayes, Multinomial Naive Bayes, decision tree, extra tree, K-nearest neighbor (KNN), linear discriminant analysis (LDA), quadratic discriminant analysis (QDA), logistic regression, passive-aggressive, random forest, Stochastic Gradient Descent (SGD), support vector machine (SVM), and ensemble algorithm. The ensemble algorithm summarized the output of the five best models [assessed by area under the receiver operating characteristic curve (AUC)] among the trained models and generated output according to the voting principle.
Model evaluation
Internal validation was conducted with 10-fold cross-validation in 60 datasets, and 10 independent repeated values among indices were collected. Then, the test set was used for external validation. The predictive performances of those models were assessed by the AUC, accuracy, precision, recall, F1-score, and area under the precision-recall curve (AUPRC). AUPRC was calculated by taking the average of precision across all recall values corresponding to different thresholds, and a high value represented both high recall and precision (22, 23).
To elucidate the contribution of different imputing methods, sampling methods, screening methods, machine learning algorithms, and variables, univariate analysis was performed. The whole process could be described as follows: (1) before analysis, the test set was expanded using the Bootstrap method with 2,000 times resampling from the test set. (2) Additionally, the average performance metrics of each method were calculated, respectively. (3) Univariate analysis was used for statistical analysis. The highest values of performance metrics meant that the method was the best than others. If the average performance metrics of models when the variable was included were significantly higher than the average performance indicators when the variable was excluded (P < 0.05), the variable would be judged as a positive contribution to the prediction improvement.
Above all, the overall process of model development and validation is shown in Figure 1.
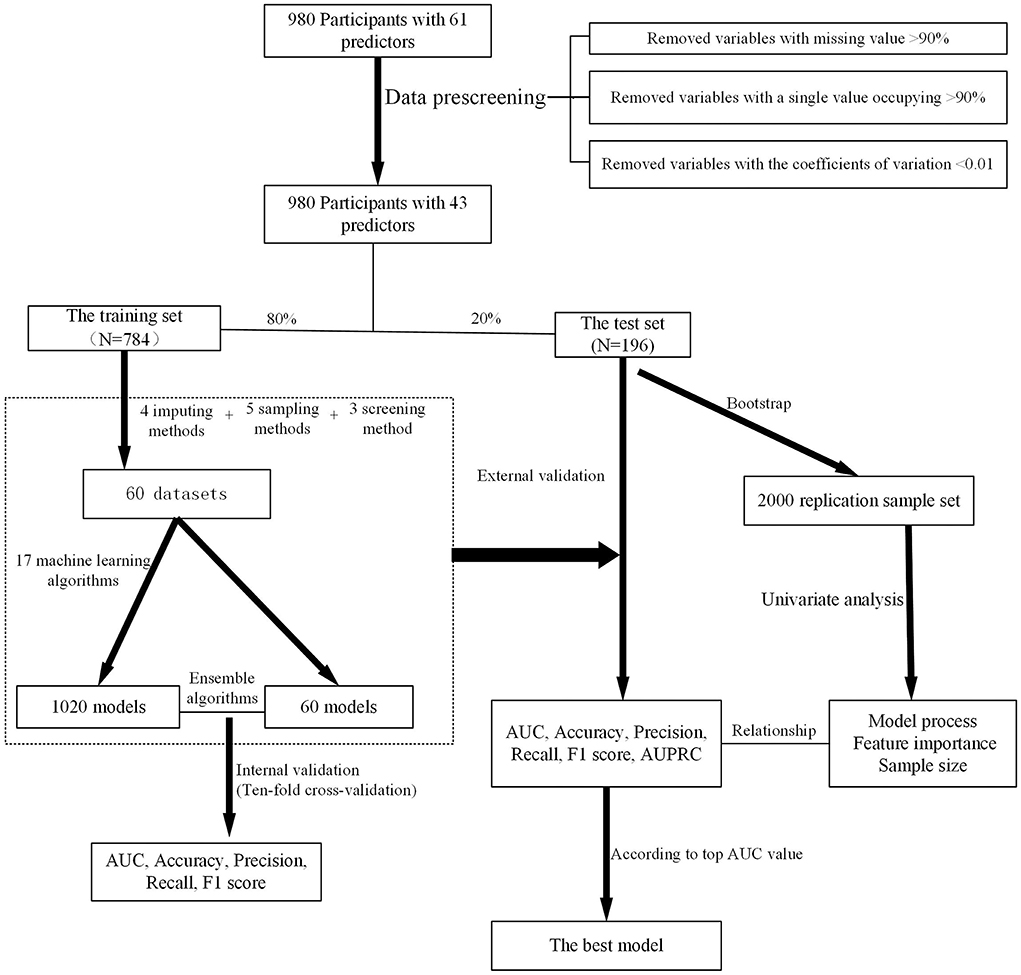
Figure 1. The schematic flow of the main steps in this study.
Sample size validation
The best model (assessed by AUC) was employed to estimate the impact of sample sizes on predictive performance (19). The total samples were randomly separated into 80% training set and 20% test set. First, 10% of the samples were randomly extracted from the training set to train the model, and AUC was evaluated in the test set. The training samples increased from 10 to 100% in increments of 10%. These steps were repeated 10 times so that ten independent repeated values of AUC were generated. The contribution of a sample size to improve the prediction performance of models was assessed according to the inflection point change of the line graph.
Statistical analysis
Continuous variables were described by mean and standard deviation, whereas categorical variables were expressed in terms of frequencies and percentages. Analysis of variance (ANOVA) and rank sum test were used for univariate analysis.
Statistical analysis was implemented using the stats package, and model development was performed using the sklearn package in Python (Python Software Foundation, Python Language Reference, version 3.6.8) on PyCharm (developed by JetBrains.r.o., version 11.0.4). The results of variable valuation assessed using univariate analysis were summarized and presented by box plots using R (R software, version 4.0.2).
Results
Participant characteristics
Overall, 980 patients completed the survey, among which 571 were male and 409 were female. The mean age was 59.2 ± 11.9 years. In total, 184 patients were defined as having poor medication adherence (18.8%). Detailed characteristics of participants are shown in Table 1.

Table 1. The detailed information of participants.
Dataset building
After data preprocessing, 43 variables were retained, and 18 variables were deleted. Sixty datasets were set up by applying different imputing methods, sampling methods, and screening methods with 43 variables. Additionally, the different number of variables and samples in each dataset is listed in Table 2.
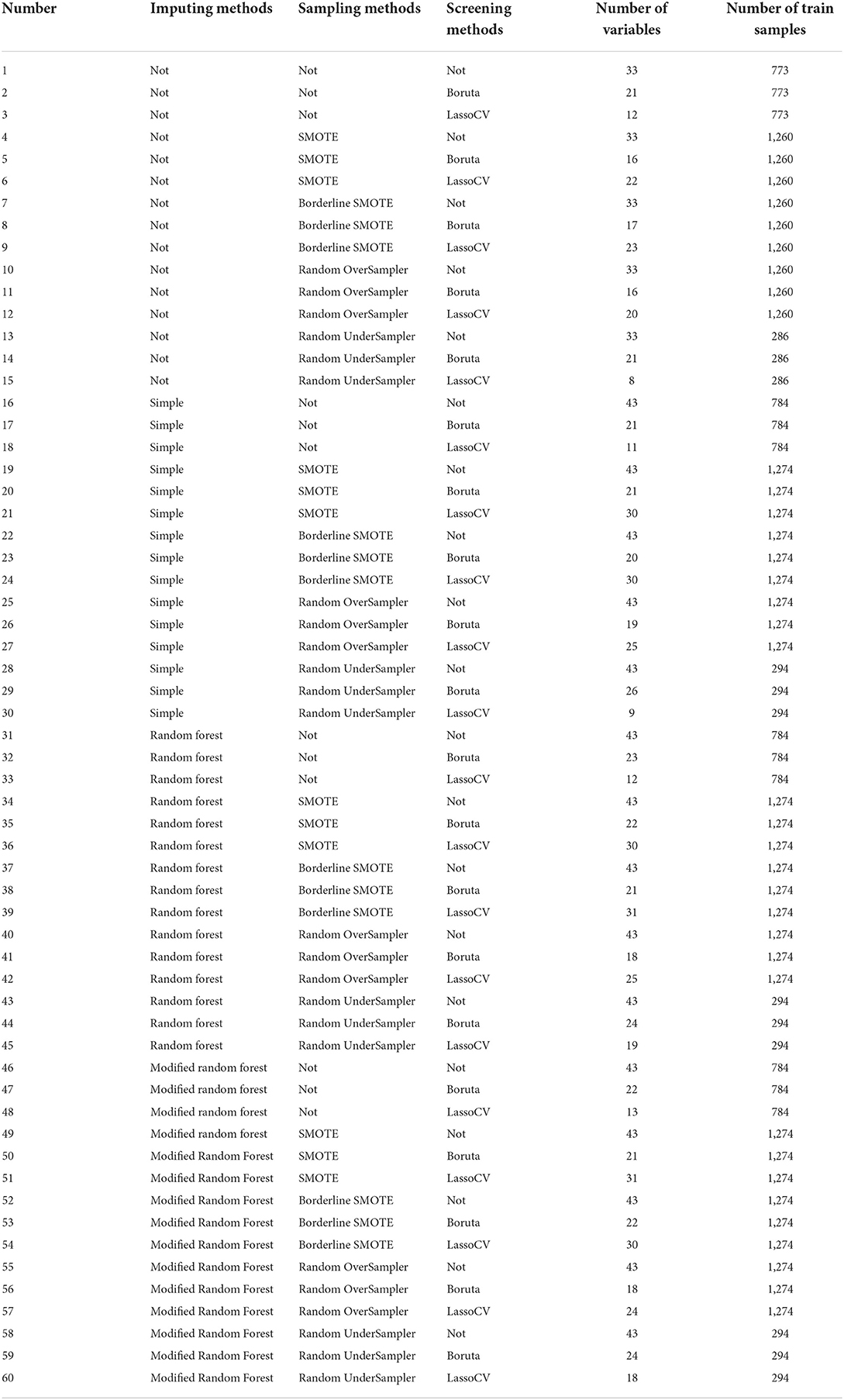
Table 2. The detailed information of 60 datasets.
Model validation
A total of 1,080 models were validated in the test set, considered as external validation, and the performance metrics were output. As shown in Table 3, the best five models were listed in sequence according to the AUC value. The best model (model 1) was applied the ensemble algorithm and trained in the No. 59 dataset (applied modified random forest as imputing method, random under sampler as sampling method, and Boruta as screening method). AUC, accuracy, precision, recall, F1 score, and AUPRC of the best model (model 1) were 0.8369, 0.9474, 0.6792, 0.7912, and 0.9574, respectively (Table 3; Figure 2). Especially in unbalanced data, the high value of AUPRC indicated that the best model (model 1) performed well to identify patients at risk for non-adherence.
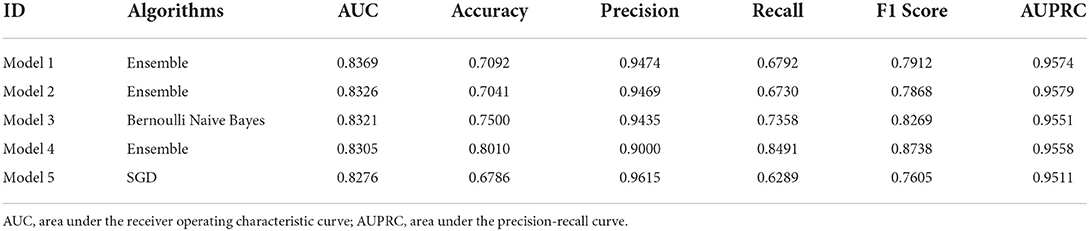
Table 3. The summary of the performance of five best models.
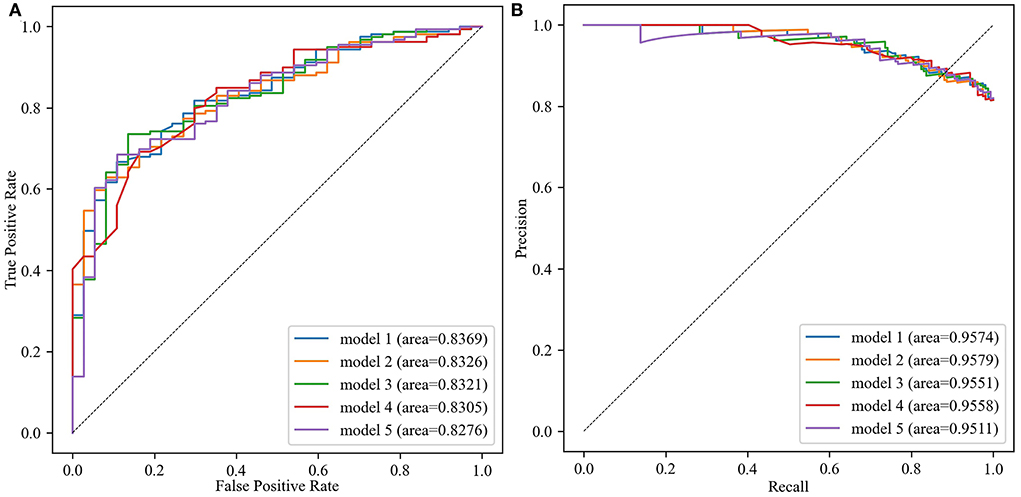
Figure 2. The area under the receiver operating characteristic curve (AUC) and area under the precision-recall curve (AUPRC) of the best five models. (A) The receiver operator characteristic curve. (B) The precision-recall curves.
As shown in Table 4, the effects of various factors on model performance were compared using univariate analysis. With a decrease in the number of samples (AUC=-0.071, P < 0.0001) and an increase in the number of variables (AUC=0.047, P < 0.0001), the prediction model would achieve a high AUC value. Among the three imputing methods, modified random forest (AUC = 0.726 ± 0.076, vs. not 0.657 ± 0.075, simple 0.702 ± 0.087, and random forest 0.723 ± 0.081, P < 0.0001) was performed to improve performance of models, as well as random under sampler (AUC = 0.724 ± 0.076, vs. not 0.723 ± 0.080, random over sampler 0.698 ± 0.090, SMOTE 0.683 ± 0.086, and Border line SMOTE 0.682 ± 0.081, P < 0.0001) in five sampling methods, and Boruna (AUC = 0.709 ± 0.083, vs. not 0.700 ± 0.084, and LassoCV 0.698 ± 0.087, P < 0.0001) in three screening methods. In addition, the ensemble algorithm also performed well compared with other 17 algorithms (AUC = 0.790 ± 0.053, P < 0.0001). It should be mentioned that the above results were the same as the methods applied in the best model (model 1).
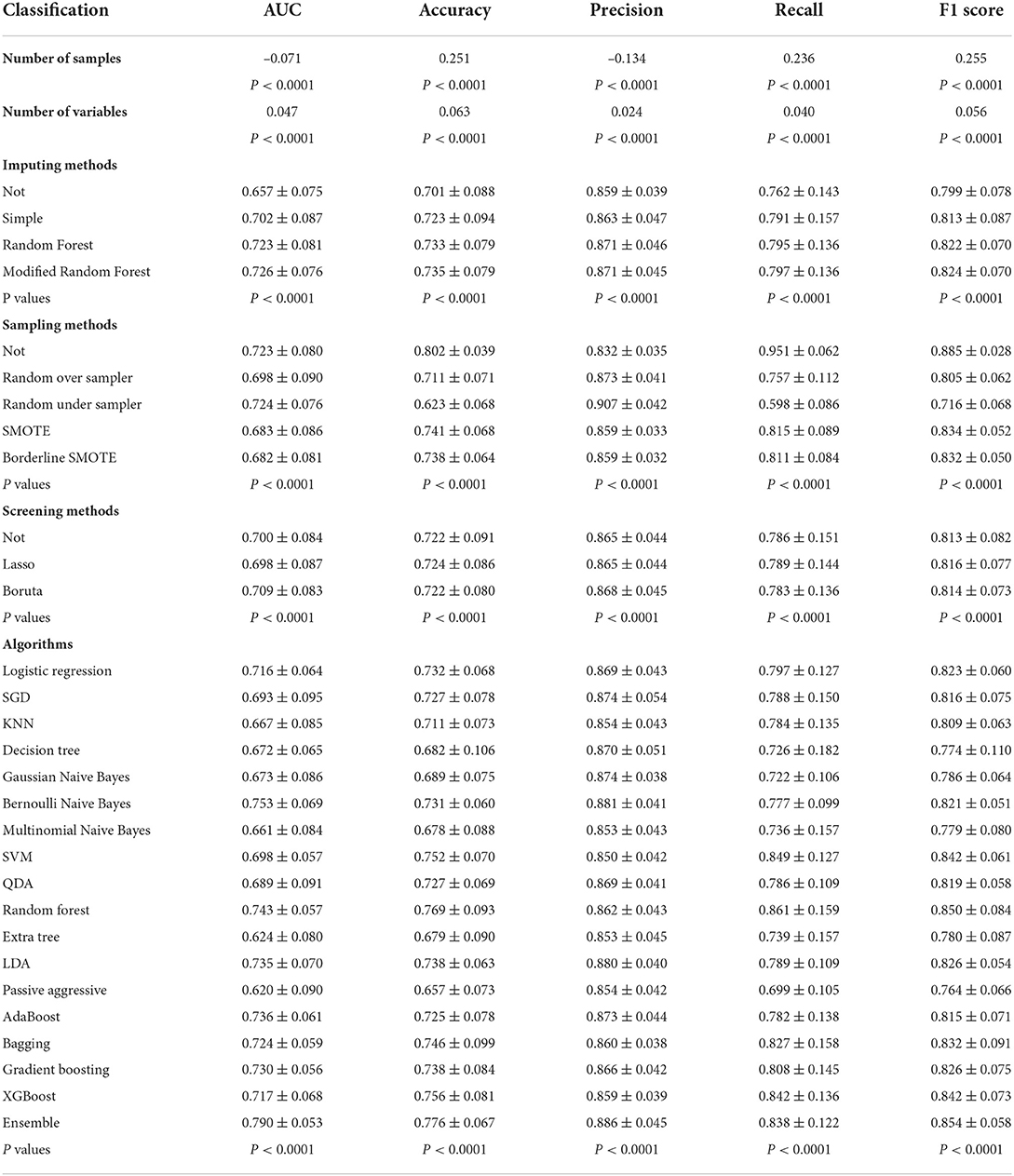
Table 4. The results of univariate analysis ( ± SD).
Feature selection and validation
The best five models involved the following three datasets: No. 27, No. 44, and No. 59. In those datasets, the variable importance scores are ranked in Figure 3. Age, times of insulin use, use of other types of drugs, present HbA1c values, and hypertension were top 5 highest variable importance in No. 27 dataset (Figure 3A). The top 5 variables with the highest importance score in No. 44 dataset and No. 59 dataset were age, present FBG values, present HbA1c values, present random blood glucose (RBG) values, and BMI (Figures 3B,C).
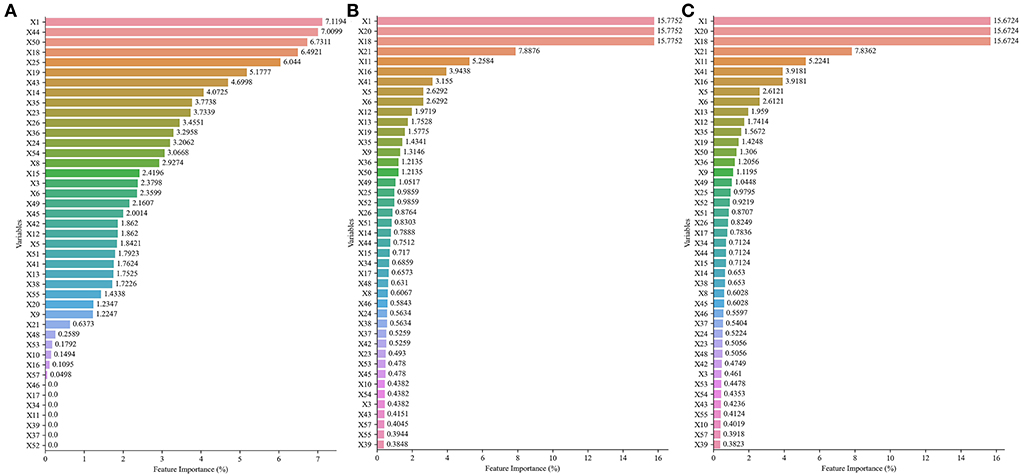
Figure 3. The importance scores and ranking of each variable in No. 27 dataset, No. 44 dataset, and No. 59 dataset with different variable selection methods. (A) Details of No. 27 dataset. (B) Details of No. 44 dataset. (C) Details of No. 59 dataset.
In addition, the contribution of variables was evaluated by comparing the AUC of models to identify whether the variable was included or excluded. In addition, the mean AUC of variables was from 0.689 to 0.724 in the included cohort and between 0.669 and 0.762 in the excluded cohort (details in Table 5; Figure 4). The variable that had higher AUC when the variable was included would be considered as a positive contribution to the prediction model. Those variables provided positive contributions and were in line with variables that had high variable importance scores, which was output in No. 59 dataset (the best model applied).
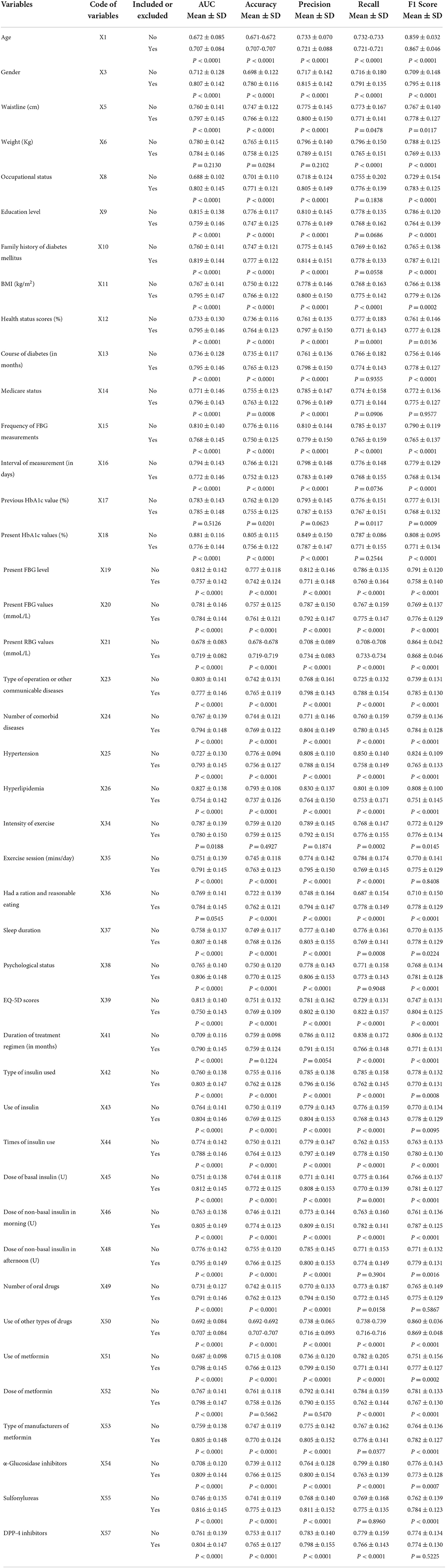
Table 5. The influence of model performances whether the variable was included or excluded.
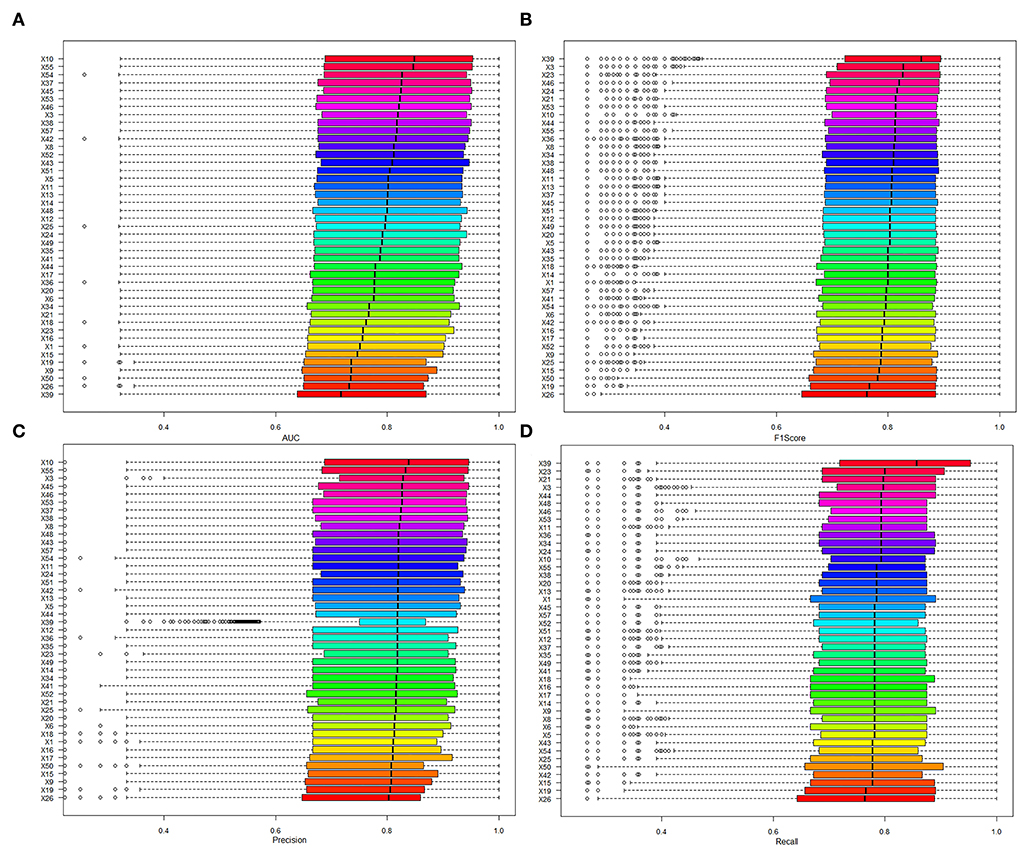
Figure 4. The model performance of models when the variables were included. (A) The results of AUC. (B) The results of the F1 score. (C) The results of precision. (D) The results of recall.
Sample size assessment
As shown in Figure 5, with the size of sample data incorporated into the model from small to large, the values of AUC continued to increase. When the sample size was extremely small ( ≤ 30%), compared with the 100% sample size, the SDs of AUC were dispersed, and the AUCs were statistically significant (P < 0.05). As the sample size increased, the above situation was alleviated (P>0.05). In addition, the growth rate of AUC slowed down when the sample size was more than or equal to 40%. These results indicated that the performance of the proposed model might be affected less when expanding the sample size. The sample size was suitable for the prediction model construction.
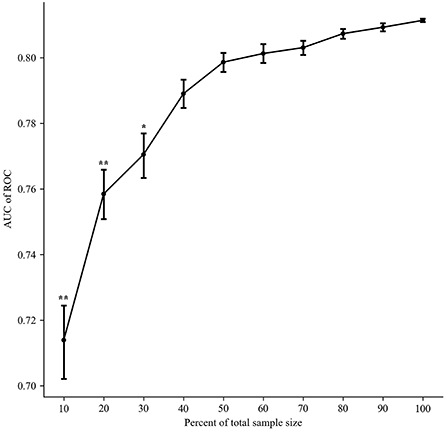
Figure 5. The impact of sample data size on model performances (mean ± SD).
Discussion
Early detection of non-adherence to medication in patients with T2D will help devise strategies for personalized treatment. In this research, we developed a total of 1,080 models for the prediction of adherence in patients with T2D. The AUC, accuracy, precision, recall, F1 score, and AUPRC of the best model were 0.8369, 0.9474, 0.6792, 0.7912, and 0.9574, respectively. Meanwhile, various methods in model development and variables were validated by univariate analyses. Interestingly, the imputing method, the sampling method, the variable selection method, and the machine learning algorithm applied in the best model were the same as the results of univariate analysis. Additionally, variables with high importance scores in the best model were similar to the results of variable validation, which provided a positive contribution to the model prediction.
The adherence to the medication of patients with T2D has received great attention worldwide (24, 25). Nonadherence is associated with bad outcomes, including increased mortality and avoidable healthcare costs. Previous studies reported models to predict drug non-adherence in Crohn's disease maintenance therapy (26), patients with hypertension (27), and patients with heart failure (28). However, few studies reported on prediction models of non-adherence to medication in patients with T2D. Intelligence technology is becoming more prevalent in healthcare as a tool to improve practice patterns and patient outcomes (29–31). With technology development, ensemble models have been commonly used to explore disease progression in the field of molecular biology (32–36). Recently, the ensemble algorithm has been frequently applied to develop prediction models (37, 38). In our prior study, we reported that the ensemble algorithm was superior to the Bayesian network, KNN, SVM, C&R Tree, and CHAID (19). In this study, we added more machine learning classifications, including XGBoost, Bernoulli Naive Bayes, SGD, etc. Additionally, the ensemble algorithm was still the best.
Many variables have previously been reported to associate with drug adherence, such as age, population, level of education, etc. For example, according to the data from the National Health Insurance Service-National Sample Cohort (NHIS-NSC) of Korea, adherence consistently increased as the age increased until 69 years and started to decrease from the age of 70 years. When the same number of drugs was taken, the proportion of adherent patients according to age featured an inverted U-shape with a peak at 60–69 years (39). Additionally, Aditama et al. (25) stated that the factors influencing non-adherence included complex instructions for taking medication, the absence of a reminder, the unwanted side effects of the drug, feeling of repetition, feeling that the drugs were ineffective, and concern for the effects of the drug on the kidney. Therefore, more patient-related and drug-related variables were considered in this study, including the number of comorbid diseases, EQ-5D scores, number of oral drugs, use of other types of drugs, and so on.
The results of the univariate analysis suggested that more variables can improve the accuracy of the prediction model (AUC = 0.063, P < 0.001). In clinical research, more variables mean collecting more data and increasing the missing data. Thus, feature selection plays an important role in the field of machine learning. In this study, no screening (marked as Not), Boruta, and LassoCV were performed. Boruta is a feature selection algorithm to identify the minimal set of relevant variables, which was applied in the best model. According to the variable importance score, the ten most important variables were age, present FBG values, present HbA1c values, present RBG values, BMI, duration of the treatment regimen, interval of measurement, waistline, weight, and course of diabetes. Glycemic control in patients with T2D can be accessed via the following three key parameters: glycated hemoglobin (HbA1c), FBG, and RBG. The results of variable importance demonstrated that patients with non-adherence should strongly encourage to monitor their blood glucose and receive reinforced education.
Limitation
First, this was a single-center study, and the patient profile might be biased and not representative of the Chinese as a whole. People from Sichuan Province may have different distributions of risk factors than patients in other areas of China. A large multicenter sample study is desired, which can verify the applicability of the model. However, for some variables, recall bias still exists, such as the intensity of exercise and exercise sessions.
Conclusion
In summary, the present research introduced 1,080 machine-learning models to predict non-adherence in patients with T2D and proposed an ensemble model with better classifier performance. This study also reconfirmed that variables including age, BMI, and interval of measurement were risk factors for non-adherence. We are in the process of developing a mobile App or a web server for caregivers and patients in an effort to integrate the adherence enhancement intervention into daily T2D management.
Data availability statement
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding authors.
Ethics statement
The studies involving human participants were reviewed and approved by the Ethics Committee of the Sichuan Provincial People's Hospital (Approval # 2018-53). The patients/participants provided their written informed consent to participate in this study.
Author contributions
ML and XL contributed to data analysis and writing and approval of the final manuscript. HY and RY assisted in the face-to-face questionnaire. RT and YY were responsible for designing and coordinating the research. XW was involved in the questionnaire design, data analysis, model design, and contributed to revision of the manuscript. All authors agree to be accountable for the content of this study.
Funding
This study was funded by the National Natural Science Foundation of China (Grant No. 72004020), the Key Research and Development Program of Science and Technology Department of Sichuan Province (Grant No. 2019YFS0514), the Postgraduate Research and Teaching Reform Project of the University of Electronic Science and Technology of China (Grant No. JYJG201919), the Research Subject of Health Commission of Sichuan Province (Grant No. 19PJ262), Sichuan Science and Technology Program (Grant No. 2021YJ0427), and Scientific Research Foundation of Sichuan Provincial People's Hospital (Grant No. 2022BH10).
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
1. American Diabetes Association. 2. Classification and Diagnosis of Diabetes: Standards of Medical Care in Diabetes-2020. Diab Care. (2020). 43(Suppl 1):S14–31. doi: 10.2337/dc20-S002
2. Zimmet P, Alberti KG, Shaw J. Global and societal implications of the diabetes epidemic. Nature. (2001) 414:782–7. doi: 10.1038/414782a
3. Lam DW, LeRoith D. The worldwide diabetes epidemic. Curr Opin Endocrinol Diab Obes. (2012) 19:93–6. doi: 10.1097/MED.0b013e328350583a
4. Arredondo A. Diabetes: a global challenge with high economic burden for public health systems and society. Am J Public Health. (2013) 103:e1–2. doi: 10.2105/AJPH.2012.301106
5. Bommer C, Sagalova V, Heesemann E, Manne-Goehler J, Atun R, Bärnighausen T, et al. Global economic burden of diabetes in adults: projections from 2015 to 2030. Diabetes Care. (2018) 41:963–70. doi: 10.2337/dc17-1962
6. Simpson SH, Eurich DT, Majumdar SR, Padwal RS, Tsuyuki RT, Varney J, et al. A meta-analysis of the association between adherence to drug therapy and mortality. BMJ. (2006) 333:15. doi: 10.1136/bmj.38875.675486.55
7. Osterberg L, Blaschke T. Adherence to medication. N Engl J Med. (2005) 353:487–97. doi: 10.1056/NEJMra050100
8. Lerman I. Adherence to treatment: the key for avoiding long-term complications of diabetes. Arch Med Res. (2005) 36:300–6. doi: 10.1016/j.arcmed.2004.12.001
9. Quisel T, Foschini L, Zbikowski SM, Juusola JL. The association between medication adherence for chronic conditions and digital health activity tracking: retrospective analysis. J Med Internet Res. (2019) 21:e11486. doi: 10.2196/11486
10. Bryson CL, Au DH, Maciejewski ML, Piette JD, Fihn SD, Jackson GL, et al. Wide clinic-level variation in adherence to oral diabetes medications in the VA. J Gen Intern Med. (2013) 28:698–705. doi: 10.1007/s11606-012-2331-y
11. Farmer AJ, Rodgers LR, Lonergan M, Shields B, Weedon MN, Donnelly L, et al. Adherence to oral glucose-lowering therapies and associations with 1-year HbA1c: a retrospective cohort analysis in a large primary care database. Diabetes Care. (2016) 39:258–63. doi: 10.2337/dc15-1194
12. Park LG, Howie-Esquivel J, Chung ML, Dracup K. A text messaging intervention to promote medication adherence for patients with coronary heart disease: a randomized controlled trial. Patient Educ Couns. (2014) 94:261–8. doi: 10.1016/j.pec.2013.10.027
13. Kurtyka K, Nishikino R, Ito C, Brodovicz K, Chen Y, Tunceli K. Adherence to dipeptidyl peptidase-4 inhibitor therapy among type 2 diabetes patients with employer-sponsored health insurance in Japan. J Diabetes Investig. (2016) 7:737–43. doi: 10.1111/jdi.12474
14. Gentil L, Vasiliadis HM, Berbiche D, Préville M. Impact of depression and anxiety disorders on adherence to oral hypoglycemics in older adults with diabetes mellitus in Canada. Eur J Ageing. (2017) 14:111–21. doi: 10.1007/s10433-016-0390-3
15. O'Connor PJ, Schmittdiel JA, Pathak RD, Harris RI, Newton KM, Ohnsorg KA, et al. Randomized trial of telephone outreach to improve medication adherence and metabolic control in adults with diabetes. Diabetes Care. (2014) 37:3317–24. doi: 10.2337/dc14-0596
16. van Dulmen S, Sluijs E, Van Dijk L, de Ridder D, Heerdink R, Bensing J. Patient adherence to medical treatment: a review of reviews. BMC Health Serv Res. (2007) 7:55. doi: 10.1186/1472-6963-7-55
17. Azulay R, Valinsky L, Hershkowitz F, Magnezi R. Repeated automated mobile text messaging reminders for follow-up of positive fecal occult blood tests: randomized controlled trial. JMIR Mhealth Uhealth. (2019) 7:e11114. doi: 10.2196/11114
18. Khachadourian V, Truzyan N, Harutyunyan A, Thompson ME, Harutyunyan T, Petrosyan V. People-centered tuberculosis care versus standard directly observed therapy: study protocol for a cluster randomized controlled trial. Trials. (2015) 16:281. doi: 10.1186/s13063-015-0802-2
19. Wu XW, Yang HB, Yuan R, Long EW, Tong RS. Predictive models of medication non-adherence risks of patients with T2D based on multiple machine learning algorithms. BMJ Open Diabetes Res Care. (2020) 8:e001055. doi: 10.1136/bmjdrc-2019-001055
20. Chowdhury R, Khan H, Heydon E, Shroufi A, Fahimi S, Moore C, et al. Adherence to cardiovascular therapy: a meta-analysis of prevalence and clinical consequences. Eur Heart J. (2013) 34:2940–8. doi: 10.1093/eurheartj/eht295
21. Cramer JA, Benedict A, Muszbek N, Keskinaslan A, Khan ZM. The significance of compliance and persistence in the treatment of diabetes, hypertension and dyslipidaemia: a review. Int J Clin Pract. (2008) 62:76–87. doi: 10.1111/j.1742-1241.2007.01630.x
22. Tuwani R, Wadhwa S, Bagler G. BitterSweet: building machine learning models for predicting the bitter and sweet taste of small molecules. Sci Rep. (2019) 9:7155. doi: 10.1038/s41598-019-43664-y
23. Fernandes M, Mendes R, Vieira SM, Leite F, Palos C, Johnson A, et al. Predicting intensive care unit admission among patients presenting to the emergency department using machine learning and natural language processing. PLoS ONE. (2020) 15:e0229331. doi: 10.1371/journal.pone.0229331
24. Lee CS, Tan JH, Sankari U, Koh YL, Tan NC. Assessing oral medication adherence among patients with type 2 diabetes mellitus treated with polytherapy in a developed Asian community: a cross-sectional study. BMJ Open. (2017) 7:e016317. doi: 10.1136/bmjopen-2017-016317
25. Aditama L, Athiyah U, Utami W, Rahem A. Adherence behavior assessment of oral antidiabetic medication use: a study of patient decisions in long-term disease management in primary health care centers in Surabaya. J Basic Clin Physiol Pharmacol. (2020) 30:20190257. doi: 10.1515/jbcpp-2019-0257
26. Wang L, Fan R, Zhang C, Hong L, Zhang T, Chen Y, et al. Applying machine learning models to predict medication nonadherence in Crohn's disease maintenance therapy. Patient Prefer Adherence. (2020) 14:917–26. doi: 10.2147/PPA.S253732
27. Aziz F, Malek S, Ali AM, Wong MS, Mosleh M, Milow P. Determining hypertensive patients' beliefs towards medication and associations with medication adherence using machine learning methods. PeerJ. (2020) 8:e8286. doi: 10.7717/peerj.8286
28. Karanasiou GS, Tripoliti EE, Papadopoulos TG, Kalatzis FG, Goletsis Y, Naka KK, et al. Predicting adherence of patients with HF through machine learning techniques. Healthc Technol Lett. (2016) 3:165–70. doi: 10.1049/htl.2016.0041
29. Lind ML, Mooney SJ, Carone M, Althouse BM, Liu C, Evans LE, et al. Development and validation of a machine learning model to estimate bacterial sepsis among immunocompromised recipients of stem cell transplant. JAMA Netw Open. (2021) 4:e214514. doi: 10.1001/jamanetworkopen.2021.4514
30. Xie F, Ong ME, Liew JN, Tan KB, Ho AF, Nadarajan GD, et al. Development and assessment of an interpretable machine learning triage tool for estimating mortality after emergency admissions. JAMA Netw Open. (2021) 4:e2118467. doi: 10.1001/jamanetworkopen.2021.18467
31. Xue B, Li D, Lu C, King CR, Wildes T, Avidan MS, et al. Use of machine learning to develop and evaluate models using preoperative and intraoperative data to identify risks of postoperative complications. JAMA Netw Open. (2021) 4:e212240. doi: 10.1001/jamanetworkopen.2021.2240
32. Zhao S, Liu J, Nanga P, Liu Y, Cicek AE, Knoblauch N, et al. Detailed modeling of positive selection improves detection of cancer driver genes. Nat Commun. (2019) 10:3399. doi: 10.1038/s41467-019-11284-9
33. Eggerth A, Hayn D, Schreier G. Medication management needs information and communications technology-based approaches, including telehealth and artificial intelligence. Br J Clin Pharmacol. (2020) 86:2000–7. doi: 10.1111/bcp.14045
34. Chivian D, Baker D. Homology modeling using parametric alignment ensemble generation with consensus and energy-based model selection. Nucleic Acids Res. (2006) 34:e112. doi: 10.1093/nar/gkl480
35. Sacks MS, Zhang W, Wognum S. A novel fibre-ensemble level constitutive model for exogenous cross-linked collagenous tissues. Interface Focus. (2016) 6:20150090. doi: 10.1098/rsfs.2015.0090
36. Choi JH, Laurent AH, Hilser VJ, Ostermeier M. Design of protein switches based on an ensemble model of allostery. Nat Commun. (2015) 6:6968. doi: 10.1038/ncomms7968
37. Wang M, Wang H, Wang J, Liu H, Lu R, Duan T, et al. A novel model for malaria prediction based on ensemble algorithms. PLoS ONE. (2019) 14:e0226910. doi: 10.1371/journal.pone.0226910
38. Lewin-Epstein O, Baruch S, Hadany L, Stein GY, Obolski U. Predicting antibiotic resistance in hospitalized patients by applying machine learning to electronic medical records. Clin Infect Dis. (2020) 72:e848–55. doi: 10.1093/cid/ciaa1576
Keywords: medication adherence, T2D, machine learning, prediction model, ensemble model
Citation: Li M, Lu X, Yang H, Yuan R, Yang Y, Tong R and Wu X (2022) Development and assessment of novel machine learning models to predict medication non-adherence risks in type 2 diabetics. Front. Public Health 10:1000622. doi: 10.3389/fpubh.2022.1000622
Received: 22 July 2022; Accepted: 24 October 2022;
Published: 17 November 2022.
Edited by:
Ping Wang, Michigan State University, United StatesReviewed by:
Rasaq Adisa, University of Ibadan, NigeriaSeyed Davar Siadat, Pasteur Institute of Iran (PII), Iran
Copyright © 2022 Li, Lu, Yang, Yuan, Yang, Tong and Wu. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Yong Yang, eXl4cG93ZXJAMTYzLmNvbQ==; Rongsheng Tong, MjIwNzEzMjQ0OEBxcS5jb20=; Xingwei Wu, NzE5MDE3NUB1ZXN0Yy5lZHUuY24=
†These authors have contributed equally to this work and share first authorship