 Tomoki Tokuda
Tomoki Tokuda Okito Yamashita
Okito Yamashita Yuki Sakai
Yuki Sakai Junichiro Yoshimoto
Junichiro Yoshimoto
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Psychiatry, 18 August 2021
Sec. Computational Psychiatry
Volume 12 - 2021 | https://doi.org/10.3389/fpsyt.2021.683280
This article is part of the Research TopicGearing up for Phase II: Front-Line Issues in MRI Marker Development for Psychiatric DisordersView all 6 articles
Recently, the dimensional approach has attracted much attention, bringing a paradigm shift to a continuum of understanding of different psychiatric disorders. In line with this new paradigm, we examined whether there was common functional connectivity related to various psychiatric disorders in an unsupervised manner without explicitly using diagnostic label information. To this end, we uniquely applied a newly developed network-based multiple clustering method to resting-state functional connectivity data, which allowed us to identify pairs of relevant brain subnetworks and subject cluster solutions accordingly. Thus, we identified four subject clusters, which were characterized as major depressive disorder (MDD), young healthy control (young HC), schizophrenia (SCZ)/bipolar disorder (BD), and autism spectrum disorder (ASD), respectively, with the relevant brain subnetwork represented by the cerebellum-thalamus-pallidum-temporal circuit. The clustering results were validated using independent datasets. This study is the first cross-disorder analysis in the framework of unsupervised learning of functional connectivity based on a data-driven brain subnetwork.
Abnormal functional connectivity (FC) in the brain has been extensively studied for a better understanding of psychiatric disorders (1–3). Typically, an FC study focuses on a particular psychiatric disorder, and reports the brain regions related to abnormal FC for psychiatric disorders. The results of these individual studies are not necessarily consistent, even for the same psychiatric disorder (4, 5). Nonetheless, several meta-analyses imply that there may be shared brain regions of abnormal FC that are related to different psychiatric disorders. A meta-analysis focusing on the default mode network (DMN) (6) suggests that the DMN is a consistent biological correlate of various psychiatric disorders, including major depressive disorder (MDD), bipolar disorder (BD), and schizophrenia (SCZ). Furthermore, a meta-analysis focusing on psychomotor systems, including the DMN (7), suggests that the balance in psychomotor mechanisms may determine MDD, BD, and SCZ. Recently, a large sample study by (8) showed that shared connectomic abnormalities among MDD, BD, and SCZ are bilateral thalamus, cerebellum, frontal pole, supramarginal gyrus, postcentral gyrus, lingual gyrus, lateral occipital cortex, and parahippocampus. Another recent large sample study by (9) showed that the common abnormality among MDD, BD, and SCZ is frontoparietal network connectivity. In contrast, in non-FC based studies, a genome-wide association study (10) showed substantial overlap of genetic influences among MDD, BD, and SCZ. A meta-analysis by (11) showed that gray matter density decreased in the dorsal anterior cingulate and right/left insula for MDD, BD, SCZ, addiction, obsessive-compulsive disorder, and anxiety disorders. In a large sample study (12), it was shown that SCZ, BD, and ASD subjects shared similar white matter microstructural differences in the body of their corpus callosum, as compared to healthy subjects. Such cross-disorder analysis is vital for a comprehensive understanding of various psychiatric disorders and for deepening our understanding of a particular psychiatric disorder. In the present study, we aimed to perform cross-disorder analysis using a novel unsupervised approach to reveal the underlying shared functional connectivity related to psychiatric disorders.
Typically, to elucidate the relevant functional connectivity for a psychiatric disorder, FC is contrasted between patients and healthy control (HC) subjects using various machine learning techniques in a supervised manner (13–17). Diagnostic label information is used as the response variable in supervised learning, which is based on clinical criteria such as the Diagnostic and Statistical Manual of Mental Disease (DSM) (18). DSM diagnosis defines various types of psychiatric disorders based on several clinical symptoms that are shared by these psychiatric disorders. It relies on clinical interviews to which patients respond, which makes the diagnosis subjective by nature. Moreover, various psychiatric disorders share common cognitive deficits with high comorbidity across psychiatric labels, which raises questions about the underlying structure and assumptions of the classification (19, 20). All these aspects of DSM diagnosis imply that the diagnostic label does not necessarily denote the “ground truth” (21).
To overcome this problem of the diagnostic label, it will be of interest to perform unsupervised analysis, that is, cluster analysis. Combined with the feature selection procedure, the unsupervised method allows the identification of functional connectivity related to psychiatric disorders, without explicitly using psychiatric labels. Such an approach is in line with the dimensional approach proposed by the Research Domain Criteria (RDoC), which is based on the mechanism of disorders rather than their symptoms (22). Moreover, it is quite useful to perform a cluster analysis that includes multiple psychiatric disorders because it enables us to reveal a common or different functional connectivity for cross-disorder analysis without directly using psychiatric labels. Nonetheless, cluster analysis for cross-disorders is currently limited to clinical data, such as symptom data, genetic data, and EEG data only (23–25). Though several studies have performed FC-based cluster analysis for a single disorder (26, 27), to the best of our knowledge, no study for cross-disorders has performed cluster analysis using FC data.
The objective of the present study was hence to examine whether there is a common functional connectivity related to various psychiatric disorders. We performed a cross-disorder analysis using FC data in an unsupervised manner. To this end, we applied the ROI-based multiple clustering method, which has been recently developed specifically for clustering functional connectivity matrices (28). This ROI-based multiple clustering method is unique because it optimally divides ROIs into several subsets; for each subset of ROIs, an optimal cluster solution is identified accordingly. In the present paper, we refer to each subset of ROIs as a “view” in which the terminology carries connotations that help us view only a particular set of ROIs for a single clustering. For multiple clustering, we identify multiple views in which subject clustering is performed separately. The ROI-based method that we use optimizes both view structures and subject clustering in each view simultaneously (for more details, please see section 2.1). This specific aspect of the method enables us to identify a data-driven brain subnetwork that is relevant to subject cluster patterns. Furthermore, this method reduces the search space of parameters from combinations of connectivity to combinations of nodes, enabling efficient inferences of clustering for high-dimensional FC data. We applied this method to the FC dataset consisting of 322 subjects with various psychiatric disorders. For a specific brain subnetwork, there were four clusters characterized by MDD, young HC, SCZ/BD, and ASD, respectively. To examine the reproducibility of the clustering results, we applied the yielded model of classification to independent data, which largely confirmed the reproducibility of the results.
In the following sections, we first outline the multiple clustering method, which is unique to the present study. Second, we describe the datasets for both discovery and validation. Third, we analyze the clustering results for discovery data and classification results for the validation data. Finally, we discuss the interpretations of the clustering results and methodological novelty of the present study.
In this study, we applied a recently developed multiple clustering method (28) to perform cluster analysis. Multiple clustering is generally based on the assumption that multiple cluster solutions of objects (subjects) exist in a given dataset, and there are several approaches to revealing the underlying multiple-view structure in data [for comprehensive reviews, see (29, 30)]. In the present study, we focused on “subspace clustering,” in which cluster solutions were obtained for several subspaces (i.e., subsets) of features. It was not known in advance which subsets of features should be used for optimal cluster solutions; hence, the multiple clustering method entailed the optimization of both (exclusive) feature partitioning and cluster solutions. The advantage of such an approach was that we did not discard from the analysis any irrelevant features for a particular cluster solution, but utilized these features for another cluster solution, which widened the scope of possibilities to identify optimal cluster solutions.
The novel multiple clustering method (28) was developed specifically for clustering subjects based on functional connectivity matrices without vectorization. The uniqueness of this method is its ROI-based approach rather than the conventional FC-based approach, which is achieved by fitting the data to the Wishart mixture model (hereafter referred to as “ROI-based multiple clustering method”). As an output, the method yields several pairs of relevant ROIs and subject cluster solutions (Figure 1A), where each pair is referred to as “view.” It is noteworthy that all FCs pertaining to a selected subset of ROIs are evaluated by fitting to the Wishart mixture model, which results in subnetwork identification. The number of views and clusters are automatically inferred in the nonparametric Bayesian framework (31), setting the concentration parameter for the Chinese restaurant process to one (32).
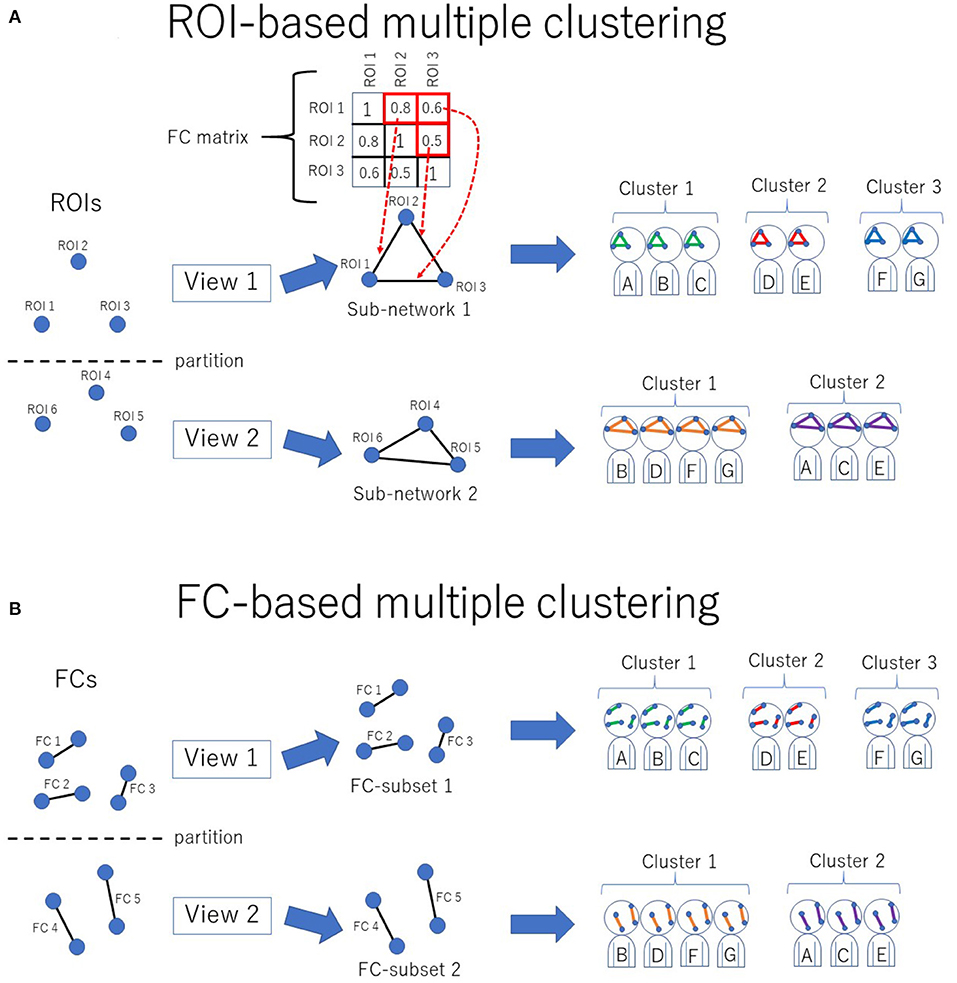
Figure 1. Conceptual illustration of multiple clustering methods. (A) ROI-based multiple clustering method. ROIs are partitioned into several groups (views). In each view, the subject cluster solution is obtained using a particular subset of ROIs (i.e., a subnetwork). The FC matrix represents connectivity within the subnetwork. For instance, in this illustration, the connectivity within view 1 consists of three ROIs, which are denoted by the 3 × 3 FC matrix. This method identifies optimal pairs of subnetworks and cluster solutions, where optimization is performed simultaneously for both the subnetwork and cluster solution. The color in the subnetwork for subjects A–G denotes a cluster-specific pattern of functional connectivity. For simplicity, there are two views in this example. (B) FC-based multiple clustering method. Instead of ROIs, FCs are exclusively partitioned for the subject cluster solutions. This method identifies optimal pairs of subsets of FCs and cluster solutions.
The key idea of this method is the assumption of independence between subnetworks, each of which consists of several ROIs. This assumption does not hold for real data because subnetworks in the brain are putatively interconnected in a complex manner (33). Hence, to meet this assumption, the “whitening” procedure is applied for the correlation matrices as a pre-processing requirement [for more details, please refer to (28)]. It is expected that the whitening procedure preserves cluster structures within subnetworks, whereas the functional connectivity between subnetworks becomes zero. Furthermore, it is expected that this procedure normalizes the correlation matrices such that it enhances the generalization of the yielded model.
One limitation of the method is that a conventional approach to removing the influence of confounding factors (e.g., age and sex) based on Generalized Linear Model (GLM) cannot be applied for pre-processing of FC. This is because the positive definiteness of the FC matrices would be lost by the application of the GLM. As an alternative approach, we consider the confounding factors in the post-hoc analysis (for more details, please refer to section 4.4).
The optimization strategy of the method was based on a greedy search, which was initialized with a random configuration of views and clusters. We set the number of initializations to 1,000, which in turn yielded 1,000 models. For model selection, we used the heuristic method used by (28), aiming to select a stable and well-fitted model. First, we selected the top ten models in terms of their posterior distribution of the relevant parameters. Among these ten models, we subsequently evaluated the agreement of view memberships between models using the Adjusted Rand Index (ARI) (34). Then, we identified a pair of models that gave the largest value of ARI. The final model was the one in this pair, which gave a larger posterior value. To regularize the correlation matrices, we simply added a small fraction (0.05) to the diagonal elements and subsequently converted it into a correlation matrix.
As a reference method for clustering, we also performed an FC-based multiple clustering method (27, 35), in which a connectivity matrix was vectorized, and each FC was considered a feature (Figure 1B). The vectorized FCs were then partitioned into views by fitting to Gaussian mixture models, in which the number of views and clusters were automatically determined in a data-driven manner.
We used two resting-state FC datasets that are publicly available at the Strategic Research Program for Brain Sciences (SRPBS)1, in which FC was evaluated in a conventional manner using Pearson's correlation coefficient for mean blood-oxygen-level-dependent signals between two ROIs. These two datasets were collected at the University of Tokyo (hereafter referred to as “UTO”) and Kyoto University (hereafter referred to as “KYO”), respectively. The FC dataset of the UTO was obtained using the same MRI scanner, while the KYO dataset was obtained using two different MRI scanners. Hence, we further divided the KYO data into two datasets according to the scanner type: “KYO-A” and “KYO-B.” Detailed information on MRI scanning for UTO and KYO is provided in Table 1. Regarding brain parcellation, the BAL atlas, which is a composite of the BrainVisa Sulci Atlas (BSA) (36) and automated anatomical labeling (AAL) atlas (37) with 140 ROIs [for more details, please refer to (38)], was used for both UTO and KYO.
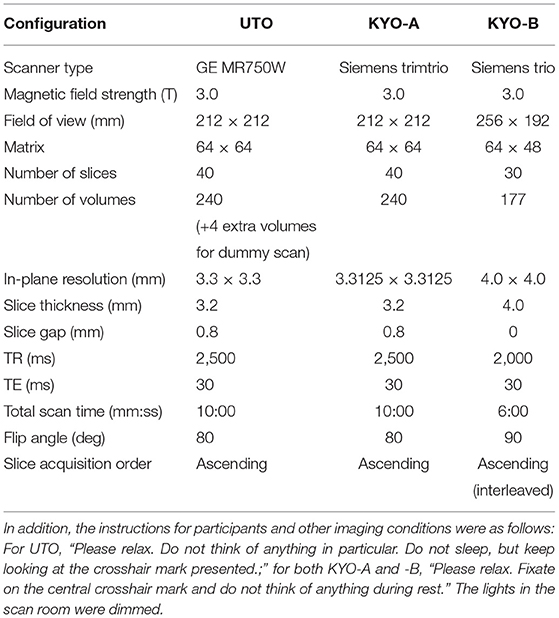
Table 1. MRI scanning information for UTO (the University of Tokyo) and KYO (Kyoto University) data.
The UTO dataset consisted of 322 subjects: 170 HC, 62 MDD, 41 BD, 35 SCZ, 10 ASD, and 4 dysthymia (DY) subjects, respectively (Table 2). The KYO-A dataset consisted of 219 subjects: 159 HC, 16 MDD, and 44 SCZ. The KYO-B dataset consisted of 119 subjects: 75 HC and 44 SCZ. We used the UTO data as discovery data, where cluster analysis was performed using the ROI-based multiple clustering method, and used the KYO-A and KYO-B datasets as validation data to examine the reproducibility of the UTO clustering results. In addition, we used the dataset of traveling subjects (TS) as validation data. The SRPBS depository included FC datasets for nine HC subjects who underwent fMRI scanning at different sites or with different scanners. These subjects were scanned three times for the UTO and KYO-A scanners. There was no overlapping of subjects observed among the UTO, KYO, and TS datasets.
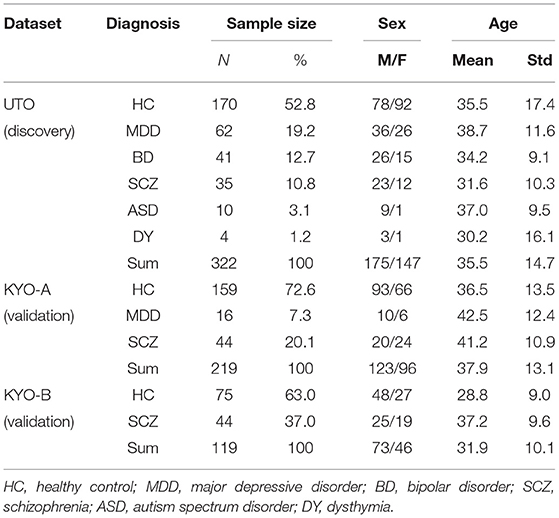
Table 2. Psychiatric and demographic information of subjects in UTO (The University of Tokyo) and KYO (Kyoto University) datasets.
First, we performed cluster analysis for the UTO data by fitting the ROI-based multiple clustering method. Second, to verify the clustering results of the UTO data, we classified the subjects in the KYO data based on the statistical model inferred from the UTO data. For further verification, we classified the subjects in the TS dataset based on the UTO model. Finally, for the purpose of comparison, we performed a supplementary analysis of the UTO data using the supervised learning method.
We applied the ROI-based multiple clustering method to UTO data. For comparison with the clustering results, we also applied the FC-based multiple clustering method accordingly.
The ROI-based multiple clustering method yielded 15 views (number of ROIs, 2–25; number of clusters, 3–77; Table 3). In this analysis, we assigned view labels and cluster labels as follows. Views were sorted in ascending order of the number of subject clusters in a view, whereas clusters in each view were sorted in a descending order of the number of subjects. The FC-based multiple clustering method yielded 13 views (number of FCs, 26–2,830; number of clusters, 5–10). Views and clusters were sorted in the same manner as the results of the ROI-based multiple clustering method.
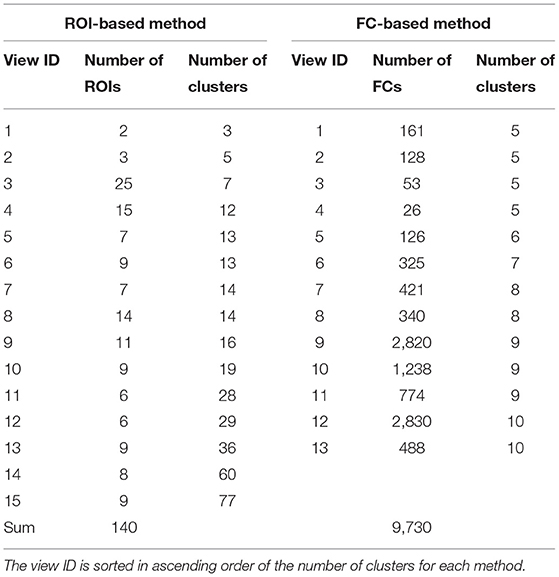
Table 3. Summary of the multiple clustering results.
For each view, we evaluated the association between cluster labels and psychiatric disorders, including HC. For the ROI-based multiple clustering method, the subject clusters in view 4 were significantly associated with psychiatric disorders, as shown by the Pearson's χ2 test for contingency tables (simply referred to as “χ2 test” hereafter) (p = 0.0002, significant at the 0.05 level with Bonferroni correction; Figure 2A). In contrast, for the FC-based multiple clustering method, no significant association was found with the Bonferroni correction (Figure 2B). Therefore, for further analysis, we focused on view 4 yielded by the ROI-based multiple clustering method (we discuss the remainder of the views in section 4.1).
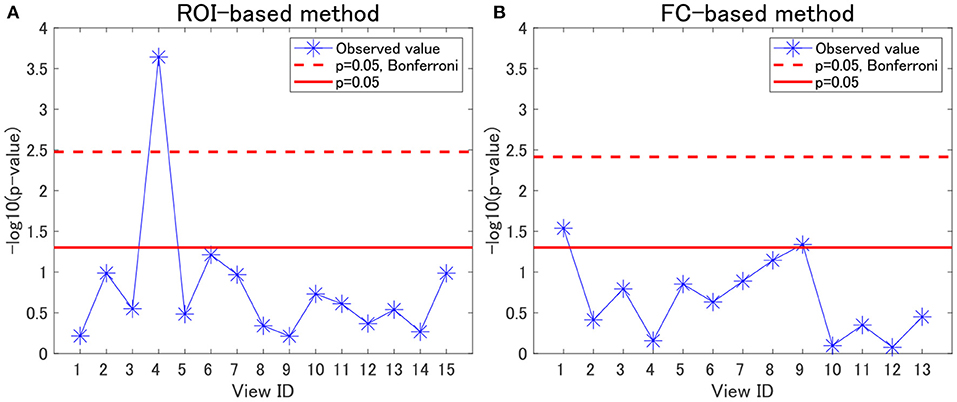
Figure 2. Associations between cluster labels and psychiatric disorders. (A) Results of the ROI-based multiple clustering method. (B) Results of the FC-based multiple clustering method. The horizontal axis denotes the view ID, whereas the vertical axis denotes the negative logarithm of the p-value yielded by the χ2 test to evaluate the association between the corresponding cluster labels in the view and psychiatric labels. The red line denotes the significance level at 0.05, whereas the dotted line denotes the significance level at 0.05, with Bonferroni correction.
Regarding view 4, we first examined the distribution of psychiatric labels in the clusters. In this view, 12 clusters were yielded, with sample sizes of 111, 77, 75, 45, 4, 4, 1, 1, 1, 1, 1, and 1 for clusters 1–12, respectively (Table 4). For further analysis, we focused on clusters 1–4, which had sample sizes larger than 10. To alleviate the imbalanced distribution of psychiatric labels in the data, we evaluated the proportions of subjects in the disorder-wise manner (Figure 3A), which showed that the subject distribution of these clusters was closely associated with psychiatric labels. In contrast, the proportions of subjects evaluated in a cluster-wise manner reflected the imbalanced distribution of psychiatric labels in the data (Figure 3B). For a better understanding of clusters, hereafter, we deal with the proportions of subjects in a disorder-wise manner, as in Figure 3A. Based on the disorder-wise proportions of subjects, we characterized these clusters in terms of the proportion of each psychiatric label over the clusters as follows: cluster 1, MDD; cluster 2, HC; cluster 3, SCZ/BD; and cluster 4, ASD. Note that we combined SCZ and BD because their subject distributions were similar for clusters 1–4; for any pair of clusters, there was no difference noted in the distributions for the two psychiatric labels using the χ2 test.
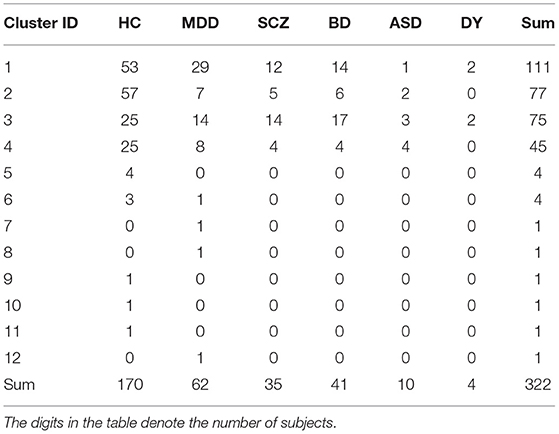
Table 4. Distribution of psychiatric disorders of UTO data for clusters in view 4.
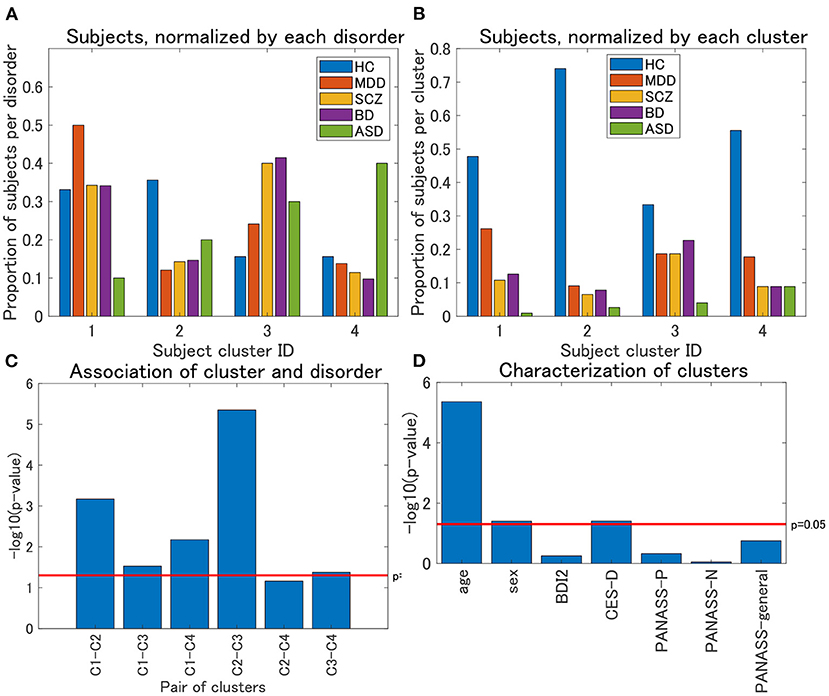
Figure 3. (A) Distribution of subjects of UTO data for view 4, normalized by each disorder. The horizontal axis denotes the cluster ID, whereas the vertical axis denotes the proportion of subjects for each psychiatric disorder over all the four clusters. For each cluster, the proportion of subjects with a particular psychiatric disorder is denoted by a colored bar. Note that the proportion is evaluated in the disorder-wise manner. That is, the summation of the four proportions becomes one for each disorder (e.g., for HC, the summation of the proportions denoted by blue bars becomes one). Furthermore, note that clusters with <10 subjects were removed. (B) Distribution of subjects of UTO data for view 4, normalized by each cluster. In contrast with (A), the proportion of subjects is evaluated in a cluster-wise manner. That is, the summation of the five proportions becomes one for each cluster (e.g., for cluster 1, the summation of the proportions denoted in blue, red, orange, purple, and green becomes one). (C) Results of the χ2 test for the association between pairs of cluster labels and pairs of psychiatric labels in view 4. For the pairs of psychiatric labels, we consider those psychiatric labels that characterize the pair of clusters in question. Namely, MDD and HC for clusters 1 and 2, MDD and SCZ/BD for clusters 1 and 3, MDD and ASD for clusters 1 and 4, HC and SCZ/BD for clusters 2 and 3, HC and ASD for clusters 2 and 4, and SCZ/BD and ASD for clusters 3 and 4. The horizontal axis denotes the pair of cluster labels, whereas the vertical axis denotes the negative logarithm of the p-value by the χ2 test. (D) Characterization of four clusters in view 4. The horizontal axis denotes demographic/clinical indices, whereas the vertical axis denotes the negative logarithm of the p-value by the χ2 test on cluster labels and sex, and the Kruskal-Wallis test on cluster labels and the remainder of the indices. BDI2, beck depression inventory II; CES-D, center for epidemiologic studies depression scale; PANASS-P, positive and negative syndrome scale consisting of positive psychopathology scale; PANASS-N, negative scales; PANASS-general, general scales.
For each pair of clusters, we performed the χ2 test on the association between the cluster and psychiatric labels. To this end, we focused on specific psychiatric disorders that characterized the pairs of clusters in question. For instance, to test the pair of clusters 1 and 2, we considered the psychiatric labels of MDD and HC only because these psychiatric labels characterize clusters 1 and 2, respectively. We found that these associations were significant at a level of 0.05, for any pair of clusters (Figure 3C), except for the pair of clusters 2 and 4 (p = 0.069), which supported the aforementioned characterization of the four clusters.
We also characterized the subject clusters using demographic and clinical information. It was found that age was significantly related to these clusters (p = 4.4 × 10−6; Figure 3D). The mean age is at 36.4, 29.5, 35.8, and 40.9 years for clusters 1–4, respectively (Supplementary Figure 1A), showing that it is rather small for cluster 2. Moreover, we examined the association between age and psychiatric disorders. For HC, the age difference between cluster 2 and the remaining three clusters was significant (Kruskal–Wallis test, p = 0.0003), whereas such differences were not significant for MDD, SCZ, and BD (p = 0.21, 0.39, and 0.10, respectively; Supplementary Figures 1B–D).
To summarize, the results of the analysis of the four clusters suggest that we may characterize the clusters in view 4 as follows:
• Cluster 1: MDD
• Cluster 2: young HC
• Cluster 3: SCZ/BD
• Cluster 4: ASD
where “young HC” denotes the HC subjects of a relatively young age (around 20 years).
For the characterization of the clusters, it is noteworthy that HC (as well as the remainder of the psychiatric disorders) is, to some extent, included in all clusters. One may wonder whether there is a difference in depression scores (BDI or CES-D) for HC between these clusters. For BDI, the difference among clusters was not significant (Kruskal–Wallis test, p = 0.58), whereas for CES-D, the difference was significant (p = 0.016). Furthermore, for CES-D, the pairwise test for these clusters suggests that the difference was significant for the following pairs of clusters: cluster 4 < cluster 3 (p = 0.0044), cluster 4 < cluster 2 (p = 0.022), and cluster 1 < cluster 3 (p = 0.048). In particular, this result provides additional characterization for Cluster 4 as a non-depressive disorder. We discuss the interpretation of this result in section 4.3.
Furthermore, we examined the relevant brain regions for the four clusters in view 4. The subnetwork for view 4 consisted of a cerebellum-thalamus-pallidum-temporal circuit. The relevant ROIs for this subnetwork are as follows: left posterior intra-lingual sulcus; right anterior occipito-temporal lateral sulcus; left median occipito-temporal lateral sulcus; right median occipito-temporal lateral sulcus; left posterior occipito-temporal lateral sulcus; right anterior inferior temporal sulcus; left posterior inferior temporal sulcus; right posterior inferior temporal sulcus; right polar temporal sulcus; left superior temporal sulcus; left thalamus; left pallidum; right thalamus; left cerebellum; and vermis.
For these ROIs, we identified FCs that were specifically relevant to a pair of clusters. To this end, we evaluated Cohen's d (39) for FC differences between the pairs of clusters. We found that several FCs largely discriminate between two clusters, following the conventional criterion of d > 0.8 (Figure 4, Supplementary Figure 2). Moreover, to narrow down to an individual cluster, we examined the commonly important FC in Figure 4 for a particular cluster against the remainder of the clusters. We found that clusters 2 and 4 have a common important FC, as shown in Figure 5:
• Cluster 2: right thalamus−left cerebellum−left thalamus
• Cluster 4: right polar temporal sulcus−right anterior inferior temporal sulcus−right anterior occipito-temporal lateral sulcus−(left and right) median occipito-temporal lateral sulcus.
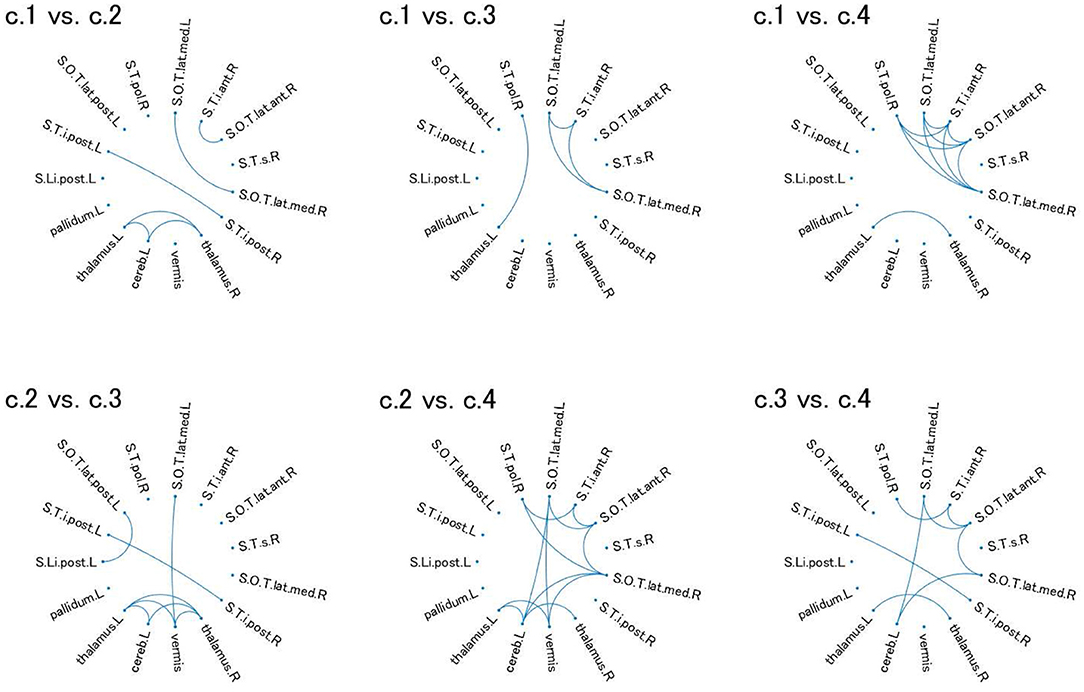
Figure 4. Relevant connectivity for differences between pairs of the four clusters in view 4. The relevant connectivity for the difference between cluster i and cluster j is displayed in panel “c.i vs. c.j.” The relevance of connectivity is evaluated by Cohen's d for the effect size of FC differences between two clusters. The connectivity with d > 0.8 [large separability; (39)] is shown in the diagram in which the ROI is denoted as a dot. S.Li.post.L, left posterior intra-lingual sulcus; S.O.T.lat.ant.R, right anterior occipito-temporal lateral sulcus; S.O.T.lat.med.L, left median occipito-temporal lateral sulcus; S.O.T.lat.med.R, right median occipito-temporal lateral sulcus; S.O.T.lat.post.L, left posterior occipito-temporal lateral sulcus; S.T.i.ant.R, right anterior inferior temporal sulcus; S.T.i.post.L, left posterior inferior temporal sulcus; S.T.i.post.R, right posterior inferior temporal sulcus; S.T.pol.R, right polar temporal sulcus; S.T.s.R, left superior temporal sulcus; thalamus.L, left thalamus; pallidum.L, left pallidum; thalamus.R, right thalamus; cereb.L, left cerebellum; vermis, vermis. For visualization of these brain regions, see Supplementary Figure 2.
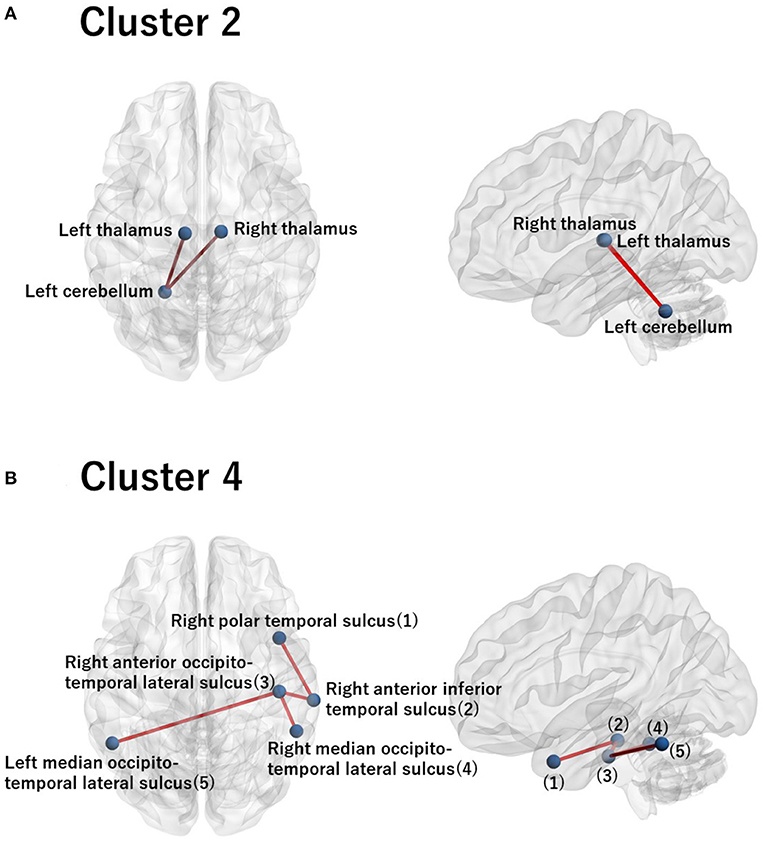
Figure 5. Visualization of the commonly important FC for cluster 2 (A) and for cluster 4 (B). (A) The commonly important FC that discriminates cluster 2 against the remainder of the clusters with the criterion Cohen's d > 0.8: right thalamus−left cerebellum−left thalamus. (B) The commonly important FC that discriminates cluster 4 against the remainder of the clusters with the criterion Cohen's d > 0.8: right polar temporal sulcus−right anterior inferior temporal sulcus−right anterior occipito-temporal lateral sulcus− (left and right) median occipito-temporal lateral sulcus. The numbering in the sagittal image denotes the corresponding ROI names in the axial image. Note that there is no commonly important FC for clusters 1 and 3 with the criterion Cohen's d > 0.8. Hence, we did not visualize brain images for these clusters.
We discuss the interpretation of these results in more detail in section 4.2.
In this section, we examine the reproducibility of the clustering results from view 4. Here, we classified the subjects of two independent datasets, KYO-A and KYO-B, using the clustering model in view 4. Furthermore, we also classified subjects in the TS data to examine the reproducibility of classification at the individual subject level.
We examined the validity of the clustering results from view 4, which was obtained in the previous section. We classified KYO subjects based on the UTO model (Table 5). Note that the KYO data were not used for model estimation; hence, they were independent of the estimated model. For pre-processing, we separately applied the whitening procedure for KYO-A and KYO-B (referred to as “KYO-whitening”). Subsequently, the classification was performed for each subject by fitting the Wishart mixture model of view 4 to the subject correlation matrix. To compare the performance, a similar classification was also performed for the KYO datasets that were whitened using the UTO data (referred to as “UTO-whitening”).
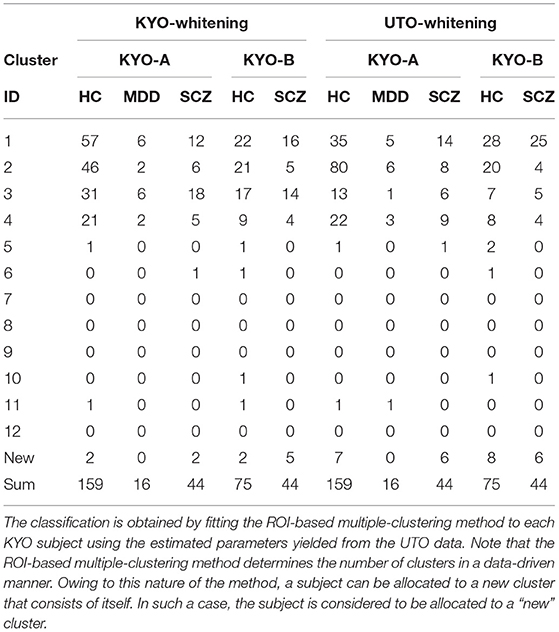
Table 5. Summary of classification of KYO subjects for view 4 with KYO-whitening and UTO-whitening.
To examine the reproducibility of the clustering results, we consider psychiatric labels and age distributions in the study sample. First, a visual inspection suggests that for KYO-whitening, the psychiatric label distribution of subjects over clusters is quite similar between KYO-A/B and UTO (Figures 6A,C,E), whereas this is not the case for UTO-whitening (Figures 6B,D,E). More precisely, focusing on HC, SCZ, and MDD (MDD is applicable only for KYO-A), the χ2 test for the difference in the subject distribution between KYO and UTO supports this observation (Table 6). For KYO-whitening, the difference between KYO-A and UTO was not significant for HC, SCZ, or MDD (p = 0.52, 0.97, and 0.73, respectively). Similarly, the difference between KYO-B and UTO was not significant for either HC or SCZ (p = 0.43 and 0.94, respectively). In contrast, for UTO-whitening, the difference between KYO-A and UTO was significant for HC and MDD (p = 0.010 and 0.045, respectively) but not for SCZ (p = 0.11). Furthermore, the difference between KYO-B and UTO was significant for SCZ but not for HC (p = 0.031 and p = 0.44, respectively). Next, we evaluated the extent of the difference between two clustering results by means of Cramér's V (40, 41) (Table 6). For KYO-whitening, the average Cramér's V is 0.09 for both KYO-A and KYO-B, whereas for UTO-whitening it is 0.27 and 0.23 for KYO-A and KYO-B, respectively. Following Cohen's criterion for effect size V (equivalent to Cohen's w: small 0.10; medium 0.30; large 0.50) (39), this result suggests that the clustering difference is small for KYO-whitening, whereas for UTO-whitening, the difference is medium.
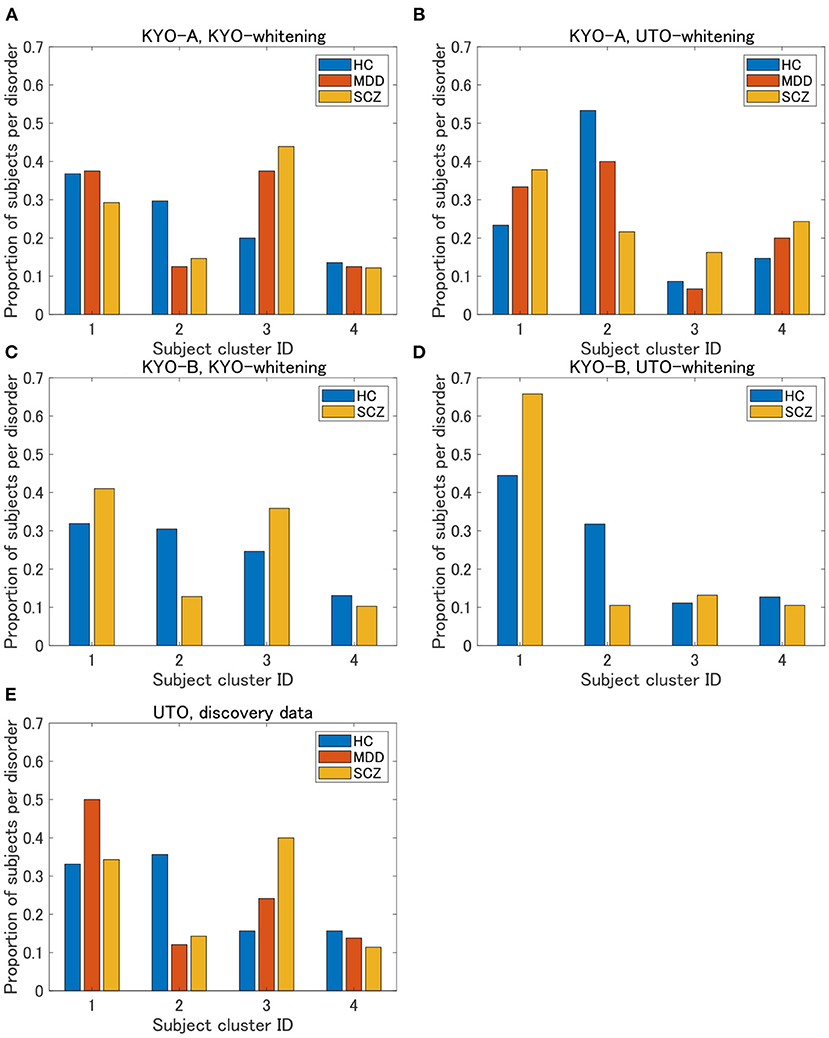
Figure 6. Results of validation for KYO data. (A,B) Proportion of subjects per disorder of KYO-A data with KYO-whitening and with UTO-whitening, respectively. (C,D) Similar graphs for KYO-B data. (E) Proportion of subjects per disorder of UTO data. This is a copy of Figure 3A, but to compare with the results of the KYO data, the proportion is displayed only for HC, MDD, and SCZ.
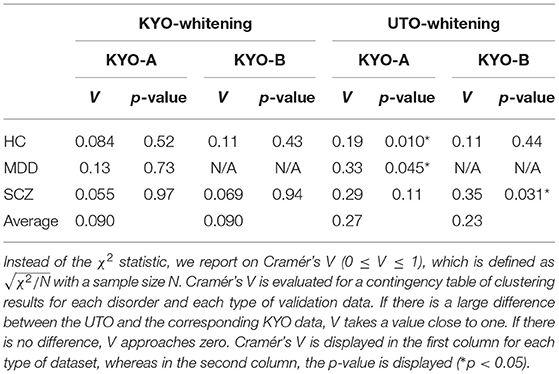
Table 6. Differences of clustering results (clusters 1–4 in view 4) between the discovery and validation data based on the χ2 test.
Regarding age distribution, we then examined whether the age difference among clusters for the UTO data was reproduced for the KYO data. For both KYO- and UTO-whitening, the age of the subjects in cluster 2 was relatively small (Supplementary Figure 3); however, the age difference among the clusters was minor. More precisely, for KYO-whitening, the difference was not significant for KYO-A and KYO-B (Kruskal–Wallis test; p = 0.41, and p = 0.53, respectively), whereas for UTO-whitening, the difference was significant for KYO-A but not for KYO-B (Kruskal–Wallis test; p = 0.0034 and p = 0.36, respectively).
Finally, we examined the reproducibility of the view 4 clustering results using TS data. We found that the reproducibility of cluster labels at the individual level was rather limited, with some variations in cluster labels observed for three scans at the same site (Supplementary Table 1). Nonetheless, focusing on the pattern of cluster labels, the reproducibility at the individual level was statistically significant between UTO and KYO-A using the permutation test (Figure 7). Furthermore, at the group level, the cluster-wise distribution of the total number of subjects was similar between UTO and KYO-A (Supplementary Table 2; p = 0.26, using the χ2 test).
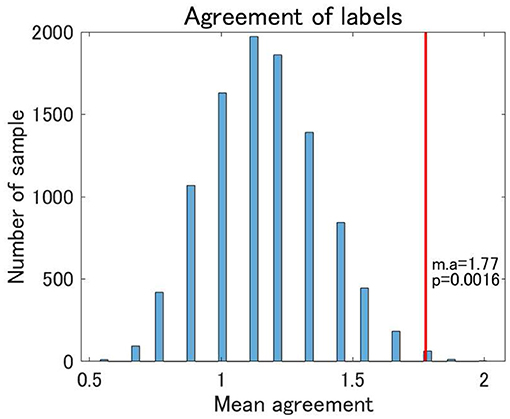
Figure 7. Agreement of cluster labels of traveling subjects (TS) between UTO scanner and KYO-A scanner. The agreement was measured as follows: each traveling subject performed three repetitions of fMRI scans for both the UTO scanner and KYO-A scanner. For each scan, we evaluated the FC matrix, which was subsequently used for classification based on the estimated model of view 4. Next, we evaluated the number of scans out of the three agreements between UTO and KYO-A (minimum 0; maximum 3). Finally, we took the average of the agreement for all traveling subjects (nine subjects). The null distribution of agreement is shown in the bar chart, which is based on 10,000 randomly shuffled TS data. The red line denotes the observed value of the mean agreement (the observed mean agreement and p-value are displayed on the right). Note that the correlation matrices are whitened by the corresponding datasets.
The framework of our analysis has so far been unsupervised learning, without explicitly using psychiatric label information. We used the label information only when we characterized the clustering results, which showed a correspondence between the yielded clusters and psychiatric disorders. One may wonder whether such a correspondence may become clearer in the framework of supervised learning, explicitly using the label information for model development. To address this issue, as a supplementary analysis, we performed a supervised classification of the UTO data. For simplicity, we based our multiclass classification on a pairwise classification. First, we created a classification model for each pair of five psychiatric disorders (HC, MDD, SCZ, BD, and ASD) in a supervised manner. In so doing, we balanced the sample size for the corresponding psychiatric disorders by subsampling subjects with psychiatric disorders with a larger sample size. For this balanced data, we evaluated the classification probability of the subjects in the data in a framework of leave-one-out cross-validation. Subsequently, we created a classification model using all the subjects in this balanced dataset. Second, using the classification model, we evaluated the classification probabilities of the remaining subjects. In this classification method, all subjects were classified as the test data. We then repeated this procedure for all pairs of psychiatric disorders, which yielded a vector of classification probability of the pair of psychiatric disorders for each subject. Therefore, for subject i, we obtained a classification probability pi(j, k) (j ≠ k), which denoted the probability that subject i belonged to a psychiatric disorder j in the classification model of that psychiatric disorder j vs. psychiatric disorder k. Note that pi(j, k) = 1 − pi(k, j). Third, for each subject i, we evaluated the marginal classification probability for a particular psychiatric disorder j by averaging the classification probabilities pi(j, k) over psychiatric disorders k. Finally, we assigned a classification label to each subject based on the marginal classification probability (i.e., the label with the largest marginal probability). For the pairwise classification, we applied elastic net classification to vectorized FC data, which is a linear classification method with L1 and L2 regularization (42). We considered two pre-processing steps: regression-out and non-regression-out of age and sex effects from the data.
The HC classification worked well for both the regression-out and non-regression-out cases (Figure 8, Supplementary Table 3). However, the performance of the classification of psychiatric disorders was rather poor, except for BD in the non-regression-out case, in which the majority of BD subjects were correctly classified into the BD category. Further, we evaluated the agreement between the classification results and the clustering results (clusters 1–4 in view 4) by means of ARI. For the regression-out and non-regression-out cases, ARI was 0.036 (p = 1.4×10−4 in the permutation test) and 0.054 (p = 6.0×10−6), respectively. When we excluded HC, the ARI was 0.022 (p = 0.048) and 0.025 (0.028), respectively. This suggested that there might be a small correspondence between the supervised and unsupervised results.
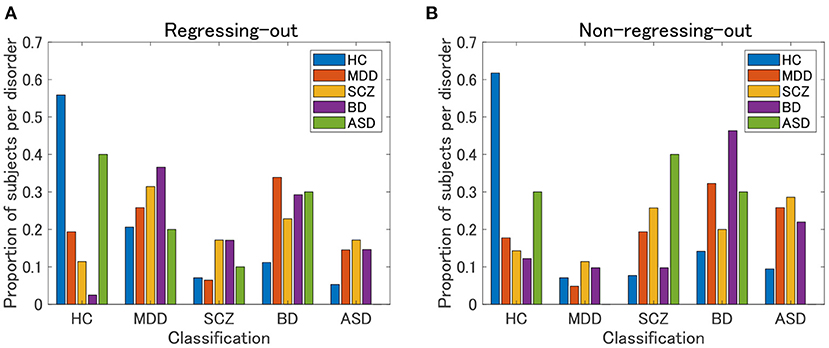
Figure 8. Classification results of UTO subjects in the supervised approach. First, a classification model is built for each pair of psychiatric disorders, including HC, by applying elastic net classification to vectorized FC data. Second, based on the marginal probability yielded by these classification models, a subject is classified into one of the psychiatric categories. (A) FC is pre-processed by regressing-out of the effect of age and sex. (B) FC is not preprocessed.
The ROI-based multiple clustering method revealed four clusters in view 4 of the UTO data that were characterized by psychiatric disorders: cluster 1 by MDD, cluster 2 by young HC, cluster 3 by SCZ/BD, and cluster 4 by ASD. The difference in psychiatric label distributions between a pair of clusters was significant when we focused on psychiatric disorders characterizing the clusters in question (except for the pair of clusters 2 and 4). The relevant subnetwork for these clusters consisted of 15 ROIs in a cerebellum-thalamus-pallidum-temporal circuit, which may suggest common functional connectivity to discriminate between HC, MDD, SCZ/BD, and ASD.
Regarding cluster 2 and the age effect, the statistical test showed that the age difference among clusters was significant for HC, whereas this was not the case for the remainder of the psychiatric disorders. This suggested that the effect of age was limited to HC only. Accordingly, it is worth noting that in Cluster 2, the proportion of psychiatric disorders was rather small. Hence, we can interpret that the FC pattern of the majority of psychiatric disorders is largely different from that of young HCs.
For cluster 3, note that SCZ and BD were not discriminated in the present study because there was no difference in the distributions between SCZ and BD over clusters using the χ2 test. This result is consistent with the growing evidence in the literature for phenological, biological, and genetic overlaps between SCZ and BD (43, 44).
The association between the four clusters and psychiatric disorders was largely reproduced by the validation datasets. First, the distribution pattern of psychiatric labels for the UTO data was reproduced for HC, SCZ, and MDD of KYO-A data and for HC and SCZ of KYO-B data with KYO-whitening. Regarding the age difference between clusters, the same tendency was observed between the UTO and KYO data, although it was not statistically significant. Moreover, reproducibility was not obtained when we inappropriately whitened the KYO data using the UTO data, which further strengthened the validity of the classification results with KYO-whitening. Nonetheless, the reproducibility discussed here is limited to the sense of grouped data since the subjects differed between the discovery and validation data. The analysis of the TS data showed that even under the same conditions of the site and scanner, the classification results may differ among the three scans for a single subject. Nonetheless, the distribution pattern of cluster labels was statistically consistent at the individual subject level. This demonstrated the extent to which the clustering results were valid and the level of statistical consistency of the distribution pattern of cluster labels at the individual subject level. One possible interpretation of this result is dynamic FC, a phenomenon in which FC presumably changes dynamically (45, 46). The dynamic nature of FC may contribute to the variation in classification results for a single subject, possibly because of the insufficient number of fMRI volumes.
Finally, we discuss views other than View 4. In the present study, we mainly focused on view 4, in which the cluster labels and psychiatric labels, including HC, showed a close association. Nonetheless, this does not rule out the usefulness of the remainder of the views. An additional analysis of paired psychiatric disorders suggests that view 6 is relevant for ASD and SCZ (Supplementary Figure 4). Likewise, it is expected that the remainder of these views may have clinical and biological implications. However, because of the limited clinical information on the subjects, it is not straightforward to characterize these views in the present framework.
Combined with the characterization of the clusters using psychiatric labels, we also interpreted clusters 2 and 4 in terms of the commonly important FC (Figure 5). First, cluster 2 was dominated by young HCs, with a small proportion of subjects with psychiatric disorders (Figure 3A). This suggests that the relevant FC in the cerebellothalamic circuit for cluster 2 is related to the contrast between young HCs and various psychiatric disorders. Several previous studies have reported on the relevance of this circuit for SCZ, which is referred to as the “cognitive dysmetria” theory (47). Cognitive dysmetria theory posits that dysfunction in this circuit impairs coordination of the mental process. A recent study (48) using two independent datasets showed that the abnormality of this circuit for SCZ is trait-dependent rather than state-dependent, which implies the underlying dysfunction of the circuit for SCZ. Furthermore, a study (49) suggested that the circuit can function as a possible biomarker for SCZ progression. In contrast, for MDD, this circuit has not been considered as a major biomarker of the disease (50). A study (51) showed that this circuit and DMN are closely associated with MDD, which is correlated with the Hamilton Depression Rating scale (51). In contrast, for BD, the role of the cerebellum in brain circuits remains unclear (52). To the best of our knowledge, there are no reports on the association between this circuit and BD, except for the recent cross-disorder study by (8). Nonetheless, for a better understanding of various psychiatric disorders, it has recently been suggested that the cerebellothalamic circuit may be added to psychomotor modulation (7, 53). The results of the present study are in line with the state-of-the-art understanding of shared neural circuits for various psychiatric disorders.
Second, cluster 4 is characterized by ASD with the relevance of FC between several temporal regions, including the occipito-temporal region. However, the important connectivity patterns for ASD remain unclear in literature (54). Nonetheless, it has been reported that the fluid intelligence of ASD is strongly associated with FC between the occipito-temporal region and the angular gyrus, posterior cingulate, and precuneus (55). Furthermore, it has been shown that FC between the occipito-temporal region and the posterior right temporo-parietal junction is correlated with social deficits in ASD (56). In conclusion, the yielded brain circuit in the present study is a new finding that discriminates ASD against HC and the remainder of the psychiatric disorders.
The ROI-based multiple clustering method is unique in two ways. First, it reveals the underlying multiple-view structure in the data, which allows feature selection for a particular cluster solution. Second, it identifies the relevant subnetworks of the ROI for cluster solutions. As shown in Figure 4, these properties are useful for identifying the underlying loop or tree structure of several ROIs related to a particular cluster solution. It is expected that this novel clustering method will pioneer data-driven subnetwork analysis for psychiatric disorders. However, the FC-based multiple clustering method does not provide a useful view in the present research. A possible reason for the poor performance is the considerably high feature dimension when an FC matrix is vectorized, which hinders the effective search of the optimal solution and leads to unstable cluster solutions. In addition, it could be attributed to the vectorization of the FC matrix, which may mask the underlying useful information to discriminate between psychiatric labels.
Next, the classification results of the KYO data suggests the importance of whitening the FC matrices. The whitening procedure involves a linear transformation of correlation matrices using the sample mean correlation matrix as the benchmark, which is analogous to normalization in conventional data processing. The better performance of KYO-whitening than UTO-whitening suggests that the measurement bias attributed to the site or scanner (57) may be removed through whitening.
Furthermore, in the present study, the supervised approach using elastic net classification did not work well for the classification of psychiatric disorders. HC subjects were classified well into the correct category, whereas psychiatric patients were not. Note that most patients were classified into non-HC categories, which suggested that the supervised classifier correctly discriminated between HC and non-HC subjects. Notably, none of the subjects with ASD were correctly categorized. This was possibly due to the very small sample size of ASD subjects (N = 10). In contrast, our unsupervised approach was able to identify cluster 4, which was characterized by ASD. This was possibly due to the prominence of cluster 4 in the unsupervised approach, not only by ASD but also by other non-ASD subjects with FC patterns similar to those of ASD subjects. However, it is currently not clear whether the misclassification of patients in the supervised approach was due to the intrinsic nature of the supervised approach using the diagnostic label or because of the small sample size for building a classification model in the present study.
Finally, the present cluster analysis provides a useful framework for the dimensional approach to psychiatric disorders. To the best of our knowledge, there have been few attempts to structurally elucidate the relationships among various psychiatric disorders (12). Thus, we consider one possible attempt to project cluster centers onto a two-dimensional plane using multidimensional scaling (MDS). MDS is a dimension-reduction method that preserves the distance between objects (58). In the present study, we use the Euclidean distance between the mean correlation matrices for cluster centers. The MDS results for clusters 1–4 in view 4 suggest that cluster 1 (MDD) and cluster 3 (SCZ/BD) are located nearby, whereas cluster 2 (young HC) and cluster 4 (ASD) are far apart (Figure 9). A closer look at the figure shows that young HC, MDD, and SCZ/BD are in the same continuum (red line), in which MDD is slightly closer to young HC than SCZ/BD. ASD is not located in this continuum, which suggests that it may comprise its own dimension. This interpretation of ASD is consistent with our finding that the depression scale (CES-D) of HC subjects is lower in cluster 4 than in clusters 2 and 3, implying less depressiveness for ASD.
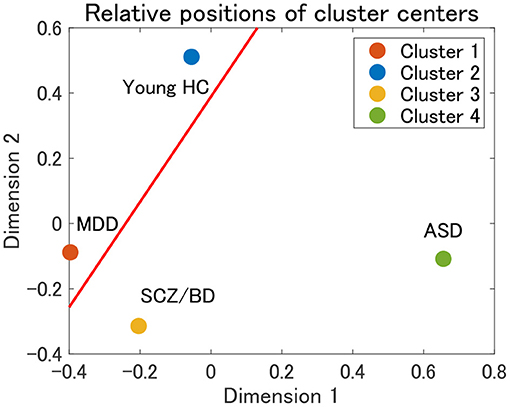
Figure 9. Relative positions of cluster centers in view 4 by means of multidimensional scaling (MDS). The red line denotes a possible axis for the continuum of clusters 1–3, which is a linear regression line for the centers of clusters 1–3.
The first major limitation of the present study was the small sample size for psychiatric disorders, which lowered the statistical power for the characterization of the yielded clusters. The reason for the small sample size was that we focused on the specific site or scanner for the discovery data to alleviate the issue of site or scanner biases. Second, the main characterization of the yielded clusters was based on single diagnostic label information, due to the limited availability of other clinical information of the subjects. With the availability of more clinical data, it would be possible to characterize the clusters in a more comprehensive manner. Third, we did not remove the effects of confounding factors, such as age and sex. This was due to the intrinsic nature of the ROI-based multiple clustering method (not due to the FC-based method), which fitted a correlation matrix to the Wishart distribution. Note that the Wishart distribution required an input matrix to satisfy the positive-definite condition. This strict condition on the input matrix did not allow us to perform arithmetic operations for the matrix in an element-wise manner. Hence, the conventional GLM approach (57) to remove the confounding effect in an element-wise manner was not readily applicable to the present framework. For the same reason, it would not be straightforward to perform harmonization to remove the site or scanner bias, such as ComBat (59) and TS (57). It will be important for future work to overcome these difficulties for the ROI-based multiple clustering method.
Publicly available datasets were analyzed in this study. This data can be found at: https://bicr-resource.atr.jp/srpbsfc/.
Ethical review and approval was not required for the study on human participants in accordance with the local legislation and institutional requirements. Written informed consent for participation was not required for this study in accordance with the national legislation and the institutional requirements.
TT, OY, YS, and JY contributed to conception and design of the study. TT wrote the first draft of the manuscript. All authors contributed to manuscript revision, read, and approved the submitted version.
This research was partially conducted as a contract project supported by Japan Agency for Medical Research and Development (AMED) under Grant Number JP20dm0307002 (TT), JP20dm0307008 (JY, YS, and TT), JP20dm0307009 (OY), and JP20dm0107096 (JY).
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fpsyt.2021.683280/full#supplementary-material
1. ^SRPBS Multidisorder Connectivity Dataset. Available online at: https://bicrresource.atr.jp/srpbsfc/
1. Du Y, Fu Z, Calhoun VD. Classification and prediction of brain disorders using functional connectivity: Promising but challenging. Front Neurosci. (2018) 12:525. doi: 10.3389/fnins.2018.00525
2. Woodward ND, Cascio CJ. Resting-state functional connectivity in psychiatric disorders. JAMA Psychiatry. (2015) 72:743–44. doi: 10.1001/jamapsychiatry.2015.0484
3. Xia CH, Ma Z, Ciric R, Gu S, Betzel RF, Kaczkurkin AN, et al. Linked dimensions of psychopathology and connectivity in functional brain networks. Nat Commun. (2018) 9:1–14. doi: 10.1038/s41467-018-05317-y
4. Mulders PC, van Eijndhoven PF, Schene AH, Beckmann CF, Tendolkar I. Resting-state functional connectivity in major depressive disorder: a review. Neurosci Biobehav Rev. (2015) 56:330–44. doi: 10.1016/j.neubiorev.2015.07.014
5. Sheffield JM, Barch DM. Cognition and resting-state functional connectivity in schizophrenia. Neurosci Biobehav Rev. (2016) 61:108–20. doi: 10.1016/j.neubiorev.2015.12.007
6. Doucet GE, Janiri D, Howard R, O'Brien M, Andrews-Hanna JR, Frangou S. Transdiagnostic and disease-specific abnormalities in the default-mode network hubs in psychiatric disorders: a meta-analysis of resting-state functional imaging studies. Eur Psychiatry. (2020) 63:e57. doi: 10.1192/j.eurpsy.2020.57
7. Northoff G, Hirjak D, Wolf RC, Magioncalda P, Martino M. All roads lead to the motor cortex: Psychomotor mechanisms and their biochemical modulation in psychiatric disorders. Mol Psychiatry. (2020) 26:92–102. doi: 10.1038/s41380-020-0814-5
8. Tu PC, Chen MH, Chang WC, Kao ZK, Hsu JW, Lin WC, et al. Identification of common neural substrates with connectomic abnormalities in four major psychiatric disorders: a connectome-wide association study. Eur Psychiatry. (2021) 64:e8. doi: 10.1192/j.eurpsy.2020.106
9. Baker JT, Dillon DG, Patrick LM, Roffman JL, Brady RO, Pizzagalli DA, et al. Functional connectomics of affective and psychotic pathology. Proc Natl Acad Sci USA. (2019) 116:9050–9. doi: 10.1073/pnas.1820780116
10. Huang J, Perlis RH, Lee PH, Rush AJ, Fava M, Sachs GS, et al. Cross-disorder genomewide analysis of schizophrenia, bipolar disorder, and depression. Am J Psychiatry. (2010) 167:1254–63. doi: 10.1176/appi.ajp.2010.09091335
11. Goodkind M, Eickhoff SB, Oathes DJ, Jiang Y, Chang A, Jones-Hagata LB, et al. Identification of a common neurobiological substrate for mental illness. JAMA Psychiatry. (2015) 72:305–15. doi: 10.1001/jamapsychiatry.2014.2206
12. Koshiyama D, Fukunaga M, Okada N, Morita K, Nemoto K, Usui K, et al. White matter microstructural alterations across four major psychiatric disorders: mega-analysis study in 2937 individuals. Mol Psychiatry. (2020) 25:883–95. doi: 10.1038/s41380-019-0553-7
13. Anderson JS, Nielsen JA, Froehlich AL, DuBray MB, Druzgal TJ, Cariello AN, et al. Functional connectivity magnetic resonance imaging classification of autism. Brain. (2011) 134:3742–54. doi: 10.1093/brain/awr263
14. Yu Y, Shen H, Zhang H, Zeng LL, Xue Z, Hu D. Functional connectivity-based signatures of schizophrenia revealed by multiclass pattern analysis of resting-state fMRI from schizophrenic patients and their healthy siblings. Biomed Eng Online. (2013) 12:1–13. doi: 10.1186/1475-925X-12-10
15. Shimizu Y, Yoshimoto J, Toki S, Takamura M, Yoshimura S, Okamoto Y, et al. Toward probabilistic diagnosis and understanding of depression based on functional MRI data analysis with logistic group LASSO. PLoS ONE. (2015) 10:e0123524. doi: 10.1371/journal.pone.0123524
16. Iidaka T. Resting state functional magnetic resonance imaging and neural network classified autism and control. Cortex. (2015) 63:55–67. doi: 10.1016/j.cortex.2014.08.011
17. Cabral C, Kambeitz-Ilankovic L, Kambeitz J, Calhoun VD, Dwyer DB, Von Saldern S, et al. Classifying schizophrenia using multimodal multivariate pattern recognition analysis: evaluating the impact of individual clinical profiles on the neurodiagnostic performance. Schizophr Bull. (2016) 42(Suppl. 1):S110–7. doi: 10.1093/schbul/sbw053
18. American Psychiatric Association. Diagnostic and Statistical Manual of Mental Disorders (DSM-5®). American Psychiatric Association (2013).
19. Hyman SE. The diagnosis of mental disorders: the problem of reification. Annu Rev Clin Psychol. (2010) 6:155–79. doi: 10.1146/annurev.clinpsy.3.022806.091532
20. Krueger RF, Hopwood CJ, Wright AG, Markon KE. DSM-5 and the path toward empirically based and clinically useful conceptualization of personality and psychopathology. Clin Psychol. (2014) 21:245–61. doi: 10.1111/cpsp.12073
21. Maj M. Why the clinical utility of diagnostic categories in psychiatry is intrinsically limited and how we can use new approaches to complement them. World Psychiatry. (2018) 17:121. doi: 10.1002/wps.20512
22. Cuthbert BN, Insel TR. Toward the future of psychiatric diagnosis: the seven pillars of RDoC. BMC Med. (2013) 11:126. doi: 10.1186/1741-7015-11-126
23. Reininghaus U, Böhnke JR, Hosang G, Farmer A, Burns T, McGuffin P, et al. Evaluation of the validity and utility of a transdiagnostic psychosis dimension encompassing schizophrenia and bipolar disorder. Br J Psychiatry. (2016) 209:107–13. doi: 10.1192/bjp.bp.115.167882
24. Grisanzio KA, Goldstein-Piekarski AN, Wang MY, Ahmed APR, Samara Z, Williams LM. Transdiagnostic symptom clusters and associations with brain, behavior, and daily function in mood, anxiety, and trauma disorders. JAMA Psychiatry. (2018) 75:201–9. doi: 10.1001/jamapsychiatry.2017.3951
25. Fusar-Poli P, Solmi M, Brondino N, Davies C, Chae C, Politi P, et al. Transdiagnostic psychiatry: a systematic review. World Psychiatry. (2019) 18:192–207. doi: 10.1002/wps.20631
26. Drysdale AT, Grosenick L, Downar J, Dunlop K, Mansouri F, Meng Y, et al. Resting-state connectivity biomarkers define neurophysiological subtypes of depression. Nat Med. (2017) 23:28. doi: 10.1038/nm.4246
27. Tokuda T, Yoshimoto J, Shimizu Y, Okada G, Takamura M, Okamoto Y, et al. Identification of depression subtypes and relevant brain regions using a data-driven approach. Sci Rep. (2018) 8:1–13. doi: 10.1038/s41598-018-32521-z
28. Tokuda T, Yamashita O, Yoshimoto J. Multiple clustering for identifying subject clusters and brain sub-networks using functional connectivity matrices without vectorization. Neural Netw. (2021) 142:269–87. doi: 10.1016/j.neunet.2021.05.016
29. Bailey J. Alternative clustering analysis: a review. In: Aggarwal C, Reddy C, editors. Data Clustering: Algorithms and Applications. London: Taylor & Francis (2013). p. 535–50.
30. Hu J, Qian Q, Pei J, Jin R, Zhu S. Finding multiple stable clusterings. Knowl Inform Syst. (2017) 51:991–1021. doi: 10.1007/s10115-016-0998-9
31. Gershman SJ, Blei DM. A tutorial on Bayesian nonparametric models. J Math Psychol. (2012) 56:1–12. doi: 10.1016/j.jmp.2011.08.004
32. Gelman A, Carlin JB, Stern HS, Dunson DB, Vehtari A, Rubin DB. Bayesian Data Analysis. CRC Press (2013). doi: 10.1201/b16018
33. Bressler SL, Menon V. Large-scale brain networks in cognition: emerging methods and principles. Trends Cogn Sci. (2010) 14:277–90. doi: 10.1016/j.tics.2010.04.004
35. Tokuda T, Yoshimoto J, Shimizu Y, Okada G, Takamura M, Okamoto Y, et al. Multiple co-clustering based on nonparametric mixture models with heterogeneous marginal distributions. PLoS ONE. (2017) 12:e186566. doi: 10.1371/journal.pone.0186566
36. Perrot M, Riviére D, Mangin JF. Cortical sulci recognition and spatial normalization. Med Image Anal. (2011) 15:529–50. doi: 10.1016/j.media.2011.02.008
37. Tzourio-Mazoyer N, Landeau B, Papathanassiou D, Crivello F, Etard O, Delcroix N, et al. Automated anatomical labeling of activations in SPM using a macroscopic anatomical parcellation of the MNI MRI single-subject brain. NeuroImage. (2002) 15:273–89. doi: 10.1006/nimg.2001.0978
38. Yahata N, Morimoto J, Hashimoto R, Lisi G, Shibata K, Kawakubo Y, et al. A small number of abnormal brain connections predicts adult autism spectrum disorder. Nat Commun. (2016) 7:1–12. doi: 10.1038/ncomms11254
39. Cohen J. Statistical Power Analysis for the Behavioral Sciences. New York, NY: Academic Press (2013). doi: 10.4324/9780203771587
40. Cramér H. Mathematical Methods of Statistics (PMS-9). Vol. 9. Princeton, NJ: Princeton University Press (2016).
41. Prematunga RK. Correlational analysis. Austr Crit Care. (2012) 25:195–9. doi: 10.1016/j.aucc.2012.02.003
42. Zou H, Hastie T. Regularization and variable selection via the elastic net. J R Stat Soc Ser B. (2005) 67:301–20. doi: 10.1111/j.1467-9868.2005.00503.x
43. Keshavan MS, Morris DW, Sweeney JA, Pearlson G, Thaker G, Seidman LJ, et al. A dimensional approach to the psychosis spectrum between bipolar disorder and schizophrenia: the Schizo-Bipolar Scale. Schizophr Res. (2011) 133:250–4. doi: 10.1016/j.schres.2011.09.005
44. Ruderfer DM, Ripke S, McQuillin A, Boocock J, Stahl EA, Pavlides JMW, et al. Genomic dissection of bipolar disorder and schizophrenia, including 28 subphenotypes. Cell. (2018) 173:1705–15. doi: 10.1016/j.cell.2018.05.046
45. Hutchison RM, Womelsdorf T, Allen EA, Bandettini PA, Calhoun VD, Corbetta M, et al. Dynamic functional connectivity: Promise, issues, and interpretations. NeuroImage. (2013) 80:360–78. doi: 10.1016/j.neuroimage.2013.05.079
46. Li C, Dong M, Womer FY, Han S, Yin Y, Jiang X, et al. Transdiagnostic time-varying dysconnectivity across major psychiatric disorders. Hum Brain Mapp. (2021) 42:1182–96. doi: 10.1002/hbm.25285
47. Andreasen NC, O'Leary DS, Cizadlo T, Arndt S, Rezai K, Ponto L, et al. Schizophrenia and cognitive dysmetria: a positron-emission tomography study of dysfunctional prefrontal-thalamic-cerebellar circuitry. Proc Natl Acad Sci USA. (1996) 93:9985–90. doi: 10.1073/pnas.93.18.9985
48. Cao H, Chén OY, Chung Y, Forsyth JK, McEwen SC, Gee DG, et al. Cerebello-thalamo-cortical hyperconnectivity as a state-independent functional neural signature for psychosis prediction and characterization. Nat Commun. (2018) 9:1–9. doi: 10.1038/s41467-018-06350-7
49. Bernard JA, Orr JM, Mittal VA. Cerebello-thalamo-cortical networks predict positive symptom progression in individuals at ultra-high risk for psychosis. NeuroImage. (2017) 14:622–8. doi: 10.1016/j.nicl.2017.03.001
50. Zhao L, Wang Y, Jia Y, Zhong S, Sun Y, Zhou Z, et al. Cerebellar microstructural abnormalities in bipolar depression and unipolar depression: a diffusion kurtosis and perfusion imaging study. J Affect Disord. (2016) 195:21–31. doi: 10.1016/j.jad.2016.01.042
51. Chen Y, Wang C, Zhu X, Tan Y, Zhong Y. Aberrant connectivity within the default mode network in first-episode, treatment-naive major depressive disorder. J Affect Disord. (2015) 183:49–56. doi: 10.1016/j.jad.2015.04.052
52. Chen G, Zhao L, Jia Y, Zhong S, Chen F, Luo X, et al. Abnormal cerebellum-DMN regions connectivity in unmedicated bipolar II disorder. J Affect Disord. (2019) 243:441–7. doi: 10.1016/j.jad.2018.09.076
53. Mittal VA, Bernard JA, Walther S. Cerebellar-thalamic circuits play a critical role in psychomotor function. Mol Psychiatry. (2020). doi: 10.1038/s41380-020-00935-9. [Epub ahead of print].
54. Hull JV, Dokovna LB, Jacokes ZJ, Torgerson CM, Irimia A, Van Horn JD. Resting-state functional connectivity in autism spectrum disorders: a review. Front Psychiatry. (2017) 7:205. doi: 10.3389/fpsyt.2016.00205
55. Pua EPK, Malpas CB, Bowden SC, Seal ML. Different brain networks underlying intelligence in autism spectrum disorders. Hum Brain Mapp. (2018) 39:3253–62. doi: 10.1002/hbm.24074
56. Chien HY, Lin HY, Lai MC, Gau SSF, Tseng WYI. Hyperconnectivity of the right posterior temporo-parietal junction predicts social difficulties in boys with autism spectrum disorder. Autism Res. (2015) 8:427–41. doi: 10.1002/aur.1457
57. Yamashita A, Yahata N, Itahashi T, Lisi G, Yamada T, Ichikawa N, et al. Harmonization of resting-state functional MRI data across multiple imaging sites via the separation of site differences into sampling bias and measurement bias. PLoS Biol. (2019) 17:e3000042. doi: 10.1371/journal.pbio.3000042
58. Carroll JD, Arabie P. Multidimensional scaling. In: Birnbaum MH, editor. Measurement, Judgment and Decision Making. San Diego, CA: Elsevier (1998). p. 179–250. doi: 10.1016/B978-012099975-0.50005-1
Keywords: clustering, functional connectivity, biomarker, multiple clustering, psychiatric disorder
Citation: Tokuda T, Yamashita O, Sakai Y and Yoshimoto J (2021) Clustering of Multiple Psychiatric Disorders Using Functional Connectivity in the Data-Driven Brain Subnetwork. Front. Psychiatry 12:683280. doi: 10.3389/fpsyt.2021.683280
Received: 20 March 2021; Accepted: 26 July 2021;
Published: 18 August 2021.
Edited by:
Jong-Hwan Lee, Korea University, South KoreaReviewed by:
Chao Li, The First Affiliated Hospital of China Medical University, ChinaCopyright © 2021 Tokuda, Yamashita, Sakai and Yoshimoto. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Tomoki Tokuda, dC10b2t1ZGFAYXRyLmpw
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.