
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Psychiatry , 21 December 2023
Sec. Computational Psychiatry
Volume 14 - 2023 | https://doi.org/10.3389/fpsyt.2023.1266548
This article is part of the Research Topic Women in Psychiatry 2024: Computational Psychiatry View all 4 articles
 María Alejandra Palacios-Ariza1*Esteban Morales-Mendoza2†Jossie Murcia2†Rafael Arias-Duarte3†Germán Lara-Castellanos3†Andrés Cely-Jiménez4†
María Alejandra Palacios-Ariza1*Esteban Morales-Mendoza2†Jossie Murcia2†Rafael Arias-Duarte3†Germán Lara-Castellanos3†Andrés Cely-Jiménez4† Juan Carlos Rincón-Acuña4,5‡
Juan Carlos Rincón-Acuña4,5‡ Marcos J. Araúzo-Bravo4,6,7,8‡Jorge McDouall9‡
Marcos J. Araúzo-Bravo4,6,7,8‡Jorge McDouall9‡Introduction: Bipolar disorder (BD) is a chronically progressive mental condition, associated with a reduced quality of life and greater disability. Patient admissions are preventable events with a considerable impact on global functioning and social adjustment. While machine learning (ML) approaches have proven prediction ability in other diseases, little is known about their utility to predict patient admissions in this pathology.
Aim: To develop prediction models for hospital admission/readmission within 5 years of diagnosis in patients with BD using ML techniques.
Methods: The study utilized data from patients diagnosed with BD in a major healthcare organization in Colombia. Candidate predictors were selected from Electronic Health Records (EHRs) and included sociodemographic and clinical variables. ML algorithms, including Decision Trees, Random Forests, Logistic Regressions, and Support Vector Machines, were used to predict patient admission or readmission. Survival models, including a penalized Cox Model and Random Survival Forest, were used to predict time to admission and first readmission. Model performance was evaluated using accuracy, precision, recall, F1 score, area under the receiver operating characteristic curve (AUC) and concordance index.
Results: The admission dataset included 2,726 BD patients, with 354 admissions, while the readmission dataset included 352 patients, with almost half being readmitted. The best-performing model for predicting admission was the Random Forest, with an accuracy score of 0.951 and an AUC of 0.98. The variables with the greatest predictive power in the Recursive Feature Elimination (RFE) importance analysis were the number of psychiatric emergency visits, the number of outpatient follow-up appointments and age. Survival models showed similar results, with the Random Survival Forest performing best, achieving an AUC of 0.95. However, the prediction models for patient readmission had poorer performance, with the Random Forest model being again the best performer but with an AUC below 0.70.
Conclusion: ML models, particularly the Random Forest model, outperformed traditional statistical techniques for admission prediction. However, readmission prediction models had poorer performance. This study demonstrates the potential of ML techniques in improving prediction accuracy for BD patient admissions.
Bipolar disorder (BD) is a chronically progressive mental disorder with a prevalence that ranges from 1.1 to 2.4% (1, 2). BD is classified as type I if the patient has presented at least one manic episode, with or without depressive episodes, and as type II in the presence of at least one hypomanic episode, with no full manic episodes, and one major depressive episode (3). This condition is associated with a reduced quality of life and greater disability. Patients have been shown to have lower incomes, higher financial burdens, issues with social interactions and a greater overall frequency of use of health services (4–7). Furthermore, significant suicide attempt rates have been reported in patients with BD type I (36.3%) and BD type II (32.4%) (8, 9). Additionally, manic episodes give rise to destructive and reckless behavior secondary to an unstable mood, which in the long term can degrade cognitive functioning, interpersonal relationships, global functioning and social adjustment (10, 11).
Patient admissions are preventable events with a considerable impact on healthcare costs and a key quality metric for health systems around the world (12–14). Among psychiatric patients, whose disorders are characterized by chronicity and high recurrence rates, readmissions are of particular concern. The period immediately after a hospitalization is known to be a period of high risk for outcomes such as suicide and substance abuse relapse. Patient admission and readmission due to BD places a significant financial burden on medical services and caregivers (2, 15). Studies have reported relapse rates of up to 50% after 2 years in individuals receiving adequate psychopharmacological care (16). Self-monitoring data from the Sanitas Healthcare Management Organization (HMO) in Colombia show that in 2017, 319 patients with a BD diagnosis had a total of 427 hospital admissions (27% of the overall number of readmissions) with a mean hospital stay duration of 19 days.
The prediction of risk for patient admission and readmission may aid in disease management as well as in reducing the economic and social burdens caused by BD. Despite the considerable number of publications in the field of patient admission prediction, most studies address this issue in patients with non-psychiatric illness (17–21), substance abuse disorders, schizophrenia or postpartum depression (22–24). Prior work by Rotenberg et al. aimed to predict depressive relapses in patients with bipolar disorder using machine learning techniques, achieving F measures as high as 0.993 for a random forest model (25). Although certainly related, depressive relapses are only one potential form of relapse of BD and may indeed be less likely to require hospitalization than manic episodes. This is why this study developed prediction models for hospital admission/readmission within 5 years of diagnosis in patients with BD using ML techniques. With clinical data that is readily available in electronic health records, we show that random forest models are good predictors of both admission and time to admission in patients with BD.
Sanitas is a major Healthcare Management Organization (HMO) in Colombia with over 5 million patients under its care. Data used in this study were obtained from patients who received an incident diagnosis of BD (including both type I and type II patients) during outpatient visits to any of the Sanitas EPS healthcare facilities in Colombia during 2016. The patients were followed for 5 years after diagnosis until December 31st, 2020. The Sanitas EPS network includes high-complexity centers which offer inpatient mental health services, day hospitals, and priority and general psychiatric outpatient appointments. Patients were retrospectively included if they had an International Classification of Diseases 10 diagnostic code of F31 assigned to them at any of their outpatient visits during the study period. Subjects with a BD diagnosis were excluded if they required long-term hospitalization due to functioning or psychotic symptoms, or if their social context (poor social support) required them to remain hospitalized in mental health units despite their psychiatric condition no longer requiring hospitalization. This study followed the guidelines of the Colombian Ministry of Health resolution 8,430 of 1993, as well as the World Medical Association’s Declaration of Helsinki in its 2013 version, and the Council for International Organizations of Medical Sciences’ International Ethical Guidelines for Health-related Research Involving Humans. The protocol for this study was approved by the Research Ethics Committee of the Fundación Universitaria Sanitas (CEIFUS 341–19).
Starting from an overall HMO patient cohort of over 3 million patients over the age of 18, we selected patients with an incident diagnosis of BD (diagnostic code F31), which totaled 2,726 patients. Of these, 354 patients had at least one psychiatric ward inpatient admission registered over 5 years. A complete record for the admission was available for 352 patients. These 352 patients comprised the admission dataset. Readmission occurred in 165 patients in whom a complete record for the readmission was available. The readmission dataset was obtained from these 165 patients (Figure 1).
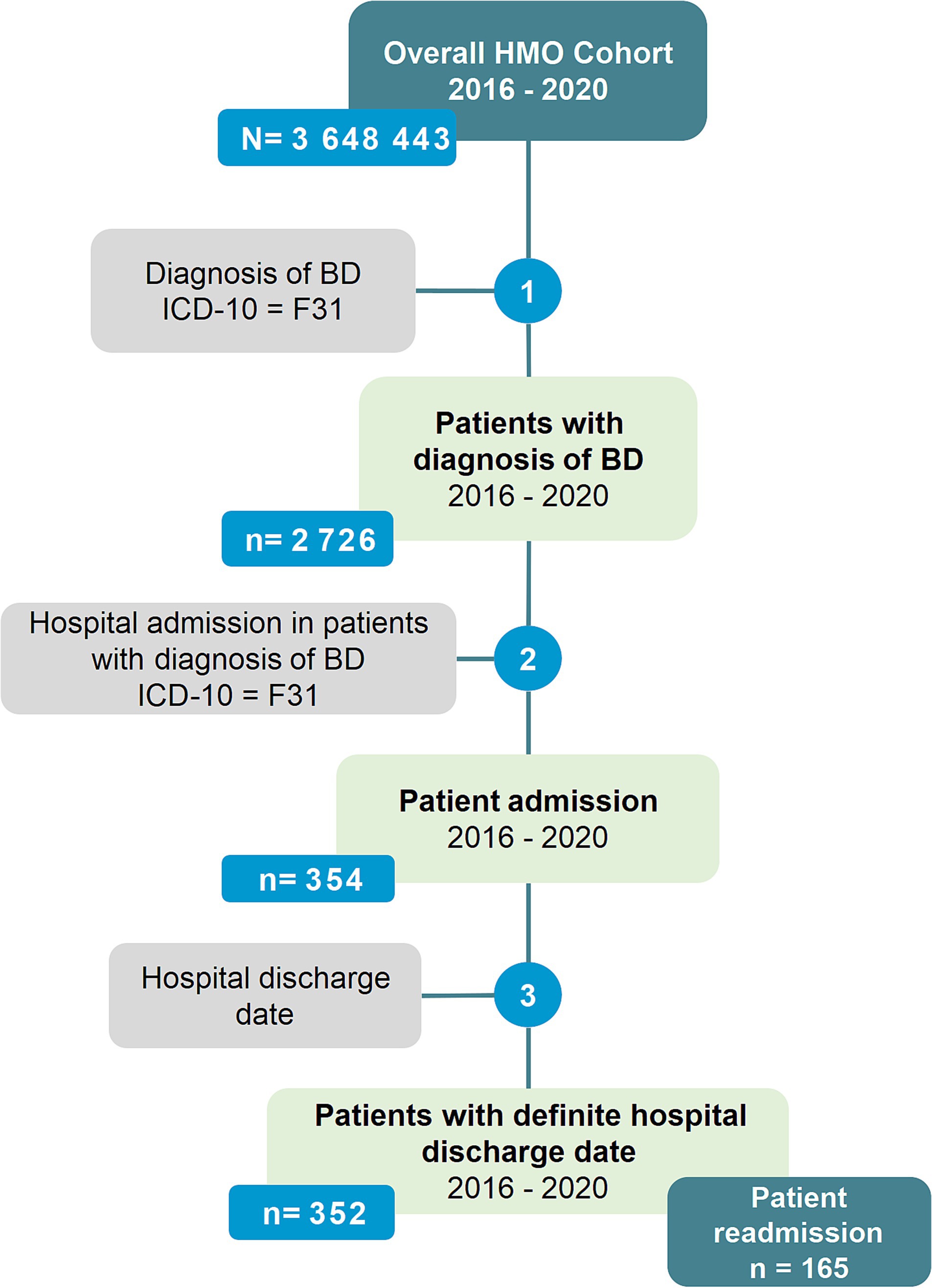
Figure 1. Patient flowchart.
The primary outcome in this study was a composite of hospital admission or readmission during the study period, although these outcomes were considered separately in model construction and selection. We selected this composite outcome as it is a key indicator of disease status in BD. An initial group of models aimed to predict a binary outcome of admission/readmission during the observation period, and a second group of survival models aimed to predict time to admission/readmission.
Candidate predictors for ML models were selected from features available in the standard electronic health record (EHR) and making use of established knowledge regarding risk factors for the study outcome. The initial set of extracted predictors included sociodemographic variables, and variables related to the psychiatric and medical history. Specifically, for the outcome of patient readmission a group of variables describing the characteristics of the prior hospitalization was included.
A total of 47 candidate variables were considered initially for the outcome of admission. However, since not all variables were plausibly related to the outcome of either admission or readmission (e.g., type of discharge cannot be used as a predictor), this led to variable exclusion and a reduced set of 29 variables. After completeness analysis, we excluded variables with missing data in more than 35% of the subjects, further reducing the set to 18 variables. The readmission dataset was refined from the same starting pool of variables. After an initial analysis, we were left with a reduced set of 33 variables (note that variables like “type of discharge” for the first admission can now be included). After completeness analysis, we were left with 21 predictor variables (Supplementary Table S1).
Variables with multiple categories were dichotomized into the presence or absence of their most frequent value prior to inclusion in the models but are presented in Table 1 as extracted from the EHRs. Continuous data were normalized/standardized and analyzed using correlation matrices. Variables were normalized by subtracting the minimum value of the variable and dividing the result by its range (difference between maximum and minimum). Standardized variables were the result of subtracting by the variables mean and dividing the result by their standard deviation. Although we planned to merge variables with correlations exceeding a pre-established threshold of 0.8, no such correlations were identified. Feature engineering made use of two techniques: Recursive Feature Elimination (RFE) and Sequential Feature Selection (SFS) (Figure 2). The RFE used a random forest to select features based on the top F1 scores, and the SFS used a sequential method to obtain a reduced set which minimized standard error and dimensionality (26, 27).
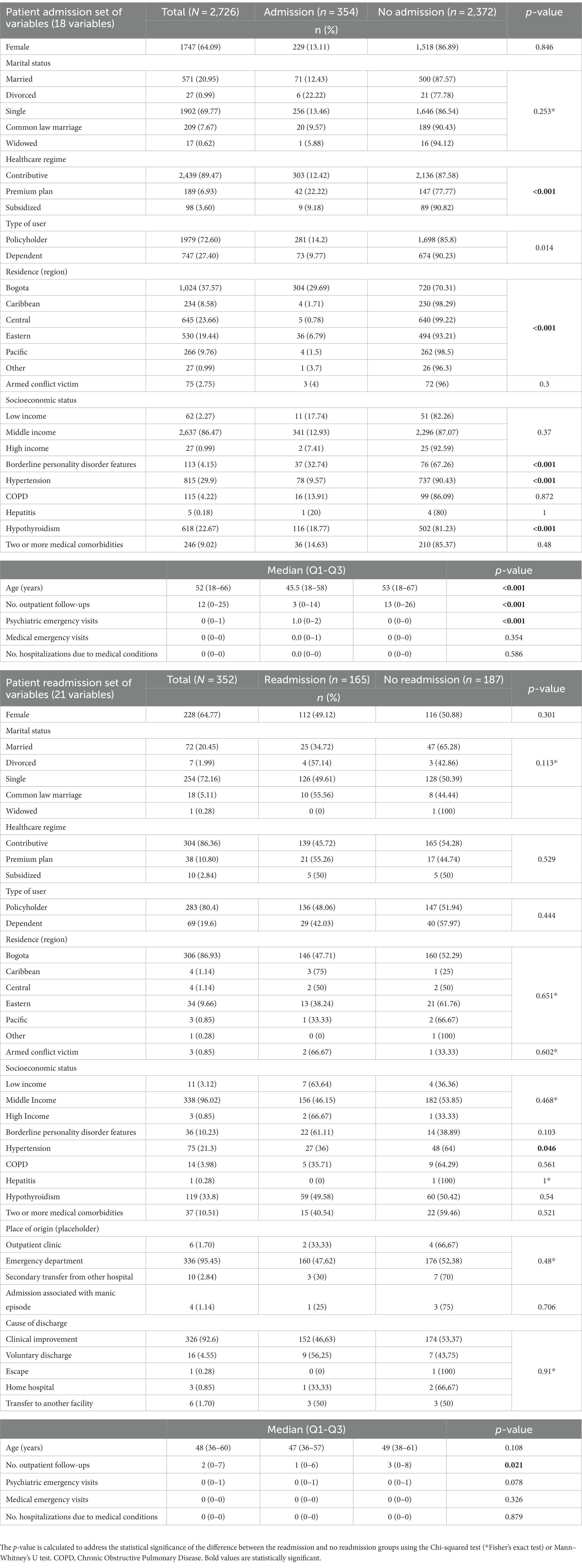
Table 1. Patient characteristics according to patient admission/readmission stratification.
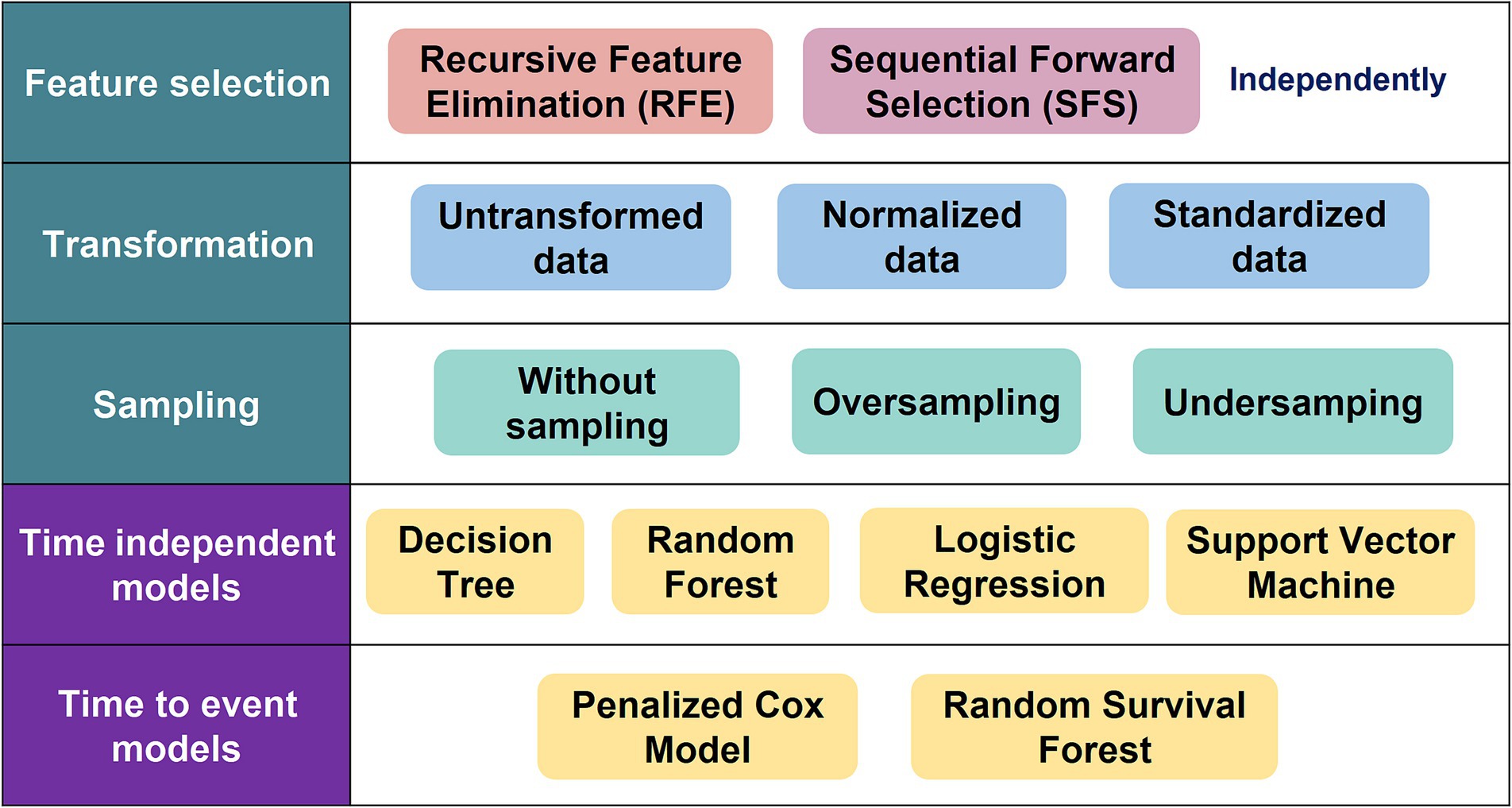
Figure 2. Study methods.
Sample size was calculated based on the outcome of readmission since this was deemed to be the less frequent of the two outcomes in the composite. Sample size was estimated for the outcome of readmission assuming a Cox proportional hazards model with a hazard ratio of 1.8 and an overall readmission rate of 30%. Requiring a power of 90%, a significance level α of 5%, and a coefficient of determination of 0.3, we obtained a final sample size of 754 subjects, split between 174 readmissions and 580 controls.
Since the sample was heavily skewed toward patients with no admission, we made use of oversampling techniques to balance the classes and to facilitate prediction model training. Using a Synthetic Minority Oversampling Technique (SMOTE), in which synthetic data for patients with admission were generated, an oversampling set with 1,660 patients in each group was created (28). Additionally, an Edited Nearest Neighbor (ENN) method was used to generate an undersampling set which reduced the size of the larger non-admitted group, which generated a training set with 248 admitted and 1,479 non-admitted patients (29). The undersampling (US), oversampling (OS), and without sampling (WS) datasets were used to train models (Figure 2).
Means and standard deviations are presented for quantitative variables, and absolute and relative frequencies are presented for categorical variables. Normality was determined using both quantile-quantile plots and the Shapiro–Wilk test. All analyses were performed using Python software version 3.10.7 for Ubuntu version 20.04.5 LTS (Long Term Support).
The data were randomly split into two sets in a 70:30 ratio using holdout validation, in which the training set was used to generate the prediction model for each algorithm and the test set was used to evaluate model performance. We used a more traditional statistical parametric model such as the Logistic Regression (LR) and three ML models to predict patient admission or readmission: Decision Trees (DT) (30), Random Forest (RF) (31), and Support Vector Machine (SVM) (32) (Figure 2). Each of these techniques has been applied in various ways in different mental disorders, including dementia, autism spectrum disorders, and obsessive compulsive disorder (33–35). Model performance was evaluated using the area under the receiver operating characteristic curve (AUC). Additionally, we report model accuracy, precision, recall and F1 score.
Survival models were fitted to predict time to admission and first readmission. As with the ML models, data for survival model calibration were split into a training and test sets in a 70:30 ratio using holdout validation. Two survival models were used to estimate time to patient admission or readmission: one more standard such as the penalized Cox Model (P-Cox) (36) and a ML methods such as the Random Survival Forest (RSF) (37) (Figure 2). The performance of each model was evaluated using the concordance index (C-index), which is a generalization of the AUC which considers data censoring.
Regarding sex distribution, females were similarly common in either group (admission vs. no admission). Age was also a significant factor and admitted patients tended to be younger. The type of healthcare regime coverage showed a significant association with admission, with premium plan policy holders being most likely to be admitted. Patients from Bogotá were also more likely to be admitted than patients from the rest of Colombia. Armed conflict victim status did not differ significantly between admitted and non-admitted patients. Socioeconomic status, as systematically determined by the governmental statistical department, did not differ between groups (Table 1).
Concerning prior medical history, a history of hypothyroidism or hypertension was associated with admission. Admission was more likely in patients with borderline personality disorder features and in those with prior psychiatric emergency department visits. Interestingly, patients who were not admitted tended to have a greater number of outpatient follow-up visits (Table 1).
Feature engineering led to a reduced set of seven variables including psychiatric emergency visits, number of outpatient follow-ups, age, medical emergency visits, place of residence, sex, and history of hypothyroidism. Both the RFE and SFS methods were explored as alternatives for feature selection with the RFE method displaying better results. The RFE method displayed an F1 score of 0.941, compared with the F1 score of the SFS method of 0.939. Therefore, the RFE method was selected to determine the number of optimal variables (Figure 3A).
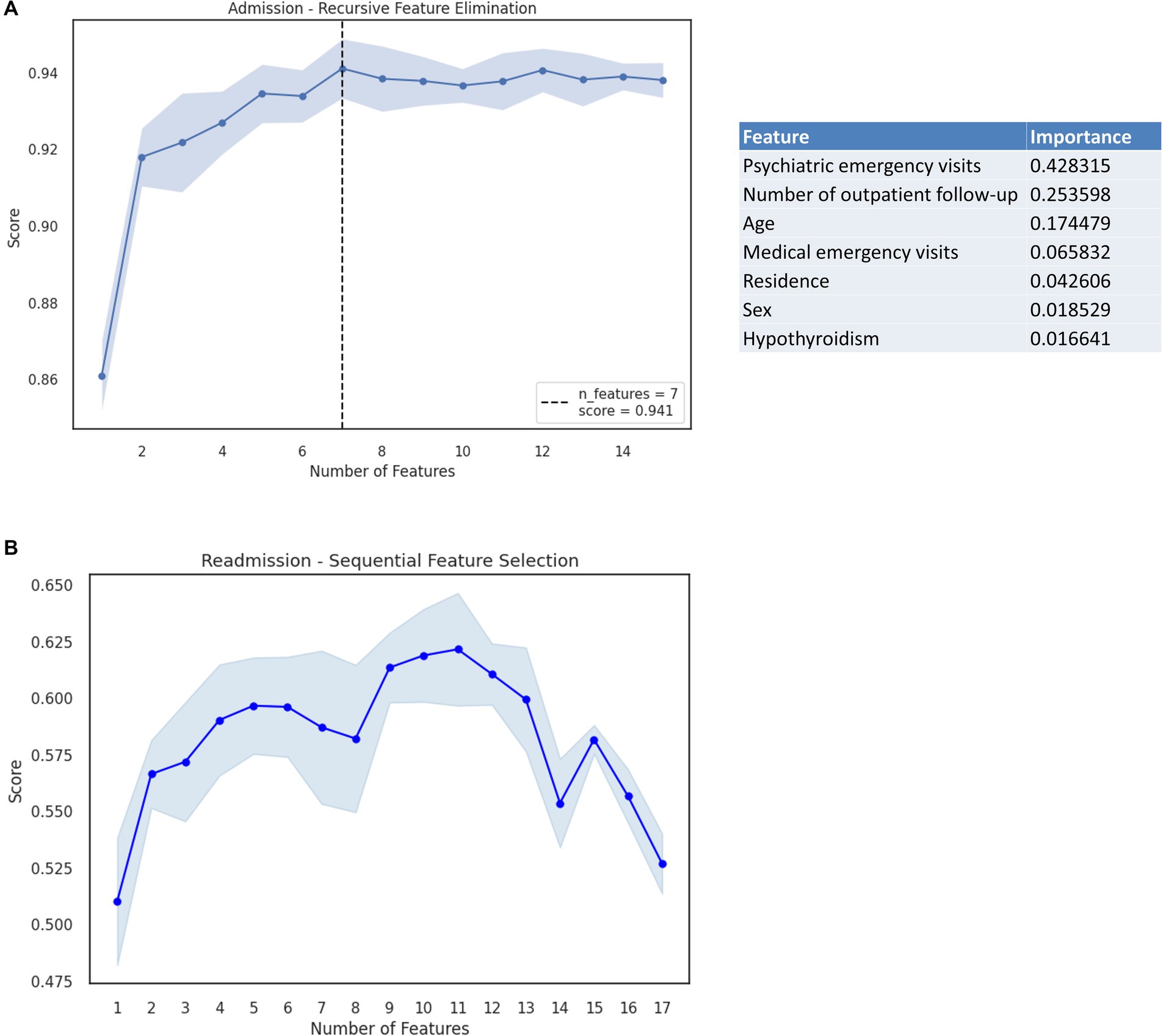
Figure 3. (A) RFE method considering the outcome of admission for BD and the importance analysis for each variable. (B) SFS method considering the outcome of readmission for BD (Shaded area corresponds to the standard error).
Using the reduced set of variables to train models, the best performing model in this study was the Random Forest model, with an accuracy score of 0.951 and an AUC of 0.98 (Figure 4A). This best-performing model was trained using the starting dataset, without over or undersampling. The worst performing model was the Decision Tree model trained on the starting dataset (Table 2). We obtained similar results for the survival models for time to admission, where the random survival forest obtained the best results, with a C-index of 0.95 (the P-Cox model obtained a C-index of 0.897). The median follow-up for patients in the readmission group was of 52 months (IQR 40–57).
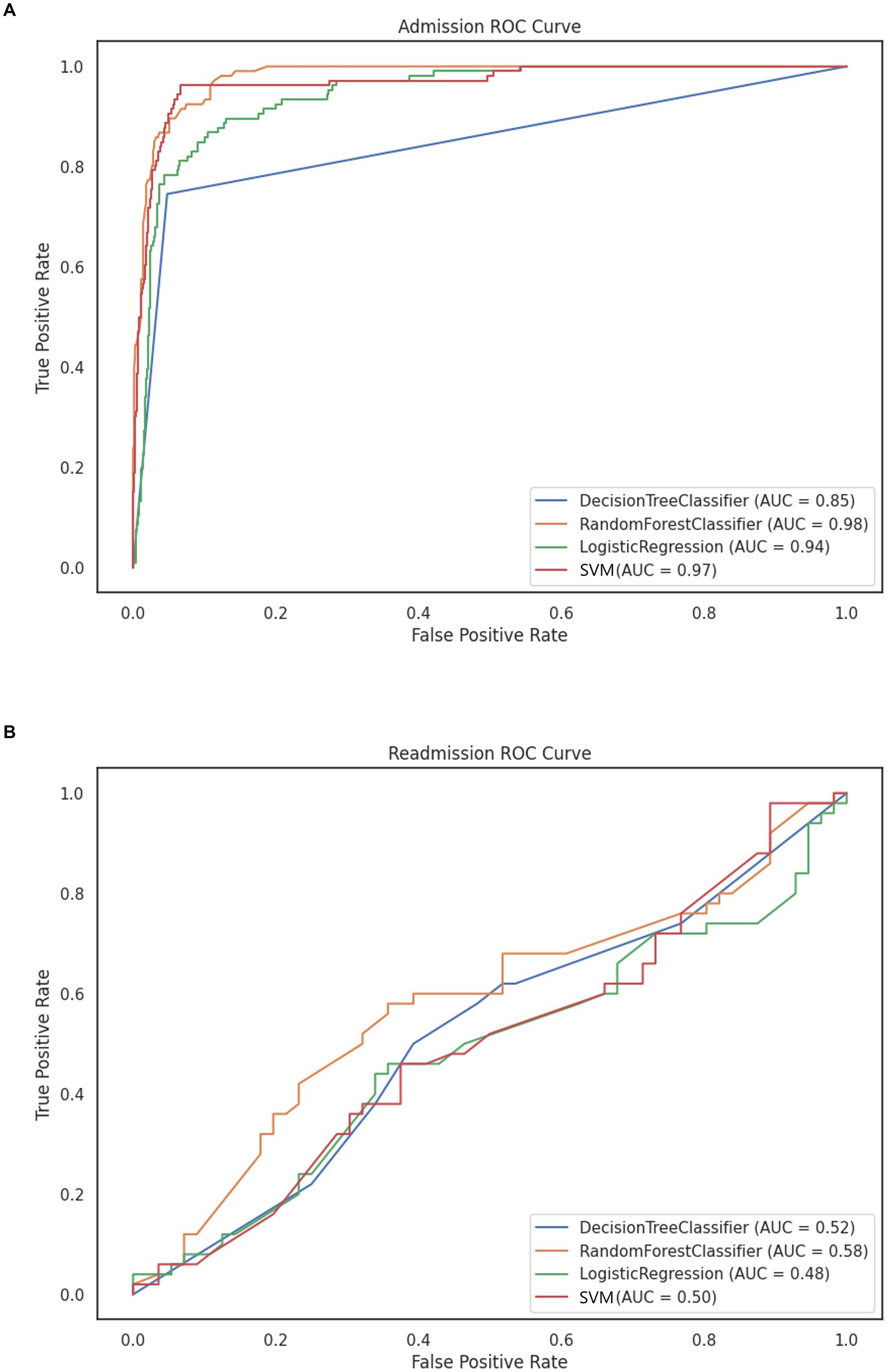
Figure 4. ROC curve of prediction models using (A) RFE and standardized data for BD admission without sampling. (B) SFS and normalized data for BD readmission.
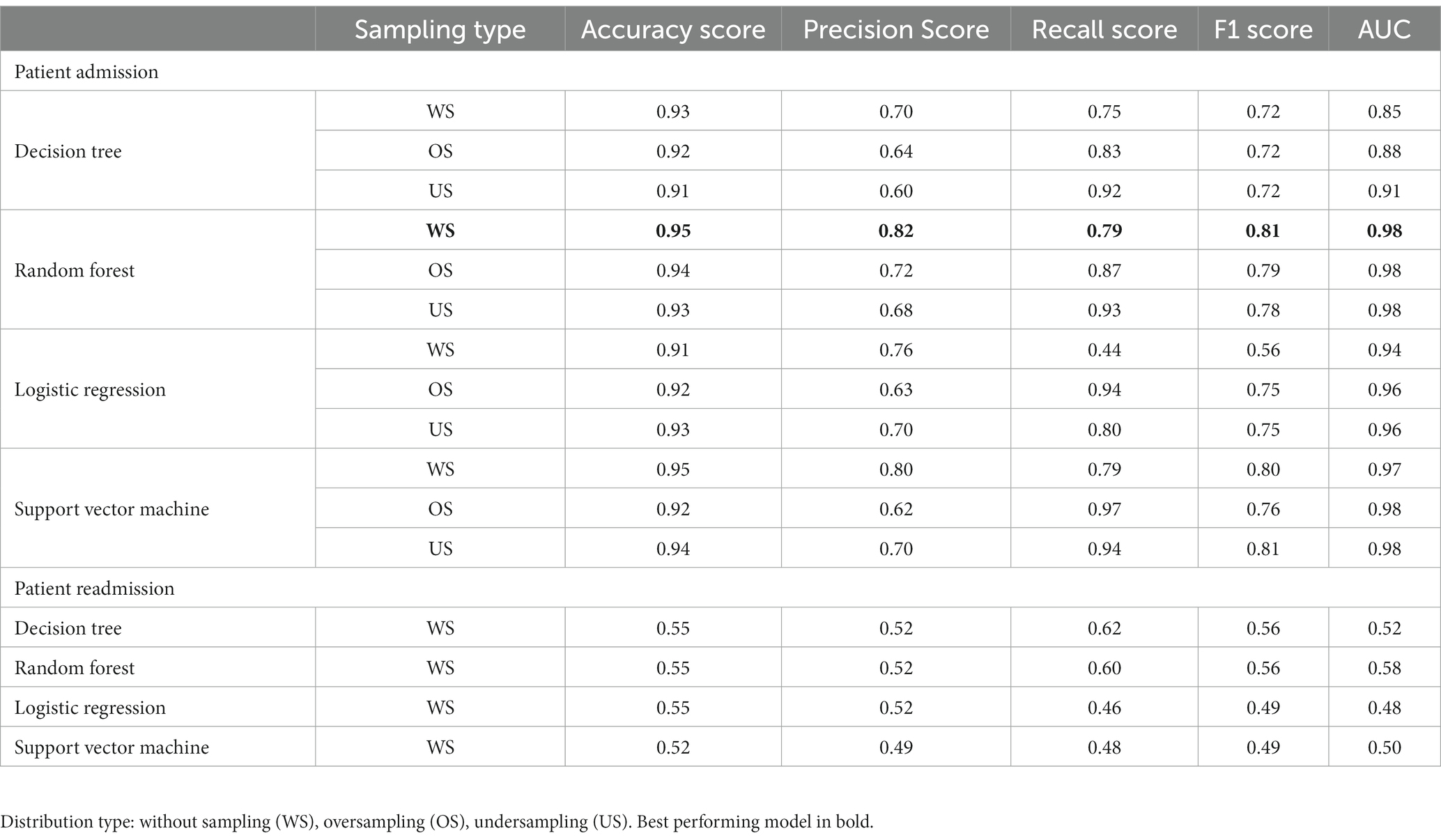
Table 2. Performance evaluation metrics for prediction of patient admission/readmission.
Significant associations between study variables and the outcome of readmission were identified only for a prior medical history of hypertension and for the number of outpatient follow-ups (Table 1). Feature engineering led to a reduced set of 11 variables including psychiatric emergency visits, medical emergency visits, number of hospitalizations due to medical conditions, sex, type of user, place of residence, socioeconomic status, history of hypertension, history of Chronic Obstructive Pulmonary Disease (COPD), place of origin (placeholder), and cause of discharge. The SFS and RFE methods were considered in determining the optimal number of variables, ultimately obtaining a better performance under the F1 score metric for the SFS method (0.621 vs. 0.566) with the normalized data (Figure 3B).
Model performance for the outcome of patient readmission was poor, with the best performing model being again a RF (Table 2). None of the models, however, reached an AUC above 0.70 (Figure 4B). Performance for the time to readmission survival models was likewise poor, with the RSF reaching a C-index of 0.592 (the penalized Cox model obtained a C-index of 0.497). The median follow-up time for patients in this group was of 18 months (IQR 6–35).
The prediction of patient admissions in any chronic disease is of great importance to researchers, public health planners and administrators (38, 39). Due to the varying features of different health systems, it is necessary to obtain different prediction tools for each population and health system to provide adequate risk management. To the best of our knowledge, this is the first study aiming to predict this outcome in a sample of subjects with BD in Colombia. We studied the outcomes of admission and readmission in subjects with BD in a large sample of 2,726 patients in Colombia, obtaining models with excellent predictive performance for the outcome of admission.
The ML models used in this study outperformed traditional statistical techniques (LR and P-Cox) in all cases with the random forest being the superior model in all cases. However, when comparing the results for the outcome of admission the random forest is only marginally superior to the LR model (AUC 0.98 vs. 0.94, respectively), which has the advantage of the latter of providing an easily interpretable model. This interpretability may be of critical importance in decision making. The difference between traditional statistical models and ML became more evident in the survival models for admission, in which the P-Cox model achieved a C-index of 0.897, while the SRF reached a C-index of 0.95. This difference between traditional statistical models and ML models was still evident in the survival models for readmission, though both models had very poor performance. This poor performance is likely due to the intrinsic difficulties associated with the prediction of survival (no readmission) compared with merely predicting the occurrence of the event within a given time frame. In addition, holdout validation was used to split the dataset corresponding to this outcome, which contained a smaller number of patients, leading to less precise estimates.
Random forest models are almost always superior to individual decision trees due to a variety of reasons. First, the random forest combines multiple decision trees which allows for a reduced variance and over-adjustment inherent to isolated trees. More robust and generalizable models can be derived from the averaging of several decision trees. Furthermore, the random forest models can also capture non-linear relationships and interactions between features. Lastly, random forest models can efficiently handle large datasets with high dimensionality, which makes them an adequate solution to complex problems like the prediction of BD admissions and readmissions.
All of the models explored for the outcome of admission had good to excellent performance, which was in contrast to the readmission models. ML models are known to require larger datasets than traditional statistical methods in order to produce better relative performance, and despite over and undersampling, the training dataset for readmission was considerably smaller (40). Prospective validation for these models is also lacking and it is an area for further research. The results suggested that ML analytics has the potential to provide risk calculators to aid in predicting clinical prognosis (including patient admissions), for individual patients (41).
Two prior studies have aimed to predict admission or readmission in BD patients. The study by Salem et al. aimed to predict readmission within 30 days after inpatient treatment of patients with a Diagnostic and Statistical Manual of Mental Disorders (DSM)-IV diagnosis of BD using a SVM technique. Importantly, this study relied on features extracted from the Borderline Personality Questionnaire (BPQ), the scores of which were available for all subjects. The study found good discriminative ability with an area under the Receiver Operating Curve (ROC) of 0.86, concluding that borderline personality features, as measured using the BPQ, were good predictors of early readmission. The external validity of this study is limited by the availability of data on its primary predictor, which is not a standard feature of electronic health records of patients with BD (42). A second study, by Edgcomb et al., also aimed to predict risk of readmission after 30 days in patients with BD. This study took into consideration standard data from EHRs, not including any kind of standardized measurement. Using classification trees, this model achieved high accuracy with an area under the ROC curve of 0.88. An additional strength of this study was the interpretability of the model which can be easily adapted into medical thinking (43).
In this study, the presence of borderline personality disorder features was significantly associated with admission in our first analyses. Prior work has identified these features as being a key predictor in rapid readmissions in patients with BD (42). Although this variable was not significantly associated with readmission, it did meet the requirements for inclusion as a feature in the predictive models. Similarly, some medical comorbidities were both significantly associated with admission (hypertension, hypothyroidism), and met criteria for inclusion in the readmission models. This highlights their importance in considering the risk of admission/readmission in patients with BD.
A number of clinical variables related to the patient’s mood, sleep quality, self-reported energy levels and medication adherence were not available to us, and they are known to be good predictors of both depressive and manic episodes in BD (43, 44). This was probably due to the paucity of information registered in EHRs which is more likely to contain specific changes in the disease’s symptoms and signs throughout clinical follow-up, instead of the evolution of all the clinical variables considered.
In obtaining the final sample, we were significantly limited by the availability of information. Despite having access to a larger cohort of patients with BD, data availability in EHRs limited their inclusion in the study. Both the number of registries and the information contained within them may have varied systematically. Physicians may be less inclined to describe clinical features in detail for patients who they deem low risk. Patients at greater risk of admission may also be those with poor adherence to outpatient follow-up, leading to fewer records from which to draw information. This may have led to selection bias in our sample.
Future work will concentrate on the prospective validation of the models obtained in this project, including the use of cross-validation methods (e.g., K-fold, leave one out) to allow more robust estimates of model performance by evaluating the model on different combinations of data. The limitations caused by the scarcity of data could be mitigated by EHR systems which can more intuitively allow the psychiatrist to rapidly register certain features of the mental exam, enabling more comprehensive work in mental health to be carried out. Additionally, the incorporation of longitudinal data, genetic analysis and dynamic modeling could facilitate the development of personalized treatment strategies that account for individual variations in disease progression and response to interventions in BD.
This study highlights the potential of utilizing ML techniques to predict hospital admission and readmission in patients with BD. The results demonstrate that ML models, particularly the Random Forest algorithm, exhibit superior predictive performance compared to traditional statistical methods. By leveraging EHRs and incorporating a range of sociodemographic and clinical variables, these models provide valuable insights into the factors influencing hospitalization in BD patients.
The use of ML techniques in psychiatric research, particularly in the context of BD, has the potential to deepen our understanding of the underlying mechanisms and pathophysiology of the condition. By uncovering novel associations and risk factors for patient admissions, these models contribute to the ongoing efforts to unravel the complexities of BD and guide future research directions.
The datasets presented in this article are not readily available due to patient confidentiality and data protection. The raw data supporting the conclusions of this article will be made available by the corresponding author only if this request is approved by the Research Ethics Committee of Fundación Universitaria Sanitas, Bogotá D.C., Colombia, following patient protection regulations in Colombia. Requests to access the datasets should be directed to the corresponding author.
The studies involving humans were approved by Comité de Ética en Investigación Fundación Universitaria Sanitas (CEIFUS). The studies were conducted in accordance with the local legislation and institutional requirements. Written informed consent for participation was not required from the participants or the participants’ legal guardians/next of kin in accordance with the national legislation and institutional requirements.
MP-A: Conceptualization, Data curation, Formal analysis, Funding acquisition, Investigation, Methodology, Software, Supervision, Validation, Visualization, Writing – original draft, Writing – review & editing, Project administration. EM-M: Data curation, Formal analysis, Investigation, Methodology, Software, Validation, Visualization, Writing – original draft, Writing – review & editing. JMu: Data curation, Formal analysis, Investigation, Methodology, Software, Validation, Visualization, Writing – original draft, Writing – review & editing. RA-D: Data curation, Investigation, Methodology, Validation, Visualization, Writing – original draft, Writing – review & editing. GL-C: Conceptualization, Data curation, Investigation, Supervision, Visualization, Writing – original draft, Writing – review & editing. AC-J: Conceptualization, Data curation, Formal analysis, Supervision, Visualization, Writing – review & editing. JR-A: Conceptualization, Data curation, Formal analysis, Methodology, Supervision, Validation, Visualization, Writing – review & editing. MA-B: Conceptualization, Investigation, Methodology, Resources, Supervision, Validation, Visualization, Writing – review & editing. JMc: Conceptualization, Funding acquisition, Investigation, Methodology, Project administration, Resources, Supervision, Visualization, Writing – review & editing.
The author(s) declare financial support was received for the research, authorship, and/or publication of this article. Research reported in this article was supported by the National Program of Science, Technology and Innovation in Health of the Ministry of Science and Technology of the Republic of Colombia under award number 844–2019 of the Pact to Generate New Knowledge.
The authors gratefully acknowledge Sanitas EPS and Fundación Universitaria Sanitas for their contributions to this article. The authors also acknowledge the Ministry of Science and Technology of the Republic of Colombia for its continued financial support of science.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The author(s) declared that they were an editorial board member of Frontiers, at the time of submission. This had no impact on the peer review process and the final decision.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
The Supplementary material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fpsyt.2023.1266548/full#supplementary-material
1. Merikangas, KR, Akiskal, HS, Angst, J, Greenberg, PE, Hirschfeld, RMA, Petukhova, M, et al. Lifetime and 12-month prevalence of bipolar Spectrum disorder in the National Comorbidity Survey Replication. Arch Gen Psychiatry. (2007) 64:543–52. doi: 10.1001/archpsyc.64.5.543
2. Yatham, LN, Kennedy, SH, Parikh, SV, Schaffer, A, Bond, DJ, Frey, BN, et al. Canadian network for mood and anxiety treatments (CANMAT) and International Society for Bipolar Disorders (ISBD) 2018 guidelines for the management of patients with bipolar disorder. Bipolar Disord. (2018) 20:97–170. doi: 10.1111/bdi.12609
3. American Psychiatric Association. Diagnostic and statistical manual of mental disorders. DSM-5-TR. Arlington, TX: American Psychiatric Association Publishing (2022).
4. Judd, LL, and Akiskal, HS. The prevalence and disability of bipolar spectrum disorders in the US population: re-analysis of the ECA database taking into account subthreshold cases. J Affect Disord. (2003) 73:123–31. doi: 10.1016/S0165-0327(02)00332-4
5. Reed, C, Goetz, I, Vieta, E, Bassi, M, and Haro, JM. Work impairment in bipolar disorder patients – results from a two-year observational study (EMBLEM). Eur Psychiatry. (2010) 25:338–44. doi: 10.1016/j.eurpsy.2010.01.001
6. Yatham, LN, Lecrubier, Y, Fieve, RR, Davis, KH, Harris, SD, and Krishnan, AA. Quality of life in patients with bipolar I depression: data from 920 patients. Bipolar Disord. (2004) 6:379–85. doi: 10.1111/j.1399-5618.2004.00134.x
8. Novick, DM, Swartz, HA, and Frank, E. Suicide attempts in bipolar I and bipolar II disorder: a review and meta-analysis of the evidence. Bipolar Disord. (2010) 12:1–9. doi: 10.1111/j.1399-5618.2009.00786.x
9. Dome, P, Rihmer, Z, and Gonda, X. Suicide risk in bipolar disorder: a brief review. Medicina. (2019) 55:403. doi: 10.3390/medicina55080403
11. Daglas, R, Yücel, M, Cotton, S, Allott, K, Hetrick, S, and Berk, M. Cognitive impairment in first-episode mania: a systematic review of the evidence in the acute and remission phases of the illness. Int J Bipolar Disord. (2015) 3:9. doi: 10.1186/s40345-015-0024-2
12. Bessonova, L, Ogden, K, Doane, MJ, O’Sullivan, AK, and Tohen, M. The economic burden of bipolar disorder in the United States: a systematic literature review. Clinicoecon Outcomes Res. (2020) 12:481–97. doi: 10.2147/CEOR.S259338
13. Hirschfeld, RMA, and Vornik, LA. Bipolar disorder--costs and comorbidity. Am J Manag Care. (2005) 11:S85–90.
14. Simon, J, Pari, AAA, Wolstenholme, J, Berger, M, Goodwin, GM, and Geddes, JR. The costs of bipolar disorder in the United Kingdom. Brain Behav. (2021) 11:e2351. doi: 10.1002/brb3.2351
15. Hong, J, Reed, C, Novick, D, Haro, JM, Windmeijer, F, and Knapp, M. The cost of relapse for patients with a manic/mixed episode of bipolar disorder in the EMBLEM study. Pharmacoeconomics. (2010) 28:555–66. doi: 10.2165/11535200-000000000-00000
16. Perlis, RH, Ostacher, MJ, Patel, JK, Marangell, LB, Zhang, H, Wisniewski, SR, et al. Predictors of recurrence in bipolar disorder: primary outcomes from the systematic treatment enhancement program for bipolar disorder (STEP-BD). Am J Psychiatr. (2006) 163:217–24. doi: 10.1176/appi.ajp.163.2.217
17. Kansagara, D, Englander, H, Salanitro, A, Kagen, D, Theobald, C, Freeman, M, et al. Risk prediction models for hospital readmission. JAMA. (2011) 306:1688–98. doi: 10.1001/jama.2011.1515
18. Zhou, H, Della, PR, Roberts, P, Goh, L, and Dhaliwal, SS. Utility of models to predict 28-day or 30-day unplanned hospital readmissions: an updated systematic review. BMJ Open. (2016) 6:e011060. doi: 10.1136/bmjopen-2016-011060
19. Huang, Y, Talwar, A, Chatterjee, S, and Aparasu, RR. Application of machine learning in predicting hospital readmissions: a scoping review of the literature. BMC Med Res Methodol. (2021) 21:96. doi: 10.1186/s12874-021-01284-z
20. Cusidó, J, Comalrena, J, Alavi, H, and Llunas, L. Predicting hospital admissions to reduce crowding in the emergency departments. Appl Sci. (2022) 12:10764. doi: 10.3390/app122110764
21. Monahan, AC, and Feldman, SS. Models predicting hospital admission of adult patients utilizing prehospital data: systematic review using PROBAST and CHARMS. JMIR Med Inform. (2021) 9:e30022. doi: 10.2196/30022
22. Morel, D, Yu, KC, Liu-Ferrara, A, Caceres-Suriel, AJ, Kurtz, SG, and Tabak, YP. Predicting hospital readmission in patients with mental or substance use disorders: a machine learning approach. Int J Med Inform. (2020) 139:104136. doi: 10.1016/j.ijmedinf.2020.104136
23. Góngora Alonso, S, Marques, G, Agarwal, D, De la Torre, DI, and Franco-Martín, M. Comparison of machine learning algorithms in the prediction of hospitalized patients with schizophrenia. Sensors. (2022) 22:2517. doi: 10.3390/s22072517
24. Betts, KS, Kisely, S, and Alati, R. Predicting postpartum psychiatric admission using a machine learning approach. J Psychiatr Res. (2020) 130:35–40. doi: 10.1016/j.jpsychires.2020.07.002
25. Rotenberg, L, Borges-Júnior, RG, Lafer, B, Salvini, R, Dias, RS, Dias, R, et al. Exploring machine learning to predict depressive relapses of bipolar disorder patients. J Affect Disord. (2021) 295:681–7. doi: 10.1016/j.jad.2021.08.127
26. Li, F, and Yang, Y. Analysis of recursive feature elimination methods. Proceedings of the 28th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. SIGIR’05. New York, NY: Association for Computing Machinery (2005), 633–634.
27. Jovic, A, Brkic, K, and Bogunovic, N. A review of feature selection methods with applications 2015 38th International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO). Opatija: IEEE (2015),. 1200–1205.
28. Chawla, NV, Bowyer, KW, Hall, LO, and Kegelmeyer, WP. SMOTE: synthetic minority over-sampling technique. JAIR. (2002) 16:321–57. doi: 10.1613/jair.953
29. Wilson, DL. Asymptotic properties of nearest neighbor rules using edited data. IEEE Trans Syst Man Cybern. (1972) SMC-2:408–21. doi: 10.1109/TSMC.1972.4309137
30. Jenhani, I, Amor, NB, and Elouedi, Z. Decision trees as possibilistic classifiers. Int J Approx Reason. (2008) 48:784–807. doi: 10.1016/j.ijar.2007.12.002
32. Cortes, C, and Vapnik, V. Support-vector networks. Mach Learn. (1995) 20:273–97. doi: 10.1007/BF00994018
33. Huang, F-F, Yang, X-Y, Luo, J, Yang, X-J, Meng, F-Q, Wang, P-C, et al. Functional and structural MRI based obsessive-compulsive disorder diagnosis using machine learning methods. BMC Psychiatry. (2023) 23:792. doi: 10.1186/s12888-023-05299-2
34. Cohen, IL, and Flory, MJ. Autism Spectrum disorder decision tree subgroups predict adaptive behavior and autism severity trajectories in children with ASD. J Autism Dev Disord. (2019) 49:1423–37. doi: 10.1007/s10803-018-3830-4
35. Yang, J, Sui, H, Jiao, R, Zhang, M, Zhao, X, Wang, L, et al. Random-Forest-algorithm-based applications of the basic characteristics and serum and imaging biomarkers to diagnose mild cognitive impairment. Curr Alzheimer Res. (2022) 19:76–83. doi: 10.2174/1567205019666220128120927
36. Goeman, JJ. L1 penalized estimation in the cox proportional hazards model. Biom J. (2010) 52:70–84. doi: 10.1002/bimj.200900028
37. Ishwaran, H, Kogalur, UB, Blackstone, EH, and Lauer, MS. Random survival forests. Ann Appl Stat. (2008) 2:841–60. doi: 10.1214/08-AOAS169
38. Symum, H, and Zayas-Castro, JL. Prediction of chronic disease-related inpatient prolonged length of stay using machine learning algorithms. Healthc Inform Res. (2020) 26:20–33. doi: 10.4258/hir.2020.26.1.20
39. Oh, SM, Stefani, KM, and Kim, HC. Development and application of chronic disease risk prediction models. Yonsei Med J. (2014) 55:853–60. doi: 10.3349/ymj.2014.55.4.853
40. Cerqueira, V, Torgo, L, and Soares, C. Machine learning vs statistical methods for time series forecasting: size matters. (2019). Available at: https://arxiv.org/abs/1909.13316 (Accessed June 20, 2023).
41. Passos, IC, Ballester, PL, Barros, RC, Librenza-Garcia, D, Mwangi, B, Birmaher, B, et al. Machine learning and big data analytics in bipolar disorder: a position paper from the International Society for Bipolar Disorders big Data Task Force. Bipolar Disord. (2019) 21:582–94. doi: 10.1111/bdi.12828
42. Salem, H, Ruiz, A, Hernandez, S, Wahid, K, Cao, F, Karnes, B, et al. Borderline personality features in inpatients with bipolar disorder: impact on course and machine learning model use to predict rapid readmission. J Psychiatr Pract. (2019) 25:279–89. doi: 10.1097/PRA.0000000000000392
43. Edgcomb, J, Shaddox, T, Hellemann, G, and Brooks, JO. High-risk phenotypes of early psychiatric readmission in bipolar disorder with comorbid medical illness. Psychosomatics. (2019) 60:563–73. doi: 10.1016/j.psym.2019.05.002
Keywords: bipolar disorder, electronic health records, machine learning, patient admission, patient readmission, risk factors
Citation: Palacios-Ariza MA, Morales-Mendoza E, Murcia J, Arias-Duarte R, Lara-Castellanos G, Cely-Jiménez A, Rincón-Acuña JC, Araúzo-Bravo MJ and McDouall J (2023) Prediction of patient admission and readmission in adults from a Colombian cohort with bipolar disorder using artificial intelligence. Front. Psychiatry. 14:1266548. doi: 10.3389/fpsyt.2023.1266548
Edited by:
Steven Fernandes, Creighton University, United StatesReviewed by:
Xinyuan Yan, University of Minnesota Twin Cities, United StatesCopyright © 2023 Palacios-Ariza, Morales-Mendoza, Murcia, Arias-Duarte, Lara-Castellanos, Cely-Jiménez, Rincón-Acuña, Araúzo-Bravo and McDouall. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: María Alejandra Palacios-Ariza, bWFwYWxhY2lvc2FyQHVuaXNhbml0YXMuZWR1LmNv
†These authors have contributed equally to this work
‡These authors share senior authorship
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.