 Songtao Yang
Songtao Yang Yongqi Ge
Yongqi Ge Jing Wang1
Jing Wang1 Rui Liu
Rui Liu- 1College of Information Engineering, Ningxia University, Yinchuan, China
- 2Ningxia Key Laboratory of Artificial Intelligence and Information Security for Channeling Computing Resources from the East to the West, Yinchuan, China
- 3College of Resources Environment and Life Sciences, Ningxia Normal University, Guyuan, China
Leaf area index (LAI) of alfalfa is a crucial indicator of its growth status and a predictor of yield. The LAI of alfalfa is influenced by environmental factors, and the limitations of non-linear models in integrating these factors affect the accuracy of LAI predictions. This study explores the potential of classical non-linear models and deep learning for predicting alfalfa LAI. Initially, Logistic, Gompertz, and Richards models were developed based on growth days to assess the applicability of nonlinear models for LAI prediction of alfalfa. In contrast, this study combines environmental factors such as temperature and soil moisture, and proposes a time series prediction model based on mutation point detection method and encoder-attention-decoder BiLSTM network (TMEAD-BiLSTM). The model’s performance was analyzed and evaluated against LAI data from different years and cuts. The results indicate that the TMEAD-BiLSTM model achieved the highest prediction accuracy (R² > 0.99), while the non-linear models exhibited lower accuracy (R² > 0.78). The TMEAD-BiLSTM model overcomes the limitations of nonlinear models in integrating environmental factors, enabling rapid and accurate predictions of alfalfa LAI, which can provide valuable references for alfalfa growth monitoring and the establishment of field management practices.
1 Introduction
Alfalfa (Medicago sativa L.) is regarded as the “king of forages” upon account of its remarkable forage properties, prolific production, high protein and nutritious content, and good palatability (Baral et al., 2022). Between 2010 and 2020, China’s import of alfalfa hay increased from 200,000 tons to 1.4 million tons in response to the growing market demand (Wang and Zhang, 2023). To reduce import dependence, China actively expanded its alfalfa cultivation area and increased alfalfa production (Wang et al., 2023). However, alfalfa production faces significant challenges due to regional climate variations, limited water resources, and soil conditions (Qian et al., 2020). The leaf area index (LAI) of alfalfa is a crucial indicator for defining the canopy structure of alfalfa, statistically describing the growth and density changes of alfalfa leaf populations (Tooley et al., 2024). It can be used to assess the dynamics of leaf growth and yield in alfalfa (Tripathi et al., 2018). Therefore, predicting the alfalfa leaf area index is significant for monitoring growth dynamics and guiding field management.
Methods for predicting LAI through direct measurement of leaf area are often destructive and can be costly. Numerous studies have developed nonlinear models for LAI prediction by analyzing the optimal growth requirements at each developmental stage of plants. Examples include the Logistic model, Gompertz model, Richards model, and Schnute model (Zhang et al., 2021; Duran and Ünal, 2024). Guo et al. (2022) established a generalized Logistic model using growing degree days (GDD) and relative growing degree days (RGDD) as key parameters to describe the height, leaf area index, and biomass accumulation of maize. Karadavut et al. (2010) was carried out on five maize varieties (Monton, Ranchero, Progen 1550, 35 P12, and TTM 81-19) to explain the fitting performance of the Richards model on leaf data. Chaturvedi et al. (2017) developed allometric models for estimating the leaf area index (LAI) of Tectona grandis (teak) trees across ten diameter classes in India. Non-linear regression models, especially logistic and Gompertz, effectively explained over 60% of LAI variability. The advantages of such models include their simplicity, ease of calculation, and reasonable interpretability. However, the limitations are also obvious. This is mainly reflected in two aspects: first, the parameter settings of such models need to be verified and calibrated through years of field experiments, and their applicability in different regions is poor (Lin et al., 2023; Brogi et al., 2020); second, such models are usually one-dimensional, lacking the consideration of a large number of environmental influences, and the dynamic change of variables over time is not taken into account (Desai et al., 2020).
In contrast, deep learning is more suitable for handling non-linear prediction problems. Deep learning models can improve their predictive ability by self-learning the relationships between data from multiple dimensions based on historical datasets, including crop growth information, crop environmental information, and field management strategies. Ze-hao et al. (2020) used LSTM to model winter wheat temporal LAI and LAI in different growth periods, and the results showed that the LSTM network has good prediction ability. Long Short-Term Memory (LSTM), while capable of obtaining long-term dependent time series estimates from continuous time series data, uses only prior state knowledge and ignores back propagation of information about current vegetation changes (Sherstinsky, 2020). BiLSTM adds a reverse operation based on LSTM, which is better than LSTM at capturing the relationship between sequential features (Siami-Namini et al., 2019). LSTM shows excellent performance in time-series based prediction results, but performs poorly in dealing with data mutations.
LSTM has strong self-learning and self-adaptive ability, which overcomes the shortcomings of classical non-linear models to a certain extent. However, alfalfa is often at the maximum LAI value during the cutting, which leads to LAI data mutations after cutting. The presence of these mutation points may greatly reduce the predictive performance of LSTM. Researchers have proposed detection strategies for the change point problem, including maximum likelihood, least squares, minimum absolute length, and minimum descriptive length (Anastasiou and Fryzlewicz, 2022; Chen et al., 2022). This paper examines the number and location of mutations in alfalfa leaf area index data using moving sum (MOSUM) method. The MOSUM method not only effectively detects data mutations, but also greatly reduces the computational complexity (Burczaniuk and Jastrzębska, 2024).
To overcome the limitations of nonlinear models in integrating environmental factors and the inefficiency of LSTM in handling abrupt changes in LAI data, this study proposes a TMEAD-BiLSTM method for the rapid and accurate prediction of alfalfa leaf area index. The main contributions of this paper are as follows:
1) We established Logistic, Gompertz, and Richards models for predicting alfalfa leaf area index based on growing degree days, achieving a prediction accuracy (R²) greater than 0.78 for all three models.
2) To address the issue of abrupt data changes after alfalfa harvesting, we proposed a TMEAD-BiLSTM model that combines the MOSUM method with a bidirectional long short-term memory (BiLSTM) encoder-decoder neural network. This model predicts the leaf area index (LAI) of alfalfa by utilizing its annual cycle and different planting strategies. The results demonstrate that this deep learning model achieved the highest prediction accuracy (R² > 0.99).
2 Materials and methods
This section introduces the experimental dataset, which comes from the publicly available dataset we previously worked on. Secondly, we describe the non-linear model and TMEAD-BiLSTM model used for predicting alfalfa leaf area index, and display the model training parameters and evaluation indicators. Then the training process and techniques used to optimize model performance were discussed. Finally, we propose evaluation metrics for assessing and comparing the accuracy of the models.
2.1 Dataset
The acquisition of alfalfa LAI data requires a significant amount of manpower and resources, and adverse weather conditions may affect the accuracy and feasibility of data collection, further increasing the challenge of obtaining continuous time series data. To the best of our knowledge, only we have publicly released the alfalfa leaf area index dataset (Yang et al., 2024a). The dataset provides growth data of alfalfa under different water and nitrogen treatments, as well as meteorological data for the entire growth period of alfalfa and soil moisture data at different depths (0-10 cm, >10-20 cm, >20-30 cm). The dataset includes field trial data from three years of history (2017-2018, 2022), with a 7-day interval for collecting alfalfa LAI data. During the period from 2019 to 2021, the experimental field was utilized for planting silage maize using a rotation method. The dataset contains a total of 955 leaf area index data. The interval between meteorological and soil moisture data is one day. Integrating multiple features is beneficial for expanding the applicability of estimation and prediction models and improving their accuracy. This paper used non-linear regression models and deep learning models to model the alfalfa leaf area index.
We used this dataset to model the alfalfa leaf area index, as shown in Figure 1. The dataset contains 955 leaf area index data, the dataset is divided according to the following proportion: (Train: Val = 8: 2): Test = 8: 2. Deep learning models require a large number of samples to participate in training, and we use logistic models with relative leaf area index and growth days for data augmentation. Calculate daily LAI based on the maximum measured LAI value, as shown in equation (14). Thus, a daily LAI dataset with a history of three years is generated, and the partially enhanced dataset is shown in Table 1.

Figure 1. Dataset partitioning and prediction strategies.
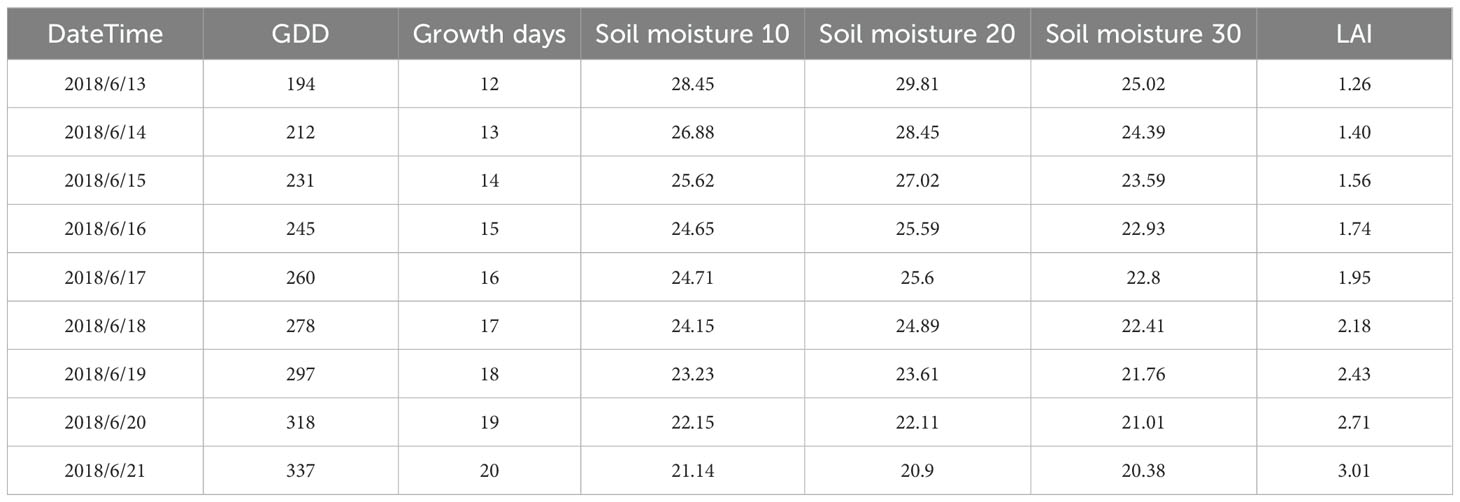
Table 1. Partial data of LAI dataset.
Where, f(·) represents the fitting curve; GD represents the number of growing days; LAImax represents the maximum measured LAI value.
2.2 Non-liner model
The growth of plants over time typically follows an “S” shaped curve, and such growth characteristics are often simulated using mathematical models such as the Logistic model, Gompertz model, and Richards model. Currently, research on modeling the leaf area index of alfalfa using mathematical models is still in its early stages. In this study, the growth days are taken as influencing factors, and single variable Logistic, Gompertz, and Richards models are used to model four different cuttings of alfalfa. The applicability of Logistic, Richards, and Gompertz models in predicting the leaf area index of alfalfa is evaluated.
While the trend of alfalfa LAI growth days is basically consistent, significant differences in the LAI values among different water and nitrogen treatment plots. The relative leaf area index (RLAI) can eliminate the influence of mathematical models on the fitting of alfalfa LAI under different water and nitrogen treatments, thereby allowing for more accurately analyzing the growth status of alfalfa under different treatments (Su et al., 2022; Liu et al., 2020). Using three non-linear regression models, Logistic (Formula 2), Richards (Formula 3), Gompertz (Formula 4), to describe the trend of LAI changes during plant growth (Nhu et al., 2020; Roosa et al., 2020; Vaghi et al., 2020):
Where, RLAI is the relative leaf area index; LAI is leaf area index; LAImax is the theoretical maximum LAI. a1, b1, c1, a2, b2, c2, a3, b3, c3 and d are model fitting parameters; x is the growth days.
2.3 TMEAD-BiLSTM model
2.3.1 Overall framework
The construction of the model can be divided into three parts: (1) The MOSUM method is used to detect mutation points in time series data (Figures 2A, B). (2) A model based on encoder decoder was constructed, where both the encoder and decoder are BiLSTM models (Figures 2C, E). In order to solve the problem of feature disappearance and information loss caused by covariate feature compression in long sequence data, we introduced an attention mechanism in the model to capture the long-term dependency relationship between input decoder covariates and feature variables (Figure 2D). The fully connected layer outputs the predicted results (Figure 2F). (3) During the training process, training batches containing mutation points are eliminated through pre-defined functions. This section focuses on the construction process of the TMEAD-BiLSTM model, the overall structure of which is shown in Figure 2.
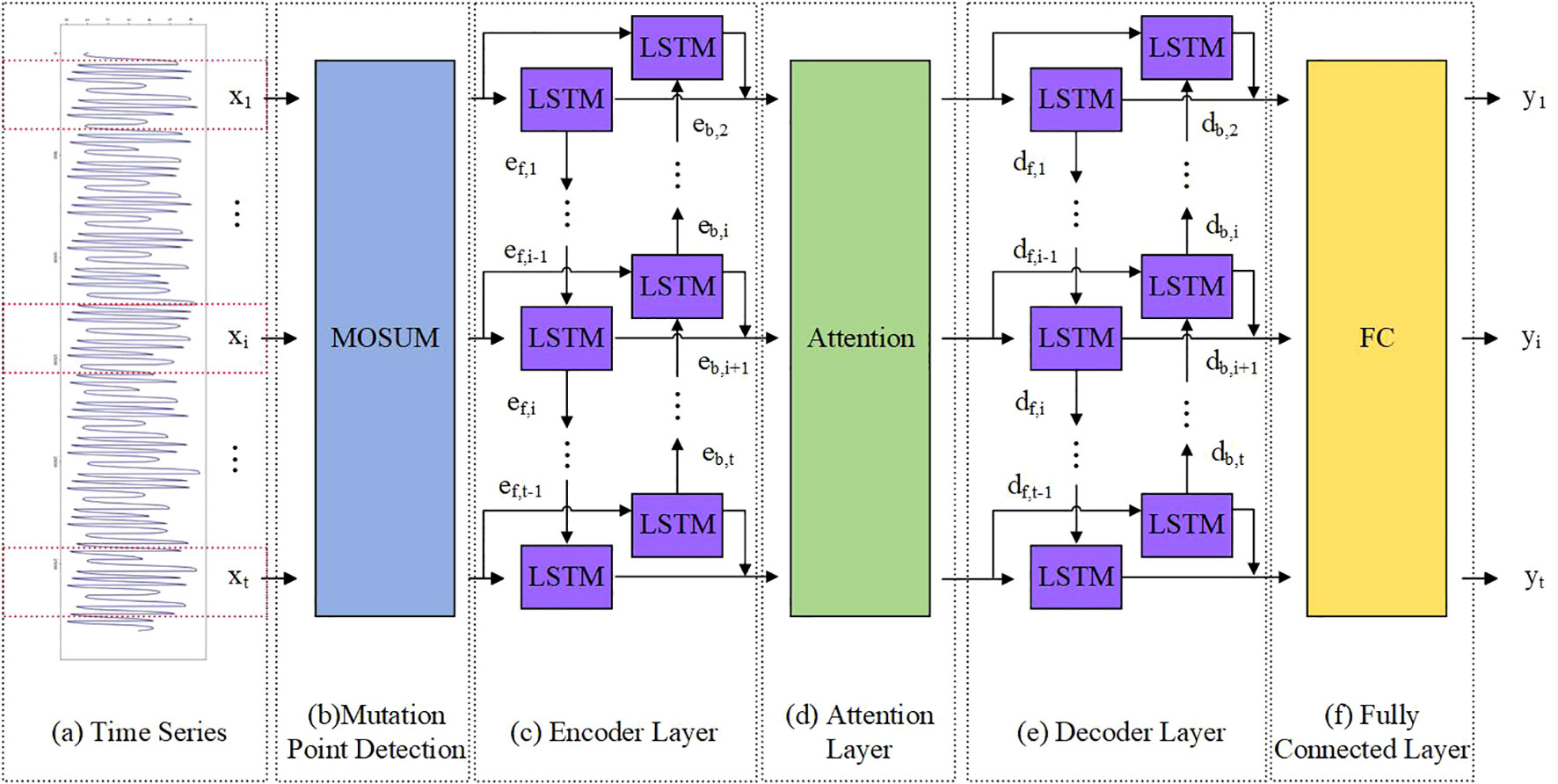
Figure 2. A hybrid model combining attention based BiLSTM encoder-decoder neural network and MOSUM (TMEAD-BiLSTM for short).
2.3.2 Mutation point detection based on MOSUM
Time series data usually contains mutation points, and there is currently no widely recognized method to handle these mutation data points. The currently known processing methods include removing abnormal data or using linear interpolation for filling (Liguori et al., 2021). However, these methods may disrupt the time series properties of the data and affect the accuracy of the analysis. Time series prediction has made remarkable progress in recent years, evolving from traditional statistical methods and machine learning to the latest deep learning techniques, thereby advancing the field of time series analysis (Masini et al., 2023). However, there are still some basic problems in practice, and one of the main problems is the existence of lag difference. Lag differences are deviations or delays that occur in the predicted sequence, which can affect the accuracy and robustness of the model (Samanta et al., 2020). Time series data usually contain abrupt change, and the presence of abrupt change greatly reduces the prediction performance of the model when there is a lag in the prediction process, as shown in Figure 3. As a forage crop, alfalfa shows a positive correlation between leaf area index (LAI), and final yield throughout its growth cycle. During mowing, alfalfa LAI was generally reaches its maximum value, and LAI mutations occur afterward, significantly impacting the prediction performance of deep learning models.
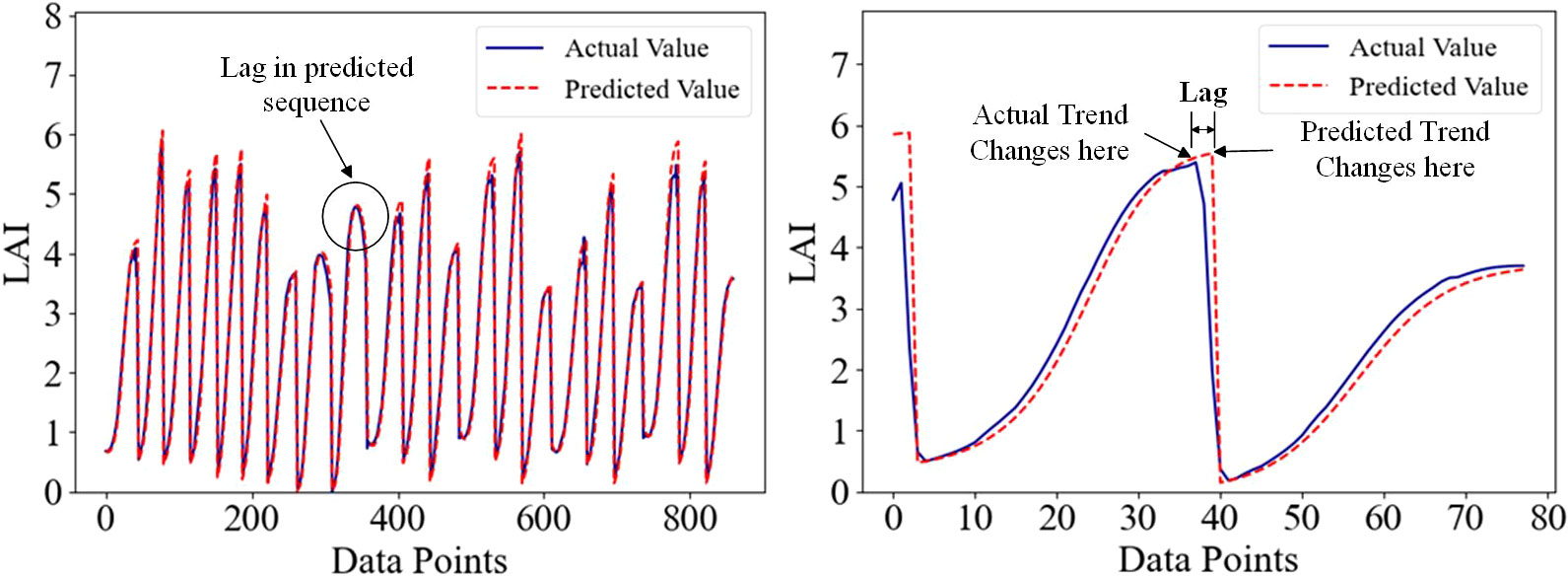
Figure 3. Demonstration of lag in time series forecasting.
The MOSUM method is a technique used to detect structural changes in time series, commonly used for detecting outliers (Eichinger and Kirch, 2018). The core principle is to monitor the evolution of data by calculating the cumulative sum within a sliding window. As the window slides, calculate the magnitude of the cumulative sum change within the current window and set a predetermined threshold. When the cumulative sum changes beyond this threshold, the corresponding window position is marked as an outlier. The MOSUM method utilizes the bandwidth parameter (G value) to adjust the size of the sliding window to adapt to different degrees of variation. The mathematical formula of the MOSUM method is as follows:
Where, St represents the cumulative sum of the sliding window in the time series; Rtrepresents the amount of change in the time series at time t; Xi represents the data point in the time series; k represents the size of the sliding window; and G represents the bandwidth parameter.
As a forage crop aimed at obtaining plants, alfalfa has a positive correlation between leaf area index (LAI) and crop growth and final yield during its growth cycle. The maximum LAI of alfalfa during the growth period is generally observed during cutting, which leads to LAI mutations and significantly affects the predictive performance of deep learning models. Therefore, we consider using the MOSUM method to detect mutation points in alfalfa LAI data, as shown in Figure 4.
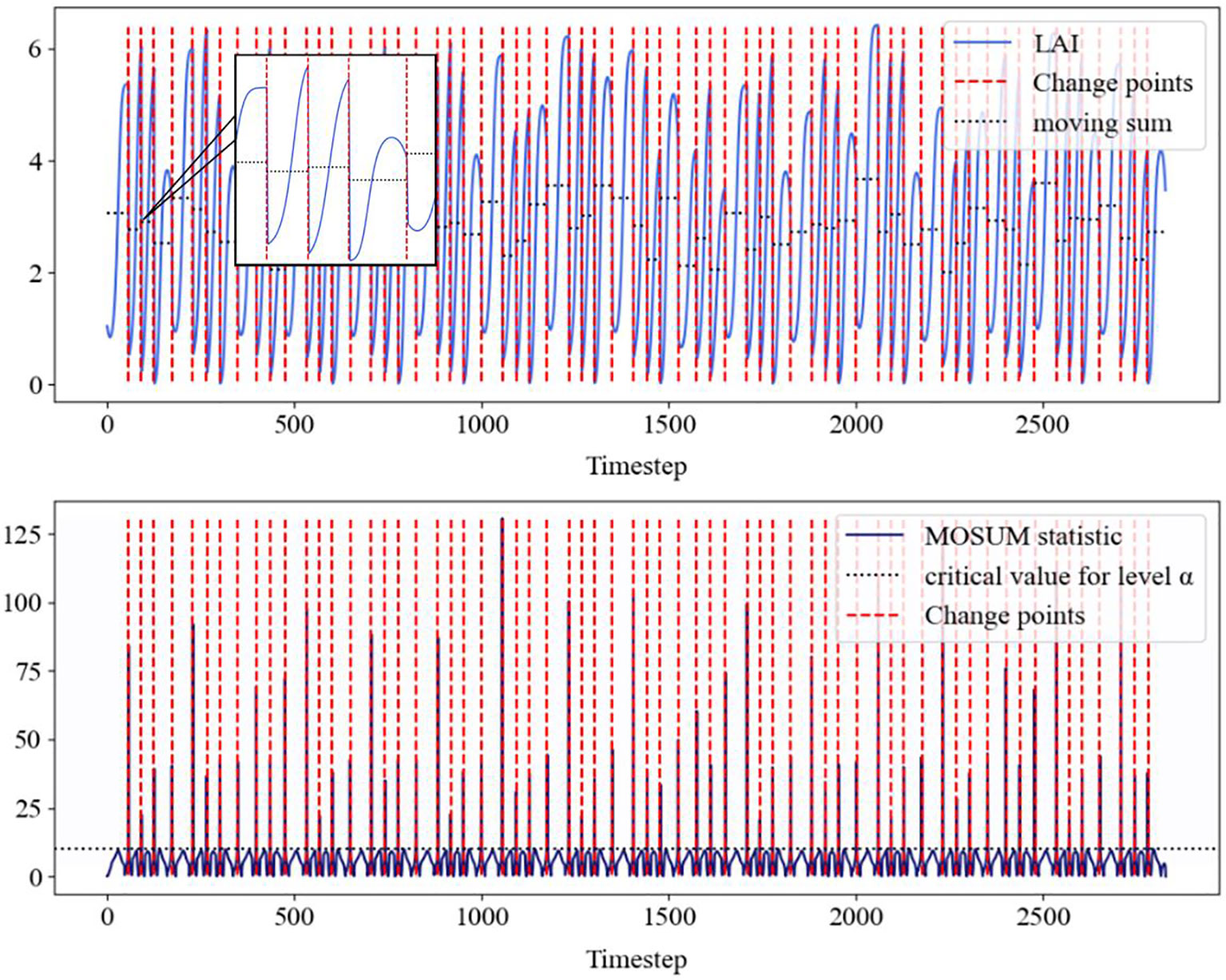
Figure 4. The above figure shows the LAI data of alfalfa detected by MOSUM (blue solid line), the mutation points (red dashed line), as well as the corresponding movement and (black dashed line). The following figure shows the MOSUM statistic, which identifies the mean, threshold (black dashed line), and corresponding change points (red dashed line).
2.3.3 Attention with encoder and decoder
The encoder network is a BiLSTM that sequentially transforms the input time series {x1,…, xi,…, xt}. The mapping from xi to eh,i and eb,i can be obtained, as shown in Formula 6–8:
Where, eh,i and eb,i are the forward and backward hidden layer outputs of encoder i at time; Wf and Wb represent the weight matrices of forward and backward units, respectively; f1 and f2 are units of LSTM; encoder_outputsi represents the output of the encoder at time step i.
Using weighted attention to compute the weighted average of encoder outputs to generate context vectors:
Where, attn_weightsi represents the attention weights; context represents the context vectors.
The decoder network is also a BiLSTM, dh,i and db,i are the hidden layer outputs of the decoder at time i. As shown in Formula 11, 12, dh,i and db,i can be obtained:
Where, Wf and Wb indicates the weight matrices of forward and backward units, respectively; f3 and f4 are units of LSTM; dh,i and db,i respectively represent the forward and backward hidden layer outputs of the decoder at time step i.
BiLSTM can extract complex features of time series, and attention layer output and hidden state information df,i-1、db,i+1 can improve the prediction performance. Afterwards, the predicted values are output through the fully connected layer:
Where, outputi represents the prediction result; fc denotes the fully connected layer.
2.3.4 Predefined function
Before the start of training, the MOSUM method is used to detect potential mutation points in the data. When selecting a training batch, predefined functions are used to determine whether to include mutation points in the upcoming training batch. If a mutation point exists, the batch will be skipped until a batch without the mutation point is found. The specific process is shown in Figure 5.
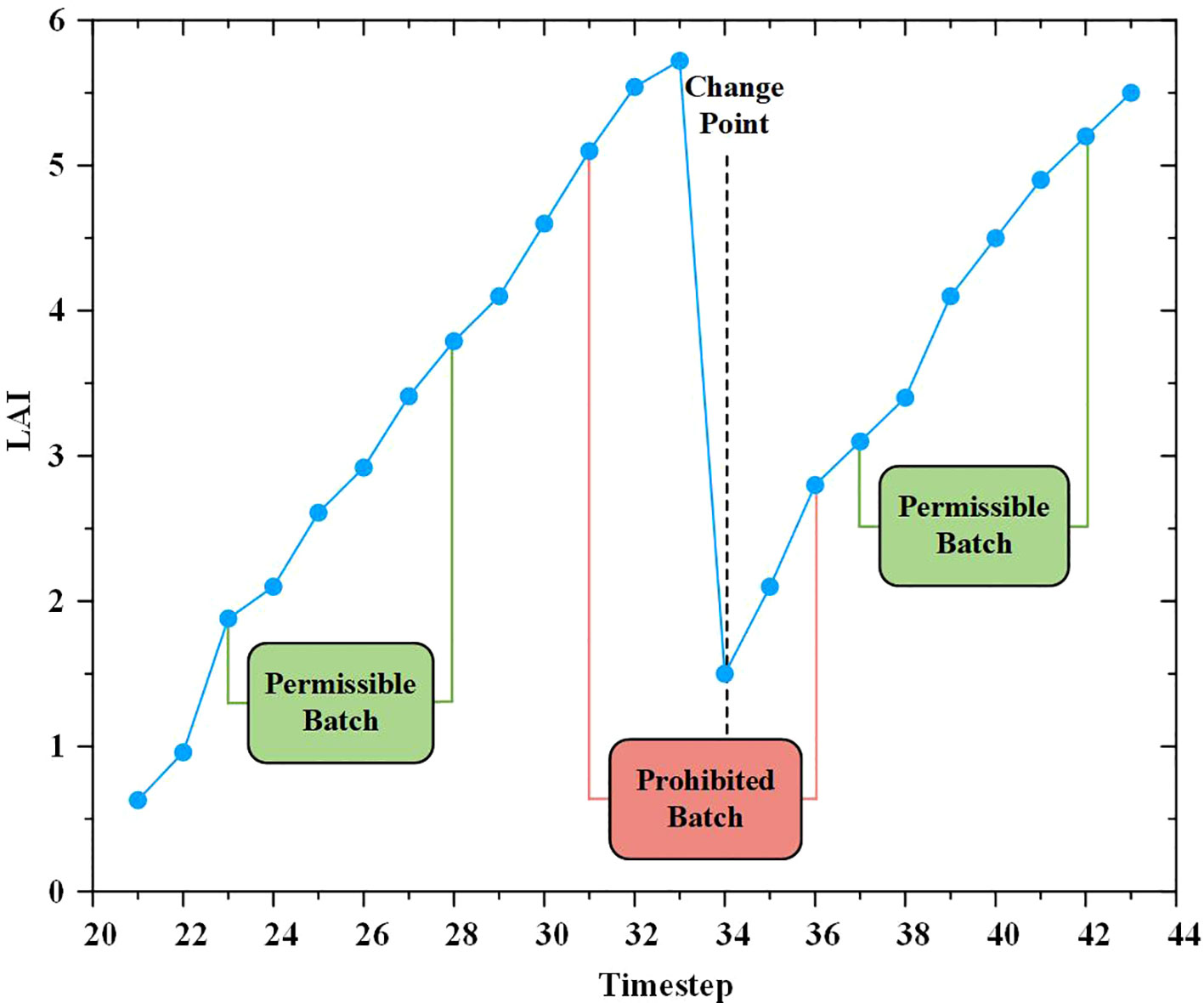
Figure 5. Example of batch processing selection around mutation points. The first green area shows a batch created by choosing t = 23 as the start index, and with a selected batch size of s = 6, the batch contains the points t = 23 to t = 28. The change point is located at t = 34 and is therefore outside the detected batch. The batch is therefore permissible. The red area next to it shows a prohibited batch. The start index of this batch is t = 31 and the end index at t = 36, so the change point is located inside the batch and is not allowed in training. A new batch must be found. The green area to the right indicates another permissible batch, since the change point lies outside of it.
In detail, the batch size s is one of the most important control parameters of our method. We have to choose s in such a way that it could cover at most one change point. If s is larger than the distance between two change points ci, cj, the part of the time series between time index i and j would never be learned. The batches containing this part of the time series would always contain at least one change point and would, therefore, not be allowed. To avoid this, we develop a method that automatically selects the maximum batch size based on the change points. In this method we calculate the distance between all detected change points. We then set smax to be half of the smallest distance between the change points. Taking half of this distance increases the probability of selecting the allowable batch between the change points, and the resulting number smax is the maximum batch size that should be selected. See Algorithm 1 for details.
Algorithm 1. Find change points and maximum batch size.

In the TMEAD-BiLSTM model, we pass a batch size s ≤ smax and the detected change points c0,…, ck−1 to the algorithm. Our goal is to find the start and end points of the batches that do not contain any change points. To do this, we select indices that lie between 0 and n-s-1. For each change point, we check whether the index of the respective change point lies between the previously selected start index and end index of the batch. If the change point lies in the batch, we repeat the method and select a new start index, and perform the same process for this, as shown in Algorithm 2. For example, a set of change points has been found through the MOSUM method:
Algorithm 2. Find valid batch.

Select batch size s ≤ smax in Algorithm 1. Select a random starting index start, that is in the range [0, n-s-1] of the time series. This gives us a batch with start point istart and end point:
Assume that one of the change points lies in the batch, thus without loss of generality ∃j ∈ {0,…, k-1} such that cj∈[istart, iend]. Then again a random start index istart’ is chosen and:
If now ∀j∈{0,…, k − 1} holds:
In the following batch [istart’,iend’] is the valid batch.
2.4 Model training
Train the hybrid model using the interpolated dataset, with a training-to-testing ratio of 8:2. The encoder and decoder are both BiLSTM with 12 hidden units, using the ReLU activation function. The attention mechanism generates context vectors to enhance output by calculating the correlation between queries and keys. The model uses a learning rate of 0.6e-3 and an Adam optimizer, with a batch size of 32 and a maximum of 300 rounds of training, combined with an early stopping strategy to prevent overfitting. All experiments in this paper were performed on Windows 10 Professional, version 21H2, on a computer with the following main parameters (CPU: AMD Ryzen 5 3600 6-core processor 3.60 GHz; GPU: NVIDIA GeForce GTX 1080 Ti GPU). The code was compiled using PyCharm version 2021.2.3 compiler, and the full syntax followed Python version 3.7.
2.5 Evaluation metrics
To prove the prediction performance of TMEAD-BiLSTM and non-linear model, three metrics are adopted to evaluate its prediction accuracy. Specifically, mean absolute error (MAE), coefficient (R2) and root mean square (RMSE) are adopted. The R2 signifies the agreement between estimated and measured values, with a value closer to 1 indicating a better fit of the model. The RMSE indicates the extent of deviation between estimated and measured values, with smaller values suggesting a better model fit. The MAE assesses the actual deviation between estimated and measured values, with smaller values indicating higher model accuracy. The calculation formula is as follows:
3 Experiment results
3.1 Prediction results annual alfalfa leaf area index
3.1.1 Prediction results of non-linear model
The relationship between the relative leaf area index and the number of growing days is illustrated in Figure 6. The Logistic, Richards, and Gompertz models were employed to fit the changes in the relative leaf area index over the growing days shown in Figure 6, respectively. The fitting results of the logistic (Formula 22), Richards (Formula 23), and Gompertz (Formula 24) models are as follows:
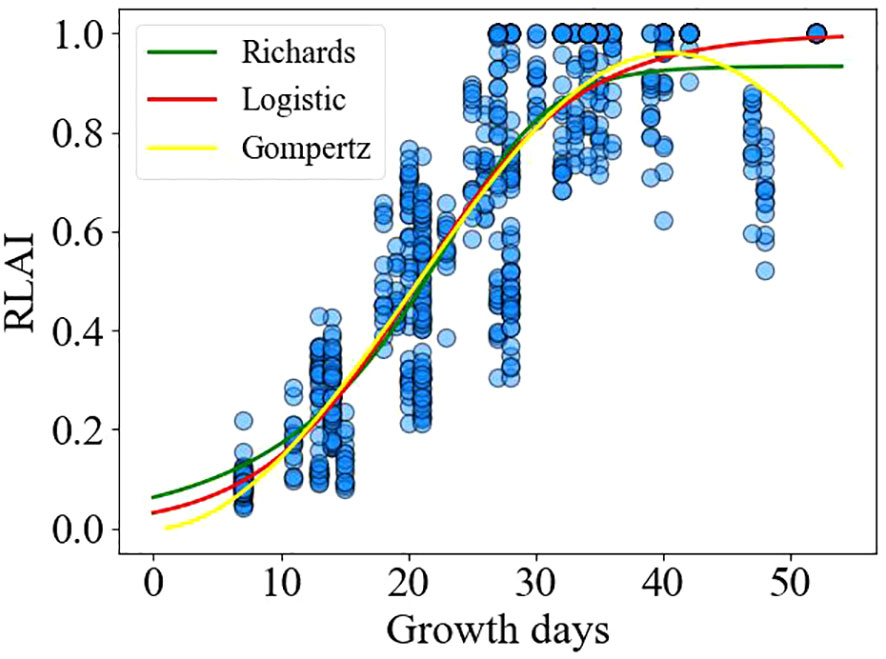
Figure 6. Fitting diagram of annual leaf area index of alfalfa.
Table 2 illustrates the fitting and validation results of three non-linear models for the relative leaf area index. It can be observed that all three models exhibit acceptable fits (R2>0.78), and the models were validated using test data. It is evident that there is no significant difference in the predictive performance of the three models for the alfalfa leaf area index.

Table 2. Modeling and validation results.
3.1.2 Prediction results of deep learn model
Due to differences in alfalfa phenology under different meteorological conditions and soil moisture, growth days, and soil moisture at different depths (>0-10 cm, >10-20 cm, >20-30 cm) corresponding to LAI at time t were also used as input features. To ensure consistency in input features, the features were normalized and scaled to 0-1. Parallel control experiments were conducted between the TMEAD-BiLSTM model and four models: LSTM, BiLSTM, MLSTM and MBiLSTM. The prediction results of each model are compared using RMSE、MAE and R2 measures the degree of fitting of the model. The prediction results of each model are shown in Table 3.

Table 3. Comparison of prediction accuracy of different LAI prediction models.
As shown in Figure 7, the model has a high accuracy in predicting 1.5 ≤ LAI ≤ 5.5, with both predicted and labeled values near the 1:1 line. When LAI < 1.5 and LAI > 5.5, the prediction accuracy is slightly lower compared to the previous situation. This may be because under different growth conditions, the time for alfalfa to turn green and set pods is different, and there are significant differences in LAI changes during the corresponding stages of LAI increase and decrease.

Figure 7. LAI prediction model prediction results.
The LSTM network performs well in temporal data processing due to its structural features, but the prediction results are not ideal under the influence of multiple feature factors. In contrast, BiLSTM networks have the ability to perceive forward and backward data, enabling stronger causality between forward and backward data. Based on the data presented in Table 3, it can be seen that the BiLSTM model has a 27.90% reduction in MAE compared to LSTM. In addition, after adding the MOSUM method, the prediction accuracy of all models was significantly improved, verifying that the MOSUM method can better preserve time series features and effectively reduce the impact of mutation points on model prediction accuracy. To further improve the model’s capacity to mine feature factors and time, this study combines the MOSUM approach with the BiLSTM encoder decoder network model based on attention mechanism. The prediction results show that the R2 and RMSE of the TMEAD-BiLSTM model are 0.9986 and 0.0662, respectively.
3.2 Prediction results of leaf area index of alfalfa in different cutting
3.2.1 Prediction results of non-linear model
Due to the influence of growth environment temperature, the growth rates of alfalfa vary between different cuttings (Lloveras et al., 1998). It is challenging to simulate the leaf area index changes for multiple cuttings within a year using nonlinear models. Therefore, we modeled the leaf area index of alfalfa for different cuttings separately. Although the variation trend of alfalfa leaf area index with growth days is basically consistent for the same cutting, there are significant differences in LAI values among the experimental plots. In order to analyze its intrinsic mechanism, the relative leaf area index was used to analyze its common growth characteristics.
Figure 8 shows the relationship between the relative leaf area index (RLAI) and growth days. The RLAI of alfalfa was fitted using the Logistic, Richards and Gompertz models. Tables 4, 5 presents the fitting effects and fitting coefficients of the models, respectively. The R2, RMSE and MAE values of three models were acceptable. Additionally, the maximum LAI of the fourth cutting in the observed region was around 5, and the LAI of the fourth cutting exhibited a declining trend in the later growth period (Figure 8). The Logistic and Gompertz models effectively capture the decline process of the leaf area index of the fourth cutting of alfalfa (R2 > 0.9). We utilized the Logistic, Richards, and Gompertz models to analyze the rate of change between the alfalfa leaf area index and growth days, computing the first derivative of the fitting curves for different cuttings. Setting growth days to 15, 20, 25, 30, 35, and 40, we averaged the slopes obtained from the three models. The results indicate that the fastest growth rates of alfalfa in different cutting occur at approximately 32, 23, 20, and 18 days after sowing for different cuttings, which is consistent with the results of Yang et al. (2024a)’s study.
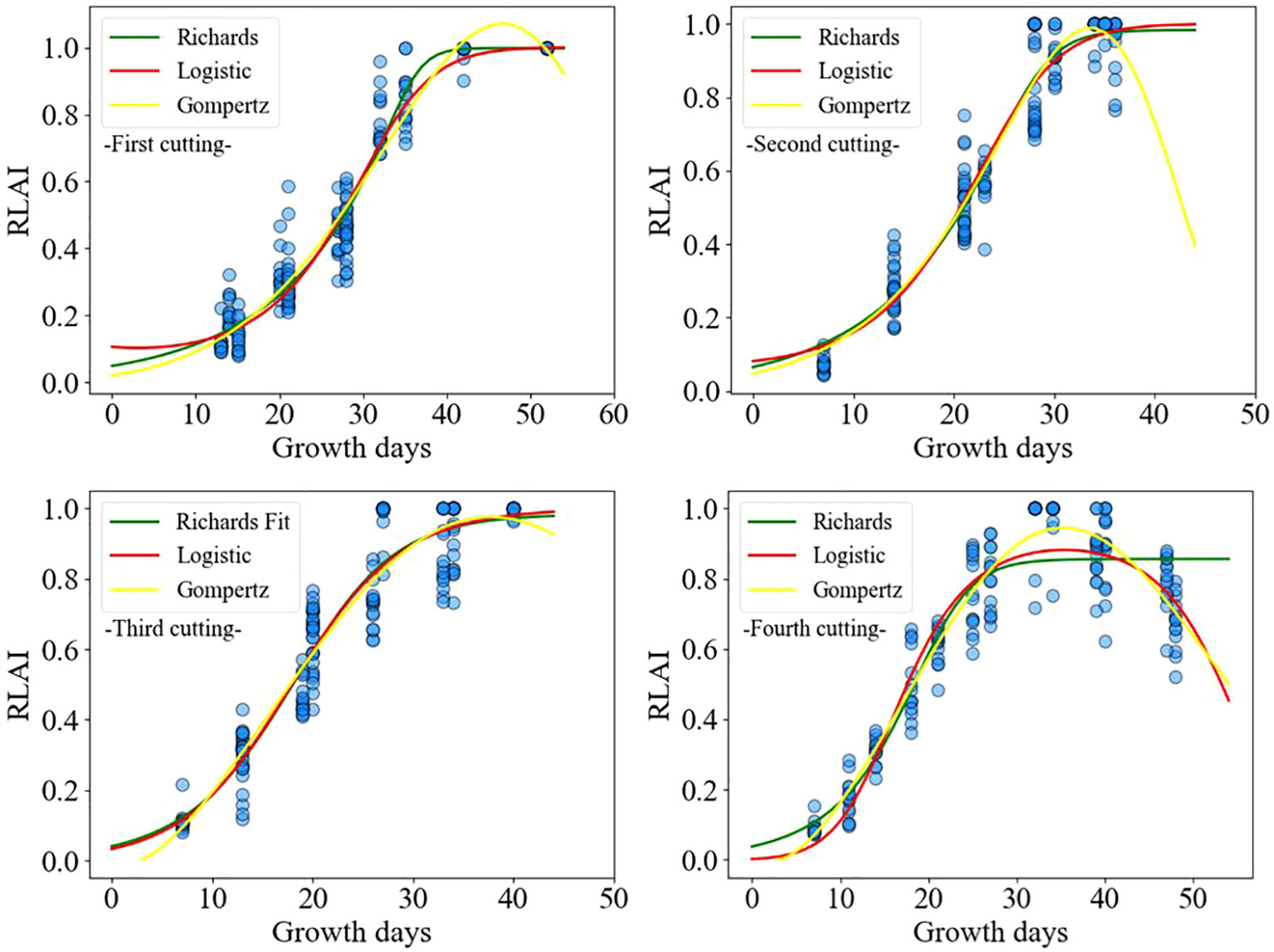
Figure 8. Relationships between relative leaf area index (RLAI) and growth days.
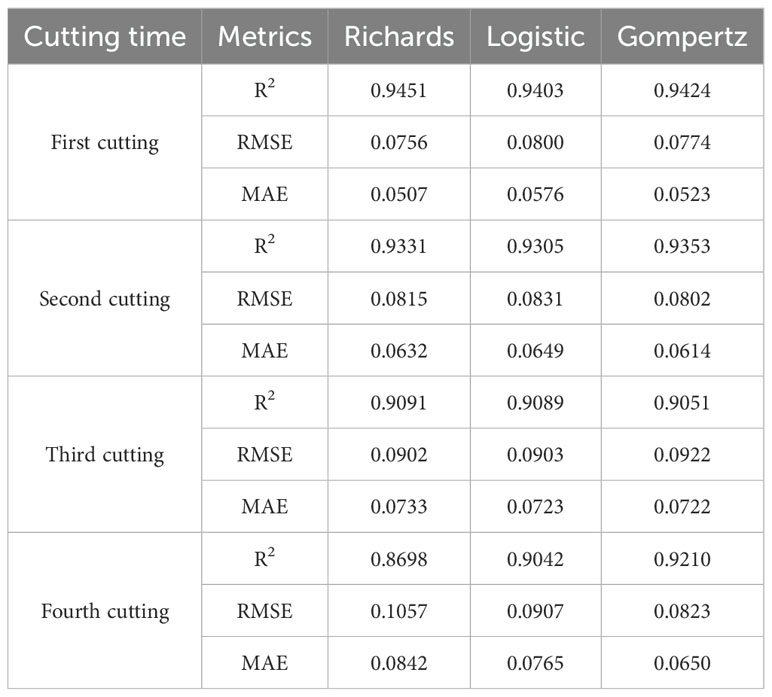
Table 4. Modeling results for different cutting.
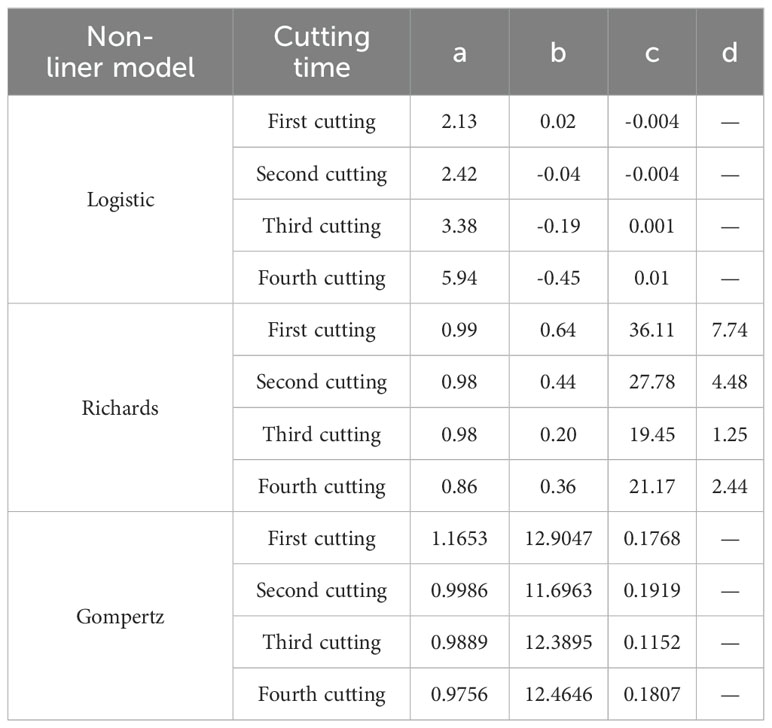
Table 5. Change of leaf area index with growing days.
The model obtained was validated using the test dataset, and the validation results are shown in Table 6. The simulated values of the leaf area index (LAI) based on the Logistic and Gompertz models for alfalfa exhibit a high degree of agreement with the measured values. The R2 values for the simulated curves of different cutting times are all greater than 0.9, indicating strong goodness-of-fit. Compared to the Logistic and Gompertz models, the Richards model shows no significant advantage in fitting the data from the first three cuttings, and it performs poorly in fitting the data from the fourth cutting. In summary, the fitting of the Logistic and Gompertz models is satisfactory.
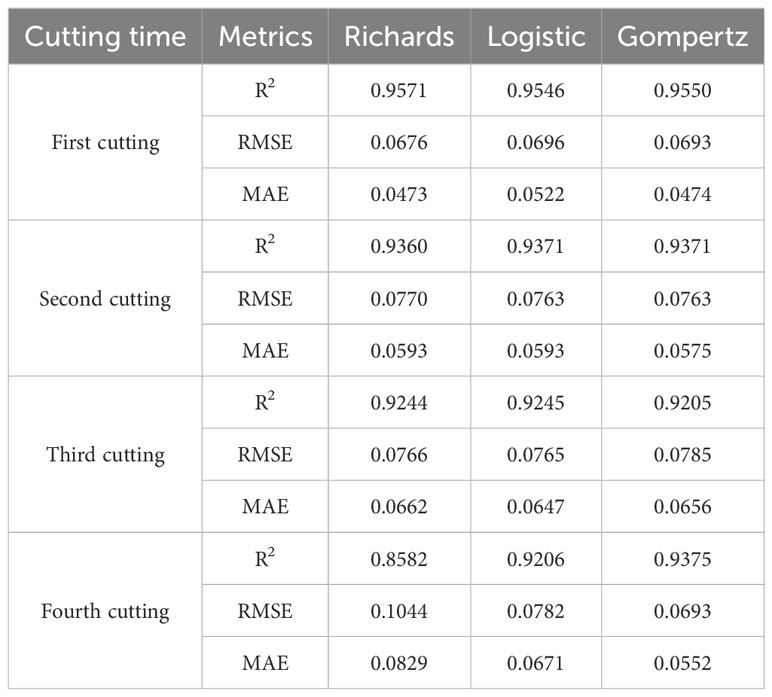
Table 6. Verification results of different cutting.
3.2.2 Prediction results of deep learn model
Alfalfa is harvested multiple times annually, and the publicly published dataset used in this study includes data from 3-4 harvests per year. During the growth process of alfalfa, there are differences in the changes in LAI of alfalfa in different cutting. Therefore, there are differences in the accuracy of LAI prediction models for alfalfa in different cutting. As shown in Figure 9, the alfalfa LAI dataset was divided into four batches, namely the first, second, third, and fourth batches. The accuracy analysis of these four batches was performed using the TMEAD-BiLSTM prediction model.
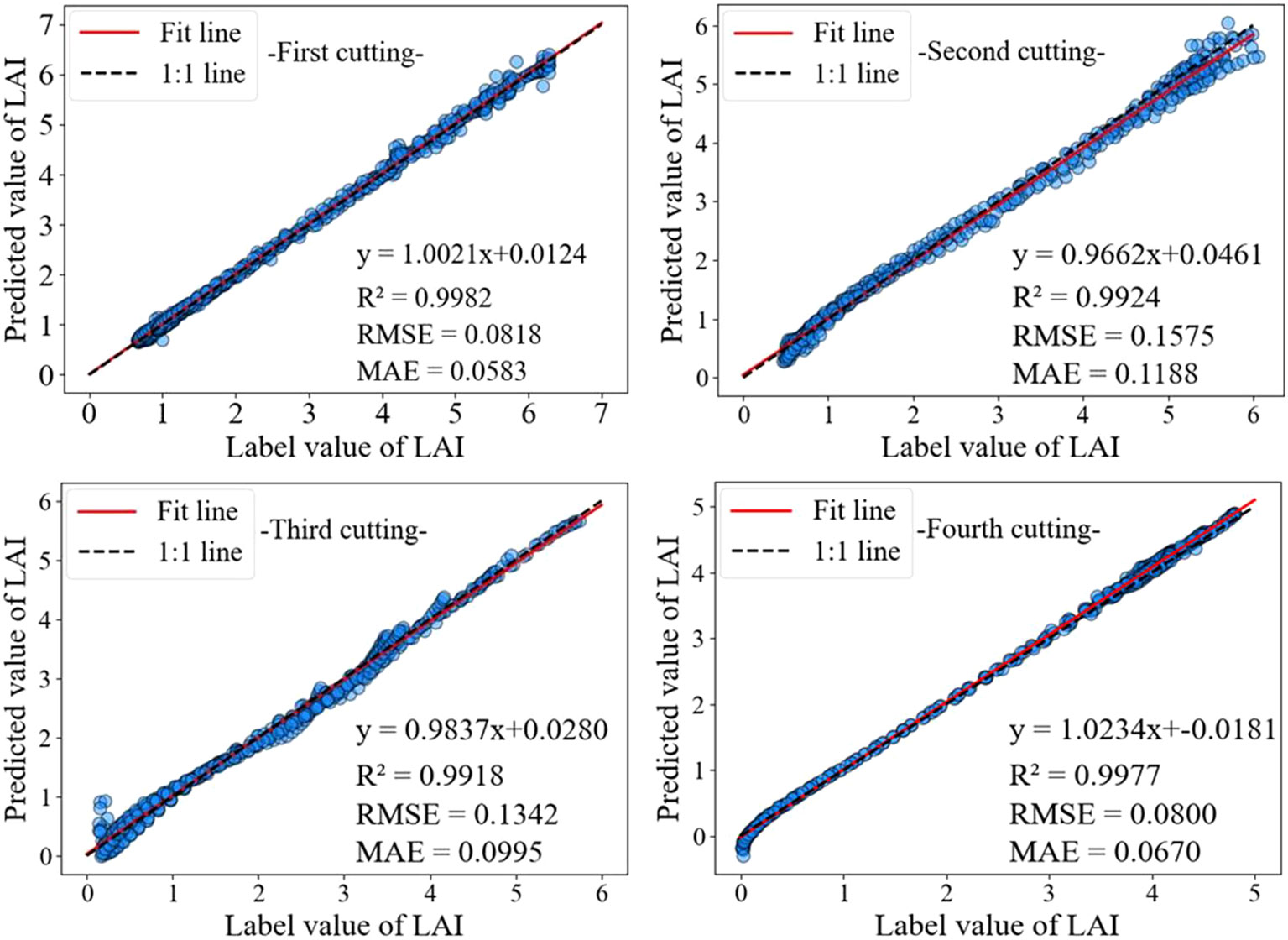
Figure 9. LAI prediction results in different crop cycles.
As shown in Table 7, the prediction accuracy of the TMEAD-BiLSTM model was higher than that of other experimental models in four different crop cycles. Due to the significant impact of temperature on the growth of alfalfa, the growth periods of the second and third batches of alfalfa are from May to September each year, and the LAI growth rate is relatively high. The model’s ability to capture rapid changes in LAI is insufficient, resulting in a slight decrease in prediction accuracy.
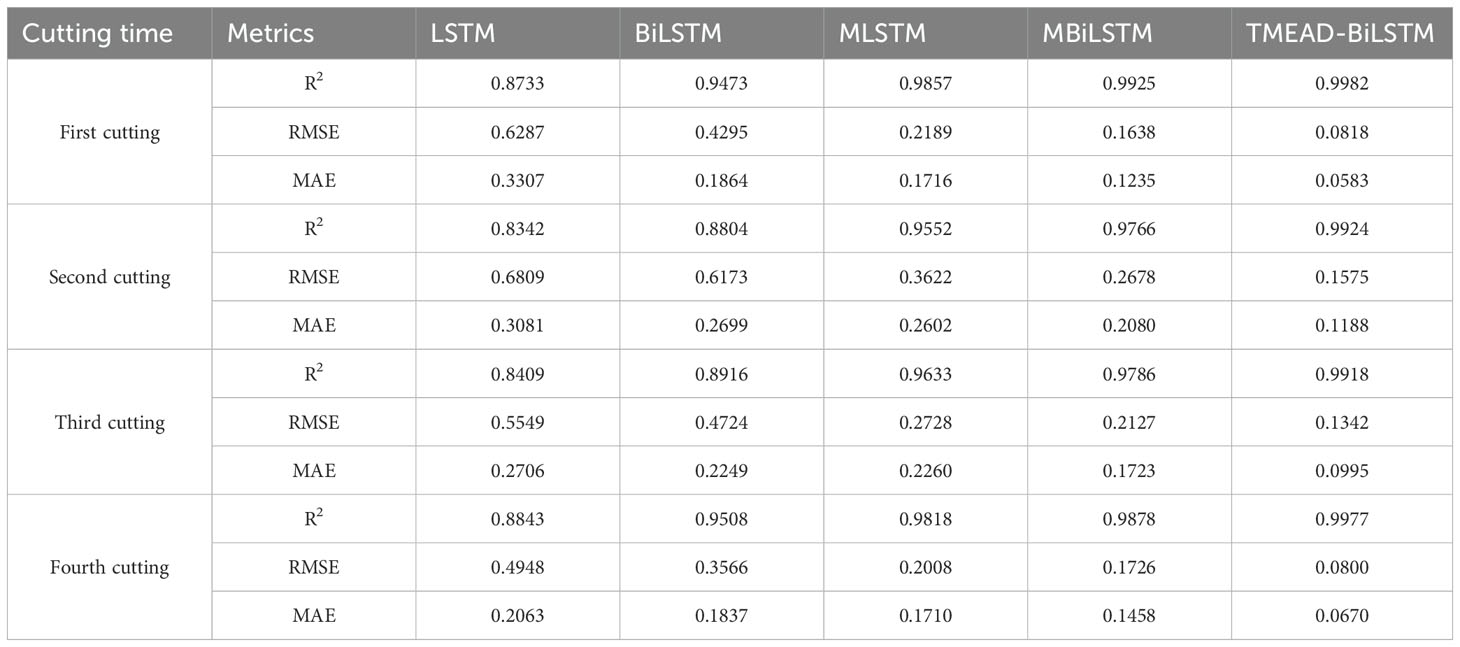
Table 7. Comparison of the precision of four LAI prediction results in different cutting.
4 Discussion
4.1 Comparative analysis of model accuracy
In this study, non-linear and deep learning models were used to predict alfalfa LAI. The results indicate that the prediction accuracy of the TMEAD-BiLSTM model is the highest, followed by the baseline time series forecasting models (LSTM, BiLSTM, MLSTM, MBiLSTM), while the logistic, Richards, and Gompertz models exhibit the poorest predictive performance (R2 > 0.78), with no significant difference observed among the three nonlinear models in terms of predictive efficacy. In contrast to traditional nonlinear models, deep learning models have the capability to integrate multiple environmental factors (e.g., water and nitrogen treatments, soil moisture, meteorological data) for LAI prediction (Cheng et al., 2022). This may account for the superiority of deep learning models over other methods. Extensive studies have revealed that the growth of alfalfa is influenced by various environmental factors (Kaiwen et al., 2020; Liu et al., 2021). Based on our previous work on the dataset, we found that even under the same growth days, the leaf area index (LAI) of alfalfa varies under different water and nitrogen treatments. This observation is consistent with the findings of Ma et al. (2024) and Feng et al. (2016). The dataset we provide includes LAI data from the years 2017-2018 and 2022. The year 2022 marks the first year of alfalfa planting, and the planting period experienced higher temperatures in the region. Alfalfa growth is highly sensitive to temperature, leading to substantial variability in LAI across different growing years. This observation aligns with the studies by Ren et al. (2021) and Kim et al. (2023). These factors also contribute to the decreased accuracy in fitting non-linear models.
Different alfalfa cuttings exhibit significantly different growth rates, thus the use of nonlinear models significantly improves the accuracy of fitting the leaf area index (LAI) for different cuttings. The LAI of the fourth cutting shows a declining trend in the later stages of growth, consistent with the findings of Bai and Bao (2002) The Logistic and Gompertz models effectively captures this changing trend. We observe that the baseline time-series models (LSTM, BiLSTM) have the poorest predictive accuracy. This is attributed to the lagged effect in predictions and the presence of breakpoints in the LAI time-series data, consistent with the findings of Samanta et al. (2020). We use the MOSUM method to achieve mutation point detection and eliminate training batches containing mutation points through predefined functions, avoiding damage to the original dataset and the impact of data mutations on prediction accuracy. Despite the predictive accuracy of three nonlinear models for alfalfa LAI across different cuttings has significantly improved, the differences in growth environments across different years still constrain the predictive performance of nonlinear models, especially concerning temperature and soil moisture, consistent with the findings of Yang et al. (2024b) and Su et al. (2015).
4.2 Analysis of Model Complexity and Applicability
In the prediction of alfalfa leaf area index (LAI), deep learning models and nonlinear models each have their advantages and disadvantages. Deep learning models can handle multiple features, including effective accumulated temperature, growth days, meteorological data, soil moisture, and leaf area index, making them suitable for complex environments. However, they have high computational complexity O(T×n×m2) and space complexity O(n×m+m2), with a large number of parameters (for instance, BiLSTM can reach 8×(m×d+m2)), leading to significant memory usage (Shah and Bhavsar, 2022; Maji and Mullins, 2018). Here, n represents the sequence length (i.e., number of time steps), m represents the number of hidden units, T represents the number of training iterations, and d represents the dimensionality of the input features (such as the total number of effective accumulated temperature, growth days, meteorological data, soil moisture, and leaf area index). In contrast, nonlinear models rely only on growth days and leaf area index, resulting in low complexity (time complexity O(T) and space complexity O(n), with fewer parameters (usually 3-5), and high computational efficiency (De Cock et al., 2017). For example, when processing thousands of samples, the training time for the Logistic model is only a few seconds, and the memory usage is less than one-tenth of that of deep learning models (Banerjee, 2007).
Deep learning models typically exhibit superior suitability for supporting offline predictions compared to nonlinear models (Jin et al., 2022). This preference stems from the inherent characteristics of deep learning architectures, which can leverage pre-trained weight parameters for offline inference without necessitating real-time computations or extensive computational resources. Once the training phase is completed, deep learning models can be seamlessly deployed on relatively modest hardware setups for prediction tasks, rendering them particularly advantageous in scenarios characterized by resource constraints or where continuous online computation is impractical. Conversely, nonlinear models often entail recalculating parameters with each prediction, making them better suited for online prediction scenarios or applications requiring real-time computations (Kalhor et al., 2010). This distinction underscores the versatility and efficiency of deep learning models in facilitating offline predictions, thereby catering to a diverse array of research and practical applications within various scientific domains. Deep learning models can integrate multiple environmental factors for LAI prediction, including water and nitrogen treatment, soil moisture, and meteorological data. This ability significantly improves prediction accuracy, but also increases computational load and parameter complexity (Justus et al., 2018). In addition, deep learning models are suitable for predicting leaf area index (LAI) in different ecological environments due to their powerful feature extraction ability and the advantage of cross regional prediction through transfer learning. They can quickly deploy data from the source region in new areas and achieve good prediction results (Zeng et al., 2020). Although non-linear models perform well in specific regions, their applicability is mainly limited to local data due to the lack of generalization ability and adaptability to cross regional data, making it difficult to effectively meet the needs of cross regional prediction. However, the training of deep learning models requires the participation of large datasets to effectively capture complex patterns and interactions in the data (Najafabadi et al., 2015). The implementation of deep learning models may be challenging in resource constrained environments or with limited data availability (Liu et al., 2024). In this case, traditional nonlinear models provide a practical solution that balances the trade-off between computational efficiency and predictive performance.
5 Conclusion
To overcome the limitations of non-linear models in incorporating environmental factors and the inefficiency of LSTM in handling abrupt changes in LAI data, we proposed a TMEAD-BiLSTM model. This model was compared with classical non-linear models such as Logistic, Gompertz, and Richards. The TMEAD-BiLSTM model demonstrated superior predictive accuracy compared to the non-linear models. The strength of classic non-linear models lies in their simplicity, low computational demand, and suitability for low cost applications, particularly in resource constrained embedded devices. In contrast, the TMEAD-BiLSTM model offers high accuracy but requires high performance computing support, making it suitable for applications with high accuracy requirements and ample computational resources. Considering the potential of drones in monitoring alfalfa growth, we plan to lightweighten the model in future work and deploy it on drones to evaluate the method in real-world environments.
Data availability statement
The original contributions presented in the study are included in the article/supplementary material. Further inquiries can be directed to the corresponding author.
Author contributions
SY: Methodology, Software, Validation, Writing – original draft, Writing – review & editing. YG: Funding acquisition, Resources, Writing – review & editing. JW: Data curation, Formal analysis, Visualization, Writing – review & editing. RL: Data curation, Project administration, Visualization, Writing – review & editing. LF: Formal analysis, Supervision, Writing – review & editing.
Funding
The author(s) declare financial support was received for the research, authorship, and/or publication of this article. This work was supported in part by National natural science foundation of China (62162052, 62262052), in part by Key Research and Development Project of Ningxia Province (2021BEB04016, 2022BDE03007), Natural Science Foundation of Ningxia (2022AAC03004).
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Anastasiou, A., Fryzlewicz, P. (2022). Detecting multiple generalized change-points by isolating single ones. Metrika 85, 141–174. doi: 10.1007/s00184-021-00821-6
Bai, W., Bao, X. (2002). Simulation alfalfa growth in Wulanbuhe sandy region. Ying Yong Sheng tai xue bao= J. Appl. Ecol. 13, 1605–1609.
Banerjee, A. (2007). “An analysis of logistic models: Exponential family connections and online performance,” in Proceedings of the 2007 SIAM international conference on data mining (Minneapolis, Minnesota, USA: Society for Industrial and Applied Mathematics), 204–215. doi: 10.1137/1.9781611972771
Baral, R., Lollato, R. P., Bhandari, K., Min, D. (2022). Yield gap analysis of rainfed alfalfa in the United States. Front. Plant Sci. 13. doi: 10.3389/fpls.2022.931403
Burczaniuk, M., Jastrzębska, A. (2024). On the Improvements of Metaheuristic Optimization-Based Strategies for Time Series Structural Break Detection. Informatica, 1–33. doi: 10.15388/24-INFOR572
Brogi, C., Huisman, J. A., Herbst, M., Weihermüller, L., Klosterhalfen, A., Montzka, C., et al. (2020). Simulation of spatial variability in crop leaf area index and yield using agroecosystem modeling and geophysics-based quantitative soil information. Vadose zone J. 19, e20009. doi: 10.1002/vzj2.20009
Chaturvedi, R. K., Singh, S., Singh, H., Raghubanshi, A. S. (2017). Assessment of allometric models for leaf area index estimation of Tectona grandis. Trop. Plant Res. 4, 274–285. doi: 10.1186/s40663-021-00284-1
Chen, Y., Wang, T., Samworth, R. J. (2022). High-dimensional, multiscale online changepoint detection. J. R. Stat. Soc. Ser. B: Stat. Method. 84, 234–266. doi: 10.1111/rssb.12447
Cheng, Q., Xu, H., Fei, S., Li, Z., Chen, Z. (2022). Estimation of maize LAI using ensemble learning and UAV multispectral imagery under different water and fertilizer treatments. Agriculture 12, 1267. doi: 10.3390/agriculture12081267
De Cock, M., Dowsley, R., Horst, C., Katti, R., Nascimento, A. C., Poon, W. S., et al. (2017). Efficient and private scoring of decision trees, support vector machines and logistic regression models based on pre-computation. IEEE Trans. Dependable Secure Computing 16, 217–230. doi: 10.1109/TDSC.2017.2679189
Desai, R. J., Wang, S. V., Vaduganathan, M., Evers, T., Schneeweiss, S. (2020). Comparison of machine learning methods with traditional models for use of administrative claims with electronic medical records to predict heart failure outcomes. JAMA network Open 3, e1918962. doi: 10.1001/jamanetworkopen.2019.18962
Duran, O., Ünal, D. (2024). The proposed modified schnute model. Süleyman Demirel Üniversitesi Fen Bilimleri Enstitüsü Dergisi 28, 89–95. doi: 10.3390/en14020258
Eichinger, B., Kirch, C. (2018). A MOSUM procedure for the estimation of multiple random change points. Bernoulli 24, 526–564. doi: 10.3150/16-BEJ887
Feng, M., Yu, C., Lin, L., Wu, D., Song, R., Liu, H. (2016). Effects of water and nitrogen fertilizer on biomass distribution and water use efficiency of alfalfa (Medicago sativa) in Hexi Corridor. Chin. J. Eco-Agriculture 24, 1623–1632. doi: 10.13930/j.cnki.cjea.160449
Guo, Y., Liu, Y., Wang, Q., Su, L., Zhang, J., Wei, K. (2022). Regional growth model for summer maize based on a logistic model: Case study in China. Int. J. Agric. Biol. Eng. 15, 41–55. doi: 10.25165/j.ijabe.20221505.6584
Jin, H., Li, Y., Wang, B., Yang, B., Jin, H., Cao, Y. (2022). Adaptive forecasting of wind power based on selective ensemble of offline global and online local learning. Energy Conversion Manage. 271, 116296. doi: 10.1016/j.enconman.2022.116296
Justus, D., Brennan, J., Bonner, S., McGough, A. S. (2018). “Predicting the computational cost of deep learning models,” in 2018 IEEE international conference on big data (Big Data) (Seattle, WA, USA: IEEE), 3873–3882. doi: 10.1109/BigData.2018.8622396
Kaiwen, G., Zisong, X., Yuze, H., Qi, S., Yue, W., Yanhui, C., et al. (2020). Effects of salt concentration, pH, and their interaction on plant growth, nutrient uptake, and photochemistry of alfalfa (Medicago sativa) leaves. Plant Signaling Behav. 15, 1832373. doi: 10.1080/15592324.2020.1832373
Kalhor, A., Araabi, B. N., Lucas, C. (2010). An online predictor model as adaptive habitually linear and transiently nonlinear model. Evolving Syst. 1, 29–41. doi: 10.1007/s12530-010-9004-z
Karadavut, U., Palta, Ç., Kökten, K., Bakoğlu, A. (2010). Comparative study on some non-linear growth models for describing leaf growth of maize. Int. J. Agric. Biol. 12, 227–230. doi: 10.1186/s13717-021-00285-6
Kim, J. Y., Han, K. J., Sung, K. I., Kim, B. W., Kim, M. (2023). Assessment of growing condition variables on alfalfa productivity. J. Anim. Sci. Technol. 65, 939. doi: 10.5187/jast.2023.e14
Liguori, A., Markovic, R., Dam, T. T. H., Frisch, J., van Treeck, C., Causone, F. (2021). Indoor environment data time-series reconstruction using autoencoder neural networks. Building Environ. 191, 107623. doi: 10.1016/j.buildenv.2021.107623
Lin, S., Deng, M., Wei, K., Wang, Q., Su, L. (2023). A new regional cotton growth model based on reference crop evapotranspiration for predicting growth processes. Sci. Rep. 13, 7368. doi: 10.1038/s41598-023-34552-7
Liu, H. I., Galindo, M., Xie, H., Wong, L. K., Shuai, H. H., Li, Y. H., et al. (2024). Lightweight deep learning for resource-constrained environments: A survey. ACM Comput. Surv. 56, 1–42. doi: 10.1145/36572
Liu, M., Wang, Z., Mu, L., Xu, R., Yang, H. (2021). Effect of regulated deficit irrigation on alfalfa performance under two irrigation systems in the inland arid area of midwestern China. Agric. Water Manage. 248, 106764. doi: 10.1016/j.agwat.2021.106764
Liu, Y., Su, L., Wang, Q., Zhang, J., Shan, Y., Deng, M. (2020). Comprehensive and quantitative analysis of growth characteristics of winter wheat in China based on growing degree days. Adv. Agron. 159, 237–273. doi: 10.1016/bs.agron.2019.07.007
Lloveras, J., Ferran, J., Alvarez, A., Torres, L. (1998). Harvest management effects on alfalfa (Medicago sativaL.) production and quality in Mediterranean areas. Grass forage Sci. 53, 88–92. doi: 10.1046/j.1365-2494.1998.00100.x
Ma, H., Jiang, P., Zhang, X., Ma, W., Cai, Z., Sun, Q. (2024). Effects of nitrogen fertilization combined with subsurface irrigation on alfalfa yield, water and nitrogen use efficiency, quality, and economic benefits. Front. Plant Sci. 15. doi: 10.3389/fpls.2024.1339417
Maji, P., Mullins, R. (2018). On the reduction of computational complexity of deep convolutional neural networks. Entropy 20, 305. doi: 10.3390/e20040305
Masini, R. P., Medeiros, M. C., Mendes, E. F. (2023). Machine learning advances for time series forecasting. J. economic surveys 37, 76–111. doi: 10.1111/joes.12429
Najafabadi, M. M., Villanustre, F., Khoshgoftaar, T. M., Seliya, N., Wald, R., Muharemagic, E. (2015). Deep learning applications and challenges in big data analytics. J. big Data 2, 1–21. doi: 10.1186/s40537-014-0007-7
Nhu, V. H., Shirzadi, A., Shahabi, H., Singh, S. K., Al-Ansari, N., Clague, J. J., et al. (2020). Shallow landslide susceptibility mapping: A comparison between logistic model tree, logistic regression, naïve bayes tree, artificial neural network, and support vector machine algorithms. Int. J. Environ. Res. Public Health 17, 2749. doi: 10.3390/ijerph17082749
Qian, Z. H., Han, B. F., Liu, Z. T., Cai, W., Fu, B. Z., Ma, H. B. (2020). Effects of infiltration irrigation on growth characters and water use efficiency of alfalfa in the ningxia yellow river diversion irrigation area. Acta Pratacult. Sin. 29, 147. doi: 10.11686/Cyxb2019254
Ren, L., Bennett, J. A., Coulman, B., Liu, J., Biligetu, B. (2021). Forage yield trend of alfalfa cultivars in the Canadian prairies and its relation to environmental factors and harvest management. Grass forage Sci. 76, 390–399. doi: 10.1111/gfs.12513
Roosa, K., Lee, Y., Luo, R., Kirpich, A., Rothenberg, R., Hyman, J. M., et al. (2020). Short-term forecasts of the COVID-19 epidemic in Guangdong and Zhejiang, China: February 13–23, 2020. J. Clin. Med. 9, 596. doi: 10.3390/jcm9020596
Samanta, S., Pratama, M., Sundaram, S., Srikanth, N. (2020). “A dual network solution (DNS) for lag-free time series forecasting,” in 2020 international joint conference on neural networks (IJCNN) (Glasgow, UK: IEEE), 1–8. doi: 10.1109/IJCNN48605.2020.9207022
Shah, B., Bhavsar, H. (2022). Time complexity in deep learning models. Proc. Comput. Sci. 215, 202–210. doi: 10.1016/j.procs.2022.12.023
Sherstinsky, A. (2020). Fundamentals of recurrent neural network (RNN) and long short-term memory (LSTM) network. Physica D: Nonlinear Phenomena 404, 132306. doi: 10.1016/j.physd.2019.132306
Siami-Namini, S., Tavakoli, N., Namin, A. S. (2019). “The performance of LSTM and BiLSTM in forecasting time series,” in 2019 IEEE International conference on big data (Big Data) (Los Angeles, CA, USA: IEEE), 3285–3292. doi: 10.1109/BigData47090.2019.9005997
Su, L., Tao, W., Sun, Y., Shan, Y., Wang, Q. (2022). Mathematical models of leaf area index and yield for grapevines grown in the turpan area, xinjiang, China. Agronomy 12, 988. doi: 10.3390/agronomy12050988
Su, L., Wang, Q., Wang, C., Shan, Y. (2015). Simulation models of leaf area index and yield for cotton grown with different soil conditioners. PloS One 10, e0141835. doi: 10.1371/journal.pone.0141835
Tooley, E. G., Nippert, J. B., Ratajczak, Z. (2024). Evaluating methods for measuring the leaf area index of encroaching shrubs in grasslands: From leaves to optical methods, 3-D scanning, and airborne observation. Agric. For. Meteorology 349, 109964. doi: 10.1016/j.agrformet.2024.109964
Tripathi, A. M., Pohanková, E., Fischer, M., Orság, M., Trnka, M., Klem, K., et al. (2018). The evaluation of radiation use efficiency and leaf area index development for the estimation of biomass accumulation in short rotation poplar and annual field crops. Forests 9, 168. doi: 10.3390/f9040168
Vaghi, C., Rodallec, A., Fanciullino, R., Ciccolini, J., Mochel, J. P., Mastri, M., et al. (2020). Population modeling of tumor growth curves and the reduced Gompertz model improve prediction of the age of experimental tumors. PloS Comput. Biol. 16, e1007178. doi: 10.1371/journal.pcbi.1007178
Wang, W., Liang, Y., Ru, Z., Guo, H., Zhao, B. (2023). World forage import market: competitive structure and market forces. Agriculture 13, 1695. doi: 10.3390/agriculture13091695
Wang, T., Zhang, W. H. (2023). Priorities for the development of alfalfa pasture in northern China. Fundam. Res. 3, 225–228. doi: 10.1016/j.fmre.2022.04.017
Yang, S., Ge, Y., Wang, J., Liu, R., Tang, D., Li, A., et al. (2024a). A dataset for estimating alfalfa leaf area and predicting leaf area index. Front. Plant Sci. 15. doi: 10.3389/fpls.2024.1290920
Yang, T., Zhao, J., Fu, Q. (2024b). Quantitative relationship of plant height and leaf area index of spring maize under different water and nitrogen treatments based on effective accumulated temperature. Agronomy 14, 1018. doi: 10.3390/agronomy14051018
Ze-hao, L., Qi-ming, Q., Tian-yuan, Z., Wei, X. (2020). Prediction of continuous timeseries leaf area index based on long short-term memory network: A case study of winterwheat. Spectrosc. Spectral Anal. 40, 898–904. doi: 10.3964/j.issn.1000-0593(2020)03-0898-07
Zeng, Q., Sun, Q., Chen, G., Duan, H., Li, C., Song, G. (2020). Traffic prediction of wireless cellular networks based on deep transfer learning and cross-domain data. IEEE Access 8, 172387–172397. doi: 10.1109/ACCESS.2020.3025210
Keywords: alfalfa, leaf area index, non-liner model, deep learning model, MOSUM.
Citation: Yang S, Ge Y, Wang J, Liu R and Fu L (2024) Predicting alfalfa leaf area index by non-linear models and deep learning models. Front. Plant Sci. 15:1458337. doi: 10.3389/fpls.2024.1458337
Received: 02 July 2024; Accepted: 17 October 2024;
Published: 11 November 2024.
Edited by:
Syed Tahir Ata-Ul-Karim, Aarhus University, DenmarkReviewed by:
Ke Zhang, Nanjing Agricultural University, ChinaHaozhou Wang, The University of Tokyo, Japan
Copyright © 2024 Yang, Ge, Wang, Liu and Fu. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Yongqi Ge, Z2V5b25ncWlAbnh1LmVkdS5jbg==